Модельное мышление. Как анализировать сложные явления с помощью математических моделей [Скотт Пейдж] (epub) читать онлайн
Книга в формате epub! Изображения и текст могут не отображаться!
[Настройки текста] [Cбросить фильтры]
[Оглавление]
НАД КНИГОЙ РАБОТАЛИ
Руководитель редакции Артем Степанов
Шеф-редактор Ренат Шагабутдинов
Ответственный редактор Наталья Шульпина
Литературный редактор Татьяна Сковородникова
Арт-директор Алексей Богомолов
Верстка обложки Наталия Майкова
Верстка Олег Бачурин
Корректоры Елена Попова, Ольга Танская
ООО «Манн, Иванов и Фербер»
mann-ivanov-ferber.ru
Электронная версия книги подготовлена компанией Webkniga.ru, 2020
Модельное мышление
Пролог
ГЛАВА 1. Многомодельное мышление
ГЛАВА 2. Зачем нужны модели?
ГЛАВА 3. Наука о множестве моделей
ГЛАВА 4. Моделирование поведения людей
ГЛАВА 5. Нормальное распределение: колоколообразная кривая
ГЛАВА 6. Степенное распределение: длинный хвост
ГЛАВА 7. Линейные модели
ГЛАВА 8. Вогнутость и выпуклость
ГЛАВА 9. Модели ценности и влияния
ГЛАВА 10. Сетевые модели
ГЛАВА 11. Трансляция, диффузия и заражение
ГЛАВА 12. Энтропия: моделирование неопределенности
ГЛАВА 13. Случайные блуждания
ГЛАВА 14. Зависимость от первоначально выбранного пути
ГЛАВА 15. Модели локальных взаимодействий
ГЛАВА 16. Функции Ляпунова и равновесие
ГЛАВА 17. Модели Маркова
ГЛАВА 18. Модели системной динамики
ГЛАВА 19. Пороговые модели с обратной связью
ГЛАВА 20. Пространственные и гедонические модели выбора
ГЛАВА 21. Три класса моделей теории игр
ГЛАВА 22. Модели кооперации
ГЛАВА 23. Проблемы коллективных действий
ГЛАВА 24. Дизайн механизмов
ГЛАВА 25. Модели сигнализирования
ГЛАВА 26. Модели обучения
ГЛАВА 27. Задачи о многоруком бандите
ГЛАВА 28. Модели пересеченного ландшафта
ГЛАВА 29. Опиоиды, неравенство и смирение
Библиография
Примечания
БИБЛИОГРАФИЯ
Acemoglu, Daron, and David Autor 2011 “Skills, Tasks and Technologies Implications for Employment and Earnings “ In Orley Ashenfelter and David Card, eds, Handbook of Labor Economics, 4 1043–1171 Amsterdam Elsevier-North Holland.
Acemoglu, Daron, and James Robinson 2012 Why Nations Fail The Origins of Power, Prosperity, and Poverty Cambridge, MA Harvard Umver sity Press. (Дарен Аджемоглу, Джеймс Робинсон. Почему одни страны богатые, а другие бедные. Происхождение власти, процветания и нищеты. М.: Эксмо, 2017.)
Adler, Mortimer Jerome 1970 The Time of Our Lives The Ethics of Common Sense. New York: Holt, Rinehart and Winston.
Akerlof, G , and R Kranton 2010 Identity Economics Princeton, NJ Princeton University Press. (Джордж Акерлоф, Рейчел Крэнтон. Экономика идентичности. Как наши идеалы и социальные нормы определяют, кем мы работаем, сколько зарабатываем и насколько несчастны. М: Карьера Пресс, 2010.)
Albert, Rika, Istvan Albert, and Gary L Nakarado 2004 “Structural Vulnerability of the North American Power Grid” Physical Review E 69 025103.
Allesina, Stefano, and Mercedes Pascual 2009 “Googling Food Webs: Can an Eigenvector Measure Species’ Importance for Coextmctions?” PLOS Computational Biology 9, no 4.
Allison, Graham 1971 Essence of Decision Explaining the Cuban Missile Crisis New York Little, Brown. (Алисон Грэм. Квинтэссенция решения. На примере Карибского кризиса 1962 года. М.: Едиториал УРСС, 2012.)
Alvaredo, Facundo, Anthony B Atkinson, Thomas Piketty, and Emmanuel Saez 2013 “The World Top Incomes Database” https://www.inet.ox.ac.uk/projects/view/149.
Anderson, Chris 2008a “The End of Theory The Data Deluge Makes the Scientific Method Obsolete“ Wired 16, no 7.
Anderson, Chris 2008b The Long Tail Why the Future of Business Is Selling Less of More New York Hachette Anderson, Phillip 1972 “More Is Different “ Science 177, no 4047 393–396.
Arrow, Kenneth, 1963. Social Choice and Individual Values. New Haven, CT: Yale University Press. (Кеннет Эрроу. Коллективный выбор и индивидуальные ценности. М.: ГУ ВШЭ, 2004.)
Arthur, W. B. 1994. “Inductive Reasoning and Bounded Rationality (The El Farol Problem).” American Economic Review Papers and Proceedings 84: 406–411.
Arthur, W. B. 2011. The Nature of Technology: What It Is and How It Evolves. New York: Free Press.
Ashenfelter, Orley. 2010. “Predicting the Quality and Prices of Bordeaux Wine.” Journal of Wine Economics 5, no. 1: 40–52.
Athey, Susan, Jonathan Levin, and Enrique Seira. 2011. “Comparing Open and Sealed Bid Auctions: Evidence from Timber Auctions.” Quarterly Journal of Economics 126, no. 1: 207–257.
Austin, David. 2008. “Percolation: Slipping Through the Cracks.” American Mathematical Society, www.ams.org/publicoutreach/feature-column/fcarc-percolation.
Axelrod, Robert. 1984. The Evolution of Cooperation. New York: Basic Books.
Axelrod, David, Robert Axelrod, and Kenneth J. Pienta. 2006. “Evolution of Cooperation Among Tumor Cells.” Proceedings of the National Academy of Sciences 103, no. 36: 13474–13479.
Axtell, Robert L. 2001. “Zipf Distribution of U.S. Firm Sizes.” Science 293: 1818–1820.
Bajari, Patrick, and Matthew E. Kahn. 2008. “Estimating Hedonic Models of Consumer Demand with an Application to Urban Sprawl.” In Hedonic Methods in Housing Markets, 129–155. New York: Springer.
Bak, Per. 1996. How Nature Works: The Science of Self-Organized Criticality. New York: Springer. (Бак Пер. Как работает природа. Теория самоорганизованной критичности. М.: Либроком, 2015.)
Baldwin, Carliss Y, and Kim B. Clark. 2000. Design Rules. Vol. 1, The Power of Modularity. Cambridge, MA: MIT Press.
Ball, Eric, and Joseph LiPuma. 2012. Unlocking the Ivory Tower: How Management Research Can Transform Your Business. Palo Alto, CA: Kauffman Fellow Press.
Banzhaf, John F. 1965. “Weighted Voting Doesn’t Work: A Mathematical Analysis.” Rutgers Law Review 19, no. 2: 317–343.
Barber, Gerald M. 1997. “Sequencing Highway Network Improvements: A Case Study of South Sulawesi.” Economic Geography 53, no. 1: 55–69.
Bass, Frank. 1969. “A New Product Growth Model for Consumer Durables.” Management Science 15, no. 5: 215–227.
Baxter, G. William. 2009. “The Dynamics of Foraging Ants.” Paper presented at the annual meeting of the American Physical Society, March 16–20, abstract H40.00011.
Bednar, Jenna. 2007. “Credit Assignment and Federal Encroachment.” Supreme Court Economic Review 15: 285–308.
Bednar, Jenna. 2008. The Robust Federation: Principle of Design. Cambridge: Cambridge University Press.
Bednar, Jenna, Aaron Bramson, Andrea Jones-Rooy, and Scott E. Page. 2010. “Emergent Cultural Signatures and Persistent Diversity: A Model of Conformity and Consistency.” Rationality and Society 22, no. 4: 407–444.
Bednar, Jenna, and Scott E. Page. 2007. “Can Game(s) Theory Explain Culture? The Emergence of Cultural Behavior Within Multiple Games.” Rationality and Society 19, no. 1: 65–97.
Bednar, Jenna, and Scott E. Page. 2018. “When Order Affects Performance: Culture, Behavioral Spillovers and Institutional Path Dependence.” American Political Science Review 112, no. 1: 82–98.
Bell, Alex, Raj Chetty, Xavier Jaravel, Neviana Petkova, and John Van Reenen. 2018 “Who Becomes an Inventor in America? The Importance of Exposure to Innovation: Executive Summary.” www.equality-of-opportunity.org.
Bendor, Jonathan, Daniel Diermeier, and Michael Ting. 2003. ‘A Behavioral Model of Turnout.” American Political Science Review 97, no. 2: 261–280.
Bendor, Jonathan, and Piotr Swistak. 1997. “The Evolutionary Stability of Cooperation.” American Political Science Review 91: 290–307.
Bendor, Jonathan, and Scott E. Page. 2018. “A Model of Team Problem Solving.” Неопубликованная рукопись.
Berg, Nathan, and Gerd Gigerenzer. 2010. ‘As-If Behavioral Economics: Neoclassical Economics in Disguise?” History of Economic Ideas 18, no. 1: 133–166.
Bergemann, Dirk, and Juuso Valimaki. 2008. “Bandit Problems.” In The New Palgrave Dictionary of Economics, 2nd ed., ed. Steven N. Durlauf and Lawrence E. Blume. London: Palgrave Macmillan.
Berlekamp, Elwyn R., John H. Conway, and Richard K. Guy. 1982. “What Is Life?” In Winning Ways for Your Mathematical Plays. Vol. 2, Games in Particular. London: Academic Press.
Bertrand, Marianne, and Sendhil Mullainathan. 2001. “Are CEOs Rewarded for Luck? The Ones Without Principles Are.” Quarterly Journal of Economics 116: 901–932.
Bickel, P. J., E. A. Hammel, and J. W. O’Connell. 1974. “Sex Bias in Graduate Admissions: Data from Berkeley.” Science 187 (4175): 398–404.
Biernaskie, Jay, M. 2011. “Evidence for Competition and Cooperation Among Climbing Plants.” Proceedings of the Royal Society B 278: 1989–1996.
Bird, Rebecca, and Eric Smith. 2004. “Signaling Theory, Strategic Interaction, and Symbolic Capital.” Current Anthropology 46, no. 2: 222–248.
Boldrin, Michele, and David Levine. 2010. Against Intellectual Monopoly. Cambridge: Cambridge University Press.
Borges, Jorge Luis. 1974. A Universal History of Infamy. Trans. Norman Thomas de Giovanni. London: Penguin. (Хорхе Луис Борхес. Всемирная история низости. М.: Амфора, 2006.)
Bowers, Jake, Nathaniel Higgins, Dean Karlan, Sarah Tulman, and Jonathan Zinman. 2017. “Challenges to Replication and Iteration in Field Experiments: Evidence from Two Direct Mail Shots.” American Economic Review Papers & Proceedings 107, no. 5: 1–3.
Bowles, Samuel, and Herbert Gintis. 2002. “The Inheritance of Inequality.” Journal of Economic Perspectives 16, no. 3: 3–30.
Box, George E. P., and Norman Draper. 1987. Empirical Model-Building and Response Surfaces. New York: Wiley.
Boyd, Robert. 2006. “Reciprocity: You Have to Think Different.” Journal of Evolutionary Biology 19: 1380–1382.
Breiman, Leo. 1996. “Bagging Predictors.” Machine Learning 24, no. 2: 123–140.
Briggs, Andrew, and Mark Sculpher. 1998. “An Introduction to Markov Modeling for Economic Evaluation.” Pharmaco Economics 13, no. 4: 397–409.
Brock, William, and Steven Durlauf. 2001. “Discrete Choice with Social Interactions.” Review of Economic Studies 68: 235–260.
Broido, A. D., and A. Clauset. 2018. “Scale-Free Networks Are Rare” (рабочий доклад).
Bshary, R., and A. S. Grutter. 2006. “Image Scoring and Cooperation in a Cleaner Fish Mutualism.” Nature 441, no. 7096: 975–978.
Burt, Ronald. 1995. Structural Holes: The Social Structure of Competition. Cambridge, MA: Harvard University Press.
Bush, Robert, and Frederick Mosteller. 1954. Stochastic Models for Learning. New York: John Wiley and Sons.
Camerer, Colin F. 2003. Behavioral Game Theory: Experiments in Strategic Interaction. Princeton, NJ: Princeton University Press.
Camerer, Colin, Linda Babcock, George Loewenstein, and Richard Thaler. 1997. “Labor Supply of New York City Cabdrivers: One Day at a Time.” Quarterly Journal of Economics 112, no. 2: 407–441.
Camerer, Colin, and Tek Ho. 1999. “Experience-Weighted Attraction Learning in Normal Form Games.” Econometrica 67, no. 4: 827–874.
Camerer, Colin, George Loewenstein, and Drazen Prelec. 2005. “Neuroe-conomics: How Neuroscience Can Inform Economics.” Journal of Economic Literature 43: 9–64.
Campbell, Donald T. 1976. “Assessing the Impact of Planned Social Change.” Public Affairs Center, Dartmouth College.
Campbell, James E., Bryan J. Dettrey, and Hongxing Yin. 2010. “The Theory of Conditional Retrospective Voting: Does the Presidential Record Matter Less in Open-Seat Elections?” Journal of Politics 72, no. 4: 1083–1095.
Cancian, Maria, and Deborah Reed. 1999. “The Impact of Wives’ Earnings on Income Inequality: Issues and Estimates.” Demography 36, no. 2: 173–184.
Carvalho, Vasco, and Xavier Gabaix. 2013 “The Great Diversification and Its Undoing,” American Economic Review 103, no. 5: 1697–1727.
Castellano, Claudio, Santo Fortunate, and Vittorio Loreto. 2009. “Statistical Physics of Social Dynamics.” Review of Modern Physics 81: 591–646.
Cederman, Lars Erik. 2003. “Modeling the Size of Wars: From Billiard Balls to Sandpiles.” American Political Science Review 97: 135–150.
Centola, Damon, and Michael Macy. 2007. “Complex Contagions and the Weakness of Long Ties.” American Journal of Sociology 113: 702–734.
Chance, Donald. 2009. “What Are the Odds? Another Look at DiMaggio’s Streak.” Chance 22, no. 2: 33–42.
Christakis, N. A., and J. Fowler. 2009. Connected: The Surprising Power of Our Social Networks and How They Shape Our Lives. New York: Little, Brown. (Николас Кристакис, Джеймс Фаулер. Связанные одной сетью. Как на нас влияют люди, которых мы никогда не видели. М.: Юнайтед Пресс, 2014.)
Churchland, Patricia, and Terry J. Sejnowski. 1992. The Computational Brain. Cambridge, MA: MIT Press.
Chwe, Michael. 2013. Jane Austen: Game Theorist. Princeton, NJ: Princeton University Press.
Clarida, Richard, Jordi Gall, and Mark Gertler. 2000. “Monetary Policy Rules and Macroeconomic Stability: Evidence and Some Theory.” Quarterly Journal of Economics 115, no. 1: 147–180.
Clark, Gregory. 2014. The Son Also Rises: Surnames and the History of Social Mobility. Princeton, NJ: Princeton University Press. (Грегори Кларк. Отцы и дети. Фамилии и история социальной мобильности. М.: Издательство Института Гайдара, 2018.)
Clark, William, Matt Golder, and Sona Nadenicheck Golder. 2008. Principles of Comparative Politics. Washington, DC: Congressional Quarterly Press.
Clauset, Aaron, M. Young, and K. S. Gleditsch. 2007. “On the Frequency of Severe Terrorist Attacks.” Journal of Conflict Resolution 51, no. 1: 58–88.
Cohen, Tyler. 2013. Average Is Over: Powering America Beyond the Age of the Great Stagnation. New York: Dutton. (Тайлер Коуэн. Среднего более не дано. Как выйти из эпохи Великой стагнации. М.: Издательство Института Гайдара, 2015.)
Cooke, Nancy J., and Margaret L. Hilton, eds. 2014. Enhancing the Effectiveness of Team Science. Washington, DC: National Academies Press.
Cornes, Richard, and Todd Sandler. 1996. The Theory of Externalities, Public Goods, and Club Goods. 2nd ed. Cambridge: Cambridge University Press.
Craine, Joseph, and Ray Dybzinski. 2013. “Mechanisms of Plant Competition for Nutrients, Water and Light.” Functional Ecology 27: 833–840.
Cyert, Richard M., and James G. March. 1963. A Behavioral Theory of the Firm. Englewood Cliffs, NJ: Prentice-Hall.
Dan, Avi. 2018. “How Michelle Peluso Is Redefining Marketing at IBM.” Forbes, January 18.
Dann, Carrie. 2016. “Pro-Clinton Battleground Ad Spending Outstrips Trump Team by 2.” NBC News, November 4.
Dawes, Robyn. 1979. “The Robust Beauty of Improper Linear Models in Decision Making.” American Psychologist 34: 571–582.
de Marchi, Scott. 2005. Computational and Mathematical Modeling in the Social Sciences. Cambridge: Cambridge University Press.
DeMiguel, Victor, Lorenzo Garlappi, and Raman Uppal. 2009. “Optimal Versus Naive Diversification: How Inefficient Is the 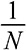 Portfolio Strategy?” Review of Financial Studies 22, no. 5: 1915–1953.
Portfolio Strategy?” Review of Financial Studies 22, no. 5: 1915–1953.
Dennett, Daniel C. 1991. Consciousness Explained. Boston: Back Bay Books.
Dennett, Daniel C. 1994. Darwin’s Dangerous Idea: Evolution and the Meanings of Life. New York: Simon & Schuster.
Denrell, Jerker, and Chengwei Liu. 2012. “Top Performers Are Not the Most Impressive When Extreme Performance Indicates Unreliability.” Proceedings of the National Academy of Sciences 109, no. 24: 9331–9336.
Diamond, Jared. 2005. Collapse: How Societies Choose to Fail or Succeed. New York: Viking Penguin. (Джаред Даймонд. Коллапс. Почему одни общества приходят к процветанию, а другие — к гибели. М.:АСТ, 2008.)
Dodds, Peter, Robby Muhamad, and Duncan Watts. 2003. ‘An Experimental Study of Search in Global Social Networks.” Science 301: 827–829.
Downing, John A., et al. 2006. “The Global Abundance and Size Distribution of Lakes, Ponds, and Impoundments.” Limnology and Oceanography 51, no. 5: 2388–2397.
Downs, Anthony. 1957. An Economic Theory of Democracy. New York: Harper.
Dragulescu, Adrian, and Victor M. Yakovenko. 2001. “Exponential and Power-Law Probability Distributions of Wealth and Income in the United Kingdom and the United States.” Physica A 299: 213–221.
Drucker, Peter. 1969. The Age of Discontinuity: Guidelines to Our Changing Society. New York: Harper and Row. (Питер Друкер. Эпоха разрыва. Ориентиры для нашего меняющегося общества. М.: Вильямс, 2007.)
Dubos, Jean. 1987. The White Plague: Tuberculosis, Man and Society. New Brunswick, NJ: Rutgers University Press.
Dunne, Anthony. 1999. Hertzian Tales: Electronic Products, Aesthetic Experience and Critical Design. London: Royal College of Art.
Dyson, Freeman. 2004. ‘A Meeting with Enrico Fermi.” Nature 427: 297.
Easley, David, and Jon Kleinberg. 2010. Networks, Crowds, and Markets: Reasoning About a Highly Connected World. Cambridge: Cambridge University Press.
Easley, David, Marcos Lopez de Prado, and Maureen O’Hara. 2012. “Flow Toxicity and Liquidity in a High Frequency World.” Review of Financial Studies 24, no. 5: 1457–1493.
Easterly, William, and Stanley Fischer. 1995. “The Soviet Economic Decline.” World Bank Economic Review 9, no. 3: 341–371.
Ebbinghaus, Herman. 1885. Memory: A Contribution to Experimental Psychology. Online in Classics in the History of Psychology. http://psychclassics.yorku.ca/Ebbinghaus/index.htm.
Ehrenberg, Andrew. 1969. “Towards an Integrated Theory of Consumer Behaviour.” Journal of the Market Research Society 11, no. 4: 305–337.
Einstein, Albert. 1934. “On the Method of Theoretical Physics.” Philosophy of Science 1, no. 2: 163–169.
Eliot, Matt, Ben Golub, and Matthew Jackson. 2014. “Financial Networks and Contagion.” American Economic Review 104, no. 10: 3115–3153.
Eom, Young-Ho, and Hang-Hyun Jo. 2014. “Generalized Friendship Paradox in Complex Networks: The Case of Scientific Collaboration.” Scientific Reports 4: 4603.
Epstein, Josh. 2006. Generative Social Science: Studies in Agent-Based Computational Modeling. Princeton, NJ: Princeton University Press.
Epstein, Joshua. 2008. “Why Model?” Journal of Artificial Societies and Social Simulation 11, no. 4: 12.
Epstein, Joshua. 2014. Agent Zero: Toward Neurocognitive Foundations for Generative Social Science. Princeton, NJ: Princeton University Press.
Ericsson, K. A. 1996. “The Acquisition of Expert Performance: An Introduction to Some of the Issues.” In The Road to Excellence: The Acquisition of Expert Performance in the Arts and Sciences, Sports, and Games, ed. K. A. Ericsson, 1–50. Mahwah, NJ: Erlbaum.
Fair, Raymond. 2012. Predicting Presidential Elections and Other Things. 2nd ed. Stanford, CA: Stanford University Press.
Farmer, J. Doyne 2018. “Collective Awareness: A Conversation with J. Doyne Farmer.” The Edge. https://www.edge.org/conversation/jdoynefarmer-collective-awareness.
Feld, Scott L. 1991. “Why Your Friends Have More Friends than You Do.” American Journal of Sociology 96, no. 6: 1464–1477.
Flegal, Katherine M., Brian K. Kit, Heather Orpana, and Barry I. Graubard. 2012. “Association of All-Cause Mortality with Overweight and Obesity Using Standard Body Mass Index Categories: A Systematic Review and Meta-analysis.” Journal of the American Medical Association 309, no. 1: 71–82.
Flores, Thomas, and Irfan Nooruddin. 2016. Elections in Hard Times: Building Stronger Democracies in the 21st Century. Cambridge: Cambridge University Press.
Florida, Richard. 2005. Cities and the Creative Class. New York: Routledge.
Foster, Dean, and H. Peyton Young. 2001. “On the Impossibility of Predicting the Behavior of Rational Agents.” Proceedings of the National Academy of Sciences 98, no. 22: 12848–12853.
Frank, Kenneth, et al. 2018. “Teacher Networks and Educational Opportunity.” In Handbook on the Sociology of Education, ed. Barbara Schneider and Guan Saw. New York: Oxford University Press.
Frank, Robert. 1985. Choosing the Right Pond. Oxford: Oxford University Press.
Frank, Robert. 1996. The Winner-Take-All Society: Why the Few at the Top Get So Much More than the Rest of Us. New York: Penguin.
Freeman, Richard, and Wei Huang. 2015. “Collaborating with People Like Me: Ethnic Co-authorship Within the U.S.” Journal of Labor Economics 33 no. SI: S289–S318.
Fudenberg, Drew, and David Levine. 1998. Theory of Learning in Games. Cambridge, MA: MIT Press.
Fudenberg, Drew, and David Levine. 2006. “A Dual-Self Model of Impulse Control.” American Economic Review 96: 1449–1476.
Gammill, James F., Jr., and Terry A. Marsh. 1988. “Trading Activity and Price Behavior in the Stock and Stock Index Futures Markets in October 1987.” Journal of Economic Perspectives 2, no. 3: 25–44.
Gawande, Atul. 2009. The Checklist Manifesto: How to Get Things Right. New York: Henry Holt. (Атул Гаванде. Чек-лист. Как избежать глупых ошибок, ведущих к фатальным последствиям. М.: Альпина Паблишер, 2014.)
Geithner, Timothy. 2014. Stress Test: Reflections on Financial Crises. New York: Crown.
Gerschenkron, Alexander. 1952. “Economic Backwardness in Historical Perspective.” In The Progress of Underdeveloped Areas, ed. B. F. Hoselitz. Chicago: University of Chicago Press.
Gertner, Jon. 2012. The Idea Factory: Bell Labs and the Great Age of American Innovation. New York: Penguin.
Gibrat, Robert. 1931. Les inegalites economique. Paris: Sirely.
Gigerenzer, Gerd, and Reinhard Selten. 2002. Bounded Rationality: The Adaptive Toolbox. Cambridge, MA: MIT Press.
Gigerenzer, Gerd, and Peter Todd. 2000. Simple Heuristics That Make Us Smart. New York: Oxford University Press.
Gilboa, Itzhak, and David Schmeidler. 1994. “Case-Based Decision Theory.” Quarterly Journal of Economics 110: 605–639.
Gilovich, Thomas, Amos Tversky, and R. Vallone. 1984. “The Hot Hand in Basketball: On the Misperception of Random Sequences.” Cognitive Psychology 17, no. 3: 295–314.
Gittins, J., Jones, D. 1972. A dynamic allocation index for sequential design of experiments. In Progress in statistics, European Meeting of Statisticians (Vol. 1, pp. 241–266).
Glaeser, Edward, Bruce Sacerdote, and Jose Scheinkman. 1996. “Crime and Social Interactions.” Quarterly Journal of Economics 111, no. 2: 507–548.
Glantz, Andrew. 2008. “A Tax on Light and Air: Impact of the Window Duty on Tax Administration and Architecture, 1696–1851.” Penn History Review 15, no. 2: 18–40.
Glasserman, Paul, and H. Peyton Young. 2014. “Contagion in Financial Networks.” Office of Financial Research Working Paper.
Godard, Renee. 1993. “Tit for Tat Among Neighboring Hooded Warblers.” Behavioral Ecology and Sociobiology 33, no. 1: 45–50.
Gode, Dhananjay K., and Shyam Sunder. 1993. ‘Allocative Efficiency of Markets with Zero-Intelligence Traders: Market as a Partial Substitute for Individual Rationality.” Journal of Political Economy 101, no. 1: 119–137.
Goldin, Claudia, and Lawrence F. Katz. 2008. The Race Between Education and Technology. Cambridge, MA: Harvard University Press.
Gordon, Robert J. 2016. The Rise and Fall of American Growth: The U.S. Standard of Living Since the Civil War. Princeton, NJ: Princeton University Press.
Granovetter, Mark. 1973. “The Strength of Weak Ties.” American Journal of Sociology 78, no. 6: 1360–1380. (Марк Грановеттер. Сила слабых связей. —Экономическая социология. Сентябрь 2009.)
Granovetter, Mark. 1978. “Threshold Models of Collective Behavior.” American Journal of Sociology 83, no. 6: 1360–1443.
Greenwood, Jeremy, Nezih Guner, Georgi Kocharkov, and Cezar Santos. 2014. “Marry Your Like: Assortative Mating and Income Inequality.” American Economic Review: Papers & Proceedings 104, no 5: 348–353.
Greif, Avner. 2006. Institutions and the Path to the Modern Economy: Lessons from Medieval Trade. Cambridge: Cambridge University Press. (Авнер Грейф. Институты и путь к современной экономике. Уроки средневековой торговли. М.: Издательский дом Высшей школы экономики, 2013.)
Griliches, Zvi. 1957, 1988. “Hybrid Corn: An Exploration of the Economics of Technological Change.” In Technology, Education and Productivity: Early Papers with Notes to Subsequent Literature. New York: Basil Black-well.
Groseclose, Tim, and James Snyder. 1996. “Buying Supermajorities.” American Political Science Review 90: 303–315.
Grossman, S., and J. Stiglitz. 1980. “On the Impossibility of Informationally Efficient Markets.” American Economic Review 70, no. 3: 393–408.
Groysberg, Boris. 2012. Chasing Stars: The Myth of Talent and the Portability of Performance. Princeton, NJ: Princeton University Press.
Guy, Richard. 1983. “Don’t Try to Solve These Problems.” American Mathematical Monthly 90: 35–41.
Haidt, Jonathan. 2006. The Happiness Hypothesis: Finding Modern Truth in Ancient Wisdom. Basic Books. New York: NY.
Haldene, Andrew. 2012. “The Dog and the Frisbee.” Speech given at the Federal Reserve Bank of Kansas City’s 36th Economic Policy Symposium, Jackson Hole, WY.
Haldene, Andrew. 2014. “The Dappled World.” Speech given at the University of Michigan Law School, Ann Arbor, October 23.
Haldane, John B. S. 1928. “On Being the Right Size.” Интернет-версия доступна здесь: http://irl.cs.ucla.edu/papers/right-size.html.
Hardin, Garret. 1968. “The Tragedy of the Commons.” Science 162, no. 3859: 1243–1248.
Harrell, Frank E. 2001. Regression Modeling Strategies with Applications to Linear Models, Logistic Regression, and Survival Analysis. New York: Springer.
Harstad, Ronald M., and Reinhard Selten. 2013. “Bounded Rationality Models: Tasks to Become Intellectually Competitive.” Journal of Economic Literature 51, no. 2: 496–511.
Harte, John. 1988. Consider a Spherical Cow. Mill Valley, CA: University Science Books.
Hathaway, Oona. 2001. “Path Dependence in the Law: The Course and Pattern of Change in a Common Law Legal System.” Iowa Law Review 86.
Havel, Vaclav. 1985. The Power of the Powerless: Citizens Against the State in Central-Eastern Europe. Ed. John Keane. Armonk, NY: M. E. Sharpe. (Вацлав Гавел. Сила бессильных. — Минск: Полифакт, 1991.)
Hawking, Stephen, and Leonard Mlodinow. 2011. The Grand Design. New-York: Bantam. (Стивен Хокинг, Леонард Млодинов. Высший замысел. М.: АСТ, 2017.)
Hecht, Jeff. 2008. “Prophecy of Economic Collapse ‘Coming True.’” New Scientist. November 17.
Herrnstein, Richard J. 1970. “On the Law of Effect.” Journal of the Experimental Analysis of Behavior 13: 243–266.
Hills, Thomas, Peter M. Todd, David Lazer, A. David Redish, Iain D. Couzin, and the Cognitive Search Research Group. 2015. “Exploration Versus Exploitation in Space, Mind, and Society.” Trends in Cognitive Science 19, no. 1: 46–54.
Hofstadter, Douglas, and Emmanuel Sander. 2013. Surfaces and Essences: Analogy as the Fuel and Fire of Thinking. New York: Basic Books.
Holland, John. 1975. Adaptation in Natural and Artificial Systems. Ann Arbor: University of Michigan Press.
Hong, Lu, and Scott E. Page. 2009. “Interpreted and Generated Signals.” Journal of Economic Theory 144: 2174–2196.
Hotelling, Harold. 1929. “Stability in Competition.” Economic Journal 39, no. 153: 41–57.
Huffaker, Carl Burton. 1958. “Experimental Studies on Predation: Dispersion Factors and Predator-Prey Oscillations.” Hilgardia 27, no. 14: 343–383.
Hurwicz, Leo, and David Schmeidler. 1978. “Outcome Functions Which Guarantee the Existence and Pareto Optimality of Nash Equilibria.” Econometrica 46: 144–174.
Inman, Mason. 2011. “Sending Out an SOS.” Nature Climate Change 1: 180–183.
International Monetary Fund. 2009. Global Financial Stability Report.
Jackson, Matthew. 2008. Social and Economic Networks. Princeton, NJ: Princeton University Press.
Jackson, Matthew and Asher Wolinsky. 1996. “A Strategic Model of Social and Economic Networks.” Journal of Economic Theory 71: 44–74.
Jacob, Francois. 1977. “Evolution and Tinkering.” Science 196: 1161–1166.
Jacobs, Jane. 1989. Revolving Doors: Sex Segregation and Women’s Careers. Stanford, CA: Stanford University Press.
Johnson, James. 2014. “Models Among the Political Theorists.” American Journal of Political Science 58, no. 33: 547–560.
Johnson-Laird, Philip. 2009. How We Reason. New York: Oxford University Press.
Jones, Benjamin E, Brian Uzzi, and Stefan Wuchty. 2008. “Multi-University Research Teams: Shifting Impact, Geography and Social Stratification in Science.” Science 322: 1259–1262.
Jones, Charles, and Jihee Kim. 2018 “A Schumpeterian Model of Top Income Inequality.” Journal of Political Economy. Готовится к публикации.
Kahneman, Daniel. 2011. Thinking Fast and Slow. New York: Farrar, Straus and Giroux. (Даниэль Канеман. Думай медленно… решай быстро. М.: АСТ, Neoclassic, 2017.)
Kahneman, Daniel, and Amos Tversky. 1979. “Prospect Theory: An Analysis of Decisions Under Risk.” Econometrica 47, no. 2: 263–291. (Канеман Д. and Тверски А. Теория перспектив: анализ принятия решений в условиях риска. Журнал Экономика и математические методы (ЭММ), 2015, vol. 51, issue 1, 3-25.)
Kalyvas, Stathis. 1999. “The Decay and Breakdown of Communist One-Party Systems.” Annual Review of Political Science 2: 323–343.
Kamin, Leon J. 1969. “Predictability, Surprise, Attention and Conditioning.” In Punishment andAversive Behavior, ed. B. A. Campbell and R. M. Church, 279–296. New York: Appleton-Century-Crofts.
Kaplan, Steven, and Joshua D. Rauh. 2013a. “Family, Education, and Sources of Wealth Among the Richest Americans, 1982–2012.” American Economic Review Papers and Proceedings 103, no. 3: 158–162.
Kaplan, Steven, and Joshua D. Rauh. 2013b. “It’s the Market: The Broad-Based Rise in the Return to Top Talent.” Journal of Economic Perspectives 27, no. 3: 35–56.
Karlsson, Bengt. 2016. “The Forest of Our Lives: In and Out of Political Ecology.” Conservation and Society 14, no. 4: 380–390.
Kauffman, Stuart. 1993. The Origins of Order: Self-Organization and Selection in Evolution. Oxford: Oxford University Press.
Kennedy, John F. 1956. Profiles in Courage. New York: Harper & Brothers. (Джон Ф. Кеннеди. Профили мужества. М.: Международные отношения, 2013.)
Khmelev, Dmitri, and E J. Tweedie. 2001. “Using Markov Chains for Identification of Writers.” Literary and Linguistic Computing 16, no. 4: 299–307.
Kleinberg, Jon, and M. Raghu. 2015. “Team Performance with Test Scores.” Working paper, Cornell University School of Information.
Knox, Grahame. n.d. “Lost at Sea.” Insight, http://insight.typepad.co.uk/lost_at_sea.pdf.
Kollman, Ken, J. Miller, and S. Page. 1992. “Adaptive Parties in Spatial Elections.” American Political Science Review 86: 929–937.
Kooti, Farshad, Nathan O. Hodas, and Kristina Lerman. 2014. “Network Weirdness: Exploring the Origins of Network Paradoxes.” Работа представлена на Международной конференции блогов и социальных медиа (International Conference on Weblogs and Social Media, ICWSM) в марте.
Kurlansky, Mark. 1998. Cod: A Biography of the Fish That Changed the World. New York: Penguin.
Kydland, Finn E., and Edward C. Prescott. 1977. “Rules Rather than Discretion: The Inconsistency of Optimal Plans.” Journal of Political Economy 85, no. 3: 473–491.
Lai, T. L, and Herbert Robbins. 1985. ‘Asymptotically Efficient Adaptive Allocation Rules.” Advances in Applied Mathematics 6, no. 1: 4–22.
Laibson, David. 1997. “Golden Eggs and Hyperbolic Discounting.” Quarterly Journal of Economics 112, no. 2: 443–477.
Lamberson, P J., and Scott E. Page. 2012a. “The Effect of Feedback Variability on Success in Markets with Positive Feedbacks.” Economics Letters 114: 259–261.
Lamberson, E J., and Scott E. Page. 2012b. “Tipping Points.” Quarterly Journal of Political Science 7, no. 2: 175–208.
Lancaster, Kelvin J. 1966. “A New Approach to Consumer Theory.” Journal of Political Economy 74: 132–157.
Landemore, Helene. 2013. Democratic Reason: Politics, Collective Intelligence, and the Rule of the Many. Princeton, NJ: Princeton University Press.
Lango, Allen H., et al. 2010. “Hundreds of Variants Clustered in Genomic Loci and Biological Pathways Affect Human Height.” Nature 467, no. 7317: 832–838.
Langville, Amy N., and Carl D. Meyer. 2012. Who’s #1 ?: The Science of Rating and Ranking. Princeton, NJ: Princeton University Press.
Lave, Charles, and James G. March. 1975. An Introduction to Models in the Social Sciences. Lanham, MD: University Press of America.
Ledyard, John, David Porter, and Antonio Rangle. 1997. “Experiments Testing Multiobject Allocation Mechanisms.” Journal of Economics and Management Strategy 6, no. 3: 639–675.
Ledyard, John, David Porter, and Randii Wessen. 2000. “A Market-Based Mechanism for Allocating Space Shuttle Secondary Payload Priority.” Experimental Economics 2, no. 3: 173–195.
Levins, Richard. 1966. “The Strategy of Model Building in Population Biology.” American Scientist 54: 421–431.
Levinthal, Daniel A. 1997. “Adaptation on Rugged Landscapes.” Management Science 43: 934–950.
Levinthal, Daniel. 1991. “Random Walks and Organizational Mortality.»Administrative Science Quarterly 36, no. 3: 397–420.
Levitt, Steven, and Stephen Dubner. 2009. SuperFreakonomics: Global Cooling, Patriotic Prostitutes, and Why Suicide Bombers Should Buy Life Insurance. New York: William Morrow. (Левитт С., Дабнер С. Суперфрикономика. М. : Манн, Иванов и Фербер, 2010.)
Lewis, Michael. 2014. Flash Boys: A Wall Street Revolt. New York: W. W. Norton. (Майкл Л.. Flash Boys. Высокочастотная революция на Уолл-стрит. М. : Альпина Паблишер, 2019.)
Limpert, Eckhard, Werner A. Stahel, and Markus Abbt. 2001. “Log-normal Distributions Across the Sciences: Keys and Clues.” BioScience 51, no. 5: 341–352.
Little, Daniel. 1998. Microfoundations, Method, and Causation: On the Philosophy of the Social Sciences. Piscataway, NJ: Transaction Publishers.
Lo, Andrew W, and A. Craig MacKinlay. 2007. A Non-Random Walk Down Wall Street. Princeton, NJ: Princeton University Press.
Lo, Andrew W 2012. “Reading About the Financial Crisis: A Twenty-One-Book Review.” Journal of Economic Literature 50, no. 1: 151–178.
Lucas, Robert. 1976. “Econometric Policy Evaluation: A Critique.” In The Phillips Curve and Labor Markets, ed. K. Brunner and A. Meltzer, 19–46. Carnegie-Rochester Conference Series on Public Policy 1. New York: Elsevier.
Lucking-Reiley, David. 1999. “Using Field Experiments to Test Equivalence Between Auction Formats: Magic on the Internet.” American Economic Review 89, no. 5: 1063–1080.
MacKenzie, Debora. 2012. “Boom and Doom: Revisiting Prophecies of Collapse.” New Scientist, January.
Mannes, Albert E., Jack B. Soil, and Richard E Larrick. 2014. “The Wisdom of Select Crowds.” Journal of Personality and Social Psychology 107: 276–299.
Markowitz, Harold M. 1952. “Portfolio Selection.” Journal of Finance 7, no. 1: 77–91.
Markus, Greg B. 1988. “The Impact of Personal and National Economic Conditions on the Presidential Vote: A Pooled Cross-Sectional Analysis.” American Journal of Political Science 32: 137–154.
Martin, Andrew D., and Kevin M. Quinn. 2002. “Dynamic Ideal Point Estimation via Markov Chain Monte Carlo for the U.S. Supreme Court, 1953–1999.” Political Analysis 10: 134–153.
Martin, Francis, et al. 2008. “The Genome of Laccana Bicolor Provides Insights into Mycorrhizal Symbiosis.” Nature 452: 88–92.
Martinez Peria, Maria Soledad, Giovanni Majnoni, Matthew T. Jones, and Winfrid Blaschke. 2001. “Stress Testing of Financial Systems: An Overview of Issues, Methodologies, and FSAP Experiences.” IMF Working Paper no. 01/88.
Mas-Colell, Andreu, Michael D. Whinston, and Jerry R. Green. 1994. Microeconomic Theory. New York: Oxford University Press. (Мас-Колелл А., Уинстон М., Грин Д. Микроэкономическая теория М.: Дело, 2016.)
Mauboussin, Michael. 2012. The Success Equation: Untangling Skill and Luck in Business. Cambridge, MA: Harvard University Press.
May, Robert M., Simon A. Levin, and George Sugihara. 2008. “Ecology for Bankers.” Nature 451: 893–895.
McCarty, Nolan. 2011. “Measuring Legislative Preferences.” In Oxford Handbook of Congress, ed. Eric Schickler and Frances Lee. New York: Oxford University Press.
McCarty, Nolan, and Adam Meirowitz. 2014. Political Game Theory: An Introduction. Cambridge: Cambridge University Press.
McKelvey, Richard. 1979. “General Conditions for Global Intransitivities in Formal Voting Models.” Econometnca 47: 1085–1112.
McPhee, William N. 1963. Formal Theories of Mass Behaviour. New York: Free Press of Glencoe.
Meadows, D., G. Meadows, J. Randers, and W. W Behrens III. 1972. The Limits to Growth. New York: Universe Books. (Медоуз Д., Медоуз Б. и т.д. и Йорген Рандерс. Пределы роста. М. : Издательство МГУ, 1991. Медоуз Д., Медоуз Б. и Рандерс Й. Пределы роста: 30 лет спустя. М. : Бином. Лаборатория знаний, 2016.)
Medin, Douglas, Will Bennis, and Michel Chandler. 2010. “The Home-Field Disadvantage.” Perspectives on Psychological Science 5, no. 6: 708–713.
Merriam, Daniel F., and John C. Davis. 2009. “Using Zipf’s Law to Predict Future Earthquakes in Kansas.” Transactions of the Kansas Academy of Science 112, nos. 1&2: 127–129.
Merton, Robert C. 1969. “Lifetime Portfolio Selection Under Uncertainty: The Continuous-Time Case.” Review of Economics and Statistics 51, no. 3: 247–257.
Merton, Robert K. 1963. “Resistance to the Systematic Study of Multiple Discoveries in Science.” European Journal of Sociology 4, no. 2: 237–282.
Milgrom, Paul, and John Roberts. 1986. “Pricing and Advertising Signals of Product Quality.” Journal of Political Economy 94, no. 4: 796–821.
Miller, John H. 1998. “Active Nonlinear Tests (ANTs) of Complex Simulation Models.” Management Science 44, no. 6: 820–830.
Miller, John H. 2015. A Crude Look at the Whole. New York: Basic Books.
Miller, John H., and Scott E. Page. 2004. “The Standing Ovation Problem.” Complexity 9, no. 5: 8–16.
Miller, John H., and Scott E. Page. 2007. Complex Adaptive Systems: An Introduction to Computational Modeb of Social Life. Princeton, NJ: Princeton University Press.
Miller, Joshua B., and Adam Sanjurjo. 2015. “Surprised by the Gambler’s and Hot Hand Fallacies: A Truth in the Law of Small Numbers.” IGIER Working Paper no. 552.
Mitchell, Melanie. 1996. An Introduction to Genetic Algorithms. Cambridge, MA: MIT Press.
Mitchell, Melanie. 2009. Complexity: A Guided Tour. Oxford: Oxford University Press.
Mlodinow, Leonard. 2009. The Drunkard’s Walk: How Randomness Rules Our Lives. New York: Penguin. (Леонард Млодинов. (Не)совершенная случайность. Как случай управляет нашей жизнью. М.: Гаятри/Livebook, 2013.)
Mokyr, Joel. 2002. The jpgts of Athena: Historical Origins of the Knowledge Economy. Princeton, NJ: Princeton University Press. (Джоэль Мокир. Дары Афины. Исторические истоки экономики знаний. М.: Издательство Института Гайдара, 2012.)
Morgan, John, and Tanjim Hossain. 2006. ”… Plus Shipping and Handling: Revenue (Non)Equivalence in Field Experiments on eBay.” Advances in Economic Analysis & Policy 6, no. 2: 3.
Moss-Racusin, Corinne, John F. Dovidio, Victoria L. Brescoll, Mark J. Graham, and Jo Handelsman. 2012. “Science Faculty’s Subtle Gender Biases Favor Male Students.” Proceedings of the National Academy of Sciences. 1647–1649.
Munger, Charles. 1994. “A Lesson on Elementary, Worldly Wisdom as It Relates to Investment Management & Business.” University of Southern California Business School.
Murphy, Kevin M., and Robert H. Topel. 2016. “Human Capital Investment, Inequality and Growth.” Journal of Labor Economics 34: 99–127.
Murray, J. D. 1988. “Mammalian Coat Patterns: How the Leopard Gets Its Spots.” Scientific American 256: 80–87.
Myerson, Roger B. 1999. “On the Value of Game Theory in Social Science.” Rationality and Society 4: 62–73.
Myerson, Roger B. 1999. “Nash Equilibrium and the History of Economic Theory.” Journal of Economic Literature 37, no. 3: 1067–1082.
Nagel, Rosemarie. 1995. “Unraveling in Guessing Games: An Experimental Study.” American Economic Review 85, no. 5: 1313–1326.
Newman, Mark E. 2005. “Power Laws, Pareto Distributions and Zipf’s Law.” Contemporary Physics 46: 323–351.
Newman, Mark E. 2010. Networks: An Introduction. Oxford: Oxford University Press.
Nowak, Martin. 2006. “Five Rules for the Evolution of Cooperation.” Science 314, no. 5805: 1560–1563.
Nowak, Martin A., and Karl Sigmund. 1998. “Evolution of Indirect Reciprocity by Image Scoring.” Nature 393: 573–577.
Olson, Mancur. 1965. The Logic of Collective Action: Public Goods and the Theory of Groups. Cambridge, MA: Harvard University Press.
O’Neil, Cathy 2016. Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. New York, NY: Crown.
Open Science Collaboration. 2015. “Estimating the Reproducibility of Psychological Science.” Science 349: 6251.
Organization for Economic Co-operation and Development. 1996. The Knowledge Based Economy. Paris: OECD.
Ormerod, Paul. 2012. Positive Linking: How Networks Can Revolutionise the World. London: Faber and Faber.
Ostrom, Elinor. 2004. Understanding Institutional Diversity. Princeton, NJ: Princeton University Press.
Ostrom, Elinor. 2010. “Beyond Markets and States: Polycentric Governance of Complex Economic Systems.” Transnational Corporations Review 2, no. 2: 1–12.
Ostrom, Elinor, Marco A. Janssen, and John M. Anderies. 2007. “Going Beyond Panaceas.” Proceedings of the National Academy of Sciences 104: 15176–15178.
Ostrovsky, Michael, Benjamin Edelman, and Michael Schwarz. 2007. “Internet Advertising and the Generalized Second Price Auction: Selling Billions of Dollars Worth of Keywords.” American Economic Review 97, no. 1: 242–259.
Paarsch, Harry J., and Bruce S. Shearer. 1999. “The Response of Worker Effort to Piece Rates: Evidence from the British Columbia Tree-Planting Industry.” Journal of Human Resources 34, no. 4: 643–667.
Packer, Craig, and Anne E. Pusey. 1997. “Divided We Fall: Cooperation Among Lions.” Scientific American, May, 52–59.
Paczuski, Maya, and Kai Nagel. 1996. “Self-Organized Criticality and 1// Noise in Traffic.” arXiv: cond-mat/9602011.
Page, Scott E. 1997. “An Appending Efficient Algorithm for Allocating Public Projects with Complementarities,” Journal of Public Economics 64, no 3: 291–322.
Page, Scott E. 2001. “Self Organization and Coordination.” Computational Economics 18: 25–48.
Page, Scott E. 2006. “Essay: Path Dependence.” Quarterly Journal of Political Science 1: 87–115.
Page, Scott E. 2007. The Difference: How the Power of Diversity Creates Better Groups, Teams, Schools, and Societies. Princeton, NJ: Princeton University Press.
Page, Scott E. 2010a. Diversity and Complexity. Princeton, NJ: Princeton University Press.
Page, Scott E. 2010b. “Building a Science of Economics for the Real World.” Presentation to the House Committee on Science and Technology Subcommittee on Investigations and Oversight, July 20.
Page, Scott E. 2012. “A Complexity Perspective on Institutional Design.” Politics, Philosophy and Economics 11: 5–25.
Page, Scott E. 2017. The Diversity Bonus. Princeton, NJ: Princeton University Press.
Pan, Jessica. 2014. “ Gender Segregation in Occupations: The Role of Tipping and Social Interactions.” Journal of Labor Economics 33, no. 2: 365–408.
Parrish, Susan Scott. 2017. The Flood Year 1927: A Cultural History. Princeton, NJ: Princeton University Press.
Parsa, H. G., John T. Self, David Njite, and Tiffany King. 2005. “Why Restaurants Fail.” Cornell Hospitality Quarterly 46, no. 3: 304–322.
Patel, Kayur, Steven Drucker, James Fogarty, Ashish Kapoor, and Desney Tan. 2011. “Using Multiple Models to Understand Data.” Proceedings of the International Joint Conference on Artificial Intelligence, 1723–1728.
Peel, L. and A. Clauset. 2014. “Predicting Sports Scoring Dynamics with Restoration and Anti-Persistence.” Proceedings of the International Conference on Data Mining. Philadelphia: SIAM.
Pfeffer, Fabian T, and Alexandra Killewald. 2017. “Generations of Advantage: Multigenerational Correlations in Family Wealth.” Social Forces, 1–31.
Piantadosi, Steven. 2014. “Zipf’s Word Frequency Law in Natural Language: A Critical Review and Future Directions.” Psychonomic Bulletin & Review 21, no. 5: 1112–1130.
Pierson, Paul. 2004. Politics in Time: History, Institutions, and Social Analysis. Princeton, NJ: Princeton University Press.
Piketty, Thomas. 2014. Capital in the 21st Century. Trans. Arthur Goldhammer. Cambridge, MA: Belknap Press. (Тома Пикетти. Капитал в XXI веке. М.: Ad Marginem, 2015.)
Plott, C. R. 'A Notion of Equilibrium and its Possibility under Majority Rule', American Economic Review, 57 (1967), 787–806.
Pollack, John. 2014. Shortcut: How Analogies Reveal Connections, Spark Innovation, and Sell Our Greatest Ideas. New York: Gotham.
Poole, Keith T, and Howard Rosenthal. 1984. ‘A Spatial Model for Legislative Roll Call Analysis.” American Journal of Political Science 29, no. 2: 357–384.
Porter, David, and Vernon Smith. 2007. “FCC Spectrum Auction Design: A 12-Year Experiment.” Journal of Law, Economics, and Policy 3, no. 1: 63–80.
Powell, Robert. 1991. “Absolute and Relative Gains in International Relations Theory.” American Political Science Review 85, no. 4: 1303–1320.
Przeworski, Adam, Jose Antonio Cheibub, Michael E. Alvarez, and Fernando Limongi. 2000. Democracy and Development: Political Institutions and Material Well-Being in the World, 1950–1990. Cambridge: Cambridge University Press.
Raby, Fiona. 2001. Design Noir: The Secret Life of Electronic Objects. Basel: Birkhauser.
Ramo, Joshua Cooper. 2016. The Seventh Sense: Power, Fortune, and Success, in the Age of Networks. New York: Little, Brown and Company.
Rand, David G., Hisashi Ohtsukia, and Martin A. Nowak. 2009. “Direct Reciprocity with Costly Punishment: Generous Tit-for-Tat Prevails.” Journal of Theoretical Biology 256, no. 1: 45–57.
Rapoport, Anatol. 1978. “Reality-Simulation: A Feedback Loop.” Sociocybernetics, 123–141.
Rauch, Jeffrey. 2012. Hyperbolic Partial Differential Equations and Geometric Optics. Graduate Studies in Mathematics. Providence, RI: American Mathematical Society.
Rawls, John. 1971. A Theory of Justice. Cambridge, MA: Harvard University Press. (Джон Ролз. Теория справедливости. — М.: Ленанд, 2017.)
Rescorla, Robert, and Allan Wagner. 1972. “A Theory of Pavlovian Conditioning: Variations in the Effectiveness of Reinforcement and Non-reinforcement.” In Classical Conditioning II, ed. A. H. Black and W F. Prokasy, 64–99. New York: Appleton-Century-Crofts.
Reynolds, Noel B., and Arlene Saxonhouse. 1994. Three Discourses. Chicago: University of Chicago Press.
Roberts, D. C, and D. L. Turcotte. 1998. “Fractality and Self-Organized Crit-icality of Wars.” Fractals 6: 351–357.
Roberts, Seth. 2004. “Self-Experimentation as a Source of New Ideas: Ten Examples About Sleep, Mood, Health, and Weight.” Behavioral and Brain Sciences 27, no. 2: 227–262.
Romer, Paul. 1986. “Increasing Returns and Long-Run Growth.” Journal of Political Economy 94: 1002–1037.
Rosen, Sherwin. 1981. “The Economics of Superstars.” American Economic Review 71: 845–858.
Roth, Alvin, and Ido Erev. 1995. “Learning in Extensive Form Games: Experimental Data and Simple Dynamic Models in the Intermediate Term.” Games and Economics Behavior 8: 164–212.
Russakoff, Dale. 2015. The Prize: Who’s in Charge of America’s Schools? Boston: Houghton Mifflin Harcourt.
Rust, Jon. 1987. “Optimal Replacement of GMC Bus Engines: An Empirical Model of Harold Zurcher.” Econometrica 55, no. 5: 999–1033.
Ryall, Michael D., and Aaron Bramson. Inference and Intervention: Causal Models for Business Analysis. New York: Routledge.
Salganik, Matthew, Peter Dodds, and Duncan J. Watts. 2006. “Experimental Study of Inequality and Unpredictability in an Artificial Cultural Market.” Science 311: 854–856.
Samuelson, Paul. 1964. “Proof That Properly Anticipated Prices Fluctuate Randomly.” Industrial Management Review 6: 41–49.
Schrodt, Philip. 1998. “Pattern Recognition of International Crises Using Hidden Markov Models.” In Non-Linear Models and Methods in Political Science, ed. Diana Richards. Ann Arbor: University of Michigan Press.
Schwartz, Christine R., and Robert D. Mare. 2004. “Trends in Educational Assortative Marriage from 1940 to 2003.” Demography 42, no. 4: 621–646.
Schelling, Thomas. 1978. Micromotives and Macrobehavior. New York: W. W. Norton. (Шеллинг Т. Микромотивы и макровыбор. М. : Издательство Института Гайдара, 2016.)
Shiller, Robert. 2005. Irrational Exuberance. 2nd ed. Princeton, NJ: Princeton University Press.
Scott, Steven L. 2010. “A Modern Bayesian Look at the Multi-Armed Bandit.” Applied Stochastic Models in Business and Industry 26: 639–658.
Shalizi, Cosma, and Andrew C. Thomas. 2011. “Homophily and Contagion Are Generically Confounded in Observational Social Network Studies.” Sociological Methods and Research 40: 211–239.
Shapiro, Thomas, Tatjana Meschede, and Sam Osoro. 2013. “The Roots of the Widening Racial Wealth Gap: Explaining the Black-White Economic Divide.” Research and Policy Brief, Institute on Assets and Social Policy, Brandeis University, Waltham, MA.
Shi, Xiaolin, Lada A. Adamic, Belle L. Tseng, and Gavin S. Clarkson. 2009. “The Impact of Boundary Spanning Scholarly Publications and Patents.” PLoS ONE 4, no. 8: e6547.
Silver, Nate. 2012. The Signal and the Noise: Why So Many Predictions Fail — but Some Don’t. New York: Penguin. (Сильвер Н. Сигнал и шум. Почему одни прогнозы сбываются, а другие — нет. — М.: КоЛибри, 2015.)
Simler, Kevin, and Robin Hanson. 2018. The Elephant in the Brain: Hidden Motives in Everyday Life. Oxford: Oxford University Press.
Simmons, Matthew, Lada Adamic, and Eytan Adar. 2011. “Memes Online: Extracted, Subtracted, Injected, and Recollected.” Paper presented at the International Conference on Web and Social Media.
Slaughter, Ann Marie. 2017. The Chessboard and the Web: Strategies of Connection in a Networked World. New Haven, CT: Yale University Press.
Smaldino, Paul. 2013. “Measures of Individual Uncertainty for Ecological Models: Variance and Entropy.” Ecological Modelling 254: 50–53.
Small, Dana M., Robert J. Zatorre, Alain Dagher, Alan C. Evans, and Marilyn Jones-Gotman. 2001. “Changes in Brain Activity Related to Eating Chocolate: From Pleasure to Aversion.” Brain 124, no. 9: 1720–1733.
Smith, Eric, Rebecca Bliege Bird, and D. Bird. 2003. “The Benefits of Costly Signaling: Meriam Turtle Hunters.” Behavioral Ecology 14: 116–126.
Smith, Vernon. 2002. “Constructivist and Ecological Rationality.” Nobel Prize lecture. (Вернон Смит. Конструктивистская и экологическая рациональность в экономической науке. — МЭМ, т. V, кн. 2, стр. 755).
Sneppen, Kim, Per Bak, Henrik Flyvbjerg, and Mogens Jensen. 1994. “Evolution as a Self-Organized Critical Phenomenon.” Proceedings of the National Academy of Sciences 92: 5209–5213.
Solow, Robert M. 1956. “A Contribution to the Theory of Economic Growth.” Quarterly Journal of Economics 70, no. 1: 65–94.
Spence, A. Michael. 1973. ‘Job Market Signaling.” Quarterly Journal of Economics 87, no. 3: 355–374.
Squicciarini, Mara, and Nico Voigtlander. 2015. “Human Capital and Industrialization: Evidence from the Age of Enlightenment.” Quarterly Journal of Economics 30, no. 4: 1825–1883.
Starfield, Anthony, Karl Smith, and Andrew Bleloch. 1994. How to Model It: Problem Solving for the Computer Age. Minneapolis, MN: Burgess International.
Stein, Richard A. 2011. “Superspreaders in Infectious Diseases.” International Journal of Infectious Diseases 15, no. 8: e510-e513.
Sterman, John D. 2000. Business Dynamics: Systems Thinking and Modeling for a Complex World. New York: McGraw-Hill.
Sterman, John. 2006. “Learning from Evidence in a Complex World.” American Journal of Public Health 96, no. 3: 505–515.
Stiglitz, Joseph. 2013. The Price of Inequality: How Today’s Divided Society Endangers Our Future. New York: W W Norton. (Стиглиц дж.. Цена неравенства. Чем расслоение общества грозит нашему будущему. М.: Эксмо, 2015.)
Stock, James H., and Mark W. Watson. 2003. “Has the Business Cycle Changed and Why?” In National Bureau of Economic Research Macroeconomics Annual 2002, vol. 17, ed. Mark Gertler and Kenneth Rogoff, 159–218. Cambridge, MA: MIT Press.
Stone, Lawrence D., Colleen M. Keller, Thomas M. Kratzke, and Johan E. Strumpfer. 2014. “Search for the Wreckage of Air France Flight AF 447.” Statistical Science 29, no. 1: 69–80.
Storchmann, Karl. 2011. “Wine Economics: Emergence, Developments, Topics.” Agrekon 50, no. 3: 1–28.
Suki, Bela, and Urs Frey. 2017. “A Time Varying Biased Random Walk Model of Growth: Application to Height from Birth to Childhood.” Journal of Critical Care 38: 362–370.
Suroweicki, James. 2006. The Wisdom of Crowds. New York: Anchor Press. (Шуровьески Дж.. Мудрость толпы. Почему вместе мы умнее, чем поодиночке, и как коллективный разум влияет на бизнес, экономику, общество и государство. М. : Манн, Иванов и Фербер, 2013.)
Syverson, Chad. 2007. “Prices, Spatial Competition, and Heterogeneous Producers: An Empirical Test.” Journal of Industrial Economics 55, no. 2: 197–222.
Taleb, Nassim. 2001. Fooled by Randomness. New York: Random House. (Талеб Н. Одураченные случайностью. О скрытой роли шанса в бизнесе и в жизни. М. : Манн, Иванов и Фербер, 2018.)
Taleb, Nassim. 2007. The Black Swan: The Impact of the Highly Improbable. New York: Random House. (Талеб Н. Черный лебедь. Под знаком непредсказуемости. Азбука Аттикус, КоЛибри, 2018.)
Taleb, Nassim. 2012. Antifragile: Things That Gain from Disorder. New York: Random House. (Талеб Н. Антихрупкость. Как извлечь выгоду из хаоса. КоЛибри, 2016.)
Tassier, Troy. 2013. The Economics of Epidemiology. Amsterdam: Springer.
Tetlock, Phillip. 2005. Expert Political Judgment: How Good Is It? How Can We Know? Princeton, NJ: Princeton University Press.
Thaler, R. H. 1981. “Some Empirical Evidence on Dynamic Inconsistency.” Economic Letters 8, no. 3: 201–207.
Thompson, Derek. 2014. “How You, I, and Everyone Got the Top 1 Percent All Wrong: Unveiling the Real Story Behind the Richest of the Rich.” Atlantic, March 30.
Thorndike, Edward L. 1911. Animal Intelligence. New York: Macmillan.
Tilly, Charles. 1998. Durable Inequality. Berkeley: University of California Press.
Tsebelis, George. 2002. Veto Players: How Political Institutions Work. Princeton, NJ: Princeton University Press.
Turchin, Peter. 1998. Quantitative Analysis of Movement: Measuring and Modeling Population Redistribution in Animals and Plants. Sunderland, MA: Sinauer Associates.
Tweedle, Valerie, and Robert J. Smith. 2012. “A Mathematical Model of Bieber Fever: The Most Infectious Disease of Our Time?” In Understanding the Dynamics of Emerging and Re-Emerging Infectious Diseases Using Mathematical Models,, ed. Steady Mushayabasa and Claver P. Bhunu. Cham, Switzerland: Springer.
Ugander, Johan, Brian Karrer, Lars Backstrom, and Cameron Marlow. 2011. “The Anatomy of the Facebook Social Graph.” arXiv:1111.4503.
Updike, John. 1960. “Hub Fans Bid Kid Adieu.” New Yorker, October 22.
US Bureau of Labor Statistics. 2013. Consumer Expenditures in 2011. Report 1042, April. Washington, DC: BLS.
Uzzi, Brian, Satyam Mukherjee, Michael Stringer, and Ben Jones. 2013. “Atypical Combinations and Scientific Impact.” Science 342: 468–471.
Van Noorden, Richard. 2015. “Interdisciplinary Research by the Numbers.” Nature, September 16.
von Neumann, John, and Morgenstern, Oskar. 1953. Theory of Games and Economic Behavior. Princeton, NJ: Princeton University Press. (Джон фон Нейман, Оскар Моргенштерн. Теория игр и экономическое поведение. М.: Наука, 1970).
Vriend, Nicolaas J. 2000. “An Illustration of the Essential Difference Between Individual and Social Learning, and Its Consequences for Computational Analyses.” Journal of Economic Dynamics and Control 24: 1–19.
Wainer, Howard. 2009. Picturing the Uncertain World. Princeton, NJ: Princeton University Press.
Wakeland, W, A. Nielsen, and E Geissert. 2015. “Dynamic Model of Non-medical Opioid Use Trajectories and Potential Policy Interventions.” American Journal of Drug and Alcohol Abuse 41, no. 6: 508–518.
Waltz, Kenneth. 1979. Theory of International Politics. New York: McGraw-Hill.
Washington Post. 2012. “Mad Money: TV Ads in the 2012 Presidential Campaign.” http://www.washingtonpost.com/wp-srv/special/politics/track-presidential-campaign-ads-2012.
Watts, Duncan. 2011. Everything Is Obvious Once You Know the Answer. New York: Crown Business.
Watts, Duncan, and Steven Strogatz. 1998. “Collective Dynamics of’Small-World’ Networks.” Nature 393, no. 6684: 440–442.
Weisberg, Michael. 2007. “Three Kinds of Idealization.” Journal of Philosophy 104, no. 12: 639–659.
Weisberg, Michael. 2012. Simulation and Similarity: Using Models to Understand the World. Oxford: Oxford University Press.
Weisberg, Michael, and Muldoon, Ryan. 2009. “Epistemic Landscapes and the Division of Cognitive Labor.” Philosophy of Science 76, no. 2: 225–252.
Weitzman, Martin L. 1979. “Optimal Search for the Best Alternative.” Econometrica 77: 641–654.
Weitzman, Martin L. 1998. “Recombinant Growth.” Quarterly Journal of Economics 2: 331–361.
Wellman, Michael. 1990. “Fundamental Concepts of Qualitative Probabilistic Networks.” Artificial Intelligence 44: 257–303.
Wellman, Michael. 2013. “Head to Head: Does US High-Frequency Trading Need Stricter Regulatory Oversight? (YES).” International Financial Law Review, September.
West, Geoffrey. 2017. Scale: The Universal Laws of Growth, Innovation, Sus-tainability, and the Pace of Life in Organisms, Cities, Economies, and Companies. New York: Penguin. (Уэст Дж.. Масштаб. Универсальные законы роста, инноваций, устойчивости и темпов жизни организмов, городов, экономических систем и компаний. М. : Азбука, 2018.)
Whittle, Peter. 1979. “Discussion of Dr Gittins’ Paper.” Journal of the Royal Statistical Society, Series B 41, no. 2: 148–177.
Whitty, Robin W. 2017. “Some Comments on Multiple Discovery in Mathematics.” Journal of Humanistic Mathematics 7, no. 1: 172–188.
Wigner, Eugene. 1960. “The Unreasonable Effectiveness of Mathematics in the Natural Sciences.” Communications in Pure and Applied Mathematics 13, no. 1. (Вигнер Е.. Инвариантность и законы сохранения. Этюды о симметрии. Ленанд, 2015.)
Wilkinson, Richard, and Kate Pickett. 2009. The Spirit Level: Why Greater Equality Makes Societies Stronger. London: Bloomsbury.
Wilson, David Sloan. 1975. “A Theory of Group Selection.” Proceedings of the National Academy of Sciences 72, no. 1: 143–146.
Wolfram, Stephen. 2001. A New Kind of Science. Champaign, IL: Wolfram Media.
Wright, Robert. 2001. Nonzero: The Logic of Human Destiny. New York: Vintage.
Wu, Jianzhong, and Robert Axelrod. 1995. “How to Cope with Noise in the Iterated Prisoner’s Dilemma.” Journal of Conflict Resolution 39, no. 1: 183–189.
Wuchty Stefan, Benjamin F. Jones, and Brian Uzzi. 2007. “The Increasing Dominance of Teams in the Production of Knowledge.” Science 316, no. 5827: 1036–1039.
Xie, Yu. 2007. “Otis Dudley Duncan’s Legacy: The Demographic Approach to Quantitative Reasoning in Social Science.” Research in Social Stratification and Mobility 25: 141–156.
Xie, Yu, Alexandra Killewald, and Christopher Near. 2016. “Between- and Within-Occupation Inequality: The Case of High Status Professions.” Annals of the American Academy of Political and Social Science 663, no. 1: 53–79.
Youn, Hyejin, Deborah Strumsky, Luis Bettencourt, and Jose Lobo. 2015. “Inventions as a Combinatorial Process: Evidence From US Patents.” Journal of the Royal Society Interfaces 12: 0272.
Zagorsky, Jay. 2007. “Do You Have to Be Smart to Be Rich? The Impact of IQ on Wealth, Income and Financial Distress.” Intelligence 35: 489–501.
Zahavi, Amotz. 1974. “Mate Selection: A Selection for a Handicap.” Journal of Theoretical Biology 53, no. 1: 205–214.
Zak, Paul, and Stephen Knack. 2001. “Trust and Growth.” Economic Journal 111, no. 470: 295–321.
Zaretsky, Adam. 1998. “Have Computers Made Us More Productive? A Puzzle.” Regional Economist, Federal Reserve Bank of St. Louis.
Ziliak, Stephen T., and Deirdre N. McCloskey. 2008. The Cult of Statistical Significance: How the Standard Error Costs Us Jobs, Justice, and Lives. Ann Arbor: University of Michigan Press.
Эту книгу хорошо дополняют:
Теория игр
Авинаш Диксит, Барри Нейлбафф
Экономика всего
Александр Аузан
Как устроена экономика
Ха Джун Чанг
Момент истины
Сайен Бейлок
Принцип ставок
Энни Дьюк
SCOTT E. PAGE
THE MODEL THINKER
WHAT YOU NEED TO KNOW TO MAKE DATA WORK FOR YOU
BASIC BOOKS
NEW YORK
СКОТТ ПЕЙДЖ
МОДЕЛЬНОЕ МЫШЛЕНИЕ
КАК АНАЛИЗИРОВАТЬ СЛОЖНЫЕ ЯВЛЕНИЯ С ПОМОЩЬЮ МАТЕМАТИЧЕСКИХ МОДЕЛЕЙ
МОСКВА«МАНН, ИВАНОВ И ФЕРБЕР»
2020
Информация
от издательства
Научные редакторы Игорь Красиков, Александр Минько
Издано с разрешения автора и c/o Brockman, Inc.
На русском языке публикуется впервые
Пейдж, Скотт
Модельное мышление. Как анализировать сложные явления с помощью математических моделей / Скотт Пейдж; пер. с англ. Н. Яцюк; [науч. ред. И. Красиков, А. Минько]. — М. : Манн, Иванов и Фербер, 2020.
ISBN 978-5-00146-867-7
В какой бы области вы ни работали — в науке, бизнесе или государственном управлении, вам приходится решать сложные задачи с огромным количеством данных. Из этой книги вы узнаете, как заставить эти данные работать на вас.
Автор объясняет, как с помощью 25 классов математических моделей анализировать данные и решать проблемы в повседневных ситуациях. Это хорошо бы знать каждому, кто должен ежедневно принимать решения, лавируя в потоке информации, — предпринимателям, менеджерам, аналитикам, социологам, ученым, студентам и не только.
Книга будет полезна всем, кто работает с большими массивами данных и принимает решения на их основе.
Все права защищены.
Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
© Scott Page, 2018 All rights reserved
© Перевод на русский язык, издание на русском языке, оформление. ООО «Манн, Иванов и Фербер», 2020
Посвящается Майклу Коэну (1945−2013)
Едва ли можно отрицать, что высшая цель любой теории — сделать неприводимые базовые элементы как можно проще и немногочисленнее, не отказываясь от адекватного представления исходной единицы опыта.
Альберт Эйнштейн
ГЛАВА 1
МНОГОМОДЕЛЬНОЕ МЫШЛЕНИЕ
Мудрость — это умение организовать свой опыт (как опосредованный, так и непосредственный) и знания на матрице различных моделей.
Чарльз Мангер
Это книга о моделях. В ней просто и понятно описываются десятки моделей и способы их применения. Модели — это формальные структуры, представленные в видематематических формул и диаграмм, которые помогают нам понять этот мир. Их освоение улучшает способность рассуждать, объяснять, разрабатывать, коммуницировать, действовать, прогнозировать и исследовать.
В книге рассматривается подход под названием многомодельное мышление: использование совокупности моделей для осмысления сложных явлений. Основная идея состоит в том, что многомодельное мышление порождает мудрость посредством применения разнообразного ансамбля логических структур. Различные модели акцентируются на отдельных причинно-следственных факторах. В итоге их выводы и следствия перекрываются и переплетаются. Используя множество моделей в качестве логических структур, мы добиваемся детального, глубокого понимания происходящего. В книгу включены формальные аргументы, убедительно обосновывающие концепцию множества моделей, а также многочисленные примеры из реальной жизни.
Книга имеет прагматическую направленность, а многомодельное мышление — огромную практическую ценность. Практикуя его, вы сможете лучше понять сложные явления. Научитесь эффективнее выстраивать логические умозаключения. В ваших рассуждениях будет меньше пробелов и вы станете принимать более взвешенные решения в отношении карьеры, общественной деятельности и личной жизни. А возможно, даже обретете мудрость.
Двадцать пять лет назад книга о моделях заинтересовала бы преподавателей и аспирантов, изучающих бизнес, политику и общественные науки, а также финансовых аналитиков, страховых агентов и сотрудников спецслужб. Именно они применяли модели на практике и чаще всего имели дело с большими массивами данных. Сегодня аудитория книги о моделях существенно расширилась — это огромное количество работников умственного труда, которые в связи с появлением больших данных теперь считают работу с моделями частью повседневной жизни.
Организация и интерпретация данных с помощью моделей стала ключевым умением специалистов по бизнес-стратегиям, градостроителей, экономистов, медиков, инженеров, страховых аналитиков и ученых-экологов. Каждый, кто анализирует данные, формирует бизнес-стратегии, распределяет ресурсы, разрабатывает продукты и протоколы или принимает решения о найме, сталкивается с моделями. Следовательно, усвоение материала данной книги (особенно моделей, охватывающих такие области, как инновации, прогнозирование, биннинг данных2, обучение и расчет времени выхода на рынок) будет иметь для многих практическую ценность.
Многомодельное мышление не просто повысит вашу эффективность на работе, но и сделает вас более достойными гражданами и более вдумчивыми участниками общественной жизни. Благодаря ему вы станете настоящими экспертами в оценке экономических и политических событий. Научитесь обнаруживать изъяны в своей логике и логике других. Сможете определять, когда идеология вытесняет здравый смысл, и выработаете более глубокое, многоуровневое понимание последствий политических инициатив, будь то в отношении зеленых зон или обязательных тестов на наркотики.
Все эти преимущества будут получены в результате использования множества различных моделей — не сотен, а нескольких десятков. Модели, о которых пойдет речь в книге, — хороший базовый набор. Они проистекают из разных дисциплин и включают дилемму заключенного, гонку по нисходящей и модель распространения инфекционных заболеваний SIR. Все эти модели имеют общую форму: они предполагают наличие множества объектов (чаще всего это люди или организации) и описывают взаимодействие между ними.
Представленные в книге модели можно разделить на три категории: упрощенные модели мира, математические аналогии и исследовательские, искусственные конструкции. Какой бы ни была форма, модель должна быть разрешимой, то есть достаточно простой, чтобы в ней можно было применять логику. Например, в книгу включена модель распространения инфекционных заболеваний, позволяющая на основе данных о трех группах людей — инфицированных, восприимчивых к болезни и излечившихся от нее — определять степень распространения болезни, а также вычислять пороговый уровень заражения (переломный момент, после которого болезнь начинает распространяться) и количество людей, которых необходимо вакцинировать, чтобы остановить распространение заболевания.
Однако какими бы действенными ни были отдельные модели, их комбинация позволяет добиться большего, поскольку исключает свойственную им ограниченность. Многомодельный подход проливает свет на белые пятна каждой модели, входящей в комбинацию. Политические решения, принятые на основе одиночных моделей, могут не учитывать важных особенностей окружающего мира, таких как неравенство в распределении доходов, многообразие идентичности и взаимосвязи с другими системами [1]. Использование набора моделей помогает выстраивать логическую интерпретацию множества процессов. Мы видим, как они перекрываются и взаимодействуют, создаем почву для осмысления той сложности, которая присуща нашей экономической, политической и социальной жизни. И делаем это, не поступаясь строгостью, — модельное мышление гарантирует логическую связность. Далее эту логику можно подкрепить фактическими данными, применив к ним модели для проверки, уточнения и совершенствования. В общем, когда наше мышление опирается на последовательную, эмпирически подтвержденную систему координат, это повышает вероятность принятия мудрых решений.
МОДЕЛИ В ЭПОХУ ДАННЫХ
Появление книги о моделях может показаться неуместным в эпоху больших данных, которые сегодня характеризуются беспрецедентной размерностью и степенью детализации. Данные о покупках клиентов, раньше поступавшие в виде ежемесячных совокупных показателей, распечатанных на бумаге, теперь представляют непрерывный поток геопространственных, временных и потребительских тегов. Данные об академической успеваемости студентов теперь включают баллы за каждое домашнее задание, работу, тест и экзамен, в отличие от итоговых оценок в конце семестра. В прошлом фермер мог упомянуть о засушливой почве на ежемесячном собрании ассоциации фермеров. Теперь тракторы передают мгновенные данные о состоянии почвы и уровне влажности в расчете на каждый квадратный метр. Инвестиционные компании отслеживают десятки показателей и тенденций по тысячам акций и используют инструменты обработки текстов на естественных языках для синтаксического анализа документов. Врачи могут страница за страницей получать данные из истории болезни пациентов, в том числе важные генетические маркеры.
Всего каких-то двадцать пять лет назад большинство из нас имели доступ к знаниям, размещавшимся на нескольких книжных полках. Возможно, у вас на работе была небольшая библиотека справочной литературы или коллекция энциклопедий и несколько десятков справочников дома. Хотя ученые и исследователи из правительственного и частного сектора имели доступ к большим библиотечным фондам, им все равно приходилось физически их посещать, чтобы получить необходимые материалы. Даже на рубеже нового тысячелетия еще можно было увидеть, как ученые курсируют туда-сюда между библиотечными картотеками, коллекциями микрофильмов, книжными стеллажами и специальными хранилищами в поисках информации.
Сегодня все по-другому. Контент, веками отображаемый исключительно на бумаге, теперь передается крохотными блоками по воздуху, так же как и информация о событиях, происходящих здесь и сейчас. Новости, приходившие к нам один раз в день в виде газеты, теперь поступают в виде непрерывного цифрового потока на наши персональные устройства. При помощи нескольких движений пальцев или мышки можно узнать курс акций и результаты спортивных соревнований, а также новости о политических и культурных событиях.
Но какими бы впечатляющими ни были данные, это не панацея. Да, теперь мы знаем, что уже произошло или происходит в настоящий момент, но из-за сложности современного мира не всегда способны понять, почему. Выводы, полученные эмпирическим путем, могут вводить в заблуждение. Данные о сдельной оплате труда часто показывают, что чем больше людям платят за единицу продукции, тем меньше они производят. Модель, в которой оплата зависит от условий труда, может объяснить этот парадокс. Если условия плохие и затрудняют выпуск продукции, оплата за единицу продукции может быть высокой. Если условия хорошие, оплата может быть низкой. Таким образом, более высокая оплата не приводит к снижению производительности, скорее наоборот, тяжелые условия труда требуют более высокой оплаты за единицу продукции [2].
Кроме того, большая часть социальных данных (об экономических, социальных и политических явлениях) отражает только отдельные моменты или промежутки времени и редко раскрывает универсальные истины. Наш экономический, социальный и политический мир не статичен. Например, мальчики могут превзойти девочек по стандартизованным тестам в одно десятилетие, а девочки — в следующее. Причины, по которым люди голосуют сегодня, могут отличаться от причин, по которым они проголосуют завтра.
Нам нужны модели, чтобы осмыслить потоки данных, изливающихся на наши компьютерные экраны как из пожарного шланга. Именно из-за их беспрецедентного объема современную эпоху можно также назвать эпохой множества моделей. Взгляните на научный и деловой мир, сферу государственного управления и некоммерческий сектор — вряд ли вы найдете там область исследований или принятия решений, не основанную на использовании моделей. Консалтинговые гиганты McKinsey и Deloitte создают модели для разработки бизнес-стратегий. Такие финансовые компании, как BlackRock и JPMorgan Chase, используют модели для выбора объектов для инвестиций. Актуарии страховых компаний State Farm и Allstate применяют модели для определения риска при расчете цены страховых полисов. Отдел персонала компании Google разрабатывает аналитические модели прогнозирования для оценки более чем трех миллионов кандидатов на вакантные должности. Приемные комиссии колледжей и университетов создают прогностические модели для отбора студентов из десятков тысяч абитуриентов.
Административно-бюджетное управление разрабатывает экономические модели для прогнозирования последствий налоговой политики. Компания Warner Brothers использует анализ данных для создания моделей отклика аудитории. Amazon разрабатывает модели машинного обучения для предоставления рекомендаций по продуктам. Исследователи, финансируемые Национальными институтами здравоохранения, строят математические модели генома человека для поиска и оценки вероятных методов лечения онкологических заболеваний. Фонд Билла и Мелинды Гейтс применяет эпидемиологические модели для разработки стратегий вакцинации. Даже спортивные команды применяют модели для оценки своих потенциальных членов, возможностей для обмена и формирования стратегий игры. Опираясь на модели при отборе игроков и стратегий, бейсбольный клуб Chicago Cubs сумел выиграть чемпионат США по бейсболу после более чем столетия неудач.
Для людей, использующих модели, объяснение популяризации модельного мышления звучит еще проще: модели делают нас умнее. Без них люди страдают от длинного списка когнитивных искажений: придают чрезмерное значение недавним событиям, присваивают значения вероятности, руководствуясь благоразумием, и игнорируют базовые процентные ставки. Без моделей наша способность учитывать данные ограничена. Применение моделей вносит ясность в исходные предположения и позволяет логически мыслить. Кроме того, благодаря моделям мы можем использовать большие данные для подбора, точной формулировки и проверки каузальных и коррелятивных утверждений. Модели помогают нам эффективнее мыслить. В прямом состязании между моделями и людьми побеждают модели [3].
ПОЧЕМУ НАМ НУЖНО МНОГО МОДЕЛЕЙ
В книге подчеркивается важность применения не одной, а множества моделей к каждой конкретной ситуации. Логическое обоснование многомодельного подхода строится на прошедшей проверку временем идее, что мы обретаем мудрость благодаря всестороннему анализу происходящего. Эта идея восходит к Аристотелю, который писал о ценности объединения достоинств многих людей. Разнообразие точек зрения стало также мотиватором движения за популяризацию великих книг, в ходе которого были отобраны 102 лучшие идеи, вошедшие в двухтомник The Great Ideas: A Syntopicon of Great Books of the Western World («Великие идеи: синтопикон великих книг западного мира»). Современная трактовка этого подхода представлена в работе Максин Хонг Кингстон, которая в своей книге The Woman Warrior («Воительница») пишет: «Ввиду величия Вселенной я научилась увеличивать свой разум, с тем чтобы было место как для Вселенной, так и для парадоксов». Кроме того, этот подход также служит основой прагматических действий в мире бизнеса и политики. В опубликованных в последнее время книгах утверждается, что, если мы хотим понять суть международных отношений, мы не должны моделировать мир исключительно как группу движимых собственными интересами стран, преследующих четко обозначенные цели, или только как развивающуюся взаимосвязанную систему транснациональных корпораций и межправительственных организаций. Мы должны делать и то и другое [4].
Каким бы здравым ни казался многомодельный подход, не стоит забывать, что он противоречит стандартным методам обучения моделям и практике их построения. Традиционный подход (который преподают в средней школе) опирается на взаимно-однозначную логику: одна задача требует одной модели. Например: здесь мы применяем первый закон Ньютона, тут — второй, а здесь третий. Или: здесь мы используем уравнение репликативной динамики для определения размера популяции кроликов в следующем периоде. При применении традиционного подхода задача заключается в том, чтобы, во-первых, найти одну подходящую модель и, во-вторых, правильно ее применить. Многомодельное мышление бросает вызов этому подходу и исповедует принцип применения множества моделей. Если бы вы использовали многомодельное мышление в девятом классе, вас бы, возможно, оставили на второй год. Используя его сейчас, вы будете двигаться вперед.
Авторы научных трудов также в основном придерживаются взаимно-однозначного подхода, даже когда применяют отдельные модели для простого объяснения сложных явлений: избирателями Трампа 2016 года были люди, которые оказались на обочине экономической жизни. Или: квалификация учителя ребенка-второклассника определяет его экономический успех во взрослой жизни [5]. Поток бестселлеров в категории научно-популярной литературы предлагает средства от всех наших бед, основанные на одномодельном мышлении: успех обучения зависит от твердости характера. Неравенство обусловлено концентрацией капитала. Слабое здоровье нации — результат потребления сахара. Каждая из этих моделей может быть верной, но ни одна не является всеобъемлющей. Для того чтобы справиться с высоким уровнем сложности подобных проблем и создать мир более широких достижений в области образования, понадобятся матрицы моделей.
Изучив представленные в книге модели, вы сможете выстроить собственную матрицу. Эти модели берут свое начало в широком диапазоне дисциплин и затрагивают самые разные проблемы, такие как причины неравенства доходов, распределение власти, распространение заболеваний и модных увлечений, предпосылки социальных волнений, эволюция кооперации, формирование порядка в больших городах и структура интернета. Модели, рассматриваемые в книге, разнятся по своим исходным предположениям и структуре. Одни описывают небольшое количество рационально мыслящих индивидуумов, движимых личными интересами. Другие — большие группы альтруистов, соблюдающих правила. Третьи — равновесные процессы. Четвертые объясняют сложность и зависимость от первоначально выбранного пути. Все они также различаются областями применения. Одни позволяют прогнозировать и объяснять. Другие служат руководством к действию, помогают в процессе разработки или облегчают коммуникации. Третьи создают искусственные миры, которые исследует наш разум.
Все эти модели имеют три общие характеристики. Во-первых, они упрощают, устраняя несущественные детали, абстрагируясь от реальности или создавая нечто совершенно новое. Во-вторых, обеспечивают формализацию, давая точные определения. Используют математику, а не слова. Могут представлять убеждения в виде распределения вероятностей по состояниям мира или предпочтения в виде упорядоченного списка альтернатив. Создают путем упрощения и точного определения пространство, в котором можно применять логику, выдвигать гипотезы, разрабатывать решения и подбирать данные. Формируют структуры, в рамках которых мы можем логически мыслить. Как писал Людвиг Витгенштейн в своем труде Tractatus Logico-Philosophicus («Логико-философский трактат»), «логика заботится о себе сама, нам нужно лишь следить за тем, как она это делает». Логика помогает объяснять, прогнозировать, коммуницировать и разрабатывать. Тем не менее логика имеет свою цену, что ведет к третьей характеристике моделей: все модели неправильны, как отметил Джордж Бокс [6]. И это действительно верно в отношении всех моделей: даже грандиозные творения Ньютона, которые мы называем законами, действуют только в определенных масштабах. Модели неправильны, потому что упрощают действительность. Опускают детали. Рассмотрение множества моделей позволяет преодолеть ограничение научной строгости путем охвата всего пространства возможного.
Полагаться на одну модель — это высокомерие, чреватое катастрофой. Верить в то, что одно уравнение может объяснить или спрогнозировать сложные явления реального мира, — значит стать жертвой притягательной силы чистых, строгих математических форм. Не стоит рассчитывать на то, что какая-либо одна модель позволит составить точный численный прогноз уровня моря через 10 000 лет или уровня безработицы через 10 месяцев. Для осмысления сложных систем понадобится множество моделей. Такие сложные системы, как политика, экономика, международные отношения или мозг, демонстрируют непрерывно меняющиеся системные эффекты и закономерности, которые заключены между порядком и хаосом. Сложные явления по определению трудно объяснять, развивать или прогнозировать [7].
В результате мы наблюдаем явное несоответствие. С одной стороны, нам нужны модели, чтобы последовательно мыслить, а с другой — любая отдельная модель с несколькими меняющимися элементами не способна объяснить суть сложных многомерных явлений, таких как закономерности в международной торговой политике, тенденции в отрасли потребительских товаров или адаптивная реакция мозга. Никакой Ньютон не сможет написать уравнение с тремя переменными, объясняющее ежемесячные показатели занятости, результаты выборов или снижение уровня преступности. Если мы хотим понять закономерности распространения болезней, изменчивость показателей успеваемости, разнообразие флоры и фауны, воздействие искусственного интеллекта на рынки труда, влияние людей на климат планеты или вероятность социальных волнений, нам следует все это проанализировать с помощью моделей машинного обучения, моделей динамических систем, моделей теории игр и агентных моделей.
ИЕРАРХИЯ МУДРОСТИ
Чтобы изложить в общих чертах аргументы в пользу многомодельного мышления, начнем с цитаты поэта и драматурга Томаса Стернза Элиота: «Где мудрость, утраченная нами ради знания? Где знание, утраченное нами ради сведений?». Мы могли бы к этому добавить: где информация, утраченная нами ради данных?
Вопросы Элиота можно формально описать как иерархию мудрости. На ее нижнем уровне находятся данные: первичные, незакодированные события, переживания и явления, такие как рождение, смерть, рыночные сделки, голосование, загрузка музыки, осадки, футбольные матчи и эпизоды видообразования. Данные могут представлять собой длинные цепочки нулей и единиц, временных меток и связей между страницами. В данных нет смысла, упорядоченности или структуры.
Информация описывает данные и делит их на категории. Следующие примеры объясняют различие между данными и информацией. Дождь, падающий вам на голову, — это данные. Общее количество осадков за июль в Берлингтоне, а также уровень воды в озере Онтарио — это информация. Ярко-красный перец и желтая кукуруза в фермерских палатках, расположенных вокруг здания законодательного собрания в Мэдисоне во время субботней ярмарки, — это данные. Совокупный объем реализации продукции фермерских хозяйств — это информация.
Рис. 1.1. Как модели преобразуют данные в мудрость
Мы живем в эпоху изобилия информации. Полтора столетия назад обладание информацией обеспечивало высокий экономический и социальный статус. Эмма, героиня одноименного романа Джейн Остин, спрашивает, производит ли Фрэнк Черчилл впечатление информированного молодого человека. Сегодня она не стала бы задавать этот вопрос. У Черчилла, как и у всех нас, был бы смартфон. Вопрос в том, как бы он воспользовался имеющейся информацией. В романе «Преступление и наказание» Федор Достоевский пишет: «У нас есть, дескать, факты! Да ведь факты не все; по крайней мере половина дела в том, как с фактами обращаться умеешь!»
Платон определял знание как обоснованное истинное убеждение. В современных определениях оно трактуется как понимание корреляционных, причинных и логических связей. Знание организует информацию и часто принимает форму модели. Экономические модели рыночной конкуренции, социологические модели сетей, геологические модели землетрясений, экологические модели формирования ниш и психологические модели познания — все заключают в себе знание, объясняют и прогнозируют. Модели химических связей объясняют, почему связи в молекулах металла мешают нам просунуть руку сквозь металлическую дверь, тогда как движение молекул воды уменьшает наш вес, когда мы ныряем в озеро [8].
На вершине иерархии находится мудрость — способность выявлять и применять соответствующие знания. Мудрость требует многомодельного мышления. Иногда она сводится к выбору лучшей модели, как при извлечении стрелы из колчана. А иногда достигается за счет усреднения моделей, что часто происходит при составлении прогнозов. (Мы обсудим важность усреднения моделей в следующем разделе.) Перед тем как предпринять те или иные действия, мудрые люди применяют несколько моделей, так же как врачи совокупность диагностических тестов. Это позволяет исключить одни действия и отдать предпочтение другим. Мудрые люди и команды выстраивают диалог между моделями, анализируя области их пересечения и различия.
Мудрость может состоять в выборе правильных знаний или модели. Рассмотрим такую физическую задачу: маленькая мягкая игрушка гепарда падает с самолета, летящего на высоте 6000 метров. Чем чревато ее падение на землю? Студент может знать модель гравитации и модель предельной скорости падения. Эти модели рассматривают происходящее под разными углами. Гравитационная модель прогнозирует, что мягкая игрушка пробьет крышу автомобиля. Но модель предельной скорости с учетом сопротивления воздуха говорит о том, что скорость игрушечного гепарда приблизится примерно к 16 километрам в час [9]. Мудрость состоит в знании о том, что следует применить модель предельной скорости. Стоящий на земле человек может поймать мягкую игрушку руками. Как сказал по этому поводу эволюционный биолог Джон Бердон Сандерсон Холдейн, «можно уронить мышь в угольную шахту глубиной в тысячу ярдов; достигнув дна, мышь, отделавшись легким сотрясением, убежит, если только земля будет достаточно мягкой. Крыса погибнет, человек разобьется, а лошадь превратится в лепешку».
В задаче с мягкой игрушкой для получения правильного решения требуется информация (вес игрушки), знания (модель предельной скорости) и мудрость (выбор правильной модели). Бизнес-лидеры и политики тоже полагаются на информацию и знания в ходе принятия мудрых решений. Девятого октября 2008 года стоимость денежной единицы Исландии (кроны) начала стремительно падать. Эрику Боллу, в то время финансовому директору компании Oracle (гиганта в области разработки программного обеспечения), предстояло принять решение. За несколько недель до этого он уже столкнулся с внутренними последствиями кризиса ипотечного кредитования. Ситуация в Исландии вызывала озабоченность на международном уровне. Oracle держала миллиарды долларов в зарубежных активах. Болл проанализировал сетевые модели распространения финансового кризиса и рассмотрел экономические модели спроса и предложения, указывающие на наличие корреляции между величиной изменения цен и степенью рыночных потрясений. В 2008 году ВВП Исландии составлял 12 миллиардов долларов, что эквивалентно доходу корпорации McDonald‘s менее чем за полгода. Болл вспоминает, что тогда подумал: «Исландия меньше Фресно. Возвращайся к работе» [10]. Ключ к пониманию этого события и многомодельному мышлению в целом заключается в осознании того факта, что Болл проанализировал множество моделей не для того, чтобы найти среди них одну в поддержку своих действий. И не использовал принцип многомодельного мышления ради их обоснования. Напротив, он оценил две модели как потенциально полезные, а затем выбрал более подходящую. У Болла была правильная информация (Исландия — маленькая страна), он выбрал правильную модель (спрос и предложение) и принял мудрое решение.
Далее мы покажем, как обеспечить диалог между различными моделями посредством переосмысления двух исторических событий: краха мирового финансового рынка 2008 года, приведшего к сокращению совокупного богатства (или того, что считалось таковым) на триллионы долларов и последующей четырехлетней глобальной рецессии, а также Карибского кризиса 1961 года, который едва не перерос в ядерную войну.
Финансовый кризис 2008 года объясняется разными причинами: избыток иностранных инвестиций, чрезмерная задолженность инвестиционных банков, отсутствие надзора за ипотечным кредитованием, блаженный оптимизм всех представителей рынка недвижимости, сложность финансовых инструментов, непонимание рисков и алчность банкиров, которые знали о существовании пузыря, но рассчитывали на спасение. Поверхностные доказательства совпадают с каждым из этих объяснений: поток денег поступал из Китая, инициаторы займов предоставляли проблемные ипотечные кредиты, у инвестиционных банков был высокий коэффициент заемного капитала, финансовые инструменты были слишком сложными для понимания большинства, а некоторые банки действительно рассчитывали на финансовую помощь. Модели позволяют проанализировать эти объяснения и их внутреннюю согласованность: имеют ли они логический смысл? Кроме того, мы можем откалибровать их и проверить величину воздействия.
Экономист Эндрю Ло, практикующий многомодельное мышление, проанализировал двадцать одно объяснение причин кризиса и нашел каждое из них недостаточно убедительным. Нет никакой логики в том, что инвесторы будут способствовать образованию пузыря, зная, что это приведет к глобальному кризису. Следовательно, масштаб пузыря должен был стать для многих неожиданностью. Финансовые компании вполне могли предположить, что другие компании проявили должную осмотрительность, тогда как на самом деле этого не было. Кроме того, ипотечные пакеты, которые впоследствии оказались явно проблемными (низкого качества), нашли своих покупателей. Если бы глобальный кризис был предрешен, этих покупателей просто не было бы. К тому же, хотя после 2002 года коэффициенты заемного капитала выросли, они были ненамного выше, чем в 1998-м. Что же касается надежд на финансовую помощь государства, то когда 15 сентября 2008 года банк Lehman Brothers потерпел крах, правительство не вмешивалось в происходящее, несмотря на то что это было самое крупное банкротство в истории США, так как стоимость активов холдинговой компании Lehman Brothers составляла более 600 миллиардов долларов.
Ло считает, что каждое из этих объяснений содержит логический пробел. Сами по себе данные не указывают на преимущество какого-то из них. Ло подытоживает свои выводы так: «Мы должны стремиться изначально иметь как можно больше интерпретаций одной и той же совокупности объективных данных в расчете на то, что в свое время получим более детальное и внутренне согласующееся объяснение кризиса». Далее он говорит: «Только сформировав разноплановый набор нередко противоречивых интерпретаций, мы в итоге придем к более полному пониманию причин кризиса» [11]. Какой-либо одной отдельно взятой модели для этого будет недостаточно.
В своей книге Essence of Decision3 Грэм Аллисон применяет многомодельный подход для объяснения причин Карибского кризиса4. Подготовленная ЦРУ военизированная группа 17 апреля 1961 года высадилась на берегу Кубы, предприняв неудавшуюся попытку свержения коммунистического режима Фиделя Кастро, что усилило напряженность между Соединенными Штатами и Советским Союзом, который поддерживал Кубу. В ответ глава советского правительства Никита Хрущев перебросил на Кубу ядерные ракеты малой дальности. Президент Джон Кеннеди отреагировал на это блокадой Кубы. Советский Союз и США пошли навстречу друг другу и пересмотрели ситуацию, в результате кризис благополучно завершился.
Аллисон интерпретирует эти события с помощью трех моделей. Первая — модель рационального выбора — показывает, что у Кеннеди было три варианта действий: развязать ядерную войну, вторгнуться на Кубу или ввести блокаду. Он выбрал блокаду. Модель рационального выбора подразумевает, что Кеннеди рисует дерево игры, отображающее каждый вариант действий и возможную реакцию СССР. Затем Кеннеди анализирует, каким будет оптимальный ответный ход Советского Союза. Например, если бы Кеннеди предпринял ядерный удар, Советы нанесли бы ответный удар, что привело бы к гибели миллионов людей. Если бы Кеннеди ввел блокаду, это обрекло бы кубинцев на голод. В этом случае Советский Союз либо отступил бы, либо запустил ракеты. При таком выборе СССР должен был пойти на уступки. Эта модель объясняет главную стратегическую логику игры и обосновывает решение Кеннеди в пользу блокады Кубы.
Однако, как и все модели, она неправильна, поскольку не учитывает важных деталей, из-за чего первоначальное объяснение выглядит лучше, чем на самом деле. В модели игнорируется этап размещения Советским Союзом ракет на Кубе. Если бы СССР вел себя более рационально, они нарисовали бы такое же дерево, как и Кеннеди, и осознали бы, что придется вывести ракеты. Кроме того, модель рационального выбора не объясняет, почему СССР не спрятал ракеты.
Для разъяснения этих противоречий Аллисон использует модель организационного процесса. Отсутствие организационных возможностей поясняет неспособность Советского Союза разместить ракеты в укрытиях. Эта же модель может объяснить решение Кеннеди ввести блокаду. В то время ВВС США не имели возможности уничтожить ракеты одним ударом. Даже одна уцелевшая ракета грозила погубить миллионы американцев. Аллисон умело сочетает обе модели. Выводы, сделанные на основании модели организационных процессов, меняют выигрыши в модели рационального выбора.
Аллисон использует также модель бюрократической политики. Две первые модели сводят страны к их лидерам: Кеннеди действует от имени США, а Хрущев — от имени СССР. Модель бюрократической политики признает, что Кеннеди приходится отстаивать свою позицию в конгрессе, а Хрущеву — сохранять политическую базу поддержки. Таким образом, размещение Хрущевым ракет на Кубе было демонстрацией силы.
Книга Аллисона показывает эффективность отдельных моделей и их комбинации. Каждая модель проясняет наше мышление. Модель рационального выбора позволяет определить возможные действия после размещения ракет и их последствия. Организационная модель подчеркивает тот факт, что эти действия выполняют организации, а не отдельные люди. Модель бюрократической политики обращает внимание на политическую цену вторжения. Такой трехсторонний анализ позволяет достичь более полного и глубокого понимания. Все модели неправильны, но их совокупность способна принести пользу.
В обоих примерах разные модели объясняют различные причинно-следственные факторы. Множество моделей могут также фокусироваться на событиях разных масштабов. В известной истории ребенок заявляет, что Земля покоится на спине гигантского слона. Ученый спрашивает ребенка, на чем стоит слон, на что ребенок отвечает: «На гигантской черепахе». Предвидя, что последует дальше, ребенок быстро добавляет: «Даже не спрашивайте. Там одни черепахи до самого конца» [12]. Если бы мир состоял из одних черепах (другими словами, был бы самоподобным), то модель верхнего уровня была бы применима на всех остальных уровнях. Однако экономика, мир политики и общество — это не только черепахи. То же самое можно сказать и о мозге. На субмикронном уровне мозг состоит из молекул, образующих синапсы, которые, в свою очередь, образуют нейроны5. Нейроны объединяются в сети. Сети накладываются друг на друга замысловатыми способами, которые можно изучить посредством нейровизуализации. Нейронные сети существуют на уровне, отличном от уровня функциональных систем, таких как мозжечок, например. Учитывая, что головной мозг имеет особую структуру на каждом уровне, нам необходимо множество моделей — и они разнятся. У моделей, характеризующих устойчивость нейронных сетей, мало общего с моделями молекулярной биологии, служащими для объяснения работы клеток головного мозга, которые, в свою очередь, отличаются от психологических моделей, применяемых для объяснения когнитивных искажений.
Успех многомодельного мышления зависит от степени разделимости. В процессе анализа финансового кризиса 2008 года мы полагались на отдельные модели покупки активов зарубежными инвесторами, группирования активов и повышения коэффициента левериджа. Аллисон сделал выводы из теоретико-игровой модели без учета организационной модели. Изучая организм человека, врачи выделяют скелетную, мышечную, лимбическую и нервную систему. Тем не менее многомодельное мышление не требует, чтобы отдельные модели разделяли систему на независимые части. Столкнувшись со сложной системой, мы не можем, перефразируя Платона, разделять мир по его сочленениям. Мы можем частично выделить основные причинно-следственные нити, а затем изучить, как они переплетаются. При этом мы обнаружим, что данные, сгенерированные экономической, политической и социальной системой, демонстрируют внутреннюю согласованность. Социальные данные — это нечто большее, чем коллекция непостижимых историй из личной жизни.
АННОТАЦИЯ И КРАТКОЕ СОДЕРЖАНИЕ КНИГИ
Итак, мы живем в эпоху изобилия информации и данных. Генерирующие их технологические достижения сокращают время и расстояние, делая экономических, политических и социальных агентов6 более динамичными, способными мгновенно реагировать на экономические и политические события. Кроме того, они усиливают связанность, а значит, и сложность. В результате возник технологический парадокс: мы знаем об окружающем мире больше, но мир стал сложнее. С учетом этой сложности любая отдельная модель, скорее всего, потерпит неудачу. Тем не менее нам не следует отказываться от моделей. Напротив, мы должны отдавать предпочтение логической связности перед интуицией, а также в два, три и даже четыре раза активнее использовать модели, придерживаясь многомодельного мышления.
А для этого понадобится изучить множество моделей, получив о них практические знания; понять их формальное описание и знать, как их применять. Однако нам не нужно быть экспертами. Поэтому в книге и соблюдается баланс между доступностью и глубиной. Она может служить как источником информации, так и руководством. Формальное описание моделей размещено в специальных врезках. В книге нет многострочных уравнений, которые ужаснут даже самых самоотверженных читателей. Представленные математические формулировки подлежат анализу и усвоению. Моделирование — это мастерство, для овладения которым нужна полная вовлеченность. Оставаясь страстным болельщиком, вы его не достигнете. Нужна осознанная практика. В моделировании математика и логика играют роль опытного тренера и исправляют наши ошибки.
Оставшаяся часть книги организована следующим образом. В главе 2 и главе 3 обосновывается целесообразность многомодельного подхода. В главе 4 рассказывается о проблемах моделирования поведения людей. Следующие двадцать с лишним глав посвящены отдельным моделям или классам моделей. Рассматривая по одному типу моделей за раз, вы сможете лучше осмыслить области их применения, исходные предположения и последствия. Кроме того, такая структура изложения материала позволяет в любой момент взять книгу с книжной полки или открыть ее в браузере и найти исчерпывающий анализ линейных моделей, прогностических моделей, сетевых моделей, моделей последействия, а также моделей распределения с длинным хвостом, обучения, пространственной конкуренции, потребительских предпочтений, зависимости от первоначально выбранного пути, инноваций и экономического роста. Во всех главах приводятся примеры применения многомодельного мышления для решения различных задач и проблем. Книга завершается глубоким анализом эпидемии опиоидов и неравенства в распределении доходов.
ПРОЛОГ
Для меня успех означает эффективность в окружающем мире, способность привнести в него свои идеи и ценности и изменить его к лучшему.
Максин Хонг Кингстон
Все началось со случайной встречи с Майклом Коэном в 2005 году возле цветника на аллее, примыкающей к зданию West Hall Мичиганского университета. Тогда Майкл — ученый, известный своим великодушием, — подбросил мне идею, которая изменила мою преподавательскую карьеру. С блеском в глазах он сказал: «Скотти, когда-то я читал курс под названием “Введение в моделирование для специалистов в области общественных наук”, основанный на книге Чарльза Лейва и Джеймса Марча. Ты должен возродить его. Он нуждается в тебе».
Нуждается во мне? Вернувшись в свой кабинет в некотором замешательстве, я отыскал программу старого курса. Как оказалось, Майкл ввел меня в заблуждение. Не курс нуждался во мне, а, наоборот, я в нем. Я давно хотел разработать курс, который бы позволил студентам ознакомиться с основными концепциями сложных систем (такими как сети, разнообразие, машинное обучение, редкие события, зависимость от предшествующего развития, переломные моменты), что напрямую касалось их повседневной жизни и будущей карьеры. Преподавая моделирование, я мог бы рассказать им о концепции сложности и научить эффективно мыслить. Я помог бы им освоить инструменты, улучшающие способность рассуждать, объяснять, прогнозировать, проектировать, общаться, действовать и исследовать.
Источником мотивации во время обучения могла бы стать уверенность в том, что множество моделей помогут разобраться во всех перипетиях современного мира. В конце семестра, вместо того чтобы видеть мир под определенным углом, студенты обрели бы способность рассматривать его с разных сторон. Находясь в доме с огромным количеством окон, они могли бы смотреть в нескольких направлениях и были бы лучше подготовлены к комплексу стоящих перед ними сложных задач, таких как совершенствование системы образования, снижение уровня бедности, обеспечение устойчивого роста, поиск значимой работы в эпоху искусственного интеллекта, управление ресурсами и разработка надежных финансовых, экономических и политических систем.
Осенью следующего года я возродил курс. Сначала я хотел дать ему новое название «Тридцать две модели, которые превратят вас в гения», но, учитывая, что культура Мичиганского университета не одобряет использования гипербол, оставил вариант Майкла «Введение в моделирование». Безусловно, книга Лейва и Марча была блестящим фундаментом. Однако ввиду того, что за последующие десятилетия в области моделирования был достигнут существенный прогресс, мне требовалась обновленная версия курса, включающая распределение с длинным хвостом1, сети, адаптивный ландшафт и случайные блуждания. Мне также нужна была книга, рассматривавшая вопросы сложности.
И я начал ее писать. На протяжении двух лет почва была очень каменистой, и мой плуг двигался медленно. Однажды весной я снова столкнулся с Майклом, на этот раз в арке West Hall, и начал расспрашивать его о курсе, на который записалось уже двадцать человек. Не слишком ли абстрактны модели для студентов базового университетского курса? Следует ли мне преподаватьотдельные курсы по конкретным проблемам или областям политики? Майкл улыбнулся и сказал, что любое стоящее начинание заслуживает критической оценки, и на прощание подчеркнул, насколько важно помогать людям учиться четко мыслить. Он советовал не сдаваться и отметил, что его вдохновляют стоящие передо мной вызовы.
Осенью 2012 года ситуация улучшилась. Заместитель проректора Марта Поллак предложила мне вести онлайн-версию курса — то, что сейчас называют MOOC (massive open online course — массовый открытый онлайн-курс). Так с помощью планшета, камеры за 29 долларов и микрофона за 90 долларов и появился курс «Модельное мышление». При содействии сотрудников Мичиганского университета, проекта Coursera и Стэнфордского университета (которых слишком много, чтобы я мог должным образом их всех поблагодарить; упомяну только Тома Хикки, проделавшего колоссальную работу) я перевел свои лекции в формат, подходящий для онлайн-курса, разделив каждую тему на модули и удалив все материалы, защищенные авторским правом. Со своим псом по кличке Баундер в качестве слушателя я упорно записывал и переписывал лекции.
Первый курс лекций «Модельное мышление» привлек 60 000 студентов. Сегодня их количество приближается к миллиону. Такая популярность онлайн-курса заставила меня прекратить работу над книгой, поскольку я решил, что теперь она не нужна. Однако в течение следующих двух лет мой почтовый электронный ящик заполнили письма с просьбой дополнить онлайн-курс книгой. А когда Майкл Коэн проиграл битву с раком, я почувствовал, что просто обязан закончить книгу, и снова открыл папку с рукописью.
Написание книги требует много времени и пространства, чтобы ясно мыслить. Поэт Уоллес Стивенс писал: «Возможно, правда зависит от прогулки вокруг озера». Я полагался на близкий аналог там, где моя семья проводит лето, — на проясняющие разум заплывы в озере Уинанс. Время работы над книгой скрашивали члены моей семьи — любовь всей моей жизни Дженна Беднар, наши сыновья Орри и Купер и наши огромные собаки Баундер, Ода и Хильди. Оно было наполнено смехом, умиротворением и возможностями — в частности, Орри на протяжении недели исправлял математические ошибки в предпоследнем черновике, а Дженна посвятила две недели поиску в тексте угловатых конструкций, логических ошибок и сбивчивых рассуждений. Как и большинство моих работ, эту правильнее всего представить как черновик Скотта Пейджа, существенно переработанный Дженной Беднар.
За те семь лет, что я писал эту книгу, мои дети из подростков превратились в прекрасных молодых юношей. Орри уехал учиться в колледж, а Купер отправится туда в следующем году. За это время члены моей семьи поглотили изрядное количество бибимбапа, пасты карбонара и шоколадного овсяного печенья, срезали и срубили множество веток и сучьев, залатали десятки дыр в заборе на заднем дворе, предприняли множество безуспешных попыток уменьшить энтропию в подвале и гараже, а также с нетерпением каждый раз ждали и надеялись, что лед на озере будет достаточно крепким для катания на коньках. Нам также довелось пережить потерю. Когда я проделал примерно половину работы над книгой, от сердечного приступа внезапно умерла моя мама Мэрилин Тамбуэр Пейдж. Это произошло во время одной из ежедневных прогулок с собакой, которые она обожала. С тех пор не проходит и дня, чтобы я не вспоминал о той любви, которой мама одаривала семью, и о ее неиссякаемом желании помогать людям.
Книга, которую вы держите в руках, настолько исчерпывающа, насколько это возможно в данный момент. Безусловно, будут созданы новые модели, а для старых появятся новые области применения, из-за чего возникнут определенные пробелы в представленном материале. Смиренно отправляя рукопись в большой мир, я чувствую, что мои усилия будут вознаграждены, если вы, читатель, сочтете содержащиеся в ней модели и идеи полезными и продуктивными и сможете применить их в реальном мире, чтобы изменить его к лучшему.
Если однажды, сидя в кабинете какого-либо профессора или аспиранта (желательно в одном из колледжей или университетов моего любимого Среднего Запада), я, просматривая книжные полки, увижу там эту книгу, как в свое время увидел потрепанный экземпляр книги Лейва и Марча, значит, мои усилия не пропали зря.
ГЛАВА 2
ЗАЧЕМ НУЖНЫ МОДЕЛИ?
Познание реальности означает построение систем трансформации, более-менее адекватно соответствующих реальности.
Жан Пиаже
В этой главе мы определим типы моделей. Модели часто описываются как упрощенное представление мира. Они действительно могут выполнять такую функцию, но могут также выступать в виде аналогий или вымышленных миров, в которых можно найти новые идеи или знания. Кроме того, мы рассмотрим области применения моделей. В учебных заведениях модели служат для объяснения данных. В реальной жизни их можно использовать для прогнозирования, разработки и совершения действий, поиска идей и возможностей, а также распространения идей и представлений.
Ценность моделей — в их способности выявлять условия, при которых достижим тот или иной результат. Большая часть того, что мы знаем, возможна только в определенных случаях: квадрат самой длинной стороны треугольника равен сумме квадратов двух других сторон только в случае, если самая длинная сторона расположена напротив прямого угла. Модели раскрывают аналогичные условия для наших интуитивных выводов. С их помощью мы можем проанализировать, когда распространяются заболевания, когда работают рынки, когда голосование приводит к благоприятным результатам и когда группы людей дают точные прогнозы. На все эти вопросы нет однозначных ответов.
Эта глава состоит из двух частей. В первой описываются три типа моделей, во второй рассматриваются области их применения — рассуждение, объяснение, прогнозирование, разработка, коммуникация, действие и исследование, — которые образуют акроним REDCAPE7 (reason, explain, design, communicate, act, predict, explore), не такой уж тонкий намек на то, что многомодельное мышление наделяет нас сверхспособностями [1].
ТИПЫ МОДЕЛЕЙ
При построении модели придерживаются одного из трех подходов. Можно использовать подход максимального воплощения, стремящийся к максимальной достоверности. Такие модели включают важные детали и либо исключают ненужные параметры и свойства, либо объединяют их. По этому принципу создаются модели экологических ниш, законодательной власти и транспортных систем, а также климатические модели и модели головного мозга. Можно применить метод аналогий и абстрагироваться от реальности. Можно смоделировать распространение преступности по аналогии с распространением заболеваний, а выбор политической позиции считать одним из вероятных вариантов в диапазоне между левыми и правыми взглядами. Сферическая корова — излюбленный учебный пример метода аналогий: чтобы рассчитать площадь шкуры животного, мы исходим из того, что корова имеет сферическую форму. И делаем это потому, что таблицы интегралов в конце учебников по матанализу содержат такие значения, как tg(x) или cos(x), но не cow(x) [2].
Тогда как метод воплощения акцентируется на реалистичности, метод аналогий позволяет уловить суть процесса, системы или явления. Когда физик не учитывает трение, но в остальном исходит из реалистичных предположений, он использует метод воплощения. Когда экономист представляет конкурирующие компании как разные виды и определяет продуктовые ниши, он тоже проводит аналогию. И делает это с помощью модели, разработанной для воплощения другой системы. Четкого разграничения между методом воплощения и методом аналогий нет. Психологические модели процесса познания, в которых альтернативам присваиваются веса, сводят воедино дофаминовую реакцию и другие факторы; кроме того, они используют аналогию с уровнем, на котором мы приводим альтернативы в равновесие.
Третий подход, метод альтернативной реальности, намеренно не представляет и не отражает реальность. Эти модели работают как аналитические и вычислительные игровые площадки, на которых можно исследовать различные возможности. Метод позволяет обнаружить общие идеи, применимые за пределами физического и социального мира. Такие модели помогают понять последствия ограничений реального мира (а что если бы энергию можно было безопасно и эффективно передавать по воздуху?) или проводить неосуществимые эксперименты (а что если бы мы попытались развить головной мозг?). В книге описывается несколько подобных моделей, в частности игра «Жизнь», которая представляет собой плоскость (нечто вроде шахматной доски), разделенную на живые (черные) и мертвые (белые) клетки, которые переходят из одного состояния в другое согласно установленным правилам. Хотя эта модель нереалистична, она углубляет понимание сути самоорганизации, сложности и, как утверждают некоторые, даже самой жизни.
Что бы ни делала модель — воплощала более сложную реальность, создавала аналогию или выстраивала вымышленный мир для исследования идей, она должна быть распространяемой и разрешимой, поддающейся описанию формальным языком, таким как математика или машинный код. При описании модели нельзя использовать такие термины, как убеждения и предпочтения, без их формального определения. Убеждения могут быть представлены в виде распределения вероятностей в пределах множества событий или гипотез. Предпочтения — в виде упорядоченного списка альтернатив или математической функции.
Степень разрешимости чего-либо говорит о том, насколько это поддается анализу. В прошлом анализ опирался на математические или логические рассуждения. Автор модели должен был обосновывать каждый шаг. Такое ограничение привело к формированию эстетики, придававшей особое значение строгим моделям. Английский монах и теолог Уильям Оккам (1287–1347) писал: «Не должно множить сущее без необходимости». Эйнштейн переформулировал этот принцип, известный как «бритва Оккама», так: «Все следует упрощать до тех пор, пока это возможно, но не более того». Сегодня, столкнувшись с ограничением в плане аналитической разрешимости, можно прибегнуть к вычислениям. Мы можем создавать сложные модели со множеством меняющихся частей, не заботясь об их аналитической разрешимости. Ученые придерживаются такого подхода при построении моделей глобальной климатической системы, головного мозга, лесных пожаров и транспортных систем. Они по-прежнему прислушиваются к совету Оккама, но осознают, что принцип «все следует упрощать» может потребовать множества меняющихся параметров.
СЕМЬ ОБЛАСТЕЙ ПРИМЕНЕНИЯ МОДЕЛЕЙ
В научной литературе описаны десятки вариантов применения моделей. Мы же остановимся на семи: рассуждение, объяснение, прогнозирование, разработка, коммуникация, действие и исследование.
Области применения моделей (REDCAPE)
Рассуждение: определение условий и вывод логических следствий.
Объяснение: предоставление (поддающихся проверке) объяснений эмпирических явлений.
Разработка: выбор характеристик институтов, политик и правил.
Коммуникация: передача знаний и представлений.
Действие: обеспечение выбора политических альтернатив и стратегических действий.
Прогнозирование: получение численных и категорийных прогнозов будущих и неизвестных явлений.
Исследование: изучение возможностей и гипотез.
REDCAPE: РАССУЖДЕНИЕ
При построении модели мы выделяем такие важные составляющие, как агенты и объекты, наряду с соответствующими характеристиками, а затем описываем способы взаимодействия и объединения отдельных фрагментов, что позволяет определить, что из чего следует и почему. Такой подход повышает эффективность наших рассуждений. Хотя полученные выводы зависят от исходных предположений, процесс рассуждений раскрывает нечто большее, чем тавтологии. Крайне редко можно получить весь спектр последствий наших предположений только из одного наблюдения — нужна еще и формальная логика. Логика позволяет раскрыть возможности и невозможности. С ее помощью можно установить точные и порой неожиданные связи. Это позволяет обнаружить обусловленность интуитивных выводов.
Теорема Эрроу (теорема невозможности) — пример того, как логика раскрывает невозможное. Модель рассматривает вопрос о том, приводит ли объединение индивидуальных предпочтений к формированию коллективного предпочтения. Предпочтения представлены в ней в виде упорядоченного списка альтернатив. Применительно к пяти итальянским ресторанам, обозначенным буквами от A до E, эта модель допускает любой из 120 упорядоченных списков. Согласно введенным Эрроу требованиям, общий упорядоченный список должен быть монотонным (если каждый ставит в своем списке A выше B, то же происходит в общем списке), независимым от посторонних альтернатив (если относительный ранг A и B в каждом списке остается неизменным, а ранг других альтернатив меняется, то порядок A и B в общем упорядоченном списке не меняется) и недиктаторским (ни один человек не должен определять общий упорядоченный список альтернатив). Далее Эрроу доказывает, что если разрешены любые предпочтения, то коллективное упорядочение списка может и не существовать [3].
Кроме того, логика раскрывает парадоксы. Применение моделей позволяет продемонстрировать возможность ситуации, когда в каждой подгруппе содержится более высокий процент женщин, чем мужчин, но в общей совокупности наблюдается более высокий процент мужчин. Этот феномен известен как парадокс Симпсона. И он действительно имел место: в 1973 году Калифорнийский университет в Беркли зачислил на большинство факультетов больше студенток, чем студентов. Однако в целом университет принял больше студентов мужского пола. Модели также показывают, что чередование двух проигрышных ставок может обеспечить положительный ожидаемый результат (Парадокс Паррондо); или что включение дополнительной вершины в граф позволяет сократить общую длину ребер, необходимых для соединения всех вершин [4].
Не следует отбрасывать эти примеры как математические новшества. Каждый из них имеет практическое применение: усилия по увеличению численности женщин могут иметь обратный эффект, сочетание проигрышных инвестиций способно обеспечить выигрыш, а общую длину сети электрических линий, трубопроводов, Ethernet-линий или дорог можно сократить путем добавления дополнительных узлов.
Логика также раскрывает математические зависимости. Исходя из аксиом Эвклида, треугольник однозначно определяется любыми двумя углами и стороной или любыми двумя сторонами и углом. Стандартные предположения о поведении потребителей и компаний позволяют сделать вывод, что на рынках с большим количеством конкурентов цена равна предельным издержкам. Некоторые результаты оказываются неожиданными, как в случае парадокса дружбы, который гласит, что в любой сети дружеских связей у друзей человека больше друзей, чем у него самого.
Этот парадокс объясняется тем, что у очень популярных людей больше друзей. На рис. 2.1 показана сеть дружеских связей в клубе карате, описанная Уэйном Закари. У человека, представленного черным кружком, шесть друзей, которые обозначены серыми кружками. У его друзей в среднем семь друзей, отмеченных белыми кружками. В целом в сети двадцать девять из тридцати четырех человек имеют друзей, которые пользуются большей популярностью, чем они сами [5]. Далее вы увидите, что если сделать ряд других допущений, то друзья большинства людей в среднем будут также более красивыми, добрыми, богатыми и умными, чем они сами.
Рис. 2.1. Парадокс дружбы: у друзей человека больше друзей, чем у него самого
И последнее, самое важное: логика раскрывает обусловленность истины. Политик может утверждать, что снижение налогов увеличивает налоговые поступления в государственный бюджет, стимулируя экономический рост. Простейшая модель, в которой доход исчисляется как произведение налоговой ставки на уровень дохода, доказывает, что объем налоговых поступлений увеличивается только в случае, если процентный рост дохода превышает процентное сокращение налогов [6]. Следовательно, 10-процентное снижение подоходного налога увеличит объем налоговых поступлений только тогда, когда приведет к повышению уровня доходов более чем на 10 процентов. Логические рассуждения политика верны лишь при некоторых условиях, которые позволяют определить модели.
Сила обусловленности становится очевидной при сопоставлении утверждений, полученных с помощью моделей, и описательных утверждений, пусть и имеющих эмпирическое обоснование. Рассмотрим управленческую поговорку «в первую очередь самое важное», смысл которой сводится к тому, что при наличии множества задач прежде всего нужно решать самую важную. Это правило также известно как «сначала крупные камни», поскольку, складывая в ведро камни разных размеров, сначала вы должны уложить большие камни, потому что если первыми сложить мелкие камни, то крупные могут не поместиться.
Правило «сначала крупные камни», выведенное на основе экспертных наблюдений, может быть верным в большинстве случаев, но оно не безусловно. Подход, основанный на применении моделей, вывел бы оптимальное правило, исходя из конкретных предположений о задаче. В задаче об упаковке в контейнеры множество предметов разных размеров (или с разным весом) необходимо уложить в контейнеры определенного объема, использовав при этом как можно меньше контейнеров. Представьте, что вы упаковываете вещи из своей квартиры и складываете их в коробки размером примерно 60×60 сантиметров. Упорядочить вещи по размеру и положить каждую из них в первую коробку с достаточным объемом (метод, известный как алгоритм первого подходящего) — весьма эффективный подход. И правило «сначала крупные камни» здесь вполне применимо. Однако предположим, что мы рассматриваем более сложную задачу: выделить место на Международной космической станции для исследовательских проектов. У каждого проекта есть вес полезного груза, размер и требования к системе электропитания наряду с требованиями ко времени и когнитивным способностям астронавтов. Кроме того, каждый исследовательский проект вносит определенный научный вклад. Даже если бы мы установили какой-либо показатель значимости как взвешенное среднее всех этих характеристик, правило «сначала крупные камни» не сработало бы, учитывая размерность взаимозависимостей. В данном случае гораздо лучше работали бы более сложные алгоритмы и, возможно, рыночные механизмы [7]. Таким образом, при одних условиях правило «сначала крупные камни» эффективно, тогда как при других нет. Применение моделей позволяет выяснить, когда целесообразно сначала складывать крупные камни, а когда нет.
Критики формального подхода заявляют, что модели просто переформатируют то, что нам уже известно, что они наливают старое вино в сверкающие математические бутылки, что нам не нужна модель для понимания того, что две головы лучше одной и что промедление смерти подобно. Мы можем осознать ценность самоотверженности, прочитав историю о том, как Одиссей привязал себя к мачте корабля. Такая критика не признает того факта, что выводы, сделанные с помощью моделей, принимают условную форму: если условие A выполняется, то наступает следствие B (например, если вы складываете что-то в контейнеры и размер — единственное ограничение, укладывайте сначала самые крупные предметы). Уроки, почерпнутые из литературы, или общеизвестные советы великих мыслителей во многих случаях не содержат никаких условий. Пытаясь жить или управлять другими людьми согласно безусловным правилам, мы потеряемся в море противоположных поговорок. Действительно ли две головы лучше одной? Или у семи нянек дитя без глазу?
Поговорка | Противоположная поговорка |
Одна голова — хорошо, а две лучше | У семи нянек дитя без глазу |
Промедление смерти подобно | Семь раз отмерь, один раз отрежь |
Привяжи себя к мачте | Не загоняй себя в угол |
Лучшее — враг хорошего | Делай работу хорошо или не делай ее вовсе |
Дела говорят громче слов | Перо сильнее меча |
Противоположных поговорок множество, а вот противоположных теорем не бывает. С помощью моделей мы делаем предположения и доказываем теоремы. Две теоремы, которые расходятся в отношении оптимальных действий, дают разные прогнозы или предлагают несовпадающие объяснения, скорее всего, исходят из разных предположений.
REDCAPE: ОБЪЯСНЕНИЕ
Модели дают четкое логическое объяснение эмпирических явлений. Экономические модели объясняют динамику цен и рыночной доли. Физические — скорость падающих предметов и форму траекторий. Биологические — распределение видов. Эпидемиологические — скорость и характер распространения заболеваний. Геофизические — распределение очагов землетрясений по размерам.
Модели способны объяснить выраженные в пунктах показатели и изменение их значений. В частности, модель может объяснить нынешнюю цену фьючерсов на свиную грудинку и причины роста цен на нее за последние шесть месяцев. Модель может также объяснить, почему президент назначает на должность судьи Верховного суда человека с умеренными взглядами и почему тот или иной кандидат склоняется в сторону левых или правых. Кроме того, модели объясняют форму: модели распространения идей, технологий и болезней дают S-образную кривую принятия (или распространения).
Модели, которые мы изучаем в рамках курса физики, такие как закон Бойля-Мариотта (модель, которая гласит, что произведение давления газа на его объем есть величина постоянная PV = k), объясняют различные явления непостижимо хорошо [8]. Зная начальные объем и давление, мы можем вычислить постоянную k, а затем объяснить или спрогнозировать давление P как функцию V и k: P = k/V. Точность модели обусловлена тем фактом, что газы состоят из огромного количества простых частиц, которые следуют фиксированным правилам: любые две молекулы газа, помещенные в идентичную среду, подчиняются одним и тем же физическим законам. Таких молекул настолько много, что статистическое усреднение исключает любую случайность. Большинству социальных явлений не свойственна ни одна из этих характеристик: социальные агенты неоднородны, взаимодействуют в небольших группах и не подчиняются твердым правилам. К тому же люди умеют думать. Более того, они попадают под влияние социальной среды, а значит, вариации их поведения могут не быть взаимно скомпенсированы. По этой причине социальные явления гораздо менее предсказуемы, чем физические [9].
Наиболее эффективные модели объясняют как очевидные, так и неожиданные результаты. Классические модели рынков могут объяснить, почему непредвиденное повышение спроса на обычный товар, такой как обувь или картофельные чипсы, приводит к росту цен в краткосрочной перспективе — это интуитивно понятный результат. Эти же модели объясняют, почему увеличение спроса в долгосрочной перспективе меньше сказывается на ценах, чем предельные издержки производства товара. Увеличение спроса может даже привести к снижению цен вследствие повышения рентабельности за счет роста масштабов производства — более неожиданный результат. Те же модели могут объяснить парадоксы, например, почему алмазы, не представляющие большой практической ценности, настолько дороги, а вода, столь необходимая для выживания, такая дешевая.
Что касается утверждения, что модели могут объяснить все что угодно, то это правда, так и есть. Вместе с тем объяснение, полученное на основе модели, включает исходные предположения и четко обозначенные причинно-следственные связи, которые могут быть преобразованы в данные. Модель, гласящая, что высокий уровень преступного поведения можно объяснить низкой вероятностью разоблачения, поддается проверке.
REDCAPE: РАЗРАБОТКА
Модели облегчают процесс разработки, обеспечивая концептуальные схемы, в рамках которых можно проанализировать последствия сделанного выбора. Инженеры используют модели для проектирования цепей поставок. Программисты — для разработки интернет-протоколов. Социологи — для создания институтов.
В июле 1993 года группа экономистов собралась в Калифорнийском технологическом институте в Пасадене для подготовки аукциона по распределению радиочастот для мобильной связи. В прошлом правительство предоставляло право на использование радиочастотного спектра крупным компаниям за умеренную плату. Всеобщий закон об урегулировании бюджетных противоречий 1993 года включал положение, разрешавшее проводить такие аукционы с целью сбора средств.
Учитывая, что радиосигнал с вышки охватывает определенную территорию, правительство намеревалось продавать лицензии по конкретным регионам: Западная Оклахома, Северная Калифорния, Массачусетс, Восточный Техас и так далее. Это вызвало вопросы к формату проведения аукциона. Стоимость любой лицензии для компании зависела от других полученных ею лицензий. Например, лицензия на частоты в Южной Калифорнии обошлась бы компании, имеющей лицензию на частоты в Северной Калифорнии, дороже. Экономисты называют такие взаимозависимые оценки экстерналиями, или внешними эффектами. В данном примере у экстерналий были две основные причины: строительство и реклама. Владение лицензиями на частоты в соседних регионах означало снижение затрат на строительство и возможность использования перекрывающихся медиарынков.
Экстерналии создавали проблему с проведением одновременных аукционов. Компания, пытающаяся получить пакет лицензий, могла проиграть одну лицензию другому участнику аукциона, соответственно, утратить экстерналии и в результате отказаться от своих заявок на другие лицензии. У последовательных аукционов был другой недостаток. На первых аукционах участники торгов могли предлагать заниженную цену, чтобы застраховаться от потери лицензий на следующих аукционах.
Предполагалось, что эффективный формат проведения аукциона должен обеспечивать выгодный результат, быть защищенным от стратегических манипуляций и понятен участникам торгов. Экономисты использовали модели теории игр, чтобы определить, могут ли стратегически действующие участники торгов использовать свойства аукциона в своих интересах, модели компьютерной симуляции для сравнения эффективности различных форматов аукциона и статистические модели для выбора параметров экспериментов с реальными людьми. Окончательный формат (многораундовый аукцион, который позволял его участникам отзывать заявки и запрещал пропускать первые этапы, чтобы скрыть свои намерения) оказался успешным. На протяжении последних тридцати лет Федеральная комиссия по средствам связи собрала на аукционах такого типа почти 60 миллиардов долларов [10].
REDCAPE: КОММУНИКАЦИЯ
Создавая общее представление, модели улучшают коммуникацию. Модели требуют формального описания соответствующих характеристик и их взаимосвязей, что обеспечивает точную передачу информации. Модель F = ma соотносит три измеримые величины — силу (F), массу (m) и ускорение (a), делая это в форме уравнения, каждый член которого выражен в измеримых единицах, информацию о которых можно распространять, не опасаясь ошибочного толкования. Напротив, утверждение, что «более крупные, быстрые объекты генерируют больше мощности», обеспечивает гораздо более низкую степень точности. Многое теряется при переводе. Более крупный означает вес или размер? Более быстрый — имеется в виду скорость или ускорение? Мощность — это энергия или сила? И как соединяется более крупное и быстрое, чтобы генерировать мощность? Попытки формализовать это утверждение могут привести к получению ряда формул; при этом мощность может быть некорректно описана как вес плюс скорость (P = w + v), как вес умножить на скорость (P = wv) или как вес плюс ускорение (P = w + a).
При формальном описании абстрактных концепций (таких как политическая идеология) с помощью воспроизводимой методики они приобретают некоторые свойства, аналогичные физическим параметрам, таким как масса и ускорение. Мы можем использовать ту или иную модель, чтобы сказать, что один политик более либерален, чем другой, на основании их голосования. Затем можем точно сформулировать и распространить это утверждение. Либеральность хорошо поддается определению и количественному измерению. Кто-то может применить аналогичный метод для сравнения других политиков. Безусловно, данные о результатах голосования не единственный показатель либеральности. Мы можем сконструировать еще одну модель, определяющую идеологию на основе текстового анализа речей. В комбинации с первой она позволит четко обозначить, что мы имеем в виду, говоря о более либеральных взглядах.
Многие недооценивают влияния коммуникации на прогресс. Идея, которую нельзя распространить, подобна упавшему дереву в лесу, где этого никто не заметит. Поразительный экономический рост в эпоху Просвещения был в значительной мере обусловлен возможностью передачи знаний, нередко в форме моделей. Фактически данные указывают на то, что возможность передачи идей скорее объяснялась экономическим ростом, чем уровнем образования: развитие городов во Франции XVIII столетия в большей степени соотносится с количеством подписок на «Энциклопедию» Дидро, чем с уровнем грамотности [11].
REDCAPE: ДЕЙСТВИЕ
Фрэнсис Бэкон писал: «Величайший итог жизни — не знание, а действие». Эффективные действия требуют эффективных моделей. Все правительства, корпорации и некоммерческие организации используют модели в качестве руководства к действию. Будь то повышение или снижение цен, открытие нового магазина, поглощение компании, обеспечение всеобщего доступа к медицинскому обслуживанию или финансирование программы внеклассного обучения — во всех этих случаях лица, принимающие решения, полагаются на модели. Для самых важных действий ответственные за принятие решений используют модели высокой сложности. Модели связаны с данными.
В 2008 году в рамках программы по спасению проблемных активов (Troubled Asset Relief Program, TARP) Федеральная резервная система США выделила 182 миллиарда долларов финансовой помощи на спасение транснациональной страховой компании American International Group (AIG) от банкротства. По данным министерства финансов США, правительство предпочло стабилизировать ситуацию в AIG, «поскольку ее банкротство во время финансового кризиса имело бы катастрофические последствия для нашей финансовой системы и экономики» [12]. Целью этой финансовой помощи было не спасение компании AIG как таковой, а поддержка финансовой системы в целом. В конце концов, компании терпят крах каждый день, но правительство не вмешивается [13].
Конкретные решения, принятые в рамках программы TARP, основывались на моделях. На рис. 2.2 представлен один из вариантов сетевой модели, разработанной Международным валютным фондом. Вершины графа (кружки) представляют финансовые учреждения. Ребра графа (линии между кружками) отражают корреляцию между стоимостью активов этих учреждений. Цвет и ширина ребра соответствуют степени корреляции между учреждениями: более темные и широкие линии означают более высокую степень корреляции [14].
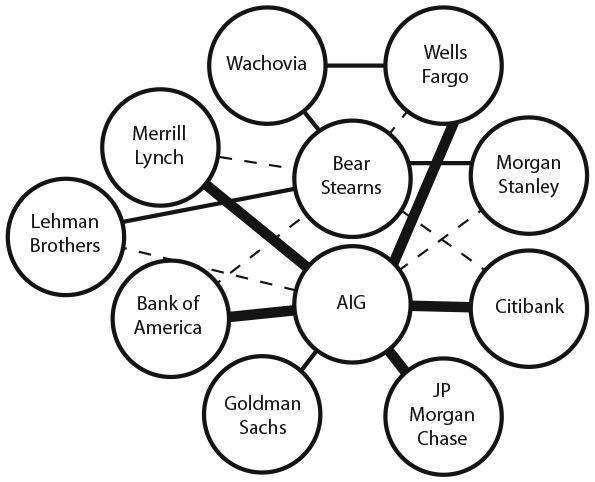
Рис. 2.2. Граф корреляций между финансовыми учреждениями
Компания AIG занимает центральное место в этой сети, поскольку предоставляла услуги страхования другим компаниям и обязывалась им заплатить в случае, если их активы потеряют стоимость. Из-за падения курса акций AIG была бы должна этим компаниям деньги. Следовательно, ее банкротство повлекло бы за собой и банкротство связанных с ней компаний, что могло бы привести к каскаду банкротств. Стабилизация положения AIG позволила правительству поддержать рыночную стоимость активов других компаний, входящих в сеть [15].
Рис. 2.2 также помогает объяснить, почему правительство допустило банкротство Lehman Brothers. Lehman Brothers не занимала центрального места в сети. Повернуть историю вспять невозможно, поэтому нам не дано знать, предприняла ли Федеральная резервная система правильные действия. Однако мы знаем, что банкротство Lehman Brothers не привело к коллапсу всей финансовой отрасли. Нам также известно, что правительство заработало 23 миллиарда долларов прибыли на займе компании AIG. Следовательно, мы можем сделать вывод, что выбор политики (основанный на многомодельном мышлении) не был провальным.
Модели, выступающие в качестве руководства к действию (такие как модели политики), часто полагаются на данные, но это касается не всех моделей. В большинстве моделей политики также используется математика, хотя так было не всегда. В прошлом политические деятели создавали и физические модели. Гидравлическая модель британской экономики Филлипса использовалась для анализа политических альтернатив в середине ХХ века, а физическая модель залива Сан-Франциско сыграла ключевую роль в решении об отказе от строительства в нем дамбы для создания резервуара пресной воды [16]. Модель экспериментальной станции водных путей площадью около 80 гектаров в бассейне реки Миссисипи возле города Клинтон — миниатюрная копия бассейна реки, построенная в горизонтальном масштабе 1:100. Эта модель позволяет проверить воздействие строительства новых плотин и резервуаров на территорию вверх и вниз по течению реки. В пределах этой физической системы сбрасываемая вода подчиняется физическим законам. В таких физических моделях объекты сами по себе являются аналогами объектов реального мира. Подобные модели логичны, поскольку подчиняются законам физики.
Во всех представленных примерах речь шла об организациях, использующих модели в качестве руководства к действию. Но люди могут делать то же самое. При принятии важных решений в личной жизни мы тоже должны применять модели. В ходе размышлений о покупке дома, переходе на новую работу, поступлении в магистратуру, покупке или аренде автомобиля мы можем использовать модели как основу. И хотя эти модели будут скорее качественными, чем опирающимися на данные, они все равно заставят нас задавать правильные вопросы.
REDCAPE: ПРОГНОЗИРОВАНИЕ
Модели давно используются для прогнозирования. Метеорологи, консультанты, гандикаперы и руководители центральных банков составляют с их помощью прогнозы. Полиция и спецслужбы используют их для прогнозирования преступного поведения. Эпидемиологи — для прогнозирования того, какой штамм гриппа получит самое широкое распространение в предстоящем эпидемическом сезоне. Поскольку данные стали доступнее и детализированнее, эта область применения моделей расширилась. Ленты в Twitter и инструменты поиска в интернете применяются для прогнозирования предпочтений потребителей и социальных волнений.
Модели позволяют прогнозировать как отдельные события, так и общие тенденции. Первого июня 2009 года самолет авиакомпании Air France, выполнявший рейс AF447 по маршруту Рио-де-Жанейро — Париж, потерпел крушение над Атлантическим океаном. В следующие нескольких дней после катастрофы спасатели находили плавающие обломки авиалайнера, но не смогли обнаружить фюзеляж. В июле аккумуляторы акустических маяков самолета разрядились, и поиски были прекращены. Проведенная год спустя вторая поисковая операция, организованная Океанографическим институтом Вудс-Хоул с участием кораблей ВМФ США, оборудованных гидролокаторами бокового обзора, а также автономных глубоководных аппаратов, тоже не дала результатов. В итоге французское бюро по расследованию и анализу безопасности гражданской авиации обратилось к моделям. Специалисты бюро применили вероятностные модели для анализа океанических течений и обнаружили небольшую прямоугольную область, где с наибольшей вероятностью мог находиться фюзеляж. С помощью прогноза, составленного на основании этой модели, поисковые команды в течение недели нашли обломки самолета [17].
В прошлом объяснение и прогнозирование, как правило, были тесно связаны. Электротехнические модели, которые объясняют картину распределения напряжения, также могут прогнозировать напряжение. Пространственные модели, объясняющие результаты прошлых голосований, позволяют прогнозировать результаты будущих голосований. В, пожалуй, самом знаменитом примере использования объяснительной модели для прогнозирования французский математик Урбен Леверье применил законы Ньютона, объясняющие движение планет, для анализа отклонений орбиты Урана. И пришел к выводу, что орбиты планет указывают на присутствие большой планеты во внешней области Солнечной системы. Леверье отправил свой прогноз в Берлинскую обсерваторию 18 сентября 1846 года, а через пять дней астрономы обнаружили планету Нептун именно там, где и предсказывал математик.
Вместе с тем прогнозирование отличается от объяснения. Модель может прогнозировать, но не объяснять. Алгоритмы глубокого обучения позволяют прогнозировать продажи продуктов, погоду на завтра, тенденции изменения цен и некоторые показатели состояния здоровья, но мало что предлагают в плане объяснения. Такие модели напоминают собак, вынюхивающих бомбы. Хотя обонятельная система собаки способна определить, есть ли взрывчатые вещества в пакете, не стоит искать объяснений у собаки, почему бомба там оказалась, как она работает и как ее обезвредить.
Обратите также внимание, что другие модели, наоборот, могут давать объяснения, но не представлять особой ценности с точки зрения прогнозирования. Модели тектоники плит объясняют, как возникают землетрясения, но не предсказывают, когда они произойдут. Модели динамических систем объясняют возникновение ураганов, но не позволяют успешно прогнозировать, когда сформируется ураган и каким будет его траектория движения. А экологические модели, хотя и могут объяснить закономерности видообразования, не способны прогнозировать появление новых видов [18].
REDCAPE: ИССЛЕДОВАНИЕ
И наконец, модели можно использовать для проверки интуитивных выводов и возможностей. Такие исследования могут быть связаны с курсом действий: а что если сделать все городские автобусы бесплатными? Что если позволить студентам выбирать, от каких заданий будет зависеть их итоговая оценка за курс обучения? Что если установить на газонах таблички с указанием их энергопотребления? Каждое из этих гипотетических предположений можно проанализировать с помощью моделей. Кроме того, модели будут полезны при изучении нереальной среды. Что если бы Ламарк был прав и приобретенные признаки могли передаваться потомству, чтобы детям родителей, прошедших ортодонтическую коррекцию зубов, не нужны были брекеты? Как был бы устроен такой мир? Постановка этого вопроса и анализ вытекающих из него следствий позволяет определить границы эволюционных процессов. Устранение ограничений реальности может стимулировать креативность. По этой причине сторонники движения критического дизайна прибегают к умозрительным построениям для генерации новых идей [19].
Иногда исследование сводится к сопоставлению распространенных допущений в разных областях. Для того чтобы понять сетевой эффект, специалист по моделированию может сформировать совокупность условных сетевых структур, а затем выяснить, влияет ли сетевая структура на кооперацию, распространение болезней или социальные волнения, и если да, то каким образом. Кроме того, он может применить совокупность моделей обучения к процессу принятия решений и играм с двумя или несколькими участниками. Цель таких действий не в объяснении, прогнозировании или разработке, а в изучении и обучении.
Применять ту или иную модель на практике можно любым из нескольких способов. Одна и та же модель может объяснять, прогнозировать и выступать в качестве руководства к действию. Рассмотрим следующий пример: 14 августа 2003 года обвисшие ветви склонившихся над линиями электропередач возле Толедо (штат Огайо) деревьев стали причиной локального прекращения подачи электроэнергии, которое распространилось, когда из-за сбоя программного обеспечения техники не смогли передать предупреждение о необходимости перераспределения электроэнергии. В тот день более 50 миллионов жителей северо-восточных районов США и Канады остались без электричества. В том же году буря вывела из строя линию электропередачмежду Италией и Швейцарией, оставив без электричества 60 миллионов европейцев. Инженеры и ученые обратились к моделям, в которых энергосистема представлена как сеть. И эти модели помогли объяснить, как происходили сбои, позволили составить прогнозы, в каких регионах сбои наиболее вероятны, и стали руководством к действию, определив места, где новые линии электропередач, трансформаторы и электростанции могли повысить надежность электросети. Использование одной модели для множества целей станет лейтмотивом этой книги. Как мы увидим далее, этот принцип дополняет ее основную тему: использование множества моделей для осмысления сложных явлений.
ГЛАВА 3
НАУКА О МНОЖЕСТВЕ МОДЕЛЕЙ
Нет ничего менее реального, чем реализм. Детали вводят в заблуждение. Только путем отбора, исключения, акцента мы постигаем истинный смысл вещей.
Джорджия О’Кифф
В этой главе мы научно обоснуем эффективность многомодельного подхода. И начнем с теоремы Кондорсе о жюри присяжных и теоремы о прогнозе разнообразия, которые содержат поддающиеся количественной оценке аргументы в пользу ценности множества моделей как помощников в принятии решений, прогнозировании и объяснении. Однако эти теоремы могут преувеличивать такие аргументы. Чтобы объяснить, почему, мы обратимся к моделям категоризации, которые делят мир на блоки. Применение моделей категоризации покажет, что построение множества моделей может оказаться более сложной задачей, чем мы предполагали. Использование этого же класса моделей позволит нам обсудить степень их детализации (насколько точными они должны быть), а также решить, применять ли одну большую модель или несколько маленьких. Выбор будет зависеть от области применения. При прогнозировании мы часто стремимся действовать с размахом. В случае объяснения разумнее руководствоваться принципом «чем меньше, тем лучше».
Этот вывод решает одну давнюю проблему. На первый взгляд может показаться, что многомодельное мышление требует изучения большого количества моделей. Хотя нам действительно нужно освоить некоторые модели, их не так много, как вы думаете. Нам не придется изучать сто или даже пятьдесят моделей, поскольку они обладают важным свойством, известным как «один ко многим». Мы можем применять одну и ту же модель в разных ситуациях, введя новые переменные, параметры и изменив допущения. Это свойство в какой-то мере противоречит идее многомодельного мышления. Использование модели в новой области требует креативности, открытости разума и скептицизма. Мы должны признать, что не каждая модель подходит для решения любой задачи. Если модель не может объяснить, спрогнозировать или помочь нам рассуждать, ее нужно исключить из рассмотрения.
Навыки, необходимые для использования одной модели во многих областях, отличаются от математических и аналитических способностей, наличие которых многие считают обязательным условием для достижения успеха в моделировании. Процесс использования одной модели во многих областях подразумевает творческий подход. Прежде всего задайте себе вопрос: «Сколько областей применения я могу найти для модели случайного блуждания?» Чтобы вы могли составить представление о том, какие формы может принимать креативность, в конце главы мы используем геометрическую формулу площади и объема в качестве модели и применим ее для объяснения размера супертанкеров, критики индекса массы тела, прогноза масштабирования метаболизма и объяснения, почему так мало женщин-руководителей.
МНОЖЕСТВО МОДЕЛЕЙ КАК НЕЗАВИСИМЫХ СЛУЧАЕВ ЛЖИ
Теперь обратимся к моделям, которые помогают раскрыть преимущества многомодельного мышления. И представим в их контексте две теоремы: теорему Кондорсе о жюри присяжных и теорему о прогнозе разнообразия. Теорема Кондорсе о жюри присяжных основана на модели, созданной для объяснения преимуществ принципа большинства. В соответствии с ней присяжные принимают бинарное решение о виновности или невиновности подсудимого. Каждый присяжный в основном выносит правильное решение. Чтобы применить эту теорему к совокупности моделей, а не членов жюри присяжных, мы интерпретируем принятие решения каждым присяжным как классификацию согласно той или иной модели. В качестве классов могут выступать действия (купить или продать) или прогнозы (победителем станет представитель демократической или республиканской партии). Далее теорема указывает на то, что конструирование множества моделей и применение принципа большинства обеспечит более высокий уровень точности, чем при использовании одной из моделей данного множества. Модель опирается на концепцию состояния мира — полное описание всей значимой информации. Для жюри присяжных состояние мира складывается из доказательств, представленных в суде. Для моделей, которые оценивают социальный вклад благотворительного проекта, оно может представлять команду проекта, организационную структуру, план проведения мероприятий и особенности проблемы или ситуации, которую должен решить проект.
Теорема Кондорсе о жюри присяжных
Каждый из нечетного количества людей (моделей) классифицирует неизвестное состояние мира как истинное или ложное. Каждый человек (модель) классифицирует правильно с вероятностью 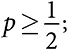 вероятность того, что другой человек (модель) выполнит правильную классификацию, статистически независима от правильности классификации любого другого человека (модели).
вероятность того, что другой человек (модель) выполнит правильную классификацию, статистически независима от правильности классификации любого другого человека (модели).
Теорема Кондорсе о жюри присяжных: большинство голосов обеспечивают правильную классификацию с более высокой вероятностью, чем любой отдельный человек (модель), а по мере увеличения количества членов жюри (моделей) точность решения, принятого большинством, приближается к 100 процентам8.
Эколог Ричард Левинс объясняет, как применить логику этой теоремы к многомодельному подходу: «Мы пытаемся решить одну и ту же задачу с помощью ряда альтернативных моделей с разными упрощениями, но общим биологическим предположением. В таком случае, если эти модели, несмотря на различие исходных предположений, приводят к аналогичным результатам, мы имеем то, что можно назвать устойчивой теоремой, относительно свободной от деталей модели. Следовательно, истина находится на пересечении независимых случаев лжи» [1]. Обратите внимание, что здесь Левинс рассчитывает на единство классификации. Когда многие модели дают одну и ту же классификацию, наша уверенность должна повыситься.
Следующая теорема, о прогнозе разнообразия, применима к моделям, которые делают численные прогнозы или оценки. Она количественно оценивает влияние точности моделей и их разнообразия на точность их среднего [2], 9.
Теорема о прогнозе разнообразия
Погрешность множества моделей = средняя погрешность модели — разнообразие прогнозов моделей
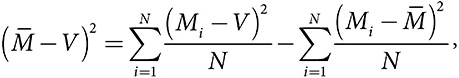
где Mi — это прогноз i-й модели,  — среднее значений моделей, а V — истинное значение.
— среднее значений моделей, а V — истинное значение.
Теорема о прогнозе разнообразия описывает математическое тождество. Нам не нужно его проверять — оно всегда справедливо. Вот пример. Две модели прогнозируют количество «Оскаров», которые присудят одному из фильмов. Одна модель предсказывает два «Оскара», а другая — восемь. Среднее значение прогнозов двух моделей (прогноз на основе множества моделей) равно пяти. Если на самом деле фильм получит четыре «Оскара», то квадратичная погрешность прогноза первой модели будет равна 4 (2 в квадрате), второй — 16 (4 в квадрате), а множества моделей — 1. Разнообразие прогностических моделей составляет 9, поскольку прогноз каждой модели отличается от среднего прогноза на 3. В таком случае теорему о прогнозе разнообразия можно записать так: 1 (погрешность множества моделей) = 10 (средняя погрешность моделей) – 9 (разнообразие прогностических моделей).
Логика этой теоремы опирается на противоположные (плюсы и минусы) взаимоисключающие типы погрешностей. Если одна модель прогнозирует слишком высокое значение, а другая — слишком низкое, то эти модели демонстрируют разнообразие прогнозов. Обе погрешности исключают друг друга, а среднее значений моделей будет точнее, чем значение каждой модели в отдельности. Даже если оба прогнозируемых значения слишком высоки, ошибка среднего этих прогнозов все равно будет не больше, чем средняя двух завышенных прогнозов.
Из теоремы не следует, что совокупность различных моделей обеспечивает точную картину. Если всем моделям свойственна общая систематическая ошибка, то и среднее тоже будет ее содержать. Данная теорема подразумевает, что любая совокупность различных моделей (или людей) будет точнее, чем средний член этой совокупности — феномен, известный как «мудрость толпы». Этот математический факт объясняет эффективность ансамблевых методов в информатике, которые выводят среднее множества классификаций, а также то, что люди, использующие в рассуждениях множество моделей и концептуальных схем, делают более точные прогнозы по сравнению с теми, кто ориентируется лишь на отдельные модели. Любой однобокий взгляд на мир упускает важные детали и оставляет белые пятна. У таких людей меньше шансов предвидеть крупные события, такие как крах рынка или арабская весна 2011 года [3].
Обе теоремы приводят убедительные аргументы в пользу применения множества моделей, по крайней мере в контексте прогнозирования. Однако порой эти аргументы излишне убедительны. Теорема Кондорсе подразумевает, что при достаточном количестве моделей мы бы практически никогда не ошибались, а теорема о прогнозе — что формирование разнопланового множества умеренно точных моделей прогнозирования позволило бы нам свести погрешность множества моделей практически к нулю. Однако, как мы увидим далее, наша способность строить множество разноплановых моделей не беспредельна.
МОДЕЛИ КАТЕГОРИЗАЦИИ
Чтобы объяснить, почему обе теоремы могут преувеличивать аргументы в пользу многомодельного подхода, прибегнем к моделям категоризации, которые обеспечивают микрообоснования теоремы Кондорсе о жюри присяжных и делят состояния мира на непересекающиеся блоки. Эти модели восходят к эпохе античности. В своем труде The Categories10 Аристотель выделил десять атрибутов, в том числе такие как субстанция, количество, место и положение, которые использовал для разделения мира на категории. Каждая комбинация этих атрибутов образует отдельную категорию.
Мы используем категории каждый раз, когда употребляем нарицательное существительное. «Брюки» — это категория, так же как «собаки», «ложки», «камины» и «летние каникулы». Нам свойственно использовать категории в качестве руководства к действию. Мы распределяем рестораны по национальному признаку (итальянские, французские, турецкие или корейские), чтобы выбрать, где пообедать. Классифицируем акции по отношению рыночной цены акции к чистой прибыли на одну акцию и продаем малодоходные акции. Используем категории для объяснения тех или иных явлений — как в случае с утверждением, что численность населения Аризоны возросла, потому что в этом штате благоприятные погодные условия. Кроме того, категории применяются для прогнозирования: мы можем предсказать, что у кандидата на государственную должность, имеющего военный опыт, более высокие шансы на победу.
Мы можем интерпретировать вклад моделей категоризации в рамках иерархии мудрости. Объекты образуют данные. Группирование объектов по категориям порождает информацию. Определение оценок по категориям требует знаний. Для критического анализа теоремы Кондорсе мы полагаемся на модель бинарной категоризации, которая делит объекты или состояния мира на две категории — «виновен» и «невиновен». Основная идея состоит в том, что количество соответствующих атрибутов ограничивает число отдельных вариантов категоризации, а значит, и число полезных моделей.
Модели категоризации
Существует множество объектов или состояний мира, каждое из которых определяется множеством атрибутов и имеет то или иное значение. Модель категоризации М делит эти объекты или состояния на конечное множество категорий {S1, S2, …, Sn} на основе атрибутов объекта и присваивает оценки {M1, M2, …, Mn} каждой категории.
Представьте, что у нас есть сто заявок на получение студенческого кредита, половина из которых были погашены, а половина — нет. По каждому кредиту нам известны две детали: превышал ли его размер 50 000 долларов и специализировался ли его получатель в инженерном деле или в гуманитарных науках. Это и есть два атрибута. С их помощью мы можем выделить четыре типа кредитов: крупные кредиты студентам со специализацией «инженерное дело», мелкие кредиты студентам со специализацией «инженерное дело», крупные кредиты студентам со специализацией «гуманитарные науки» и мелкие кредиты студентам со специализацией «гуманитарные науки».
Модель бинарной категоризации классифицирует каждый из четырех типов кредитов как выплаченный или невыплаченный. Одна модель может классифицировать мелкие кредиты как выплаченные, а крупные как невыплаченные. Другая может классифицировать кредиты студентам со специализацией «инженерное дело» как погашенные, а студентам со специализацией «гуманитарные науки» как непогашенные. Вполне вероятно, что каждая из этих моделей может быть правильной более чем в половине случаев и что эти две модели могут быть практически независимы друг от друга. Проблема возникает при попытке создать больше моделей. Существуют только шестнадцать уникальных моделей, которые соотносят четыре категории с двумя возможными исходами. Две классифицируют все кредиты как выплаченные или невыплаченные, у каждой из оставшихся четырнадцати есть полная противоположность. Всякий раз, когда модель обеспечивает правильную классификацию, ее противоположный вариант дает неправильную классификацию. Таким образом, из четырнадцати возможных моделей максимум семь могут быть правильными более чем в половине случаев. И если та или иная модель окажется правильной ровно в половине случаев, то же произойдет и с ее противоположностью.
Размерность наших данных ограничивает количество моделей, которые мы можем создать. У нас может быть максимум семь моделей. Мы не можем построить одиннадцать независимых моделей, не говоря уже о семидесяти семи. Даже если бы у нас были данные с более высокой размерностью (например, если бы мы знали возраст, средний балл, доход, семейное положение и адрес получателей кредита), категоризация, основанная на этих атрибутах, должна обеспечивать точные прогнозы. Каждое подмножество атрибутов должно быть релевантным тому, погашен ли кредит, и не связанным с другими атрибутами. В обоих случаях речь идет о сильных предположениях. Например, если между адресом, семейным положением и доходом наблюдается корреляция, то модели, в которых эти атрибуты поменяны местами, тоже должны коррелировать [4]. В случае строгой вероятностной модели независимость кажется обоснованной: разные модели порождают разные ошибки. Объяснение этой логики с помощью моделей категоризации позволяет осознать сложность построения множества независимых моделей.
Попытки формирования совокупности разноплановых, точных моделей сопряжены с аналогичной проблемой. Предположим, нам нужно создать ансамбль моделей категоризации, прогнозирующих уровень безработицы в пятистах городах среднего размера. Точная модель должна разделить города на категории таким образом, чтобы в рамках одной категории в них наблюдался схожий уровень безработицы. Кроме того, модель должна точно прогнозировать безработицу в каждой категории. Для того чтобы две модели обеспечивали разные прогнозы, они должны по-разному делить города на категории, по-разному составлять прогнозы, или и то и другое. Хотя эти два критерия не противоречат друг другу, могут возникнуть трудности с их удовлетворением. Если один вариант категоризации основан на среднем уровне образования, а другой — на среднем уровне дохода, они могут обеспечивать разбиение на аналогичные категории. Тогда обе модели будут точными, но не разнообразными. Формирование двадцати шести категорий с использованием первой буквы названия каждого города обеспечит разноплановую категоризацию, но, по всей вероятности, не позволит создать точную модель. Поэтому здесь снова напрашивается вывод, что на практике количество элементов «множества» обычно ближе к пяти, чем к пятидесяти.
Результаты эмпирических исследований прогнозирования согласуются с этим выводом. Хотя увеличение числа моделей повышает уровень точности (как и должно быть согласно теоремам), после формирования группы моделей предельный вклад каждой из них снижается. В компании Google обнаружили, что привлечение одного интервьюера для оценки кандидатов на вакантную должность (вместо случайного выбора) повышает вероятность найма высококвалифицированного сотрудника с 50 до 74 процентов, привлечение второго интервьюера повышает эту вероятность до 81 процента, привлечение третьего интервьюера — до 84 процентов, а четвертого — до 86 процентов. Наличие двадцати интервьюеров повышает вероятность всего до 90 процентов с небольшим. Это указывает на ограничение предельного количества значимых способов оценки потенциального сотрудника.
Аналогичный вывод справедлив и при оценке десятков тысяч прогнозов экономистов в отношении безработицы, экономического роста и инфляции. В этом случае следует рассматривать экономистов как модели. Включение второго экономиста повышает точность прогноза примерно на 8 процентов, еще два экономиста повышают его на 12 процентов, а еще три — более чем на 15 процентов. Десять экономистов увеличивают точность прогноза примерно на 19 процентов. Кстати, прогноз лучшего экономиста всего на 9 процентов точнее, чем среднего, при условии, что вы знаете, какой экономист лучший. Таким образом, три произвольно выбранных экономиста эффективнее, чем один лучший [5]. Еще одна причина использования нескольких средних экономистов, не полагаясь на одного, пусть в прошлом и лучшего, — изменчивость мира. Экономист, демонстрирующий сегодня самые высокие результаты, завтра может стать середняком. Аналогичная логика объясняет, почему Федеральная система США полагается на совокупность экономических моделей, а не на одну модель: как правило, множество моделей обеспечивают более высокий средний результат, чем самая лучшая одиночная модель.
Урок должен быть очевиден: формирование множества разноплановых, точных моделей позволяет нам составлять очень точные прогнозы и оценки и выбирать правильные действия. Теоремы обосновывают логику многомодельного мышления. Чего они не делают и не могут сделать, так это построить множество моделей, удовлетворяющих их исходным предположениям. На практике мы можем обнаружить, что имеем возможность создать три-пять хороших моделей. И если так, то это здорово! Нам нужно только вернуться к предыдущему абзацу: включение второй модели обеспечивает улучшение на 8 процентов, а третьей — уже на 15 процентов. Учтите, что вторая и третья модели не обязательно должны быть лучше первой. Они могут быть хуже. Однако если эти модели чуть менее точны, но отличаются в категорийном смысле, их следует включить в совокупность.
ОДНА БОЛЬШАЯ МОДЕЛЬ И ВОПРОС О СТЕПЕНИ ДЕТАЛИЗАЦИИ
Многие модели работают в теории и на практике. Но это не значит, что многомодельный подход всегда верен. Иногда лучше разработать одну большую модель. В этом разделе мы проанализируем, когда целесообразнее использовать каждый из подходов и попутно рассмотрим вопрос о степени детализации, то есть о том, насколько детальным должно быть разделение данных.
Для того чтобы ответить на первый вопрос (использовать одну большую модель или множество маленьких), вспомните об областях применения моделей: рассуждение, объяснение, разработка, коммуникация, действие, прогнозирование и исследование. Четыре из них (рассуждение, объяснение, коммуникация и исследование) требуют упрощения, благодаря чему мы можем использовать логику, позволяющую объяснять те или иные явления, распространять свои идеи и исследовать возможности.
Вспомните теорему Кондорсе о жюри присяжных. С ее помощью мы смогли раскрыть логику, объяснить, почему подход с использованием множества моделей с большой вероятностью обеспечит правильный результат, и сделать выводы. Если бы мы включили в модель жюри присяжных типы личности и представили доказательства в виде одномерного массива слов, мы заблудились бы в лесу деталей. Борхес рассуждает об этом в своем эссе о науке, рассказывая о составителях карт, стремившихся к чрезмерной детализации: «Коллегия картографов создала карту империи, которая была размером с империю и совпадала с ней до единой точки. Потомки, не столь преданные изучению картографии, сочли эту пространную карту бесполезной»11.
Модели с высоким уровнем точности будут полезны и для трех оставшихся областей применения моделей, таких как прогнозирование, разработка и действие. При наличии БОЛЬШИХ данных мы должны их использовать. Эмпирическое правило звучит так: чем больше у нас данных, тем детализированнее должна быть модель. Это можно продемонстрировать на примере применения моделей категоризации для структурирования мышления. Допустим, нам нужно построить модель для объяснения вариации во множестве данных. Для создания контекста предположим, что у нас есть огромный массив данных сети продуктовых магазинов, содержащий подробную информацию о ежемесячных расходах нескольких миллионов домохозяйств на продукты питания. По объему расходов они разнятся, что мы измеряем как вариацию — сумму квадратов разности между величиной расходов каждого домохозяйства и средним объемом расходов по всем домохозяйствам. Если средний объем расходов составляет 500 долларов в месяц, а семья тратит 520 долларов, она вносит вклад в общую вариацию, равный 400, или 20 в квадрате12.
Если общая вариация составляет 1 миллиард долларов, а модель объясняет 800 миллионов этой вариации, то ее показатель R2 составляет 0,8. Величина объясненной вариации соответствует тому, насколько данная модель улучшает оценку среднего значения. Если оценка, полученная с помощью модели, указывает, что домохозяйство потратит 600 долларов, и оно действительно тратит 600 долларов, то данная модель объясняет все 10 000, которые это домохозяйство вносит в общую вариацию. Если семья потратила 800 долларов, а согласно модели должна была потратить 700 долларов, тогда то, что было вкладом в общую вариацию 90 000 ((800 – 500)2), теперь составляет всего 10 000 ((800 – 700)2). Таким образом, данная модель объясняет 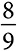 вариации.
вариации.
R2: процент объясненной дисперсии (коэффициент детерминации)
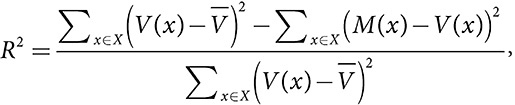
где V(x) — это значение x на множестве X, 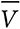 — среднее значение, а M(x) — оценка модели.
— среднее значение, а M(x) — оценка модели.
В данном контексте модель категоризации делит домохозяйства на категории и определяет значение по каждой. Более детализированная модель обеспечивает создание большего числа категорий. Это может потребовать анализа большего количества атрибутов домохозяйств. Увеличение числа категорий позволяет объяснить большую долю вариации, но мы можем зайти слишком далеко. Последовав примеру картографов Борхеса и отнеся каждое домохозяйство к отдельной категории, мы сможем объяснить всю вариацию. Но такое объяснение, как и карта в натуральную величину, не принесет особой пользы.
Создание избыточного количества категорий приводит к чрезмерной подгонке данных, а она препятствует прогнозированию будущих событий. Предположим, мы хотим использовать данные о покупках продуктов за прошлый месяц для прогнозирования данных за нынешний месяц. Ежемесячные расходы домохозяйств отличаются. Модель, которая относит каждое домохозяйство к его собственной категории, предскажет, что оно потратит столько же, сколько и в прошлом месяце. Но это будет не очень хороший прогноз, учитывая ежемесячные колебания расходов. Отнеся домохозяйства к категории им подобных, мы сможем использовать средний объем расходов на продукты аналогичных домохозяйств для создания более точного прогноза.
Для этого мы будем рассматривать ежемесячный объем расходов каждого домохозяйства как одно из значений распределения (о распределениях рассказывается в главе 5). У этого распределения есть среднее значение и дисперсия. Задача построения модели категоризации — создать категории на основе атрибутов таким образом, чтобы у домохозяйств в рамках одной категории были близкие средние значения. Тогда объем расходов одной семьи за первый месяц позволит определить объем расходов другой семьи за второй месяц. Однако ни один вариант категоризации не может быть идеальным. Средний объем расходов домохозяйств, входящих в одну категорию, будет немного отличаться. Мы называем это погрешностью категоризации.
Увеличивая категории, мы увеличиваем и погрешность категоризации, поскольку возрастает вероятность отнесения к одной категории домохозяйств с разными средними значениями. Впрочем, более крупные категории основаны на большем количестве данных, а значит, оценки среднего в каждой категории будут точнее (см. правило квадратного корня в главе 5). Погрешность, возникающая из-за неправильной оценки среднего, называется погрешностью оценки. По мере увеличения категорий погрешность оценки уменьшается. Включение одного или даже десяти домохозяйств в одну категорию не позволит получить точную оценку среднего, если они будут существенно разниться по ежемесячному объему расходов. Тысяча домохозяйств в одной категории обеспечат такую оценку.
Итак, мы получили важный интуитивный вывод: увеличение количества категорий влечет за собой погрешность категоризации в связи с отнесением домохозяйств с разными средними значениями к одной категории. Статистики называют это систематической ошибкой модели. Вместе с тем создание большего количества категорий увеличивает погрешность оценки среднего в пределах каждой категории. Статистики называют это увеличением дисперсии среднего значения. Компромиссное решение в отношении того, сколько категорий необходимо выделить, можно формально описать с помощью теоремы о декомпозиции погрешности модели. Статистики называют этот результат компромиссом между смещением и дисперсией.
Теорема о декомпозиции погрешности модели
Компромисс между смещением и дисперсией
Погрешность модели = погрешность категоризации + погрешность оценки
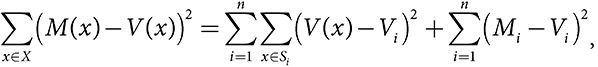
где M(x) и Mi — это значения модели для элемента данных x в категории Si, а V(x) и Vi — истинные значения [6], 13.
ИСПОЛЬЗОВАНИЕ ОДНОЙ МОДЕЛИ ВО МНОГИХ ОБЛАСТЯХ
Для изучения моделей требуется время, усилия и широта охвата. Снизить эти требования помогает подход «использование одной модели во многих областях». Мы предлагаем освоить небольшое количество гибких моделей и креативно их применять. Мы используем модель из области эпидемиологии, чтобы понять процесс распространения семян кукурузы, сети Facebook, преступности и поп-музыки. Мы применяем модель распространения сигнала к рекламе, браку, оперению павлинов и страховым взносам. Кроме того, мы используем модель пересеченного адаптивного ландшафта, чтобы объяснить, почему у людей нет дыхала. Безусловно, не каждая модель применима в любом контексте, но большинство моделей достаточно гибкие. Мы выигрываем даже в случае неудачи, поскольку попытки креативного применения моделей позволяют установить их пределы. К тому же это интересно.
Подход «использование одной модели во многих областях» сравнительно новый. В прошлом модели относились к конкретным дисциплинам. У экономистов были модели спроса и предложения, монопольной конкуренции и экономического роста; у политологов — модели предвыборной борьбы; у экологов — модели видообразования и репликации, а у физиков модели, описывающие законы движения. Все эти модели разрабатывались для определенных целей. Никто не применял модель из физики к экономике или модель из экономики к головному мозгу, как никто не стал бы использовать швейную машинку для ремонта протекающей трубы.
Выход моделей за рамки своих дисциплин и использование одной модели в нескольких областях позволило добиться значительных успехов. Пол Самуэльсон переосмыслил модели из физики для объяснения нюансов рыночного равновесия. Энтони Даунс использовал модель конкуренции между продавцами мороженого на пляже для объяснения позиционирования кандидатов на политические должности, ведущих идеологическую борьбу. Социологи применили модели взаимодействия частиц для объяснения ловушек бедности, колебаний уровня преступности и даже экономического роста в разных странах. А экономисты использовали модели саморегулирования, основанного на экономических принципах, чтобы понять, как функционирует головной мозг [7].
ИСПОЛЬЗОВАНИЕ ОДНОЙ МОДЕЛИ ВО МНОГИХ ОБЛАСТЯХ: ПРИМЕР — ВЫСОКИЕ СТЕПЕНИ XN
Креативное применение моделей требует практики. Для того чтобы получить предварительное представление о потенциале подхода использования одной модели во многих областях, возьмем знакомую формулу возведения переменной в степень, XN, и используем ее в качестве модели. Кода степень равна 2, формула дает площадь квадрата со стороной Х, а когда 3 — объем куба со стороной Х. В случае более высоких степеней формула отражает геометрическое расширение или геометрический спад.
Супертанкеры. Наш первый пример применения этого подхода — супертанкер в виде прямоугольного параллелепипеда, длина которого в восемь раз превышает его высоту и ширину, обозначенные символом S. Как показано на рис. 3.1, площадь поверхности супертанкера равна 34S2, а объем — 8S3. Стоимость строительства супертанкера зависит прежде всего от площади его поверхности, которая определяет количество используемой стали. Размер дохода от эксплуатации супертанкера зависит от его объема. Вычисление отношения объема к площади поверхности по формуле 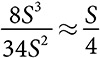 показывает линейное повышение рентабельности (которая пропорциональна объему) за счет увеличения размера.
показывает линейное повышение рентабельности (которая пропорциональна объему) за счет увеличения размера.
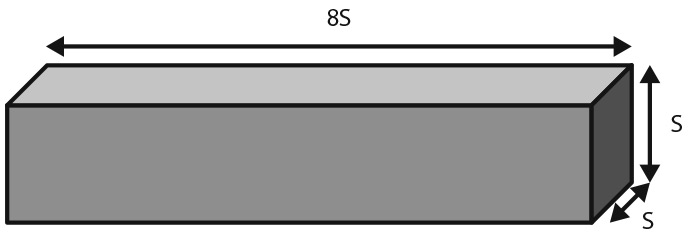
Рис. 3.1. Супертанкер в виде прямоугольного параллелепипеда: площадь поверхности = 34S2, объем = 8S3
Судоходный магнат Ставрос Ниархос, знавший об этом соотношении, построил первые современные супертанкеры и заработал миллиарды в период восстановления после Второй мировой войны. Чтобы вы могли получить некоторое представление о масштабах, давайте сравним: длина нефтяного танкера T2, который использовался во время Второй мировой войны, составляла 152,4 метра, высота 7,62 метра и ширина 15,24 метра. У современных супертанкеров, таких как Knock Nevis, следующие размеры: длина 457,2 метра, высота 24,38 метра и ширина 54,87 метра. Представьте, что башня Willis (Sears) в Чикаго легла на бок и плывет по озеру Мичиган. Супертанкер Knock Nevis похож на танкер Т2, но увеличен в три с небольшим раза. Площадь поверхности Knock Nevis в десять раз превышает площадь поверхности Т2, а объем в тридцать раз больше. Возникает вопрос, почему супертанкеры не бывают еще крупнее? Ответ прост: танкеры должны проходить через узкий Суэцкий канал; Knock Nevis буквально протискивается через него, оставляя всего несколько десятков сантиметров с каждой стороны [8].
Индекс массы тела. Индекс массы тела (body mass index, BMI) используется в медицине для определения весовых категорий. Разработанный в Англии, BMI равен отношению веса человека (в килограммах) к квадрату его роста в метрах [9]. При постоянном росте индекс массы тела находится в линейной зависимости от веса. Если один человек весит на 20 процентов больше, чем другой человек того же роста, BMI первого человека будет на 20 процентов больше.
Сначала мы используем нашу модель для приближенного представления человека в виде идеального куба, состоящего из жира, мышц и костей. Обозначим символом M вес одного кубического метра нашего кубического человека. Вес человека-куба равен произведению его объема на вес кубического метра, или H3 · M, а BMI равен H · M. Данная модель указывает на два недостатка: BMI увеличивается линейно в зависимости от роста, а учитывая, что мышцы тяжелее жира, у людей, которые находятся в хорошей физической форме, более высокое значение M, а значит, и более высокий индекс массы тела. Рост не должен быть связан с ожирением, а мускулатура — вовсе не тучность, а ее противоположность. Эти недостатки сохраняются и в более реалистичной модели. Если мы сделаем глубину (толщину от груди до спины) и ширину человека пропорциональной росту посредством введения параметров d и w, то индекс массы тела можно будет записать так: 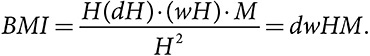 BMI многих звезд NBA и других спортсменов относит их к категории людей с избыточным весом (BMI > 25), как и многих лучших мужчин-десятиборцев мира [10]. Учитывая, что высокий BMI бывает даже у людей среднего роста, находящихся в хорошей физической форме, не стоит удивляться тому, что согласно метаанализу результатов примерно сотни исследований с размером смешанной выборки, исчисляемым миллионами, дольше всего живут люди со слегка избыточным весом [11].
BMI многих звезд NBA и других спортсменов относит их к категории людей с избыточным весом (BMI > 25), как и многих лучших мужчин-десятиборцев мира [10]. Учитывая, что высокий BMI бывает даже у людей среднего роста, находящихся в хорошей физической форме, не стоит удивляться тому, что согласно метаанализу результатов примерно сотни исследований с размером смешанной выборки, исчисляемым миллионами, дольше всего живут люди со слегка избыточным весом [11].
Уровень метаболизма. Теперь применим нашу модель для прогнозирования обратной зависимости между размером животного и уровнем его метаболизма. У каждого живого существа происходит обмен веществ — повторяющаяся последовательность химических реакций, которые расщепляют органические вещества и преобразуют их в энергию. Скорость обмена веществ в организме, или уровень метаболизма, измеряемый в калориях, эквивалентен количеству энергии, необходимой для поддержания жизнедеятельности. Если мы сконструируем кубические модели мыши и слона, то, как показывает рис. 3.2, у куба меньшего размера отношение площади поверхности к объему будет гораздо больше.
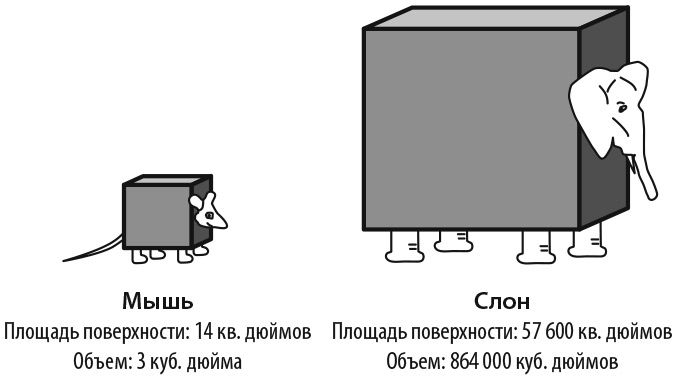
Рис. 3.2. Взрывающийся слон
Мы можем представить мышь и слона в качестве модели, состоящей из ячеек объемом 1 кубический дюйм, каждая из которых обладает метаболизмом. Эти метаболические реакции создают тепло, которое должно рассеиваться через поверхность животного. Площадь поверхности мыши равна 14 квадратных дюймов, а объем — 3 кубических дюйма, а значит, отношение площади поверхности к объему составляет 5:1 [12]. На каждую ячейку объема в один кубический дюйм у мыши есть пять квадратных дюймов площади поверхности, через которую она может рассеивать тепло. Площадь поверхности каждой теплообразующей ячейки слона равна всего одной пятнадцатой квадратного дюйма. Следовательно, мышь может рассеивать тепло в семьдесят пять раз быстрее слона.
Для того чтобы у обоих животных была одинаковая внутренняя температура, у слона должен быть более медленный метаболизм. Слону с метаболизмом мыши понадобилось бы 15 000 фунтов (около 7 тонн) пищи в день. Кроме того, ячейки слона выделяли бы слишком много тепла, чтобы его можно было рассеивать через шкуру животного. В итоге слон начал бы тлеть, а затем взорвался бы. Однако слоны не взрываются, потому что уровень их метаболизма примерно в двадцать раз ниже, чем у мышей. Данная модель прогнозирует не скорость изменения уровня метаболизма в зависимости от размера, а только направление. Более сложные модели могут объяснить законы масштабирования [13].
Доля женщин-руководителей. В последнем примере мы увеличим показатель степени в формуле и используем данную модель для объяснения того, почему так мало женщин становятся руководителями компаний. В 2016 году менее чем в 5 процентах компаний из списка Fortune 500 должность СЕО14 занимали женщины. Для того чтобы стать СЕО, человек должен получить ряд повышений. Мы можем представить шансы на повышение как вероятностные события: у человека есть определенная вероятность получить повышение. Кроме того, будем исходить из предположения, что для назначения на должность СЕО человек должен продвигаться по служебной лестнице при каждом удобном случае. Возьмем пятнадцать повышений в качестве эталона, поскольку это соответствует повышению каждые два года за тридцатилетний путь к креслу СЕО. Факты свидетельствуют о небольшом смещении в пользу мужчин, что мы можем представить как наличие у мужчин более высокой вероятности продвижения по службе [14]. Обозначим это как вероятность повышения мужчин PM, которая немного выше вероятности продвижения женщин PW. Если оценить эти вероятности как 50 и 40 процентов соответственно, то у мужчины будет примерно в 30 раз больше шансов стать СЕО, чем у женщины [15]. Данная модель показывает, как постепенно накапливаются скромные смещения. Десятипроцентная разница в темпах продвижения по карьерной лестнице в итоге превращается в 30-кратное отличие. Эта же модель объясняет, почему гораздо более высокая доля (25 процентов) президентов колледжей и университетов — женщины. В колледжах и университетах меньше административных уровней, чем в компаниях из списка Fortune 500. Профессор может стать президентом всего за три повышения: заведующий кафедрой, декан, а затем президент. На трех уровнях накапливается меньшее смещение. Следовательно, более значительная доля женщин-президентов колледжей и университетов не означает, что в учебных заведениях уровень эгалитарности по сравнению с корпорациями выше.
РЕЗЮМЕ
Итак, в начале главы мы заложили логические основы применения одной модели во многих областях, воспользовавшись теоремой Кондорсе о жюри присяжных и теоремой о прогнозе разнообразия, а затем с помощью моделей категоризации показали пределы многообразия моделей. Мы выяснили, какое количество моделей может усилить нашу способность прогнозировать, действовать, разрабатывать и так далее, и, кроме того, поняли, что найти много разноплановых моделей не так просто. Иначе мы бы составляли прогнозы с почти идеальной точностью, что, как мы знаем, нереально. Тем не менее наша задача по-прежнему состоит в построении как можно большего числа полезных, разноплановых моделей.
В следующих главах представлен базовый набор моделей, описывающих разные аспекты мира. Они исходят из разных предположений о причинно-следственных связях и благодаря многообразию создают условия для продуктивного многомодельного мышления. Акцентируясь на отдельных аспектах более сложного целого, каждая модель вносит свой вклад. Кроме того, каждая модель может входить в состав еще более эффективного ансамбля моделей.
Как отмечалось выше, многомодельное мышление требует знания более чем одной модели. Однако это не означает, что нам нужно знать огромное количество моделей, учитывая возможность применения каждой модели во многих областях. Это не всегда будет просто. Успешное использование одной модели во многих областях зависит от креативной модификации исходных предположений ивыстраивания необычных аналогий для применения модели в новом контексте. Таким образом, чтобы научиться многомодельному мышлению, необходимо нечто большее, чем просто знание математики; для этого нужен креативный подход, о чем свидетельствуют примеры применения модели куба.
Пакетирование и множество моделей
Нередко мы подбираем модель так, чтобы она соответствовала выборке из имеющегося набора данных, а затем тестируем ее на оставшихся данных. В других случаях мы приспосабливаем модель к существующим данным и используем для прогнозирования будущих данных. Моделирование такого типа создает противоречие: чем больше параметров мы включаем в модель, тем лучше подбираем данные и тем выше становится риск чрезмерной подгонки (переобучения). Хорошее соответствие не всегда дает хорошую модель. Физик Фримен Дайсон рассказывает о реакции Энрико Ферми на одно из исследований, в котором была задействована исключительно точно подобранная модель. «В отчаянии я спросил Ферми, разве его не впечатлило соответствие между нашими расчетными показателями и его результатами измерений. Он спросил в ответ: “Сколько произвольных параметров вы использовали в своих вычислениях?” Я подумал немного о наших процедурах исключения и ответил: “Четыре”. Он сказал: “Помню, как мой друг Джонни фон Нейман говорил, что с четырьмя параметрами он может описать слона, а с пятью — заставить его махать хоботом”. На этом разговор закончился» [16].
Оценки, используемые для того, чтобы «заставить слона махать хоботом», очень часто включают в себя члены высшего порядка — квадраты, кубы и четвертые степени. Это создает риск крупных ошибок, поскольку члены высшего порядка усиливают соответствующие признаки. 10 в два раза больше 5, тогда как 104 уже в 16 раз больше 54. На представленном ниже рисунке показан пример переобучения.
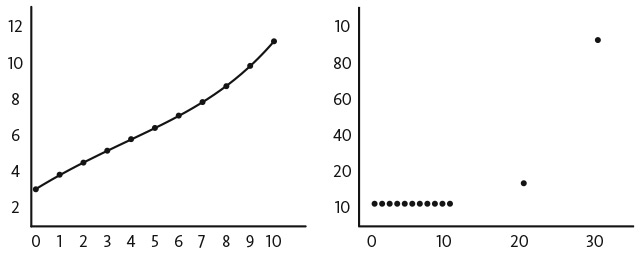
Переобучение и вневыборочная ошибка
На графике слева отображены (гипотетические) данные о продажах в компании по производству 3D-принтеров в зависимости от среднего количества визитов сотрудников отдела продаж на места за месяц. На графике представлено нелинейное наилучшее соответствие, включающее нелинейные члены вплоть до пятой степени. На графике справа показано, что данная модель прогнозирует продажу 100 принтеров, если количество визитов торговых агентов достигнет 30. Этот прогноз не может быть правильным, если клиенты покупают максимум по одному 3D-принтеру.
Чтобы предотвратить чрезмерную подгонку модели, мы могли бы избегать использования членов высшего порядка. Более сложное решение, известное как бутстрэп-агрегирование, или пакетирование, позволяет сконструировать множество моделей. Для выполнения бутстрэп-анализа набора данных мы создаем несколько наборов данных одинакового размера путем случайного выбора элементов данных из исходных данных с их последующим возвратом — после извлечения того или иного элемента данных мы возвращаем его назад, чтобы можно было выбрать его снова. Этот метод позволяет получить совокупность одинаковых по размеру наборов данных, каждый из которых содержит множество копий определенных элементов данных и ни одной копии других элементов данных.
Далее мы подбираем (нелинейные) модели к каждому набору данных и в итоге получаем множество моделей [17], которые затем можем отобразить в одной системе координат, получив при этом спагетти-график (см. рис. ниже). Темная линия показывает среднее для различных моделей.
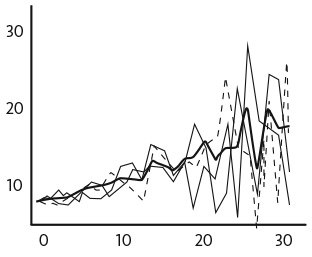
Бутстрэппинг и спагетти-график
Пакетирование позволяет обнаружить устойчивые нелинейные эффекты, поскольку они проявляются во многих случайных выборках, и при этом избежать подгонки моделей к специфическим закономерностям в любом отдельно взятом наборе данных. Обеспечивая многообразие посредством случайных выборок и усреднение множества моделей, пакетирование использует логику, лежащую в основе теоремы о прогнозе разнообразия. Такой подход позволяет создать разноплановые модели, среднее которых, как мы знаем, гораздо точнее, чем сами модели.
ГЛАВА 4
МОДЕЛИРОВАНИЕ ПОВЕДЕНИЯ ЛЮДЕЙ
Пока невозможно указать на единую теорию человеческого поведения, которая была бы успешно сформулирована и проверена в различных условиях.
Элинор Остром
В этой главе мы рассмотрим вопрос, лежащий в основе книги: как мы моделируем поведение людей? Во многих из описанных ниже моделях люди выступают в качестве базовой единицы анализа. Мы создадим модели людей, которые участвуют в голосовании, поддерживают кооперацию, поднимают восстания, поддаются модным увлечениям, вносят деньги на пенсионные счета и подсаживаются на наркотики. В рамках каждой модели нам предстоит сделать предположения о людях. Каковы их цели? Они заботятся только о себе или действуют из альтруистических побуждений? Каковы их вероятные действия? Как они их выбирают, или у них нет выбора?
Мы могли бы выдвинуть специальные предположения для каждой модели, но это вызвало бы путаницу и привело к потере благоприятных возможностей. Нам пришлось бы иметь дело с уникальной совокупностью конструкций. Каждая новая модель требовала бы новых представлений о человеческом поведении. Возникающая в связи с этим разнородность ограничивала бы нашу способность широко мыслить и объединять модели. Мы не смогли бы эффективно использовать принцип многомодельного мышления.
Подход, которого мы будем придерживаться, ставит во главу угла согласованность наряду с разнообразием. Мы будем моделировать людей либо как агентов, действующих на основе правил, либо как рациональных агентов15. В рамках множества агентов, действующих на основе правил, мы будем рассматривать тех, кто действует на основе простых фиксированных правил, и тех, кто действует на основе адаптивных правил. Агент, действующий на основе адаптивного правила, может изменить свое поведение исходя из полученной информации, прошлых успехов или наблюдений за другими. Как мы увидим, между этими случаями нет четкого разграничения: адаптивное правило иногда можно интерпретировать как фиксированное, а рациональные действия порой принимают форму простых правил.
То, как именно мы решим моделировать людей, будет зависеть от контекста и наших целей. Мы прогнозируем или объясняем? Оцениваем те или иные политические меры? Пытаемся разработать тот или иной институт? Или занимаемся исследованием? В среде с низкой степенью важности (такой как моделирование того, какой цвет курток предпочитают люди, или аплодируют ли они стоя после спектакля) мы чаще всего будем исходить из того, что люди применяют фиксированные правила. Когда люди решают, стоит ли сотрудничать в рамках какого-то предприятия и доверять ли другому человеку, мы будем считать, что они учатся и адаптируются. И наконец, в среде с высокой степенью важности мы будем исходить из предположения, что информированные, опытные люди делают оптимальный выбор.
Прежде чем подробно описывать наш подход, рассмотрим ряд распространенных заблуждений. Многие люди впервые сталкиваются с формальными моделями социальных явлений на вводных курсах по экономике. Эти модели часто основаны на простейшей модели рационального агента, согласно которой все руководствуются личными интересами и способны делать оптимальный выбор. Модель также может исходить из того, что у всех одинаковые предпочтения и уровень дохода. Затем экономисты находят равновесие в рамках этих моделей, что позволяет им оценивать последствия рыночных потрясений или изменения политического курса. Хотя подобные модели и основаны на ошибочных предположениях, они полезны, поскольку помогают экономистам коммуницировать, а студентам — понимать изучаемый материал.
На основе такого опыта многие люди приходят к выводу, что формальное моделирование требует узкого, нереалистичного взгляда на человеческую природу, согласно которому люди руководствуются личными интересами и никогда не ошибаются. Однако это не так. На самом деле даже экономисты так не думают. В передовых областях экономики используются модели с недостаточно информированными, разнородными агентами, которые адаптируются в соответствии с новыми знаниями и иногда (хотя и не всегда) заботятся о выигрыше других людей. Степень, в которой люди склонны учитывать интересы окружающих, также зависит от ситуации. Например, при пожертвовании в благотворительный фонд или волонтерстве человек может быть более участливым, чем при покупке дома.
Тем не менее продолжает бытовать мнение, что моделирование исходит из эгоистичности и нереалистичной рациональности людей. Мы должны избавиться от него. Проведем аналогию: сделав несколько шагов в океан, вы можете подумать, что он мелкий, но отплывая все дальше и дальше, начнете ощущать его глубину. В данном случае мы стартуем с берега, но время от времени будем двигаться дальше и покажем, что модели могут включать сфокусированных на других, ограниченно рациональных людей.
Какие бы предположения мы ни делали, нам не удастся избежать их последствий. Мы привязаны к мачте логической согласованности и не можем фабриковать последствия. Если мы предполагаем сильное социальное влияние на выбор потребителей, наша модель даст ряд продуктов с большой рыночной долей. Если мы исходим из того, что люди получают информацию из сетей, то властью будут обладать те, кто заполняет структурные пустоты.
В оставшейся части главы мы сначала кратко опишем ряд проблем, связанных с моделированием поведения людей: все мы разные, подвержены социальному влиянию и склонны к ошибкам, нацелены на результат, адаптивны и способны действовать. Мы не можем включить все эти характеристики в одну модель, не создавая запутанный хаос, поэтому должны выбирать.
Если неоднородность мало что значит, мы можем исходить из идентичности агентов. Если проблема проста или люди имеют богатый опыт, мы предполагаем, что они не совершают ошибок.
Далее мы проанализируем модель рационального агента и обсудим ее теоретические аспекты и обоснования применения, несмотря на ее описательную неточность. Что именно представляет собой модель рационального агента — золотой стандарт, соломенное чучело или нечто среднее, — зависит от задачи нашей модели. Модель рационального агента будет менее эффективна в области прогнозирования человеческого поведения, чем в качестве инструмента коммуникации, оценки действий и разработки политики.
Затем мы продемонстрируем, как включить психологическое смещение и альтруистические предпочтения в стандартную модель рационального агента. Решение об их включении зависит от того, что именно мы изучаем. Иногда потребуется включить в модель определенные человеческие предубеждения, такие как страх потери и презентистский подход (когда человек больше озабочен срывом сроков в настоящем, чем в будущем). Например, они могут быть важны в моделях пенсионных накоплений или массовых волнений и менее значимы в моделях манеры вождения или распространения заболеваний.
В четвертом разделе рассказывается о поведении, основанном на правилах. Преимущество этой категории моделей — в их гибкости (любая линия поведения, поддающаяся описанию, в большинстве случаев представляет собой игру по правилам) и разрешимости. Достаточно описать такое поведение с помощью компьютерной программы (выполнить агентное моделирование) — и наблюдать за развитием событий. Подобная свобода действий подразумевает ответственность. Поскольку мы можем выбрать любое правило поведения, нам следует остерегаться специальных предположений. Иногда правила поведения можно считать обоснованными с учетом их целевой функции, хотя так бывает не всегда.
Глава заканчивается пересмотром значения рациональности как эталонного поведения. Даже не принимая оптимальных решений, люди все равно адаптируются к меняющимся обстоятельствам и новым знаниям. Это наблюдение порождает своего рода парадокс. Когда мы разрабатываем тот или иной общественный институт или политику, исходя из предположения, что людям свойственна предвзятость или они действуют не в своих интересах, остается риск того, что люди могут изменить свое поведение. Людей можно обмануть один раз, но одурачить два или три раза гораздо труднее. Мы не должны считать, что рациональность — единственное правдоподобное предположение, но логика все же говорит в ее пользу как значимого эталона. Кроме того, логика также поддерживает рассмотрение простых правил поведения как нижней границы рациональности. Помимо всего прочего, при моделировании конкретной ситуации мы можем применить любое количество адаптивных и психологических правил в качестве способа, позволяющего исследовать огромное пространство между этими двумя крайностями.
ПРОБЛЕМЫ МОДЕЛИРОВАНИЯ ПОВЕДЕНИЯ ЛЮДЕЙ
Моделирование поведения людей — сложная задача, поскольку модели требуют низкоразмерного представления, а люди не поддаются простому описанию. Все мы разные, подвержены социальному влиянию, склонны к ошибкам, целеустремленны и обучаемы. Кроме того, мы обладаем агентивностью — способностью действовать.
Напротив, физические объекты, такие как атомы углерода или бильярдные шары, не демонстрируют ни одного из этих свойств. Атомам углерода не присуще многообразие (хотя они могут занимать различные позиции в соединениях, например в пропане). Они никогда не нарушают законов физики и не живут целеустремленной жизнью. Они не меняют свое поведение с учетом прошлого опыта и лишены агентивности; они не решают возглавить восстание или сменить сферу деятельности. Отсюда и проистекает часто повторяемый шуточный комментарий социологов: насколько сложной была бы физика, если бы электроны могли думать. Физика была бы еще сложнее, если бы электроны могли описывать модели.
Мы можем начать с проблем, обусловленных многообразием. Люди отличаются по предпочтениям, способности действовать, сети социальных связей, уровню альтруизма и уровню когнитивного внимания, которое они уделяют действиям. Моделирование было бы проще, если бы все мы были одинаковыми. Иногда мы прибегаем к статистической логике и предположению, что поведенческое многообразие уравновешивается. Например, мы могли бы построить модель, которая прогнозирует благотворительные пожертвования как функцию дохода. При определенном уровне дохода и налоговой ставки некоторые люди могут быть более, а другие менее альтруистичными, чем мы предполагаем. Если отклонения от модели исключаются путем усреднения (в главе 5 мы поговорим о моделях распределений, объясняющих, почему это происходит), то наша модель может быть точной. Такое уравновешивание многообразия возможно только в случае независимых действий. Когда поведение формируется под влиянием социальных факторов, экстремальные действия могут привести к побочным эффектам. Так происходит, когда политические активисты побуждают избирателей к действиям. Мы столкнемся с этим при моделировании массовых волнений.
Произойдет ли взаимоисключение ошибок в их общей совокупности, зависит от контекста. Ошибки, возникающие из-за отсутствия когнитивной привязанности, могут быть случайными и независимыми. Ошибки, обусловленные когнитивными искажениями, могут быть систематическими и коррелированными. Например, люди могут придавать чрезмерное значение недавним событиям и вспоминать описательную информацию лучше, чем статистические данные. Общее смещение такого рода не уравновешивается.
Следующая проблема связана с желаниями людей. Самая большая трудность в описании моделей людей — дать точную оценку их целей и задач. Одни люди жаждут богатства и славы. Другие хотят внести вклад в улучшение жизни своих общин и мира в целом. В модели рационального агента мы представляем выигрыш человека непосредственно в виде функции. В моделях, основанных на правилах, цели носят более имплицитный характер. Правило поведения, согласно которому люди стремятся жить в интегрированных районах, но покидают район, если доля людей их расы падает ниже 10 процентов, отражает определенные убеждения в отношении стремлений людей.
И наконец, последняя проблема моделирования людей связана с их агентивностью — способностью действовать, менять то, что они делают, и учиться. Вместе с тем в некоторых контекстах людей лучше охарактеризовать как рабов привычек. Действия могут быть нам неподвластны. Мало кто стремится к зависимости от опиоидов или к бедности. Тем не менее люди совершают действия, приводящие к таким результатам.
Когда действия человека влекут за собой негативные последствия, он во многих случаях адаптирует свое поведение. Мы можем учесть это, включив в свои модели обучение. То, как люди учатся, зависит от контекста. Сколько часов нужно готовиться к экзамену, чтобы получить хорошую оценку, или сколько раз в неделю тренироваться — этому люди учатся на основе личного опыта и самоанализа. В каких продуктовых магазинах делать покупки и жертвовать ли на благотворительность — об этом люди узнают, наблюдая за другими. В главе 26 мы покажем, как обычно работает обучение в нестратегических контекстах. Люди осваивают наиболее подходящие действия. Кроме того, мы продемонстрируем, что в стратегических контекстах, которые мы моделируем как игры, все ставки аннулируются. Однако индивидуальное и социальное обучение не обязательно обеспечивает хорошие результаты.
Каждая из шести характеристик является потенциальным свойством модели. Включая то или иное свойство в модель, мы должны решить, в каком объеме это делать. Насколько разноплановыми должны быть наши агенты? Какое социальное влияние мы учитываем? Учатся ли люди у других? Как мы определяем задачи? В какой степени людям свойственна активность? Мы можем обладать меньшей свободой действий, чем думаем. Джонатан Хайдт описывает отсутствие способности действовать с помощью метафоры о наезднике и слоне. «Образ, который я придумал для себя, когда поражался своей слабости, — что я наездник, сидящий на спине слона. Я держу в руках поводья и, потянув их в ту или иную сторону, могу велеть слону повернуть, остановиться или двигаться дальше. Я могу управлять происходящим, но только если у слона нет собственных желаний. Если же слон действительно захочет что-то сделать, мне его не одолеть» [1]. Иногда нам удается прокатиться верхом на слоне, а иногда нет. Ни один подход к моделированию людей не может быть применим при любых обстоятельствах, поэтому мы моделируем их разными способами.
МОДЕЛЬ РАЦИОНАЛЬНОГО АГЕНТА
Модель рационального агента предполагает, что люди делают оптимальный выбор с учетом функции выигрыша или полезности. Действиями могут выступать решения — тогда выигрыш зависит только от действий человека, или осуществляться в рамках игры — тогда выигрыш зависит от действий других игроков. В игре с одновременным выбором или неполной информацией модель также определяет убеждения в отношении действий других агентов.
Модель рационального агента
Предпочтения индивида представлены математической функцией полезности или выигрыша, определенной на множестве возможных действий. Человек выбирает действие, максимизирующее значение функции. В игре такой выбор может потребовать убеждений в отношении действий других игроков.
Давайте построим в качестве примера простую модель рационального агента, отражающую индивидуальное решение о том, какую часть дохода выделять на жилье. Модель отражает полезность как функцию от затрат на жилье и все остальные виды потребления, в том числе продукты питания, одежду и развлечения (см. врезку). В данной модели делается предположение в отношении цены на жилье и цены всех остальных товаров. Модель далека от реалистичности: она одинаково подходит ко всем вариантам жилья, объединяет все остальные товары в одну категорию «потребление» и устанавливает на них одну и ту же цену. Мы можем игнорировать какое-то время все эти неточности, поскольку задача модели — объяснить долю дохода, выделенную на жилье.
Модель рационального агента в контексте потребления
Исходное предположение: польза, получаемая человеком от общего потребления C и расходов на жилье H, можно описать как:
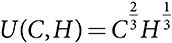
Результат: человек, максимизирующий полезность (рациональный агент), тратит на жилье ровно треть доходов [2], 16.
В этой модели доля дохода, выделяемая человеком на жилье, не зависит от цены жилья или дохода. Оба результата представляют собой достаточно точное приближение данных [3]. За исключением тех, кто находится на концах шкалы распределения доходов, большинство людей тратят на жилье около трети дохода. Этот вывод имеет политические последствия: если цены на жилье упадут на 10 процентов, люди будут покупать его на 10 процентов больше. Кроме того, он также обосновывает предположение об идентичности агентов. Если люди тратят на жилье фиксированный процент дохода, то общий объем расходов на жилье зависит только от среднего дохода.
Использование функции полезности делает модели разрешимыми, поддающимися анализу и проверке. Мы можем оценить такие функции с помощью данных, вывести оптимальные действия, а также задать вопросы типа «что, если», изменив значения параметров. Делая предположение относительно функции полезности, мы подразумеваем согласованность предпочтений, которой может не существовать. Для того чтобы предпочтения были представимы посредством функции полезности, они должны удовлетворять определенным аксиомам. Теоремы, доказывающие существование функций полезности, предполагают наличие совокупности альтернатив в сочетании с упорядочением предпочтений. Представьте, что мы можем перечислить все возможные группы товаров, которые может купить человек. Упорядочение предпочтений ранжирует эти группы от наиболее до наименее предпочтительных. Человек может предпочесть кофе с молоком чаю с лимоном и тогда разместит группу {кофе, молоко} выше группы {чай, лимон}.
Функция полезности отражает предпочтения, если она присваивает группе A более высокое значение, чем группе B, тогда и только тогда, когда порядок предпочтений ставит группу A выше группы B. Для того чтобы предпочтения можно было представить в виде функции полезности, они должны удовлетворять таким условиям, как полнота, транзитивность, независимость и непрерывность. Полнота требует, чтобы порядок предпочтений был определен на всех парах альтернатив. Транзитивность исключает циклы предпочтений. Если человек предпочитает группу A группе B, а группу B группе C, то он должен также отдавать предпочтение группе A перед группой C. Иначе говоря, если человек предпочитает яблоки бананам, а бананы сыру, то он должен также отдавать предпочтение яблокам перед сыром. Это условие исключает противоречивые предпочтения.
Независимость требует, чтобы люди оценивали результаты лотереи по отдельности. Лотерея — это распределение вероятностей по совокупности альтернатив, например, вероятность результата A составляет 60 процентов, а результата B — 40 процентов. Предпочтения удовлетворяют условию независимости, если, когда A находится в порядке предпочтений выше B, в любой лотерее, включающей в себя B в качестве результата, человек отдает предпочтение альтернативной лотерее, где место B занимает A17. Условие независимости исключает сильное неприятие риска. Человек, не склонный рисковать, может ставить поездку в Новый Орлеан выше поездки в Disney World, но предпочитает точно знать, что поедет в Disney World, чем участвовать в лотерее, которая отправит его в Новый Орлеан с вероятностью 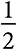 и в Disney World в остальных случаях. Последнее условие, непрерывность, гласит, что если человек ставит A выше B, а B выше C, то существует лотерея, в которой он получит A с вероятностью p и C с вероятностью (1 − p), которая нравится ему точно так же, как и лотерея B18. Это предположение исключает сильные предпочтения в отношении определенных результатов [4].
и в Disney World в остальных случаях. Последнее условие, непрерывность, гласит, что если человек ставит A выше B, а B выше C, то существует лотерея, в которой он получит A с вероятностью p и C с вероятностью (1 − p), которая нравится ему точно так же, как и лотерея B18. Это предположение исключает сильные предпочтения в отношении определенных результатов [4].
Условия независимости и транзитивности, которые люди нарушают, в дополнение к спорным утверждениям, что люди склонны к оптимизации, побуждают многих ставить под сомнение модель рационального агента, особенно популярную среди экономистов. Тем не менее существуют веские основания исходить из рациональности. Во-первых, люди могут действовать, «как будто» они склонны к оптимизации, и могут применять правила, обеспечивающие почти оптимальное поведение. Когда люди играют в бильярд, ловят летающий диск фрисби или водят автомобиль, они не составляют математических уравнений. Математические расчеты времени прыжка, необходимого, чтобы поймать фрисби, озадачат практически любого. Тем не менее люди ловят фрисби. Кстати, собаки тоже это умеют. Таким образом, люди и собаки действуют так, будто решают сложную задачу оптимизации.
Эта же логика распространяется и на задачи высокой размерности. Анализ действий Гарольда Зерчера, директора отдела технического обслуживания муниципальной автобусной компании в Мэдисоне, показал, что он принял почти оптимальное решение относительно замены двигателей автобусов [5]. Зерчер не делал никаких математических расчетов, а полагался на эвристику, основанную на опыте, а это означало, что он действовал (почти) как рациональный агент.
Во-вторых, даже если люди действительно совершают ошибки, при повторении подобной ситуации способность учиться должна подталкивать нас к оптимальным действиям. В-третьих, в тех случаях, когда ставки высоки, люди должны вкладывать время и силы в принятие почти оптимальных решений. Люди могут переплачивать 30 процентов за кофе или батарейки, но они не переплачивают 30 процентов за автомобили или дома. Утверждение, что обучение и высокие ставки повышают уровень рациональности, подкреплено большим объемом эмпирических и экспериментальных данных [6].
Как ни парадоксально, четвертое основание для принятия модели рационального агента состоит в том, что она упрощает анализ. В случае большинства функций полезности есть единственное оптимальное действие. Человек может вести себя неоптимально тысячами способов. Утверждение, что люди не склонны к оптимизации, открывает огромное окно возможностей. Исходя из предположения, что люди делают выбор в пользу сохранения своей идентичности или соблюдения культурных норм, мы можем не получить одного четкого ответа. Рациональный выбор не реалистичен, но реализм имеет свою цену — он порождает путаницу. Ответ, пусть и заведомо неправильный, может быть полезнее, чем отсутствие ответа вообще, поскольку это позволяет применить модель к данным и проанализировать последствия изменения переменных [7].
Аргументы в пользу рационального выбора
«Как будто»: разумное поведение, основанное на правилах, может быть неотличимо от оптимального или почти оптимального поведения.
Обучение: в повторяющихся ситуациях люди должны приближаться к оптимальному поведению.
Большие ставки: в случае важных решений люди собирают информацию и думают медленно.
Уникальность: оптимальное поведение часто носит уникальный характер, что делает модель поддающейся проверке.
Непротиворечивость: оптимальное поведение создает непротиворечивую модель. Освоив ее, люди не будут менять свое поведение.
Эталон: оптимальное поведение выступает в качестве эталона, позволяющего определить верхнюю границу когнитивных способностей людей.
В-пятых, предположение о рациональном агенте обеспечивает внутреннюю непротиворечивость. Если модель предполагает субоптимальное поведение и находится в открытом доступе, ее можно изучить. Люди могут менять поведение. Они могут не быть оптимальны, однако любое предположение, отличное от предположения об оптимальности, подвергается критике за отсутствие непротиворечивости. Мы вернемся к этому вопросу в конце главы.
И последнее, по мнению некоторых, самое важное: рациональность может выступать в качестве эталона [8]. При разработке политики, составлении прогноза или выборе действия мы должны анализировать, что бы произошло, если бы у людей были рациональные предпочтения и склонность к оптимизации. Это указало бы на изъяны в наших рассуждениях. Кроме того, мы должны быть готовы к тому, что это действие приведет нас к выводу, что модель рационального агента неприменима и нам следует использовать другие модели. К этому списку можно добавить и седьмую причину: многомодельное мышление. Когда люди применяют множество моделей, вероятность ошибок снижается.
ПСИХОЛОГИЧЕСКИЕ СМЕЩЕНИЯ
Модель рационального агента ставят под сомнение психологи, экономисты и нейроученые, заявляя, что она не соответствует поведению людей. Эмпирические результаты лабораторных и естественных экспериментов указывают на то, что люди подвержены различным искажениям и смещениям, в том числе и смещению в отношении статус-кво. При вычислении вероятностей мы игнорируем базовые ставки, придаем слишком большое значение беспроигрышным вариантам и стараемся избегать потерь.
По мере того как исследователи начинают связывать поведение и убеждения с процессами, протекающими в головном мозге, доказательства предрасположенности людей к психологическим смещениям становятся все более убедительными. Например, нейроэкономика использует исследования мозга для изучения экономически значимых аспектов поведения, таких как отношение к риску, уровень доверия и реакция на информацию [9]. По утверждению Канемана, то, что нам известно на данный момент, позволяет провести различие между двумя типами мышления: быстрые, интуитивные правила (быстрое мышление) и неторопливые размышления (медленное мышление). Быстрое мышление более подвержено такого рода смещениям [10]. В долгосрочной перспективе мы можем определить некоторые поведенческие шаблоны на основе структур головного мозга, но следует помнить, что мозг обладает огромной пластичностью — и способен преодолеть смещения посредством медленного мышления.
Кроме того, мы должны проявлять осмотрительность и не считать универсальным любой вывод, задокументированный всего в нескольких исследованиях. Результаты многих психологических исследований не подтвердились. В ходе одного из последних исследований не удалось воспроизвести и половины из сотни результатов, опубликованных в ведущих психологических журналах [11]. Кроме того, воспроизводимость не всегда подразумевает универсальность. Во многих исследованиях совокупность объектов исследования лишена экономического и культурного многообразия [12]. Можно предположить, что в более разнообразной выборке поведенческих закономерностей будет еще меньше, что дает еще больше оснований избегать обобщений в отношении поведения.
Наконец, при создании более реалистичных моделей мы должны помнить о разрешимости. К тому же они могут потребовать более сложной математики [13]. Однако ни одна из этих причин не убедительна настолько, чтобы отказаться от моделей с психологически реалистичным поведением, но в совокупности они указывают на то, что мы должны действовать осмотрительно и уделять особое внимание документально подтвержденным поведенческим закономерностям.
Два неоднократно воспроизведенных отклонения — это неприятие потерь и гиперболическое дисконтирование. Неприятие потерь означает, что люди не склонны рисковать в случае потенциальной выгоды и готовы рискнуть в случае возможных потерь. Канеман и Тверски обозначают эту общую теорию как «теорию перспектив» [14]. Неприятие потерь поначалу не кажется иррациональным, но говорит о том, что люди выбирают разные действия, если один и тот же сценарий представлен как потенциальная потеря или потенциальный выигрыш.
Например, люди предпочитают выиграть 400 долларов наверняка, чем участвовать в лотерее с равными шансами выиграть 1000 долларов. Тем не менее они примут участие в лотерее с равными шансами проиграть 1000 долларов, чем наверняка потерять 600 долларов. Такая непоследовательность распространяется и на неденежные сферы. Врачи, которым дают варианты выбора, представленные в виде выгоды, избегают риска. Когда эти варианты представлены в виде потерь, врачи в основном идут на риск [15].
Теория перспектив: пример
Представление альтернатив в виде выгоды
У вас есть два варианта выбора:
Вариант A: однозначно получить 400 долларов.
Вариант B: получить 1000 долларов, если при подбрасывании симметричной монеты выпадет орел, и 0 долларов, если выпадет решка.
Представление альтернатив в виде потери
Вам дают 1000 долларов и два варианта выбора:
Вариант Â: однозначно потерять 600 долларов.
Вариант 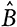 : потерять 0 долларов, если при подбрасывании симметричной монеты выпадет орел, и 1000 долларов, если выпадет решка.
: потерять 0 долларов, если при подбрасывании симметричной монеты выпадет орел, и 1000 долларов, если выпадет решка.
Варианты A и Â эквивалентны вариантам B и . Согласно теории перспектив, большинство людей выбирают варианты A и .
Гиперболическое дисконтирование подразумевает более высокий коэффициент дисконтирования для ближайшего будущего. Стандартные экономические модели опираются на экспоненциальное дисконтирование, при котором ценность будущих благ убывает по экспоненте. Человек с годовой ставкой дисконтирования 10 процентов оценивает сумму в 1000 долларов в следующем году как эквивалентную 900 долларам сегодня. Этот человек дисконтировал бы деньги следующего года на 10 процентов каждый очередной год. Однако опыт показывает, что большинство людей не дисконтируют будущие доходы по фиксированной ставке дисконтирования. Напротив, они подвержены смещению в сторону безотлагательности, то есть дисконтируют ближайшее будущее в гораздо большей степени, чем более отдаленное [16]. Например, если вы спросите людей, что они предпочли бы — 9500 долларов через двадцать лет или 10 000 долларов через двадцать лет и один день, практически каждый подождал бы еще один день ради дополнительных 500 долларов. Но если вы спросите этих же людей, что они предпочли бы — 9500 долларов сегодня или 10 000 долларов завтра, многие бы взяли 9500 долларов сейчас. Это и есть пример смещения в сторону безотлагательности [17].
Такое смещение порождает поведение, рассогласованное во времени. Через год большинство людей предпочтут подождать еще один день и получить 10 000 долларов. Такие предпочтения не являются логически противоречивыми. Гиперболическим дисконтированием объясняют, почему люди накапливают задолженность по кредитным картам, едят нездоровую пищу, вступают в незащищенные половые связи и не откладывают на пенсию.
Таким образом, в зависимости от того, как мы будем использовать модель, мы можем предпочесть неприятие потерь и гиперболическое дисконтирование, учитывая, что эти допущения лучше соответствуют поведению большинства людей. Основная причина этого не делать — если они усложняют модель без качественного изменения того, что мы находим, или если при допущении гиперболического дисконтирования наша модель приводит к нереалистичному поведению.
МОДЕЛИ, ОСНОВАННЫЕ НА ПРАВИЛАХ
Теперь рассмотрим модели, основанные на правилах [18]. Тогда как модели на основе оптимизации опираются на базовую функцию полезности или выигрыша, который люди стремятся максимизировать, модели, основанные на правилах, предполагают определенное поведение. Они могут исходить из того, что во время аукциона человек предложит за тот или иной лот на 10 процентов меньше его истинной стоимости или скопирует действия друга, если этот друг неизменно получает более высокие выигрыши. Многие приравнивают модели на основе оптимизации к математике, а основанные на правилах — к вычислениям. Хотя различие между ними не столь однозначное, как может показаться на первый взгляд. Вспомните нашу модель затрат на жилье. Оптимальное поведение приняло форму простого правила: выделять на жилье треть дохода. Ключевое различие между двумя подходами заключается в их базовых предположениях. В моделях на основе оптимизации главную роль играют предпочтения или выигрыш, а в модели, основанной на правилах, — поведение.
Правила поведения могут быть фиксированными или адаптивными. Фиксированное правило подразумевает применение одного и того же алгоритма во всех случаях. Модели рационального выбора обеспечивают верхний предел когнитивных способностей людей, а модели с фиксированными правилами — нижний предел. Распространенное на рынках фиксированное правило, правило нулевого интеллекта, подразумевает принятие любого предложения, обеспечивающего более высокий выигрыш. Это правило не допускает глупых действий (например, снижающих полезность). Предположим, мы хотим оценить эффективность одностороннего рынка, на котором продавцы размещают предложения о продаже товара без возможности торга. Продавец, придерживающийся правила нулевого интеллекта, случайным образом выберет цену, превышающую ценность этого товара для него. Покупатель купит любой товар по цене ниже ценности, которую представляет для него этот товар. Проанализировав эти варианты поведения с помощью компьютерной модели, мы обнаружим, что на рынках трейдеры с нулевым интеллектом обеспечивают почти оптимальные результаты. Следовательно, эффективное функционирование фондовых рынков не зависит от наличия рациональных покупателей и продавцов [19].
Адаптивное правило подразумевает переключение между вариантами наборов поведения, развитие новых типов поведения или копирование поведения других. Эти действия предпринимаются ради повышения выигрыша. Следовательно, в отличие от фиксированных правил адаптивные правила требуют функции полезности или выигрыша. Сторонники этого подхода утверждают, что в любой ситуации люди склоняются к простым и эффективным правилам, а раз люди ведут себя именно так, мы должны моделировать их поведение аналогичным образом [20]. Хотя модели, основанные на правилах, не содержат явно выраженных предположений в отношении рациональности, модели на основе адаптивных правил демонстрируют экологическую рациональность — более эффективные правила начинают доминировать [21].
Для того чтобы объяснить, как работают модели на основе адаптивных правил, опишем модель самоорганизованной координации под названием Эль Фароль [22]. «Эль Фароль» — ночной клуб в Санта-Фе, в котором каждый вторник проводится вечер танцев. Каждую неделю 100 потенциальных танцоров решают, пойти в «Эль Фароль» на танцы или остаться дома. Все 100 человек любят танцевать, но не хотят идти в клуб, когда он переполнен. Модель основана на строгой системе предпочтений. Человек получит нулевой выигрыш, оставшись дома, выигрыш 1 — при посещении клуба при условии, что там будет 60 или менее посетителей, и выигрыш −1 — при посещении клуба, если там будет более 60 посетителей.
Если мы построим модель, основанную на фиксированных правилах, это может привести к чему угодно. Например, если бы мы предписали каждому человеку придерживаться правила «ходить каждую неделю; если в клубе будет более 60 посетителей, не идти на следующей неделе; а затем отправиться туда через неделю», то в клубе «Эль Фароль» было бы 100 посетителей в первую неделю, ноль посетителей во вторую и 100 посетителей в третью. Модель «Эль Фароль» создает адаптивные правила, позволяя каждому человеку использовать совокупность правил. Каждое правило говорит человеку о том, идти в клуб или не идти. Этиправила принимают несколько форм. Одни носят фиксированный характер: ходить в клуб каждую неделю. Другие основаны на закономерностях в количестве людей, посетивших клуб на протяжении последних недель. Третьи могут предсказывать, что количество посетителей заведения на этой неделе будет таким же, как и на прошлой. Если на прошлой неделе в клубе было меньше 60 посетителей, правило посоветует человеку посетить его на этой неделе.
Модель адаптивных правил поведения может присваивать каждому правилу оценку, эквивалентную проценту недель, на которые оно предоставило правильный совет. Тогда каждый человек мог бы использовать данную модель в своей совокупности правил с самой высокой оценкой. Лучшее правило будет меняться на протяжении нескольких недель. Моделирование такого типа показывает, что при наличии большой совокупности правил клуб каждую неделю посещают около 60 человек: координация происходит без централизованного планирования. Иначе говоря, система адаптивных правил путем самоорганизации обеспечивает почти оптимальные результаты.
Модель «Эль Фароль»: адаптивные правила
Еженедельно в течение года каждый из 100 человек независимо друг от друга решают, идти в клуб «Эль Фароль» или нет. Человек, посетивший клуб, получает выигрыш 1, если в нем будет 60 или менее посетителей, и выигрыш –1 в противном случае. Тот, кто не идет в клуб, получает нулевой выигрыш.
У каждого человека есть совокупность правил, на основании которых он решает, идти ли в ему клуб. Эти правила могут быть фиксированными или зависеть от посещаемости клуба в последнее время. Каждый человек еженедельно придерживается того правила из своей совокупности, выполнение которого обеспечивало максимальный выигрыш в прошлом.
Мы можем интерпретировать поведение в рамках моделей, основанных на адаптивных правилах, с помощью микро-макро цикла (см. рис. 4.1). На микроуровне группа индивидов совершают действия (обозначенные как ai) в соответствии с правилами. Эти правила порождают явления макроуровня (обозначенные как макро1 и макро2), на которые указывают стрелки, направленные вверх. В задаче клуб «Эль Фароль» в качестве явлений макроуровня выступают последовательности посещений за прошедший период. Стрелки, направленные вниз, указывают на то, как эти явления макроуровня отражаются на поведении людей. В модели «Эль Фароль» каждый индивид может применять разные правила. Если в результате примененных людьми правил клуб «Эль Фароль» переполнен четыре недели подряд, тогда правила, которые советуют реже посещать клуб, обеспечат более высокие выигрыши. Когда люди переключатся на эти правила, количество посетителей клуба уменьшится. Правила микроуровня порождают явление макроуровня (слишком высокая посещаемость), которое учитывается в правилах микроуровня.
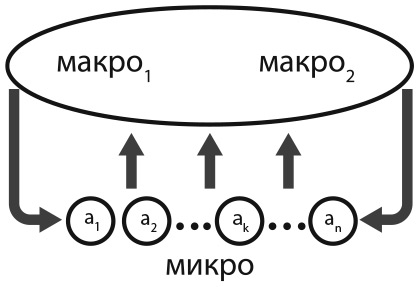
Рис. 4.1. Микро-макро цикл
КОГНИТИВНАЯ ЗАВЕРШЕННОСТЬ, БОЛЬШОЙ ВОПРОС И МНОЖЕСТВО МОДЕЛЕЙ
Микро-макро цикл позволяет преодолеть основные разногласия относительно того, насколько умными следует делать агентов. Должны ли люди определять все последствия своих действий? Кроме того, цикл подразумевает более крупный вопрос (с которым мы будем постоянно сталкиваться в книге) о том, какую категорию результатов обеспечивает та или иная модель: переходит ли она к равновесию, порождает последовательность случайных событий, создает цикл или сложную серию результатов?
Начнем с вопроса о том, насколько умными должны быть агенты. Предположим, мы считаем, что люди обладают весьма скромными когнитивными способностями, поэтому разрабатываем модель с агентами с нулевым интеллектом19. Совокупность их действий образует агрегированные явления макроуровня. Если макроуровень обеспечивает оптимальные или почти оптимальные результаты (как в случае одностороннего рынка покупателей и продавцов), то наше предположение может быть обоснованным. Легковыполнимое фиксированное правило дает хорошие результаты. У людей будет мало стимулов прилагать усилия к разработке более сложных правил.
Противоречие возникает, когда наша модель обеспечивает неоптимальные или даже очень плохие результаты. Так было в случае модели «Эль Фароль», когда общее фиксированное правило могло привести к циклу, в ходе которого клуб «Эль Фароль» был бы переполнен на протяжении одной недели и пуст на следующей. Столкнувшись с неоптимальным результатом, мы можем предположить, что люди будут адаптировать свое поведение. Они могут экспериментировать, могут анализировать логику ситуации, чтобы выработать новый план действий. Если мы последуем этой логике вплоть до ее экстремального значения и будем исходить из низких затрат на мышление, то может получиться так, что мы поддержим модель рационального агента. Любой неоптимально действующий человек мог бы добиться большего. И хотя это так, люди также должны уметь определять более эффективные действия.
Это поднимает большой вопрос: какую категорию результатов обеспечивает данная модель? У нас есть четыре варианта: равновесие20, цикличность, хаотичность или сложность. Категория результатов будет иметь значение при принятии решения о том, насколько серьезно мы принимаем аргумент, что люди должны изучать свой путь к равновесию. Во-первых, если модель создает последовательность случайных событий на макроуровне, скорее всего, люди не смогут ничему научиться. С нашей моделью все в порядке. Аналогичная логика применима к моделям, порождающим сложные структуры. В таких случаях мы предположили бы, что люди продолжат адаптировать новые правила, но необязательно исходили бы из того, что они могут сделать оптимальный выбор. Напротив, сложность явлений макроуровня делает оптимальную реакцию неправдоподобной. По всей вероятности, люди противопоставили бы сложности совокупность простых правил, как в модели «Эль Фароль».
Модели, порождающие циклы или равновесия, создают стационарную среду, в связи с чем можно ожидать, что люди способны учиться, что никто не стал бы постоянно совершать неоптимальные действия. В качестве примера предположим, что у нас есть модель движения транспорта, в которой каждый выбирает маршрут поездки на работу с помощью фиксированного правила. В ней система движения транспорта приходит в равновесие. В его рамках участница дорожного движения по имени Лейн каждое утро тратит 75 минут на поездку из Калабасаса в деловой район Лос-Анджелеса. При наличии равновесия, если бы Лейн поехала по боковым улицам через каньон Топанга, дорога заняла бы всего 45 минут. С учетом ценности дополнительных 30 минут в день и частоты, с которой жители Лос-Анджелеса говорят о пробках, скорее всего, Лейн нашла бы более короткий маршрут. У нее нет недостатка в методах его поиска: можно воспользоваться системой автомобильной навигации, поговорить с соседями или поэкспериментировать.
Таким образом, если наша модель обеспечивает равновесие (или простой цикл), и оно не согласуется с оптимизацией поведения, то в нее закралась логическая ошибка. Если людям доступно более эффективное действие, они должны определить его. Они должны учиться. Обратите внимание, что нам нет надобности исходить из оптимальности поведения, чтобы достичь равновесия. Люди могут следовать простым правилам и обеспечивать равновесие, в котором никто не может извлечь выгоду посредством изменения своих действий. При таком равновесии ситуация выглядела бы так, «как будто» люди делают оптимальный выбор, поскольку на самом деле так и есть. Опять же, эту логику не нужно применять по отношению к сложным или случайным результатам. Если схема движения транспорта в Лос-Анджелесе порождает сложную последовательность транспортных тянучек и заторов, у нас мало оснований полагать, что Лейн сможет каждый день выбирать оптимальный маршрут. У нее почти наверняка не получится.
Если адаптивные правила, которые могут одобрить любые действия, порождают равновесие, то оно должно быть совместимо с поведением оптимизирующих агентов. Если те же правила создают сложность, поведение агентов не обязательно должно быть оптимальным. Мы можем сформулировать эту идею так: оптимальное поведение может быть нереалистичным предположением, особенно в сложных ситуациях. С другой стороны, если система обеспечивает устойчивый результат, при котором у человека есть более эффективные действия, скорее всего, он сможет определить, какое из них ему следует предпринять.
Расширенный вариант этой логики применим и к политике вмешательства. Предположим, мы используем данные для оценки правила поведения людей — например, вероятности того, что человек придет в отделение скорой помощи больницы в свой обеденный перерыв, чтобы решить мелкие проблемы со здоровьем. Прибегнув к фиксированному правилу, мы могли бы увеличить размер отделения, чтобы людям не приходилось ждать. Если люди продолжат придерживаться этого фиксированного правила, мы получим новое равновесие с коротким периодом ожидания в полдень. Однако при новом, более коротком периоде ожидания люди, которые не обращались в отделение скорой помощи с вывихнутыми лодыжками и простудой, теперь могут начать это делать. Данное равновесие опирается на то, что люди выбирают неоптимальные действия, такие как отказ от посещения отделения скорой помощи, даже тогда, когда им не пришлось бы долго ждать. Если люди учатся, мы не можем полагаться на данные за прошедший период для прогнозирования результатов в случае изменения политики. Эта идея, известная как критика Лукаса, представляет собой вариант закона Кэмбелла, который гласит, что люди реагируют на любой показатель или стандарт таким образом, что это делает его менее эффективным [23].
Критика Лукаса
Изменения в политике или среде обитания с большой вероятностью повлекут за собой поведенческую реакцию тех, кого это затрагивает. Следовательно, модели, которые оценены на основе данных о прошлом поведении людей, будут неточными. Модели должны учитывать тот факт, что люди реагируют на политические и экологические изменения.
Как должно быть ясно на данный момент, наилучшего решения о том, как моделировать поведение людей, нет. Насколько рациональными делать их, или адаптивными — их правила, зависит от обстоятельств. Мы должны проявлять максимальную проницательность в каждой ситуации. С учетом факторов неопределенности нам нужно отдавать предпочтение большему числу моделей, а не меньшему.
Даже если мы склонны отбрасывать модели рационального выбора как нереалистичные, нам следует признать их разрешимость, способность выявлять направляющую силу стимулов, а также их ценность как эталона. Простые модели поведения, основанного на правилах (такие как нулевой интеллект), также далеки от реальности. Однако даже будучи неправильными, они могут быть полезны. Их легко анализировать и они позволяют определить, какой уровень интеллекта важен в определенной среде.
Человеческое поведение попадает в диапазон между двумя крайними вариантами — нулевым интеллектом и полной рациональностью, поэтому имеет смысл строить модели, в которых люди адаптируются с помощью правил. Эти правила должны учитывать тот факт, что люди отличаются когнитивной привязанностью и способностями в пределах одной области. В связи с этим нам следует ожидать поведенческого многообразия. Кроме того, мы можем рассчитывать на определенную непротиворечивость в пределах группы. Это также можно включить в модели [24].
В общем, с учетом сложностей, связанных с моделированием людей, у нас есть все основания для применения множества разноплановых моделей. Возможно, нам не удастся точно прогнозировать действия человека, но мы сможем определить набор возможных вариантов. Это позволит извлечь пользу из создания моделей, поскольку мы будем знать, что может произойти.
В заключение мы призываем к смирению и состраданию. При построении моделей людей специалист по моделированию должен быть скромным. Учитывая такие сложные аспекты моделирования, как многообразие, социальное влияние, когнитивные ошибки, целеустремленность и адаптация, наши модели неизбежно будут в чем-то неправильными — именно поэтому мы используем многомодельный подход. Упрощенные модели поведения вполне соответствуют некоторым ситуациям и позволяют сфокусироваться на других аспектах окружающей среды. Более содержательные модели поведения уместны при наличии более качественных данных. У нас должны быть скромные ожидания. Все мы разные: нам свойственна целеустремленность, адаптивность и предвзятость, мы подвержены социальному влиянию и обладаем определенной степенью агентивности. Как мы можем не ожидать, что какая-то отдельная модель человеческого поведения будет неправильной? Так и должно быть. Наша задача — построить множество моделей, ансамбль которых будет полезен.
ГЛАВА 5
НОРМАЛЬНОЕ РАСПРЕДЕЛЕНИЕ: КОЛОКОЛООБРАЗНАЯ КРИВАЯ
Я не считал себя умнее шестидесяти пяти человек, но умнее среднего из шестидесяти пяти человек — безусловно.
Ричард Фейнман
Распределения — один из элементов базовых знаний для любого разработчика моделей. В дальнейшем мы используем распределения для построения и анализа таких моделей, как зависимость от первоначально выбранного пути, случайные блуждания, процессы Маркова, поиск и обучение. Кроме того, навыки работы с распределениями нужны для оценки неравенства в распределении власти, доходов и богатства, а также для выполнения статистических тестов. Наш подход к использованию распределений представлен в двух небольших главах — одна посвящена нормальному распределению, а другая — распределению по степенному закону (распределению с длинным хвостом), — где мы будем рассуждать скорее как специалисты по моделированию, чем как статистики. Нас как разработчиков моделей интересуют два серьезных вопроса: почему распределения имеют именно такой вид и почему они так важны?
Для того чтобы ответить на первый вопрос, прежде всего нужно вспомнить, что такое распределение. Распределение математически описывает вариацию (различия в пределах одного типа) и многообразие (различия между типами) путем представления их в виде распределения вероятностей, заданного на числовых значениях или классах. Нормальное распределение принимает знакомую форму колоколообразной кривой. Рост и вес представителей большинства видов удовлетворяют нормальному распределению. Такое распределение симметрично относительно среднего значения и не включает особо крупные или мелкие события. Вряд ли мы встретим двухметрового муравья или двухкилограммового лося. Мы можем использовать центральную предельную теорему, чтобы объяснить широкую распространенность нормального распределения. Эта теорема говорит, что, выполняя сложение или усреднение случайных величин, мы можем ожидать получения нормального распределения. Многие эмпирические явления, в частности любой совокупный показатель (такой как данные о продажах или итоги голосования), можно записать в виде суммы случайных событий.
Однако не все события распределены по нормальному закону. Землетрясения, количество погибших во время военных действий и данные о продажах книг демонстрируют распределение с длинным хвостом, которое в основном состоит из крохотных событий, но иногда включает единичные масштабные события. Ежегодно калифорнийцы переживают более 10 000 землетрясений. Если не смотреть на трепещущие лепестки жасмина, вы их даже не заметите. Однако время от времени разверзается земля, рушатся автомагистрали и содрогаются города.
Знать, порождает ли система нормальное распределение или распределение с длинным хвостом, важно по ряду причин. Нам необходимо знать, будет ли энергосистема подвержена массовым отключениям и приведет ли рыночная система к появлению горстки миллиардеров и миллиардов бедняков (что гарантирует распределение с длинным хвостом). Знание распределений позволит нам прогнозировать вероятность наводнений, в результате которых вода перельется через дамбу, вероятность того, что рейс 238 авиакомпании Delta прибудет в Солт-Лейк-Сити вовремя, а также вероятность того, что транспортный хаб обойдется вдвое дороже заложенной в бюджете суммы. Знание распределений также понадобится при проектировании. Нормальное распределение не подразумевает значительных отклонений, поэтому авиаконструкторам не нужно выделять в самолете место для ног пятиметрового человека. Кроме того, знание распределений также может служить руководством к действию. Как мы узнаем чуть ниже, предотвращение массовых беспорядков зависит не столько от снижения среднего уровня недовольства, сколько от умиротворения людей, занимающих крайние позиции.
Эта глава организована по принципу «структура — логика — функция». Мы дадим определение нормальному распределению, опишем, как оно возникает, а затем спросим, почему оно имеет такое большое значение. Опираясь на знание распределений, мы объясним метод управления процессами «шесть сигм», а также почему хорошее происходит в малых количествах и как проверить значимость эффекта. Затем мы вернемся к вопросу логики и зададимся вопросом, что произойдет, если умножить, а не суммировать случайные величины. И узнаем, что при этом будет получено логарифмически нормальное распределение, которое включает более крупные события и не симметрично относительно среднего значения. Отсюда следует, что умножение эффектов приводит к усилению неравенства — вывод, указывающий на то, как политика повышения заработной платы сказывается на распределении доходов.
НОРМАЛЬНОЕ РАСПРЕДЕЛЕНИЕ: СТРУКТУРА
Распределение присваивает вероятности событиям или величинам. Распределение суточного количества осадков, результатов тестов или роста людей присваивает вероятность каждому возможному значению этих результатов. Статистические показатели представляют информацию, содержащуюся в распределении, в виде отдельных чисел, таких как математическое ожидание (среднее значение) распределения. Средняя высота деревьев в горном массиве Шварцвальд в Германии может быть более 24 метров, а средний период пребывания в больнице после операции на открытом сердце может составлять пять дней. Социологи используют среднее значение распределения для сравнения социально-экономических условий в разных странах. В 2017 году ВВП США на душу населения в размере 57 000 долларов превысил ВВП Франции на душу населения, который составил 42 000 долларов, тогда как средняя продолжительность жизни во Франции превышает этот показатель в США на три года.
Второй статистический показатель, дисперсия, измеряет разброс распределения — среднее значение квадрата отклонения данных от их математического ожидания [1]. Если все точки распределения имеют одно и то же значение, дисперсия равна нулю. Если одна половина данных имеет значение 4, а другая — значение 10, то в среднем каждая точка отстоит от среднего значения на 3, а дисперсия равна 9. Стандартное отклонение распределения (еще один распространенный статистический показатель) равно квадратному корню из дисперсии.
Совокупность возможных вероятностных распределений безгранична. Мы можем нарисовать любую линию на листе координатной бумаги и интерпретировать ее как распределение вероятностей. К счастью, распределения, с которыми мы сталкиваемся, как правило, относятся к нескольким классам. На рис. 5.1 показано самое распространенное распределение — нормальное распределение, или колоколообразная кривая.
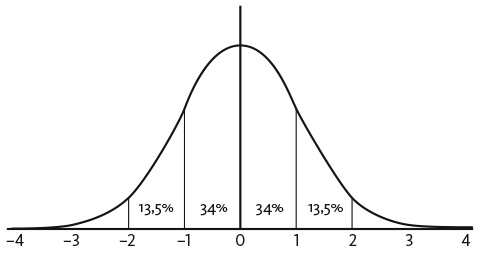
Рис. 5.1. Нормальное распределение со стандартными отклонениями
Нормальное распределение симметрично относительно среднего значения. Если среднее значение равно нулю, вероятность значений больше 3 равна вероятности значений меньше −3. Нормальное распределение характеризуется математическим ожиданием и стандартным отклонением (или, что то же самое, дисперсией). Другими словами, графики нормального распределения всегда выглядят одинаково: примерно 68 процентов результатов в пределах одного стандартного отклонения от среднего значения, 95 процентов результатов в двух стандартных отклонениях и более 99 процентов результатов в трех стандартных отклонениях от среднего значения. Нормальное распределение допускает результат или событие любого масштаба, хотя крупные события происходят редко. Событие, лежащее в пяти стандартных отклонениях от среднего, происходит примерно один раз на каждые два миллиона случаев.
Мы можем использовать регулярность нормальных распределений для присвоения вероятностей диапазонам результатов. Если средняя площадь домов в Милуоки равна 2000 квадратных футов со стандартным отклонением в 500 квадратных футов, то площадь 68 процентов домов составляет от 1500 до 2500 квадратных футов, а площадь 95 процентов домов — от 1000 до 3000 квадратных футов. Если автомобили Ford Focus 2019 года способны проехать в среднем 40 миль на галлон со стандартным отклонением в 1 милю на галлон, то более 99 процентов этих авто будут проходить от 37 до 43 миль на галлон. Как бы ни хотел потребитель, его новый Focus не проедет 80 миль на одном галлоне бензина.
ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА: ЛОГИКА
Множество явлений демонстрируют нормальное распределение: физические размеры представителей флоры и фауны, экзаменационные оценки учащихся, дневной оборот мини-маркетов и продолжительность жизни морских ежей. Центральная предельная теорема, которая гласит, что сумма или усреднение случайных величин дает нормальное распределение, объясняет, почему так происходит (см. врезку).
Центральная предельная теорема
Сумма N ≥ 20 случайных величин будет иметь распределение, близкое к нормальному, при условии, что случайные величины независимы, что каждая из них имеет конечную дисперсию и что ни одно малое подмножество случайных величин не вносит определяющего вклада в вариацию [2].
Один примечательный аспект этой теоремы состоит в том, что сами по себе случайные величины не нуждаются в нормальном распределении. У них может быть любое распределение при условии, что каждая из них имеет конечную дисперсию и ни одно малое подмножество случайных величин не вносит определяющего вклада в вариацию. Предположим, данные о покупательском поведении жителей небольшого поселка с населением 500 человек говорят о том, что каждый из них тратит на покупки в среднем 100 долларов в неделю. Некоторые жители тратят 50 долларов за одну неделю и 150 долларов — за вторую. Другие могут тратить по 300 долларов каждую третью неделю, а кто-то может еженедельно выделять на покупки произвольную сумму в диапазоне от 20 долларов до 180 долларов. При условии, что расходы каждого человека имеют конечную дисперсию и ни одно малое подмножество людей не вносит определяющего вклада в вариацию, сумма распределений будет распределена по нормальному закону с математическим ожиданием 50 000 долларов. Совокупный недельный объем расходов также будет симметричным: он может с одинаковой вероятностью оказаться выше 55 000 долларов и ниже 45 000 долларов. Согласно той же логике, количество бананов, литров молока или коробок корзиночек тако, которые покупают люди, тоже будет подлежать нормальному распределению.
Мы можем использовать центральную предельную теорему, например, для объяснения распределения роста людей. Рост человека определяется совокупностью генетики, среды обитания и взаимодействия между этими двумя факторами. Вклад генетики может достигать 80 процентов, поэтому будем считать, что рост зависит только от генов. На него влияют как минимум 180 генов [3]. Один ген может внести вклад в длину шеи или размер головы, а другой — в длину большой берцовой кости. Хотя гены взаимодействуют друг с другом, в первом приближении можно исходить из того, что каждый ген вносит свой вклад независимо от других генов. Если рост человека равен сумме вкладов 180 генов, то он будет иметь нормальное распределение. Согласно этой же логике, так же будет распределен вес волков и длина больших пальцев панд.
ПРИМЕНЕНИЕ ЗНАНИЙ О РАСПРЕДЕЛЕНИЯХ: ФУНКЦИЯ
Наш первый пример применения нормального распределения объясняет, почему исключительные результаты гораздо чаще имеют место в малых совокупностях, почему лучшие школы небольшие и почему страны с самым высоким уровнем заболеваемости раком, как правило, малонаселенные. Напомним, что в случае нормального распределения около 95 процентов результатов находятся в пределах двух стандартных отклонений и 99 процентов результатов — в пределах трех стандартных отклонений и что согласно центральной предельной теореме математическое ожидание совокупности независимых случайных величин распределено по нормальному закону (с оговорками о дисперсии и независимости). Отсюда следует, что мы можем быть в достаточной степени уверены, что совокупные средние показатели по результатам тестов и другие подобные показатели будут иметь нормальное распределение. Вместе с тем стандартное отклонение среднего случайных величин не равно среднему стандартных отклонений этих величин, так же как стандартное отклонение суммы не равно сумме стандартных отклонений. На самом деле в основе этих формул лежит квадратный корень из величины совокупности (см. врезку).
Правило квадратного корня
Стандартные отклонения σμ математического ожидания μ и суммы σΣ N независимых случайных величин, каждая из которых имеет стандартное отклонение σ, описываются следующими формулами [4]:
Формула стандартного отклонения математического ожидания означает, что большие совокупности имеют более низкие показатели стандартного отклонения, чем малые. Из этого следует, что в малых совокупностях должно быть больше хорошего и больше плохого. На самом деле так и есть. Маленькие города — наиболее и в то же время наименее безопасное место для проживания. Страны с самым высоким уровнем ожирения и заболеваемости раком обычно малонаселенные. Все эти факты можно объяснить различиями в стандартных отклонениях.
Неспособность учитывать размер выборки и выявить причинно-следственные связи из отклоняющихся значений может привести к неправильным политическим действиям. По этой причине Говард Уэйнер называет формулу стандартного отклонения математического ожидания «самым опасным уравнением в мире». Например, в 1990-х годах Фонд Билла и Мелинды Гейтс и другие некоммерческие организации выступили за разделение школ на более маленькие, основываясь на доказательствах, что такие школы лучше [5]. Для того чтобы найти ошибку в этих рассуждениях, представьте, что школы бывают двух типов (маленькие, рассчитанные на 100 учащихся, и большие, на 1600 учащихся) и что оценки их учеников получены на основе одного и того же распределения со средним баллом 100 и стандартным отклонением 80. В маленьких школах стандартное отклонение от среднего значения равно 8 (стандартное отклонение оценок учеников 80, деленное на 10, квадратный корень из количества учеников), в больших — 2.
Если мы обозначим школы со средним баллом выше 110 как школы «с высокими показателями успеваемости», а школы со средним баллом выше 120 как «с исключительными показателями успеваемости», то только небольшие школы будут отвечать любому из этих пороговых значений. Для маленьких школ средний балл 110 находится в 1,25 стандартного отклонения выше среднего значения; такие события имеют место примерно в 10 процентах случаев. Средний балл 120 находится в 2,5 стандартного отклонения выше среднего; подобные события встречаются примерно один раз на 150 школ. Выполнив аналогичные расчеты для крупных школ, мы обнаружим, что пороговое значение среднего балла в школах с высокой успеваемостью находится в пяти стандартных отклонениях выше среднего, а пороговое значение в школах с исключительной успеваемостью — в десяти стандартных отклонениях от среднего. В действительности такие события никогда не наступят. Следовательно, тот факт, что самые лучшие школы маленькие, не доказывает того, что они лучше работают. Самые лучшие школы будут небольшими (хотя размер ни на что не влияет) исключительно в силу правил квадратного корня.
ПРОВЕРКА ЗНАЧИМОСТИ
Регулярность нормального распределения можно также использовать для проверки существенных различий между средними значениями. Если эмпирическое среднее лежит более чем в двух стандартных отклонениях от гипотетического среднего, социологи отклоняют гипотезу об их идентичности [6]. Предположим, мы выдвинем гипотезу, что время поездки на работу в Балтиморе соответствует аналогичному показателю в Лос-Анджелесе. Допустим, наши данные показывают, что поездка в Балтиморе в среднем занимает 33 минуты, а в Лос-Анджелесе — 34 минуты. Если оба множества данных имеют стандартное отклонение от среднего, равное одной минуте, то мы не можем отклонить гипотезу о том, что значения этого показателя идентичны. Средние значения отличаются, но всего на одно стандартное отклонение. Если бы продолжительность поездки на работу в Лос-Анджелесе составляла в среднем 37 минут, тогда мы бы отклонили эту гипотезу, потому что средние значения отличаются на четыре стандартных отклонения.
Однако физики, возможно, так не поступили бы — по крайней мере, если данные получены на основе физических экспериментов. Физики вводят более строгие стандарты, потому что располагают более крупными и более достоверными множествами данных (атомов гораздо больше, чем людей). Экспериментальные данные, на которые полагались физики в 2012 году в качестве доказательства существования бозона Хиггса, менее одного раза на 7 миллионов испытаний указывали на то, что его не существует.
Процесс утверждения лекарственных препаратов, используемый Управлением по санитарному надзору за качеством пищевых продуктов и медикаментов США (Food and Drug Administration, FDA), также основан на проверке значимости. Если фармацевтическая компания заявляет, что ее новое лекарство снижает тяжесть атопического дерматита, она должна провести два рандомизированных контролируемых испытания. Для того чтобы их организовать, компания формирует две идентичные группы страдающих атопическим дерматитом людей. Одна группа получает лекарственный препарат, а другая — плацебо. В конце исследования сравниваются показатели средней тяжести заболевания и среднего уровня негативных побочных эффектов. Затем компания проводит статистические тесты. Если лекарственный препарат существенно снижает тяжесть атопического дерматита (в стандартных отклонениях) и не вызывает значительного повышения уровня негативных побочных эффектов, он будет одобрен. FDA не придерживается непреложного правила о двух стандартных отклонениях. Статистический показатель будет ниже для препарата, излечивающего смертельное заболевание и демонстрирующего незначительные побочные эффекты, чем для лекарства от грибка ногтей, с применением которого связан более высокий уровень заболеваемости раком костей, чем ожидалось. Кроме того, FDA обращает внимание на мощность статистического теста — вероятность того, что тест продемонстрирует эффективность лекарственного препарата.
МЕТОД «ШЕСТЬ СИГМ»
В этом разделе мы продемонстрируем, как применение нормального распределения обеспечивает контроль качества с помощью метода «шесть сигм». Разработанный компанией Motorola в 1980-х годах, этот метод снижает частоту ошибок. Он моделирует свойства продукта на основе нормального распределения. Представьте себе компанию, выпускающую болты для дверных ручек, изготовленных другим производителем, которые должны точно им соответствовать. Согласно техническим спецификациям диаметр болтов должен равняться 14 миллиметрам, хотя любой болт диаметром от 13 до 15 миллиметров будет функционировать должным образом. Если диаметры болтов распределены по среднему закону со средним значением 14 миллиметров и стандартным отклонением 0,5 миллиметра, то любой болт, диаметр которого отличается больше чем на два стандартных отклонения, будет непригоден. События с двумя стандартными отклонениями встречаются в 5 процентах случаев — слишком большой показатель для производителей.
Метод «шесть сигм» подразумевает работу по уменьшению размера стандартного отклонения для снижения вероятности отказа. Компании могут сократить частоту ошибок путем ужесточения контроля качества. Например, 26 февраля 2008 года сеть кофеен Starbucks на три часа закрыла семь тысяч своих заведений для переподготовки сотрудников. Аналогично чек-листы, используемые авиакомпаниями, а теперь и больницами, сокращают вариацию [7]. Метод «шесть сигм» позволяет сократить стандартное отклонение таким образом, что даже при шести стандартных отклонениях ошибка не приводит к отказам. В нашем примере с болтом это потребовало бы сокращения стандартного отклонения диаметра болта до одной шестой миллиметра. Шесть стандартных отклонений подразумевают 2 ошибки на миллиард случаев. Пороговое значение, используемое на практике, допускает неизбежный уровень в полтора стандартных отклонения. Получается, что событие со стандартным отклонением шесть сигм фактически соответствует событию с отклонением четыре с половиной сигмы, означающим допустимую погрешность — около одной ошибки на три миллиона случаев.
Применение центральной предельной теоремы (а значит, и подразумеваемой модели аддитивной ошибки) в методе «шесть сигм» носит настолько неочевидный характер, что остается почти незамеченным. Разумеется, производитель болтов не выполняет точного измерения диаметра каждого болта. Он может провести выборочные измерения нескольких сотен болтов и на основании этой выборки вычислить среднее значение и стандартное отклонение, а затем, исходя из того, что разброс диаметра обусловлен суммой случайных воздействий, таких как вибрация станка, различия в качестве металлов и колебания температуры и скорости пресса, обратиться к центральной предельной теореме и определить нормальное распределение значений диаметра. Так производитель получит эталонное стандартное отклонение, которое может попытаться сократить.
ЛОГНОРМАЛЬНОЕ РАСПРЕДЕЛЕНИЕ: УМНОЖЕНИЕ АНОМАЛЬНЫХ ВЕЛИЧИН
Центральная предельная теорема требует сложения или усреднения независимых случайных величин для того, чтобы получить нормальное распределение. Если случайные величины не суммируются, но каким-то образом взаимодействуют, или не удовлетворяют условию независимости, то полученное в итоге распределение не обязательно должно быть нормальным. На самом деле оно, как правило, таковым и не является. Например, случайные величины, которые представляют собой произведение независимых случайных величин, дают логарифмически нормальное, а не нормальное распределение [8]. В логнормальном распределении отсутствует симметрия, поскольку произведения чисел, которые больше 1, возрастают быстрее, чем их суммы (4 + 4 + 4 + 4 = 16, но 4 × 4 × 4 × 4 = 256), а произведения чисел меньше 1 уменьшаются быстрее, чем суммы 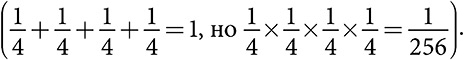 Если мы перемножим множества из двадцати случайных величин с равномерно распределенными значениями от 0 до 10, то их произведение будет состоять из множества результатов, близких к нулю, и нескольких больших результатов, что создаст асимметричное распределение, показанное на рис. 5.221.
Если мы перемножим множества из двадцати случайных величин с равномерно распределенными значениями от 0 до 10, то их произведение будет состоять из множества результатов, близких к нулю, и нескольких больших результатов, что создаст асимметричное распределение, показанное на рис. 5.221.
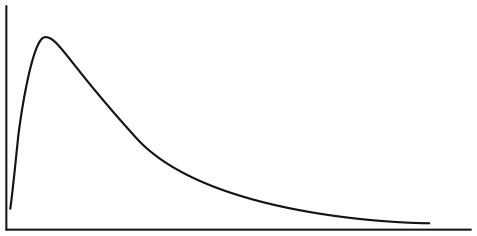
Рис. 5.2. Логнормальное распределение
Длина хвоста логнормального распределения зависит от дисперсии случайных величин, умноженных друг на друга. Если у этих величин низкая дисперсия, хвост будет коротким, если высокая, хвост будет достаточно длинным, поскольку, как уже отмечалось, умножение последовательности больших чисел дает очень большое число. Логнормальное распределение возникает в широком диапазоне примеров, включая размер британских ферм, концентрацию полезных ископаемых в недрах земли и продолжительность периода от заражения болезнью до появления симптомов [9]. Распределение доходов во многих странах стремится к логнормальному распределению, хотя в некоторых странах может отклоняться от него у верхней границы в связи с наличием слишком большого количества людей с высокими доходами.
Простая модель, объясняющая, почему распределение доходов ближе к логнормальному, чем к нормальному, связывает политику повышения заработной платы с распределением доходов, которое она подразумевает. Большинство организаций повышают зарплату на определенный процент. Сотрудники, эффективность работы которых выше среднего, получают более высокий процент повышения. Сотрудники с эффективностью ниже среднего получают повышение на более низкий процент. Вместо такого подхода организации могли бы повышать заработную плату на абсолютную величину. Средний сотрудник мог бы получить прибавку в 1000 долларов. Тот, кто работает лучше, мог бы получить больше, а тот, кто хуже, — меньше. Различие между относительными и абсолютными значениями может показаться семантическим, но это не так [10]. Повышение заработной платы на определенный процент в зависимости от эффективности работы сотрудников (когда показатели эффективности в разные годы — это независимые и случайные величины) порождает логнормальное распределение. Различия в доходах в будущем усугубляются даже при идентичной последующей эффективности. Сотрудник, который работал хорошо в прошлом и зарабатывает 80 000 долларов, получит 4000 долларов в случае повышения зарплаты на 5 процентов. Другой сотрудник, зарабатывающий 60 000 долларов, получит всего 3000 долларов при повышении на 5 процентов. Неравенство порождает еще большее неравенство даже при идентичной эффективности работы. Если бы организация повышала оплату труда на абсолютную величину, оба сотрудника получили бы одинаковое повышение, и в результате распределение доходов было бы ближе к нормальному распределению.
РЕЗЮМЕ
В этой главе мы рассмотрели структуру, логику и функцию нормального распределения и увидели, что его можно описать математическим ожиданием и стандартным отклонением. Мы сформулировали центральную предельную теорему, которая показывает, как возникает нормальное распределение при сложении или усреднении независимых случайных величин с конечной дисперсией. Кроме того, мы представили формулы стандартного отклонения математического ожидания и суммы случайных величин, а затем продемонстрировали следствия, вытекающие из этих свойств. Мы узнали, что малые генеральные совокупности с гораздо большей вероятностью порождают исключительные события и что из-за непонимания этого мы делаем неправильные выводы и совершаем недальновидные поступки. Мы узнали, как предположение о распределении случайных величин по нормальному закону позволяет ученым формулировать утверждения о значимости и мощности статистических тестов, а также как управление процессами помогает прогнозировать вероятность отказов исходя из допущения о нормальном характере распределения.
Не каждый показатель можно записать как сумму или среднее значение независимых случайных величин. Следовательно, не всякое распределение будет нормальным. Некоторые показатели представляют собой произведение независимых случайных величин и имеют логнормальное распределение. Логнормальное распределение принимает только положительные значения. Кроме того, у него более длинный хвост, а значит, оно включает больше крупных событий и гораздо больше очень мелких. Хвост такого распределения становится длинным, когда случайные величины, умноженные друг на друга, имеют высокую дисперсию. Распределение с длинным хвостом указывает на более низкую предсказуемость, тогда как нормальное распределение подразумевает регулярность. Как правило, мы предпочитаем регулярность вероятности крупных событий. Таким образом, мы можем извлечь выгоду из понимания логики, создающей разныераспределения. В целом мы предпочли бы суммировать аномальные случайные величины, а не умножать их, чтобы снизить вероятность наступления крупных событий.
ГЛАВА 6
СТЕПЕННОЕ РАСПРЕДЕЛЕНИЕ: ДЛИННЫЙ ХВОСТ
В каждом фундаментальном законе есть исключения. Однако закон все равно нужен, иначе все, что у вас есть, — это наблюдения, не имеющие смысла. И это не наука. А просто ведение записей.
Джеффри Уэст
В этой главе мы рассмотрим степенные распределения, которые часто называют распределениями с длинным, или тяжелым хвостом. При построении графика такие распределения создают длинный хвост по горизонтальной оси, отражая крупные события. Численность населения городов, вымирание видов, количество гипертекстовых ссылок во Всемирной паутине и размер компаний — все эти распределения имеют длинные хвосты, как и в случае загруженных видео, проданных книг, цитирования научных статей, военных потерь, наводнений и землетрясений. Другими словами, все они включают в себя крупные события: в Токио 33 миллиона жителей, книг Джоан Роулинг о Гарри Поттере продано более полмиллиарда экземпляров, великое наводнение на Миссисипи в 1927 году покрыло территорию больше площади штата Западная Вирджиния, а глубина затопления превышала 9 метров [1].
Анализ степенного распределения роста людей показывает, насколько такие распределения отличается от нормальных распределений. Если бы значения роста людей распределялись по степенному закону подобно распределению численности населения городов и если бы мы установили, что средний рост составляет 176 сантиметров, то в Соединенных Штатах был бы один человек ростом с Empire State Building, более 10 000 человек выше жирафа и 180 миллионов человек ростом не менее 213 сантиметров [2].
Распределение с длинным хвостом подразумевает отсутствие независимости, часто в форме положительной обратной связи [3]. Такие события, как продажи книг, лесные пожары и население городов, в отличие от походов в продуктовые магазины, не являются независимыми. Когда один человек покупает книгу о Гарри Поттере, он рекомендует другим тоже ее купить. Когда загорается одно дерево, огонь может перекинуться на соседние деревья. Когда растет численность населения города, в нем увеличивается количество объектов инфраструктуры и возможностей для трудоустройства, что делает его более привлекательным для людей. Социолог Роберт Мертон называет тот факт, что имеющий больше и получит больше, эффектом Матфея: «Ибо всякому имеющему дастся и приумножится, а у неимеющего отнимется и то, что имеет» (Евангелие от Матфея, 25:29).
Учитывая разнообразие областей, в которых можно обнаружить распределения по степенному закону, было бы просто замечательно, если бы один механизм мог объяснить их все, но, увы, такого механизма нет. Было бы еще лучше, если бы каждый случай степенного распределения имел единственное уникальное объяснение, но и его нет. Вместо этого мы имеем совокупность отдельных моделей, порождающих степенные распределения, причем все модели объясняют разные явления.
В этой главе мы сосредоточимся на двух моделях — модели предпочтительного присоединения, которая объясняет размер городов, продажи книг и гипертекстовые ссылки во Всемирной паутине, и модели самоорганизованной критичности, объясняющей образование транспортных заторов, количество погибших во время военных действий, землетрясения, пожары и масштаб лавин. В главе 12, где речь пойдет об энтропии, мы изучим третью модель, в которой степенной закон максимизирует неопределенность при наличии фиксированного математического ожидания. В главе 13 показано, что время возврата в модели случайного блуждания также удовлетворяет степенному закону. Другие модели демонстрируют, как степенное распределение возникает вследствие оптимального кодирования, правил случайной остановки и объединения распределений [4]. Оставшаяся часть главы посвящена структуре, логике и функции степенного распределения с последующим обсуждением, в ходе которого мы переосмыслим последствия крупных событий и определим пределы нашей способности их предотвращать и планировать.
СТЕПЕННОЕ РАСПРЕДЕЛЕНИЕ: СТРУКТУРА
В распределении по степенному закону вероятность события пропорциональна его масштабу, возведенному в отрицательную степень. Так, например, знакомая функция 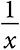 описывает степенной закон распределения. В степенном распределении вероятность события обратно пропорциональна его масштабу: чем крупнее событие, тем ниже вероятность его наступления. Поэтому в степенном распределении больше мелких событий, чем крупных.
описывает степенной закон распределения. В степенном распределении вероятность события обратно пропорциональна его масштабу: чем крупнее событие, тем ниже вероятность его наступления. Поэтому в степенном распределении больше мелких событий, чем крупных.
Степенное распределение
Степенное распределение [5], заданное на интервале [xmin, ∞), можно записать следующим образом:
p(x) = Cx−a,
где показатель степени a > 1 определяет длину хвоста, а постоянный член 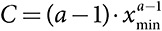 гарантирует, что полная вероятность распределения равна единице.
гарантирует, что полная вероятность распределения равна единице.
Величина показателя степени распределения по степенному закону определяет вероятность и масштаб крупных событий. Когда показатель степени равен 2, вероятность события обратно пропорциональна квадрату его масштаба. Событие с масштабом 100 происходит с вероятностью, пропорциональной 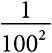 , или 1 раз на 10 000 случаев. Когда показатель степени увеличивается до 3, вероятность этого же события пропорциональна
, или 1 раз на 10 000 случаев. Когда показатель степени увеличивается до 3, вероятность этого же события пропорциональна 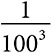 . При показателе степени 2 или менее у степенного распределения нет четко определенного среднего значения. Математическое ожидание данных, полученных на основе степенного распределения с показателем степени 1,5, никогда не сходится, а беспредельно возрастает.
. При показателе степени 2 или менее у степенного распределения нет четко определенного среднего значения. Математическое ожидание данных, полученных на основе степенного распределения с показателем степени 1,5, никогда не сходится, а беспредельно возрастает.
На рис. 6.1 представлен приближенный график распределения количества ссылок на веб-страницы во Всемирной паутине.
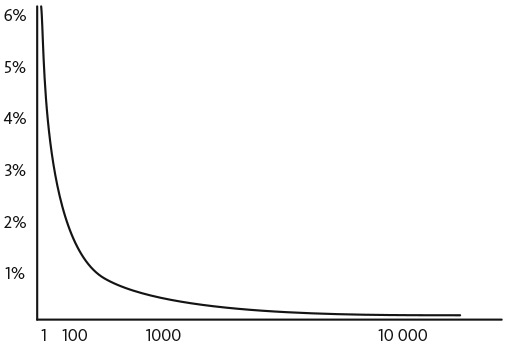
Рис. 6.1. Приближенное степенное распределение ссылок на веб-страницы
Вероятность крупных событий отличает степенное распределение от нормального распределения, в котором крупных событий практически не бывает. В случае распределения с длинным хвостом такие события происходят редко, но с частотой, достаточной для привлечения внимания и подготовки. Даже события, которые происходят один раз на миллион, стоит рассматривать. Например, масштаб землетрясений примерно удовлетворяет степенному закону с показателем степени около 2. Предположим, в определенном регионе землетрясение магнитудой 9,0 по шкале Рихтера (землетрясение, которое разрушает здания и меняет рельеф местности) происходит каждый день с вероятностью один на миллион. В течение столетия землетрясение такого масштаба наступит с вероятностью 3,5 процента [6].
Для того чтобы увидеть разницу между вероятностью наступления событий один раз на миллион в случае нормального распределении и распределения с длинным хвостом, используем распределение количества погибших в результате террористических актов, которое соответствует распределению по степенному закону с показателем степени 2 [7]. Событие с вероятностью один на миллион включает почти 800 погибших. Если бы количество погибших в результате терактов подчинялось нормальному распределению с математическим ожиданием 20 и стандартным отклонением 5, событие с вероятностью один на миллион привело бы к гибели менее 50 человек.
У распределения по степенному закону есть точное определение. Не каждое распределение с длинным хвостом — это степенное распределение. Построение графика распределения в двойном логарифмическом масштабе позволяет выполнить приближенную проверку того, является ли данное распределение степенным. График в логарифмическом масштабе по обеим осям преобразует значения масштаба событий и их вероятности в логарифмы, а степенное распределение выглядит как прямая линия [8].
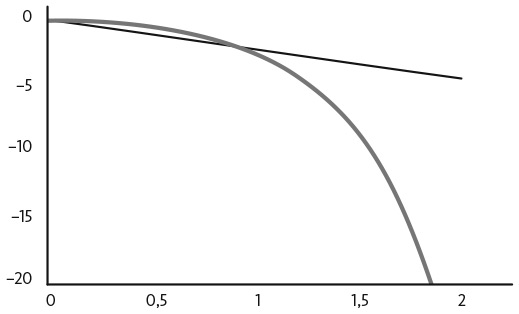
Рис. 6.2. Распределение по степенному закону (черная линия) vs логнормальное распределение (серая линия)
Другими словами, прямая линия на графике в двойном логарифмическом масштабе — наглядное подтверждение степенного закона, тогда как первоначально прямая линия, которая отклоняется от прямой вниз, соответствует логнормальному (или экспоненциальному) распределению. Скорость, с которой график логнормального распределения изгибается вниз, зависит от значения величин, характеризующих распределение [9]. По мере увеличения дисперсии логнормального распределения длина хвоста увеличивается, делая его более близким к линейному на графике в двойном логарифмическом масштабе [10].
Особый случай степенного распределения с показателем степени, равным 2, известен как распределение Ципфа. Для степенного распределения с показателем степени 2 произведение ранга события на его вероятность равно постоянной величине — закономерность, известная как закон Ципфа. Частота слов отвечает закону Ципфа. Наиболее распространенное английское слово the встречается в 7 процентах случаев. Второе по распространенности слово of — в 3,5 процента случаев. Обратите внимание, что умножение его ранга (2) на частоту 3,5 процента дает 7 процентов [11].
Закон Ципфа
В случае степенного распределения с показателем степени 2 (a = 2) произведение ранга события22 на его вероятность равно постоянной величине:
Ранг события × Масштаб события = константа
Примерно по такому закону распределена численность населения городов во многих странах, в том числе и в США. На основе данных о численности населения городов за 2016 год можно сделать вывод, что произведение ранга города на численность населения дает значение около 8 миллионов.
Ранг | Город | Население в 2016 г. | Ранг × население |
1 | Нью-Йорк | 8 600 000 | 8 600 000 |
2 | Лос-Анджелес | 4 000 000 | 8 000 000 |
3 | Чикаго | 2 7000 000 | 8 1000 000 |
4 | Хьюстон | 2 3000 000 | 9 2000 000 |
5 | Феникс | 1 6000 000 | 8 0000 000 |
МОДЕЛИ С РАСПРЕДЕЛЕНИЕМ ПО СТЕПЕННОМУ ЗАКОНУ: ЛОГИКА
Теперь рассмотрим модели, которые порождают распределение по степенному закону, поскольку без них степенное распределение остается закономерностью без объяснения.
Наша первая модель, модель предпочтительного присоединения, касается структур, темп роста которых зависит от их размера. Речь идет об эффекте Матфея: большее порождает большее. Данная модель описывает совокупность, которая увеличивается за счет входящего потока объектов. Новый объект либо присоединяется к существующей структуре, либо создает новую. Во втором случае вероятность присоединения к существующей структуре пропорциональна ее размеру.
Модель предпочтительного присоединения
Новые объекты (люди) прибывают последовательно один за другим. Первый прибывший объект создает структуру. Каждый очередной объект применяет следующее правило: с вероятностью p (небольшой) прибывший объект образует новую структуру и с вероятностью (1 − p) присоединяется к существующей структуре. Вероятность присоединения к определенной структуре равна ее размеру, деленному на количество объектов, прибывших на данный момент.
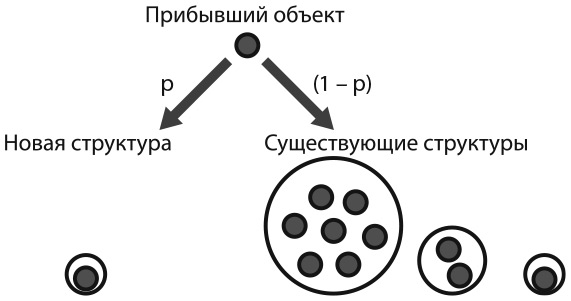
Представьте, что в университетский городок приезжают студенты. Первый студент создает новый клуб. С небольшой долей вероятности второй студент тоже создаст собственный клуб, однако вероятность того, что он присоединится к клубу первого студента, выше. Первых десять студентов могут открыть три клуба: один с семью членами, второй с двумя и третий с одним. Студент, прибывший одиннадцатым, с небольшой долей вероятности создаст четвертый клуб, но скорее присоединится к одному из существующих. Присоединяясь к клубу, студент выбирает клуб с семью членами в 70 процентах случаев, клуб с двумя членами в 20 процентах случаев и клуб с одним членом в 10 процентах случаев.
Модель предпочтительного присоединения позволяет объяснить, почему распределение текстовых гиперссылок во Всемирной паутине, численность населения городов, размер компаний, объемы продаж книг и частота цитирования научных работ подчиняются степенному закону. В каждом из этих случаев совершается действие (скажем, человек покупает книгу), что повышает вероятность того, что так же сделают другие. Если вероятность покупки продукции компании пропорциональна ее нынешней доле на рынке, а новые компании выходят на рынок низкими темпами, то данная модель прогнозирует, что распределение размеров компаний будет подчиняться степенному закону. Аналогичная логика применима к продаже книг, загрузке музыкальных файлов и росту городов.
Наша вторая модель, модель самоорганизованной критичности, порождает степенное распределение вследствие процесса, который формирует взаимозависимости в системе до тех пор, пока она не достигнет критического состояния. Существуют разные варианты модели самоорганизованной критичности, например модель песчаной кучи. Предположим, кто-то роняет песчинки на стол примерно с метровой высоты. По мере накопления песчинок образуется куча, которая в конце концов достигает критического состояния, когда дополнительные песчинки могут провоцировать обвалы. В этом критическом состоянии дополнительные песчинки часто не оказывают никакого воздействия или приводят к падению максимум нескольких песчинок. Это и есть множество мелких событий в распределении по степенному закону. Но иногда одна дополнительная песчинка вызывает настоящий обвал. Это крупное событие.
Следующая модель, модель лесных пожаров, представлена в виде двумерной сетки, на которой могут расти деревья; имеется риск попадания в них случайного удара молнии. При низкой плотности леса любой пожар, вызванный ударом молнии, будет небольшим и затронет максимум несколько клеток. При большой плотности деревьев пожар в результате удара молнии распространится почти по всей сетке.
Самоорганизованная критичность: модель лесных пожаров
Изначально лес состоит из пустой сетки размером N×N. На протяжении каждого периода случайным образом выбирается участок на сетке. Если участок пустой, то с вероятностью g на нем вырастет дерево, а с вероятностью (1 − g) в него ударит молния. Если на участке растет дерево, оно загорается, и огонь распространяется на все примыкающие участки с деревьями.
Обратите внимание, что в модели лесных пожаров вероятность удара молнии равна единице минус вероятность роста дерева. Такая структура позволяет менять относительные темпы роста деревьев и частоты ударов молнии. Это упрощение сокращает количество параметров в нашей модели. Поэкспериментировав со скоростью роста деревьев, мы обнаружим, что при темпе роста, близком к единице, плотность деревьев достигает критического состояния — мы получаем относительно густой лес, где удар молнии способен уничтожить огромные участки. В этом критическом состоянии распределение размера лесных прогалин, а значит, и масштаба пожаров, удовлетворяет распределению по степенному закону. Более того, лес естественным образом стремится к такому уровню плотности. Если лес менее густой, уровень его плотности повышается, потому что возникают не очень большие пожары. Если же плотность превышает пороговое значение, то любой пожар может уничтожить весь лес. Поэтому плотность деревьев самоорганизуется до критического состояния [12].
Как в модели песчаной кучи, так и в модели лесных пожаров переменная макроуровня — высота кучи или плотность леса — имеет критическое значение, поскольку ее значение снижается, когда происходят события (обвалы и пожары). Варианты этой модели могут объяснить распределение вспышек на Солнце, землетрясений и транспортных заторов. Увеличение переменной макроуровня, значение которой уменьшается при наступления событий, — необходимое, но недостаточное условие самоорганизованной критичности. Равновесные системы тоже обладают этим свойством. Вода поступает в озера и вытекает из них по ручьям, но поскольку ее отток носит равномерный характер, уровень воды в озере меняется постепенно. Ключевое условие самоорганизации до критического уровня состоит в том, что нагрузка увеличивается равномерно (как вода, поступающая в озеро), а сокращается рывками, с возможным наступлением крупных событий.
СЛЕДСТВИЯ РАСПРЕДЕЛЕНИЙ С ДЛИННЫМ ХВОСТОМ
Мы рассмотрим три следствия распределений с длинным хвостом: их влияние на справедливость, катастрофы и волатильность. Распределение с длинным хвостом по определению подразумевает несколько крупных лидеров (таких как большие коллапсы, землетрясения, пожары и транспортные заторы) и много отстающих, в отличие от нормального распределения, которое симметрично относительно математического ожидания. Кроме того, распределение с длинным хвостом может внести свой вклад в волатильность, поскольку случайные флуктуации в более крупных структурах влекут за собой более серьезные последствия.
СПРАВЕДЛИВОСТЬ
Автор бестселлера, песенного хита или более качественной научной работы должен получать больше дохода от продаж и более высокую степень признания. Несправедливо, когда человек работает на толику лучше или ему просто сопутствует удача, а зарабатывает гораздо больше. Как мы видели в случае модели предпочтительного присоединения, положительная обратная связь создает крупных лидеров вследствие эффекта Матфея. Для того чтобы на рынке она имела место, люди должны знать, что покупают другие, и быть в состоянии купить соответствующий продукт. Что касается не имеющих веса информационных товаров, таких как приложения для смартфонов, второе допущение вполне логично. Для iPhone-приложений нет производственных ограничений, замедляющих положительную обратную связь, как это происходит, скажем, в случае грузовиков F-150. Компания Ford может увеличить их производство только до определенного уровня. Напротив, компания Intuit может продать программу TurboTax в таком количестве, в каком пользователи готовы ее скачать.
Как показывают результаты эмпирических исследований, воздействие социальных факторов приводит к появлению более крупных лидеров. В ходе музыкальных лабораторных экспериментов студенты колледжей должны были выбирать и загружать песни. В одном варианте условий эксперимента участники не знали, какие песни скачивают другие, поэтому распределение загрузок имело более короткий хвост: ни одна песня не получила более двухсот скачиваний и только одна получила меньше тридцати загрузок. В другом варианте условий студенты знали, что загружают другие участники эксперимента. Хвост распределения вырос: одна песня получила более трехсот скачиваний. Пожалуй, еще более примечательным стал тот факт, что более половины песен получили меньше тридцати загрузок. Хвост стал длиннее. Влияние социальной среды усилило неравенство. Тем не менее такое неравенство не представляет проблемы, если социальное воздействие побуждает людей загружать лучшие песни. Однако корреляция между загрузками в двух вариантах условий эксперимента не была сильной. Если представить количество загрузок какой-то песни в первом варианте в качестве косвенного показателя ее качества, то влияние социальной среды не привело к скачиванию лучших песен. Крупные лидеры были не случайными, но они не были лучшими [13].
Однако давайте проявим осмотрительность и не будем делать поспешных выводов на основе одного исследования. Тем не менее мы можем прийти к заключению, что, хотя автор, продающий 50 миллионов книг, или ученый, чья работа цитируется 200 000 раз, заслуживают всяческих похвал, такой чрезвычайный успех подразумевает, что центральная предельная теорема в данном случае не выполняется. Люди не покупают книги и не цитируют научные работы независимо. По всей вероятности, поразительный успех предполагает наличие положительной обратной связи и, возможно, немного везения. Мы вернемся к этим идеям при обсуждении причин неравенства в распределении доходов в заключительной главе книги [14].
КАТАСТРОФЫ
Распределения с длинным хвостом включают в себя катастрофические события: землетрясения, пожары, финансовые коллапсы и транспортные заторы. Хотя модели не могут предсказать землетрясения, они помогают понять, почему их распределение подчиняется степенному закону. Такая информация позволяет определить вероятность землетрясений разного масштаба. В итоге мы хотя бы будем знать, чего ожидать, раз уж не знаем, когда [15].
Модель лесных пожаров действительно может служить руководством к действию. Большие пожары можно предотвратить путем выборочной вырубки леса, чтобы уменьшить его загущенность. Можно также создать противопожарные просеки. Кто-то может возразить, что нам не нужна модель для того, чтобы проредить лес или сделать просеки. Это действительно так. Однако модель помогает понять, существует ли критическая плотность. У каждого леса она своя, и может зависеть от типа деревьев, преобладающей скорости ветра и рельефа местности. Модель лесных пожаров объясняет, почему лес может самоорганизоваться до критического состояния.
Эту модель можно также использовать в качестве аналогии. Помните, как в главе 1 мы обсуждали крах сетей финансовых учреждений? Мы можем применить в этом контексте модель лесных пожаров, представив банки и другие финансовые структуры в виде деревьев на плоскости, разделенной на клетки, где примыкающие клетки соответствуют непогашенным кредитам. В этой модели банкротство одного банка эквивалентно возгоранию дерева и может распространиться на соседние банки.
Такое примитивное применение модели лесных пожаров к банкам предсказывало бы масштабные банкротства по мере усиления взаимосвязей между банками. Однако анализ этой аналогии выявляет четыре недостатка. Во-первых, финансовая сеть не встроена в физическое пространство. Банки отличаются по количеству связей. У одного банка могут быть десятки финансовых обязательств, тогда как у другого всего одно-два. Во-вторых, дерево в лесу не может предпринять действий по снижению вероятности распространения пожара, в то время как банки могут, например, увеличив объем резервов. В-третьих, чем больше у банка связей, тем меньше вероятность распространения банкротств, поскольку убытки банка будут распределены между другими банками. Например, если банк не возвращает кредит в размере 100 000 долларов, взятый в другом банке, второй банк вполне может обанкротиться. Однако если первый банк взял кредит у консорциума из двадцати пяти банков, ни один из них не понесет больших убытков. Такая система способна поглотить убытки в связи с невыплатой кредита, не допустив коллапса [16]. И наконец, распространение краха от одного банка к другому зависит от портфелей банков. Если в двух связанных банках аналогичные портфели, то банкротство одного банка, скорее всего, ослабит другой банк. Худший сценарий наступает тогда, когда все банки в сети имеют идентичные портфели. В таком случае крах одного банка повышает вероятность банкротства остальных банков [17]. Но если у каждого банка особый портфель, неэффективная работа одного банка не обязательно указывает на низкие показатели другого банка. Банкротство банков может не охватить другие банки. Следовательно, эффективная модель должна учитывать активы, входящие в состав разных портфелей. Без этой информации знания того, у каких банков есть обязательства перед другими банками, будет недостаточно для прогнозирования или предотвращения банкротств, а совокупный эффект более сильной связанности банков остается нечетким.
ВОЛАТИЛЬНОСТЬ (ИЗМЕНЧИВОСТЬ)
В заключение рассмотрим более тонкое следствие распределений с длинным хвостом. Если объекты, образующие степенное распределение, отличаются по размерам, то экспонента степенного закона становится косвенным показателем волатильности на уровне системы. Из этого следует, что распределение размеров компаний должно влиять на волатильность рынка. В данном контексте представьте валовой внутренний продукт (ВВП) страны как совокупный продукт тысяч компаний. Если объем выпуска продукции — это независимый показатель, имеющий конечную вариацию, то согласно центральной предельной теореме распределение ВВП будет подчинено нормальному закону. Из этого также следует, что чем больше вариация объема выпуска продукции в разных компаниях, тем выше совокупная волатильность. Если распределение размеров компаний с более длинным хвостом приводит к более высокому уровню вариации объема производства, то это распределение также будет коррелировать с более высокой совокупной волатильностью.
Анализ динамики волатильности в США показывает, что в 1970-х и 1980-х годах она росла, а затем на протяжении следующих двух десятилетий снижалась во время так называемой эпохи великой умеренности [18]. Примерно в 2000 году волатильность снова начала усиливаться. Эти флуктуации волатильности можно объяснить изменениями в распределении размеров компаний [19]. По мере того как хвост распределения размеров компаний становится длиннее (короче), самые крупные компании оказывают непропорционально большое (меньшее) влияние на волатильность. Иначе говоря, совокупная волатильность повышается (снижается), когда хвост распределения размеров компаний удлиняется (укорачивается). В 1995 году, когда волатильность была низкой, объем доходов компании Walmart составлял 90 миллиардов долларов, что соответствует 1,2 процента от ВВП. К 2016 году объем доходов Walmart достиг 480 миллиардов долларов, или 2,6 процента от ВВП. Доля компании Walmart в валовом национальном продукте увеличилась более чем вдвое. В 2016 году увеличение или сокращение объема доходов Walmart в два раза бы увеличило вклад в совокупную волатильность.
Никто не опровергает логику этой аргументации. Но возникает вопрос: оказывает ли откалиброванная модель воздействие, масштаб которого соответствует фактическим уровням волатильности? Соответствие оказалось достаточно близким. Распределение размеров компаний хорошо коррелирует с историческими данными об эпохе «великой умеренности». Эта корреляция не доказывает, что именно изменения в распределении размеров компаний (а не эффективное государственное управление экономикой или надлежащее управление товарно-материальными запасами) обусловили такую умеренность, но и не позволяет отвергать данную модель [20]. Кроме того, этот факт дает основания сохранять ее в нашем арсенале, чтобы использовать для оценки флуктуаций в будущем.
РАЗМЫШЛЕНИЯ О МИРЕ РАСПРЕДЕЛЕНИЙ С ДЛИННЫМ ХВОСТОМ
В случае распределений с длинным хвостом крупные события происходят с вероятностью, достаточной для того, чтобы это вызвало беспокойство. В рассмотренных нами моделях распределения с длинным хвостом возникают вследствие обратных связей и взаимозависимостей. Нам следует учесть это наблюдение. Поскольку мир становится взаимосвязаннее, а количество обратных связей растет, мы будем видеть все больше распределений с длинным хвостом. А у нынешних распределений хвосты могут стать еще длиннее. Неравенство может усугубиться, катастрофы — стать масштабнее, а волатильность — более выраженной. Все эти последствия нежелательны.
Пока мы обсуждали возможные сценарии на макроуровне, однако они могут иметь место и в более мелких масштабах. Большой бостонский тоннель (длиной 5,6 километра, пролегающий через центр города) — пример катастрофы умеренного масштаба. Проект обошелся налогоплательщикам в 14 миллиардов долларов (что более чем втрое превышает первоначальную смету) и стал самым дорогостоящим проектом строительства автострады в истории США. Модельное мышление представляет Большой бостонский тоннель не как один проект, а как совокупность подпроектов, таких как рытье рва, заливка тоннеля бетоном, прокладка дренажной системы, а также строительство стен и свода. Общая сумма затрат на весь проект равна сумме затрат на подпроекты.
Если бы затраты на каждый подпроект были аддитивными, то их распределение на весь проект подчинялось бы нормальному закону [21]. Однако они были взаимосвязаны. Когда материал на основе эпоксидной смолы, который использовали для фиксации свода тоннеля, оказался непригодным, его заменили на более дорогостоящий и прочный, что увеличило затраты на проект. Просчет с первым эпоксидным материалом повлек за собой дополнительные затраты в связи с извлечением и заменой рухнувшего свода. Общий объем затрат увеличился более чем вдвое, поскольку несколько других частей проекта пришлось переделывать. Взаимозависимости привели к крупному и дорогостоящему событию.
Вероятность наступления крупных событий затрудняет процесс планирования. Распределение таких стихийных бедствий, как землетрясения, подчиняется степенному закону. Следовательно, большинство событий будут мелкими, но несколько — крупными. Если катастрофические события подчиняются степенному закону с показателем степени 2, правительствам нужно держать в резерве или как минимум наготове много денег, то есть подготовиться к «черному дню». Если правительства сделают это, сохраняя огромный излишек в резервном фонде для чрезвычайных обстоятельств, они могут воздержаться от расходования этих денег или снизить налоги, если крупные события так и не наступят.
Поиск и благоприятные возможности
Мы можем применить свои знания о распределениях в рамках моделей поиска, чтобы объяснить, почему количество возможностей, получаемых человеком, сильно коррелирует с его успехом. Мы встроим один класс моделей (модели распределения) в другой класс (модели поиска). Когда мы что-то ищем, будь то новая пара обуви, работа или место для отдыха, мы не знаем значения выбранного варианта, пока не опробуем его. Вместе с тем мы можем знать кое-что о распределении значений, таких как математическое ожидание, стандартное отклонение и является ли распределение нормальным или имеет длинный хвост.
Мы смоделируем выбор профессии как процесс поиска. При наличии профессии человек пытается сделать карьеру, которую мы смоделируем как выбор значения из распределения. Предположим, что человек либо будет придерживаться этого карьерного пути, либо попробует строить карьеру заново. Новая попытка соответствует новому значению из распределения. Рассмотрим в качестве примера выбор профессии для талантливого молодого ученого. Он может поступить на медицинский факультет или заняться исследованиями в области квантовых вычислений. Медицинский факультет обеспечивает более надежный путь. Выбор в пользу квантовых вычислений подразумевает серьезные риски и необходимость заняться бизнесом. Для того чтобы учесть эти различия, представим распределение заработной платы врачей в виде нормального распределения с математическим ожиданием 250 000 долларов и стандартным отклонением 25 000 долларов, а распределение заработной платы в случае предпринимательской карьеры в виде степенного распределения с показателем степени 3 и ожидаемой заработной платой 200 000 долларов [22].
Наш ученый в рамках каждой профессии может попробовать себя во множестве специализаций. Врач может переключиться с онкологии на радиологию. Неудачник-предприниматель — собрать осколки своего стартапа и начать все заново. Каждый случай изменения карьеры предполагает определенные издержки. Для врача это означает дополнительное обучение. Для предпринимателя в области квантовых вычислений — больше длинных ночей работы при небольшой или нулевой компенсации.
Мы будем исходить из того, что наш молодой ученый найдет две в равной степени интересные профессии и сделает выбор с учетом заработной платы. Наша модель указывает на то, что более удачный выбор зависит от того, сколько раз наш герой может себе позволить строить новую карьеру. Если он вынужден остановиться на ее первом варианте, профессия врача обеспечивает более высокую заработную плату. Если у него есть ресурсы для продолжения попыток в области предпринимательства, со временем он найдет высокооплачиваемый вариант выбора из длинного хвоста. На представленном ниже рисунке показана средняя максимальная заработная плата по двадцати попыткам в случае одного, двух, пяти и десяти вариантов поиска карьеры в каждой профессии. Если у нашего молодого ученого есть возможность десять раз попробовать свои силы в создании стартапов по квантовым вычислениям, его заработная плата будет почти вдвое больше, чем он заработал бы, если бы выбрал медицинский факультет и экспериментировал с десятью вариантами карьеры в этой области.
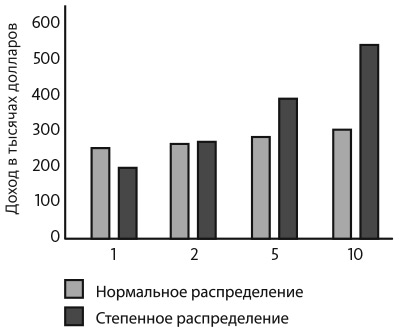
Средний доход в зависимости от количества благоприятных возможностей
Если богатство и поддержка со стороны семьи соотносятся с количеством благоприятных возможностей для того, чтобы попробовать новую карьеру, наша модель прогнозирует, что более состоятельные люди предпочтут профессии, в большей степени сопряженные с риском [23]. Данные о патентах согласуются с этой моделью. Вероятность того, что человек получит патент, соотносится с его математическими способностями. Люди, принадлежащие к одному проценту людей с развитыми математическими способностями, с гораздо большей вероятностью владеют патентами. Среди тех, кто относится к одному проценту лучших из лучших, у представителей семей, принадлежащих к верхним 10 процентам шкалы распределения доходов, вероятность получить патент еще выше [24]. Минимум две модели могут объяснить это неравноправие. Одна модель может исходить из того, что талантливые ученики из более бедных семей не поступают в колледж. Они выполняют рутинную работу и перед ними не стоит выбор между медицинским факультетом и квантовыми вычислениями. Кроме того, ученики из класса неимущих могут выбирать более надежную карьеру.
Логические рассуждения о том, что расширение благоприятных возможностей создает стимул для риска, применимы в более широком контексте. Венчурные инвесторы рискуют, потому что делают множество инвестиций. Начальные инвестиции в одного единорога (миллиардную компанию) с избытком компенсируют инвестиции во многие неудачные проекты. Научно-исследовательские лаборатории фармацевтических компаний тоже рискуют, выделяя миллиарды долларов на разработку новых лекарственных препаратов. Эта же логика применима и при решении о том, где пообедать. Проехав сотни километров и остановившись в незнакомом городе, мы можем пообедать в одном из ресторанов какой-либо сети. При переезде в этот город нам придется экспериментировать.
ГЛАВА 7
ЛИНЕЙНЫЕ МОДЕЛИ
Да, я вру, потому что ты требуешь от меня однозначных ответов, а однозначные ответы почти всегда ложь.
Элена Ферранте
Нередко модели устанавливают определенную функциональную зависимость между переменными. Она может быть линейной, вогнутой, выпуклой, S-образной или содержать пороговый эффект. Из всех этих вариантов линейные модели самые простые и распространенные — и именно они будут находиться в центре внимания в этой главе. Влияние образования на уровень доходов, увеличение продолжительности жизни благодаря физической активности, а также зависимость явки избирателей от дохода — все это можно количественно измерить с помощью линейных моделей. В начале главы мы освежим ваши знания о линейных функциях с одной переменной. Затем покажем, как регрессия приводит данные в соответствие с линейной функцией, раскрывая знак, величину и значимость эффекта. Кроме того, мы обсудим, почему ошибки, помехи и разнородность означают, что данные не попадают точно на линию регрессии. Затем мы расширим линейную модель, включив в нее несколько переменных, и объясним, как выполнить подгонку моделей со множеством переменных. Для того чтобы выработать интуитивное понимание таких моделей, мы опишем модель успеха как линейную функцию навыков и удачи. В конце главы мы поговорим о том, как использование данных и регрессий в качестве руководства к действию ограничивает количество ошибок, но может также привести к малозначимым, консервативным действиям. Мышление, ориентированное на большие коэффициенты, способно сдерживать инновации. Для выявления более инновационных вариантов мы рассмотрим возможность построения других, более умозрительных моделей.
ЛИНЕЙНЫЕ МОДЕЛИ
В линейной зависимости величина изменения одной переменной в результате изменения другой переменной не зависит от значения второй переменной. Если высота дерева находится в линейной зависимости от его возраста, это дерево ежегодно вырастает на одну и ту же величину. Если стоимость дома возрастает линейно в зависимости от его площади, то ее увеличение на 200 квадратных футов повышает стоимость дома вдвое по сравнению с увеличением на 100 квадратных футов. Увеличение площади дома на 400 квадратных футов повышает стоимость дома в четыре раза.
Линейные модели
В линейной модели изменения независимой переменной x приводят к линейным изменениям зависимой переменной y по следующей формуле:
y = mx + b,
где m — это наклон линии, а b — отрезок, отсекаемый на координатной оси, значение зависимой переменной, когда независимая переменная равна нулю23.
Модель линейной регрессии находит линию, которая минимизирует расстояние до точек данных. Линейная регрессия может объяснить колебания уровня преступности, объема продаж стиральных машин и даже цен на вина [1]. Предположим, у нас есть данные о взрослых в возрасте от двадцати до шестидесяти лет, в том числе расстояние, которое они проходят каждую неделю. Мы находим следующее уравнение регрессии:
Проходимое человекомi расстояние в милях = −0,1 · возрастi + 12 + ei
Это уравнение регрессии указывает знак (с возрастом расстояние уменьшается) и величину (каждый год возраста сокращает расстояние на десятую часть мили) эффекта. В данном примере отрезок на координатной оси не имеет отношения к делу, поскольку находится вне нашего диапазона данных, то есть не включает данные о людях в возрасте около нуля лет. Уравнение позволяет предположить, что сорокалетний человек должен проходить восемь миль в неделю, а пятидесятилетний — семь миль. Данные, используемые для построения регрессии, не попадают точно на линию регрессии. На рис. 7.1 показаны гипотетические данные, на основе которых построена наша линия регрессии. Серым кружком обозначена сорокалетняя женщина по имени Бобби, которая проходит одиннадцать миль в неделю — расстояние, превышающее оценочный показатель модели на три мили. Для того чтобы привести эти данные в соответствие с моделью, в уравнение включена погрешность по каждой точке данных, которая обозначена символом e и равна разности между оценкой, полученной с помощью модели, и фактическим значением зависимой переменной. В случае Бобби погрешность e равна +3 мили.
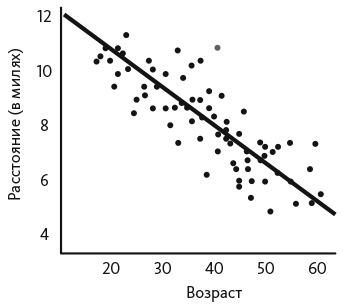
Рис. 7.1. Диаграмма разброса и линия регрессии
В социальном и биологическом контекстах мы не ожидаем идеальных линейных соответствий. Результат зависит от множества переменных, а регрессия с одной переменной по определению содержит только одну переменную. Прогнозируемые значения могут отклоняться от фактических именно из-за этих пропущенных переменных. Бобби может пройти больше, чем ожидается, потому чтокак профессор ботаники водит своих студентов на прогулки в лес. Модель не учитывает профессию как переменную, что объясняет, почему данные на рис. 7.1 не находятся на линии. Член уравнения e может также быть следствием погрешности измерения. Фитнес-данные, которые собирают смартфоны, содержат ошибки, если люди забывают где-то свои устройства или одалживают их другим. Кроме того, ошибка может возникнуть из-за помех окружающей среды — набрать дополнительное расстояние можно за счет поездки на работу по ухабистой дороге [2].
Чем ближе линия регрессии к данным, тем больше данных объясняет модель и тем выше значение R в квадрате (доля объясненной вариации). Если все данные находятся точно на линии регрессии, то значение R в квадрате равно 100 процентам. При прочих равных условиях мы предпочитаем модели с более высокими значениями R в квадрате24.
Знак, значимость и величина
Линейная регрессия предоставляет нам информацию о коэффициентах независимых переменных.
Знак: корреляция (положительная или отрицательная) между независимой и зависимой переменной, определяется по знаку коэффициента m.
Значимость (p-значение): вероятность того, что коэффициент m отличен от нуля25.
Величина: наилучшая оценка коэффициента при независимой переменной.
В регрессии с одной переменной чем ближе данные к линии регрессии и чем больше их объем, тем больше мы можем доверять знаку и величине коэффициентов. Статистики измеряют значимость коэффициента с помощью p-значения, которое равно основанной на регрессии вероятности того, что коэффициент отличен от нуля. P-значение, равное 5%, означает наличие одного шанса из двадцати, что данные были сгенерированы процессом, в котором коэффициент равен нулю. Стандартные пороговые уровни значимости — 5 процентов (обозначается как *) и 1 процент (обозначается как **). Однако значимость — это не все, что нам нужно. Коэффициент может быть значимым, но иметь малую величину (когда это так, мы можем быть уверены в наличии корреляции, но переменная оказывает незначительное воздействие), или может быть большим, но не иметь значимости. Так часто происходит с данными с искажениями или со множеством пропущенных переменных.
Для того чтобы увидеть, как использовать регрессию в качестве руководства к действию, представьте компанию, которая поставляет специи. Компания предлагает более ста видов специй. Клиенты покупают наборы из шести, двенадцати или двадцати четырех специй, которые сотрудники упаковывают и отгружают. Регрессия, оценивающая количество заказов, отгруженных за восьмичасовую смену, как функцию стажа работы сотрудника, дает следующее уравнение:
количество выполненных заказов = 200 + 20** · стаж
Уровень значимости коэффициента 20, который указан перед стажем работы, составляет 1 процент. Мы можем быть уверены, что значение этого коэффициента положительное. Если зависимость носит причинно-следственный характер (см. ниже), модель можно использовать для прогнозирования количества заказов, которые сотрудник может выполнить за одну смену в зависимости от стажа работы. Кроме того, мы можем использовать эту модель для прогнозирования количества заказов, которые эти сотрудники выполнят в следующем году. Здесь мы имеем пример модели, которая позволяет составить прогноз и служит руководством к действию.
КОРРЕЛЯЦИЯ VS КАУЗАЦИЯ
Регрессия выявляет только корреляцию между переменными, но не причинность [3]. Если мы сначала построим модель, а затем используем регрессию, чтобы проверить, подкреплены ли данными результаты, полученные с помощью этой модели, это тоже не поможет доказать наличие причинно-следственной связи (казуальности). Тем не менее описать модель с самого начала — гораздо лучше, чем выполнять регрессионный анализ в поисках значимой корреляции, то есть использовать метод, известный как глубинный анализ данных. В случае глубинного анализа данных существует риск обнаружить переменную, которая коррелирует с другими каузальными переменными. Например, глубинный анализ данных может выявить значимую положительную корреляцию между уровнем витамина D и общим состоянием здоровья. Люди получают витамин D от солнца, а значит, этот факт может быть обусловлен тем, что люди, ведущие активный образ жизни, проводят больше времени на свежем воздухе и имеют более крепкое здоровье. Кроме того, регрессионный анализ может выявить сильную корреляцию между уровнем успеваемости в школе и количеством учеников, входящих в состав школьной команды конного спорта. Скорее всего, команды конного спорта не оказывают прямого причинно-следственного воздействия, но соотносятся с уровнем семейного дохода и объемом финансирования школы — факторами, такое воздействие оказывающими.
Глубинный анализ данных может также приводить к обнаружению ложной корреляции, когда связь между переменными обусловлена случайным стечением обстоятельств. Мы можем обнаружить, что компании с более длинными названиями получают более высокую прибыль, или что у людей, живущих неподалеку от пиццерий, выше риск заболеть гриппом. При пороговом уровне значимости 5 процентов одна из двадцати проверяемых переменных будет значимой. Следовательно, проанализировав достаточное количество переменных, мы обязательно найдем значимую (и ложную) корреляцию.
Избежать ложных корреляций можно путем создания обучающих и проверочных наборов данных. Корреляция, выявленная на обучающем наборе данных и присутствующая в проверочном наборе данных, с гораздо большей вероятностью является истинной. Тем не менее у нас по-прежнему нет никаких гарантий наличия причинно-следственной связи. Для того чтобы доказать каузальность, необходимо провести эксперимент, в ходе которого мы будем манипулировать с независимой переменной и наблюдать, изменится ли зависимая переменная. В качестве альтернативы можно найти естественный эксперимент, то есть когда это произошло совершенно случайно.
ЛИНЕЙНЫЕ МОДЕЛИ СО МНОЖЕСТВОМ ПЕРЕМЕННЫХ
В большинстве явлений задействовано несколько каузальных и корреляционных переменных. Счастье человека можно связать со здоровьем, семейным положением, потомством и религиозной принадлежностью. Стоимость дома зависит от его площади, размера участка, количества ванных комнат и спален, типа строительства и качества местных школ. Все эти переменные можно включить в регрессию, чтобы объяснить стоимость жилья. Однако мы должны помнить, что при добавлении дополнительных переменных нам понадобится больше данных для получения значимых коэффициентов регрессии.
Прежде чем обсуждать множественную регрессию, выработаем интуитивное понимание уравнений со множеством переменных, введя уравнение успеха Майкла Мобуссина [4]. Это уравнение описывает успех, будь то в работе, спорте или играх, как взвешенную линейную функцию мастерства и удачи.
Уравнение успеха
успех = a · мастерство + (1 − a) · удача,
где значение a в диапазоне [0,1] равно относительному весу мастерства.
Присвоение относительного веса мастерству и удаче (возможно, с помощью регрессии при наличии данных) позволило бы нам использовать модель для прогнозирования результатов. Если менеджер команды агентов по продаже рекреационных автомобилей обнаруживает, что успех, выраженный в объеме продаж, содержит большой элемент удачи, он будет ожидать регрессии к среднему значению: продавцы, обеспечившие высокий уровень продаж в этом месяце, скорее всего, покажут средние результаты в следующем месяце. В таком случае менеджер может использовать эту модель как основу для дальнейших действий. Возможно, он не захочет поднимать зарплату агенту по продажам, у которого было два удачных месяца подряд, до уровня оплаты в конкурирующей компании. Однако если бы вместо этого регрессионный анализ показал, что удача не сыграла почти никакой роли, а высокий результат за два месяца был бы хорошим предиктором аналогичной результативности в следующие месяцы, тогда менеджер, возможно, захотел бы заплатить лучшему продавцу столько же, сколько платят в других компаниях.
Аналогичные соображения применимы и к оплате труда СЕО. Совет директоров не должен выплачивать бонусы СЕО, работающим в отраслях, где удача определяет успех. Прибыль нефтедобывающей компании зависит от рыночной цены нефти — переменной, которая находится вне контроля компании. Следовательно, совет директоров нефтедобывающей компании должен воздерживаться от вознаграждения СЕО за хороший год. В рекламном агентстве целесообразно поступать с точностью до наоборот — если компания работает хорошо, выплачивать большие бонусы СЕО. Словом, платите за мастерство, а не за удачу. На самом деле корпорации с более эффективной системой управления платят за удачу меньше [5].
Даже такие простые модели, как эта, позволяют сделать глубокие выводы. Проанализировав данное уравнение, мы видим, что даже в контексте, почти полностью зависящем от мастерства (как в случае бега, велоспорта, плавания, шахмат или тенниса), при небольших отличиях в его уровне именно удача в значительной мере определяет успех. Можно предположить, что в самых конкурентных средах (таких как Олимпийские игры) различия в навыках несущественные, а значит, значение имеет удача. Мобуссин называет это парадоксом мастерства. Величайший пловец в истории Майкл Фелпс был на его обеих сторонах. Во время Олимпийских игр 2008 года в конце 100-метровой дистанции баттерфляем Фелпс отставал от Милорада Чавича, но по счастливой случайности коснулся стены первым. Во время Олимпийских игр 2012 года Фелпс опережал Чада ле Кло на финише, но первым к стене прикоснулся ле Кло. Да, Фелпс обладает невероятным мастерством, но эта победа и поражение — продукты удачи.
МНОЖЕСТВЕННАЯ РЕГРЕССИЯ
Модели множественной линейной регрессии соответствуют линейным уравнениям со множеством переменных и минимизируют суммарное расстояние до данных. Эти уравнения содержат коэффициенты для каждой независимой переменной. Представленное ниже уравнение описывает конечный результат гипотетической регрессии оценок учащихся по математическим тестам как функцию количества часов обучения (HRS), социально-экономического статуса семьи (SES) и количества курсов ускоренного обучения (AC).
оценка по математике = 21,1 + 9,2** · HRS + 0,8 · SES + 6,9* · AC.
Согласно этой регрессии, оценка учащегося повышается на 9,2 пункта на каждый дополнительный час обучения. У коэффициента две звездочки, а значит, он существенно отличается от нуля на уровне значимости 1 процент. Это подразумевает наличие сильной корреляции, но не причинно-следственной связи.
Уравнение также показывает, что оценка одного учащегося повышается почти на семь пунктов на каждый курс ускоренного обучения. Этот коэффициент тоже имеет значимость, но только на уровне 5 процентов. Социально-экономический статус семьи (переменная, принимающая значения от 1 (низкий статус) до 5 (высокий статус)) имеет положительный коэффициент, который незначительно отличается от нуля, поэтому можно предположить, что он, по всей вероятности, оказывает небольшое причинно-следственное воздействие.
На основании этого или любого другого регрессионного анализа мы можем прогнозировать конечные результаты. Модель прогнозирует, что учащийся, который уделяет учебе семь часов и проходит один курс ускоренного обучения, должен набрать около 90 баллов. Кроме того, модель также можно использовать в качестве руководства к действию, но с осторожностью, поскольку здесь мы не можем вывести причинно-следственную связь. Данные показывают, что учащиеся, которые усердно учатся и проходят ускоренные курсы обучения, получают более высокие оценки. Одна из причин того, что упорная учеба или ускоренные курсы обучения могут не принести пользы — смещение отбора. Возможно, такие учащиеся более сильны в математике.
Хотя регрессия не может доказать, что именно порождает те или иные закономерности в данных, она позволяет исключить некоторые объяснения. Рассмотрим различия в уровне благосостояния разных рас. В 2016 году средний уровень благосостояния белых семей (около 110 000 долларов) более чем в десять раз превышал уровень благосостояния семей афро- и латиноамериканцев. Этот разрыв можно объяснить множеством причин, в том числе институциональными факторами, различиями в доходах, поведением в отношении сбережений или процентом браков. Регрессия поддерживает одни объяснения и исключает другие. Например, регрессионный анализ указывает на отсутствие значимой зависимости между семейным положением и уровнем благосостояния афроамериканцев, а значит, семейное положение не может быть причиной. Различий в доходах, хотя они и достаточно большие, тоже оказалось недостаточно для объяснения данного разрыва [6].
БОЛЬШОЙ КОЭФФИЦИЕНТ И НОВЫЕ РЕАЛИИ
Как уже говорилось, модели линейной регрессии играют важнейшую роль в области научных исследований, политического анализа и принятия стратегических решений — отчасти потому, что их легко оценить и интерпретировать. По мере повышения доступности данных их применение стало еще шире. Фраза «Мы верим Богу, все остальные должны предоставлять данные» звучит в деловых и правительственных кругах все чаще. Широкое применение данных (которое нередко означает использование моделей линейной регрессии) может подталкивать нас к совершению второстепенных действий — в сторону, противоположную реализации перспективных новых идей. Компании, правительства или фонды, которые собирают данные, а затем используют модель линейной регрессии и находят переменную с самым большим коэффициентом статистической значимости, — практически не в состоянии воздержаться от корректировки этой переменной и получения предельного выигрыша.
При совершении того или иного действия лучше выбрать переменную с большим коэффициентом, чем с малым. Кроме того, мышление с ориентацией на большие коэффициенты опирается на консервативный подход, который фокусируется на определенных незначительных улучшениях и отвлекает внимание от принципиально нового курса действий. Вторая проблема мышления, ориентированного на большие коэффициенты, состоит в том, что их величина соответствует предельному эффекту с учетом имеющихся данных. Нередко, как мы увидим в следующей главе, величина эффекта уменьшается по мере повышения значения переменной. Если это так, большой коэффициент становится меньше, когда мы пытаемся его использовать.
Большой коэффициент и новые реалии
Линейная регрессия указывает на величину корреляции между независимыми переменными и изучаемой переменной. Если такая корреляция каузальна (описывает причинность), изменение переменной с большим коэффициентом будет иметь серьезные последствия. Курс действий, опирающийся на большие коэффициенты, гарантирует улучшения, но исключает новые реалии, которые подразумевают более фундаментальные перемены.
Альтернативой мышлению, ориентированному на большие коэффициенты, является мышление, ориентированное на новые реалии. Мышление с ориентацией на большие коэффициенты расширяет дороги и строит полосы для транспортных средств с пассажирами, чтобы снизить интенсивность дорожного движения. Мышление с ориентацией на новые реалии строит сети железнодорожного и автобусного сообщения. Мышление с ориентацией на большие коэффициенты финансирует покупку компьютеров для студентов с низкими доходами. Мышление с ориентацией на новые реалии предоставляет компьютеры всем без исключения и сокращает сроки доставки почты до трех дней в неделю. Мышление с ориентацией на большие коэффициенты увеличивает ширину сидений в самолетах. Мышление с ориентацией на новые реалии создает такой салон самолета, который можно заполнять взаимозаменяемыми отсеками для людей с разными габаритами. Большие коэффициенты — это хорошо. Предпринимать действия, основанные на фактических данных, — мудро, но мы также должны быть открыты для новых идей. А обнаружив их, должны использовать модели, чтобы выяснить, обеспечат ли они требуемые результаты. Регрессионный анализ дорожно-транспортных происшествий с участием подростков может указывать на то, что возраст имеет самый большой коэффициент, подразумевая, что правительство может захотеть повысить возраст для получения водительских прав. Это действительно может сработать, но такого результата позволяют добиться и принципиально новые меры, такие как запрет на вождение в ночное время, автоматический мониторинг водителей-подростков через их смартфоны или введение ограничений на количество пассажиров в автомобилях подростков. Действия с учетом новых реалий могут дать более масштабный эффект, чем использование большого коэффициента.
РЕЗЮМЕ
Таким образом, линейные модели исходят из постоянной величины эффекта. Линейная регрессия — мощный инструмент предварительного анализа данных, позволяющий определить знак, величину и значимость переменных. Если мы хотим знать о влиянии потребления кофе, алкоголя и газированных напитков на здоровье человека, регрессионный анализ поможет нам в этом. Мы можем обнаружить, что потребление кофе снижает риск сердечно-сосудистых заболеваний, так же как и умеренное потребление алкоголя. Однако нам следует скептически относиться к экстраполяции линейных эффектов слишком далеко за пределы диапазона имеющихся данных. Мы не должны думать, что выпивать за день тридцать чашек кофе, не говоря уже о шести бокалах вина, это хорошо. Не стоит также делать линейные прогнозы на слишком отдаленное будущее. За период с 1880 по 1960 год численность населения Калифорнии росла со скоростью 45 процентов. Применив линейную экстраполяцию, мы получили бы численность населения Калифорнии в 2018 году в размере 100 миллионов человек, что более чем в два раза превышает фактический показатель.
Имейте в виду, что мы только начинаем. Большинство изучаемых явлений носят нелинейный характер. По этой причине многие регрессионные модели содержат нелинейные параметры, такие как квадрат возраста, квадратный корень из возраста и даже логарифм возраста. Для того чтобы объяснить нелинейные характеристики, мы также можем организовать непрерывную последовательность линейных моделей. Эти сопряженные линейные модели могут аппроксимировать кривую во многом подобно тому, как из прямоугольных кирпичей можно выложить извилистую дорожку. Хотя линейность может быть слишком сильным и нереалистичным предположением, это хорошая отправная точка. При наличии данных можно использовать линейные модели для проверки интуитивных выводов, а затем разработать более сложные модели, в которых воздействие переменной слабеет по мере увеличения ее значения (убывающая отдача) или усиливается (положительная отдача). Такие нелинейные модели — тема следующей главы.
Бинарная классификация данных
В эпоху больших данных организации используют для их классификации алгоритмы, основанные на моделях. Политическая партия может захотеть выяснить, кто голосует, авиакомпании может понадобиться информация о характеристиках часто летающих пассажиров, а организатор мероприятий может захотеть узнать о его участниках. В каждом из этих случаев организация распределяет людей на две категории: те, кто покупает, вносит свой вклад или регистрируется на мероприятие, обозначаются как положительные величины (+), а те, кто этого не делает, — как отрицательные величины (–).
Модели классификации используют алгоритмы для разделения людей на категории с учетом таких характеристик, как возраст, доход, уровень образования или количество часов, проведенных в интернете. Разные алгоритмы подразумевают разные базовые модели взаимосвязи между характеристиками и результатами. Применение множества алгоритмов (использование множества моделей) обеспечивает более точную классификацию.
Линейная классификация. На рис. M1 положительные величины (+) представляют участников голосования, а отрицательные величины (–) — тех, кто не голосовал. Линейная функция возраста и уровня образования человека позволяет определить, примет ли он участие в голосовании. Данные указывают на то, что более образованные люди и люди старшего возраста с большей вероятностью голосуют. В данном примере прямая линия почти идеально делит избирателей на категории [7].
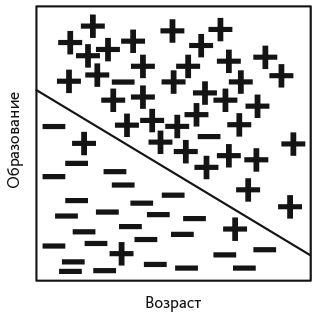
Рис. M1. Использование линейной модели для классификации поведения избирателей
Нелинейная классификация. На рис. M2 положительные величины (+) представляют часто путешествующих пассажиров (которые летают более 10 000 миль в год), а отрицательные величины (–) всех остальных клиентов авиакомпании. Люди среднего возраста и более обеспеченные летают чаще. Для классификации этих данных необходима нелинейная модель, которую можно рассчитать с помощью алгоритмов глубокого обучения, таких как нейронные сети. Нейронные сети содержат больше переменных, поэтому могут построить практически любую кривую.
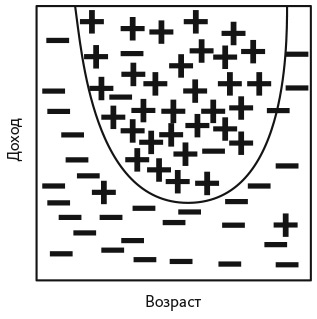
Рис. M2. Использование нелинейной модели для классификации часто путешествующих пассажиров
Лес деревьев принятия решений. На рис. M3 положительные величины (+) представляют людей, которые участвовали в конференции по научной фантастике, с учетом их возраста и количества часов, проведенных в интернете. В этом случае мы классифицируем данные с помощью трех деревьев принятия решений. Деревья принятия решений обеспечивают классификацию на основе наборов условий по характеристикам. На рисунке показаны следующие деревья:
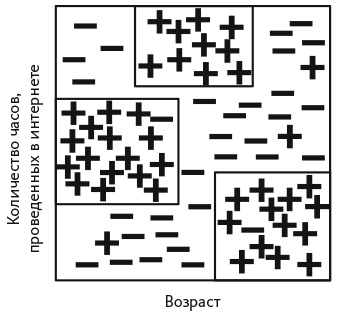
Рис. M3. Лес деревьев принятия решений, классифицирующий участников конференции
Дерево 1: если (возраст < 30) и (количество часов в интернете за неделю в диапазоне [15, 25]).
Дерево 2: если (возраст в диапазоне [20, 45]) и (количество часов в интернете за неделю >30).
Дерево 3: если (возраст >40) и (количество часов в интернете за неделю >20).
Такая совокупность деревьев принятия решений называется лесом. Алгоритмы машинного обучения создают деревья в произвольном порядке на обучающих наборах данных, а затем сохраняют те, которые обеспечивают точную классификацию на проверочном и обучающем наборах.
ГЛАВА 8
ВОГНУТОСТЬ И ВЫПУКЛОСТЬ
Говорить о нелинейной науке — все равно что говорить о неслоновьей зоологии.
Джон фон Нейман
Рассмотрим теперь нелинейные модели и нелинейные функции. Нелинейные функции могут изгибаться вниз или вверх, иметь S-образную форму, образовывать петли, скачки и завитки. В свое время мы опишем все эти варианты. А пока начнем с моделей, основанных на выпуклости и вогнутости, и покажем, как рост и положительная обратная связь создают выпуклость, а убывающая отдача и отрицательная обратная связь — вогнутость. Большинство предметных областей содержат модели обоих типов. Экономические модели производства предполагают, что затраты на доставку и хранение товарно-материальных запасов сокращаются в зависимости от размера компании, в связи с чем прибыль на единицу проданной продукции имеет вид выпуклой функции26 размера компании. Это объясняет, почему Walmart получает такую большую прибыль [1]. Экономические модели потребления исходят из того, что полезность (или ценность) — это вогнутая функция (пятый кусок пиццы приносит нам меньше удовольствия, чем первый). В экосистемах, когда новый вид захватывает среду обитания и не встречает там хищников, его популяция растет с постоянной скоростью, создавая выпуклую функцию. По мере роста численности вида количество пищи уменьшается. Поэтому приспособленность как функция размера популяции имеет вогнутую форму.
В главе три части. В первой рассматриваются модели увеличения и сокращения численности популяций. Вторая посвящена вогнутости. В ней мы увидим, как вогнутость приводит к неприятию риска и предпочтениям разнообразия. В третьей мы изучим ряд моделей роста из области экономики, сочетающих вогнутые и линейные функции.
ВЫПУКЛОСТЬ
Выпуклые функции имеют возрастающий наклон: значение функции увеличивается на большую величину по мере повышения значения переменной. Количество возможных пар людей — это выпуклая функция от численности группы. Группа из трех человек включает три уникальные пары, группа из четырех человек — шесть уникальных пар, а группа из пяти человек — десять. Каждое увеличение численности группы увеличивает количество пар на большую величину. Аналогично, когда шеф-повар добавляет новые специи в блюда, он увеличивает количество сочетаний специй на большую величину.
Наша первая модель выпуклости, модель экспоненциального роста, описывает величину переменной (в основном это популяция или ресурс) как функцию ее исходного значения, скорости роста и количества периодов.
Модель экспоненциального роста
Величину Vt ресурса в момент времени t, имеющую исходное значение V0 и возрастающую со скоростью R, можно описать так:
Vt = V0(1 + R)t.
Эта модель в виде одного уравнения играет важную роль в области финансов, экономики, демографии, экологии и технологий. Применительно к финансам в качестве переменной выступают деньги. С помощью данного уравнения можно рассчитать, что облигация стоимостью 1000 долларов с годовой процентной ставкой 5 процентов увеличивается в цене на 50 долларов за первый год и более чем на 100 долларов в двадцатый год. Для чистоты выводов будем подразумевать постоянный темп роста. С учетом такого предположения на основе уравнения экспоненциального роста можно вывести правило 72.
Правило 72
Если та или иная величина регулярно увеличивается на небольшой (менее 15 процентов) процент R в течение некоторого периода, то приблизительно определить срок ее удвоения позволяет следующее уравнение:
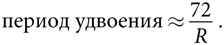
Правило 72 позволяет наглядно продемонстрировать, как работают сложные проценты. В 1966 году ВВП Зимбабве составлял 2000 долларов на душу населения и вдвое превышал этот показатель в Ботсване. На протяжении следующих тридцати шести лет в Зимбабве наблюдался только незначительный рост ВВП, в то время как в Ботсване средний рост за год составил 6 процентов, а значит, ВВП Ботсваны удваивался каждые двенадцать лет. За тридцать шесть лет он удвоился три раза, в целом увеличившись в восемь раз. В результате в 2004 году ВВП Ботсваны на душу населения в размере 8000 долларов в четыре раза превышал ВВП Зимбабве.
Эта формула объясняет, почему пузыри на рынке недвижимости непременно лопаются, а технологический прогресс — нет. В 2002 году цены на дома в США выросли на 10 процентов, что подразумевает удвоение каждые семь лет. Если бы эта тенденция сохранялась на протяжении тридцати пяти лет, то цены на дома удваивались бы пять раз, что означало бы их общее повышение в 32 раза. Дом стоимостью 200 000 долларов в 2002 году в 2037-м оценивался бы в 6,4 миллиона долларов. Но цены не могут расти такими темпами. Пузырь должен был лопнуть. В отличие от закона Мура, который гласит, что количество транзисторов, которые могут поместиться на микросхеме, удваивается каждые два года. Закон Мура актуален27, поскольку расходы на исследования и разработки обеспечивают постоянное улучшение технологий.
Демографы применяют модель экспоненциального роста к народонаселению. Если численность населения ежегодно увеличивается на 6 процентов, то она удваивается каждые двенадцать лет. За тридцать шесть лет этот показатель удваивается трижды, а за сто лет — восемь раз (что означает общее увеличение в 256 раз). В 1798 году британский экономист Томас Мальтус обратил внимание на то, что численность населения растет по экспоненте, и описал модель, показавшую, что, если способность экономики производить продукты питания будет возрастать линейно, наступит кризис. Сокращенная версия этой модели выглядит так. Численность населения возрастает как 1, 2, 4, 8, 16, 32… Выпуск продуктов питания растет как 1, 2, 3, 4, 5… Мальтус предсказывал катастрофу. К счастью, уровень рождаемости упал, а наступившая промышленная революция обусловила рост производительности. Если бы ничего не изменилось, Мальтус оказался бы прав. Однако он не учел потенциала процесса инноваций, который находится в центре внимания моделей, представленных далее. Инновации обернули эту тенденцию вспять.
Модель экспоненциального роста можно также применить к распространению видов, причем не только к кроликам. Когда вы подхватываете бактериальную инфекцию, крошечные бактерии воспроизводятся с невероятной скоростью. Их численность в носовых пазухах человека увеличивается примерно на 4 процента в минуту. Применив правило 72, мы можем вычислить, что их численность удваивается каждые двадцать четыре минуты. Всего за один день каждая первоначальная бактериальная клетка порождает более миллиарда (!) потомства [2]. Рост останавливается, когда из-за физических ограничений ваших носовых пазух в них не остается свободного места. Дефицит пищевых ресурсов, хищники и отсутствие свободного места — все это замедляет рост. Некоторые виды, например олени в пригородной зоне Америки или гиппопотамы, которых наркобарон Пабло Эскобар завез в Колумбию, не встречают серьезных препятствий для роста, поэтому их численность стремительно увеличивается, хотя и не с такой скоростью, как численность бактерий [3].
Выпуклая функция с положительным наклоном повышается с увеличением значения. Выпуклая функция с отрицательным наклоном становится менее наклонной. Выпуклая функция с изначально большим отрицательным наклоном становится плоской. Это верно в случае уравнения, используемого в модели периода полураспада, описывающей радиоактивный распад, обесценивание и забывание.
В модели периода полураспада каждые H периодов половина количественной величины распадается, поэтому показатель H называют периодом полураспада. Для некоторых физических процессов период полураспада — величина постоянная. Вся органическая материя содержит два типа углерода: нестабильный изотоп углерод-14 и стабильный изотоп углерод-12. В живой органической материи они присутствуют в постоянном соотношении. Когда организм умирает, углерод-14 в его теле начинает распадаться с периодом полураспада 5734 года. При этом количество углерода-12 не меняется. Специалист по физической химии Уиллард Либби понял, что, измерив соотношение между содержанием углерода-14 и углерода-12, можно определить возраст окаменелости или артефакта — метод, известный как «радиоуглеродное датирование». Археологи применяют этот метод для оценки подлинности артефактов, а палеонтологи используют аналогичный метод (в том числе и с другими, гораздо более долгоживущими изотопами) для оценки возраста останков динозавров, шерстистых мамонтов и доисторических рыб. Возраст останков ледяной мумии человека Эци, найденной в итальянских Альпах, оценивается в пять тысяч лет. Туринская плащаница, впервые продемонстрированная в 1357 году как погребальная плащаница Иисуса Христа, датируется XIV столетием, а не временами Христа28.
Модель периода полураспада
Если каждые H периодов половина количественной величины распадается, то после t периодов верно следующее выражение:
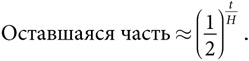
Модель периода полураспада нашла применение и в психологии. Ранние психологические исследования показали, что люди забывают информацию с почти постоянной скоростью. Период полураспада нашей памяти зависит от значимости события [4]. В 2016 году фильм Spotlight («В центре внимания») получил премию Американской киноакадемии в номинации «Лучший фильм». Если память человека о лауреатах премии «Оскар» имеет двухгодичный период полураспада, то в 2018 году о фильме вспомнили бы 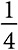 людей, а в 2026-м и вовсе
людей, а в 2026-м и вовсе 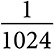 . У разных людей разные воспоминания об определенном событии. Том Маккарти, режиссер и один из авторов сценария фильма, скорее всего, никогда не забудет тот год, когда он получил «Оскар».
. У разных людей разные воспоминания об определенном событии. Том Маккарти, режиссер и один из авторов сценария фильма, скорее всего, никогда не забудет тот год, когда он получил «Оскар».
ВОГНУТЫЕ ФУНКЦИИ
Вогнутые функции — противоположность выпуклым. Наклон вогнутых функций снижается. Вогнутые функции с положительным наклоном отражают убывающую отдачу: дополнительная ценность каждого нового объекта уменьшается по мере увеличения количества таких объектов. Полезность или ценность практически всех благ демонстрирует убывающую отдачу. Чем больше у нас досуга, денег, мороженого или даже времени, проведенного с близкими людьми, тем меньше мы все это ценим. Подтверждением служит тот факт, что чем больше мы потребляем практически всего, в том числе шоколада, тем меньше удовольствия получаем и тем меньше готовы за него платить [5].
Убывающая отдача может объяснить целый ряд явлений, включая и то, почему отношения на расстоянии часто бывают такими счастливыми. Если вы видитесь с партнером всего несколько часов в месяц, каждая дополнительная минута прекрасна. Через месяц непрерывной близости наклон кривой счастья выравнивается и несколько дополнительных моментов теряют свою значимость [6]. Это объясняет, почему девелоперы предлагают людям бесплатное посещение своих кондоминиумов на берегу во время уик-энда (а не дольше). За этот срок вы склоняетесь к решению о покупке, однако после десяти дней на пляже вы можете заскучать.
Предполагая наличие вогнутости, мы подразумеваем предпочтение разнообразия и неприятие риска. Для демонстрации первого требуется вогнутая функция со множеством аргументов. Если наше счастье отражает вогнутая функция и оно возрастает в зависимости от досуга и денег, мы предпочитаем иметь какое-то количество досуга и денег, а не весь досуг и отсутствие денег или все деньги и отсутствие досуга. Неприятие риска означает предпочтение беспроигрышного варианта перед лотереей со случайным исходом. Человек, избегающий риска, предпочитает гарантированный выигрыш в размере 100 долларов лотерее, в которой в половине случаев можно выиграть 200 долларов, а в другой половине — ничего. Такой человек выберет вафельный стаканчик с двумя шариками мороженого вместо варианта получить либо ничего, либо большую порцию мороженого из четырех шариков.
На рис. 8.1 показано, почему вогнутость подразумевает неприятие риска. На рисунке отображен уровень радости в отношении ценности трех результатов: высокий результат (H), низкий результат (L) и среднее значение этих результатов (M). Учитывая, что кривая изгибается вниз, радость в отношении среднего результата превышает средний уровень радости по поводу низкого и высокого результатов. Для выпуклых функций верно обратное. Выпуклость подразумевает склонность к риску: мы предпочитаем крайние варианты среднему. Количество акций, которые вы можете купить, представляет собой выпуклую функцию их цены. В связи с этим их покупатели предпочитают волатильность цен. Если цена акций повышается и снижается, покупатели приобретают больше акций, чем в случае, когда цена не меняется [7].
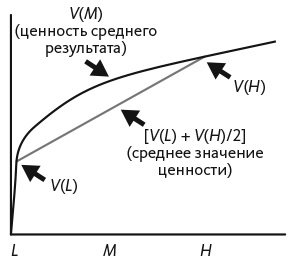
Рис. 8.1. Неприятие риска: ценность среднего результата больше среднего значения ценности низкого и высокого результатов
МОДЕЛИ ЭКОНОМИЧЕСКОГО РОСТА
Далее мы построим ряд моделей экономического роста. Эти модели раскрывают причины роста и могут объяснить и спрогнозировать его закономерности в разных странах. Кроме того, они могут стать руководством к действию, например, в случае повышения нормы накоплений. Чтобы заложить основу для изучения моделей роста, введем стандартную экономическую модель производства, в которой выпуск продукции зависит от трудовых ресурсов и физического капитала. Эмпирические данные и логические выводы подтверждают вогнутость функции объема производства по таким параметрам, как трудовые ресурсы и капитал. При неизменном объеме капитала ценность трудовых ресурсов должна уменьшаться по мере увеличения их объема. Аналогично увеличение количества машин или компьютеров приводит к снижению их ценности при фиксированном числе работников. Логика также подсказывает, что выпуск продукции должен увеличиваться линейно. Удвоение количества работников и объема капитала должно обеспечить удвоение объема производства. Компания по выпуску веников с шестьюдесятью сотрудниками и одним цехом, которая строит второй цех и нанимает еще шестьдесят работников, должна увеличить объем производства в два раза. Модель Кобба — Дугласа (широко используемая в экономике) включает оба свойства. Производственная функция будет вогнутой по трудовым ресурсам и капиталу и линейной по масштабу производства. Эту модель можно применить для описания экономики и отдельной компании, и страны в целом [8].
Модель Кобба — Дугласа
При наличии L работников и K единиц капитала общий объем производства равен:
объем производства = Constant · LaK(1 − a),
где a — действительное число от 0 до 1, соответствующее относительной важности трудовых ресурсов.
Воспользуемся моделью Кобба — Дугласа для построения моделей экономического роста. Для упрощения задачи предположим, что в экономике занято 10 000 человек, не будем учитывать заработную плату и цены, что позволит нам сфокусироваться на том, как количество машин влияет на объем производства. Тогда мы сможем связать инвестиции в капитал с ростом. Чтобы максимально упростить модель, допустим, что объем производства представлен в форме одного товара, скажем, кокосовых орехов, мякоть и жирное молоко которых можно употреблять в пищу. Однако кокосовые орехи растут высоко на пальмах, поэтому работникам необходимы машины для их сбора. Далее мы сделаем весьма нереалистичное предположение, что машины конструируются из кокосовых орехов. Это упрощает модель, но поддерживает важный компромисс между текущим потреблением и будущими инвестициями. В качестве особого случая модели Кобба — Дугласа мы запишем объем производства как квадратный корень из количества работников, умноженный на квадратный корень из количества машин:
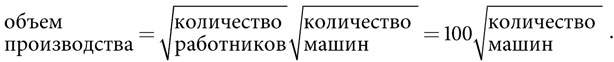
Если в экономике используется одна машина, объем производства составляет 100 тонн. Если люди потребляют все 100 тонн кокосовых орехов, они не инвестируют в новые машины. В следующем году объем производства не изменится. Экономика демонстрирует отсутствие роста. Если люди вложат 1 тонну кокосов в создание второй машины, объем производства увеличится до 141 тонны, то есть на 41 процент. В случае создания третьей машины объем производства составит 173 машины [9]. Постоянные инвестиции приводят к снижению темпов роста экономики. Следовательно, объем производства — это вогнутая функция.
Теперь, получив базовое представление о том, как инвестиции стимулируют рост, построим более сложную модель, включающую правило инвестиций. Представим инвестиции как произведение нормы накоплений и объема производства, а также будем исходить из того, что фиксированная норма амортизации машин (такая как количество машин, которые к концу года подлежат списанию) равна фиксированному проценту от их количества. Далее мы можем записать общее количество машин в следующем году как количество машин в прошлом году плюс инвестиции в новые машины минус машины, потерянныепо причине износа. Полная простая формула роста состоит из четырех уравнений.
Простая модель роста
Производственная функция: 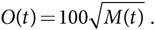
Правило инвестиций: I(t) = s·O(t).
Уравнение потребления и инвестиций: O(t) = C(t) + I(t).
Уравнение инвестиций и амортизации:
M(t + 1) = M(t) + I(t) − d · M(t).
O(t) = объем производства, M(t) = количество машин, I(t) = инвестиции, C(t) = потребление, s = норма накоплений и d = норма амортизации.
Если предположить, что в экономике есть 100 машин, норма накоплений составляет 20 процентов, а норма амортизации — 10 процентов, то объем производства будет равен 1000 тонн кокосовых орехов, потребление — 800 тонн, а новые инвестиции составят 200 машин. В общей сложности 10 машин будут списаны из-за износа, а значит, в начале следующего года останется 290 машин. Аналогичные расчеты показывают, что объем производства за второй год составит 1702 тонны, а за третий — почти 2500 тонн [10]. В первые три года темпы роста объема производства увеличиваются. Первоначальная выпуклость — это следствие того, что из-за небольшого количества машин на протяжении первых нескольких лет эффект амортизации почти не проявляется. Со временем количество машин растет и амортизация становится значимым фактором, делающим функцию объема производства вогнутой. В долгосрочной перспективе она вообще перестает расти, как показано на рис. 8.2. Проанализировав модель, мы сможем понять, почему так происходит. Функция инвестиции линейна по объему производства: количество новых машин увеличивается линейно вместе с объемом производства. Функция объема производства является вогнутой по количеству машин. Однако амортизация — это линейная функция по количеству машин, поэтому со временем значения линейной амортизации приближаются к уровню вогнутой функции увеличения объема производства.
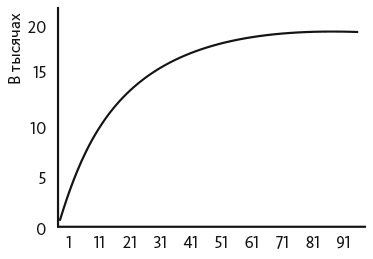
Рис. 8.2. Объем производства в базовой модели роста на сто лет
В случае долгосрочного равновесия экономики количество новых машин, созданных за счет инвестиций, равно количеству машин, потерянных по причине износа. В нашей модели равновесие наступает, когда в экономике задействовано 40 000 машин и 20 000 тонн кокосовых орехов. На этом этапе экономика инвестирует 20 процентов (или 4000 кокосов) в новые машины и теряет ровно столько же машин из-за износа (10 процентов от 40 000). Таким образом, количество новых машин, потерянных по причине физического износа, равно количеству машин, созданных за счет инвестиций, — и рост останавливается [11].
МОДЕЛЬ ЭКОНОМИЧЕСКОГО РОСТА СОЛОУ*
Теперь построим обобщенную модель, которая будет упрощенным (в связи с чем обозначим ее звездочкой) вариантом модели роста Солоу. Мы заменим машины физическим капиталом и используем труд в качестве переменной. Кроме того, включим параметр технологий, обеспечивающий линейный рост объема производства. Инновации увеличивают этот параметр. Как и в предыдущей модели, долгосрочное равновесие возникнет, когда инвестиции равны амортизации. Однако в данной модели выпуск продукции на уровне равновесия зависит от количества труда и параметра технологий, а также от нормы накоплений и нормы амортизации [12].
Модель роста Солоу*
Общий объем производства в экономике описывается следующим уравнением:
объем производства = A√L√K,
где L — количество труда, K — объем физического капитала, а A — уровень технологий. Объем производства в случае долгосрочного равновесия O* описывается уравнением [13]:
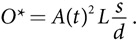
Объем производства при долгосрочном равновесии увеличивается в зависимости от количества труда, развития технологий и роста нормы накоплений, а сокращается по мере повышения нормы амортизации. Эти результаты не вызывают удивления. Чем больше работников, более развитые технологии и больше накоплений, тем выше объем производства, однако рост темпов амортизации снижает его. На интуитивном уровне менее понятно то, что объем производства растет линейно вместе с количеством труда и нормой накоплений. Затраты труда порождают убывающую отдачу, поэтому, не проанализировав модель, мы могли бы ожидать, что функция объема производства в долгосрочной перспективе будет вогнутой по количеству труда. Однако, когда трудозатраты увеличиваются, то же самое происходит и с объемом производства, что, в свою очередь, повышает объем инвестиций и приводит к дальнейшему росту объема производства. Положительная обратная связь со стороны инвестиций полностью компенсирует убывающую доходность. Функция равновесного объема производства является выпуклой по норме амортизации. Снижение амортизации на 20 процентов увеличивает объем производства на 25 процентов.
И наконец, объем производства при долгосрочном равновесии увеличивается как квадрат темпов совершенствования технологий. Следовательно, инновации увеличивают объем производства более чем линейно. С помощью этой модели мы можем объяснить, почему. Если мы начнем с экономики в состоянии долгосрочного равновесия и повысим параметр технологий на 50 процентов, то объем производства увеличится на 50 процентов, так же как и объем инвестиций. Тогда объем инвестиций превысит норму амортизации, поэтому экономика продолжит расти. Инвестиции будут опережать амортизацию до тех пор, пока рост экономики снова не составит 50 процентов — в этот момент капитал, утерянный по причине износа, уравновесит инвестиции. Эти расчеты показывают, что процесс инноваций оказывает двоякое воздействие, создавая мультипликатор инноваций. Во-первых, инновации непосредственно увеличивают объем производства. Во-вторых, опосредовано они приводят к росту капиталовложений, обеспечивая дополнительное увеличение объема производства. Следовательно, главный фактор устойчивого роста производства — инновации [14].
Однако объем производства не увеличивается мгновенно. Во время прорыва параметр технологий меняется медленно. Последствия проявляются на протяжении длительного периода. Устаревший физический капитал необходимо заменить новым с более совершенной технологией. Быстродействие компьютеров компании не увеличивается при изменении технологии, оно увеличивается тогда, когда технология меняется и компания покупает новые компьютеры. Повышение второго порядка, обусловленное ростом объема инвестиций в физический капитал, происходит на протяжении еще более длительного периода. Разрыв между появлением новых технологий и их влиянием на рост указывает на то, что инновации обеспечивают рост в течение десятилетий. Поезда были изобретены в начале XIX столетия. «Позолоченный век» наступил только в конце XIX столетия, то есть более чем через пятьдесят лет. Стремительное развитие интернета началось через три десятилетия после создания ARPANET29, [15].
ПОЧЕМУ ОДНИ СТРАНЫ УСПЕШНЫ, А ДРУГИЕ ТЕРПЯТ НЕУДАЧУ
Мы можем применить модели роста для поиска ответов на серьезные политические вопросы, такие как могут ли отсталые страны ускорить развитие, почему одни страны добиваются успеха, а другие терпят неудачу, и какова роль правительства в стимулировании роста. Все эти исследования показывают ценность и ограничения наших моделей. Начнем со способности стран с низким ВВП добиться стремительного роста. Приведенные выше модели показывают, что наращивание капитала может обусловить быстрый рост, так же как инвестиции в технологии. Отсталая страна с меньшим объемом капитала в случае выхода на передовые рубежи технологий с помощью новых капиталовложений могла бы продемонстрировать поразительный рост [16].
Необходимость инноваций для долгосрочного роста, как показано во второй модели, подтверждает ограниченность однократного заимствования новой технологии. Непрерывный рост требует постоянных инноваций. Когда после Второй мировой войны Советский Союз демонтировал немецкие заводы и перенес их на свою территорию, это обеспечило краткосрочный рост, причем такой, что 18 ноября 1956 года премьер Никита Хрущев, выступая в посольстве Польши перед послами стран Запада, заявил: «Мы вас похороним!» Но этого не произошло. СССР не смог это сделать из-за отсутствия в стране инноваций [17]. Советы ограничивали свободу и подавляли предпринимательство.
Эти модели также показывают, как изъятие ресурсов и коррупция, использование экономики для государственных нужд сдерживают рост в связи с сокращением накоплений. Анализ темпов роста в разных странах подтверждает оба вывода: сокращение изъятия ресурсов и коррупции наряду со стимулированием инноваций способствует дальнейшему росту. Достижение этих целей требует сильной, но ограниченной центральной власти, поощряющей плюрализм. Сильный центр обеспечивает соблюдение прав собственности и верховенство права. Плюрализм предотвращает захват власти элитой, которая часто предпочитает сложившееся положение вещей и не приветствует инновации, что может иметь пагубные последствия.
В качестве примера деструктивных инноваций приведем сайт Craigslist, на котором размещаются объявления о продаже и найме. В начале 2000-х деятельность Craigslist привела к потере сотен тысяч рабочих мест в газетах США. В то время на самом сайте работало всего несколько десятков человек. Хотя люди потеряли работу, сайт Craigslist сделал экономику более эффективной, повысив параметр технологий. В менее плюралистическом обществе печатные средства массовой информации добивались бы от правительства закрытия сайта Craigslist, что привело бы к замедлению экономического роста.
Экономическое господство Японии Китая
Линейная модель + правило 72. С 1960 по 1970 год ВВП Японии ежегодно рос на 10 процентов. Линейная проекция дальнейшего роста ВВП на 10 процентов позволила бы сделать вывод об удвоении японской экономики каждые семь лет (согласно правилу 72). В 1970 году ВВП Японии на душу населения равнялся примерно 2000 долларам. Если бы эта тенденция сохранилась, то к 2012 году он удвоился бы шесть раз и в результате составил бы 128 000 долларов.
Модель роста. Данная модель объясняет рост японской экономики инвестициями в физический капитал и подразумевает вогнутую функцию темпов роста на протяжении длительного периода. Модель роста прогнозирует, что по мере приближения ВВП Японии к ВВП США и Европы темпы его роста должны снизиться до исторического среднего значения по всем странам, составляющего 1–2 процента [18]. Фактические данные подтверждают это. С 1970 по 1990 год ВВП Японии увеличивался примерно на 4 процента в год, а с 1990 по 2017 год его рост составлял не более 1 процента.
Экономический рост Китая. ВВП Китая с 1990 по 2016 год вырос почти на 10 процентов. В 2016 году ВВП на душу населения в Китае достиг примерно 8000 долларов и, как предсказывала модель роста, экономический рост страны замедлился: с 2013 по 2017 год рост ВВП составлял около 6 процентов. Таким образом, в Китае устойчивый 10-процентный рост вступил в противоречие с правилом 72. Если бы на протяжении следующего столетия рост китайской экономики составлял в среднем 10 процентов, ВВП на душу населения превысил бы 100 миллионов долларов.
И ВСЕ ЖЕ МИР НЕЛИНЕЕН
Мы строим нелинейные модели, потому что немногие линейные явления представляют для нас интерес. В этой главе мы увидели, что убывающая и возрастающая отдача — общие свойства экономических, физических, биологических и социальных явлений. Мы также обнаружили в наших моделях ряд следствий, включая кривизну. Пожалуй, самое важное из увиденного то, что функциональные формы структурируют наше мышление, а их согласование с данными позволяет составлять точные формулировки. Ученые могут вычислить возраст артефактов с помощью данных об изотопе углерод-14. Экономисты могут оценить долгосрочные последствия небольшого увеличения роста.
Самый важный вывод из этой главы — интуиции становится недостаточно, когда мы включаем в рассмотрение нелинейность. Интуиция подсказывает нам направление воздействия: рост увеличивается за счет повышения заработной платы, наращивания трудовых ресурсов и внедрения технологических инноваций. Накопления, как и следовало ожидать, имеют линейный эффект. Наращивание трудовых ресурсов оказывает аналогичное воздействие в долгосрочной перспективе, хотя модель исходит из краткосрочной убывающей отдачи. Рост инноваций оказывает мультипликативный эффект и дает квадратный рост вышеуказанных эффектов. Первое увеличение объема производства — прямое следствие инноваций. Второе обусловлено ростом капиталовложений.
Подобные выводы становятся очевидны благодаря использованию моделей. Без них мы лишь можем определить, какой показатель растет, а какой падает, но это не дает нам понимания формы функциональной зависимости. В итоге мы часто делаем линейные экстраполяции — например, китайская экономика вскоре захватит весь мир. Модели позволяют нам тщательнее проанализировать логику, порождающую нелинейные эффекты. Набор нелинейных функций огромен. Вогнутые и выпуклые модели, о которых шла речь в этой главе, — лишь малая его часть. Если мы хотим улучшить свою способность рассуждать, объяснять и действовать в этом сложном мире, нам нужно еще глубже погрузиться в изучение нелинейных явлений.
ГЛАВА 9
МОДЕЛИ ЦЕННОСТИ И ВЛИЯНИЯ
Ваша ценность не в том, что вы знаете, а в том, чем вы делитесь.
Джинни Рометти
В этой главе мы рассмотрим модели, количественно определяющие ценность и степень влияния отдельных агентов. Некоторые случаи довольно просты. Когда группа обеспечивает результат, равный сумме индивидуальных вкладов ее членов, ценность каждого члена группы эквивалентна его вкладу. Если коллективный результат не делится на составляющие (например, когда команда программистов пишет программу или группа предпринимателей предлагает креативный способ применения новой технологии), определение заслуг усложняется. Оценка влияния политических партий создает аналогичные проблемы: количество мест, которые контролирует партия, коррелирует с ее влиянием, но не идеально.
Мы определим два показателя ценности и влияния: предельная ценность игрока (предельный вклад агента при условии, что группа уже сформирована) и вектор Шепли (средний предельный вклад агента во все возможные последовательности включения новых людей в группу). В группе из трех человек мы вычислим среднее значение дополнительной ценности человека, если он присоединяется к группе первым, вторым и третьим. Мы определим эти показатели в рамках моделей кооперативных игр, состоящих из множества игроков, а также функции ценности, которая присваивает коллективный выигрыш каждому возможному подмножеству игроков.
Глава состоит из четырех частей. В первой мы рассмотрим модели кооперативных игр, предельную ценность игрока, вектор Шепли и несколько примеров. Во второй опишем аксиоматику вектора Шепли. Мы докажем, что это показатель, удовлетворяющий четырем условиям. Первое условие: игроку, не повышающему ценность, должно быть присвоено нулевое значение ценности. Согласно второму условию, сумма значений ценности игроков должна равняться общему значению ценности игры. В третьей части мы применим вектор Шепли по отношению к группе, выполняющей творческую задачу (когда каждый член группы предлагает свои идеи), и продемонстрируем, как в этом контексте данный показатель порождает интуитивно понятное значение ценности. В четвертой части мы рассмотрим особый случай применения вектора Шепли в играх голосования, чтобы провести различие между влиянием участников голосования и процентом голосов. Мы увидим, что эти два показателя не всегда совпадают. Партия может иметь 20 процентов мест и ноль влияния в одном случае и треть от общего объема влияния в другом.
КООПЕРАТИВНЫЕ ИГРЫ
Кооперативная игра состоит из множества игроков и функции ценности, присваивающей определенное значение ценности каждому возможному подмножеству игроков, которое часто называют коалицией. Кооперативные игры предназначены для описания коллективной работы и совместных проектов. В данной модели мы будем исходить из предположения, что люди участвуют в игре, чтобы сосредоточиться на присвоении ценности их вкладу.
Кооперативные игры
Кооперативная игра состоит из множества N игроков и характеристической функции V(S), присваивающей значение ценности любому подмножеству S⊆N. Эти подмножества называются коалициями. Ценность пустой коалиции (без игроков) равна нулю: V(∅) = 0; ценность всех N игроков, V(N), равна общей ценности игры.
В кооперативной игре предельная ценность игрока равна той ценности, которую он добавляет, присоединяясь к группе последним. Предельная ценность игрока отражает предельное значение ценности. Если четырех человек нанимают для перестановки стола, и они создают ценность 10, при этом нужны все четверо, то каждый человек имеет предельную ценность, равную 10. Если требуются только три человека, каждый из них имеет нулевую предельную ценность. Обратите внимание, что значения предельной ценности не обязательно в сумме должны давать общую ценность игры. В частности, если функция ценности демонстрирует убывающую отдачу от масштаба, то сумма значений предельной ценности будет меньше общей ценности, а если дополнительная ценность демонстрирует растущую отдачу от масштаба, то этот показатель превысит общую ценность.
Ценность игрока по Шепли равна его предельному вкладу при вступлении в коалицию, усредненному по всем возможным вариантам порядка, в котором формируется коалиция всех игроков. Иначе говоря, мы представляем себе включение игроков в коалицию в определенной последовательности и вычисляем дополнительную ценность игрока в каждой последовательности. Рассмотрим небольшую компанию, ведущую бизнес в Испании и Франции. В ней работают три сотрудника: один владеет испанским языком, второй — французским, а третий говорит на обоих языках.
Предположим, наша кооперативная игра присваивает ценность 1200 долларов любому множеству сотрудников, владеющих французским и испанским языками. Эта сумма равна суточному доходу компании, когда она работает. Если в офис приходят любые два сотрудника, третий не нужен. Следовательно, каждый игрок имеет предельную ценность, равную нулю.
Чтобы определить ценность игрока, владеющего французским языком, рассмотрим все шесть последовательностей, в которых сотрудники могут приходить на работу. Только в одном случае (когда испаноговорящий сотрудник приходит первым, а франкоговорящий вторым) франкоговорящий сотрудник увеличивает ценность; его ценность по Шепли равна 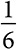 , умноженной на 1200 долларов, то есть 200 долларов. Испаноговорящий сотрудник добавляет ценность только в случае, когда он приходит вторым, а франкоговорящий первым, поэтому его ценность по Шепли тоже равна 200 долларов. В четырех оставшихся вариантах последовательности двуязычный сотрудник приходит либо первым, либо вторым и увеличивает ценность. Таким образом, его ценность по Шепли составляет 800 долларов. Сумма значений ценности по Шепли равна 1200 долларов, то есть общей ценности игры.
, умноженной на 1200 долларов, то есть 200 долларов. Испаноговорящий сотрудник добавляет ценность только в случае, когда он приходит вторым, а франкоговорящий первым, поэтому его ценность по Шепли тоже равна 200 долларов. В четырех оставшихся вариантах последовательности двуязычный сотрудник приходит либо первым, либо вторым и увеличивает ценность. Таким образом, его ценность по Шепли составляет 800 долларов. Сумма значений ценности по Шепли равна 1200 долларов, то есть общей ценности игры.
Вектор Шепли
При наличии кооперативной игры {N, V} вектор Шепли определяется следующим образом: пусть O представляет все N! вариантов последовательности, в котором N игроков могут быть включены в группу. Для каждого варианта последовательности во множестве O определим дополнительную ценность i-го игрока как изменение функции ценности, имеющее место в случае добавления игрока i. Ценность i-го игрока по Шепли равна среднему его значений дополнительной ценности по всем вариантам порядка в O.
Теперь, уловив общую идею, составим более сложный пример. Представьте себе команду, в которой должно быть четыре гребца и один рулевой — человек более низкого роста, который задает темп гребли и управляет рулем. В наш экипаж (включающий участников кооперативной игры) входит шесть человек: пять рослых, сильных гребцов и один более низкий человек с навыками рулевого. Для участия в состязаниях в команде должно быть четыре гребца и один рулевой. Команда из пяти человек, в которую входит специально обученный рулевой, будет конкурентоспособной и имеет ценность 10. Команда из пяти гребцов без рулевого тоже может участвовать в соревнованиях, но не покажет высоких результатов из-за избыточного веса. Присвоим ей ценность 2.
Для того чтобы вычислить вектор Шепли, представим, что игроки прибывают в команду во всех возможных последовательностях. Если более низкий рулевой прибывает первым, вторым, третьим или четвертым, он не добавляет ценности. Прибывая пятым (что происходит в одной шестой случаев), он создает ценность 10. Если он прибывает шестым, то заменяет одного из гребцов в качестве рулевого, и его дополнительная ценность составит 8. Вычислив среднее значение всех этих вариантов, мы сможем определить, что ценность рулевого по Шепли равна 3.
Каждый гребец увеличивает ценность тогда и только тогда, когда он прибывает пятым, что происходит в одном из шести случаев. Если рулевой не прибыл, гребец, который прибывает пятым, увеличивает ценность на 2. Если рулевой прибыл, гребец создает ценность 10. Учитывая вероятность один к пяти того, что рулевой окажется последним из пяти оставшихся игроков, а также вероятность четыре к пяти того, что рулевой прибудет в первой четверке, мы получим ценность каждого гребца по Шепли, равную 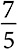 30, [1]. Интуитивно понятно, что ценность рулевого должна быть больше ценности отдельного гребца и, с учетом того, что без рулевого гребцы могут состязаться (пусть и плохо), меньше совокупной ценности всех гребцов. Существует бесконечное количество способов определить значения ценности, удовлетворяющие этим ограничениям. Ценность игроков по Шепли имеет конкретные значения: 3 — ценность рулевого и 7 — общая ценность пяти гребцов.
30, [1]. Интуитивно понятно, что ценность рулевого должна быть больше ценности отдельного гребца и, с учетом того, что без рулевого гребцы могут состязаться (пусть и плохо), меньше совокупной ценности всех гребцов. Существует бесконечное количество способов определить значения ценности, удовлетворяющие этим ограничениям. Ценность игроков по Шепли имеет конкретные значения: 3 — ценность рулевого и 7 — общая ценность пяти гребцов.
АКСИОМАТИКА ВЕКТОРА ШЕПЛИ
Теперь опишем набор аксиом, которым однозначно удовлетворяют значения вектора Шепли. Этот результат объясняет, почему мы можем предпочесть вектор Шепли другим показателям. Во-первых, обратите внимание, что мы вычисляем значения вектора Шепли путем определения среднего значения предельного вклада игрока по всем возможным вариантам порядка, поэтому ценность игрока, который не добавляет ценности, по Шепли равна нулю. Кроме того, любым двум идентичным игрокам (то есть тем, которые вносят одинаковый вклад в каждую коалицию) должна быть присвоена одна и та же ценность по Шепли. А с учетом того, что сумма значений дополнительной ценности равна общей ценности игры при любом варианте упорядочения, значения вектора Шепли тоже должны давать в сумме ценность игры. Это и есть три из четырех аксиом. Обратите внимание, что ценность последнего игрока удовлетворяет двум первым аксиомам, но не третьей.
Добавим к этим трем свойствам четвертое, аддитивность, согласно которому, если функция ценности кооперативной игры делится на две функции ценности, каждая из которых соответствует отдельной кооперативной игре, то ценность участника объединенной игры должна равняться сумме значений его ценности в двух играх, входящих в состав общей игры. Быстрый анализ показывает, что вектор Шепли удовлетворяет и этому свойству. Тот факт, что все четыре свойства однозначно определяют вектор Шепли, менее очевиден.
Демонстрация того, что тот или иной показатель однозначно удовлетворяет набору аксиом, позволяет логически его обосновать. Без аксиом показатель интуитивно понятен, но его можно рассматривать как произвольный, то есть один из ряда возможных. Теорема также указывает на то, что при выборе любого другого показателя нам придется отбросить одну из аксиом. Это не означает, что вектор Шепли — единственный приемлемый показатель. Возможно, экономист и математик Ллойд Шепли сначала описал показатель и только потом сформулировал аксиомы, которым он однозначно удовлетворяет. Не имеет значения, что именно первично. Даже если аксиомы были сформулированы после описания показателя, приняв их, мы должны принять и сам показатель. Приемлемость показателя зависит от обоснованности аксиом. В данном случае первые три трудно оспорить. Четвертая, аксиома аддитивности, сложнее остальных, но ее можно подтвердить тем, что если бы она не выполнялась, то игроки были бы заинтересованы в разрыве отношений или формировании коалиции.
Аксиоматика вектора Шепли
Вектор Шепли однозначно удовлетворяет следующим аксиомам.
Нулевое свойство: если дополнительная ценность, создаваемая игроком, равна нулю в любой коалиции, то ценность игрока тоже равна нулю.
Справедливость (симметрия): если два игрока создают одну и ту же дополнительную ценность в любой коалиции, то они имеют одинаковую ценность.
Полное распределение: сумма значений ценности игроков равна общей ценности игры, V(N).
Аддитивность: при наличии двух игр, определенных на одном множестве игроков, с функциями ценности V и 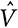 ценность игрока в игре
ценность игрока в игре 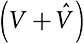 равна сумме значений его ценности в играх V и .
равна сумме значений его ценности в играх V и .
ВЕКТОР ШЕПЛИ И ТЕСТ НА АЛЬТЕРНАТИВНЫЕ ВАРИАНТЫ ПРИМЕНЕНИЯ
Теперь используем значения вектора Шепли в кооперативной игре, основанной на тесте на альтернативные варианты применения. В ходе теста каждый человек должен придумать новые варианты использования какого-либо обычного объекта, скажем, кирпича. Такой тест позволяет оценить креативность человека, исходя из количества вариантов или категорий применения, которые он предложит. При вычислении значений вектора Шепли мы увидим, что можем вывести интуитивно понятное правило подсчета результатов.
Допустим, у нас есть три игрока — Арун, Бетти и Карлос, каждый из которых ищет альтернативы использования блокчейна (технологии распределенного реестра), как показано на рис. 9.1. Арун и Карлос выдвинули по шесть идей, что дает каждому из них по 6 баллов за креативность, а Бетти — семь, что обеспечивает ей 7 баллов. Общий уровень креативности группы равен 9, поскольку всего было выдвинуто девять оригинальных идей. Для того чтобы вычислить значения вектора Шепли, мы могли бы записать все шесть возможных последовательностей, в которых может формироваться группа, начислить ее членам баллы только за уникальные идеи, предложенные в группе, а затем вывести среднее значение по всем шести случаям. Мы можем также заметить, что при вычислении значения вектора Шепли вероятность того, что кто-то получит баллы за ту или иную идею, равна единице, деленной на количество предложивших ее людей. Любой, кто предлагает уникальную идею, всегда получает максимальное количество баллов. На рис. 9.1 такие идеи (например, идея Аруна об использовании блокчейна для регистрации сделок в области искусства) выделены жирным шрифтом. Если два человека выдвигают какую-то идею, каждый из них имеет один шанс из двух присоединиться к группе первым. Аналогично, если все трое выдвигают ту или иную идею, у каждого из них есть один шанс из трех войти в группу первым. Следовательно, равное распределение баллов между теми, кто предложил идею, дает значения вектора Шепли. Таким образом, это и есть уникальный способ присвоить значения, удовлетворяющие всем четырем аксиомам. Эти значения показывают, что хотя Арун предложил не большинство идей, он создал самую большую ценность [2].
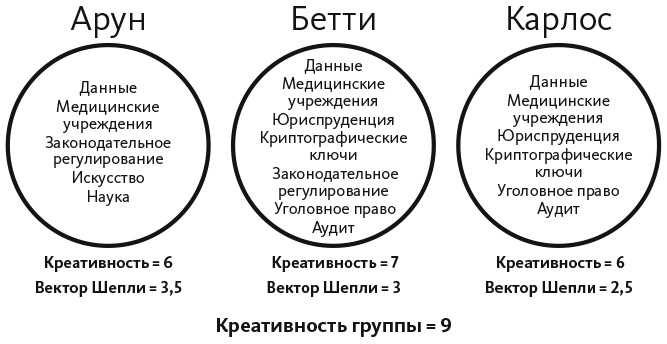
Рис. 9.1. Вектор Шепли и тест на альтернативные варианты применения
ИНДЕКС ШЕПЛИ — ШУБИКА
Теперь применим вектор Шепли к классу игр голосования. В такой игре каждый игрок (представляющий политическую партию или должностное лицо) контролирует фиксированное число мест или голосов, при этом большинство этих мест или голосов нужно для принятия решений. В играх голосования вектор Шепли обозначается термином «индекс влияния Шепли — Шубика» [3]. Вычислив его, мы увидим, что прямого соответствия между процентом мест (голосов), которые контролирует партия, и ее влиянием нет.
Для расчета индексов влияния проанализируем все возможные последовательности вхождения партий в коалицию. Если партия присоединяется к коалиции и формирует строгое большинство, то ее дополнительная ценность равна 1. В таких случаях партия считается ключевой. В противном случае партия не добавляет никакой ценности. Рассмотрим в качестве примера парламент со 101 местом, которые распределены между четырьмя политическими партиями следующим образом: партия A контролирует 40 мест, партия B— 39 мест, а у партий C и D по 11 мест. В этом примере партия A не может быть ключевой, если входит в состав коалиции первой или последней, соответственно, входя в коалицию второй или третьей, она всегда будет ключевой. Следовательно, ее индекс влияния равен 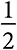 . Когда партия B входит в состав коалиции первой или последней, она тоже не увеличивает ценность. В случае же вхождения в коалицию второй она становится ключевой только тогда, когда партия A присоединилась к коалиции первой. Если партия B входит в коалицию третьей, она может стать ключевой, только если партия A присоединится к коалиции последней. Каждая из этих комбинаций происходит с вероятностью
. Когда партия B входит в состав коалиции первой или последней, она тоже не увеличивает ценность. В случае же вхождения в коалицию второй она становится ключевой только тогда, когда партия A присоединилась к коалиции первой. Если партия B входит в коалицию третьей, она может стать ключевой, только если партия A присоединится к коалиции последней. Каждая из этих комбинаций происходит с вероятностью 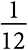 . Таким образом, индекс влияния партии B равен 31. Партии C и D становятся ключевыми в такой же совокупности случаев, как и партия B. Ни одна из этих партий не может быть ключевой, войдя в коалицию первой. Каждая партия становится ключевой, если присоединяется к коалиции второй, при условии, что партия A вошла в ее состав первой. Каждая партия становится ключевой, входя в коалицию третьей, только когда партия A присоединится к ней последней. А значит, каждая из партий также имеет индекс влияния .
. Таким образом, индекс влияния партии B равен 31. Партии C и D становятся ключевыми в такой же совокупности случаев, как и партия B. Ни одна из этих партий не может быть ключевой, войдя в коалицию первой. Каждая партия становится ключевой, если присоединяется к коалиции второй, при условии, что партия A вошла в ее состав первой. Каждая партия становится ключевой, входя в коалицию третьей, только когда партия A присоединится к ней последней. А значит, каждая из партий также имеет индекс влияния .
Партия | Количество мест | Влияние |
A | 40 |
|
B | 39 |
|
C | 11 |
|
D | 11 |
|
Рис. 9.2. Разрыв между количеством мест и влиянием
Этот пример демонстрирует возможный разрыв между процентом мест, контролируемых партией, и ее влиянием. Партии A и B контролируют почти одинаковое количество мест, но у партии A в три раза больше влияния, чем у партии B, имеющей столько же влияния, как и партии C и D. Аналогичное распределение мест часто происходит в реальных условиях в странах с парламентской формой правления. В итоге партии с небольшим количеством мест часто могут обладать значительным влиянием. В парламенте Израиля, кнессете, 120 мест. В 2014 году коалиция во главе с партией «Ликуд» получила 43 места. Оппозиция контролировала 59 мест (немногим менее большинства), а ортодоксальная коалиция 18 мест. У всех трех партий был одинаковый индекс Шепли — Шубика. Это не означает, что на практике мелкие ортодоксальные партии столь же влиятельны — все модели неправильные. Но это действительно указывает на то, что их влияние более значительно, чем можно было бы предположить, исходя из количества контролируемых ими мест в парламенте.
Еще более поразительный разрыв между количеством мест и влиянием имел место в наблюдательном совете округа Нассау (штат Нью-Йорк) в середине 1960-х годов. В то время совет состоял из шести членов, каждый из которых контролировал количество голосов, пропорциональное численности населения соответствующего административного района (рис. 9.3). Решение большинством голосов требовало 58 или более из 115 голосов. Обратите внимание, что любые два из трех крупнейших районов округа имели большинство, а значит, голоса оставшихся трех районов ни при каких обстоятельствах не могли стать решающими. Следовательно, представители остальных районов не имели влияния.
Район | Количество голосов | Влияние |
Хемпстед 1 | 31 |
|
Хемпстед 2 | 31 |
|
Ойстер-Бей | 28 |
|
Северный Хемпстед | 21 | 0 |
Лонг-Бич | 2 | 0 |
Глен-Коув | 2 | 0 |
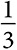
Рис. 9.3. Есть голоса, но нет влияния
Индекс влияния Шепли — Шубика можно применить к любой ситуации с неравным распределением мест или голосов, например в случае Евросоюза или коллегии выборщиков. Это не значит, что он приемлем во всех без исключения случаях. Пятьдесят штатов США можно упорядочить 50! (3 · 1064) разными способами. Учитывая региональные корреляции в предпочтениях избирателей, не все коалиции возможны. Так, штат Миссисипи вряд ли сформирует коалицию со штатом Нью-Йорк. Для того чтобы разработать более полезный показатель влияния, понадобилось бы поставить одни коалиции в привилегированное положение по отношению к другим или вообще исключить некоторые коалиции. Чуть ниже мы рассмотрим вектор Майерсона, позволяющий сделать второе — исключить ряд коалиций.
РЕЗЮМЕ
Значение ценности отдельного игрока по Шепли соответствует его среднему дополнительному вкладу в коалиции по мере их формирования. Это показатель дополнительной ценности. В играх голосования вектор Шепли можно также интерпретировать как показатель влияния, хотя он не всегда бывает наилучшим. Предельная ценность игрока может быть более эффективным показателем влияния в ситуации, когда группа уже сформировалась, поскольку это демонстрирует, какую выгоду каждый отдельный игрок мог бы получить вследствие угрозы выйти из состава группы (при условии, что угроза реальна). В таких случаях коалиции необходимо уменьшить значение ценности последнего игрока. Коалицию с высокой ценностью, но низкой предельной ценностью игрока можно создать путем увеличения ее размера. Включение дополнительных членов в коалицию делает ее действующих членов теми, кем можно пожертвовать, и сводит их предельную ценность к нулю. Мы часто наблюдаем это на практике. Работодатели нанимают больше, чем нужно, сотрудников, чтобы снизить их влияние. Производственные компании пользуются услугами множества конкурирующих поставщиков промежуточных продуктов. Правительства заключают контракты, чтобы многочисленные подрядчики оставались в бизнесе.
Аналогичные интуитивные рассуждения применимы и к созданию коалиций в законодательных органах. Лоббисты Конгресса и лидеры партий стремятся принимать законы (результат, представляющий ценность), но ограничивают влияние отдельных членов палаты представителей и сенаторов [4]. Если лоббист оказывает содействие минимальному количеству членов палаты представителей и сенаторов, необходимому для того, чтобы выиграть голосование, то каждый член палаты представителей и каждый сенатор имеет огромную предельную ценность. Любой может проголосовать иначе, полностью изменив судьбу законопроекта. Такой лоббист может сократить значение предельной ценности политиков, заручившись поддержкой квалифицированного большинства членов палаты представителей и сенаторов. Та же логика подразумевает, что партией, имеющей незначительное большинство, трудно руководить. У каждого ее члена высокая предельная ценность. В подавляющем большинстве ни один член палаты представителей или сенатор не имеет большого влияния.
Если мы расширим перспективу и поразмыслим о влиянии в современном связанном мире, то придем к выводу о полезности применения как предельной ценности игроков, так и вектора Шепли. Влияние отдельного человека, организации, корпорации, правительства или террористической группы отчасти зависит от того, какой ущерб они могут нанести, отклонившись от кооперативного режима (предельная ценность игрока). Опытный компьютерный хакер (человек, способный уничтожить значительный объем богатства) обладает огромным влиянием. Это верно даже в случаях, когда хакер не способен создавать ценность.
В отношении корпораций или других транснациональных организаций вектор Шепли может быть более эффективным показателем. В таких случаях выход может быть нецелесообразным. Энергетическая компания участвует в таких играх, как производство и распределение электроэнергии, недвижимость, защита окружающей среды и так далее. Общая дополнительная ценность этой компании равна сумме значений дополнительной ценности в разных областях.
Анализ влияния и ценности сквозь призму кооперативной теории игр позволяет сделать действенные, основополагающие выводы. Кроме того, он также указывает на направление дальнейшего движения. В политике и бизнесе не все коалиции вероятны. Данная модель исходит из возможности любой коалиции. Более содержательная модель должна учитывать связанность мира. Консалтинговые и финансовые компании покупают программное обеспечение у технологических компаний. Технологические и консалтинговые компании инвестируют и берут кредиты через финансовые компании. А финансовые и технологические компании нанимают консультантов. В рамках подобных сетей каждый агент создает ценность и обладает влиянием. Определить влияние в таких ситуациях помогут сетевые модели, о которых мы и поговорим в следующей главе.
ГЛАВА 10
СЕТЕВЫЕ МОДЕЛИ
Теория сетей —это целая область науки, но она относительно новая с точки зрения последних 20–30 лет. У нас не было возможности вывести эту науку из университетов и применить на практике, поставив вопрос так: «Какие виды сетей и для каких целей нам следует создавать?»
Энн-Мари Слотер
В этой главе мы рассмотрим модели сетей. Для их всестороннего изучения понадобится множество книг. Наши цели гораздо скромнее. Мы хотим понять азы теории сетей, изучить их составляющие и выяснить, почему они важны для моделирования. Ответ, к которому мы придем, покажет, что сети почти всегда имеют значение. Любую построенную нами модель, будь то модель рынка, модель распространения заболеваний или модель передачи информации, можно улучшить путем включения в сеть агентов [1].
Сети распространены повсеместно. Люди говорят о торговых сетях, террористических сетях и сетях волонтеров. Виды образуют пищевые сети. Компании выстраивают сети цепей поставок. Как уже отмечалось, финансовую систему полезно представлять как сеть обещаний произвести платеж. Сети всегда были важны для понимания социальных отношений. На протяжении большей части истории человечества сети социальных связей ограничивались географией и трудностями с их отображением. Сегодня благодаря развитию технологий многие социальные взаимодействия и экономические операции осуществляются в виртуальных сетях, которые можно проанализировать с помощью моделей.
Эта глава организована в том же формате «структура — логика — функция», который мы использовали для распределений. Сначала мы опишем структуру сетей с помощью таких статистических показателей, как степень, длина пути, коэффициент кластеризации и структура сообщества. Затем обсудим общие классы сетей: случайные сети, звездообразные сети, географические сети, сети малого мира и сети со степенным распределением. А потом перейдем к логике формирования сетей. Мы построим процессы микроуровня, порождающие те сети, которые мы наблюдаем. И в заключение рассмотрим функцию, то есть вопрос о том, почему структура сети имеет значение. Основное внимание в главе уделяется пяти следствиям. Мы начнем с парадокса дружбы, а затем рассмотрим теорию шести рукопожатий и концепцию силы слабых связей. И наконец, проанализируем устойчивость сетей к отказу узлов или звеньев, а также агрегирование информации в сетях. Глава завершается обсуждением влияния сетей на результаты, полученные с помощью моделей.
СТРУКТУРА СЕТИ
Сеть состоит из узлов и звеньев (ребер), которые их соединяют. Узлы, соединенные одним звеном, называются соседями. Сеть считается связанной, если из любого ее узла можно добраться к любому другому узлу по звеньям. Сети можно представить в виде графов, списков звеньев или матриц из нулей и единиц, в которых единица в строке A и в столбце B обозначает звено между узлами A и B. Хотя люди предпочитают графическое представление сетей, списки и матрицы лучше подходят для статистических расчетов по сети.
Звенья сети могут быть направленными, то есть указывать на переход от одного узла к другому. В информационной сети направленное звено говорит о том, что один человек получает информацию от другого. В сети экосистемы направленное звено от краснохвостого ястреба к серой белке означает, что ястреб охотится на белку. Звенья также могут быть ненаправленными — к их числу относятся звенья, соединяющие друзей. В ненаправленной сети степень узла равна количеству ведущих к нему звеньев. Сети характеризуются набором статистических параметров. Для каждого статистического параметра можно вычислить среднее значение степени в сети и распределение степеней по всем узлам. Средняя степень сети дружеских связей говорит о том, сколько в среднем друзей у каждого человека. Распределение степеней указывает на то, что одни узлы более связанные, чем другие. В сетях социальных связей более равномерное распределение, чем во Всемирной паутине, интернете и сетях цитирования, где наблюдается распределение с длинным хвостом.
Статистические параметры сети
Степень: количество соседей (а также звеньев) узла.
Длина пути: минимальное количество звеньев, которые необходимо пройти, чтобы попасть из одного узла в другой.
Промежуточность: количество проходящих через данный узел путей минимальной длины, связывающих два других узла.
Коэффициент кластеризации: процент пар соседей узла, связанных между собой звеном.
Длина пути — минимальное расстояние между двумя узлами — изменяется обратно пропорционально степени. Включение дополнительных звеньев сокращает длину пути между узлами. В сети рейсов авиакомпании длина пути соответствует среднему количеству рейсов, которыми человеку нужно воспользоваться, чтобы попасть из одного города сети в другой. При наличии выбора между двумя авиакомпаниями при прочих равных условиях (а именно одинаковых ценах) путешественник предпочтет авиакомпанию с более низким средним значением длины пути. Кроме того, средняя длина пути коррелирует с потерей информации. Информация, передаваемая через нескольких людей, в большей степени подвержена искажению, чем та, которой двое обмениваются непосредственно. Узлы, лежащие на путях минимальной длины, играют в сетях важнейшую роль. Информация проходит по кратчайшему маршруту, если передается по узлам, расположенным на минимальном пути. Показатель промежуточности узла равен проценту минимальных путей, проходящих через один узел. В сети социальных связей люди с высоким показателем промежуточности более информированы и обладают более сильным влиянием.
Последний статистический параметр, коэффициент кластеризации, равен проценту пар соседей узла, которые одновременно являются соседями друг друга. Например, у человека, имеющего 10 друзей, 45 пар друзей. Если 15 из этих 45 пар тоже друзья, то коэффициент кластеризации этого человека равен  . Если бы дружеские связи существовали во всех 45 парах, то коэффициент кластеризации этого человека составил бы 1, максимально возможное значение. Коэффициент кластеризации всей сети равен среднему коэффициентов кластеризации отдельных узлов.
. Если бы дружеские связи существовали во всех 45 парах, то коэффициент кластеризации этого человека составил бы 1, максимально возможное значение. Коэффициент кластеризации всей сети равен среднему коэффициентов кластеризации отдельных узлов.
На рис. 10.1 показаны две сети, состоящие из тринадцати узлов: звездообразная и географическая. В звездообразной сети центральный узел имеет степень 12, а все остальные — степень 1, значит, средняя степень меньше 2. Распределение степеней неравномерное. Расстояние от любого узла до центрального узла равно 1, а до всех остальных узлов — 2. Центральный узел, который лежит на каждом минимальном пути между всеми остальными узлами, имеет показатель промежуточности 1. Внешние узлы не расположены ни на одном минимальном пути, соединяющем другие узлы, поэтому их показатель промежуточности равен 0. И наконец, в звездообразной сети узлы, связанные с одним из узлов, не связаны друг с другом. Следовательно, коэффициент кластеризации такой сети равен нулю.
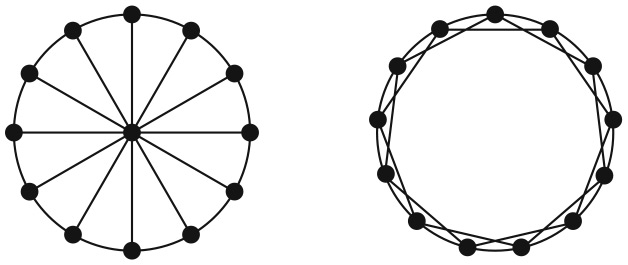
Рис. 10.1. Звездообразная сеть и географическая сеть
Показатель сети | Звездообразная сеть | Географическая сеть | |
Центральный узел | Внешний узел | ||
Степень | 12 | 1 | 4 |
Средняя длина пути | 1 |
| 2 |
Промежуточность | 1 | 0 | |
Коэффициент кластеризации | 0 | 0 |
|
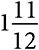
В географической сети каждый узел связан с двумя узлами справа от него и с двумя узлами слева, поэтому средняя степень равна 4. Каждый узел находится на расстоянии 1 от четырех узлов, на расстоянии 2 от четырех узлов и на расстоянии 3 от четырех узлов. Следовательно, среднее расстояние составляет ровно 2. Распределение степени и расстояния в этом графе является вырожденным: все узлы имеют одну и ту же степень и одинаковое среднее расстояние. Можно продемонстрировать, что промежуточность каждого узла равна [2]. У каждого узла четыре соседа, что дает шесть пар. Из них три пары связаны: два узла непосредственно слева и справа связаны с внешним узлом и друг с другом. Таким образом, коэффициент кластеризации равен .
Альтернативный метод определения кластеризации состоит в разделении узлов на сообщества. В сети дружеских связей в средней школе сообщества могут включать подростков, которые интересуются искусством, спортом или естественными науками. Сообщества могут быть также выделены по принципу расовой или гендерной принадлежности. Сеть политических объединений может быть разделена на региональные или идеологические союзы. Существует множество методов определения сообществ. Один из подходов подразумевает последовательное удаление звеньев с самым высоким значением промежуточности, поскольку такие звенья в большей мере связывают отдельные кластеры. Другие подходы принимают количество кластеров как данность и ищут оптимальные способы разбиения с учетом целевой функции, такой как минимизация количества звеньев между сообществами или максимизация доли звеньев внутри сообществ [3].
Мы можем использовать алгоритм обнаружения сообществ, чтобы задавать вопросы о данных сети. Исследования показывают, что человек может принадлежать к интернет-пузырям, то есть к сообществам людей, которые получают новости из аналогичных источников. В таком случае это имеет последствия с точки зрения социальной сплоченности. До появления интернета такое положение вещей тоже могло иметь место, но демонстрация этого с помощью данных была затруднена. Сегодня специалисты по их анализу и обработке могут с помощью веб-скрейпинга выявить часто посещаемые источники новостей и сказать нам, что, по сути, мы действительно в каком-то смысле обитаем в пузырях. Модели предоставляют формальное описание сообществ, а об их силе говорят данные. Руководствуясь здравым смыслом и основываясь на том, о чем говорят данные, мы можем делать мудрые выводы.
ОБЩИЕ СЕТЕВЫЕ СТРУКТУРЫ
В ходе анализа сетей мы сталкиваемся с проблемой многообразия. Немногочисленные статистические параметры сетей не способны описать особую сетевую структуру: можно сконструировать миллиарды сетей с десятью узлами и средней степенью 2. Альтернативный подход к описанию сети сводится к проверке, существенно ли отличаются ее статистические параметры от статистических параметров общей сетевой структуры. Например, ученый может собрать данные о цитировании в суде и представить их в виде сети, отображая звено каждый раз, когда один судья цитирует мнение другого судьи. Граф такой сети может содержать интересные структуры и кластеры. Мы можем проверить, является ли сеть случайной, сравнив ее статистические параметры со статистическими параметрами случайной сети с аналогичным количеством узлов и звеньев. Коэффициент кластеризации случайной сети равен вероятности случайного звена, поскольку вероятность того, что два соседа того или иного узла содержат определенное звено, не больше, чем у любого другого случайно выбранного узла.
Метод Монте-Карло в контексте случайных сетей
Для того чтобы проверить, является ли сеть из N узлов и E звеньев случайной, необходимо создать большое количество случайных сетей с N узлами и E звеньями и вычислить распределения для степени, длины пути, коэффициента кластеризации и промежуточности. А затем выполнить стандартные статистические тесты, чтобы принять или отклонить гипотезу о том, что статистические параметры сети могли быть получены на основе имитационных распределений [4].
Теоретические модели часто принимают форму определенной сетевой структуры. Многие имеют вид случайных сетей, тогда как другие — форму географических сетей с упорядоченной структурой, как в случае, когда узлы выстроены в круг и каждый узел связан с ближайшими узлами в каждом направлении. В других географических сетях узлы размещены на плоскости, разделенной на клетки; при этом каждый узел соединен с соседями, расположенными к северу, югу, востоку и западу. У большинства распространенных географических сетей низкая степень (они связаны только с локальными соседями) и относительно высокое среднее значение длины пути. В географических сетях промежуточность и коэффициент кластеризации не имеют вариации.
Сеть третьего типа — сеть со степенным распределением — имеет степень, распределенную по степенному закону. У немногочисленных узлов есть множество связей, но большинство узлов имеют очень мало связей. Сеть четвертого типа (сеть малого мира) сочетает в себе свойства географических и случайных сетей [5]. Для ее построения необходимо начать с географической сети, а затем «переделать» ее, произвольно выбрав звено и заменив один из узлов, которые оно связывает, случайным узлом. Если вероятность такой «перепрошивки» равна нулю, мы имеем географическую сеть, а если единице, то случайную сеть. В промежутке между этими значениями мы получаем сеть малого мира, которую можно отличить от географической сети по небольшим кластерам, соединенным случайными связями с другими кластерами. Сети социальных связей выглядят примерно так же. У каждого человека есть кластер друзей и случайные друзья.
Рис. 10.2. Случайная сеть, географическая сеть, сеть, распределенная по степенному закону, и сеть малого мира
ФОРМИРОВАНИЕ СЕТЕЙ: ЛОГИКА
Теперь кратко опишем модели формирования сетей. Они предоставляют логику для объяснения структуры сетей. Большинство структур сетей, с которыми мы сталкиваемся, возникают в результате решений отдельных агентов по поводу установления связей. Это касается сетей дружеских связей, Всемирной паутины и электросетей. Все эти сети не являются запланированными. Другие сети, такие как сети цепей поставок, — результат планирования. Устойчивость запланированных сетей к отказу узлов вполне ожидаема. Тот факт, что возникающие сетевые структуры устойчивы — скорее загадка.
Мы уже рассказывали, как создавать случайные сети и сети малого мира. Первые создаются путем случайного формирования совокупности узлов и построения звеньев, связывающих случайные пары узлов. Сети малого мира создаются так: сначала мы формируем регулярную географическую сеть (часто посредством выстраивания узлов в круг и связывания k соседей в каждом направлении), а затем случайным образом переставляем часть звеньев.
Модели формирования электросети опираются на экономические и инженерные принципы. Такая сеть должна обеспечивать электроэнергией дома, предприятия и правительственные учреждения. Какие бы организации ни выступали в качестве производителей электроэнергии, коммерческие компании или коммунальные предприятия, у них мало стимулов для создания сетей с высоким коэффициентом кластеризации, поскольку это было бы неэффективно. Однако отсутствие кластеров снижает устойчивость сети. Кроме того, из экономических и инженерных соображений в таких сетях исключаются дальние прыжки — связи, которые проходят через всю сеть.
Энергетические компании не осуществляют прямую подачу электроэнергии из Чикаго в Даллас, но люди и компании поддерживают непосредственные связи друг с другом. Житель Чикаго может подружиться с кем-то из Далласа, а компания из Сингапура вести бизнес с компанией из Детройта. Как мы увидим в следующем разделе этой главы, такие длинные прыжки способствуют укреплению устойчивости сети.
Для создания сети с распределением с длинным хвостом можно использовать один из вариантов модели предпочтительного присоединения. Для этого мы создадим узлы случайным образом, а затем нарисуем звенья, соединяющие новые узлы с существующими. Сделав так, чтобы вероятность подсоединения к узлу была пропорциональна его степени, мы получим распределение по степенному закону. В этой модели появившиеся в сети на начальном этапе узлы с гораздо большей вероятностью будут иметь высокую степень. Недостаток модели состоит в том, что она не учитывает различий в качестве узлов. Более качественные узлы должны иметь более высокую степень. Модель формирования сети с высоким качеством и степенью узлов позволяет исправить это упущение и одновременно обеспечивает распределение с длинным хвостом.
Модель формирования сети с высоким качеством и степенью узлов
Создайте d несвязанных узлов. За каждый период t создавайте новый узел с качеством Qt, выбранным из распределения F. Соедините этот узел с d другими узлами, исходя из их степени. Если Dit обозначает степень узла i в период t, вероятность выбора узла i при наличии N узлов равна
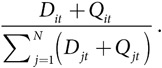
Если у качества новых узлов низкое среднее значение и низкая дисперсия, то эта модель напоминает стандартную модель предпочтительного присоединения. Если у распределения качества длинный хвост, то новые узлы очень высокого качества могут получить большую степень [6].
ПОЧЕМУ СЕТИ ВАЖНЫ: ФУНКЦИЯ
В главе 1 мы упоминали о парадоксе дружбы — том факте, что в любой сети в среднем у людей не может быть больше друзей, чем у их друзей. Логику того, почему так происходит, можно продемонстрировать на примере звездообразной сети. В такой сети у двенадцати человек есть по одному другу и у одного человека есть двенадцать друзей. Двенадцать человек, имеющих одного друга, связаны с одним центральным узлом, а он имеет двенадцать друзей. Именно эта особенность (тот факт, что люди с высокой степенью связаны с большим количеством других людей) определяет данный результат. В звездообразной сети у людей в среднем меньше двух друзей. При этом у друзей каждого человека в среднем больше одиннадцати друзей.
Парадокс дружбы присутствует в любой сети: сетях цитирования, сетях контактов электронной почты, сетях сексуальных контактов, банковских сетях и сетях международной торговли. В среднем источники, цитируемые в научной статье, получают более высокий уровень цитирования, чем сама статья; торговые партнеры страны в среднем торгуют с большим количеством стран, чем сама страна; а многочисленные виды, связанные с отдельным видом в пищевой сети, имеют в среднем больше связей, чем этот вид. Разрыв между количеством друзей и количеством друзей друзей еще более ярко выражен в сетях, где распределение степени имеет более высокую дисперсию. Анализ дружеских связей в Facebook показал, что у среднестатистического человека около двухсот друзей, а его друзья имеют в среднем более шестисот друзей [7].
Парадокс дружбы
Если у двух любых узлов в сети разные значения степени, в среднем узел имеет более низкую степень, чем его соседи. Иначе говоря, друзья человека пользуются в среднем большей популярностью, чем он сам [8].
Логика парадокса дружбы распространяется на любое свойство, которое соотносится с количеством друзей. Если активные, счастливые, умные, богатые и добрые люди имеют в среднем больше друзей, то друзья таких людей будут в среднем активнее, счастливее, умнее, богаче и красивее [9]. Представьте себе сеть, в которой у 90 процентов несчастливых людей четыре друга и у 10 процентов — десять друзей. Изменим соотношение на обратное для счастливых людей: у 10 процентов четыре друга и у 90 процентов — десять друзей. Среди друзей этих людей будет непропорционально много людей с десятью друзьями. Подавляющее большинство людей будут счастливы, а значит, большинство друзей этих людей будут счастливее, чем они сами.
Теперь продемонстрируем такой феномен, как теория шести рукопожатий (шесть степеней разделения), — утверждение о том, что два любых человека на планете связаны друг с другом не более чем через шесть человек. Тогда как парадокс дружбы справедлив в любой сети, теория шести рукопожатий верна только для некоторых типов сетей. Название феномена появилось в результате эксперимента Стэнли Милгрэма, проведенного им в 1960-х годах. Милгрэм отправил конверты 296 жителям Омахи (штат Небраска) и Уичито (штат Канзас), которые требовалось отправить человеку в Бостон (штат Массачусетс). Участники эксперимента должны были придерживаться одних и тех же правил: им разрешалось отправлять конверты по почте только тем людям, с которыми они знакомы лично и которые, по их мнению, могли знать нужного человека в Бостоне, с указанием сделать то же самое. Люди составляли список, в котором фиксировался путь, и отправляли почтовые открытки исследователям, чтобы те могли отследить разрывы в цепочке. В Бостон прибыло шестьдесят четыре конверта, среди которых средняя длина пути была немногим меньше шести — отсюда и название «шесть степеней разделения».
В ходе второго, более масштабного, эксперимента, проведенного через пятьдесят лет, 20 000 человек было поручено найти восемнадцать адресатов во всем мире с помощью электронной почты. Средняя длина цепочек электронных писем составляла от пяти до семи, в зависимости от географического расстояния между источником и адресатом. Длина обнаруженных путей не была эквивалентна минимальной длине пути между участниками эксперимента. Таким образом, полученные данные указывают на то, что большинство людей связаны менее чем шестью степенями [10].
Давайте сконструируем упрощенную версию сети малого мира, чтобы получить интуитивное представление о феномене шести степеней разделения. Наш вариант сети подразумевает, что у людей есть небольшой кластер близких друзей, которые знают друг друга, и друзья за пределами кластера, которых мы назовем случайными друзьями [11]. На рис. 10.3 показан человек (обозначенный черным кружком), имеющий пять близких и двух случайных друзей. Кроме того, на рисунке отображен выбор друзей друзей этого узла (светло-серые кружки).
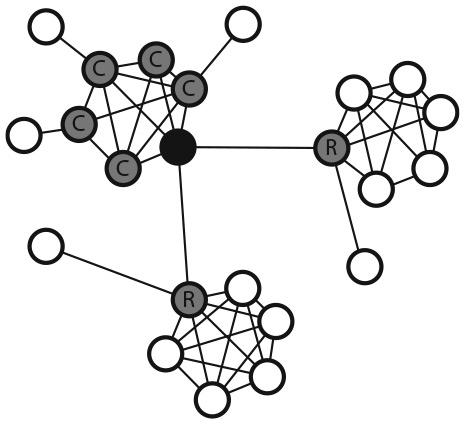
Рис. 10.3. Близкие друзья узла (C) и случайные друзья (R)
Случайных друзей можно также рассматривать как слабые связи, то есть как людей, которые связывают вас с другими сообществами. Слабые связи (случайные друзья в нашей сети) играют важную информационную роль, соединяя сообщества с разными интересами и информацией. Именно поэтому социологи говорят о силе слабых связей [12].
Эта конструкция позволяет вычислить количество соседей второй степени (друзей друзей), определив количество друзей случайных друзей, но добавляя только случайных друзей близких друзей. Мы не будем подсчитывать близких друзей близких друзей, поскольку это члены круга близких друзей узла. Аналогичным образом мы рассчитаем количество друзей друзей друзей. Мы подсчитаем друзей случайных друзей близких друзей, не включая в расчеты близких друзей близких друзей случайных друзей, так как они уже были подсчитаны как соседи второй степени. Для получения феномена шести степеней разделения мы применим ту же логику к сети, состоящей из 100 близких и 20 случайных друзей.
Шесть степеней разделения
Предположим, каждый узел имеет 100 близких друзей (C), которые дружат друг с другом, и 20 случайных друзей (R), у которых нет общих друзей с узлом. Вычислим количество соседей разных степеней:
Степень 1: C + R = 120
Степень 2: CR + RC + RR = 2000 + 2000 + 400 = 4400
Степень 3: CRC + CRR + RCR + RRC + RRR = 328 000
Степень 4: 17 360 000 [13]
Степень 5: > 1 миллиарда
Степень 6: > 20 миллиардов
При отсутствии частичного совпадения друзей случайных друзей модель по умолчанию исходит из существования бесконечной генеральной совокупности. В реальной сети социальных связей частичное совпадение друзей имеет место по мере увеличения степени. В сети, включающей совпадения и другие реальные свойства, такие как неоднородность количества друзей, значения будут отличаться от вычисленных выше. Относительная величина количества соседей узла каждой степени останется аналогичной. У человека будет гораздо больше соседей третьей степени (друзей друзей друзей), чем второй (друзей друзей).
Большое количество друзей третьей степени (более четверти миллиона в нашем примере) может быть полезным. В отличие от близких друзей человека, его друзья третьей степени обычно живут в разных городах, посещают разные школы и располагают разной информацией. Они более многообразны. В то же время они достаточно близки для установления доверительных отношений: друг друга друга может быть коллегой матери вашего соседа по комнате или тетей парня вашей сестры. Количество друзей третьей степени, их разнообразие и относительная близость делают их важным активом. Они могут предоставить вам ценную информацию и перспективы трудоустройства. Все эти люди охотно помогут человеку найти работу, переехать в новый город или стать партнером в жизни или бизнесе.
НАДЕЖНОСТЬ СЕТИ
Наше последнее следствие структуры сети численно выражает надежность (устойчивость) ее свойств, то есть насколько сеть близка к отказу узла (или звена). Самое важное свойство сети — сохраняет ли она свою связность. Мы можем использовать модели для вычисления вероятности того, что сеть останется связной, как функцию от количества удаленных узлов. Мы можем также задаться вопросом, что происходит со средней длиной пути при удалении узлов. В контексте сети авиалиний анализ средней длины пути сказал бы нам, сколько дополнительных рейсов понадобилось бы в случае закрытия аэропорта из-за погодных условий или аварийного отключения электроснабжения.
Здесь мы рассмотрим вопрос о том, как размер самой большой связанной составляющей сети, гигантской компоненты, меняется при отказе узлов в случайном порядке. На рис. 10.4 показан размер гигантской компоненты большой случайной сети и большой сети малого мира. В случайной сети размер гигантской компоненты сначала уменьшается линейно. При критическом значении, когда вероятность звена равна единице, деленной на количество узлов, размер самой большой компоненты сокращается до сколь угодно малой доли первоначального размера сети. Сеть малого мира не демонстрирует таких резких изменений. Большинство связей существуют в пределах географических кластеров. Каждый кластер способен выдержать отказ множества узлов. Это свойство в сочетании со случайными связями предотвращает коллапс всей сети.
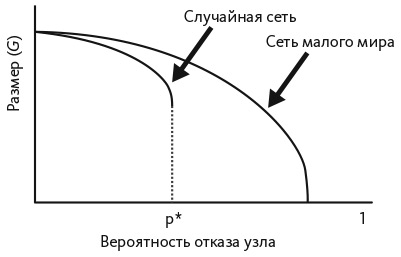
Рис. 10.4. Размер гигантской компоненты (G) как функция отказа узла
На основании этого рисунка можно сделать вывод, что разреженная сеть, в которой отсутствует кластеризация на локальном уровне, подвержена отказам. Мы можем применить этот вывод к энергосети, в которой нет длинных связей и плотных кластеров, обеспечивающих устойчивость сетей малого мира. В энергосети отказ одного узла или звена невозможно компенсировать за счет других звеньев кластера или соединения с удаленным рабочим узлом. Локальные отказы могут каскадом распространиться по всей сети [14]. Интернет же, напротив, имеет длинный хвост распределения значений степени узлов и устойчив к случайному отказу последних. Такое распределение степени подразумевает, что у подавляющего большинства узлов мало связей, поэтому даже при их отказе сеть останется связной.
До сих пор мы исходили из предположения о случайном отказе узлов, но можно также рассмотреть вероятность стратегического удаления узлов. Сегодня сети с длинными хвостами, такие как интернет, становятся неустойчивыми. Стратегическое удаление узлов с самой высокой степенью способно разрушить такую сеть. Эту логику можно отследить на примере звездообразной сети. При случайном удалении узлов сеть остается связной до тех пор, пока не будет удален центральный узел, что маловероятно. Стратегическое удаление, уничтожающее центральный узел, разъединяет сеть за один шаг.
В некоторых сетях, таких как террористические сети и сети наркоторговли, может возникнуть необходимость в разъединении сети. Если такие сети разреженные (как энергосеть) или имеют распределение с длинным хвостом, их можно разъединить путем стратегического удаления узлов. В случае террористической сети это потребовало бы ареста самых связанных членов. Если такие сети подобны сетям малого мира, они будут устойчивы даже к стратегическому удалению узлов. Попытки отделить от сети любой географический сегмент потерпят неудачу из-за случайных связей, соединяющих этот сегмент с остальной частью сети.
РЕЗЮМЕ
Мы часто создаем сетевые модели людей, чтобы отразить факторы социального влияния, когда успех, поведение, информация или убеждения человека, входящего в сеть, воздействуют на успех, поведение, информацию или убеждения его друзей. Поведение может зависеть от контекста или быть присуще человеку, так же как его ценность или вклад в коллективный проект. Ценность или вклад человека могут зависеть от его качеств, таких как талант, объем усилий и везение. Успех человека может также определяться его сетью друзей и коллег. Здесь возникает извечный вопрос: так от чего зависит успех — от того, что вы знаете, или от того, кого вы знаете?
Представьте себе группу ученых, работающих вместе в исследовательской лаборатории. Они делятся друг с другом советами, идеями и знаниями. Количество научных работ, патентов или прорывов одного из ученых, безусловно, зависит от его знаний, но может также быть обусловлено его контактами, то есть взаимодействием с другими учеными. Размышляя в категориях контекстных характеристик (сетей дружеских связей) и врожденных качеств (способностей человека), мы можем определить, какую часть успеха ученого можно приписать каждому из них.
Инвестиционные компании, нанимающие фондовых менеджеров из числа суперзвезд, руководствуясь убеждением, что успех в значительной мере зависит от таланта, получают не очень обнадеживающие результаты. Эмпирические данные говорят о том, что успешные инвесторы также полагаются на сети коллег, предоставляющих им определенные виды информации [15]. Этот конкретный вывод можно рассмотреть сквозь призму гораздо большего количества публикаций (часть которых основана на моделях), показывающих, как положение человека в организации влияет на его успех.
Тем не менее успех коррелирует со способностями. Бизнес-идея, на которой инвесторы зарабатывают миллионы, скорее всего, была хорошей. Ученый, который публикует сотни работ и получает многочисленные награды, безусловно, талантлив. В то же время наибольший вклад вносят люди, занимающие лучшее положение в сети. Мы можем оценить положение человека с помощью промежуточности и других признаков центральности. Люди, занимающие в сети положение с высокой степенью промежуточности, заполняют то, что Рон Берт называет структурными пустотами между сообществами, которые можно обнаружить с помощью алгоритмов [16]. Доступ к информации и идеям из множества сообществ наделяет людей, заполняющих структурные пустоты, властью и влиянием. Заполнение структурной пустоты требует определенных талантов и способностей. Человек не может просто так заполнить любую пустоту. Он должен завоевать доверие и понимание в каждом сообществе, а также овладеть базой знаний каждого сообщества.
Практически идентичную логику можно применить и к оценке стоимости компаний и определению влияния отдельных стран. Мы можем определять стоимость компании, оценивая ее активы и пассивы на основе балансовой ведомости. А можем назначить цену, проанализировав контекст, в котором работает компания, в частности ее позицию в цепи поставок. Аналогично влияние страны зависит от ее ресурсов и союзников. Как в случае компаний, так и стран присущие им качества и связность коррелируют. Тот, кто занимает влиятельное положение в сети, обладает и важными качествами.
В этой книге, так же как и в большинстве других работ, узел рассматривается как единица анализа. Звенья тоже могут играть важную роль. Если придерживаться еще более широкого подхода, то в качестве единицы анализа можно рассматривать и саму сеть. Например, сети преподавателей, обеспечивающие передачу идей и информации между классами, могут повысить результаты обучения, а администратор с широкими связями может эффективно координировать реформу программы обучения. Аналогично учитель второго класса много знает о своих учениках, которые переходят в третий класс, — и эта информация может пригодиться учителю третьего класса. Учитель математики знает, какие математические понятия ученики еще не освоили, — и эта информация поможет учителю физики структурировать свои уроки. Таким образом в хороших школах формируются сильные сети преподавателей. Это только один пример того, как сетевые модели могут улучшить наше мышление [17].
Вектор Майерсона и структурные пустоты Берта
Люди, заполняющие структурные пустоты, более влиятельны и связывают сообщества в сети. Различные статистические параметры сети, такие как промежуточность, должны коррелировать с заполнением структурной пустоты. Альтернативный показатель влияния в сети, вектор Майерсона, опирается на ту же логику, что и вектор Шепли. Чтобы вычислить значения вектора Майерсона, мы разработаем кооперативную игру в сети, но разрешим в ней только коалиции, включающие связанные компоненты. Рассмотрим трех человек, выстроенных в линию. Предположим, их местоположение отражает их политическую идеологию; при этом человек B находится в центре, как показано ниже. При запрете на коалицию с ближайшими соседями A, крайний человек слева, может установить связь с C, крайним человеком справа, только в случае, если B не входит в состав коалиции. Чтобы определить ценность каждого игрока по Майерсону, сначала присвоим дополнительную ценность всем возможным коалициям, а затем вычислим значения вектора Шепли по каждой коалиции, рассматривая ее как отдельную игру. И наконец, суммируем значения вектора Шепли по каждой коалиционной игре, чтобы получить значения вектора Майерсона.
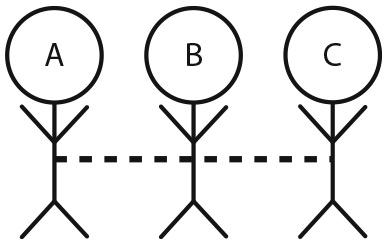
Возможные последовательности: ABC, BAC, BCA, CBA
Исключены: ACB, CAB
В качестве примера предположим, что любая коалиция из двух игроков обеспечивает результат с ценностью 10, а все три игрока вместе — результат с ценностью 14. Тогда получим следующее: ценность по Майерсону игроков 1 и 3 составит 3, а игрока 2 — 8 [18].
Показатели центральности, такие как промежуточность, основаны только на сетях. Значения вектора Майерсона зависят от функции ценности. Использование обоих показателей позволяет вычленить зависимость влияния от положения человека в сети и от выполняемых им функций. В нашем примере значения ценности трех игроков по Майерсону (3, 8, 3) идеально коррелируют с их показателями промежуточности (0, 1, 0). Так бывает не всегда, особенно в случае более сложных сетей и функций ценности.
ГЛАВА 11
ТРАНСЛЯЦИЯ, ДИФФУЗИЯ И ЗАРАЖЕНИЕ
Подобно тому как заражение болезнью вызывает болезнь, заражение доверием порождает доверие.
Марианна Мур
В этой главе мы будем моделировать распространение информации, технологий, моделей поведения, убеждений и заболеваний в рамках совокупности с помощью моделей трансляции, диффузии и заражения. Эти модели играют центральную роль в области коммуникации, маркетинга и эпидемиологии. Все три модели делят население на людей, которые что-то знают или имеют, и тех, кто этого не знает или не имеет. Со временем люди переходят из одной группы в другую. Кто-то переходит от восприимчивости к болезни к заражению либо из категории неинформированных о новом продукте или идее в группу информированных.
Эмпирический график количества людей, которые со временем подхватывают болезнь, покупают продукт или узнают какую-то информацию (кривая принятия), как правило, либо вогнутый, либо S-образный. Форма графика зависит от того, как люди получают информацию или заражаются болезнью, то есть происходит ли это в результате трансляции или диффузии. Особенность главы состоит в том, что она связывает протекающие на микроуровне процессы распространения идей и болезней с формой кривых принятия. Глава начинается с анализа модели трансляции, которая применяется, когда люди узнают об идее или заражаются болезнью из одного источника. Эта модель дает графики в форме r-образной кривой. Затем мы рассмотрим модель диффузии, в которой распространение происходит в результате контакта, как при передаче болезни от человека к человеку. Эта модель дает график в форме S-образной кривой.
Многие продукты, программы, идеи и фрагменты информации распространяются как посредством трансляции, так и из уст в уста. Мы можем моделировать эти среды с учетом и трансляции, и диффузии. Полученная в итоге модель, известная как модель Басса, играет центральную роль в маркетинге. Какой график она порождает, r- или S-образный, зависит от силы этих двух процессов. И последней мы проанализируем SIR-модель заражения из области эпидемиологии, которая учитывает темпы выздоровления. Эта модель может описывать иммунную систему, борющуюся с болезнью, модели поведения или стили, выходящие из моды, или информацию, которая утрачивает свою ценность в плане передачи ее другим. SIR-модель позволяет определить тот переломный момент, когда от небольших изменений свойств продукта или признаков заболевания зависит провал или успех. Незначительное снижение вирулентности может превратить массовую инфекцию в небольшую вспышку заболевания, а небольшое повышение вероятности распространения молвы — новую популярную группу, игравшую в 1960-х годах несколько месяцев в пабах Ливерпуля, в легендарную «Битлз».
МОДЕЛЬ ТРАНСЛЯЦИИ
Во всех моделях, рассматриваемых в главе, используется такой параметр, как релевантная совокупность, обозначаемый как NPOP. В целевую группу входят люди, которые потенциально могут подхватить болезнь, узнать информацию или принять продукт. Релевантная совокупность — это не все население, скажем, города или страны. Если мы моделируем распространение метода протезирования аортального клапана непрерывным швом, релевантной группой будут кардиохирурги, а не все жители Филадельфии.
В любой момент времени кто-то заболевает, получает информацию или принимает определенную модель поведения. Мы будем называть таких людей либо инфицированными, либо информированными (обозначим их как It). Остальные члены релевантной совокупности относятся к категории восприимчивых (обозначим их как St). Они могут подхватить болезнь, получить информацию или принять модель поведения [1]. Численность релевантной совокупности равна сумме количества инфицированных (или информированных) и количества восприимчивых людей: NPOP = It + St.
Модель трансляции описывает распространение идей, слухов, информации или технологий посредством телевидения, радио и интернета. Информация обо всех происходящих событиях распространяется методом трансляции. Модель отражает процессы, позволяющие источнику, которым может быть правительство, корпорация илигазета, распространять информацию. Она также может описывать загрязнение, распространяющееся по системе водоснабжения, но неприменима к болезням и идеям, передающимся от человека к человеку напрямую. Поскольку модель трансляции более уместна в случае распространения идей и информации, чем болезней, мы будем говорить о числе информированных, а не зараженных людей.
Количество информированных людей в указанный период равно количеству информированных людей за предыдущий период плюс вероятность того, что восприимчивый человек услышит информацию, умноженную на количество восприимчивых людей (см. врезку). По определению первоначальная совокупность содержит только восприимчивых людей. Чтобы вычислить количество информированных людей во всех будущих периодах, необходимо включить количество информированных и восприимчивых людей в разностное уравнение. Результатом будет r-образная кривая принятия.
Модель трансляции
It+1 = It + Pтрансл · St,
где Pтрансл — вероятность трансляции; It и St — количество информированных и восприимчивых в момент времени t.
Первоначально I0 = 0 и S0 = NPOP.
Представьте, что мэр города с одним миллионом жителей объявляет о введении новой политики в области налогообложения. До этого о такой политике никто ничего не знал. Предположим, вероятность того, что кто-то услышит определенную новость в тот или иной день, равна 30 процентам (Pтрансл = 0,3). Тогда в первый день эту новость услышат 300 000 человек, а во второй — 30 процентов от оставшихся 700 000, то есть 210 000 человек. За каждый период количество информированных людей увеличивается, но все меньшими темпами, как показано на рис. 11.1.
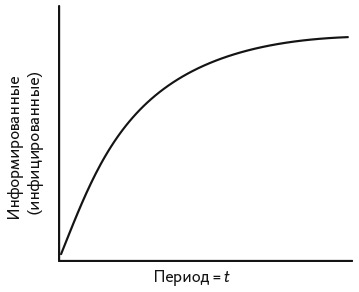
Рис. 11.1. r-образная кривая принятия, образованная моделью трансляции
В модели трансляции каждый член релевантной группы узнает информацию или покупает продукт. Следовательно, используя исходные данные о продажах, мы можем рассчитать размер релевантной группы. Предположим, компания выводит на рынок новую линейку обуви для людей, практикующих тай-чи, и за первую неделю получает заказы на 20 000 пар. Если за вторую неделю поступают заказы еще на 16 000 пар, мы можем вывести приближенную оценку итогового общего объема продаж — размер релевантной совокупности, который составит 100 000.
Согласование модели трансляции с данными
Период 1: I1 = 20 000 = Pтрансл · NPOP.
Период 2: I2 = 36 000 = 20 000 + Pтрансл · (NPOP − 20 000).
Решение [2]: Pтрансл = 0,2 и NPOP = 100 000.
Не стоит слишком доверять оценке, основанной на двух элементах данных. В модели не учтен ряд аспектов реального мира. Люди могут получать информацию из уст в уста или из средств массовой информации, некоторые могут купить несколько пар обуви, а реклама может быть ориентирована на вероятных покупателей. Включение этих аспектов в модель изменит полученные оценки. Но если опустить оговорки, модель все же позволит получить приближенную оценку. Компании не стоит рассчитывать на продажу двух миллионов пар обуви, но она может быть уверена, что продаст более 100 000 пар. По мере поступления дополнительных данных оценку можно улучшить. Если за третью неделю объем продаж составит 13 000 пар (объем, который прогнозирует модель), то компания может больше доверять первоначальному прогнозу.
МОДЕЛЬ ДИФФУЗИИ
Большинство болезней, так же как и информация о многих продуктах, идеях и прорывах, распространяются от человека к человеку. Такие процессы описывает модель диффузии. В ее основе лежит предположение, что когда один человек начинает использовать какую-то технологию или подхватывает болезнь, существует некоторая вероятность ее передачи тем, с кем он контактирует. В случае болезни выбор роли не играет. Вероятность того, что человек заболеет, зависит от ряда факторов, таких как генетика, вирулентность заболевания и даже температура воздуха. Во время жаркого, влажного сезона малярия распространяется гораздо быстрее, чем во время холодного и сухого.
Распространение технологии подразумевает выбор со стороны тех, кто ее применяет, а значит, более полезные технологии будут приняты с большей вероятностью. Однако мы не будем учитывать этот выбор в данной модели непосредственно. Поэтому мода на часы Apple Watch играет такую же роль, как и вирулентность штамма гриппа.
Мы придаем особое значение распространению информации, поэтому будем обозначать людей как информированных или неинформированных. Новые люди становятся информированными, когда встречают информированного человека и информация распространяется между ними. Это два разных событиях, зависящих от контекста. У городских жителей вероятность контактов выше, чем у сельских, а у сенсационной новости, скажем о прибытии инопланетян, вероятность передачи выше, чем у новости о повторном выводе на рынок крендельков M&M’s. Таким образом, мы представим вероятность диффузии как произведение вероятности контактов на вероятность передачи. Мы можем описать модель в терминах вероятности диффузии, но в ходе оценки или применения модели следует отслеживать две вероятности независимо друг от друга.
Модель диффузии допускает случайное перемешивание, то есть тот факт, что любые два члена релевантной совокупности с одинаковой степенью вероятности могут вступить в контакт. Однако это предположение дает повод для сомнений, поскольку оно совершенно справедливо в модели распространения болезни в дошкольном учреждении, где дети постоянно взаимодействуют друг с другом, но трудно применимо по отношению к населению города. Люди не перемешиваются случайным образом. Они взаимодействуют в основном в рамках соответствующих групп — коллеги, семья, социальные связи. Тем не менее следует помнить, что предположение не обязательно должно быть точным, чтобы стать частью полезной модели. Поэтому мы продолжим его использовать, помня о том, что его можно изменить.
Модель диффузии
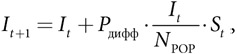
где Pдифф = Pпер · Pконт.
Согласно этой модели, все члены релевантной совокупности со временем также узнают информацию. Однако кривая принятия в модели диффузии имеет S-образную форму. Изначально к числу информированных относится совсем немного людей, а I0 имеет малое значение. Отсюда следует, что количество восприимчивых людей, которые встречаются с информированным человеком, тоже должно быть небольшим. По мере того как число информированных людей растет, число контактов между информированными и неинформированными людьми увеличивается, приводя к увеличению количества информированных людей. Когда практически все члены релевантной совокупности становятся информированными, число только что узнавших информацию людей сокращается, образуя вершину S-образной кривой. Кривые принятия технологий, как правило, имеют такую же форму. Например, кривые принятия гибридных семян в прошлом веке разнятся в зависимости от штата (в штате Айова начали использовать гибридные семена раньше, чем в Алабаме), но при этом все имеют S-образную форму [3].
В модели трансляции оценка размера релевантной совокупности на основе данных не вызывает затруднений. Исходное количество людей, принимающих технологию или продукт, в значительной степени коррелирует с релевантной совокупностью. Напротив, оценить размер релевантной совокупности с помощью модели диффузии достаточно трудно. Одно и то же увеличение объема продаж может быть следствием большой вероятности диффузии среди членов малой релевантной совокупности или малой вероятности среди членов большой совокупности. На рис. 11.2 представлены данные по двум гипотетическим приложениям для смартфонов. В первый день каждое приложение купили 100 человек. В каждый из следующих пяти дней первое приложение демонстрирует как более высокий общий объем продаж, так и большее увеличение темпов продаж. При отсутствии модели мы, скорее всего, пришли бы к выводу, что у первого приложения будет более крупный рынок, но согласование модели с обоими наборами данных говорит об обратном.
День | Приложение 1 | Приложение 2 |
1 | 100 | 100 |
2 | 136 | 130 |
3 | 183 | 169 |
4 | 242 | 220 |
5 | 316 | 286 |
… | ||
365 | 1000 | 1 000 000 |
Рис. 11.2. Кривые принятия, отражающие объем продаж двух приложений
Первое приложение соответствует вероятности диффузии 40 процентов и релевантной группе численностью 100 человек, тогда как второе — вероятности диффузии 30 процентов и численности релевантной группы миллион человек [4]. За несколько дней мы пришли бы к заключению, что есть более крупная релевантная группа пользователей второго приложения. Тем не менее при отсутствии модели мы сделали бы ошибочный вывод об общем объеме продаж, если бы основывались только на данных за пять дней.
При использовании модели диффузии как руководства к действию вероятность диффузии равна произведению вероятности передачи и вероятности установления контакта. Для того чтобы повысить темпы продаж приложения, его разработчик мог бы увеличить частоту встреч между людьми или вероятность того, что они поделятся информацией о данном приложении. Изменить первую вероятность довольно трудно, а вот для повышения второй разработчик мог бы предоставлять стимулы за привлечение новых покупателей, что, кстати, многие и делают. Разработчик игр мог бы начислять пользователям баллы за привлечение новых покупателей в рамках игры. Это увеличило бы скорость диффузии, но не сказалось бы на общем объеме продаж (по крайней мере модель на это не указывает). Как уже говорилось, общий объем продаж равен размеру релевантной совокупности, независимо от вероятности передачи. Увеличение темпов продаж не дает долгосрочного эффекта.
Большинство потребительских товаров и информация распространяются как посредством диффузии, так и трансляции. Наша следующая модель, модель Басса, объединяет оба процесса в одну модель [5]. Разностное уравнение в модели Басса представляет собой совокупность разностных уравнений из модели трансляции и модели диффузии. Кривая принятия в модели Басса становится все более S-образной по мере повышения вероятности диффузии. Кривые принятия телевизоров, радиоприемников, автомобилей, компьютеров, обычных и мобильных телефонов — все это сочетание r- и S-образных форм.
Модель Басса
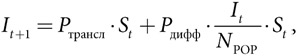
где Pтрансл — вероятность трансляции, а Pдифф — вероятность диффузии.
SIR-МОДЕЛЬ
В уже рассмотренных нами моделях человек, принимающий какую-то технологию, никогда не отказывается от нее. Это касается таких технологий, как электричество, посудомоечная машина и телевидение, — мы никогда не изменим к ним отношения. Однако это предположение не относится ко всему тому, что распространяется посредством диффузии. После болезни мы выздоравливаем. Когда мы отдаем дань моде, выбирая определенный стиль одежды или танцевальное движение, то со временем можем отказаться от него. Следуя принятому соглашению, мы будем обозначать таких людей (отказавшихся) излечившимися. Полученная в итоге модель под названием SIR-модель (сокр. от susceptible — восприимчивый, infected — инфицированный, recovered — излечившийся) занимает центральное место в эпидемиологии.
Учитывая происхождение этой модели, а также тот факт, что излечение более естественно в случае болезней, мы опишем ее на примере распространения болезни. Во избежание чрезмерного усложнения математических выкладок будем исходить из того, что выздоровевшие люди снова становятся восприимчивы к болезни, то есть что их организм не вырабатывает от нее иммунитет.
SIR-модель
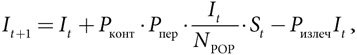
где Pпер, Pконт и Pизлеч — вероятность передачи болезни, контакта и излечения соответственно.
Эпидемиологи отслеживают вероятность контакта и вероятность передачи отдельно, поэтому так же поступим и мы. Частота контактов зависит от того, как именно болезнь передается от одного человека к другому. ВИЧ передается при половых контактах, дифтерия — через слюну, а вирусы гриппа — воздушно-капельным путем. Следовательно, у гриппа вероятность контактов выше, чем у дифтерии, у которой, в свою очередь, более высокая вероятность контактов, чем у ВИЧ. После контакта вероятность передачи также бывает разной. Коклюш (судорожный кашель) передается другому человеку легче, чем атипичная пневмония.
SIR-модель позволяет определить переломный момент в формировании показателя, известного как базовое репродуктивное число (R0), — отношение вероятности контакта, умноженной на вероятность передачи, к вероятности излечения. Болезни со значениями R0 больше 1 могут охватить всю группу. Заболевания со значением R0 меньше 1 сходят на нет. В этой модели информация (или в данном случае болезнь) не всегда охватывает всю релевантную совокупность, все зависит от значения R0. Поэтому правительственные учреждения, такие как центры по контролю и профилактике заболеваний, используют значение показателя R0 для выработки плана действий [6].
R0: базовое репродуктивное число
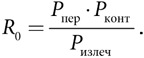
Как показано в таблице ниже, корь, которая передается воздушным путем, имеет более высокое базовое репродуктивное число, чем ВИЧ, который распространяется половым путем или при совместном использовании игл и шприцев. Оценка значений R0 не учитывает того факта, что люди меняют свое поведение как ответную реакцию на болезнь. Родители могут в ответ на заражение детей педикулезом в школе оставить их дома, снизив тем самым вероятность контакта. Или побрить им головы, уменьшив вероятность передачи в случае контакта. В обоих сценариях изменение поведения ведет к снижению R0 педикулеза.
Корь | Полиомиелит | ВИЧ | Грипп | |
R0 | 15 | 6 | 4 | 3 |
При отсутствии вакцины можно ввести карантин, но это очень затратно [7]. Если вакцина есть, то вакцинация способна предотвратить распространение болезни; ее можно остановить даже без всеобщей вакцинации. Доля людей, подлежащих вакцинации (порог вакцинации), определяется по формуле V ≥ (R0 − 1) / R0, которую можно вывести из данной модели [8].
Чем больше значение R0, тем выше порог вакцинации. Чтобы предотвратить распространение полиомиелита, у которого значение R0 равно 6, вакцинация должна охватить 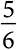 от общей численности населения, а распространение кори, значение которой равно 15, —
от общей численности населения, а распространение кори, значение которой равно 15, —  от общей численности населения. Математический вывод порога вакцинации служит ориентиром для представителей правительственных структур. Если привито слишком мало людей, то болезнь распространится, поэтому правительство обеспечивает вакцинацию, превышая пороговое значение, установленное с помощью модели. В случае заболеваний с высоким базовым репродуктивным числом, таких как корь и полиомиелит, правительственные учреждения стремятся проводить всеобщую вакцинацию.
от общей численности населения. Математический вывод порога вакцинации служит ориентиром для представителей правительственных структур. Если привито слишком мало людей, то болезнь распространится, поэтому правительство обеспечивает вакцинацию, превышая пороговое значение, установленное с помощью модели. В случае заболеваний с высоким базовым репродуктивным числом, таких как корь и полиомиелит, правительственные учреждения стремятся проводить всеобщую вакцинацию.
Некоторые люди беспокоятся по поводу побочных эффектов вакцин и предпочитают не участвовать в программах вакцинации. Если процент таких людей невелик, вакцинация позволит остальным не подхватить болезнь. Эпидемиологи называют этот феномен «популяционным иммунитетом». Люди, отказывающиеся от вакцинации, бесплатно пользуются преимуществами вакцинации других людей. Мы рассмотрим эту тему подробнее в книге чуть позже [9].
R0, суперраспространители и возведение степени в квадрат
Вывод R0, базового репродуктивного числа основан на предположении о случайном перемешивании: на протяжении каждого временного интервала члены популяции случайно встречаются друг с другом. Как отмечалось выше, предположение о случайном перемешивании может примерно соответствовать болезням, которые передаются воздушно-капельным путем или через прикосновения, но не столь уместно в случае болезней, передающихся половым путем.
Встроив SIR-модель в сеть, мы увидим роль распределения степени в распространении болезни. Здесь мы сравним сеть в виде прямоугольной сетки (как шахматная доска), в которой каждый узел связан с узлами к северу, югу, востоку и западу, со звездообразной сетью, где центральный узел связан со всеми остальными узлами.
Предположим, болезнь случайным образом возникает в каком-то узле. Пусть Pконт = 1 в данной сети, то есть каждый человек контактирует со всеми людьми, с которыми он связан. На протяжении следующего периода болезнь может распространиться на каждого соседа по отдельности с заданной вероятностью, соответствующей вирулентности заболевания.
Сначала рассмотрим прямоугольную сетку. В течение каждого периода болезнь может распространиться на любой из четырех узлов к северу, югу, востоку и западу. Если вероятность распространения болезни выше , то можно ожидать, что она распространится. Заглянув в будущее на один период, мы увидим, что, если один узел подхватит болезнь, у него есть три соседа, которые также рискуют заразиться. Если два соседа (к северу и востоку от первоначального узла) подхватят болезнь, то есть шесть узлов, на которые она может перейти. Следовательно, такая сеть, по всей видимости, не сильно влияет на вероятность распространения заболевания.
Теперь рассмотрим звездообразную сеть. Первым заразившимся узлом может стать либо центральный, либо внешний узел. Если центральный узел подхватит болезнь, он может передать ее любому внешнему узлу. В этом случае следует ожидать распространения болезни даже при низкой вероятности передачи. Если болезнь подхватит один из внешних узлов, то единственным узлом, находящимся в зоне риска, будет центральный узел. А, как мы только что выяснили, это чревато распространением болезни даже при низкой вероятности передачи.
В звездообразной сети значение R0 менее информативно, поскольку при заражении центрального узла болезнь быстро распространится. Эпидемиологи называют людей, выступающих в качестве узлов с высокой степенью, суперраспространителями. Именно они способствовали раннему распространению ВИЧ и атипичной пневмонии [10]. Суперраспространитель не обязательно должен иметь высокий уровень социальной активности или много связей. Он может активно общаться с людьми в рамках своей профессии — оператор пропускного пункта, кассир в банке, стоматолог-гигиенист и так далее. В начале ХХ столетия Мэри Маллон («тифозная Мэри») работала поваром в Нью-Йорке. Она переходила из семьи в семью, заражая каждую брюшным тифом. Когда выяснилось, что Мэри — источник инфекции, ее поместили в карантин принудительно.
Для того чтобы определить влияние узлов с высокой степенью, следует сначала отметить, что такие узлы в большей мере распространяют болезнь и с большей вероятностью подхватывают ее. Для человека, у которого в три раза больше друзей, чем у кого-то другого, в три раза выше вероятность подхватить болезнь и в три раза выше вероятность ее распространить. Следовательно, его общий вклад в распространение болезни будет в девять раз больше, чем у других. Если узел A имеет степень в K раз больше степени узла B, то узел A будет распространять болезнь с вероятностью, в K раз большей, чем узел B, и передаст эту болезнь в K раз большему количеству узлов, чем узел B. Общее воздействие узла A будет в K2 раз превышать воздействия узла B— феномен, известный как возведение степени в квадрат.
ПРИМЕНЕНИЕ МОДЕЛИ ВО МНОГИХ ОБЛАСТЯХ
Хотя SIR-модель разрабатывалась для анализа распространения болезней, ее можно применить и к социальным явлениям, которые передаются в результате диффузии, а затем теряют актуальность. К их числу относятся книги, песни, танцевальные движения, фразы, сайты, диеты и комплексы упражнений. Мы можем вычислить вероятность контактов, распространения, излечения и базовое репродуктивное число также и в этих контекстах. Модель подразумевает, что небольшие изменения этих вероятностей увеличивают значение базового репродуктивного числа выше нуля, что определяет разницу между успехом и неудачей. Успех может зависеть от того, что Джон Апдайк, описывая последний выход Теда Уильямса на биту, назвал «тонким различием между хорошей и плохой работой» [11]. Предположим, вы придумываете новую шутку. Если сделать ее немного смешнее, это может поднять значение базового репродуктивного числа выше 1 и шутка распространится. Аналогичная логика применима к притягательности идей. Если идея закрепилась в сознании людей более прочно, темп излечения будет ниже, что также повысит базовое репродуктивное число.
Не все случаи относятся к пороговому уровню. Группа «Битлз» была необычайно талантлива. Очевидно, что ее базовое репродуктивное число существенно превышало 1. Безусловно, это предположение. Для оценки базового репродуктивного числа современных поп-звезд можно использовать количество интернет-загрузок и просмотров. Оценочное значение R0 поп-звезды Джастина Бибера равно 24, что делает его более вирулентным, чем корь [12].
В SIR-модели мы вывели две важные пороговые величины — R0 и порог вакцинации, — которые становятся контекстными переломными моментами, когда небольшие изменения во внешней среде (контексте) существенно сказываются на конечном результате. Такие моменты отличаются от непосредственных переломных моментов, когда небольшие действия в определенный момент навсегда меняют дальнейший путь системы. Непосредственные переломные моменты наступают в неустойчивых точках, как в случае, когда мяч находится на вершине холма. Небольшой толчок в любом направлении отправляет мяч вниз либо по одному, либо по другому склону. Этот небольшой толчок и есть непосредственный переломный момент32 (точка перелома) [13].
При наступлении контекстного переломного момента изменение параметра меняет поведение системы. В случае непосредственного переломного момента траектория будущих результатов делает резкий поворот. Изгиб, подобный первому повороту S-образной кривой принятия в модели диффузии, не удовлетворяет ни одному из определений переломного момента. Такой изгиб соответствует той точке, в которой наклон кривой максимально повышается. В этой точке диффузия идет полным ходом и нет никаких переломов.
На рис. 11.3 показано количество пользователей сети Google+ за первые две недели ее существования [14]. Изгиб графика происходит через шесть дней после появления сети. К тому времени процесс диффузии уже набрал обороты. Речь не о том, что на первоначальном этапе сеть Google+ развивалась с трудом и что непосредственный переломный момент наступил на шестой день, вследствие чего количество пользователей сети достигло 16 миллионов за две недели. Такое сочетание переломов и резких подъемов приводит к чрезмерному использованию термина «переломный момент». Моменты, называемые в новостных СМИ и интернете переломными, редко удовлетворяют формальному определению.
Рис. 11.3. Изгиб (а не перелом) на графике количества пользователей Google+
Ожирение тоже можно рассматривать как эпидемию. Хотя люди не могут им заразиться так, как подхватывают простуду, под влиянием социальных факторов у них могут сформироваться привычки, приводящие к ожирению [15]. Чтобы обратить эпидемию ожирения вспять, мы должны уменьшить его базовое репродуктивное число путем снижения вероятности контактов или передачи либо посредством повышения вероятности излечения. Применение SIR-модели в контексте ожирения, отсева учащихся или преступности дает не намного лучшие результаты, чем экономические и социологические модели. Но поскольку она отличается от других, то дает иные объяснения и прогнозы. Кроме того, SIR-модель может указывать на другие действия или меры. Она вносит свой вклад в ансамбль моделей, которые помогают нам осмыслить этот мир. Но это не волшебная палочка, способная решить проблему.
При применении моделей трансляции, диффузии и заражения по отношению к социальным явлениям мы можем обнаружить, что одни предположения верны, а другие — нет. В случае распространения болезни каждый контакт имеет независимую вероятность ее передачи. В социальной сфере заражение может быть более вероятным, поскольку принятие — это вопрос выбора. Мы не выбираем грипп — мы просто подхватываем его. Но мы сознательно решаем купить, например, обтягивающие джинсы. Чем больше людей их носят, тем выше вероятность того, что мы тоже будем их носить. Аналогичная логика применима к решениям об участии в общественном движении, принятии новой технологии или нанесении тату. В этих случаях, как и при распространении убеждений или доверия, может понадобиться внести изменения в модель с учетом того, что вероятность принятия в расчете на одно воздействие может повышаться по мере увеличения количества воздействий [16]. Необходимость в таких изменениях часто возникает при расширении области применения модели.
ГЛАВА 12
ЭНТРОПИЯ: МОДЕЛИРОВАНИЕ НЕОПРЕДЕЛЕННОСТИ
Информация — это разрешение неопределенности.
Клод Шеннон
Эта глава посвящена энтропии, формальной мере неопределенности. Энтропия позволяет продемонстрировать взаимосвязь между неопределенностью, количеством информации и неожиданностью. Низкий уровень энтропии соответствует низкому уровню неопределенности и небольшому объему раскрываемой информации. Когда результат относится к системе с низким уровнем энтропии (как Солнце, которое восходит на востоке), он не вызывает удивления. Но когда результат носит неопределенный характер — в системах с высоким уровнем энтропии, как при розыгрыше в лотерее, — а сам факт его получения раскрывает определенную информацию, все это становится для нас неожиданностью.
Энтропия позволяет сравнивать несопоставимые явления. Мы можем установить, когда результаты выборов в Новой Зеландии носят более неопределенный характер, чем голосование по вопросу о вынесении вотума недоверия в Организации Объединенных Наций. Мы можем сравнить неопределенность курсов акций с неопределенностью результатов спортивных соревнований. Мы также можем использовать энтропию для проведения различий между четырьмя классами результатов, такими как равновесие, периодичность, сложность и хаотичность. Мы можем отличить сложные структуры, которые кажутся хаотичными, от истинной хаотичности, а также понять, хаотично ли на самом деле то, что кажется закономерностью.
Кроме того, энтропию можно использовать для описания распределений. При отсутствии управляющего или регулирующего фактора некоторые совокупности могут смещаться в сторону повышения энтропии. При наличии ограничений, таких как фиксированное математическое ожидание или дисперсия, мы можем находить распределения с максимальной энтропией. Результаты, полученные с помощью этого метода, могут также способствовать принятию решений в процессе моделирования, обосновывая выбор распределений.
В главе пять частей. В первой мы поможем вам составить интуитивное представление об информационной энтропии и дадим ее определение. Во второй опишем аксиоматику Шеннона для общего класса показателей энтропии по Шеннону. В третьей поговорим о том, как с помощью энтропии провести различие между равновесием, упорядоченностью, хаотичностью и сложностью. А в заключение обсудим, почему люди иногда предпочитают сложность равновесию.
ИНФОРМАЦИОННАЯ ЭНТРОПИЯ
Энтропия — это мера неопределенности, связанной с распределением вероятности результатов. Энтропия отличается от дисперсии, которая измеряет разброс множества или распределения числовых значений. Неопределенность коррелирует с разбросом, но это разные понятия. Распределения с высоким уровнем неопределенности имеют нетривиальные вероятности для многих результатов (которые не обязательно имеют числовые значения). Распределения с высоким разбросом принимают крайние числовые значения.
Эти различия становятся очевидны при сравнении двух распределений — с максимальной энтропией и максимальной дисперсией. При наличии результатов, принимающих значения от 1 до 8, распределение с максимальной энтропией присваивает один и тот же вес каждому результату [1]. Распределение с максимальной дисперсией принимает значение 1 с вероятностью и значение 8 с вероятностью , как показано на рис. 12.1.
Рис. 12.1. Максимальная энтропия и максимальная дисперсия
Энтропия зависит от распределения вероятностей. Следовательно, ее можно применять для описания распределений нечисловых данных, таких как виды птиц в лесу или рыночная доля разных сортов джема. Формальное выражение для энтропии записывается как минус сумма произведений вероятностей и их логарифмов. Звучит сложно, но скоро все станет интуитивно понятно.
Начнем с особого случая — информационной энтропии, которая измеряет неопределенность в категориях количества случайных подбрасываний симметричной монеты. Предположим, что в каждой семье ровно по двое детей и что появление мальчиков и девочек одинаково вероятно. Пол детей в семье (перечисленных в порядке рождения) эквивалентен двум подбрасываниям монеты. Следовательно, распределение результатов имеет информационную энтропию 2, поскольку она соответствует двум случайным событиям. Количество информации тоже равно двум, так как мы смогли узнать результат, задав два вопроса, требующих ответа «да» или «нет».
Аналогично пол детей в семьях с тремя детьми эквивалентен трем подбрасываниям монеты. Чтобы выяснить информацию о детях такой семьи, нам понадобилось бы задать три вопроса. Та же логика применима к любому количеству детей. В общем случае, чтобы узнать пол N детей, нам придется задать N вопросов.
Обратите внимание, что N вопросов позволяют провести различие между 2N возможных вариантов очередности рождения. Такая математическая зависимость — ключ к пониманию меры энтропии: N бинарных случайных событий порождают 2N возможных последовательностей результатов и, что то же самое, позволяют выяснить последовательность результатов, задав N вопросов. По этой причине информационная энтропия присваивает для равномерного распределения 2N результатов уровень неопределенности (и количества информации) N.
Для того чтобы описать эту зависимость с помощью формальной математики, сначала отметим, что вероятность каждой последовательности результатов —  . Чтобы превратить ее в N, необходимо воспользоваться довольно сложным выражением
. Чтобы превратить ее в N, необходимо воспользоваться довольно сложным выражением 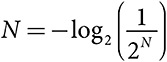 [2]. Эту конструкцию можно обобщить на случай произвольных значений вероятностей. Если последовательность результатов возникает с вероятностью p, то мы присвоим ей значение неопределенности, log2(p) которое приблизительно соответствует количеству вопросов «да» или «нет», необходимых для идентификации данной последовательности. Чтобы вычислить информационную энтропию распределения, следует найти среднее значение ожидаемого количества вопросов по всем результатам или, как в данном примере, по всем последовательностям результатов.
[2]. Эту конструкцию можно обобщить на случай произвольных значений вероятностей. Если последовательность результатов возникает с вероятностью p, то мы присвоим ей значение неопределенности, log2(p) которое приблизительно соответствует количеству вопросов «да» или «нет», необходимых для идентификации данной последовательности. Чтобы вычислить информационную энтропию распределения, следует найти среднее значение ожидаемого количества вопросов по всем результатам или, как в данном примере, по всем последовательностям результатов.
Информационная энтропия
При наличии распределения вероятностей (p1, p2, …, pN) информационная энтропия H2 равна
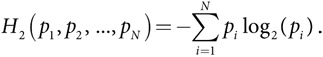
Примечание: нижний индекс 2 означает использование логарифма с основанием 2.
Поначалу такое математическое представление скорее все усложняет, чем проясняет, однако анализ примера сделает данную формулу интуитивно понятнее. Представьте, что семьи, в которых сначала рождаются девочки, больше не хотят заводить детей, а в семьях, в которых сначала рождается мальчик, появляется еще двое детей. В половине этих семей будет одна девочка. Вторая половина семей будет разделена поровну на четыре группы по результатам: три мальчика; два мальчика и девочка; мальчик и две девочки; мальчик, затем девочка, а затем еще один мальчик. Каждый из этих четырех результатов наступает с вероятностью 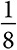 .
.
Информационная энтропия равна ожидаемому количеству вопросов, которые мы должны задать, чтобы узнать, какие дети есть в семье. Сначала мы спросим: первый ребенок девочка? С вероятностью 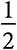 ответ будет утвердительным, и нам не придется больше задавать вопросов. Таким образом, в половине случаев мы ставим один вопрос. Мы можем записать это как
ответ будет утвердительным, и нам не придется больше задавать вопросов. Таким образом, в половине случаев мы ставим один вопрос. Мы можем записать это как 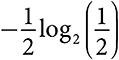 . Если ответ отрицательный, мы должны задать еще два вопроса, чтобы в общей сложности их было три. Каждый из четырех случаев происходит с вероятностью , а значит, каждый вносит в информационную энтропию вклад
. Если ответ отрицательный, мы должны задать еще два вопроса, чтобы в общей сложности их было три. Каждый из четырех случаев происходит с вероятностью , а значит, каждый вносит в информационную энтропию вклад 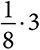 . Мы запишем каждый случай как
. Мы запишем каждый случай как 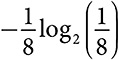 . Информационная энтропия равна сумме пяти членов, равной 2 [3]. Если оставить в стороне систему обозначений и логарифмы, интуитивно должно быть понятно: информационная энтропия соответствует ожидаемому количеству вопросов, требующих ответа «да» или «нет». Если нам нужно задать много вопросов, распределению свойственна неопределенность. Знание результата раскрывает требуемую информацию.
. Информационная энтропия равна сумме пяти членов, равной 2 [3]. Если оставить в стороне систему обозначений и логарифмы, интуитивно должно быть понятно: информационная энтропия соответствует ожидаемому количеству вопросов, требующих ответа «да» или «нет». Если нам нужно задать много вопросов, распределению свойственна неопределенность. Знание результата раскрывает требуемую информацию.
АКСИОМАТИКА ЭНТРОПИИ
Аксиоматика энтропии
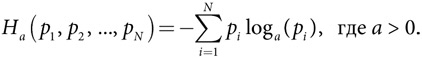
Представленный выше класс мер энтропии единственный, удовлетворяющий следующим четырем аксиомам:
Симметричная, непрерывная функция: 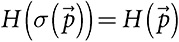 для любой перестановки вероятностей σ.
для любой перестановки вероятностей σ.
Максимизация: 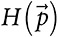 имеет максимальное значение при
имеет максимальное значение при 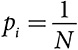 для всех значений N.
для всех значений N.
Нулевое свойство: H(1, 0, 0, …, 0) = 0.
Разложимость: если 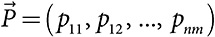 :
:
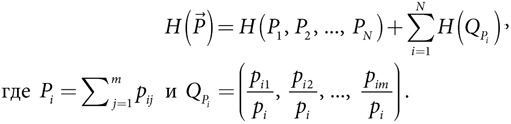
Для получения общего выражения, описывающего энтропию, применен аксиоматический подход. Клод Шеннон определил для меры энтропии четыре условия. Первые три понятны. Она должна быть непрерывной, симметричной, достигать максимального значения, когда все результаты могут быть получены с равной вероятностью, и равняться нулю для ситуаций, в которых имеется только единственный результат, вероятность которого равна 1. Четверное условие (разложимость) гласит, что энтропия распределения вероятностей, определенного на n категориях, каждая из которых состоит из m подкатегорий, должна быть равна энтропии распределения по категориям плюс сумма энтропий каждой из подкатегорий. Это естественное предположение для произведений распределений. Например, если результаты представляют собой произведение двух независимых событий, данное предположение подразумевает, что информационное содержание общего события равно сумме информационного содержания отдельных событий. Далее Шеннон доказал, что общий класс мер энтропии единственный, удовлетворяющий этим аксиомам.
Как и в случае с аксиомами, описывающими вектор Шепли, вклад этих аксиом определяется скорее не их существованием, а их логической непротиворечивостью. Опытный математик всегда может сформулировать аксиомы, однозначно определяющие ту или иную функцию. Первые две аксиомы трудно подвергнуть сомнению. Можно было бы придраться к произвольности приравнивания неопределенности распределения, в котором имеется одно событие с вероятностью 1, нулю — однако это вполне приемлемое граничное условие. Другой вариант состоял бы в присвоении такому распределению значения неопределенности, равного 1 [4]. Аксиому разложимости хотя и трудно объяснить, но в равной мере трудно и оспорить. Неопределенность совокупности двух случайных событий должна равняться сумме значений неопределенности каждого события в отдельности. В целом эти аксиомы более чем обоснованны. И на самом деле их трудно опровергнуть.
ИСПОЛЬЗОВАНИЕ ЭНТРОПИИ ДЛЯ РАЗЛИЧЕНИЯ КЛАССОВ РЕЗУЛЬТАТОВ
Теперь мы покажем, как мера энтропии может помочь классифицировать эмпирические данные в рамках четырех классов Вольфрама: равновесие, цикличность (периодичность), хаотичность и сложность [5]. Согласно классификации Вольфрама, лежащий на столе карандаш находится в состоянии равновесия. Движение планет вокруг Солнца носит циклический характер. Последовательность подбрасываний монеты случайна, так же как (предположительно) и курсы акций на Нью-Йоркской фондовой бирже. И наконец, «выстрел» (генерация электрического импульса) нейрона в мозге человека — сложный процесс, происходящий не случайно, но и не подчиняющийся закономерности. На рис. 12.2 эти четыре класса представлены графически.
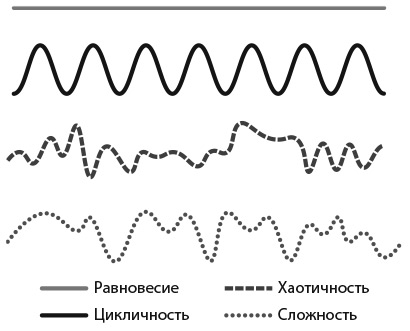 математических моделей. Скотт Пейдж. Иллюстрация 108">
математических моделей. Скотт Пейдж. Иллюстрация 108"> Рис. 12.2. Четыре класса Вольфрама
У равновесного результата неопределенности нет, и, следовательно, его энтропия равна нулю. У циклических (или периодических) процессов низкая энтропия, которая не изменяется со временем, а у совершенно случайных процессов энтропия максимальна. Класс сложности имеет промежуточную энтропию — она лежит между упорядоченной и случайной энтропиями. Хотя энтропия дает нам точно определенный ответ в двух крайних случаях, равновесном и случайном, это не так для циклических и сложных результатов. Чтобы различать эти случаи, нам придется использовать другие меры.
Для того чтобы классифицировать временной ряд данных, необходимо вычислить информационную энтропию по всем последовательностям разной длины. Предположим, человек отслеживает то, какой головной убор он надевает каждый день — либо берет (B), либо шляпу (F). Выбор головного убора на протяжении года образует бинарный временной ряд из 365 событий. Сначала мы можем вычислить энтропию последовательностей длиной 1, то есть энтропию вероятности ношения головного убора каждого типа. И если обнаружим, что человек с одинаковой вероятностью надевает головной убор каждого типа, значит, энтропия по всем последовательностям длиной 1 равна 1. Следовательно, мы можем исключить равновесие, поскольку человек меняет варианты выбора, однако возможна любая их трех других категорий.
Чтобы определить категорию, далее вычислим энтропию последовательностей длиной от 2 до 6. Если все последовательности имеют максимальную энтропию, можно исключить простой цикл. Предположим, что по мере анализа более длинных последовательностей энтропия постепенно увеличивается, пока не достигнет максимального значения — 8. Другими словами, независимо от длины последовательности она никогда не превышает 8. Энтропия, равная 8, эквивалентна равномерному распределению по 256 результатам. Это не может быть простым циклом; вероятно, мы имеем дело со сложной последовательностью, содержащей структуры и закономерности. Мы не можем с уверенностью сказать, что этот временной ряд сложный. Возможно, человек пытался предпринимать случайные действия, но ему это плохо удавалось.
МАКСИМАЛЬНАЯ ЭНТРОПИЯ И ПРЕДПОЛОЖЕНИЯ О ХАРАКТЕРЕ РАСПРЕДЕЛЕНИЯ
Многие моделируемые нами ситуации содержат элемент неопределенности, поэтому разработчики моделей должны делать предположения о соответствующих распределениях. Обычно мы стараемся не делать специальных предположений. Не исключено, что мы обладаем определенным пониманием процесса, порождающего то или иное распределение. Если это так, то во многих случаях мы можем вывести статистическую структуру, производимую таким процессом, с помощью подхода «логика — структура — функция».
Например, допустим, что нам нужно сделать предположение о распределении общей стоимости предметов, выставленных на аукцион по распродаже унаследованного имущества. Общая стоимость равна сумме значений стоимости отдельных предметов. Следовательно, воспользовавшись центральной предельной теоремой, мы можем предположить, что в данном случае имеет место нормальное распределение. Мы можем также сделать предположение о нормальном распределении возможных значений стоимости дома, поскольку она зависит от его характеристик, таких как количество спален, ванных комнат и размер участка.
Нормальное распределение может не иметь смысла, если речь идет о возможных значениях стоимости предмета искусства или редкой рукописи. Как мы уже видели, если исходить из минимальной и максимальной стоимости, равномерное распределение максимизирует энтропию. Многие социологические модели, представленные в книгах и журналах, исходят из предположения о равномерном распределении. Мы можем поставить его под сомнение на основании того, что в реальном мире мало равномерных распределений. Тем не менее принцип безразличия (если мы не знаем ничего, кроме диапазона или совокупности возможностей) может обосновать равномерное распределение.
Иногда нам может быть известно математическое ожидание распределения, а также тот факт, что все значения должны быть положительными. С учетом этих ограничений распределение максимальной энтропии должно иметь длинный хвост, а по мере расширения распределения на большее количество значений мы должны уравновешивать высокие значения со множеством результатов с низким значением. Можно доказать, что распределение, максимизирующее энтропию, обязательно будет экспоненциальным распределением. Таким образом, если мы описываем модель, основанную на распределении посещений сайта или величины рыночной доли, то при отсутствии конкретных данных естественным предположением будет экспоненциальное распределение.
И наконец, если мы зафиксируем математическое ожидание и дисперсию (и разрешим отрицательные значения), то распределение максимальной энтропии будет нормальным распределением. Логика здесь та же, что и в предыдущем случае. Для создания большей неопределенности мы вводим крайние значения. В таком случае мы можем уравновесить положительные и отрицательные значения, не меняя математическое ожидание. Вместе с тем это обусловит повышение дисперсии, а значит, мы должны включить больше значений, близких к среднему, что приведет к формированию колоколообразной кривой.
Мы можем интерпретировать такие распределения максимальной энтропии в рамках концептуальной схемы «логика — структура — функция». Если мы считаем, что в заданном социальном, биологическом или физическом контексте процесс микроуровня максимизирует энтропию, тогда нам следует ожидать одного из этих распределений. Иначе мы будем исходить из процесса микроуровня и сможем показать, что энтропия возрастает. Если это так, сформируется одно из следующих распределений.
Распределения с максимальной энтропией
Равномерное распределение: максимизирует энтропию в диапазоне [a, b].
Экспоненциальное распределение: максимизирует энтропию для данного математического ожидания μ.
Нормальное распределение: максимизирует энтропию для заданного математического ожидания μ и дисперсии σ2.
Эти результаты можно также интерпретировать как исследовательские. Мы можем обнаружить данные, распределенные по степенному или нормальному закону. Хотя мы не обязаны ставить вопрос о том, увеличивает ли энтропию некоторый глубинный аспект поведения при наличии того или иного ограничения, это позволит нам получить новое представление о происходящем. Ранее мы объяснили нормальное распределение высоты, веса и длины представителей биологических видов, обратившись к центральной предельной теореме. В этой главе дано объяснение, основанное на модели энтропии. Если мутация максимизирует энтропию (чтобы наилучшим образом исследовать ниши), а размер и общий разброс имеют фиксированное значение, то размеры будут распределены по нормальному закону. Дело не в том, что метод максимальной энтропии предлагает лучшее объяснение, а в том, что максимизация энтропии при наличии ограничений дает нормальное распределение. Следовательно, когда мы встречаем его, оно может быть результатом максимизации энтропии.
ПОЛОЖИТЕЛЬНЫЕ И НОРМАТИВНЫЕ СЛЕДСТВИЯ ЭНТРОПИИ
Мы видели, как энтропия измеряет неопределенность, информацию и неожиданность, чем она отличается от дисперсии, измеряющей разброс, и как она позволяет определять и сравнивать классы результатов. Дальше, в главе 13 и главе 14, которые посвящены изучению случайных блужданий и зависимости от первоначально выбранного пути, мы используем энтропию для идентификации хаотичности и оценки степени зависимости от пути. Меру энтропии можно использовать в любом количестве реальных областей применения. Мы можем определить, к повышению или снижению неопределенности приводит интервенция на финансовых рынках, или проверить, случайны ли результаты выборов, спортивных соревнований или азартных игр.
В каждой из этих областей применения энтропия выступает в качестве положительной меры. Она говорит нам о том, каков мир на самом деле, а не каким он должен быть. Энтропия — это система, которая по своей сути не плохая или хорошая. Какой уровень энтропии нам необходим, зависит от ситуации. В процессе разработки налогового кодекса нужны равновесные модели поведения, а не хаотичность. При проектировании города мы можем стремиться к сложности; равновесие или даже циклы привели бы к скучным решениям. Мы бы предпочли, чтобы в городе бурлила жизнь и было много возможностей для случайных встреч и взаимодействий. Чем больше энтропии, тем лучше, но только до определенного момента. Нам не нужна хаотичность, затрудняющая планирование и подавляющая наши когнитивные способности. В идеале миру должна быть свойственна определенная сложность, это позволит нам жить в интересные времена.
Архитектор Кристофер Александер показывает, как геометрические свойства, такие как сильные центры, широкие границы и отсутствие разделенности, позволяют создавать сложные, живые здания, районы и города [6]. Александер отстаивает идею сложности в городах и среде обитания. Руководители центральных банков, наоборот, не испытывают больших симпатий к сложности, предпочитая предсказуемые равновесные результаты и пути устойчивого роста. Ключевой вывод этой главы: нас часто волнует то, приходит ли система в равновесие, порождает ли порядок или хаос и приводит ли к формированию сложных новых последовательностей структур. С помощью моделей мы можем определить, как именно будут развиваться события, и в некоторых случаях разработать системы, обеспечивающие требуемый класс результатов, будь то сложность или равновесие.
ГЛАВА 13
СЛУЧАЙНЫЕ БЛУЖДАНИЯ
Пьяный человек найдет дорогу домой, а опьяневшая птица может потеряться навсегда.
Сидзуо Какутани
В этой главе мы изучим две классические модели из теории вероятностей и статистики: модель испытаний Бернулли и модель случайного блуждания [1]. Обе описывают случайные процессы, хотя может показаться, что они порождают сложные структуры. Без сбора данных распознать хаотичность достаточно трудно. Во многих случаях мы видим закономерности в итогах выборов, курсе акций и результатах спортивных соревнований, однако, если позаимствовать удачное выражение Нассима Талеба, случайность нас одурачивает [2].
Модель испытаний Бернулли описывает случайные процессы с дискретными исходами, такие как подбрасывание монеты или игральной кости. Разработанная несколько столетий назад для объяснения вероятности выигрыша в азартных играх, сегодня она занимает центральное место в теории вероятностей. Модель случайного блуждания основывается на модели Бернулли, подсчитывая текущее общее количество последовательных выпадений орлов и решек. Данная модель может описывать движение частиц в жидкости и газах, перемещения животных в физическом пространстве и увеличение роста человека с момента рождения до детского возраста [3].
Глава начинается с краткого обзора модели испытаний Бернулли наряду с анализом длины полос удач и неудач. Далее описывается модель случайного блуждания. Мы узнаем, что одномерное и двумерное случайное блуждание возвращаются в исходную точку бесконечно часто, тогда как трехмерное вообще может не вернуться к началу. Мы также узнаем, что временные промежутки между возвращениями к нулю в случае одномерного случайного блуждания распределены по степенному закону. Этот вывод, который нам хотелось бы отбросить как математический казус, может объяснить продолжительность жизни биологических видов и компаний. В последнем разделе главы мы используем модель случайного блуждания для оценки гипотезы эффективного рынка и определения размера сети.
МОДЕЛЬ ИСПЫТАНИЙ БЕРНУЛЛИ
Модель испытаний Бернулли строится на извлечении серых и белых шаров из урны. Извлеченные шары — это результаты случайных событий. Каждое очередное извлечение шара не зависит от предыдущих и будущих извлечений, а значит, мы можем применить закон больших чисел: за длительный период доля извлеченных шаров каждого цвета сходится к доле шаров соответствующего цвета в урне. Это не означает, что тысяча извлечений из урны, содержащей семь белых и три серых шара, дадут в точности семь сотен белых шаров и три сотни серых. Это всего лишь значит, что доля белых шаров будет стремиться к 70 процентам [4].
Модель испытаний Бернулли
На протяжении каждого периода шар в произвольном порядке извлекается из урны, содержащей G серых и W белых шаров. Результат эквивалентен цвету шара. Перед извлечением шаров в ходе следующего периода шар возвращается в урну. Пусть P = G / (G + W) обозначает долю серых шаров. В случае N извлечений можно вычислить ожидаемое количество извлеченных серых шаров NG и стандартное отклонение 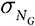 :
:
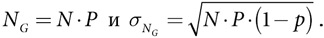
Результаты применения модели испытаний Бернулли представляют собой последовательности событий предсказуемой длины. В урне с равным количеством серых и белых шаров вероятность извлечения белых шаров равна . Вероятность извлечения двух белых шаров подряд равна , умноженной на . В общем случае, если доля серых шаров в урне равна P, то вероятность извлечения N белых шаров подряд составляет PN. Вычислив значения вероятности, мы можем определить, была ли та или иная совокупность событий вероятной, редкостной или настолько маловероятной, что возможен обман. Когда баскетболист делает результативный трехочковый бросок девять раз подряд, это значит, что у него наступила полоса удачи, или нам стоит ожидать последовательность случайных событий такой длины? Математические расчеты показывают, что за десятилетнюю карьеру вероятность результативных трехочковых бросков та же, что и отсутствие девяти таких бросков подряд в одном матче [5].
С помощью аналогичных вычислений можно определить, сопутствовала ли инвестору удача, был ли он хорошим инвестором или мошенником. Berkshire Hathaway — конгломерат под управлением Уоррена Баффета — на протяжении сорока двух из пятидесяти лет (с 1965 по 2014 год) демонстрировал результаты выше рыночных. Доллар, вложенный в Berkshire Hathaway в 1964 году, стоил более 10 000 долларов в 2016-м, тогда как доллар, инвестированный в акции компаний S&P 500, около 23 долларов. Если бы шансы Berkshire Hathaway превзойти рынок составляли 50 процентов, то за пятидесятилетний период компания сделала бы это двадцать пять раз со стандартным отклонением 3,5 года 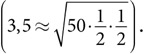 Фактическое количество лет, когда компания Berkshire Hathaway превосходила рынок, находится примерно в четырех стандартных отклонениях выше среднего, а это событие из разряда «один на миллион». В данном случае мы можем исключить из рассмотрения удачу. А учитывая тот факт, что Berkshire Hathaway раскрывает информацию о своих инвестициях, то и мошенничество тоже. «Аферист века» Берни Мэдофф не обнародовал информацию об инвестициях. Объявленная им полоса успехов (десятилетия положительной доходности) была настолько неправдоподобной, что его клиентам следовало бы потребовать прозрачности инвестиций [6].
Фактическое количество лет, когда компания Berkshire Hathaway превосходила рынок, находится примерно в четырех стандартных отклонениях выше среднего, а это событие из разряда «один на миллион». В данном случае мы можем исключить из рассмотрения удачу. А учитывая тот факт, что Berkshire Hathaway раскрывает информацию о своих инвестициях, то и мошенничество тоже. «Аферист века» Берни Мэдофф не обнародовал информацию об инвестициях. Объявленная им полоса успехов (десятилетия положительной доходности) была настолько неправдоподобной, что его клиентам следовало бы потребовать прозрачности инвестиций [6].
МОДЕЛИ СЛУЧАЙНОГО БЛУЖДАНИЯ
Наша следующая модель, модель простого случайного блуждания, основывается на модели испытаний Бернулли при подсчете текущей общей суммы предыдущих исходов. Мы установим исходное значение (состояние модели) равным нулю. При извлечении белого шара будем прибавлять 1 к общей сумме, а серого — вычитать 1 из общей суммы. Состояние модели в любой момент времени равно сумме предыдущих результатов (то есть разности между общим количеством извлеченных белых и серых шаров).
Простое случайное блуждание
Vt+1 = Vt + R(−1,1),
где Vt — значение случайного блуждания в момент времени t, V0 = 0, а R(−1,1) — случайная величина, которая с равной вероятностью равна –1 или 1. Ожидаемое значение случайного блуждания в любой период равно нулю и имеет стандартное отклонение √t, где t равно количеству периодов [7].
На рис. 13.1 показано простое случайное блуждание. Создается впечатление, что на графике присутствует закономерность: после длинного нисходящего тренда наступает восходящий тренд, за которым следует умеренный обвал, когда процесс пересекает нулевую линию. Эта закономерность носит случайный характер.
Рис. 13.1. График простого случайного блуждания за 300 периодов
Простое одномерное случайное блуждание может быть как рекуррентным (возвращается к нулю бесконечно часто), так и неограниченным (превышает любое наперед заданное положительное или отрицательное пороговое значение). За длительный промежуток времени случайное блуждание превышает 10 000 и опускается ниже отрицательного значения 1 миллион. Оно бесконечно часто пересекает нулевую линию. Кроме того, распределение количества шагов, необходимых для возврата к нулю, удовлетворяет степенному закону [8]. Большая часть возвратов к нулю происходит за несколько шагов. Половина всех блужданий возвращается за два шага. Однако остальным блужданиям требуется много времени для возврата. Так и должно быть, учитывая неограниченность случайных блужданий. Блуждание, пересекающее пороговый уровень 1 миллион, потребует свыше двух миллионов шагов для достижения этого значения и последующего возврата к нулю.
Полученное в итоге степенное распределение имеет неожиданные области применения. При моделировании объема продаж компаний (или количества сотрудников) в виде случайного блуждания значения продолжительности жизни компаний подчиняются степенному закону. Точнее говоря, если исходить из того, что в период высоких продаж компания нанимает работника, а в период низких — увольняет и закрывается, когда в компании больше нет работников, то распределение значений времени возврата эквивалентно распределению значений продолжительности жизни компаний, которое будет степенным распределением. Кроме того, в первом приближении продолжительность жизни компаний подчинена степенному закону [9]. Ту же логику можно использовать для прогнозирования продолжительности жизни биологических таксонов (таких как царство, тип, класс, семейство, род и вид). Если количество членов таксона меняется по принципу случайного блуждания (например, если количество видов, входящих в состав рода, увеличивается и сокращается случайным образом), размеры таксонов должны удовлетворять степенному закону. Данные подтверждают этот вывод [10].
Мы можем применить эту модель как аналогию, представив случайное блуждание как движение ледника по земле. Согласно прогнозу, сделанному с помощью этой модели, распределение размеров ледниковых озер должно удовлетворять степенному закону. Каждый раз, когда ледник опускается ниже поверхности суши и снова возвращается наверх, образуется озеро, диаметр которого соответствует времени возврата. В этом случае данные также приблизительно согласуются с прогнозом [11].
Модель простого случайного блуждания можно модифицировать несколькими способами. Мы можем создать нормальное случайное блуждание, значение которого за каждый период меняется на величину, взятую из нормального распределения. Нормальное случайное блуждание не возвращается в точности к нулю, хотя и пересекает нулевую линию бесконечное число раз.
Мы также можем сделать один результат вероятнее другого, тем самым сформировав смещенное случайное блуждание, которое можно использовать для прогнозирования вероятности выигрыша в азартных играх. В рулетке вероятность выиграть ставку на красное равна 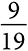 [12]. Мы можем смоделировать совокупные выигрыши (или проигрыши) последовательности ставок как случайное блуждание, которое увеличивается на 1 с вероятностью (около 47,4 процента) и уменьшается на 1 с вероятностью
[12]. Мы можем смоделировать совокупные выигрыши (или проигрыши) последовательности ставок как случайное блуждание, которое увеличивается на 1 с вероятностью (около 47,4 процента) и уменьшается на 1 с вероятностью 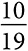 . После 100 ставок ожидаемые проигрыши составят 5 долларов со стандартным отклонением 10 долларов. Мы можем на 95 процентов быть уверены, что проиграем не более 25 долларов и выиграем не более 15 долларов. После 10 000 ставок ожидаемые проигрыши равны 526 долларам со стандартным отклонением 100. Следовательно, в 95 процентах случаев мы проигрываем от 325 до 725 долларов [13]. Выигрыш после 10 000 равных ставок — это событие, находящееся в более чем пяти стандартных отклонениях выше среднего, вероятность один на миллион. Из этого следует, что для выигрыша в рулетку игроку лучше делать одну большую ставку, чем много мелких.
. После 100 ставок ожидаемые проигрыши составят 5 долларов со стандартным отклонением 10 долларов. Мы можем на 95 процентов быть уверены, что проиграем не более 25 долларов и выиграем не более 15 долларов. После 10 000 ставок ожидаемые проигрыши равны 526 долларам со стандартным отклонением 100. Следовательно, в 95 процентах случаев мы проигрываем от 325 до 725 долларов [13]. Выигрыш после 10 000 равных ставок — это событие, находящееся в более чем пяти стандартных отклонениях выше среднего, вероятность один на миллион. Из этого следует, что для выигрыша в рулетку игроку лучше делать одну большую ставку, чем много мелких.
Некоторые спортивные соревнования, такие как баскетбол, можно смоделировать в виде двух смещенных случайных блужданий. У каждой команды есть вероятность заработать очки после каждого прохождения по площадке. Эта вероятность оценивается на основе профиля способности команды нападать и способности соперника защищаться. Мы будем моделировать прохождение команды по площадке как случайное событие. Количество набранных каждой командой очков соответствует значению ее случайного блуждания. У команды с более высокой вероятностью заработать очки больше шансов выиграть. Анализ данных NBA указывает на близкое соответствие с этой моделью. Количество набранных очков отклоняется от случайного блуждания только в случаях, когда одна команда получает огромное преимущество, после чего оно с большей вероятностью сокращается, а не увеличивается. Этот феномен можно объяснить тем, что у побеждающей команды меньше стимулов увеличивать количество очков, чем у проигрывающей команды заработать их как можно больше [14].
Когда мы смотрим баскетбол, результаты кажутся далеко не случайными. Умные, сильные игроки разыгрывают сложные комбинации и демонстрируют лучшие качества в решающий момент. Это действительно так, однако эффект от таких усилий может сойти на нет. Дополнительные усилия, направленные на увеличение очков за счет атаки, могут быть нейтрализованы дополнительными усилиями в обороне. Превосходный отбор мяча может быть нивелирован игроком, который быстро перемещается по площадке, чтобы заблокировать бросок из-под кольца. Модель также предлагает стратегию: более сильные команды должны ускорять игру, чтобы создать больше возможностей для овладения мячом. Командам, получившим преимущество, следует чаще крутить колесо рулетки, поскольку быстрое прохождение площадки приносит им пользу.
Простое случайное блуждание происходит в одном измерении, но можно смоделировать и многомерные случайные блуждания. Двумерное случайное блуждание возникает в начале координат на плоскости (0,0), а затем на протяжении каждого периода в случайном порядке переходит на север, юг, восток или запад. Двумерное случайное блуждание напоминает ломаную линию, нарисованную на листе бумаги. Двумерные случайные блуждания также удовлетворяют условиям рекуррентности и неограниченности. Случайный поиск поможет найти потерянную сережку в вашей гостиной. Применение такого математического подхода, как рекуррентность, позволяет муравьям использовать стратегию случайного поиска корма [15]. Если бы двумерное случайное блуждание не было рекуррентным, муравьям понадобились бы более детальные внутренние карты или более сильные феромонные следы для поиска своих муравейников. Случайные блуждания в трех измерениях не удовлетворяют условию рекуррентности. Мухи, носящиеся по комнате, и молекулы, перемещающиеся в воздухе, возвращаются в исходную точку конечное число раз — именно это объясняет приведенную в начале главы цитату Какутани о пьяном человеке и опьяневших птицах [16].
Отсутствие рекуррентности случайных блужданий — еще один пример того, как модели могут внести ясность в наше мышление. Интуиция говорит, что рекуррентность по мере добавления измерений должна встречаться реже. Логика указывает на резкое изменение состояния. В случае одного и двух измерений случайное блуждание возвращается в исходную точку бесконечное число раз, а трех — уходит навсегда. Для того чтобы получить этот результат, требуется серьезная математика — одной интуиции для этого недостаточно.
ИСПОЛЬЗОВАНИЕ СЛУЧАЙНЫХ БЛУЖДАНИЙ ДЛЯ ОЦЕНКИ РАЗМЕРА СЕТИ
Рекуррентность случайных блужданий с низкой размерностью можно использовать для оценки размера сети. Метод прост. Выбираем случайным образом узел, начинаем случайное блуждание по звеньям сети и отслеживаем, как часто оно возвращается к исходному узлу. Средний период времени между возвратами соотносится с размером сети. Для оценки размера социальной сети можно попросить кого-то назвать друга, а затем этого друга попросить назвать своего друга. Процесс можно продолжить, отслеживая, как часто мы возвращаемся к одному и тому же человеку.
На рис. 13.2 показаны две сети. Сеть слева состоит из трех узлов, образующих треугольник. Сеть справа — из шести узлов, образующих два треугольника. Мы можем начать случайное блуждание в сети с узла A. Предположим, блуждание переходит к узлу B, затем к узлу C и снова к узлу A. Таким образом, случайное блуждание возвращается в исходную точку за три шага. В правой сети случайное блуждание начинается с узла D и может пройти семишаговый путь F−H−G−F−E−F−D. При многократном повторении этих экспериментов средний период времени возврата в левой сети будет короче. В случае небольших подобных сетей этот метод не нужен, его целесообразно использовать для более крупных сетей, таких как Всемирная паутина и большие сети электронной почты.

Рис. 13.2. Случайные блуждания в сетях
СЛУЧАЙНЫЕ БЛУЖДАНИЯ И ЭФФЕКТИВНЫЕ РЫНКИ
Как оказалось, курсы акций почти полностью согласуются с нормальным случайным блужданием с положительным дрейфом, отражающим рост на рынке. Курсы множества отдельных акций также почти случайны. На рис. 13.3 представлены данные о суточных котировках акций Facebook за следующий год после их первичного размещения 18 мая 2012 года. Акции Facebook предлагались по 42 доллара за штуку. По состоянию на 1 июня 2012 года их курс упал до 28,89 доллара, а через год снизился до 24,63 доллара. На рисунке также показано случайное блуждание, откалиброванное таким образом, чтобы у него была аналогичная вариация.
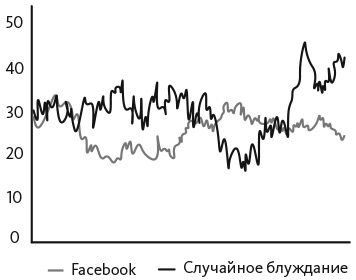
Рис. 13.3. Суточные котировки акций Facebook за период с июня 2012 года по июнь 2013 года и случайное блуждание
Мы можем применить статистические тесты к последовательности курсов акций Facebook, чтобы определить, отвечает ли она предположениям о нормальном случайном блуждании. Во-первых, курс акций должен повышаться и снижаться с равной вероятностью. Из 249 операционных дней курс акций Facebook падал 127 дней, или в 51 проценте случаев. Во-вторых, при случайном блуждании вероятность повышения должна быть независима от повышения, произошедшего в предыдущий период. Курс акций Facebook двигался в том же направлении в течение нескольких дней подряд в 54 процентах случаев. И наконец, самая длинная ожидаемая последовательность движения в том же направлении должна составлять восемь дней. Курс акций Facebook повышался на протяжении десяти дней подряд один раз за этот период. Таким образом, мы не можем опровергнуть утверждение, что курс акций Facebook согласуется с нормальным случайным блужданием.
Аналогичный анализ можно выполнить для суточных котировок всех акций. Для этого сначала необходимо исключить из рассмотрения средний восходящий тренд в курсах акций. Согласно исследованиям, в период с 1950-х по 1980-е годы суточные котировки имели небольшую положительную корреляцию. После исключения тренда вероятность нового роста после роста превысила . Начиная с 1980 года, когда инвесторы стали более осведомленными, вероятность повышения после повышения снизилась до 50 процентов, что сопоставимо со случайным блужданием. Тот факт, что курсы акций могут следовать закономерности, свойственной случайному блужданию, объясняется тем, что умные инвесторы обнаруживают и устраняют закономерности. Например, в 1990-х годах аналитики заметили, что курсы акций растут в начале каждого года — феномен, получивший название «эффект января». Умные инвесторы могли в декабре купить акции по низким ценам и продать их в январе по высоким, получив прибыль. Возможно, эта стратегия кажется вам слишком хорошей для того, чтобы быть правдой, но так оно и есть. Если инвесторы покупают акции в декабре, это приводит к росту курса, что устраняет эффект января. Не стоит удивляться тому, что эффекта января больше не существует.
Экономисты проводят аналогию между распознаваемой устойчивой закономерностью в рыночных котировках и стодолларовой купюрой на тротуаре. Увидев стодолларовую купюру, человек поднимает ее, после чего она исчезает. Такая же логика применима к закономерностям в курсах акций: даже если они существуют, то сходят на нет. Поэтому рынок, на котором действуют умные инвесторы, содержит мало предсказуемых ценовых моделей. Если курсы акций не демонстрируют никаких закономерностей, оставшаяся часть движения котировок должна соответствовать случайному блужданию (с оговоркой, что общий восходящий рыночный тренд следует исключить из рассмотрения).
Пол Самуэльсон разработал первую модель, производящую случайное блуждание. Она не требовала, чтобы инвесторы знали стоимость акций на протяжении всех будущих периодов — достаточно было знать только распределение. Сам Самуэльсон заметил: «Не стоит вкладывать особый смысл в хорошо известную теорему. Она не доказывает, что реальные конкурентные рынки работают удовлетворительно» [17]. Не все разделяли сдержанность Самуэльсона. Другие расширили его подход и сформулировали гипотезу об эффективности рынка, которая гласит, что в любой момент времени курс акций отражает всю релевантную информацию, а будущий курс должен следовать принципу случайного блуждания. Гипотеза об эффективности рынка основывается на парадоксальной логике [18]. Определение точного курса требует времени и усилий. Финансовый аналитик должен собрать данные и разработать модели. Если бы курсы акций следовали принципу случайного блуждания, эти действия не обеспечивали бы ожидаемой отдачи. Тем не менее, если никто не приложит усилий для оценки курсов акций, то цены станут неточными и тротуар покроется стодолларовыми купюрами. В общем, парадокс Гроссмана — Стиглица гласит, что, если инвесторы верят в гипотезу об эффективности рынка, они перестают анализировать происходящее, что делает рынки неэффективными. Если инвесторы считают, что рынок неэффективен, они выполняют анализ с помощью моделей и это делает рынки эффективными.
На самом деле движения курсов акций достаточно близки к случайным блужданиям, хотя сложные статистические методы позволяют выявить краткосрочные закономерности [19]. Конечно, стодолларовые купюры могут на тротуарах и не валяться, но на полях в траве всегда можно найти четырехлистный клевер, если проявить усердие.
По утверждению критиков гипотезы, некоторые инвесторы неизменно выигрывают на протяжении периодов более длительных, чем можно было бы ожидать при случайном развитии событий [20]. Кроме того, курсы акций могут колебаться в случайном порядке по какой-либо иной причине, например в результате применения совокупности сложных правил биржевой торговли. Ежедневная волатильность курсов акций превышает объем информации, поступающей на рынки, а рынок совершает огромные скачки вверх и вниз, когда в мире на первый взгляд происходит мало значимых событий, — что свидетельствует о наличии пузырей. То, что для одного человека может быть неудобным фактом, другой будет воспринимать как «несмотря на это». Да, волатильность высокая, но небольшой объем информации может иметь серьезные последствия. И хотя рынок действительно демонстрирует огромные скачки вверх и вниз, он все же может подчиняться принципу случайного блуждания с более длинным хвостом, когда ежедневные колебания проистекают из распределения с более длинным хвостом.
Хотя нельзя утверждать, что курс акций всегда достоверен, в долгосрочной перспективе их цена не может значительно отклоняться от их истинной стоимости. Мы можем в этом убедиться, применив правило 72. Если бы экономика росла на 3 процента в год, то через полстолетия она выросла бы в четыре раза. В 1967 году ВВП США составлял около 4,2 триллиона долларов (в долларах 2009 года), а к 2017-му достиг почти 17 триллионов долларов (в долларах 2009 года), то есть увеличение в четыре раза, как и следовало ожидать при трехпроцентном росте. За этот же период реальная стоимость акций S&P 500 тоже увеличилась примерно в 4 раза. Если бы рост фондового рынка составлял 12 процентов в год (в реальном долларовом выражении), курс акций повысился бы в 256 раз, а это невозможно [21].
В долгосрочной перспективе есть все основания исходить из гипотезы об эффективности рынка или чего-то в этом роде, а в краткосрочной ставка на корректировку курсов может быть сопряжена с риском. Случай с хедж-фондом Long Term Capital Management (LTCM), в совет директоров которого входили два лауреата Нобелевской премии по экономике, весьма поучителен. В 1996 и 1997 годах фонд LTCM обеспечивал доходность инвестиций, превышающую 40 процентов, отчасти за счет обнаружения факторов неэффективности и прогнозирования корректировки рынка. В 1998 году в LTCM (совершенно верно) заметили, что цена российских облигаций не соответствует цене казначейских облигаций США, — и сделали на это большую ставку. Однако дефолт в России (первый с 1917 года) еще больше усугубил это несоответствие в краткосрочном периоде. В результате фонд LTCM потерял 4,6 миллиарда долларов и едва не стал причиной коллапса финансовых рынков. Вскоре после того, как LTCM получил финансовую помощь, цены облигаций выровнялись, хотя и недостаточно быстро. Вывод очевиден: не стоит слишком полагаться на одну модель.
РЕЗЮМЕ
Итак, в этой главе мы изучили модель испытаний Бернулли и модель случайного блуждания, а также сферы их применения. Мы также узнали, как отличить случайность от полосы удачи, разработать стратегии для азартных игр, определить временные ряды курсов акций и логически объяснить результаты баскетбольных матчей. Мы увидели, как использовать степенное распределение времени возврата при случайном блуждании, чтобы глубже понять продолжительность жизни компаний и биологических таксонов.
На основании всех этих областей применения мы убедились, что модель случайного блуждания предоставляет полезную концептуальную схему для оценки временных рядов. Нас не должны вводить в заблуждение несколько лет успеха — это не всегда подразумевает наличие устойчивого превосходства. В одной из самых продаваемых бизнес-книг Good to Great: Why Some Companies Make the Leap and Others Don’t33 ее автор Джим Коллинз перечислил характеристики неизменно успешных компаний, такие как скромные руководители, привлечение в команду подходящих специалистов и поддержание дисциплины (то, что Коллинз назвал «полоскать свой творог», отдавая дань уважения привычке шестикратного победителя чемпионата по триатлону Ironman Дэйва Скотта в буквальном смысле полоскать свой творог для снижения его жирности). Коллинз выделил одиннадцать великих компаний, которые придерживались его принципов. Через десять лет после публикации книги только одна из них демонстрировала высокий рост. Одна из остальных была выкуплена, еще одна перешла под контроль правительства, а оставшиеся восемь показывали нулевую доходность.
Тот факт, что великим компаниям свойственны общие качества, не означает, что они способствуют успеху. Компании с самыми низкими показателями тоже могут ими обладать. Выбор лучших компаний и анализ их характеристик не имеет ничего общего с модельным мышлением. Последнее определило бы характеристики, обеспечивающие успех, такие как наличие талантливых сотрудников, а затем проверило бы сделанные выводы на соответствие фактическим данным и, если это возможно, искало бы естественные эксперименты, примеры изменения случайным образом указанных характеристик. Другие модели (такие как модели сложного ландшафта, о которых пойдет речь в главе 28) ставят под сомнение ключевые предположения Коллинза. Если экономика — сложное явление, то те качества, которые оказались успешными сегодня, вряд ли обеспечат требуемый результат в будущем. То, что порождает огромный успех сейчас («сначала крупные камни»), через десять лет может оказаться не лучшей стратегией. В большинстве случаев нужно использовать множество моделей, прежде чем делать далеко идущие утверждения, — в противном случае существует риск столь же масштабных ошибок. Кроме того, мы не должны позволять закономерностям вводить себя в заблуждение. То, что кажется тенденцией, может оказаться случайностью.
ГЛАВА 14
ЗАВИСИМОСТЬ ОТ ПЕРВОНАЧАЛЬНО ВЫБРАННОГО ПУТИ
Ни один человек не может войти в одну реку дважды, поскольку это будет уже не та река и не тот человек.
Гераклит
В этой главе рассказывается о моделях зависимости от первоначально выбранного (предшествующего) пути34. В любой области, где поведение людей зависит от действий других, будь то международные отношения, искусство, музыка, спорт, бизнес, религия, технологии или политика, следует ожидать определенной степени зависимости от первоначально выбранного пути. Выбирая курс обучения, студент отдает предпочтение одной карьере перед другой. Выдвижение кандидата может дать старт его политической карьере. Дружба может привести к формированию других социальных связей. Одежда, которую мы носим, книги, которые читаем, фильмы, которые смотрим, и занятия, которым уделяем время, — все это в определенной степени зависит от первоначально выбранного пути.
Такая зависимость существует и в более крупных масштабах. Судебные решения, основанные на общем праве, создают и подкрепляют прецеденты, что сказывается на будущих судебных решениях [1]. Первые институциональные структуры воздействуют на последующие институциональные предпочтения. Разрешение на предоставление услуг медицинского страхования частными компаниями привело к формированию в США крупной отрасли частного медицинского страхования, появлению страховых медицинских организаций и созданию совокупности государственных и частных клиник [2]. Учреждения также способствуют выработке определенных моделей поведения (такие как эгоизм или склонность к сотрудничеству), от которых, в свою очередь, зависит эффективность будущих учреждений [3].
В этой главе мы построим динамические урновые модели, которые порождают последовательность результатов, демонстрирующих зависимость от первоначально выбранного пути. Эти модели расширяют модель испытаний Бернулли, делая возможным изменение распределения шаров в урне в зависимости от прошлых результатов. После того как эти моделиструктурируют наше мышление, мы рассмотрим формальное определение зависимости от первоначально выбранного пути и проведем различие между зависящими от пути результатами и зависящими от пути равновесиями. Эти формальные определения позволят разграничить зависимость от первоначально выбранного пути и переломные моменты, которые предполагают более резкие изменения результатов.
Глава состоит из четырех частей. В первых двух рассматривается процесс Пойа и процесс уравновешивания. Процесс Пойа исходит из предположения о положительной обратной связи и порождает как зависимые от пути результаты, так и зависимые от пути равновесия. Многие классические примеры зависимости от первоначально выбранного пути, в том числе распространение клавиатуры QWERTY, основаны на положительной обратной связи, известной также как возрастающая отдача. Процесс уравновешивания подразумевает наличие отрицательной обратной связи и порождает зависимые от пути результаты, но не зависимые от пути равновесия. В третьей части определяется мера зависимости от первоначально выбранного пути на основе энтропии, а в четвертой обсуждаются новые области применения этих моделей.
ПРОЦЕСС ПОЙА
Процесс Пойа отражает положительную обратную связь с помощью расширения модели испытаний Бернулли, когда в урну добавляется шар, аналогичный выбранному шару. Этот процесс порождает зависимость результатов от пути, когда результаты каждого периода зависят от предыдущих результатов. Верно и то, что долгосрочное распределение результатов (зависимость равновесия от пути) тоже зависит от результатов [4]. Различие между этими двумя типами зависимости крайне важно для того, о чем пойдет речь ниже. Процесс, зависимый от пути в плане равновесия, должен быть зависимым от пути в плане результатов. То, что происходит сейчас, может зависеть от прошлого, но долгосрочное равновесие может быть определено с самого начала.
Процесс Пойа
Урна содержит один белый и один серый шар. На протяжении каждого периода один шар в случайном порядке извлекается из урны и возвращается в нее вместе с дополнительным шаром того же цвета, что и извлеченный шар. Цвет извлеченного шара определяет результат.
Процесс Пойа отражает целый ряд социальных и экономических явлений. Когда человек решает, в какую игру учиться играть, теннис или ракетбол, его выбор может зависеть от выбора других. Человек может предпочесть теннис, потому что большинство его друзей тоже выбрали теннис, так как это повышает его шансы найти партнера для игры. Аналогично решение человека о том, какое программное обеспечение установить, какой язык изучать или смартфон какой компании купить, также зависит от выбора, сделанного ранее его друзьями. Та же логика применима к компаниям, которые выбирают, какие технологические стандарты применять. Такие компании тоже могут основывать свой выбор на действиях других компаний.
Модель учитывает эти факторы социального влияния посредством изменения распределения шаров. Если серый шар представляет людей, выбирающих теннис, а белый — выбирающих ракетбол, то, по мере того как все больше людей выбирают теннис, в урне становится больше серых шаров, что повышает вероятность того, что следующие люди тоже выберут теннис. Это усиливающееся тяготение к результату, который предпочло большинство, создает зависимость от первоначально выбранного пути.
Из процесса Пойа можно вывести два неожиданных свойства. Во-первых, любая последовательность из одного и того же количества белых результатов встречается с равной вероятностью. Во-вторых, каждое распределение белых и серых шаров происходит с равной вероятностью. Второе свойство подразумевает очень сильную зависимость от первоначально выбранного пути. Может произойти все что угодно. Все в равной степени вероятно. После 1000 периодов вероятность того, что урна содержит 40 процентов белых шаров, равна вероятности того, что она содержит 2 процента белых шаров.
Для того чтобы понять, почему так происходит, давайте рассмотрим все возможные последовательности результатов за первые три периода. Результат первого периода может быть серым с вероятностью . Если это так, мы добавляем серый шар, увеличивая вероятность того, что второй результат будет серым, до 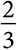 . Если этот результат тоже серый, добавляем третий серый шар, увеличивая вероятность того, что третий результат будет серым, до
. Если этот результат тоже серый, добавляем третий серый шар, увеличивая вероятность того, что третий результат будет серым, до 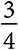 . Из этого следует, что общая вероятность трех серых шаров (или трех белых) равна умножить на и умножить на , что равно 35.
. Из этого следует, что общая вероятность трех серых шаров (или трех белых) равна умножить на и умножить на , что равно 35.
Три последовательности, в которых первых три результата состоят из двух белых и одного серого шара, показаны на рис. 14.1. В верхнем ряду следующий порядок результатов: серый, белый, белый. Вероятность такой последовательности равна 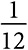 , как и вероятность других последовательностей. Стало быть, вероятность получения одной из этих трех последовательностей равна . В силу симметрии вероятность выбора двух серых шаров и одного белого тоже равна . Следовательно, каждый набор результатов (три белых; три серых; два белых и один серый; два серых и один белый) встречается с одной и той же вероятностью . Кроме того, последовательности из двух белых и одного серого шара также встречаются с равной вероятностью. Аналогичные результаты можно продемонстрировать для любого количества периодов испытаний [5].
, как и вероятность других последовательностей. Стало быть, вероятность получения одной из этих трех последовательностей равна . В силу симметрии вероятность выбора двух серых шаров и одного белого тоже равна . Следовательно, каждый набор результатов (три белых; три серых; два белых и один серый; два серых и один белый) встречается с одной и той же вероятностью . Кроме того, последовательности из двух белых и одного серого шара также встречаются с равной вероятностью. Аналогичные результаты можно продемонстрировать для любого количества периодов испытаний [5].
Рис. 14.1. Результаты выбора, состоящего из двух белых и одного серого шара
Если расширить процесс Пойа, включив в модель шары других цветов, расширения обоих свойств регулярности сохраняются. Формирование любого соотношения цветов в равной степени вероятно. Эти выводы создают серьезную проблему для производителей потребительских товаров. Долгосрочные предпочтения потребителей в отношении тех или иных характеристик продуктов могут носить случайный характер. Тем не менее понимание того, что прогнозировать результат невозможно, все еще может стать толчком к действиям. Вряд ли компания Ford хотела бы выпустить 40 000 желтых грузовых пикапов, а затем, исходя из зависимого от пути процесса обнаружить, что любимый цвет потребителей — красный. Перспектива накопления больших объемов нереализованных продуктов невостребованного цвета указывает на два варианта действий. Компания могла бы организовать свою цепь поставок таким образом, чтобы выбор цвета осуществлялся в последнюю очередь — например, компания по выпуску одежды могла бы отложить покраску свитеров до того момента, когда выяснится, какой цвет будет популярен. Или компания могла бы вообще лишить людей возможности выбора. Генри Форд предлагал своим клиентам любой цвет автомобиля Model T, какой они пожелают, лишь бы он был черным. Компания Apple сделала то же самое, выпустив свой первый iPhone: вы могли купить либо черный iPhone, либо по той же цене… черный.
ПРОЦЕСС УРАВНОВЕШИВАНИЯ
Наша вторая модель, процесс уравновешивания, исходит из предположения, противоположного процессу Пойа. После извлечения шара одного цвета мы добавляем в урну шар противоположного цвета. Если мы извлечем белые шары за первых два периода, в урне будет три серых шара и только один белый, а значит, вероятность извлечения серого шара составит 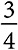 . Этот процесс порождает зависимые от пути результаты в том смысле, что вероятность того или иного результата за любой период зависит от истории прошлых результатов. Вместе с тем процесс не формирует зависимые от пути равновесия. В долгосрочном периоде в урне образуется равное соотношение шаров каждого цвета [6].
. Этот процесс порождает зависимые от пути результаты в том смысле, что вероятность того или иного результата за любой период зависит от истории прошлых результатов. Вместе с тем процесс не формирует зависимые от пути равновесия. В долгосрочном периоде в урне образуется равное соотношение шаров каждого цвета [6].
Процесс уравновешивания
Урна содержит один белый и один серый шар. На протяжении каждого периода один шар в случайном порядке извлекается из урны и возвращается в нее вместе с дополнительным шаром противоположного цвета. Цвет извлеченного шара обозначает результат.
Процесс уравновешивания охватывает последовательности решений или действий, включающих элементы давления в сторону равного распределения. Родители, имеющие двоих детей, пытаются уделять им одинаковое количество времени. Проведенный вечер с одним ребенком вызывает желание уделить больше времени второму. Процесс уравновешивания даже позволяет смоделировать организационные усилия по достижению справедливости. Международный олимпийский комитет (МОК) хотел бы, чтобы каждый регион мира стал местом проведения Олимпийских игр. В 2013 году МОК объявил, что Токио станет местом проведения летних Олимпийских и Паралимпийских игр 2020 года. Два европейских города, Стамбул и Мадрид, проиграли. Через четыре года МОК выбрал Париж для проведения Олимпийских игр 2024 года, а североамериканский город Лос-Анджелес — игр 2028 года. Токио победил в конкурсе на проведение Олимпийских игр 2020 года отчасти благодаря силе своего предложения, а отчасти потому, что летние Олимпийские игры не проводились в Японии с 1964 года. Создается впечатление, что географическая справедливость повлияла на ситуацию. За период после Второй мировой войны игры проводились в Европе, Азии, Океании и обеих Америках примерно равное количество раз: Европа получала это право восемь раз, Южная и Северная Америка — шесть раз, Азия и Океания — семь раз.
ЗАВИСИМОСТЬ ОТ ПЕРВОНАЧАЛЬНО ВЫБРАННОГО ПУТИ И ПЕРЕЛОМНЫЙ МОМЕНТ
Зависимость от первоначально выбранного пути (постепенное воздействие на результаты) отличается от переломного момента (резкое изменение результатов). Рост компании Microsoft — наглядный пример зависимости от первоначально выбранного пути. Основанная в 1975 году, Microsoft разрабатывала интерпретаторы для языка программирования BASIC. В 1979 году она заключила договор с компанией International Business Machines (IBM) о разработке операционной системы для персонального компьютера IBM. Благодаря этой сделке Microsoft стала на путь, который превратил ее из компании с сорока сотрудниками в одну из самых дорогостоящих корпораций мира.
Контракт с IBM способствовал росту Microsoft, но не гарантировал ей долгосрочного успеха. В то время рынок персональных компьютеров был небольшим. Интернета еще не было, так же как и современных инструментов обработки текстов, программного обеспечения для бизнеса или видеоигр. Кроме того, успех ПК отчасти зависел от операционной системы DOS, разработанной Microsoft. По мере роста рынка персональных компьютеров другие компании начали писать программы, совместимые с DOS, обеспечивая еще больший объем положительной обратной связи. Эти события (успех DOS, рост рынка ПК и разработка ПО для платформы DOS) можно представить в виде шаров одного цвета, постоянно извлекаемых из урны и возвращаемых обратно. Каждый очередной результат повышал вероятность следующего результата. Возможно, наступление компьютерной эры было неизбежным, но центральная роль Microsoft и рост рынка ПК — один из множества потенциальных путей.
Зависимость роста компании Microsoft от первоначально выбранного пути можно противопоставить убийству эрцгерцога Франца Фердинанда 28 июня 1914 года, которое многие считают переломным моментом, приведшим к Первой мировой войне. За шесть лет до убийства эрцгерцога Австро-Венгрия аннексировала Боснию и Герцеговину. Среди сербов, недовольных таким развитием событий, был Гаврило Принцип, который застрелил Франца Фердинанда и его жену Софию. Австро-Венгрия обвинила Сербию, что было практически предсказуемой реакцией, и обратилась к кайзеру Германии Вильгельму за гарантиями по подготовке к войне против Сербии. Напряженность усиливалась. У Сербии был союз с Россией, которая, в свою очередь, заключила союз с Францией и Великобританией. Второго августа Германия объявила войну Франции. А после того как третьего августа Бельгия отказалась предоставить Германии свободный проход к территории Франции, началась полномасштабная война. Эта значительно упрощенная версия событий говорит о том, что при наличии альянсов убийство эрцгерцога подтолкнуло мир к войне.
Зависимость от первоначально выбранного пути и переломные моменты можно оценить на основе изменения вероятностей возможных результатов [7]. Для процесса Пойа исходное распределение вероятностей одинаково по всем распределениям в урне. Это распределение максимальной энтропии. По мере дальнейшего развития событий распределение постепенно сужается, что указывает на формирование зависимости от первоначально выбранного пути: возможное развитие событий меняется по мере появления результатов. Энтропия уменьшается постепенно. В переломный момент распределение вероятностей резко меняется. Энтропия может уменьшиться быстро. На рис. 14.2 показана разница между двумя процессами, каждый из которых порождает два возможных результата. После наступления того или иного события (такого как контракт компании Microsoft или убийство эрцгерцога) вероятность каждого результата меняется. Последующие события также меняют вероятности. Процесс, включающий переломный момент, содержит отчетливый изгиб. Процесс, зависимый от первоначально выбранного пути, меняется постепенно.
Рис. 14.2. Переломный момент и зависимость от первоначально выбранного пути
ДАЛЬНЕЙШЕЕ ПРИМЕНЕНИЕ
В реальных ситуациях зависимость от первоначально выбранного пути может не быть столь сильной, как в случае процесса Пойа. Тем не менее на основании этой модели мы можем сделать вывод, что, когда в поведении присутствует сильная социальная составляющая, может произойти что угодно. В одном университетском городке большинство студентов могут носить черные зимние куртки, а в другом — синие бушлаты. Модельное мышление позволяет предположить, что такие различия могут быть в равной степени следствием социального влияния или индивидуальных глубинных предпочтений. Это верно в любом контексте, где люди выбирают из фиксированного множества вариантов и их выбор зависит от выбора, сделанного ранее другими людьми. В качестве примеров можно привести демократические выборы, выбор фильма для просмотра и технологии для покупки.
Модель можно расширить, чтобы она учитывала изменение социального влияния в зависимости от выбранной альтернативы. Ванильное мороженое может иметь неизменный уровень обратной связи. А вот более экзотическое мороженое с зеленым чаем — генерировать более широкий разброс обратной связи: друг, которому оно не понравилось, отговорит вас от его дегустации, а друг, которому оно понравилось, скорее всего, посоветует вам его заказать. Мы можем доказать, что более низкий уровень разброса обратной связи повышает вероятность выбора того или иного результата [8]. Модель также можно изменить таким образом, чтобы она учитывала различия между людьми в восприимчивости к социальному влиянию: некоторые люди придают большую или меньшую значимость шарам, добавляемым в урну.
В любом варианте модели можно измерить (оценить) степень зависимости от первоначально выбранного пути и сравнить ее с другими вариантами. Если предположения, сделанные в процессе построения модели выпуска нового продукта, указывают на то, что результаты зависят от начального этапа пути, тогда выход на рынок, принятие необходимых мер или получение финансирования в самом начале будет хорошей стратегией. Модель предоставляет компаниям логическое обоснование для быстрого вывода продуктов на рынок или предложения значительных скидок для привлечения ранних последователей. Другие предположения могут указывать на то, что создание более совершенного продукта гораздо важнее, чем быстрый выход на рынок; и тогда лучшей стратегией будет сосредоточиться на качестве. Применение моделей позволяет выявить особенности той или иной ситуации (относительная важность индивидуальных предпочтений и воздействия социальных факторов, разброс обратной связи и относительные различия в качестве) и использовать эти знания как основу для разработки стратегии и руководства по сбору данных.
В заключение хотелось бы отметить, что процесс Пойа демонстрирует, как положительная обратная связь порождает зависимые от пути результаты и равновесия. Зависимость от первоначально выбранного пути возникает в гораздо более широком диапазоне контекстов. Определенная степень зависимости от первоначально выбранного пути (в случае неравновесных результатов) наблюдается каждый раз, когда одно действие сталкивается или взаимодействует с будущими действиями. Так происходит при принятии решений о крупных социально значимых проектах [9]. Решение построить парк или автомагистраль ограничивает будущие решения в области планирования. Как правило, степень такой зависимости от первоначально выбранного пути обусловлена масштабом проекта — например, Центральный парк существенно повлиял на застройку Нью-Йорка. Хотя процесс Пойа раскрывает основную идею о том, что взаимодействие порождает зависимость от первоначально выбранного пути, нужны более реалистичные модели, чтобы использовать эту информацию как руководство к действию.
Стоимостная мера риска и волатильность
Мы можем интерпретировать стандартное отклонение временных рядов данных как волатильность. Инвестициям в акции, недвижимость и частные компании свойственна волатильность. Стоимостная мера риска (value at risk, VaR) используется для оценки вероятности потерь в заданном объеме за определенный период. Инвестиция с годовым показателем 5% VaR, равным 10 000 долларов, означает равную 5 процентам вероятность потери 10 000 долларов к концу года [10]. Банки используют вычисление показателя VaR для определения объема активов, которые необходимо иметь в наличии для избежания банкротства. Например, чтобы застраховать инвестицию с двухнедельным показателем 40% VaR, равным 100 000 долларов, инвестору могут предложить хранить 100 000 долларов наличными.
Если инвестиция подчиняется принципу простого случайного блуждания с увеличением или сокращением в размере M на протяжении каждого периода, то показатель 2,5% VaR за период N равен 2M√N [11]. Таким образом, инвестиция, размер которой ежедневно увеличивается или уменьшается на 1000 долларов, имеет девятидневный показатель 2,5% VaR, равный 6000 долларам, а годовой показатель 2,5% VaR — 38 000 долларов. Обратите внимание, что значение VaR возрастает линейно в зависимости от размера шагов, но при этом возрастает как квадратный корень от количества периодов. Мы можем использовать формулу вычисления показателя VaR для объяснения того, почему Федеральная корпорация страхования банковских вкладов требует, чтобы банки держали только 2 процента своих активов наличными на протяжении суток, а сами банки требуют, чтобы клиенты делали первый взнос по ипотечному кредиту в размере 20 процентов. Срок действия суточного кредита — один день. Ипотечный кредит может быть рассчитан более чем на десять лет. Квадратный корень из трех тысяч шестисот пятидесяти дней (десять лет) равен примерно шестидесяти.
Здесь мы исходили из предположения о наличии простого случайного блуждания. Аналитики, вычисляющие VaR, часто учитывают эмпирическое распределение доходности за прошедший период. Если оно имеет более длинный хвост, то есть включает более крупные события, то значение VaR будет увеличиваться при повышении вероятности наступления крупных событий.
Хотя показатель VaR разрабатывался в области финансов, эта идея может найти более широкое применение. Предположим, некоммерческой организации, которая открывает утром по субботам волонтерскую бесплатную столовую, требуются для работы двадцать пять волонтеров. Организации может понадобиться информация о вероятности нехватки волонтеров. Если их количество подчиняется принципу простого случайного блуждания, увеличиваясь или уменьшаясь на 1 каждую неделю, то, воспользовавшись представленной выше формулой для вычисления VaR и установив M = 1 и N = 52, можно определить, что годовой показатель 2,5% VaR равен 15. Значит, вероятность нехватки волонтеров составляет 2,5 процента.
ГЛАВА 15
МОДЕЛИ ЛОКАЛЬНЫХ ВЗАИМОДЕЙСТВИЙ
Каждое поколение смеется над модами предыдущего, но благоговейно следует новым.
Генри Дэвид Торо
В этой главе мы изучим две модели локальных взаимодействий — модель локального большинства и игру «Жизнь». Обе модели представлены на плоскости, разделенной на клетки, которые находятся в одном из двух состояний. В остальном модели существенно разнятся. В модели локального большинства клетки обновляются путем перехода в то состояние, в котором находится большинство соседних клеток. В игре «Жизнь» клетки подчиняются более сложному правилу со множеством пороговых значений. Результаты, полученные с помощью этих моделей, тоже разнятся. Модель локального большинства всегда сходится к равновесию, тогда как игра «Жизнь» в зависимости от ее исходного состояния может обеспечить любой класс результатов: равновесие, цикличность, сложность или хаотичность.
Модель локального большинства можно использовать для объяснения и прогнозирования реальных результатов в социальных и физических системах. Она может представлять дискретный выбор, который делают отдельные люди, или описывать такие физические системы, как спиновые стекла, где магнитные структуры приходят в соответствие с соседними структурами. Напротив, игра «Жизнь» носит сугубо исследовательский характер. Она разрабатывалась для изучения того, как совокупность простых правил может порождать сложные явления. В игре «Жизнь» взаимодействие приводит к появлению периодических структур, сложных последовательностей и хаоса. Эта модель демонстрирует, что целое может отличаться по своей сути от своих частей. В качестве грубой аналогии можно привести мозг человека, который также порождает явления (такие как эмоции, познание и сознание), возникающие из гораздо более простых составляющих.
Сначала мы рассмотрим модель локального большинства и продемонстрируем, как стандартная координационная игра обеспечивает микрооснования для правила поведения, принятого в модели. В связи с этим мы можем интерпретировать агентов в модели либо как агентов, придерживающихся правил, либо как рациональных агентов, использующих стратегию лучшего ответа. Далее мы опишем игру «Жизнь» и покажем, как она создает сложность из простых правил. А в конце главы обсудим важность проведения исследований с помощью моделей локальных взаимодействий.
МОДЕЛЬ ЛОКАЛЬНОГО БОЛЬШИНСТВА
Модель локального большинства подразумевает, что плоскость разделена на клетки [1]. Каждая клетка находится в одном из двух состояний, которые мы обозначим как «включено» или «выключено». Сначала мы будем присваивать клеткам состояния в случайном порядке; впоследствии состояние клетки будет зависеть от состояния ее соседей. Соседи могут быть определены несколькими способами. Мы будем считать соседями клетки C четыре клетки, расположенные к северу, югу, востоку и западу, а также четыре клетки, смежные по диагонали. Следовательно, размер окрестности равен восьми клеткам.
Модель локального большинства
Каждая клетка на двумерной сети координат находится в одном из состояний — «включено» или «выключено». У каждой клетки есть восемь соседей (как показано на рисунке ниже) [2]. На протяжении каждого периода клетка выбирается случайным образом [3]. Она меняет свое состояние тогда и только тогда, когда пять или более ее соседей находятся в другом состоянии.
Локальные взаимодействия в модели локального большинства содержат положительную обратную связь: клетки переходят в состояние, в котором находятся другие клетки. На рис. 15.1 показана типичная равновесная конфигурация модели локального большинства.
Рис. 15.1. Равновесная структура в модели локального большинства
В случае равновесия состояние каждой клетки соответствует состоянию большинства ее соседей. Равновесные конфигурации напоминают черно-белую пятнистость коров голштинской породы. Хотя равновесная конфигурация зависит от исходной конфигурации клеток, модель не проявляет высокой чувствительности к исходным условиям. Изменение состояния одной клетки приводит лишь к незначительным изменениям конечной конфигурации. Данная структура также зависит от того, в каком порядке активируются клетки. Таким образом, модель локального большинства демонстрирует зависимость от первоначально выбранного пути. Модель порождает огромное количество равновесий. Два равновесия, полученные с ее помощью, похожи не больше, чем две голштинки в поле.
Модель разработана для описания физических систем, в которых состояние каждой клетки отражает спин атома: представьте каждую клетку в виде магнита с отрицательным или положительным зарядом. Каждый магнит находится в локальном магнитном поле, которое на физическом уровне приводит его в соответствие со спинами соседей. С помощью этой модели можно также описать стекла и кристаллы.
Мы же используем ее для описания локальной координации или согласованности действий людей. Предположим, каждая клетка отражает действие отдельного человека. Это может быть любое общепринятое действие, такое как рукопожатие, кивок в знак приветствия или поднятие руки. Человеку необходимо выбрать действие, соответствующее действиям его соседей. Разделенная на клетки плоскость отображает сеть социальных связей. Такая плоскость будет подходящей сетью социальных связей для домовладельца, принимающего решение поддерживать чистоту во дворе, посадить деревья или применить принципы экологического благоустройства, или для людей в зрительном зале, решающих, аплодировать ли исполнителям стоя [4]. И хотя разделенная на клетки плоскость — грубое приближение, оно позволяет уловить некоторые важные моменты на интуитивном уровне.
Если мы запустим модель на компьютере, то обнаружим, что она всегда образует пятнистую равновесную конфигурацию. В главе 16 мы поясним, почему так происходит. В физической интерпретации модели локального большинства пятнистая равновесная структура соответствует фрустрированному состоянию. У многих клеток соседи находятся как в состоянии «включено», так и «выключено». Если интерпретировать модель в социальном контексте, то фрустрированное состояние можно рассматривать как субоптимальное равновесие. Если состояние «включено» соответствует приветствию людей рукопожатием, а «выключено» — кивку головой, то люди, расположенные на границах пятен, испытывают дискомфорт при взаимодействии с некоторыми соседями: они кивают в знак приветствия, когда другие обмениваются рукопожатием, и пожимают руку, когда другие кивают. В целом люди были бы счастливее, если бы все выбирали одни и те же действия, то есть решали бы координационную игру. Субоптимальное равновесие (фрустрированное состояние) наступает из-за эффекта взаимодействия, возникающего на локальном уровне. Если бы вместо этого клетки переходили в состояние глобального большинства, то очень быстро все они были бы в одном и том же состоянии. Этот вывод подразумевает, что формирование общих моделей поведения может потребовать широких сетей влияния. Когда люди координируют свои действия с действиями локальных соседей, образуются зоны разноплановых моделей поведения. Парадокс заключается в том, что координация ведет к разнообразию.
Чистые координационные игры
В чистой координационной игре каждый игрок выбирает одно из двух действий: A или B. Если оба игрока выбирают одно и то же действие, каждый получает выигрыш 1. Если игроки выбирают разные действия, каждый получает выигрыш 0.
Действия | A | B |
A | 1, 1 | 0, 0 |
B | 0, 0 | 1, 1 |
В чистой координационной игре есть два эффективных равновесия: оба игрока выбирают действие A или действие B. Кроме того, в ней есть неэффективное равновесие, в котором каждый игрок в случайном порядке выбирает либо A, либо B. В данном случае модель локального большинства можно интерпретировать так: каждая клетка соответствует игроку, который должен выбрать общее действие, чтобы играть с восемью соседями. Если игроки могут менять свои действия только при их активации в случайном порядке, игрок может увеличить свой выигрыш, выбрав действие, совпадающее с действиями большинства соседей. Такую стратегию называют недальновидным наилучшим ответом, поскольку она не учитывает возможных будущих действий соседей. Игрок с пятью соседями, выбравшими действие B, может увеличить свой выигрыш в краткосрочном периоде путем перехода от действия A к действию B, но если игрок и его соседи находятся в окружении множества других игроков, выбравших действие A, то у него может быть более высокий ожидаемый выигрыш, если он сохранит действие A. Главный вывод — правило поведения, из которого исходит модель локального большинства, может основываться на теоретико-игровой модели.
Парадокс координации объясняет различия между группами как свойственную им отличительную особенность. Некоторые действия (например, храните ли вы соевый соус в шкафу или в холодильнике, ходят ли люди дома в обуви или снимают ее у порога) целесообразно координировать с действиями других людей. Обусловленные этим региональные различия обогащают нашу жизнь. Крохотная чашечка ристретто в Италии, средняя чашка эспрессо во Франции и огромная чашка kawa ze smietanka (кофе со сливками) в Варшаве только усиливают удовольствие от путешествий по Европе.
Однако другие особенности могут быть неэффективными. Вариации электрических вилок (с двумя штырями и с тремя) способны свести с ума. Поскольку мир становится более интегрированным, просчеты с технологической координацией могут обойтись очень дорого. Шведы решили перейти с левостороннего на правостороннее движение, чтобы соответствовать остальной части континентальной Европы. Переход, известный как Dagen H, состоялся в 4:45 утра 3 сентября 1967 года. Все автомобили в Швеции (а многие шведы выехали тем утром на дороги, чтобы поучаствовать в этом событии) резко остановились, а затем в течение следующих пятнадцати минут перестроились с левой стороны дороги на правую. В 5 часов утра автомобили снова начали движение, но уже по противоположной стороне дороги. Несмотря на наличие стимулов координировать свои действия, люди порой не делают этого. Жители Англии, связанной с континентом тоннелем, продолжают ездить по «неправильной» стороне дороги, как и обитатели некоторых (хотя и не всех) островных колоний.
Парадокс координации
Если люди координируют свои действия на локальном уровне, то глобальная конфигурация носит неоднородный и разноплановый характер.
Применяя эту модель, необходимо помнить, что многие скоординированные культурные нормы (например, то, как люди оплакивают умерших или празднуют рождение ребенка) — не отличительная особенность, а элемент культуры, целостная совокупность моделей поведения, обычаев и артефактов, которые определяют сущность людей и наделяют их чувством значимости и принадлежности [5].
Как и для любой другой модели, мы можем поэкспериментировать с параметрами и понаблюдать, как это скажется на результатах. В модели локального большинства размер сегментов, формирующихся в случае равновесия, увеличивается быстрее, чем размер окрестности. Если мы в два раза увеличим окрестности (то есть количество квадратов, влияющих на отдельный квадрат сетки), сегменты увеличатся более чем вдвое. Таким образом, модель указывает на то, что, поскольку вследствие развития технологий и урбанизации мы становимся связаннее, сила координации может привести к формированию более крупных однородных сегментов моделей поведения и убеждений.
Эксперименты также показывают, что, если сделать конфигурацию в виде вытянутого узкого прямоугольника, модель обычно формирует горизонтальные и вертикальные полосы, как показано на рис. 15.2 [6]. Похожие на зебру полосы равновесны, поскольку у каждой, «включенной»/«выключенной» клетки есть пять соседей в состоянии «включено»/«выключено». Подобная структура равновесна и в случае квадрата, хотя и редко. Озадачивающие выводы такого рода могут быть получены в результате глубокого погружения в «кроличьи норы», не имеющие большой эмпирической или теоретической ценности. Вместе с тем эти выводы позволяют получить представление о происходящем, что приведет к более глубоким, неожиданным открытиям.
Рис. 15.2. Устойчивые линии в модели локального большинства
В этом случае результат «квадраты порождают структуры в стиле пятнистости коров голштинской породы, а из узких прямоугольников получаются структуры в стиле зебры» практически обязывает нас спросить, могут ли подобные модели объяснить узоры на шкуре животных. Анализ публикаций по этой теме говорит о том, что могут [7].
ИГРА «ЖИЗНЬ»
Наша следующая модель, игра «Жизнь», также представлена в виде клеток на плоскости, находящихся в одном из двух состояний. Ключевое отличие от предыдущей модели состоит в том, что правило обновления клеток имеет два пороговых значения и что все клетки переходят в новое состояние одновременно. Следовательно, мы можем говорить об исходной конфигурации, конфигурации в момент времени 1, конфигурации в момент времени 2 и так далее. Синхронное обновление клеток можно рассматривать как «динамику марширующего оркестра» (Обновить! Обновить! Обновить!) [8].
Игра «Жизнь»
Каждая клетка на пространственной координатной сетке может быть либо живой («включено»), либо мертвой («выключено»). Соседями каждой клетки являются восемь смежных клеток. Клетки обновляют свое состояние одновременно в соответствии со следующими двумя правилами.
Правило жизни: мертвая клетка с ровно тремя живыми соседями оживает.
Правило смерти: живая клетка с менее чем двумя или более чем с тремя живыми соседями умирает.
Начнем с трех живых клеток, расположенных по горизонтали, как показано на рис. 15.3. В следующем периоде в результате применения правил жизни и смерти к каждой клетке мы получим три клетки, расположенные по вертикали. У живой клетки, находящейся посредине, двое соседей, поэтому она остается живой. Две живые клетки по краям имеют по одному живому соседу, поэтому они умирают. И наконец, клетки, находящиеся выше и ниже центральной клетки, оживают, поскольку у каждой из них по три живых соседа (два их соседа по диагонали). В силу симметрии после очередного обновления три клетки снова выстраиваются в ряд по горизонтали. При повторном применении правила данная структура поочередно принимает горизонтальное и вертикальное положение — другими словами, «мигает».

Рис. 15.3. Фигура «мигалка» в игре «Жизнь»
Мигалка формируется вследствие взаимодействия между клетками. Этот результат не относится к числу исходных предположений. Ученые, изучающие сложные системы, называют такие явления макроуровня эмерджентными. Мигалка относится к числу наиболее распространенных и наименее впечатляющих эмерджентных структур, порождаемых игрой «Жизнь». На рис. 15.4 показаны еще три простые конфигурации: блок, планер и R-пентамино. Блок — это равновесная конфигурация. У каждой живой клетки ровно три живых соседа, а у каждой мертвой — не более двух живых соседей. Ни одна живая клетка не умирает и ни одна мертвая не оживает. Средняя конфигурация порождает цикл длиной 4 такта, который плавно перемещает указанную конфигурацию по диагонали на одну клетку вниз и вправо. Более сложные конфигурации под названием «планерные ружья» порождают бесконечный поток планеров. Третья конфигурация, R-пентамино, создает сложную последовательность фигур. Если выполнять модель на протяжении более чем тысячи шагов на большой сетке, она генерирует планеры и мигалки, а также несколько небольших стабильных конфигураций. Кроме того, игра «Жизнь» может порождать хаос [9]. Таким образом, она способна генерировать любой класс результатов в зависимости от исходного состояния.
Рис. 15.4. Конфигурации в игре «Жизнь»
Эти возможности поднимают философские вопросы. Игра «Жизнь» состоит из расположенных на сетке клеток с двумя состояниями, которые обновляются в соответствии с простыми правилами. Игра может порождать сложные структуры, поэтому при надлежащем кодировании ее можно превратить в универсальный компьютер. Исходную структуру можно рассматривать как входные данные. Правила генерируют результат, который можно интерпретировать как вычисление. Следовательно, можно провести грубую аналогию между данной моделью и человеческим мозгом, который тоже состоит из простых пространственно связанных элементов, функционирующих на основе правил с пороговыми значениями (хотя и более сложных). Это не означает, что структуры, которые мы видим в игре «Жизнь», могут объяснить сознание. Книги с названием «Игра “Жизнь”: объяснение сознания» не существует, однако Дэниел Деннет действительно написал книгу Consciousness Explained («Объяснение сознания»), в которой утверждает, что простые модели типа игры «Жизнь» позволяют глубже понять эволюцию сознания. Такую же мысль высказал и физик Стивен Хокинг, написав: «Нетрудно представить, что игра “Жизнь” с помощью всего лишь нескольких элементарных правил может порождать в высшей степени сложные объекты, возможно, даже интеллект» [10].
РЕЗЮМЕ
В этой главе мы изучили две модели, состоящие из взаимодействующих клеток на координатной сетке. Первая, модель локального большинства, всегда переходит в одно из множества возможных равновесий, поэтому мы можем интерпретировать ее как аналог различных физических и социальных процессов. Вторая, игра «Жизнь», может порождать любой класс результатов, от равновесий до хаоса. Эта модель не претендует на явную связь с реальным миром, но представляет пример того, как создание альтернативной реальности позволяет получить ценную информацию (как в случае появления динамических структур макроуровня из правил микроуровня), углубляющую наше пониманиемира. Как показывает игра «Жизнь», целое может выполнять функции, которые существенно превосходят возможности его частей. Например, если создать наклонную цифру восемь, соединив два квадрата 3 на 3 углами, игра «Жизнь» порождает циклическую конфигурацию с периодом, равным восьми. Игра последовательно образует ряд структур и возвращается к цифре 8 ровно за восемь шагов. Тот факт, что напоминающая восьмерку структура функционирует так, будто она считает до восьми, просто удивителен.
Для того чтобы понять, как и почему игра «Жизнь» порождает сложность, тогда как модель локального большинства стремится к равновесию, понадобятся дополнительные инструменты анализа и концептуальные схемы. В главе 16 вводятся функции Ляпунова, которые относят состояние мира к тому или иному классу с помощью разностных уравнений. Тщательно построенные функции Ляпунова позволяют объяснить, почему модель локального большинства должна стремиться к равновесию и почему игре «Жизнь» это не нужно.
В заключение хотелось бы отметить, что актуальность вопроса о том, порождают ли модели (а значит, и реальный мир) равновесия, структуры, сложность или хаотичность, естественным образом возникла в процессе исследования моделей. Изучая их, мы обнаружили, что одни приходят в равновесие, а другие нет. Обычно мы размышляем об использовании модели для получения ответов на вопросы. В этой главе мы увидели, что модели тоже могут задавать вопросы.
ГЛАВА 16
ФУНКЦИИ ЛЯПУНОВА И РАВНОВЕСИЕ
Красота математики открывается только более терпеливым последователям.
Мариам Мирзахани
В этой главе мы изучим функции Ляпунова, которые создают условия для достижения моделью равновесия. Функции Ляпунова — это определенные на системе конфигураций действительные функции, которые индексированы по времени. На каждом временном шаге функция Ляпунова присваивает конфигурации конкретное значение. Если конфигурация меняется (то есть модель не находится в состоянии равновесия), то значение функции Ляпунова уменьшается на фиксированную величину. Функция Ляпунова также имеет минимальное значение, это означает, что в конечном счете ее значение перестает уменьшаться. Когда это происходит, модель достигает равновесия. Функцию Ляпунова можно использовать, например, чтобы показать, почему модель локального большинства в теории коллективного выбора сходится.
Ключевой вывод этой главы — если мы сможем построить функцию Ляпунова для модели, то эта модель обязательно придет в равновесие. Мы не можем получить периодическую орбиту, хаотичность или сложность. Более того, мы можем ограничить время сходимости к равновесию, что станет очевидным при конструировании функции Ляпунова для модели локального большинства.
Глава состоит из шести частей. Сначала мы дадим определение функций Ляпунова, а затем применим их в игре «Гонка по нисходящей». Потом построим функции Ляпунова для модели локального большинства и модели упорядочивающих действий. В четвертой части мы поясним, почему можно построить функции Ляпунова для одних валютных рынков и невозможно — для других. А затем выясним, почему в игре «Жизнь» нет функции Ляпунова. Далее мы обсудим обманчиво досадную математическую задачу, которая всегда стремится к равновесию и для которой была найдена функция Ляпунова, а в заключительной части вернемся к вопросу о целесообразности равновесий.
ФУНКЦИИ ЛЯПУНОВА
Дискретная динамическая система состоит из пространства возможных конфигураций (рассматривайте их как многомерные состояния мира, такие как первичная совокупность живых и мертвых клеток в игре «Жизнь») и правила перехода, которое отображает данную конфигурацию в момент времени t на конфигурацию в момент времени t + 1. Функция Ляпунова преобразовывает конфигурации в действительные числа и удовлетворяет двум предположениям. Во-первых, если функция перехода не является равновесием, значение функции Ляпунова уменьшается на фиксированную величину (подробнее об этом чуть позже). Во-вторых, функция Ляпунова имеет минимальное значение. Если оба предположения верны, данная динамическая система должна достичь равновесия.
Теорема Ляпунова
Для динамической системы с дискретным временем, содержащей правило перехода xt+1 = G(xt), действительная функция F(xt) является функцией Ляпунова, если F(xt) ≥ M для всех xt и если существует значение A > 0 такое, что
F(xt+1) ≤ F(xt), если G(xt) ≠ xt.
Если F — функция Ляпунова для G, тогда, начиная с любого x0, существует значение t* такое, что G(xt*) + xt* и система достигает равновесия за конечный промежуток времени.
Сначала построим функцию Ляпунова в рамках игры «Гонка по нисходящей», описывающей стратегическую среду, в которой игроки выбирают уровни поддержки так, что каждый игрок предпочитает предоставлять ее немногим меньше среднего уровня.
Игра «Гонка по нисходящей»
Каждый из N игроков предлагает уровень поддержки в диапазоне {0, 1, …, 100} на протяжении каждого периода. Игрок, максимально приблизившийся к среднего уровня поддержки, получает за этот период приз.
Эта игра помогает объяснить сокращение расходов правительства штата на социальные программы, такие как помощь малоимущим. Ни один губернатор или законодательное собрание штата не хочет казаться бессердечным. Но при этом никто не склонен предлагать щедрые программы, которые привлекали бы неимущих из соседних штатов. Каждый штат готов предоставить определенное финансирование, но меньшее среднего объема. Аналогичные стимулы существуют и для стран, выбирающих экологические стандарты или ставки налогообложения. Страны предпочитают придерживаться менее ограничительной экологической политики и устанавливать ставки налогообложения ниже среднего уровня для привлечения бизнеса.
Достигнет ли игра «Гонка по нисходящей» равновесия, зависит от правил поведения игроков. Например, если игроки выбирают случайные уровни поддержки, то и результаты будут случайными. Случайные уровни не имели бы смысла при наличии структуры выигрышей в игре. Здесь мы предполагаем следующее правило поведения, которое согласуется с экспериментальными данными [1]. Допустим, на протяжении первого периода каждый игрок выбирает случайный уровень поддержки менее 50. После этого каждый игрок выбирает уровень хотя бы на 1 меньше от среднего предыдущего периода. Если это число меньше ноля, то каждый игрок выбирает ноль.
Несложно продемонстрировать, что максимальный уровень поддержки со стороны любого игрока удовлетворяет условиям функции Ляпунова. У максимального уровня поддержки нулевой минимум. И в каждом периоде максимальный уровень поддержки снижается минимум на 1 при условии, что уровни поддержки принимают целые значения. Таким образом, в определенный момент все предлагают нулевую поддержку. Участники игры достигли дна. В этом примере модель порождает нежелательный результат. Предотвращение гонки по нисходящей требует изменения правил игры. Для того чтобы увеличить поддержку малоимущих, федеральное правительство может перейти на федеральное финансирование или установить минимальный уровень расходов [2].
В качестве отступления предположим, что мы разрешаем игрокам выбирать любое действительное число в интервале от 0 до 100, а не только целые числа. Если в ходе каждого раунда игроки выбирают уровень поддержки, равный от предыдущего среднего, средний уровень поддержки будет со временем снижаться, но никогда не достигнет нулевого равновесия. Как и в случае парадокса Зенона, процесс будет все больше приближаться к нулю, но так и не достигнет его. Следовательно, для обеспечения равновесия мы должны ввести минимальное уменьшение (A).
РАВНОВЕСИЕ В МОДЕЛИ ЛОКАЛЬНОГО БОЛЬШИНСТВА
Теперь вернемся к модели локального большинства. Определим функцию Ляпунова как общее несовпадение в рамках совокупности: вычисленную по всем клеткам сумму количества соседних клеток в противоположном состоянии. Чтобы доказать, что модель достигнет равновесия, мы должны продемонстрировать, что если клетка изменит свое состояние, то общее несовпадение сократится как минимум на фиксированную величину.
Доказательство не слишком сложное. Во-первых, если клетка меняет состояние, значит, она должна быть в меньшинстве по отношению к своим соседям. Мы знаем, что минимум пять ее соседей были в противоположном состоянии и максимум три — в том же, что и она. Поэтому, когда клетка переходит в другое состояние, количество не совпадающих с ним клеток сокращается минимум на 2 (рис. 16.1). Для того чтобы вычислить изменение общего несовпадения, необходимо добавить изменения к общему несовпадению, привнесенному соседними клетками. Пять или более клеток, состояние которых теперь совпадает с состоянием данной клетки, имеют более низкий уровень несовпадения (на 1 каждая), а три или менее клеток, состояние которых ранее совпадало с состоянием данной клетки, — более высокий уровень несовпадения (на 1 каждая). Следовательно, общее несовпадение по всем соседним клеткам уменьшается на 4.
Рис. 16.1. Общее несовпадение сокращается на 4 в модели локального большинства
Таким образом, мы доказали, что хотя некоторые клетки могут иметь более высокий уровень несовпадения, общее несовпадение удовлетворяет условиям функции Ляпунова. А значит, модель локального большинства должна сходиться к равновесию, причем не в некоторых или большинстве случаев, а постоянно. Нам также известна скорость сходимости. Каждый раз, когда клетка меняет свое состояние, общее несовпадение сокращается минимум на 4. Отсюда следует, что конфигурация с общим несовпадением 100 должна достичь равновесия за 25 периодов. В общем случае конфигурация с общим несовпадением D должна достичь равновесия за 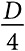 периодов. Как отмечалось в главе 15, достигнутое равновесие почти всегда будет представлять собой неэффективную пятнистую структуру, содержащую фрустрированные клетки.
периодов. Как отмечалось в главе 15, достигнутое равновесие почти всегда будет представлять собой неэффективную пятнистую структуру, содержащую фрустрированные клетки.
САМООРГАНИЗАЦИЯ: НЬЮ-ЙОРК И DISNEY WORLD
В следующей области применения функция Ляпунова используется для доказательства существования равновесия в модели самоорганизации. Модель включает совокупность людей и набор действий, которые каждый человек может выполнять в течение дня. Основное предположение модели состоит в том, что каждый человек предпочитает менее многолюдные события, поскольку чем меньше людей, тем короче время ожидания в спортзале либо очередь в булочной или кафе. Стимулом к созданию модели стала цитата Томаса Шеллинга из книги Micromotives and Macrobehavior36, в которой он описывает поразительный процесс самоорганизации городов — как схема дорожного движения, поток пешеходов, количество людей в парках и ресторанах, а также товарный запас в магазинах достигают приемлемого уровня при почти полном отсутствии центрального планирования. Как так получается, что в магазине на углу всегда есть четыре бутылки кленового сиропа из Сидарвилла? Почему свежий ржаной хлеб заканчивается в булочной примерно за двадцать минут до закрытия? Такой порядок формируется, даже несмотря на то что действующие в городе разнообразные агенты (туристы, владельцы магазинов, жители и сотрудники служб доставки) обладают ограниченной информацией обо всем городе.
Модель самоорганизации
Город предлагает A действий. Каждый день состоит из L периодов. Каждый член большой совокупности людей размером M выбирает определенный режим, или порядок участия в наборе L действий (из более крупного множества K возможностей) на протяжении L периодов. Уровень перегруженности этого человека равен количеству других людей, выбравших те же действия в то же время.
Чтобы доказать сходимость модели, мы продемонстрируем, что общая перегруженность (сумма уровней перегруженности всех членов совокупности) удовлетворяет условиям функции Ляпунова. Снижая уровень перегруженности, человек уменьшает свой вклад в общую перегруженность, а также снижает уровень перегруженности на 1 для каждого человека, с которым его выбор больше не совпадает, и повышает уровень перегруженности на 1 для каждого нового человека, с которым теперь его выбор одинаков. Учитывая тот факт, что человек снижает собственный уровень перегруженности, в первой группе будет больше людей, чем во второй. Рассмотрим следующий пример. Предположим, человек ходит в переполненный тренажерный зал в 8:00 и в переполненное кафе в 16:00. Поменяв местами время посещения этих заведений, он обнаружит, что кафе почти пустует в 8:00, а тренажерный зал менее переполнен в 16:00, тем самым снизив уровень перегруженности для себя и всех тех людей, с которыми встречался ранее. Все это ведет к повышению уровня перегруженности для небольшого числа людей, с которыми этот человек теперь встречается, однако общая перегруженность уменьшится (как минимум на 1). Учитывая, что общая перегруженность не может быть ниже нуля, система должна достичь равновесия.
Хотя в общем мы не можем гарантировать, что система обнаружит эффективное равновесие, эта модель почти всегда сходится к конфигурации с почти минимальной общей перегруженностью. В неэффективной конфигурации люди чаще выбирают какое-то одно действие (например, поход в тренажерный зал) на протяжении определенного периода, чем другое (например, посещение кафе). Если разница в перегруженности между этими двумя действиями существенная, человек может снизить уровень перегруженности, изменив время посещения тренажерного зала и кафе. Если в течение другого периода в тренажерном зале и кафе будет одинаковое количество посетителей, такое изменение приведет к сокращению общей перегруженности [3].
Модель объясняет некоторые аспекты сложившегося в мире порядка и помогает понять, как города могут самоорганизоваться до почти эффективной конфигурации без централизованного планирования. Она также объясняет, почему центры развлечений (такие как Disney World) не способны на такую самоорганизацию. Каждый день в Disney World приходят новые посетители, которым не хватает времени опробовать новые маршруты. Без централизованного планирования к некоторым аттракционам Disney World выстроились бы огромные очереди, тогда как к другим совсем не было бы людей. Disney World пытается избежать такого сценария, предоставляя людям возможность записываться на конкретные аттракционы на определенное время и поручая сотрудникам направлять посетителей в менее оживленные зоны.
ЭКОНОМИКА ЧИСТОГО ОБМЕНА
Мы также можем использовать функции Ляпунова, чтобы исследовать, когда экономика чистого обмена достигает равновесия, а когда нет. Экономика чистого обмена включает совокупность потребителей, каждый из которых имеет первоначальный запас товаров и определенные предпочтения. Предположим, члены некой совокупности приходят на рынок или ярмарку с чем-то, чем будут обмениваться (торговать) с другими, например с баклажанами, сыром или одеялами. Каждый обмен требует затрат времени и усилий с обеих сторон. Для того чтобы два человека договорились, каждый должен получить выгоду, превышающую затраты на обмен.
Вместо того чтобы строить функцию Ляпунова, которая всегда уменьшается на фиксированную величину и имеет минимум, мы сделаем наоборот: продемонстрируем, что общий уровень счастья всегда повышается на фиксированную величину и имеет максимальное значение. Допустим, каждый раз, когда два человека совершают обмен, их уровни счастья повышаются как минимум на величину затрат на этот обмен. Кроме того, каждый человек приносит фиксированный первоначальный запас товаров, значит, у общего уровня счастья есть максимальное значение. Предположения функции Ляпунова выполнены, поэтому система приходит в равновесие. Но при таком равновесии распределение благ не всегда эффективно. И когда оно неэффективно, некоторые участники рынка могут отыскать вариант обмена, который повысит их уровень счастья.
При построении доказательства мы исходили из того, что счастье (или несчастье) обретают только стороны обмена. Однако так бывает не всегда. Представьте, что Ирак обещает поставлять нефть в обмен на ядерное оружие из Пакистана. Лидеры обеих стран могут быть счастливы, но общий уровень счастья (в глобальном масштабе) снизится. Другие страны мира вряд ли придут в восторг от того, что Ирак наращивает свой ядерный арсенал.
Воздействие, которое ощущают жители других стран, обозначается термином «отрицательный внешний эффект». Когда на рынке обмена имеют место отрицательные внешние эффекты (отрицательные экстерналии), обмен не всегда повышает общий уровень счастья. В предыдущем примере рынка чистого обмена (где люди обмениваются фруктами, овощами, одеялами и инструментами) мало экстерналий. Присутствие внешних эффектов не позволяет определить, достигнет ли система равновесия. Обмен оружием и нефтью (как в примере выше) может породить другие формы обмена. В ответ на наращивание Ираком запаса ядерного оружия Саудовская Аравия может потребовать от союзников усилить военную поддержку, что, в свою очередь, может обусловить определенные действия со стороны других стран региона. Уровень глобального счастья (или глобальной безопасности, если уж на то пошло) может резко повышаться и падать после каждого такого действия. При этом мы не можем быть уверены, что процесс обмена когда-либо прекратится.
Существуют ли функции Ляпунова в контексте обмена или нет, зависит от размера отрицательных внешних эффектов, что наглядно иллюстрирует пример, который привела мне одна моя бывшая студентка. Ее работодатель переезжал в новый, так называемый офис открытого типа (open space), где должны были разместиться аналитики. Руководитель предложил моей бывшей студентке в случайном порядке распределить столы среди аналитиков, а затем разрешить им меняться местами на свое усмотрение. По его мнению, такой подход даст хороший результат, поскольку свободный обмен обеспечивает эффективность.
Моя бывшая студентка понимала, что даже если два любых человека, обменявшихся столами, станут счастливее, то их прежние и новые соседи не всегда будут довольны. Человек может почувствовать себя уязвленным, если нынешний сосед (особенно тот, с кем он хотел сидеть рядом) перейдет за рабочий стол в другом конце комнаты. Кроме того, бывшему соседу может не понравиться новый сосед, который, к примеру, громко разговаривает по телефону, и тогда бывший сосед сам предпочтет другое рабочее место. Такие перемещения могут продолжаться бесконечно, и каждое будет подрывать моральный дух коллектива. План казался рискованным. В организации хотели, чтобы среди сотрудников царила атмосфера доверия и уважения, а обмен рабочими столами не способствовал этому. Проанализировав модель, руководитель отказался от своей идеи [4].
Однако на этом история не заканчивается. Тот же руководитель купил офисные кресла разных конструкций и разного цвета и хотел в случайном порядке распределить их среди персонала и разрешить обмениваться ими. В этом случае моя студентка (применив метод модельного мышления) пришла к выводу, что обмен креслами можно разрешить, поскольку он не создавал никаких внешних эффектов, да и сотрудников бы это развеселило. Обмен креслами — пример экономики чистого обмена. Эти два случая позволяют понять, как использовать модели в качестве ориентира при совершении условных действий. Рынки обмена эффективны при обмене офисными креслами, но не при расстановке рабочих столов.
МОДЕЛИ БЕЗ ФУНКЦИЙ ЛЯПУНОВА
Даже когда наши попытки построить функцию Ляпунова для модели нерезультативны, мы все равно накапливаем знания. Часто это позволяет понять, почему модель не обеспечивает равновесия. В игре «Жизнь» одни конфигурации достигают равновесия, а другие нет. Когда игра действительно порождает равновесие, мы можем составить функцию Ляпунова для конкретной конфигурации. Например, любая исходная конфигурация, принимающая форму диагональной линии, будет уменьшаться на 2 каждый период, поскольку две живые клетки в конце линии умирают, а оживающих клеток нет. Данная конфигурация заканчивается тем, что все ее клетки умирают. Для таких конфигураций количество живых клеток будет выступать в качестве функции Ляпунова. Если начать с другой конфигурации (например, R-пентамино), порождающей сложную последовательность конфигураций, построить функцию Ляпунова будет невозможно, так как система не приходит в равновесие.
Однако невозможность построить функцию Ляпунова не означает, что модель или система не достигают равновесия. Оно может иметь место. Некоторые системы приходят в равновесие во всех известных случаях, однако еще никому не удалось построить для них функцию Ляпунова. Один популярный пример — задача о правиле «разделить на два или умножить на три плюс один» (half or triple plus one rule, HOTPO), также известная как гипотеза Коллатца, — обманчиво прост. В задаче HOTPO сначала необходимо взять целое число. Если оно нечетное, умножаем его на 3 и прибавляем 1. Если четное, то делим на 2. Процесс прекращается, когда будет получено значение 1. Если мы начнем с 5 (нечетное число), умножим его на 3 и добавим 1, то получим 16. Разделив 16 на 2, получим 8, разделив 8 на 2, получим 4, разделив 4 на 2, получим 2, а разделив 2 на 2, получим 1, достигнув равновесия. Для любого числа до 264 процесс вычисления HOTPO прекращается. Тем не менее никто не доказал, что HOTPO всегда достигает равновесия. Математик Пол Эрдёш якобы сказал: «Математика еще не созрела для таких задач» [5]. Неспособность математиков определить, достигает ли HOTPO равновесия, указывает на более общий вывод: модели предлагают вероятность доказательства результатов, но не гарантируют их получения. Нередко мы строим модель только для того, чтобы обнаружить, что доказать результаты трудно, а то и невозможно.
РЕЗЮМЕ
Из этой главы мы узнали, как функции Ляпунова помогают доказать, достигнет ли (и как быстро) система или модель равновесия. Даже неудачные попытки построить функцию Ляпунова полезны, так как помогают понять причины сложности. Так обстояло дело с экономикой обмена с внешними эффектами и с обменом рабочими столами. Ни в одном из этих случаев нам не удалось вывести глобальную переменную, значение которой всегда снижается или повышается. Таким образом, у нас нет никаких гарантий, что эти процессы придут в равновесие.
Вернувшись к областям применения моделей (рассуждение, объяснение, разработка, коммуникация, действие, прогнозирование и исследование), мы обнаружим, что функции Ляпунова могут пригодиться в каждой. Как уже отмечалось, функции Ляпунова позволяют понять, почему системы приходят в равновесие. Их можно использовать для разработки информационных систем, как было с записью на аттракционы в Disney World. Знания, полученные с помощью данной модели, можно использовать как руководство к действию (например, не разрешать обмен рабочими столами), а также для распространения информации о том, как система приходит в равновесие, для прогнозирования времени достижения равновесия и для исследований, как в примере с самоорганизацией городов.
ГЛАВА 17
МОДЕЛИ МАРКОВА
История есть циклическая поэма, записанная временем на человеческой памяти.
Перси Биши Шелли
Модели Маркова — это системы, которые совершают вероятностный переход между состояниями, образующими конечное множество. Политическая система может переходить от демократической к диктаторской, рынок — от волатильности к стабильности, а человек — поочередно испытывать счастье, тревогу или уныние. В модели Маркова перемещения между состояниями происходят с фиксированными вероятностями. Вероятность того, что страна перейдет от авторитаризма к демократии в течение года, может составлять 5 процентов, а того, что человек перейдет от тревоги к усталости за один час, — 20 процентов. Если, кроме этого, система может перейти из одного состояния в любое другое путем последовательности переходов и не существует ни одного простого цикла, то модель Маркова достигнет единственно возможного статистического равновесия37.
В случае статистического равновесия отдельные объекты продолжают переходить из одного состояния в другое, но распределение вероятностей по всем состояниям остается неизменным. Статистическое равновесие в марковской модели идеологии допускает, что люди могут менять свои взгляды с либеральных на консервативные и независимые, но относительное количество носителей каждой идеологии не меняется. Применительно к отдельному объекту статистическое равновесие означает, что долгосрочная вероятность его пребывания в каждом состоянии неизменна. Человек может находиться в статистическом равновесии, при котором он счастлив 60 процентов времени и грустит 40 процентов времени. Ментальное состояние человека может меняться ежечасно, но его долгосрочное распределение по всем состояниям останется неизменным.
Единственно возможное статистическое равновесие подразумевает, что долгосрочное распределение результатов не может зависеть от исходного состояния или полосы событий. Иначе говоря, исходные условия не имеют значения, так же как история и меры воздействия38. Со временем процесс, удовлетворяющий предположениям данной модели, неизбежно стремится к уникальному статистическому равновесию и остается в нем. Модель и здесь демонстрирует условную логику: если мир отвечает предположениям модели Маркова, то в долгосрочной перспективе история не играет роли. Модель Маркова не утверждает, что история вообще не важна. Во-первых, модель учитывает зависимость результатов от первоначально выбранного пути: дальнейшее развитие событий зависит от нынешнего состояния. Во-вторых, она также допускает моделирование истории в долгосрочной перспективе, но для этого требуется нарушить одно из предположений модели.
Модели Маркова имеют множество областей применения. Их можно использовать для интерпретации динамических явлений, таких как демократические преобразования, подготовка к войне и меры по борьбе с употреблением наркотиков, для ранжирования сайтов, научных журналов и спортивных команд и даже для установления авторства книг и статей. В этой главе мы рассмотрим все перечисленные области применения. Сначала проанализируем два примера, а затем сформулируем общую теорему о существовании статистического равновесия. В третьем разделе мы перейдем к областям применения моделей Маркова, а в конце главы вернемся к вопросу о том, в какой степени и когда история имеет значение, и проанализируем его в свете полученных знаний о моделях Маркова.
ДВА ПРИМЕРА
Модель Маркова включает множество состояний и вероятностей перехода между ними. В нашем первом примере настроение человека в тот или иной день может быть представлено либо как интеллектуальная увлеченность, либо как скука. Формально оно выступает в качестве двух состояний модели. Вероятности перехода определяют вероятность перемещения между состояниями. Например, как показано на рис. 17.1, мы будем исходить из предположений, что, когда человек интеллектуально увлечен, вероятность того, что он останется в этом состоянии, составляет 90 процентов, а вероятность того, что он начнет скучать, — соответственно 10 процентов. В случае скуки соотношение иное: вероятность, что человек продолжит скучать, равна 70 процентам, а что он перейдет в состояние интеллектуальной увлеченности — 30 процентам.
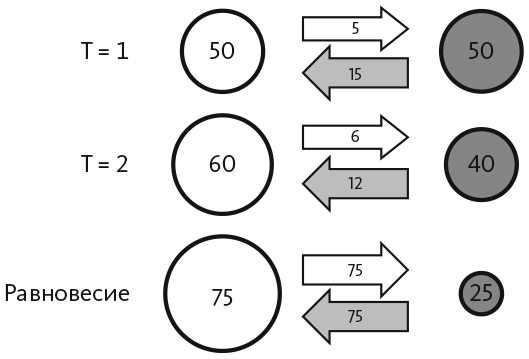
Рис. 17.1. Процесс Маркова
Предположим, эти вероятности перехода верны для 100 студентов, изучающих биологию. Изначально половина студентов увлечены, а другая половина скучает, как показано на рисунке. Применив приведенные выше вероятности перехода, можно ожидать, что на следующий день 5 (10 процентов) интеллектуально увлеченных студентов начнут скучать, а 15 (30 процентов) скучающих студентов увлекутся материалом. Это даст нам 60 интеллектуально увлеченных и 40 скучающих студентов. На следующий день 6 из 60 интеллектуально увлеченных студентов должны скучать, а 12 скучающих — испытать интеллектуальную увлеченность, в результате у нас будет 66 увлеченных и 34 скучающих студента. При продолжении процесса он сойдется к такому статистическому равновесию: 75 интеллектуально увлеченных и 25 скучающих студентов. В этом равновесии студенты продолжат переходить из одного состояния в другое, но количество студентов, находящихся в каждом состоянии, не изменится.
Если процесс начнется со 100 увлеченных студентов, то на следующий день только 90 из них испытают интеллектуальную увлеченность. Еще через день их число сократится до 84. Продолжив процесс, мы обнаружим, что в долгосрочной перспективе 75 студентов будут находиться в состоянии интеллектуальной увлеченности, а 25 студентов — испытывать скуку. Модель достигнет того же статистического равновесия.
Во втором примере мы разделим страны на три категории: свободные, частично свободные и несвободные, которые будем отождествлять с состояниями. На рис. 17.2 показана доля стран в каждой категории за тридцатипятилетний период, закончившийся в 2010 году (по данным Freedom House). На рисунке прослеживается четкая тенденция к усилению демократизации. За прошедших тридцать пять лет доля свободных стран увеличилась до 20 процентов. Если эта линейная тенденция продолжится, то к 2040 году две трети всех стран станут свободными, а к 2080-му — восемь из девяти стран.
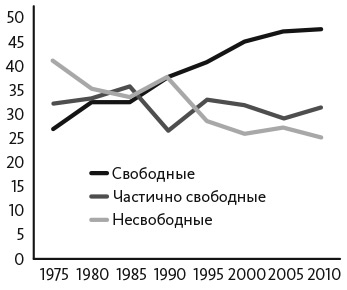
Рис. 17.2. Freedom House: процент свободных, частично свободных и несвободных стран
У модели Маркова иной прогноз. Для его составления мы возьмем пятилетний период и приближенно откалибруем вероятности перехода на основе данных за прошедший период (табл. 17.1) [1].
Таблица 17.1. Вероятности перехода к демократическому режиму согласно модели Маркова
Состояние в следующем периоде | ||||
Свободная | Частично свободная | Несвободная | ||
Нынешнее состояние | Свободная | 95% | 5% | 0% |
Частично свободная | 10% | 80% | 10% | |
Несвободная | 5% | 15% | 80% |
Если мы инициализируем модель, используя относительное количество стран в каждой категории по состоянию на 1975 год, то откалиброванная модель (как и следовало ожидать) почти идеально соответствует распределению 2010 года: 48 процентов стран относятся к категории свободных, 31 процент — частично свободных и 21 процент — несвободных. Фактические данные за 2010 год составляли: 46 процентов, 30 процентов и 24 процента соответственно. Если мы продолжим применять модель, она даст такой прогноз: в 2080 году 62,5 процента стран будут свободными, 25 процентов частично свободными и 12,5 процента несвободными.
Менее радужный прогноз модели Маркова обусловлен тем, что линейная проекция не учитывает вероятность перехода свободных стран в категорию частично свободных и несвободных. По мере того как все больше стран становятся свободными, количество свободных стран, переходящих в категорию частично свободных, увеличивается по ряду причин. Во-первых, для поддержания демократии необходимо налоговое ведомство и другие учреждения, которые способны проводить соответствующую политику. Говоря словами Томаса Флореса и Ирфана Нооруддина, в некоторых местах демократии не так легко укорениться [2]. В таких местах следует ожидать перехода стран из свободных в категорию частично свободных. Модель Маркова учитывает все эти нюансы.
ТЕОРЕМА ПЕРРОНА — ФРОБЕНИУСА
В обоих примерах модель сходится к единственно возможному статистическому равновесию — и это не случайно. Любая модель Маркова с конечным множеством состояний, фиксированными вероятностями перехода, возможностью перемещения из одного состояния в любое другое посредством ряда переходов, а также с отсутствием циклов между состояниями сходится к единственно возможному равновесию. Из теоремы следует, что, когда все эти четыре условия соблюдены, исходное состояние, история и меняющие его меры воздействия не могут изменить долгосрочное равновесие. Если страны переходят от диктатуры к демократии в соответствии с фиксированными вероятностями, то меры воздействия, которые вводят или стимулируют демократию в некоторых странах, не возымеют длительного эффекта. Если колебания в господствующих политических идеологиях удовлетворяют этим предположениям, то история не может влиять на долгосрочное распределение по идеологиям. А если психическое состояние человека можно представить в виде модели Маркова, то ободряющие слова и жесты поддержки не оказывают долгосрочного воздействия.
Теорема Перрона — Фробениуса
Процесс Маркова сходится к единственному статистическому равновесию, если он удовлетворяет следующим четырем условиям:
Наличие конечного множества состояний: S = {1, 2, …, K}.
Фиксированные правила перехода: вероятности переходов между состояниями имеют фиксированное значение. Например, вероятность перехода из состояния A в состояние B равна P(A,B) на протяжении каждого периода.
Эргодичность (достижимость состояния): система может перейти из одного состояния в любое другое посредством некоторой последовательности переходов.
Отсутствие цикличности: система не порождает детерминированный цикл, включающий последовательность состояний.
Вывод из этой теоремы должен заключаться не в том, что история не может иметь значения, а в том, что если история действительно важна, то одно из предположений модели должно быть нарушено. Два предположения — конечное множество состояний и отсутствие простых циклов — выполняются почти всегда. Эргодичность может быть нарушена, как, например, в случае, когда союзники начинают войну и не могут восстановить союз. За исключением таких примеров условие эргодичности тоже всегда выполняется.
Остается только ограничение на фиксированные вероятности перехода между состояниями, которое выполняется реже всего. Таким образом, модель говорит, что когда история имеет значение, базовые структурные факторы должны изменить вероятности перехода (или множество состояний). Рассмотрим в качестве примера вопрос, как помочь семьям преодолеть бедность. Факторы, создающие социальное неравенство, оказались невосприимчивы к политическим мерам воздействия [3]. В моделях Маркова меры воздействия, меняющие состояние семей (такие как специальные программы для отстающих учеников или однодневная благотворительная раздача продуктов), могут привести к временному улучшению, но не способны изменить долгосрочное равновесие. Напротив, меры воздействия, обеспечивающие ресурсы и обучение, что повышает шансы людей сохранить работу, а значит, меняет их вероятность перехода из категории занятых в категорию безработных, могут изменить долгосрочные результаты. Модель как минимум предоставляет нам терминологию (о разграничении состояний и вероятностей перехода) и логику, позволяющую понять ценность изменения структурных факторов, а не нынешнего состояния.
Парадокс продаж-долговечности
Парадокс продаж-долговечности гласит, что распространенность продукта (или идеи) зависит не столько от относительного объема продаж, сколько от его долговечности. Модели Маркова позволяют объяснить этот парадокс, если в качестве состояний выступает процент людей, владеющих такими товарами. Рассмотрим два типа напольных покрытий: керамическая плитка (долговечный товар) и линолеум (товар с более высоким объемом продаж). Парадокс возникает тогда, когда товар с более высоким объемом продаж (в данном случае линолеум) оказывается менее распространенным.
В нашей модели мы будем исходить из того, что объем продаж линолеума втрое превышает объем продаж керамической плитки. Для того чтобы описать различия в долговечности этих товаров, предположим, что каждый год линолеум меняет 1 из 10 человек, а керамическую плитку — 1 из 60. Полученная в итоге модель Маркова имеет равновесие, в котором две трети напольных покрытий — это керамическая плитка [4].
Логика, лежащая в основе парадокса продаж-долговечности, объясняет также и положительную зависимость между рыночной долей и лояльностью к бренду (вероятностью перехода к другому бренду). Если мы составим модель Маркова, более низкая лояльность к бренду должна подразумевать более низкую рыночную долю в равновесии, поскольку лояльность действует так же, как долговечность. Эта эмпирическая закономерность известна как закон двойного риска. Низкая лояльность к бренду обычно означает более низкие продажи [5].
ОБЛАСТИ ПРИМЕНЕНИЯ МОДЕЛЕЙ МАРКОВА
Модели Маркова можно применять в разных контекстах. Даже для моделирования дрейфа генов между четырьмя нуклеиновыми кислотами: аденин (A), цитозин (C), тимин (T) и гуанин (G). Если каждая нуклеиновая кислота имеет небольшую и одинаковую вероятность перейти в одну из трех оставшихся категорий, можно составить матрицу переходов для дрейфа. Модели Маркова можно также использовать для моделирования траекторий здоровья, представив состояния в виде категорий здоровья, таких как отличное, среднее и слабое. Модель позволяет оценить, каким образом протоколы лечения, изменение поведения и оперативное вмешательство меняют вероятности перехода и распределение вероятностей по результатам. Меры воздействия, обеспечивающие более эффективные равновесия (когда больше людей имеют отличное здоровье), заслуживают реализации [6].
Модели Маркова также используются для выявления закономерностей в развитии международных кризисов и различения переходов, ведущих к войне и ведущих к миру и компромиссам [7]. Эта сфера применения требует оценки двух разных моделей, в одной из которых используются случаи, когда кризисы приводили к войне, а в другой — когда урегулирование достигалось еще до начала войны. Если в этих двух моделях вероятности перехода существенно отличаются, можно сопоставить существующие схемы (такие как бомбардировка, захват заложников, отказ от обмена пленными и усиленная демонстрация позиции) и посмотреть, какой процесс больше соответствует данным.
Использование моделей Маркова для различения стилей и образцов позволяет урегулировать споры об авторстве. При наличии известных работ автора можно оценить вероятность того, что одно слово будет следовать за другим. Например, в английской версии этой книги слово the следует за словом for в четыре раза чаще, чем слово example. Мы могли бы представить эту информацию в виде вероятностей перехода в большой матрице. Матрица для этой книги выглядела бы иначе, чем для книги другого автора. Сконструировав отдельные матрицы переходов между словами для книг Мелвилла, Моррисона и Мао Цзэдуна, мы бы увидели различия в их переходах между парами слов [8].
Такой метод позволяет использовать модели для установления авторства Federalist Papers («Записки федералиста») — сборника из восьмидесяти пяти эссе, написанных в 1787 и 1788 годах Александром Гамильтоном, Джоном Джеем и Джеймсом Мэдисоном с целью убедить жителей Нью-Йорка в необходимости поддержать Конституцию США. Каждое эссе было подписано псевдонимом Публий. Хотя авторство большинства эссе установлено, несколько из них до сих пор остаются предметом спора. Модель Маркова приписывает все спорные эссе Джеймсу Мэдисону [9]. Гамильтон или Джей могли бы их написать,но только при условии, что писали бы их в стиле Мэдисона. Аналогичный анализ четырех трактатов и двенадцати коротких эссе неустановленного происхождения, обнаруженных Арлин Саксонхаус, продемонстрировал, что как минимум три работы можно с высокой вероятностью приписать Гоббсу [10]. Во всех этих случаях модель не обязательно дает правильный ответ, но она порождает знания. Полагаясь на свою мудрость, мы можем решить, как оценить эту модель в сравнении с другими моделями или интуицией.
В качестве примера последней области применения давайте посмотрим, как модели Маркова использовались для разработки исходного алгоритма PageRank от Google, в корне изменившего поиск во Всемирной паутине [11]. Всемирная паутина состоит из сети связанных гиперссылками сайтов. Для оценки важности каждого сайта можно подсчитать количество ссылок с сайта и на сайт. В сети сайтов, представленной на рис. 17.3, сайты B, C и E имеют по две ссылки, A — одну, а у D нет ссылок. Этот метод позволяет получить приближенную оценку важности сайта, но у него есть недостатки. У сайтов B, C и E по две ссылки, но сайт E кажется важнее, чем B, учитывая его место в сети.
Рис. 17.3. Связи между сайтами во Всемирной паутине
Алгоритм PageRank рассматривает каждый сайт как состояние в модели Маркова. Затем он устанавливает положительную вероятность перехода между двумя сайтами, если они имеют общую ссылку. В этот момент мы присваиваем одну и ту же вероятность всем ссылкам, то есть предполагаем, что пользователь, осуществляющий поиск в A, с одинаковой вероятностью перейдет на сайт B или E. В случае перехода на сайт E он будет чередовать сайты C и E бесконечно. А при выборе сайта B он перейдет на сайт C и снова начнет поочередно выбирать C и E. При этом создается впечатление, что сайты C и E наиболее важны. К сожалению, эта модель не соответствует двум предположениям теоремы Перрона — Фробениуса. Система не может перейти с одного сайта на любой другой: нет способа перейти с сайта C на сайт D. Кроме того, вероятности перехода создают цикл между сайтами C и E.
Для того чтобы устранить обе проблемы, в Google прибавили небольшую случайную вероятность перехода с одного сайта на любой другой, как показано на рис. 17.4. Теперь модель удовлетворяет всем предположениям теоремы и имеет единственно возможное статистическое равновесие, в котором сайты можно ранжировать по их вероятностям. Пользователь, начинающий поиск с сайта A, вероятнее всего, попадет на сайт C или E за несколько сеансов поиска. Оказавшись там, пользователь будет переходить с одного сайта на другой, пока не зайдет на какой-либо случайный сайт. Если он отправится на сайт A или D, путь назад к сайту C, скорее всего, будет пролегать через сайт B или E. Отсюда следует, что у сайта B должен быть более высокий рейтинг, чем у A или D, но все три сайта должны иметь малую вероятность. Именно это происходит в рамках уникального статистического равновесия, показанного на рис. 17.5. У сайтов A, B и D мало посещений, но B среди них наиболее посещаемый.
Рис. 17.4. Добавление случайных перемещений между сайтами
Рис. 17.5. Статистическое равновесие модели PageRank
Модель PageRank можно рассматривать как сочетание модели случайного блуждания и модели Маркова. Думая о PageRank как об алгоритме, мы начинаем понимать, что его можно использовать для составления рейтингов в любой сети. В виде узлов можно представить бейсбольные или футбольные команды, а вероятности перехода могут обозначать процент времени, когда одна команда побеждает другую [12]. Если команды проводят только одну игру, вероятности перехода можно установить на основании отрыва от соперников. Итоговый рейтинг хотя и не является определяющим, дополняет субъективные экспертные оценки. Модель PageRank также можно использовать для вычисления важности видов с помощью данных о пищевой сети [13].
РЕЗЮМЕ
Модели Маркова описывают динамические системы, перемещающиеся между состояниями в соответствии с фиксированными вероятностями перехода. Если исходить из того, что процесс может перемещаться между любыми двумя состояниями и не порождает цикла, то модель Маркова достигает единственно возможного статистического равновесия. В его рамках люди или объекты перемещаются между состояниями таким образом, что распределение вероятностей по всем состояниям не меняется. Отсюда следует, что по мере приближения процесса к равновесию изменение вероятностей уменьшается. Если представить эту ситуацию в виде графика, то наклон кривой выравнивается. Вспомните, как мы обсуждали рост населения Калифорнии, когда изучали линейные модели. Он замедлился, потому что по мере его увеличения росло число людей, которые уезжали из штата. Этот результат справедлив, даже если доля уезжающих калифорнийцев не меняется. При применении моделей Маркова для объяснения явлений или прогнозирования тенденций выбор состояний создателем модели критически важен. От него зависят вероятности перехода между состояниями. Марковская модель наркозависимости может предусматривать два состояния: употреблять наркотики и отказаться от наркотиков. Более сложная модель может различать наркоманов по частоте употребления наркотиков. Независимо от выбора состояний, когда выполняются четыре предположения (а в данном случае ключевым критерием проверки будет то, остаются ли вероятности перехода фиксированными), система образует уникальное статистическое равновесие. Любое однократное изменение системы производит не более чем временный эффект. При наличии равновесия сокращение потребления наркотиков потребует изменения вероятностей перехода.
Придерживаясь той же логики, можно сделать вывод, что однодневное мероприятие, которое подстегнет интерес к образованию, может не оказать значимого воздействия. Волонтеры, решившие убрать городской парк, создают не так уж много долгосрочных благ. Эффект от любого разового вливания денег, независимо от его размера, рассеется, если это не меняет вероятностей перехода. В 2010 году Марк Цукерберг пожертвовал 100 миллионов долларов на развитие государственных школ в Ньюарке; такую же сумму пожертвовали и другие доноры. Но это разовое вливание, составившее примерно 6000 долларов на одного ученика, ощутимо не повлияло на академическую успеваемость [14].
Модели Маркова выступают в качестве руководства к действию, позволяя провести различие между мерами, которые меняют вероятности перехода и оказывают долгосрочный эффект, и мерами, которые меняют состояние и имеют краткосрочные последствия. Если изменить вероятности перехода невозможно, то для изменения результатов необходимо на регулярной основе выполнять перезагрузку состояния. Трудовая жизнь человека может создавать вероятности перехода, порождающие негативные психические состояния, такие как агрессия, нездоровое соперничество, стресс и так далее. Ежедневные физические упражнения, медитация или религиозные практики помогают перейти в более благодарное, сострадательное и расслабленное состояние, с которого следует начинать каждый день. Выходные выполняют аналогичную функцию, так же как и регулярные романтические свидания супружеских пар. Оба способа на какое-то время выводят состояние человека из сложившегося равновесия.
Не всякая динамическая система удовлетворяет предположениям модели Маркова. В системах, этого не делающих, меры воздействия и события могут иметь долгосрочные последствия. В процессе Пойа результаты меняют долгосрочное равновесие. Серьезные меры воздействия или крупные потрясения в системе могут изменить вероятности перехода и даже множество состояний. Важнейшие технологические достижения, такие как паровой двигатель, электричество, телеграф или интернет, меняют множество возможных состояний экономики. Политические и социальные движения, которые определяют новые права или создают новую политику, тоже меняют множество состояний. Следовательно, мы можем рассматривать историю как последовательность моделей Маркова, а не как единый процесс, движущийся к неизбежному равновесию.
Марковские модели принятия решений
Марковская модель принятия решений — это усовершенствованный вариант модели Маркова, включающий действия. Действие обеспечивает вознаграждение, которое зависит от состояния и влияет на вероятности перехода между состояниями. Учитывая влияние действия на вероятности перехода, оптимальное действие не всегда максимизирует мгновенное вознаграждение.
Рассмотрим в качестве примера студентов, у которых есть выбор между двумя действиями: веб-серфинг или учеба. Интернет-серфинг всегда дает один и тот же выигрыш. Учеба обеспечивает высокий выигрыш, если студент увлеченно учится, и низкий, если студенту скучно. Для того чтобы учесть влияние действий на вероятности перехода, предположим, что скучающий студент, просматривающий сайты в интернете, продолжает скучать, а увлеченный учебой студент, путешествующий по интернету, начинает скучать в половине случаев. Студент, который усердно учится, имеет 75-процентную вероятность войти в состояние интеллектуальной увлеченности на протяжении следующего периода независимо от его нынешнего состояния.
Действия: веб-серфинг (U), учеба (S).
Состояния: скука (B), интеллектуальная увлеченность (E).
Структура вознаграждений:
Скука (B) | Увлеченность (E) | |
Серфинг (U) | 6 | 6 |
Учеба (S) | 4 | 8 |
Матрица переходов:
Скука (B) | Увлеченность (E) | |
Серфинг, скука (U, B) | 1 | 0 |
Серфинг, увлеченность (U, E) | 1/2 | 1/2 |
Учеба, скука (S, B) | 1/4 | 3/4 |
Учеба, увлеченность (S, E) | 1/4 | 3/4 |
Решение марковской задачи сводится к действию, которое нужно предпринять в каждом состоянии. Недальновидный наилучший ответ, с которым мы уже сталкивались, подразумевает выбор действия, обеспечивающего максимальное вознаграждение в каждом состоянии. В нашем примере это соответствует интернет-серфингу в состоянии скуки и учебе в состоянии интеллектуальной увлеченности.
Такое недальновидное решение приводит к тому, что студент впадает в состояние скуки. Как только это происходит, он выбирает интернет-серфинг и продолжает скучать на протяжении всех оставшихся периодов. Таким образом, долгосрочное среднее вознаграждение равно 6. Решение, подразумевающее постоянную учебу, вводит студента в состояние интеллектуальной увлеченности в 75 процентах случаев и в состояние скуки в 25 процентах случаев. Это решение обеспечивает более высокий средний выигрыш, поскольку студент чаще находится в состоянии интеллектуальной увлеченности.
Как следует из этого примера, предоставление выбора в виде марковской задачи о принятии решений обеспечивает более эффективные действия. С учетом последствий совершения действий в том или ином состоянии мы делаем более мудрый выбор. Сон допоздна приносит более высокое мгновенное вознаграждение, чем ранний утренний подъем и гимнастика. Покупка дорогого кофе дает более высокое вознаграждение, чем чашка кофе, приготовленного самостоятельно. Тем не менее в долгосрочной перспективе мы можем стать счастливее, занимаясь спортом и экономя деньги на кофе. Нужна ли модель, чтобы прийти к такому выводу? Мы могли бы вместо этого просто вспомнить стих 21:17 из Книги притчей Соломоновых: «Кто любит веселье, обеднеет; а кто любит вино и тук, не разбогатеет». Возможно, так оно и есть, ну а если обратиться к Книге Екклесиаста (стих 8:15): «И похвалил я веселье; потому что нет лучшего для человека под солнцем, как есть, пить и веселиться»? У этой фразы противоположный смысл. Включение вариантов выбора в марковскую модель принятия решений позволяет использовать логику, чтобы определить, какой разумный совет имеет смысл в конкретных условиях.
ГЛАВА 18
МОДЕЛИ СИСТЕМНОЙ ДИНАМИКИ
Мало кто понимает принципы, управляющие поведением систем.
Джей Форрестер
В этой главе мы рассмотрим модели системной динамики [1], которые анализируют системы с обратными связями и взаимозависимостями. Эти модели используются для моделирования экологических и экономических систем, цепей поставок и производственных процессов. Они улучшают нашу способность выстраивать и анализировать логические цепочки, содержащие положительную и отрицательную обратную связь. Модель системной динамики включает такие элементы, как источники, стоки, запасы, потоки, скорость и константы. Источники генерируют поток, входящий в систему. Стоки принимают входящие потоки. Запасы характеризуют значения накопленных в системе величин, а потоки отражают обратную связь между уровнями запасов. Скорости и константы — это параметры потоков, которые могут быть фиксированными или меняться с течением времени.
Модели системной динамики могут включать как положительную, так и отрицательную обратную связь. Положительная обратная связь (такая как эффект Матфея, описанный в главе 6) возникает тогда, когда увеличение значения переменной (или атрибута) приводит к его дальнейшему увеличению. Успех порождает успех, продажи приводят к дополнительным продажам, а цитирование научных работ и патентов повышает частоту цитирования.
Отрицательная обратная связь ослабляет тенденции. Следует избегать поспешных выводов из слова «отрицательный»: отрицательная обратная связь нередко обеспечивает требуемый результат. Она может предотвращать пузыри и кризисы. Когда мы едим, наш мозг получает сигналы о том, что пора прекратить есть. Когда прибыль компании превышает нормальную экономическую отдачу, в игру вступают конкуренты, снижая эту прибыль и не позволяя компании впутывать в игру клиентов. Когда численность вида быстро увеличивается, его члены начинают бороться за пищу, что снижает рост популяции. В каждом из этих случаев отрицательная обратная связь способствует повышению устойчивости системы.
Модели системной динамики часто помогают установить причины сложности. Когда система содержит как положительную, так и отрицательную обратную связь, она может порождать сложность. Именно это происходит в игре «Жизнь», где существующие клетки пробуждают к жизни новые клетки, а переизбыток клеток приводит к их смерти.
Модели системной динамики, представляющие потоки и уровни запаса в виде математических функций, можно откалибровать таким образом, чтобы они объясняли величину запаса за прошедший период, прогнозировали будущие значения и позволяли оценить эффект мер воздействия. Тогда их можно использовать для объяснения, прогнозирования и совершения действий. Кроме того, модели системной динамики могут быть не только количественными, но и качественными. Мы можем обозначить каждую стрелку знаком «плюс» или «минус», чтобы внести ясность в логику системы [2].
Оставшаяся часть главы состоит из пяти смысловых блоков. Для введения терминов системной динамики мы построим качественную модель булочной. Затем сконструируем модель «хищник — жертва» на основе уравнений Лотки — Вольтерры. Наша версия модели описывает взаимодействие между лисами и зайцами и включает как отрицательную, так и положительную обратную связь. Далее мы продемонстрируем, как с помощью моделей системной динамики можно прогнозировать формирование порочного круга, а затем расскажем о глобальной модели развития мировой экономики под названием «WORLD 3» («Мир-3»). И в заключение поговорим о том, почему модели системной динамики часто дают парадоксальные результаты, что свидетельствует об ограниченности человеческого мышления и ценности моделей как инструментов логических рассуждений.
ЭЛЕМЕНТЫ МОДЕЛИ СИСТЕМНОЙ ДИНАМИКИ
Модель системной динамики включает такие элементы, как источник, сток, запас и поток. Источник создает запас, то есть объем или уровень той или иной величины. Поток описывает, как меняется уровень запаса. Сток принимает исходящий поток, поступающий из запаса. Сток и источник — это места для процессов, не включенных в модель. Уровень запаса со временем меняется в зависимости от источника и потоков. В модели системной динамики парка развлечений, например, количество посетителей парка (запас) увеличивается по мере прихода новых посетителей (источник). Темпы роста запаса могут, в свою очередь, зависеть от других параметров, таких как погода, количество рекламы или цена входного билета.
В моделях системной динамики используется система представления, показанная на рис. 18.1. В ней источники и стоки представлены в виде облаков, запасы — прямоугольников, а потоки — стрелок со знаком «плюс» или «минус». Переменные потоки обозначены обращенными друг к другу треугольниками, а постоянные потоки — рассеченными пополам стрелкой потока кружками. Стрелка со знаком «плюс» означает положительную обратную связь, когда большее порождает большее, а стрелка со знаком «минус» — отрицательную обратную связь от одной величины к другой.
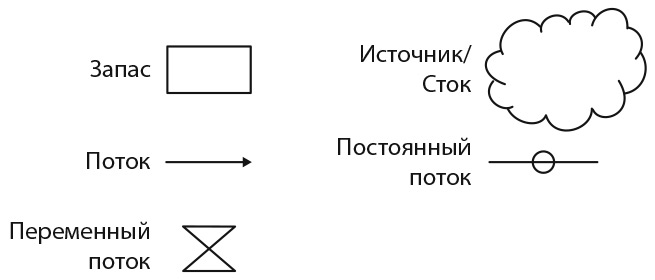
Рис. 18.1. Элементы моделей системной динамики
Для предварительного ознакомления с этой темой сначала сконструируем базовую модель системной динамики булочной, состоящую из булочника, хлеба и клиентов. Булочник печет хлеб, а клиенты его покупают. Если скорость, с которой булочник выпекает хлеб, превышает скорость, с которой клиенты его покупают, запас хлеба увеличивается и накапливается в булочной. И наоборот: если скорость продаж превышает скорость, с которой булочник выпекает хлеб, в булочной постоянно будет не хватать хлеба. Для того чтобы сделать модель более реалистичной, разрешим булочнику корректировать скорость выпекания хлеба в зависимости от его запаса, как показано на рис. 18.3, где представлен поток (стрелка) от запаса хлеба к скорости его выпекания. Указанный возле стрелки знак «минус» означает, что скорость выпекания хлеба снижается по мере увеличения его запаса. Если скорость корректировки установлена правильно, в модели сформируется равновесие, при котором скорость выпекания хлеба будет эквивалентна скорости его покупки клиентами.
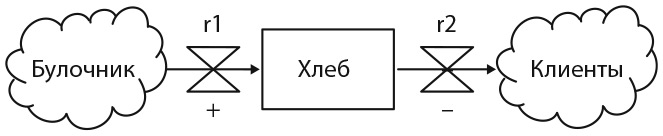
Рис. 18.2. Модель системной динамики булочной
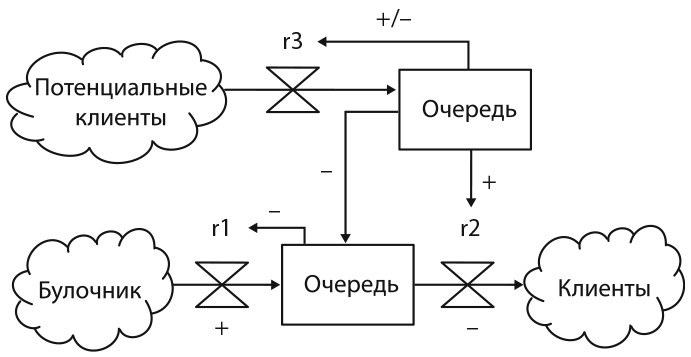
Рис. 18.3. Более сложная модель булочной
Для того чтобы сделать модель еще реалистичнее, включим в нее еще один запас (очередь), который равен количеству людей, ожидающих у булочной, а также второй источник (потенциальные клиенты), добавляющий новых людей в очередь. Короткая и средняя очередь может привлечь клиентов, тогда как длинная — отпугнуть. Для того чтобы оценить переменное воздействие длины очереди на скорость потока, поступающего из источника, напишем знак «+/−» над стрелкой. Кроме того, поставим знак «плюс» над стрелкой, направленной от очереди к скорости, с которой клиенты покупают хлеб, исходя из того, что чем больше людей в очереди, тем быстрее они принимают решение.
Эту модель можно откалибровать в соответствии с данными. Скорость присоединения людей к очереди можно определить по ее длине. Кроме того, булочник может установить оптимальную скорость корректировки процесса выпекания в зависимости от запаса хлеба и длины очереди. Это значение станет отправной точкой для поиска более подходящей скорости. Сам процесс описания модели полезен даже без калибровки. Булочник осознает важность длины очереди с точки зрения объема продаж.
МОДЕЛЬ «ХИЩНИК — ЖЕРТВА»
Далее рассмотрим модель «хищник — жертва» — экологическую модель, отражающую взаимосвязь между количеством зайцев (жертва) и лис (хищник). Модель включает в себя две положительные (зайцы рождают зайцев, а лисы — лис) и одну отрицательную (лисы поедают зайцев) обратную связь. Модель исходит из предположения, что когда численность популяции зайцев высокая, лисы производят больше потомства. На рис. 18.4 эти предположения представлены качественно, но не отражают количественной оценки соотношения. Судя по рисунку, увеличение количества лисиц ведет к уменьшению числа зайцев, что, в свою очередь, приводит к уменьшению численности лисиц. Когда это происходит, зайцы начинают быстро размножаться, и тогда количество лисиц опять повышается. Эта логика указывает на вероятность формирования цикла, а может, и равновесия — точно определить невозможно.
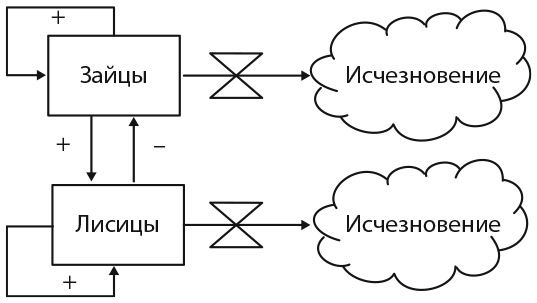
Рис. 18.4. Системная динамика модели «хищник — жертва»
Чтобы лучше понять суть происходящего, необходимо построить количественную версию модели, включив в нее линейные потоки, зависящие от уровня запаса. При отсутствии лис количество зайцев растет с постоянной скоростью; при отсутствии зайцев количество лис сокращается с постоянной скоростью из-за нехватки пищи. Согласно модели, вероятность встречи зайца и лисы пропорциональна количеству лисиц, умноженному на количество зайцев. Для того чтобы учесть тот факт, что при этом лисы едят зайцев, будем исходить из того, что количество лисиц растет с постоянной скоростью, умноженной на произведение количества зайцев и количества лисиц, а количество зайцев сокращается с постоянной скоростью, умноженной на это произведение. Полученные в итоге уравнения известны как уравнения Лотки — Вольтерры.
Модель Лотки — Вольтерры
Экосистема состоит из H зайцев и F лисиц. Популяция зайцев растет со скоростью g, а популяция лисиц сокращается со скоростью d. При встрече зайцев и лисиц зайцы погибают со скоростью a, а лисицы размножаются со скоростью b. На основе этих предположений можно составить следующие дифференциальные уравнения [3]:
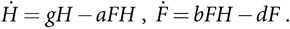
Эти уравнения имеют равновесие вымирания (F = H = 0), а также внутреннее равновесие, представленное уравнениями 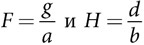 39.
39.
Дифференциальные уравнения описывают, как численность зайцев и лисиц меняется с течением времени. Когда уравнения равны нулю, количество зайцев и лисиц не меняется и система находится в равновесии. Одно из равновесий, равновесие вымирания, подразумевает полное отсутствие зайцев и лисиц. Следовательно, модель прогнозирует, что при определенных условиях взаимосвязи между хищниками и жертвами приводят к вымиранию обоих видов. Это не может происходить во всех случаях, иначе на планете не осталось бы никаких видов.
Внутреннее равновесие включает положительные числа лис и зайцев. В нем количество лис увеличивается по мере роста количества зайцев и сокращается, если каждое взаимодействие между лисой и зайцем сокращает популяцию зайцев более быстрыми темпами. Оба результата интуитивно понятны. Если зайцы размножаются быстрее, система может поддерживать большее количество лис. А если каждой лисе требуется больше зайцев для поддержания жизни, система может поддерживать меньше лис. Оба результата согласуются с нашими интуитивными выводами. Именно такой результат нам и нужен: модели должны генерировать интуитивные выводы.
Вместе с тем модели должны приводить и к менее интуитивным выводам, что они и делают, показывая, что равновесное количество лисиц вообще не зависит от их уровня смертности. Если лисы умирают быстрее, равновесное количество зайцев увеличивается и у оставшихся лисиц образуется изобилие пищи, поэтому их численность растет быстрее, что уравновешивает более высокий уровень смертности лисиц.
Аналогичная логика применима к популяции зайцев. Равновесное количество зайцев не зависит от темпов роста их численности или скорости их поедания лисами. Количество зайцев зависит от скорости вымирания лисиц и от скорости, с которой лисы превращают зайцев в новых лисиц. Интуиция подводит нас в таких случаях, поскольку мы не можем продумать обратные связи до конца. Прямое следствие повышения темпов роста численности зайцев — больше зайцев. Косвенное следствие — больше лисиц, что означает меньше зайцев. Эти два следствия уравновешивают друг друга. Неинтуитивные выводы такого рода — отличительная особенность моделей системной динамики. Интуиция подводит нас, потому что мы слишком увлекаемся прямым следствием и не анализируем всю логическую цепочку. Даже если прямым следствием увеличения (сокращения) скорости или потока становится увеличение (или сокращение) запаса, наличие системных эффектов в виде положительной и отрицательной обратной связи означает, что величина других запасов тоже изменится, а значит, чистый эффект от изменения скорости или потока может быть уменьшен, аннулирован или обращен вспять.
С помощью математики можно доказать наличие двух равновесий для уравнений Лотки — Вольтерры. Но мы не знаем, какое из них наступит, если это вообще произойдет. Верно то, что, если модель начинается с равновесия, она в нем и останется. Однако до запуска модели мы не будем знать, что именно порождает уравнение — равновесие, цикл, хаос или сложность. Нам известно только то, что равновесие существует.
Имитационное моделирование этих уравнений порождает запаздывающие циклы. Сначала численность одного вида увеличивается, затем сокращается, а численность другого вида возрастает. Эмпирические исследования указывают на распространенность таких циклов. На рис. 18.5 отображено количество волков (хищников) и лосей (жертв) на Айл-Ройал (острове длиной немногим более 72 километров на озере Верхнем) за пятидесятилетний период. Обратите внимание, что уровни видов хищников и жертв колеблются в зависимости от запаздывающих циклов. Представленные на графике структуры не столь регулярны, как структуры, которые порождает модель, поскольку в модель не включены такие факторы, как география, наличие других видов животных, различия в погодных условиях и гетерогенность в пределах двух видов.
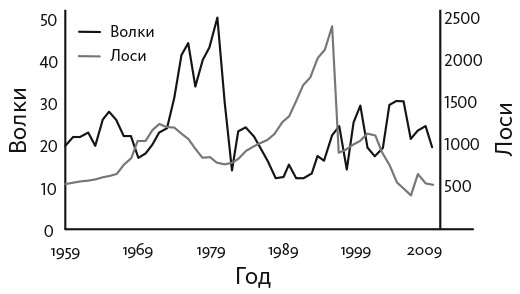
Рис. 18.5. Волки и лоси на Айл-Ройал, штат Мичиган (isleroyalewolf.org)
Анализ уравнений Лотки — Вольтерры подтверждает наше более раннее наблюдение относительно того, что мы не должны путать существование равновесия с его достижением. В данном случае система порождает циклы, а не равновесие. Вместе с тем динамический процесс образует цикл в рамках равновесия. Таким образом, равновесие позволяет определить среднее количество лисиц и зайцев. Из этого следует, что полученный ранее парадоксальный результат — то, что скорость роста численности лисиц (или зайцев) никак не влияет на их равновесный уровень, — сохраняет силу и в общем случае.
ИСПОЛЬЗОВАНИЕ МОДЕЛЕЙ СИСТЕМНОЙ ДИНАМИКИ КАК РУКОВОДСТВА К ДЕЙСТВИЮ
Модели системной динамики могут включать петли (как положительной, так и отрицательной) обратной связи. Петли положительной обратной связи могут приводить к формированию добродетельных циклов, как в случае, когда возросшее доверие между странами ведет к активизации торговли и сокращению военных расходов, а значит, и дальнейшему укреплению доверия. Петли положительной обратной связи могут также порождать порочные циклы. Уменьшение количества рабочих мест в регионе может снизить для людей стимулы овладевать профессиональными навыками, что, в свою очередь, побудит компании покинуть регион из-за нехватки квалифицированной рабочей силы, а это еще больше снизит стимулы приобретать профессиональные навыки.
Модели системной динамики позволяют прогнозировать порочные циклы. В 2008 году в экономике многих стран наступил серьезный финансовый кризис. Когда цены активов резко снизились, банки с высоким уровнем задолженности оказались на грани банкротства. Инвесторы и вкладчики начали беспокоиться о безопасности своих инвестиций. Некоторые страны, такие как США, страхуют банковские депозиты в определенных пределах, тогда как другие (в частности, Австралия) этого не делают.
Для предотвращения паники Австралия решила ввести страхование банковских вкладов. На первый взгляд логика кажется вполне разумной: страхование вкладов предотвращает их массовое изъятие. Однако такое решение учитывает только часть системы, поэтому содержит фатальную ошибку, которая становится очевидной при построении модели системной динамики. В модели финансовой системы каждый банк (запас) имеет определенный уровень активов. Вкладчики вносят деньги в банки и получают доход. Заемщики используют эти деньги для инвестирования. Страхование банковских вкладов гарантирует вкладчикам, что деньги хранятся в банке.
Кроме того, люди держат деньги на фондовом рынке и в фондах денежного рынка. Каждый тип инвестиций выступает в качестве запаса. Как только мы начнем рисовать стрелки (потоки между прямоугольниками), ошибочность такой политики станет очевидной. Прямым следствием страхования банковских вкладов является повышение надежности банков, что делает банки более привлекательными (стрелка 1 на рис. 18.6), но при этом уменьшает привлекательность других типов инвестиций. Представьте, что вы инвестор, у которого есть деньги как в банках, так и на денежном рынке в неспокойный период. Ваши банковские вклады теперь застрахованы, а фонды денежного рынка — нет. В такой ситуации кажется разумным увеличить банковские вклады (стрелка 2) и изъять инвестиции из фондов денежного рынка (стрелка 3).
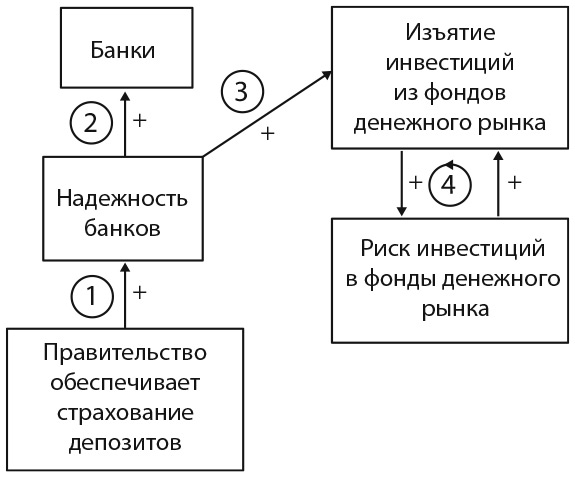
Рис. 18.6. Модель системной динамики финансовой системы
И тут образуется порочный цикл: сокращение объема инвестиций на денежных рынках делает их более рискованными. Повышение риска приводит к дальнейшему изъятию инвестиций из фондов денежного рынка, что создает петлю положительной обратной связи (цикл 4). Очередная волна изъятий еще больше повышает риск, который порождает очередную волну изъятий, что, в свою очередь, влечет за собой дальнейшее повышение риска. Создается впечатление, что такая политика неизбежно приведет к краху отрасли денежных рынков, что, собственно, и произошло. В течение четырех дней после введения страхования банковских вкладов правительство заморозило счета денежных рынков в попытке спасти отрасль от коллапса — решение, приведшее к катастрофическим последствиям. Миллионы пенсионеров, которые использовали деньги, снятые с этих счетов, для оплаты продуктов питания, жилья и других предметов первой необходимости, теперь не могли удовлетворить даже самые базовые потребности [4].
Хотя в ретроспективе этот порочный цикл кажется очевидным, нет никаких гарантий того, что даже если бы австралийские власти построили модель системной динамики, то они увидели бы последствия своей политики. Тем не менее процесс построения такой модели позволил бы обнаружить эффект страхования банковских вкладов в рамках финансовой системы в целом и, возможно, сделал бы очевидным вытекающий из этого решения порочный цикл. Этот пример демонстрирует также ограниченные возможности данных. Данные о ситуации в других странах могли бы указывать на то, что страхование депозитов стабилизирует финансовую систему. Однако в этих странах страхование банковских вкладов вводилось не во время кризиса, а значит, их опыт мог бы ввести в заблуждение.
МОДЕЛЬ «WORLD 3»
Теперь рассмотрим более сложную модель системной динамики, охватывающую мировую экономику. Эта модель, известная как «WORLD 3», была создана в 1970-х годах и прогнозировала коллапс мировой экономики, если правительства стран не изменят политику экономического роста и охраны окружающей среды [5]. Модель «WORLD 3» включает множество взаимодействующих процессов, которые развиваются разными темпами в рамках общей структуры, что позволяет лидерам стран отслеживать взаимозависимости [6]. Многие ведущие экономисты отвергают «WORLD 3» как слишком сложную модель, не учитывающую рациональную реакцию экономических акторов.
Модель исходит из предположения, что численность населения и объем производства ежегодно увеличиваются на фиксированный процент. С течением времени земля истощается, численность населения превышает способность экономики производить достаточное количество товаров, и в результате мировая экономика потерпит крах. Этот прогноз напоминает зловещие предостережения Мальтуса почти двухсотлетней давности.
Модель содержит около 150 переменных, 300 уравнений и 500 параметров, таких как коэффициенты рождаемости, темпы экономического роста и интенсивность землепользования. Для калибровки модели необходимо рассчитать скорость возрастания этих параметров на основе данных. Модель «WORLD 3» учитывает также взаимодействие между переменными, а это подразумевает, что изменения в нескольких параметрах нередко приводят к нелинейным эффектам. Поэтому проверка устойчивости модели требует одновременного изменения пар и троек параметров. Пятьсот параметров означают более 120 тысяч пар параметров и более 20 миллионов троек параметров — что слишком много для того, чтобы кто-то мог проанализировать последствия таких изменений.
Согласно прогнозу данной модели, численность населения должна сократиться к 2100 году до 4 миллиардов человек. Джон Миллер считает, что незначительное изменение всего двух параметров (таких как доля объема промышленного производства, которая приходится на потребление, и продолжительность репродуктивного периода женщин) почти удваивает прогнозируемую моделью численность населения, увеличивая этот показатель до 7,4 миллиарда человек. Столь существенное увеличение обусловлено положительной обратной связью. Более продолжительный репродуктивный период означает рождение большего количества детей, которым требуется больше еды. Увеличение доли объема промышленного производства, приходящейся на продукты питания, обеспечивает выживание большего числа детей. У выживших женщин более продолжительный репродуктивный период, поэтому они рожают больше детей. Результат — активный рост численности населения [7].
Вывод об удвоении численности населения вследствие незначительного изменения параметров настораживает. Однако факт сильной зависимости результатов от значений параметров нельзя считать недостатком модели. Напротив, модель разрабатывалась для использования в качестве руководства к действию, для определения эффективных политических мер. В частности, она указывает, что снижение коэффициента рождаемости (которое на самом деле произошло) должно замедлить рост численности населения. Кроме того, откалиброванная модель позволяет определить величину уменьшения прироста населения. Затем ее можно включить в ансамбль моделей для составления более точных прогнозов.
Со временем первоначальные прогнозы модели «WORLD 3» стали менее точными — отчасти потому, что темпы роста населения замедлялись по мере его увеличения. Эти прогнозы больше не соответствовали предположениям модели. Именно такую адаптивную реакцию предвидели экономисты [8]. Сторонники модели «WORLD 3» принимают критику, но при этом подчеркивают тот факт, что многие прогнозы модели, в том числе относительно экономического роста и общей численности населения Земли, достаточно точны. Что касается снижения уровня рождаемости, сторонники модели «WORLD 3» отмечают, что даже если она и сыграла какую-то роль в собственном провале (другими словами, способствовала повышению осведомленности о перенаселенности и важности заботы об окружающей среде), то они будут только рады, что ошиблись.
РЕЗЮМЕ
При построения модели системной динамики необходимо выбрать ключевые элементы (запасы), описать взаимосвязи между ними (потоки), а затем воспроизвести модель, чтобы определить последствия. Эти модели отличаются от моделей Маркова тем, что в них происходит корректировка значений скорости (которые выступают в качестве вероятностей перехода). Поэтому такая модель не всегда приводит к равновесию. Для того чтобы увидеть, что произойдет, необходимо применить модель. Кроме того, поскольку нам не нужно вычислять конечный результат, можно не беспокоиться о трактовке исходных предположений.
Модели системной динамики могут содержать множество переменных и включать любой тип обратной связи между ними. Можно описать модель и без обратных связей, но если в ней есть прямоугольники, обозначающие запасы, создателю модели ничего не остается, как нарисовать между ними стрелки. Разработчик модели должен задаться вопросом: «Сколько еще переменных можно задействовать и как изменение их значений скажется на имеющейся модели?» Такая постановка вопроса может привести к созданию еще более сложных моделей.
Подобная гибкость имеет свою цену: чем больше запасов и потоков включается в модель, тем менее понятной она становится. Искусство построения полезной модели системной динамики заключается в способности включить в нее достаточно деталей, чтобы она помогала нам там, где нас подводит интуиция, но не слишком много, чтобы случайно не оказаться в модели, запутанной не менее, чем реальный мир. Модели такого рода помогают обнаруживать нежелательные последствия и разрабатывать более эффективные политические меры. Как мы уже убедились, даже самые благие намерения (например, австралийская политика страхования банковских вкладов) могут привести к нежелательным результатам.
Модели системной динамики также показывают, как петли отрицательной обратной связи могут ограничить эффект предпринимаемых мер. Законы, требующие наличия в автомобилях систем безопасности (таких как антиблокировочная тормозная система или подушки безопасности), могут привести к снижению внимания за рулем. Расширение дорог может обусловить массовое переселение людей в пригороды, что повысит перегруженность транспортных магистралей. Снижение содержания никотина в сигаретах может привести к курению большего числа сигарет. Разработка более эффективных методов лечения заболеваний, передающихся половым путем (таких как ВИЧ), может повысить частоту незащищенных половых контактов. Список можно продолжать [9]. В ретроспективе многие из этих случаев отрицательной обратной связи кажутся очевидными, но предвидеть их гораздо труднее. Сам процесс описания качественной модели системной динамики проливает свет на такие петли обратной связи и помогает нам эффективнее мыслить.
Преимущество моделей системной динамики состоит в том, что они побуждают нас учитывать обратные связи. В 1696 году король Англии Вильгельм III ввел налог на дома с базовой ставкой два шиллинга и дополнительным сбором в зависимости от количества окон: за дом с более чем десятью окнами платили еще четыре шиллинга, а за дом с более чем двадцатью окнами — восемь шиллингов. Король ввел налог на окна, потому что их можно было без труда увидеть, измерить и соотнести со стоимостью дома. Если бы король полагался на оценку стоимости домов, это привело бы к распространению фаворитизма и взяточничества. Налог на окна оказался настолько хорошей идеей, что на протяжении следующего столетия его ввели также во Франции, Испании и Шотландии, причем Франция отменила его (impôt sur les portes et fenêtres) только в 1926 году.
Как специалисты по модельному мышлению мы понимаем, что целеустремленные и легко приспосабливающиеся люди должны были принять какие-то ответные меры на этот налог. И они действительно нашли массу способов его обойти. Некоторые заложили окна в уже построенных домах кирпичом. Архитекторы из-за налога изменили проекты домов. Во многих построенныхв тот период домах представителей среднего класса спальни второго этажа вообще были без окон [10]. Объем налоговых поступлений сократился. Закон Кэмбелла снова вступил в силу: политики разработали меру воздействия, а люди нашли способ ее обойти. Более подробная модель системной динамики учитывала бы последствия уменьшения количества окон, включив стрелки от величины запаса (количества окон) к таким характеристикам, как здоровье граждан, уровень которого снизился бы из-за недостатка свежего воздуха и света.
Большая ценность моделей системной динамики отчасти заключается в их способности помогать нам анализировать последствия наших действий. Во многих случаях мы можем тщательно взвесить прямые следствия политических мер. Введение налога на окна приводит к увеличению доходов. Требование об установке антиблокировочных тормозных систем спасает жизнь людей. Хотя мы не всегда можем предвидеть каждое косвенное следствие (положительные и отрицательные обратные связи), модели помогают нам четче и глубже проанализировать последствия тех обратных связей, которые нам все же удастся обнаружить.
ГЛАВА 19
ПОРОГОВЫЕ МОДЕЛИ С ОБРАТНОЙ СВЯЗЬЮ
Интеграция расовых, этнических и других групп, представляющих значительные направления социального неравенства, — жизненно важный идеал для демократического общества.
Элизабет Андерсон
В этой главе мы рассмотрим модели порогового поведения. Оно возникает, когда люди меняют свои действия, если значение внешней переменной превышает или опускается ниже некоторого порогового уровня. В частности, пороговое поведение проявляется тогда, когда человек покупает пальто при падении его цены ниже 100 долларов или присоединяется к общественному движению, когда число его членов достигает 1000 человек. Пороговое поведение интуитивно понятно и легко поддается анализу, но при этом часто приводит к парадоксальным результатам — как в случае, когда толерантность порождает сегрегацию. Пороговые модели нередко создают переломные моменты. Например, если решение человека присоединиться к общественному движению зависит от количества его членов, то по мере присоединения к движению все большего числа людей общая численность его участников с большой вероятностью превысит порог присоединения других людей, что создаст переломный момент.
Представленные в главе модели можно отнести к категории агентных моделей — компьютерных программ, моделирующих каждого агента в отдельности. Агентные модели допускают более высокий уровень детализации, чем модели системной динамики, в которых вся совокупность представлена в виде одной переменной запаса. Агентные модели позиционируют агентов в пространстве и могут включать разнообразные модели поведения. Эта дополнительная степень свободы обеспечивает определенные преимущества, но мы не должны забывать, что чрезмерная детализация может дискредитировать некоторые причины для построения моделей. Например, нецелесообразно моделировать каждый нейрон в голове человека при моделировании того, как люди решают, присоединиться ли к какому-то общественному движению. Оптимальный уровень детализации зависит от целей модели.
Глава начинается с анализа модели мятежа Грановеттера, а затем модели двойного мятежа, которая воспроизводит процесс развития стартапов. Затем следуют две модели сегрегации. Первая касается перемещений людей из комнаты в комнату во время вечеринки, а во второй рассматривается сегрегация в масштабах крупных городов. Далее мы представим модель пинг-понга, которая включает отрицательную обратную связь и может порождать цикл или равновесие, а в конце главы снова вернемся к игре «Жизнь» и увидим, как правило двойного порога образует сочетание положительной и отрицательной обратной связи. Положительная обратная связь порождает коррелированные линии поведения, а отрицательная их подавляет. Мы также вернемся к теме детализации модели.
МОДЕЛЬ МЯТЕЖА ГРАНОВЕТТЕРА
В пороговой модели человек совершает одно из двух действий в зависимости от того, превышает ли агрегированная переменная пороговое значение или нет. Если да, человек совершает одно действие, если нет — другое. Наша первая модель описывает мятежи и общественные движения. В соответствии с ней каждый человек решает, присоединиться к мятежу или воздержаться. Решение обычно зависит от количества протестующих. Пороговая модель не занимает стандартную позицию. Общественное движение или восстание может быть обоснованным протестом против тирана или футбольных фанатов, уничтожающих собственность. Модель применима в обоих случаях.
В модели мятежа каждому человеку присваивается определенный порог. Человек присоединяется к мятежу, когда количество его участников превышает этот порог [1]. Поначалу к мятежу присоединяются только люди с нулевым порогом. Для целей нашего обсуждения мы будем рассматривать скорее общественное движение, чем мятеж, поэтому в данном случае присоединение может означать сбор на центральной площади или шествие. Предположим, в первый день 200 человек с нулевым порогом начинают движение. На второй день эти 200 человек продолжают протестовать, и к ним присоединяются те, чей порог участия ниже 200. Если количество таких людей достигает 500 человек, то на третий день к протестам присоединяются люди с порогом выше 700 — а это может быть уже несколько тысяч человек.
Модель мятежа
Каждый из N человек под номером i имеет порог участия в мятеже T(i)∈{0, 1, …, N}. На первоначальном этапе к мятежу присоединяется любой человек с нулевым порогом участия T(i) = 0. Значение R(t) равно количеству людей, присоединяющихся к мятежу в момент времени t. Человек i участвует в мятеже в момент t, если T(i) < R(t − 1).
Анализ модели показывает, что разброс пороговых уровней имеет как минимум такое же значение, что и средний порог. Мы поймем, почему это так, сравнив три сценария формирования общественного движения с участием 1000 человек. Согласно первому сценарию, все имеют порог 10, поэтому никакого общественного движения не возникает. Во втором сценарии у пяти человек порог 0, у десяти — порог 1, а у всех остальных — 20. По этому сценарию, в начале к движению присоединяются 5 человек, на следующий день — еще 10 человек. После этого не присоединяется никто. В третьем сценарии каждый человек имеет уникальный порог в диапазоне от 0 до 999. Для удобства пронумеруем людей от 0 до 999 в соответствии с их порогами, то есть у человека с номером i порог i. За первый день присоединяется человек 0. На второй день — человек 1. На третий день — человек 2. И так каждый последующий день до тех пор, пока количество участников движения не достигнет 1000 человек. В первом сценарии самый низкий средний порог, но он не приводит к появлению общественного движения, поскольку ни у кого нет нулевого порога. Согласно второму сценарию, у некоторых людей есть нулевой порог, но их количества недостаточно для формирования масштабного общественного движения. И только в третьем сценарии общественное движение получает широкое распространение.
Модель раскрывает важность распределения порогов, а не только среднего их значения и, соответственно, указывает на трудности прогнозирования того, какие общественные движения будут успешными. Она также может выступать в качестве руководства к действию, информируя революционеров, планирующих поднять восстание против тирана, о том, что для его начала им понадобится не только основная группа протестующих, но и группа людей, которые их поддержат. Варианты модели мятежа можно применить к овациям стоя, изменению политических взглядов (признание прав гомосексуалистов), модным тенденциям (ношение галстуков-бабочек) и рыночной динамике (участие в фондовом рынке или в пузыре на рынке недвижимости). В каждом из этих случаев поведение людей можно примерно предугадать с помощью порогового правила, причем у разных людей разный порог. Во всех этих ситуациях вероятность крупного события (будь то массовое движение или увлечение очками с более толстой оправой) может в той же или в большей степени зависеть от распределения порогов, чем от среднего значения порога.
СОЗДАНИЕ РЫНКА И ДВОЙНЫЕ МЯТЕЖИ
Модель мятежа можно расширить на интернет-стартапы, создающие новые рынки покупателей и продавцов. Для создания нового рынка стартап должен сформировать совокупность покупателей и совокупность продавцов. На сайте, который помогает владельцам собак и тем, кто занимается выгулом собак, должны зарегистрироваться как хозяева собак, так и собачьи няни. Аналогичные стимулы существуют и для сайтов, предлагающих такие услуги, как доставка посылок, транспортные перевозки и уборка домов и квартир. Успех каждого такого сайта зависит от формирования двух совокупностей, причем их численность должна расти примерно одинаковыми темпами — иначе либо продавцы, либо покупатели не смогут найти свою пару и испытают разочарование. Другими словами, стартап должен организовать одновременный двойной мятеж.
Успешный стартап Airbnb — наглядный мини-пример двойного мятежа. Airbnb сводит людей, желающих сдать в аренду дом, комнату или квартиру, с людьми, которые ищут, где остановиться на непродолжительное время. Airbnb требовалось сформировать две группы: арендаторов и арендодателей. Люди, которые ищут сдаваемое в аренду жилье, посетят сайт только при условии, что на нем есть широкий выбор объявлений о сдаче жилья. Поэтому Airbnb было нужно, чтобы на сайте зарегистрировались владельцы квартир, желающие сдать их в аренду. Однако первые два запуска сайта Airbnb оказались неудачными. Размещение на сайте объявлений о сдаче жилья требовало определенных усилий — загрузки фотографий и прочей информации. Но ни у кого не было особого стимула этим заниматься, пока на сайте не сформировалась большая группа арендаторов.
Таким образом, Airbnb требовалось разместить достаточно объявлений о сдаче жилья в аренду, чтобы организовать мятеж среди арендаторов, то есть привлечь их на сайт. Кроме того, в Airbnb нуждались в достаточном количестве арендаторов, чтобы организовать мятеж среди арендодателей. Успех Airbnb зависел от пороговых значений этих двух групп. Сложнее всего было убедить людей размещать свои объявления на сайте, поскольку это требовало дополнительных усилий. В Airbnb решили эту задачу так: ходили по домам и помогали людям это делать. И однажды все срослось: начался мятеж арендаторов, за которым последовал мятеж арендодателей [2]. Компания добилась успеха, потому что ее основатели сумели привлечь оптимальное количество первых арендаторов, для того чтобы далее последовал двойной мятеж. Основатели Airbnb создали хвост, который начал вилять собакой.
ДВЕ МОДЕЛИ СЕГРЕГАЦИИ
Две следующие модели, разработанные Томасом Шеллингом, описывают сегрегацию. Разделение людей по расовому и этническому признаку происходит в разных масштабах. Мы разделены по странам и регионам внутри стран. США — по районам городов и даже по столам в школьных столовых. Хотя эти факты можно истолковывать как свидетельство нетерпимости, такой вывод противоречит росту числа межрасовых и межэтнических браков. Как одни и те же люди, предпочитая не жить поблизости и даже не обедать за одним столом с представителями других рас, могут при этом вступать с ними в брак?
Эти факты можно было бы объяснить, если бы межрасовые браки заключались между представителями конкретных социальных классов. Но это не так. Уровень дохода здесь ни при чем, а разделенные по расовому признаку столы можно встретить даже в самых элитных колледжах и университетах. Модели Шеллинга учитывают оба набора фактов, показывая, как толерантность людей может обусловить сегрегацию.
Первую из двух моделей, модель вечеринки Шеллинга, можно рассматривать как смешение модели случайного блуждания и модели мятежа. Модель описывает вечеринку, которая проходит в доме с двумя комнатами. Хозяева вечеринки пригласили гостей, которые зримо делятся на два типа. Это могут быть мужчины и женщины, чернокожие и белые, испанцы и австралийцы, готы и качки. Ключевое предположение — каждый человек может определить тип любого другого человека.
Модель вечеринки Шеллинга
Каждый из N человек относится к различимому типу A или B. Каждый человек в случайном порядке выбирает одну из двух комнат. В каждый момент времени человек переходит в другую комнату с вероятностью p. Человек i имеет порог толерантности Ti и покидает комнату, если в ней процент людей его типа становится ниже этого порога.
Для того чтобы понять, как сегрегация возникает вопреки наличию толерантности, представьте себе вечеринку с участием 20 австралийцев и 20 бразильцев. Всем гостям свойственна толерантность и каждый будет оставаться в комнате до тех пор, пока 25 процентов присутствующих принадлежат к той же этнической группе. Предположим, что сначала в одной комнате находится 12 австралийцев и 9 бразильцев, а в другой 8 австралийцев и 11 бразильцев. Никто не считает нужным переходить в другую комнату, однако между комнатами происходят случайные перемещения, меняющие процентное соотношение людей в каждой комнате. В результате, как показано на рис. 19.1, в одной комнате оказываются 11 австралийцев и только 4 бразильца. Эта конфигурация находится на грани переломного момента: если кто-то из бразильцев выйдет из комнаты, процент бразильцев упадет ниже 25, что заставит оставшихся бразильцев тоже покинуть комнату. Если это произойдет, бразильцы больше в нее не войдут.
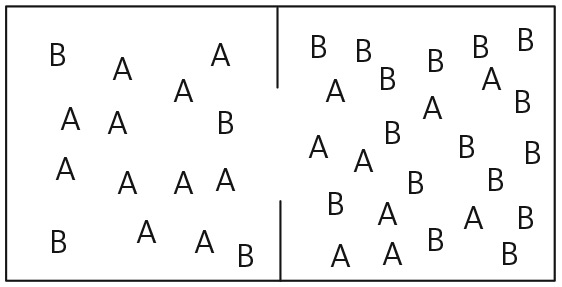
Рис. 19.1. Конфигурация, близкая к возникновению сегрегации
Как отмечалось в описании модели случайных блужданий, одномерное случайное блуждание способно преодолеть любой порог. А количество австралийцев в комнате и есть одномерным случайным блужданием. Поэтому, если вечеринка продлится достаточно долго, сегрегация неизбежна. Однако даже лучшие вечеринки столько не длятся, так что не все заканчиваются сегрегацией. Мы также знаем, что на вечеринках со множеством гостей вероятность сегрегации ниже, поскольку случайному блужданию требуется преодолеть гораздо более высокий порог. На вечеринке с участием 1000 гостей, проходящей в двух одинаковых комнатах, доля гостей любого типа вряд ли упадет ниже 25 процентов. Это возможно на вечеринке с участием 12 гостей. Стало быть, на небольших вечеринках следует ожидать более высокого уровня сегрегации.
Более высокого уровня сегрегации следует ожидать и в случае, когда у людей разные значения порога толерантности. Для того чтобы понять, почему, предположим, что на вечеринку приглашены 10 бразильцев и 10 австралийцев, и присвоим каждому из них порог толерантности в диапазоне от 5 до 43 процентов таким образом, чтобы средний порог толерантности в каждой группе составлял 25 процентов, как показано на рис. 19.2.
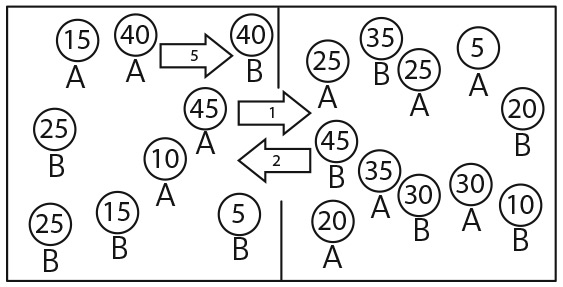
Рис. 19.2. Перемещения, обусловленные неоднородностью порогов толерантности
В комнате слева находятся 5 бразильцев и 4 австралийца, а значит, доля австралийцев ниже 45 процентов, что заставляет наименее толерантного австралийца перейти в комнату справа (обозначено стрелкой 1). Переходя в другую комнату, он сокращает в ней долю бразильцев, что вынуждает наименее толерантного бразильца перейти в другую комнату (обозначено стрелкой 2). Оба перемещения снижают долю австралийцев ниже 40% в комнате слева, что вынуждает второго наименее толерантного австралийца следовать за ним в комнату справа (обозначено стрелкой 2). Далее следует каскад переходов. Тем не менее, как показано на рис. 19.3, в результате не всегда наступает полная сегрегация, поскольку самые толерантные люди комфортно себя чувствуют в любой комнате. Модель порождает два следствия разброса порогов: они делают перелом в сторону сегрегации более вероятным, а полную сегрегацию менее вероятной, так как люди с высоким уровнем толерантности довольны пребыванием в любой комнате.
Рис. 19.3. Сегрегация, обусловленная неоднородностью порогов толерантности
Эта модель помогает объяснить различие в соотношении числа мужчин и женщин в разных профессиях — почему среди медсестер больше женщин, а среди менеджеров по продажам — мужчин. Такие различия могут быть обусловлены личными предпочтениями, но могут возникать и потому, что некоторые люди предпочитают работать вместе с представителями того же пола. Эту ситуацию можно формально описать с помощью модели вращающейся двери, в которой делаются два основанных на эмпирических наблюдениях допущения: 1) женщины, которые уходят из одной профессии, выбирают новую профессию с большим количеством женщин; 2) женщины уходят из профессий чаще, чем мужчины [3]. Если женщины, занимающиеся науками о жизни, бросают медико-биологические исследования чаще, чем мужчины, и переходят на работу в те профессиональные области, где работает больше женщин, скажем в сферу здравоохранения, то их действия усиливают гендерную сегрегацию в обеих профессиях.
МОДЕЛЬ СЕГРЕГАЦИИ ШЕЛЛИНГА
В модели сегрегации Шеллинга агенты размещены в разных точках географического пространства в виде разделенной на клетки плоскости (шахматной доски). Во всем остальном модель аналогична модели вечеринки. В ней выделено два типа людей и делается такое же допущение в отношении поведения, как и в модели вечеринки Шеллинга.

Рис. 19.4. Исходная конфигурация в модели сегрегации Шеллинга
Модель сегрегации Шеллинга
N человек, каждый из которых относится к типу A или B, в случайном порядке размещены на разделенной на квадраты плоскости размером M на M, где остается свободное пространство. Каждый человек i имеет порог толерантности Ti и перемещается на выбранное случайным образом новое место, если процент людей его типа на восьми соседних квадратах становится ниже его порога.
Если средний порог толерантности людей близок к 50 процентам, модель порождает сегрегацию, как показано на рис. 19.5. Сегрегация возникает потому, что люди учитывают только окрестности, включающие максимум восемь соседей. Практически любая случайная исходная конфигурация содержит несколько человек, окруженных людьми другого типа. Если люди перемещаются в области с большим количеством людей того же типа, это может обусловить перемещение людей другого типа. Сегрегация наступает в результате накопления таких перемещений. Нет необходимости снова выстраивать цепочку логических рассуждений о том, почему разброс порогов усугубляет эти эффекты.

Рис. 19.5. Конфигурация в модели сегрегации Шеллинга, сформировавшаяся после перемещений
То, что толерантность людей может порождать сегрегированную структуру расселения, является базовой идеей основополагающего труда Томаса Шеллинга Micromotives and Macrobehavior40: то, что происходит на макроуровне, не обязательно напрямую связано с мотивацией индивидов на микроуровне.
ПОРОГОВЫЕ МОДЕЛИ С ОТРИЦАТЕЛЬНОЙ ОБРАТНОЙ СВЯЗЬЮ
Наша следующая модель, модель пинг-понга, описывает пороговое поведение, порождающее отрицательные обратные связи. Вспомните о том, что отрицательная обратная связь может стабилизировать систему или, как мы видели в модели «хищник — жертва», продуцировать циклы. Данная модель включает в себя конечное число объектов, которые могут быть людьми или механическими, биологическими и химическими устройствами. В течение каждого периода каждый объект совершает либо положительное (+1), либо отрицательное (−1) действие. В первом периоде каждый агент выбирает произвольное действие. Исходное состояние системы равно сумме этих действий. Все последующие состояния системы равны ее состоянию за предыдущий период плюс среднее всех действий и случайный член. Каждый объект имеет пороговое значение, взятое из распределения, и выбирает действие, уменьшающее абсолютное значение состояния, если оно превышает его порог. Проще говоря, если значение состояния превышает порог объекта (на положительную или отрицательную величину), объект делает все возможное, чтобы уменьшить величину состояния.
Модель пинг-понга
Каждый объект в совокупности размером N в случайном порядке совершает исходное положительное (+1) или отрицательное (−1) действие. Исходное состояние системы S0 устанавливается равным нулю. Все будущие состояния системы St равны среднему действию плюс случайная переменная:
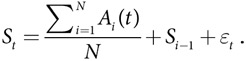
Каждый объект i имеет порог отклика Ti > 0, выбранный равномерно из интервала [0, RANGE]. Объект выполняет то же действие, что и раньше, если величина состояния |St| меньше его порога, и стремится к уменьшению величины состояния в противном случае.
Если |St| ≤ Ti, Ai(t + 1) = Ai(t).
В противном случае At(t + 1) = −signSi(t), где εt выбрано случайным образом из множества {−1, +1}.
Существует множество сфер применения модели пинг-понга. Вот пример двух применений данной модели. Люди вкладывают время и ресурсы в различные благотворительные проекты. Если какой-то благотворительный проект получает слишком много внимания или денег, люди могут переключиться на другие проекты, чтобы выровнять их доходы. Или, например, в стране может находиться два объекта мирового наследия ЮНЕСКО, за состоянием которых следят волонтеры. Если на одном объекте слишком много волонтеров, некоторые могут перенаправить свою энергию на другой объект.
Как следует из самого названия, модель пинг-понга может порождать циклическое поведение в рамках равновесия. В одном периоде слишком много людей выбирают одно действие, а в другом — другое действие. Когда все объекты имеют нулевой порог, они все выбирают действие «плюс один» (+1) в первый период и действие «минус один» (−1) в следующий период.
Для того чтобы проанализировать, почему от разброса порогов зависит, действуют ли люди подобно шарикам для пинг-понга или находят равновесие, давайте рассмотрим три случая с участием 100 человек. В первом случае будем исходить из того, что пороги равномерно распределены от 0 до 10. Если состояние в первом периоде равно −6, то это значение превышает порог примерно 60 человек. Около 30 из этих 60 человек выполняют действие «плюс один» и переключаются на другие действия. Теперь сумма действий превышает 50, а значит, новое состояние системы (среднее состояний за два предыдущих периода) превышает 20. Это значение превышает все пороги, создавая эффект пинг-понга, показанный на верхнем графике на рис. 19.6.
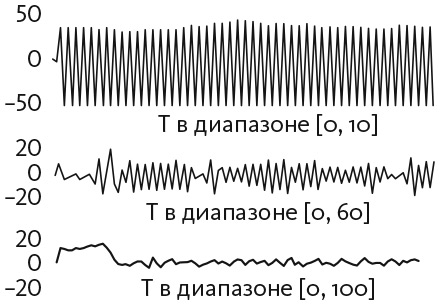
Рис. 19.6. Временной ряд для модели пинг-понга в трех вариантах диапазона порогов
Если увеличить разброс порогов, сделав их равномерно распределенными в диапазоне от 0 до 100, эффект пинг-понга исчезнет. Чтобы понять, почему, предположим, что в первом периоде состояние равно −6, что в среднем отвечает порогу только шести человек. Если три человека изменят свои действия, состояние будет сходиться к нулю. Такое уменьшение отклонения отображено на нижнем графике на рис. 19.6, который соответствует пороговым значениям в диапазоне от 0 до 100. Как и следовало ожидать, в промежуточном случае, когда пороги равномерно распределены в диапазоне от 0 до 60, имеет место более умеренный цикл, как видно на среднем графике. Таким образом, в системах с отрицательной обратной связью разброс порогов обеспечивает стабильность, но оказывает противоположный эффект в моделях с положительной обратной связью.
РЕЗЮМЕ: СТЕПЕНЬ ДЕТАЛИЗАЦИИ МОДЕЛИ
Базовая логика обратных связей довольно проста: положительная обратная связь активизирует действия, отрицательная — подавляет. Система с только положительными обратными связями либо взорвется, либо потерпит крах. Система с только отрицательными обратными связями либо стабилизируется, либо сформирует цикл. Система как с положительными, так и с отрицательными обратными связями может порождать сложность.
В моделях системной динамики обратные связи воздействуют на переменные величины запаса (количество зайцев) и скорость (повышение частоты покупок в булочной). В агентных моделях (таких как пороговые модели) обратные связи являются следствием отдельных действий. Модели с более высоким уровнем детализации могут включать диапазон порогов, что усиливает эффект позитивной обратной связи и ослабляет эффект негативной обратной связи. Разброс в хвосте кривой распределения делает мятежи более вероятными. Разброс порогов толерантности усиливает сегрегацию. Разброс ответных реакций в системах с отрицательной обратной связью прекращает большие колебания, возникающие в случае однородных обратных связей. В моделях экономической конкуренции между компаниями неоднородные издержки производства могут выполнять аналогичную функцию. Ответная реакция компаний на повышение или падение цен зависит от различий в издержках [4].
Разница между двумя типами моделей поднимает вопрос о степени детализации. Следует ли вводить переменную (или прямоугольник) под названием «зайцы» и описывать, как популяция зайцев увеличивается или сокращается в зависимости от других переменных, или целесообразнее смоделировать каждого зайца в отдельности? Дезагрегирование переменных повышает точность описания, однако модели оценивают не по этому критерию. Вспомните утверждение Бокса о том, что все модели неправильны, а также карту Борхеса, составленную в реальном масштабе. Многие создатели моделей, включая Эйнштейна, придерживаются мнения, что следует искать оптимальный уровень детализации. Например, в описание модели, объясняющей, какой силой обладает рука человека, нет необходимости включать ДНК.
Для изучения социальных систем может не существовать идеального уровня. Возможно, такие системы понадобится исследовать на нескольких уровнях детализации. Построение ряда моделей со своим уровнем детализации позволяет организовать между ними диалог. Если мы пытаемся разобраться в структуре торговли между Швецией и Финляндией, можно начать с представления этих двух стран в качестве переменных и определить широкие макроструктуры. Далее мы могли бы разделить импорт и экспорт каждой страны по отраслям, а затем по компаниям внутри этих отраслей. Данные по отраслям позволят лучше объяснить структуру торговли за прошедший период и сделать более точные прогнозы на будущее. Более глубокий анализ данных по компаниям, работающим в соответствующих отраслях (в том числе информация о структуре издержек и направлениях развития), позволил бы получить еще более весомые результаты, но для этого понадобится большой объем информации для построения полезной модели с таким количеством динамичных элементов. Можно даже смоделировать структуру руководства в этих компаниях. Скорее всего, это не принесет особой пользы, однако может выявить, что некоторые руководители придерживаются экспансионистской стратегии.
В общем случае более высокая степень детализации — это не всегда хорошо, поскольку модели могут включать слишком много деталей. Но даже когда мы можем понять излишне подробные модели, мы выигрываем от построения более приближенных моделей как элемента сравнения. При сопоставлении различий в прогнозах, объяснениях и рекомендациях по политике, составленных с помощью этих моделей, мы может отследить, как исходные допущения влияют на результаты, что позволяет определить условия, при которых эти допущения выполняются. Следовательно, модели должны отличаться не только по переменным, которые они содержат, но и по степени дезагрегации этих переменных.
Алгоритмические мятежи
Модели мятежа и пинг-понга помогают лучше понять причины биржевого краха и отскока цен. Здесь мы рассмотрим два показательных случая. Первый произошел в понедельник, 19 октября 1987 года, когда индекс промышленных акций Доу-Джонса упал на 22 процента. На следующий день этот обвал вызвал резонанс во всем мире. Причины краха анализируют до сих пор. В тот период экономика США переживала четвертый год подъема. За первых восемь месяцев года индекс промышленных акций Доу-Джонса вырос на 40 процентов. Несмотря на, а может, и по причине столь стремительного роста многие считали курс акций завышенным. В воскресенье накануне биржевого краха министр финансов США Джеймс Бейкер пригрозил ослабить доллар, если Германия не снизит тарифы. Но тогда этот комментарий не вызвал особого интереса. На следующий день рынок рухнул, а через четырнадцать месяцев вернулся в прежнее состояние.
Для того чтобы применить эти модели, представим весь рынок в виде одного финансового актива. Допустим, каждый владеющий этим активом человек имеет определенный порог обвала. Если в течение дня цена актива падает ниже порога обвала, инвестор продает актив и выводит свои деньги с рынка. Это правило описывает поведение трендовых и шумовых трейдеров и создает один из вариантов модели мятежа. Предположим, что утром 19 октября определенный процент инвесторов решили продать значительный объем активов и это вызвало падение рынка. Если оно превысило порог обвала других инвесторов, они тоже продадут свои активы, из-за чего образуется спираль снижения цен. В результате формируется классическая петля положительной обратной связи: продажа активов приводит к снижению цен, что обусловливает дальнейшую продажу активов.
Теперь проанализируем информацию, полученную с помощью модели пинг-понга. Если цены падают слишком низко, некоторые инвесторы применяют другое правило, правило порогового значения выгодной цены. Согласно ему человек покупает активы, если цена падает ниже этого значения. В данном случае инвестор действует с учетом стоимости, а не трендов. Когда цены резко падают, пороговое значение выгодной цены создает отрицательную обратную связь. Покупатели спешат купить активы по выгодной цене, что останавливает падение цен.
Реальные рынки гораздо сложнее, чем наша простая история о продавцах с пороговыми ценами и покупателях, ждущих своего часа. На фондовом рынке работают разные трейдеры, в том числе крупные учреждения, пенсионные фонды, правительства зарубежных стран, страховщики портфелей, спекулянты и мелкие инвесторы [5]. При таком разнообразии кто-то почти всегда готов покупать активы в случае падения цен, что порождает отрицательную обратную связь, необходимую для стабилизации рынка.
Первоначальный анализ биржевого краха 1987 года указывал на широкое распространение программного трейдинга. Речь идет о пороговых правилах, закодированных в компьютерных программах. Такие правила (например, «Продать все акции, если рыночный индекс упадет ниже установленной цены») выполнялись автоматически, без участия человека. Сегодня большинство аналитиков убеждены, что программный трейдинг способствовал наступлению биржевого краха 1987 года, но не был его основной причиной. Более детальный анализ краха 1987 года показал, что большое количество страховщиков портфелей (трейдеров, которые гарантируют инвесторам определенную доходность инвестиционных портфелей) создали сильные положительные обратные связи, которые не были смягчены отрицательными обратными связями. После падения рынка страховщики портфелей начали продавать акции, чтобы предотвратить убытки. И по мере дальнейшего обвала продавали все больше акций. По сути, они действовали так, будто представляли группы людей с разными порогами. Один страховщик продал акций на более чем миллиард долларов. Для того чтобы оценить происходящее в более широком контексте, обратите внимание на тот факт, что только за один день было продано акций на сумму 20 миллиардов долларов.
Второе крушение фондового рынка, известное как «мгновенный обвал», произошло 6 мая 2010 года, когда индекс промышленных акций Доу-Джонса упал на 5 процентов за три минуты. Это событие стало результатом алгоритмического трейдинга. Учитывая сложность и скорость современных финансовых рынков, никто точно не знает, что именно послужило причиной столь мгновенного обвала. Известно только, что один крупный взаимный фонд разместил огромный приказ на продажу, в результате чего фьючерсные сделки с акциями на сумму 4 миллиарда долларов наводнили рынок, на котором действовали алгоритмы высокочастотного трейдинга, пытающиеся использовать выгодные сделки. Эти алгоритмы обнаружили ценовой тренд и начали исполнять сделки с головокружительной скоростью. Это можно представить как скоростную модель мятежа. В итоге на рынке сложилась нездоровая ситуация: трейдеры заволновались, что крупные институциональные инвесторы знают то, чего не знают они, поэтому покинули рынок [6]. Многие алгоритмы прекратили трейдинг, учитывая аномальное поведение рынка, тогда как другие продолжали продажу, что привело к обвалу, наступившему буквально за пару минут. В течение двадцати минут начали действовать правила выгодной цены и, как и предсказывала модель пинг-понга, цены вернулись (почти) к прежнему уровню.
ГЛАВА 20
ПРОСТРАНСТВЕННЫЕ И ГЕДОНИЧЕСКИЕ МОДЕЛИ ВЫБОРА
Мы считаем, что если вам нужно спрашивать своих пользователей, что вы продаете, значит, вы сами не знаете, что продаете, и это вряд ли останется незамеченным.
Марисса Майер
В этой главе мы рассмотрим модели индивидуального выбора альтернатив, представленных их характеристиками (атрибутами). Эти модели разрабатывались для описания потребительского выбора. Человек при покупке дома учитывает его площадь, количество спален, ванных комнат и качество строительства. Такие модели также помогают деканам приемных комиссий колледжей делать выбор среди абитуриентов, менеджерам по найму персонала — среди претендентов на вакантные должности, а избирателям — среди кандидатов. Декан приемной комиссии анализирует результаты отборочных тестов будущих студентов, их средний академический балл и пройденные факультативы. Избиратель оценивает кандидатов на основании их позиции по вопросам образования, инфраструктуры, преступности и налогов. Эти модели не только помогают понять суть индивидуального выбора, но и поясняют, почему он именно такой — например, почему у нас столь широкий ассортимент готовых зерновых завтраков.
В рассматриваемой нами модели мы будем называть одни атрибуты пространственными, а другие гедоническими41. Пространственный атрибут, такой как цвет куртки или толщина куска хлеба, не имеет конкретного наибольшего значения. Каждый человек предпочитает определенную величину соответствующей характеристики: у любителя свиных ребрышек есть предпочтительное сочетание специй, а у горнолыжника-любителя — предпочтительный угол спуска по склону. Модель основывается на допущении, что чем ближе свойства продукта к идеальной точке человека, тем больше человек ценит этот продукт. Но у разных людей разные идеальные точки: одному человеку нравятся более острые свиные ребрышки, а другой предпочитает более мягкий вкус.
В случае гедонических характеристик, чем больше (а иногда чем меньше) их величина, тем лучше. Люди предпочитают смартфоны с аккумуляторами большей емкости, обувь с более прочной подошвой и автомобили с меньшим расходом бензина. Цвет автомобиля — это пространственный атрибут, а расход бензина — гедонический.
В этой главе мы будем исходить из предположения, что люди выбирают ту альтернативу, которая представляет для них наибольшую ценность. И сделаем это по причинам, упомянутым в главе 4, посвященной моделированию человеческого поведения: рациональное поведение выступает в качестве эталона, аналитически разрешимо, дает уникальный прогноз и соответствует эмпирическим наблюдениям, когда ситуация повторяется, а ставки высоки.
Модели пространственной и гедонической конкуренции широко используются в экономике и политологии — отчасти из-за возможности включить в них данные [1]. В этой главе вы получите представление об их применимости. Сначала мы рассмотрим пространственную модель продуктовой конкуренции. Затем применим ее к политике и покажем, как ее можно использовать для анализа эффекта статус-кво, силы повестки дня и влияния вето-игроков42. Далее опишем модель гедонических атрибутов и гибридную модель для более глубокого понимания сути ценовой конкуренции и параллельно продемонстрируем, как ввести данные в модели, чтобы определить позицию кандидатов и судей на основе их голосования по законопроектам и судебным делам и сделать выводы об имплицитной стоимости атрибутов, не имеющих рыночной цены, таких как более чистый воздух или более короткая дорога на работу [2].
МОДЕЛЬ ПРОСТРАНСТВЕННОЙ КОНКУРЕНЦИИ
Модель пространственной конкуренции описывает альтернативы, представленные совокупностью характеристик (атрибутов), и потребителей со свойственными им идеальными точками. Простейшая версия модели анализирует продукты с одним атрибутом. В оригинальной пространственной модели Хотеллинга им является географическое местоположение [3].
Модель Хотеллинга включает совокупность расположившихся вдоль пляжа потребителей (представлены кружками на рис. 20.1) и двух продавцов мороженого (обозначены символами A и B). Каждый клиент покупает одну пачку мороженого у ближайшего продавца. Точка раздела находится на равном расстоянии от двух продавцов и определяет, кто у кого покупает мороженое. Семь потребителей слева от точки раздела покупают у продавца A, а шесть потребителей справа от точки раздела покупают у продавца B.
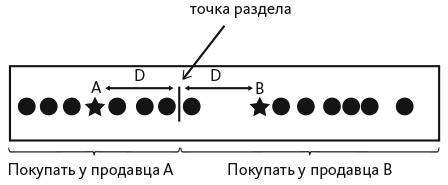
Рис. 20.1. Географическая модель Хотеллинга, описывающая продавцов мороженого на пляже
Учитывая тот факт, что потребители предпочитают товары, которые продаются ближе, мы можем более абстрактно интерпретировать расстояние. Например, можем представить, что продавцы мороженого находятся в одном месте, но предлагают мороженое с разным процентом жирности. Тот же рисунок может отражать информацию о том, что продавец B предлагает более сливочный продукт, чем продавец A. В этой интерпретации местоположение потребителей — это не их физическое место на пляже, а предпочтительная жирность мороженого.
В этом случае также можно применить многомодельное мышление и использовать эту же модель для анализа политической конкуренции. В модели Даунса географическое пространство Хотеллинга представлено как идеологический континуум от левых до правых сил. Мы можем видоизменить рис. 20.1 так: продавцу A соответствует либеральный политический кандидат, продавцу B — более консервативный, а кружки обозначают идеологические идеальные точки избирателей. Расширяя аналогию дальше, будем исходить из допущения, что избиратели предпочитают ближайших кандидатов.
Смещение акцента с географического местоположения компаний и свойств продуктов на политическую идеологию подразумевает переход от физических характеристик, таких как место и процент жирности, к более абстрактной концепции идеологии. Существуют четкие критерии оценки физических характеристик, однако определение идеологических позиций требует конкретного способа преобразования действий кандидатов в цифры. Если есть документы с информацией о голосовании кандидатов, мы можем установить их идеологическую позицию, сначала собрав данные о том, за что они отдавали свои голоса. При этом следует исключить все голосования по вопросам, не содержащим идеологической составляющей, как в случае единодушногоголосования за введение национального Дня молока или чего-то в этом роде. В остальных случаях можно определить позицию кандидата как либеральную или консервативную, опираясь на мнение экспертов. Пространственное расположение кандидата в интервале значений можно представить в виде процента случаев, когда он голосует в соответствии с консервативной позицией [4]. Кандидата, который всегда занимает консервативную позицию, следует разместить у крайнего правого края интервала. Кандидата, который голосует как консерватор и как либерал в соотношении 50 на 50, необходимо расположить в центре.
Эта модель позволяет оценить истинность утверждений о том, что идеологические различия между американскими политическими партиями становятся все более заметными, о чем говорят эмпирические данные. Одно исследование, результаты которого представлены на рис. 20.2, указывает на усиливающуюся поляризацию средних идеальных точек в каждой партии. Это не доказывает, что поляризация усилилась, но свидетельствует о текущем процессе. Результаты исследования также показывают, что позиция республиканцев смещается вправо.
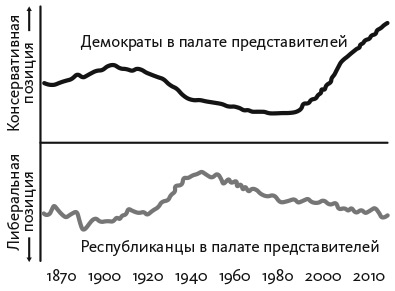
Рис. 20.2. Усиление идеологической поляризации в Конгрессе США
УВЕЛИЧЕНИЕ КОЛИЧЕСТВА АТРИБУТОВ
Общая модель пространственной конкуренции включает произвольное количество атрибутов. Диван может быть представлен физическими параметрами: длина, ширина, глубина, тип конструкции и тип обивки. Ценность (полезность), которую потребитель получает от продукта, зависит от расстояния этого продукта до идеальной точки потребителя по каждому параметру. Мы можем записать эту функцию ценности как постоянная минус расстояние между альтернативой и идеальной точкой [5].
Модель пространственной конкуренции
Альтернатива состоит из N пространственных атрибутов: 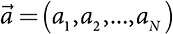 .
.
Человек представлен идеальной точкой: 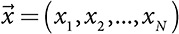 .
.
Выигрыш (полезность) альтернативы для человека составляет:
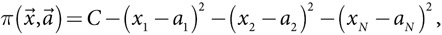
где C — константа.
Пример: 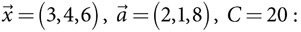
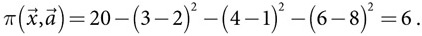
В общей модели пространственной конкуренции два шоколадных батончика можно представить с помощью процентного содержания в них какао и сахара (как показано на рис. 20.3). В качестве линии раздела выступает серединный перпендикуляр к линии, соединяющей оба продукта. Потребители с идеальными точками слева от линии раздела предпочитают батончик A, а потребители справа — B [6].
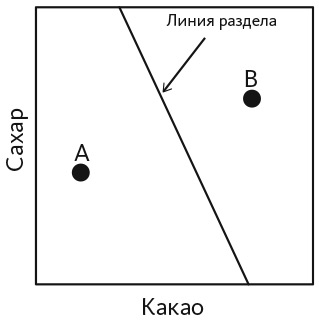
Рис. 20.3. Продуктовые характеристики двух шоколадных батончиков и линия раздела
Эта модель может описывать любое количество продуктов. Чтобы включить в нее третий шоколадный батончик, добавим еще одну точку в пространстве характеристик. Затем, чтобы определить, какой шоколадный батончик будут покупать потребители, начертим дополнительные линии раздела, как показано на рис. 20.4. Полученная совокупность линий раздела делит пространство идеальных точек на три области (известные как окрестности Вороного), которые разбивают пространство идеальных точек на основании их расстояния до продуктов.
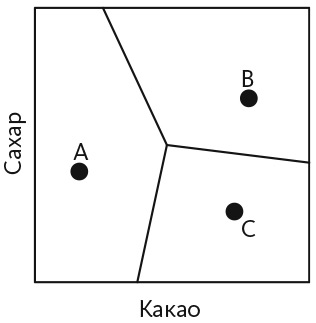
Рис. 20.4. Пространственная модель, включающая в себя три продукта (окрестности Вороного)
ДАУНСОВСКАЯ МОДЕЛЬ ПРОСТРАНСТВЕННОЙ КОНКУРЕНЦИИ
Теперь используем модель пространственной конкуренции для описания позиционирования кандидатов. Для этого предположим, что кандидаты добиваются голосов избирателей и для них крайне важна победа на выборах. Начнем с примера, позволяющего получить представление о мотивах кандидатов. На рис. 20.5 представлены два сценария с участием тринадцати избирателей и двух кандидатов. Вспомним, что избиратели предпочитают ближайшего кандидата. На верхнем рисунке либеральный кандидат, обозначенный символом L, получает пять голосов, а консервативный, обозначенный символом R, — восемь. На нижнем рисунке либеральный кандидат перемещается в центр, получает голоса семи избирателей и выигрывает выборы.
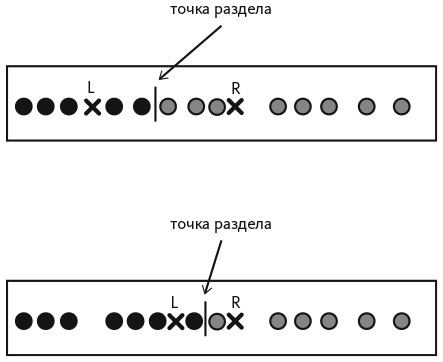
Рис. 20.5. Перемещение партии в центр ради победы в выборах
У либерального кандидата есть стимул переместиться в центр. Согласно той же логике, и у консервативного кандидата тоже. Консервативный кандидат может двигаться влево, по-прежнему оставаясь справа от L, и тоже победить. Если продолжить логические построения, то либеральный кандидат L может занять позицию еще ближе к идеальной точке медианного избирателя. Следуя далее этой логике, мы увидим, что кандидаты должны сойтись в этой точке. Такой результат известен как теорема о медианном избирателе.
У теоремы о медианном избирателе есть строгая и менее строгая интерпретация. Строгая интерпретация подразумевает, что кандидаты занимают идентичные позиции в идеальной точке медианного избирателя, что явно не соответствует эмпирическим данным. Согласно менее строгой интерпретации, у кандидатов есть стимулы перемещаться в сторону умеренных позиций. Эмпирические данные подтверждают, что в действительности именно так и есть. Во время выборов кандидаты смещаются к центру, однако такое перемещение не должно происходить поспешно. Кандидаты, имеющие идеологические убеждения или активную поддержку наиболее радикальных ключевых сторонников, весьма осмотрительно меняют свои позиции.
Модель сводит каждого кандидата и каждого избирателя к одной идеологической точке. Чешский писатель и политик Вацлав Гавел возражает против одномерных идеологических прогнозов: «Неприкаянному человеку она [идеология] предлагает легкодоступное убежище: достаточно принять эту идеологию — и все опять становится ясным, жизнь наполняется смыслом, отступают неясные вопросы, беспокойство и одиночество. Однако за это дешевое убежище человеку приходится дорого платить — отречением от собственного разума, совести и ответственности, а неизбежным следствием принятия этой идеологии будет делегирование разума и совести вышестоящим» [7]. Гавел прав. Мы не должны отрекаться от разума ради идеологии. Модели предоставляют нам инструменты, позволяющие более эффективно мыслить, и помогают понять, почему политики действуют именно так, а не иначе. Используя данные, мы можем определить достоверность расположения каждого политика в интервале «левые–правые». Политика, который всегда занимает умеренную позицию, можно поместить посредине этого интервала с высокой степенью достоверности.
Кстати, утверждение Гавела о том, что человека нельзя свести к одной точке, можно проверить на основе данных. Если оно верно, то есть определить идеологию политика по результатам его голосования невозможно, нам нет необходимости отбрасывать эту модель. Неопределенность в отношении идеологии Гавела можно представить, присвоив ему интервал, а не точку. Или сконструировать временной ряд его фактической идеологии, чтобы проверить, остается ли он последовательным. Анализ идеологических позиций членов Верховного суда США указывает на то, что чем больше времени некоторые судьи находятся на своих должностях, тем либеральнее становятся их взгляды [8].
И наконец, можно увеличить размерность модели. Двумерная модель позволяет провести различие между социальной и фискальной политикой. Она описывает действия политика, который занимает либеральную позицию по вопросам социальной политики и консервативную — по вопросам фискальной политики. В Конгрессе США одномерная модель объясняет примерно 83 процента разброса голосов. Включение второго измерения добавляет всего 4 процента [9].
Дополнительные измерения не только позволяют точнее моделировать предпочтения, но и меняют наши теоретические выводы. Начнем с двумерной модели. Как показывает анализ одномерной модели, когда кандидат не занимает среднюю позицию ни по одному вопросу, другой кандидат может выиграть выборы, если займет ту же позицию, что и первый кандидат, по одному вопросу (там самым делая этот вопрос неактуальным), и среднюю позицию по второму вопросу. Аналогично, если один кандидат занимает среднюю позицию только по одному вопросу, то второй кандидат может занять среднюю позицию по обоим вопросам и выиграть выборы. Следовательно, единственная позиция, в которой у кандидата есть шанс избежать поражения, — двумерная медиана. На рис. 20.6 показано, как победить двумерную медиану, представленную кружком. Если кандидат, обозначенный квадратом, занимает позицию слева по первому вопросу и позицию справа по второму, возникает линия раздела, благодаря которой он выиграет, набрав три голоса.
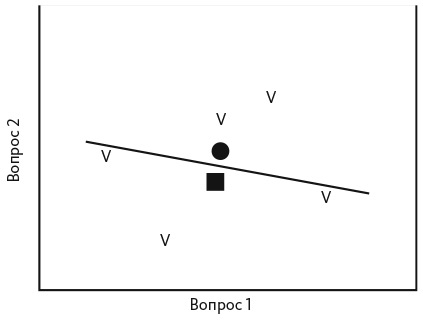
Рис. 20.6. Двумерная медиана проигрывает сопернику
Этот пример позволяет интуитивно понять, что данная двумерная медиана будет непобедима только тогда, когда идеальные точки избирателей расположатся таким образом, что их меньшая часть будет лежать во всех направлениях от медианы, — условие, которое называется радиальной симметрией. Условие радиальной симметрии будет удовлетворено, если идеальные точки избирателей равномерно распределятся по всему диску или квадрату, что маловероятно. Вывод о том, что любая позиция может быть побеждена, известен как вывод Плотта об отсутствии победителей. Он верен в случае двух и более измерений [10].
Разница в результатах, полученных с помощью этих моделей, очевидна. Одномерная модель подразумевает, что кандидаты должны располагаться в медианной точке. Многомерные модели говорят о том, что этого делать не стоит. Так какого типа моделям верить? Мы не должны полностью верить ни одной модели, но понять обязаны обе. Одномерная модель указывает на то, что у кандидатов, заинтересованных в голосах избирателей, есть серьезный стимул к смещению в сторону умеренной политики. Многомерные модели демонстрируют ограниченность таких стимулов. Ни одна позиция не гарантирует победы, поэтому ожидать равновесия не стоит. Вместо этого следует ожидать сложности — бесконечной борьбы за голоса избирателей посредством создания коалиций [11].
ЭФФЕКТ СТАТУС-КВО, КОНТРОЛЬ ПОВЕСТКИ ДНЯ И ВЕТО-ИГРОКИ
Даунсовскую модель можно также применять как инструмент интерпретации идеологических аспектов законопроектов, принятых комитетами, советами, законодательными органами и президентскими системами. Здесь опять же важно отобразить законодательные акты в том же идеологическом измерении, что и члены комитета. Мы проанализируем три стратегических эффекта: влияние проводимой политики (эффект статус-кво), сила контроля над повесткой дня и эффект включения игроков, обладающих правом вето.
Рассмотрим пример с участием комитета из трех человек с идеальными точками 40, 60 и 80, в котором члену комитета с идеальной точкой 40 предстоит предложить политический курс, требующий одобрения большинством голосов. На рис. 20.7 отображено влияние эффекта статус-кво на окончательный выбор курса. Если статус-кво находится в точке 80, автору предложения необходим закон, которому медианный участник голосования (член комитета с идеальной точкой 60) отдаст предпочтение перед статус-кво. В данном случае медианный участник голосования примет предложение в точке 40 (идеальной точке члена комитета, выдвинувшего это предложение), поскольку оно ничем не хуже статус-кво [12]. Если сместить статус-кво в точку 70, медианный участник голосования отклонит предложение с идеальной точкой 40. Член комитета, который его внес, должен предложить курс с идеальной точкой 50. И наконец, если статус-кво находится в идеальной точке медианного участника голосования 60, автор предложения не имеет никакой власти. Таким образом, можно сделать вывод, что автор предложения обладает наибольшим влиянием, когда статус-кво имеет предельное значение.

Рис. 20.7. Влияние статус-кво на окончательный выбор курса
Этот вывод актуален в любом контексте, где люди голосуют, а их мнение можно отобразить в одном измерении. Руководитель некоммерческой организации, предлагающий членам совета директоров увеличить расходы на программу строительства доступного жилья, почти не имеет силы повестки дня, если нынешний уровень расходов соответствует пожеланиям медианного члена совета директоров. Глава организации может обладать такой силой, если проводимая политика не отвечает идеалу этого члена совета директоров.
Для того чтобы продемонстрировать силу внесения предложений, давайте рассмотрим случай, когда статус-кво находится в точке 70, как показано на рис. 20.8. На верхнем рисунке отображен предыдущий случай, где автор предложения имеет идеальную точку 40 и предлагает курс в точке 50. На среднем рисунке представлен случай, в котором медианный участник голосования может предложить свою идеальную точку 60 и получить голос члена комитета в точке 40. Нижний рисунок отражает случай, когда автор предложения имеет идеальную точку 80. Он не может предложить курс, которому и он, и медианный участник голосования отдали бы предпочтение перед статус-кво, поэтому принимает статус-кво.

Рис. 20.8. Влияние статус-кво на окончательный выбор курса
Этот пример раскрывает пределы влияния автора предложения. Законодательная инициатива может смещаться в сторону идеальной точки человека, наделенного властью, но, как мы уже знаем, репрезентативность статус-кво снижает степень такого влияния [13].
И наконец, эту же модель можно использовать для анализа множества уровней управления и большого количества вето-игроков. Здесь мы представим трех членов комитета в качестве таких медианных участников голосования, как палата представителей, сенат и президент. Для принятия законопроекта каждый из троих должен отдать ему предпочтение перед статус-кво. В таком сценарии каждый игрок обладает правом вето. Давайте снова обратимся к рис. 20.8, где статус-кво находится в точке 70. Если все три участника голосования должны одобрить любое изменение, то ни одно предложение не сможет преодолеть статус-кво. Любой политический курс слева от точки 70 будет ветирован участником голосования с идеальной точкой 80. Любой курс справа от точки 80 будет заблокирован обоими оставшимися участниками голосования [14]. Если все трое могут наложить вето на законопроект, то не будет принят ни один новый закон, за исключением тех случаев, когда статус-кво попадает в интервал от 40 до 80 — другими словами, если нынешний статус-кво находится слева или справа от идеальной точки любого участника голосования. Данная модель раскрывает тесную связь между количеством и идеологическим многообразием вето-игроков и безвыходностью положения. Этот важный вывод актуален и в более общем случае. Организации со множеством разных вето-игроков не смогут действовать.
ГЕДОНИЧЕСКАЯ МОДЕЛЬ КОНКУРЕНЦИИ
В гедонической модели конкуренции альтернативы (как правило, продукты) также представлены характеристиками, но в ней они включают такие параметры, как качество, эффективность или цена, по которым большая (в случае цены меньшая) величина характеристики всегда предпочтительнее. Для того чтобы отобразить подобную неоднородность, модель позволяет присваивать этим параметрам разный вес.
Воспользовавшись линейной регрессией, можно оценить имплицитную величину характеристик товаров с помощью гедонической модели конкуренции (известной как модель Ланкастера). Применение модели не вызывает затруднений. Модель исходит из предположения, что выигрыш должен представлять линейную функцию от характеристик продукта и весовых коэффициентов, которые присваивает им человек. При наличии информации о ценах тысяч домов и их соответствующих характеристиках (площадь, количество спален и ванных комнат, качество местных школ, размер двора и качество строительства) регрессия позволит вычислить средний вес каждой характеристики (в долларах) для людей, купивших эти дома. Это называется гедонической регрессией.
Гедоническая модель конкуренции
Альтернатива состоит из N валентных характеристик (атрибутов): 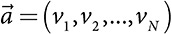 .
.
Индивидуальные предпочтения представлены весовыми коэффициентами: 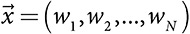 .
.
Выигрыш (полезность) альтернативы для человека составляет:
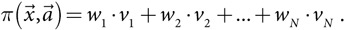
Пример: 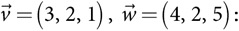
Некоторые из этих характеристик, такие как наличие бассейна или новой кухни, имеют рыночную цену. Для проверки модели можно сравнить расчетные цены с рыночной стоимостью. Если регрессия показывает, что бассейн увеличивает цену дома на 150 000 долларов, а стоимость бассейнов составляет 15 000 долларов, значит, в модель не включены какие-то атрибуты. Если регрессия показывает, что добавленная стоимость составляет всего 8000 долларов, скорее всего, это означает, что затраты на строительство бассейнов не возмещены в полном объеме.
Другие характеристики, такие как продолжительность поездки от дома до центра города, не имеют рыночной цены. В этих случаях регрессия дает имплицитную цену соответствующей характеристики, и она может быть информативной. В представленной ниже таблице показаны гипотетические данные о ценах шести домов.
Дом | Площадь (кв. футов) | Количество спален | Продолжительность поездки | Цена (долл.) |
Пайн-стрит, 204 | 2000 | 3 | 30 мин. | 200 000 |
Мейпл-стрит, 312 | 3000 | 5 | 60 мин. | 380 000 |
Геддес-стрит, 211 | 2500 | 4 | 10 мин. | 310 000 |
Мартин-стрит, 342 | 1500 | 2 | 20 мин. | 150 000 |
Кларк-стрит, 125 | 2000 | 4 | 30 мин. | 220 000 |
Браун-стрит, 918 | 4000 | 6 | 50 мин. | 360 000 |
Предположив, что остальные характеристики этих домов идентичны, и выполнив гедоническую регрессию, мы получим следующее уравнение:
Цена (в долларах) = 100*(кв. футов) + 20 000*(количество спален) – 2000* (продолжительность поездки)
Согласно этому уравнению регрессии, люди оценивают каждый дополнительный квадратный фут в 100 долларов, каждую спальню в 20 000 долларов и каждую минуту, сэкономленную на поездках в центр города, в 2000 за период владения домом. Человек, который живет в доме двадцать лет, тратит на поездки от 4000 до 5000 дней. Если взять меньшее из двух чисел, каждая дополнительная минута продолжительности ежедневных поездок дает 4000 минут, или 60 часов, потраченных на поездки из пригорода в город и обратно. Расчетный показатель 2000 долларов эквивалентен примерно 30 долларам в час. Иначе говоря, люди оплачивают близость дома к центру города так, «как будто» платят себе по 30 долларов в час за проведение времени в транспортных заторах [15].
ГИБРИДНАЯ МОДЕЛЬ ПРОДУКТОВОЙ КОНКУРЕНЦИИ
Пространственные и гедонические модели отличаются тем, как в них представлены предпочтения в отношении альтернатив. В пространственной модели конкуренции у каждого человека есть предпочтительный уровень всех атрибутов, а ценность, которую имеет для него та или иная альтернатива, увеличивается по мере приближения к его идеальной точке по соответствующим параметрам. В гедонической модели люди предпочитают либо большую, либо меньшую величину каждой характеристики.
Многие из моделируемых нами ситуаций — выбор потребительских товаров и услуг, идеальных спутников жизни, государственной политики, религии и кандидатов на вакантные должности — содержат как пространственные, так и гедонические характеристики. У каждого из нас может быть свой предпочтительный уровень хрусткости картофеля фри, но все мы предпочитаем платить меньше за одну порцию. Хрусткость — это пространственная характеристика, цена — гедоническая. Безусловно, работодатели не всегда едины во мнении относительно личных качеств, которые они ищут в потенциальных сотрудниках. Одни компании предпочитают экстравертов, тогда как другие — интровертов. Однако все ценят честность и порядочность. Таким образом, тип личности — это пространственная характеристика, а честность — гедоническая.
Следовательно, мы можем построить гибридную модель, в которой альтернативы имеют и пространственные, и гедонические атрибуты. Ее можно будет использовать для анализа выхода на рынок, дифференциации продуктов и уровня ценовой конкуренции. Если вернуться к примеру с шоколадными батончиками, то прежде чем выбирать характеристики нового продукта, компания может сначала разместить три существующих продукта в пространстве характеристик, а потом провести опрос потребителей, чтобы узнать распределение их идеальных точек. Это поможет компании оценить окрестности Вороного для будущего продукта. Если в этих окрестностях мало потребителей, рассчитывать на большой объем продаж не стоит. Этот подход может применить любой предприниматель, рассматривающий перспективу выхода на рынок. Дизайнер обуви может нанести на схему все модели утепленных ботинок и в итоге обнаружить, что забыл о ботинках из лакированной кожи. Разработчик мобильного приложения для составления списков дел может нанести на схему все существующие приложения, определить общий рыночный спрос и составить прогноз возможных продаж.
Мы можем представить снижение цены в пространственной модели конкуренции в виде смещения линии раздела. Вернемся к рис. 20.3, на котором отображены два шоколадных батончика. Линия раздела соответствует идеальным точкам потребителей, для которых батончики A и B представляют одинаковую ценность. Если компания, выпускающая продукт B, снизит цену, а потребители предпочитают платить за шоколадные батончики меньше, это сместит линию раздела в сторону батончика A и увеличит рыночную долю батончика B. Однако нам нужна модель не для того, чтобы понять, что снижение цены батончика B должно увеличить его рыночную долю, а для того чтобы оценить величину этого эффекта. Основная задача будет состоять в проведении различия между переполненными рынками с большим количеством продуктов в низкоразмерном пространстве характеристик и разреженными рынками с небольшим количеством конкурентов. На переполненном рынке каждый продукт имеет малую окрестность Вороного. На разреженном — окрестность Вороного огромна.
У изменения цен разные последствия на рынках этих двух типов. На рис. 20.9 показан эффект гипотетического снижения цены шоколадного батончика B на 10 процентов (с 2 до 1,8 доллара). Рисунок слева отображает разреженный рынок. Снижение цены на батончик B смещает линию раздела между продуктами A и B и увеличивает рыночную долю продукта B с 50 до 54 процентов, то есть на 8 процентов. Падение цены на 10 процентов и увеличение объема продаж на 8 процентов сокращает объем доходов на 3 процента. Следовательно, в данном случае снижение цен нецелесообразно. На рисунке справа показан переполненный рынок с семью типами шоколадных батончиков. Здесь снижение цены меньше влияет на абсолютную рыночную долю шоколадного батончика B, увеличивая ее на 5 процентов (с 15 до 20 процентов), но эти 5 процентов отражают большее пропорциональное увеличение рыночной доли батончика B (33 процента). Суммарный эффект — рост доходов на 20 процентов [16]. Таким образом, модель прогнозирует более высокий уровень ценовой конкуренции на переполненных рынках по сравнению с разреженными рынками, а также чрезвычайно высокий уровень конкуренции на рынке сырьевых товаров — продуктов, неотличимых друг от друга (таких как нефть, свинина и краснозерная пшеница №2). Модель также прогнозирует более низкий уровень ценовой конкуренции на рынке модных высококачественных товаров, где дизайнеры могут сохранять существенные наценки, поскольку размерность продукта создает разреженный рынок.
Рис. 20.9. Ценовая конкуренция на разреженном и переполненном рынке
Зависимость между количеством характеристик и уровнем ценовой конкуренции наводит на мысль, что добавление новых характеристик было бы эффективной стратегией, поскольку она делает рынок более разреженным, снижает уровень ценовой конкуренции и приводит к увеличению прибыли. Однако, даже если этот вывод правильный, такую стратегию легче сформулировать, чем реализовать на практике. Люди должны по достоинству оценить новую характеристику продукта. На каждую удачную попытку (беспроводные акустические системы) приходится множество неудачных (как злополучное одноразовое нижнее белье Bic).
РЕЗЮМЕ
Пространственная модель конкуренции, гедоническая модель конкуренции и гибрид этих двух моделей обеспечивают концептуальную схему, в рамках которой мы можем представить различные продукты, политических кандидатов и даже претендентов на вакантные должности. Такие модели позволяют измерить идеологические позиции и атрибуты продуктов с имплицитной ценой, а также оценить перспективы выхода на рынок. Эти модели помогают лучше понять, как рыночная конкуренция создает стимул для дифференциации, политическая борьба — для конвергенции и почему ценовая конкуренция должна быть гораздо ожесточеннее для продуктов с меньшим количеством характеристик.
В этих моделях мы делаем довольно смелые, но весьма сомнительные с эмпирической точки зрения допущения. Например, мы исходим из того, что люди не меняют предпочтений и не поддаются социальному давлению. Но если это так, тогда почему компании и политики столько сил тратят на попытки изменить предпочтения? Хотя эту критику можно и отбросить, в очередной раз сославшись на утверждение Бокса о том, что все модели неправильны.
Вместе с тем мы можем сформулировать более подробный ответ, который объясняет различие между фундаментальными предпочтениями (результатами, к которым стремится человек) и инструментальными предпочтениями (предпочтениями человека в отношении характеристик, обеспечивающих фундаментальные результаты). Фундаментальные предпочтения студента могут приводить к равновесию между его популярностью, здоровьем и академической успеваемостью. Он может добиться этих фундаментальных целей с помощью инструментальных действий — раннего подъема, свежего сока по утрам и выполнения домашних заданий, чтобы оставалось время на общение с друзьями по вечерам. Выбор фруктового коктейля поможет студенту реализовать свое фундаментальное предпочтение в отношении крепкого здоровья. Это и есть инструментальное предпочтение. Если студент прочитает научную статью, в которой говорится о высоком содержании сахара в фруктовых коктейлях, он может начать пить вместо соков воду. Тогда его инструментальные предпочтения поменяются, но фундаментальные останутся прежними. Мы вновь видим, что модель не является целью сама по себе, а обеспечивает архитектуру для структурирования мышления.
Множество моделей ценности
В рыночной экономике ценность, которую представляет для человека тот или иной товар, можно определить по цене, которую он готов за него заплатить. Человек может оценивать бутерброд с бастурмой в 7 долларов, картину Гойя в 3 миллиона долларов, а земельный участок площадью один акр в Окале (штат Флорида) в 75 тысяч долларов. Многие экономические модели не учитывают причину этих оценок. Как известно, Джордж Стиглер процитировал слова сладострастника Мити из романа Достоевского «Братья Карамазовы», который сказал: «De gustibus non est disputandum» («О вкусах не спорят»). Представленные здесь модели описывают не столько вкусы, сколько то, как вкусы преобразуются в денежную ценность, которую люди приписывают товарам.
Модель гедонических характеристик объясняет ценность товара на основе присущих ему свойств. Различия в оценках зависят от различных базовых предпочтений в отношении характеристик товара. Этими характеристиками могут быть физические составляющие товара. Бутерброд с бастурмой состоит из ржаного хлеба, ста семидесяти граммов бастурмы, швейцарского сыра, горчицы, маринованных огурцов и лука. Значит, его ценность можно записать в виде взвешенной линейной комбинации этих ингредиентов. Более сложные гедонические модели могут включать параметры, характеризующие взаимодействие. Бастурма может быть еще более ценной, если подается на поджаренном на гриле ржаном хлебе.
Модель координации объясняет цены как социально сконструированный феномен. Ценность картины Гойи зависит от того, какую ценность ей приписывают люди. Изначально у людей есть определенные убеждения или мнения в отношении ценности картины. Затем они взаимодействуют с другими людьми из своей сети социальных контактов и корректируют свои убеждения. Два человека могут приписывать товару ценность, эквивалентную среднему из двух значений ценности; один человек может изменить свою ценность так, чтобы она совпадала с ценностью другого, или каждый человек может смещать свою ценность в сторону ценности других людей. В случае любого из этих предположений оценки сходятся локально. У людей, связанных друг с другом, будут аналогичные оценки. Максимальная ценность, присвоенная товару, будет зависеть от исходного распределения значений ценности, сети социальных контактов и порядка образования пар.
Прогностические модели объясняют цены как прогноз будущей стоимости. Ценность земельного участка в один акр в Окале, биткоина или акций зависит от того, сколько люди заплатят за них в будущем. Эти оценки зависят от прогностических моделей, которые, в свою очередь, зависят от атрибутов и категорий. Окалу можно охарактеризовать как удаленный от моря город с теплым климатом и низкими налогами. Разброс оценок людей возникает в связи с использованием разных прогностических моделей. Инвесторы используют множество подобных моделей, которые могут основываться на характеристиках или, как при оценке биткоина, делать предположения о координации.
Эти три типа моделей дают три разных объяснения ценности товара. Ни одна модель не будет лучшей во всех случаях, но у каждой есть случаи, когда она наиболее эффективна. Эти модели функционируют как стрелы в нашем колчане. Ценность бутерброда с бастурмой проистекает, вероятнее всего, из его внутренних свойств. Ценность картины Гойи может быть в значительной мере социально сконструированной: картина имеет ценность, если люди в это верят. Цена земельного участка во Флориде зависит от оценок, полученных на основании прогнозов будущей стоимости объектов недвижимости.
ГЛАВА 21
ТРИ КЛАССА МОДЕЛЕЙ ТЕОРИИ ИГР
Дедуктивное умозаключение движется от абстрактного к конкретному. Оно начинается с набора аксиом и использует законы логики и математики, для того чтобы посредством манипуляций с ними формировать прогнозы в отношении окружающего мира.
Рейчел Кросон
Теория игр моделирует стратегические взаимодействия. Многие из описанных ниже моделей, в том числе модели кооперации, сигнализирования, механизмов и коллективных действий, включают игры. Мы не будем особо углубляться в анализ игр, потому что этой теме посвящено множество отдельных книг, а просто дадим общее представление о теории игр. Для этого рассмотрим три основных класса игр: игры в нормальной форме, в которых игроки выбирают из дискретного набора действий (как правило, двух); последовательные игры, в которых игроки выбирают действия последовательно; и игры непрерывного действия, в которых игроки выбирают действия любого масштаба или с эффектом любой величины. Эти примеры вводят основные понятия, помогают осмыслить модели, представленные ниже, и сами по себе добавляют ценность.
Глава состоит из четырех частей. В первой рассказывается об играх с нулевой суммой. В такой игре каждый из двух игроков выбирает одно из двух действий. Какие бы действия ни выбрали игроки, выигрыш одного игрока эквивалентен проигрышу другого. Мы используем игры с нулевой суммой, чтобы дать определение основных терминов теории игр, провести различие между стратегиями и действиями и ввести понятие итеративного удаления доминируемых стратегий. Затем мы проанализируем последовательную игру «Выход на рынок», в которой потенциальный игрок рынка конкурирует с действующей компанией. Многократное повторение игры порождает так называемый парадокс сети магазинов. В третьей части мы рассмотрим игру усилий, в которой игроки выбирают уровень усилий, которые они готовы приложить, чтобы выиграть фиксированную сумму. Активизация усилий повышает шансы игрока получить приз. Глава завершается кратким обсуждением ценности моделей теории игр в целом.
ИГРЫ С НУЛЕВОЙ СУММОЙ В НОРМАЛЬНОЙ ФОРМЕ
В этом разделе мы проанализируем две игры с нулевой суммой в нормальной форме с участием двух игроков. В обеих играх каждый игрок выбирает действие и получает выигрыш, который зависит от его собственных действий и от действий другого игрока. Кроме того, сумма выигрышей игроков равна нулю. В первой игре под названием «Орел — решка» (рис. 21.1) каждый игрок выбирает одно из двух действий: орел или решка. Игроку, которому соответствует строка матрицы (назовем его игрок строки), выбирает то же действие, что и другой игрок, а игрок, которому соответствует столбец матрицы (назовем его игрок столбца), выбирает другое действие.
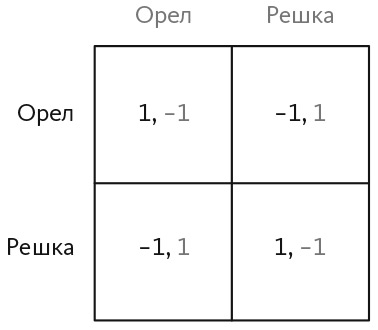
Рис. 21.1. Игра «Орел — решка»
Стратегия — это правило ведения игры. Это может быть выбор одного действия, случайный выбор между действиями или, как мы увидим в следующем разделе, последовательность действий. Равновесие Нэша в игре — это пара стратегий, подобранных таким образом, что стратегия каждого игрока оптимальна с учетом стратегии другого игрока. В игре «Орел — решка» в случае уникальной равновесной стратегии оба игрока в равной степени делают случайный выбор между двумя действиями. Для того чтобы доказать, что рандомизация обеспечивает равновесие, необходимо показать, что если один игрок делает случайный выбор, то другому тоже лучше его сделать. Продемонстрировать это не составит труда. Если игрок строки (действия и выигрыши которого выделены жирным шрифтом) выбирает орла с вероятностью и решку с вероятностью , то выигрыш игрока столбца будет равен нулю независимо от его действий. Следовательно, рандомизация — это оптимальная стратегия для игрока столбца. В силу симметрии рандомизация будет оптимальной стратегией и для игрока строки.
Такая оптимальность рандомизации влияет на поведение в стратегических ситуациях. Спорт — это игра с нулевой суммой: одна команда (или игрок) выигрывает, а другая проигрывает. Выполняя пенальти, нападающий пытается в случайном порядке выбирать, куда целиться — в правый или левый угол ворот. В теннисе подающему игроку необходимо в случайном порядке подавать мяч в пределах или за пределы корта. В американском футболе в ситуации «четвертый и гол»43 команде нападения нужно случайным образом сделать выбор между пробежкой и пасом. В каждом из этих случаев соперник также стремится рандомизировать запланированные ответные действия. Любое неслучайное действие может быть использовано. Это верно и для карточных игр, таких как покер. Хороший игрок в покер блефует в случайном порядке. Если бы он блефовал всегда, соперники разгадали бы его стратегию и остались бы в игре. Тогда игрок проигрывал бы каждый раз, блефуя. Аналогично, если бы игрок никогда не блефовал, его соперники научились бы сбрасывать карты. Оптимальный блеф заставляет противников колебаться, решая, оставаться им в игре или сбросить карты.
На рис. 21.2 показана вторая игра, игра с минимизацией риска. В ней каждый игрок может предпринять рискованное либо безопасное действие. Это асимметричная игра с нулевой суммой. Выигрыши зависят не только от действий, но и от того, какой игрок совершает какое действие. В этой игре доминирующая стратегия игрока строки — не рисковать. Независимо от того, какое действие выберет игрок столбца, игрок строки получает более высокий выигрыш, выбирая безопасное действие. У игрока столбца нет доминирующей стратегии. Если игрок строки выбирает рискованное действие, игрок столбца тоже должен выбрать рискованное действие. Если игрок строки выбирает безопасное действие, то и игрок столбца должен его выбрать.
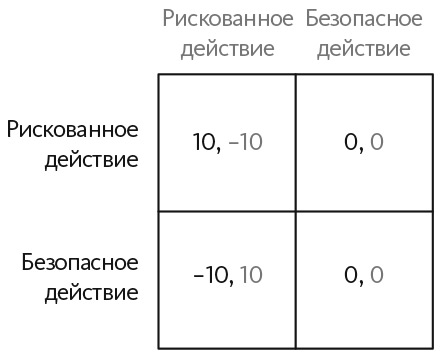
Рис. 21.2. Игра с минимизацией риска
Проанализировав стимулы игрока строки, игрок столбца может сделать вывод, что игрок строки никогда не выберет рискованное действие, поскольку безопасное действие предпочтительнее рискованного. Следовательно, игрок столбца знает, что игрок строки выберет безопасное действие. С учетом этого факта он тоже должен выбрать безопасное действие. Такой тип логических рассуждений, в соответствии с которым один игрок исключает доминируемые (преобладающие) стратегии другого, известен как итеративное удаление доминируемых стратегий. В этой игре использование итеративного удаления доминируемых стратегий показывает, что выбор безопасного действия обоими игроками и есть уникальное равновесие Нэша.
ПОСЛЕДОВАТЕЛЬНЫЕ ИГРЫ
В последовательной игре игроки выполняют действия в определенном порядке, как показано на дереве игры, состоящем из узлов и ветвей. Каждый узел соответствует тому моменту, когда игрок должен совершить действие. Каждая ветвь, исходящая из этого узла, обозначает одно из возможных действий. У концевых ветвей дерева игры записывается выигрыш в случае выбора соответствующей цепочки действий. На рис. 21.3 представлено дерево игры «Выход на рынок».
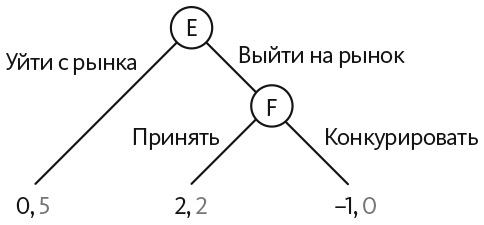
Рис. 21.3. Игра «Выход на рынок»
В игре «Выход на рынок» два участника — потенциальный игрок рынкаи действующая компания. Если потенциальный игрок решает не выходить на рынок (левая ветвь дерева), он не получает никакого выигрыша, а действующая компания получает выигрыш 5. Если потенциальный игрок выходит на рынок, действующая компания должна выбирать — принять его, что повлечет за собой снижение прибыли с 5 до 2, или конкурировать с ним, сведя свою прибыль до нуля, а нового игрока рынка — до отрицательной. Мы будем считать, что прибыль нового игрока рынка должна быть отрицательной, поскольку он вынужден оплатить стоимость выхода на рынок.
В последовательной игре стратегия соответствует выбору действия в каждом узле. Предположим, действующая компания решает конкурировать, если потенциальный игрок выйдет на рынок. Зная об этом, потенциальный игрок решает этого не делать, так как это приведет к отрицательной прибыли. Такая совокупность действий — потенциальный игрок решает не выходить на рынок, а действующая компания планирует вести конкурентную борьбу, если он все же передумает, — представляет собой равновесие Нэша, но это не единственное равновесие и не наиболее вероятный исход игры. Существует еще одно равновесие, в котором потенциальный игрок решает выйти на рынок, а действующая компания принимает этот ход и не вступает в конкуренцию.
Для того чтобы выбрать одно из двух равновесий, требуется применить уточняющий критерий. В последовательных играх наиболее распространенный уточняющий критерий позволяет выбрать совершенное под-игровое равновесие. Его можно найти с помощью метода обратной индукции: начиная с концевых узлов выбирать оптимальное действие в каждом узле, а затем пройти дерево игры в обратном порядке, предполагая, что каждый игрок выбирает наилучшее действие с учетом действий другого игрока в последующих узлах. В игре «Выход на рынок» следует начать с концевого узла действующей компании. У нее оптимальное действие — принять. Перемещаясь далее вверх по дереву, мы увидим, что оптимальная стратегия потенциального игрока — выйти на рынок.
Игра становится еще интереснее в случае повторения. Представьте, что компания присутствует на многих рынках. Это может быть торговая сеть с франшизными магазинами в десятках городов. Допустим также, что существует ряд потенциальных игроков рынка. Тогда компания будет разыгрывать одну игру «Выход на рынок» за другой.
Применив метод обратной индукции и начав с последнего рынка, действующая компания примет нового игрока рынка, поскольку это действие максимизирует выигрыш. Следуя той же логике, компания примет предпоследнего нового игрока рынка, так же как и всех остальных. Таким образом, в данной последовательности игр уникальное совершенное равновесие под-игры состоит в том, что все потенциальные игроки решают выйти на рынок, и действующая компания принимает их всех.
Хотя выход на рынок и принятие нового игрока рынка — это уникальное совершенное под-игровое равновесие, в действительности так бывает не всегда. Представьте, что мы — члены совета директоров действующей компании и сталкиваемся с первым потенциальным игроком, который (изучив теорию игр) выходит на рынок. У нас может возникнуть желание вступить с ним в конкурентную борьбу, чтобы предотвратить выход новых игроков на другие рынки. Конкуренцию можно считать разумной стратегией, если она достоверна, то есть если мы можем создать репутацию компании, готовой конкурировать. В таком случае исход игры, к которому мы стремимся, отличается от совершенного равновесия под-игры.
Разрыв между тем, что прогнозирует теория игр, и тем, чего пытаются добиться реальные игроки, специалисты по теории игр называют парадоксом сети магазинов. Это один из примеров, когда поведение, которое теория игр считает оптимальным, может не совпадать с поведением, выбираемым опытным игроком в случае высоких ставок. Этот пример не опровергает теорию игр и не подрывает предположение о рациональном выборе, но показывает, почему мы должны всегда ставить предположения под сомнение.
ИГРЫ НЕПРЕРЫВНОГО ДЕЙСТВИЯ
Теперь давайте рассмотрим игру, участники которой выбирают из непрерывного множества возможных действий. В ней действия соответствуют уровням усилий. Выбирая более высокий уровень усилий, игрок повышает вероятность получить приз. Игра позволяет смоделировать любое количество игроков.
Выражение, описывающее равновесные усилия, раскрывает ряд важных моментов. Как и следовало ожидать, уровень индивидуальных усилий игрока повышается вместе с увеличением размера приза. Кроме того, при равновесии общий уровень усилий будет ниже стоимости приза. Это тоже вполне ожидаемо, учитывая, что игроки выбирают оптимальные действия. Игроки должны прилагать усилия, чтобы выиграть, но в разумных пределах.
Игра усилий
Каждый из N игроков выбирает уровень усилий (который можно представить в денежном выражении), чтобы выиграть приз стоимостью M. Вероятность того, что игрок выиграет приз, равна частному от уровня его усилий и общего уровня усилий всех игроков. Если Ei — уровень усилий игрока i, его вероятность выиграть приз можно описать следующим уравнением [1]:
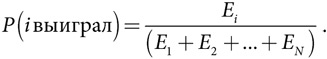
Равновесие:
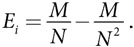
Мы можем увидеть воздействие увеличения количества игроков на уровень индивидуальных и общих усилий. Здесь выводы менее интуитивно понятны. Согласно этой модели, уровень усилий отдельных игроков снижается, а суммарный уровень усилий всех игроков повышается. Следовательно, модель подразумевает, что попытки организаторов всевозможных конкурсов привлечь больше участников, как ни парадоксально, могут привести к снижению качества победителей, поскольку у участников более крупных конкурсов будет меньше стимулов прилагать дополнительные усилия.
РЕЗЮМЕ
Мы начали главу с рассмотрения игры с нулевой суммой. Такие игры подразумевают полное отсутствие взаимовыгодных комбинаций действий. Любое действие, выигрышное для одного игрока, неизбежно будет проигрышным для другого. В решении с нулевой суммой любое действие наносит кому-то вред в такой же степени, в какой приносит другому пользу. Многие личные действия и выбор курса действий — это действия с нулевой суммой как минимум по одному из аспектов. У каждого из нас есть определенное количество часов в сутках, денег на расходы и ресурсов, которые можно на что-то выделить. Вместе с тем действие с нулевой суммой по одному аспекту может не быть действием с нулевой суммой по другому аспекту. Перераспределение бюджета может быть действием с нулевой суммой с финансовой точки зрения, но с положительной или отрицательной суммой с точки зрения счастья или самореализации людей.
В каждом конкретном случае мы всегда должны анализировать, порождает ли предложенное изменение игру с нулевой суммой. Например, многие люди выступают за выбор школы, в которую будет ходить их ребенок, поскольку это усиливает конкуренцию. Рыночная логика говорит о том, что когда школы вынуждены конкурировать, у них появляется стимул к повышению качества обучения.
Однако такой стимул имеет место только при наличии избыточного предложения образовательных услуг. В противном случае выбор школы может создать игру с нулевой суммой среди учеников. Представьте себе город с 10 000 учеников и 10 школами, рассчитанными на 1000 учеников каждая. Если ученики ранжируют эти школы в одном и том же порядке, места в лучших школах придется распределять с помощью лотереи. Тот, кто ее выиграет, будет ходить в лучшую школу. Проигравшим достанутся худшие школы, которые будут продолжать работать ввиду отсутствия избыточного предложения. Ученики играют в игру с нулевой суммой. Если откроется новая школа или имеющаяся повысит качество обучения, эта игра перестанет быть с нулевой суммой. В таком случае выиграть могут все.
Как рыночная модель, так и модель с нулевой суммой позволяют глубже понять происходящее. Рыночная модель раскрывает стимулы к повышению качества обучения и созданию новых школ. Модель с нулевой суммой показывает, что просто выбор школы означает, что одни ученики выиграют, а другие проиграют. Относительная значимость, которую нам следует присвоить каждой модели, зависит от контекста: существует ли избыток мощностей в лучших школах, чтобы они могли принять дополнительных учеников? Есть ли у школ ресурсы и знания для повышения качества обучения? Построят ли предприниматели новые школы? Позволяет ли транспортная система без проблем добираться до разных школ, чтобы между ними могла возникнуть конкуренция?
Из всего этого можно сделать вывод, что ни одна из двух моделей не дает правильного ответа, но каждая позволяет получить полезную информацию. Выбор школы действительно создает конкуренцию. Перевесят ли положительные аспекты конкуренции такой отрицательный аспект, как затраты на распределение учеников, зависит от контекста. Для того чтобы выбрать правильный курс действий, необходимо упорядочить совокупность моделей на множестве фактов.
Проблема идентификации
Данные о действиях людей часто указывают на кластерное поведение. Хорошие студенты с большей вероятностью дружат с другими хорошими студентами, а не с отстающими. Люди, которые занимаются преступной деятельностью, чаще сотрудничают с себе подобными преступниками, чем с добропорядочными гражданами. Многие положительные и отрицательные аспекты социальной жизни (такие как курение, физическое состояние, ожирение и даже счастье) образуют кластеры в социальных сетях. Кроме того, люди объединяются в кластеры по убеждениям — демократы, республиканцы или либертарианцы.
У нас есть два типа моделей, объясняющих кластеризацию: модели эффекта окружения и модели сортировки. Первые объясняют кластеризацию с помощью теории игр. Люди играют в координационную игру со своими друзьями. В моделях сортировки люди перемещаются ближе к себе подобным. Кластер хороших студентов может сформироваться либо в результате координации ими своих действий на основе общей модели поведения (эффект окружения), либо потому, что хорошие студенты предпочитают общаться друг с другом (сортировка). На основании мгновенного снимка данных эти два исхода неотличимы.
Данные. Студенты получают либо высокие (H), либо средние (M) баллы, которые в равной степени вероятны. Студенты образуют дружеские группы численностью 4 человека со следующим распределением:
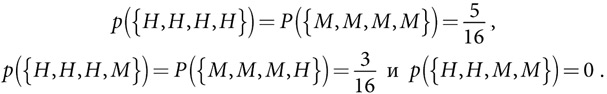
Модель эффекта окружения. Сначала студенты формируют произвольные группы из четырех человек:
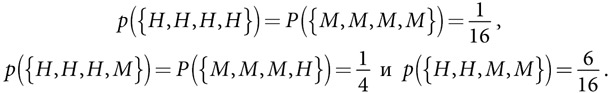
Тип студентов, принадлежащих к группам, состоящим только из одного типа людей, не меняется. Человек, тип которого отличается от остальных, меняет его, в результате чего группа {H, H, H, M} становится группой {H, H, H, H}. В группах с равным количеством студентов каждого типа один член группы меняет свой тип. Группа {H, H, M, M} может с равной вероятностью стать и группой {H, H, H, M}, и группой {M, M, M, H}.
Модель сортировки. Сначала студенты образуют произвольные группы из четырех человек. В любой группе с двумя типами студент, тип которого противоположен типу как минимум двух других людей, меняется группами с кем-то, имеющим другой тип. Из этого следует, что группа {H, H, H, M} становится группой {H, H, H, H}, а группа {M, M, M, H} — группой {M, M, M, M}, а также что любая группа вида {H, H, M, M} может с равной вероятностью стать группой {H, H, H, M} или {M, M, M, H}.
Обе модели согласуются с данными, что создает проблему идентификации. На основании только снимка данных мы не можем определить, относится ли курение, чтение манги (японских комиксов) или катание на лонгбордах к модели эффекта окружения или к модели сортировки. Иногда можно установить, какая модель применима. Склонность людей на Среднем Западе говорить «шипучка», а на побережьях — «содовая» позволяет смело предположить, что ими движет эффект окружения — мало кто переезжает в Бостон, чтобы называть кока-колу «содовой». Более важные аспекты поведения, такие как академическая успеваемость, употребление наркотиков, ожирение и счастье, требуют временных рядов данных, чтобы выяснить, какая из моделей применима. Анализ данных за определенный период помогает определить, меняют ли люди свое поведение, чтобы соответствовать друзьям (эффект окружения), или меняют друзей и сохраняют поведение (сортировка). Во многих значимых случаях, таких как успеваемость в школе, могут наблюдаться оба эффекта [2].
ГЛАВА 22
МОДЕЛИ КООПЕРАЦИИ
Никто еще не стал бедным, отдавая.
Анна Франк
Когда экспертов просят перечислить самые важные научные вопросы, они обычно предлагают ограниченный набор вариантов: как возникла Вселенная? Как появилось сознание? Будет ли найдено лекарство от рака? Один из вопросов, который они упоминают, касается социальных и биологических наук: как возникает кооперация? [1] Кооперация подразумевает совершение действия, не отвечающего личным интересам, а значит, вряд ли стоит ожидать широкую кооперацию. Тем не менее мы наблюдаем кооперацию во множестве областей и в самых разных масштабах. Клетки кооперируют посредством адгезии, когда одна клетка вырабатывает внеклеточное вещество, к которому могут прикрепляться другие клетки. Кооперацию можно увидеть между муравьями, пчелами, людьми, организациями и даже странами, которые поддерживают ее в рамках создания соглашений и международных законов.
В этой главе мы используем модели для поиска ответов на вопросы о том, как возникает кооперация, как она поддерживается и как ее расширить. Эти модели не дают исчерпывающего объяснения всего существующего в мире многообразия кооперации: почему вороны делятся найденной ими падалью; почему голые землекопы (heterocephalus glaber) совместно защищаются от хищников; почему вьющиеся растения пускают меньше корней, если их высадить рядом с родственными им растениями; почему термиты и пчелы строят сложные гнезда и почему муравьи сплетают конечности и делают перемычки для переноски пищи. Тем не менее эти модели позволяют глубже понять суть происходящего [2].
Несмотря на массу примеров внутри- и межвидовой кооперации, есть и примеры неудач. Степень кооперации зависит от обстоятельств. Федерации получают, а затем теряют новых членов; Великобритания участвовала в создании Евросоюза, а теперь выходит из него. Те же люди, которые собирают средства для школ в качестве волонтеров, могут проталкиваться без очереди к кассе в супермаркете или мошенничать с налогами. Лев, который охотится на азиатского буйвола в стае, может спрятать пойманного бородавочника. Кроме того, кооперация имеет место не у всех видов. Корни черного ореха выделяют в почву гербицид юглон для подавления роста расположенных рядом растений.
Разнообразие моделей поведения взаимодействующих субъектов (таких как клетки, корни, вороны, люди, компании и страны) требует применения многомодельного подхода. Клетки и растения лучше всего моделировать на основе установленных правил; вороны, муравьи и львы используют больше правил, которые диктует среда обитания или результаты, полученные в прошлом; люди, компании и страны делают прогнозы на будущее и вычисляют соотношение затрат и результатов.
Один из самых важных выводов этой главы состоит в том, что кооперация возникает и поддерживается с помощью различных механизмов. Мы остановимся на четырех: повторение, репутация, локальная кластеризация и групповой отбор. Все они делают кооперацию возможной без внешнего вмешательства или управления и применимы к взаимодействующим голым землекопам, пчелам и людям. У людей, кроме того, есть более формальные способы стимулировать и поддерживать кооперацию. В конце главы описываются такие институциональные решения, как, например, платить людям за сотрудничество, наказывать их, если они отказываются сотрудничать, и сделать кооперативное поведение обязательным согласно закону.
Второй вывод состоит в том, что эффективность любого из механизмов зависит от поведенческого репертуара объектов кооперации. Некоторые механизмы (особенно повторение) работают практически для любого поведения. Репутация и нормы требуют дальновидного поведения и обмена информацией. Эти механизмы наиболее эффективны для более развитых акторов.
С другой стороны, эффект кластеризации зависит от модели. Кооперация между субъектами, отобранными или отброшенными факторами эволюции, чаще всего возникает в разреженных сетях. Кооперация посредством норм требует плотных сетей. Эффективность группового отбора зависит (в более развернутом смысле) от степени дальновидности акторов и их способности придерживаться своих темпов адаптации. Обеспечение их дальновидности усиливает потенциал группового отбора. Предоставление им возможности адаптироваться быстрее может создавать помехи. Чтобы проанализировать все эти вопросы и объяснить взаимосвязь между поведенческими предположениями и кооперацией, мы используем известную игру «Дилемма заключенного», а также модель совместных действий. Вторая модель позволит нам охарактеризовать действия, которые приносят пользу многим игрокам, и смоделировать кооперацию в сетях.
Оставшаяся часть главы выглядит так: сначала мы опишем дилемму заключенного и покажем, как рациональные агенты могут поддерживать кооперацию. Затем продемонстрируем, как повторение может стимулировать кооперацию между субъектами, действующими на основе правил, а также почему сформировать кооперацию труднее, чем поддерживать. Далее мы рассмотрим менее развитые биологические объекты и покажем, каким образом могут способствовать кооперации родственный отбор и локальная кластеризация. В последних двух разделах мы обсудим групповой отбор и вопрос о том, как использовать эти модели для расширения сотрудничества.
ДИЛЕММА ЗАКЛЮЧЕННОГО
Происхождение этого названия связывают с историей о двух людях, обвиняемых в совместном совершении преступления. У полиции есть косвенные улики, поэтому каждому подозреваемому предлагают сознаться. Обвиняемые сталкиваются с дилеммой. Если ни один из них не признает своей вины, каждый получит мягкий обвинительный приговор на основании имеющихся доказательств. Если сознается кто-то один, он вообще не будет наказан, а другой получит строгое наказание. Если оба сознаются, оба получат достаточно суровое наказание, но не настолько, как в случае признания вины только кем-то одним. На рис. 22.1 эта история представлена в виде игры с участием двух игроков. Каждый игрок может либо сотрудничать (С), либо отказаться от сотрудничества (D). Выделенные полужирным шрифтом числа — это выигрыши игрока строки, а обычным шрифтом показаны выигрыши игрока столбца. У каждого игрока есть доминирующая стратегия отказа от сотрудничества: какое бы действие не предпринял другой игрок, отказ от сотрудничества обеспечивает более высокий выигрыш. Однако если оба игрока откажутся от сотрудничества, каждый получит более низкий выигрыш, чем если бы оба предпочли сотрудничество. Таким образом, преследование личных интересов приводит к получению обоими игроками более низких результатов.
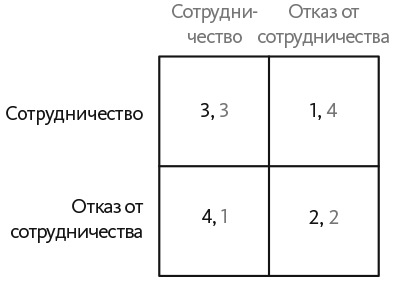
Рис. 22.1. Пример игры «Дилемма заключенного»
Дилемма заключенного отражает основные стимулы, присутствующие во многих реальных ситуациях. Она позволяет смоделировать гонку вооружений между США и СССР, где отказ от сотрудничества соответствует расходам на вооружение, а сотрудничество — экономическому развитию. Кроме того, эта игра может моделировать проведение политической кампании и выбрать один из вариантов агитации — распространять порочащую информацию (отказ от сотрудничества) или размещать позитивную политическую рекламу (сотрудничество). Дилемма заключенного может даже объяснить, почему у самцов павлина такой длинный хвост: у каждого павлина есть причины казаться сильнее и выносливее других самцов.
Некоторые примеры дилеммы заключенного можно понять только постфактум. Первые пользователи многих технологий (например банки, которые первыми внедрили банкоматы) увидели рост прибыли. Однако когда за ними последовали другие, прибыль упала в связи с усилением конкуренции. Оказалось, что установка банкоматов аналогична отказу от сотрудничества [3].
Общий вид игры «Дилемма заключенного», представленный на рис. 22.2, подразумевает нулевой базовый выигрыш, если оба игрока откажутся от сотрудничества. Таким образом, игру можно описать с помощью трех переменных: вознаграждение (R) в случае сотрудничества, искушение (T) отказаться от сотрудничества и выигрыш простака (S), которым воспользовались в своих интересах (см. врезку). Приведенные на рисунке неравенства гарантируют, что выбор отказа от сотрудничества — это доминирующая стратегия, а сотрудничество обеспечивает эффективный исход.
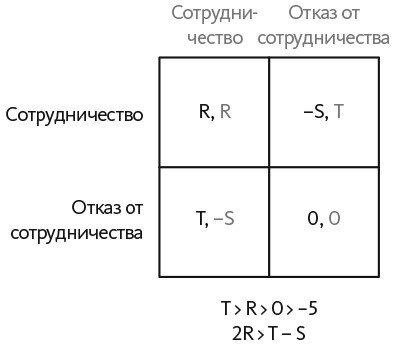
Рис. 22.2. Дилемма заключенного
КООПЕРАЦИЯ ПОСРЕДСТВОМ ПОВТОРЕНИЯ И РЕПУТАЦИИ
Сначала мы продемонстрируем, как повторение игры и создание репутации может поддерживать кооперацию между рациональными агентами. Тот факт, что кооперацию можно поддерживать, не гарантирует, что она будет достигнута, а лишь указывает на то, что, если она действительно возникнет, рациональные игроки могут не дать ей угаснуть. Для того чтобы доказать, что повторение поддерживает кооперацию, построим модель повторяющейся игры, в которой после каждой итерации игры с вероятностью P игра будет проведена снова. Теоретически процесс игры может продолжаться бесконечно.
Когда игроки применяют стратегии повторяющейся игры, их действия основываются на истории предыдущих итераций. Здесь мы рассмотрим стратегию повторяющейся игры, известную как «триггер вечной кары», в соответствии с которой игрок сотрудничает в первой и последующих итерациях до тех пор, пока другой игрок не отказывается от сотрудничества. Если другой игрок отказывается сотрудничать, игрок, который следует стратегии «триггер вечной кары», отказывается от сотрудничества навсегда.
Для того чтобы доказать, что триггер вечной кары поддерживает сотрудничество в повторяющейся игре, необходимо продемонстрировать, что если один игрок выберет стратегию вечной кары, то другой игрок максимизирует свой выигрыш, тоже выбрав эту стратегию. Учитывая, что отклонение второго игрока приводит к бесконечному отказу первого игрока от сотрудничества, второму игроку необходимо просто сопоставить ожидаемый выигрыш от постоянного сотрудничества с ожидаемым выигрышем от однократной выгоды отказа от сотрудничества, а также с выигрышем в том случае, если после этого оба игрока предпочтут отказ [4]. Обеспечит ли триггер вечной кары более высокий выигрыш, зависит от степени искушения, вознаграждения от сотрудничества и вероятности повторения игры.
Повторение поддерживает кооперацию
В повторяющейся игре «Дилемма заключенного» триггер вечной кары поддерживает кооперацию, если вероятность продолжения игры P превышает отношение разности между выигрышем от искушения T и выигрышем от вознаграждения R к выигрышу от искушения [5]:
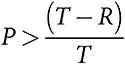
Этот результат говорит о том, что, если выигрыш от искушения превышает тройной выигрыш от вознаграждения (T > 3R), игра должна повториться с вероятностью, превышающей  . Неравенство также говорит о том, что поддерживать сотрудничество становится легче, если вознаграждение и вероятность продолжения игры повышаются или соблазн отказаться от сотрудничества уменьшается. Каждое из этих следствий указывает интуитивный путь к расширению кооперации: увеличьте вознаграждение, повысьте вероятность продолжения взаимодействия и уменьшите искушение отказаться от сотрудничества. Хотя это довольно простые выводы, возможно, до построения модели они не были столь очевидны.
. Неравенство также говорит о том, что поддерживать сотрудничество становится легче, если вознаграждение и вероятность продолжения игры повышаются или соблазн отказаться от сотрудничества уменьшается. Каждое из этих следствий указывает интуитивный путь к расширению кооперации: увеличьте вознаграждение, повысьте вероятность продолжения взаимодействия и уменьшите искушение отказаться от сотрудничества. Хотя это довольно простые выводы, возможно, до построения модели они не были столь очевидны.
В поисках необходимого условия кооперации мы можем сделать и не столь простые выводы. Представленное выше выражение подразумевает, что если бы игроки исходили из того, что вероятность продолжения игры окажется ниже порогового значения в будущем, то рациональные игроки прекратили бы сотрудничество до, а не после изменения вероятности [6].
Логика, согласно которой повторение поддерживает кооперацию между рациональными игроками, основана на таком частном свойстве модели, как вероятность продолжения игры. Если бы вместо этого мы исходили из фиксированного количества повторений (скажем, игра должны повторяться три раза), рациональные игроки не сотрудничали бы, что можно доказать с помощью метода обратной индукции. Предположим, игра проводится только три раза и первый игрок заявляет о применении триггера вечной кары. Допустим, T = 3, R = 2 и S = 1. С учетом этих выигрышей, если второй игрок сотрудничает в ходе всех трех раундов, он получает общий выигрыш 6. Нам необходимо убедиться, что больше ни одна стратегия не обеспечивает более высокий выигрыш. Отказ от сотрудничества в первом раунде дает выигрыш всего лишь 2, поскольку после этого первый игрок прибегнет к отказу и в последних двух раундах. Отказ от сотрудничества во втором раунде дает выигрыш 5. Ни одно из этих действий не является рациональным. Тем не менее отказ от сотрудничества в третьем раунде дает выигрыш 7: выигрыш 2 в каждом из двух первых периодов и выигрыш 3 в последнем периоде. Следовательно, рациональный игрок откажется от сотрудничества в последнем раунде.
Первый игрок, применивший триггер вечной кары, должен понимать, что отказ от сотрудничества произойдет в третьем раунде, и тоже отказаться от сотрудничества. Тогда второй игрок поймет, что они оба намерены отказаться от сотрудничества в третьем раунде, поэтому сделает это во втором раунде. Согласно той же логике первый игрок также откажется от сотрудничества. Процесс будет продолжаться до первого раунда. Аналогичные рассуждения применимы при повторении игры любое конечное количество раз. В последнем сыгранном раунде рациональные игроки отказываются от сотрудничества. Следовательно, у обоих игроков есть стимул выбрать отказ от сотрудничества в предпоследнем раунде — и так далее. Единственная рациональная стратегия — всегда отказываться от сотрудничества.
До сих пор мы анализировали действия двух обособленных игроков, а это не учитывало того, как отказ человека от сотрудничества может повлиять на отношение к нему окружающих и как они будут обращаться с ним во время будущих взаимодействий. По сути, мы оградили двух играющих в эту игру человек. Однако модель можно расширить, включив в нее сообщество людей, которые следят за поведением друг друга и наказывают тех, кто не хочет сотрудничать.
Для того чтобы сделать это в формальном виде, предположим, что люди каждый день в произвольном порядке образуют пары и играют в игру «Дилемма заключенного». Члены сообщества убеждены, что эти игры будут продолжаться бесконечно, поэтому вероятность будущей игры равна 1. При таких предположениях человек, скорее всего, не станет играть с тем же человеком на следующий день, а значит, у него будет более высокий стимул отказаться от сотрудничества. Однако мы допускаем вероятность того, что сообщество это заметит, и тогда человек заработает плохую репутацию и, согласно договоренности, ни один член сообщества не будет с ним сотрудничать в будущем. Если мы обозначим символом PD вероятность того, что человека уличат в отказе от сотрудничества и он будет наказан во всех будущих играх, то условие, что сотрудничество будет поддерживаться посредством репутации, (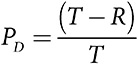 ), тождественно условию его поддержания при помощи повторения, за исключением того, что вероятность повторения игры P заменит PD — вероятность того, что человека уличат в отказе от сотрудничества.
), тождественно условию его поддержания при помощи повторения, за исключением того, что вероятность повторения игры P заменит PD — вероятность того, что человека уличат в отказе от сотрудничества.
В модели репутации сообщество усиливает кооперацию. Тот, кто отказался от сотрудничества и был в этом уличен, столкнется с осуждением со стороны всех будущих игроков. В этой ситуации люди снова вычисляют выгоды и потери от отказа от сотрудничества. Кроме того, они должны быть убеждены, что остальные присоединятся к наказанию, что в данном случае подразумевает отказ от сотрудничества всеми членами сообщества. Но для этого люди должны либо знать друг друга, либо располагать каким-то методом идентификации или маркировки тех, кто отказывался сотрудничать в прошлом. Из этого следует, что при прочих равных условиях у людей в небольших сообществах больше возможностей для усиления кооперации посредством повторения. В маленьких северных городках люди оставляют зимой автомобили на парковках у магазинов с включенным двигателем. Они не боятся, что автомобиль украдут (отказ от сотрудничества), поскольку знают всех жителей города. Любой, кто угонит автомобиль (даже в качестве шалости), понесет репутационный ущерб.
Физические метки могут сделать информацию о репутации общедоступной, что способствует поддержанию кооперации. В романе Натаниэля Готорна The Scarlet Letter44 Эстер Прин вынуждена носить на одежде вышитую алыми нитками букву «А» (от англ. «adultery» — «прелюбодеяние») за нарушение супружеской верности. В некоторых культурах осужденным ворам принято отрубать руки — надо сказать, довольно дорогая метка для осужденного. Маркировка отступников присутствует даже в некоторых видах. Рыба-чистильщик Labroides dimidiatus может очищать других рыб от паразитов (сотрудничество) или поедать более вкусную альтернативную пищу (отказ от сотрудничества). Если рыба поддерживает кооперацию, ее соседи будут избавлены от паразитов. Отсутствие паразитов видят другие рыбы. Чистота соседних рыб становится меткой, визуальной репутацией [7].
Связанность и репутация
Поддержание кооперации посредством механизма формирования репутации требует, чтобы соседи человека знали о допущенном им отклонении от норм поведения. Для того чтобы оценить вероятность распространения о нем такой информации, можно применить три вывода, которые мы сделали при включении сетей в модель заражения. Во-первых, чем выше степень сети, тем больше вероятность распространения слухов об отклонении. Во-вторых, вероятность усиливает вариация распределения степеней (особенно наличие чрезвычайно активных распространителей информации). В-третьих, если член совокупности отказывается от сотрудничества с тем, кто не связан с другими его соседями, то соседи вряд ли узнают об отклонении. Следовательно, для распространения информации о репутации сеть должна иметь высокий коэффициент кластеризации. Коэффициент кластеризации — это косвенный показатель социального капитала.
КООПЕРАЦИЯ МЕЖДУ МОДЕЛЯМИ ПОВЕДЕНИЯ, ПОДРАЗУМЕВАЮЩИМИ ИГРУ ПО ПРАВИЛАМ
Теперь смягчим предположение о рациональности и допустим, что игроки применяют стратегии, основанные на правилах, такие как триггер вечной кары. Мы используем эту модель, чтобы понять, может ли (и как) возникнуть сотрудничество. Наша модель включает совокупность отдельных игроков, которые проводят многократные раунды игры «Дилемма заключенного», играя друг против друга. Мы будем исходить из того, что каждое взаимодействие продолжится с определенной вероятностью. Такая структура игры побуждает рациональных игроков к сотрудничеству, если вероятность продолжения игры достаточно высокая.
В отличие от предыдущего случая, здесь мы предполагаем, что игроки применяют правила поведения. Одни могут использовать триггер вечной кары, другие — всегда сотрудничать, а третьи постоянно отказываться от сотрудничества. Различные варианты этих стратегий могут использовать другие виды. Самцы древесницы применяют стратегию «доброго врага», в соответствии с которой не участвуют в громком пении и не вступают в схватки для расширения владений за счет соседей. Мы можем рассматривать это как совместное действие [8].
Для удобства изложения будем исходить из того, что каждый член совокупности играет со всеми остальными ее членами. После того как каждый игрок сыграет все свои игры, все объявляют о полученном результате, равном среднему выигрышу за одну итерацию игры. Мы будем использовать средний выигрыш за игру, а не общий выигрыш, поскольку одни игроки могут по воле случая сыграть гораздо больше игр, чем другие, при условии вероятностного продолжения игры. Согласно данной структуре модели, результативность стратегии зависит от распределения стратегий. Отсюда следует, что выигрышная стратегия может также зависеть от исходного распределения. Если кооперативные стратегии обеспечивают более высокий результат на начальном этапе, то сотрудничество в данной совокупности с большой вероятностью будет усиливаться.
В целях нашего анализа присвоим в случайном порядке каждому игроку одну из пяти поведенческих стратегий: всегда сотрудничать (All C), всегда отказываться от сотрудничества (All D), триггер вечной кары (GRIM), око за око (TFT) и троллинг (TROLL). Стратегия GRIM сотрудничает на начальном этапе и продолжает сотрудничество до тех пор, пока соперник не выберет отказ от сотрудничества, после чего отказывается от сотрудничества навсегда. Стратегии All C и All D поступают в соответствии со своими названиями: слепо сотрудничают или отказываются от сотрудничества независимо от действий другого игрока. Стратегия TFT сотрудничает в первом периоде, а во всех последующих периодах копирует действие другого игрока за предыдущий период. Два игрока, выбирающих стратегию TFT, всегда будут сотрудничать. Стратегия TROLL стремится использовать игроков, которые всегда выбирают сотрудничество. Она отказывается от сотрудничества во время первых двух периодов, и если другой игрок не отказывается от сотрудничества в любом из этих периодов, TROLL отказывается от сотрудничества навсегда. Если другой игрок все же откажется от сотрудничества, TROLL переключается на сотрудничество в течение двух периодов, а затем выбирает GRIM.
Сначала вычислим выигрыши для каждой поведенческой стратегии, играющей против всех остальных стратегий, воспользовавшись выигрышами из дилеммы заключенного, представленной на рис. 22.1. Начнем со стратегии All D. Если она играет против стратегии All C, то получает выигрыш 4 в каждой игре. All C, со своей стороны, в ходе таких взаимодействий получает средний выигрыш всего лишь 1. Если All D играет против TFT или GRIM, она получает выигрыш 4 во время первого раунда игры и выигрыш 2 во всех последующих раундах. Если мы предположим, что игра повторяется многократно, средний выигрыш составит немногим более 2, что мы запишем как 2+. Когда All D играет против TROLL, обе стратегии отказываются от сотрудничества в первые два периода; при этом TROLL сотрудничает в третьем и четвертом периоде, а затем отказывается от сотрудничества. Стратегия All D снова получает средний выигрыш 2+. TROLL получает средний выигрыш немногим менее 2, что мы запишем как 2−.
Мы можем выполнить аналогичные операции и вычислить ожидаемые выигрыши по каждой паре стратегий [9]. В табл. 22.1 показан выигрыш каждой стратегии, играющей против всех остальных стратегий.
Таблица 22.1. Средние выигрыши стратегий строки, играющих против стратегий столбца
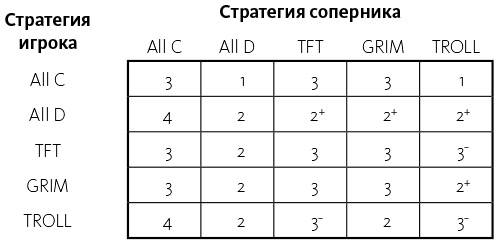
В таблице представлено сочетание взаимного сотрудничества, взаимного отказа от сотрудничества, а также стратегий, извлекающих пользу из ошибок в других стратегиях. Внимательный анализ таблицы показывает, что четыре из пяти стратегий сотрудничают сами с собой. Мы будем называть их потенциально кооперативными стратегиями. Только TFT сотрудничает с ними всеми. Следовательно, если любая комбинация этих четырех стратегий составляет большую часть данной совокупности, стратегия TFT обеспечит хорошие, если не лучшие результаты [10].
Тысячи экспериментов по дилемме заключенного с участием людей обнаруживают огромную неоднородность выбираемых ими стратегий. Поэтому мы используем приведенные в таблице выигрыши, чтобы проанализировать исходы в случае разных распределений. Учитывая многообразие выигрышей для различных комбинаций стратегий, лучшая стратегия будет зависеть от состава совокупности. В совокупности, состоящей в основном из стратегий All C, стратегия All D работает эффективнее всего. Если отдельные члены совокупности решают воспользоваться лучшей стратегией или если отбор работает быстро, тогда, возможно, члены данной совокупности никогда не смогут сотрудничать. Если процесс обучения или отбора идет умеренными темпами, игрокам следует воздерживаться от использования стратегии All C. Если совокупность содержит небольшое количество стратегий All C, стратегия All D будет обеспечивать менее высокие результаты, чем GRIM, TROLL и TFT. Одна из этих стратегий должна возобладать. Такую закономерность, когда на начальном этапе отказ от сотрудничества обеспечивает хорошие результаты, а затем берет верх сотрудничество, можно обнаружить во многих экспериментах с участием людей, а также в имитационных экспериментах с участием компьютерных интеллектуальных агентов. То, что происходит в этих случаях, можно описать как возникновение или эволюцию сотрудничества.
Можно представить любое распределение по этим пяти стратегиям или по любому другому ансамблю стратегий, вычислить средние выигрыши, а затем проанализировать, что произойдет в результате обучения или отбора. В следующей главе мы построим формальные модели обучения и отбора, а пока будем использовать неформальные аргументы, поскольку просто хотим подчеркнуть, что возникновение кооперации зависит от исходных стратегий, входящих в состав совокупности, и от того, как люди осваивают или развивают новые стратегии.
Необходимое условие возникновения или эволюции кооперации заключается в том, что выигрыш от сотрудничества должен превышать выигрыш в случае отказа от него в заданной совокупности. Иначе и отбор, и обучение приведут всю совокупность к отказу от сотрудничества. Для упрощения анализа представим, что совокупность состоит из кооперативных стратегий, таких как GRIM, All C и TFT, а также стратегий отказа от сотрудничества, таких как All D. А затем вычислим, при каких условиях кооперативные стратегии гарантируют более высокий средний результат. Результаты вычислений показывают, что развивать кооперацию труднее, чем поддерживать, и что она не способна самообеспечиваться — небольшая совокупность кооператоров не может стать источником возникновения кооперации [11].
Такое различие между поддержанием кооперации, ее возникновением или эволюцией и бутстрэппингом45 заслуживает повторного возвращения к этому вопросу. Поддержание кооперации возможно в случае, если при условии сотрудничества всех игроков она обеспечивает самые высокие результаты. Она имеет место тогда, когда стратегия GRIM является равновесием Нэша в повторяющейся игре. Кооперация может возникнуть или развиваться в случае, если стратегии, сотрудничающие между собой в рамках совокупности, в среднем демонстрируют более высокие результаты по сравнению со стратегиями, отказывающимися от сотрудничества. Как уже отмечалось, труднее удовлетворить условия для возникновения кооперации, чем условия для ее поддержания. На самом деле математические расчеты показывают, что бутстрэппинг — почти невыполнимая задача. Если доля кооператоров близка к нулю, они получают более низкие выигрыши, чем те, кто отказывается от сотрудничества. Вывод заключается не в том, что бутстрэппинг кооперации вообщеневозможен, а в том, что он невозможен именно в этой модели. Для того чтобы добиться кооперации, изначально необходима определенная доля людей, готовых к сотрудничеству. Это может произойти с людьми, которые анализируют игру, но маловероятно в отношении пчел и корней деревьев. Для того чтобы понять, как может произойти бутстрэппинг, нужны более сложные модели, учитывающие локальное обучение, эволюцию и групповой отбор. Давайте теперь их рассмотрим.
МОДЕЛЬ СОВМЕСТНЫХ ДЕЙСТВИЙ
Для того чтобы проанализировать, как возникает сотрудничество, введем модель совместных действий, в которой люди могут либо совершать совместное действие, либо воздерживаться от него [12]. Совместное действие сопряжено с издержками для выполняющего его члена совокупности и приносит выгоду всем остальным. Отказ от совместных действий не влечет за собой никаких издержек и не приносит никакой выгоды.
Существует ряд различий между моделью совместных действий и повторяющейся дилеммой заключенного. Во-первых, в модели совместных действий члены совокупности не играют в повторяющуюся парную игру, в которой они применяют стратегии и получают выигрыши. Вместо этого они являются либо кооператорами, либо некооператорами. Во-вторых, модель не рассчитана на рациональных акторов или членов совокупности, использующих более сложные правила. В-третьих, члены совокупности принадлежат к сети взаимодействия. Их совместные действия влияют только на тех, с кем они связаны, то есть на их соседей. И последнее: поскольку члены совокупности принадлежат к определенному типу, они совершают одни и те же действия в отношении всех своих соседей. Кооператор с пятью соседями несет в пять раз большие издержки в связи с кооперацией и приносит пользу пяти другим членам совокупности.
Модель совместных действий
Совокупность из N членов состоит из кооператоров и отступников, связанных между собой в рамках сети. Кооперация сопряжена с издержками C и приносит выгоду B другому игроку в ходе каждого взаимодействия. Отказ от сотрудничества не влечет за собой никаких издержек и не приносит никакой выгоды. Коэффициент кооперативного преимущества 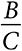 отражает потенциальную выгоду от сотрудничества.
отражает потенциальную выгоду от сотрудничества.
Сеть играет ключевую роль в создании условий для возникновения кооперации и даже для ее бутстрэппинга. Небольшой кластер или группа кооператоров, в основном взаимодействующих друг с другом, получает хорошие результаты, а затем распространяется по всей совокупности. В экосистеме потомство часто обитает рядом с родителями. Если потомки кооператоров с большей вероятностью становятся кооператорами, то бутстрэппинг кооперации становится более легкой задачей.
Чтобы продемонстрировать, что кластеризация может обеспечить бутстрэппинг кооперации, начнем с частично заполненной сети. Каждый ее узел выступает в качестве потенциального местоположения одного из членов совокупности. В биологическом контексте такими местами является подходящая среда обитания. Затем наполним часть сети членами совокупности — либо кооператорами, либо отступниками. Например, мы могли бы сначала нарисовать произвольную сеть со средней степенью 10, а затем бросить игральную кость в каждом узле. Если выпадет шестерка, мы разместим члена совокупности в этом узле. Если нет, оставим его пустым. При размещении члена совокупности в узле мы снова бросаем кость. Если выпадет пятерка, мы поместим в этот узел кооператора, в остальных случаях отступника. Эта процедура позволит заполнить шестую часть узлов в нашей сети, причем в шестой части занятых узлов будут размещены кооператоры.
В сети с такой структурой отдельные члены совокупности будут отличаться по количеству соседей: у некоторых их вообще не будет, тогда как у других будет по четыре или пять. Для того чтобы обеспечить рост или распад кооперации, заполним оставшуюся часть сети, в итеративном режиме заполняя узлы, расположенные рядом с занятыми узлами. Будем исходить из того, что пустой узел принимает тот же тип (то есть становится либо кооператором, либо отступником), что и тип наиболее результативного узла среди его соседей. На рис. 22.3 показаны два сегмента линейных сетей. Кооператоры представлены темными линиями, отступники — серыми, а пустые узлы — пунктирными линиями. Каждый сегмент содержит пустой узел в центре с двумя соседями — одним отступником и одним кооператором. На этом рисунке сотрудничество обеспечивает выгоду 2 и влечет за собой издержки 1.
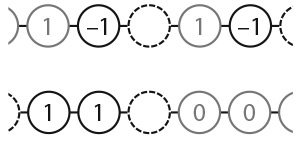
Рис. 22.3. Выигрыши соседей пустого узла в двух линейных моделях
В верхнем сегменте рисунка 22.3 у отступника справа от свободного узла есть сосед-кооператор, поэтому он получает выигрыш 1. У соседа-кооператора слева от свободного узла есть сосед-отступник, поэтому он получает выигрыш −1. Согласно нашим правилам заполнения узлов, поскольку сосед-отступник получает более высокий выигрыш, пустой узел станет отступником. В нижнем сегменте у соседа-отступника пустого узла есть сосед-отступник, тогда как сосед-кооператор пустой клетки связан с другим кооператором. Следовательно, в нижнем сегменте мы получаем противоположный результат. Здесь сосед-кооператор получает более высокий выигрыш, поэтому пустой узел станет кооператором.
В этом примере одиночный кооператор не может создать еще одного кооператора, а два соседних кооператора могут. Отсюда следует, что небольшой кластер кооперативных узлов, окруженных пустыми клетками, может расшириться на свободные узлы. Таким образом, небольшое количество кооператоров может обусловить формирование областей кооперации.
Мы можем сформулировать более общие условия того, станет ли пустая клетка кооператором или отступником, на основании доли соседних кооператоров и отступников, а также коэффициента кооперативного преимущества. Из этого следует, что обеспечить бутстрэппинг кооперации проще в сетях с более низкой степенью. Этот вывод противоположен полученному в ходе анализа того, как репутация поддерживает кооперацию, когда более связанная сеть способствует ее поддержанию. Это еще один пример того, что многомодельное мышление способствует получению условных знаний. На вопрос о том, обеспечивают ли связанные сети более высокий или более низкий уровень кооперации, нет однозначного ответа. Если кооперацию поддерживают сложно организованные агенты с помощью репутации, в более связанных сетях имеет место более широкая кооперация. Если кооперация зародилась или эволюционировала среди агентов с простой организацией, таких как деревья или муравьи, менее связанные сети должны способствовать расширению кооперации.
Кластеризация обеспечивает бутстрэппинг кооперации
Если соседи свободного узла — это кооператор со степенью D и K соседями-кооператорами, а все некооператоры пустого узла не имеют соседей-кооператоров, то свободный узел становится кооператором, тогда и только тогда, когда коэффициент кооперативного преимущества превышает отношение степени к количеству кооператоров [13]:
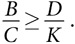
ГРУППОВОЙ ОТБОР
Наш последний механизм бутстрэппинга, эволюции и поддержки кооперации, групповой отбор, основан на конкуренции или отборе среди групп [14]. Для построения модели группового отбора разделим совокупность на подгруппы. В рамках каждой подгруппы отдельные члены совокупности входят в состав одной из версий модели совместных действий, в которой либо сотрудничают, либо отказываются от сотрудничества. Как и прежде, мы можем определить результат каждого члена совокупности. В каждой группе мы также можем вычислить результат, равный среднему результату членов группы. Модель описывает отбор среди групп, в ходе которого копии групп с высокими результатами занимают место групп с низкими результатами. Это создает преимущество для групп кооператоров, которые получают более высокие результаты.
В интуитивном выводе относительно того, что при наличии группового отбора кооперативные группы должны взять верх, есть один подвох: в рамках любой группы отступники превосходят кооператоров. Рассмотрим две группы численностью десять человек. В первую входят два кооператора и восемь отступников. Во вторую — два отступника и восемь кооператоров. Предположим, выгода равна 2, а издержки 1, как и в предыдущем случае. В первой группе результат каждого отступника равен 4, поскольку он получает выгоду 2 от каждого кооператора. Каждый кооператор несет издержки 9 и получает выгоду всего 2, а значит, его результат равен −7. Средний результат члена группы 1,8. Во второй группе каждый отступник получает выгоду 2 от каждого из восьми кооператоров, а значит, его результат равен 16. Результат каждого кооператора равен 5: он получает выгоду 14 от остальных семи кооператоров, но несет издержки 9. Во второй группе средний результат составляет 7,2.
Эти вычисления приводят к парадоксальному выводу: в каждой группе отступники получают более высокий результат, чем кооператоры, но в более результативной группе больше кооператоров. Противоречие должно быть очевидным — индивидуальный отбор поддерживает отказ от сотрудничества, тогда как групповой способствует кооперации — и проявляется в различных экологических, социальных, политических и экономических контекстах. Деревья, чьи корни сотрудничают с другими деревьями, находятся в худшем положении по отдельности, но вносят свой вклад в создание более сильных экосистем, способных захватывать свободные пространства. Кооператоры в сообществах могут получать меньше выгод, чем отступники, однако кооперативные сообщества растут быстрее. У политиков, поддерживающих свою партию, вероятность быть переизбранными ниже, чем у политиков, сфокусированных исключительно на себе, но у сплоченных партий больше шансов к развитию. Человек, работающий на компанию, может оказаться в худшем положении, развивая способности, полезные только для нынешнего работодателя, но если он это делает, его компания может превзойти конкурентов.
Модель совместных действий помогла нам выявить это противоречие и выразить его в количественной форме. Для того чтобы понять, может ли групповой отбор обеспечить бутстрэппинг, эволюцию и поддержку кооперации, нам нужно добавить в модель больше деталей. Траулсен и Новак предлагают изящную модель, в которой совокупности растут, а новые члены напоминают тех, кто получает высокие результаты. В основе такой модели лежит как индивидуальный, так и групповой отбор. Отбор осуществляется на уровне отдельных членов совокупности, но ее более результативные члены, скорее всего, происходят из групп с высоким уровнем кооперации. Когда группа становится достаточно большой, она делится на две части, создавая новую группу. Для предотвращения чрезмерного разрастания совокупности формирование новой группы приводит к удалению случайно выбранной существующей группы. Такая особенность свойственна слабой форме группового отбора [15].
Эти модели показывают, что групповой отбор усиливает кооперацию при условии, что выгода от совместных действий сравнительно велика, а максимальный размер группы небольшой относительно количества групп. Вывод о том, что эффективность группового отбора отчасти зависит от отношения максимального размера группы к количеству групп, объясняет необходимость конкуренции. Наличие большего количества групп подразумевает более высокую вероятность формирования группы только из кооператоров, а также косвенно указывает на более высокую конкуренцию. Более неожиданный результат состоит в том, что меньший максимальный размер группы обеспечивает более широкую кооперацию. Меньший максимальный размер группы предотвращает доминирование отступников над группами кооператоров, ограничивая воздействие индивидуального отбора. Вспомните о группе из восьми кооператоров и двух отступников, где отступники получают более высокий результат. Если бы ее численность увеличилась до восьмидесяти членов, группа содержала бы гораздо большую долю отступников до того, как произойдет раздел. Если группа делится на две части, как только ее размер достигнет двенадцати членов, в худшем случае после раздела в ней будет две трети кооператоров.
Способность группового отбора усиливать кооперацию можно использовать в организациях. Как правило, большинство организаций назначают оплату в зависимости от результатов работы отдельных сотрудников. Разделение сотрудников на конкурирующие друг с другом команды и распределение бонусов и возможностей на основании результатов работы команд позволяет стимулировать кооперативное поведение. Когда ресурсы предоставляются командам, у сотрудников появляется стимул хорошо в них работать, то есть поддерживать кооперацию [16]. Такие стимулы должны способствовать расширению сотрудничества в командах, если выгода от него достаточно высокая, а размер команд относительно небольшой.
Оценивая потенциал группового отбора, необходимо тщательно взвешивать уровень организации отдельных членов совокупности. Деревья адаптируются медленно, поэтому процесс группового отбора не будет протекать быстро. Люди адаптируются быстро, поэтому, если индивидуальные стимулы отказа от сотрудничества достаточно высокие, групповой отбор должен происходить соответствующими быстрыми темпами. Однако люди могут осознавать последствия группового отбора. Они могут учесть конкуренцию между группами и увидеть, что формирование сильной группы отвечает их интересам. Это повышает вероятность кооперации. Все это говорит о том, что мы не должны слишком доверять тому или иному ограничивающему условию, согласно которому в определенной модели кооперация будет усиливаться, а проанализировать вместо этого множество моделей и выяснить, сохраняют ли актуальность качественные выводы.
РЕЗЮМЕ
Загадку формирования, расширения и поддержания кооперации пытались разгадать тысячи ученых из разных областей науки. Эти исследования проводились с помощью моделей, среди которых самой известной была дилемма заключенного. Если исходить из участия рациональных акторов в повторяющейся игре, загадка исчезает. Сотрудничество можно поддерживать посредством угрозы наказания. Наказание может осуществляться напрямую в ходе повторяющейся игры или косвенным образом, в силу репутации. Эти механизмы позволяют объяснить, как кооперация возникает в условиях высоких ставок и с высокоразвитыми людьми, но они не могут объяснить, почему склонность к сотрудничеству демонстрируют муравьи, пчелы, деревья и голые землекопы. Изучив кооперацию между игроками, придерживающимися правил, мы обнаружили, что ее развитие — непростая задача. Рациональные акторы способны поддерживать кооперацию в такой среде, где играющие по правилам субъекты не могут ее развивать.
Кроме того, мы обнаружили, что, хотя примитивные стратегии (такие как «Око за око») и не оптимальны, они все же способны поддерживать сотрудничество и не становиться объектом эксплуатации. Последующие исследования показали, что стратегия «Око за око» не столь эффективна при наличии случайных ошибок в игре. Если возникает ошибка и игрок отказывается от сотрудничества, два игрока, использующих стратегию «Око за око», образуют цикл действий, включающих отказ от сотрудничества и сотрудничество. Если по стечению обстоятельств оба игрока откажутся от сотрудничества, стратегия «Око за око» приведет к взаимному отказу от сотрудничества вплоть до возникновения очередной ошибки.
В реальных играх с дилеммой заключенного ошибки действительно случаются. Самолет авиакомпании Korean Airlines, выполнявший рейс 007 из Нью-Йорка с дозаправкой в Анкоридже (Аляска) в Сеул, 1 сентября 1983 года вошел в воздушное пространство Советского Союза. Советский истребитель СУ-15 сбил самолет, в результате чего погибло 269 человек, находившихся на борту. США сочли это отказом Советского Союза от сотрудничества. СССР, полагая, что самолет выполнял секретную операцию, воспринял это как отказ США от сотрудничества.
Во избежание бесконечной серии наказаний за ошибку используются другие, более гуманные стратегии, такие как стратегия «выигрываешь — остаешься, проигрываешь — переходишь» (win — stay, lose — shift strategy), то есть повторение действия в случае победы и его замена в случае поражения. В такой стратегии выигрыш от взаимного сотрудничества (R) и выигрыш от искушения (T) условно обозначаются как победа, а два оставшихся выигрыша как поражение. Стратегия «выигрываешь — остаешься, проигрываешь — переходишь» начинается с сотрудничества, после чего в случае победы выполняется то же действие, что и в предыдущем периоде, а в случае поражения происходит переход к другому действию. Проанализировав ряд примеров, можно увидеть, как такая стратегия обеспечивает возврат к кооперативному поведению [17].
В этой главе мы также описали два других механизма. Кластеризация создает условия для бутстрэппинга кооперации. Этот механизм основывается на кооператорах, которые играют друг с другом и расширяют кооперацию посредством отбора. Групповой отбор действует в соответствии с аналогичной логикой. Группы кооператоров получают высокие результаты и вытесняют группы отступников. В процессе построения моделей мы обнаружили, что кооперация, возникающая в результате кластеризации и группового отбора, требует более строгих условий, чем кооперация через повторения или репутацию. Мы также узнали, что успех различных механизмов зависит от того, как мы моделируем отдельных членов совокупности. Не следует рассчитывать на то, что эти механизмы будут одинаково работать для людей, муравьев и деревьев. Агенты с более высоким уровнем организации в большей степени способны поддерживать кооперацию, поскольку им свойственна дальновидность, но они могут и с большей вероятностью распознавать выгоды отказа от сотрудничества, будучи в окружении кооператоров.
В большинстве случаев мы говорили о кооперации как о том, что приносит выгоду. Однако объекты могут сотрудничать и ради эксплуатации других объектов. Компании образуют картели, чтобы искусственно поддерживать высокие цены, а страны создают коалиции, чтобы ограничить поставку ресурса (такого как нефть), ради собственной выгоды, а не для блага человечества. Опухолевые клетки кооперируются, чтобы противостоять воздействию иммунной системы [18]. Следовательно, при изучении кооперации следует помнить о том, что она не всегда нацелена принести благо. Азиатский буйвол не получает никакой выгоды от совместных действий львов.
ГЛАВА 23
ПРОБЛЕМЫ КОЛЛЕКТИВНЫХ ДЕЙСТВИЙ
Устойчивое управление природными ресурсами всегда было трудной задачей, с тех пор как примерно 50 тысяч лет назад homo sapiens (человек разумный) развил в себе современную изобретательность, эффективность и охотничьи навыки.
Джаред Даймонд
В этой главе мы рассмотрим проблемы коллективных действий: ситуации, когда личные интересы не совпадают с коллективными. Подобные проблемы бывают глобальными и локальными. В аэропортах каждому отдельному путешественнику выгодно стоять как можно ближе к багажному конвейеру, но для всех было бы лучше, если бы люди отошли от него на какое-то расстояние. В демократическом обществе у людей мало стимулов становиться информированными избирателями, учитывая очень низкую вероятность того, что один голос изменит исход голосования, но демократическое государство функционирует гораздо эффективнее при наличии информированных граждан. Проблемы коллективных действий можно представить в виде дилеммы заключенного с участием множества игроков, где у каждого игрока есть стимул отказаться от сотрудничества, но вместе они добиваются большего, сотрудничая друг с другом.
Люди часто изучают модели коллективных действий в контексте исторических примеров, таких как использование шотландских общинных земель или сохранение среды обитания лобстеров на побережьях Ньюфаундленда и штата Мэн [1]. В истории также есть примеры драматических неудач, среди которых самая известная — крах полинезийской культуры острова Пасхи, описанный в книге Джареда Даймонда [2]. Остров Пасхи находится более чем в 3500 километров от Чили в южной части Тихого океана, где нет других обитаемых островов в радиусе 2000 километров. Учитывая такое местоположение, островитянам всегда приходилось со всем справляться самостоятельно. На протяжении более чем тысячи лет они жили хорошо. По некоторым оценкам, в начале XVII столетия численность населения острова Пасхи превышала пятнадцать тысяч человек. В XVI веке островитяне накопили достаточно ресурсов, чтобы высвободить рабочую силу для создания огромных каменных голов под названием моаи весом до восьмидесяти тонн. Пока жители острова Пасхи занимались строительством моаи, они не сотрудничали в области рационального использования лесов. Поэтому к 1722 году, когда европейцы впервые высадились на острове, на нем уже ощущалась нехватка продуктов питания, а численность населения сократилась примерно до двух тысяч человек. На острове осталось очень мало деревьев выше трех метров, а многие виды птиц и животных вымерли. Иначе говоря, наступил коллапс цивилизации. Этот процесс завершился, когда вирусы, завезенные европейцами, уничтожили почти все оставшееся население острова.
По мнению Даймонда, гибель цивилизации на острове Пасхи, так же как и цивилизаций майя в Центральной Америке, анасази на юго-западе США и винландцев в Гренландии, — следствие климатических изменений и чрезмерного использования природных ресурсов (вызванного организационными и культурными просчетами). Обитатели Винланда выпасали животных на малоплодородных землях и срывали хрупкий дерн для своих жилищ, из-за чего земля вскоре стала бесплодной, и винландцы начали голодать. Подобно обитателям острова Пасхи, они не смогли рационально распорядиться общими ресурсами. Неконтролируемая вырубка деревьев и использование слишком большого количества дерна привели к коллапсу.
Под влиянием этих ярких и убедительных примеров некоторые начали воспринимать проблемы коллективных действий как нечто относящееся исключительно к прошлому. Но это однобокий взгляд на проблему. Поскольку мир становится все более взаимосвязанным и сложным, проблемы коллективных действий сегодня еще более актуальны, чем в те времена. Мы сталкиваемся с ними практически на всех уровнях организации человеческого общества. Предоставление государственного образования, охрана физического и психического здоровья, инфраструктура, общественная безопасность, судебная система и национальная оборона — все это проблемы коллективных действий, так же как и регулирование мирового рыбного промысла, борьба с изменением климата и особенно сокращение содержания углерода в атмосфере. Кроме того, поскольку работа все больше становится командным видом деятельности, это неизбежно порождает проблемы коллективных действий. Работники склонны присваивать себе результаты труда окружающих. Кроме того, у них есть стимул предъявлять завышенные требования к доле общего рабочего пространства, чтобы обеспечить место для работы своих команд.
Глава организована следующим образом. Сначала мы дадим определение общей проблемы коллективных действий, а затем проанализируем три конкретных типа таких проблем. Начнем с проблем обеспечения общественных благ, когда люди выделяют деньги на финансирование дорог, школ и социальных служб или вкладывают время и усилия в уборку парков или водосборов. Затем мы изучим проблемы перегруженности, которые вынуждают людей ограничивать использование таких ресурсов, как дорожная система, пляж или парк. И в заключение рассмотрим проблемы добычи возобновляемых ресурсов, когда люди потребляют восстанавливаемый ресурс, такой как рыба, лобстеры или деревья. Проблемы перегруженности возвращаются в исходное состояние каждый день. Если слишком много автомобилей заполняют улицы Лондона, затрудняя дорожное движение, можно повысить плату за въезд в город и решить проблему, а значит, чрезмерное использование в прошлом не имеет долгосрочных последствий. А вот на устранение последствий неконтролируемой вырубки леса или чрезмерного вылова рыбы могут понадобиться десятилетия. Мы расплачиваемся за свой отказ от сотрудничества в прошлом.
В каждой из трех моделей характер несоответствия между индивидуальными стимулами и коллективными целями отличается, поэтому разнятся и решения. Проблемы обеспечения общественных благ можно решить посредством налогов, а иногда и путем сортировки. Проблемы перегруженности решаются с помощью денежных сборов или ограничений на использование. Решение проблем с возобновляемыми ресурсами требует более тщательного мониторинга и санкций, а также механизмов урегулирования конфликтов.
Предлагаемые нами решения дают обобщенную базовую информацию, которую необходимо адаптировать к конкретному контексту. Любая реальная ситуация включает в себя уровни сложности, не учитываемые моделями. Балийские водные храмы решают проблему распределения воды (которая является проблемой непрерывной перегруженности), предоставляя обитателям верховья реки возможность использовать ресурс первыми. Международные права на рыбный промысел, ограничивающие доступ к рыболовным угодьям, решают проблему использования общих ресурсов в отношении движимого ресурса, подобно тому как решение проблемы прибрежного рыбного промысла в Норвегии может быть подорвано чрезмерным выловом рыбы в прибрежных водах Швеции, России и Дании [3]. Реальные решения в какой-то мере основаны на механизмах, о которых шла речь в главе 22 в контексте формирования кооперации в дилемме заключенного, таких как повторение, репутация, сетевая структура и групповой отбор. Групповой отбор оказывает косвенное воздействие: города и страны, преуспевшие в решении этих проблем, будут процветать, а другие будут копировать их успехи.
ПРОБЛЕМЫ КОЛЛЕКТИВНЫХ ДЕЙСТВИЙ
В случае проблемы коллективных действий у каждого человека есть выбор — внести свой вклад или быть «безбилетником». Роль безбилетника отвечает интересам отдельного человека, обеспечивая ему более высокий выигрыш. Вместе с тем, когда каждый вносит свой вклад, это приносит общую выгоду.
Проблема коллективных действий
В случае проблемы коллективных действий каждый из N человек решает либо быть безбилетником (f), либо внести свой вклад (c) в коллективное действие. Выигрыш каждого человека зависит от его собственных действий и общего количества кооператоров. Отдельные люди получают более высокий выигрыш в роли безбилетника, Payoff(f, C) > Payoff(c, C + 1), однако сумма выигрышей достигает максимального значения, когда все вносят свой вклад.
Проблему коллективных действий можно представить в виде многопользовательской версии дилеммы заключенного. Следовательно, мы можем вернуться к предложенным в главе 22 решениям, чтобы почерпнуть идеи о том, как сформировать и поддерживать кооперацию. Однако такой подход будет неполным по двум причинам: проблемы коллективных действий охватывают группы и сообщества, а не просто пары игроков; кроме того, многие проблемы коллективных действий принимают определенные формы, которые делают одни решения более эффективными, чем другие.
ОБЩЕСТВЕННЫЕ БЛАГА
Первый тип проблем коллективных действий связан с обеспечением общественных благ. Общественные блага обладают такими свойствами, как неконкурентность (использование общественного блага одним человеком никоим образом не мешает другому человеку тоже его использовать) и неисключаемость (невозможно помешать людям использовать общественное благо). К общественным благам относится чистый воздух, национальная оборона, раннее предупреждение о приближении торнадо и накопление знаний. Конституция США включает в круг обязанностей правительства обеспечение правосудия, поддержание общественного порядка и создание общей системы обороны. Эти задачи тоже относятся к числу общественных благ.
Личным благам (таким как велосипеды, овсяное печенье и т. д.) не присущи свойства неконкурентности и неисключаемости. Знания, напротив, обладают обоими свойствами. Сопоставление овсяного печенья со знанием тригонометрии подчеркивает эту разницу. Учитель может сказать: «Карла съела последнее овсяное печенье, поэтому больше никто не может его съесть». Но он не может сказать: «Мелисса, извини, но Карла только что использовала теорему Пифагора, поэтому больше никто не сможет ее использовать».
Неисключаемость и неконкурентность общественных благ порождают проблему коллективных действий не потому, что люди не хотят вносить свой вклад. Они хотят. Проблема возникает по той причине, что люди недооценивают свой вклад. Каждый доллар, который вносит человек, увеличивает полезность для всех. В формальной модели, которую мы здесь описываем, каждый человек распределяет свой доход между общественным благом и репрезентативным личным благом, коим могут выступать деньги, которые можно потратить на что-то другое. Расширение модели для включения множества общественных и личных благ только усложнит анализ.
Проблема обеспечения общественных благ
Каждый из N человек распределяет свой доход I > N между общественным (PUBLIC) и личным (PRIVATE) благом, стоимость единицы которого составляет 1 доллар. Каждый человек имеет следующую функцию полезности:
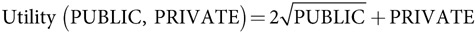
Социально оптимальное распределение: PUBLIC = N (если N = 100, каждый человек вносит 100 долларов).
Равновесное распределение: 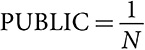 (если N = 100, каждый человек вносит 0,01 доллара) [4].
(если N = 100, каждый человек вносит 0,01 доллара) [4].
В этой модели мы исходим из того, что функция полезности является вогнутой для общественного блага, а для личного блага — линейной. Эти два допущения подразумевают наличие мотивации. Вспомните о том, что вогнутость соответствует убывающей отдаче: чем больше блага потребляет человек, тем меньше его ценит. Вогнутость в случае количества общественного блага свидетельствует об убывающей предельной отдаче от этого блага. Это стандартное предположение. Строительство третьей полосы автомагистрали приносит людям большую выгоду, чем строительство четвертой. Люди получают больше пользы от очистки воздуха с высоким уровнем загрязнения, чем от удаления последних нескольких частиц на миллион. В случае личного блага мы исходим из линейности функции полезности, потому что она представляет всю совокупность личных благ. Хотя функция полезности может быть вогнутой для любого отдельного блага, будь то шоколад, телевизоры или джинсовые куртки, для всех товаров она скорее всего более близка к линейной функции. Дополнительное преимущество этого предположения состоит в том, что оно упрощает анализ модели.
Сначала давайте найдем социально оптимальное распределение, которое определим как распределение, максимизирующее сумму значений полезности всей совокупности: наибольшее счастье наибольшего количества людей [5]. Социально оптимальное распределение требует, чтобы каждый человек выделял 1 доллар на общественное благо для каждого члена совокупности. Обратите внимание, что сумма, которую вносит каждый человек в общественное благо, увеличивается по мере роста размера совокупности. Этот результат не зависит от конкретной функции, а вытекает из того факта, что в более крупной совокупности неконкурентное общественное благо может приносить пользу большему количеству людей. Чем больше людей пользуются преимуществами чистого воздуха или национальной обороны, тем больше этих общественных благ следует предоставлять.
Равновесные взносы равны 1, деленной на размер совокупности. При увеличении ее численности у людей появляется больше стимулов извлекать выгоду из вклада других людей в общественное благо, не прилагая к его созданию никаких усилий. Для того чтобы понять, почему это происходит, можно увеличить размер совокупности на единицу. Новый человек получает такую же полезность от общественного блага, как и все остальные ранее. Если вклад остальных будет прежним, у нового человека будут более слабые стимулы вносить свой вклад в общественное благо, чем стимулы, которые были у остальных в прошлом. Поэтому он внесет меньше, чем другие. Кроме того, какую бы сумму ни внес новый человек, это увеличивает общий объем общественного блага и создает стимулы для остальных вносить меньше, чем раньше.
Таким образом, модель показывает, что по мере увеличения размера совокупности проблемы обеспечения общественных благ усугубляются. Оптимальный уровень блага повышается, тогда как стимулы вносить свой вклад ослабевают. Формулы, выведенные в нашей модели (для N и 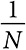 ), действительно зависят от исходных функций, однако феномен недостаточного обеспечения общественных благ в общем случае сохраняется.
), действительно зависят от исходных функций, однако феномен недостаточного обеспечения общественных благ в общем случае сохраняется.
В основе этого анализа лежит предположение о том, что люди руководствуются собственными интересами — предположение, которое широко применяется в экономических моделях. Однако результаты опросов, экспериментов и случайных наблюдений свидетельствуют о том, что людям все же свойственна склонность учитывать интересы окружающих. Люди хотят хороших школ и дорог для других в той же мере, что и для себя. Мы можем принять во внимание склонность учитывать интересы других, включив в модель показатель альтруизма. Нулевое значение этого показателя соответствует движимому личными интересами рациональному экономическому агенту, а значение 1 соответствует тому, кто заботится о других так же, как о себе. Как показано во врезке, чистые альтруисты (люди, которые заботятся обо всех одинаково) вносят свой вклад в социально оптимальный уровень общественных благ. Все, что не достигает уровня чистого альтруизма, приводит к нехватке общественных благ.
Обеспечение общественных благ среди альтруистов
N человек имеют альтруистические предпочтения с весовым коэффициентом совокупной полезности, равным α:
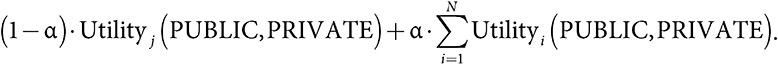
Равновесный вклад чистых альтруистов (α = 1) (PUBLIC = N).
Равновесное общее решение [6]: 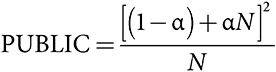 .
.
Пример: 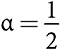 :
: 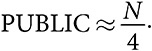
Согласно расчетам, в больших совокупностях люди вкладывают в общественное благо долю оптимального уровня, примерно равную квадрату показателя альтруизма. Хотя степень нехватки общественных благ зависит от функции полезности, этот пример демонстрирует пределы альтруизма. Люди, которые заботятся о других вдвое меньше, чем о себе, вносят в общее благо четверть оптимального уровня. Люди, забота которых о других составляет треть их заботы о себе, вносят в общее благо всего одну девятую от оптимального уровня.
Учитывая, что мы живем не в мире чистых альтруистов, нам нужно искать другие механизмы, такие как налогообложение. Правительства вводят налоги для финансирования дорог, обороны страны, образования, системы правосудия и других общественных благ. Для определения размера налогов требуется более сложная модель, учитывающая неоднородность дохода и предпочтений. Люди могли бы проголосовать за сумму и ставку единого налога. Согласно прогнозу модели пространственного голосования, ставка налога должна быть равной предпочтительному уровню общественного блага для медианного участника голосования. Этот уровень может не быть социально оптимальным в случае неоднородности дохода и предпочтений людей.
Многие общественные блага, такие как школы, дороги и программы переработки отходов, можно отнести к категории локальных общественных благ. Местное сообщество может не допускать к такому благу других, но в рамках самого сообщества общественное благо является неконкурентным и неисключаемым. В случае локальных общественных благ возможность формировать сообщества на основе своих предпочтений (так называемая сортировка Тибу) представляет собой вероятное решение проблемы обеспечения общественных благ. Люди, которым нужны лучшие школы, общественные парки, бассейны и защита полиции, могут проголосовать за введение более высоких налогов для финансирования этих общественных благ. Люди, которым это не нужно, могут жить в отдельном сообществе и платить более низкие налоги. Сортировка Тибу не панацея. Она предполагает сопутствующие издержки, в том числе снижение уровня социальной сплоченности. Более того, когда люди с высоким уровнем доходов отгораживаются от остальных, они сокращают объем общественных благ в более бедных общинах и ограничивают межсетевое взаимодействие, которое обеспечивает передачу информации и знаний [7].
МОДЕЛЬ ЗАТОРОВ
В модели коллективных действий второго типа, касающейся таких ресурсов, как дороги, пляжи и системы водоснабжения, ценность ресурса для отдельного человека снижается по мере увеличения количества пользователей. Каждый, кто когда-либо попадал в дорожные заторы, сталкивался с проблемой перегруженности на собственном опыте. Свободная дорога приносит больше удовольствия и пользы, чем дорога, забитая автомобилями. По некоторым оценкам, издержки в связи с замедленным движением транспорта на дорогах составляют в США около 100 миллиардов долларов в год. В некоторых городах (особенно в Лос-Анджелесе и Вашингтоне) люди в среднем простаивают в пробках более шестидесяти часов в год.
Наша модель заторов описывает ресурс с фиксированным объемом. Выгода, которую получает человек от его использования, находится в линейной зависимости от количества других пользователей [8]. Наклон этой линии, показатель перегруженности, отражает величину эффекта перегруженности.
Модель заторов
M из N человек решают воспользоваться ресурсом. Их полезность можно записать так:
Utility(M) = B − Θ · M,
где B — это максимальная выгода, а Θ — показатель перегруженности. Оставшиеся (N − M) людей воздерживаются от использования данного ресурса и получают нулевую полезность [9].
Социально оптимальное решение: 
Равновесие Нэша: 
В случае социально оптимального решения количество людей, использующих данный ресурс, равно максимально возможной выгоде, деленной на удвоенный показатель перегруженности. Этот результат совпадает с интуитивными выводами. Количество людей, использующих ресурс, должно расти вместе с максимальной выгодой и сокращаться по мере увеличения эффекта перегруженности. В решении, которое обеспечивает равновесие Нэша, количество людей, использующих данный ресурс, ровно вдвое больше социально оптимального количества. Уровень перегруженности повышается настолько, что никто не получает никакой выгоды. Этот результат вытекает из предположения, что использование ресурса дает нулевую полезность. Парадоксальное следствие из этого вывода состоит в том, что город, который строит красивый парк, может не создавать большую полезность для горожан, поскольку при равновесии парк будет достаточно переполнен, из-за чего пребывание в нем будет менее комфортным, чем отдых дома.
Когда модель дает результат, противоречащий здравому смыслу, его нужно проанализировать. Наличие парка должноделать людей счастливее, а значит, модель будет неправильной. Она действительно неправильна, поскольку мы исходили из предположения, что все люди получают одинаковое удовольствие от парка. Но если это не так, то одни могут получить положительную полезность от посещения парка, тогда как другие не извлекут никакой выгоды. Во-вторых, модель предполагает, что в парке всегда многолюдно, хотя на самом деле это не так. В-третьих, альтернативным вариантом домашнему отдыху может быть поход на пляж. Следовательно, новый парк может разгрузить пляж. И наконец, людям нравятся разнообразные впечатления. Если в городе есть отдельные парки для катания на скейтбордах, для выгула собак и аквапарк, люди могут извлечь выгоду из разнообразия впечатлений, полученных на протяжении нескольких недель.
Несмотря на все эти недостатки, главный результат все же сохраняет свою силу. В самое горячее время перегруженность достигнет такого уровня, что парк обеспечит выгоду не больше, чем любой другой вид деятельности. Переполненность по-прежнему будет иметь место, но не в такой степени, как при наличии одного парка. Кроме того, как показано во врезке ниже, строительство нескольких парков не гарантирует оптимального распределения людей между ними. В примере, показанном во врезке, в случае равновесия слишком много людей идут в более крупный парк.
Множество перегружаемых общественных благ
M человек посещают парк 1, а (N − M) — парк 2. С учетом того, что парк 2 больше парка 1, полезность этих парков можно описать так [10]:
Парк 1: Utility(M) = N − M.
Парк 2: Utility(N − M) = 3N − 3 · (N − M).
Социально оптимальное решение: 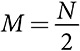 обеспечивает общую полезность N2.
обеспечивает общую полезность N2.
Равновесие Нэша: обеспечивает общую полезность 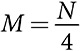 , создавая общую полезность
, создавая общую полезность 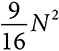 .
.
В дополнение к строительству большего количества парков город может внедрить другие решения, такие как нормированное распределение, поочередный доступ, проведение лотереи, денежные сборы и увеличение объема ресурса. При нормированном распределении каждый человек или семья получает определенный объем ресурса. Это решение уместно для делимых ресурсов, таких как вода, но менее приемлемо в случае дорог. Схемы ротации делят использование ресурса по времени. В период высокого загрязнения воздуха городские власти могут запретить въезд автомобилям с четными (или нечетными) номерами в определенные дни. Для других ресурсов, таких как места в популярных государственных школах, невозможно применить нормированное распределение или ротацию доступа. Тогда можно провести лотерею.
Что касается доступа к дорогам, то здесь весьма популярно такое решение, как денежные сборы. Оно применяется на платных дорогах с ограниченным доступом во всем мире. Плата за использование обеспечивает предоставление ресурса тем, кто готов заплатить наибольшую сумму. И это не всегда те люди, которые получили бы максимальную полезность. Сингапур использует комбинацию денежных сборов и ограниченного доступа. Для этого там ежегодно проводятся аукционы по продаже определенного количества разрешений на въезд транспортных средств. Эти разрешения, действующие на протяжении десяти лет, часто продаются по цене, превышающей стоимость обычного автомобиля. Чтобы уменьшить заторы в часы пик, в Сингапуре (как и в Лондоне) взимается плата за въезд в центральный деловой квартал. Дорожное движение Сингапура вполне благополучно как для города такого размера, а правительство собирает значительные суммы, которые затем можно направить на развитие общественного транспорта.
Увеличение пропускной способности дорог приводит к неоднозначным результатам. Когда город прибавляет к автомагистралям новые полосы, чтобы увеличить транспортный поток, это делает жилье вдоль таких магистралей более привлекательным, что создает положительную обратную связь. Обусловленная этим активизация жилищного строительства увеличивает количество транспорта, что требует еще более широких дорог. Это создает петлю положительной обратной связи, подобную той, которая описана в моделях системной динамики в главе 18.
ДОБЫЧА ВОЗОБНОВЛЯЕМЫХ РЕСУРСОВ
В заключение рассмотрим добычу возобновляемых ресурсов, когда люди совместно пользуются самовосстанавливающимся ресурсом. Эта модель применима к лесам, бассейнам рек, пастбищам и районам рыболовного промысла. В каждом из этих случаев объем ресурса, доступный в будущем, зависит от количества использования этого ресурса в настоящем. Если потребляется слишком много, то он может не восстановиться достаточно быстро. Необходимость восстановления ресурса делает эти проблемы более значимыми, чем проблемы обеспечения общественных благ и заторов. Город, который недофинансировал уличное освещение в один год, может увеличить расходы в следующем году, не сталкиваясь с долгосрочными последствиями этой ошибки. Чрезмерный вылов рыбы или вырубка леса приводят к долгосрочным издержкам, поскольку для разведения рыбы нужна рыба. Вам не нужны уличные фонари, чтобы установить уличные фонари. Кроме того, возобновляемый ресурс может относиться к числу базовых потребностей человека, таких как пища, вода и топливо. Такие ресурсы нужны людям для выживания.
Модель добычи возобновляемых ресурсов
Пусть R(t) обозначает объем возобновляемого ресурса в начале периода t. Пусть C(t) равно общему объему использованного ресурса за период t, а g обозначает темп роста ресурса. Объем ресурса за период t + 1 задается следующим разностным уравнением [11]:
R(t + 1) = (1 + g)[R(t) − C(t)].
Равновесный уровень потребления ресурса: 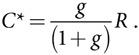
Проблемы добычи возобновляемых ресурсов указывают на переломный момент в уровне потребления ресурса. Любая норма потребления, превышающая равновесную норму добычи, приводит к коллапсу, что можно доказать с помощью формальной модели. Объем ресурса можно представить в виде кругового поля (пирога). Потребление откусывает от него куски. Рост обеспечивает возобновление ресурса в размере, пропорциональном оставшемуся объему. При низком уровне потребления ресурс будет увеличиваться в объеме. Однако восстановление ресурса не сможет компенсировать высокий уровень потребления. В промежутке между этими двумя вариантами находится равновесный уровень потребления, который полностью компенсируется за счет восстановления ресурса.
Если потребление ресурса превышает равновесный уровень, модель прогнозирует ускоряющееся снижение, которое перерастает в резкий спад. Медленное снижение, за которым следует резкий спад, служит предупреждением тем, кто занимается вопросами использования ресурсов, трудно поддающихся количественной оценке, таких как рыбные запасы. Данные о годовом улове дают определенное представление о происходящем, но весьма приблизительное. Нас не должно удивлять, что вылов трески в Североатлантическом регионе обусловил современный коллапс, сопоставимый по масштабам с трагедией винландцев, о которых рассказывает Джаред Даймонд в своей книге о гибели обществ. Треску ловят в Северной Атлантике более пятисот лет. Британские мореплаватели, которые впервые побывали на канадском побережье, рассказывали истории о том, что ловили треску корзинами и что им было трудно грести на мелководьях из-за ее огромных косяков. В 1992 году Канада ввела мораторий на вылов трески [12].
Наша модель добычи ресурсов предполагает постоянный темп роста, что позволяет вычислить равновесный уровень потребления. Однако в реальной жизни темпы роста варьируются из года в год. В случае пастбищ рост зависит от температуры и количества осадков. Темп роста популяции рыбы зависит от количества доступной пищи, которое, в свою очередь, зависит от колебаний метеоусловий и климатических изменений.
В двух других моделях вариация не имеет долгосрочных последствий. В некоторые годы образуется слишком большой объем общественных благ или чуть меньше заторов. Это сказывается на полезности, но, пожалуй, не в большей степени, чем неизбежные колебания погодных условий. Однако в случае проблем добычи возобновляемых ресурсов вариация приводит либо к резкому сокращению объема ресурсов, либо к их изобилию, при условии, что поведение не меняется. На рис. 23.1 показана средняя скорость восстановления в размере 25 процентов и 100 единиц ресурса. С учетом этих допущений равновесный уровень потребления равен 20 единицам в год. На рисунке отображена переменная скорость роста, выбранная случайным образом в диапазоне от 20 до 30 процентов. В модели также используется максимальный объем ресурса, установленный на уровне 150.
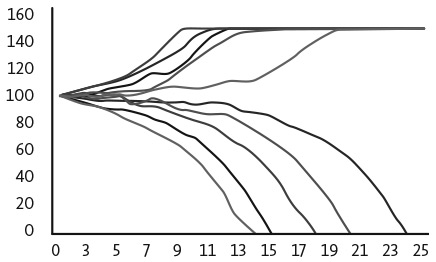
Рис. 23.1. Варианты развития событий в случае изменения скорости роста ресурса
Примерно в половине случаев объем ресурса резко сокращается, а в другой половине случаев увеличивается до максимально возможного уровня. Эти колебания не нейтрализуют друг друга. Напротив, эффект сокращения или роста со временем накапливается [13]. На основе этой имитационной модели мы видим, что оптимальная политика потребления ресурса должна сводиться к снижению уровня потребления после неблагоприятных лет, чтобы предотвратить коллапс.
Учитывая, что вариация темпов роста возобновляемых ресурсов требует, чтобы уровень потребления менялся вместе с объемом ресурса, сообщества, обеспечивающие управление возобновляемым ресурсом, должны уметь корректировать объемы добычи. Метод или механизм, используемый для внесения таких коррективов, зависит от особенностей ресурса. Здесь можно позаимствовать фразу «Панацеи не существует» [14]. Ни одно решение не может быть эффективным во всех случаях. Как местное население решает подобные проблемы, зависит от характеристик ресурса и общины.
Рыба отличается от крупного рогатого скота. Община, которая содержит несколько стад крупного рогатого скота на общинных землях, может контролировать поведение людей и объем ресурса (количество травы). Проблему пастбищ можно решить посредством схем ротации, в соответствии с которыми каждый животновод получает выделенное время или зоны для выпаса. Такая ротация позволяет корректировать выпас в зависимости от высоты травы. Однако в общинах, занимающихся рыбным промыслом, управление рыбными ресурсами требует более тщательно продуманных институтов, способных контролировать поведение отдельных людей. Количество рыбы в море подсчитать невозможно — его можно только приблизительно оценить на основании данных о вылове. Поэтому здесь проблеме добычи ресурсов свойственна более высокая неопределенность по сравнению с разведением крупного рогатого скота. Управление общим водным ресурсом требует консервативного подхода и более тщательного мониторинга.
РЕШЕННЫЕ И НЕРЕШЕННЫЕ ПРОБЛЕМЫ КОЛЛЕКТИВНЫХ ДЕЙСТВИЙ
В проблемах коллективных действий результаты, проистекающие из корыстного поведения, не отвечают целям людей. Как уже отмечалось, такие проблемы имеют место в самых разных ситуациях. Они возникают при оплате неконкурентных и неисключаемых благ, при принятии решений о времени проезда по автомагистрали и даже в ходе самой поездки. Водители, которые едут по оживленной трассе, не соблюдая дистанцию и разговаривая по сотовому, могут не учитывать последствий этих действий для едущих позади автомобилей в случае аварии.
Подобные проблемы существуют на разных уровнях. Они возникают в рамках семейных отношений: уборка дома, приготовление ужина, походы в магазин и откладывание денег на отпуск могут создать несоответствие между индивидуальными стимулами и общим благополучием. Такие проблемы возникают в городах, регионах и странах в связи с обеспечением общественных благ и использованием и управлением ограниченными ресурсами. Они также существуют в глобальном масштабе в случае выбросов углерода. Большинство стран предпочли бы самостоятельно производить больше энергии (что означает больше выбросов углерода), но иметь при этом более низкий глобальный уровень выбросов: индивидуальные рациональные действия не согласуются с общим благом.
Проблемы коллективных действий возникают и в мире природы. Деревья в лесу конкурируют за свет и воду. Если у деревьев определенного вида развивается более высокая крона или более глубокие корни, это повышает их шансы на выживание, но негативно сказывается на других видах деревьев. Деревья не могут принимать законы, запрещающие им расти слишком высокими или добираться корнями до более глубоких вод, поэтому социально оптимальное решение для них недоступно [15].
Проблемы коллективных действий, как правило, легче решать в случае более мелких и однородных групп людей или субъектов, имеющих к ним отношение, а также при наличии более качественной информации (то есть когда действия проще, а состояние системы контролируемо). Тогда как семьи обычно справляются с проблемами коллективных действий, международным организациям сотрудничество дается гораздо труднее. Мероприятия по сокращению выбросов углерода требуют координации действий в рамках большой группы разнообразных акторов, использующих методы мониторинга, которые не обеспечивают точных результатов. Решение таких проблем требует координации и механизма принуждения. История учит нас тому, что чрезмерный вылов рыбы или выпас скота создает риск коллапса. То же самое можно сказать и о тех проблемах коллективных действий, с которыми мы сталкиваемся в настоящее время. Элинор Остром, которая на протяжении десятилетий изучала предпринимаемые реальные усилия по решению проблем коллективных действий, пришла к выводу, что помимо мониторинга нарушений те сообщества, которые занимаются решением проблем коллективных действий, договариваются о четких границах, введении твердых правил, предоставлении полномочий на применение дифференцированных санкций и создании механизмов разрешения споров [16].
ГЛАВА 24
ДИЗАЙН МЕХАНИЗМОВ
Институты создаются для изменения человеческого поведения. Для того чтобы они сохраняли эффективность с течением времени, их необходимо адаптировать к изменениям в окружающей среде или обществе, которое они призваны регулировать.
Дженна Беднар
В этой главе мы покажем, как использовать модели для разработки политических и экономических институтов. Институт включает инструменты для обмена информацией, а также процедуры принятия решений, перераспределения ресурсов или получения требуемых результатов на основе имеющейся информации. На рынках люди обмениваются информацией посредством цен для заключения торговых сделок и принятия производственных решений. В иерархических системах они взаимодействуют с помощью письменного языка с целью организации выполнения рабочих планов, а в демократических странах сообщают о своих предпочтениях путем голосования. При этом правила голосования определяют политику. Тщательно разработанные институты стимулируют коммуникации и действия, которые обеспечивают требуемый результат. Неэффективные институты этого не делают.
В главе представлена концептуальная схема моделирования институтов, известная как дизайн механизмов. В ней выделяется четырем аспекта реальных институтов: информация (то, что участники знают и должны сообщить); стимулы (выгоды и издержки совершения определенных действий); агрегирование (то, как индивидуальные действия трансформируются в коллективный результат); вычислительная сложность (когнитивные требования, предъявляемые к участникам).
Истоки дизайна механизмов восходят к анализу общих вопросов, связанных с распределением благ, в частности вопроса о том, обеспечивают ли рыночные механизмы или централизованное планирование их оптимальное распределение. Первые модели исходили из поведенческих правил, таких как принятие установившихся на рынке цен или правдивое голосование. Затем автор модели анализировал последствия таких линий поведения, например, как они агрегируются. Со временем от такого подхода отказались в пользу подхода, учитывающего оптимизирующее поведение, что сделало эти конструкции поддающимися объяснению с точки зрения теории игр. Далее специалисты по дизайну механизмов находят равновесия Нэша и сравнивают институты с учетом рационального поведения.
Данная концептуальная схема доказала свою полезность. Ее можно использовать для поиска недостатков в действующих правилах и процедурах, чтобы объяснить, почему те или иные институты преуспевают или терпят неудачу, а также для прогнозирования результатов. С ее помощью разработано множество институтов, в том числе аукционы частот, о которых шла речь в главе 2, а также много других торговых интернет-площадок, государственных систем голосования и даже процедур выделения пространства для проектов на космических кораблях многоразового использования [1].
В представленном в главе анализе шесть частей. Сначала мы опишем концептуальную схему дизайна механизмов с помощью диаграммы Маунта-Рейтера. Затем рассмотрим задачу с участием трех человек, выбирающих из двух альтернатив. В третьей части проанализируем три механизма проведения аукционов и обнаружим, что все они дают одинаковые результаты. В четвертой покажем, что это не случайное совпадение, и опишем фундаментальный результат — теорему об эквивалентности доходов, которая доказывает, что любой механизм проведения аукциона, удовлетворяющий определенным исходным предположениям, обеспечивает один и тот же исход. В пятой части мы сравним механизм голосования по правилу большинства голосов с механизмом опорных точек как способами принятия решений о целесообразности реализации того или иного общественного проекта. И в заключение расширим обсуждение механизмов с учетом критики равновесий Нэша.
ДИАГРАММА МАУНТА-РАЙТЕРА
Механизм состоит из шести частей: среда (соответствующие свойства мира); набор исходов; набор действий (называемый пространством сообщений); правило поведения, которого придерживаются люди, чтобы произвести действие; функция исхода, которая устанавливает соответствие между действиями и исходами, а также соответствие общественного выбора, ставящее среду в соответствие со множеством желаемых исходов. Соответствие общественного выбора обычно включает либо исход, максимизирующий сумму значений полезности участников, либо множество Парето-эффективных распределений. Исход эффективен по Парето тогда и только тогда, когда не существует другого результата, которому бы все отдавали предпочтение. Эффективность по Парето — это нижний предел.
Эффективность по Парето
В пределах множества исходов тот или иной исход является доминируемым по Парето при наличии альтернативы, которой все отдают предпочтение. Все остальные исходы эффективны по Парето [2].
Диаграмма Маунта-Райтера отображает все эти важные элементы механизма графически (рис. 24.1), сопоставляя то, что нам нужно, с тем, что у нас есть. В ее верхней части соответствие общественного выбора описывает исходы, к которым мы обычно стремимся. В нижней части отображен адаптированный вариант реальности. Люди применяют правила поведения для передачи сообщений или выполнения действий. Функция исхода устанавливает соответствие между этими действиями и результатами. В идеале нижний, более сложный путь, обеспечивает тот же результат, что и верхний путь, то есть желаемый исход.

Рис. 24.1. Диаграмма Маунта-Райтера
Однако не все механизмы эффективны. Например, если среда включает людей с определенными предпочтениями в отношении какого-то общественного блага, соответствие общественного выбора сопоставляет их предпочтения с оптимальным уровнем этого блага. Но, как мы видели в главе 23, механизм добровольных взносов, согласно которому люди платят за определенную долю общественного блага столько, сколько пожелают, приводит к тому, что каждый человек обеспечивает 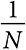 единиц общественного блага, а не оптимальное количество — N единиц. Когда исход, порождаемый определенным механизмом, не согласуется с нашими целями, мы говорим, что этот механизм не обеспечивает соответствия общественного выбора.
единиц общественного блага, а не оптимальное количество — N единиц. Когда исход, порождаемый определенным механизмом, не согласуется с нашими целями, мы говорим, что этот механизм не обеспечивает соответствия общественного выбора.
Список свойств, которым должен удовлетворять механизм, зависит от контекста. Мы опишем пять таких свойств. Во-первых, равновесный исход, полученный с помощью механизма, должен согласовываться с принципом соответствия общественного выбора (эффективность по Парето). Во-вторых, в идеале участники должны применять доминирующие стратегии, то есть их действия не должны зависеть от действий остальных. Если это так, мы говорим, что эффективный исход достижим с помощью доминирующей стратегии. В-третьих, механизм должен быть таким, чтобы не нужно было принуждать людей в нем участвовать (добровольное участие). В-четвертых, если механизм подразумевает передачу или оплату ресурсов, необходимо, чтобы не приходилось вкладывать дополнительные средства или истощать ресурсы (сбалансированность бюджета). Далее в ходе анализа механизмов принятия решений по общественно значимым проектам мы увидим, что удовлетворить эти условия непросто. И наконец, в-пятых, во многих случаях требуется раскрытие истины. Сообщения, которые отправляют люди, должны раскрывать их истинную информацию или истинный тип. Специалисты по теории игр называют это совместимостью по стимулам. В большинстве значимых случаев ни один механизм не может удовлетворять всем условиям. Таким образом, одно из важных достижений дизайна механизмов — демонстрация пределов возможного.
ПРИНЦИП БОЛЬШИНСТВА И МЕХАНИЗМ «СОЗДАТЕЛЬ КОРОЛЕЙ»
Первый тип рассматриваемой нами среды включает людей, голосующих за совершение совместного действия или принятие законопроекта. Мы возьмем трех человек (назовем их Ума, Вера и Уилл), которые хотят вместе посмотреть фильм и должны решить, что это будет — боевик, драма или комедия. Эта же среда применима к трем военным, решающим, атаковать ли противника, оборонять свои позиции или отступать. В любой интерпретации среда состоит из трех человек с предпочтениями по трем альтернативам. Запишем эти предпочтения в виде упорядоченного списка. Порядок предпочтений «боевик > комедия > драма» говорит о том, что наибольшее предпочтение отдается боевику, далее следует комедия, а затем драма. Мы будем исходить из следующих порядков предпочтений:
Ума: боевик > комедия > драма
Вера: комедия > драма > боевик
Уилл: комедия > драма > боевик
В этом примере мы представим соответствие общественного выбора как множество Парето-эффективных вариантов выбора. С учетом предполагаемых предпочтений комедия и боевик являются эффективными по Парето, а драма — доминируемой по Парето по отношению к комедии.
Сначала оценим в качестве механизма принцип большинства. В случае равного разделения голосов будем исходить из того, что выбор делается в случайном порядке. Если люди голосуют честно, то комедия получает два голоса. Однако допустим, что и Вера, и Уилл думают, что голоса двоих оставшихся распределятся между драмой и боевиком и что каждый проголосует за драму. Предположим также, что голосование проходит по очереди. Вера голосует первой и выбирает драму. Уилл голосует вторым и делает то же самое. Голос Умы уже не важен, но допустим, что во избежание конфликта она тоже голосует за драму. Эти три голоса образуют равновесие Нэша. Ни у кого нет стимула менять свой голос. В данном случае принцип большинства не всегда приводит к Парето-эффективному исходу.
Теперь рассмотрим механизм «Создатель королей» [3]. В соответствии с ним одного человека в случайном порядке выбирают «создателем королей». Затем он назначает «короля», который и определяет выбор группы. Если создателем короля будет Уилл, то он должен выбрать между Умой и Верой. Кого бы он ни выбрал, этот человек становится королем и выбирает фильм.
Если выбранный в качестве короля человек действует рационально, то он выберет свой любимый фильм. Следовательно, такой исход будет эффективным по Парето. В силу этого механизм создателя королей обеспечивает получение Парето-эффективных исходов. Дополнительное преимущество этого механизма состоит в том, что если у любых двух человек один и тот же любимый фильм, то он будет выбран независимо от того, кого Уилл назначит королем. Так произойдет, если Ума и Вера предпочитают один и тот же фильм. Однако если Уиллу и Уме нравится один и тот же фильм, то Уиллу нужно выбрать Уму.
ТРИ ТИПА АУКЦИОНОВ
Теперь, получив базовое представление о механизмах, приступим к изучению аукционов. Большинство из нас немного знакомы с аукционами ввиду широкого распространения таких интернет-площадок, как eBay. Аукционы используются и в других ситуациях, в том числе при заключении государственных контрактов, на рынках подержанных автомобилей и в большинстве случаев размещения интернет-рекламы. Мы сосредоточимся на аукционах с участием одного продавца и множества участников торгов. В качестве предмета торгов может выступать дом, автомобиль, билеты на футбольный матч или произведения искусства. Предположим также, что каждый участник торгов устанавливает предмету торгов уникальную оценочную стоимость, чтобы исключить равенство результатов. Тогда Парето-эффективным исходом будет такой исход, при котором предмет торгов достается участнику с самой высокой оценочной стоимостью. Любой другой исход будет Парето-доминируемым по отношению к этому исходу. Теперь сравним три типа аукционов: аукцион с повышением цены, аукцион первой цены и аукцион второй цены.
АУКЦИОНЫ С ПОВЫШЕНИЕМ ЦЕНЫ
В ходе аукциона с повышением цены аукционист называет цену. Любой участник торгов, готовый ее заплатить, поднимает руку. Аукционист повышает цену до тех пор, пока не останется один участник; он затем платит цену, на которой предпоследний участник опустил руку. В случае аукциона с повышением цены рациональный участник торгов участвует в аукционе до тех пор, пока цена не достигнет его оценочной стоимости. Если он выйдет раньше, то может не получить предмета торгов по хорошей цене. Если же он продолжит участие в аукционе после того, как цена превысит его оценочную стоимость, то может получить предмет торгов, но заплатит за него больше оценочной стоимости, что в итоге даст чистый убыток.
Когда все участники торгов действуют рационально, участник с самой высокой оценочной стоимостью получает предмет торгов и платит за него цену, равную оценочной стоимости участника, предложившего вторую по величине цену. В качестве примера предположим, что есть три участника торгов с оценочной стоимостью 30, 60 и 80 долларов. Когда цена, названная аукционистом, превышает 30 долларов, первый участник торгов выходит из аукциона. Когда цена достигает 60 долларов, аукцион покидает второй участник. В результате третий участник выигрывает аукцион и платит 60 долларов [4].
В случае аукциона второй цены участник торгов подает заявку в запечатанном конверте. Остальные участники торгов не видят предложенной им цены. Предмет торгов достается участнику, предложившему максимальную цену, но он заплатит сумму, равную второй по величине предложенной цене. Схема проведения аукциона второй цены делает предоставление правдивой информации оптимальным. Представьте, что участник, оценивший предмет торгов в 80 долларов, решает, как предложить цену на аукционе второй цены. Предположим, что другие участники торгов уже подали свои заявки. Наш участник торгов должен проанализировать три возможных случая: самая высокая цена остальных участников может быть меньше 80 долларов, равна 80 долларам или больше 80 долларов. В каждом из этих случаев участник торгов получит лучший результат, сообщив свою истинную оценочную стоимость предмета торгов.
Логика становится понятнее, если рассмотреть ее на примере. Будем исходить из того, что установленная участником торгов оценочная стоимость предмета составляет 80 долларов. Рассмотрим четыре варианта самых высоких цен, предложенных другими участниками: 70 долларов (ниже), 80 долларов (столько же), 82 доллара (немного выше) или 90 долларов (выше). В табл. 24.1 показаны выигрыши для различных предложений цены в диапазоне от 65 долларов до 95 долларов.
Таблица 24.1. Чистый выигрыш в зависимости от различных предложений цены при оценочной стоимости 80 долларов
Самая высокая цена | Участник с оценочной стоимостью 80 | |||
65 | 80 | 85 | 95 | |
70 (низкая) | 0 | +10 | +10 | +10 |
80 (равная) | 0 | 0 | 0 | 0 |
82 (немного выше) | 0 | 0 | −2 | −2 |
90 (высокая) | 0 | 0 | 0 | −10 |
Как следует из таблицы, предложение цены 80 всегда обеспечивает как минимум такой же высокий выигрыш, как и любое другое предложение. Подача заявки с указанием истинной оценочной стоимости — всегда наилучшее действие (доминирующая стратегия). Аналогичная логика применима ко всем участникам торгов, поэтому все должны предлагать цену, соответствующую истинной оценочной стоимости (данный механизм совместим по стимулам). Из этого следует, что в случае аукциона второй цены участник торгов с самой высокой оценочной стоимостью выигрывает аукцион и платит сумму, равную оценочной стоимости участника торгов, предложившего вторую по величине цену.
На аукционе первой цены каждый участник торгов предлагают свою цену, предложение с самой высокой ценой побеждает, а участник торгов, сделавший его, платит сумму, равную этой цене. Как и на аукционе второй цены, заявки подаются одновременно, поэтому никто не знает цен других участников торгов. Оптимальная стратегия предложения цены в ходе аукциона первой цены зависит от мнения участника торгов относительно оценочной стоимости (а значит, и вероятных предложений цены) других участников. Мы будем считать, что участники торгов не знают оценочной стоимости других участников, но имеют правильное представление о распределении оценок. Точнее говоря, будем исходить из того, что оценки участников торгов равномерно распределены в диапазоне от нуля до 100 долларов и что всем участникам торгов известно об этом распределении. Кроме того, каждый участник торгов знает, что эта информация известна всем остальным участникам.
С помощью математики мы можем продемонстрировать, что если оценки равномерно распределены и все участники торгов придерживаются оптимальной стратегии предложения цены, то при наличии двух участников торгов каждый должен предложить цену, равную половине его истинной оценочной стоимости, а при наличии N участников каждый должен предложить цену, равную 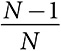 от его истинной оценочной стоимости. Следовательно, участник аукциона с еще девятнадцатью участниками должен предложить цену, составляющую 95 процентов от его истинной оценочной стоимости. При использовании этого правила торгов предмет торга всегда выигрывает участник с самой высокой оценочной стоимостью. Мы можем также показать, что сумма, которую он заплатит, эквивалентна ожидаемой стоимости участника, предложившего вторую по величине цену. Таким образом, аукцион с повышением цены также обеспечивает эффективный исход, а цена соответствует ожидаемой стоимости участника торгов, предложившего вторую по величине цену [5].
от его истинной оценочной стоимости. Следовательно, участник аукциона с еще девятнадцатью участниками должен предложить цену, составляющую 95 процентов от его истинной оценочной стоимости. При использовании этого правила торгов предмет торга всегда выигрывает участник с самой высокой оценочной стоимостью. Мы можем также показать, что сумма, которую он заплатит, эквивалентна ожидаемой стоимости участника, предложившего вторую по величине цену. Таким образом, аукцион с повышением цены также обеспечивает эффективный исход, а цена соответствует ожидаемой стоимости участника торгов, предложившего вторую по величине цену [5].
До описания данной модели многие из нас пришли бы к выводу, что чем больше участников в аукционе, тем выше цену должен предлагать каждый из них. Но без математических расчетов мы не знали бы равновесного правила предложения цены. Модель предоставляет нам точное выражение для определения цены, которую должен предлагать покупатель. Эта сумма увеличивается в соответствии с оценочной стоимостью участника торгов, а это подразумевает, что участник с самой высокой оценочной стоимостью выиграет аукцион, точно так же как и в случае аукционов двух других типов.
ТЕОРЕМА ОБ ЭКВИВАЛЕНТНОСТИ ДОХОДОВ
В каждом из трех форматов аукционов выигрывает участник с самой высокой оценочной стоимостью. Следовательно, все три механизма гарантируют эффективный исход. Кроме того, ожидаемая сумма, уплаченная победителем аукциона, равна оценочной стоимости участника торгов, предложившего вторую по величине цену. Иначе говоря, все три аукциона обеспечивают одинаковый ожидаемый доход, а предмет торгов достается одному и тому же покупателю. Это просто удивительно. Но еще удивительнее возможность доказать тот факт, что победитель и ожидаемая оценочная стоимость остаются одними и теми же для любого аукциона, где участники придерживаются оптимальной стратегии предложения цены, предмет торгов при этом достается участнику, предложившему самую высокую цену, а участник с нулевой оценочной стоимостью не получает выигрыша. Другими словами, аукционы, удовлетворяющие этим условиям, обеспечивают один и тот же ожидаемый результат, известный как теорема об эквивалентности доходов [6].
Теорема об эквивалентности доходов
Любой аукцион, участники которого выбирают независимые частные оценки стоимости из известного общего распределения, обеспечивает один и тот же доход продавцу и одинаковые ожидаемые выигрыши покупателям, если каждый участник торгов делает предложение о покупке, максимизирующее его ожидаемый выигрыш; при этом участник торгов, предлагающий самую высокую цену, всегда получает предмет торгов, а участник торгов с нулевой оценкой стоимости имеет нулевой выигрыш.
Теорема об эквивалентности доходов подразумевает, что аукцион «платят все» (в ходе которого каждый участник, даже проигравший, платит сумму своего предложения) обеспечивает тот же исход, что и аукцион второй цены [7]. Даже такой необычный формат, как аукцион третьей цены (в ходе которого выигрывает участник, предложивший самую высокую цену, и платит сумму, равную третьей по величине цене), дает того же победителя и тот же доход. Теорема об эквивалентности доходов не означает, что правила проведения аукционов не важны. Во время реальных торгов участники могут не применять оптимальных стратегий или, как в случае аукциона первой цены, по-разному представлять себе распределение оценок других участников. При выполнении любого из этих условий (участники торгов не придерживаются оптимальной стратегии или имеют разные представления о распределении оценок) доход может варьироваться в зависимости от типа аукциона. Эмпирические и экспериментальные испытания действительно выявляют определенные различия в том, какие результаты обеспечивают аукционы.
Итак, чем больше ставки и искушеннее участники торгов, тем выше вероятность, что люди будут действовать рационально. В ходе интернет-аукционов по продаже потребительских товаров некоторые люди могут придерживаться эмпирических правил или исходить из предубеждений (например, предлагать цену с шагом 10 долларов). Но на многомиллионном аукционе по аренде нефтеносных участков участники торгов, скорее всего, имеют доступ ко всей необходимой информации и соответствующий опыт.
Кроме того, тип аукциона может влиять на количество участников торгов. Например, аукционы первой цены по продаже древесины привлекают больше мелких участников торгов, чем аукционы с повышением цены, поскольку у мелких участников есть хотя бы какой-то шанс выиграть, если более крупные участники предлагают низкие цены. В случае аукциона с повышением цены у мелких участников торгов нет никаких шансов, так как более крупные компании видят их предложения и называют более высокую цену [8].
Аукционы также отличаются когнитивными требованиями, предъявляемыми к участникам. В случае некоторых аукционов научиться оптимальному поведению не сложно. В ходе аукциона с повышением цены участник торгов должен участвовать в аукционе, пока цена не достигнет его оценочной стоимости. Действия других участников, не придерживающихся оптимальной стратегии, могут привести к повышению или снижению ожидаемого выигрыша участника торгов, но они не меняют оптимальной стратегии: участник торгов должен участвовать в аукционе до тех пор, пока цена меньше его оценочной стоимости. Аналогично, в ходе аукциона второй цены участник торгов должен всегда придерживаться одной и той же стратегии — предлагать цену, соответствующую его истинной оценочной стоимости. Тем не менее для того, чтобы прийти к выводу об оптимальности правдивого предложения цены, понадобится выполнить несколько шагов логических рассуждений.
Напомним, что доминирующие стратегии являются оптимальными независимо от стратегий других участников аукциона. И аукционы с повышением цены, и аукционы второй цены имеют доминирующие стратегии. У аукциона первой цены такой стратегии нет. В аукционе первой цены изменения в стратегии предложения цены одного участника торгов могут изменить оптимальную стратегию другого участника. Если один участник торгов всегда предлагает либо ноль, либо 50, то другой участник должен всегда предлагать либо 1, либо 51. Нет никаких причин предлагать 60 или 70, поскольку тогда победителю придется переплатить за предмет торгов. Учитывая поведение другого участника, если предложение 60 может выиграть аукцион, то же может сделать и предложение 51.
Даже если у аукциона есть доминирующая стратегия, не все доминирующие стратегии одинаково легко вычислить. Для аукциона с повышением цены стратегия (участие в аукционе до тех пор, пока цена меньше оценочной стоимости участника торгов) требует одного шага логических рассуждений: если цена меньше оценки, покупать по этой цене. В случае аукциона второй цены участник торгов должен проанализировать несколько вариантов развития событий, чтобы понять, что раскрытие правдивой информации — оптимальная стратегия. Безусловно, после участия в нескольких аукционах второй цены он будет знать это точно.
И последняя особенность аукционов, требующая рассмотрения, — поощряет ли аукцион неоптимальное поведение. На аукционы первой и второй цены участники торгов подают заявки, не зная, какую цену предлагают другие участники. На аукционе с повышением цены участники торгов видят, как повышается цена, и знают, кто продолжает участвовать в торгах. Иногда это приводит к тому, что участник торгов переоценивает значимость победы в аукционе и повышает цену. Аукционисты на благотворительных аукционах пытаются поднять ставки путем эмоциональных призывов — например, показывая видео с детьми, резвящимися на новой детской площадке, которая будет построена за счет предложенных ставок.
Успех стратегий зависит от эмоций участников торгов. Трудно представить, чтобы на аукционах по продаже древесины убеждали участников торгов предлагать больше их прогнозных оценок. Но гораздо легче представить участника благотворительного аукциона, который предлагает более высокую цену, поскольку эти деньги пойдут на благое дело. Изменят ли участники торгов свои оценки в процессе проведения торгов, можно только догадываться. Нам просто нужно признать, что это может произойти. В ходе аукционов первой и второй цены участники торгов делают одно предложение, что не оставляет шансов для эмоциональных призывов во время аукциона.
И наконец, на аукционе первой ценыи аукционе с повышением цены цена равна самому высокому предложению, а в случае аукциона второй цены — второй по величине цене. Это создает впечатление, что продавец мог бы получить более высокую цену, а также отчасти объясняет, почему правительства не используют аукционы второй цены. Только представьте заголовки газет в случае, если бы правительство получило три заявки на получение прав на добычу нефти — на 6, 8 и 12 миллионов долларов: «Правительство получает заявку на 12 миллионов долларов, но продает землю за 8 миллионов долларов». Любой, кто знает теорию аукционов, понял бы, что если бы правительство провело аукцион первой цены или аукцион с повышением цен, максимальная предложенная цена составляла бы не 12, а 8 миллионов долларов.
Как уже неоднократно подчеркивалось в книге, формальные модели раскрывают условия, необходимые для обеспечения требуемого результата. Теорема об эквивалентности доходов не говорит о том, что все механизмы проведения аукционов обеспечивают один и тот же исход. Она гласит, что все аукционы, в которых участники придерживаются оптимальной стратегии, предмет торгов достается участнику, предложившему самую высокую цену, а участник торгов с нулевой оценкой стоимости получает нулевой выигрыш, эквивалентны. Продавец может собрать больше денег, ослабив одно из этих трех предположений. Однако продавцу будет трудно заставить людей действовать вопреки собственным интересам и уж тем более вряд ли удастся получить деньги от человека, для которого данный товар не представляет ценности. Остается только один вариант — не продавать предмет торгов покупателю, предложившему самую высокую цену. Один из способов сделать это — вообще не продавать товар. Если продавцу известно распределение оценок, он может установить низшую отправную цену, минимальную ставку. При определенных условиях это может повысить его ожидаемый доход. Предположим, продавец уверен, что три участника оценивают предмет торгов в 5, 10 и 60. Воспользовавшись любым из описанных выше аукционов, победитель предложит цену 60 долларов, а заплатит 10 долларов. Продавец может получить более высокий доход, установив низшую отправную цену 60 долларов и проведя аукцион первой цены.
МЕХАНИЗМЫ ПРИНЯТИЯ РЕШЕНИЙ ПО ОБЩЕСТВЕННЫМ ПРОЕКТАМ
Далее мы сравним два механизма принятия решений о целесообразности реализации таких общественных проектов, как строительство школы, новой автомагистрали или спортивной арены. И при этом будем исходить из того, что проект имеет для каждого человека индивидуальную ценность и что его реализация влечет за собой коллективные затраты.
Задача принятия решения по общественному проекту
Пусть (V1, V2, …, VN) обозначает денежную оценку полезности, которую N человек приписывают общественному проекту стоимостью C. Проект целесообразно осуществлять тогда и только тогда, когда C < V1 + V2 + … + VN.
Сначала рассмотрим механизм равного участия в расходах при принятии решения о реализации проекта большинством голосов. В соответствии с этим механизмом люди голосуют за целесообразность реализации проекта. Если большинство голосует «за», расходы на реализацию проекта делятся поровну между участниками голосования.
Механизм равного участия при принятии решения большинством голосов
Люди голосуют за или против реализации проекта. Если большинство голосует за проект, он реализуется, и каждый участник голосования платит сумму 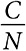 . Как следует из представленного ниже примера, этот механизм может нарушать условие эффективности и добровольного участия.
. Как следует из представленного ниже примера, этот механизм может нарушать условие эффективности и добровольного участия.
Из пространственной модели голосования мы знаем, что реализация проекта зависит от предпочтений медианного избирателя. В данном случае это будет человек с медианным значением ценности, которую представляет для него общественный проект. В силу своей структуры этот механизм удовлетворяет условию сбалансированности бюджета и условию совместимости по стимулам, но вместе с тем он не всегда удовлетворяет условиям эффективности или добровольного участия, как видно из следующего примера. Предположим, три человека оценивают общественный проект стоимостью 300 долларов в 0, 120 и 150 долларов. Эффективный исход состоит в том, что проект не следует реализовывать, поскольку его общая стоимость 300 долларов превышает сумму индивидуальных оценок. Тем не менее, ввиду того что затраты на проект будут разделены поровну, каждый решает, стоит ли осуществлять проект при затратах 100 долларов на человека. Из этого следует, что за проект проголосуют два из трех человек, и он будет реализован, но это неэффективный исход. Более того, выигрыш человека, оценившего проект в 0 долларов, составляет −100 долларов, а значит, пример также демонстрирует нарушение условия о добровольном участии.
В соответствии со вторым механизмом под названием «механизм поворота» каждый человек сообщает свою оценку проекта. Если сумма оценок превышает стоимость проекта, принимается решение о его реализации. В противном случае проект не поддерживается. Сумма, которую должен внести человек на реализацию проекта, равна разности между стоимостью проекта и суммой оценок всех остальных участников голосования. Если их оценки превышают стоимость проекта, этот человек ничего не платит.
Механизм поворота
Человек i сообщает оценку 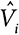 проекта стоимостью C. Если сумма индивидуальных оценок превышает эту стоимость, то проект реализуется.
проекта стоимостью C. Если сумма индивидуальных оценок превышает эту стоимость, то проект реализуется.
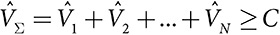 .
.
Человек i не делает взноса, если 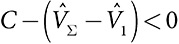 , и делает взнос
, и делает взнос 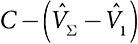 в противном случае. Этот механизм совместим по стимулам
в противном случае. Этот механизм совместим по стимулам  , эффективен и индивидуально рационален. Как показывает представленный ниже пример, он может нарушать условие сбалансированности бюджета.
, эффективен и индивидуально рационален. Как показывает представленный ниже пример, он может нарушать условие сбалансированности бюджета.
Пример: (V1, V2, V3) = (60, 120, 150) и C = 300
Проект целесообразно реализовать ввиду того, что 300 < 60 + 120 + 150.
Человек 1 делает взнос 30 долларов, что равно разности между стоимостью проекта и суммой других оценок (300 – 270); человек 2 вносит 90 долларов; а человек 3 — 120 долларов. Общая сумма взносов составляет 240, что меньше стоимости проекта.
Согласно логике, аналогичной логике аукциона второй цены, этот механизм удовлетворяет условию совместимости по стимулам. Предположим, стоимость проекта составляет 300 долларов, а человек оценивает его в 80 долларов. Существует три варианта развития событий. Если другие оценки дают в сумме меньше 220 долларов, у человека нет стимула сообщать оценку выше 80 долларов, поскольку ему придется заплатить эту сумму. Однако если сумма оценок других людей превышает 300 долларов, то он ничего не платит и может вообще не предоставлять свою оценку. Но если сумма оценок других людей составляет от 220 долларов до 300 долларов, то, сообщив оценку 80, человек заплатит разность между 300 долларами и этой суммой, и проект будет реализован (эффективный исход). Этому человеку не хотелось бы сообщать оценку, скажем, 70 долларов, поскольку сумма других оценок могла бы быть меньше 225 долларов, и его низкая оценка помешала бы реализовать проект. Если бы он предложил оценку 80 долларов, проект был бы реализован и обошелся бы ему всего в 75 долларов.
Так как механизм поворота удовлетворяет условию совместимости по стимулам, он также удовлетворяет и условию эффективности. Проект реализуется только в случае, если сумма оценок превышает его стоимость. Обратите внимание, что поскольку сообщение истинной оценки — это доминирующая стратегия, эффективный исход осуществим тоже с помощью доминирующей стратегии. Кроме того, учитывая, что каждый человек делает взнос, не превышающий его оценку проекта, механизм удовлетворяет условию добровольного участия.
В задаче принятия решений по общественным проектам ни один механизм не удовлетворяет всем необходимым критериям. Тот факт, что мы можем использовать модели для доказательства этого вывода, способен сэкономить нам массу времени, которое мы бы потратили на попытки реализовать невозможное. Подобно тому как инженеры не тратят время зря на попытки изобрести вечный двигатель, специалисты по дизайну механизмов не стремятся к созданию совместимых по стимулам, индивидуально рациональных, эффективных, обеспечивающих сбалансированность бюджета механизмов для решения проблем по общественным проектам. Таких механизмов не существует.
Механизм поворота удовлетворяет почти всем условиям, кроме сбалансированности бюджета. Эта проблема не решается путем повышения суммы взносов людей на реализацию проекта, поскольку это сделало бы механизм несовместимым по стимулам и не индивидуально рациональным. У людей появился бы стимул лгать, а некоторым предложили бы внести больше, чем их оценка полезности проекта. Один из возможных вариантов выхода из ситуации — собрать деньги каким-то иным способом и сформировать резерв денежных средств, доступных для реализации проектов. Это само по себе создаст проблемы стимулирования, хотя и не напрямую. Более эффективное решение — найти другой источник финансирования. Например, университет, имеющий как крупный центральный фонд пожертвований, так и отдельные фонды колледжей, мог бы использовать этот механизм, чтобы решить, стоит ли строить новый студенческий клуб. У декана каждого колледжа был бы стимул сообщить свою истинную оценку полезности такого клуба, а ректор университета мог бы восполнить недостающую сумму. Компания, состоящая из отдельных подразделений с бюджетными полномочиями, могла бы сделать то же самое. Решение относительно проекта перехода на облачную систему тоже можно было бы принять с помощью механизма поворота, а любую нехватку средств покрыло бы высшее руководство.
РЕЗЮМЕ
Концептуальная схема дизайна механизмов позволяет сравнивать механизмы по ряду критериев. Обеспечивает ли механизм эффективные результаты? Говорят ли люди правду? Станут ли они добровольно участвовать? Порождает ли механизм бюджетный излишек или убыток? Концептуальная схема дизайна механизмов позволяет определить, каких результатов можно достичь. Порой удовлетворить все необходимые критерии в рамках одного механизма не удается. В таких случаях создатели моделей становятся инженерами. Мы используем модели, чтобы попытаться сконструировать действенные решения.
По мере изменения технологий могут меняться и механизмы. Возьмем, к примеру, аукционы, используемые такими поисковиками, как Google. Первоначально в Google взимали фиксированную плату за тысячу кликов. Этот механизм оказался неоптимальным ввиду изменений в области информационных технологий, которые позволили Google одновременно проводить миллионы аукционов. Благодаря аукционам компания Google увеличила доход и стала более эффективно распределять места для рекламы. В настоящее время Google использует обобщенный аукцион второй цены. Каждый участник торгов предлагает плату за переход по ссылке для рекламы ключевого слова, скажем «мезотелиома» (онкологическое заболевание, вызванное воздействием асбеста). Участник торгов, предложивший самую высокую цену, получает первый рекламный блок; участник, предложивший вторую по величине цену, — второй рекламный блок, а участник, предложивший третью по величине цену, — третий рекламный блок. Цены, которые они заплатят, определяются так же, как и в случае аукциона второй цены.
Предположим, четыре предложения с максимальными ценами составляют 10, 7, 6 и 3 доллара за клик. Участник торгов, предложивший третью по величине цену, заплатит сумму, равную четвертому по величине предложению, 3 доллара. Участник торгов, предложивший вторую по величине цену, заплатит сумму, равную третьему по величине предложению, 6 долларов. А участник торгов, предложивший самую высокую цену, заплатит 7 долларов [9]. Выяснив оценки рекламодателей, в Google могли бы установить низшую отправную цену и получить еще больше денег. Однако такой исход вряд ли наступил бы, если бы участники торгов знали о плане Google. Участник торгов, полагающий, что именно он предложит самую высокую цену, не хотел бы, чтобы в Google знали его оценку. Кроме того, установление низшей отправной цены навредило бы репутации Google, поскольку было бы воспринято как отказ Google от сотрудничества: Google не может претендовать на ту или иную низшую отправную ценность для мест на веб-странице. Верхний рекламный блок на странице поиска по ключевым словам практически не имеет для Google ценности до тех пор, пока не будет продан. Однако это не относится к продажам винтажных альбомов или подержанных автомобилей, так как эти товары имеют ценность сами по себе, поэтому здесь низшая отправная цена оправданна. Заботясь о своей репутации, в Google не склонны устанавливать минимальную отправную цену в погоне за максимальной прибылью, ведь это наверняка разгневает рекламодателей.
Таким образом, модели дизайна механизмов помогают разрабатывать и выбирать институты, а также позволяют определить, что можно и нельзя реализовать на практике. В частности, невозможно разработать механизм, который обеспечивает эффективный исход, стимулирует людей говорить правду и позволяет сбалансировать бюджет. Поэтому не стоит тратить время и усилия на попытки достичь невозможного. Лучше направить энергию на поиск компромисса между эффективностью, раскрытием истины и сбалансированным бюджетом.
Дизайн механизмов можно также использовать для изучения более масштабных вопросов, например, когда следует использовать рынок, когда нужно голосовать, когда целесообразнее положиться на иерархический механизм и когда лучше прибегнуть к помощи добровольного коллектива, чтобы распределить ресурс или принять решение относительно тех или иных действий [10]. Каждый из этих четырех институтов (рынки, демократии, иерархии и коллективы) эффективно функционирует в одних условиях и менее эффективно в других. Например, не нужно голосовать за то, какие товары должны покупать люди, и не следует использовать рынки для выбора политических лидеров.
В рамках организации и общества в целом можно увидеть каждую из этих институциональных форм. Университет имеет дело с рынком профессоров, опирается на демократию при найме преподавателей, зачисляет на курсы обучения посредством иерархии и разрабатывает стратегические планы с помощью коллективов. Некоммерческие, коммерческие и правительственные организации также представляют собой сочетание этих институциональных форм. Инструменты дизайна механизмов позволяют формально сравнить, как функционируют эти институты, и оптимально распределить между ними задачи.
ГЛАВА 25
МОДЕЛИ СИГНАЛИЗИРОВАНИЯ
Честные люди не скрывают своих дел.
Эмили Бронте
В этой главе рассматриваются модели сигнализирования. Эти модели определяют условия, при которых люди передают дорогостоящие сигналы для раскрытия информации или своего типа. Человек может сигнализировать о богатстве, покупая дорогие произведения искусства, о физической выносливости, совершив восхождение на гору, или о способности к сопереживанию, размещая информацию о поддержке благотворительного проекта в социальных медиа. Сигнализирование для раскрытия статуса всегда было частью человеческой природы. В XIX столетии Торстейн Веблен углубил наше понимание сигнализирования, разработав концепцию демонстративного потребления: он обратил внимание, что вместо покупки товаров, приносящих непосредственное удовлетворение и имеющих практическую полезность, люди часто выбирают товары, позволяющие подчеркнуть их социальный статус. Веблен получил бы необыкновенное удовольствие от современных атрибутов демонстративного потребления, таких как автомобиль Maybach Landaulet с розничной ценой 1,5 миллиона долларов, шампанское Cristal десятилетней выдержки по цене более 1500 долларов за бутылку и камеры Leica, цена которых составляет десятки тысяч долларов.
Демонстративное потребление сохраняет свою силу, поскольку нас волнует то, что думают о нас другие, а то, что мы потребляем, сигнализирует им о нашем статусе [1]. Поскольку мы не видим других людей во всей их полноте, мы полагаемся на то, как они одеваются, на чем ездят и что потребляют, чтобы сделать выводы об их скрытых качествах. Если мы видим кого-то за рулем дорогого автомобиля, это дает нам основания полагать, что этот человек богат. Человек, делающий пожертвования в благотворительной фонд, демонстрирует свою щедрость — вряд ли эгоистичный человек способен на такой поступок. Тот, кто объявляет в социальных сетях о получении докторской степени в области теоретической биологии, подает сигнал о своем интеллекте и трудовой этике. Почти все действия содержат определенный элемент сигнализирования. Когда политики голосуют за начало военных действий или ввод санкций против другой страны, они демонстрируют идеологию. Политики с более долгосрочными целями (такими как участие в президентской гонке) могут голосовать так, чтобы это обеспечивало лучшие сигналы, а не более достойный политический курс.
В этой главе мы сначала проанализируем модель дискретного сигнализирования, в которой человек может либо передавать сигнал, либо нет. Люди отличаются по затратам на создание сигнала. Для того чтобы сигналы выполняли свою функцию, они должны быть дорогостоящими или поддающимися проверке. В этом и будет состоять основной вывод из этой главы. Например, у работодателя есть интересное задание на лето в Барселоне и ему предстоит выбрать одного из новых сотрудников, указавших в резюме, что они владеют испанским языком. Заявление об умении говорить на испанском — это ничего не стоящий сигнал. Вместо этого работодатель может создать программу предоставления карточек знатока языка, подразумевающую проведение часовой презентации на испанском для получения такой карточки. Для сотрудников, свободно владеющих испанским, этот сигнал (презентация) не потребует больших затрат. Для тех же сотрудников, которые плохо знают язык, затраты на подготовку часовой презентации будут непомерно высокими. На формальном языке моделей сигнализирования это означает, что такая карточка отделяет испаноговорящих сотрудников от тех, кто не владеет этим языком.
Далее мы рассмотрим модель непрерывного сигнализирования, в которой сигналы могут варьироваться по величине. В летнем лагере может быть только одна должность ведущего каякера, на которую необходимо назначить чрезвычайно выносливого человека. Тогда директор лагеря может предложить двум кандидатам на эту должность проплыть на каяке как можно дальше за десять часов. Более сильный каякер может выбрать дистанцию, которая непреодолима для слабого каякера, а это гарантирует, что испытание разделит каякеров на два типа. Обе модели описывают условия, когда сигналы обеспечивают такое разделение, а когда нет. Следовательно, они позволяют глубже понять происходящее, чем отдельные истории о сигналах людей, животных, политиков и правительств, предоставляя точные описания, когда они подают сигналы и насколько они дороги. Например, модели помогут объяснить, почему студенты так усердно работают, для того чтобы продемонстрировать свою пригодность для учебы в колледже и медицинской школе. В заключительной части главы мы обсудим роль моделей сигнализирования, а также некоторые другие следствия. А еще поговорим о том, как происходит сигнализирование в области экологии, антропологии и бизнеса.
ДИСКРЕТНЫЕ СИГНАЛЫ
Начнем с модели дискретного сигнализирования, в которой человек решает, предпринимать соответствующее действие или нет. Вы можете купить дорогие часы, чтобы продемонстрировать богатство. Или выбрать в качестве специализации физику, чтобы доказать свой интеллект. Или переплыть Ла-Манш, чтобы похвастаться физическим здоровьем. Невозможно пройти только половину пути: вы либо подаете сигнал, либо нет. Эта модель описывает два типа людей, обозначенных как сильный и слабый тип. Эти типы могут соответствовать новобранцам морской пехоты в хорошей или плохой физической форме, или сотрудникам, владеющим одним или двумя языками.
Затраты на передачу сигнала, которые могут быть сопряжены с прохождением месячной программы тренировок будущим морским пехотинцем или с подготовкой вышеупомянутой презентации на испанском языке кандидатом на вакантную должность, зависят от типа человека. Для сильных будущих морпехов прохождение программы физической подготовки менее затратно. В нашей модели будем считать, что каждый, кто подает сигнал, получает равную долю общей выгоды. Это предположение можно интерпретировать одним из двух способов. Иногда ресурс можно разделить между теми, кто транслирует сигнал. Например, каждый, кто пожертвует 1000 долларов на развитие школы (сигнал о щедрости), может рассчитывать увидеть свое имя на табличке на ее стене. В других случаях победителя (победителей) можно выбрать случайным образом из множества людей, посылающих соответствующий сигнал.
Модель поддерживает три типа исходов: объединение (когда все подают один и тот же сигнал), разделение (когда каждый тип посылает уникальный сигнал) и частичное объединение (когда одни типы подлежат разделению, а другие нет).
Модель дискретного сигнализирования
Совокупность размером N состоит из S сильных и W слабых типов, затраты которых на передачу сигнала составляют c и C соответственно, причем c < C. Члены совокупности, подающие сигнал, делят поровну выгоду B > 0. Модель обеспечивает три возможных исхода:
Объединение  : оба типа подают сигнал.
: оба типа подают сигнал.
Разделение 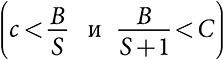 : представители сильного типа подают сигнал.
: представители сильного типа подают сигнал.
Частичное объединение 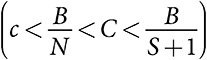 : сигнал подают представители сильного типа и часть представителей слабого типа.
: сигнал подают представители сильного типа и часть представителей слабого типа.
В данной модели мы исходим из того, что люди делают оптимальный выбор с учетом действий других, то есть рассматриваем ситуацию как игру и вычисляем равновесие. В случае объединяющего равновесия все подают сигнал. Равновесие имеет место, когда выгода высокая, а затраты слабого типа на передачу сигнала низкие. Точное условие выглядит так: выгода, деленная на количество людей, должна превышать затраты слабого типа. Предположим, благотворитель жертвует 1 миллион долларов на студенческие стипендии, причем эта сумма должна быть разделена между всеми 100 выпускниками средней школы. Допустим, 50 из них слабые и 50 сильные, а также что сильный ученик может окончить среднюю школу, выделяя на учебу два часа в неделю, а слабому приходится заниматься по десять часов. Мы можем приблизительно оценить затраты на обучение в размере 2000 долларов для сильных учеников и 5000 долларов для слабых учеников. Если все 100 учеников окончат школу, каждый получит стипендию в размере 10 000 долларов. Исходя из этих допущений ученикам обоих типов имеет смысл учиться.
Однако предположим, что размер стипендиального фонда сократился до 200 000 долларов. Тогда, если все ученики окончат школу, каждый получит только по 2000 долларов. Учеба больше не в интересах слабых учеников. Для сильных учеников, которые теперь получат по 4000 долларов, учеба по-прежнему имеет смысл. Этой суммы все еще недостаточно, чтобы побудить хотя бы одного слабого ученика окончить школу (второе условие в представленной выше врезке). В этом случае предложение стипендии порождает разделение.
И наконец, предположим, что стипендиальный фонд насчитывает 400 000 долларов. Если школу окончат все, то слабые ученики получат сумму меньше их затрат на обучение в размере 5000 долларов. Следовательно, не все слабые ученики предпочтут учебу. Однако если бы никто из слабых учеников не захотел учиться, сильные ученики получили бы по 10 000 долларов каждый. Эта сумма была бы заманчивой для слабых учеников. В случае равновесия ровно 30 слабых учеников оканчивают школу вместе с 50 сильными учениками. В общей сложности у нас будет 80 выпускников, каждый из которых получит 5000 долларов, что равно сумме затрат слабого ученика на учебу. Мы называем такой исход частичным объединением, поскольку только часть слабых учеников объединяются с сильными.
Равновесие частичного объединения сложнее других равновесий, поскольку требует координации между слабыми учениками. Можно было бы предположить, что существует некий процесс, посредством которого слабые ученики сообщают остальным, что они планируют предпринять действия, позволяющие им окончить школу. Или можно предположить, что более слабые ученики прикладывают такое количество усилий, чтобы окончание школы стало случайным событием, в результате которого 30 слабых учеников ее окончат. Второй сценарий менее правдоподобен. В целом мы должны интерпретировать равновесие частичного объединения как эталон — как то, что произойдет, если люди будут придерживаться оптимальной стратегии. Достижимо ли оно, зависит от ситуации, в частности от того, могут ли люди сообщать о запланированных действиях.
НЕПРЕРЫВНЫЕ СИГНАЛЫ
При равновесии частичного объединения модели дискретного сигнализирования представители сильного типа могут испытать разочарование. Если бы им удалось подать сильный сигнал, они могли бы полностью отделиться от слабого типа и получить более высокий выигрыш. Для того чтобы включить эту возможность в модель, мы можем изменить исходные допущения и разрешить представителям сильного типа выбирать величину подаваемого сигнала. Для этого нужно всего лишь внести небольшие изменения в модель. Давайте теперь интерпретируем затраты на передачу дискретного сигнала как затраты на единицу непрерывного сигнала. Будем считать, что в случае любой фиксированной величины сигнала у представителей сильного типа более низкие затраты на сигнализирование в расчета на единицу сигнала.
Для того чтобы обеспечить разделение в новой модели, представители сильного типа должны быть готовы выбрать сигнал такой величины, который был бы непомерно высоким для представителей слабого типа, но все же заслуживал бы передачи с учетом выгод и затрат. Анализ модели позволяет сделать вывод, что как минимум некоторые представители сильного типа (хотя и не обязательно все) могут отделиться от слабого типа сами.
Как ни странно, величина сигнала, который должны подавать представители сильного типа, уменьшается по мере увеличения размера сильной группы. Так происходит потому, что выгода от подачи сигнала для представителей слабого типа снижается в зависимости от размера сильной группы. Принадлежность к большой группе обеспечивает меньше выгод. Условие полного разделения подразумевает, что оно будет более вероятным при малом количестве представителей сильного типа или когда у представителей сильного типа гораздо более низкие затраты на передачу сигнала.
Разделение с помощью непрерывных сигналов
Совокупность размером N состоит из S сильных и W слабых типов, затраты которых на передачу сигнала в расчете на единицу сигнала составляют c и c > C соответственно. Люди, подающие самый большой сигнал, делят между собой выгоду B. Любой сигнал величиной 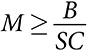 отделяет представителей сильного типа. Если CW ≥ cN, то все представители сильного типа будут отделены. Если нет, имеет место равновесие частичного объединения, при котором часть представителей сильного типа подают сигнал [2].
отделяет представителей сильного типа. Если CW ≥ cN, то все представители сильного типа будут отделены. Если нет, имеет место равновесие частичного объединения, при котором часть представителей сильного типа подают сигнал [2].
Эта модель позволяет объяснить, почему дорогие часы и ювелирные украшения выступают в качестве сигналов о богатстве. Дом или автомобиль тоже демонстрируют богатство человека, но их невозможно постоянно «носить» с собой. Одежда тоже может служить сигналом о богатстве, но не всегда обеспечивает разделение, поскольку за несколько сотен долларов человек может одеться так же, как представитель богатого круга. Часы и ювелирные украшения, ввиду их высокой стоимости, более эффективны в качестве сигналов. Бедный человек или представитель среднего класса не может себе позволить часы за 10 000 долларов. Человек, который носит такие часы, доказывает, что у него есть богатство. Выгода, которую он извлекает, может заключаться в более уважительном к нему отношении при условии, что люди так или иначе видят связь между богатством и значимостью (вывод, который можно поставить под сомнение).
ПРИМЕНЕНИЕ И ЦЕННОСТЬ СИГНАЛОВ
Мы подаем сигналы в попытке продемонстрировать свои скрытые качества окружающим. Мы предпринимаем действия, чтобы сигнализировать о своей физической форме, богатстве, интеллекте и щедрости. Порой наши действия порождают сигналы как побочный продукт. Человек, бегущий марафон исключительно ради удовольствия, подает сигнал о хорошей физической форме и целеустремленности, даже если это не входило в его планы. Модель сигнализирования обеспечивает альтернативный инструмент для интерпретации большого количества действий. Человек решил посетить мероприятие, освоить навык или купить какую-то вещь, руководствуясь личными интересами или чтобы обозначить свой тип? Возможно, нам так и не удастся разграничить эти два случая.
Кроме того, модели сигнализирования дают альтернативное объяснение эмпирических закономерностей даже касательно ценности диплома об окончании колледжа. Данные о доходах показывают, что выпускники колледжей получают гораздо более высокую заработную плату. Вполне логично было бы решить, что это обусловлено навыками и знаниями, полученными в колледже. К тому же эти данные указывают и на то, что зарплата сотрудников, изучавших в колледже математику и естественные науки, еще выше, что дает основания полагать, что навыки, полученные в процессе изучения этих дисциплин, имеют более высокую экономическую ценность. Тем не менее, если взглянуть на задачи, выполняемые сотрудниками с математическим образованием, становится ясно, что мало кто из них использует в работе математику. Более того, практически никому из претендентов на вакантные должности не предлагают взять производную функции косинуса или объяснить закон Бойля-Мариотта. В связи с этим мы можем сделать вывод, что дипломы об окончании колледжа в целом и дипломы в области естественных наук и математики в частности — всего лишь сигнал о способности человека усваивать знания. Высокая оплата, которую получает выпускник колледжа, целиком и полностью обусловлена сигнальной ценностью дипломов, а не конкретной специализацией выпускника [3].
Рассмотрим сигнализирование, необходимое для того, чтобы стать врачом. Студенты должны пройти курс физики, органической химии и математики. Но разве врачи используют математику? Вы когда-либо видели, чтобы ваш врач заглянул вам в уши или в нос, а затем нацарапал в своем блокноте дифференциальное уравнение? Разумеется, нет. Знание дифференциального исчисления по большей части не имеет никакого отношения к профессии врача, но может быть хорошим сигналом о способности человека усвоить требуемый объем знаний. Если это так, изучение математики становится полезным сигналом, хотя сам предмет в контексте профессии врача практически бесполезен.
Разрабатывая институты или правила, в соответствии с которыми люди подают сигналы, мы можем предпочесть действия, порождающие сигналы о формировании полезных навыков. Чтобы стать успешным врачом, человек должен уметь запоминать факты. Для определения такой способности можно потребовать, чтобы кандидаты запомнили столицы и денежные единицы всех стран. Успешное выполнение этого задания сигнализировало бы о прекрасной памяти кандидата, но не имело бы никакой практической ценности. Когда вы обращаетесь в отделение скорой помощи со странным ощущением в животе, вам совершенно все равно, знает ли врач, что Братислава — столица Словакии, но вы бы хотели, чтобы врач прекрасно разбирался в работе органов пищеварения. Именно поэтому медицинские комиссии требуют, чтобы врачи сдавали экзамены по анатомии. Сдача такого экзамена сигнализирует о способности запоминать. Что еще важнее, знание частей тела полезно для экзаменуемых. Таким образом, сдача экзамена по анатомии обеспечивает функциональный сигнал.
РЕЗЮМЕ
Модель сигнализирования можно применять в самых разных ситуациях. Как уже отмечалось, оперение павлина сигнализирует о его крепком здоровье. В остальном красочный веер из перьев практически не имеет функциональной ценности. Куда лучше, если бы у павлина росли более сильные когти. Но самкам павлина было бы трудно заметить их издалека, поэтому в процессе эволюции хвост одержал верх [4]. Яркие задние конечности самцов плодовой мушки выполняют ту же функцию, что и хвост павлина, так же как и стрекотание кузнечика и щебетание птиц. Стрекотание требует энергии. Поэтому только сытый кузнечик может безмятежно стрекотать, вместо того чтобы добывать пищу. Следовательно, стрекотание выступает в качестве сигнала.
Человеческие общества совершают разнообразные действия, чтобы демонстрировать свою хорошую форму. Антропологи выделяют три типа дорогостоящих сигналов: безусловная щедрость, расточительное поведение в отношении средств к существованию и ремесленные традиции [5]. Потлач — ритуал индейцев Тихоокеанского северо-запада — пожалуй, самый яркий пример демонстрации щедрости. Для того чтобы отметить то или иное событие (например, рождение или смерть), вождь раздавал (или уничтожал) большую часть богатства и призывал других вождей сделать то же самое и в том же объеме. Неспособность сравняться с вождем означала потерю престижа. Раздачу богатства можно рассматривать как социально полезное явление, но сжигать богатство — это расточительство.
Расточительное поведение в отношении средств к существованию имеет место в случаях, когда люди (как правило, мужчины) предпочитают охоту, которая приносит более низкий ожидаемый выигрыш, сбору семян и ягод. Мужчины делают это с целью заслужить особое уважение. Успешный охотник демонстрирует силу и храбрость, что может пригодиться ему в других ситуациях. Успешный собиратель ягод сигнализирует о хорошем зрении и терпении — безусловно, полезных качествах, но они не позволяют предсказать определенные аспекты хорошей физической формы так хорошо, как охота на черепах. В ходе изучения народа мериам, живущего на группе островов к северу от Австралии, было установлено, что у пятидесятилетних мужчин, охотящихся на черепах, более чем в два раза больше выживших потомков, чем у мужчин, которые на черепах не охотятся [6].
Вместе с тем многие ремесленные традиции связаны с обязательствами, выполнение которых требует достаточного количества времени и ресурсов. Такие виды деятельности могут привести к созданию полезных предметов, например покрывал. Кроме того, ремесленные традиции предусматривают изготовление ритуальных предметов, не имеющих большой практической ценности. Некоторые антропологи рассматривают их создание как сигнализирование. Смысл, вкладываемый в такие предметы (они могут быть наделены большой культурной значимостью), не всегда зависит от их функционального назначения.
Некоторые виды рекламы также можно интерпретировать как дорогостоящее сигнализирование. Размещая дорогой рекламный ролик во время матчей Суперкубка, компания демонстрирует свою состоятельность. Это сигнал о том, что в компании убеждены: ее продукт понравится потребителям в достаточной степени, чтобы прибыль возместила расходы на рекламу. Например, представьте, что два производителя выводят на рынок новую кофемашину. Один уверен в качестве своего продукта, а другой знает, что, несмотря на все усилия инженеров, его продукт наверняка сломается, что вызовет у покупателей недовольство. По оценкам второго производителя, 20 процентов его продукции будет возвращено.
На протяжении года кофемашину могут купить миллионы людей. Без рекламы эти две компании вполне могли бы разделить рынок поровну. Допустим, производитель лучшего продукта тратит 2 миллиона долларов на рекламу, чтобы подать сигнал о качестве своего продукта, рассчитывая на то, что первые клиенты купят его продукт и в долгосрочной перспективе это приведет к увеличению объема продаж. Вполне возможно, производитель руководствуется одной из версий процесса Пойа. Напротив, производитель некачественного продукта не станет размещать такую рекламу, поскольку у его продукта мало шансов на большие продажи. Затраты на передачу сигнала о качестве продукта иногда называют сжиганием денег. Такое сжигание денег привлекает покупателей так же, как хвост павлина — самок.
Во всех этих случаях сигнализирование сопряжено с затратами. Человек, посылающий сигнал, обнаруживает, что выгода от определения его большего богатства, способностей или даже щедрости сокращается на объем затрат на создание сигнала. Кроме того, время и усилия, потраченные на сигнализирование, можно рассматривать как альтернативные издержки: эти ресурсы можно было бы использовать иначе, создавая более значительный социальный излишек. Например, подросток может часами решать, что надеть, чтобы продемонстрировать свою социальную осведомленность, или посвятить время непродуктивным занятиям, которые, на его взгляд, повысят шансы на зачисление в элитный колледж.
Чтобы сигнализирование было менее дорогостоящим, мы пытаемся делать сигналы как можно более функциональными. Лучше, чтобы молодые люди подавали сигналы о своей хорошей физической форме и храбрости, занимаясь командными видами спорта, где они освоят правила спортивного поведения и соблюдения коллективных интересов, чем рисковали жизнью, совершая прыжки на мотоциклах. Как говорилось выше, лучше требовать от врачей, чтобы они запоминали анатомию человека, чем случайные наборы слов из языка эльфов в романах Дж. Р. Р. Толкина. Тем не менее, как бы мы ни старались, нерациональное сигнализирование продолжит существовать. Поэтому наша задача — использовать модели (в частности, инструменты дизайна механизмов) для создания таких институтов и протоколов, которые сделают сигналы, передаваемые людьми, максимально функциональными.
ГЛАВА 26
МОДЕЛИ ОБУЧЕНИЯ
Самая важная установка, которую можно сформировать, — это стремление продолжать учиться.
Джон Дьюи
В этой главе мы остановимся на моделях индивидуального и социального обучения и проанализируем их применение в двух контекстах. Первый подразумевает выбор наилучшего варианта из множества альтернатив. В этом случае оба типа обучения, индивидуальное и социальное, сходятся к оптимальному выбору. От выбора правила обучения зависит только степень сходимости. Затем мы рассмотрим применение правил обучения к действиям в играх. В игре выигрыш от определенного действия зависит от действий другого игрока или игроков. В этом случае оба правила обучения ставят равновесные исходы с избеганием риска выше эффективных исходов. Кроме того, мы также обнаружим, что индивидуальное и социальное обучение не всегда обеспечивает одинаковые результаты и что ни один из типов обучения не действует более эффективно во всех средах.
Все эти выводы поддерживают наш многомодельный подход к представлению поведения. Модели обучения находятся в промежутке между моделями рационального выбора, которые предполагают,что люди анализируют логику ситуаций и игр и предпринимают оптимальные действия, и моделями, основанными на правилах, которые предписывают определенные линии поведения. Модели обучения действительно исходят из того, что люди придерживаются правил, однако эти правила позволяют менять поведение. Порой поведение приближается к оптимальному — в таких случаях модели обучения можно использовать для обоснования предположения, что люди могут вести себя оптимально. Тем не менее модели обучения не всегда сходятся к равновесию: они могут формировать циклы или сложные динамические процессы. Если модели все же сходятся к равновесию, они могут выбирать одни равновесия чаще, чем другие.
Глава начинается с описания модели обучения с подкреплением и ее применения к решению задачи выбора наилучшей альтернативы. Модель усиливает действия посредством более высокого вознаграждения. Со временем учащийся предпринимает только наилучшее действие. Это базовая модель, которая идеально подходит для обучения обучению. Кроме того, она хорошо согласуется с экспериментальными данными, причем не только в отношении людей. Морские слизни, голуби и мыши также подкрепляют успешные действия. Эта модель может быть более подходящей для морских слизней с 20 000 нейронами, чем для людей, у которых их более 85 миллиардов. Такие расширенные возможности позволяют людям анализировать гипотетические построения в процессе обучения — феномен, который остается за рамками модели обучения с подкреплением.
Далее мы опишем модели социального обучения, в соответствии с которыми люди обучаются на основе собственного выбора и выбора других людей. Люди копируют только те действия или стратегии, которые наиболее распространены или дают результаты выше среднего. Социальное обучение требует наблюдений или коммуникации. Некоторые виды обеспечивают социальное обучение через стигмергию — процесс, в рамках которого успешные действия оставляют след или отпечаток, чтобы по нему могли последовать другие (как, например, козы, которые бродят по горному пастбищу, оставляя после себя вытоптанную траву, обозначающую маршрут к воде или пище).
В третьем разделе мы применим оба типа моделей обучения к играм. Как уже отмечалось, игры — более сложная среда обучения. Одно и то же действие может обеспечивать высокий выигрыш в одном периоде и низкий — в следующем периоде. Вполне ожидаемо мы обнаружим, что модели как социального, так и индивидуального обучения не сходятся к эффективному равновесию. Кроме того, они могут приводить к разным исходам. Заканчивается глава обсуждением более сложных правил обучения [1].
ИНДИВИДУАЛЬНОЕ ОБУЧЕНИЕ: ПОДКРЕПЛЕНИЕ
В случае обучения с подкреплением человек выбирает действия с учетом их веса. Действия с большим весом выбираются чаще, чем с малым. Вес, присвоенный действию, зависит от вознаграждения (выигрыша), которое человек получил при его совершении в прошлом. Такое подкрепление в виде выигрышей с высоким вознаграждением приводит к выполнению более эффективных действий. Вопрос, который мы исследуем, состоит в том, сходится ли обучение с подкреплением исключительно к выбору альтернативы с высоким вознаграждением.
На первый взгляд может показаться, что выбрать наиболее выгодную альтернативу, — проще простого. Если вознаграждение представлено в числовой форме, такой как деньги или время, можно ожидать, что люди выберут лучшую альтернативу. В главе 4 мы применили эту логику, чтобы доказать, что человек, выбирающий маршрут на работу в Лос-Анджелесе, предпочтет самый короткий путь.
Если вознаграждение не представлено в числовой форме (что обычно и бывает), людям приходится полагаться на память. Например, во время обеда в корейском ресторане нам очень понравилось блюдо кимчи, поэтому велика вероятность, что мы отправимся туда обедать снова. В понедельник мы съедаем овсяное печенье за час до пробежки и обнаруживаем, что можем поддерживать высокий темп бега десять километров. Если в среду перед пробежкой мы снова перекусим овсяным печеньем и покажем тот же результат, это даст нам основания увеличить вес этого действия. Мы узнаем, что печенье повышает нашу результативность.
Другие виды делают то же самое. Эдвард Торндайк (один из первых психологов, изучавших обучение) провел эксперимент, в ходе которого кошки, тянувшие рычаг, чтобы выбраться из коробки, вознаграждались рыбой. Когда кошку снова помещали в коробку, она в течение нескольких секунд опять тянула рычаг. Данные Торндайка позволили установить процесс непрерывного экспериментирования. Торндайк обнаружил, что кошки (и люди) учатся быстрее в случае повышения вознаграждения. Он назвал это законом эффекта [2]. Этот вывод имеет и неврологическое объяснение. Повторение того или иного действия приводит к формированию неврологических путей, порождающих аналогичное поведение в будущем. Кроме того, Торндайк обнаружил, что более неожиданное вознаграждение (которое существенно превышает прошлый или ожидаемый результат) обеспечивает более быстрое обучение у людей — феномен, известный как принцип неожиданности [3].
В нашей модели обучения с подкреплением вес, присвоенный выбранной альтернативе, корректируется с учетом того, насколько вознаграждение от этой альтернативы превышает наши ожидания (наш уровень стремлений). Эта схема включает как закон эффекта (мы чаще предпринимаем действия, обеспечивающие более высокое вознаграждение), так и принцип неожиданности (вес, присваиваемый выбранной альтернативе, зависит от того, в какой степени вознаграждение от нее превосходит уровень стремлений) [4].
Модель обучения с подкреплением
Совокупность альтернатив {A, B, C, D, …, N} имеет связанные с ними вознаграждения {π(A), π(B), π(C), π(D), …, π(N)} и множество строго положительных весовых коэффициентов {w(A), w(B), w(C), w(D), …, w(N)}. Вероятность выбора альтернативы K равна:
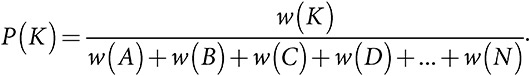
После выбора альтернативы K значение w(K) возрастает на γ · P(K) · (π(K) − A), где γ > 0 — это скорость корректировки, а A < maxKπ(K) — уровень стремления [5].
Обратите внимание, что уровень стремления должен быть ниже вознаграждения как минимум по одной альтернативе, иначе вероятность последующего выбора любой выбранной альтернативы будет уменьшаться, и все весовые коэффициенты сойдутся к нулю. Можно доказать, что, если уровень стремлений ниже вознаграждения минимум по одной альтернативе, в конечном счете почти весь вес будет присвоен лучшей альтернативе. Это происходит потому, что каждый раз, когда выбор падает на самую лучшую альтернативу, ее вес возрастает на максимальную величину, что создает более сильное подкрепление данной альтернативы. Это имеет место, даже если установить уровень стремления ниже вознаграждения по каждой альтернативе. В таком случае вес каждой альтернативы увеличивается после ее выбора. Следовательно, модель может отражать привыкание, когда мы делаем что-то в большем объеме только потому, что делали это в прошлом. Даже при низком уровне стремления быстрее всего возрастает вес альтернатив с самым высоким вознаграждением, а значит, лучшая альтернатива побеждает в долгосрочной перспективе. Однако период для схождения к наилучшей альтернативе может быть длительным. К тому же с каждым включением в рассмотрение дополнительных альтернатив растет и период схождения.
Во избежание таких сложностей включим в модель эндогенные стремления и изменим модель так, чтобы уровень стремлений корректировался с течением времени, установив его равным среднему вознаграждению. Представьте, что один из родителей выясняет, что больше любит ребенок — блины с яблоками или с бананами. Присвоим вознаграждение 20 блинам с яблоками и вознаграждение 10 блинам с бананами. Установим исходный вес 50 обеим альтернативам, скорость корректировки — 1, а уровень стремления — 5. Допустим, родитель печет в первый день блины с бананами; их вес увеличится до 55. Предположим, на следующий день родитель снова печет блины с бананами. Вознаграждение 10 соответствует новому уровню стремления, поэтому вес блинов с бананами не меняется.
Теперь представим, что на третий день родитель готовит блины с яблоками, что обеспечивает вознаграждение 20, превышающее уровень стремлений. Это увеличивает вес блинов с яблоками до 60, повышая вероятность их выбора. Высокое вознаграждение поднимает также средний выигрыш, а значит, и уровень стремлений, выше 10. Таким образом, если родитель снова приготовит блины с бананами, их вес уменьшится, поскольку вознаграждение от них ниже нового уровня стремлений. Следовательно, обучение с подкреплением сходится исключительно к выбору блинов с яблоками.
Можно доказать, что обучение с подкреплением сходится к выбору наилучшей альтернативы с вероятностью 1. Это означает, что вес наилучшей альтернативы станет сколь угодно большим по сравнению с весом других альтернатив.
Действенность обучения с подкреплением
Согласно концептуальной схеме обучения посредством поиска наилучшей альтернативы, обучение с подкреплением в конечном счете почти всегда обеспечивает выбор наилучшей альтернативы.
СОЦИАЛЬНОЕ ОБУЧЕНИЕ: РЕПЛИКАТИВНАЯ ДИНАМИКА
Обучение с подкреплением подразумевает, что человек действует в одиночку. Однако люди могут учиться, наблюдая за другими людьми. Модели социального обучения исходят из того, что люди видят действия и вознаграждения окружающих. Это может ускорить темпы обучения. Наиболее изученная модель социального обучения, репликативная динамика, подразумевает, что вероятность совершения действия зависит от произведения от его вознаграждения и его популярности. Первое можно обозначить как эффект вознаграждения, а второе как эффект конформности [6]. Чаще всего модель репликативной динамики включает в себя бесконечную совокупность, что позволяет описать предпринятые действия как распределение вероятностей по разным альтернативам. При стандартном построении модели время идет дискретными шагами, а значит, мы можем оценить процесс обучения по изменениям в распределении вероятностей.
Репликативная динамика
Совокупность альтернатив {A, B, C, D, …, N} имеет связанные с ними вознаграждения {π(A), π(B), π(C), π(D), …, π(N)}. Действия совокупности в момент t можно записать как распределение вероятностей по N альтернативам: (Pt(A), Pt(B), …, Pt(N)). Распределение вероятностей меняется в соответствии со следующим уравнением репликативной динамики:
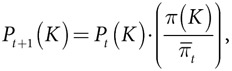
где 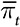 — это среднее вознаграждение за период t.
— это среднее вознаграждение за период t.
Рассмотрим сообщество, в котором родители выбирают между блинами с яблоками, с бананами и с шоколадной крошкой. Предположим, что у всех детей одинаковые предпочтения и три вида блинов обеспечивают вознаграждение 20, 10 и 5. Если изначально 10 процентов родителей пекут блины с яблоками, 70 процентов — с бананами и 20 процентов — с шоколадной крошкой, среднее вознаграждение составит 10. Применив уравнение репликативной динамики, получим следующие значения вероятности выбора каждой из трех альтернатив во втором периоде:
УРАВНЕНИЕ РЕПЛИКАТИВНОЙ ДИНАМИКИ
Альтернатива | π | P1 |
| P2 |
Яблоки | 20 | 0,1 | 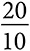 | 0,2 |
Бананы | 10 | 0,7 | 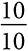 | 0,7 |
Шок. крошка | 5 | 0,2 | 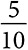 | 0,1 |
Согласно уравнению репликативной динамики, в следующем периоде блины с яблоками испекут в два раза больше родителей. Это объясняется тем, что вознаграждение за них вдвое больше среднего вознаграждения. В два раза меньше родителей приготовят блины с шоколадной крошкой, поскольку вознаграждение составляет половину среднего вознаграждения. И наконец, доля родителей, выбравших блины с бананами, обеспечивающие эквивалент среднему вознаграждению, не изменится. Объединив все эти изменения, можно показать, что среднее вознаграждение возрастает до 11,5.
Как отмечалось выше, репликативная динамика включает эффект конформности (более популярные альтернативы, скорее всего, будут скопированы) и эффект вознаграждения. В долгосрочной перспективе эффект вознаграждения преобладает, поскольку количество альтернатив с высоким вознаграждением всегда растет пропорционально количеству альтернатив с более низким вознаграждением. В модели репликативной динамики среднее вознаграждение выполняет ту же функцию, что и уровень стремлений в модели обучения с подкреплением, где уровень стремлений настраивается на соответствие среднему вознаграждению. Единственное различие — в модели репликативной динамики мы вычисляем среднее вознаграждение по всей совокупности. В модели обучения с подкреплением уровень стремления эквивалентен среднему вознаграждению отдельного человека. Это различие важно в том смысле, что совокупность представляет собой более широкую выборку. Таким образом, репликативная динамика порождает меньшую зависимость от первоначально выбранного пути, чем обучение с подкреплением.
Наша модель репликативной динамики исходит из того, что каждая альтернатива существует в исходной совокупности. Учитывая, что альтернатива с самым высоким вознаграждением всегда обеспечивает вознаграждение выше среднего, а ее доля возрастает в каждом периоде, в конечном счете репликативная динамика сходится к выбору лучшей альтернативы всей совокупностью [7]. Следовательно, в контексте поиска лучшей альтернативы как индивидуальное, так и социальное обучение сходится к альтернативе с самым высоким вознаграждением. Однако это не относится к играм.
Репликативная динамика обеспечивает наиболее эффективное обучение
В процессе поиска лучшей альтернативы из конечного множества альтернатив репликативная динамика в рамках бесконечной совокупности сходится к тому, что вся совокупность выбирает наилучшую альтернативу.
ОБУЧЕНИЕ В ИГРАХ
Теперь применим наши две модели обучения к играм [8]. Вспомним, что в игре выигрыш игрока зависит как от его собственных действий, так и от действий других игроков. Выигрыш от определенного действия, такого как сотрудничество в дилемме заключенного, может быть высоким в один период и низким в следующий период, в зависимости от действий другого игрока. Начнем с «Пожирателя топлива» — игры с двумя участниками, в которой каждый игрок должен выбрать, на каком автомобиле ездить — экономичном или потребляющем много топлива. Выбор пожирателя топлива всегда дает выигрыш 2. Выбор экономичного автомобиля, если другой игрок тоже выберет экономичный автомобиль, обеспечивает выигрыш 3, — у обоих водителей хорошая линия обзора, им требуется меньше топлива и они не боятся быть раздавленными громадным пожирателем топлива. Если другой игрок выбирает «пожирателя», водитель экономичного автомобиля должен быть осведомлен о другом водителе. Для того чтобы отобразить этот эффект, будем исходить из того, что выигрыш этого водителя падает до нуля. Выигрыши в игре представлены на рис. 26.1.
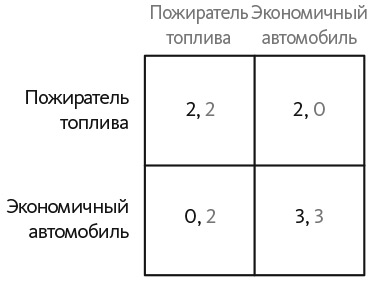
Рис. 26.1. Игра «Пожиратель топлива»
В игре «Пожиратель топлива» есть два равновесия в чистых стратегиях: оба игрока могут выбрать экономичные автомобили или оба игрока могут выбрать автомобили с большим потреблением топлива [9]. Равновесие, в котором оба выбирают экономичные автомобили, обеспечивают более высокий выигрыш. Это и есть эффективное равновесие.
Сначала предположим, что оба игрока используют модель обучения с подкреплением. На рис. 26.2 показаны результаты четырех численных экспериментов, где первоначальный вес каждого действия равен 5, уровень стремлений равен нулю, а скорость обучения (γ) составляет . В ходе всех четырех экспериментов оба игрока учатся выбирать пожирателя топлива, что является неэффективным равновесием в чистых стратегиях. Для того чтобы понять, почему это происходит, достаточно проанализировать выигрыши. Пожиратель топлива всегда обеспечивает выигрыш 2. Экономичный автомобиль иногда дает выигрыш 3, а иногда — 0. Согласно предположению, оба действия будут в равной степени представлены в исходной совокупности. Следовательно, экономичный автомобиль обеспечивает средний выигрыш всего 1,5 по сравнению с выигрышем пожирателя топлива 2. Чем больше игроки выбирают пожирателя топлива, тем ниже выигрыш от выбора экономичного автомобиля.
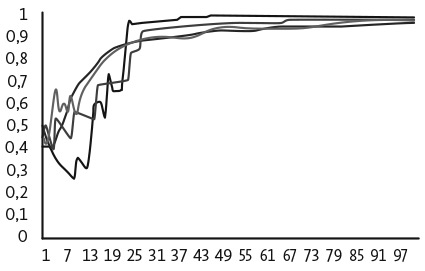
Рис. 26.2. Вероятность выбора пожирателя топлива в случае обучения с подкреплением 
Теперь применим к этой игре модель репликативной динамики. Вновь предположим, что исходная совокупность состоит из равных частей людей, выбравших автомобили с большим расходом топлива и экономичные автомобили. Кроме того, будем исходить из того, что каждый член совокупности играет против всех остальных ее членов. Игроки, выбирающие пожирателей топлива, получают более высокие выигрыши, а поскольку на начальном этапе каждое действие выбирается одинаковым количеством игроков, во втором периоде больше людей предпочтут пожирателей топлива [10]. Повторное применение уравнения репликативной динамики показывает, что количество игроков, выбирающих автомобили с большим расходом топлива, продолжает увеличиваться. Дальнейшее применение уравнения приводит к тому, что все члены совокупности выбирают пожирателей топлива. На рис. 26.3 представлены результаты четырех случаев применения модели дискретной репликативной динамики к совокупности из 100 игроков. Предположив наличие конечной совокупности, мы вводим небольшой элемент случайности. Количество людей, совершающих каждое действие, может не в точности совпадать с количеством, указанным в уравнении репликативной динамики. В каждом из четырех случаев все игроки выбирают пожирателя топлива всего лишь после семи периодов. Сходимость столь быстрая, потому что и эффект конформности, и эффект вознаграждения уже после первого периода подталкивают людей к такому выбору. Например, когда 90 процентов членов совокупности выбирают автомобили с большим расходом топлива, выигрыш от выбора экономичного автомобиля составит менее одной шестой выигрыша от выбора пожирателя топлива. Эффект конформности усиливает эффект вознаграждения, делая социальное обучение гораздо более быстрым по сравнению с индивидуальным обучением, которое потребовало бы в среднем 100 периодов для выбора 99 процентов автомобилей с большим расходом топлива.
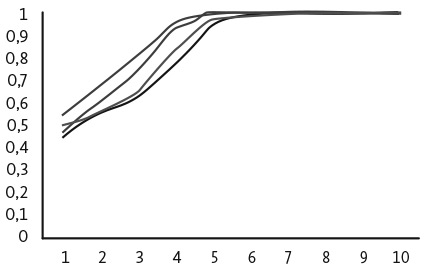
Рис. 26.3. Репликативная динамика (100 игроков): вероятность выбора пожирателя топлива
В этой игре оба правила обучения сходятся к выбору пожирателя топлива, поскольку это действие обеспечивает более высокий выигрыш, если оба действия в равной степени вероятны. Такие действия называются доминирующими по риску. Оба правила обучения предпочли доминирующее по риску равновесие эффективному равновесию. Далее рассмотрим игру, в которой оба правила обучения сходятся к разным равновесиям.
ИГРА «ВЕЛИКОДУШНЫЙ — ЗЛОБНЫЙ»
Наша следующая игра, «Великодушный — злобный», основывается на широко изучаемом вопросе, касающемся поведения: какой выигрыш волнует нас больше — абсолютный или относительный? Человека, который предпочел бы бонус в размере 10 000 долларов, притом что все его коллеги получат по 15 000 долларов, бонусу в размере 8000 долларов, тогда как его коллеги получат всего по 5000 долларов, больше заботит его абсолютный выигрыш. Человек, который принял бы меньшее количество денег, чтобы получить самый большой бонус, больше заботится о своем относительном выигрыше. Крайний случай предпочтения в пользу относительного выигрыша отражен в истории о злобном человеке и волшебной лампе.
Злобный человек и волшебная лампа
Злобный человек во время археологической экспедиции нашел бронзовую лампу. Когда он ее потер, из нее появился джинн и провозгласил: «Я исполню одно любое твое желание, но, будучи великодушным джинном, дам каждому, кого ты знаешь, вдвое больше, чем тебе». Поразмыслив немного над этим предложением, человек протянул ему палку и попросил: «Выколи мне один глаз».
Злобный человек совершает действие, которое дает ему низкий абсолютный и высокий относительный выигрыш [11]. Аналогичное противоречие существует и в международных отношениях. Неолибералы считают, что страны стремятся максимизировать абсолютный выигрыш, выраженный в виде военной мощи, экономического процветания и внутренней стабильности. Представители другого лагеря, известные как неореалисты, убеждены, что странам важен относительный выигрыш. Страна предпочла бы иметь более низкий абсолютный выигрыш, но быть сильнее своих врагов. Неореалист Кеннет Уолц в разгар холодной войны писал: «Главная задача государств не в том, чтобы максимально увеличить влияние, а в том, чтобы сохранить свои позиции в системе» [12]. Неореалисты утверждают, что если бы в разгар холодной войны либо СССР, либо США потерли волшебную лампу, то каждая из этих стран протянула бы джинну палку.
Мы можем представить конфликт между абсолютными и относительными выигрышами в игре «Великодушный — злобный» в виде великодушного действия, увеличивающего выигрыши всех игроков, и злобного действия, повышающего выигрыш только одного игрока. Эта игра отличается от игры с коллективными действиями, где щедрость имеет свою цену [13]. Формальное описание игры с выигрышами представлено во врезке. Великодушное действие — это доминирующая стратегия. Какими бы ни были действия других игроков, игрок, выбравший его, получает более высокий выигрыш. Вместе с тем игроки, выбравшие злобное действие, в среднем получают более высокий выигрыш.
Игра «Великодушный — злобный»
Каждый из N игроков предпочитает быть великодушным G или злобным S.
Payoff(G, NG) = 1 + 2 · NG.
Payoff(S, NG) = 2 + 2 · NG.
На первый взгляд эти утверждения кажутся противоречивыми, но это не так. Проявляя великодушие, игрок повышает свой абсолютный выигрыш на 3, повышая при этом и выигрыши других игроков на 2. Злобный игрок увеличивает свой выигрыш только на 2, не увеличивая при этом выигрышей остальных игроков. Каждый игрок улучшает свой выигрыш, выбирая великодушие. Когда игрок решает быть злобным, он уменьшает свой выигрыш, но еще больше (в этом и состоит ключевое предположение) уменьшает выигрыши остальных.
Если применить обучение с подкреплением к игре «Великодушный — злобный», то игроки научатся быть великодушными. Чтобы понять почему, предположим, что игроки почти пришли к равновесию, причем NG игроков делают выбор в пользу великодушия. Злобный игрок получает выигрыш 2 + 2 · NG — это и есть его уровень стремлений. Выбрав G (что происходит с малой вероятностью), он получит выигрыш 1 + 2 · (NG + 1) = 3 + 2 · NG, что превышает его уровень стремлений. В итоге он с большей вероятностью проявит великодушие. Продолжая использовать эту логику, мы увидим, что все игроки научатся быть великодушными.
В случае применения репликативной динамики члены совокупности учатся быть злобными. Это можно увидеть, обратившись к уравнению репликативной динамики. В каждом периоде игроки, решившие вести себя злобно, получают более высокий выигрыш, чем игроки, выбравшие великодушие. Следовательно, доля злобных игроков увеличивается на протяжении каждого периода.
Эти выводы подчеркивают ключевое различие между индивидуальным и социальным обучением. Индивидуальное обучение заставляет людей выбирать лучшее действие, поэтому они обнаруживают доминирующее действие, если оно существует. Социальное обучение заставляет людей выбирать более эффективные действия по сравнению с другими действиями. В большинстве случаев такие действия обеспечивают и более высокий выигрыш. Этого не относится к игре «Великодушный — злобный», где злобное действие обеспечивает более высокий средний выигрыш, а великодушное является доминирующим. Обратите внимание, что наш анализ приводит к довольно парадоксальному выводу: в случае индивидуального обучения люди учатся поступать более великодушно, чем в случае социального. Это объясняется тем, что в ходе социального обучения игроки копируют действия тех игроков, которые добиваются относительно высоких результатов.
Теперь мы можем проанализировать сделанный ранее комментарий относительно того, что репликативную динамику можно рассматривать либо как адаптивное правило, либо как выбор из фиксированных правил. Если допустить второе, то наша модель говорит о том, что отбор может отдавать предпочтение злобному типу. Отбор не всегда порождает кооперацию. Этот результат противоречит тому, что мы узнали при изучении дилеммы заключенного, где повторение приводило к сотрудничеству. Тогда мы анализировали повторяющиеся игры и допускали вероятность использования более сложных стратегий.
СОЧЕТАНИЕ МОДЕЛЕЙ ОБУЧЕНИЯ
Мы увидели, что индивидуальное и социальное обучение позволяют найти лучшее решение среди фиксированного множества альтернатив, но при применении к играм могут приводить к разным исходам. Такое отсутствие согласованности является преимуществом. Представьте огромное множество, состоящее из всех возможных игр. Представьте также еще одно множество, состоящее из всех моделей обучения. Мы могли бы применить каждую модель из второго множества к каждой игре из первого множества и оценить полученные результаты, а затем разделить множество всех игр на два подмножества: игры, в которых правило обучения обеспечивает эффективный исход, и игры, в которых этого не происходит. Кроме того, можно было бы проанализировать экспериментальные данные и оценить каждое правило обучения в качестве предиктора фактического поведения. Выполнение этих действий несомненно выявило бы дополнительные обстоятельства. Каждое правило обучения обеспечивает эффективный исход в одних играх, но не в других. Кроме того, все правила обучения отличаются друг от друга контекстом, в котором они точно описывают поведение. Поэтому мы отстаиваем целесообразность многомодельного подхода.
В этой главе описаны две канонические модели, содержащие всего по несколько меняющихся элементов. Мы ставили перед собой цель дать общее представление о содержании множества захватывающих книг. Включение дополнительных деталей в любую модель обучения обеспечивает более полное соответствие экспериментальным и эмпирическим данным. Вспомните, что в модели обучения с подкреплением люди увеличивают или уменьшают вес альтернативы или действия в зависимости от того, превышает ли вознаграждение (выигрыш) их уровень стремлений. Люди не присваивают веса действиям, которых не совершают: мы не увеличиваем вероятность выполнения какого-то действия, которое обеспечило бы более высокий выигрыш, если бы мы его предприняли.
Это предположение имеет смысл не во всех случаях. Рассмотрим случай, когда сотрудник, уезжая в отпуск, решает не брать с собой мобильный телефон. Пока сотрудник находится в отъезде, ему звонит руководитель по важному вопросу. Сотрудник, разумеется, пропускает звонок, и ему отказывают в повышении. В модели обучения с подкреплением этот сотрудник не присваивает более значительный вес решению взять телефон с собой в будущем. Модель обучения по алгоритму Эрева–Рота вносит в стандартную модель поправки, чтобы невыбранные альтернативы тоже получали определенный вес в зависимости от их гипотетических выигрышей. В данном примере сотрудник присвоил бы более значительный вес решению взять телефон с собой.
Такое изменение модели создает правило обучения на основе убеждений. Величина увеличения веса невыбранных альтернатив зависит от экспериментального показателя. Чем он выше, тем больше люди учитывают последствия действий других и тем больше увеличивают вес этих действий. Рот и Эрев также исключают из рассмотрения предысторию, чтобы можно было учитывать тот факт, что другие игроки тоже обучаются, а стратегии могут меняться [14].
Такие дополнительные предположения имеют интуитивный смысл и эмпирическое обоснование, но подходят не во всех случаях. Если вернуться к примеру с родителями, которые пекут блины, первое предположение подразумевает, что после приготовления блинов с бананами дополнительный вес присваивается альтернативе в виде приготовления блинов с яблоками, причем он пропорционален выигрышу от этих блинов. Данное предположение имеет смысл тогда, когда родителям известен выигрыш от блинов с яблоками. Это возможно, только если родители видят или могут интуитивно оценить выигрыш от невыбранных действий.
Модель Кэмерера и Хо образует функциональную форму, которая допускает обучение с подкреплением и обучение на основе убеждений в качестве особых случаев. Параметр, который можно привести в соответствие с данными, позволяет определить относительную силу каждого типа правил обучения [15]. Способность комбинировать модели была одним из побудительных мотивов для освоения многомодельного подхода. При этом комбинирование моделей неизбежно обеспечивает лучшее соответствие данным в связи с увеличением количества параметров. Но даже с учетом роста числа параметров модель Кэмерера и Хо дает более точные прогнозы и более глубокое объяснение.
Моделирование обучения сопряжено с рядом проблем. Правила обучения, хорошо работающие в одной среде, могут не охватывать другие ситуации. Кроме того, то, что люди учатся делать, может зависеть от их исходных убеждений, поэтому два человека могут по-разному учиться в одной и той же среде, а один человек может по-разному учиться в разных ситуациях. Но даже сконструировав точную модель обучения, мы непременно столкнемся с принципом эксплуатируемости: если модель объясняет, как люди учатся, то другие могут применить ее для прогнозирования (а иногда и эксплуатации) этих знаний. Тогда люди, по всей вероятности, научатся избегать эксплуатации, и наша исходная модель обучения перестанет быть достоверной. Мы уже сталкивались с этим феноменом при обсуждении критики Лукаса в процессе анализа гипотезы об эффективности рынка. Мы не можем сделать однозначный вывод о том, что, поскольку люди учатся, они придерживаются оптимальной стратегии. Можно только предположить, что обучение позволит отказаться от неэффективных действий в пользу лучших.
Действительно ли культура важнее стратегии?
Давайте применим модели заражения и модели обучения для анализа известного постулата организационной теории о том, что культура важнее стратегии [16]. Если коротко, то это утверждение гласит, что стратегические стимулы к изменению поведения не дают результата. Притягательность культуры, существующий набор знаний и убеждений слишком сильны. Экономисты утверждают обратное: стимулы определяют поведение.
Для того чтобы описать эти два противоположных утверждения с помощью условной логики, сначала используем один из вариантов модели сетевого распространения. В этой модели менеджер или директор объявляет о новой стратегии и приводит доказательства преимуществ планируемых перемен. СЕО может даже пересмотреть ключевые принципы организации, чтобы они отражали новую модель поведения. Затем сотрудники организации решают, принимать ли эту модель поведения, в зависимости от убедительности аргументов менеджера. Какое-то начальное количество сотрудников проявляют интерес к данной инициативе и, вступая в контакт с другими представителями своей рабочей сети, распространяют свой энтузиазм. Однако параллельно существует определенное сопротивление новой стратегии, когда некоторые люди не принимают ее. Три свойства, от которых зависит распространение новой стратегии (численность контактов, скорость распространения и количество отказов), естественным образом соответствуют параметрам в формуле базового репродуктивного числа R0:
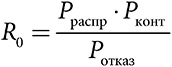
С учетом вероятности появления суперраспространителей мы можем сделать вывод, что культура превосходит стратегию в случае выполнения любого из следующих трех условий: если сотрудники не верят в новую стратегию, если они поспешно отбрасывают ее или если ее сторонники недостаточно взаимосвязаны. В противном случае стратегия вполне может превзойти культуру.
Наша вторая модель применяет репликативную динамику к игре «Культура — стратегия», которая моделирует взаимодействие между парами сотрудников. Мы можем представить эти варианты выбора в форме игры как культурное действие (то, что они делают сейчас) и инновационное стратегическое действие. Предположим, менеджер разрабатывает систему выигрышей таким образом, чтобы игроки получали более высокий выигрыш, если оба выберут инновационное поведение. При этом у одного игрока инновационный выигрыш будет ниже.
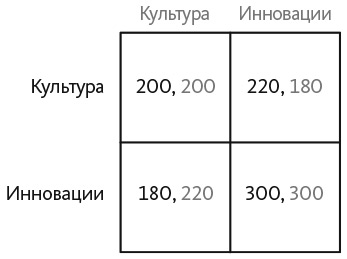
В игре два строгих стратегических равновесия Нэша: в одном оба игрока принимают инновации (стратегия превосходит культуру), а во втором оба не принимают (культура превосходит стратегию). Очевидно, что менеджер разработал систему стимулов таким образом, чтобы сотрудники выбрали инновационное стратегическое действие, обеспечивающее более высокий выигрыш. Построив модель обучения, мы увидим, что менеджеру необходим достаточный уровень первоначальной заинтересованности сотрудников для того, чтобы новая стратегия прижилась. В представленной выше игре можно доказать, что если при наличии первоначальной заинтересованности доля сотрудников, принимающих инновации, не превышает 20 процентов, то культура превзойдет стратегию [17]. Если бы мы увеличили выигрыш от инновационного стратегического действия, то уровень первоначальной заинтересованности мог бы быть даже ниже, но все же обеспечивал бы эффективный исход.
Обе модели показывают, что два противоположных тезиса «Культура важнее стратегии» и «Люди реагируют на стимулы» могут быть правильными при определенных условиях. Согласно первой модели, харизматичные руководители, способные убедить хорошо взаимосвязанных сотрудников, могут внедрить новые стратегии, которые одержат верх над культурой. Согласно второй модели, культура превосходит слабые стимулы, но уступает сильным.
ГЛАВА 27
ЗАДАЧИ О МНОГОРУКОМ БАНДИТЕ
Есть одна вещь, которая у меня действительно хорошо получается — бросать мяч через сетку. Я делаю это превосходно.
Серена Уильямс
В этой главе мы привнесем неопределенность в проблему поиска лучшей альтернативы для создания класса моделей, известных как задачи о многоруком бандите. В таких задачах вознаграждения от альтернатив представляют собой распределение, а не фиксированную величину. Задачи о многоруком бандите применимы к широкому спектру реальных ситуаций. Любой выбор из совокупности действий, обеспечивающий неопределенный выигрыш (испытания лекарственных препаратов, выбор площадки для размещения рекламы, выбор технологий, решение об использовании ноутбуков на занятиях), можно смоделировать в виде задачи о многоруком бандите; то же самое касается выбора профессии, в которой мы можем преуспеть [1].
Человек, которому нужно решить задачу о многоруком бандите, должен поэкспериментировать с альтернативами, чтобы определить распределение выигрышей. Эта особенность задач о многоруком бандите создает компромисс между использованием (поиском наилучшей альтернативы) и исследованием (выбором альтернативы, которая на данный момент показала лучшие результаты). Поиск оптимального баланса в компромиссе между исследованием и использованием требует сложных правил и моделей поведения [2].
Глава состоит из двух частей, завершающихся обсуждением важности применения моделей. В первой части описывается особый класс задач о многоруком бандите по Бернулли, в которых каждая альтернатива представляет собой урну Бернулли с неизвестной пропорцией серых и белых шаров. Мы опишем и сопоставим эвристические решения, а затем продемонстрируем, как они могут улучшить сравнительные тесты, касающиеся вариантов медикаментозного лечения, планов рекламных кампаний и методик преподавания. Во второй части представлена более общая модель, в которой распределение вознаграждений может принимать любую форму, а человек, принимающий решение, владеет информацией об априорном распределении по их типам. В этой части главы мы также покажем, как вычислить индекс Гиттинса, который определяет оптимальный выбор.
ЗАДАЧИ О МНОГОРУКОМ БАНДИТЕ ПО БЕРНУЛЛИ
Начнем с подкласса задач о многоруком бандите, в которых каждая альтернатива имеет фиксированную вероятность обеспечения успешного исхода. Этот подкласс эквивалентен выбору одной из множества урн Бернулли, содержащих разное количество серых и белых шаров. Именно поэтому мы называем данный класс задач задачами о многоруком бандите по Бернулли. Еще их называют частотными задачами, поскольку ответственный за принятие решений ничего не знает о распределениях и получает информацию о них по мере исследования альтернатив.
Задачи о многоруком бандите по Бернулли
Каждая из совокупностей альтернатив {A, B, C, D, …, N} имеет неизвестную вероятность обеспечения успешного исхода {pA, pB, pC, pD, …, pN}. В каждом периоде человек, принимающий решение, выбирает альтернативу K и получает успешный исход с вероятностью pK.
Рассмотрим следующий пример. Предположим, у компании по чистке дымоходов есть список телефонных номеров недавних покупателей домов. Компания тестирует три способа сделать коммерческое предложение: запланированная встреча («Здравствуйте! Я звоню, чтобы договориться о времени ежегодной чистки вашего дымохода»), выражение обеспокоенности («Здравствуйте! Знаете ли вы, что грязный дымоход может стать причиной пожара?») и индивидуальный подход («Здравствуйте! Меня зовут Хилди. Мы с отцом основали компанию по чистке дымоходов четырнадцать лет назад»).
Каждое коммерческое предложение имеет неизвестную вероятность успеха. Предположим, компания сначала пробует подход «запланированная встреча» и терпит неудачу. Тогда она переходит ко второму подходу — выражению обеспокоенности — и заполучает клиента. Подход срабатывает и во время следующего звонка, но еще после трех звонков тоже терпитнеудачу. Компания применяет третий подход, который срабатывает во время первого звонка и терпит неудачу в ходе следующих четырех. После десяти звонков второй подход обеспечивает самый высокий процент успеха, однако первый подход применялся только один раз. Человек, принимающий решение, становится перед выбором между использованием (выбором наиболее подходящей альтернативы) и исследованием (возвратом к двум другим альтернативам для получения дополнительной информации). Аналогичную задачу решает больница при выборе одной из хирургических процедур и фармацевтическая компания, тестирующая различные протоколы применения лекарственных препаратов. Каждый протокол имеет неизвестную вероятность успеха.
Для более глубокого понимания компромисса между исследованием и использованием сравним два эвристических алгоритма. Первый — «выборочное исследование, затем жадный выбор» — подразумевает проверку альтернатив фиксированное количество раз M, после чего следует выбор альтернативы с максимальным средним выигрышем. Для того чтобы определить величину M, можно воспользоваться урной Бернулли и правилами квадратного корня. Стандартное отклонение среднего соотношения ограничено сверху величиной 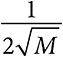 . Если каждая альтернатива тестируется 100 раз, стандартное отклонение среднего соотношения будет равно 5 процентам. Если применить правило двух стандартных отклонений для выявления значимого различия, можно уверенно провести разграничение между соотношениями, отличающимися на 10 процентов. Если одна альтернатива обеспечивает успешный исход в 70 процентах случаев, а другая — в 55 процентах случаев, мы можем с 95-процентной уверенностью утверждать, что первый вариант лучше.
. Если каждая альтернатива тестируется 100 раз, стандартное отклонение среднего соотношения будет равно 5 процентам. Если применить правило двух стандартных отклонений для выявления значимого различия, можно уверенно провести разграничение между соотношениями, отличающимися на 10 процентов. Если одна альтернатива обеспечивает успешный исход в 70 процентах случаев, а другая — в 55 процентах случаев, мы можем с 95-процентной уверенностью утверждать, что первый вариант лучше.
Вторая эвристика — «эвристический алгоритм адаптивного уровня исследования» — выделяет по десять исходных испытаний на каждую альтернативу. Следующие двадцать испытаний распределяются пропорционально доле успешных попыток. Если во время первых десяти испытаний одна альтернатива обеспечивает шесть успешных попыток, а другая только две, то первая альтернатива получит три четверти от следующих двадцати испытаний. Вторая группа из двадцати испытаний тоже может быть распределена в соответствии с отношением квадратов вероятностей успеха. Если успешные попытки продолжатся в тех же пропорциях, лучшая альтернатива получит 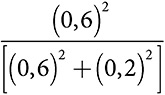 , или 90 процентов третьей группы из двадцати испытаний. В каждой последующей группе из двадцати испытаний можно с определенной скоростью увеличивать показатели степени вероятностей. Увеличивая с течением времени темпы использования, второй алгоритм улучшает первый. Если у одной альтернативы намного выше вероятность успеха по сравнению с другой альтернативой, скажем 80 процентов против 10 процентов, алгоритм не станет тратить сотню испытаний на вторую альтернативу. Однако если обе вероятности имеют близкие значения, алгоритм продолжит экспериментировать [3].
, или 90 процентов третьей группы из двадцати испытаний. В каждой последующей группе из двадцати испытаний можно с определенной скоростью увеличивать показатели степени вероятностей. Увеличивая с течением времени темпы использования, второй алгоритм улучшает первый. Если у одной альтернативы намного выше вероятность успеха по сравнению с другой альтернативой, скажем 80 процентов против 10 процентов, алгоритм не станет тратить сотню испытаний на вторую альтернативу. Однако если обе вероятности имеют близкие значения, алгоритм продолжит экспериментировать [3].
Следование эвристическому алгоритму «выборочное исследование, а затем жадный выбор» не только неэффективно, но порой даже неэтично. Когда Роберт Бартлетт испытывал искусственное легкое, процент его успеха существенно превышал показатель других альтернатив. Продолжение их тестирования, тогда как искусственное легкое демонстрировало наилучшие результаты, привело бы к бессмысленным смертельным исходам. Бартлетт прекратил эксперименты с другими альтернативами. Все пациенты получили искусственное легкое. В действительности это доказывает наличие оптимального правила: если альтернатива неизменно гарантирует требуемый результат, нужно продолжать ее выбирать. Дальнейшие эксперименты могут не иметь никакой ценности, поскольку никакая другая альтернатива не будет эффективнее.
БАЙЕСОВСКИЕ ЗАДАЧИ О МНОГОРУКОМ БАНДИТЕ
В байесовской задаче о многоруком бандите у человека, принимающего решение, есть априорные убеждения в отношении распределения вознаграждений от альтернатив. С их учетом он может количественно оценить компромисс между исследованием и использованием, а также (теоретически) принимать оптимальные решения в каждом периоде. Однако за исключением самых простых задач о многоруком бандите определение оптимального действия требует довольно сложных вычислений. Для решения реальных задач такие точные вычисления могут быть неосуществимы, что вынуждает ответственных за принятие решений лиц полагаться на приближенные оценки.
Байесовские задачи о многоруком бандите
Совокупность альтернатив {A, B, C, D, …, N} имеет соответствующие распределения вознаграждений {f(A), f(B), f(C), f(D), …, f(N)}. У человека, принимающего решение, есть априорные убеждения по каждому распределению. В каждом периоде человек, принимающий решение, выбирает альтернативу, получает вознаграждение и рассчитывает новые убеждения на его основании.
Определение оптимального действия происходит в четыре этапа. Во-первых, мы вычисляем ожидаемое немедленное вознаграждение от каждой альтернативы. Во-вторых, обновляем по каждой альтернативе убеждения в отношении распределения вознаграждений. В-третьих, на основании новых убеждений определяем наилучшие возможные действия во всех последующих периодах с учетом известной информации. И наконец, прибавляем ожидаемое вознаграждение от действия в следующем периоде к ожидаемым вознаграждениям от оптимальных будущих действий. Эта сумма известна как индекс Гиттинса. В каждом периоде оптимальное действие имеет максимальный индекс Гиттинса.
Обратите внимание, что вычисление индекса дает количественную оценку значимости исследования. При испытании той или иной альтернативы индекс Гиттинса не равен ожидаемому вознаграждению. Он равен сумме всех будущих вознаграждений при условии совершения нами оптимальных действий с учетом полученной информации. Вычислить индекс Гиттинса довольно сложно. В качестве относительно простого примера предположим, что существует надежная альтернатива, которая гарантированно обеспечит прибыль в 500 долларов, и рискованная альтернатива, которая с вероятностью 10 процентов всегда приносит 1000 долларов, а в оставшихся 90 процентах случаев не дает никакой прибыли.
Для того чтобы вычислить индекс Гиттинса для рискованной альтернативы, сперва зададимся вопросом, что может происходить: либо она всегда дает прибыль 1000 долларов, либо не дает никакой прибыли. А затем проанализируем, как каждый исход влияет на наши убеждения. Если бы мы узнали, что рискованная альтернатива принесет 1000 долларов, мы бы всегда выбирали ее. Если бы нам стало известно, что она не принесет никакой прибыли, в будущем мы всегда выбирали бы надежную альтернативу.
Таким образом, индекс Гиттинса по рискованной альтернативе соответствует 10 процентам вероятности вознаграждения в размере 1000 долларов в каждом периоде и 90 процентам вероятности вознаграждения в размере 500 долларов в каждом периоде, за исключением первого. В ситуации многократного выбора альтернативы это дает в среднем около 550 долларов за каждый период. Отсюда следует, что рискованная альтернатива — лучший выбор [4].
Индекс Гиттинса: пример
Чтобы продемонстрировать, как вычислить индекс Гиттинса, рассмотрим пример с двумя альтернативами. Альтернатива A обеспечивает определенное вознаграждение из множества {0, 80} с равной вероятностью значений 0 и 80. Альтернатива B обеспечивает определенное вознаграждение из множества с равной вероятностью {0, 60, 120} каждого из этих значений. Предположим, человек, принимающий решение, хочет максимизировать вознаграждение за десять периодов.
Альтернатива A. С вероятностью вознаграждение равно 0, поэтому альтернатива B, имеющая ожидаемое вознаграждение 60, будет выбрана во всех последующих периодах. Это дает ожидаемое вознаграждение 540 (9 × 60). С вероятностью вознаграждение равно 80. Оптимальный выбор во втором периоде даже при таком исходе состоит в выборе альтернативы B. С вероятностью альтернатива B обеспечивает вознаграждение 120, а значит, общий выигрыш составляет 1160 (80 + 9 × 120). С вероятностью альтернатива B дает вознаграждение 60. В этом случае альтернатива A является оптимальным выбором во всех последующих периодах, обеспечивая общее вознаграждение 780 (60 + 9 × 80). И наконец, с вероятностью альтернатива B дает вознаграждение 0. В этом случае альтернатива A также является оптимальным выбором во всех последующих периодах. Общий выигрыш равен 720 (9 × 80).
Объединение всех трех возможностей позволяет сделать вывод, что индекс Гиттинса за первый период по альтернативе A составляет:
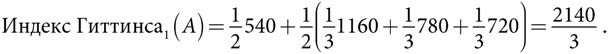
Альтернатива B. С вероятностью вознаграждение равно 120. Если это происходит, оптимальным выбором во всех будущих периодах тоже будет альтернатива B. За десять периодов общее вознаграждение составит 1200. Если вознаграждение равно 0, то оптимальным выбором во всех будущих периодах станет альтернатива A с ожидаемым вознаграждением 40. Ожидаемое общее вознаграждение составит 360 (9 × 40). Если вознаграждение равно 60, то человек, принимающий решение, может выбрать альтернативу B во всех последующих периодах, получив суммарный доход 600. Однако если он выберет альтернативу A во втором периоде, в половине случаев она всегда будет давать вознаграждение 80, благодаря чему суммарный доход составит 780 (60 + 9 × 80). В другой половине случаев эта альтернатива обеспечивает нулевое вознаграждение, поэтому оптимальным выбором во всех последующих периодах будет альтернатива B, обеспечивающая вознаграждение 60, что дает общее вознаграждение 540 (9 × 60). Отсюда следует, что ожидаемое вознаграждение от оптимального выбора после выбора альтернативы A во втором периоде составляет 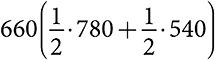 . Объединение всех трех возможностей позволяет сделать вывод, что индекс Гиттинса за первый период по альтернативе B составляет:
. Объединение всех трех возможностей позволяет сделать вывод, что индекс Гиттинса за первый период по альтернативе B составляет:
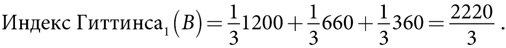
С учетом этих вычислений альтернатива B является оптимальным выбором первого периода. Оптимальный долгосрочный выбор зависит от информации, полученной за первый период. Если альтернатива B обеспечивает исход 120, мы выбираем ее навсегда.
Этот анализ показывает, что при совершении определенного действия нас должна больше интересовать вероятность того, что альтернатива будет лучшей, чем ожидаемое вознаграждение. Кроме того, если альтернатива обеспечивает очень высокое вознаграждение, мы должны с большей вероятностью выбирать ее в будущем. И наоборот, если альтернатива обеспечивает среднее вознаграждение (даже если оно превышает ожидаемое вознаграждение от другой альтернативы), мы можем выбирать ее с меньшей вероятностью. Это особенно актуально в начальных периодах, когда мы ищем альтернативы с высоким вознаграждением. Все эти выводы относятся ко многим областям применения. При условии, что действия не сопряжены с риском или высокими издержками, модель говорит о целесообразности исследования действий с потенциально высоким вознаграждением, даже если они имеют низкую вероятность.
РЕЗЮМЕ
Главный вывод из этой книги состоит в том, что модели помогают человеку принимать более взвешенные решения. Мы можем в этом убедиться, сравнив то, что людям следует делать для решения задачи о многоруком бандите, с тем, что они делают на самом деле. Сталкиваясь с задачей о многоруком бандите, большинство людей даже не пытаются оценить индекс Гиттинса. Отчасти так происходит потому, что они не хранят данные. Например, только недавно врачи начали вести учет эффективности многих процедур, в частности эффективности разных типов искусственных суставов или, скажем, преимуществ стентирования. Без таких данных врач не в состоянии определить, какое действие обеспечивает максимальный ожидаемый выигрыш.
Для практического применения уроков, извлеченных из модели, врачам, так же как и остальным людям, необходимы данные. Следовательно, если вы хотите узнать, улучшают ли сон прогулки до или после ужина, вам нужно отслеживать, как хорошо вы спали. Затем с помощью сложного эвристического алгоритма вы могли бы определить, какие именно прогулки дают наилучший результат. На первый взгляд может показаться, что это потребует много усилий. Действительно, так и есть, но сегодня выполнять эту задачу гораздо легче. Новые технологии позволяют собирать данные о режиме сна, частоте сердечных сокращений и даже о настроении.
Безусловно, большинство из нас не станут собирать данные и вычислять индекс Гиттинса для принятия жизненно важных решений — например, когда следует заниматься физической активностью. Вопрос лишь в том, что мы могли бы это делать, а если бы действительно делали, то увидели бы улучшения в жизненно важных сферах, например в режиме сна и общем состоянии здоровья. Психолог Сет Робертс изучал себя на протяжении двенадцати лет и выяснил, что если он не менее восьми часов в день находился в положении стоя, это улучшает его сон (хотя он начал спать меньше), и что пребывание в положении стоя на утреннем солнце снижает его подверженность респираторным заболеваниям верхних дыхательных путей [5]. Возможно, у нас нет подобной склонности к экспериментам над собой, однако без ведения учета и сравнения результатов мы можем пропускать завтрак, тогда как нам было бы лучше, если бы мы с утра съели грейпфрут.
При принятии крайне важных решений в области бизнеса, политики и медицины, где данные собирать легче, модели многорукого бандита применяются очень широко. Компании, творцы политики и некоммерческие организации экспериментируют с альтернативами, а затем используют наиболее результативные из них. На практике альтернативы не всегда остаются неизменными. Правительственная рассылка с призывом активнее участвовать в программе субсидирования фермерских хозяйств может меняться из года в год — например, вместо фотографии мужчины может быть использована фотография женщины [6]. Непрерывное экспериментирование такого типа описывают модели пересеченного ландшафта, представленные в следующей главе.
Президентские выборы
Теперь мы используем три модели для анализа результатов президентских выборов: пространственную модель, модель категоризации и модель многорукого бандита.
Пространственная модель. Для того чтобы привлечь избирателей, кандидаты ведут борьбу в области идеологии. Следовательно, мы должны ожидать, что кандидаты будут склоняться к умеренным позициям, что во время выборов у них будут примерно равные шансы на победу и что победившие партии образуют случайную последовательность. На президентских выборах, за редким исключением, имеет место почти равное распределение голосов между кандидатами. Чтобы проверить, образуют ли партии случайную последовательность, сначала составим временной ряд из тридцати восьми победивших партий за период с 1868 по 2016 год.
RRRRDRDRRRRDDRRRDDDDDRRDDRRDRRRDDRRDDR
Затем мы можем оценить блочную энтропию подпоследовательностей разной длины. Подпоследовательности длиной 1 имеют энтропию 0,98. Подпоследовательности длиной 4 — 3,61. Статистические тесты показывают, что мы не можем опровергнуть случайный характер последовательности. Для сравнения: случайная последовательность длиной 38 имела бы блочную энтропию с блоком размером 1, значение которой равно 1,0, а с блоком размером 4 — 3,58.
Модель категоризации. Если представить каждое состояние как категорию и предположить однородный характер всех состояний, пространственная модель указывает на то, что как только кандидаты выберут исходные позиции, некоторые состояния не будут конкурентными. Данная модель прогнозирует ожесточенную борьбу по ряду умеренных состояний. В 2012 году Обама и Ромни потратили 96 процентов своего бюджета на телевизионную рекламу в десяти штатах. Каждый из них потратил почти половину рекламного бюджета в трех умеренных штатах, таких как Флорида, Вирджиния и Огайо. В 2016 году Клинтон и Трамп также потратили более половины денег на телерекламу в трех умеренных штатах, а именно во Флориде, Огайо и Северной Каролине [7].
Модель многорукого бандита (ретроспективное голосование). Избиратели с большей вероятностью переизберут ту партию, которая демонстрирует хорошие результаты. Голосование за эффективные партии равносильно попыткам потянуть за рычаг, генерирующий высокий выигрыш. Сильная экономика должна быть на руку правящей партии. Фактические данные показывают, что избиратели с большей вероятностью переизберут партию власти, если экономика работает хорошо. Этот эффект носит более выраженный характер для действующего кандидата, чем для кандидата от партии власти, который пока не занимает никакой должности [8].
ГЛАВА 28
МОДЕЛИ ПЕРЕСЕЧЕННОГО ЛАНДШАФТА
Нечто удивительное найдет тот, кто даст себе труд отправиться на поиски.
Высказывание приписывается Сакагавее46
В этой главе мы изучим модель пересеченного ландшафта. Подобно пространственной и гедонической модели, она определяет объект как набор характеристик (атрибутов). Каждый такой набор отражает определенную ценность. Задача состоит в том, чтобы изменить характеристики для создания объекта с максимальной ценностью. Модель изначально разрабатывалась в области экологии для изучения эволюции. Сегодня она также успешно применяется для изучения процесса решения задач, конкурентной борьбы между компаниями и инновационной деятельности. Именно на этом мы здесь и сосредоточимся. Мы используем эту модель, чтобы показать, как взаимосвязь между воздействием различных атрибутов затрудняет процесс инноваций и порождает зависимость от первоначально выбранного пути в найденных решениях, а также приводит к большему разнообразию решений. Кроме того, мы также увидим, что рост разнообразных подходов к решению задач позволяет решать более сложные задачи.
Глава состоит из трех частей, за которыми следует обсуждение того, как расширить модель для описания конкуренции. В первой части мы опишем экологическую модель адаптивного ландшафта и покажем, как мы можем интерпретировать его как модель для решения проблем и инноваций. Во второй части обсудим последствия жесткости в одномерной модели, а в третьей представим NK-модель пересеченных ландшафтов, которая расширяет одномерную модель до произвольного количества бинарных измерений.
АДАПТИВНЫЙ ЛАНДШАФТ
Согласно модели адаптивного ландшафта47 у биологических видов есть признаки или качества, способствующие повышению их приспособленности, условно определяемой как их репродуктивный потенциал. Кроме того, отдельные члены популяции отличаются друг от друга по степени наличия того или иного признака. Нанеся значения величины признака по горизонтальной оси, а приспособленность видов по вертикальной оси, мы получим график, известный как адаптивный ландшафт, на котором возвышенности соответствуют высокому уровню приспособленности.
Для построения графика адаптивного ландшафта, в котором в качестве признака выступает хвост койота, мы оставим все характеристики койота прежними и изменим только длину хвоста, и измерим ее воздействие на приспособленность. Для построения графика нам нужно знать, как хвост влияет на приспособленность. Предположим, он помогает койоту сохранять равновесие во время прыжка, а также подает сигнал о радости, страхе или агрессии. Слева на горизонтальной оси отобразим длину хвоста, равную нулю. Такой хвост не может выполнять ни одной функции, а значит, соответствует нулевому уровню приспособленности. По мере увеличения длины хвоста функции сохранения равновесия и сигнализирования улучшаются. Следовательно, уровень приспособленности повышается вместе с ростом хвоста. В какой-то момент, скажем после достижения 45-сантиметровой длины, хвост будем иметь идеальный размер для сохранения баланса. Если хвост станет еще длиннее, койот будет менее подвижным. Более длинные хвосты по-прежнему могут увеличивать свою ценность с точки зрения сигнализирования, поэтому хвост длиной пятьдесят сантиметров обеспечит максимальную приспособленность. Но как только хвост станет еще длиннее, уровень приспособленности снизится. Полученный в итоге график (рис. 28.1) имеет один пик.
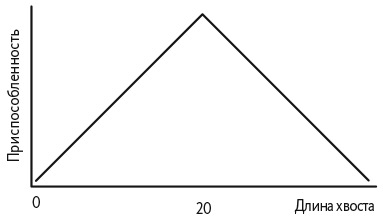
Рис. 28.1. Ландшафт «Гора Фудзияма»
Такой ландшафт образно называют «Гора Фудзияма», и он часто встречается в реальном мире. Задачи типа «Гора Фудзияма» считаются легкими. Мы полагаем, что процесс эволюции или обучения непременно найдет вершину, столкнувшись с ней. Представьте популяцию койотов с хвостами разной длины. Давление отбора приведет к тому, что длина хвостов у койотов будет около пятидесяти сантиметров. У койотов с хвостами такой длины оптимальное соотношение способности к сохранению баланса и сигнализированию. У них самый высокий уровень приспособленности и они производят больше всего потомства, а значит, численность койотов с пятидесятисантиметровыми хвостами растет. Если представить эту ситуацию как задачу оптимизации, мы увидим, что любой алгоритм восхождения обнаружит вершину.
Воспользуемся принципом применения одной модели во многих областях и интерпретируем эту ситуацию как задачу разработки некоторого продукта, конкретно — проектирования угольной лопаты. Допустим, мы уже определились с длиной черенка и формой полотна лопаты. Нам остается только решить, насколько большим должно быть полотно. Площадь полотна лопаты будет выступать в качестве признака, отображенного на горизонтальной оси. На вертикальной оси мы отметим, сколько угля рабочий может перебросить лопатой за один час при соответствующей площади полотна.
Как и в предыдущем случае, начнем с крайнего левого значения, которое соответствует лопате с нулевой площадью полотна. Технический термин для обозначения такой лопаты — «палка». Палка непригодна для перебрасывания угля, а значит, имеет нулевую ценность. По мере увеличения площади полотна (скажем, до размера чайной ложки, затем столовой, а потом игрушечной лопатки) лопата становится все более эффективной. График уровня приспособленности лопаты повышается. В какой-то момент площадь полотна становится достаточно большой. Поднять такую лопату очень трудно, поэтому количество угля, переброшенного рабочим за один час, уменьшается по мере увеличения площади полотна лопаты. Когда полотно становится слишком большим, никто не в состоянии поднять лопату, и ее уровень приспособленности снижается до нуля. Мы снова имеем ландшафт «Гора Фудзияма» и тоже можем рассчитывать найти пик, то есть идеальную площадь полотна для лопаты.
Идею построения графика эффективности лопат в зависимости от площади полотна для определения оптимальной конструкции лопаты предложил Фредерик Тейлор. В 1890-х годах Тейлор и другие предприниматели открыли эпоху научной организации труда, в которой решение производственных вопросов (как быстро должен двигаться сборочный конвейер, насколько прочным должен быть сварной шов, сколько перерывов предоставлять рабочим) моделировалось в виде задач пересеченного ландшафта. Многие великие промышленники XX столетия, в том числе Генри Форд, Джон Рокфеллер и Эндрю Карнеги, внесли свой вклад в движение за повышение эффективности, или то, что сейчас принято называть тейлоризмом.
Переход от ремесленного изготовления единичных уникальных продуктов к серийному производству, в котором процессы разбивались на операции с оптимизацией каждой, а затем формировалась стандартная последовательность действий, привел как к повышению эффективности, так и, по мнению многих, к дегуманизации труда. Здесь уместно напомнить о необходимости применения множества моделей. Любая отдельно взятая модель упрощает мир и выделяет только некоторые его аспекты. Модели научной организации труда фокусировались на эффективности процессов, что вызвало волну критики в их адрес. Принятие решений на основе эффективности производства отодвинуло другие задачи, такие как счастье и благосостояние рабочих, на второй план.
Модель ландшафта может показаться довольно очевидной идеей: отобразить на графике уровень приспособленности, эффективности или ценности той или иной характеристики как функцию признака или характеристики, а затем подняться на вершину, чтобы найти оптимальную величину соответствующего признака. Представление решения задачи в виде восхождения на вершину может показаться не более чем метафорой. Обоснованность этих критических замечаний не вызывает сомнений. Тем не менее построение формальной модели ландшафта позволяет сделать нетривиальные выводы.
ПЕРЕСЕЧЕННЫЕ ЛАНДШАФТЫ
Когда мы допускаем взаимодействие между множеством характеристик и связь влияния одной характеристики с влиянием других характеристик, мы создаем пересеченный ландшафт — иными словами, ландшафт со множеством вершин. Рассмотрим процесс проектирования дивана, в ходе которого нам предстоит выбрать толщину подушек и ширину подлокотников. Допустим, ценность проекта равна ожидаемому объему продаж дивана на рынке, который зависит от эстетического качества. Если у дивана толстые подушки, то широкие подлокотники могут создавать более привлекательный эстетический вид. Если подушки тонкие, то идеальный диван может иметь узкие подлокотники. Двумерный график ожидаемого объема продаж как функции ширины подлокотников и толщины подушек будет иметь две вершины. Одна соответствует дивану с узкими подлокотниками и тонкими подушками, а другая — версии с широкими подлокотниками и толстыми подушками.
Взаимозависимость эффектов переменных создает пересеченность ландшафта, имеющую ряд последствий. Во-первых, разные подходы к поиску самой высокой точки на пересеченном ландшафте позволяют обнаружить разные вершины. То же самое можно сказать и о разных исходных точках. Следовательно, пересеченность ландшафта порождает чувствительность к исходным условиям и возможность зависимости от первоначально выбранного пути. В каждом из этих случаев пересеченность ландшафта вносит свой вклад в многообразие исходов. Кроме того, пересеченность подразумевает вероятность субоптимальных результатов, представленных в виде локальных вершин на ландшафте.
На рис. 28.2 показан пересеченный ландшафт с пятью вершинами. Четыре из них — локальные вершины (точки, для которых все соседние точки имеют более низкую ценность) и одна глобальная вершина (точка с самой высокой ценностью). Для того чтобы понять, как поиск может привести к обнаружению локальной вершины, которая зависит от исходной точки, представьте, что вы начинаете с одной из точек, а затем поднимаетесь вверх. Такой подход известен как градиентный эвристический алгоритм, или алгоритм восхождения к вершине. На пересеченном ландшафте он останавливается в локальной вершине.
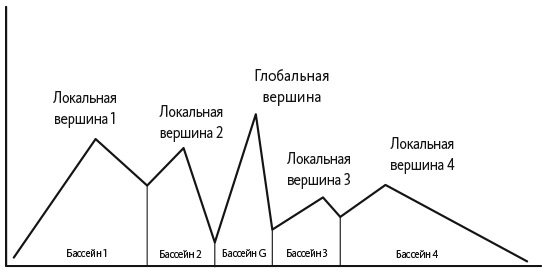
Рис. 28.2. Пересеченный ландшафт с пятью вершинами
Если отправная точка находится в крайнем левом конце, градиентный эвристический алгоритм обнаружит вершину 1, которая не является оптимальной. Если градиентный эвристический алгоритм начинается в области, обозначенной на рис. 28.2 как «Бассейн 2», то он обнаружит локальную вершину 2. У каждой из оставшихся вершин, включая глобальную вершину, есть своя область; если градиентный эвристический алгоритм начинается в одной из таких областей, он обнаружит соответствующую вершину. Эти области, представленные на рис. 28.2, обозначаются термином «бассейн притяжения». У глобальной вершины самый маленький бассейн притяжения. Если бы мы выбрали случайную отправную точку и применили градиентный эвристический алгоритм, вероятность обнаружения глобальной вершины была бы самой низкой.
Бассейны притяжения зависят от эвристического алгоритма: разные эвристики могут порождать разные бассейны. Рассмотрим, например, алгоритм «перемещаться направо», который подразумевает перемещение вправо до тех пор, пока не будет найдена локальная вершина. Эта эвристика дает те же локальные вершины, что и градиентный эвристический алгоритм, но у них другие бассейны притяжения, что можно увидеть, сопоставив рис. 28.2 с рис. 28.3.
Рис. 28.3. Бассейны притяжения, образованные эвристическим алгоритмом «перемещаться направо»
Для того чтобы найти оптимальную или почти оптимальную вершину на пересеченном ландшафте, необходимо либо многообразие, либо сложность. Ценность разнообразия должна быть очевидной. Если различные эвристические алгоритмы обнаруживают разные вершины, то применение множества разноплановых эвристических алгоритмов к решению задачи приведет к получению множества разноплановых локальных вершин, из которых можно выбрать лучшую [1]. Аналогичный результат можно получить в случае применения одного и того же эвристического алгоритма из разных отправных точек: будут найдены различные локальные оптимумы, из которых можно выбрать лучший.
Отметим также, что пересеченность ландшафта, выраженная в количестве вершин, соотносится с уровнем сложности задачи. Тем не менее решить задачу бывает непросто даже при отсутствии пересеченного ландшафта. Задачу о поиске золотой монеты на кукурузном поле можно представить в виде плоского ландшафта с одной вершиной в месте расположения монеты. Такой ландшафт не будет пересеченным, но найти на нем монету нелегко.
МОДЕЛЬ NK
Далее мы представим модель NK, впервые описанную Стюартом Кауфманом, которая позволяет формализовать связь между взаимодействиями и пересеченностью [2]. Модель описывает объекты (или то, что можно назвать альтернативными решениями) в виде бинарной строки длиной N. Ценность объекта равна сумме вкладов всех битов строки. Член K модели обозначает количество других битов, взаимодействующих с каждым битом для определения его ценности. Если значение K равно нулю, функция ценности является линейной. Если значение K равно N − 1, то каждый бит взаимодействует со всеми остальными битами, а ценность всей строки носит случайный характер. Таким образом, мы можем представить увеличение значения K в качестве настройки пересеченности ландшафта в диапазоне от «Горы Фудзияма» до хаотичности.
Модель NK
Объект состоит из N битов, s∈{0, 1}N.
Ценность объекта равна
V(s) = Vk1(s1,{s1k})+Vk2(s2,{s2k})+…+Vk2(s2,{s2k}),
где {s1k} равно случайно выбранному множеству k битов, отличных от i, а Vk1(s1{s1k}) — это случайное число из интервала [0,1].
K = 0: образует линейную зависимость битов.
K = N − 1: любое изменение бита порождает новый случайный вклад от каждого бита.
Концептуальная схема NK-модели — превосходное пространство для исследования идей и постановки вопросов. Первый вопрос, который следует задать: как число локальных оптимумов зависит от количества эффектов взаимодействия? Затем необходимо спросить: как высота глобального оптимума зависит от количества эффектов взаимодействия? На этом этапе оба вопроса некорректны, поскольку мы еще не определили, как будем осуществлять поиск в данном пространстве возможностей, то есть какой эвристический алгоритм будем использовать. Вспомните, что множество вершин зависит от выбора эвристики.
В представленном ниже примере мы будем использовать алгоритм одиночного изменения состояния.48 Он выбирает каждую характеристику по очереди и переводит ее в новое состояние. Если изменение характеристики приводит к повышению ценности, такой переход принимается, в противном случае характеристика возвращается в исходное состояние. Выбор этого алгоритма объясняется двумя причинами. Его можно интерпретировать как грубую модель генетической мутации, в ходе которой хорошие аллели генов занимают доминирующее положение в популяции, а плохие отмирают. Кроме того, это самый естественный способ представить алгоритм восхождения к вершине в данном пространстве.
Сначала проанализируем модель NK при N = 20 и K = 0. Когда K = 0, вклад каждой характеристики в совокупную ценность не зависит от других характеристик. Алгоритм одиночного изменения состояния позволяет определить более подходящее состояние каждой характеристики, а также найти глобальный оптимум. Следовательно, K = 0 (отсутствие взаимодействий) соответствует ландшафту «Гора Фудзияма». Значения ценности каждого состояния равномерно распределены в интервале [0,1]. Можно доказать, что более высокое из двух значений, случайно выбранных из равномерного распределения, имеет ожидаемую ценность . Если мы вычислим среднее значение вкладов по всем двадцати характеристикам, глобальный оптимум тоже будет иметь ожидаемую ценность .
На другом конце спектра (N = K − 1) каждая характеристика связана со всеми остальными характеристиками. При переходе одной из характеристик в новое состояние вклад остальных характеристик меняется. Это будет новое случайное число, взятое из интервала [0,1]. Ценность объекта равна сумме этих двадцати случайных чисел (по одному на каждую характеристику). Это означает, что каждое изменение характеристики создает ценность для всего объекта, не связанную с предыдущей ценностью. Следовательно, ландшафт будет чрезвычайно пересеченным — в любой точке восхождение столь же вероятно, как и спуск.
Применив эти знания, мы можем определить ожидаемое количество локальных вершин. Если начать с любой альтернативы, алгоритм одиночного изменения состояния сравнивает ее с каждой из N альтернатив. Например, если начать с альтернативы, в которой все биты принимают нулевое значение, алгоритм вычислит N альтернатив, в которых в точности один бит принимает нулевое значение.
Исходная альтернатива | 00000000000000000000 |
Изменение состояния характеристики 1 | 10000000000000000000 |
Изменение состояния характеристики 2 | 01000000000000000000 |
… | |
Изменение состояния характеристики 20 | 00000000000000000001 |
У локальной вершины должна быть более высокая ценность, чем у каждой из N альтернатив. Вероятность того, что исходная альтернатива имеет самую большую ценность, равна . Следовательно, количество локальных вершин примерно равно количеству возможных альтернатив 2N, деленному на N. При N = 20 эти вычисления дают пятьдесят тысяч локальных вершин. При таком большом количестве локальных оптимумов алгоритм одиночного изменения состояния редко обнаруживает глобальную вершину.
Актуальный вопрос заключается не в количестве локальных оптимумов, а в том, какова их ценность. Остается только сравнить ожидаемую среднюю ценность локальных оптимумов с ожидаемой ценностью глобального оптимума. Такое сравнение позволит определить, насколько эффективен алгоритм одиночного изменения состояния. Для вычисления этих значений ценности можно использовать центральную предельную теорему. Нетрудно доказать, что ожидаемая ценность локального оптимума равна примерно 0,6, тогда как ожидаемая ценность глобального оптимума составляет чуть более 0,75 [3]. Сравнение этих показателей с глобальным оптимумом для случая K = 0, который равен , указывает на то, что локальные вершины на пересеченном ландшафте имеют более низкую ценность, чем в случае ландшафта «Гора Фудзияма», но глобальная вершина имеет более высокую ценность.
Возникает вопрос, что происходит между этими двумя крайними вариантами при увеличении количества взаимодействий характеристик K от нуля до N − 1. Ответ: имеют место оба эффекта. Увеличение количества взаимодействий порождает более высокую глобальную вершину, но и большее количество (а значит, и более низкую ценность) локальных вершин. Если исходить из того, что поиск осуществляется с помощью алгоритма одиночного изменения состояния, численное исследование данной модели показывает, что при малых значениях K выгода от взаимодействий (более высокая глобальная вершина) превосходит увеличение количества локальных вершин. Таким образом, на начальном этапе ожидаемая ценность локальной вершины увеличивается на K. Возрастающая численность локальных вершин означает, что средняя ценность будет сокращаться. Следовательно, используя только алгоритм одиночного изменения состояния, мы бы предпочли сравнительно небольшое значение K, скажем 3 или 4. Но зачем нам ограничиваться применением только этой простой эвристики изменения всего одной характеристики? Эволюция посредством мутации может быть ею ограничена, но мы — нет. Мы можем изменить состояние двух или даже трех характеристик. Более сложный алгоритм сократит количество локальных оптимумов.
ПЕРЕСЕЧЕННОСТЬ И ТАНЦУЮЩИЕ ЛАНДШАФТЫ
Модель NK подразумевает, что нам нужна средняя степень взаимозависимости, поскольку это приводит к созданию более высоких вершин. Многомодельное мышление требует, чтобы мы отошли от предположений NK-модели и проанализировали логику, обеспечивающую этот результат. Мы считаем, что эта логика состоит из двух частей. Первая опирается на комбинаторику: количество пар комбинаций увеличивается прямо пропорционально квадрату количества пар и кубу количества троек. Следовательно, взаимозависимые эффекты создают больше возможностей для благоприятных взаимодействий. Вторая часть логики основывается на том, что нам просто нужно сохранять более подходящие комбинации. Представьте, что мы взяли четыре любых продукта, чтобы приготовить легкую закуску. Четыре продукта подразумевают шесть возможных комбинаций из двух продуктов. Предположим, мы сформировали следующее множество из четырех продуктов: {маринованные огурцы, бананы, курица, карамель}. Из полученных в итоге шести пар (бананы и огурцы, огурцы и курица, карамель и огурцы, бананы и курица, карамель и бананы, карамель и курица) только одно сочетание кажется сколь-нибудь привлекательным. Нам следует выбрать именно этот вариант. Мы отдаем предпочтение бананам с карамелью и отбрасываем все остальное [4].
Аналогичная логика применима кэволюционным системам. Фенотипические комбинации, порождающие положительное взаимодействие (твердый панцирь и крепкие конечности), сохраняются в популяции, тогда как выживание наиболее приспособленных особей действует против комбинаций, порождающих отрицательное взаимодействие. Имеется не так уж много медленно передвигающихся, привлекательных животных с ярким окрасом. Если они вообще когда-либо существовали, их поймали и съели.
Мы сталкивались с аналогичной проблемой в модели поиска. При наличии большого множества возможных вариантов мы предпочитаем вариации. Аналогичная логика применима и здесь: сочетание пар (и троек) создает множество возможностей. И мы бы предпочли, чтобы этому множеству возможных вариантов была свойственна значительная вариация ценности. В таком случае повышается вероятность того, что один из этих вариантов будет иметь очень высокую ценность. С учетом того, что взаимозависимые эффекты повышают вариацию, в целом они полезны, но только до определенного уровня. Как мы уже видели, слишком большое число взаимодействий делает ландшафт хаотичным. Идеальным было бы умеренное количество взаимодействий. Некоторые утверждают, что если количество и величина взаимодействий могут развиваться или адаптироваться, то системы должны естественным образом эволюционировать до пересеченного ландшафта с высокими вершинами. Это позволяет предположить, что системы тяготеют к сложности, а не к равновесию или хаотичности [5]. Верно ли это, и если да, то в каких случаях, — именно тот вопрос, который было бы интересно исследовать с помощью моделей.
И последний момент: мы воспринимали ландшафт как нечто неизменное. В экологических и социальных системах ландшафт, с которым сталкивается биологический вид или компания, зависит от действий и характеристик других видов и компаний. Адаптация конкурирующего вида или изменение стратегии другой компании преобразует и по-новому упорядочивает адаптивные ландшафты конкурентов. В таком случае мы можем интерпретировать рассмотренные ранее модели пространственной и гедонической конкуренции как движения танцующих ландшафтов. Эти движения могут привести к равновесию, в котором каждый игрок находится на локальной или глобальной вершине, или конкуренция на танцующем ландшафте может обусловить сложные схемы действий и исходов. Даже беглый взгляд на экосистемы, политику и экономику указывает на то, что чаще бывает второе. Одна из причин, почему мы наблюдаем такой высокий уровень сложности, вполне может заключаться в том, что наш мир состоит из адаптивных и целеустремленных акторов, маневрирующих на танцующих ландшафтах. Для того чтобы осмыслить эту сложность, нам понадобится множество моделей.
Следует ли патентовать знания?
Наше благополучие основано на накопленных на протяжении веков знаниях, к числу которых относятся законы физики, двигатель внутреннего сгорания, двойная запись в бухгалтерском учете, микробная теория заболеваний, рентгеновское излучение и HTML. Во многих случаях знания являются общественным благом и всегда носят неконкурентный характер. Они могут быть или не быть исключаемыми. Исключение требует проверки, которую легче выполнить, когда знания включены в материальный артефакт. Проверка того, что кто-то использовал алгоритм или метод для решения задачи, может оказаться невыполнимой. А вот проверить, что кто-то встроил этот алгоритм в компьютерную программу, вполне реально.
Когда знания могут быть исключаемыми, это ставит нас перед выбором. Мы можем обращаться с ними так же, как с дорогами и национальной обороной, и облагать людей налогом для финансирования создания знаний. Правительства платят людям за то, чтобы они размышляли, путем предоставления грантов, а также косвенным образом, поддерживая университеты. Кроме того, правительства предоставляют людям право патентовать знания. Патент создает стимул генерировать знания, обеспечивая период исключительных прав на их использование и взимание платы за их использование другими людьми. В США и Европе патенты действительны на протяжении двадцати лет с момента подачи заявки [6]. Сторонники патентов утверждают, что у физических лиц не было бы стимула тратить годы на разработку более эффективной мышеловки, компьютерного алгоритма или акустической системы, если бы их открытиями мог бесплатно воспользоваться любой желающий. По их мнению, патенты решают проблему стимулирования, присущую созданию знаний.
Мишель Болдрин и Дэвид Ливайн49 приводят аргументы против патентов, воспользовавшись идеями из ряда моделей [7]. В моделях, в которых возможно сочетание идей, патенты, по их мнению, могут препятствовать инновациям, ограничивая количество рекомбинаций. Патент одной компании на технологию сенсорных экранов может сократить количество других компаний, разрабатывающих новые продукты с использованием этой технологии. При отсутствии патентной защиты эту технологию можно было бы включить в большее количество продуктов, что активизировало бы процесс инноваций.
Приверженцы патентов возражают против этой точки зрения, отмечая, что хотя замедление процесса инноваций действительно может оказывать негативное воздействие, без патентов сокращение инвестиций было бы гораздо масштабнее. Для того чтобы опровергнуть это утверждение, Болдрин и Ливайн применяют логику, частично выстроенную на модели диффузии. Полезный продукт, основанный на новых знаниях, быстро распространится среди покупателей. Так было с радио, телевидением, поисковой системой Google и социальной сетью Facebook. Это создает преимущество первого хода. Инноватор все же может извлечь выгоду из идеи, но только если сделает что-то с ее помощью. В случае патента изобретатель ждет, пока патентообладатель реализует идею и получит прибыль.
Болдрин и Ливайн также задаются вопросом, в чем вообще заслуга изобретателя. Если бы важные открытия были продуктом гения-одиночки и идеи в большинстве своем не возникали без стимулов, то доводы в пользу патентов имели бы под собой более веские основания. Однако модель пересеченного ландшафта свидетельствует о том, что сложные задачи могут иметь множество приемлемых решений. Новые изобретения, особенно объединяющие в себе существующие идеи и технологии, такие как автомобиль, телефон и интернет-аукционы, могут быть продуктом естественного развития событий, а не результатом усилий гения. Сколь угодно много людей могли бы предложить подобные инновации, учитывая, что такого рода идеи витают вокруг сообщества мыслителей. Правильность этого вывода подтверждает синхронность многих крупных открытий, таких как дифференциальное исчисление (Исаак Ньютон и Готфрид Вильгельм Лейбниц), телефон (Александр Грейам Белл и Илайша Грей) или теория эволюции путем естественного отбора (Чарльз Дарвин и Альфред Рассел Уоллес). В целом многомодельное мышление демонстрирует преимущества и недостатки патентов. Более глубокое, детальное понимание моделей позволяет привести аргументы в пользу более гибкой патентной политики. Возможно, определенный вид идей (те, которые могут возникнуть у многих людей и сочетаемы с другими идеями) следует защищать патентами иного типа и с другим сроком действия или вообще запретить их патентовать.
ГЛАВА 29
ОПИОИДЫ, НЕРАВЕНСТВО И СМИРЕНИЕ
Все сложно; если бы это было не так, жизнь, поэзия и все остальное было бы скучным.
Уоллес Стивенс
Итак, мы успешно добрались до заключительной главы, в которой применим многомодельное мышление к анализу двух важных политических проблем — эпидемии опиоидов и экономического неравенства. Мы покажем, как использование нескольких моделей помогает лучше их осмыслить и объяснить, почему обе так трудно поддаются решению. Мы также попробуем разобраться, как (особенно в случае опиоидов) эксперты могли бы использовать многомодельный подход, чтобы предвидеть кризис до его наступления. Наш анализ эпидемии опиоидов носит поверхностный характер и служит только в качестве эталонной схемы применения многомодельного подхода в процессе анализа предложенного курса действий или мероприятия. Мы не собираем данные и не калибруем модели, а, скорее, применяем их на качественном уровне, чтобы глубже вникнуть в суть происходящего.
Однако наш анализ экономического неравенства более детальный и теснее связан с академической литературой. Он представляет другую сторону многомодельного мышления, где мы активно задействуем широкий круг моделей. В обоих случаях многомодельное мышление делает нас осведомленнее и мудрее. Глава заканчивается кратким рассуждением о необходимости смирения. Модели могут сделать нас мудрее, но сложные системы по определению трудно прогнозировать и осмысливать, а значит, ошибки неизбежны. Но мы можем учиться на них, чтобы стать еще мудрее.
МНОГОМОДЕЛЬНОЕ МЫШЛЕНИЕ И ЭПИДЕМИЯ ОПИОИДОВ
Для того чтобы вы могли составить представление о масштабе эпидемии опиоидов, приведем некоторые данные. Согласно одной из оценок, в 2015 году в штате Массачусетс более 4 процентов населения старше 11 лет страдали расстройством, связанным с употреблением опиоидов. В 2016 году в масштабах страны врачи выписали более 200 миллионов рецептов на опиоиды, от 10 до 12 миллионов человек злоупотребляли опиоидами, более чем двум миллионам человек был поставлен диагноз «расстройство, связанное с употреблением опиоидов», и более 30 000 человек умерли от связанных с опиоидами причин.
Основная причина выдачи такого количества рецептов состояла в эффективности опиоидных препаратов: они облегчают боль. Учитывая, что 100 миллионов американцев испытывают хроническую боль, у опиоидов был огромный потенциальный рынок. Безусловно, опасность возникновения зависимости от опиоидов существовала. Для того чтобы понять, как опиоиды были одобрены и как возникла эпидемия, мы используем четыре модели для получения важных интуитивных выводов относительно того, как разразился кризис.
Первая модель, модель многорукого бандита, объясняет, почему опиоиды были одобрены к применению. При получении разрешения на лекарственный препарат фармацевтическая компания проводит клинические испытания, чтобы продемонстрировать эффективность препарата и отсутствие вредных побочных эффектов. Мы можем смоделировать клинические испытания в виде задачи о многоруком бандите, в которой одна рука соответствует назначению нового лекарства, а другая — назначению плацебо или существующего лекарства.
Модель утверждения опиоидных препаратов
Модель многорукого бандита
Для того чтобы продемонстрировать их эффективность, опиоиды тестировали в сравнении с плацебо. В ходе клинических испытаний пациентам в произвольном порядке давали либо опиоиды, либо плацебо. Назначение опиоидов можно смоделировать как одну руку двурукого бандита, а плацебо — как другую. В конце курса лечения каждое клиническое испытание классифицируется как успех или неудача. Клинические испытания показали, что пациенты, принимавшие опиоиды, испытывали статистически значимое облегчение боли. По результатам испытаний с участием пациентов, которые перенесли замену тазобедренного сустава, стоматологическую операцию и противоопухолевую терапию, было установлено, что опиоиды гораздо эффективнее плацебо.
В случае любого лекарственного препарата вероятность привыкания вызывает беспокойство. Испытания показали, что в зависимость от опиоидов попало немного пациентов (менее одного процента), что позволило одобрить препараты. Однако испытания не учли того, что врачи будут выписывать рецепты на более длительный срок, иногда на месяц. Чем дольше человек принимает опиоиды, тем выше вероятность развития зависимости. Фактический уровень зависимости от опиоидов превысил 2,5 процента для пациентов, принимавших препараты более длительное время. Представленная во врезке модель Маркова показывает, как повышение уровня с 1 до 2,5 процента может впятеро увеличить равновесное количество пациентов, попавших в зависимость от опиоидов.
Модель перехода к зависимости
Модель Маркова
Модель Маркова, включающая три состояния, выявляет нелинейную связь между переходом к зависимости и общим уровнем зависимости. В модели представлены такие состояния: отсутствие боли, прием опиоидов и зависимость. Мы оцениваем вероятность переходов между состояниями, которые представлены стрелками. Модель слева исходит из того, что 1 процент людей, принимающих опиоиды, попадают в зависимость, и что 10 процентов попавших в зависимость возвращаются в состояние отсутствия боли. Кроме того, модель предполагает, что 20 процентов людей, не испытывающих боли, начинают употреблять опиоиды. В случае равновесия только 2,2 процента членов совокупности становятся зависимыми. Для того чтобы учесть выписку рецептов на более длительный период, модель слева исходит из того, что 2,5 процента людей, принимающих опиоиды, попадают в зависимость, а 5 процентов попавших в зависимость возвращаются в состояние отсутствия боли. Модель также предполагает, что 20 процентов людей, не испытывающих боли, начинают употреблять опиоиды. При таких предположениях в случае равновесия в зависимость от опиоидов попадут 10 процентов членов совокупности [1].
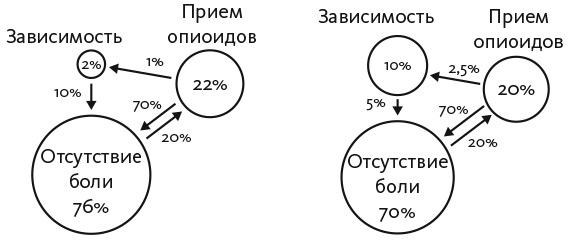
Вероятности перехода из одного состояния в другое только приближенно откалиброваны с учетом данных. Мы используем эту модель для получения интуитивного представления о том, как относительно небольшой уровень зависимости может привести к существенному увеличению количества зависимых людей. Поэкспериментировав с моделью, мы обнаружим, что при снижении вероятности выхода из состояния зависимости и повышении вероятности перехода из состояния отсутствия боли в состояние приема опиоидов доля людей, попавших в зависимость от опиоидных препаратов, может резко увеличиться. Например, если во второй модели снизить переход от отсутствия боли к зависимости до 1 процента, доля попавших в зависимость достигнет 35 процентов. Одним из последствий модельного мышления такого типа стало то, что некоторые поставщики медицинских услуг, такие как «Голубой крест», начали ограничивать количество препаратов, которые может выписывать врач. Кроме того, в ряде штатов, в том числе в Мичигане, приняли законы, ограничивающие количество препаратов в одном рецепте.
Наша третья модель основана на системной динамике и, так же как и модель Маркова, исходит из того, что есть люди, не испытывающие боли, люди, принимающие опиоиды, и люди, больше не испытывающие боли. Однако вместо того чтобы записывать вероятности перехода между этими состояниями, данная модель отображает поток от состояния боли к приему опиоидов и отсутствию боли. Более сложные модели системной динамики могут включать поставщиков других наркотиков и допускать переход от приема опиоидов к употреблению героина. Кроме того, более подробная модель может включать разнородные типы потенциальных потребителей. Следовательно, она может учитывать тот факт, что люди, страдающие от тревожности и депрессии, с большей вероятностью попадут в зависимость от опиоидов [2].
Пути к героиновой зависимости
Модель системной динамики
Совокупность людей, испытывающих боль, порождает потребителей опиоидов и попавших от них в зависимость. Люди, принимающие опиоиды, переходят в состояние отсутствия боли и в состояние зависимости от опиоидов. Попавшие в зависимость, в свою очередь, могут перейти к употреблению героина отчасти из-за отсутствия возможности получить опиоиды. Следовательно, по мере увеличения потока опиоидов растет количество потребителей героина.
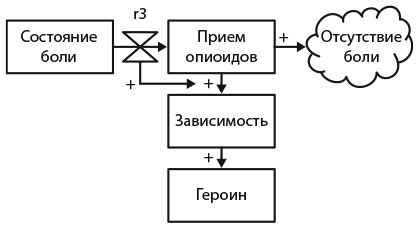
Последняя модель, которую мы формально не описываем, использует сети социальных связей для объяснения того, почему карты потребления опиоидов на душу населения демонстрируют наличие кластеризации в сельской местности. Из анализа правил квадратного корня мы узнали, что в более мелких совокупностях должна иметь место более высокая вариация. (Вспомните пример, в котором рассказывалось, что небольшие школы показывают лучшие и худшие результаты.) Более высокий уровень употребления опиоидов в сельских районах может также объясняться тем, что врачи выписывают сельским пациентам рецепты на более длительный период ввиду отсутствия поблизости аптек. Если оставить в стороне эти объяснения, то кластеризация превышает уровень, который мог бы сформироваться случайно.
Кластеризация может возникнуть, если люди дают или продают опиоиды соседям. В отличие от подержанной мебели, которую люди продают, размещая объявления, опиоиды чаще всего продаются через личные связи. Модель продажи опиоидов подразумевает сеть социальных связей членов семьи и их друзей, в рамках которой люди распространяют опиоиды. Такая модель позволяет обнаружить локальные кластеры людей, злоупотребляющих опиоидами, на основе данных [3].
МНОЖЕСТВО МОДЕЛЕЙ НЕРАВЕНСТВА
Наш последний пример применения многомодельного подхода довольно глубоко раскрывает причины экономического неравенства. Мы фокусируемся на этой теме по трем причинам. Во-первых, неравенство — одна из самых актуальных политических проблем современности. Доход и богатство соотносятся с процветанием человека. У людей с более высоким доходом крепче здоровье, выше продолжительность жизни и уровень счастья. Среди тех, кто находится в нижней части шкалы распределения доходов, более высокий уровень насильственных смертей, разводов, психических заболеваний и тревожности [4]. Не следует путать корреляцию с каузацией: существенная часть корреляции объясняется тем фактом, что более здоровые и счастливые люди зарабатывают больше. Тем не менее практически все исследования указывают на связь между доходом и процветанием. Никто не стремится быть беднее. Во-вторых, есть масса моделей неравенства, составленных экономистами, социологами, политологами и даже физиками и биологами, которые использовали для их разработки разные инструменты. В-третьих, мы располагаем большим объемом данных о доходе и богатстве внутри страны и за ее пределами. Кроме того, у нас есть данные как за нынешний период, так и временные ряды, охватывающие столетия.
Сначала мы кратко опишем некоторые эмпирические закономерности. Во-первых, во всех странах во все времена распределение доходов имело вытянутый хвост, то есть в нем много малообеспеченных людей и небольшой процент состоятельных. В прошлом распределение доходов соответствовало логнормальному распределению или распределению Парето. В последнее время более подробные данные показывают, что хвост такого распределения длиннее хвоста логнормального распределения, хотя и не достигает длины хвоста степенного распределения. В распределении богатства наблюдается аналогичный перекос.
Во-вторых, в наиболее развитых странах уровень неравенства в распределении доходов и богатства, как бы он ни измерялся, в последние десятилетия рос. Нынешний уровень неравенства в распределении доходов и богатства в США приближается к уровню позолоченного века50. Поскольку изменения во всем распределении обнаружить сложно, мы, в соответствии с принятыми соглашениями, опишем их с учетом доли дохода, которая приходится на верхнюю часть хвоста распределения. На рис. 29.1 показано, как 0,1 процента самых богатых людей увеличили свою долю дохода. Доля дохода 0,1 процента самых богатых семей постепенно сокращалась вплоть до 1950 года, а затем стабилизировалась на уровне 4 процентов и оставалась такой примерно до 1980 года, после чего начала стремительно расти. В 2018 году доля совокупного богатства этих суперсостоятельных людей составляла 10 процентов.
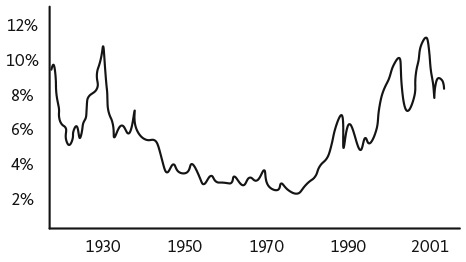
Рис. 29.1. Доля дохода 0,1 процента самых богатых семей за период с 1916 по 2010 год. Источник: Piketty, 2011
В-третьих, в мировом масштабе количество людей, живущих в условиях нищеты, резко сократилось. Между этими противоположными тенденциями нет логического противоречия. Быстрый рост доходов в бедных странах сокращает различия между странами и с избытком компенсирует рост неравенства внутри стран. Наша модель группового отбора обеспечивала аналогичные результаты. Рост количества альтруистических сообществ превосходил склонность к эгоизму в пределах каждого сообщества.
Неравенство обусловлено множеством взаимосвязанных причин. Экономические факторы, социологические тенденции, применение политической власти и бремя истории — все это усиливает неравенство. В связи с этим, как подчеркивает Стивен Дурлауф, мы не должны пытаться объяснить уровни или тенденции формирования неравенства с помощью одного уравнения. Не следует также выстраивать политику в соответствии с этим уравнением [5]. Необходимо придерживаться более гибкого подхода. Процесс концентрации богатства и дохода в руках 1 или 0,1 процента самых состоятельных людей может не иметь отношения к факторам, удерживающим 20 процентов бедных людей в порочном круге нищеты. Для того чтобы понять различные причины, следует использовать множество моделей.
Сначала опишем модели, объясняющие изменение распределения дохода. Доход поступает из четырех источников: заработная плата, доход от бизнеса, доход от капитала и прирост капитала. Относительный размер доли этих источников зависит от уровня дохода. Люди с низким уровнем дохода получают мало дохода от прироста капитала или дохода на капитал. Многие люди с высоким уровнем дохода получают значительный доход из каждого источника — заработной платы, бизнеса и капитала.
Наша первая модель расширяет производственную модель Кобба-Дугласа, поскольку включает два типа труда: квалифицированный и неквалифицированный. Оплата труда определенного типа зависит от относительного предложения труда этого типа и от технологии [6]. Модель объясняет наблюдающееся в последнее время усиление неравенства с учетом спроса и предложения. В 1950-х годах развитие промышленного производства обусловило повышение спроса на неквалифицированных работников. При этом рост численности студентов колледжей, отчасти обусловленный Законом о правах военнослужащих, увеличил предложение квалифицированных работников. В 1980-х годах уменьшение стимулов к получению высшего образования замедлило увеличение числа выпускников колледжей, а последующий приток иммигрантов с низким уровнем образования увеличил численность малоквалифицированных работников. В то же время технический прогресс (появление автоматизированного производства и переход к цифровой экономике) повысил относительную ценность квалифицированных работников, которую отображал рост их заработной платы.
Временные ряды данных о среднем доходе по уровням образования согласуются с этой моделью достаточно хорошо, поэтому многие экономисты используют ее для формирования политики. Модель отстаивает расширение доступа к образованию, поскольку это способствует снижению заработной платы квалифицированных работников и сокращению неравенства. Модель хорошо объясняет общие тенденции, но не может объяснить роста вариации в пределах каждой категории доходов.
Модель технологий и человеческого капитала
Существует следующая зависимость между объемом производства (K), квалифицированным (S) и неквалифицированным (U) трудом:
Объем производства = AKαSβUγ
Параметры A, α, β и γ обозначают технологию и относительную ценность типов труда. Относительный рыночный уровень заработной платы высоко- и низкоквалифицированных работников равен [7]:
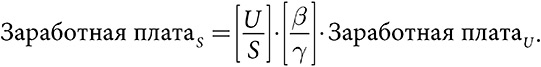
Причина неравенства: изменения в области технологий, благоприятные для квалифицированных работников, повышают β и снижают γ. Эти изменения, наряду с увеличением численности низкоквалифицированных работников, усиливают неравенство.
Следующая модель, модель положительной обратной связи, может объяснить рост вариации в рамках профессий. Она фокусируется на хвосте распределения, в частности на предпринимателях. В 2011 году предприниматели составляли 70 процентов от 400 самых богатых людей в США [8]. Модель предполагает, что технологии (в особенности интернет и смартфоны) сделали нас гораздо связаннее и более подверженными влиянию выбора других [9]. Человек, покупающий беспроводные стереодинамики, может прочитать в интернете отзывы и выбрать лучший из десятков вариантов. В прошлом же у человека в основном был единственный вариант выбора в местном магазине. Теперь же человек, вывихнувший колено, может найти в интернете имя врача своего любимого спортсмена. Такое поведение создает положительную обратную связь и усиливает неравенство. Мы смоделируем экономический выбор под влиянием социальной среды, применив модель предпочтительного присоединения для описания модели, связывающей положительную обратную связь с талантом.
Хотя модель положительной обратной связи не согласуется с временным рядом данных столь же точно, как в случае предыдущей технологической модели, мы можем обратиться к экспериментам, чтобы понять, как обратная связь способствует усилению неравенства. Вспомните музыкальные лабораторные эксперименты, описанные в главе 6. Студенты колледжей выбирали и загружали музыку при двух вариантах условий эксперимента. В первом варианте студенты не знали, какие песни скачивают другие. Эти условия описывают мир до наступления эпохи интернета. Во втором варианте студенты видели, сколько загрузок приходится на каждую песню. В варианте без социальной информации ни одна песня не получила более двухсот загрузок и только одна песня получила меньше тридцати загрузок. Когда участники эксперимента видели данные о скачиваниях, одна песня получила более трехсот загрузок и более половины песен меньше тридцати загрузок. Информация и влияние социальной среды усиливают эффект Матфея. Богатые становятся еще богаче, а бедные — относительно беднее.
Положительная обратная связь
Модель предпочтительного присоединения
Существует N производителей, каждый из которых начинает с нулевого объема продаж. Первый потребитель покупает у случайно выбранного производителя с нулевым объемом продаж, обеспечивая ему положительные продажи. Каждый последующий потребитель с вероятностью p покупает у производителя с нулевыми продажами и вероятностью (1 – p) — у производителя с положительными продажами. Покупая у производителя с положительными продажами, клиент выбирает случайным образом с вероятностью выбора определенного производителя, пропорциональной его продажам.
Причина неравенства: повышенная связанность усиливает влияние социальной среды, создавая положительную обратную связь.
Эту же логику можно применить к экономике в целом [10]. Вероятность усиления неравенства в результате формирования положительной обратной связи через сети социальных контактов отчасти зависит от характера того, что покупают люди. Товары, не имеющие веса, такие как загрузки фильмов или музыки, веб-приложения и некоторые технологии, поддаются быстрому, чуть ли не мгновенному масштабированию. Тракторы, автомобили и стиральные машины невозможно скопировать, кликнув на иконке. Следовательно, тогда как новое приложение для смартфона можно масштабировать при малых или нулевых затратах капитала, в случае популярного автомобиля это невозможно. В качестве иллюстрации приведем пример. В мае 2015 года компания Volvo объявила о выпуске седана S60 в Южной Каролине, а в сентябре начала строительство завода, рассчитывая, что первые автомобили сойдут с конвейера в конце 2018 года.
Наша следующая модель использует модель пространственного голосования для объяснения роста оплаты труда CEO, который не зависит от социальных факторов. В 2012 году средний доход CEO компаний из списка Fortune 500 превышал 10 миллионов долларов, что примерно в 300 раз больше среднего заработка работника. Для сравнения: в 1996 году зарплата CEO была всего в 25 раз больше средней заработной платы работника. В других странах CEO зарабатывают гораздо меньше. Скажем, в Японии примерно в 10 раз больше среднего работника. В Канаде и во всех странах Европы зарплата CEO примерно в 20 раз превышает среднюю заработную плату работника.
В большинстве компаний заработок CEO устанавливает комитет по оплате труда, состоящий из членов совета директоров. Этот заработок включает заработную плату, бонусы и фондовые опционы. Как правило, люди, определяющие оплату труда CEO — это другие CEO, которые заинтересованы в высоком заработке коллег, поскольку это повысит их собственный заработок. Мы можем использовать пространственную модель для представления предпочтений членов комитета по оплате труда. Согласно пространственной модели, заработная плата будет установлена на уровне предпочтений медианного участника голосования. Различия в оплате труда CEO по странам можно объяснить составом советов директоров и комитетов по оплате труда. В Германии в совет директоров входят работники, и они предпочитают, чтобы CEO получали меньше.
Политическое влияние CEO
Пространственная модель голосования
Заработок CEO определяет комитет по оплате труда путем голосования. В США в такие комитеты входят многие нынешние и бывшие CEO, которые предпочитают более высокую оплату, а также специалисты по оплате труда (X). В других странах в эти комитеты включают и работников (W), в связи с чем медианный участник голосования склоняется к более низкой оплате.
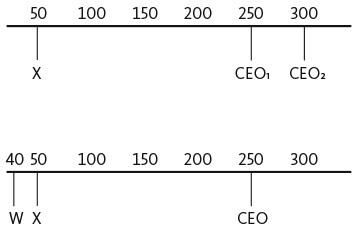
Причина неравенства: CEO сами определяют собственную зарплату благодаря контролю над комитетом по оплате труда. Повышение зарплаты любого CEO смещает предпочтения в сторону более высокой оплаты труда всех CEO.
Эта модель объясняет рост оплаты труда CEO с учетом предпочтений совета директоров относительно ее размера. Здесь мы можем вернуться к множеству моделей ценности. Вполне возможно, предпочтения членов комитета по оплате труда могут зависеть от модельного мышления, основанного на данных. С другой стороны, они могут быть социально сконструированными или являться частью тщательно продуманной практики взаимной поддержки, когда CEO фактически голосуют за повышение оплаты труда друг друга.
Наша следующая модель неравенства в распределении доходов взята из бестселлера Тома Пикетти Capital in the Twenty-First Century51. Это даже не модель, а скорее подмеченная тенденция, что доходность капитала превышает темпы прироста капитала. Когда это происходит, доля дохода, которую получают люди с высоким уровнем дохода за счет доходности капитала, со временем увеличивается. Построив более сложные версии моделей роста из главы 8, можно продемонстрировать, что доходность капитала всегда должна превышать темпы роста экономики в целом. В долгосрочном периоде рост экономики может составлять менее 2–3 процентов, тогда как доходность капитала может вдвое превышать этот показатель.
Из этого следует, что в экономике, где работники получают заработную плату, а капиталисты — рентный доход, доля капитала, которая приходится на капиталистов, увеличивается. А если более формально, то темпы прироста капитала зависят от трех показателей: нормы потребления, ставки налогообложения и доходности капитала. Потребление зависит от уровня капитала. Человек с небольшим капиталом потребляет существенную долю своего дохода. Человек, владеющий значительным объемом капитала, потребляет небольшую долю дохода. Как формально показано в представленной ниже врезке, если сделать уровень потребления неизменным, норма потребления будет равна этой величине, деленной на уровень капитала. Следовательно, у более богатых людей норма потребления будет ниже, что повышает вероятность увеличения их чистого капитала.
Модель рентного дохода от капитала (Пикетти)
Правило 72
Экономика включает в себя работников и капиталистов. Заработная плата работников увеличивается со скоростью g, равной темпу роста экономики. Капиталисты владеют богатством Wt в момент времени t и получают доход r (за вычетом налогов), а также потребляют неизменный объем A. Доход капиталистов будет расти быстрее дохода работников тогда и только тогда, когда
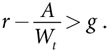
Причина неравенства: в условиях рыночной экономики доходность капитала превышает общие темпы роста (r > g). Капиталисты с большим накопленным богатством расходуют на потребление незначительную часть дохода от капитала, поэтому их доля от совокупного дохода со временем увеличивается.
Для того чтобы увидеть, как разница между этими показателями порождает неравенство, можно применить правило 72. Если изначально доход работников равен доходу капиталистов, а заработная плата растет на 2 процента, тогда как капитал на 6 процентов, то через тридцать шесть лет заработная плата удвоится, а доход от капитала увеличится в 8 раз. За семьдесят два года капиталисты получат доход, в шестьдесят четыре раза превышающий доход работников.
Пикетти применяет эту модель для объяснения долгосрочных тенденций формирования неравенства в распределении доходов и богатства. Она очень хорошо согласуется с данными о ситуации во Франции и Англии за три столетия, а кроме того, проливает свет на закономерности формирования неравенства в США и Европе за прошедшее столетие. В частности, в Европе две мировые войны разрушили акционерный капитал, сгладив распределение дохода и капитала. Одна из причин столь высокой согласованности модели с данными — то, что в ней опущены два эффекта, которые сводят друг друга на нет. Исключив из рассмотрения предпринимателей, модель недооценивает неравенство. Предполагая, что все последующие поколения капиталистов делают разумные инвестиции (хотя это не так), модель переоценивает вклад накопления капитала в усиление неравенства. Формирование нового и потеря старого класса богатых людей не обязательно должны уравновешиваться. Более детальная модель учитывала бы переход в класс богатых и выход из него.
Если оставить в стороне эту оговорку, то данная модель позволяет сделать вывод, что пока увеличивается капитал, капиталисты получают все большую долю экономического пирога. Продолжив применять правило 72, мы обнаружим, что со временем доход капиталистов существенно превзойдет доход работников. У проблемы накопления капитала есть простое решение: ввести налог на богатство (что может быть политически невозможно). В качестве альтернативы можно дождаться войны или революции, чтобы силой перераспределить богатство, или технологических прорывов, в результате которых сформируется новая совокупность богатых капиталистов.
В следующих двух моделях основное внимание уделяется социологическим факторам. Обе модели имеют серьезное эмпирическое обоснование. Первая объясняет рост неравенства в связи с ассортативностью (неслучайным выбором партнеров). Доход семьи зависит от заработка обоих супругов. Если человек с низким уровнем доходов вступает в брак с человеком с высоким уровнем доходов, то такой брак способствует выравниванию распределения доходов. Если люди с высоким уровнем доходов вступают в брак с людьми с высоким уровнем доходов, разрыв в доходах будет увеличиваться. Большинство людей женятся в таком возрасте, когда точно определить, какие доходы будут у потенциального партнера на протяжении жизни, невозможно. Но люди все же знают уровень образования и общее состояние здоровья потенциальных партнеров, а также получают сигналы об их амбициях. Практика показывает, что по мере того как мужчины и женщины становятся образованнее и обеспеченнее (вспомните модель технологий и человеческого капитала), они выбирают спутников жизни с более высоким уровнем образования.
Усиление неравенства обусловлено следующими факторами. Во-первых, все больше женщин получают высшее образование. Во-вторых, относительный уровень дохода растет вместе с уровнем образования. В-третьих, образованные мужчины и женщины предпочитают образованных партнеров. Из всего этого следует, что семьи с двумя образованными супругами с большей вероятностью имеют два высоких дохода, что способствует усилению неравенства доходов на уровне домохозяйств. Эта логика безупречна. Вопрос только в том, каков масштаб эффекта [11].
Социологи калибруют эту модель, разделяя людей на пять категорий по уровню образования: без образования, среднее образование, неоконченное высшее образование, высшее образование и аспирантура. А затем подсчитывают средний уровень доходов по каждому уровню образования и сопоставляют эти данные с количеством браков между каждой парой уровней образования, что дает приближенную оценку влияния ассортативного выбора партнеров.
Ассортативный выбор партнеров
Модель сортировки и категоризации
Каждый человек имеет уровень образования {1, 2, 3, 4, 5}, где 1 = без образования, 2 = среднее образование, 3 = неоконченное высшее образование, 4 = высшее образование и 5 = аспирантура.
Пусть P(m, j) и P(w, j) обозначают вероятность того, что мужчина и женщина имеют уровень образования j. Доход(g, l) равен предполагаемому доходу человека пола g с уровнем дохода l. Доход семейной пары, состоящей из мужчины с уровнем образования lM и женщины с уровнем образования lW, составляет [12]
Доход(M, lM) + Доход(W, lW).
Причина неравенства: увеличение количества образованных женщин, повышенная оплата труда работников с более высоким уровнем образования и ассортативный выбор партнеров (склонность людей вступать в брак с партнерами с аналогичным уровнем доходов) приводят к усилению неравенства на уровне домохозяйств.
Если бы браки носили случайный, а не ассортативный характер, уровень неравенства в распределении доходов был бы гораздо ниже. В ходе одного исследования было установлено, что уровень неравенства, выраженный через коэффициент Джини (общепринятый показатель неравенства), снизился бы на 25 процентов [13].
Наша следующая модель анализирует перемещения между категориями доходов с помощью модели Маркова. Она классифицирует людей (или домохозяйства) по уровню доходов: высокий, выше среднего, ниже среднего и низкий. Каждая категория содержит одну четверть распределения. Мы можем оценить вероятности перехода между категориями за определенный период времени (это может быть год, десятилетие или поколение), чтобы определить уровень социальной мобильности.
При отсутствии связи между доходами разных поколений доход ребенка родителя с высоким уровнем доходов с равной вероятностью принадлежал бы к одной из четырех категорий, то есть все вероятности перехода составляли бы . В предельном случае отсутствия мобильности все вероятности перехода, расположенные по диагонали, были бы равны 1. Эмпирические оценки показывают, что реальность находится между этими двумя крайностями.
Далее проведем такой эксперимент: случайным образом выберем 100 семей с низким и высоким уровнем доходов, а затем вычислим распределение вероятностей по доходам следующих поколений. На основе приведенных во врезке вероятностей можно сделать вывод, что у детей родителей с высоким доходом вероятность принадлежности к категории высокого дохода составит 60 процентов, а к категории низкого дохода — всего 5 процентов. У внуков людей с высоким доходом вероятность попасть в категорию высокого дохода равна 43 процента, а низкого дохода — 10 процентов [14].
Межпоколенческая динамика доходов (богатства)
Модель Маркова
Население можно разделить на четыре категории по уровню доходов (богатства) с равным количеством людей, а затем оценить вероятность переходачеловека (или семьи) из одной категории в другую в пределах одного поколения, как показано на рисунке ниже. Более близкие вероятности перехода соответствуют более высокому уровню социальной мобильности.
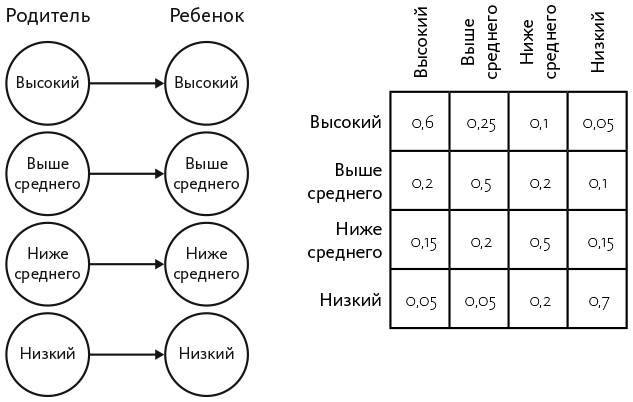
Вероятности перехода от одного уровня доходов к другому
Причины неравенства: социальные навыки, неявные знания, отношение к риску и образованию, наследство — все это снижает мобильность между категориями доходов.
Модель динамики доходов также служит в качестве точки отсчета для оценки причин мобильности доходов. Мы можем использовать линейную модель для определения дохода ребенка в зависимости от уровня богатства, доходов и талантов его родителей (при наличии соответствующих данных). Модель Пикетти дала бы положительный коэффициент в контексте богатства родителей. Модель, учитывающая фактор таланта, обеспечила бы положительный коэффициент в контексте способностей родителей при наличии корреляции между способностями родителей и способностями детей.
Обратите внимание, что для определения коэффициента в контексте родительского дохода необходимы данные о доходе каждого ребенка и каждого родителя. В распоряжении ученых есть данные об индивидуальном уровне доходов только за два прошедших десятилетия. В книге Грегори Кларка The Son Also Rises52, опубликованной в 2014 году, найдено оригинальное решение проблемы отсутствия данных: автор полагается на фамилии. Он подсчитывает средний доход всех людей с фамилией, скажем, Тэтчер, в 1888 году, и сравнивает полученный результат со средним доходом людей с фамилией Тэтчер в 1917 году. Тридцатилетний интервал соответствует длительности трудовой жизни. Кларк обнаружил значительную корреляцию между средним уровнем доходов по фамилиям, что указывает на отсутствие мобильности доходов.
Модель такого типа позволяет определить расовые различия в межпоколенческих перемещениях. Афроамериканцы демонстрируют менее высокую устойчивость уровня богатства в верхней части шкалы распределения доходов и более высокую устойчивость в нижней части шкалы распределения доходов. Богатый афроамериканец с меньшей вероятностью будет иметь богатых детей, а бедный афроамериканец с большей вероятностью будет иметь бедных детей [15].
В основе нашей последней модели лежит влияние района проживания. В модели сохраняющегося неравенства, разработанной Стивеном Дурлауфом, используется эмпирическая закономерность, отражающая сегрегацию людей по такому признаку, как категория доходов — другими словами, люди с высоким доходом живут в тех же районах, что и другие люди с высоким уровнем доходов, а люди с низким уровнем доходов живут по соседству с людьми с низким уровнем доходов. Сегрегация по признаку дохода порождает экономические, социологические и психологические экстерналии, снижающие уровень социальной мобильности. В данной модели доход людей зависит от их способностей, расходов на образование и эффектов перелива53.
Параметр образования отражает государственные расходы на образование, которые, как показывает опыт, соотносятся с уровнем доходов: в местах проживания обеспеченных людей на образование выделяется больше средств, чем в местах проживания людей с низким уровнем доходов, что приводит к тому, что в богатых районах дети получают более качественное образование и более высокий доход.
Эффект перелива можно интерпретировать как социальную передачу знаний о надлежащих инструментах, которыми необходимо овладеть. В этом случае мы можем связать модель Дурлауфа с тем, как люди, живущие в богатых районах, узнают о соответствующих инструментах. Кроме того, мы можем связать эту модель с нашей сетевой моделью и феноменом силы слабых связей: люди, живущие в богатых районах, косвенно связаны с большим количеством людей, имеющих доступ к экономически ценной информации, что приводит к формированию положительной обратной связи в отношении дохода.
Кроме того, эффект перелива можно интерпретировать как социальную передачу модели поведения, такую как количество времени, выделенного на учебу или работу. Если доход содержит случайную составляющую, то каждый обитатель бедного района увидит (вполне справедливо) низкую отдачу от времени, выделенного на самосовершенствование. Вместе с тем эффект перелива может включать психологические аспекты, такие как позитивные или негативные взгляды на жизнь, ощущение безопасности или вера в себя.
Модель сохраняющегося неравенства (модель Дурлауфа)
Модель сегрегации Шеллинга + модель локального большинства
Люди относятся к определенным категориям доходов и сегрегированы по месту жительства в соответствии с доходами. Люди выделяют часть своего дохода на образование, что порождает положительные эффекты перелива, усиливающиеся вместе с повышением уровня доходов в районе проживания. Будущий доход ребенка, живущего в районе C, зависит от врожденных способностей, расходов на образование и эффектов перелива. Вклад образования и эффектов перелива зависит от уровня дохода в данном районе, обозначенного как IC.
доходC = F(способности, образование(IC), эффект перелива(IC)).
Причина неравенства: дети, живущие в бедных районах, получают меньше образовательных возможностей и экономических эффектов перелива.
В полной модели Дурлауф вычисляет равновесные уровни расходов на образование и выводит условия, при которых возникает сохраняющееся неравенство. Такое неравенство обусловлено так называемыми ловушками бедности. Людям, живущим в районах с низким уровнем доходов, не хватает образовательных ресурсов и эффектов перелива, необходимых для получения высоких доходов независимо от уровня способностей. Модель Дурлауфа позволяет объяснить огромный расовый разрыв в уровне доходов. Непропорционально большое количество афроамериканцев живут в бедных районах, поэтому могут оказаться в ловушке низких доходов из-за отсутствия необходимых ресурсов.
Рассмотренные в книге модели описывают различные причины неравенства. В какой-то мере каждая из моделей правильна, но, как мы с вами знаем, все они так или иначе неправильны. Как показывает практика, модели отличаются тем, в какой степени и какую часть вариации уровня доходов они могут объяснить. В верхней части шкалы распределения доходов эмпирические данные однозначно подтверждают правильность моделей, в основе которых лежат изменения в области технологий [16]. Более двадцати лет Налоговое управление США отслеживало 400 самых высоких уровней дохода. В верхней части шкалы распределения доходов находятся технологии, розничная торговля и финансы — три отрасли, которые можно быстро масштабировать. Такие высокие темпы роста могут быть обусловлены рынками поисковых систем, работающими по принципу «победитель получает все» (Google), или сайтами социальных сетей (Facebook). Эти модели дают мало информации о нижней части шкалы распределения доходов. Кроме того, они предоставляют мало данных о мобильности доходов и плохо объясняют, почему оплата труда CEO в США существенно превышает этот показатель в других странах.
Для того чтобы объяснить другие особенности данных, нужны другие модели, такие как модель мобильности доходов, модель сохраняющегося неравенства Дурлауфа и модель пространственного голосования. Выстраивание диалога между разными моделями и данными обеспечивает глубокое, многогранное понимание причин неравенства. Такой подход позволяет идентифицировать множество процессов, которые его порождают и поддерживают, и увидеть, как эти процессы накладываются и пересекаются. Понимание сложности проблемы неравенства и самоусиливающихся поддерживающих его причинно-следственных факторов должно вызвать сомнения в действенности быстрых решений. Сокращение масштабов неравенства потребует согласованных усилий по нескольким направлениям.
БОЛЬШОЙ МИР
Итак, мы только что узнали, как применение ансамбля моделей позволяет объяснить многие причины неравенства в распределении доходов и эпидемии опиоидов, а также раскрывает пределы любой отдельно взятой структуры. Если бы мы были политиками, мы бы привели некоторые из этих моделей в соответствие с данными для оценки величины эффекта, а затем провели бы естественные эксперименты, которые помогли бы нам откорректировать политический курс на основании полученной информации.
Многомодельный подход можно также применить к решению целого ряда социальных проблем, таких как обращение вспять тенденции к ожирению, повышение эффективности школьного обучения, ослабление последствий изменения климата, рациональное использование водных ресурсов и улучшение международных отношений. В каждом из этих случаев включение даже одной новой модели могло бы иметь огромные последствия. Возьмем, к примеру, задачу прогнозирования финансовых кризисов. Федеральная резервная система США полагается на традиционные экономические модели, в которых используются данные национального учета инфляции, безработицы и товарно-материальных запасов. Этим данным свойственно запаздывание: они публикуются еженедельно, ежеквартально или раз в год. Кроме того, они получены в результате статистических обследований, то есть выборочного анализа экономики в целом.
Специалист по сложным системам Дж. Дойн Фармер выдвинул идею о создании второго класса моделей, основанных на данных, собираемых в интернете в режиме реального времени. Эти новые модели будут полагаться на более детальные, мгновенные данные, а значит, будут отличаться от традиционных моделей. Фармер утверждает, что они могут оказаться более эффективными, чем существующие модели. Возможно, он прав. Вместе с тем новые модели не обязательно должны быть более точными, чтобы их можно было применять в области прогнозирования и предотвращения финансовых кризисов. Учитывая тот факт, что новые модели будут использовать другие данные и исходить из других предположений, они смогут давать и другие прогнозы. А согласно теореме о прогнозе разнообразия при условии, что уровень точности новых моделей не намного ниже, в сочетании с существующими моделями они повысят качество прогнозов, что, выражаясь языком Фармера, обеспечит коллективную осведомленность политических деятелей [17].
Руководитель компании может выполнить аналогичную работу при принятии решений в отношении бизнеса. Он может применить множество моделей, основанных на данных, для определения свойств продуктов, выбора времени вывода продуктов на рынок, разработки системы оплаты труда, создания цепи поставок и прогнозирования продаж. Поскольку каждое из этих действий выполняется в рамках сложной системы, любая отдельно взятая модель была бы неправильной, но ансамбль моделей обеспечит более эффективный результат.
В общем, при необходимости сделать выбор, составить прогноз или решить задачу разработки, следует придерживаться многомодельного подхода. Он обеспечивает более высокие результаты, чем действия, основанные на догадках и интуиции. Вместе с тем у нас нет никаких гарантий успеха. Даже использование множества моделей не всегда позволяет выявить самую значимую логическую цепочку. Сфера интересов может быть настолько сложной, что даже ансамбли моделей могут объяснить лишь небольшую часть вариаций.
Применяя модели для помощи в проектировании, мы можем оказаться неспособными выявить полезные абстракции. Простота моделей в этих случаях может быть их уничтожением.
В условиях сложности мы можем обнаружить, что модели не отвечают задачам распространения идей, составления точных прогнозов или выбора наиболее эффективных действий. Даже наши изыскания с помощью моделей могут раскрывать мало значимой информации. В таких случаях и области применения моделей, такие как рассуждение, объяснение, прогнозирование, разработка, коммуникация, действие и исследования (REDCAPE), о которых шла речь в книге, не принесут много пользы. Тем не менее мы все равно извлекаем выгоду из рассмотрения и применения множества моделей, поскольку это позволяет выявить взаимозависимости и понять, почему сложный процесс способен расстроить наши попытки анализировать, объяснять и коммуницировать.
Таким образом, мы должны проявлять определенную степень смирения. Даже при помощи множества моделей наша способность рассуждать имеет свои пределы. Именно поэтому мы должны сохранять любознательность, продолжать разрабатывать новые модели и совершенствовать существующие. Если модель не учитывает ключевых свойств этого мира (таких как влияние социальных факторов, положительная обратная связь или когнитивные искажения), то мы должны построить другие модели, включающие эти свойства. Это позволит определить, имеют ли эти свойства значение, и если да, то какое именно. Тот факт, что все модели неправильны, не должен лишать нас присутствия духа — его следует воспринимать как стимул к созданию множества моделей, способных принести мудрость.
И последнее: мы должны получать удовольствие от этих усилий. Хотя в книге особое внимание уделяется прагматическим целям (научиться лучше мыслить, повысить эффективность работы и стать более информированными гражданами мира), она также преследует неявную цель: раскрыть красоту моделей и радость моделирования. Практика построения моделей может стать красивой игрой. Мы делаем предположения, формулируем правила, а затем играем в рамках этих правил, опирающихся также на законы логики. Благодаря своим логическим изысканиям мы совершенствуемся и становимся мудрыми. Давайте же привнесем эту мудрость в большой мир и поможем изменить его к лучшему.
МИФ Научпоп
Весь научпоп
на одной странице:
mif.to/science
Узнавай первым
о новых книгах,
скидках и подарках
из нашей рассылки
mif.to/sci-letter
#mifnauka




ПРИМЕЧАНИЯ
У меня огромное количество коллег и друзей, и я вряд ли могу отблагодарить должным образом их всех, да и перечислить всех не получится, но знайте: я всем вам искренне признателен. Эта книга стала значительно лучше благодаря беседам о моделировании с такими людьми, как Энк Болл, Андреа Джонс Руй, Майкл Мобуссин, Карл Саймон, Джон Миллер, Лу Хонг, Элен Ландемор, Джим Джонсон, Скип Люпия, Джош Берке, Патрик Грим, Боб Аксельрод, Пи Джей Ламберсон, Джессика Стейнберг, Джессика Флэк, Чарли Доринг, Майкл Райолл, Роберт Диген, Джей Грусин, Сара Силвестри, Зев Бергер, Кен Коллман, Джин Клиппертон, Майкл Барр, Бенджамин Блай, Элизабет Брух, Эбби Джейкобс, Марк Ньюман, Косма Шахзи, Кент Майерс и Джош Купер Рамо. Я благодарен Фонду Гуггенхайма за финансирование творческого отпуска, а также преподавателям, сотрудникам и студентам INSEAD и жителям Фонтенбло (Франция). В Энн-Арборе сотрудники Lab Cafe, Mighty Good Coffee и всех четырех кафе Sweetwaters Coffee and Tea предлагали мне кофе и молчаливую поддержку. На содержание книги очень повлияли онлайн-дискуссии с тысячами людей, которые делились своим мнением о модельном мышлении. Мой агент Макс Брокман, редактор Ти Джей Келлегер и Мелисса Веронези помогали мне сохранять сфокусированность на протяжении последнего года работы над книгой. Мита Гибсон и Линда Вуд оказывали неизменную поддержку, устраняя многочисленные отклонения от графика и демонстрируя умение работать с типографией. На последних этапах Люси Флемминг и Джон Берт решали досадные проблемы с версткой. Спасибо вам всем!
ПРИМЕЧАНИЯ РЕДАКЦИИ
1. О распределениях с длинными хвостами см. главу 6. Прим. ред.
2. Процесс обработки данных, который преобразует непрерывные данные в дискретные путем замены значений диапазонами. Прим. ред.
3. Издана на русском языке: Зеликов Ф., Аллисон Г. Квинтэссенция решения. На примере Карибского кризиса 1962 года. М. : ЛКИ, 2012. Прим. ред.
4. См. также по теме: Диксит А., Скит С., Рейли Д. Стратегические игры. М. : Манн, Иванов и Фербер, 2017. Прим. ред.
5. Синапсы — это оконечные образования нейронов, с помощью которых нервные импульсы передаются от одного нейрона к другому. Некорректно говорить, что синапсы образуют нейроны — это разные структуры. Прим. ред.
6. Большинство англоязычных исследователей для обозначения действующих лиц экономических, социальных и политических событий используют термин актор. В русскоязычном сегменте научного мира предпочитают агент. Хотя между этими словами есть определенные различия, мы будем их использовать в данной книге как синонимы. Прим. ред.
7. Red cape (англ.) — красная накидка. Атрибут Супермена. Прим. ред.
8. С математической точки зрения эту теорему можно трактовать как получение распределения вероятностей ответов с медианой, центрированной около истинного значения оцениваемой величины. Прим. ред.
9. Несложно показать, что квадратичная ошибка коллективного предсказания выражается через среднее квадратическое расстояние отдельных прогнозов от коллективного прогноза. Прим. ред.
10. См. Аристотель. Сочинения в 4 томах. Том 2. М. : Мысль, 1978. Прим. ред.
11. Борхес Х. Л. Сочинения в трех томах. Том 3. Полярис, 1997. Прим. ред.
12. Статистики обозначают долю вариации, которую объясняет модель, как R2 этой модели. (Этот коэффициент в статистике обычно называют коэффициентом детерминации, вычисляется как отношение межгрупповой вариации всей модели к внутригрупповой вариации (вариации одной модели). Прим. ред.
13. Эту теорему в дисперсионном анализе называют формулой разбиения общей суммы квадратов. Прим. ред.
14. Здесь и далее генеральный директор компании. Прим. ред.
15. Агент — это условная модель индивидуума, который может активно действовать в рамках модели. Прим. ред.
16. Можно показать (хотя бы численно), что данная функция имеет единственный максимум при Н равной трети суммарного дохода, равного С + Н. Прим. ред.
17. Формально — если лотерея L1 предпочтительнее лотереи L2, то для любого 0 < p < 1 лотерея pL1 + (1 − p)L3 предпочтительнее лотереи pL2 + (1 − p)L3 для всех лотерей L3. Прим. ред.
18. Формально — если последовательность вероятностей {pn} сходится к p, и лотерея pnL1 + (1 − pn)L2 предпочтительнее лотереи L3 для всех n, то лотерея pL1 + (1 − p)L2 предпочтительнее лотереи L3. Прим. ред.
19. Это агенты, которые пользуются фиксированным набором простых правил. Прим. ред.
20. В теории игр точка равновесия показывает путь к оптимальному (не обязательно максимальному) решению для всех игроков. Прим. ред.
21. Стандартное определение логнормального распределения: если случайная величина Х имеет логнормальное распределение, то ее логарифм Y = lnX распределен по нормальному закону. Прим. ред.
22. Ранг события — это порядковый номер события в упорядоченном списке всех событий. Прим. ред.
23. Также называется свободным членом линейной регрессии. Прим. ред.
24. Напомним, что R в квадрате также называется коэффициентом детерминации. В регрессионном анализе R2 вычисляется как отношение суммы квадратов всех ошибок измерения зависимых величин yi к сумме квадратов разностей между yi и их средним. Прим. ред.
25. Это же значение используется при проверке гипотез, что и другие коэффициенты уравнения регрессии отличны от нуля. Прим. ред.
26. Здесь и далее под термином «выпуклая» подразумевается «выпуклая вниз», а «вогнутая» — «выпуклая вверх». Ранее в отечественной литературе использовалось обратное понятие выпуклости и вогнутости. Прим. ред.
27. В последнее время темпы роста плотности транзисторов значительно упали, так что все чаще говорят о прекращении действия этого закона. Сам Мур заявил о скором прекращении действия его закона еще в 2007 году. Прим. ред.
28. Радиоуглеродное датирование имеет ряд недостатков, связанных с калибровкой метода и практически полным распадом углерода-14 при сроках более нескольких десятков тысяч лет. Поэтому сегодня он применяется в основном на историческом интервале (от десятков лет до 60–70 тысяч лет в прошлое). Прим. ред.
29. ARPANET (англ. Advanced Research Projects Agency Network — сеть Агентства передовых исследовательских проектов) — прототип сети интернет. Создана в 1969 году по поручению Министерства обороны США. Прим. ред.
30. Это число получается так: 2/6 (рулевой оказался последним в пятерке гребцов) + 10 · 4/6 (рулевой будет в первой четверке) = 42/6 = 7 — суммарная ценность всех гребцов, которую затем нужно разделить на 5 (их количество), чтобы узнать ценность одного гребца. Прим. ред.
31. Так как партия В может стать ключевой только в двух случаях из 12, то 2/12 = 1/6. Кстати, 12 = 4 · 3 · 1 — это количество вариантов формирования коалиций, если не различать партии С и D, иначе было бы 24 таких вариантов. Прим. ред.
32. Такие моменты в теории оптимального управления называются точками бифуркации. Прим. ред.
33. Коллинз Дж. От хорошего к великому. Почему одни компании совершают прорыв, а другие нет… М. : Манн, Иванов и Фербер, 2017.
34. В моделировании такие модели часто называют моделями последействия. Прим. ред.
35. Этот результат — следствие теоремы сложения вероятностей, поскольку указанные здесь события несовместимы. Прим. ред.
36. Шеллинг Т. Микромотивы и макровыбор. М. : Издательство Института Гайдара, 2016.
37. Здесь описана цепь Маркова, однородная по времени и пространству. А состояние статистического равновесия называется финальным состоянием цепи Маркова. Прим. ред.
38. Это важное свойство цепей Маркова называется отсутствием последействия. Прим. ред.
39. Отметим, что одним из решений данной системы дифференциальных уравнений будет уравнение гармонического осциллятора с постоянным периодом, что обеспечивает колебание системы около ненулевых значений хищника и жертвы. Прим. ред.
40. Шеллинг Т. Микромотивы и макроповедение. М. : Институт Гайдара, 2016.
41. Атрибуты (в статистике чаще называются индексами), исчисленные с учетом качества объекта, называются гедоническими. Этот термин отвечает задаче оценки изменения с учетом различных характеристик объекта на основе его описания по атрибутам или индексам с помощью уравнения регрессии, которое получило название гедонического. Прим. ред.
42. Концепция, предложеннная Джорджем Цебелисом. Вето-игрок — это актор, чье одобрение необходимо для изменения статус-кво. Прим. ред.
43. Стратегия нападающей стороны в американском футболе. Прим. ред.
44. Издана на русском языке: Готорн Н. Алая буква. М. : АСТ, 2018.
45. Процесс, включающий принцип повторения и самоподдержания без внешнего вмешательства или управления. Старинное английское слово, известное по идиоме: pull oneself over a fence by one's bootstraps. В переносном смысле это означало, что человек всего добился сам. Прим. ред.
46. Молодая женщина из индейского племени северных шошонов, проживавшего на территории современного штата Айдахо. Сакагавея помогла экспедиции Льюиса и Кларка в 1804—1806 годах исследовать обширные земли на американском Западе, которые тогда были только что приобретены. Прим. ред.
47. Понятие адаптивного ландшафта еще известно как ландшафт отбора — графическая модель эволюции в виде рельефной карты. Термин и модель предложены Сьюэлом Райтом в 1931 году. Прим. ред.
48. В отечественной литературе этот алгоритм известен как генетический алгоритм. Прим. ред.
49. В своей провокационной книге «Против интеллектуальной монополии» они ратуют за отказ от принципа защиты интеллектуальной собственности, утверждая, что только в этом случае возможен технологический и интеллектуальный прогресс. Прим. ред.
50. Позолоченный век — это период процветания экономики и быстрого роста населения США после Гражданской войны Севера и Юга. Начинается примерно с 1870-х годов. Прим. ред.
51. Издана на русском языке: Пикетти Т. Капитал в XXI веке. М. : Ad Marginem, 2015.
52. Кларк Г. Отцы и дети. Фамилии и история социальной мобильности. М. : Изд-во Института Гайдара, 2018.
53. Эффект перелива — это ситуация, когда одни экономически значимые события ведут к возникновению других, при этом явная связь между ними не всегда прослеживается. Прим. ред.
54. В метрических единицах он равен 10 000, умноженному на вес в килограммах, деленному на квадрат роста в сантиметрах (или просто весу в килограммах, деленному на квадрат роста в метрах). Прим. ред.
ГЛАВА 1
[1] См., например, книгу Кэти О’Нил (O’Neil, 2016), в которой рассказывается о том, как простые модели, основанные на данных, могут не учитывать некоторые слои населения и адаптивную обратную связь, которую мы обсудим в главе 4.
[2] См. статью Паарша и Ширера (Paarsch and Shearer 1999), в которой анализируется лесная промышленность. Исходные данные о посадке деревьев указывают на наличие отрицательной корреляции между сдельной оплатой труда и количеством высаженных деревьев — другими словами, чем больше человеку платят за посадку дерева, тем меньше деревьев он высаживает. Этот вывод противоречит стандартной экономической логике. Если вы платите работникам больше за каждое посаженное дерево, они должны работать усерднее. Согласно модели Паарша и Ширера, лесозаготовительные компании платят работникам сдельную ставку за каждое дерево так, что почасовая рыночная ставка заработной платы составляет 20 долларов в час. На основании этого допущения можно вывести следующую формулу расчета оплаты за одно дерево:
20 долларов = количество деревьев, высаженных за час × оплата за дерево.
Если человек посадит десять деревьев за час, то оплата за одно дерево составит 2 доллара, а если двадцать деревьев за час, то 1 доллар. Таким образом, модель указывает на наличие отрицательной корреляции между сдельной оплатой труда и количеством высаженных деревьев. Кроме того, она также говорит о том, что произведение сдельной ставки на количество деревьев равно постоянной величине.
[3] Доказательства того, что модели важнее людей, можно найти здесь: Dawes, 1979; Tetlock, 2005; Silver, 2012; Cohen, 2013. О предвзятости суждений читайте здесь: Kahneman, 2011.
[4] См. Slaughter, 2017 и Ramo, 2016.
[5] Согласно исследованиям, наиболее эффективные эксперименты и патенты в значительной степени черпают идеи из разных областей знаний. Анализ 35 миллионов научных работ показывает, что в долгосрочной перспективе междисциплинарные научные работы оказывают большее влияние (Van Noorden, 2015). Совокупность идей не обязательно является совокупностью моделей, но во многих случаях это действительно так — см. Jones, Uzzi, and Wuchty, 2008, а также Wuchty, Jones, and Uzzi, 2007. Фримен и Хуан (Freeman and Huang, 2015) в своей статье отмечают наличие корреляции между этническим многообразием и частотой цитирования. Если считать патенты наглядным подтверждением инноваций, то два отдельных направления исследований связывают многообразие типов мышления с успехом. В статье Ши, Адамич, Тсенга и Кларксона (Shi, Adamic, Tseng, and Clarkson, 2009) показано, что патенты, охватывающие разные категории, упоминаются чаще. Юн, Страмски, Беттанкур и Лобо (Youn, Strumsky, Bettencourt, and Lobo, 2015) указывают в своей статье на то, что действие большинства патентов распространяется на множество подкатегорий. Междисциплинарные исследования уверенно вышли на такой уровень, что социологи в целом цитируют работы из других научных дисциплин чаще, чем из своей области.
[6] См. Box and Draper, 1987.
[7] См. Page, 2010a.
[8] Я не приравниваю знания к моделям, а говорю о том, что модели могут отражать знания и обеспечивать надежный способ распространения соответствующих представлений. Термин «знание» имеет множество значений и включает в себя, помимо прочего, такие навыки, как игра в теннис, французкий язык и составление контрактов. Я использую более узкое определение. С более широкой концепцией можно ознакомиться здесь: Adler, 1970.
[9] Это приближенное значение можно получить на основании предельной скорости летящих парашютистов, достигающей почти 320 километров в час. Предельная скорость зависит от массы. Предположим, масса парашютиста в 400 раз больше массы игрушечного гепарда. Квадратный корень из 400 равен 20. Следовательно, предельная скорость игрушечного гепарда равна 320 километрам в час, деленным на 20, или примерно 16 километрам.
[10] Он был прав. Для справки: Фресно на 30 процентов больше Исландии. В книге Эрика Болла и Джозефа ЛиПумы (Ball and LiPuma, 2012) рассказывается о том, как можно использовать научные выводы в мире бизнеса.
[11] См. Lo, 2012. Общие аргументы можно найти здесь: Myerson, 1992.
[12] Различные версии этой истории встречаются в работах Уильяма Джеймса, Стивена Хокинга и Антонина Скалиа.
ГЛАВА 2
[1] См. Epstein 2008, где представлена более детальная классификация причин для моделирования. В книге Чарльза Лейва и Джеймса Марча (Lave and March, 1975) описаны три направления применения моделей: объяснение происходящих событий, прогнозирование новых явлений, создание и разработка систем. Косвенным образом авторы также выступают за использование моделей для исследований.
[2] См. Harte, 1988. Эта классификация заимствована из статьи Джеймса Джонсона (Johnson, 2014) о сферах применения моделей в общественных науках. Эти два подхода также известны как галилеева и минималистская идеализации. См. Weisberg, 2007. Более подробную информацию об аналогиях можно найти здесь: Pollack, 2014; Hofstadter and Sander, 2013. В книге Дугласа Хофштадтера и Эммануэля Сандера сказано, что аналогия выступает в роли «топлива и огня» мышления. Подробное описание классов моделей можно найти в книге: Schelling, 1978, 87. В блоге Дэниела Литтла Understanding Society («Понимание общества») представлены основные положения социальной онтологии.
[3] См. Arrow, 1963. Общий упорядоченный список альтернатив возможен при ограничении индивидуальных списков предпочтений. Например, если бы у каждого человека был один и тот же список предпочтений, то существовал бы и общий список. В целом у нас нет способа преобразовать индивидуальный список предпочтений в согласованный общий список.
[4] Лучшие умы моего поколения, несомненно, заметили, что я позаимствовал фразу «это действительно было» из поэмы Howl («Вопль»). См. Bickel, Hammel, and O’Connell, 1975.
На представленном ниже рисунке показан один из множества примеров того, как включение дополнительной вершины приводит к сокращению общей длины ребер графа. На графе слева четыре вершины соответствуют углам квадрата, а на графе справа добавлена пятая вершина в центре. Если длина стороны квадрата равна 1, общая длина ребер левого графа равна 3, а общая длина ребер правого графа равна 4 × 0,71, что меньше 3.
Парадокс Симпсона возникает, когда заявления на факультеты с более высоким процентом зачисления подает больше абитуриентов женского пола, чем мужского. Например, рассмотрим университет, в котором есть медицинская и ветеринарная школы. Предположим, в медицинскую школу подают заявления 900 абитуриентов мужского пола, и 480 (или 53 процента) из них зачисляются, и 300 абитуриентов женского пола, и 180 (или 60 процентов) из них зачисляются, а в ветеринарную школу подают заявления 100 абитуриентов мужского пола, и 20 (или 20 процентов) из них зачисляются, и 300 абитуриентов женского пола, и 90 (или 30 процентов) зачисляются. В каждой школе на обучение принято больше женщин, но в целом зачислено 50 процентов мужчин (500 из 1000) и только 45 процентов женщин (270 из 600).
В качестве примера парадокса Паррондо рассмотрим следующую ситуацию. Предположим, первая ставка всегда проигрывает 1 доллар, а вторая ставка проигрывает 2 доллара в любом периоде, номер которого не делится на три, и выигрывает 3 доллара в периоды 3, 6, 9, 12 и так далее. Каждая ставка обеспечивает ожидаемый проигрыш, но если вы будете делать вторую ставку только в те периоды, когда она выигрывает, а первую ставку — в остальные периоды, то будете выигрывать по 1 доллару каждые три периода.
[5] См. Kooti, Hodas, and Lerman, 2014.
[6] Предположим, каждый человек получает одинаковый доход I и выплачивает налоги по неизменной ставке налога t. Пусть c обозначает процент сокращения налоговой ставки, а r — повышение уровня дохода. Текущий объем налоговых поступлений в государственный бюджет равен I · t. После снижения налогов объем налоговых поступлений составит I(1 + r) · t(1 − c). Объем налоговых поступлений в государственный бюджет увеличится тогда, и только тогда, когда I · t < I(1 + r) · t(1 − c). Перегруппировка членов неравенства дает r > c(1 + r).
[7] См. Ledyard, Porter, and Wessen, 2000, где представлена информация о рыночном механизме, обеспечивающем более эффективное решение многомерных задач полезной нагрузки.
[8] Я позаимствовал слово «непостижимо» у физика Юджина Вигнера (Eugene Wigner, 1960), который описывал математические модели, используемые в естественных науках, как непостижимо эффективные.
[9] См. Ziliak and McCloskey, 2008. В этой книге идет речь о способности моделей, используемых в общественных науках, объяснять вариацию.
[10] Информацию об истории аукциона частот можно найти здесь: Porter and Smith, 2007.
[11] См. Squicciarini and Voigtlander, 2015. В книге Джоэля Мокира (Mokyr, 2002) представлена исчерпывающая историческая информация о важности передачи знаний.
[12] См. www.treasury.gov/initiatives/financial-stability/Pages/default.aspx.
[13] Например, в середине 1990-х годов обанкротились около 60 процентов ресторанов, открывшихся в Колумбусе. Ни один из них не получил финансовой помощи от государства, да и не должен был получить. Здоровая рыночная экономика подразумевает вероятность банкротств. См. Parsa et al., 2005.
[14] Данные взяты из доклада МВФ о глобальной финансовой устойчивости за 2009 год. Сила связи основана на корреляции по стоимости портфеля ценных бумаг. Корреляция рассчитана исходя из предельных случаев — данных за те дни, когда эти учреждения демонстрировали особенно высокие или особенно низкие результаты. Этот показатель должен был отражать вероятность того, что банкротство одной компании повлечет за собой банкротство другой компании. В действительности корреляция по результатам работы могла быть следствием сходства инвестиционных портфелей или того, что один банк владел активами другого банка.
[15] См. Geithner, 2014.
[16] См. Weisberg, 2012. В этой книге описана модель залива Сан-Франциско и ее практическая ценность с точки зрения выбора курса действий.
[17] Исчерпывающую информацию об этом крушении можно найти здесь: Stone et al., 2014.
[18] Я благодарен Джошу Эпштейну за первый пример.
[19] См. Dunne, 1999 и Raby, 2001.
ГЛАВА 3
[1] См. Levins, 1966.
[2] Более подробное описание теоремы и вывод из нее можно найти здесь: Page 2007, 2017.
[3] Мудрость толпы — тема одноименной книги Джеймса Шуровьески (Suroweicki, 2006); о том, как лисы могут перехитрить ежей, можно прочитать в книге Филипа Тетлока (Tetlock, 2005); в статье Статиса Каливаса (Kalyvas, 1999) идет речь о неспособности политической науки предвидеть падение Советского Союза; информацию об использовании ансамблевых методов в области компьютерных наук можно найти здесь: Patel et al., 2011.
[4] Лу Хонг и Скотт Пейдж показывают в своей статье (Hong and Page, 2009), что независимые модели требуют уникального набора категорий. Другими словами, существует только один способ создания множества независимых прогнозов на основе модели бинарной категоризации.
[5] См. три мои книги, опубликованные ранее: «Различие» (The Difference — Page, 2008), «Разнообразие и сложность» (Diversity and Complexity — Page, 2010) и «Преимущества разнообразия» (The Diversity Bonus — Page, 2017) — в них подробно анализируется теорема о прогнозе разнообразия. Данные об экономических прогнозах можно найти здесь: Mannes, Soil, and Larrick, 2014.
[6] Рассмотрим четыре бунгало A, B, C и D, представленные на рисунке ниже, а также их рыночную стоимость. Выделим две категории на основании наличия в бунгало студии звукозаписи (отмечена на рисунке кружком над дверью). В бунгало A и B нет студий звукозаписи, поэтому относим их к одной категории, а в бунгало C и D есть, поэтому относим их ко второй категории.

Четыре бунгало и их рыночная стоимость
Сначала вычислим полную вариацию цен бунгало. Она равна сумме квадратов разности между каждым значением стоимости и средней стоимостью. Мы будем выполнять вычисления в тысячах долларов. Средняя стоимость четырех бунгало составляет 400, а значит, полная вариация равна 100 000:
Полная вариация = (200 − 400)2 + (300 − 400)2 + (500 − 400)2 + (600 − 400)2 = 100 000.
Для того чтобы вычислить убыток от категоризации, будем исходить из реального значения средней стоимости бунгало в каждой категории: 250 000 долларов в первой категории и 550 000 долларов во второй категории (бунгало, которые переделаны в студии звукозаписи). Категоризация относит к одной группе дома с разной стоимостью. Остаточная вариация равна убытку от категоризации: убыток от категоризации A & B = (200 − 250)2 + (300 − 250)2 = 5000 и убыток от категоризации C & D = (500 − 550)2 + (600 − 550)2 = 5000. Общий убыток от категоризации составляет 10 000.
Для того чтобы вычислить погрешность оценки, предположим, что модель прогнозирует цены в размере 300 000 долларов на бунгало A и B и 600 000 долларов на бунгало C и D. Погрешность оценки равна сумме квадратов разности между прогнозом по каждой категории и истинным средним. Погрешность оценки A & B = (300 − 250)2 + (300 − 250)2 = 5000 и погрешность оценки C & D = (600 − 550)2 + (600 − 550)2 = 5000. Общая погрешность оценки составляет 10 000.
Общая погрешность модели равна сумме квадратов разности между прогнозами и фактическими значениями стоимости:
погрешность модели = (200 − 300)2 + (300 − 300)2 + (500 − 600)2 + (600 − 600)2 = 20 000.
Обратите внимание, что погрешность модели равна сумме убытка от категоризации и погрешности оценки.
[7] См. Brock and Durlauf, 2001, где идет речь о двумерной модели социального взаимодействия в виде спинового стекла. В статье Эдуарда Глазера, Брюса Сасердота и Хосе Шенкмана (Glaeser, Sacerdote, and Schenkman, 1996) описана одномерная модель, используемая для анализа преступности. В книге Дрю Фуденберга и Дэвида Ливайна (Fudenberg and Levine, 2006) представлена экономическая модель головного мозга.
[8] Ниархос был не первым кораблестроителем, попытавшимся извлечь пользу из масштаба. В 1858 году Изамбард Кингдом Брюнель (легендарный британский инженер, построивший Большую западную железную дорогу) спустил на воду корабль длиной более 211 метров под названием SS Great Eastern. Проект оказался провальным. Отсутствие гидродинамических моделей привело к неэффективной общей конструкции корабля. Он оказался пригодным к плаванию только на самых низких скоростях. В конечном счете Great Eastern использовали для прокладки трансатлантических кабелей. В книге Джеффри Уэста (West, 2017) рассказывается, как использовать множество моделей для проектирования кораблей.
[9] Индекс массы тела54 можно рассчитывать следующим образом: BMI = 703 × на вес (в фунтах) ÷ на квадрат роста (в дюймах).
[10] Рост Леброна Джеймса — 203 сантиметра, а вес — 113 килограммов, значит, его BMI равен 27,5. BMI Кевина Дюранта (рост 206 сантиметров и вес 107 килограммов) равен25,2. У Эштона Итона (золотой медалист по десятиборью Олимпийских игр 2012 года), рост которого 185 сантиметров, а вес 84 килограмма, BMI составляет 24,4 — на грани избыточного веса. У его предшественника, золотого медалиста Олимпийских игр 2008 года по десятиборью Брайана Клэя, BMI равен 25,8.
[11] См. Flegal et al., 2012.
[12] Мы исходим из того, что длина мыши 3 дюйма, высота 1 дюйм и ширина 1 дюйм, а слон имеет высоту 10 футов, длину 10 футов и ширину 5 футов. Площадь поверхности слона составляет 400 квадратных футов, или 57 600 квадратных дюймов. Объем слона — 500 кубических футов, или 864 000 кубических дюйма.
[13] Джеффри Уэст и его коллеги разработали более сложные и точные модели, согласно которым уровень метаболизма должен меняться пропорционально массе в степени три четверти. См. West, 2017.
[14] Результаты контролируемых экспериментов, в ходе которых отправлялись идентичные резюме, но менялись имена, показали, что женщины получают предложения о более низкой оплате и более низкие оценки по сравнению с мужчинами (см. Moss-Racusin et al., 2012).
[15] Вероятность того, что мужчина займет должность СЕО, равна вероятности получения пятнадцати повышений подряд, или 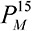 . Вероятность того, что мужчина займет должность СЕО, в сравнении с женщиной (коэффициент вероятности), равна
. Вероятность того, что мужчина займет должность СЕО, в сравнении с женщиной (коэффициент вероятности), равна 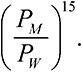 С учетом наших предположений относительно вероятности 50 и 40 процентов, коэффициент вероятности равен (1,25)15 = 28,4.
С учетом наших предположений относительно вероятности 50 и 40 процентов, коэффициент вероятности равен (1,25)15 = 28,4.
[16] См. Dyson, 2004.
[17] См. Breiman, 1996.
ГЛАВА 4
[1] См. Haidt, 2006.
[2] Предположим, человек располагает бюджетом M, цена одной единицы потребительского товара составляет 1 доллар, а цена единицы жилья равна PH. Бюджетное ограничение можно записать как M = C + PH · H. Это подразумевает, что C = M − PH − H; в таком случае мы можем описать полезность как функцию H:
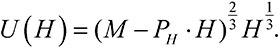
Чтобы найти значение H, максимизирующее полезность, возьмем производную по H и приравняем ее к нулю. Это требует применения правила дифференцирования сложных функций:
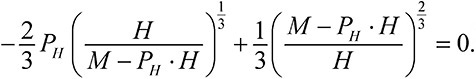
Перемещение первого члена на другую сторону уравнения и приведение к общему знаменателю дает следующее:
2PH · H = (M − PH · H).
Подстановка 2PH · H вместо (M − PH · H) в уравнении бюджетного ограничения дает M = 2PH · H + PH · H, или M = 3PH · H. Отсюда следует, что человек тратит на жилье третью часть дохода.
[3] В США это достаточно хорошее приближение. Источник: Бюро трудовой статистики США (US Bureau of Labor Statistics), 2013.
[4] Формально теорема записывается следующим образом: пусть X = {A, B, C, …, N} обозначает конечное множество результатов, и пусть лотерея представляет собой распределение вероятностей по результатам: L = (pA, pB, …, pN). Если предпочтения (n) по лотереям удовлетворяют условию полноты (любые две лотереи L и M можно сопоставить), транзитивности (если LnM, а MnN, тогда LnM), независимости (если LnM, то для произвольной лотереи N и любой вероятности p > 0, лотерея (pL + (1 − p)NnpM + (1 − p)N) и непрерывности (если LnM и MnN), тогда существует вероятность p такая, что pL + (1 − p)NnM, а значит, предпочтения можно представить в виде непрерывной функции полезности, которая присваивает каждой лотерее действительное значение, то есть полезность. Схема доказательства выглядит так. Предположим, существует лучший результат B и худший результат W. Примем полезность результата B равной 1, а полезность результата W равной нулю. Согласно аксиоме непрерывности, при наличии любого другого результата A существует вероятность p, которая делает человека безразличным к выбору между получением результата B с вероятностью p и получением результата W с вероятностью (1 − p). Запишем это как AnpB + (1 − p)W. Затем присвоим полезности результата A значение, равное p. Небольшой самоанализ (и немного математики) показывает, что чем больше человеку нравится результат (или лотерея), тем больше будет значение p. Почти как по волшебству мы превратили упорядоченные списки в числа. Полное доказательство ищите здесь: Von Neumann and Morgenstern, 1953.
[5] См. Rust, 1987.
[6] См. Camerer, 2003.
[7] См. Harstad and Selten, 2013.
[8] См. Myerson, l999, где идет речь об использовании рационального выбора в качестве эталона.
[9] Результаты первых исследований можно найти здесь: Camerer, Loewenstein, and Prelec, 2005.
[10] См. Kahneman, 2011, где дается краткий обзор этого исследования.
[11] Первая работа Open Science Collaboration, опубликованная в 2015 году, повлекла за собой другие попытки проверки воспроизводимости, показавшие аналогичные результаты.
[12] О необходимости более широкого многообразия в совокупности субъектов исследований идет речь в статье: Medin, Bennis, and Chandler, 2010.
[13] См. Berg and Gigerenzer, 2010. Авторы статьи полностью поддерживают эту линию критики, утверждая, что это подрывает психологические модели, основанные на математике.
[14] См. Kahneman and Tversky, 1979.
[15] Представление альтернатив в виде выгоды: курс лечения A точно спасет 40 процентов пациентов. Курс лечения B с 50-процентной вероятностью спасет всех. Представление альтернатив в виде потери: курс лечения A’ однозначно приведет к смерти 60 процентов пациентов. При проведении курса лечения B’ с вероятностью 50 процентов не умрет никто и с вероятностью 50 процентов умрут все. Согласно теории перспектив, большинство врачей выбирают курс лечения A при представлении альтернатив в виде выгоды и курс лечения B’ — в виде потери.
[16] Первые работы, в которых идет речь о последствиях гиперболического дисконтирования: Thaler, 1981 и Laibson, 1997.
[17] Формулу гиперболического дисконтирования можно записать в более обобщенной форме:
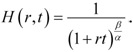
[18] См. Gigerenzer and Selten, 2002.
[19] См. Gode and Sunder, 1993.
[20] См. Gigerenzer and Selten, 2002.
[21] В своей лекции по случаю вручения Нобелевской премии Вернон Смит отметил следующее: «Экологическая рациональность использует умозаключения (рациональную реконструкцию) для анализа поведения людей на основе их опыта и знаний, проистекающих из народной мудрости. Люди придерживаются правил, не будучи способными их сформулировать, но эти правила можно открыть». См. Smith, 2002.
[22] См. Arthur, 1994.
[23] См. Lucas, 1976 и Campbell, 1976.
[24] См. de Marchi, 2005, где идет речь о том, как модели позволяют определить, что может произойти. Информацию о моделях, основанных на уравнениях, и моделях, основанных на правилах, в которых акторы задействуют различные варианты поведения в аналогичных играх, можно найти здесь: Gilboa and Schmiedler, 1995 и Bednar and Page, 2007, 2018.
ГЛАВА 5
[1] При наличии множества данных {xi, …, xN} дисперсия равна среднему квадрату отклонения от математического ожидания μ, что можно записать так:
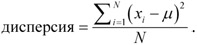
Стандартное отклонение равно квадратному корню из среднего квадрата отклонения от математического ожидания μ:
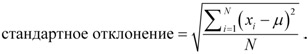
[2] Существует ряд достаточных условий. Наиболее общее условие, условие Линдеберга, требует, чтобы доля полной вариации любой случайной величины стремилась к нулю по мере увеличения количества случайных величин.
[3] См. Lango et al., 2010.
[4] В общем случае при наличии независимых случайных величин мы имеем следующие выражения:
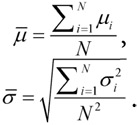
Полагая σi = σ для всех i, получим 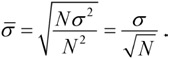
[5] В книге Говарда Уэйнера (Wainer, 2009) дается более глубокий анализ вариантов выбора политического курса.
[6] Пороговое значение в два стандартных отклонения (значимость 5 процентов) — спорное правило, однако именно его обычно применяют социологи. Большой коэффициент, значимый на уровне 6 процентов, скорее всего, заслуживает большего внимания, чем маленький коэффициент со значимостью 4,9 процента. СМ. Ziliak and McCloskey, 2008.
[7] См. Gawande, 2009.
[8] Распределение произведений случайных величин называется логарифмически нормальным потому, что логарифм такого распределения подчиняется нормальному закону. Вот краткое описание логики того, почему это происходит. Во-первых, представим произведение чисел y = x1 · x2 · x3 · … · xn в виде членов, записанных как степень 10:
10log10(y) = 10log10(x1) · 10log10(x2) · 10log10(x3) · ... · 10log10(xn) = 10log10(x1) + log10(x2) + log10(x3) + ... + log10(xn).
Затем возьмем десятичный логарифм от обеих частей уравнения, для того чтобы получить следующее:
log10(y) = log10(x1) + log10(x2) + log10(x3) + … +log10(xn).
Таким образом, логарифм величины y можно записать как сумму логарифмов случайных величин, логарифмы которых также являются случайными величинами, а если их дисперсия удовлетворяет условиям центральной предельной теоремы, то их сумма, равная log10(y), будет распределена по нормальному закону.
[9] См. Limpert, Stahel, and Abbt 2001.
[10] Эта идея была впервые сформулирована в книге Робера Гибрата «Экономическое неравенство». См. Gibrat, 1931.
ГЛАВА 6
[1] Информацию о последствиях и культурном значении этого наводнения можно найти в книге: Parrish, 2017.
[2] В этом числовом примере, позаимствованном из статьи Клосета, Янга и Гледича (Clauset, Young, and Gleditsch, 2007), используется показатель степени 2.
[3] Формальное описание моделей, представленных в данной главе, а также многочисленные примеры распределений по степенному закону ищите здесь: Newman, 2005.
[4] См. Newman, 2005 и Piantadosi, 2014.
[5] Константа C делает полную вероятность всех результатов равной 1. С учетом этого определения степенное распределение удовлетворяет условию масштабной инвариантности. Если мы изменим единицы измерения результатов, форма распределения не изменится.
[6] Эту вероятность можно вычислить, сначала определив вероятность того, что событие не произойдет на протяжении года. Если вероятность наступления события за день составляет 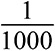 , то вероятность того, что оно не наступит в течение года, равна (0,999)365 = 0,69. Следовательно, вероятность того, что событие произойдет, составляет 31 процент. Вероятность того, что не произойдет событие, встречающееся один раз на миллион, рассчитывается аналогичным образом.
, то вероятность того, что оно не наступит в течение года, равна (0,999)365 = 0,69. Следовательно, вероятность того, что событие произойдет, составляет 31 процент. Вероятность того, что не произойдет событие, встречающееся один раз на миллион, рассчитывается аналогичным образом.
[7] См. Cederman, 2003; Clauset, Young, and Gleditsch, 2007; Roberts and Turcotte, 1998. Вероятность террористического акта с x погибших можно записать как постоянный член со значением примерно 0,06, разделенный на x в квадрате. В случае дискретного распределения, где x принимает только целые значения, распределение по степенному закону можно описать формулой: p(x) = 0,608x−2. Коэффициент 0,608 выбран так, чтобы сумма значений вероятности была равна 1: 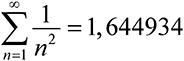 . Произведение 0,608 и 1,644934 равно 1.
. Произведение 0,608 и 1,644934 равно 1.
[8] В случае распределения по степенному закону мы берем логарифмы обеих сторон и преобразуем y = Cx−a в log(y) = log(C) − alog(x), то есть получаем линейную зависимость log(y) от log(x). Отобразив на графике значения log(y) и log(x), мы получим прямую линию. Что касается экспоненциального распределения y = C · A−x, то прологарифмировав обе стороны, получим log(y) = log(C) − xlog(A), а это означает, что log(y) линейно зависит от x. Следовательно, значение log(y) будет быстро снижаться по log(x), образуя вогнутый график.
[9] Взяв логарифм логнормального распределения, мы получим следующее уравнение: 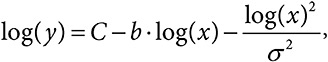 где σ — это натуральный логарифм стандартного отклонения логнормального распределения, косвенный показатель дисперсии распределения. В случае большого значения σ вклад log(x)2 будет незначительным до тех пор, пока значение log(x) не станет достаточно большим, чтобы вызвать спад на графике.
где σ — это натуральный логарифм стандартного отклонения логнормального распределения, косвенный показатель дисперсии распределения. В случае большого значения σ вклад log(x)2 будет незначительным до тех пор, пока значение log(x) не станет достаточно большим, чтобы вызвать спад на графике.
[10] Чтобы понять, как провести формальное различие между логнормальным распределением и распределением по степенному закону, см. рабочий доклад Бройдо и Клосета (Broido and Clauset, 2018). Авторы показывают, что многие сети, которые относят к категории степенных распределений, могут ими не быть.
[11] В статье Пьянтадоси (Piantadosi, 2014) описывается закон Ципфа в контексте частоты встречаемости слов, а также ряд моделей-кандидатов. Если распределение масштаба событий удовлетворяет степенному закону, то же самое можно сказать и о рангах. Общее доказательство сводится к следующему. Степенное распределение с показателем степени a на открытом интервале [1, ∞) имеет вид pa(x) = ax−a. Предположим, у нас есть 100 событий. Пусть SR обозначает ожидаемый масштаб события с порядковым номером R в списке, упорядоченном по убыванию масштаба. Вероятность события, более крупного, чем SR, должна быть равной 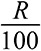 . Например, если R = 3, то вероятность события крупнее S3 должна составлять 3 процента. Следовательно,
. Например, если R = 3, то вероятность события крупнее S3 должна составлять 3 процента. Следовательно, 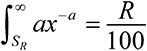 . Решая это уравнение, получим
. Решая это уравнение, получим 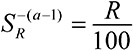 , что можно записать так:
, что можно записать так: 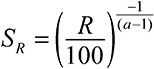 . В частном случае, когда a = 2, это выражение имеет следующий вид:
. В частном случае, когда a = 2, это выражение имеет следующий вид: 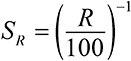 .
.
[12] См. Bak, 1996. Остается открытым вопрос о том, насколько широко можно применять эту модель. Ученые используют ее для объяснения экономических колебаний, количества погибших в ходе военных действий, террористических актов, прерывистого равновесия в процессе эволюции и транспортных заторов. См., например, Paczuski and Nagel, 1996; Sneppen et al., 1995.
[13] См. статью Салганика, Додда и Ваттса (Salganik, Dodd, and Watts, 2006), где представлены результаты первичного исследования, а также книгу Пола Ормерода (Ormerod, 2012), в которой содержится альтернативный анализ. Степенное распределение также подразумевает наличие множества мелких событий, на которые приходится бόльшая часть данного распределения вероятностей. Мелкие события могут объединиться и образовать экономическую ценность такого же масштаба, как и крупное событие. См. Anderson, 2008b. Интернет позволяет розничным торговцам формировать огромные каталоги книг, фильмов и музыки, даже если некоторые из них интересуют небольшое количество людей. Издатель, который продает 5 миллионов экземпляров бестселлера, зарабатывает столько же, сколько и издатель, продающий по 500 экземпляров каждой из 10 тысяч разных книг.
[14] Описание конкретной модели, которая показывает, как это может произойти, можно найти здесь: Denrell and Liu, 2012.
[15] Геологи измеряют магнитуду землетрясений по шкале Рихтера, определяя ее как логарифм масштаба землетрясения. Землетрясение с магнитудой 6 по шкале Рихтера в десять раз масштабнее землетрясения с магнитудой 5. Информацию о применении закона Ципфа для прогнозирования масштаба землетрясений, но не момента их наступления, ищите здесь: Merriam and Davis, 2009.
[16] См. Eliot, Golub, and Jackson, 2014, где подробно описана модель того, как усиление связанности может обусловить снижение вероятности банкротства.
[17] Обсуждение этого вопроса можно найти здесь: May, Levin, and Sugihara, 2008.
[18] См. Stock and Watson, 2003.
[19] Следующее объяснение представлено здесь: Carvalho and Gabaix, 2003.
[20] См. Clarida, Gall, and Gertler, 2000.
[21] Я благодарен Сету Ллойду за то, что указал мне на этот пример.
[22] Положим распределение заработной платы равным 100 000 долларов, умноженным на величину x , где p(x) = 2x−3 от 1 до ∞. Среднее значение величины x равно 2, а значит, распределение имеет математическое ожидание 200 000 долларов.
[23] См. Weitzman, 1979, где описывается модель, демонстрирующая этот результат в более общем виде.
[24] См. Bell et al, 2018.
ГЛАВА 7
[1] Ценные марочные вина, такие как Bordeaux (бордо), получают рейтинг, составленный экспертами. Кроме того, они имеют рыночную цену. Цены и рейтинги могут выступать в качестве косвенных показателей качества вин. Орли Ашенфельтер разработал подходящую (логарифмическую) линейную модель для определения качества вин Bordeaux с учетом количества осадков в зимний период, в период сбора урожая и средней температуры в сентябре (см. Ashenfelter, 2010). Логарифмически линейная модель выражает логарифм зависимой переменной в виде линейной суммы логарифмов независимых переменных:
log(y) = b0 + b1log(x1) + b2(x2).
Это выражение подразумевает, что зависимую переменную можно представить как произведение независимых переменных. Для этого можно возвести каждую сторону уравнения в степень e, что даст следующее уравнение:
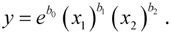
Логарифмирование превращает умножение в сложение, что позволяет использовать такой инструмент, как линейная регрессия. Если в качестве независимой переменной выступает цена марочного вина, модель Ашенфельтера имеет значение R в квадрате (то есть процент вариации, которую объясняет модель), равное 83 процентам. Как показывает опыт, данная модель предсказывает цены на вино точнее, чем эксперты по винам, использующие качественные оценки. Модель Ашенфельтера даже позволяет прогнозировать изменения в оценках экспертов. Известный оценщик вин Роберт Паркер сначала выставил винтажным винам Pomerol и St. Emilion урожая 1975 года оценку 95 баллов (из 100). Модель Ашенфельтера прогнозировала более низкий рейтинг качества этих вин. В 1983 году Паркер понизил свой рейтинг до уровня «ниже среднего», как и предсказывала модель Ашенфельтера. См. Storchmann, 2011.
[2] См. Xie, 2007.
[3] См. Ryall and Bramson, 2013, где представлено введение в каузальные модели.
[4] Майкл Мобуссин в своей книге (Mauboussin, 2012) показывает, как это уравнение помогает принимать правильные управленческие решения.
[5] См. Bertrand and Mullainathan, 2001.
[6] См. Shapiro, Meschede, and Osoro, 2013. Авторы этой работы не смешивают такие понятия, как корреляция и каузация. Если между двумя переменными нет корреляции, то не следует ожидать наличия между ними причинно-следственных связей.
[7] Для того чтобы найти оптимальную линию для классификации данных, многие аналитики используют машину опорных векторов (support vector machine, SVM) — подход, аналогичный регрессии. Ключевое отличие состоит в том, что машина опорных векторов находит линию, которая максимизирует расстояние до ближайших точек в каждом наборе, разделяющем данные на положительные и отрицательные величины. Если ни одной такой линии не существует (как часто бывает), устанавливаются штрафы за нарушения. Напротив, регрессия сравнивает расстояние до каждой точки данных и минимизирует общее расстояние.
ГЛАВА 8
[1] См. Arthur, 1994.
[2] Тридцать удвоений — это 230, что больше 1 миллиарда.
[3] См. Karlsson, 2016, где можно изучить контекст распространения гиппопотамов Эскобара.
[4] См. Ebbinghaus, 1885.
[5] Исследователи головного мозга обнаружили, что даже для шоколада существует определенный объем потребления, при котором люди начинают испытывать к нему отвращение (Small et al., 2001).
[6] Этот пример, подобно многим другим примерам, я позаимствовал из книги: Lave and March, 1975.
[7] Предположим, вы инвестируете 3000 долларов в год. Если бы цена акций была неизменной и составляла 15 долларов, то вы могли бы ежегодно покупать по 200 акций. Если бы цена акций колебалась от 20 до 10 долларов, то в год с высокой ценой вы могли бы купить 150 акций, а в год с низкой ценой 300 акций. В среднем вы покупали бы 225 акций, что больше количества акций, которые вы могли бы купить при неизменной цене.
[8] Ключевое предположение состоит в том, что в функции производства Кобба-Дугласа показатели степени a и (1 − a) дают в сумме 1. Это указывает на то, что при удвоении количества работников и объема капитала совокупный объем производства также удвоится.
объем производства = постоянная · (2 · работники)a(2 · капитал)(1 − a).
Раскрытие скобок и перегруппировка членов уравнения дают удвоение объема производства:
объем производства = 2 · постоянная · работникиa · капитал(1 − a).
[9] Объем производства за день на протяжении второго года равен 100√2 = 141. На третий год он составит 100√3 = 173. Темп роста равен процентному увеличению объема производства из года в год.
[10] Расчеты выглядят так. Год 2: машины — 290, объем производства — 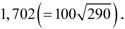 Инвестиции составляют (0,2) · 1702 = 340, а значит, потребление равно 1362. Амортизация составляет (0,1) · 290 = 29. Год 3: машины — 601, объем производства —
Инвестиции составляют (0,2) · 1702 = 340, а значит, потребление равно 1362. Амортизация составляет (0,1) · 290 = 29. Год 3: машины — 601, объем производства — 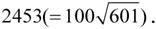 Инвестиции равны (0,2) · 2453 = 491, а значит, потребление равно 1962. Амортизация составляет (0,1) · 601 = 60.
Инвестиции равны (0,2) · 2453 = 491, а значит, потребление равно 1962. Амортизация составляет (0,1) · 601 = 60.
[11] Долгосрочное равновесие можно определить, вычислив значение M*, при котором 0,2 · 100√M* = 0,1M*. Это происходит при M* = 40 000.
[12] В полной модели Солоу вместо функций квадратного корня используется параметр a (как в модели Кобба-Дугласа), а также учитывается рынок труда.
[13] Для того чтобы вычислить равновесие, будем исходить из того, что инвестиции равны амортизации: s · A√L · √K* = d · K*. Следовательно, равновесное количество машин K* удовлетворяет уравнению 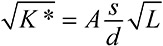 . Подстановка этого выражения в формулу функции объема производства дает такой объем производства
. Подстановка этого выражения в формулу функции объема производства дает такой объем производства 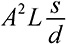 .
.
[14] Роберт Гордон (Gordon, 2016) придерживается пессимистического взгляда на то, что новые технологии, которые появятся в ближайшем будущем, обусловят существенное повышение показателя A. Модель Пола Ромера (Romer, 1986) исходит из того, что рост связан с увеличением разнообразия товаров: по мере роста экономики увеличивается и их ассортимент. Мартин Вейцман (Weitzman, 1998) в явном виде моделирует процесс генерирования и рекомбинации идей.
[15] Информацию о разрыве между появлением новой технологии и ее внедрением можно найти здесь: Arthur, 2011.
[16] Например, страны, в которых деревни так и не были подключены к телефонным линиям, смогли построить радиовышки и обеспечить услуги мобильной связи. Александр Гершенкрон (Gerschenkron, 1952) называет это преимуществом отсталости.
[17] Easterly and Fischer, 1995.
[18] В своей книге «Капитал в XXI веке» Тома Пикетти (Piketty 2014) показывает, что средний рост мирового ВВП за период с 1700 по 2012 год составил всего 1,6 процента, а также что половина этого роста обусловлена увеличением численности населения. Применив правило 72 к темпу роста 0,8 процента, мы обнаружим, что за более чем 300-летний период средний уровень жизни вырос примерно в 10 раз.
ГЛАВА 9
[1] Это значение найдено путем умножения 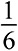 вероятности того, что гребец увеличит ценность, на его ожидаемую дополнительную ценность, которая равна
вероятности того, что гребец увеличит ценность, на его ожидаемую дополнительную ценность, которая равна 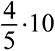 плюс
плюс 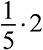 . Обратите внимание, что значения вектора Шепли дают в сумме 10, общую ценность игры.
. Обратите внимание, что значения вектора Шепли дают в сумме 10, общую ценность игры.
[2] Формальные расчеты таковы: две из шести идей Аруна уникальны, одна также предложена Бетти и три — всеми игроками. Если Арун входит в состав группы первым, что происходит с вероятностью 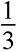 , он создает ценность 6. Если он входит в группу вторым и предлагает две уникальные идеи, ни одна из этих идей не принадлежит всем троим игрокам, поэтому у него есть один шанс из двух войти в состав группы до Бетти и предложить еще одну идею. Таким образом, Арун прибавляет 2,5 идеи. В случае присоединения к группе третьим он добавляет обе уникальные идеи. Следовательно, значение ценности Аруна по Шепли составляет 3,5. Бетти предлагает четыре идеи, которыми поделился еще один человек, и три идеи, предложенные всеми игроками. Следовательно, ее значение ценности по Шепли равно 3. И наконец, Карлос предлагает три идеи, выдвинутые еще одним человеком, и три идеи, предложенные всеми игроками. Ценность Карлоса по Шепли составляет 2,5. Обратите внимание, что значения вектора Шепли дают в сумме 9, общее количество идей.
, он создает ценность 6. Если он входит в группу вторым и предлагает две уникальные идеи, ни одна из этих идей не принадлежит всем троим игрокам, поэтому у него есть один шанс из двух войти в состав группы до Бетти и предложить еще одну идею. Таким образом, Арун прибавляет 2,5 идеи. В случае присоединения к группе третьим он добавляет обе уникальные идеи. Следовательно, значение ценности Аруна по Шепли составляет 3,5. Бетти предлагает четыре идеи, которыми поделился еще один человек, и три идеи, предложенные всеми игроками. Следовательно, ее значение ценности по Шепли равно 3. И наконец, Карлос предлагает три идеи, выдвинутые еще одним человеком, и три идеи, предложенные всеми игроками. Ценность Карлоса по Шепли составляет 2,5. Обратите внимание, что значения вектора Шепли дают в сумме 9, общее количество идей.
[3] Альтернативный индекс влияния участников голосования, индекс Банцафа-Пенроуза, определяет общее количество партий, которые могут стать ключевыми при наличии всех возможных побеждающих коалиций, и присваивает каждой партии значение ценности, равное числу случаев, когда партия становилась ключевой, деленному на количество партий. См. Banzhaf, 1965.
[4] Формальный анализ можно найти здесь: Groseclose and Snyder, 1996.
ГЛАВА 10
[1] В книге Марка Ньюмана (Newman, 2010) представлено всестороннее исследование сетей. Информацию о сетевых эффектах в социологии ищите здесь: Jackson 2008 и Tassier, 2013.
[2] В случае любого узла его минимальные пути имеют длину 1 к 4 узлам, длину 2 к 4 узлам и длину 3 к 4 узлам, что дает в общей сложности 12 узлов на минимальных путях от каждого узла. В среднем минимальные пути от того или иного узла ведут к еще одному узлу. Следовательно, среднее значение промежуточности каждого узла составляет 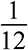 . В силу симметрии все узлы должны иметь одинаковую промежуточность.
. В силу симметрии все узлы должны иметь одинаковую промежуточность.
[3] Обзор алгоритмов обнаружения сообществ можно найти здесь: Newman, 2010. Способы разделения, созданные этими алгоритмами, скорее всего, отличаются по причине множества возможностей. Сеть из 100 узлов может быть разделена на составные части 190 миллионами способов. Учитывая случайный характер последовательности удаления звеньев, один и тот же алгоритм часто дает разные способы разделения. Использование множества алгоритмов и неоднократное применение одного алгоритма повышают надежность сделанных выводов.
[4] Из центральной предельной теоремы нам известно, что значения степени будут распределены по нормальному закону, а среднее значение составит 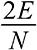 , поскольку каждое звено связывает два узла.
, поскольку каждое звено связывает два узла.
[5] Watts and Strogatz, 1998.
[6] Формальный анализ моделей формирования сетей представлен здесь: Newman, 2010.
[7] Ugander et al., 2011.
[8] Пусть в сети из N человек di равно количеству соседей узла i, то есть степени этого узла. Среднюю степень 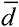 можно описать так:
можно описать так:
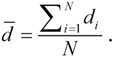
Средняя степень равна ожидаемому количеству соседей узла. При подсчете среднего числа соседей соседей узел со степенью di будет подсчитан di раз, по одному разу для каждого соседа. Следовательно, общее количество соседей N2 узла может быть выражено так:
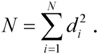
Для того чтобы получить среднюю степень соседей узла, необходимо разделить полученное значение на общее количество соседей, которое равно 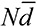 . Таким образом, достаточно показать:
. Таким образом, достаточно показать:
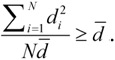
Это выражение можно записать как:
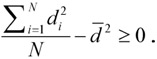
Член в левой части равен дисперсии распределения значений степени. Если у любых двух узлов разная степень, распределение значений степени имеет положительную дисперсию; следовательно, средняя степень соседей узла превышает среднюю степень самого узла.
[9] Формальная модель представлена здесь: Eom and Jo, 2014.
[10] Dodds, Muhamad, and Watts, 2003.
[11] Newman 2010, Jackson 2008.
[12] См. Granovetter, 1973.
[13] Количество друзей четвертой степени рассчитывается посредством сложения следующих восьми наборов узлов: C · R · C · R = 4 000 000, C · R · R · C = 4 000 000, R · C · R · C = 4 000 000, C · R · R · R = 800 000, R · C · R · R = 800 000, R · R · C · R = 800 000, R · R · R · C = 800 000 и R · R · R · R = 160 000.
[14] Albert, Albert, and Nakarado, 2004.
[15] См. Groysberg, 2012. Модель полос удачи и неудачи объясняет отсутствие успеха как регрессию к среднему значению.
[16] В книге Рональда Берта (Burt, 1995) идет речь о важности заполнения структурных пустот.
[17] Анализ последствий формирования сетей преподавателей можно найти здесь: Frank et al., 2018.
[18] Коалиции с ненулевым значением ценности — {A, B}, {B, C} и {A, B, C}. Ценность каждой из первых двух коалиций равна десяти. Дополнительная ценность третьей коалиции равна минус шести. Обособленная ценность этой коалиции равна четырнадцати, но она включает в себя две другие коалиции, ценность каждой из которых составляет десять. Следовательно, ценность коалиции равна четырнадцати минус двадцать: −6 = (14 − 10 − 10). Далее мы можем присвоить следующие значения вектора Шепли каждому игроку в каждой коалиции: коалиция {1, 2}: игрок 1 — 5, игрок 2 — 5; коалиция {2, 3}: игрок 2 — 5, игрок 3 — 5; коалиция {1, 2, 3} — игрок 1 — −2, игрок 2 — −2, игрок 3 — −2. Сумма этих значений дает вектор Майерсона.
ГЛАВА 11
[1] В этих моделях используются дискретные временные интервалы, такие как дни или недели, а также разностные уравнения, описывающие количество инфицированных (или информированных) людей в будущем как функцию количества инфицированных (или информированных) людей в настоящий момент. Модели с непрерывным временем требуют дифференциальных уравнений и исчисления. Тем не менее в случае перехода на непрерывное время результаты наших моделей качественно не изменятся.
[2] Подстановка первого уравнения во второе дает следующее выражение: 36 000 = 20 000 + 20 000 – Pтрансл · 20 000, что сокращает выражение до 4000 = Pтрансл · 20 000, а значит Pтрансл = 0,2 и NPOP = 100 000.
[3] См. Griliches, 1988.
[4] Первоначальный объем продаж, I, равен 100 по каждому приложению. Сначала установим Pдиффуз = 0,4, а POP = 1000. Новый объем продаж за период 3 составит 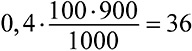 . Аналогичные расчеты дают объем продаж в будущих периодах. В случае второго набора данных пусть Pдиффуз = 0,3, а POP = 1 000 000. Новый объем продаж за второй период равен
. Аналогичные расчеты дают объем продаж в будущих периодах. В случае второго набора данных пусть Pдиффуз = 0,3, а POP = 1 000 000. Новый объем продаж за второй период равен 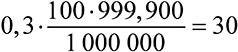 . Значения объема продаж за следующие периоды рассчитываются аналогичным способом.
. Значения объема продаж за следующие периоды рассчитываются аналогичным способом.
[5] Фрэнк Басс (Bass, 1969) называет людей, принимающих технологию или покупающих продукт, новаторами, а людей, которые их копируют, — имитаторами (последователи).
[6] Формальный вывод R0 начинается с наблюдения, что при малом количестве инфицированных людей число восприимчивых людей примерно равно размеру релевантной совокупности. Чтобы сократить число переменных, мы можем подставить размер релевантной совокупности вместо количества восприимчивых людей, а затем записать изменение количества инфицированных людей как линейную функцию от количества первоначально инфицированных (см. врезку). Значение R0 можно формально вывести следующим образом. В момент появления нового заболевания им заражается небольшое количество людей. Обозначим их как I0. Если подставить это значение в SIR-модель, количество инфицированных за период 1 составит:
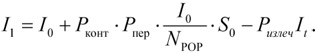
Если S0 приблизительно равно NPOP, будет получено такое выражение:
I1 = I0 + Pконт · Pпер · I0 − PизлечI0.
Следовательно, количество инфицированных увеличивается тогда и только тогда, когда Pконт · Pпер > Pизлеч, что эквивалентно выражению:
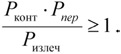
[7] Карантин сокращает вероятность контактов почти до нуля, снижая базовое репродуктивное число, но это обходится дорого. В начале ХХ столетия в США туберкулез (R0 ≈ 3) ежегодно уносил более сотни тысяч жизней. Штаты повысили налог на собственность, чтобы построить лечебницы для больных туберкулезом, поскольку хирургические методы (такие как удаление легкого, коллапс легких и их последующее наполнение с помощью шариков для пинг-понга) оказались неэффективными. См. Dubos, 1987.
[8] Для того чтобы вычислить порог вакцинации, необходимо учесть количество вакцинированных. Болезнь распространяется в случае контакта (вероятность Pконт) с невакцинированным человеком (вероятность (1 − V)) с вероятностью передачи Pпер, что дает следующее разностное уравнение за период 1:
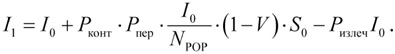
С помощью аппроксимации S0 = NPOP (как в случае вывода значения R0) это уравнение можно привести к такому виду:
I1 = I0 + Pконт · Pпер · I0 · (1 − V) · S0 − PизлечI0.
Количество инфицированных увеличивается тогда и только тогда, когда Pконт · Pпер · I0 · (1 − V) > Pизлеч. Это выражение можно записать так: R0(1 − V) ≤ 1. Разложение и перестановка членов дают следующее выражение: R0 − 1 < V · R0. Разделение обеих частей на R0 дает требуемый результат.
[9] Анализ SIR-модели и популяционного иммунитета представлен в книге: Tassier, 2013.
[10] Stein, 2011.
[11] Updike, 1960.
[12] Tweedle and Smith, 2012.
[13] См. Lamberson and Page, 2012b.
[14] Источник: wikinoticia.com.
[15] См. Christakis and Fowler, 2009.
[16] Сентола и Мейси (Centola and Macy, 2007) обозначают диффузию, требующую многократного воздействия, термином комплексное заражение.
ГЛАВА 12
[1] Более подробную информацию можно найти здесь: Smaldino, 2013.
[2] Логарифм числа x по основанию 2 равен степени, в которую необходимо возвести 2, чтобы получить x: log2 (4) = 2, log2 (2N) = N. В общем случае loga (x) равен степени, в которую необходимо возвести a, для того чтобы получить x. Таким образом, loga (ay) = y.
[3] Мы можем описать информационную энтропию в полном виде следующим образом:
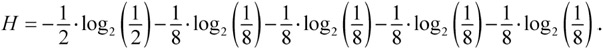
Это выражение упрощается до:
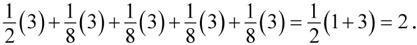
[4] Индекс разнообразия (величина, обратная сумме квадратов вероятностей) удовлетворяет первым двум аксиомам, а также аксиоме умножения. Следовательно, индекс разнообразия известного результата равен 1, а не 0 (см. Page, 2007, 2010a).
[5] Более подробное описание можно найти здесь: Wolfram 2001 или Page 2010a.
[6] Александер перечисляет пятнадцать таких свойств. Его идеи вместе с превосходными фотографиями представлены в четырех опубликованных им книгах: The Nature of Order, Book 1: The Phenomenon of Life, 2002 («Природа порядка», том 1: «Феномен жизни»); The Nature of Order, Book 2: The Process of Creating Life, 2002 («Природа порядка», том 2: «Процесс создания жизни»); The Nature of Order, Book 3: A Vision of a Living World, 2005 («Природа порядка, том 3: «Видение живого мира»); The Nature of Order, Book 4: The Luminous Ground, 2004 («Природа порядка», том 4: «Основа, излучающая свет»). Вторая книга имеет наибольшее отношение к обсуждаемой теме.
ГЛАВА 13
[1] Увлекательное путешествие по случайным блужданиям можно найти в книге: Mlodinow, 2009.
[2] См. Taleb, 2001.
[3] См. Turchin, 1998 и Suki and Frey, 2017.
[4] Закон больших чисел гласит, что среднее значение доли шаров сходится, тогда как центральная предельная теорема говорит о том, что распределение доли белых шаров подчиняется нормальному закону.
[5] Игрок, который делает 46 процентов результативных трехочковых бросков, сделает девять таких бросков подряд с вероятностью (0,469). Если игрок продолжает делать трехочковые броски, за десять лет карьеры в NBA (около 800 матчей) вероятность того, что он не сделает девять таких бросков подряд минимум один раз (0,999800) составляет 47 процентов.
Более трех десятилетий статистики искали ответ на вопрос, существует ли у баскетболистов и других профессиональных спортсменов феномен «счастливой руки», то есть действительно ли вероятность сделать результативный бросок в корзину или штрафной бросок не является независимой от успеха предыдущей попытки. Например, в статье Дональда Чанса (Chance, 2009) анализируется серия результативных ударов Джо Ди Маджо в 56 играх подряд. Рассматривая доказательствасуществования феномена «счастливой руки», следует принять во внимание поведение. Если игрок верит в то, что у него «счастливая рука», он может пытаться делать более сложные броски. Кроме того, если защитники считают, что у игрока «счастливая рука», они могут усилить защиту. Такую поведенческую реакцию можно учесть, присвоив броскам уровень сложности. Гилович, Тверски и Валлон (Gilovich, Tversky, and Vallone, 1985) не нашли никаких доказательств существования феномена «счастливой руки». Миллер и Санхурхо (Miller and Sanjurjo, 2015) обнаружили ошибку логического вывода в предыдущих вычислениях условных вероятностей, продемонстрировав, что результаты предыдущих исследований, указывавшие на отсутствие феномена «счастливой руки», на самом деле подтверждают эту гипотезу. Ошибка предыдущего анализа была обусловлена методикой формирования выборки. В ходе анализа были собраны последовательности попаданий и промахов множества игроков. Затем исследователи вычислили вероятность того, что за произвольно выбранной серией попаданий в корзину последует очередное попадание. Эта процедура формирования выборки содержит неочевидное статистическое смещение, которое можно обнаружить посредством анализа ситуации, когда большое количество игроков делают по четыре броска, и все броски имеют равную вероятность попадания или промаха. Существует шестнадцать возможных последовательностей попаданий и промахов. Пусть символ B (basket) обозначает попадание, а M (missed shot) — промах. Шесть из шестнадцати последовательностей содержат два попадания подряд, после которых следует еще один бросок: BBBB, BBBM, MBBB, BBMB, BBMM и MBBM. Они образуют выборку случаев, когда за двумя попаданиями подряд следует третий бросок. В последовательности BBBB, независимо от выбранной комбинации двух B подряд, вероятность попадания равна 100 процентам. В последовательности MBBB вероятность того, что B последует за BB, также равна 100 процентам. В последовательности BBBM вероятность промаха M после двух попаданий BB равна 50 процентам. И наконец, в последовательностях BBMB, BBMM и MBBM промах M всегда следует за попаданием B. Определение среднего по всем шести последовательностям попаданий и промахов дает условную вероятность того, что промах M последует за попаданием B:
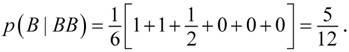
Смещение возникает из-за наличия двух комбинаций BB, которые можно выбрать в последовательности BBBB, но только одну в других последовательностях, таких как BBMB. Процедура формирования выборки делает выбор каждой из двух комбинаций в последовательности BBBB вдвое менее вероятным по сравнению с одной комбинацией в последовательности BBMB. Из этого смещения следует, что, если бы феномена «счастливой руки» не существовало, процедура формирования выборки показала бы, что за попаданиями чаще следуют промахи. Тот факт, что этого не произошло, означает, что в действительности после попаданий с большей вероятностью следуют очередные попадания.
[6] Мэдофф на протяжении десятилетий объявлял о ежемесячной положительной доходности в размере 1,5 процента. Он утверждал, что доходность его инвестиций растет каждый месяц, независимо от изменений на более широком рынке. Обеспечивать положительные показатели доходности во время экономического спада труднее, чем превзойти рынок. Когда рынок падает, опережать его можно, но при этом демонстрируя отрицательную доходность. Мэдофф объявлял о положительной доходности в период падения рынка на протяжении более восьмидесяти месяцев. Если сделать очень смелое предположение о том, что Мэдофф каким-то образом смог обеспечивать положительную доходность даже тогда, когда более широкий рынок переживал падение в течение трех четвертей этого периода, его шансы на успех на протяжении восьмидесяти месяцев подряд (0,7580) составляют 1 на 10 миллиардов.
[7] Стандартное отклонение можно вычислить с учетом того факта, что случайное блуждание представляет собой сумму идентичных, независимых случайных величин. Каждая из них имеет нулевое среднее значение и принимает значение либо +1, либо −1. Установив σ = 1 и применив формулу квадратного корня из дисперсии к сумме, можно получить требуемый результат.
[8] Формальное доказательство можно найти здесь: Newman, 2005.
[9] См. Levinthal, 1991 и Axtell, 2001.
[10] См. Newman, 2005 и Sneppen et al., 1995.
[11] Размер озера измеряется по площади его поверхности. Наша модель позволяет получить диаметр, подчиняющийся степенному закону. Площадь поверхности озера равна постоянной, умноженной на квадрат диаметра, а значит, площадь поверхности также распределена по степенному закону. См. Downing et al., 2006.
[12] На сбалансированном колесе рулетки все карманы имеют равную вероятность. Если у стола есть хотя бы небольшой наклон, то шарик, скорее всего, вылетит за внешний край, когда направится вверх. О том, как Дойн Фармер, Норман Паккард и их друзья сконструировали миниатюрный компьютер, чтобы воспользоваться этим явлением и победить рулетку, читайте здесь: http://en.wikipedia.org/wiki/Eudaemons.
[13] После N ставок ожидаемое значение этого случайного блуждания равно 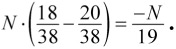 Учитывая, что вероятность выигрыша примерно равна
Учитывая, что вероятность выигрыша примерно равна 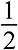 , можно записать стандартное отклонение этого значения как √N. Точное значение равно
, можно записать стандартное отклонение этого значения как √N. Точное значение равно 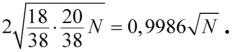
[14] Пил и Клаусет (Peel and Clauset, 2015) смоделировали каждую игру как одну последовательность и обнаружили, что последовательности набранных очков указывают на наличие антиперсистентности: команда, заработавшая очки последней, с меньшей вероятностью зарабатывает их в следующий раз. Учитывая, что команды поочередно овладевают мячом, так и должно быть.
[15] Baxter, 2009.
[16] Доказательство этого результата основано на вычислении вероятности возврата в исходную точку за N шагов и суммировании вероятностей по всем возможным значениям N. С полным доказательством можно ознакомиться здесь: http://www.math.cornell.edu/~mec/Winter2009/Thompson/randomwalks.html.
[17] См. Samuelson, 1964.
[18] См. Grossman and Stiglitz, 1980.
[19] См. Lo and MacKinlay, 2007. В книге Роберта Шиллера (Shiller, 2005) показано, что акции с относительно низким отношением рыночной цены к чистой прибыли в расчете на одну акцию обеспечивают доход, превышающий рыночные показатели.
[20] См. Mauboussin, 2012.
[21] Этот период с 1967 по 2017 год начался с максимума индекса S&P 500. На протяжении большинства таких периодов цены на акции растут быстрее, чем экономика.
ГЛАВА 14
[1] Hathaway, 2001.
[2] Pierson, 2004.
[3] Bednar and Page, 2018.
[4] См. Page, 2006.
[5] Вот краткое описание, взятое из статьи Скотта Пейджа (Page, 2006). Достаточно доказать, что вероятность извлечения K белых шаров за первые N периодов равна 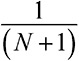 . Существует (N + 1) возможностей, поскольку K может принимать значение от нуля до N. Вероятность заданной последовательности из K белых шаров за N периодов можно записать как произведение N дробей. Знаменатели этих дробей — числа от 2 до N + 1, а числители — числа от 1 до K (белых шаров) и от 1 до (N + K) (серых шаров). Произведение числителей равно K!, умноженному на (N − K)!, а произведение знаменателей — (N + K)!. Эти вычисления дают вероятность определенной последовательности из K белых шаров. Количество возможных способов для упорядочения K белых шаров по N периодам равно
. Существует (N + 1) возможностей, поскольку K может принимать значение от нуля до N. Вероятность заданной последовательности из K белых шаров за N периодов можно записать как произведение N дробей. Знаменатели этих дробей — числа от 2 до N + 1, а числители — числа от 1 до K (белых шаров) и от 1 до (N + K) (серых шаров). Произведение числителей равно K!, умноженному на (N − K)!, а произведение знаменателей — (N + K)!. Эти вычисления дают вероятность определенной последовательности из K белых шаров. Количество возможных способов для упорядочения K белых шаров по N периодам равно 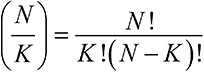 . Следовательно, общая вероятность получения ровно K белых шаров составляет:
. Следовательно, общая вероятность получения ровно K белых шаров составляет:
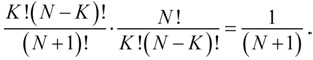
[6] Здесь используется доказательство от противного. Предположим, что вывод неверен и в долгосрочном периоде 60 процентов результатов белые. Отсюда следует, что в урне 60 процентов серых шаров. Однако это будет означать, что 60 процентов результатов серые, что является противоречием.
[7] См. Lamberson and Page, 2012b, где представлена более сложная модель, в которой используется энтропия как мера неопределенности.
[8] См. Lamberson and Page, 2012a.
[9] См. Page, 1997, где речь идет о том, как принимать решения по социально значимым проектам с положительным внешним эффектом.
[10] Значение VaR также можно вычислить как вероятность потери более чем 10 000 долларов в любой момент на протяжении года.
[11] Эти вычисления проистекают из того факта, что стандартное отклонение значений случайного блуждания длиной N равно √N; 2,5 процента соответствуют двум стандартным отклонениям.
ГЛАВА 15
[1] В физике модель локального большинства известна как модель Изинга. Модель локального большинства — это один из вариантов модели избирателя, которая подразумевает наличие выбранных в случайном порядке соседей разных размеров. См. Castellano, Fortunato, and Loreto, 2009.
[2] Для клеток, расположенных вдоль четырех граней, соединяем верхнюю грань с нижней, в результате чего образуется цилиндр, а затем соединяем левую грань с правой, чтобы получить тор (бублик).
[3] В альтернативных версиях модели локального большинства клетки могут активироваться одновременно или под воздействием стимула к обновлению, когда первыми совершают переход клетки, у которых подавляющее большинство соседей находятся в противоположном состоянии. Если клетки обновляют состояние одновременно, то модель локального большинства может порождать циклы.
[4] О модели аплодисментов стоя рассказывается в статье: Miller and Page, 2004.
[5] См. Bednar et al., 2010, где описана модель культуры, предусматривающая непротиворечивость действий в разных областях.
[6] Здесь тоже нужно соединить верхнюю и нижнюю грань, чтобы получить цилиндр, а затем соединить концы, чтобы получить тонкий бублик.
[7] Класс моделей под названием модели диффузионной реакции также порождает полосы на узких фигурах и пятна на более широких фигурах. С их помощью ученые могут прогнозировать, какие животные станут полосатыми, какие пятнистыми и у каких будет однородный окрас. Ответ зависит от размера эмбриона млекопитающего на стадии развития (когда формируются эти структуры), а не во взрослом возрасте животного — иначе слоны были бы пятнистыми. См. Murray, 1988.
[8] Я благодарен Бернардо Хуберману за этот образ.
[9] Для того чтобы это доказать, необходимо написать компьютерную программу, генерирующую случайную последовательность чисел или случайную структуру, и показать, что игра «Жизнь» имитирует компьютерную программу. Для формального доказательства требуется продемонстрировать, что игра «Жизнь» — это универсальный клеточный автомат. См. Berlekamp, Conway, and Guy, 1982.
[10] См. Dennett 1991 и Hawking and Mlodinow, 2011.
ГЛАВА 16
[1] Информацию о первоначальных экспериментах можно найти здесь: Nagel, 1995.
[2] Я признателен Дженне Беднар за пример гонки по нисходящей в рамках федеральных систем, а также за ряд других примеров, которые приводятся в книге.
[3] Формальное доказательство ищите в Page, 2001.
[4] Наличие внешних эффектов (даже отрицательных) не должно исключать построение функции Ляпунова. Как модель локального большинства, так и модель выбора маршрута содержат отрицательные экстерналии. Когда в модели локального большинства клетка меняет свое состояние, это создает отрицательный внешний эффект для ее соседей, находящихся в противоположном состоянии. Но при этом создается и более сильный положительный эффект в отношении соседей, состояние которых теперь совпадает с состоянием клетки.
[5] Guy, 1983. Если хватит смелости, начните с числа 27.
ГЛАВА 17
[1] В научной публикации использованы статистические методы для более точной оценки вероятностей перехода и вычисления диапазона погрешности. Кроме того, была выполнена проверка, позволяющая определить, будет ли скорость перехода оставаться неизменной на протяжении соответствующего периода. Скорость перехода не будет неизменной, если вероятность перехода зависит от дохода на душу населения. См. Przeworski et al., 2000.
[2] Flores and Nooruddin, 2016.
[3] См. Tilly, 1998.
[4] Равновесная доля людей, использующих керамическую плитку в качестве напольного покрытия, равна вероятности перехода от линолеума к плитке, деленной на сумму вероятностей перехода от линолеума к плитке и от плитки к линолеуму:
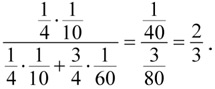
Общую модель можно записать следующим образом. Пусть D — это процент людей, которым принадлежит дорогостоящий долговечный товар, а C — процент людей, владеющих более дешевым товаром. Пусть 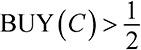 обозначает вероятность того, что кто-то купит более дешевый товар, а REPLACE(C) и REPLACE(D) обозначают вероятность замены товаров этих двух типов. Если выполняется неравенство
обозначает вероятность того, что кто-то купит более дешевый товар, а REPLACE(C) и REPLACE(D) обозначают вероятность замены товаров этих двух типов. Если выполняется неравенство
REPLACE(C) · (1 − BUY(C)) > REPLACE(D) · BUY(C),
то больше людей покупают более дешевые товары, но больше людей владеют долговечными товарами. Первая часть этого утверждения выполняется по предположению. Для того чтобы доказать вторую часть, необходимо вычислить вероятности перехода. Вероятность того, что кто-то перейдет от D к C, равна P(D, C) = REPLACE(D) · BUY(C). Вероятность того, что кто-то перейдет от C к D, равна P(C, D) = REPLACE(C) · (1 − BUY(C)). В случае равновесия D − D · P(D, C) + CP(C, D) = D. Установив C = (1 − D), получим 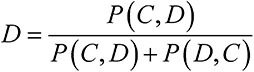 , что больше 0,5, если P(C, D > P(D, C). Это неравенство эквивалентно REPLACE(C) · (1 − BUY(C)) > REPLACE(D) · BUY(C).
, что больше 0,5, если P(C, D > P(D, C). Это неравенство эквивалентно REPLACE(C) · (1 − BUY(C)) > REPLACE(D) · BUY(C).
[5] См. McPhee, 1963 и Ehrenberg, 1969, где представлены эмпирические данные о двойном риске. Чтобы доказать этот результат, нужно просто продемонстрировать, что при переходе к другому бренду потребители покупают любой из продуктов с равной вероятностью.
[6] Краткий обзор можно найти здесь: Briggs and Sculpher, 1998.
[7] См. Schrodt, 1998.
[8] Khmelev and Tweedie, 2001.
[9] Khmelev and Tweedie, 2001.
[10] Reynolds and Saxonhouse, 1995.
[11] См. http://www.ams.org/samplings/feature-column/fcarc-pagerank.
[12] Грамотное построение таких моделей подразумевает определение полезных состояний и присвоение точных значений вероятности. См. Langville and Meyer, 2012.
[13] В пищевой сети вид связан с теми видами, которыми он питается. См. Allesina and Pascual, 2009.
[14] См. Russakoff, 2015.
ГЛАВА 18
[1] См. Sterman, 2000, где представлено общее введение.
[2] Анализ количественных моделей системной динамики можно найти здесь: Wellman, 1990.
[3] Данная модель предполагает, что зайцы умирают, будучи съеденными лисицами. Включение переменных, описывающих смерть зайцев, усложнило бы модель, не изменив результатов, поскольку это просто снизило бы темпы роста численности зайцев. Выражение H обозначает скорость изменений в H за единицу времени, или 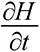 . Равновесие имеет место в случае, когда скорость изменения количества зайцев и лисиц равна нулю: H = F = 0. Для того чтобы вычислить равновесие, необходимо взять уравнение gH − aFH = 0 и разделить его на H, что дает g − aF = 0. Искомый результат при решении этого уравнения относительно F. Затем необходимо взять уравнение bFH − dF = 0 и разделить его на F, что дает bH – d = 0; искомый результат получается при решении этого уравнения относительно H.
. Равновесие имеет место в случае, когда скорость изменения количества зайцев и лисиц равна нулю: H = F = 0. Для того чтобы вычислить равновесие, необходимо взять уравнение gH − aFH = 0 и разделить его на H, что дает g − aF = 0. Искомый результат при решении этого уравнения относительно F. Затем необходимо взять уравнение bFH − dF = 0 и разделить его на F, что дает bH – d = 0; искомый результат получается при решении этого уравнения относительно H.
[4] Я благодарен Майклу Райаллу из Университета Торонто за этот пример.
[5] Выводы, сделанные на основе этой модели, обобщены в книге: Meadows et al., 1972.
[6] Эту группу моделей часто называют моделями Римского клуба, поскольку Римский клуб, основанный Дэвидом Рокфеллером в 1968 году, финансировал подготовку докладов о действии этих моделей и отстаивал выводы, сделанные на их основе.
[7] Посредством изменения значений большего количества переменных в узком диапазоне Миллер может увеличить численность населения почти до 30 миллиардов человек. См. Miller, 1998.
[8] Информацию о первом вопросе ищите здесь: Hecht, 2008. Второй вопрос рассматривается здесь: MacKenzie, 2012.
[9] См. Sterman, 2006.
[10] Glantz, 2008.
ГЛАВА 19
[1] См. Granovetter, 1978.
[2] Основатели Airbnb оплатили расходы на обход домов, продавая коробки овсяных хлопьев Obama O’s и Cap’n McCain’s во время президентских выборов 2008 года.
[3] О модели вращающейся двери речь идет здесь: Jacobs, 1989. Результаты эмпирических исследований показывают, что в сферах занятости, не требующих высокого уровня формального образования (например, работа бармена и садовника), мужчины уходят или вообще предпочитают не выбирать профессии, в которых доля женщин составляет всего 15 процентов (Pan, 2015).
[4] См. Syverson, 2007.
[5] Более подробную информацию можно найти здесь: Gammill and Marsh, 1988.
[6] См. Easley et al., 2012.
ГЛАВА 20
[1] См. Clark, Golder, and Golder, 2008.
[2] Анализ позиций судей представлен здесь: Martin and Quinn, 2002.
[3] Хотеллинг (Hotelling, 1929) анализировал географическое местоположение, Ланкастер расширил модель Хотеллинга и использовал ее для анализа гедонической конкуренции, а Даунс применил эту модель в области политики.
[4] Модель поименного голосования предлагает более продуманный подход к определению идеологических позиций на основе этой же идеи (см. Poole and Rosenthal, 1985).
[5] Константа (в данном выражении обозначенная как C) выбирается так, чтобы сделать все выигрыши положительными. Для этого можно установить ее значение равным максимальному расстоянию между идеальной точкой и альтернативой.
[6] При таком способе построения линии раздела мы исходим из того, что потребители придают одинаковую значимость двум атрибутам. Мы могли бы учитывать различия в значимости. Если сладкий вкус для людей более ценен, чем содержание какао, необходимо развернуть линию раздела против часовой стрелки. Но если люди ценят только сладкий вкус, линия раздела проходит горизонтально и делит пространство любителей продуктов A и B на равные части по вертикальной оси. Данная пространственная модель — наглядный пример того, как можно преобразовать интуитивные представления (мы предпочитаем то, что находится ближе к нашему идеалу) в формальную модель. Отобразив на графике альтернативы (шоколадные батончики) и идеальные точки потребителя, а также определив порядок предпочтений в отношении альтернатив (рейтинг альтернатив от лучшей до худшей) на основе их расстояния от идеальной точки, по сути, мы опишем функцию полезности с учетом альтернативы. Полезность продукта равна величине, обратной расстоянию от идеальной точки.
[7] Havel, 1978.
[8] См. Martin and Quinn, 2002.
[9] См. McCarty 2011. Эти проценты могут быть другими в случае изменения степени преданности партии или типов законопроектов, поставленных на голосование.
[10] Строго говоря, при наличии нечетного количества избирателей и идеальной точки отдельного избирателя в точке двумерной медианы данное условие требует, чтобы любая линия, проходящая через эту двумерную медиану, делила идеальные точки оставшихся избирателей на два равновеликих множества. См. Plott, 1967.
[11] Маккелви (McKelvey, 1979) продемонстрировал, что последовательность проведения выборов может привести к любой политике в случае двух и более изменений — результат, который некоторые называют выводом о хаосе. Особо Маккелви подчеркивал, что этот вывод не прогноз в отношении того, что произойдет в случае серии выборов, а утверждение о последовательностях результатов, возможных при наличии предпочтений. См. Kollman, Miller, and Page, 1997, где представлен вычислительный вариант многомерной пространственной модели, в которой кандидаты смещаются к центру при различных предположениях относительно поведения.
[12] Возможно, члену комитета понадобится предложить 41.
[13] Более глубокий анализ данной модели и других моделей из теории игр, применяемых в области политики, можно найти здесь: McCarty and Meirowitz, 2014.
[14] См. Tsebelis, 2002, где представлено более общее описание эффекта вето-игроков.
[15] В ходе анализа цен домов в Лос-Анджелесе была рассчитана стоимость времени поездки из пригорода в центр города и обратно — около 28 долларов (см. Bajari and Kahn, 2008).
[16] Это значение вычисляется следующим образом. Первоначальный доход равен произведению цены и количества: p · q. На первом рынке после снижения цены доход сокращается на 10 процентов, а объем продаж увеличивается на 8 процентов, а значит, доход равен:
0,9p · 1,08q = 0,972p · q.
На втором, более переполненном рынке количественный показатель увеличивается на 33 процента, поэтому общий доход равен:
0,9p · 1,33q = 1,197p · q.
ГЛАВА 21
[1] Формальную модель и доказательство можно описать следующим образом. Пусть Ei — это уровень усилий игрока i. Выигрыш игрока i равен M − Ei, если он выигрывает, и − Ei в противном случае. Предположим, вероятность того, что игрок i выиграет, равна его доле от общего уровня усилий:
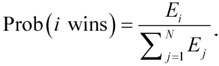
Для того чтобы найти уникальное симметричное равновесие Нэша, рассмотрим уровень усилий игрока i при условии, что все остальные игроки выберут один и тот же уровень усилий E*. Выигрыш игрока i равен:
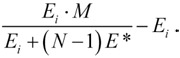
Первая производная этой функции выигрыша равна:
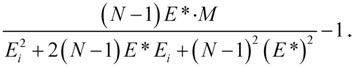
Для того чтобы найти максимум, приравняем первую производную к нулю, что дает  . В случае симметричного равновесия Ei = E*. Подстановка позволяет получить требуемый результат. Чтобы доказать, что первая производная дает максимум, необходимо просто удостовериться, что вторая производная функции выигрыша имеет отрицательное значение.
. В случае симметричного равновесия Ei = E*. Подстановка позволяет получить требуемый результат. Чтобы доказать, что первая производная дает максимум, необходимо просто удостовериться, что вторая производная функции выигрыша имеет отрицательное значение.
[2] См. Shalizi and Thomas, 2011, где рассказывается о том, как выделить сетевые эффекты и почему трудно делать какие-либо утверждения в отношении сетевых эффектов на основе снимков данных. В книге Николаса Кристакиса и Джеймса Фаулера (Christakis and Fowler, 2009) приводится много примеров кластерного поведения и его характеристик.
ГЛАВА 22
[1] См. специальный выпуск журнала Science, посвященный его 125-летию, опубликованный в 2005 году.
[2] См. Martin et al., 2008 и Biernaskie, 2011.
[3] См. Zaretsky, 1998. В примере с банками банкоматы приводили к снижению прибыли, если банки получали значительный географический доход (то есть дополнительную прибыль), поскольку у них была возможность воспользоваться затратами клиентов на поездки по городу, чтобы добраться до банка-конкурента. Я благодарен Саймону Уилки за этот и многие другие примеры.
[4] Формально мы показываем, что триггер вечной кары — это равновесная стратегия в вероятностно повторяемой игре «Дилемма заключенного». Другие стратегии, такие как «око за око», также могут быть равновесными в сочетании с триггером вечной кары.
[5] Игрок, который отказывается от сотрудничества, несмотря на триггер вечной кары, получает выигрыш T за первый период и может получить не больше нулевого выигрыша во всех последующих взаимодействиях. Если этот игрок использует триггер вечной кары против триггера вечной кары, он получит выигрыш R за каждый период, в котором проводится игра. Вероятность двух периодов проведения игры равна P, вероятность трех периодов — P2, а вероятность N периодов — pN − 1. Следовательно, ожидаемый выигрыш равен:
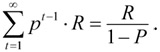
Вот набросок доказательство того, что 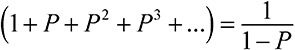 , можно описать так. Предположим, этот результат верен, а затем умножим обе стороны выражения на (1 − P). Правая сторона равна 1. Левая — (1 + P + P2 + P3 + …) − (P + P2 + P3 + …), что тоже равно 1.
, можно описать так. Предположим, этот результат верен, а затем умножим обе стороны выражения на (1 − P). Правая сторона равна 1. Левая — (1 + P + P2 + P3 + …) − (P + P2 + P3 + …), что тоже равно 1.
[6] Необходимо просто еще раз выполнить вычисления для поддержания сотрудничества, снизив значение P до 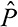 . Если не поддерживает кооперацию, то ее не смогут поддержать и несколько периодов с вероятностью продолжения P, за которой следует вероятность продолжения .
. Если не поддерживает кооперацию, то ее не смогут поддержать и несколько периодов с вероятностью продолжения P, за которой следует вероятность продолжения .
[7] Новак и Зигмунд (Nowak and Sigmund, 1998) называют это оценкой образа. См. также Bshary and Grutter, 2006.
[8] Обе формы агрессивного поведения можно отнести к категории отказа от сотрудничества, если предположить, что они увеличивают размер территории древесницы. См. Godard, 1993.
[9] Четыре пары исходов заслуживают более тщательного рассмотрения. Когда стратегия TFT играет против GRIM, обе стратегии всегда сотрудничают и каждая получает средний выигрыш 3. Когда стратегия TROLL играет против себя, обе стратегии отказываются от сотрудничества в первых двух периодах, а затем выбирают сотрудничество навсегда со средним выигрышем немногим менее 2. Когда стратегия GRIM играет против стратегии TROLL, GRIM сотрудничает в первом раунде, а TROLL отказывается от сотрудничества; во втором раунде обе стратегии отказываются сотрудничать; в третьем и четвертом раундах GRIM выбирает отказ от сотрудничества, а TROLL — сотрудничество; во время последующих периодов обе стратегии отказываются от сотрудничества. Последовательность выигрышей стратегии GRIM можно записать как 1, 2, 4, 4, после чего идет длинная цепочка выигрышей 2, что дает в среднем 2+. Последовательность выигрышей стратегии TROLL можно записать как 4, 3, 1, 1, а далее следует длинная цепочка выигрышей 2, что дает в точности 2. Когда стратегия TFT играет против стратегии TROLL, TFT выбирает сотрудничество в первом раунде, тогда как TROLL отказывается от сотрудничества. Во втором раунде обе стратегии отказываются от сотрудничества. В третьем раунде стратегия TROLL сотрудничает, а стратегия TFT продолжает отказываться от сотрудничества. В четвертом раунде TROLL выбирает сотрудничество во второй раз, а стратегия TFT возвращается к сотрудничеству. В последующих периодах обе стратегии сотрудничают всегда. Каждая стратегия получает один выигрыш 1, один выигрыш 4, один выигрыш 2 и длинную последовательность выигрышей 3, что обеспечивает средний выигрыш немногим менее 3.
[10] В действительности стратегии All C и GRIM являются доминируемыми по отношению к стратегии TFT. В игре против любой стратегии TFT обеспечивает как минимум такие же или более высокие результаты, чем All C или GRIM. Стратегия TFT доминирует над All C, поскольку стратегии All D и TROLL не могут извлечь выгоду из стратегии TFT. Стратегия TFT доминирует над стратегией GRIM, так как она может сотрудничать с TROLL исходя из того, что стратегия TFT прощает стратегии TROLL отказы от сотрудничества, тогда как GRIM — нет. В ходе знаменитого эксперимента Роберт Аксельрод предложил ученым разработать стратегии повторяющейся игры «Дилемма заключенного» с вероятностью продолжения. Из четырнадцати представленных стратегий TFT обеспечивала самый высокий результат. Затем Аксельрод предложил ученым прислать ему новые стратегии. На этот раз откликнулись шестьдесят два человека. И в этот раз победила TFT. Аксельрод относит успех TFT на счет ряда свойств этой стратегии: она сотрудничает, наказывает и прощает. Стратегия GRIM не прощает, поэтому не может возобновить сотрудничество с TROLL. См. Axelrod, 1984. В таблице не указан средний выигрыш в играх против всех стратегий, поскольку это означало бы, что все стратегии в равной степени вероятны. В рамках одной совокупности большинство людей могут предпочесть стратегию TFT. Другая совокупность может включать большую долю людей, использующих TROLL. В третьей совокупности может быть много тех, кто выберет стратегии All D и All C.
[11] Предположим, что выигрыш от искушения в четыре раза превышает выигрыш простака (T = 4S) и что 5 процентов членов совокупности готовы сотрудничать. В таком случае значение P должно превышать 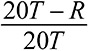 . Поддержка кооперации требует, чтобы значение P превышало
. Поддержка кооперации требует, чтобы значение P превышало 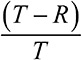 . В случае, когда T = 4 и R = 3, развитие кооперации требует
. В случае, когда T = 4 и R = 3, развитие кооперации требует 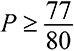 . Поддержка кооперации требует
. Поддержка кооперации требует 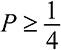 . Для общего доказательства предположим, что доля совокупности Θ использует стратегию TFT (или GRIM), а доля (1 − Θ) — стратегию All D. Допустим также, что каждый человек играет против всей совокупности. Стратегия TFT (или GRIM), играющая против TFT, получает выигрыш R на протяжении каждого периода, что дает ожидаемый выигрыш
. Для общего доказательства предположим, что доля совокупности Θ использует стратегию TFT (или GRIM), а доля (1 − Θ) — стратегию All D. Допустим также, что каждый человек играет против всей совокупности. Стратегия TFT (или GRIM), играющая против TFT, получает выигрыш R на протяжении каждого периода, что дает ожидаемый выигрыш 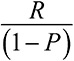 . Стратегия TFT, играющая против All D, получает выигрыш –S. Стратегия All D, играющая против All D, получает нулевой выигрыш. А стратегия All D, играющая против TFT, получает выигрыш T. Следовательно, средний выигрыш TFT равен
. Стратегия TFT, играющая против All D, получает выигрыш –S. Стратегия All D, играющая против All D, получает нулевой выигрыш. А стратегия All D, играющая против TFT, получает выигрыш T. Следовательно, средний выигрыш TFT равен 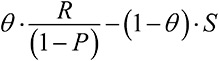 , а All D получает средний выигрыш Θ · T. Стратегия TFT обеспечивает более высокий результат, чем All D, если и только если
, а All D получает средний выигрыш Θ · T. Стратегия TFT обеспечивает более высокий результат, чем All D, если и только если 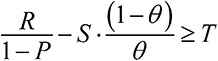 . Таким образом, TFT получает более высокий выигрыш, тогда и только тогда, когда выполняется следующее условие:
. Таким образом, TFT получает более высокий выигрыш, тогда и только тогда, когда выполняется следующее условие:
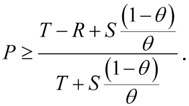
Если Θ имеет небольшое значение, то значение 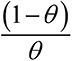 будет большим, поэтому данное условие вряд ли будет выполнено. Анализ сложности развития кооперации по сравнению с ее поддержанием представлен здесь: Boyd, 2006.
будет большим, поэтому данное условие вряд ли будет выполнено. Анализ сложности развития кооперации по сравнению с ее поддержанием представлен здесь: Boyd, 2006.
[12] Эта модель позаимствована из статьи Новака (Nowak, 2006), который показывает, что повторение, репутация и родственный отбор также могут поддерживать кооперацию.
[13] Открытый узел копирует действия самого результативного соседа. Согласно предположению, все соседи-отступники получают нулевой выигрыш. Сосед-кооператор получает выигрыш K · B − D · C. Этот выигрыш больше ноля, тогда и только тогда, когда 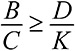 .
.
[14] Основные положения теории группового отбора представлены здесь: Wilson, 1975. Дэвид Слоун Уилсон написал ряд книг, в которых содержится более подобный анализ группового отбора.
[15] Модель Траулсена и Новака работает следующим образом. Необходимо разделить совокупность из N человек на M отдельных групп равного размера. В каждой группе следует применить модель совместных действий и определить результат каждого человека. Пусть вероятность выбора человека i равна результату i, деленному на сумму результатов всех N человек. Клон этого человека включается в ту же группу. Если теперь размер группы превышает пороговое значение 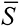 , то с вероятностью (1 − q) удаляется случайно выбранный человек из этой же группы и с вероятностью q группа делится на две группы, а каждый член в случайном порядке включается в одну из этих групп. Для того чтобы сохранять постоянное количество групп, необходимо в случайном порядке выбрать одну из существующих групп и удалить ее. При больших значениях M и нечастом разделении групп (то есть при малом значении q) количество кооператоров увеличивается, тогда и только тогда, когда выполняется следующее условие:
, то с вероятностью (1 − q) удаляется случайно выбранный человек из этой же группы и с вероятностью q группа делится на две группы, а каждый член в случайном порядке включается в одну из этих групп. Для того чтобы сохранять постоянное количество групп, необходимо в случайном порядке выбрать одну из существующих групп и удалить ее. При больших значениях M и нечастом разделении групп (то есть при малом значении q) количество кооператоров увеличивается, тогда и только тогда, когда выполняется следующее условие: 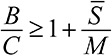 . См. Nowak, 2006.
. См. Nowak, 2006.
[16] Когда сторонница Agile-менеджмента Мишель Пелузо стала директором по маркетингу в IBM, она сформировала конкурирующие команды, результаты работы которых видели другие команды, и вознаграждала лучшие команды (см. Dan, 2018). Такая практика Agile-менеджмента заимствует идеи из области Agile-программирования, где вместо стандартного каскадного метода последовательной разработки программного обеспечения используется метод одновременного написания программ, их тестирования и взаимодействия с пользователями.
[17] Еще одна стратегия, «Великодушное око за око», подразумевает сотрудничество на начальном этапе и наказание отступников только в некоторых случаях. В ходе одной серии экспериментов с наличием ошибок эта стратегия показала более высокие результаты, чем стратегии «Око за око» и «Выигрываешь — остаешься, проигрываешь — переходишь». См. Rand et al., 2009 и Wu and Axelrod, 1995.
[18] См. Axelrod, Axelrod, and Pienta, 2006.
ГЛАВА 23
[1] Описание трагедии общин представлено здесь: Hardin, 1968.
[2] См. Diamond, 2005.
[3] См. Ostrom, 2005 и Ostrom, Janssen, and Anderies, 2007.
[4] Для того чтобы вычислить социальный оптимум, предположим, что каждый человек выделяет сумму X на общественное благо. Общая полезность для всей совокупности равна:
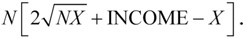
Взяв производную по X и приравняв ее к нулю, получим следующее уравнение:
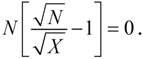
Решение этого уравнения дает:
X = N.
Для того чтобы найти симметричное равновесие Нэша, предположим, что каждый новый человек вносит в общественное благо одну и ту же сумму; обозначим ее как A. Пусть Y обозначает сумму, которую вносит отдельный человек. Его полезность составляет:
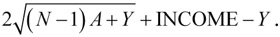
Взяв производную по Y и приравняв ее к нулю, получим следующее уравнение: 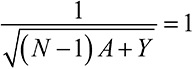 . Перегруппировка его членов и возведение обеих его сторон в квадрат дает [Y + (N − 1)A] = 1. Если имеет место симметричное равновесие, при котором все вносят одну и ту же сумму (Y = A), то
. Перегруппировка его членов и возведение обеих его сторон в квадрат дает [Y + (N − 1)A] = 1. Если имеет место симметричное равновесие, при котором все вносят одну и ту же сумму (Y = A), то 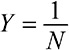 .
.
[5] Утилитаризм придает одинаковую значимость участию каждого человека. Ролз (Rawls, 1971) предложил альтернативу — принцип максимина, согласно которому идеальный социальный результат максимально увеличивает полезность для наименее обеспеченного человека. Ролз приводит доводы в пользу оценки результатов под покровом неведения, чтобы было неизвестно, кто станет богатым, знаменитым и обладающим большими возможностями или окажется в трудном положении под влиянием обстоятельств.
[6] Полезность человека j можно записать так:
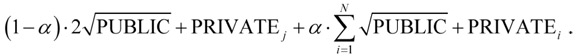
Для того чтобы найти симметричное равновесие Нэша, мы будем исходить из того, что каждый новый человек вносит в общественное благо сумму A. Пусть Y обозначает сумму, которую вносит человек j. Пусть I — это общий уровень доходов. Полезность человека j равна:
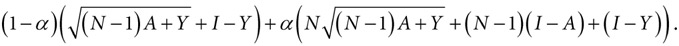
Взяв производную по Y и приравняв ее к нулю, получим следующее уравнение:
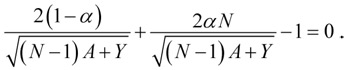
Перегруппировка его членов дает: 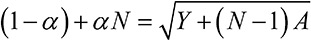 . В случае симметричного равновесия Y = A. Из этого следует, что
. В случае симметричного равновесия Y = A. Из этого следует, что 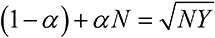 . Возведение обеих сторон уравнения в квадрат дает: [(1 − α) + αN]2 = NY, а значит,
. Возведение обеих сторон уравнения в квадрат дает: [(1 − α) + αN]2 = NY, а значит, 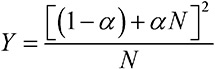 .
.
[7] См. книгу Cornes and Sandler, 1996, где представлен детальный анализ.
[8] Более реалистичная модель исходила бы из нелинейных издержек в связи с перегруженностью, которые можно представить S-образной кривой. Это предположение касалось бы таких ресурсов, как дороги, где первых несколько новых пользователей не влияют на выгоду отдельного человека, но в какой-то момент перегруженность данного ресурса возрастает до такого уровня, что он становится бесполезным.
[9] Общая полезность, когда M человек используют данный ресурс, составляет (B − Θ · M). Взяв производную по M и приравняв ее к нулю, получим (B − 2MΘ) = 0. Решение уравнения дает 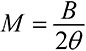 . Для того чтобы найти равновесие Нэша, установим стоимость отказа от использования ресурса равной нулю. Люди используют ресурс до тех пор, пока выгода от этого эквивалентна сторонней альтернативе: .
. Для того чтобы найти равновесие Нэша, установим стоимость отказа от использования ресурса равной нулю. Люди используют ресурс до тех пор, пока выгода от этого эквивалентна сторонней альтернативе: .
[10] Обратите внимание: мы устанавливаем максимальную выгоду B равной размеру совокупности N с целью сокращения количества переменных. Для того чтобы вычислить социально оптимальные исходы и равновесие Нэша, сначала отметим, что общая полезность равна (N − M) · M + 3(N − (N − M)) · (N − M). Это выражение можносократить до 4(N − M)M. Взяв производную по M, получим 4N − 8M = 0. Решение уравнения дает 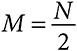 . Общая полезность равна
. Общая полезность равна 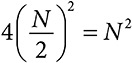 . Для того чтобы найти равновесие, мы вычислим такое значение M, при котором оба парка имеют одинаковую предельную полезность. Это происходит, когда (N − M) = 3N − 3(N − M), что можно записать как N = 4M. Общая полезность вычисляется посредством подстановки значений M и N − M в функциях полезности.
. Для того чтобы найти равновесие, мы вычислим такое значение M, при котором оба парка имеют одинаковую предельную полезность. Это происходит, когда (N − M) = 3N − 3(N − M), что можно записать как N = 4M. Общая полезность вычисляется посредством подстановки значений M и N − M в функциях полезности.
[11] Для того чтобы найти равновесный уровень использования ресурса, необходимо приравнять R* = (1 − g)(R* − C*) и решить уравнение относительно R*.
[12] См. Kurlansky, 1998.
[13] Для того чтобы понять, почему вариация не сходит на нет, рассмотрим модель, охватывающую два периода. Темп роста 20 процентов за первый год дает всего 96 единиц ресурса (80 · 1,2 = 96). Темп роста за второй год в размере 30 процентов обеспечивает 98,8 = (96 − 20) · (1,3) единиц ресурса. Если поменять эти темпы роста местами, то к концу первого года будет 104 единицы ресурса, а по истечении второго года 100,8 = (104 − 20) · (1,2) единиц ресурса.
[14] Ostrom, Janssen, and Anderies, 2007.
[15] См. Craine and Dybzmski, 2013.
[16] Краткий обзор представлен здесь: Ostrom, 2010; более полное описание можно найти здесь: Ostrom, 2004.
ГЛАВА 24
[1] См. Ledyard, Porter, and Rangel, 1997.
[2] В качестве примера Парето-эффективности рассмотрим следующие четыре профиля выигрышей трех человек: {(3, 3, 4), (9, 0, 0), (0, 8, 1), (2, 2, 3)}. Все профили, за исключением (2, 2, 3), эффективны по Парето. Распределение (2, 2, 3) является доминируемым по отношению к (3, 3, 4).
[3] См. Hurwicz and Schmeidler, 1978.
[4] Третий участник торгов мог бы предложить цену немного выше 60 долларов, но для упрощения анализа мы исходим из того, что он предлагает ровно 60 долларов.
[5] Приведенное здесь доказательство основано на равномерном распределении оценок в диапазоне [0, 1], но результат сохраняет свою силу и для более крупного класса распределений. Предположим, остальные (N − 1) участников торгов предлагают цену, равную их истинной оценочной стоимости, умноженную на 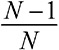 . Предложение b будет выше предложения другого участника торгов при условии, что произведение оценочной стоимости другого участника на меньше b. Вероятность того, что это произойдет, равна
. Предложение b будет выше предложения другого участника торгов при условии, что произведение оценочной стоимости другого участника на меньше b. Вероятность того, что это произойдет, равна 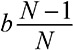 . Таким образом, вероятность превысить остальные (N − 1) предложений равна этому значению, возведенному в степень (N − 1). Следовательно, если оценочная стоимость участника торгов равна V, ожидаемый выигрыш от предложения b равен разности между этой оценочной стоимостью и предложенной ценой (V − b), умноженной на вероятность того, что b окажется самым высоким предложением. В таком случае ожидаемый выигрыш можно записать так:
. Таким образом, вероятность превысить остальные (N − 1) предложений равна этому значению, возведенному в степень (N − 1). Следовательно, если оценочная стоимость участника торгов равна V, ожидаемый выигрыш от предложения b равен разности между этой оценочной стоимостью и предложенной ценой (V − b), умноженной на вероятность того, что b окажется самым высоким предложением. В таком случае ожидаемый выигрыш можно записать так: 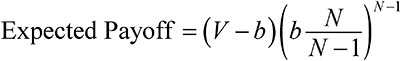 . Для того чтобы максимизировать это значение, возьмем производную по b и приравняем ее к нулю, что дает следующее условие:
. Для того чтобы максимизировать это значение, возьмем производную по b и приравняем ее к нулю, что дает следующее условие:
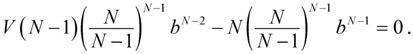
Упрощение этого уравнения дает V(N − 1) − Nb = 0, что можно записать как 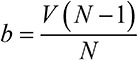 . Чтобы продемонстрировать, что участник торгов, предложивший самую высокую цену, платит сумму, равную ожидаемой оценочной стоимости участника торгов, предложившего вторую по величине цену, обратите внимание, что при наличии N случайных величин, взятых из равномерного распределения в интервале [0, 1], ожидаемая стоимость самого высокого предложения равна
. Чтобы продемонстрировать, что участник торгов, предложивший самую высокую цену, платит сумму, равную ожидаемой оценочной стоимости участника торгов, предложившего вторую по величине цену, обратите внимание, что при наличии N случайных величин, взятых из равномерного распределения в интервале [0, 1], ожидаемая стоимость самого высокого предложения равна 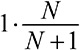 . Следовательно, ожидаемое предложение участника торгов, предложившего самую высокую цену, составляет
. Следовательно, ожидаемое предложение участника торгов, предложившего самую высокую цену, составляет 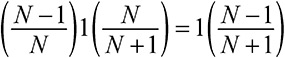 , что равно ожидаемой стоимости участника торгов, предложившего вторую по величине цену.
, что равно ожидаемой стоимости участника торгов, предложившего вторую по величине цену.
[6] Роджер Майерсон, который был моим научным руководителем, получил Нобелевскую премию в том числе и за этот результат.
[7] В случае аукциона «платят все» оптимальную стратегию (когда оценки участников торгов находятся в интервале [0, 1]) можно записать так: участник торгов с оценочной стоимостью V предлагает цену 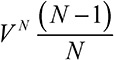 . Следовательно, когда есть три участника торгов, участник с оценочной стоимостью должен предложить цену
. Следовательно, когда есть три участника торгов, участник с оценочной стоимостью должен предложить цену 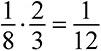 .
.
[8] Экспериментальные данные можно найти здесь: Lucking-Reiley, 1999. Данные, полученные в ходе экспериментов с аукционом eBay, ищите здесь: Morgan and Hossain, 2006. Ознакомиться с анализом аукционов по продаже древесины можно здесь: Athey, Levin, and Seira, 2011.
[9] Ostrovsky, Edelman, and Schwarz, 2007.
[10] Краткий обзор можно найти здесь: Page, 2012.
ГЛАВА 25
[1] В книге Кевина Симлера и Робина Хансона (Simler and Hanson, 2018) приведено множество примеров того, как демонстрация статуса влияет на поведение и решения людей.
[2] Затраты представителя слабого типа на подачу сигнала составляют MC. Выгода от передачи сигнала равна 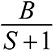 с учетом предположения, что все S представителей сильного типа подают сигнал. Следовательно, ни один представитель слабого типа не будет подавать сигнал, если
с учетом предположения, что все S представителей сильного типа подают сигнал. Следовательно, ни один представитель слабого типа не будет подавать сигнал, если 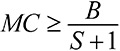 . Напротив, представители сильного типа предпочитают подавать сигнал, если их выгода от разделения
. Напротив, представители сильного типа предпочитают подавать сигнал, если их выгода от разделения 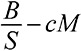 превышает выгоду от отсутствия сигнала и все N агентов делят между собой выгоду
превышает выгоду от отсутствия сигнала и все N агентов делят между собой выгоду 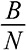 .
.
Согласно предыдущим расчетам, минимальный сигнал, который не станет для представителя слабого типа поводом подать сигнал, равен 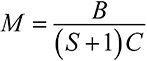 . Из этого следует, что если мы допустим
. Из этого следует, что если мы допустим 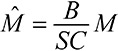 , то представители слабого типа не будут подавать сигнал. Для того чтобы представители сильного типа предпочли подать сигнал
, то представители слабого типа не будут подавать сигнал. Для того чтобы представители сильного типа предпочли подать сигнал 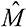 , должно выполняться неравенство
, должно выполняться неравенство 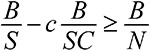 . Мы можем разделить обе стороны на B и умножить на C, чтобы получить
. Мы можем разделить обе стороны на B и умножить на C, чтобы получить 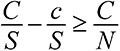 , что упростит выражение до (C − c)N ≥ CS, а это можно записать как C(N − S) ≥ cN.
, что упростит выражение до (C − c)N ≥ CS, а это можно записать как C(N − S) ≥ cN.
[3] Эту возможность обнаружил Майкл Спенс, который в 2001 году получил Нобелевскую премию по экономике за построение модели образовательного сигнализирования на рынке труда и за анализ рынков с ассиметричной информацией (Spence, 1973).
[4] Хвост с огромными перьями делает павлина менее сильным, чем если бы он был с более скромным оперением. См. Zahavi, 1975.
[5] См. Bird and Smith, 2004.
[6] См. Smith, Bird, and Bird, 2003.
ГЛАВА 26
[1] Исследование психологических аспектов обучения охватывает гораздо более широкое множество контекстов, чем мы здесь рассматриваем. Человек может узнать какой-то факт, например название столицы штата Арканзас, или получить неявные знания, скажем как испечь хлеб, отремонтировать двигатель или написать программу для компьютера. Кроме того, человек может освоить определенную область знаний, такую как органическая химия.
[2] См. Thorndike, 1911, 244.
[3] См. Rescorla and Wagner, 1972.
[4] Описанная здесь модель основана на оригинальной модели Рескорла — Вагнера (Rescorla and Wagner, 1972), а также на моделях Геррнштейна (Herrnstein, 1970), Буша и Мостеллера (Bush and Mosteller, 1955), Сайерта и Марча (Cyert and March, 1963), Бендора, Дирмайера и Тинга (Bendor, Diermeier, and Ting, 2003), а также Эпштейна (Epstein, 2014).
[5] Параметр γ необходимо выбрать так, чтобы вес альтернативы оставался положительным. Это возможно при условии, что γ превышает величину, обратную разности между максимально высоким уровнем стремления и минимальным вознаграждением от любой альтернативы.
[6] Представленное здесь описание основано на статье: Bendor and Swistak, 1997.
[7] Если мы сконструируем модель репликативной динамики на основе конечной совокупности с произвольным выбором последующих совокупностей, то наилучшая альтернатива может не быть воспроизведена. Если это действительно так, то репликативная динамика не обнаружит наилучшей альтернативы, поскольку не существует способа вернуть альтернативы в совокупность.
[8] См. Fudenberg and Levine, 1998 и Camerer, 2003.
[9] В игре также имеет место равновесие в смешанных стратегиях, при котором игроки в двух третях случаев выбирают экономичный автомобиль и в одной трети случаев автомобиль с большим расходом топлива. Но при тех правилах обучения, которые мы используем, оно неустойчиво, поэтому мы не будем принимать его во внимание.
[10] Формальное доказательство выглядит так: Р(эконом, 1) = 0,5, Р(пожиратель, 1) = 0,5, Выигрыш (эконом, 1) = 1,5, 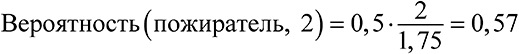 , Вероятность (пожиратель, 1) = 2, средний выигрыш = 1,75. Применение уравнения репликативной динамики дает
, Вероятность (пожиратель, 1) = 2, средний выигрыш = 1,75. Применение уравнения репликативной динамики дает 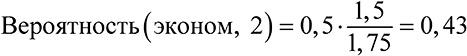 и
и 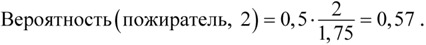
[11] Более глубокий анализ таких ситуаций представлен здесь: Frank, 1985.
[12] См. Waltz, 1979. См. также Powell, 1991, где идет речь об абсолютных и относительных преимуществах в международных отношениях.
[13] См. Vriend, 2000, где анализируется аналогичная структура выигрышей, представленная главным образом в виде конкуренции между компаниями, выпускающими идентичные продукты и одновременно выбирающими количество. Экономисты называют это модель олигополии Курно.
[14] Модель обучения по алгоритму Эрева — Рота корректирует вес W(k, t) альтернативы k за период t согласно следующей формуле: W(k, t + 1) = (1 − r) · W(k, t) + Δ(k, t, e). Параметр r — это показатель новизны, а Δ(k, t, e) = (1 − e) · выигрыш(k, t), если действие k выбрано, и Δ(k, t, e) = e · выигрыш(k, t), если действие k не выбрано. Параметр e (экспериментальный показатель) определяет вес невыбранных альтернатив.
[15] См. Camerer and Ho, 1999.
[16] Этот анализ в значительной мере основан на моделях поведенческого перелива Дженны Беднар и Скотта Пейджа (Bednar and Page, 2007, 2018), а также на идеях, представленных в книге Авнера Грейфа (Greif, 2006). Беднар и Пейдж подчеркивают влияние первоначальных действий на формирование равновесия, тогда как Грейф фокусируется на роли убеждений. Введение в теорию принятия решений на основе прецедентов можно найти в книге Ицхака Гильбоа и Дэвида Шмейдлера: Gilboa and Schmeidler, 1995. См. также книгу Джорджа Акерлофа и Рейчел Крэнтон (Akerlof and Kranton, 2010), где говорится о роли идентичности в экономическом выборе.
[17] Формальное доказательство можно записать следующим образом. Пусть B — это доля игроков, которые проявили заинтересованность и с самого начала выбрали инновационное стратегическое действие. Не составит труда вычислить следующие выигрыши по каждому типу действий:
Выигрыш в случае выбора культурного действия: (1 − B) · 200 + B · 220.
Выигрыш в случае выбора инновационного стратегического действия: (1 − B) · 180 + B · 300.
Для того чтобы доказать этот результат в контексте репликативной динамики, обратите внимание на то, что культурное действие обеспечивает более высокий выигрыш, тогда и только тогда, когда выполняется следующее неравенство:
(1 − B) · 200 + B · 220 > (1 − B) · 180 + 300B.
Перестановка членов неравенства дает 20(1 − B) > 80B. Таким образом, применение модели репликативной динамики указывает на то, что культурное действие возрастает, тогда и только тогда, когда 0,2 > B.
ГЛАВА 27
[1] См. Bergemann and Valimaki, 2008, где объясняется, как это связано с экономическими явлениями.
[2] Краткий обзор можно найти здесь: Hills et al., 2015.
[3] Анализ задачи о многоруком бандите и различных эвристик представлен в статье: Scott, 2010.
[4] Гиттинс и Джонс (Gittins and Jones, 1972) впервые описали оптимальное правило. Индекс Гиттинса можно переформулировать в виде уравнения Беллмана, применимого к любой задаче, подразумевающей последовательность выборов, каждый из которых обеспечивает вознаграждение. Теорема Беллмана основана на построении функции ценности, равной сумме последовательности выигрышей, с учетом того, что будущие выигрыши дисконтируются по определенной ставке процента.
[5] Roberts, 2004.
[6] Анализ эксперимента с программой микрокредитов, который провело Управление обслуживания фермеров министерства сельского хозяйства США, представлен здесь: Bowers et al., 2017.
[7] Данные взяты из следующих источников: Washington Post, 2012 и Dann, 2016.
[8] Эл Гор, Джордж Буш и Хиллари Клинтон получили бы более высокую оценку заслуг в обеспечении экономического процветания, если бы были действующими президентами. В статье Маркуса (Markus, 1988) анализируется начальный этап этого периода; более свежие данные можно найти в книге Рэя Фейра (Fair, 2012), а размер эффекта в случае отдельных кандидатов и партий рассматривается в статье Кемпбелла, Деттри и Иня (Campbell, Dettrey, and Yin, 2010).
ГЛАВА 28
[1] См. Page, 2007, где представлен более глубокий анализ ценности многообразия.
[2] Полное описание модели NK можно найти здесь: Kauffman, 1993.
[3] Мы можем вычислить ожидаемую ценность локальных и глобальных вершин при N = 20, K = 19. Значения вклада каждого атрибута равномерно распределены в интервале [0,1]. Это распределение имеет математическое ожидание и дисперсию . Ценность каждой альтернативы равна среднему значению вкладов двадцати альтернатив. Следовательно, согласно центральной предельной теореме, значения ценности имеют нормальное распределение с математическим ожиданием и дисперсией 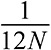 , а значит, при N = 20 каждое стандартное отклонение составляет
, а значит, при N = 20 каждое стандартное отклонение составляет 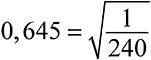 . Далее мы можем вычислить среднюю ценность локального пика: 0,609. Локальный пик можно рассматривать как лучшее из 21 значения, случайно выбранное из этого распределения. Следовательно, его ожидаемая ценность будет примерно равна такому значению, взятому из нормального распределения, что
. Далее мы можем вычислить среднюю ценность локального пика: 0,609. Локальный пик можно рассматривать как лучшее из 21 значения, случайно выбранное из этого распределения. Следовательно, его ожидаемая ценность будет примерно равна такому значению, взятому из нормального распределения, что 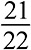 альтернатив имеют более низкую ценность. Это немногим меньше двух стандартных отклонений выше среднего. С помощью вычислительной таблицы нормального распределения можно определить, что ожидаемая средняя ценность равна 0,609. Для того чтобы вычислить ожидаемую ценность глобального пика, равную 0,759, обратим внимание на то, что он имеет самую большую ценность из 220 альтернатив. Каждую альтернативу можно рассматривать как значение ценности, случайным образом выбранное из распределения, а значит, ожидаемая ценность примерно равна такому значению ценности из нормального распределения, при котором
альтернатив имеют более низкую ценность. Это немногим меньше двух стандартных отклонений выше среднего. С помощью вычислительной таблицы нормального распределения можно определить, что ожидаемая средняя ценность равна 0,609. Для того чтобы вычислить ожидаемую ценность глобального пика, равную 0,759, обратим внимание на то, что он имеет самую большую ценность из 220 альтернатив. Каждую альтернативу можно рассматривать как значение ценности, случайным образом выбранное из распределения, а значит, ожидаемая ценность примерно равна такому значению ценности из нормального распределения, при котором 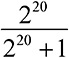 альтернатив имеют более низкую ценность. С помощью нормального распределения определяем, что ожидаемая средняя ценность равна 0,759. Глобальный пик имеет более высокую ценность, чем можно было бы ожидать в случае миллиона испытаний.
альтернатив имеют более низкую ценность. С помощью нормального распределения определяем, что ожидаемая средняя ценность равна 0,759. Глобальный пик имеет более высокую ценность, чем можно было бы ожидать в случае миллиона испытаний.
[4] См. Wright, 2001, где идет речь о том, что такая рекомбинация с положительной суммой способствовала возникновению человека, общества, а также нынешних научно-технических достижений.
[5] См. Kauffman, 1993 и Miller and Page, 2007.
[6] В США предоставляется семнадцать лет после даты выдачи патента, если процесс выдачи занимает более трех лет.
[7] Boldrin and Levine, 2010.
ГЛАВА 29
[1] С учетом этих вероятностей точное статистическое равновесие выглядит так: 70,7 процента людей находятся в состоянии отсутствия боли, 19,5 процента принимают опиоиды и 9,8 процента попадают от них в зависимость. В первом случае эти показатели составляют 76,3, 21,5 и 2,2 процента соответственно.
[2] См. Wakeland, Nielsen, and Geissert, 2015.
[3] Я благодарен Эбби Джейкобс за комментарии и идеи в отношении этого раздела книги.
[4] См. Wilkinson and Pickett, 2009.
[5] Комментарии, сделанные в Институте экономических исследований Беккера-Фридмана Чикагского университета: “Understanding Inequality and What to Do About It”, November 6, 2015.
[6] См. Goldin and Katz, 2008; Acemoglu and Autor, 2011 и Murphy and Topel, 2016.
[7] См. Mas-Colell, Whinston, and Green, 1995, где можно узнать, как доказать этот результат.
[8] См. Kaplan and Rauh, 2013a, а также модель, представленную в статье Джонса и Кима (Jones and Kim, 2018), в которой талант используется в качестве косвенного показателя масштабируемости предпринимательской идеи. В книге Роберта Фрэнка (Frank, 1996) представлены результаты ранних исследований по вопросу возникновения неравенства в каждой профессии. Результаты более поздних исследований можно найти здесь: Xie, Killewald, and Near, 2016.
[9] См. Ormerod, 2012.
[10] В своей книге Пол Ормерод (Ormerod, 2012) подробно описывает, как рост связанности способствует усилению неравенства.
[11] См. Cancian and Reed, 1999 и Schwartz and Mare, 2005.
[12] Полное описание модели можно найти здесь: Greenwood et al., 2014.
[13] Согласно этой оценке, данный коэффициент составил бы 0,34, а не 0,43. См. Greenwood et al., 2014. Коэффициент Джини отражает расстояние между распределением доходов и равномерным распределением. Пусть S(P) — это общая доля дохода (или богатства), полученного (принадлежащего) нижними P процентами населения (например, если нижние 30 процентов населения получают 2 процента доходов, то S(30) = 2):
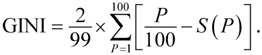
Если доход равномерно распределен, 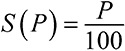 и GINI = 0. Если весь доход достается верхнему 1 проценту, S(P) = 0 при P < 100 и S(100) = 1, а значит, GINI = 1.
и GINI = 0. Если весь доход достается верхнему 1 проценту, S(P) = 0 при P < 100 и S(100) = 1, а значит, GINI = 1.
[14] Эти показатели можно вычислить следующим образом. Дети принадлежат к четырем категориям с вероятностью (0,6, 0,25, 0,1, 0,05). Иначе говоря, 60 процентов детей родителей с высокими доходами, 20 процентов детей родителей с уровнем доходов выше среднего, 15 процентов детей родителей с уровнем доходов ниже среднего и 5 процентов детей родителей с низкими доходами имеют высокий уровень доходов. Процент внуков людей с высоким уровнем доходов равен (0,6)(0,6) + (0,25)(0,2) + (0,1)(0,15) + (0,05)(0,05) = 0,4275, а процент внуков людей с низким уровнем доходов равен (0,6)(0,05) + (0,25)(0,1) + (0,1)(0,15) + (0,05)(0,7) = 0,105.
[15] Pfeffer and Killewald, 2017.
[16] Kaplan and Rao, 2013b.
[17] См. Farmer, 2018.
ОГЛАВЛЕНИЕ
Пролог
ГЛАВА 1. Многомодельное мышление
ГЛАВА 2. Зачем нужны модели?
ГЛАВА 3. Наука о множестве моделей
ГЛАВА 4. Моделирование поведения людей
ГЛАВА 5. Нормальное распределение: колоколообразная кривая
ГЛАВА 6. Степенное распределение: длинный хвост
ГЛАВА 7. Линейные модели
ГЛАВА 8. Вогнутость и выпуклость
ГЛАВА 9. Модели ценности и влияния
ГЛАВА 10. Сетевые модели
ГЛАВА 11. Трансляция, диффузия и заражение
ГЛАВА 12. Энтропия: моделирование неопределенности
ГЛАВА 13. Случайные блуждания
ГЛАВА 14. Зависимость от первоначально выбранного пути
ГЛАВА 15. Модели локальных взаимодействий
ГЛАВА 16. Функции Ляпунова и равновесие
ГЛАВА 17. Модели Маркова
ГЛАВА 18. Модели системной динамики
ГЛАВА 19. Пороговые модели с обратной связью
ГЛАВА 20. Пространственные и гедонические модели выбора
ГЛАВА 21 Три класса моделей теории игр
ГЛАВА 22. Модели кооперации
ГЛАВА 23. Проблемы коллективных действий
ГЛАВА 24. Дизайн механизмов
ГЛАВА 25. Модели сигнализирования
ГЛАВА 26. Модели обучения
ГЛАВА 27. Задачи о многоруком бандите
ГЛАВА 28. Модели пересеченного ландшафта
ГЛАВА 29. Опиоиды, неравенство и смирение
Библиография
Примечания
Последние комментарии
17 минут 28 секунд назад
1 час 57 минут назад
1 день 7 часов назад
1 день 14 часов назад
1 день 14 часов назад
1 день 14 часов назад