Разработка приложений в среде Linux
Второе издание
Лорен и Яну — за то, что давали мне возможность иногда отвлекаться от работы.
Эрик
Памяти моей бабушки, Элинор Джонсон, научившей меня верить в Бога, и глубоко верившей в меня самого.
Майкл
Введение
Данная книга предназначена для опытных (или не столь опытных, но желающих обучаться) программистов, которые намереваются разрабатывать программное обеспечение для Linux или переносить его в Linux с других платформ. Эта книга понадобиться во время обучения программированию в Linux, потом же она станет настольным справочником. После написания первых трех глав первого издания мы использовали черновики как справочный материал во время повседневной работы.
Второе издание книги было существенно обновлено. Кроме того, был открыт сайт, посвященный книге, — http://ladweb.net/.
Операционная система Linux разработана так, чтобы быть максимально похожей на Unix. Книга даст вам хорошие основы программирования в Unix-стиле. Linux существенно ничем не отличается от Unix; впрочем, некоторые различия есть, но они не более значительны, чем типичные отличия между двумя версиями Unix. Эта книга представляет собой руководство по программированию Unix, написанное с точки зрения Linux, с информацией, специфической для Linux.
Linux также имеет уникальные расширения, например, возможности прямого доступа к экрану (см. главу 21), а также средства, используемые в нем более часто, чем в других системах вроде библиотеки
popt (см. главу 26). Материал этой книги охватывает многие такие средства и возможности, поэтому вы сможете создавать программы, по- настоящему пользующиеся преимуществами Linux.
• Если вы являетесь программистом на языке С, но не знакомы ни с Unix, ни с Linux, то внимательное чтение этой книги и работа с примерами окажет серьезную помощь на пути вашего становления квалифицированным программистом для Linux. Воспользовавшись дополнительно системной документацией, вы легко сможете перейти в любую версию Unix.
• Если вы являетесь профессиональным программистом, эта книга облегчит вам переход в Linux. Мы постарались упростить поиск всей необходимой информации. Мы также тщательно раскрываем темы, вызывающие затруднения даже у опытных программистов в Unix, например, группы процессов и сеансов, управление заданиями и работа с
tty.
• Если вы являетесь программистом в Linux, в данной книге раскрыты "проблемные" темы и облегчены многие задачи программирования. Почти каждая глава покажется вам знакомой, поскольку вы уже обладаете необходимыми знаниями Linux. Тем не менее, несмотря на имеющийся опыт, материал этой книги вы сочтете полезным.
Настоящая книга отличается от стандартных пособий по программированию в Unix, поскольку является специфической для определенной операционной системы. Мы не пытаемся охватить все различия систем, подобных Unix; это не принесет особой пользы программистам, ориентированным на Linux и Unix, или программистам на языке С, которые с Linux или Unix не знакомы. По своему опыту мы знаем, что навыки программирования в любой системе, подобной Unix, облегчают изучение остальных систем.
Данная книга не охватывает
всех подробностей программирования в Linux. В ней не рассказывается о базовом интерфейсе, определенном ANSI/ISO С — об этом можно прочитать в других книгах. В ней не рассматриваются другие языки программирования, доступные в Linux, а также графические библиотеки, являющиеся идентичными независимо от используемой системы — это рассматривается в книгах, ориентированных на упомянутые области. Мы предоставляем информацию, необходимую для прохождения пути от программиста на С для систем, подобных Windows, Macintosh или даже DOS, до программиста на С для Linux.
Структурно книга состоит из четырех частей.
• Первая часть представляет собой введение в Linux, описывая операционную систему, условия лицензии и онлайновую системную документацию.
• Во второй части рассматриваются наиболее важные аспекты среды разработки — компиляторы, компоновщик и загрузчик, а также некоторые отладочные инструменты, не столь широко применяемые на других платформах.
• В третьей, основной, части рассматривается интерфейс ядра и системных библиотек, в первую очередь задуманных в качестве интерфейса ядра. В этой части только главы 19, 20 и 21 обладают ярко выраженной спецификой Linux; внимание в основном уделяется общему программированию в Unix с точки зрения Linux. В новой во втором издании главе 22 описаны основы разработки защищенных программ.
• Четвертая часть дополняет информацию предыдущих частей. Она включает описания некоторых важных библиотек, которые предоставляют интерфейсы, более зависимые от ядра. По сути, эти библиотеки не являются специфическими для Linux, но некоторые из них используются чаще в системах Linux, чем в других системах.
Если вы уже знакомы с программированием в Linux или Unix, можете читать главы этой книги в любом порядке, пропуская то, что вас не интересует. Если вы не знакомы с Linux или Unix, большинство глав будут полезны, но для начала рекомендуется чтение глав 1, 2, 4, 5, 9, 10, 11 и 14, поскольку они предоставляют большинство информации, знание которой необходимо для чтения других глав. В частности, в главах 10, 11 и 14 формируется основа модели программирования в Unix и Linux.
Следующие книги, несмотря на то, что некоторые темы в них совпадают, в основном дополняют данную книгу, будучи проще, сложнее, либо рассматривая сходные темы.
•
The С Programming Language, second edition (Язык программирования С (Си), Брайан У. Керниган, Деннис М. Ритчи, ИД "Вильямс", 2005 год) [15]. Кратко обучает стандартному программированию на ANSI С с небольшой ссылкой на операционную систему. Она предназначена для читателей, имеющих навыки программирования.
•
Practical С Programming [27]. Обучает программированию и стилю С шаг за шагом. Это пособие для начинающих, предназначенное для тех, кто не имеет никакого опыта программирования.
•
Programming with GNU Software [19]. Представляет собой введение в среду программирования GNU, включающее главы, посвященные запуску компилятора С, отладчика, утилиты make и системы управления исходным кодом RCS.
•
Advanced Programming in the UNIX Environment [35]. Охватывает наиболее важные системы Unix и системы, подобные Unix, однако предшествует появлению Linux. В книге рассматривается материал, аналогичный представленному в двух заключительных глав настоящей книги: системные вызовы и библиотеки совместного использования. Кроме того, в ней предложено множество примеров и объясняются различия между версиями Unix.
•
UNIX Network Programming [33]. Подробно рассматривает сетевое программирование, включая традиционные виды организации сетей, недоступных в Linux. Во время чтения этой книги особое внимание следует уделять интерфейсу сокетов Беркли (см. главу 17), который обеспечивает максимальную переносимость. Эта книга пригодится, если возникнет потребность в модификации кода для переноса сетевой программы Linux в среду какой-нибудь новой разновидности Unix.
•
A Practical Guide to Red Hat Linux 8 [32]. Книга почти на 1500 страниц, содержащая информацию о применении Linux, программировании оболочки и системном администрировании. Несмотря на то что в названии книги упоминается Red Hat Linux 8, большинство содержащейся в ней информации относится ко всем разновидностям Linux. Она также содержит краткую ссылку на многие утилиты, содержащиеся в системе Linux.
•
Linux in a Nutshell [31]. Предоставляет краткую информацию об утилитах.
•
Linux Device Drivers, second edition [28]. Обучает написанию драйверов устройств Linux как тех, кто знаком с кодом операционной системы, так и тех, кто с ним не знаком.
Полный список рекомендуемой литературы можно найти в конце книги.
Все исходные коды данной книги являются производными от тщательно протестированных рабочих примеров. Исходные коды доступны на сайте http://ladweb.net, а также на сайте издательства. Для ясности в некоторых коротких фрагментах кода оставлены проверки лишь наиболее типичных ошибок, а не всех возможных. Тем не менее, в загружаемых кодах вы найдете проверки всех существенных ошибок.
В книге рассматриваются функции, которые должны использоваться, а также их совместимость. Мы также рекомендуем пользоваться справочной документацией, большая часть которой должна присутствовать в вашей системе. В главе 3 описаны способы поиска онлайновой информации о вашей системе Linux.
Операционная система Linux стремительно развивается, и ко времени прочтения книги некоторые факты могут измениться. Данная книга была написана с учетом ядра Linux 2.6 и библиотеки GNU С версии 2.3.
Второе издание
Ниже перечислены добавления и модификации, появившиеся во втором издании книги.
• Вся книга была обновлена с учетом новой спецификации Unix версии 6 — обновленной версии стандарта POSIX.
• Небольшие фрагменты исходного кода примеров приводятся с номерами строк, облегчая ориентирование в соответствии с полным исходным кодом.
• Глава 1 содержит обновленную и расширенную историю разработки Linux.
• В главе 4 рассматриваются утилиты
strace и
ltrace.
• В главе 6 рассматривается библиотека GNU С (glibc) и стандарты, на которых она основана. Также в этой главе объясняется, как и почему следует использовать макросы проверки свойств. Кроме того, описываются основные системные вызовы, рассматриваемые во всех разделах книги; способы обнаружения возможностей системы во время выполнения; разнообразные интерфейсы, предоставляемые
glibc; подход
glibc к обратной совместимости.
• Глава 7 содержит значительно расширенную информацию об инструментах отладки памяти, включая новые свойства отладки памяти библиотеки GNU С, новую версию mpr и новый инструмент Valgrind.
• В главе 12 рассматриваются сигналы реального времени и контексты сигналов.
• В главе 13 документируются системные вызовы
poll() и
epoll, предоставляющие рекомендуемые альтернативы
select().
• В главе 16 рассматривается и рекомендуется новый механизм распределения псевдотерминалов (Pseudo TTY). Также внимание уделяется системным базам данных
utmp и
wtmp.
• В главе 17 рассматривается как IPv6, так и IPv4, включая новые интерфейсы системных библиотек для написания программ, которые могут равнозначно использовать IPv6 и IPv4. Также рассматриваются более ранние интерфейсы, которым уделялось внимание в первом издании, чтобы дать возможность поддерживать код, использующий эти интерфейсы, и переносить его в более новые интерфейсы. Кроме того, обсуждается более широкий набор функций, чем нужен для многих сетевых серверов, например, неблокирующая
accept().
• Глава 22 — это новая глава, в которой рассматриваются основные требования к написанию защищенных программ и объясняется, почему вопросы безопасности относятся ко всем программам, а не только к системным демонам и утилитам.
• Глава 23 содержит более полное обсуждение использования регулярных выражений, включая простую версию утилиты
grep в качестве примера.
• В главе 26 рассматриваются новейшие улучшения библиотеки
popt и усовершенствованный код примера.
• К главе 28 добавлена реализация Linux-PAM.
• В главе 25 документируется библиотека
qdbm, а не Berkeley db, поскольку лицензия
qdbm является менее ограничивающей.
• Почти каждая глава содержит важные обновления.
Описанные ниже материалы из книги были изъяты.
• Поиск информации о Linux в списках рассылки, группах новостей и на Web-сайтах; эта информация меняется слишком быстро, чтобы стать частью книги, которая будет полезна в течение многих лет.
• Информация об управлении портами ввода-вывода; это обычно использовать не рекомендуется, поскольку оно конфликтует со структурой управления устройствами и режимом электропитания Linux.
• Точные копии общедоступной лицензии GNU и библиотеки GNU. Несмотря на свою важность, перепечатка этих лицензий не улучшает знание их содержания. Также со времени публикации первого издания увеличилась важность ряда других лицензий.
• Инструмент отладки памяти Checker больше не поддерживается, поэтому во втором издании не рассматривается.
Благодарности
Мы благодарим наших технических рецензентов за потраченное время и тщательность. Их предложения помогли улучшить эту книгу. Особую благодарность выражаем Линусу Торвальдсу (Linus Torvalds), Алану Коксу (Alan Сох), Теду Тсо (Ted Ts'o) и Арьену ван де Вену (Arjan van de Ven), которые нашли время, чтобы ответить на наши вопросы.
Поддержав нас в написании первого издания, наши жены — Ким Джонсон (Kim Johnson) и Бригид Троан (Brigid Troan) были так терпеливы и великодушны, что побудили нас написать второе издание. Без их помощи и поддержки не удалось бы написать эту книгу, не говоря уже о ее переиздании.
От издательства
Вы, читатель этой книги, и есть главный ее критик. Мы ценим ваше мнение и хотим знать, что было сделано нами правильно, что можно было сделать лучше и что еще вы хотели бы увидеть изданным нами. Нам интересны любые ваши замечания в наш адрес.
Мы ждем ваших комментариев и надеемся на них. Вы можете прислать нам бумажное или электронное письмо либо просто посетить наш Web-сервер и оставить свои замечания там. Одним словом, любым удобным для вас способом дайте нам знать, нравится ли вам эта книга, а также выскажите свое мнение о том, как сделать наши книги более интересными для вас.
Отправляя письмо или сообщение, не забудьте указать название книги и ее авторов, а также свой обратный адрес. Мы внимательно ознакомимся с вашим мнением и обязательно учтем его при отборе и подготовке к изданию новых книг.
Наши электронные адреса:
E-mail: info@williamspublishing.com
WWW: http://www.williamspublishing.com
Наши почтовые адреса:
в России: 115419, Москва, а/я 783
в Украине: 03150, Киев, а/я 152
Часть I
Начало работы
Глава 1
История создания Linux
Термин
Linux используется для обозначения разных понятий. Технически точным определением является следующее.
Linux — это свободно распространяемое ядро Unix-подобной операционной системы.
Однако многие подразумевают под термином
Linux всю операционную систему, основанную на ядре Linux.
Linux — это свободно распространяемая Unix-подобная операционная система, включающая ядро, системные инструменты, приложения и завершенную среду разработки.
В этой книге используется второе определение, поскольку вы будете программировать не только для ядра, а для всей операционной системы.
Linux (в соответствие со вторым определением) предоставляет хорошую платформу для переноса программ, поскольку рекомендованные им интерфейсы (которые подробно рассматриваются в книге) поддерживаются почти каждой доступной версией Unix, равно как и большинством клонов Unix. Как следует ознакомившись с материалом настоящей книги, вы сможете переносить свои программы почти во все системы Unix и системы, подобные Unix, проделывая лишь небольшую дополнительную работу.
С другой стороны, после работы с Linux вы можете предпочесть пользоваться только ею, не утруждая себя переносом.
Linux — это не просто еще одна система, подобная Unix. Это не просто хорошая платформа, куда можно переносить программы — это также хорошая платформа, на которой можно создавать и запускать приложения. Она широко используется во всем мире, помогая популяризировать концепцию
открытого исходного кода (Open Source) или
свободного программного обеспечения (Free Software). Краткий экскурс в историю поможет понять, как и почему это случилось.
1.1. Краткая история свободного программного обеспечения Unix
Предлагаемая история упрощена и основана на самых важных элементах системы Linux. Более длинную и равномерную историю можно прочесть в книге
A Quarter Century of UNIX [29].
Во времена появления вычислительной техники программное обеспечение (ПО) рассматривалось лишь как свойство оборудования. При продаже внимание уделялось именно аппаратуре, поэтому компании отдавали ПО вместе со своими системами. Улучшения, новые алгоритмы и идеи свободно распространялись среди студентов, профессоров и корпоративных исследователей.
Вскоре компании обратили внимание на ценность ПО как интеллектуальной собственности. Они начали придавать законную силу авторским правам на свои технологии ПО и ограничивать распространение исходных и двоичных кодов. Инновации, ранее рассматривавшиеся как общественная собственность, стали яростно защищаемым корпоративным имуществом, что изменило культуру разработки компьютерного ПО.
Ричард Столлман (Richard Stallman) из Массачусетсского технологического института (MIT) не хотел, чтобы инновации ПО во всем мире контролировались корпоративными амбициями, поэтому он основал Фонд свободного программного обеспечения (Free Software Foundation — FSF). Целью FSF стало поощрение разработки и использования ПО без ограничений на свободное распространение.
Однако слово "free" в этом контексте вызвало недоразумения. Под словом "free" Ричард Столлман подразумевал свободу, а не нулевую цену. Он твердо убежден, что ПО и связанная с ним документация должны быть доступны с исходным кодом, без ограничений на дополнительное распространение. Не так давно появился термин
Open Source (открытый исходный код) для описания тех же целей (без слова "free", вызывающего недоразумения). Термины
Open Source и
Free Software (свободное ПО) обычно рассматриваются как синонимы.
С целью продвижения своей идеи Ричард Столлман не без помощи других создал общедоступную лицензию (General Public License — GPL). Эта лицензия оказала настолько большое влияние, что аббревиатура
GPL вошла в жаргон разработчиков как глагол; вместо "применить условия GPL к создаваемому вами ПО" часто говорят "
to GPL".
Лицензия GPL состоит из трех пунктов.
1. Каждый получатель ПО, подпадающего под условия GPL, имеет право получить исходный код этого ПО без дополнительной платы (исключая плату за доставку).
2. Любое ПО, производное от ПО, подпадающего под условия GPL, должно сохранить GPL в качестве лицензии для свободного распространения.
3. Любой владелец ПО, подпадающего под условия GPL, имеет право распространения этого ПО на условиях, не конфликтующих с GPL.
Важным является то, что в этих лицензионных условиях не упоминается цена (за исключением ситуации, когда исходный код не разрешается поставлять как продукт с дополнительной стоимостью). ПО, подпадающее под условия GPL, может продаваться клиентам по любой цене. Однако затем эти клиенты имеют права на распространение ПО, включая исходный код, по собственному усмотрению. С появлением Internet это право приобрело эффект сохранения низкой цены ПО, соответствующего лицензии GPL (обычно она равняется нулю), одновременно давая компаниям возможность продавать такое ПО и предоставлять услуги вроде поддержки, которые его дополняют.
Частью GPL, вызывающей больше всего противоречий, является второй пункт: к ПО, производному от ПО, соответствующего лицензии GPL, должны быть также применены условия GPL. Хотя недоброжелатели из-за этого пункта называют GPL "вирусом", сторонники настаивают на том, что этот пункт является одной из самых сильных сторон GPL. Он предотвращает ситуации, когда компании получают ПО, подпадающее под условия GPL, добавляют в него несколько свойств и делают из результата патентованный пакет.
Основным проектом участников FSF является проект GNU's Not Unix (GNU), цель которого — создание свободно распространяемой Unix-подобной операционной системы. При запуске проекта GNU было очень мало высококачественного свободно распространяемого ПО, поэтому его участники начали с создания приложений и инструментов для будущей системы, а не с самой операционной системы. Поскольку лицензия GPL была также произведена FSF, ко многим ключевым компонентам операционной системы GNU применены условия GPL, но на протяжении многих лет проект GNU принял многие другие пакеты, например, X Window System, систему верстки ТЕХ и язык Perl, свободно распространяемые под другими лицензиями.
Результатом проекта GNU стало несколько основных пакетов и множество второстепенных. Основные пакеты включают редактор Emacs, библиотеку GNU С, коллекцию компиляторов GNU (
gcc, как изначально назывался компилятор GNU С перед добавлением С++), оболочку
bash и
gawk (GNU's awk). Второстепенные пакеты включают высококачественные утилиты оболочек и программы обработки текста, которые обычно присутствуют в системе Unix.
1.2. Разработка Linux
В 1991 году Линус Торвальдс (Linus Torvalds), в то время студент Хельсинкского университета, начал проект, целью которого было обучение низкоуровневому программированию для процессора Intel 80386. В то время он работал с операционной системой Minix, созданной Эндрю Таненбаумом (Andrew Tanenbaum), поэтому изначально совмещал свой проект с системными вызовами Minix и структурой дисковой файловой системы. Реализовав первую версию ядра Linux в Internet под довольно ограничивающей лицензией, вскоре он, однако, сменил эту лицензию на GPL.
Сочетание GPL и первоначального набора функций ядра Linux убедило других разработчиков предложить свою помощь при разработке ядра. Реализация библиотеки С, производная от потенциального в то время проекта библиотеки GNU С, позволила разработчикам создавать "родные" пользовательские приложения. Затем последовали собственные версии
gcc, Emacs и
bash. В 1992 году разработчик со средней квалификацией мог установить и загрузить версию Linux 0.95 на большинстве машин с процессором Intel 80386.
Проект Linux с самого начала был тесно связан с проектом GNU. Исходная база проекта GNU стала очень важным ресурсом сообщества Linux для создания завершенной системы. Хотя значительное количество систем, основанных на Linux, произведены из источников, которые включают свободно доступный код Unix Калифорнийского университета в Беркли и консорциума X Consortium, многие важные части функциональной системы Linux напрямую связаны с проектом GNU.
По мере развития Linux некоторые лица, а позже и компании, сосредоточились на облегчении инсталляции и практичности систем Linux для новых пользователей, создав пакеты ядра Linux, называемые
дистрибутивами, а также логически полный набор утилит. Все это образовало завершенную операционную систему.
Кроме ядра Linux, дистрибутив Linux содержит библиотеки разработки, компиляторы, интерпретаторы, оболочки, приложения, утилиты, графические операционные среды, конфигурационные инструменты и многие другие компоненты. При построении системы Linux разработчики дистрибутива собирают компоненты из разных мест с целью создания полной коллекции всех компонентов ПО, необходимых для нормального функционирования. Большинство дистрибутивов также содержат пользовательские компоненты, облегчающие инсталляцию и эксплуатацию системы Linux.
Доступно множество дистрибутивов Linux. У каждого есть свои преимущества и недостатки, однако все они имеют общее ядро и библиотеки разработки, которые отличают Linux от других операционных систем. Эта книга предназначена для помощи разработчикам в написании программ для любой системы Linux. Поскольку все дистрибутивы Linux используют один и тот же код для системных служб, двоичный и исходный код во всех дистрибутивах совместимы.
Одним из проектов, повлиявших на эту совместимость, является
стандарт иерархии файловых систем (Filesystem Hierarchy Standard — FHS), ранее называемый
стандартом файловых систем Linux (Linux Filesystem Standard — FSSTND), определяющий, где следует хранить множество файлов, и объясняющий в общих чертах, каким образом должна быть организована оставшаяся часть файловой системы. Позднее проект под названием
стандартная база Linux (Linux Standard Base — LSB) был расширен без учета структуры файловой системы, определяя программные интерфейсы приложений (Application Programming Interface — API) и двоичные интерфейсы приложений (Application Binary Interface — ABI). Эти интерфейсы предназначены для возможности компиляции приложения один раз и развертывания его на любой системе, подчиняющейся определению LSB для данной архитектуры процессора. Эти и другие документы доступны на Web-сайте по адресу http://freestandards.org.
1.3. Важные факты в создании систем Unix
Хотя большая часть общего кода Linux разрабатывалась независимо от традиционных исходных баз Unix, на интерфейсы, предоставляемые Linux, сильно влияли существующие системы Unix.
На заре восьмидесятых годов прошлого столетия разработчики Unix были разделены на два "лагеря": первый — Калифорнийский университет в Беркли, а второй — компания AT&T Bell Laboratories. Оба учреждения разрабатывали и поддерживали операционные системы Unix, которые происходили от исходной реализации Unix, созданной в Bell Laboratories.
Версия Unix от Беркли стала известной как
программный дистрибутив Беркли (Berkeley Software Distribution — BSD) и приобрела популярность в научном сообществе. Система BSD впервые включила организацию сетей TCP/IP, что повлияло на ее успех и помогло убедить компанию Sun Microsystems основать на BSD первую операционную систему Sun — SunOS.
В компании Bell Laboratories также трудились над совершенствованием Unix, но, к сожалению, несколько другими способами, чем в Беркли. Разнообразные выпуски Bell Laboratories обозначались словом "System", сопровождаемым римским числом. Окончательным выпуском Unix от Bell Laboratories была
System V (или SysV);
UNIX System У Release 4 (SVR4) сегодня предоставляет кодовую базу для большинства коммерческих операционных систем Unix. Стандартным документом, описывающим System V, является
System V Interface Definition (SVID).
Эта разветвленная разработка Unix значительно разнообразила системные вызовы, системные библиотеки и основные команды систем Unix. Одним из лучших примеров такого расщепления являются сетевые интерфейсы, сопровождающие приложения каждой операционной системы. Системы BSD использовали интерфейс под названием сокетов, позволяющий программам сообщаться друг с другом по сети. С другой стороны, System V предоставила
интерфейс транспортного уровня (Transport Layer Interface — TLI), полностью несовместимый с сокетами, и официально определенный транспортный интерфейс X/Open (X/Open Transport Interface — XTI). Такая разнородная разработка значительно снизила переносимость программ между версиями Unix, увеличивая стоимость и уменьшая доступность сторонних продуктов для всех версий Unix.
Еще одним примером несовместимости систем Unix является команда
ps, позволяющая запрашивать информацию о процессах операционной системы. В системах BSD команда
ps aux выдает полный листинг всех процессов, работающих на машине; в System V эта команда недопустима, вместо нее необходимо использовать
ps -ef. Форматы вывода так же несовместимы, как и аргументы командной строки. (Команда
ps в Linux пытается поддерживать оба стиля.)
Пытаясь стандартизовать все аспекты Unix, которые разошлись из-за разных подходов к разработке в этот период (это еще известно как "войны Unix"), индустрия Unix спонсировала создание набора стандартов, которые определяют предоставляемые Unix интерфейсы. Часть стандартов, имеющая дело с интерфейсами программных и системных инструментов, была названа
POSIX (технически это серия IEEE Std 1003, составленная из многих отдельных и черновых стандартов) и выпущена
Институтом инженеров по электротехнике и электронике (Institute of Electrical and Electronics Engineers — IEEE).
Однако исходные серии стандартов POSIX были не полностью завершены. Например, основные концепции UNIX вроде процессов считались необязательными. Более полный стандарт прошел через несколько версий и названий (например, серия стандартов
руководства по переносимости X/Open (X/Open Portability Guide — XPG)) перед тем, как был переименован в
одиночную спецификацию Unix (Single Unix Specification — SUS), выпущенную
The Open Group (владельцем торговой марки UNIX). SUS после нескольких пересмотров была принята IEEE как самая новая версия стандарта POSIX, в настоящее время это IEEE Std 1003.1-2004 [25], и время от времени обновлялась несколькими поправками. IEEE Std 1003.1-2003 был также принят в качестве стандарта ISO/IEC 9945-2003. Самую новую онлайновую версию этого стандарта можно найти по адресу http://www.unixsystems.org/.
Более ранние стандарты, на основе которых был создан этот обновленный унифицированный стандарт, включают все ранние стандарты IEEE Std 1003.1 (POSIX.1 — программный интерфейс С), IEEE Std 1003.2 (POSIX.2 — интерфейс оболочки), а также все связанные стандарты POSIX наподобие расширений реального времени, определенных как POSIX.4, которые позже были переименованы в POSIX.1b, и несколько черновых стандартов.
Поскольку "POSIX" и "SUS" теперь являются синонимами, на комбинированную работу в этой книге мы будем ссылаться как на POSIX.
1.4. Происхождение Linux
"Широта выбора — самое лучшее качество, присущее стандартам".
[1] К услугам разработчиков Linux была двадцатилетняя история Unix, но более важным является то, что справочными материалами им служили высококачественные стандарты. Изначально Linux разрабатывался в соответствии с POSIX; там, где не было POSIX, Linux следовала практике System V, за исключением организации сетей, где и системные вызовы, и организация сетей придерживались намного более популярной модели BSD. Теперь, когда существует объединенный стандарт SUS/POSIX, дальнейшее развитие обычно совместимо с более новым стандартом POSIX, а прошлые отклонения от него по возможности откорректированы.
Самым существенным отличием между SVR4 и Linux с точки зрения программирования является то, что Linux не предоставляет столько же дублированных программных интерфейсов. Например, даже программисты, занимавшиеся написанием кода исключительно для систем SVR4, предпочитали сокеты Беркли интерфейсу транспортного уровня (TLI) из SysV; Linux избегает накладных расходов TLI и предоставляет только сокеты.
Когда доступных стандартов (официальных,
де-юре, и неофициальных,
де-факто) недостаточно для реализации, Linux иногда предлагает свои собственные расширения, не учитывающие POSIX. Например, асинхронная POSIX-спецификация асинхронного ввода-вывода в большинстве случаев рассматривается как неадекватная для многих реальных приложений, поэтому в Linux реализован стандарт POSIX как оболочка для более общей и полезной реализации. Также не существует общей спецификации для высоко масштабируемого интерфейса опроса ввода-вывода, поэтому был разработан и добавлен совершенно новый интерфейс
epoll. Мы обратимся к этим нестандартным интерфейсам, как только они будут документированы.
Глава 2
Лицензии и авторские права
Новички в мире свободного ПО часто смущены большим количеством лицензий, с ним связанных. Некоторые приверженцы свободного ПО превращают нормальные слова в жаргон и ожидают понимания всех нюансов, связанных с каждым элементом жаргона.
Для написания и распространения ПО, работающего на свободной платформе, такой как Linux, необходимо ориентироваться в лицензиях и авторском праве. Эти понятия часто путаются интеллигентными и образованными людьми, среди которых находятся и приверженцы свободного ПО. Если вы намереваетесь написать свободное или коммерческое ПО, вы будете работать с инструментами, сопровождаемыми множеством лицензионных условий. Общее понимание сферы авторского права и лицензирования поможет избежать распространенных ошибок.
В эти спорные времена крайне необходимо предупредить вас о том, что
мы не являемся юристами. Глава отражает наше понимание обсуждаемых проблем, но не предлагает юридических советов. Перед тем, как принимать решения относительно вашей или чьей-либо интеллектуальной собственности, следует более глубоко изучить проблему и в случае необходимости проконсультироваться с юристом.
2.1. Авторское право
Сначала рассмотрим более простую проблему.
Авторское право (copyright) — это простая защита владения определенными видами интеллектуальной собственности. В соответствии с новейшими соглашениями об авторском праве вам даже не понадобится требовать авторских прав на создаваемый вами материал. Пока вы явно не откажетесь от права собственности, другим лицам будет разрешено использовать вашу интеллектуальную собственность только в строго определенном порядке, называемом
законным использованием, пока вы явно не предоставите им разрешение, называемое
лицензией, на другие действия. Так что если вы напишете книгу или элемент ПО, вам не нужно помещать на них фразу типа "copyright ©
год", чтобы получить право собственности на них. Однако если вы не поместите эту фразу в свою работу, вам будет намного сложнее требовать защиты права собственности в суде, если кто-то нарушит либо ваши авторские права (заявляя о том или действуя так, как будто вам не принадлежат авторские права), либо ваши лицензионные условия.
Бернское соглашение об авторском праве (http://www.wipo.org), международный договор о соглашениях об авторском праве и смежных правах, требует от стран-участниц придавать авторским правам законную силу только в случае:
… если со времени первой публикации все копии работы, опубликованной автором либо другим владельцем авторских прав, снабжены символом "с" нижнего регистра внутри круга ©, который сопровождается именем владельца авторских прав и годом первой публикации, расположенными таким образом, чтобы обратить внимание на заявление об авторских правах.
Последовательность
(с) обычно используется в качестве замены "с" нижнего регистра внутри круга, но суды этого не поддерживают. Всегда используйте слова
Copyright (в дополнение к последовательности
(с), если вы решили ее применять) при упоминании своих авторских прав. Если вам доступен символ ©, лучше воспользоваться им, но все-таки не игнорировать слово
Copyright.
Авторские права не вечны. Вся интеллектуальная собственность со временем становится
всеобщим достоянием; это означает, что общество со временем присваивает авторские права на собственность, и любой человек может сделать с этой собственностью все, что угодно. Лицензионные условия утрачивают свою обязательность, как только собственность становится всеобщим достоянием. Существует следующая уловка: если вы создаете
производную работу, основанную на работе общего пользования, вы получаете авторские права на свои
изменения. Поэтому, несмотря на то, что авторские права на многие старые книги уже
истекли, став всеобщим достоянием, редакторы часто вносят небольшие изменения, исправляя ошибки, допущенные в оригинале. Затем они часто требуют права собственности на производную работу, включающую внесенные ими изменения. Эти авторские права предотвращают законное копирование отредактированной версии, хотя вы можете свободно копировать оригинал с истекшими авторскими правами, который является всеобщим достоянием.
Существуют ограничения того, что может охраняться авторскими правами. Невозможно опубликовать книгу, содержащую только слово "the", и затем пытаться требовать лицензионной платы от всех, кто использует это слово в своих книгах. Однако если вы создадите стилизованное изображение слова "the", то сможете приобрести на это авторские права, если докажете, что ранее такого написания не существовало. Несмотря на то что мы можем открыто использовать слово "the", мы не имеем право продавать репродукции вашей работы, не получив от вас лицензию.
Такие ограничения применяются и к ПО. Если вы имеете лицензионное право на изменение чьего-либо ПО, но вносите совершенно незначительное изменение, будет абсурдно требовать авторские права на это изменение. Вы не сможете защищать требование авторских прав на это изменение в суде; ваше изменение будет общим достоянием, так же, как и слово "the". Однако если вы внесли значительные изменения в ПО, то получите авторские права на это изменение. Исключением может быть ситуация, когда, например, владельцы авторских прав на оригинал лицензируют изменения в ПО так, что владение авторскими правами на все изменения возвращается к ним.
2.2. Лицензирование
Владельцы авторских прав могут открыто ставить условия лицензии. Наиболее распространенные области ограничения (или разрешения) включают использование, копирование, распространение и изменение. Конкретным примером является общедоступная лицензия GNU (GPL, часто называемая
законной левой копией), явно не ограничивающая использование. Она ограничивает только "копирование, распространение и изменение".
Приведем пример жаргона сферы свободного ПО, с которым вы наверняка намереваетесь ознакомиться. В сфере свободного ПО фраза
общее достояние используется исключительно касательно права собственности. Ссылки в журнальных статьях на GPL как на "авторское право общественного достояния" неверны, поскольку GPL не предоставляет общественному достоянию владение авторским правом; ссылки же на нее как на "лицензию общественного достояния" верны, поскольку GPL явно не помещает лицензионных ограничений на использование. Однако фанатики свободного ПО считают такое использование
общественного достояния полностью некорректным.
Определенные лицензионные ограничения могут быть незаконными в некоторых местностях. Большинство государственных органов предотвращают ограничение того, что считается ими
законным использованием в лицензионном соглашении. Например, многие европейские страны явно разрешают реконструирование ПО и оборудования в определенных целях, несмотря на лицензионные ограничения подобной деятельности. Поэтому большинство лицензионных соглашений включают
статью о разделимости вроде приведенной ниже статьи из GPL.
Если любая часть этого раздела считается недействительной либо не снабженной исковой силой, баланс этого раздела действителен, и весь раздел действителен при других обстоятельствах.
В большинстве лицензионных соглашений для выражения этой же мысли используется менее понятный язык.
Многие из тех, кто пытается написать собственные лицензионные условия без помощи юриста, пишут лицензии с условиями, не имеющими законной силы, и немногие из этих лицензий содержат статью о разделимости. Если вы намереваетесь предусмотреть собственные лицензионные условия для своего ПО, и если вам небезразлично подчинение этим условиям, то пусть их просмотрит юрист, специализирующийся на интеллектуальной собственности.
2.3. Лицензии на свободное ПО
Как описывалось в главе 1, термин
открытый исходный код (Open Source) был создан как результат попытки разрешить споры вокруг слов "свободный" и "открытый" (free) в словосочетании "свободное ПО" ("free software"). Для управления понятием "открытый исходный код" была создана
Инициатива открытого исходного кода (Open source Initiative — OSI) и, несмотря на то, что ее попытки зарегистрировать торговую марку термина (для защиты его значения) были отклонены Службой патентов и торговых знаков США (US Patent and Trademark Office), OSI получила в свое распоряжение знак сертификации "
свободное ПО, сертифицированное OSI". (Законных ограничений на использование термина
открытый исходный код не существует, но они существуют относительно знака сертификации "
свободное ПО, сертифицированное OSI".)
OSI поддерживает
определение открытого исходного кода (Open Source Definition — OSD) — описание прав, предоставляемое лицензиями открытого исходного кода; она также поддерживает полный список сертифицированных ею лицензий, чтобы удовлетворить запросы OSD, среди которых — доступность исходного кода, отсутствие ограничений на свободное распространение продукта, разрешение производных работ, а также запрет дискриминации лиц, групп или областей для попыток. Полное OSD вместе со списком лицензий, сертифицированных как "свободное ПО, сертифицированное OSI", доступно на сайте http://opensource.org/.
2.3.1. Общедоступная лицензия GNU
GPL является одной из самых ограничивающих лицензий свободного ПО. Если вы включаете исходный код, лицензированный GPL в другой программе, к этой программе при лицензировании также должны быть применены условия GPL
[2]. В Фонде свободного программного обеспечения (FSF, автор GPL) считают, что выполнение связывания с помощью библиотеки "создает производную работу"; другие трактуют ее как "работу простого агрегирования". Поэтому в FSF утверждают, что вам нельзя выполнять компоновку с библиотекой, к которой применены условия GPL, если к компонуемой программе не применяется лицензия GPL. Однако некоторые лица придерживаются мнения, что связывание — это "простое агрегирование", тогда как GPL утверждает следующее.
Кроме того, простое агрегирование другой работы, не основанной на Программе, с Программой (или с работой, основанной на Программе) с помощью тома внешней памяти либо носителя дистрибутива не помещает другую работу в область действия данной Лицензии.
Если вы рассматриваете исполняемый файл как "том внешней памяти", можете прибегнуть к полному агрегированию.
Насколько нам известно, это определение еще не было проверено в суде. В маловероятном случае возникновения желания связать с библиотекой программу, к которой не применены условия GPL, обратитесь к авторам библиотеки за их интерпретацией.
2.3.2. Общедоступная лицензия библиотеки GNU
Общедоступная библиотечная лицензия GNU (GNU Library General Public Licence — LGPL) предназначена для увеличения общей полезности библиотек. Цель LGPL — разрешить пользователям обновлять или улучшать свои библиотеки без необходимости получения новых версий программ, компонуемых с этими библиотеками. С этой целью LGPL не пытается установить какие-то лицензионные ограничения на программы, компонуемые с библиотекой, до тех пор, пока эти программы скомпонованы с совместно используемыми версиями библиотек, к которым применены условия LGPL, или которые снабжены объектными файлами для приложения, позволяя пользователю заново связывать приложение с новыми либо усовершенствованными версиями библиотеки.
На практике это ограничение незначительно; будет неразумно не применять для компоновки совместно используемые библиотеки, если они доступны.
К очень немногим библиотекам применены условия GPL; большинство из них подпадает под действие LGPL. Библиотеки, подчиняющиеся GPL, обычно трактуются в соответствие с LGPL, поскольку авторы библиотек не были в курсе либо не приняли во внимание существование LGPL. В ответ на вежливую просьбу многие авторы обновляют лицензию своих
библиотек, применяя к ним условия LGPL.
2.3.3. Лицензии стиля MIT/X/BSD
Лицензии стиля MIT/X намного проще, чем GPL или LGPL; их единственным ограничением является (если по простому) поддержка всех существующих уведомлений об авторских правах и лицензионных условий в исходном либо двоичном распространении, и запрет использования имени любого автора без его письменного соглашения в целях подтверждения либо продвижения производных работ.
2.3.4. Лицензии старого стиля BSD
Лицензии старого стиля BSD добавляют к условиям лицензий MIT/X существенное ограничение, которое состоит в том, что рекламные материалы, упоминающие свойства ПО, включают подтверждение. Сама лицензия BSD была изменена с целью устранения этого ограничения, но некоторое ПО продолжает пользоваться лицензиями, смоделированными по старой лицензии BSD.
2.3.5. Лицензия Artistic License
Исходный код языка Perl распространяется под действием лицензии, позволяющей соблюдать условия или GPL, или альтернативной лицензии с причудливым названием
Artistic License (Творческая лицензия). Основной целью этой лицензии является сохранение прав на неограниченное открытое распространение и предотвращение продажи пользователями усовершенствованных патентованных изменений, выдающих себя за официальные версии. Другие авторы ПО приняли соглашение Perl, позволяющее пользователям следовать условиям либо GPL, либо Artistic License; к некоторым применяются условия лишь Artistic License.
2.3.6. Несовместимости лицензий
Различные лицензионные условия свободного ПО допускают различные типы коммерческого использования, изменения и распространения. Чаще всего желательно повторно использовать существующий код в ваших собственных проектах. До известной степени это неизбежно — почти каждая написанная вами программа будет связана с библиотекой С, так что знания лицензионных условий библиотеки С будут необходимы так же, как и знания условий других библиотек, с которыми вы компонуете свою программу. Также вы можете изъявить желание включить фрагменты исходного кода других программ в свои собственные программы.
Смешивание кода ПО с разнообразными лицензиями может иногда вызывать проблемы. Проблемы не возникают при компоновке с совместно используемыми библиотеками, но они определенно связаны с созданием производных работ. Если вы изменяете чье-либо ПО, вам необходимо знать лицензионные условия. Если вы пытаетесь сочетать в одной производной работе два элемента ПО с разными лицензиями, вам придется определить, конфликтуют ли эти лицензии. И снова это не имеет значения, когда вы пишете свой собственный код с нуля.
Если вы работаете с кодом, к которому применена лицензия GPL или LGPL, вы не сможете включить его в код, к которому применены условия лицензии стиля раннего BSD, поскольку GPL и LGPL запрещают "дополнительные ограничения", а старая лицензия BSD содержит дополнительные ограничения (не учитывающие ограничения GPL или LGPL) касательно рекламы и поддержки. По причине этого конфликта к некоторым элементам ПО применены альтернативные условия — условия и GPL, и лицензии раннего стиля BSD; у вас есть право выбора, каких лицензионных условий придерживаться.
Если код, к которому применены условия GPL или LGPL, включен в работу, производную от лицензии стиля BSD/MIT/X, ко всей производной работе (для всех практических целей) должны быть применены условия GPL либо LGPL соответственно.
Также существует много других потенциальных несовместимостей. Если вы сомневаетесь в том, что вам разрешается делать с определенными элементами свободного ПО, не смущайтесь — спросите об этом владельца авторских прав. Запомните, что он может предоставить вам лицензию на использование ПО любым удобным ему способом.
Глава 3
Онлайновая системная документация
Web-сайт, посвященный этой книге и доступный по адресу http://ladweb.net, содержит дополнения к тексту книги, детальную информацию по темам, выходящим за рамки книги, и ссылки на дополнительные сведения в Internet.
3.1. Оперативные страницы руководства
Доступ к оперативным страницам руководства (man-страницам), дающим справку о системе, можно получить с помощью команды
man. Чтобы прочитать справочную страницу самой команды
man, введите в командной строке
man man. Оперативные страницы руководства обычно содержат справочную документацию, а не консультативную информацию, и славятся своей краткостью, из-за чего иногда возникают трудности в их понимании. Однако если вам понадобится справочный материал, они могут оказаться именно тем, что вам нужно.
Доступ к оперативным страницам руководства предоставляется тремя программами. Программа
man отображает отдельные оперативные страницы руководства, а команды
apropos и
whatis ищут ключевые слова в наборе оперативных страниц руководства. Команды
apropos и
whatis производят поиск в одной и той же базе данных; различие состоит в том, что
whatis отображает только строки, в точности соответствующие слову, которое вы ищете, a
apropos отображает любую строку, содержащую слово, которое вы ищете. К примеру, если вы ищете
man,
apropos отобразит
manager и
manipulation, в то время как
whatis отобразит лишь слово
man, отделенное от других букв пробелом либо знаком пунктуации, например,
man.config. Попробуйте запустить команды
whatis man и
apropos man, чтобы увидеть разницу.
Многие оперативные страницы руководства в Linux являются частью большого пакета, собранного процессором лингвистической информации (language data processor — LDP). А именно, страницы разделов 2 (системные вызовы), 3 (библиотеки), 4 (специальные файлы или файлы устройств) и 5 (форматы файлов) принадлежат в основном к коллекции оперативных страниц руководства LDP и являются наиболее полезными в программировании. Если необходимо выяснить, какой раздел следует просмотреть, укажите номер этого раздела перед названием оперативной страницы руководства, которую вы намереваетесь просмотреть.
Например,
man man предоставляет оперативную страницу руководства для команды
man из раздела 1; если вы хотите просмотреть спецификацию о написании оперативных страниц руководства, укажите раздел 7 —
man 7 man.
Во время просмотра оперативных страниц руководства помните, что многие системные вызовы и библиотечные функции имеют одинаковые имена. В большинстве случаев вам требуются сведения о библиотечных функциях, с которыми вы будете осуществлять компоновку, а не о системных вызовах, к которым периодически обращаются эти библиотечные функции. Для доступа к описанию библиотечных функций применяйте
man 3 функция, поскольку имена некоторых библиотечных функций совпадают с именами системных вызовов из раздела 2.
Также обратите особое внимание на то, что оперативные страницы руководства библиотеки поддерживаются отдельно от самой библиотеки С. Поскольку библиотека С обычно не меняет своего поведения, это не является проблемой. Все дистрибутивы Linux теперь используют библиотеку GNU С, которая рассматривается в главе 6. К библиотеке GNU С прилагается полная документация. Эта информация доступна в форме Texinfo.
3.2. Информационные страницы
В проекте GNU для представления документации был принят формат Texinfo. Документацию Texinfo можно распечатать (используя преобразование в ТЕХ) либо прочитать в онлайне (в формате "info", очень раннем гипертекстовом формате, предшествующем World Wide Web). В Linux существует множество программ для чтения информационной документации. Ниже приведен небольшой перечень.
• В редакторе Emacs есть режим чтения информации; наберите
<ESC> X info для входа в этот режим.
• Программы
info и
pinfо являются небольшими программами текстового режима для быстрого просмотра информационных страниц.
• Большинство программ системной документации (например, программы
yelp от GNOME и
khelpcenter от KDE) могут отображать информационные страницы. Мы рекомендуем эти инструменты, поскольку они предоставляют гипертекстовый интерфейс к информационным страницам, более знакомый всем, кто умеет использовать Web-браузер, чем интерфейс, предоставляемый Emacs,
info или
pinfо. (Эти инструменты также предлагают другую системную документацию, например, оперативные страницы руководства и документацию по системе, частью которой они являются.)
3.3. Прочая документация
Каталог
/usr/share/doc представляет собой всеохватывающее место для несобранной иными способами документации. Большинство пакетов, установленных в вашей системе, инсталлируют внутри каталога
/usr/share/doc файлы "README", документацию в разных форматах (включая простой текст, PostScript, PDF и HTML) и примеры. У каждого пакета имеется свой собственный каталог, носящий имя этого пакета и номер его версии.
Часть II
Инструментальные средства и среда разработки
Глава 4
Инструментальные средства разработки
Для работы в Linux доступно потрясающее разнообразие средств разработки. Любому программисту, работающему в Linux, нужно ознакомиться с некоторыми наиболее важными из них.
Дистрибутивы Linux включают в себя множество серьезных и проверенных средств разработки; большинство из этих средств на протяжении нескольких лет входили в системы разработки под Unix. Средства разработки Linux не отличаются ненужными излишествами и броскостью; большинство из них представляют собой инструменты командной строки без графического интерфейса пользователя. За все годы их применения эти средства зарекомендовали себя с самой лучшей стороны, и их изучение лишним не будет.
Если вы уже знакомы с Emacs,
vi,
make,
gdb,
strace и
ltrace, в этой главе ничего нового вы для себя не найдете. Тем не менее, в оставшейся части книги предполагаются хорошие знания какого-нибудь текстового редактора. Практически весь свободный исходный код Unix и Linux собирается при помощи
make, a
gdb — один из самых распространенных отладчиков, доступных для Linux и Unix. Утилита
strace (или подобная утилита под названием
trace либо
truss) доступна в большинстве систем Unix; утилита
ltrace была изначально написана для Linux и в большинстве систем недоступна (на момент написания книги).
Однако не стоит думать, что для Linux нет графических средств разработки; на самом деле, все как раз наоборот. Этих средств огромное количество.
На момент написания этой книги привлекали внимание две интегрированных среды разработки (Integrated Development Environment — IDE), которые могут входить в используемый вами дистрибутив: KDevelop (http://kdevelop.org/), часть среды рабочего стола KDE, и Eclipse (http://eclipse.org/), межплатформенная среда, основанная на Java, которая первоначально, была разработана IBM, а теперь поддерживается крупным консорциумом. Однако в этой книге мы не будем останавливаться на рассмотрении упомянутых сред, поскольку они сопровождаются детальной документацией.
Даже несмотря на то, что для работы в Linux доступны многочисленные IDE, они пользуются не такой популярностью, как на других платформах. Даже если среда IDE применяется, все же более практичным считается написание программного обеспечения с открытым исходным кодом без ее задействования. Все это делается для того, чтобы другие программисты, которые захотят сделать свой вклад в ваш проект, не были стеснены вашим выбором IDE. Среда KDevelop поможет собрать проект, который будет использовать стандартные инструменты Automake, Autoconf и Libtool, используемые в многочисленных проектах с открытым исходным кодом.
Сами по себе стандартные средства Automake, Autoconf и Libtool играют важную роль в процессе разработки. Они были созданы для помощи в построений приложений таким образом, чтоб эти приложения могли быть почти автоматически перенесены в другие операционные системы. Ввиду того, что эти средства сложны, в настоящей книге мы рассматривать их не будем. Кроме того, эти средства регулярно изменяются; электронные версии
GNU Autoconf,
Automake и
Libtool [41] доступны по адресу http://sources.redhat.com/autobook/.
4.1. Редакторы
Разработчики Unix традиционно придерживались строгих и разнотипных предпочтений особенно в выборе редакторов.
Доступно множество редакторов, которые легко изучить самостоятельно; наиболее распространенными можно считать
vi и
Emacs. Оба редактора являются мощными представителями своего типа, чего не скажешь на первый взгляд. У обоих редакторов сравнительно крутая кривая обучения, и они радикально отличаются друг от друга. Emacs является достаточно крупным; он сам себе операционная среда,
vi не занимает много места и разработан специально для внедрения в среду Unix. Было написано множество клонов и альтернативных версий каждого редактора, и у самих версий также имеются свои клоны.
В этой книге мы не будем углубляться в изучение
vi и Emacs, поскольку материал занял бы слишком много места. В [32] каждому редактору посвящены отдельные главы, кроме того, рекомендуем обратиться к [5] и [17]. В нашей книге мы только сравним Emacs и
vi и расскажем, как получить оперативную справку по каждому из них.
Emacs включает исчерпывающий набор руководств, в которых объясняется не только использование Emacs как редактора, но и показывается, как применять Emacs для чтения и отправки электронной почты и новостей в Usenet, для игр (игра гомоку очень даже неплоха) и для ввода команд оболочки. В Emacs, написав полное имя внутренней команды, всегда можно ее выполнить, даже если она не привязана к клавишам.
В отличие от Emacs, документация по
vi менее развернутая и менее известна.
vi является только редактором, и многие важные команды можно выполнить путем нажатия одной клавиши. Здесь можно переключаться между режимом, в котором при нажатии стандартных букв алфавита они помещаются в текст, и режимом, в котором эти буквы являются командами. Например, можно использовать клавиши
h,
j,
k и
l в качестве клавиш управления курсором для навигации по документу.
Оба редактора позволяют создавать макросы для упрощения работы, но их макроязыки очень сильно отличаются. Emacs включает в себя целый язык программирования под названием
elisp (Emacs Lisp), который очень тесно связан с языком программирования Common Lisp. В первоначальном варианте
vi встроен более спартанский язык, ориентированный на стек. Большинство пользователей просто связывают с клавишами простые однострочные команды
vi, но эти команды зачастую запускают программы за пределами vi, чтобы управлять данными внутри
vi. По Emacs Lisp написано огромное руководство, включающее пособие по использованию; по языку, встроенному в
vi, документация сравнительно скупа.
Некоторые редакторы позволяют смешивать и совмещать функциональности. Так, существуют редакторы, в которых можно использовать Emacs в режиме
vi (viper), позволяющем использование стандартных команд
vi; в другом клоне
vi под названием
vile ("vi like Emacs") можно использовать
vi в режиме Emacs.
4.1.1. Emacs
Emacs встречается в нескольких вариациях. Первоначальный редактор Emacs был написан Ричардом Столлманом (Richard Stallman), одним из лидеров Фонда свободного ПО (Free Software Foundation — FSF). В течение многих лет его GNU Emacs был самым популярным редактором. С недавних пор популярностью начал пользоваться другой вариант GNU Emacs — XEmacs, в котором больше места уделяется поддержке графического интерфейса. XEmacs начал свою жизнь в качестве Lucid Emacs, набора расширений GNU Emacs, разработанного теперь уже распавшейся компанией Lucid Technologies. В намерения этой компании входило официально включить XEmacs в GNU Emacs. Но из-за технических различий команды не смогли слить свои коды. Несмотря ни на что, эти два редактора отлично совмещаются, а программисты обоих команд заимствуют коды друг у друга. Ввиду того, что обе эти версии очень похожи, в дальнейшем мы будем ссылаться на них как на Emacs.
Лучший способ для удобной работы с редактором Emacs — изучить пособие по работе с ним. Запустите
emacs и наберите
^ht. Наберите
^x^c для выхода из Emacs. С помощью обучающей программы можно узнать, где получить дополнительную информацию по Emacs. Здесь вы не узнаете, как получить руководство по Emacs, распространяемое вместе с самим редактором. Для вызова этого руководства наберите
^hi.
Несмотря на то что пользовательский интерфейс Emacs не такой красочный, как некоторые графические среды IDE, в этом редакторе есть множество мощных средств, которые могут понадобиться многим программистам. Например, при использовании Emacs для редактирования кода С. Emacs распознает тип файла и переходит в режим редактирования С, в котором распознается синтаксис С, что может помочь при поиске опечаток. Если вы запускаете компилятор из Emacs, редактор распознает сообщения об ошибках и предупреждениях компилятора, и позволяет перейти на строку с ошибкой при помощи одной команды, даже если для этого придется открыть новый файл. В Emacs также имеется режим отладки: отладчик находится в одном окне и проходит по коду, который вы отлаживаете в другом окне.
4.1.2. vi
Если вы быстро набираете текст и хотите, чтоб ваши пальцы находились в правильном положении
[3],
vi вам наверняка понравится, поскольку его набор команд был разработан таким образом, чтобы движений пальцев печатающего было как можно меньше. Этот редактор также ориентирован на пользователей Unix. Если вы знакомы с
sed или
awk либо другими программами Unix, использующими стандартные регулярные выражения с
^ для перехода к началу строки и
$ для перехода к ее концу, работа с
vi покажется вам простой и естественной.
К сожалению, освоение
vi может оказаться более сложным, нежели Emacs. Дело в том, что хоть пособия по
vi подобны учебникам по Emacs, ни в одной версии
vi нет стандартного способа запуска учебного пособия. Тем не менее, многие версии, включая версию, поставляемую с обычными дистрибутивами Linux, поддерживают команду
:help.
В наиболее общей версии
vi,
vim ("Vi IMproved"), есть множество интегрированных средств из набора разработки Emacs, включая выделение синтаксиса, автоматическое расположение текста, язык написания сценариев и разбор ошибок компилятора.
4.2. make
Основой программирования под Unix является
make — средство, которое существенно упрощает описание компиляции программ. Даже притом, что небольшим программам порой достаточно одной команды для компиляции их исходного кода в исполняемый файл, все же намного легче написать
make, чем строку вроде
gcc -02 -ggdb -DSOME DEFINE -о foo foo.c. Более того, если имеется множество файлов для компиляции, а код был изменен лишь в некоторых из них,
make создаст новые объектные файлы только для тех файлов, на которые повлияли изменения. Чтобы
make совершила это "чудо", потребуется описать все файлы в make-файле (
Makefile), пример которого показан ниже.
1: # Makefile
2:
3: OBJS = foo.о bar.о baz.o
4: LDLIBS = -L/usr/local/lib/ -lbar
5:
6: foo: $(OBJS)
7: gcc -o foo $ (OBJS) $ (LDLIBS)
8:
9: install: foo
10: install -m 644 foo /usr/bin
11: .PHONY: install
• Строка 1 — это комментарий;
make следует обычной традиции Unix определения комментариев с помощью символа
#.
• В строке 3 определяется переменная по имени
OBJS как
foo.о bar.о baz.о.
• В строке 4 определяется другая переменная —
LDLIBS.
• В строке 6 начинается определение
правила, которое указывает на то, что файл foo зависит от (в этом случае, собран из) файлов, имена которых содержатся в переменной
OBJS.
foo называется
целевым объектом, а
$(OBJS) — списком зависимостей. Обратите внимание на синтаксис расширения переменной: имя переменной помещается в
$(...).
Строка 7 — это командная строка, указывающая на то, как построить целевой объект из списка зависимостей. Командных строк может быть много, и
первым символом в командной строке
должна быть табуляция.
• Строка 9 — довольно интересный целевой объект. Фактически тут не предпринимается попытка создать файл по имени
install; вместо этого (как видно в строке 10)
foo инсталлируется в
/usr/bin с помощью стандартной программы
install. Эта строка вызывает неоднозначность в
make: что, если файл
install уже существует и является более новым, нежели
foo? В этом случае запуск команды
make install приведет к выдаче сообщения
'install' is up to date (install является новее) и завершению работы.
• Строка 11 указывает
make на то, что
install не является файлом, и что необходимо игнорировать любой файл по имени
install при вычислении зависимости
install. Таким образом, если зависимость
install была вызвана (как это сделать мы рассмотрим далее), команда в строке 10 всегда будет выполняться.
.PHONY — это директива, которая изменяет операцию
make; в этом случае она указывает
make на то, что целевой объект
install не является именем файла. Целевые объекты
.PHONY часто используются для совершения действий вроде инсталляции или создания одиночного имени целевого объекта, которое основывается на нескольких других уже существующих целевых объектов, например:
all: foo bar baz
.PHONY: all
К сожалению,
.PHONY не поддерживается некоторыми версиями make. Менее очевидный, не такой эффективный, но более переносимый способ для этого показан ниже.
all: foo bar baz FORCE
FORCE:
Это срабатывает только тогда, когда нет файла по имени
FORCE.
Элементы в списках зависимостей могут быть именами файлов, но, поскольку это касается
make, они являются целевыми объектами. Элемент
foo в списке зависимости
install — это целевой объект. При попытке
make вычислить зависимость
install становится ясно, что в первую очередь необходимо вычислить зависимость
foo. А для этого
make потребуется вычислить зависимости
foo.о,
bar.о и
baz.о.
Обратите внимание на отсутствие строк, явно указывающих
make, как строить
foo.о,
bar.о или
baz.о. Вы не будете определять эти строки непосредственно в редакторе.
make обеспечивает предполагаемые зависимости, которые записывать не нужно. Если в файле есть зависимость, заканчивающаяся на
.о, и есть файл с таким же именем, но он заканчивается на
.с,
make предполагает, что этот объектный файл зависит от исходного файла. Встроенные
суффиксные правила, которые поддерживаются
make, позволяют значительно упростить многие
make-файлы и, если встроенное правило не соответствует требованиям, можно создать свои собственные суффиксные правила (речь об этом пойдет ниже).
По умолчанию
make прекращает работу, как только любая из заданных команд дает сбой (возвращает ошибку). Существуют два способа избежать этого.
Аргумент
-k заставляет
make создавать максимально возможное количество файлов без останова, даже если какая-то команда вернула ошибку. Это полезно, например, при переносе программы; можно построить столько объектных файлов, сколько нужно, а потом перенести файлы, которые вызвали ошибку, без нежелательных перерывов в работе.
Если известно, что какая-то одна команда будет всегда возвращать ошибку, но вы хотите проигнорировать ее, можно воспользоваться "магией" командной оболочки. Команда
/bin/false всегда возвращает ошибку, таким образом,
/bin/false всегда будет вызывать прекращение работы, если только не указана опция
-k. С другой стороны, конструкция
любая_команда || /bin/true никогда не вызовет прекращение работы; даже если
любая_команда возвращает
false, оболочка затем запускает
/bin/true, которая вернет успешный код завершения.
make интерпретирует нераспознанные аргументы командной строки, которые не начинаются с минуса (
-), как целевые объекты для сборки. Таким образом,
make install приводит к сборке целевого объекта
install. Если целевой объект
foo устарел, make сначала соберет зависимости
foo, а затем инсталлирует его. Если требуется собрать целевой объект, начинающийся со знака минус, этот знак перед именем целевого объекта должен быть продублирован (
--).
4.2.1 Сложные командные строки
Каждая командная строка выполняется в своей собственной подоболочке, таким образом, команды
cd в командной строке влияют только на строку, в которой они записаны. Любую строку в make-файле можно расширить на множество строк, указывая в конце каждой обратный слэш. Ниже показан пример того, как иногда могут выглядеть командные строки.
1: cd первый_ каталог; \
2: сделать что-то с файлом $ (FOO) ; \
3: сделать еще что-то
4: cd второй_каталог; \
5: if [ -f некоторый_файл ] ; then\
6: сделать что-то другое; \
7: done; \
8: for i in * ; do \
9: echo $$i >> некоторый__файл ; \
10: done
make находит в этом фрагменте кода только две строки. Первая командная строка начинается в строке 1 и продолжается до строки 3, а вторая начинается в строке 4 и заканчивается в строке 10. Здесь следует отметить несколько моментов.
•
второй_каталог является относительным не к каталогу
первый_каталог, а к каталогу, в котором запущен
make, поскольку эти команды выполняются в разных подоболочках.
• Строки, образующие каждую командную строку, передаются оболочке в виде одной строки. Таким образом, все символы
;, которые нужны оболочке, должны присутствовать, включая даже те, которые обычно в сценариях оболочки опускаются, поскольку их наличие подразумевается благодаря символам новой строки. Более детально о программировании программной оболочки рассказывается в [22].
• Если требуется разыменовывать переменную
make, это делается обычным образом (то есть
$(переменная)), но если нужно разыменовывать переменную оболочки, необходимо применять двойной символ
$:
$$i.
4.2.2. Переменные
Часто бывает необходимо определить только один компонент переменной за раз. Можно написать, например, такой код:
OBJS = foo.о
OBJS = $(OBJS) bar.о
OBJS = $(OBJS) baz.о
Ожидается, что здесь
OBJS будет определен как
foo.о bar.о baz.о, но в действительности он определен как
$(OBJS) baz.о, поскольку
make не разворачивает переменные до момента их использования
[4]. При ссылке в правиле на
OBJS make войдет в бесконечный цикл
[5]. Во избежание этого во многих make-файлах разделы организуются следующим образом:
OBJS1 = foo.о
OBJS2 = bar.о
OBJS3 = baz.о
OBJS = $(OBJS1) $(OBJS2) $(OBJS3)
Объявления переменных вроде предыдущего встречаются, когда объявление одной переменной оказывается слишком длинным и потому не удобным.
Развертывание переменной вызывает типичный вопрос, который программист в Linux должен решить. Инструменты GNU, распространяемые с Linux, обычно более функциональны, чем версии инструментов, включенных в другие системы, и GNU
make — не исключение. Авторы GNU make предусмотрели альтернативный способ присваивания переменных, но не все версии
make понимают эти альтернативные формы. К счастью, GNU
make можно собрать для любой системы, в которую можно перенести исходный код, написанных под Linux. Существует форма
простого присваивания переменных, которая показана ниже.
OBJS := foo.о
OBJS := $(OBJS) bar.о
OBJS := $(OBJS) baz.о
Операция
:= заставляет GNU
make вычислить выражение переменной при присваивании, а не ждать вычисления выражения при его использовании в правиле. В результате выполнения этого кода
OBJS действительно получит
foo.о bar.о baz.о.
Простое присваивание переменной используется очень часто, но в GNU
make есть еще и другой синтаксис присваивания, который позаимствован из языка С:
OBJS := foo.о
OBJS += bar.о
OBJS += baz.о
4.2.3. Суффиксные правила
Суффиксные правила — это другая область, в которой вам нужно решить, писать ли стандартные make-файлы или использовать расширения GNU. Стандартные суффиксные правила намного ограниченнее, нежели шаблонные правила GNU, но во многих ситуациях стандартные суффиксные правила могут оказаться полезными. К тому же шаблонные правила поддерживаются не во всех версиях
make. Суффиксные правила выглядят следующим образом:
.c.o:
$(CC) -с $ (CFLAGS) $ (CPPFLAGS) -о $<
.SUFFIXES: .с .о
В этом правиле говорится (если не касаться излишних деталей), что
make должна,
если не было других явных указаний, превратить файл
а.с в
а.о путем запуска приложенной командной строки. Каждый файл
.с будет рассматриваться так, будто он явно внесен в список в качестве зависимости соответствующего файла
.о в вашем make-файле.
Это суффиксное правило демонстрирует другую возможность
make — автоматические переменные. Понятно, что нужно найти способ подставить зависимость и целевой объект в командную строку. Автоматическая переменная
$@ выступает в качестве целевого объекта,
$< выступает в качестве первой зависимости, а
$^ представляет все зависимости.
Существуют и другие автоматические переменные, которые рассматриваются в руководстве по
make. Все автоматические переменные можно использовать в обыкновенных правилах, а также в суффиксных и шаблонных правилах.
Последняя строка примера представляет еще одну директиву.
.SUFFIXES указывает
make на то, что
.с и
.о являются суффиксами, которые должен использовать
make для нахождения способа превратить существующие исходные файлы в необходимые целевые объекты.
Шаблонные правила более мощные и, следовательно, немного сложнее, чем суффиксные правила. Ниже приведен пример эквивалентного шаблонного правила для показанного выше суффиксного правила.
% .о: % .с
$(CC) -с $(CFLAGS) $(CPPFLAGS) -о $<
Дополнительные сведения о
make можно получить в [26]. GNU
make также включает замечательное и удобное в обращении руководство в формате Texinfo, которое можно почитать на сайте FSF, распечатать или заказать у них в форме книги.
Большинство крупных проектов с открытым исходным кодом используют инструменты Automake, Autoconf и Libtool. Эти инструменты представляют собой коллекцию знаний об особенностях различных систем и стандартах сообщества, которая может помочь в построении проектов. Таким образом, потребуется писать лишь немного кода, специфического для проекта. Например, Automake пишет целевые объекты
install и
uninstall, Autoconf автоматически определяет возможности системы и настраивает программное обеспечение для его соответствия системе, a Libtool отслеживает различия в управлении совместно используемыми библиотеками на разных системах.
По этим трем инструментам написана целая книга — [41]; здесь мы даем лишь основу, которая понадобится для работы с GNU Autoconf, Automake и Libtool.
4.3. Отладчик GNU
gdb — это отладчик, рекомендуемый Free Software Foundation,
gdb представляет собой хороший отладчик командной строки, на котором строятся некоторые инструменты, включая режим
gdb в Emacs, графический отладчик Data Display Debugger (http://www.gnu.org/software/ddd/) и встроенные отладчики в некоторых графических интерфейсах IDE. В этом разделе рассматривается только
gdb.
Запустите
gdb с помощью команды
gdb имя_программы.
gdb не будет просматривать значение
PATH в поисках исполняемого файла. Отладчик загрузит символьную информацию для исполняемого файла и запросит дальнейших действий.
Существует три способа проверить процесс с помощью
gdb.
• Используя команду
run для обычного выполнения программы.
• Используя команду
attach для начала проверки уже запущенного процесса. При подключении к процессу, последний останавливается.
• Исследуя существующий файл ядра для определения состояния процесса при его завершении. Для исследования файла ядра
gdb потребуется запустить с помощью команды
имя_программы файл_ядра.
Перед запуском программы или подключением к уже запущенному процессу можно установить точку прерывания, просмотреть исходный код и выполнить другие операции, которые не обязательно относятся к запущенному процессу.
gdb не требует написания полного имени команды; указание
r достаточно для
run,
n — для
next,
s — для
step. Более того, для повторения наиболее часто употребляемой команды, нужно просто нажать клавишу <Enter>. Таким образом, пошаговое выполнение программы становится проще.
Ниже предложен небольшой набор полезных команд
gdb;
gdb включает полное онлайновое руководство в формате GNU info (запустите
info gdb), в котором детально объясняются все опции
gdb. В [19] содержится неплохое подробное руководство по работе с
gdb.
gdb также поддерживает оперативную справку, ссылки на которую можно найти внутри
gdb; доступ к справочным файлам можно получить, введя команду
help. Можно также получить справку по каждой определенной команде, набрав
help команда или
help тема.
Подобно командам оболочки, команды
gdb могут принимать аргументы. "Вызвать
help с аргументом
команда" означает то же самое, что и "набрать
help команда".
Некоторые команды
gdb также принимают идентификаторы формата для спецификации вывода значений. Идентификаторы формата располагаются за именем команды и отделяются от него косой чертой. После выбора формата необходимость использовать его каждый раз при повторе команды отпадает;
gdb запоминает выбранный формат и использует его по умолчанию.
Идентификаторы формата отделены от команд символом
/ и состоят из трех элементов: цифра, буква формата и буква, отражающая размер. Цифра и буква размера не обязательны; по умолчанию в качестве цифры устанавливается
1, а размер получает подходящее значение по умолчанию, основанное на букве формата.
Буквы формата следующие:
о для обозначения восьмеричного числа,
x для шестнадцатеричного числа,
d для десятичного числа, и для беззнакового десятичного числа,
t для двоичных данных,
f для числа с плавающей запятой, а для адреса,
i для инструкций, с для символа,
s для строки.
Символы, отображающие размер, таковы:
b — байт,
h — полуслово (2 байта),
w — слово (4 байта),
g — слово-гигант (8 байт).
attach,
at
Подключает отладчик к уже запущенному процессу. Единственным аргументом является идентификатор процесса (pid), к которому осуществляется подключение. Процессы, с которыми установлено подключение, останавливаются, прерывая любые ожидающие или текущие системные вызовы, которые разрешено прерывать. См.
detach.
backtrace,
bt,
where,
w
Выводит трассировку стека.
break,
b
Устанавливает точку прерывания. Можно указать имя функции, номер строки текущего файла (файл, содержащий выполняемый в данный момент код), пару
имя_файла:номер_строки или даже произвольный адрес с помощью
*адрес.gdb назначает и выводит уникальный номер для каждой точки прерывания. См.
condition,
clear и
delete.
clear
Удаляет точку прерывания. Принимает такой же аргумент, как
break. См.
delete.
condition
Изменяет точку прерывания, определенную номером (см.
break), для прерывания, только если выражение истинно. Допускаются произвольные выражения.
(gdb) b664
Breakpoint 3 at 0х804а5с0: file ladsh4.c, line664.
(gdb) condition 3 status==0
delete
Удаляет точку прерывания, определенную номером.
detach
Отключается от текущего подключенного процесса.
display
Отображает значение выражения каждый раз при остановке выполнения. Принимает такие же аргументы (включая модификаторы формата), как
print. Выводит номер отображения, которое впоследствии может использоваться для отмены отображения. См.
undisplay.
Help
Вызывает справку. При вызове без аргумента предоставляет краткое описание доступной справочной информации. При вызове с другой командой в качестве аргумента выводит справку по этой команде. Доступны перекрестные ссылки.
jump
Переходит на произвольный адрес и продолжает выполнение процесса с этой точки. Адрес — единственный аргумент; его можно определить в форме номера строки или адреса, указанного как
*адрес.
list,
l
Выданная без аргументов
list сначала выводит 10 строк, расположенных возле текущего адреса. Последующие вызовы list выводят последующие 10 строк. При использовании аргумента
- выводит предыдущие 10 строк. При указании номера строки выводит 10 строк, окружающих эту строку. При указании пары
имя_файла:номер_строки выводит 10 строк, окружающих заданную. При указании имени функции выводит 10 строк возле начала функции. При указании адреса в виде
*адрес выводит 10 строк, окружающих код, находящийся по этому адресу. При указании двух строк, разграниченных запятыми, выводит все строки между заданными.
next,
n
Переходит на следующую строку исходного кода в текущей функции, без захода внутрь функций. См.
step.
nexti
Переходит на следующую инструкцию машинного языка без захода внутрь функций. См.
stepi.
print,
p
Выводит значение выражения в понятной форме. Если есть переменная
char* с, команда
print с выведет адрес строки, a
print *с выведет саму строку. Для структур выводятся их члены. Можно использовать приведения типов, которые
gdb будет учитывать. Если код скомпилирован с опцией
-ggdb, в выражениях станут доступны перечислимые значения и определения препроцессора. См.
display. Команда
print принимает идентификаторы формата, несмотря на то, что при указании и преобразовании типов идентификаторы формата зачастую не нужны. См.
x.
run,
r
Запускает текущую программу с начала. Аргументы команды run передаются в командную строку для запуска программы. В
gdb, подобно оболочке, можно универсализировать имена файлов с помощью
* и
[], а также осуществлять переадресацию посредством
<,
> и
>>, но нельзя создавать каналы или внутренние документы. Без аргументов
run использует аргументы, которые были определены в самой последней команде
run или
set args. Для запуска без аргументов после их задействования используется команда
set args без дополнительных аргументов.
set
gdb позволяет менять значения переменных, например:
(gdb) set а = argv[5]
Также каждый раз при выводе выражения с помощью
print создается сокращенная переменная вроде
$1, на которую впоследствии можно ссылаться. Таким образом, если ранее был выведен
argv[5] и
gdb указал на то, что результат сохранен в
$6, можно переписать предыдущее присваивание так:
(gdb) set а = $6
Команда
set имеет также множество подкоманд. Перечислять в этой книге их не имеет смысла, поскольку список слишком велик. Воспользуйтесь
help set для получения более детальной информации.
step,
s
Выполняет инструкции программы до достижения новой строки исходного кода. См.
next.
stepi
Выполняет в точности одну инструкцию машинного языка; с заходом внутрь функций. См.
nexti.
undisplay
Если выдана без аргумента, отменяет все отображения. В противном случае отменяет отображения указанные номерами. См.
display.
whatis
Выводит тип данных выражения, переданного в качестве аргумента команды.
where,
w
См.
backtrace.
x
Команда
x подобна
print с тем исключением, что она явно ограничивается выводом содержимого по указанному адресу в произвольном формате. Если идентификатор формата не используется,
gdb будет применять самый последний идентификатор из указанных.
4.4. Действия при трассировке программы
Существуют две программы, помогающие трассировать исполняемые файлы. Ни одной из этих программ исходный код не нужен; фактически, они не могут использовать исходные коды. Обе программы выводят в символьной текстовой форме журнал действий, выполняемых приложением.
Первая,
strace, выводит запись о каждом системном вызове программы. Вторая,
ltrace, выводит запись о каждой функции библиотеки, которую вызывает программа (и по выбору может также трассировать системные вызовы). Эти инструменты могут оказаться полезными при определении неполадок в случаях явного сбоя.
Например, предположим, что имеется системный демон, функционирующий уже некоторое время, который начал выдавать ошибки сегментации. Скорее всего, это вызвано изменением в некоторых файлах данных, но неизвестно каких именно. Первым шагом должен быть запуск системного демона под управлением
strace. Нужно просмотреть несколько последних файлов, которые демон открывал перед тем, как произошла ошибка сегментации, и найти в этих файлах возможные причины. Либо предположим, что другой демон внезапно начал занимать много процессорного времени; в этом случае можно запустить его сначала под
strace, а затем и под
ltrace, если
strace четко не покажет, что конкретно делал демон. В результате можно определить входные параметры или условия, которые привели к потреблению такого количества процессорного времени.
Подобно
gdb,
strace и
ltrace можно использовать для выполнения программы от
начала до конца или подключаться к уже запущенным программам. По умолчанию
strace и
ltrace производят вывод на стандартное устройство вывода. Обе программы требуют указания сначала собственных опций, за которыми должен следовать исполняемый файл для запуска, и, если исполняемый файл указан, то все опции, которые передаются ему, должны записываться следом.
Обе утилиты поддерживают похожий набор опций.
-С или --demangle |
Только для ltrace. Декодирует (или расшифровывает) имена библиотечных символов в читабельные имена. В результате убираются начальные символы подчеркивания (многие функции glibc имеют внутренние имена с начальными символами подчеркивания) и функции библиотеки С++ становятся более читабельными (С++ шифрует информацию о типе в символьные имена). |
-е |
Только для strace. Указывает подмножество вызовов, которые нужно вывести. Существует множество возможных спецификаций, описанных на man-странице strace; самой распространенной спецификацией является -е trace=file, которая трассирует только системные вызовы, связанные с файловым вводом-выводом и обработкой файлов. |
-f |
Пытается «следовать вызову fork()», по возможности трассируя дочерние процессы. Обратите внимание, что дочерний процесс может некоторое время работать без трассировки до тех пор, пока strace или ltrace сможет подключиться к нему и трассировать его действия. |
-о имя_файла |
Вместо вывода на стандартное устройство вывода выводит в файл имя файла. |
-р pid |
Вместо запуска нового экземпляра программы подключается к процессу с идентификатором pid. |
-S |
Только для ltrace. Отслеживает системные и библиотечные вызовы. |
-v |
Только для strace. Не сокращает большие структуры в системных вызовах вроде семейства вызовов stat(), termios и так далее. |
На man-страницах утилит можно найти описание этих и других опций, здесь не упомянутых.
Глава 5
Опции и расширения gcc
Для правильного использования
gcc, стандартного компилятора С для Linux, необходимо изучить опции командной строки. Кроме того,
gcc расширяет язык С. Даже если вы намерены писать исходный код, придерживаясь ANSI-стандарта этого языка, некоторые расширения
gcc просто необходимо знать для понимания заголовочных файлов Linux.
Большинство опций командной строки такие же, как применяемые в компиляторах С. Для некоторых опций никаких стандартов не предусмотрено. В этой главе мы охватим наиболее важные опции, которые используются в повседневном программировании.
Стремление соблюсти ISO-стандарт С весьма полезно, но в связи с тем, что С является низкоуровневым языком, встречаются ситуации, когда стандартные средства недостаточно выразительны. Существуют две области, в которых широко применяются расширения
gcc: взаимодействие с ассемблерным кодом (эти вопросы раскрываются по адресу http://www.delorie.com/djgpp/doc/brennan/) и сборка совместно используемых библиотек (см. главу 8). Поскольку заголовочные файлы являются частью совместно используемых библиотек, некоторые расширения проявляются также в системных заголовочных файлах.
Конечно, существует еще множество расширений, полезных в любом другом виде программирования, которые могут очень даже помочь при кодировании. Дополнительную информацию по этим расширениям можно найти в документации
gcc в формате Texinfo.
5.1. Опции gcc
gcc принимает множество командных опций. К счастью, набор опций, о которых действительно нужно иметь представление, не так велик, и в этой главе мы его рассмотрим.
Большинство опций совпадают или подобны опциям других компиляторов,
gcc включает в себя огромную документацию по своим опциям, доступную через info gcc (
man gcc также выдает эту информацию, однако man-страницы не обновляются настолько часто, как документация в формате Texinfo).
-о имя_файла |
Указывает имя выходного файла. Обычно в этом нет необходимости, если осуществляется компиляция в объектный файл, то есть по умолчанию происходит подстановка имя_файла.с на имя_файла.о. Однако если вы создаете исполняемый файл, по умолчанию (по историческим причинам) он создается под именем а.out. Это также полезно в случае, когда требуется поместить выходной файл в другой каталог. |
-с |
Компилирует без компоновки исходный файл, указанный для командной строки. В результате для каждого исходного файла создается объектный файл. При использовании make компилятор gcc обычно вызывается для каждого объектного файла; таким образом, в случае возникновения ошибки легче обнаружить, какой файл не смог скомпилироваться. Однако если вы вручную набираете команды, часто в одном вызове gcc указывается множество файлов. В случае, если при задании множества файлов в командной строке может возникнуть неоднозначность, лучше указать только один файл. Например, вместо gcc -с -о а.о а.с b.с имеет смысл применить gcc -с -o a.o b.c. |
-Dfoo |
Определяет препроцессорные макросы в командной строке. Возможно, потребуется отменить символы, трактуемые оболочкой как специальные. Например, при определении строки следует избегать употребления ограничивающих строки символов ". Вот два наиболее употребляемых способа: '-Dfoo="bar"' и -Dfoo=\"bar\". Первый способ работает намного лучше, если в строке присутствуют пробелы, поскольку оболочка рассматривает пробелы особым образом. |
-Iкаталог |
Добавляет каталог в список каталогов, в которых производится поиск включаемых файлов. |
-Lкаталог |
Добавляет каталог в список каталогов, в которых производится поиск библиотек, gcc будет отдавать предпочтение совместно используемым библиотекам, а не статическим, если только не задано обратное. |
-lfoo |
Выполняет компоновку с библиотекой libfoo. Если не указано обратное, gcc отдает предпочтение компоновке с совместно используемыми библиотеками (libfoo.so), а не статическими (libfoo.a). Компоновщик производит поиск функций во всех перечисленных библиотеках в том порядке, в котором они перечислены. Поиск завершается тогда, когда будут найдены все искомые функции. |
-static |
Выполняет компоновку с только статическими библиотеками. См. главу 8. |
-g, -ggdb |
Включает отладочную информацию. Опция -g заставляет gcc включить стандартную отладочную информацию. Опция -ggdb указывает на необходимость включения огромного количества информации, которую в силах понять лишь отладчик gdb. |
|
Если дисковое пространство ограничено или вы хотите пожертвовать некоторой функциональностью ради скорости компоновки, следует использовать -g. В этом случае, возможно, придется воспользоваться другим отладчиком, а не gdb. Для максимально полной отладки необходимо указывать -ggdb. В этом случае gcc подготовит максимально подробную информацию для gdb. Следует отметить, что в отличие от большинства компиляторов, gcc помещает некоторую отладочную информацию в оптимизированный код. Однако трассировка в отладчике оптимизированного кода может быть сопряжена со сложностями, так как во время выполнения могут происходить прыжки и пропуски фрагментов кода, которые, как ожидалось, должны были выполняться. Тем не менее, при этом можно получить хорошее представление о том, как оптимизирующие компиляторы изменяют способ выполнения кода. |
-O, -On |
Заставляет gcc оптимизировать код. По умолчанию, gcc выполняет небольшой объем оптимизации; при указании числа (n) осуществляется оптимизация на определенном уровне. Наиболее распространенный уровень оптимизации — 2; в настоящее время в стандартной версии gcc самым высоким уровнем оптимизации является 3. Мы рекомендуем использовать -O2 или -O3; -O3 может увеличить размер приложения, так что если это имеет значение, попробуйте оба варианта. Если для вашего приложения важна память и дисковое пространство, можно также использовать опцию -Os, которая делает размер кода минимальным за счет увеличения времени выполнения. gcc включает встроенные функции только тогда, когда применяется хотя бы минимальная оптимизация (-O). |
-ansi |
Поддержка в программах на языке С всех стандартов ANSI (X3.159-1989) или их эквивалента ISO (ISO/IEC 9899:1990) (обычное называемого С89 или реже С90). Следует отметить, что это не обеспечивает полное соответствие стандарту ANSI/ISO. |
|
Опция -ansi отключает расширения gcc, которые обычно конфликтуют со стандартами ANSI/ISO. (Вследствие того, что эти расширения поддерживаются многими другими компиляторами С, на практике это не является проблемой.) Это также определяет макрос __STRICT_ANSI__ (как описано далее в этой книге), который заголовочные файлы используют для поддержки среды, соответствующей ANSI/ISO. |
-pedantic |
Выводит все предупреждения и сообщения об ошибках, требуемые для ANSI/ISO-стандарта языка С. Это не обеспечивает полное соответствие стандарту ANSI/ISO. |
-Wall |
Включает генерацию всех предупреждений gcc, что обычно является полезным. Но таким образом не включаются опции, которые могут пригодиться в специфических случаях. Аналогичный уровень детализации будет установлен и для программы синтаксического контроля lint в отношении вашего исходного кода, gcc позволяет вручную включать и отключать каждое предупреждение компилятора. В руководстве по gcc подробно описаны все предупреждения. |
5.2. Заголовочные файлы
Время от времени вы можете застать себя на том, что просматриваете заголовочные файлы Linux. Скорее всего, вы найдете рад конструкций, не совместимых со стандартом ANSI/ISO. Некоторые из них стоят того, чтобы в них разобраться. Все конструкции, рассматриваемые в этой книге, более подробно изложены в документации по
gcc.
5.2.1. long long
Тип
long long указывает на то, что блок памяти, по крайней мере, такой же большой, как
long. На Intel i86 и других 32-разрядных платформах
long занимает 32 бита, а
long long — 64 бита. На 64-разрядных платформах указатели и
long long занимают 64 бита, a
long может занимать 32 или 64 бита в зависимости от платформы. Тип
long long поддерживается в стандарте С99 (ISO/IEC 9899:1999) и является давним расширением С, которое обеспечивается
gcc.
5.2.2. Встроенные функции
В некоторых частях заголовочных файлов Linux (в частности тех, что специфичны для конкретной системы) встроенные функции используются очень широко. Они так же быстры, как и макросы (нет затрат на вызовы функции), и обеспечивают все виды проверки, которые доступны при нормальном вызове функции. Код, вызывающий встроенные функции, должен компилироваться, по крайней мере, с включенной минимальной оптимизацией (
-O).
5.2.3. Альтернативные расширенные ключевые слова
В
gcc у каждого расширенного ключевого слова (ключевые слова, не описанные стандартом ANSI/ISO) есть две версии: само ключевое слово и ключевое слово, окруженное с двух сторон двумя символами подчеркивания. Когда компилятор применяется в стандартном режиме (обычно тогда, когда задействована опция
-ansi), обычные расширенные ключевые слова не распознаются. Так, например, ключевое слово
attribute в заголовочном файле должно быть записано как
__attribute__.
5.2.4. Атрибуты
Расширенное ключевое слово
attribute используется для передачи
gcc большего объема информации о функции, переменной или объявленном типе, чем это позволяет код С, соответствующий стандарту ANSI/ISO. Например, атрибут
aligned дает указание gcc о том, как именно выравнивать переменную или тип; атрибут
packed указывает на то, что заполнение использоваться не будет;
noreturn определяет то, что возврат из функции никогда не произойдет, что позволяет
gcc лучше оптимизироваться и избегать фиктивных предупреждений.
Атрибуты функции объявляются путем их добавления в объявление функции, например:
void die_die_die(int, char*) __attribute__ ((__noreturn__));
Объявление атрибута размещается между скобками и точкой с запятой и содержит ключевое слово
attribute, за которым следуют атрибуты в двойных круглых скобках. Если атрибутов много, следует использовать список, разделенный запятыми.
int printm(char*, ...)
__attribute__((const,
format(printf, 1, 2)));
В этом примере видно, что
printm не рассматривает никаких значений, кроме указанных, и не имеет побочных эффектов, относящихся к генерации кода (
const), printm указывает на то, что
gcc должен проверять аргументы функции так же, как и аргументы
printf(). Первый аргумент является форматирующей строкой, а второй — первым параметром замены (
format).
Некоторые атрибуты будут рассматриваться по мере дальнейшего изложения материала (например, во время описания сборки совместно используемых библиотек в главе 8). Исчерпывающую информацию по атрибутам можно найти в документации
gcc в формате Texinfo.
Глава 6
Библиотека GNU C
Библиотека GNU С (
glibc) — это стандартная библиотека языка С, разработанная для Linux-систем. Существуют и другие библиотеки С, которые иногда используются в определенных целях (например, очень маленькое подмножество стандартных библиотек С применяется во встроенных системах и для начальной загрузки). Но во всех дистрибутивах Linux стандартной библиотекой языка С, предоставляющей значимый объем функциональности, является
glibc. Именно эта библиотека и описывается в настоящей книге.
6.1. Выбор возможностей glibc
В
glibc существует набор макросов для выбора возможностей. Эти макросы используются для выбора стандарта, которому будет подчиняться
glibc. Иногда стандарты конфликтуют между собой, a
glibc позволяет выбирать именно тот набор стандартов (формальный,
де-юре, и неформальный,
де-факто), которым нужно соответствовать полностью либо частично. Технически такие макросы называются
макросами проверки возможностей.
Знание этих макросов необходимо, так как набор макросов, определенных по умолчанию, не обеспечивает полную функциональность
glibc. Некоторые механизмы, описанные в этой книге, в выбранном по умолчанию наборе функций не доступны; далее мы опишем макросы, необходимые для включения каждого такого механизма.
Макросы проверки возможностей разработаны для определения стандартов (
де-юре или
де-факто), и в некоторых случаях они определяют, каким именно версиям этих стандартов должна соответствовать
glibc. Это соглашение часто не включает определения функций и макросов, не указанных стандартом, в стандартных заголовочных файлах. Это значит, что приложение, написанное в соответствии со стандартом, может определять свои собственные функции и макросы, не конфликтуя с расширениями, которые этим стандартом не определены.
Макросы проверки возможностей не гарантируют того, что приложение будет полностью совместимо со стандартами, определяемыми набором макросов. Настройка макроса проверки возможности может обнаружить использование непереносимых расширений, но при этом не будет обнаружено использование, скажем, заголовочных файлов, которые полностью не определены стандартом.
Макросы определяются в системном заголовочном файле
feature.h, который не должен включаться непосредственно. Взамен его включают все другие заголовочные файлы, которые зависят от содержимого
feature.h.
Набор макросов по умолчанию содержит
_SVID_SOURCE=1,
_BSD_SOURCE=1,
_POSIX_SOURCE=1 и
_POSIX_C_SOURCE=199506L. Описание каждой из этих опций можно найти ниже, но все это, по сути, транслируется в поддержку возможностей стандарта 1995 POSIX (этот стандарт использовался до объединения стандартов POSIX и Single Unix), всех стандартных функций System V и всех функций BSD, которые не конфликтуют с функциями System V. Данного набора макросов достаточно для большинства программ.
При определении в
gcc опции
-ansi, как было описано ранее, автоматически определяется внутренний макрос
__STRICT_ANSI__, который отключает все макросы, определенные по умолчанию.
За исключением
__STRICT_ANSI__, который представляет собой специальный макрос (и должен настраиваться только компилятором в контексте опции командной строки
-ansi), эти макросы имеют накопительный характер, то есть можно определять любые их комбинации. Точное определение изменений
_BSD_SOURCE зависит от настройки других макросов (более детально об этом — ниже); все
остальные макросы — исключительно накопительные.
Некоторые макросы определяются различными версиями POSIX или других стандартов, другие являются общими, а третьи могут использоваться только в
glibc.
_POSIX_SOURCE |
Если указан этот макрос, становятся доступными все интерфейсы, определенные как часть оригинальной спецификации POSIX.1. Данный макрос был определен в первоначальном стандарте POSIX.1-1990. |
_POSIX_C_SOURCE |
Этот макрос может заменять _POSIX_SOURCE. Если установлен в 1, то эквивалентен _POSIX_SOURCE. Если его значение больше либо равно 2, макрос включает интерфейсы С, соответствующие POSIX.2, и задействует регулярные выражения. Если значение больше либо равно 199309L, макрос включает в себя дополнительные интерфейсы С, соответствующие пересмотренному в 1993 году стандарту POSIX, в частности, включая функциональность реального времени. Если его значение больше либо равно 199506L (по умолчанию), макрос включает дополнительные интерфейсы С, соответствующие пересмотренному в 1995 году стандарту POSIX, в частности, включая потоки POSIX. Этот макрос был описан версией POSIX, выпущенной после 1990 года для разграничения поддержки различных версий стандартов POSIX (а теперь также и Single Unix). Во многих случаях полностью замещается _XOPEN_SOURCE. |
_XOPEN_SOURCE |
Макрос _XOPEN_SOURCE определен XSI-частью стандарта Single Unix и описывает логическое надмножество интерфейсов, включенных с помощью _POSIX_C_SOURCE. Этот макрос также был определен XPG. Если макрос определен, указываются функциональные возможности из начального стандарта XPG4 (Unix95). Если макрос определен со значением 500, включаются функциональные возможности из стандарта XPG5 (Unix98, SuS версии 2). Если установлено значение 600, включаются функциональные возможности из начального стандарта IEEE Std 1003.1-2003 (комбинированный документ по POSIX и SuS). |
_ISOC99_SOURCE |
Этот макрос проверки возможностей экспортирует интерфейсы, определенные в новых стандартах ISO/IEC С99. |
_SVID_SOURCE |
При указании данного макроса для выбора возможностей становится доступным стандарт SVID (System V Interface Definition). Это не значит, что glibc обеспечивает полную реализацию стандарта SVID; она всего лишь открывает указанную функциональность SVID, существующую в glibc. |
_BSD_SOURCE |
Функции BSD могут конфликтовать с другими функциями, и эти конфликты всегда разрешаются в пользу поведения, соответствующего стандарту System V, или, если определен или подразумевается любой макрос функций POSIX, X/Open или System V, единственным макросом, который включает поведение BSD является _ISOC99_SOURCE. (Точное определение этого макроса временами изменялось и может меняться в дальнейшем, поскольку он не регламентируется каким-либо стандартом.) |
_GNU_SOURCE |
В случаях конфликта _GNU_SOURCE включает все, что возможно, отдавая предпочтение интерфейсам System V, а не BSD. Этот макрос также добавляет некоторые специальные для GNU и Linux интерфейсы, например, владение файлами. |
Когда стандартного набора макросов недостаточно, обычно определяют макрос
_GNU_SOURCE (включает все — самое простое решение),
_XOPEN_SOURCE=600 (наиболее вероятно, что пригодится поднабор
_GNU_SOURCE) или
_ISOC99_SOURCE (использование функций наиболее позднего стандарта С, поднабор
_XOPEN_SOURCE=600).
6.2. Интерфейсы POSIX
6.2.1. Обязательные типы POSIX
POSIX описывает некоторые определения типов в заголовочном файле
<sys/types.h>, которые используются для многих аргументов и возвращаемых значений. Эти определения типов важны, потому что стандартные типы языка С могут быть разными на различных машинах, так как они нестрого определены в стандарте С. Из-за такого нестрогого определения язык С полезен на широком диапазоне оборудования — размер слов на 16-разрядных машинах отличается от такового на 64-разрядных машинах, а язык программирования низкого уровня не должен скрывать эту разницу — но для POSIX требуется большая гарантия. От заголовочного файла библиотеки С
<sys/types.h> требуется определение набора соответствующих типов для каждой машины, которая поддерживает POSIX. Каждый из этих определений типов можно легко отличить от собственного типа С, поскольку он заканчивается на
_t.
Ниже описано подмножество, используемое для интерфейсов.
dev_t |
Арифметический тип данных, содержащий старшие (major) и младшие (minor) числа, соответствующие специальным файлам устройств, обычно расположенным в подкаталоге /dev. В Linux dev_t можно манипулировать с помощью макросов major(), minor() и makedev(), которые определены в <sys/sysmacros.h>. Обычно dev_t используется только в системном программировании, описанном в главе 11. |
uid_t, gid_t |
Целочисленные типы, содержащие уникальные идентификаторы, соответственно, пользователя и группы. Удостоверения идентификаторов пользователя и группы рассматриваются в главе 10. |
pid_t |
Целочисленный тип, обеспечивающий уникальное значение для системного процесса (описан в главе 10). |
id_t |
Целочисленный тип, способный хранить без усечения любой тип pid_t, uid_t или gid_t. |
off_t |
Целочисленный тип со знаком для измерения размера файла в байтах. |
size_t |
Целочисленный тип без знака для измерения размеров объектов в памяти, например, символьных строк, массивов или буферов. |
ssize_t |
Целочисленный тип со знаком для подсчета байтов (положительные значения) или хранения кода возврата ошибки (отрицательные значения). |
time_t |
Целочисленный тип (во всех обычных системах) или тип с плавающей точкой (позволяет рассматривать VMS как операционную систему POSIX), выдающий время в секундах, как описано в главе 18. |
Типы намеренно описаны нечетко. Нет никакой гарантии, что типы будут одинаковыми на двух разных платформах Linux или даже в двух различных средах, работающих на одной и той же платформе. Скорее всего, 64-разрядная машина, поддерживающая как 64-разрядную, так и 32-разрядную среды, будет иметь разные значения для некоторых из этих типов в каждой среде.
Кроме того, в будущих версиях Linux представленные типы могут изменяться в рамках, установленных стандартом POSIX.
6.2.2. Раскрытие возможностей времени выполнения
Многие системные возможности имеют ограничения, другие являются необязательными, а некоторые могут содержать связанную с ними информацию. Ограничение на длину строки аргументов, передаваемых новой программе, защищает систему от произвольных запросов памяти, которые в ряде случаев могут вызвать крах системы. Не во всех системах POSIX реализовано управление заданиями. Любая программа может получить сведения о наиболее поздней версии стандарта POSIX, которая реализована в системе.
Функция
sysconf() выдает такой тип системной информации, которая для одного и того же исполняемого файла в различных системах может отличаться и которую невозможно узнать во время компиляции.
#include <unistd.h>
long sysconf (int);
Целочисленный аргумент в
sysconf() — это один из наборов макросов с префиксом
_SC_. Ниже перечислены макросы, которые используются чаще всего.
_SC_CLK_TCK |
Возвращает количество тактов в секунду внутренних часов ядра, различаемое программами. Следует отметить, что ядро может содержать одни или больше часов, работающих на более высокой частоте. _SC_CLK_TCK обеспечивает подсчет тактов, которые используются для получения информации из ядра, и этот макрос не является индикатором времени ожидания системы. |
_SC_STREAM_MAX |
Возвращает максимальное количество стандартных потоков ввода-вывода С, которые могут быть одновременно открыты в системе. |
_SC_ARG_MAX |
Возвращает максимальную длину аргумента командной строки и переменных окружения в байтах, которые используются любой из функций exec(). Если это ограничение превышено, exec() вернет ошибку Е2ВIG. |
_SC_OPEN_MAX |
Возвращает максимальное количество файлов, которые одновременно могут быть открыты процессом; это то же самое, что и программное ограничение RLIMIT_NOFILE, которое может быть запрошено функцией getrlimit() и установлено функцией setrlimit(). Это единственное значение sysconf(), которое может изменяться во время выполнения программы; при вызове setrlimit() для изменения ограничения RLIMIT_NOFILE. _SC_OPEN_MAX также подчиняется новому программному ограничению. |
_SC_PAGESIZE или _SC_PAGE_SIZE |
Возвращает размер одной страницы в байтах. В системах, которые могут поддерживать разные размеры страниц, возвращается размер одной обычной страницы, для которой выделено определенное количество памяти и которая считается естественным размером страниц для конкретной системы. |
_SC_LINE_MAX |
Возвращает максимальную длину в байтах входной строки, обрабатываемой текстовыми утилитами, включая завершающий символ новой строки. Следует отметить, что во многих утилитах GNU, используемых в Linux-системах, фактически нет жестко закодированной максимальной длины строки, потому могут применяться входные строки произвольной длины. Однако переносимая программа не должна вызывать текстовые утилиты для строк, длина которых превышает _SC_LINE_MAX; во многих Unix-системах утилиты работают с фиксированным максимальным размером строки, и его превышение может привести к неопределенным результатам. |
_SC_NGROUPS_MAX |
Возвращает количество дополнительных групп (см. главу 10), которые может иметь процесс. |
6.2.3. Поиск и настройка базовой системной информации
Существует несколько порций полезной информации о системе, которая может понадобиться программе. Например, название и версия операционной системы могут служить для определения функциональности, предлагаемой системными программами.
Системный вызов
uname() позволяет программе обнаружить информацию времени ее выполнения.
#include <sys/utsname.h>
int uname(struct utsname* unameBuf);
В случае ошибки функция возвращает ненулевое значение, что происходит только в ситуациях, когда передается недопустимый указатель
unameBuf. При нормальном завершении структура, на которую он указывает, заполняется строками, завершаемыми
NULL, которые описывают текущую систему. В табл. 6.1 представлены члены структуры
utsname.
Таблица 6.1. Члены структуры utsname
| Член |
Описание |
sysname |
Название операционной системы (в данном случае Linux). |
release |
Номер версии выполняющегося ядра. Это полная версия вроде 2.6.2. Номер может быть легко изменен тем, кто выполнял сборку ядра, и вполне возможно, что цифр будет больше трех. Во многих версиях можно встретить дополнительную цифру для описания примененных исправлений, например, 2.4.17-23. |
version |
Под Linux здесь содержится временная метка, описывающая время, когда собиралось ядро. |
machine |
Короткая строка, указывающая тип микропроцессора, на котором работает операционная система. Для Pentium Pro или более мощных она может быть i686, для процессоров класса Alpha — alpha, а для 64-разрядных процессоров PowerPC — ррс64. |
nodename |
Имя хоста машины, которое обычно является первичным именем хоста в Internet. |
domainname |
Домен NIS (или YP), которому принадлежит машина. |
Член
nodename (имя узла) часто называется системным именем хоста (то, что отображает команда
hostname), однако его не следует путать с именем Internet-хоста. Несмотря на то что во многих системах эти члены не различаются, путать их не стоит. В системе с множеством Internet-адресов есть множество имен Internet-хостов, но только одно имя узла, поэтому эти имена не являются эквивалентными.
Более распространенная ситуация связана с домашними компьютерами, которые используют Internet-каналы широкополосной связи. Обычно их имя хоста в Internet выглядит вроде
host127-56.raleigh.myisp.com, а имена Internet-хостов меняются каждый раз при отключении на длительное время от модема
[6]. Владельцы этих машин дают своим компьютерам имя узла, которое им больше нравится, например,
loren или
eleanor, что совершенно не относится к адресам Internet. При наличии множества машин, работающих на одном домашнем шлюзе, все они будут разделять один Internet-адрес (и одно имя Internet-хоста), но могут иметь имена вроде
Linux.mynetwork.org и
freebsd.mynetwork.org, которые все еще не являются именами Internet-хоста. В связи со всеми вышеперечисленными причинами, предполагать, что имя системного узла является допустимым именем Internet-хоста для машины не верно.
Имя узла системы устанавливается с помощью системного вызова
sethostname()[7], и имя домена NIS (YP)
[8] — посредством системного вызова
setdomainname().
#include <unistd.h>
int sethostname(const char * name, size_t len);
int setdomainname(const char * name, size_t len);
Оба этих системных вызова принимают указатель на строку (не обязательно завершающуюся
NULL), которая содержит подходящее имя, и целочисленный аргумент, указывающий размер строки.
6.3. Совместимость
Приложения, которые скомпилированы с заголовочными файлами из библиотеки
glibc и привязанные к одной из ее версий, будут работать и с более поздними версиями библиотеки. Эта
обратная совместимость обычно означает, что программисту не придется пересобирать свои приложения только из-за того, что выпущена новая версия
glibc.
Существуют практические ограничения для обратной совместимости. Во-первых, смешивание объектов из разных версий
glibc в одном исполняемом файле может иногда работать, но специально для такой совместимости ничего не предпринимается. Следует отметить, что это касается динамически загружаемых, а также статически связанных объектов. Во-вторых, приложение должно использовать только стандартные возможности
glibc. Приложение, которое зависит от побочных эффектов ошибок или основано на неопределенном поведении одной из версий
glibc, может не работать с более поздними версиями этой библиотеки. Приложение, компонуемое с приватными символами
glibc (обычно они имеют префикс
а_), также вряд ли будет работать с более новыми версиями
glibc.
Обратная совместимость поддерживается тогда, когда задействованы символы, разработанные специально для соответствия стандартам версий. Когда разработчики
glibc хотят внести несовместимое изменение в
glibc, они сохраняют оригинальную реализацию или пишут совместимую реализацию данного интерфейса и помечают его более старым номером версии
glibc. Затем они реализуют новый интерфейс (который может отличаться по семантике, сигнатуре или и тем, и другим) и помечают его новым номером версии
glibc. Приложения, построенные на базе старой версии
glibc, используют старый интерфейс, а приложения, построенные на основе новой версии — новый интерфейс.
Большинство других библиотек поддерживают совместимость, включая номер версии в имя библиотеки и позволяя множеству разных версий быть установленными одновременно. Например, инструментальные наборы GTK+ 1.2 и GTK+ 2.0 могут быть одновременно установлены в одной системе, каждый со своим собственным набором заголовочных и библиотечных файлов, путем встраивания в путь к заголовочным файлам и файлам библиотек имени версии.
Раздел стандарта по наименованию разделяемых библиотек в Linux включает старший номер версии для возможности установки в системе множества версий библиотеки. Это используется не очень часто, поскольку в одной системе невозможно скомпоновать новые приложения с множеством версий библиотеки; это просто обеспечивает поддержку лишь обратной совместимости для существующих приложений, построенных на более старых системах. На практике разработчикам требуется собирать приложения со многими версиями одной и той же библиотеки, поэтому большинство основных библиотек содержат в своем названии и номер версии.
Глава 7
Средства отладки использования памяти
Несмотря на то что С бесспорно является стандартным языком программирования в системах Linux, он имеет ряд особенностей, не дающих программистам возможности писать код, не содержащий тонких ошибок, которые впоследствии очень сложно отладить.
Утечки памяти (когда память, выделенная с помощью
malloc(), никогда не освобождается посредством
free()) и
переполнение буфера (например, запись за пределы массива) — наиболее распространенные и трудные для обнаружения программные ошибки.
Недогрузка буфера (вроде записи перед началом массива) — менее распространенное, но обычно еще более тяжелое для отслеживания явление. В этой главе представлены несколько средств отладки, которые могут значительно упростить обнаружение и изоляцию упомянутых проблем.
7.1. Код, содержащий ошибки
1: / * broken.с* /
2:
3: #include <stdlib.h>
4: #include <stdio.h>
5: #include <string.h>
6:
7: char global[5];
8:
9: int broken(void){
10: char *dyn;
11: char local[5];
12:
13: /* Для начала немного перезаписать буфер */
14: dyn = malloc(5);
15: strcpy(dyn, "12345");
16: printf ("1: %s\n", dyn);
17: free(dyn);
18:
19: /* Теперь перезаписать буфер изрядно */
20: dyn = malloc(5);
21: strcpy(dyn, "12345678");
22: printf("2: %s\n", dyn);
23:
24: /* Пройти перед началом выделенного с помощью malloc локального буфера */
25: * (dyn-1) ='\0';
26: printf ("3: %s\n", dyn);
27: /* обратите внимание, что указатель не освобожден! */
28:
29: /* Теперь двинуться после переменной local */
30: strcpy(local, "12345");
31: printf ("4: %s\n", local);
32: local[-1] = '\0';
33: printf("5: %s\n", local);
34:
35: /* Наконец, атаковать пространство данных global */
36: strcpy(global, "12345");
37: printf ("6: %s\n", global);
38:
39: /* И записать поверх пространства перед буфером global */
40: global[-1] = '\0';
41: printf("7: %s\n", global);
42:
43: return 0;
44: }
45:
46: int main (void) {
47: return broken();
48: }
В этой главе мы рассмотрим проблемы в показанном выше сегменте кода. Этот код разрушает три типа областей памяти: память, выделенную из динамического пула памяти (
кучи) с помощью
malloc(), локальные переменные размещенные в стеке программы и глобальные переменные, хранящиеся в отдельной области памяти, которая была статически распределена при запуске программы
[9]. Для каждого класса памяти эта тестовая программа выполняет запись за пределами зарезервированной области памяти (по одному байту) и также сохраняет байт непосредственно перед зарезервированной областью. К тому же в коде имеется утечка памяти, что позволит продемонстрировать, как с помощью различных средств отследить эти утечки.
Несмотря на то что в представленном коде кроется много проблем, в действительности, он работает нормально. Не означает ли это, что проблемы подобного рода не важны? Ни в коем случае! Переполнение буфера часто приводит к неправильному поведению программы задолго до фактического его переполнения, а утечки памяти в программах, работающих длительное время, приводят к пустой растрате ресурсов компьютера. Более того, переполнение буфера является классическим источником уязвимостей безопасности, как описано в главе 22.
Ниже показан пример выполнения программы.
$ gcc -Wall -о broken broken.с
$ ./broken
1: 12345
2: 12345678
3: 12345678
4: 12345
5: 12345
6: 12345
7: 12345
7.2. Средства проверки памяти, входящие в состав glibc
Библиотека GNU С (
glibc) предлагает три простых средства проверки памяти. Первые два —
mcheck() и
MALLOC_CHECK_ — вызывают проверку на непротиворечивость структуры данных кучи, а третье средство —
mtrace() — выдает трассировку распределения и освобождения памяти для дальнейшей обработки.
7.2.1. Поиск повреждений кучи
Когда память распределяется в куче, функциям управления памятью необходимо место для хранения информации о распределениях. Таким местом является сама куча; это значит, что куча состоит из чередующихся областей памяти, которые используются программами и самим функциями управления памятью. Это означает, что переполнения или недополнение буфера может фактически повредить структуру данных, которую отслеживают функции управления памятью. В такой ситуации есть много шансов, что сами функции управления памятью, в конце концов, приведут к сбою программы.
Если вы установили переменную окружения
MALLOC_CHECK_, выбирается другой, несколько более медленный набор функций управления памятью. Этот набор более устойчив к ошибкам и может обнаруживать ситуации, когда
free() вызывается более одного раза для одного и того же указателя, а также когда происходят однобайтные переполнения буфера. Если
MALLOC_CHECK_ установлена в
0, функции управления памятью просто более устойчивы к ошибкам, но не выдают никаких предупреждений. Если
MALLOC_CHECK_ установлена в
1, функции управления памятью выводят предупреждения о стандартных ошибках при замеченной проблеме. Если
MALLOC_CHECK_ установлена в
2, функции управления памятью вызывают
abort(), когда замечают проблемы.
Установка
MALLOC_CHECK_ в
0 может оказаться полезной, если вам мешает найти ошибку в памяти другая ошибка, которую в этот момент исправить нет возможности; эта установка позволяет работать с другими средствами отслеживания ошибок памяти.
Установка
MALLOC_CHECK_ в
1 полезна в случае, когда никаких проблем не видно,
поэтому определенные уведомления могут помочь.
Установка
MALLOC_CHECK_ в
2 наиболее полезна при работе в отладчике, поскольку при возникновении ошибки он позволяет выполнить обратную трассировку вплоть до функций управления памятью. В результате вы максимально приблизитесь к месту возникновения ошибки.
$ MALLOC_CHECK_=1 ./broken
malloc: using debugging hooks
malloc: используются отладочные функции
1: 12345
free(): invalid pointer 0x80ac008!
free(): недопустимый указатель 0x80ac008!
2: 12345678
3: 12345678
4: 12345
5: 12345
6: 12345
7: 12345
$ MALLOC_CHECK_=2 gdb ./broken
...
(gdb) run
Starting program: /usr/src/lad/code/broken
Запуск программы: /usr/src/lad/code/broken
1: 12345
Program received signal SIGABRT, Aborted.
Программа получила сигнал SIGABRT, прервана.
0x00 с 64 с 32 in _dl_sysinfo_int80() from/lib/ld-linux.so.2
(gdb) where
#0 0x00c64c32 in _dl_sysinfo_int80() from /lib/ld-linux.so.2
#1 0x00322969 in raise() from /lib/tls/libc.so.6
#2 0x00324322 in abort() from /lib/tls/libc.so.6
#3 0x0036d9af in free_check() from /lib/tls/libc.so.6
#4 0x0036afa5 in free() from /lib/tls/libc.so.6
#5 0x0804842b in broken() at broken.c:17
#6 0x08048520 in main() at broken.с:47
Другой способ заставить
glibc проверить кучу на непротиворечивость — воспользоваться функцией
mcheck():
typedef void(*mcheck Callback)(enummcheck_status status);
void mcheck(mcheck Callback cb) ;
В случае вызова функции
mcheck(), функция
malloc() размещает известные последовательности байтов перед и после возвращенной области памяти, чтобы можно было обнаружить переполнение или недогрузку буфера,
free() ищет эти сигнатуры и, если они были повреждены, вызывает функцию, указанную аргументом
cb. Если
cb равен
NULL, выполняется выход. Запуск программы, связанной с
mcheck(), в gdb может показать, какие именно области памяти были повреждены, если только они явно освобождаются с помощью
free(). Однако метод
mcheck() не может точно определить место ошибки; лишь программист может вычислить это, основываясь на понимании логики работы программы.
Компоновка нашей тестовой программы с
mcheck дает следующие результаты:
$ gcc -ggdb -о broken broken.с -lmcheck
$ ./broken
1: 12345
memory clobbered past end of allocated block
память разрушена после конца распределенного блока
Вследствие того, что
mcheck всего лишь выдает сообщения об ошибках и завершает работу, найти ошибку невозможно. Для точного обнаружения ошибки потребуется запустить программу внутри
gdb и заставить
mcheck вызывать
abort() при обнаружении ошибки. Можно просто вызвать
mcheck() внутри
gdb или поместить
mcheck(1) в первой строке вашей программы (веред вызовом
malloc()). (Следует отметить, что
mcheck() можно вызвать в
gdb без необходимости компоновки программы с библиотекой
mcheck.)
$ rm -f broken; make broken
$ gdb broken
...
(gdb) break main
Breakpoint 1 at 0x80483f4: file broken.c, line 14.
Точка прерывания 1 по адресу 0x80483f4: файл broken, с, строка 14.
(gdb) command 1
Type commands for when Breakpoint 1 is hit, one per line.
End with a line saying just "end".
Наберите команды, которые выполнятся при достижении точки прерывания 1, по одной в строке.
Завершите строкой, содержащей только "end".
> call mcheck(&abort)
> continue
> end (gdb) run
Starting program: /usr/src/lad/code/broken
Запуск программы: /usr/src/lad/code/broken
Breakpoint 1, main () at broken.с: 14
47 return broken();
$1 = 0
1: 12345
Program received signal SIGABRT, Aborted.
Программа получила сигнал SIGABRT, прервана.
0x00e12c32 in _dl_sysinfo_int80() from /lib/ld-linux.so.2
(gdb) where
#00x00el2c32 in _dl_sysinfo_int80() from /lib/ld-linux.so.2
#1 0x0072c969 in raise() from /lib/tls/libc.so.6
#2 0x0072e322 in abort() from /lib/tls/libc.so.6
#3 0x007792c4 in freehook() from /lib/tls/libc.so.6
#4 0x00774fa5 in free() from /lib/tls/libc.so.6
#5 0x0804842b in broken() at broken.c:17
#6 0x08048520 in main() at broken.с:47
Важной частью этого кода является обнаруженная ошибка в строке 17 файла
broken.с. Видно, что ошибка была обнаружена во время первого вызова free(), который указал на наличие проблемы в области памяти
dyn. (
freehook() представляет собой ловушку, с помощью которой
mcheck выполняет проверки.)
Библиотека
mcheck не может помочь в обнаружении переполнения или недогрузки буфера в локальных или глобальных переменных, а только в областях памяти, распределенных с помощью
malloc().
7.2.2. Использование mtrace() для отслеживания распределений памяти
Один из простых способов нахождения всех утечек памяти в программе предусматривает регистрацию всех вызовов
malloc() и
free(). По окончании программы очень легко сопоставить блоки, распределенные через
malloc(), с точками, где они были освобождены с помощью
free() или сообщить об ошибке, если для какого-то блока
free() не вызывалась.
В отличие от
mcheck(), в
mtrace() нет соответствующей библиотеки для компоновки. Это не проблема, поскольку трассировку можно осуществлять в
gdb. Однако для включения трассировки с помощью
mtrace() должна быть установлена переменная окружения
MALLOC_TRACE в допустимое имя файла; это может быть либо имя существующего файла, в который процесс может вести запись, либо имя нового файла, который процесс создаст и будет в него записывать.
$ MALLOC_TRACE=mtrace.log gdb broken
...
(gdb) breakmain
Breakpoint 1 at 0x80483f4: filebroken.c, line 14.
(gdb) command 1
Type commands for when Breakpoint 1 is hit, one per line.
End with a line saying just "end".
>call mtrace()
>continue
>end
(gdb) run
Starting program: /usr/src/lad/code/broken
Breakpoint 1, main() at broken.с:47
47 return broken();
$1 = 0
1: 12345
2: 12345678
3: 12345678
4: 12345
5: 12345
6: 12345
7: 12345
Program exited normally.
Программа завершена нормально.
(gdb) quit
$ ls -l mtrace.log
-rw-rw-r-- 1 ewt ewt 220 Dec 27 23:41 mtrace.log
$ mtrace ./broken mtrace.log
Memory not freed:
He освобождена память:
----------------------
Address Size Caller
Адрес Размер Место вызова
0x09211378 0x5 at /usr/src/lad/code/broken.с:20
Обратите внимание, что программа
mtrace точно обнаружила утечку памяти. Также она может найти факт освобождения с помощью
free() памяти, которая ранее не распределялась, если этот факт будет зафиксирован в журнальном файле, но на практике так не происходит, поскольку в этом случае программа немедленно аварийно завершается.
7.3. Поиск утечек памяти с помощью mpr
Возможности
mtrace() в
glibc достаточно неплохие, но профилировщик распределения памяти
mpr (http://www3.telus.net/taj_khattra/mpr.html) в некоторых аспектах более прост в использовании и содержит более совершенные сценарии для обработки выходных журнальных файлов.
Первый шаг в применении
mpr (после сборки кода с включенной отладочной информацией
[10]) состоит в установке переменной окружения
MPRFI, которая указывает
mpr, с какой командой связывать журнал (если переменная не установлена, журнал не генерируется). Для небольших программ
MPRFI устанавливается подобно
cat >mpr.log. Для программ покрупнее
MPRFI можно существенно сэкономить пространство за счет сжатия журнального файла во время его записи, установив
MPRFI в
gzip -1 >mpr.log.gz.
Самый легкий способ — воспользоваться сценарием
mpr для запуска программы; если
MPRFI еще не установлена, она получит значение
gzip -1 >log.%p.gz, что приведет к созданию журнального файла с идентификатором процесса отлаживаемой программы и загрузке библиотеки
mpr. В результате сборка программы не понадобится. Ниже показан пример создания журнального файла для исправленной версии нашей тестовой программы.
$ MPRFI="cat >mpr.log" mpr ./broken
1: 12345
2: 12345678
3: 12345678
4: 12345
5: 12345
6: 12345
7: 12345
$ ls -l mpr.log
-rw-rw-r-- 1 ewt ewt 142 May 17 16:22 mpr.log
После создания журнального файла доступны многие средства для его анализа. Все эти программы получают журнальный файл mpr в качестве стандартного ввода. Если вывод из этих средств содержит числа в тех местах, где ожидаются имена функций (возможно, с предупреждением вроде "cannot map pc to name" ("невозможно отобразить программный счетчик на имя")), проблема может быть связана с версией утилиты
awk, которую использует
mpr. В документации
mpr для достижения лучших результатов рекомендуется экспортировать переменную окружения
MPRAWK для выбора
mawk в качестве версии
awk:
export MPRAWK='mawk -W sprintf=4096'. Кроме того, сбить с толку mpr может еще и рандомизация стека, которая обеспечивается функциональностью ядра "Exec-shield"; исправить положение можно за счет использования команды
setarch, отключающей Exec-shield во время работы исследуемой программы и во время работы фильтров
mpr:
setarch i386 mpr программа и setarch i386 mprmap ...
В конечном итоге для некоторых стековых фреймов
mpr может не найти символическое имя; в этом случае просто проигнорируйте их.
mprmap программа |
Преобразует адреса программы в журнале mpr в имена функций и местоположения в исходном коде. В аргументе указывается имя исполняемого файла, для которого должен генерироваться журнал. Чтобы увидеть все распределения в программе вместе с цепочкой вызовов функций, которые осуществили эти распределения, можно использовать mprmap программа < mpr.log. По умолчанию отображаются имена функций. При указании флажка -f отображаются также имена файлов, а при указании -l — еще и номера строк внутри файлов. Флажок -l подразумевает наличие -f. Вывод этой программы является допустимым журнальным файлом mpr, который может быть связан каналом с любой другой утилитой mpr. |
mprchain |
Преобразует журнал в вывод, сгруппированный по цепочкам вызовов. Цепочка вызовов функций — это список всех функций, активных в программе на определенный момент. Например, если main() вызывает getargs(), которая впоследствии вызывает parsearg(), активная цепочка вызовов во время работы parsearg() отображается как main:getargs:parsearg. Для каждой отдельной цепочки вызовов, в которой распределялась память во время выполнения программы, mprchain отображает количество распределений и общее количество распределенных байт. |
mprleak |
Этот фильтр просматривает журнальный файл на предмет наличия всех неосвобожденных фрагментов памяти. В качестве стандартного вывода генерируется новый журнальный файл, содержащий только те распределения, которые могут привести к утечкам памяти. Вывод этой программы является допустимым журнальным файлом mpr, который может быть связан каналом с любой другой утилитой mpr. |
mprsize |
Этот фильтр сортирует распределения памяти по размеру. Чтобы просмотреть утечки памяти по размеру, нужно передать вывод mprleak на вход mprsize. |
mprhisto |
Отображает гистограмму распределений памяти. |
Теперь, когда известно об анализаторах журнальных файлов, очень просто найти утечки памяти в нашей тестовой программе. Для этого достаточно воспользоваться командой
mprleak mpr.log | mprmap -l ./broken (что эквивалентно
mprmap -l ./broken mpr.log | mprleak) и в результате обнаружить утечку памяти в строке 20.
$ mprleak mpr.log | mpr map -l ./broken
m:broken(broken.c,20): main(broken.c,47):5:134518624
7.4. Обнаружение ошибок памяти с помощью Valgrind
Valgrind (http://valgrind.kde.org/) представляет собой специфический для Intel х86 инструмент, эмулирующий центральный процессор класса х86 для непосредственного наблюдения над всеми обращениями к памяти и анализа потока данных (он может, например, выявлять чтения неинициализированной памяти, тем не менее перенос содержимого неинициализированной ячейки в другую ячейку, которая никогда для читается, как неинициализированное чтение он не трактует). Valgrind обладает множеством других возможностей, включая просмотр использования кэша и поиск состязаний в многопоточных программах. В действительности, в Valgrind имеется универсальное средство для добавления большего количества возможностей, основанных на его эмуляторе центрального процессора. Однако для наших целей мы лишь кратко рассмотрим выполнение с его помощью агрессивного поиска ошибок памяти, что представляет его стандартное поведение.
Valgrind не требует повторной компиляции программы, хотя, как и все средства отладки, он имеет возможность компилировать программы с отладочной информацией.
$ valgrind ./broken
==30882== Memcheck, a.k.a. Valgrind, a Memory ERROR detector for x86-linux.
==30882== Copyright (C) 2002-2003, and GNU GPL'd, by Julian Seward.
==30882== Using valgrind-2.0.0, a program super vision framewok for x86-linux.
==30882== Copyright (C) 2000-2003, and GNU GPL'd, by Julian Seward.
==30882== Estimated CPU clock rate is 1547 MHz
==30882== For more details, rerun with: -v
==30882==
==30882== Invalid write of size 1
==30882== Недопустимая запись размером 1
==30882== at 0xC030DB: strcpy (mac_replace_strmem.с:174)
==30882== by 0x8048409: broken (broken.с:15)
==30882== by 0x804851F: main (broken.с:47)
==30882== by 0x802BAE: libc_start_main (in /lib/libc-2.3.2.so)
==30882== Address 0x650F029 is 0 bytes after a block of size 5 alloc'd
==30882== at 0xC0C28B: malloc (vg_replace_malloc.с:153)
==30882== by 0x80483F3: broken (broken.с:14)
==30882== by 0x804851F: main (broken.с:47)
==30882== by 0x802BAE: libc_start_main (in /lib/libc-2.3.2.so)
==30882==
==30882== Conditional jump or move depends on uninitialised value(s)
==30882== Условный переход или перемещение зависит от
неинициализироваиного значения(й)
==30882== at 0x863D8E: __GI_strlen (in /lib/libc-2.3.2.so)
==30882== by 0x83BC31: _IO_printf (in /lib/libc-2.3.2.so)
==30882== by 0x804841C: broken (broken.с:16)
==30882== by 0x804851F: main (broken.с:47)
1: 12345
==30882==
==30882== Invalid write of size 1
==30882== at 0xC030D0: strcpy (mac_replace_.с: 173)
==30882== by 0x804844D: broken (broken.с:21)
==30882== by 0x804851F: main (broken.с:47)
==30882== by 0x802BAE: _libc_start_main (in /lib/libc-2.3.2.so)
==30882== Address 0x650F061 is 0 bytes after a block of size 5 alloc'd
==30882== at 0xC0C28B: malloc (vg_replace_ malloc.с:153)
==30882== by 0x8048437: broken (broken.с:20)
==30882== by 0x804851F: main (broken.с:47)
==30882== by 0x802BAE: libc_start_main (in /lib/libc-2.3.2.so)
==30882==
==30882== Invalid write of size 1
==30882== at 0xC030DB: strcpy (mac_replace_strmem.с:174)
==30882== by 0x804844D: broken (broken.с:21)
==30882== by 0x804851F: main (broken.с:47)
==30882== by 0x802BAE: libc_start_main (in /lib/libc-2.3.2.so)
==30882== Address 0x650F064 is 3 bytes after a block of size 5 alloc'd
==30882== at 0xC0C28B: malloc (vg_replace_malloc.с:153)
==30882== by 0x8048437: broken (broken.с:20)
==30882== by 0x804851F: main (broken.с:47)
==30882== by 0x802BAE: __libc_start_main (in /lib/libc-2.3.2.so)
==30882==
==30882== Invalid read of size 4
==30882== Недопустимое чтение размером 4
==30882== at 0x863D50: __GI_strlen (in /lib/libc-2.3.2.so)
==30882== by 0x83BC31: _IO_printf (in /lib/libc-2.3.2.so)
==30882== by 0x8048460: broken (broken.с:22)
==30882== by 0x804851F: main (broken.с:47)
==30882== Address 0x650F064 is 3 bytes after a block of size 5 alloc'd
==30882== at 0xC0C28B: malloc (vg_replace_malloc.с:153)
==30882== by 0x8048437: broken (broken.с:20)
==30882== by 0x804851F: main (broken.с:47)
==30882== by 0x802BAE: __libc_start_main (in /lib/libc-2.3.2.so)
==30882==
==30882== Invalid read of size 1
==30882== at 0x857A21: _IO_file_xsputn@@GLIBC_2.1 (in /lib/libc-2.3.2.so)
==30882== by 0x835309: _IO_vfprintf_internal (in /lib/libc-2.3.2.so)
==30882== by 0x83BC31: _IO_printf(in /lib/libc-2.3.2.so)
==30882== by 0x8048460: broken (broken.с:22)
==30882== Address 0x650F063 is 2 bytes after a block of size 5 alloc'd
==30882== at 0xC0C28B: malloc (vg_replace_malloc.с:153)
==30882== by 0x8048437: broken (broken.с:20)
==30882== by 0x804851F: main (broken.c:47)
==30882== by 0x802BAE: __libc_start_main (in /lib/libc-2.3.2.so)
==30882==
==30882== Invalid read of size 1
==30882== at 0x857910: _IO_file_xsputn@@GLIBC_2.1 (in /lib/libc-2.3.2.so)
==30882== by 0x835309: _IO_vfprintf_internal (in /lib/libc-2.3.2.so)
==30882== by 0x83BC31: _IO_printf (in /lib/libc-2.3.2.so)
==30882== by 0x8048460: broken (broken.с:22)
==30882== Address 0x650F061 is 0 bytes after a block of size 5'alloc'd
==30882== at 0xC0C28B: malloc (vg_replace_malloc.с:153)
==30882== by 0x8048437: broken (broken.с:20)
==30882== by 0x804851F: main (broken.с:47)
==30882== by 0x802BAE: __libc_start_main (in /lib/libc-2.3.2.so)
2: 12345678
==30882==
==30882== Invalid write of size 1
==30882== at 0x8048468: broken (broken.с:25)
==30882== by 0x804851F: main (broken.с:47)
==30882== by 0x802BAE: __libc_start_main (in /lib/libc-2.3.2.so)
==30882== by 0x8048354: (within /usr/src/d/lad2/code/broken)
==30882== Address 0x650F05B is 1 bytes before a block of size 5 alloc'd
==30882== at 0xC0C28B: malloc (vg_replace_malloc.c:153)
==30882== by 0x8048437: broken (broken.с:20)
==30882== by 0x804851F: main (broken.с:47)
==30882== by 0x802BAE: __libc_start_main (in /lib/libc-2.3.2.so)
==30882==
==30882== Invalid read of size 4
==30882== at 0x863D50: __GI_strlen (in /lib/libc-2.3.2.so)
==30882== by 0x83BC31: _IO_printf (in /lib/libc-2.3.2.so)
==30882== by 0x804847A: broken (broken.c:2 6)
==30882== by 0x804851F: main (broken.c:47)
==30882== Address 0x650F064 is 3 bytes after a block of size 5 alloc'd
==30882== at 0xC0C28B: malloc (vg_replace_malloc.c:153)
==30882== by 0x8048437: broken (broken.с:20)
==30882== by 0x804851F: main (broken.c:47)
==30882== by 0x802BAE: __libc_start_main (in /lib/libc-2.3.2.so)
==30882==
==30882== Invalid read of size 1
==30882== at 0x857A21: _IO_file_xsputn@@GLIBC_2.1 (in /lib/libc-2.3.2.so)
==30882== by 0x835309: _IO_vfprintf_internal (in /lib/libc-2.3.2.so)
==30882== by 0x83BC31: _IO_printf (in /lib/libc-2.3.2.so)
==30882== by 0x804847A: broken (broken.c:2 6)
==30882== Address 0x650F063 is 2 bytes after a block of size 5 alloc'd
==30882== at 0xC0C28B: malloc (vg_replace_malloc.c:153)
==30882== by 0x8048437: broken (broken.с:20)
==30882== by 0x804851F: main (broken.с:47)
==30882== by 0x802BAE: __libc_start_main (in /lib/libc-2.3.2.so)
==30882==
==30882== Invalid read of size 1
==30882== at 0x857910: _IO_file_xsputn@@GLIBC_2.1 (in /lib/libc-2.3.2.so)
==30882== by 0x835309: _IO_vfprintf_internal (in /lib/libc-2.3.2.so)
==30882== by 0x83BC31: _IO_printf (in /lib/libc-2.3.2.so) ==30882== by 0x804847A: broken (broken.c:2 6)
==30882== Address 0x650F061 is 0 bytes after a block of size 5 alloc'd
==30882== at 0xC0C28B: malloc (vg_replace_malloc.с:153)
==30882== by 0x8048437: broken (broken.с:20)
==30882== by 0x804851F: main (broken.с:47)
==30882== by 0x802BAE: __libc_start_main (in /lib/libc-2.3.2.so)
3: 12345678
4: 12345
==30882==
==30882== Invalid write of size 1
==30882== at 0x80484A6; broken (broken.c:3 2)
==30882== by 0x804851F: main (broken.с:47)
==30882== by 0x802BAE: __libc_start_main (in /lib/libc-2.3.2.so)
==30882== by 0x8048354: (within /usr/src/d/lad2/code/broken)
==30882== Address 0xBFF2D0FF is just below %esp. Possibly a bug in GCC/G++
==30882== v 2.96 or 3.0.X. To suppress, use: --workaround-gcc 296-bugs = yes
5: 12345
6: 12345
7: 12345
==30882==
==30882== ERROR SUMMARY: 22 ERRORS from 12 contexts (suppressed: 0 from 0)
==30882== malloc/free: in use at exit: 5 bytes in 1 blocks.
==30882== malloc/free: 2 allocs, 1 frees, 10 bytes allocated.
==30882== For a detailed leak analysis, rerun with: --leak-check=yes
==30882== For counts of detected ERRORS, rerun with: -v
==30882== ИТОГИ ПО ОШИБКАМ: 22 ошибки в 12 контекстах (подавлено: 0 из 0)
==30882== malloc/free: используются после завершения: 5 байт в 1 блоке.
==30882== malloc/free: 2 распределения, 1 освобождение, 10 байт распределено.
==30882== Для детального анализа утечек памяти запустите с: --leak-check=yes
==30882== Для подсчета обнаруженных ошибок запустите с: -v
Обратите внимание, что Valgrind нашел все, кроме глобального переполнения и недогрузки, и указал на ошибки более точно, нежели любое другое ранее описанное средство.
Имеется опция, позволяющая включить агрессивную проверку утечек памяти, при которой для каждого распределения находятся все доступные указатели, хранящие ссылку на эту память. Это более точный способ, поскольку часто в программе память распределяют, но в конце не освобождают, так как память в любом случае будет возвращена операционной системе после того, как программа завершится.
$ valgrind --leak-check=yes ./broken
...
==2292== searching for pointers to 1 not-freed blocks.
==2292== checked 5318724 bytes.
==2292== поиск указателей на 1 неосвобожденный блок.
==2292== проверено 5318724 байт.
==2292==
==2292== 5 bytes in 1 blocks are definitely lost in loss record 1 of 1
==2292== 5 байт в 1 блоке определенно потеряны в потерянной записи 1 из 1
==2292== at 0хЕС528В: malloc (vg_replace_malloc.с:153)
==2292== by 0x8048437: broken (broken.с:20)
==2292== by 0x804851F: main (broken.с:47)
==2292== by 0x126BAE: __libc_start_main (in /lib/libc-2.3.2.so)
==2292==
==2292== LEAK SUMMARY:
==2292== definitely lost: 5 bytes in 1 blocks.
==2292== possibly lost: 0 bytes in 0 blocks.
==2292== still reachable: 0 bytes in 0 blocks.
==2292== suppressed: 0 bytes in 0 blocks.
==2292== Reachable blocks (those to which a pointer was found) are not shown.
==2292== To see them, rerun with: --show-reachable=yes
==2292== ИТОГИ ПО УТЕЧКАМ:
==2292== определенно потеряно: 5 байт в 1 блоке.
==2292== возможно потеряно: 0 байт в 0 блоке.
==2292== пока достижимы: 0 байт в 0 блоке.
==2292== подавлено: 0 байт в 0 блоке.
==2292== Достижимые блоки (на которые найдены указатели) не показаны.
==2292== Чтобы увидеть их, запустите с: --show-reachable=yes
Инструмент Valgrind включает детализированную информацию по своим возможностям и поддерживает множество опций командной строки, которые модифицируют его поведение. Поскольку Valgrind использует эмулятор центрального процессора, программа в нем выполняется во много раз медленнее, чем обычно в системе. Точное замедление зависит от программы, однако Valgrind задумывался для интерактивных программ.
Valgrind могут слегка ввести в заблуждение программы, скомпилированные с высокими уровнями оптимизации. Если вы получаете отчет об ошибке памяти, которая не выглядит осмысленно, попробуйте перекомпилировать программу с
-О вместо
-O2 (или выше) и сгенерировать новый отчет.
7.5. Electric Fence
Следующее средство, которое мы рассмотрим — это Electric Fence (доступен на ftp://sunsite.unc.edu/pub/Linux/devel/lang/c и во многих дистрибутивах). Несмотря на то что Electric Fence не обнаруживает утечки памяти, он очень помогает в изоляции переполнений буфера. Каждый современный компьютер (включая все машины, работающие под Linux) обеспечивают аппаратную защиту памяти. Linux этим пользуется для изоляции программ друг от друга (например, сеанс
vi не имеет доступа к памяти
gcc) и для безопасного разделения кода между процессами, делая его только для чтения. Системный вызов
mmap() в Linux (см. главу 13) позволяет процессу воспользоваться также аппаратной защитой памяти.
Electric Fence заменяет обычную функцию
malloc() библиотеки С версией, которая распределяет запрошенную память и (обычно) непосредственно после запрошенной выделяет фрагмент памяти, доступ к которой процессу не разрешен. Если процесс попытается получить доступ к этой памяти, ядро немедленно остановит его с выдачей ошибки сегментации. За счет такого распределения памяти Electric Fence обеспечивает уничтожение программы, если та предпримет попытку чтения или записи за границей буфера, распределенного
malloc(). Детальную информацию по использованию Electric Fence можно прочитать на его man-странице (
man libefence).
7.5.1. Использование Electric Fence
Одна из наиболее примечательных особенностей Electric Fence заключается в простоте ее использования. Нужно всего лишь скомпоновать свою программу с библиотекой
libefence.а, указав
-lefence в качестве последнего аргумента. В результате код будет готов к отладке. Давайте посмотрим, что происходит при запуске тестовой программы с применением Electric Fence.
$ ./broken
Electric Fence 2.2.0 Copyright (C) 1987 - 1999 Bruce Perens.
1: 12345
Segmentation fault (core dumped)
Ошибка сегментации (дамп ядра сброшен)
Хотя Electric Fence непосредственно не указывает на место, где произошла ошибка, проблема становится намного очевидней. Можно легко и точно определить проблемный участок, запустив программу под управлением отладчика, например
gdb. Для того чтоб
gdb смог точно указать на проблему, соберите программу с отладочной информацией, указав для
gcc флажок
-g, затем запустите
gdb и зададите имя исполняемого файла, который нужно отладить. Когда программы уничтожается,
gdb точно показывает, в какой строке произошел сбой.
Вот как выглядит описанная процедура.
$ gcc -ggdb -Wall -о broken broken.с -lefence
$ gdb broken
...
(gdb) run
Starting program: /usr/src/lad/code/broken
Electric Fence 2.2.0 Copyright (C) 1987 - 1999 Bruce Perens.
1: 12345
Program received signal SIGSEGV, Segmentation fault.
Программа получила сигнал SIGSEGV, ошибка сегментации.
0х007948с6 in strcpy() from /lib/tls/libc.so.6
(gdb) where
#0 0x007948c6 in strcpy() from /lib/tls/libc.so.6
#1 0x08048566 in broken() at broken.c:21
#2 0x08048638 in main() at broken.c:47
(gdb)
Благодаря Electric Fence и
gdb, становится понятно, что в строке 21 файла
broken.с имеется ошибка, связанная со вторым вызовом
strcpy().
7.5.2. Выравнивание памяти
Хотя инструмент Electric Fence очень помог в обнаружении второй проблемы в коде, а именно — вызова
strcpy(), переполнившего буфер, первое переполнение буфера найдено не было.
Проблему в этом случае нужно решать с помощью выравнивания памяти. Большинство современных компьютеров требуют, чтобы многобайтные объекты начинались с определенных смещений в оперативной памяти. Например, процессоры Alpha требуют, чтобы 8-байтовый тип — длинное целое (
long) — начинался с адреса, кратного 8. Это значит, что длинное целое может располагаться по адресу 0x1000 или 0x1008, но не 0x1005
[11].
На основе этих соглашений реализации
malloc() обычно возвращают память, первый байт которой выровнен в соответствии с размером слова процессора (4 байта для 32-разрядных и 8 байтов на 64-разрядных процессоров). По умолчанию Electric Fence пытается эмулировать такое поведение, предлагая функцию
malloc(), возвращающую только адреса, кратные
sizeof(int).
В большинстве программ подобное выравнивание не критично, то есть распределение памяти происходит инкрементным образом на основе размера машинного слова либо в виде простых символьных строк, для которых требования по выравниванию не предусмотрены (поскольку каждый элемент занимает всего 1 байт).
В случае с нашей тестовой программой первый вызов
malloc() распределил пять байт.
Для того чтобы Electric Fence удовлетворял своим ограничениям по выравниванию, он трактует этот вызов как запрос восьми байт, с дополнительными тремя доступными байтами. В этом случае небольшие переполнения буфера, распространяющиеся на эту область, не перехватываются.
В связи с тем, что выравнивание
malloc() обычно можно игнорировать, а выравнивание может способствовать незаметному переполнению буфера, Electric Fence предоставляет возможность управление выравниванием через переменную окружения
ЕF_ALIGNMENT. Если эта переменная установлена, все результаты
malloc() выравниваются в соответствии с ее значением. Например, если переменная установлена в значение 5, все результаты
malloc() будут рассматриваться как кратные 5 (тем не менее, это значение не особенно полезно). Для отключения выравнивания памяти перед запуском программы установите
ЕF_ALIGNMENT в
1. В среде Linux некорректно выровненный доступ в любом случае исправляются в ядре, несмотря на то, что в результате скорость выполнения программы может существенно снизиться. Программа будет функционировать корректно, если только в ней не присутствуют небольшие переполнения буфера.
Ниже приведен пример поведения тестовой программы, скомпонованной с Electric Fence, после установки
ЕF_ALIGNMENT в
1.
$ export EF_ALIGNMENT=1
$ gdb broken
...
(gdb) run
Starting program: /usr/src/lad/code/broken
Electric Fence 2.2.0 Copyright (C) 1987 - 1999 Bruce Perens.
Program received signal SIGSEGV, Segmentation fault.
0x002a78c6 in strcpy() from /lib/tls/libc.so.6
(gdb) where
#0 0x002a78c6 in strcpy() from /lib/tls/libc.so.6
#1 0x08048522 in broken() at broken.c:15
#2 0x08048638 in main() at broken.с:47
На этот раз Electric Fence нашел переполнение буфера, которое произошло первым.
7.5.3. Другие средства
Electric Fence не только помогает обнаружить переполнение буфера, но и может найти недогрузку буфера (выполняя доступ к памяти, расположенной перед началом выделяемого
malloc() буфера) и получает доступ к памяти, освобождаемой с помощью
free(). Если переменная окружения
EF_PROTECT_BELOW установлена в
1, Electric Fence перехватывает недогрузку буфера вместо его переполнения. Это происходит путем размещения недоступной области памяти непосредственно перед фактической областью памяти, возвращаемой функцией
malloc(). При этом Electric Fence не сможет обнаружить переполнение буфера из-за страничной организации памяти, реализованной в большинстве процессоров. Выравнивание памяти может затруднить обнаружение переполнения буфера, однако оно не влияет на недогрузку буфера. Функция
malloc() из Electric Fence всегда возвращает адрес памяти в начале страницы, которая всегда выровнена по границе слова.
Если
EF_PROTECT_FREE установлена в
1,
free() делает переданную ей область памяти недоступной, но не возвращает ее в пул свободной памяти. Если программа пытается получить доступ к этой памяти на любом этапе в будущем, ядро обнаружит несанкционированный доступ. Настройка
EF_PROTECT_FREE помогает удостовериться, что код ни на одном этапе выполнения не использует память, освобожденную с помощью
free().
7.5.4. Ограничения
Несмотря на то что Electric Fence выполняет неплохую работу по обнаружению переполнения буферов, выделенных
malloc(), он не помогает отслеживать проблемы ни с глобальными, ни с локальными данными. Electric Fence также не обнаруживает утечки памяти, потому решать эту проблему придется другими средствами.
7.5.5. Потребление ресурсов
Хотя Electric Fence является мощным, легким в употреблении и быстрым инструментом (поскольку все проверки доступа осуществляются аппаратными средствами), за все это приходится платить свою цену. Большинство процессоров позволяют системе управлять доступом к памяти только в единицах, равных странице, за один раз. На процессорах Intel 80x86, например, каждая страница занимает 4096 байт. Вследствие того, что Electric Fence требует от
malloc() установки двух разных областей памяти для каждого вызова (одна — позволяющая доступ, а другая — запрещающая), каждый вызов
malloc() потребляет страницу памяти, или 4 Кбайт
[12]! Если в тестируемом коде распределяется множество небольших участков памяти, его компоновка с Electric Fence может легко увеличить потребление памяти программы на два или три порядка. При этом использование
EF_PROTECT_FREE еще более усугубляет положение, поскольку память никогда не освобождается.
Для систем с большими относительно размера отлаживаемой программы объемами памяти при поиске источника определенной проблемы Electric Fence может действовать быстрее, чем Valgrind. Тем не менее, если для функционирования Electric Fence требуется организовать пространство для свопинга размером в 1 Гбайт, то Valgrind, вполне вероятно, окажется намного быстрее, даже несмотря на то, что он использует эмулятор, а не собственно центральный процессор.
Глава 8
Создание и использование библиотек
Исполняемые файлы могут получать функции из библиотек одним из двух способов: функции можно скопировать из статической библиотеки непосредственно в образ исполняемого файла или на них могут иметься неявные ссылки в файле совместно используемой библиотеки, который читается во время запуска исполняемого файла. В этой будет показано, как использовать и создавать оба типа архивов.
8.1. Статические библиотеки
Статические библиотеки представляют собой простые коллекции объектных файлов, объединенных утилитой
ar (архиватор),
ar группирует объектные файлы в один архив и добавляет таблицу, в которой указано, какие объектные файлы в архиве какие символы определяют. Затем компоновщик,
ld, связывает ссылки на символ в одном объектном файле с определением этого символа в объектном файле архива. Для статических библиотек используется суффикс
.а.
В статическую библиотеку можно преобразовать группу объектных файлов с помощью такой команды:
ar res libname.a foo.o bar.о baz.o
Также в архив можно добавлять объектные файлы по одному.
ar res libname.a foo.o
ar res libname.a bar.о
ar res libname.a baz.o
В любом случае
libname.a получится одинаковым. В команде использованы перечисленные ниже опции.
r |
Включает объектные файлы в библиотеку, заменяя любой уже существующий в архиве файл с таким же именем. |
с |
Молча создает библиотеку, если таковой еще не существует. |
s |
Поддерживает в таблице соответствие названий символов объектным файлам. |
При сборке статических библиотек необходимость в использовании других опций возникает не часто. Однако ar поддерживает другие опции и возможности, о которых подробно можно прочесть на man-странице команды.
8.2. Совместно используемые библиотеки
Совместно используемые, или разделяемые, библиотеки обладают рядом преимуществ по сравнению со статическими библиотеками.
• Linux разделяет используемую для кода исполняемого файла память между всеми процессами, которые совместно пользуются библиотекой. Таким образом, если запущено несколько программ, которые работают с одним и тем же кодом, в ваших интересах и для удобства пользователя будет поместить код в совместно используемую библиотеку.
• В связи с тем, что совместно используемые библиотеки экономят системную память, с их помощью система может работать быстрее, особенно в ситуациях, когда памяти не слишком много.
• Поскольку код в совместно используемых библиотеках не копируется в исполняемый файл, на диске хранится лишь одна копия библиотечного кода, что экономит дисковое пространство и время, которое могло бы уйти на копирование кода с диска в память при запуске программы.
• При обнаружении ошибки совместно используемую библиотеку можно заменить исправленной версией, а не компилировать повторно каждую программу, ее использующую.
Плата за такие преимущества, главным образом, заключается в сложности использования. Исполняемый файл состоит из нескольких независимых частей, и в случае передачи этого файла тому, у которого нет необходимой для файла совместно используемой библиотеки, файл не запустится. Следующая плата — время, которое уходит на поиск и загрузку совместно используемых библиотек при запуске программы. Обычно это не является проблемой, так как библиотеки обычно уже загружены в память для других процессов и, следовательно, при запуске нового процесса в повторной загрузке с диска они не нуждаются.
В Linux первоначально использовался упрощенный формат двоичных файлов (фактически, три вариации упрощенного формата), что делало процесс создания совместно используемых библиотек сложным и трудоемким. После создания библиотеки не так- то просто было расширять, поддерживая при этом обратную совместимость. Создатели библиотеки вынуждены были оставлять место для расширения структуры данных путем ручного редактирования таблиц, и даже это не всегда давало желаемые результаты.
Теперь стандартный формат двоичного файла практически на каждой платформе Linux представляет собой современный, расширяемый файловый формат
ELF (
Executable and Linking Format — формат исполняемых и компонуемых модулей), описанный в [24], ftp://tsx-11.mit.edu/pub/linux/packages/GCC/ELF.doc.tar.g и ftp://tsx-11.mit.edu/pub/linux/packages/GCC/elf.ps.gz. Это значит, что практически на всех платформах Linux шаги, предпринимаемые для создания и использования разделяемых библиотек, совершенно одинаковы.
8.3. Разработка совместно используемых библиотек
Создание совместно используемых библиотек не намного труднее разработки обычных статических библиотек. Существует лишь несколько ограничений, но с ними очень легко справиться. Однако совместно используемым библиотекам присуща одна уникальная и основная функциональность, позволяющая управлять бинарной совместимостью в различных версиях библиотек.
Совместно используемые библиотеки ориентированы на поддержание обратной совместимости. Это значит, что двоичный файл, собранный с ранней версией библиотеки, будет работать и с более поздней ее версией. Однако в некоторых случаях библиотеки не являются совместимыми: например, при необходимости модифицировать интерфейсы способом, не предусматривающим обратную совместимость.
8.3.1. Управление совместимостью
Каждой совместно используемой библиотеке Linux присваивается специальное имя, называемое
soname, которое включает имя библиотеки и номер ее версии. При изменении интерфейсов в имени библиотеки изменяется номер версии. В некоторых библиотеках нет стабильных интерфейсов; разработчики меняют их так, что они перестают быть совместимыми со старой версией, которая отличается лишь младшим номером версии. Большинство разработчиков стараются поддерживать постоянные интерфейсы, которые при изменении перестают быть совместимыми только тогда, когда выходит библиотека с новым старшим номером версии.
Например, разработчики и службы поддержки библиотеки С в Linux стараются поддерживать обратную совместимость для всех выпусков библиотеки С с одним и тем же старшим номером версии. Версия 5 библиотеки С прошла через пять небольших ревизий и, за некоторыми исключениями, программы, работающие с первой младшей версией, будут работать и с последней. (Исключения составляют неудачно написанные программы, основанные на неопределенном поведении библиотеки С или библиотеке С с ошибками, которые были исправлены в более новых версиях.) Ввиду того, что все библиотеки С версии 5 рассчитаны на обратную совместимость с предыдущими версиями, все они используют одно и то же имя soname —
libc.so.5, относящееся к имени файла, в котором оно хранится —
/lib/libc.so.5.m.r, где
m — младший номер версии, a
r — номер выпуска.
Приложения, которые компонуются с совместно используемой библиотекой, не компонуются непосредственно, например, с
/lib/libc.so.6, даже если этот файл существует. Программа
ldconfig, стандартная системная утилита, создает символическую ссылку
/lib/libc.so.6 (soname) на
/lib/libc-2.3.2.so, действительное имя библиотеки.
В результате упрощается модернизация совместно используемых библиотек. Для обновления версии 2.3.2 до 2.3.3 потребуется всего лишь скопировать новую версию
libc-2.3.3.so в каталог
/lib и запустить
ldconfig.
ldconfig просматривает все библиотеки с soname, равным
libc.so.6, и создает символическую ссылку из soname на самую новую библиотеку, включающую это soname. Затем все приложения, скомпонованные с
/lib/libc.so.6, автоматически используют новую библиотеку при последующих запусках, a
/lib/libc-2.3.2.so можно смело удалить, поскольку потребность в ней полностью отпадает.
Не компонуйте программы со специфическими версиями библиотеки, если на то нет веских причин. Всегда используйте стандартную опцию
-lимя_библиотеки компилятора или компоновщика. Таким образом, вы никогда не скомпонуете по ошибке приложение с неправильной версией. Компоновщик всегда будет искать файл
libимя_библиотеки.so, который будет символической ссылкой на новую версию библиотеки.
Итак, для компоновки с библиотекой С компоновщик находит
/usr/lib/libc.so, указывающую на то, что нужно использовать
/lib/libc.so.6, который является ссылкой на
/lib/libc-2.3.2.so. Приложение компонуется с soname-именем libc-2.3.2.so —
libc.so.6, и при запуске оно находит
/lib/libc.so.6 и связывается с
libc-2.3.2.so, поскольку
libc.so.6 является символической ссылкой на
libc-2.3.2.so.
8.3.2. Несовместимые библиотеки
Если новая версия библиотеки не должна быть совместимой с предшествующими ее версиями, ей потребуется присвоить другое имя soname. Например, для выпуска новой версии библиотеки С, не совместимой со старой версией, разработчики использовали soname
libc.so.6 вместо
libc.so.5. В результате делается акцент на несовместимости, а приложения, скомпонованные с разными версиями библиотеки, могут сосуществовать в одной системе. Приложения, скомпонованные с одной из версий
libc.so.5, будут продолжать использовать последнюю версию библиотеки с soname
libc.so.5, а приложения, скомпонованные с одной из версий
libc.so.6, будут работать с последней версией библиотеки, соответствующей soname
libc.so.6.
8.3.3. Разработка совместимых библиотек
При разработке собственных библиотек необходимо знать факторы, делающие библиотеку несовместимой. Существуют три основных причины несовместимости.
1. Изменение или удаление интерфейсов экспортированных функций.
2. Изменение экспортированных элементов данных, исключая добавление необязательных элементов в конец структур, размещенных внутри библиотеки.
3. Изменение поведения функций, выходящее за пределы первоначальной спецификации.
Для поддержания совместимости версий библиотеки можно предпринимать следующие действия.
• Добавлять новые функции под другими именами, а не изменять определения или интерфейсы существующих функций.
• При изменении определений экспортированных структур элементы следует добавлять только в конец структур и сделать дополнительные элементы необязательными либо заполняемыми самой библиотекой. Не расширяйте структуры, распределяемые за пределами библиотеки. В противном случае приложения не смогут распределить правильный объем памяти. Не расширяйте структуры, используемые в массивах.
8.4. Сборкасовместно используемых библиотек
Если вы разобрались с концепцией имен soname, все остальное просто. Достаточно следовать нескольким несложным правилам, которые перечислены ниже.
• Собирайте свой исходный код с указанием флага
-fPIC для
gcc. В результате сгенерируется независимый от места расположения код, который можно компоновать и загружать по любому адресу
[13].
• Не используйте опцию компилятора
-fomit-frame-pointer. Библиотеки по-прежнему будут работать, но отладчики станут бесполезными. Если в библиотеке будет найдена ошибка, пользователь не сможет осуществить обратную трассировку ошибки в коде.
• При компоновке библиотеки используйте
gcc вместо
ld. Компилятору С известно, как вызывать загрузчик для правильной компоновки, к тому же нет никакой гарантии, что интерфейс для
ld останется неизменным.
• При компоновке библиотеки не забывайте предоставлять имя soname. Для этого используется специальная опция компилятора
-Wl. Для сборки своей библиотеки используйте команду
gcc -shared -Wl, -soname, soname -о libname filelist liblist
где
soname — имя soname,
libname — имя библиотеки, включая полное имя версии, например,
libc.so.5.3.12,
filelist — список объектных файлов, которые нужно разместить в библиотеке, a
liblist — список других библиотек, предоставляющих символы, к которым будет получать доступ эта библиотека. Последний элемент очень легко пропустить, поскольку без него библиотека будет работать в системе, в которой она создана, но может не работать в других ситуациях. Практически для любой библиотеки в список следует включать библиотеку С, поместив
-lс в конце списка.
Чтобы создать файл
libfоо.so.1.0.1 с soname-именем
libfоо.so.1 из объектных файлов
fоо.о и
bar.о, используйте следующую команду:
gcc -shared -Wl,-soname,libfoo.so.1 -о libfoo.so.1.0.1 foo.o bar.о -lc
• He разбивайте на полосы библиотеку, если только не сталкиваетесь с окружением, где пространство ограничено. Разбитые на полосы библиотеки будут функционировать, но будут иметь такие же основные недостатки, что и библиотеки, собранные из объектных файлов, скомпилированных с
-fomit-frame-pointer.
8.5. Инсталляция совместно используемых библиотек
Программа
ldconfig выполняет всю рутинную работу по инсталляции совместно используемых библиотек. Вам всего лишь нужно получить файлы и запустить
ldconfig. Выполните описанные ниже шаги.
1. Скопируйте совместно используемую библиотеку в каталог, в котором она должна быть сохранена.
2. Если нужно, чтоб компоновщик смог найти библиотеку без указания ее с помощью флажка
-Lбиблиотека, инсталлируйте библиотеку в
/usr/lib или создайте символическую ссылку в
/usr/lib по имени
имя_библиотеки.so, которая указывает на файл совместно используемой библиотеки. Вы должны использовать относительную символическую ссылку (когда
/usr/lib/libc.so указывает на
../../lib/libc.so.5.3.12), а не абсолютную (когда
/usr/lib/libc.so указывает на
/lib/libc.so.5.3.12).
3. Если нужно, чтобы компоновщик смог обнаружить библиотеку без ее инсталляции в системе (или до ее инсталляции), создайте ссылку
имя_библиотеки.so в текущем каталоге. Затем используйте
-L., чтоб указать
gcc на поиск библиотек в текущем каталоге.
4. Если полный путь к каталогу, в который вы инсталлировали файл совместно используемой библиотеки, не перечислен в
/etc/ld.so.conf, добавьте его в этот файл, указав в отдельной строке.
5. Запустите программу
ldconfig, которая создаст в каталоге, где инсталлирован файл совместно используемой библиотеки, еще одну символическую ссылку из имени soname на установленный файл. Затем в кэше динамического загрузчика появится соответствующая запись. В результате динамический загрузчик сможет найти вашу библиотеку при запуске скомпонованных с нею программ, не проводя поиск ее во множестве каталогов
[14].
Создавать записи в
/etc/ld.so.conf и запускать
ldconfig нужно только тогда, когда библиотеки инсталлируются в качестве системных.
8.5.1. Пример
В качестве очень простого, но все же информативного примера создадим библиотеку, содержащую одну короткую функцию. Ниже показано содержимое файла
libhello.c.
1: /* libhello.c */
2:
3: #include <stdio.h>
4:
5: void print_hello (void) {
6: printf("Добро пожаловать в библиотеку!\n");
7: }
Разумеется, необходима программа, которая использует библиотеку
libhello.
1: / * usehello.c * /
2:
3: #include "libhello.h"
4:
5: int main(void) {
6: print_hello();
7: return 0;
8: }
Содержимое
libhello.h оставлено в качестве упражнения для самостоятельной проработки. Для того чтобы скомпилировать и воспользоваться этой библиотекой без ее инсталляции в системе, выполните перечисленные ниже шаги.
1. С использованием флажка
-fPIC соберите объектный файл совместно используемой библиотеки:
gcc -fPIC -Wall -g -с libhello.c
2. Скомпонуйте
libhello с библиотекой С для достижения лучших результатов во всех системах:
gcc -g -shared -Wl, -soname,libhello.so.0 -о libhello.so.0.0 libhello.о -lc
3. Создайте ссылку из soname на библиотеку:
ln -sf libhello.so.0.0 libhello.so.0
4. Создайте ссылку для использования компоновщиком при компиляции приложений с опцией
-lhello:
ln -sf libhello.so.0 libhello.so
5. С помощью флажка
-L. укажите компоновщику на необходимость поиска библиотек в текущем каталоге, а с помощью
-lhello определите, с какой библиотекой выполнять компоновку:
gcc -Wall -g -с usehello.c -о usehello.o
gcc -g -о usehello usehello.o -L. -lhello
(В этом случае приложение будет компоноваться, даже если вы инсталлируете библиотеку в системе вместо того, чтобы оставить ее в текущем каталоге.)
6. Теперь запустите
usehello:
LD_LIBRARY_PATH=$(pwd) ./usehello
Переменная окружения
LD_LIBRARY_PATH указывает системе места, где следует искать библиотеки (более детальная информация представлена в следующем разделе). Конечно, по желанию можно установить
libhello.so.* в
/usr/lib и избежать настройки переменной окружения
LD_LIBRARY_PATH.
8.6. Работа с совместно используемыми библиотеками
Самый легкий способ работы с совместно используемыми библиотеками — игнорировать тот факт, что она совместная. Компилятор С автоматически задействует совместно используемые библиотеки вместо статических, если ему явно не указано обратное.
Тем не менее, существуют и три других способа взаимодействия с совместно используемыми библиотеками. Первый способ, явно загружающий и выгружающий библиотеки из программы во время ее работы, называется динамической загрузкой и рассматривается в главе 27. Два других способа описаны ниже.
8.6.1. Использование деинсталлированных библиотек
После запуска программы динамический загрузчик обычно ищет необходимые программе библиотеки в кэше (
/etc/ld.so.cache, созданном
ldconfig) библиотек, которые находятся в каталогах, записанных в
/etc/ld.so.conf. Однако если установлена переменная окружения
LD_LIBRARY_PATH, поиск осуществляется сначала в каталогах, перечисленных в ней. Это значит, что если вы хотите использовать измененную версию библиотеки С при работе с определенной программой, эту библиотеку можно поместить в любой каталог и соответствующим образом изменить
LD_LIBRARY_PATH. Например, некоторые версии браузера Netscape, скомпонованные с версией 5.2.18 библиотеки С, не будут работать вследствие ошибки сегментации при запуске со стандартной библиотекой С 5.3.12. Это происходит из-за более строгой политики
malloc(). Многие помещают копию библиотеки С 5.2.18 в отдельный каталог, например,
/usr/local/netscape/lib/, переносят туда исполняемый файл браузера Netscape и заменяют
/usr/local/bin/netscape сценарием оболочки, который выглядит примерно так:
#!/bin/sh
export LD_LIBRARY_PATH=/usr/local/netscape/lib:$LD_LIBRARY_PATH
exec /usr/local/netscape/lib/netscape $*
8.6.2. Предварительная загрузка библиотек
В некоторых случаях вместо замены целой библиотеки совместно использования возникает необходимость замены лишь нескольких функций. Вследствие того, что динамический загрузчик выполняет поиск функций, начиная с первой загруженной библиотеки, и продолжает искать в порядке очереди среди массы библиотек, было бы удобно иметь возможность помещать альтернативную библиотеку в начало списка для замены только необходимых функций.
Пример может служить
zlibc. Эта библиотека заменяет файловые функции библиотеки С функциями, которые работают со сжатыми файлами. При открытии файла
zlibc ищет как запрашиваемый файл, так и gzip-версию файла. Если запрашиваемый файл существует,
zlibc в точности воспроизводит функцию библиотеки С, но если файла нет, а вместо него обнаруживается gzip-версия, библиотека распаковывает gzip-файл безо всякого уведомления приложения. Связанные с ней ограничения описаны в документации,
zlibc позволяет значительно увеличить количество свободного пространства на диске, разумеется, за счет снижения скорости. Существуют два способа предварительной загрузки библиотеки. Для действия только на определенные программы, можно установить переменную окружения для необходимых случаев:
LD_PRELOAD=/lib/libsomething.o exec /bin/someprogram $*
Кроме того, как и с
zlibc, может возникнуть потребность предварительно загрузить библиотеку для всех программ в системе. Самый простой способ для этого — добавить в файл
/etc/ld.so.preload строку, которая указывает библиотеку, подлежащую загрузке. Для случая
zlibc строка будет выглядеть следующим образом:
/lib/uncompress.о
Глава 9
Системное окружение Linux
В этой главе рассматривается процесс запроса системных служб, включая низкоуровневые средства ядра и высокоуровневые возможности библиотек.
9.1. Окружение процесса
Как подробно описано в главе 10, в каждом выполняющемся процессе есть
переменные окружения. Переменные окружения представляют собой пары "имя-значение", и некоторые из них представляют ценность для программистов на языке С. (Многие переменные в первую очередь используются при программировании оболочки, как ускоренные альтернативы запуску программ, вызывающих функции библиотек; в этой книге они описываться не будут.)
EDITOR или VISUAL |
При установке EDITOR или VISUAL у пользователя появляется возможность выбирать текстовый редактор для редактирования текстового файла. Использование двух различных переменных объясняется тем, что когда-то EDITOR применялась для телетайпной машины, a VISUAL — для полноэкранного терминала. |
LD_LIBRARY_PATH |
Обеспечивает разделенные двоеточиями пути к каталогам, в которых следует искать библиотеки. Обычно эту переменную устанавливать не нужно, поскольку в системном файле /etc/ld.so.conf есть вся необходимая информация. Модифицировать его в своих программах вряд ли придется; эта переменная предоставляет информацию для системного компоновщика времени выполнения, ld.so. Однако, как было описано в главе 8, LD_LIBRARY_PATH может оказаться полезной при разработке совместно используемых библиотек. |
LD_PRELOAD |
Перечисляет библиотеки, которые должны быть загружены для переопределения символов в системных библиотеках. LD_PRELOAD, как и LD_LIBRARY_PATH, более подробно описана в главе 8. |
PATH |
Предоставляет разделенный двоеточиями путь к каталогам, где следует искать исполняемые программы для запуска. Следует отметить, что в Linux (как и во всех вариантах Unix), в отличие от некоторых операционных систем, не принят автоматический поиск исполняемого файла в текущем каталоге. Для этого путь должен включать каталог . (точка). Более подробно о работе с этой переменной рассказывается в главе 10. |
TERM |
Предоставляет информацию о типе терминала, установленного у пользователя; это определяет способ позиционирования символов на экране. Более подробно об этом читайте в главах 24 и 21. |
9.2. Системные вызовы
В этой книге практически повсеместно упоминаются системные вызовы, которые являются фундаментальными для программного окружения. На первый взгляд, они выглядят как обычные вызовы функций С. И это не случайно; они представляют собой специальную разновидность вызовов функций. Чтобы понять различия, нужно иметь общее представление о структуре операционной системы. Несмотря на то что операционная система Linux состоит из множества фрагментов кода (утилиты, библиотеки, приложения, программные библиотеки, драйверы устройств, файловые системы, управление памятью и так далее), все эти кодовые фрагменты работают в одном из двух контекстов: режиме пользователя или режиме ядра.
При разработку программы написанный код работает в
режиме пользователя (user mode). Драйверы устройств и файловые системы, наоборот, работают в
режиме ядра (kernel mode). В пользовательском режиме программы тщательно защищены от повреждений, вызванных их взаимодействием друг с другом или остальной частью системы. Код, работающий в режиме ядра, имеет полный доступ к компьютеру и может делать или же разрушать все, что угодно.
Драйвер, который разработан для управления и контроля аппаратного устройства, должен иметь полный доступ к нему. Устройство нужно защитить от случайных программ, чтобы они не смогли нарушить свою работу или работу друг друга, повредив само устройство. Память, с которой работает устройство, также защищена от случайных программ. Весь код, работающий в режиме ядра, существует исключительно для обслуживания кода, который работает в режиме пользователя.
Системный вызов — это то, посредством чего код приложения, выполняющегося в пользовательском режиме, запрашивает службу, предоставляемую кодом, который выполняется в режиме ядра.
Возьмем, к примеру, процесс выделения памяти. Пользовательский процесс запрашивает память у защищенного кода, выполняющегося в режиме ядра, который и производит выделение физической памяти для процесса. В качестве следующего примера возьмем файловые системы, которые нуждаются в защите для поддержания целостности данных на диске (или в сети), но вашим повседневным, обычным процессам требуется считывать файлы из файловой системы.
Неприятные детали вызова через барьер пространств пользователь/ядро часто скрыты в библиотеке С. Процесс вызова через этот барьер не использует обычные вызовы функций; он использует неуклюжий интерфейс, оптимизированный по скорости и обладающий существенными ограничениями. Библиотека С скрывает большинство интерфейсов от глаз пользователя, предлагая взамен обычные функции С, которые являются оболочками для системных вызовов. Применение этих функций станет понятнее, если получить некоторое представление о том, что происходит внутри них.
9.2.1. Ограничения системных вызовов
Режим ядра защищен от влияния режима пользователя. Одна из таких защит состоит в том, что тип данных, передаваемых между режимами ядра и пользователя, ограничен, легко верифицируется и следует строгим соглашениям.
• Длина каждого аргумента, передаваемого из режима пользователя в режим ядра, практически всегда соответствует размеру слов, используемых машиной для представления указателей. Этого размера достаточно как для передачи указателей, так и длинных целых. Переменные типа
char и
short перед передачей расширяются до большего типа.
• Тип возвращаемого значения ограничен размером слова со знаком. Первые несколько сотен небольших отрицательных целых чисел зарезервированы в качестве кодов ошибок, и в пределах системных вызовов имеют одинаковое значение. Это значит, что системные вызовы, возвращающие указатель, не могут вернуть некоторые указатели, соответствующие адресам в верхней области доступной виртуальной памяти. К счастью, эти адреса находятся в зарезервированном пространстве и в любом случае никогда не возвращаются, потому возвращаемые слова со знаком могут быть без проблем преобразованы в указатели.
В отличие от соглашений С о вызовах, в котором структуры С могут передаваться по значению в стеке, нельзя передавать структуры по значению из пользовательского режима в режим ядра; точно также ядро не может вернуть структуру в пользовательский режим. Большие элементы данных можно передавать только по ссылке. Передавайте указатели на структуры, как всегда поступаете, когда их необходимо модифицировать.
9.2.2. Коды возврата системных вызов
Коды возврата, зарезервированные для всех системных вызовов — это универсальные коды возврата ошибок, представленные небольшими отрицательными числами. Библиотека С проверяет наличие ошибок каждый раз, когда происходит системный вызов. При возникновении ошибки библиотека помещает значение ошибки в глобальную переменную
errno[15]. В большинстве случаев все, что вам необходимо при проверке ошибки — посмотреть, отрицательный ли код возврата. Коды ошибок определены в
<errno.h>, и
errno можно сравнить с любым номером ошибки из этого файла, после чего обработать ее специальным образом.
Переменная
errno используется и в другом случае. Библиотека С предлагает три способа получения строк, предназначенных для описания возникшей ошибки.
perror()
Печатает сообщение об ошибке. Передайте в функцию строку с информацией о том, что код намеревался предпринять.
if ((file = open(DB_PATH, O_RDONLY)) < 0) {
perror("не удается открыть файл базы данных");
}
Функция
perror() выведет сообщение, описывающее возникшую ошибку, а также объяснение того, что код собирался делать:
не удается открыть файл базы данных: No such file or directory
Обычно неплохо делать свои аргументы для
perror() уникальными на протяжении всей программы, в результате при получении сообщений об ошибках из
perror() вы будете точно знать, откуда начинать поиск. Обратите внимание, что в строке, передаваемой
perror(), нет символа новой строки. Его передавать не нужно — функция сама его выведет.
strerror()
Возвращает статически распределенную строку, описывающую ошибку с номером, передаваемым в единственном аргументе. Это можно использовать при построении, например, своей собственной версии
perror().
if ((file = open(DB_PATH, O_RDONLY) ) < 0) {
fprintf(stderr,
"не удается открыть файл базы данных %s, %s\n",
DB_PATH, strerror(errno));
}
sys_errlist
He очень хорошая альтернатива
strerror().
sys_errlist — это массив размером
sysnerr указателей на статические, доступные только для чтения символьные строки, которые описывают ошибки. Попытка записи в эти строки приводит к нарушению сегментации и сбросу дампа ядра.
if ((file = open(DB_PATH, O_RDONLY)) < 0) {
if (errno < sys_nerr) {
fprintf(stderr,
"не удается открыть файл базы данных %s, %s\n",
DB_PATH, sys_errlist[errno]);
}
}
Этот массив не является ни стандартным, ни переносимым, и упоминается здесь лишь потому, что вы можете столкнуться с кодом, от него зависящим. Заменив такой код вызовом функции
strerror(), вы получите существенный выигрыш.
Если вы не собираетесь использовать
errno сразу же после генерации ошибки, сохраните ее копию. Любая библиотечная функция может установить
errno в любое значение, поскольку в ней могут присутствовать системные вызовы, о которых вы даже не подозреваете. А некоторые библиотечные функции могут устанавливать
errno даже без системных вызовов.
9.2.3. Использование системных вызовов
Интерфейс, с которым вам, как программисту, возможно, доведется работать, представляет собой набор оболочек библиотеки С для системных вызовов. В оставшейся части этой книги под системным вызовом будет подразумеваться функция оболочки С, которая используется для реализации системного вызова, а не тот неуклюжий интерфейс, который скрывает библиотека С.
Большинство, но не все, системные вызовы объявлены в
<unistd.h>. Фактически файл
<unistd.h> представляет собой универсальное вместилище практически для всех системных вызовов. Чтобы определить, какие включаемые файлы нужно использовать, обычно нужно обратиться к системным man-страницам. Хотя описания функций на man-страницах зачастую весьма лаконичны, там можно найти точные указания о том, какой файл должен быть включен для использования функции.
Есть одна особенность, свойственная системам Unix. Системные вызовы документированы в отдельном разделе man-страниц для библиотечных функций, и вы будете использовать библиотечные функции для доступа к системным вызовам. Там, где библиотечные функции отличаются от системных вызовов, предусмотрены отдельные man- страницы. Это не вызывало бы проблем, однако практически всегда требуется читать страницу, описывающую библиотечную функцию, номер которой больше номера страницы с описанием соответствующего системного вызова. Ввиду того, что man-страницы выводятся, начиная с меньших номеров, приходится проделывать лишнюю работу.
Простого указания номера раздела недостаточно. Системные вызовы, которые помещены в минимальные функции-оболочки из библиотеки С, не документированы как часть библиотеки, следовательно команда
man 3 функция не найдет их. Для того чтобы убедиться, что вы прочли всю необходимую для вас информацию, вначале взгляните на man-страницу, не указывая раздел. Если это раздел 2 на man-странице, посмотрите, есть ли там раздел 3 с таким же именем. Если открывается раздел 1 man-страницы, как это часто случается, внимательно просмотрите разделы 2 и 3.
К счастью, существует другой способ решения такой проблемы. Многие версии программы
man, включая используемую в системах Linux, позволяют указывать альтернативный путь поиска man-страниц. Прочтите man-страницу о самой программе
man, чтобы определить, поддерживается ли в вашей версии
man переменная окружения
MANSECT и аргумент
-S. Если переменная поддерживается, можно установить
MANSECT в что-нибудь вроде
3:2:1:4:5:6:7:8:tcl:n:l:p:о. Просмотрите в файле конфигурации
man (в большинстве систем Linux это
/etc/man.config) текущую настройку
MANSECT.
Большинство системных вызовов возвращает
0 при успешном выполнении. В случае возникновения ошибки они возвращают отрицательное значение. Вследствие этого, во многих случаях, подходит простейшая форма обработки ошибок.
if (ioctl(fd, FN, data)) {
/* обработка ошибки на основе errno */
}
Часто встречается следующая форма:
if (ioctl(fd, FN, data) < 0) {
/* обработка ошибки на основе errno */
}
Для системных вызовов, которые возвращают
0, обозначая успех, оба эти случая идентичны. В своем коде можете выбрать то, что вам больше подходит. Будьте готовы к тому, что столкнетесь с этими и другими способами обработки в чужих кодах.
9.2.4. Общие коды возврата ошибок
Существует множество общих кодов ошибок, для которых вы вполне могли наблюдать сообщения. Некоторые из этих сообщений могут сбивать с толку. Без знаний о том, что можно делать в Linux-системе, трудно понять ошибки, которые могут возникать в процессе работы. Внимательно прочитайте приведенный ниже список.
Для многих кодов возврата ошибок даны примеры одного или двух системных вызовов, которые обычно могут выдать то или иное сообщение об ошибке. Это не означает, что к таким ошибкам могут привести исключительно представленные системные вызовы.
Для определения того, какую ошибку можно ожидать от определенного системного вызова, обращайтесь к соответствующим man-страницам. В частности, с помощью команды
man 3 errno можно получить список кодов ошибок, определенных POSIX. Тем не менее, ситуация часто изменяется, и man-страницы не всегда отвечают существующему состоянию дел. Если системный вызов возвращает неожиданный код ошибки, можно предположить, что скорее man-страница устарела, а не системный вызов дал сбой. Исходный код Linux поддерживается более тщательно, чем документация.
E2BIG |
Список аргументов слишком длинный. При запуске нового процесса с помощью exec() существует ограничение на длину задаваемого списка аргументов. См. главу 10. |
EACCESS |
В доступе будет отказано. Эта ошибка возвращается системным вызовом access(), рассматриваемым в главе 11, и представляет собой более информативный код возврата, чем само состояние ошибки. |
EAGAIN |
Возвращается при попытке выполнения неблокируемого ввода-вывода, если нет доступных данных. EWOULDBLOCK является синонимом EAGAIN. При блокируемом вводе-выводе системный вызов установил бы блокировку и ожидал бы данных. |
EBADF |
Неправильный номер файла. Был передан номер файла, не ссылающийся на открытый файл, в функцию read(), close(), ioctl() или другой системный вызов, принимающий номер файла в качестве аргумента. |
EBUSY |
Системный вызов mount() возвращает эту ошибку при попытке смонтировать файловую систему, которая уже смонтирована, или размонтировать файловую систему, которая в настоящий момент используется. |
ECHILD |
Дочерние процессы отсутствуют. Возвращается семейством системных вызовов wait(). См. главу 10. |
EDOM |
Это ошибка не системного вызова, а ошибка из библиотеки С системы. EDOM устанавливается математическими функциями, если аргумент выходит за пределы допустимого диапазона. (Это EINVAL для области функции.) Например, функция sqrt() не работает с комплексными числами и потому не принимает отрицательные аргументы. |
EEXIST |
Возвращается creat(), mknod() или mkdir(), если файл уже существует, или функцией open() в том же случае, если указаны флаги O_CREAT и O_EXCL. |
EFAULT |
Неверный указатель (указывающий на недоступную область памяти) был передан в качестве аргумента системному вызову. Обращение по этому указателю из пользовательской программы, которая произвела системный вызов, приведет к ошибке сегментации. |
EFBIG |
Возвращается write() при попытке записи файла, который длиннее, чем может логически обработать файловая система (физические ограничения пространства во внимание не принимаются). |
EINTR |
Системный вызов был прерван. Прерываемые системные вызовы рассматриваются в главе 12. |
EINVAL |
Возвращается, если системный вызов получил недопустимый аргумент. |
EIO |
Ошибка ввода-вывода. Обычно генерируется драйвером устройства для обозначения ошибки в оборудовании или неисправимой ошибку взаимодействия с устройством. |
EISDIR |
Возвращается системными вызовами, требующими имя файла, например unlink(), если последний компонент в имени пути является каталогом, а не файлом, а данная операция не может быть применена к каталогу. |
ELOOP |
Возвращается системными вызовами, которые принимают путь, если при разборе пути встречается слишком много символических ссылок в строке (то есть символические ссылки, указывающие на символические ссылки, которые, в свою очередь, указывают на символические ссылки и так далее). Текущее ограничение — 16 символических ссылок на строку. |
EMFILE |
Возвращается, если для вызываемого процесса нельзя открыть больше файлов. |
EMLINK |
Возвращается link(), если в компонуемом файле уже содержится максимальное количество ссылок для файловой системы (в стандартной файловой системе Linux этот максимум составляет 32 000). |
ENAMETOOLONG |
Имя пути слишком длинное либо для системы, либо для файловой системы, к которой вы пытаетесь получить доступ. |
ENFILE |
Возвращается, если ни один процесс системы не может открыть больше ни одного файла. |
ENODEV |
Возвращается mount(), если запрошенный тип файловой системы не доступен. Возвращается open() при попытке открыть специальный файл для устройства, для которого нет ассоциированного драйвера в ядре. |
ENOENT |
Файл или каталог не существует. Возвращается при попытке получить доступ к несуществующему файлу или каталогу. |
ENOEXEC |
Ошибка исполняемого формата. Может появиться при попытке запустить (устаревший) а.out в системе, в которой отсутствует поддержка бинарных файлов а.out. Может также встречаться при попытке запуска бинарного файла формата ELF, собранного для другой архитектуры центрального процессора. |
ENOMEM |
Не хватает памяти. Возвращается функциями brk() и mmap() при неудачной попытке распределения памяти. |
ENOSPC |
Возвращается write() при попытке записать файл длиннее, чем объем свободного пространства в файловой системе. |
NOSYS |
Системный вызов не реализован. Обычно происходит при запуске нового исполняемого файла на старом ядре, которое не поддерживает системный вызов. |
ENOTBLK |
Системный вызов mount() возвращает эту ошибку при попытке смонтировать в качестве файловой системы файл, не являющийся специальным файлом блочного устройства. |
ENOTDIR |
Промежуточный компонент пути существует, но не является каталогом. Возвращается любым системным вызовом, принимающим имя файла. |
ENOTEMPTY |
Возвращается rmdir(), если удаляемый каталог не пуст. |
ENOTTY |
Обычно встречается, когда приложение, которое пытается обратиться к терминалу, запущено с перенаправлением ввода или вывода в канал. Но также может встречаться при попытке совершить операцию ввода-вывода на неправильном типе устройства. Стандартное сообщение об ошибке в этом случае, "not a typewriter", может сбить с толку. |
ENXIO |
Нет такого устройства или адреса. Обычно генерируется при попытке открыть специальный файл устройства, который ассоциируется с частью не установленного или не настроенного оборудования. |
EPERM |
У процесса недостаточно полномочий для завершения операции. Эта ошибка обычно встречается в файловых операциях. См. главу 11. |
EPIPE |
Возвращается write(), если читающая сторона канала или сокета закрыта и захвачен или проигнорирован сигнал SIGPIPE. См. главу 12. |
ERANGE |
Не являясь ошибкой системного вызова, ERANGE устанавливается математическими функциями, если результат невозможно представить возвращаемым типом. Эта ошибка может также возникать в других функциях, если им передается слишком короткий буфер для возвращаемой строки. (Для диапазона этой ошибке соответствует EINVAL.) |
EROFS |
Возвращается write() при попытке записать в файловую систему, доступную только для чтения. |
ESPIPE |
Возвращается lseek() при навигации по файлу, дескриптор которого не поддерживает навигацию (включая файловые дескрипторы для каналов, именованных каналов и сокетов). См. главы 11 и 17. |
ESRCH |
Нет такого процесса. См. главу 10. |
ETXTBSY |
Возвращается open() при попытке открыть на запись запущенный исполняемый файл или совместно используемую библиотеку или любой другой файл, отображенный на память с установленным флажком MAP_DENYWRITE (см. главу 13). Чтобы избежать такого поведения, необходимо переименовать файл, сделать новую копию с таким же именем, как у старого файла, и работать с этой новой копией. См. главу 11 с обсуждением того, почему так происходит. |
EXDEV |
Возвращается link(), если исходные и целевые файлы находятся в разных файловых системах. |
Распространены и некоторые другие коды возврата ошибок, которые относятся только к сетевым функциям. Более подробную информацию можно найти в главе 17.
9.3. Поиск заголовочных и библиотечных файлов
Заголовочные файлы в системе Linux хранятся в иерархии каталогов
/usr/include. Именно там по умолчанию компилятор ищет включаемые файлы. (Заголовочные файлы могут храниться за пределами
/usr/include, но тогда на них имеются ссылки внутри
/usr/include. Например, на момент написания книги включаемые файлы системы X были расположены в
/usr/X11R6/include/X11, но благодаря символической ссылке компилятор мог найти их через
/usr/include/X11.)
С библиотеками дело обстоит практически так же, правда, с некоторыми нюансами. Библиотеки, которые считаются важными для загрузки системы (и ее отладки в случае необходимости), расположены в
/lib. Другие системные библиотеки находятся в
/usr/lib, кроме библиотек X11R6, которые хранятся в
/usr/X11R6/lib. Компилятор по умолчанию будет искать стандартные системные библиотеки.
Некоторые библиотеки обеспечивают поддержку разработки в одной системе для нескольких основных своих версий. В большинстве случаев доступны специальные утилиты конфигурации, которые обеспечивают включение корректных версий заголовочных файлов и компоновку с подходящими версиями библиотек. Унифицированный инструмент под названием
pkg-config обеспечивает эту информацию для каждой версии каждой библиотеки, разработанной для его поддержки.
Часть III
Системное программирование
Глава 10
Модель процессов
Модель процессов — один из "фирменных знаков" Unix. Это — ключ к пониманию прав доступа, отношений между открытыми файлами, сигналов, управления заданиями и большинства других низкоуровневых понятий, описанных в этой книге. Linux адаптирует большую часть модели процессов Unix и добавляет собственные новые идеи, касающиеся реализации облегченных потоков.
10.1. Определение процесса
Что такое процесс? В исходной реализации Unix процессом была любая выполняющаяся программа. Для каждой программы ядро системы отслеживает перечисленные ниже аспекты.
• Текущая точка выполнения (такая как ожидание возврата системного вызова из ядра), часто называемая программным
контекстом.
• К каким файлам имеет доступ программа.
• Сертификаты (credentials) программы (например, какой пользователь и группа владеют процессом).
• Текущий каталог программы.
• К какому пространству памяти имеет доступ программа и как оно распределено.
Процесс также является базовой единицей планирования для операционной системы. Только процессам разрешено выполняться в центральном процессоре.
10.1.1. Усложнение концепции — потоки
Хотя определение процесса может показаться очевидным, концепция потока (thread) делает все это несколько менее ясным. Поток позволяет единственной программе выполняться во многих местах одновременно. Все потоки, созданные одной программой, разделяют большинство характеристик, которые отличают процессы друг от друга. Например, множество потоков, порожденных от одной программы, разделяют информацию об открытых файлах, правах доступа, текущем каталоге и образе памяти. Как только один из потоков модифицирует глобальную переменную, все потоки увидят новое значение, а не только тот, что это сделал.
Многие реализации Unix (включая каноническую версию AT&T System V) были перепроектированы, чтобы сделать потоки фундаментальным элементом планирования для ядра, и процесс превратился в коллекцию потоков, разделяющих ресурсы. Поскольку множество ресурсов разделяется между потоками, ядро может быстрее переключаться между потоками одного процесса, чем оно это делает при полноконтекстном переключении между процессами. В результате в большинстве ядер Unix существует двухуровневая модель процессов, которая различает потоки и процессы.
10.1.2. Подход Linux
В Linux, однако, все идет другим путем. Переключение контекстов в Linux всегда было исключительно быстрым (примерно на том же уровне, как новые "переключатели потоков", представленные в двухуровневом подходе), что стимулировало разработчиков ядра вместо смены подхода к планированию процессов позволить процессам разделять ресурсы более либерально.
Под Linux процесс определен исключительно как планируемая сущность, и единственная вещь, которая уникальна для процесса — это текущий контекст выполнения. Он не предполагает ничего относительно разделенных ресурсов, потому что процесс, создающий новый дочерний процесс, имеет полный контроль над тем, какие из ресурсов процессы могут разделять между собой (см. детали в описании системного вызова clone() в конце этой главы). Эта модель позволяет сохранять традиционную систему управления процессами Unix, в то время как традиционный интерфейс потоков строится вне ядра.
К счастью, разница между моделью процессов Linux и двухуровневым подходом проявляется редко. В настоящей книге мы используем термин
процесс для обозначения набора из (обычно, одной) планируемых сущностей, которые разделяют основные ресурсы. Когда процесс состоит из одного потока, мы используем эти термины как взаимозаменяемые. Чтобы не усложнять, в большей части этой главы мы будем игнорировать потоки полностью. До ее завершения мы обсудим системный вызов
clone(), который используется для создания потоков (и может также создавать нормальные процессы).
10.2 Атрибуты процессов
10.2.1. Идентификатор процесса и происхождение
Два из наиболее фундаментальных атрибутов — это
идентификатор процесса (process ID), или
pid, а также идентификатор его родительского процесса. Идентификатор pid — это положительное целое число, которое уникально идентифицирует работающий процесс и сохраняется в переменной типа
pid_t. Когда создается новый процесс, исходный процесс, известный как
родитель нового процесса, будет уведомляться, когда этот дочерний процесс будет завершен.
Когда процесс "умирает", его код возврата сохраняется до тех пор, пока родительский процесс не запросит его. Состояние завершения сохраняется в таблице процессов ядра, что заставляет ядро сохранять единицу процесса активной до тех пор, пока оно не сможет безопасно отбросить это состояние завершения. Процессы, которые завершились, но сберегаются для предохранения их состояния завершения, называются
зомби. Как только состояние завершения такого зомби получено, он удаляется из таблицы процессов системы.
Если родитель процесса завершается (делая дочерний процесс
висячим), такой процесс становится дочерним для
начального процесса (init). Начальный процесс — это первый процесс, который запускается при загрузке машины и которому присваивается значение pid, равное 1. Одной из основных задач начального процесса является сбор кодов завершения процессов, чьи родители исчезли, позволяя ядру удалять такие дочерние процессы из таблицы процессов системы. Процессы могут получать свой pid и pid родителя с помощью функций
getpid() и
getppid().
pid_t getpid(void) |
Возвращает pid текущего процесса. |
pid_t getppid(void) |
>Возвращает pid родительского процесса. |
10.2.2. Сертификаты
В Linux используются традиционные механизмы обеспечения безопасности Unix для пользователей и групп. Идентификаторы пользователя (uid) и группы (gid) — это целые числа
[16], которые отображаются на символические имена пользователей и групп в файлах
/etc/passwd и
/etc/group, соответственно (более подробную информацию о базах данных пользователей и групп можно получить в главе 28). Однако ядро ничего не знает об именах — оно имеет дело только с целочисленными представлениями. Идентификатор uid, равный 0, зарезервирован за системным администратором, обычно имеющим имя
root. Все обычные проверки безопасности отключаются для процессов, запущенных от имени
root (то есть с uid, равным 0), что дает администратору полный контроль над системой.
В большинстве случаев процесс имеет единственный uid и единственный gid, ассоциированный с ним. Это идентификаторы, которые используются для большинства целей обеспечения безопасности (как, например, назначение прав владения вновь созданным файлам). Системные вызовы, которые могут модифицировать принадлежность процессов, обсуждаются далее в настоящей главе.
Со времен разработки Unix ограничение процессов принадлежностью к одной группе создало новые трудности. Пользователи, работающие со многими проектами, должны явно переключать свой gid, когда им нужен доступ к файлам, доступ к которым ограничен определенной группой пользователей.
Дополнительные группы были представлены в BSD 4.3 для решения этой проблемы. Хотя каждый процесс по-прежнему имеет собственный первичный gid (который используется, например, как gid для вновь создаваемых файлов), он также связан с набором
дополнительных групп. Проверки безопасности, которые используются для обеспечения того, что процесс относится к определенной группе (и только этой группе), теперь позволяет обеспечить доступ и в случае, когда данная группа является одной из дополнительных групп, к которым процесс относится. Макрос
sysconf() по имени
_SC_NGROUPS_МАХ специфицирует, к скольким дополнительным группам может относиться процесс. (Подробно о
sysconf() см. главу 6.) В Linux 2.4 и более ранних версиях
_SC_NGROUPS_MAX был равен 32. В Linux 2.6 и последующих версиях
_SC_NGROUPS_MAX равен 65536. Не используйте статические массивы для хранения дополнительных групп. Вместо этого выделяйте память динамически, принимая во внимания значение, возвращаемое
sysconf(_SC_NGROUPS_MAX). Старый код может пользоваться макросом
NGROUPS_MAX для определения количества поддерживаемых групп, установленных в системе. Этот макрос не обеспечивает корректную работу, когда код компилируется в одной среде, а используется в другой.
Установка списка групп для процесса осуществляется системным вызовом
setgroups() и может быть выполнена процессом, имеющим полномочия root.
int setgroups(size_t num, const gid_t * list);
Параметр
list указывает на массив из
num идентификаторов групп gid. Дополнительная группа процесса устанавливается этим списком идентификаторов групп, переданным в массиве
list.
Функция
getgroups() позволяет получить список дополнительных групп, установленных для процесса.
int getgroups(size_t num, gid_t * list);
list должен указывать на массив элементов типа
gid_t, который наполняется идентификаторами дополнительной группы процесса, a
num определяет, сколько элементов может типа
gid_t содержать
list. В случае ошибки системный вызов
getgroups() возвращает
-1 (обычно это происходит, когда
list недостаточно велик, чтобы вместить дополнительный список групп процесса), или же количество дополнительных групп. В особом случае, когда
num равно 0,
getgroups() просто возвращает количество дополнительных групп процесса.
Ниже показан пример использования
getgroups().
gid_t *groupList;
int numGroups;
numGroups = getgroups(0, groupList);
if (numGroups) {
groupList = alloca(numGroups * sizeof(gid_t));
getgroups(numGroups, groupList);
}
Более сложный пример
getgroups() приведен в главе 28.
Таким образом, процесс имеет uid, первичный gid и набор дополнительных групп, ассоциированных с ним. К счастью, это все, о чем нужно знать большинству программистов. Существуют два класса программ, которым необходимо очень гибкое управление идентификаторами пользователей и групп — это программы setuid/setgid и системные демоны.
Системные демоны — это программы, которые всегда запущены в системе и выполняют определенные действия в ответ на внешние воздействия. Например, большинство демонов World Wide Web (
http) функционируют всегда, ожидая подключения к ним клиента, чтобы обрабатывать клиентские запросы. Другие демоны, такие как
cron (которые запускаются периодически), пребывают в спящем состоянии до тех пор, пока не наступает время, когда они должны выполнить какие-то действия. Большинство демонов должны быть запущены с полномочиями root, но выполняют действия по запросу пользователя, который может попытаться нарушить системную безопасность с помощью демонов.
ftp — хороший пример демона, который нуждается в гибком управлении uid. Изначально он запускается с правами root и затем переключает свой uid на uid пользователя, который подключился к нему (большинство систем запускают дополнительный процесс для обработки каждого ftp-запроса, поэтому такой подход работает достаточно хорошо). Это оставляет работу по проверке доступа к файлам ядру, к которому он относится. Однако в некоторых случаях демон
ftp должен открывать сетевое подключение таким способом, который разрешен только root, поскольку пользовательские процессы не могут выдать сами себе административные полномочия (по вполне ясной причине), но сохранение идентификатора uid пользователя root вместо переключения на пользовательский uid должен потребовать от демона
ftp самостоятельной проверки всего доступа к файловой системе. Решение этой дилеммы применяется симметрично — к обоим uid и первичным gid, поэтому мы и говорим здесь об uid.
В действительности процесс имеет три uid: реальный, сохраненный и эффективный uid
[17]. Эффективный uid используется для всех проверок безопасности и является единственным uid процесса, который обычно имеет какой-то эффект.
Сохраненный и действительный идентификаторы uid проверяются только тогда, когда процесс пытается изменить его эффективный uid. Любой процесс может изменять свой эффективный uid на сохраненный или действительный. Только процессы с эффективным uid, равным 0 (процессы, запущенные от имени root), могут изменять свой эффективный uid на произвольное значение.
Обычно эффективный, реальный и действительный uid процесса совпадают. Однако этот механизм решает дилемму демона
ftp. Когда он запускается, все его идентификаторы устанавливаются в 0, что предоставляет ему полномочия root. Когда подключается пользователь, демон устанавливает свой эффективный uid равным uid пользователя, оставляя сохраненный и действительный uid равными 0. Когда демону
ftp требуется выполнить действие, разрешенное только root, он устанавливает свой эффективный uid в 0, выполняет действие, а затем переустанавливает эффективный uid в значение uid подключенного пользователя.
Хотя демон
ftp вообще не нуждается в сохраненном uid, другие классы программ, применяющие этот механизм — двоичные модули setuid и setgid — используют его.
Программа
passwd — это простой пример того, зачем нужна функциональность setuid и setgid. Программа
passwd позволяет пользователям изменять свои пароли. Пользовательские пароли обычно хранятся в файле
/etc/passwd. Выполнять запись в этот файл может только пользователь root, что предотвращает изменение информации о пользователях другими пользователями. Но пользователи должны иметь возможность изменять свои собственные пароли, поэтому необходим какой-то способ предоставить программе
passwd права на изменение
/etc/passwd.
Чтобы обеспечить эту гибкость, пользователь программы может устанавливать специальные биты в группе бит прав доступа этой программы (см. главу 11). Это сообщает ядру, что всякий раз, когда программа запускается, она должна выполняться с тем же эффективным uid (или gid), как у пользователя, который владеет файлом программы, независимо от того, какой пользователь запустил программу. Такие программы называются
setuid- или
setgid-программами.
Принадлежность программы
passwd пользователю root и установка бита setuid в наборе битов доступа программы позволяют всем пользователям изменять свои пароли. Когда пользователь запускает
passwd, эта программа выполняется с эффективным идентификатором пользователя 0, что позволяет ей модифицировать
/etc/passwd и изменять пользовательский пароль. Конечно, passwd должна быть реализована очень тщательно, дабы исключить побочные эффекты. Программы setuid — это популярная цель для злоумышленников, проникающих в систему, поэтому плохо написанная программа подобного рода дает простую возможность получить неавторизованный доступ.
Существуют много случаев, когда программы setuid требуют специальных прав доступа на короткий период времени и должны переключаться на uid действительного пользователя в остальное время (как это делает демон
ftp). Программы setuid имеют установленный эффективный uid равным uid ее владельца, но они также "знают" uid того пользователя, который их запустил (сохраненный uid), что упрощает обратное переключение. В дополнение они могут устанавливать свой действительный uid в значение setuid (не затрагивая сохраненный uid), при необходимости повторно получая эти специальные полномочия. В этой ситуации эффективный, сохраненный и действительный идентификаторы пользователя работают вместе, насколько возможно, упрощая систему безопасности.
К несчастью, применение этого механизма может сбивать с толку, поскольку в POSIX и BSD применяются слегка отличающиеся подходы, a Linux поддерживает оба. Решение BSD более полнофункционально, чем метод POSIX. Оно использует функцию
setreuid().
int setreuid(uid_t ruid, uid_t euid);
Действительный uid процесса устанавливается в
ruid, а эффективный — в
euid. Если любой из параметров равен
-1, идентификатор вызовом не затрагивается.
Если эффективный uid процесса равен 0, такой вызов всегда выполняется успешно. В противном случае идентификаторы могут быть установлены равными либо сохраненному uid, либо реальному uid процесса. Следует отметить, что этот вызов никогда не изменяет сохраненный uid или реальный uid текущего процесса. Чтобы сделать это, используйте функцию POSIX
setuid(), которая может модифицировать сохраненный uid.
int setuid(uid_t euid);
Как и в случае
setreuid() эффективный uid процесса устанавливается в
euid, если
euid равен действительному uid процесса либо эффективный uid процесса на момент вызова равен 0.
Когда
setuid() используется процессом, чей эффективный uid установлен в 0, все uid процесса изменяются на
euid. К сожалению, это делает невозможным использование
setreuid() в setuid-программах, которым нужно временное использование другого uid, поскольку после вызова
setreuid() процесс не может восстановить свои полномочия root.
Хотя способность переключать uid упрощает написание кода, с помощью которого нельзя нарушить безопасность системы, все же это не панацея. Существует очень много популярных методов обманного проникновения в выполняющийся код [18]. До тех пор пока либо сохраненный, либо действительный uid процесса равен 0, такие атаки легко могут устанавливать эффективный uid процесса в 0. Это не дает возможности переключению uid эффективно предотвращать серьезную уязвимость системных программ. Однако если процесс может передать любой доступ к полномочиям root, устанавливая эффективный, сохраненный и действительный идентификаторы в ненулевые значения, это ограничивает эффективность любых атак против него.
10.2.3. Идентификатор uid файловой системы
В очень специальных случаях программе может понадобиться сохранять свои права root для всего, кроме доступа к файловой системе, при котором она использует пользовательский uid. Изначально использовавшийся в Linux NFS-сервер пространства пользователя может служить иллюстрацией проблемы, которая возникает, когда процесс предполагает применение пользовательского uid. Хотя NFS-сервер в прошлом применял
setreuid() для переключения uid при доступе к файловой системе, такое поведение позволяло пользователю, чей uid совпадает с uid NFS-сервера, уничтожать NFS-сервер. В конечном итоге, пользователь получал владение процессом NFS-сервера. Чтобы предотвратить проблемы подобного рода, Linux использует
uid файловой системы (fsuid) для контроля доступа к файловой системе.
Всякий раз когда изменяется эффективный uid процесса, его fsuid устанавливается равным новому эффективному идентификатору пользователя, что делает fsuid прозрачным для большинства приложений. Те приложения, которые нуждаются в дополнительных возможностях, предоставляемых отличающимся значением fsuid, должны применять вызов
setfsuid() для явной установки fsuid.
int setfsuid(uid_t uid);
Значение fsuid может быть установлено равным текущим эффективному, сохраненному или действительному идентификаторам пользователя. В дополнение следует сказать, что
setfsuid() выполняется успешно, если fsuid остается неизменным или эффективный uid процесса равен 0.
10.2.4. Резюме по идентификаторам пользователей и групп
Подведем итоги обо всех системных вызовах, которые модифицируют права доступа выполняющегося процесса. Большинство перечисленных здесь функций, имеющих отношение к идентификаторам пользователей, уже детально рассматривались в настоящей главе, но те, что относятся к группам — еще нет. Поскольку эти функции отражают соответствующие функции, модифицирующие идентификаторы пользователя, их поведение должно быть понятно.
Все эти функции возвращают
-1 в случае ошибки и
0 — в случае успеха, если только не указано иначе. Большинство их прототипов находятся в
<unistd.h>. Те, что расположены где-то еще, отмечены ниже.
int setreuid(uid_t ruid, uid_t euid); |
Устанавливает действительный uid текущего процесса в ruid и эффективный uid процесса в euid. Если оба параметра равны -1, то uid остаются неизменными. |
int setregid(gid_t rgid, gid_t egid); |
Устанавливает действительный gid текущего процесса в rgid и эффективный gid процесса в egid. Если оба параметра равны -1, то gid остаются неизменными. |
int setuid(uid t uid); |
Если применяется обычным пользователем, то устанавливает эффективный uid текущего процесса в значение параметра uid. Если используется процессом с эффективным uid, равным 0, то устанавливает действительный, эффективный и сохраненный uid в значение параметра uid. |
int setgid(gid_t gid); |
Если применяется обычным пользователем, то устанавливает эффективный gid текущего процесса в значение параметра gid. Если используется процессом с эффективным gid, равным 0, то устанавливает действительный, эффективный и сохраненный gid в значение параметра gid. |
int seteuid(uid_t uid); |
Эквивалент setreuid(-1, uid). |
int setegid(gid_t gid); |
Эквивалент setregid(-1, gid). |
int setfsuid(uid_t fsuid); |
Устанавливает fsuid текущего процесса в значение параметра fsuid. Прототип находится в <sys/fsuid.h>. Возвращает предшествующий fsuid. |
int setfsgid(gid_t fsgid); |
Устанавливает fsgid текущего процесса в значение параметра fsgid. Прототип находится в <sys/fsuid.h>. Возвращает предшествующий fsgid. |
int setgroups(size_t num, const gid_t * list); |
Устанавливает дополнительные группы текущего процесса из списка, переданного в массиве list, который должен содержать num элементов. Макрос SC_NGROUPS_MAX указывает, сколько групп может быть в списке (от 32 до 65536, в зависимости от работающей у вас версии Linux). |
uid_t getuid(); |
Возвращает действительный uid процесса. |
uid_t geteuid(); |
Возвращает эффективный uid процесса. |
gid_t getgid(); |
Возвращает действительный gid процесса. |
gid_t getegid(); |
Возвращает эффективный gid процесса. |
size_t getgroups (size_t size, gid_t list[]); |
Возвращает текущий набор дополнительных групп процесса в массиве list. Параметр size сообщает, сколько элементов типа gid_t может содержать list. Если размер list недостаточен, чтобы вместить все группы, возвращается -1, а errno устанавливается в EINVAL. В противном случае возвращается фактическое количество групп в list. Если size равен 0, возвращается количество групп, но list не затрагивается. Прототип функции getgroups() находится в <grp.h>. |
10.3. Информация о процессе
Ядро предоставляет значительное количество информации о каждом процессе и часть ее передается новым программам во время их загрузки. Вся эта информация образует среду выполнения для процесса.
10.3.1. Аргументы программы
Есть два типа значений, передаваемых новым программам при их запуске:
аргументы командной строки и
переменные окружения. Для их использования установлено множество соглашений, но система сама по себе не придерживается их автоматически. Однако хорошим тоном считается придерживаться этих соглашений, чтобы помочь вашим программам попасть в мир Unix.
Аргументы командной строки — это набор строк, передаваемый программе. Обычно они представляют собой текст, набранный вслед за именем команды в оболочке, с необязательными аргументами, начинающимися с символа "минус"
(-).
Переменные окружения — это набор пар "имя-значение". Каждая пара представляет отдельную строку в форме
ИМЯ=ЗНАЧЕНИЕ, и набор таких строк образует окружение (environment) программы. Например, домашний каталог текущего пользователя обычно указан в переменной окружения HOME, поэтому программы, скажем, пользователя Joe часто запускаются, имея в своем окружении
HOME=/home/joe.
И аргументы, и окружение становятся доступными программе при запуске. Аргументы командной строки передаются в виде параметров главной функции программы —
main(), в то время как указатель на окружение помещается в глобальную переменную
environ, которая определена в
<unistd.h>[18].
Ниже представлен полный прототип функции
main() в мире Linux, Unix и языка ANSI/ISO С.
int main(int argc, char *argv[]);
Возможно, вас удивит, что
main() возвращает значение (отличное от
void). Это значение, возвращаемое функцией main(), передается родительскому процессу после завершения данного. По соглашению 0 означает, что процесс завершен успешно, а ненулевое значение означает возникновение сбоя. При этом принимаются во внимание только младшие 8 бит из этого кода возврата. Отрицательные значения от -1 до -128 зарезервированы для ненормального завершения процессов по инициативе другого процесса или ядра системы. Код выхода 0 сигнализирует об успешном завершении, а значения от 1 до 127 говорят о том, что программа завершена по ошибке.
Первый параметр,
argc, содержит количество аргументов командной строки, переданных программе, тогда как
argv — массив указателей на строки — хранит сами аргументы. Первый элемент в массиве,
argv[0], содержит имя вызванной программы (хотя и не обязательно полный путь к ней). В элементе
argv[argc-1] расположен указатель на завершающий аргумент командной строки, а
argv[argc] содержит
NULL.
Чтобы получить прямой доступ к окружению, используйте следующую глобальную переменную:
extern char *environ[];
Это представляет
environ как массив указателей на каждый элемент программного окружения (помните, каждый элемент — это пара
ИМЯ=ЗНАЧЕНИЕ), и финальный элемент массива содержит
NULL. Это объявление находится в
<unistd.h>, поэтому вам не обязательно объявлять его самостоятельно.
Наиболее общий способ проверки элементов окружения — это вызов
getenv, который исключает непосредственное обращение к переменной
environ.
const char *getenv(const char * name);
Единственный параметр
getenv() — это имя переменной окружения, значение которой интересует. Если переменная существует,
getenv() вернет указатель на ее значение. Если переменная не существует в текущем окружении (то есть окружении, на которое указывает
environ), функция вернет
NULL.
Linux предоставляет два способа добавления строк в программное окружение:
setenv() и
putenv(). POSIX определяет только
putenv(), что делает его более переносимым.
int putenv(const char * string);
Переданный функции параметр
string должен иметь форму
ИМЯ=ЗНАЧЕНИЕ.
putenv() добавляет переменную по имени
ИМЯ к текущему окружению и присваивает ей значение
ЗНАЧЕНИЕ. Если окружение уже содержит переменную
ИМЯ, ее значение изменяется на
ЗНАЧЕНИЕ.
BSD определяет функцию
setenv(), которую Linux также поддерживает. Это более гибкий и удобный способ добавления переменных к окружению.
int setenv(const char * name, const char * value, int overwrite);
Здесь имя и новое значение переменной окружения передаются раздельно, что обычно программам делать проще. Если
overwrite равно 0, окружение не модифицируется, если оно уже содержит переменную по имени
name. В противном случае значение переменной модифицируется, как и в
putenv().
Ниже приведен короткий пример использования обеих функций. Оба вызова делают одно и то же, заменяя переменную окружения
PATH для запущенной программы.
putenv("PATH=/bin:/usr/bin");
setenv("PATH","/bin:/usr/bin", 1);
10.3.2 Использование ресурсов
Ядро Linux отслеживает, сколько ресурсов использует каждый процесс. Хотя отслеживается только небольшое их число, их измерения могут быть полезными разработчикам, администраторам и пользователям. В табл. 10.1 перечислены ресурсы, использование которых отслеживается ядром Linux версии 2.6.7.
Таблица 10.1. Ресурсы процессов, отслеживаемые Linux
| Тип |
Член |
Описание |
struct timeval |
ru_utime |
Общее время, затраченное на выполнение кода в режиме пользователя. Это включает в себя все время, потраченное на выполнение инструкций приложения, но исключая время, потраченное ядром на обслуживание запросов приложения. |
struct timeval |
ru_stime |
Общее время, потраченное ядром на выполнение запросов процесса. Это не включает времени блокировки процесса в период ожидания выполнения системных вызовов. |
long |
ru_minflt |
Количество второстепенных сбоев (minor faults), вызванных данным процессом. Второстепенные сбои — это попытки доступа к памяти, переключающие процессор в режим ядра, но не вызывающих обращений к диску. Это случается, когда процесс пытается писать за пределами стека, что вынуждает ядро распределить больше пространства стека, прежде чем продолжить выполнение процесса. |
long |
ru_majflt |
Количество первостепенных сбоев (major faults), вызванных данным процессом. Первостепенные сбои — это обращения к памяти, заставляющие ядро обратиться к диску, прежде чем программа сможет продолжить работу. Одной из частых причин этого может быть обращение к части исполняемой памяти, которая еще не была загружена в ОЗУ с диска либо была временно выгружена на диск. |
long |
ru_nswap |
Количество страниц памяти, для которых был выполнен обмен с диском при обращении к памяти из процесса. |
Процесс может проверять использование ресурсов им самим, общее использование ресурсов его дочерними процессами либо сумму того и другого.
Системный вызов
getrusage() возвращает структуру
struct rusage (определенную в
<sys/resource.h>), содержащую информацию о текущем использовании ресурсов.
int getrusage(int who, struct rusage * usage);
Первый параметр,
who, сообщает, какой из трех счетчиков ресурсов должен быть возвращен.
RUSAGE_SELF возвращает использование ресурсов текущим процессом,
RUSAGE_CHILDREN — его дочерними процессами, a
RUSAGE_BOTH — общее использование ресурсов текущим процессом и всеми его дочерними процессами. Второй параметр
getrusage() — это указатель на
struct rusage, куда помещается информация об использовании ресурсов. Хотя struct rusage и содержит относительно немного членов (список унаследован из BSD), большинство этих членов пока не используются Linux). Ниже представлено полное определение этой структуры. В табл. 10.1 описаны члены, используемые в настоящее время Linux.
#include <sys/resource.h>
struct rusage {
struct timeval ru_utime;
struct timeval ru_stime;
long intru_maxrss;
long intru_ixrss;
long intru_idrss;
long intru_isrss;
long intru_minflt;
long intru_majfit;
long intru_nswap;
long intru_inblock;
long intru_oublock;
long intru_msgsnd;
long intru_msgrcv;
long intru_nsignals;
long intru_nvcsw;
long intru_nivcsw;
};
10.3.3. Применение ограничений использования ресурсов
Чтобы помочь в предотвращении неконтролируемого снижения производительности процессами, Unix отслеживает многие ресурсы, которые может использовать процесс, и позволяет системному администратору и самим пользователям накладывать ограничения на расход ресурсов процессами.
Предусмотрены два класса доступных ограничений: жесткие и мягкие ограничения. Жесткие обычно установлены при запуске системы в
RLIM_INFINITY, что означает отсутствие каких-либо ограничений. Единственное исключение из этого —
RLIMIT_CORE (максимальный размер дампа памяти), который Linux инициирует нулем, чтобы предотвратить неожиданный сброс дампов ядра. Многие дистрибутивы сбрасывают этот лимит при запуске, однако, большинство технических пользователей ожидают появления дампов памяти при некоторых условиях (информацию о дампах памяти можно найти далее в главе). Мягкие ограничения — это те ограничения, которые установлены в ядре в данный момент. Любой процесс может наложить мягкое ограничение на использование ресурса на определенном уровне — равном или более низком, чем установленное жесткое ограничение.
Таблица 10.2. Ограничения ресурсов
| Значение |
Лимит |
RLIMIT_AS |
Максимальный объем памяти, доступный процессу. Включает память для стека, глобальных переменных и динамически выделенную память. |
RLIMIT_CORE |
Максимальный размер дампа памяти, генерируемого ядром (если файл дампа получается слишком большим, он не создается). |
RLIMIT_CPU |
Общее используемое время процессора (в секундах). Более подробно об этом ограничении рассказывается при описании SIGXCPU в главе 12. |
RLIMIT_DATA |
Максимальный объем памяти данных (в байтах). Это не включает динамически выделенную память. |
RLIMIT_FSIZE |
Максимальный размер открытого файла (проверяется при записи). Более подробно об этом ограничении рассказывается при описании SIGXFSZ в главе 12. |
RLIMIT_MEMLOCK |
Максимальный объем памяти, которая может быть блокирована с помощью mlock(). Функция mlock() рассматривается в главе 13. |
RLIMIT_NOFILE |
Максимальное количество открытых файлов. |
RLIMIT_NPROC |
Максимальное количество дочерних процессов, которые может породить данный процесс. Это ограничивает только количество дочерних процессов, которые могут существовать одновременно. Это не ограничивает количества наследников дочерних процессов — каждый из них может иметь до RLIMIT_NPROC потомков. |
RLIMIT_RSS |
Максимальный объем ОЗУ, использованный в любой момент (всякое превышение этого объема используемой памяти вызывает страничную подкачку). Это также известно под названием размера резидентной части (resident set size). |
RLIMIT_STACK |
Максимальный размер памяти стека (в байтах), включая все локальные переменные. |
Различные ограничения, которые могут быть установлены, перечислены в табл. 10.2 и определены в
<sys/resource.h>. Системные вызовы
getrlimit() и
setrlimit() устанавливают и получают ограничения для отдельного ресурса.
int getrlimit(int resource, struct rlimit *rlim);
int setrlimit(int resource, const struct rlimit *rlim);
Обе эти функции используют структуру
struct rlimit, определенную следующим образом:
struct rlimit {
long int rlim_cur; /* мягкое ограничение */
long int rlim_max; /* жесткое ограничение */
};
Второй член структуры —
rlim_max, указывает жесткое ограничение лимита, переданного в параметре
resource, a
rlim_cur — мягкое ограничение. Это те же наборы лимитов, которыми манипулируют команды
ulimit и
limit, одна из которых встроена в большинство командных оболочек.
10.4. Примитивы процессов
Несмотря на относительно длинную дискуссию, необходимую для описания процесса, создание и уничтожение процессов в Linux достаточно просто.
10.4.1. Создание дочерних процессов
В Linux предусмотрены два системных вызова, которые создают новые процессы:
fork() и
clone(). Как упоминалось ранее,
clone() используется для создания потоков, и этот вызов будет кратко описан далее. А сейчас мы сосредоточимся на
fork() — наиболее популярном методе создания процессов.
#include <unistd.h>
pid_t fork(void);
Этот системный вызов имеет уникальное свойство возвращать управление не один раз, а дважды: один раз в родительском процессе и другой — в дочернем. Обратите внимание, что мы не говорим "первый — в родительском" — написание кода, который делает какие-то предположения относительно предопределенного порядка — очень плохая идея.
Каждый из двух возвратов системного вызова
fork() имеет разные значения. В родительский процесс этот системный вызов возвращает pid вновь созданного дочернего процесса, а в дочернем он возвращает 0.
Разница возвращаемых значений — это единственное отличие, видимое процессам. Оба имеют одинаковые образы памяти, права доступа, открытые файлы и обработчики сигналов
[19]. Рассмотрим простой пример программы, порождающей дочерний процесс.
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main(void) {
pid_t child;
if (!(child = fork())) {
printf("в дочернем\n");
exit (0);
}
printf("в родительском - дочерний: %d\n", child);
return 0;
}
10.4.2. Наблюдение за уничтожением дочерних процессов
Сбор состояний возврата дочернего процесса называется
ожиданием процесса. Это можно делать четырьмя способами, хотя только один из вызовов предоставляется ядром. Остальные три метода реализованы в стандартной библиотеке С. Поскольку системный вызов ядра принимает четыре аргумента, он называется
wait4().
pid_t wait4(pid_t pid, int *status, int options, struct rusage *rusage);
Первый аргумент,
pid, представляет собой процесс, код возврата которого должен быть возвращен. Он может принимать ряд специальных значений.
pid < -1 Ожидать завершения любого дочернего процесса, чей pgid равен абсолютному значению
pid.
pid = -1 Ожидать прерывания любого дочернего процесса.
pid = 0 Ожидать завершения дочернего из той же группы процессов, что и текущий
[20].
pid > 0 Ожидать выхода процесса
pid.
Второй параметр — это указатель на целое, которое устанавливается в значение, равное соду возврата того процесса, который заставляет
wait4() вернуть управление (мы будем зазывать его "проверяемым" процессом). Формат возвращенного состояния довольно закрученный, и для того, чтобы сделать его осмысленным, существует набор макросов.
Три события заставляют
wait4() вернуть состояние проверяемого процесса. Процесс может завершиться, он может быть прерван вызовом
kill() (получит фатальный сигнал) либо он может быть остановлен по какой-либо причине
[21]. Вы можете узнать, что именно случилось, с помощью описанных ниже макросов, каждый из которых принимает возвращаемое состояние
wait4() в качестве единственного параметра.
WIFEXITED(status) |
Возвращает true, если процесс завершился нормально. Процесс завершается нормально, когда его функция main() выходит из программы посредством вызова exit(). Если WIFEXITED истинно, то WEXITSTATUS(status) возвращает код возврата процесса. |
WIFSIGNALED(status) |
Возвращает true, если процесс был прерван сигналом (это происходит, когда он прерывается вызовом kill()). В этом случае WTERMSIG(status) возвращает номер сигнала, прервавшего процесс. |
WIFSTOPPED(status) |
Если процесс приостановлен сигналом, WIFSTOPPED() возвращает true, a WSTOPSIG(status) возвращает номер сигнала, приостановившего процесс. wait4() возвращает информацию только о приостановленных процессах, если указана опция WUNTRACED. |
Аргумент
options управляет поведением вызова.
WHOHANG заставляет функцию немедленно вернуть управление. Если в данный момент нет ни одного процесса, готового сообщить свое состояние, то возвращается 0 вместо допустимого pid.
WUNTRACED заставляет
wait4() возвратить соответствующий остановленный дочерний процесс. Более подробно о приостановленных процессах рассказывается в главе 15. Оба флажка могут быть объединены вместе битовой операцией "или".
Финальный параметр
wait4(), указатель на
struct rusage, наполняется информацией об использовании ресурсов проверяемым процессом и всеми его потомками. Более подробная информация об этом давалась при обсуждении
getrusage() и
RUSAGE_BOTH ранее в главе. Если этот параметр равен
NULL, информация о состоянии не возвращается.
Существуют три других интерфейса к
wait4(), каждый из которых представляет подмножество его функциональности.
pid_t wait(int *status) |
Единственный параметр wait() — это указатель на место, куда следует поместить код возврата прерванного процесса. Эта функция всегда блокирует выполнение до тех пор, пока дочерний процесс не будет прерван. |
pid_t waitpid (pid_t pid, int *status, int options) |
Функция waitpid() подобна wait4(). Единственное отличие в том, что она не возвращает информации об использовании ресурсов прерванным процессом. |
pid_t wait3(int *status, int options, struct rusage *rusage) |
Эта функция также подобна wait4(), но не позволяет специфицировать дочерний процесс, который должен быть проверен. |
10.4.3. Запуск новых программ
Хотя доступно целых шесть способов запустить одну программу из другой, все они делают почти одно и то же — заменяют текущую выполняющуюся программу другой программой. Обратите внимание на слово "
заменяет" — все следы текущей выполняющейся программы при этом исчезают. Если вы хотите оставить исходную программу работающей, вы должны создать новый процесс вызовом
fork(), а затем запустить новую программу из дочернего процесса.
Эти шесть функций лишь слегка отличаются по интерфейсу. Только одна из них —
execve() — является системным вызовом Linux. Остальные реализованы в библиотеках пользовательского пространства и вызывают
execve() для запуска новой программы. Ниже представлены прототипы семейства функций
exec().
int execl(const char *path, const char *arg0, ...);
int execlp(const char *file, const char *arg0, ...);
int execle(const char *path, const char *arg0, ...);
int execv(const char *path, const char **argv);
int execvp(const char *file, const char **argv);
int execve(const char *file, const char **argv, const char **envp);
Как уже упоминалось, все эти программы пытаются заменить текущую программу новой. Если это удается, то управление не возвращается (то есть программа, которая вызвала другую программу, уже не выполняется). Если не удается, то возвращается значение
-1 и устанавливается код ошибки в
errno, как при любом другом системном вызове. Когда новая программа запускается, она принимает массив аргументов (
argv) и массив переменных окружения (
envp). Каждый элемент
envp имеет форму
ПЕРЕМЕННАЯ=значение[22].
Основная разница между функциями семейства
exec() состоит в том, как новой программе передаются аргументы командной строки. Функции
execl() передают каждый элемент в отдельном аргументе
argv, причем список завершается
NULL. Традиционно первый элемент
argv — это команда, использованная для запуска программы. Например, команда оболочки
/bin/cat /etc/passwd /etc/group обычно получается в результате следующей вызова
exec:
execl("/bin/cat", "/bin/cat", "/etc/passwd", "/etc/group", NULL);
Первый аргумент — это полный путь к программе, которую требуется выполнить, а остальные аргументы передаются программе в виде
argv. Заключительный параметр
execl() должен быть равен
NULL — это служит признаком конца списка параметров. Если вы пропустите
NULL, то, скорее всего, функция завершится ошибкой сегментации либо вернет
EINVAL. Окружение, переданное новой программе — это то, на что указывает глобальная переменная
environ, как упоминалось ранее в настоящей главе.
Функциям
execv аргументы командной строки передаются как массив С строк
[23], имеющих тот же формат, что применяется для передачи
argv новой программе.
Последним элементом должен быть
NULL для обозначения конца массива, а первый элемент (
argv[0]) должен содержать имя вызываемой программы.
Наш пример с
bin/cat /etc/passwd /etc/group может быть закодирован, используя
execv, следующим образом:
char *argv[] = { "/bin/cat", "/bin/cat", "/etc/passwd", "/etc/group", NULL }; execv("/bin/cat", argv);
Если нужно передать специфическое окружение новой программе, для этого подойдут
execle() и
execve(). Они в точности похожи на
execl() и
execv(), но принимают указатель на окружение в качестве последнего аргумента. Окружение устанавливается так же, как
argv.
Например, ниже показан один способ запуска
/usr/bin/env (эта программа печатает окружение, которое ей передано) с небольшим набором переменных окружения:
char *newenv[] = { "PATH=/bin:/usr/bin", "HOME=/home/sweethome", NULL };
execle("/usr/bin/env", "/usr/bin/env", NULL, newenv);
Вот та же идея, реализованная с помощью
execve():
char *argv[] = { "/usr/bin/env", NULL };
char *newenv[] = { "PATH=/bin:/usr/bin", "HOME=/home/sweethome", NULL };
execve("/usr/bin/env", argv, newenv);
Последние две функции,
execlp() и
execvp(), отличаются от первых двух тем, что выполняют поиск программы, которую нужно запустить, в текущем пути (установленном переменной окружения
PATH). Аргументы программы, однако, не модифицируются, поэтому
argv[0] не содержит полного пути к запускаемой программе. Ниже показана модифицированная версия нашего первого примера, который ищет
cat в текущем
PATH.
execlp("cat", "cat", "/etc/passwd", "/etc/group", NULL);
char *argv[] = { "cat", "/etc/passwd", "/etc/group", NULL };
execvp("cat", argv);
Если вместо этого воспользоваться
execl() или execv(), этот фрагмент кода завершится ошибкой, если только
cat не окажется в текущем каталоге.
Если вы пытаетесь запустить программу со специфическим окружением, при этом желая выполнять поиск пути, вам придется искать путь вручную и использовать
execle() или
execve(), поскольку ни одна из функций
exec() не делает того, что
вам нужно.
Обработчики сигналов предохраняются внутри функций
exec() несколько неочевидным образом. Этот механизм рассматривается в главе 12.
10.4.4. Ускоренное создание процессов с помощью vfork()
Обычно процессы, в которых вызывается
fork(), немедленно вызывают
exec() для другой программы (это то, что оболочка делает всякий раз, когда вы вводите команду), что делает полную семантику
fork() более расточительной по вычислительным ресурсам, чем это необходимо.
Чтобы оптимизировать этот общий случай, существует
vfork().
#include <unistd.h>
pid_t vfork(void);
Вместо создания совершенно новой среды выполнения для нового процесса
vfork() создает новый процесс, который разделяет память с исходным процессом. Ожидается, что новый процесс запустит другой процесс посредством
exit() или
exec() очень быстро, но его поведение непредсказуемо, если он модифицирует память, возвратит управление из функции
vfork(), содержащейся в нем, либо вызовет любую новую функцию. В дополнение к этому исходный процесс приостанавливается, до тех пор, пока новый либо не будет прерван, либо вызовет функцию
exec()[24]. Однако не все системы обеспечивают семантику разделения памяти и приостановки родительского процесса
vfork(), поэтому приложения не должны полагаться на такое поведение.
10.4.5. Уничтожение процессом самого себя
Процессы прерывают себя вызовом либо
exit(), либо
_exit(). Когда функция процесса
main() возвращает управление, стандартная библиотека С вызывает
exit() со значением, возвращаемым
main() в качестве параметра.
void exit(int exitCode);
void _exit(int exitCode);
Две формы,
exit() и
_exit(), отличаются тем, что
exit() — функция из библиотеки С, a
_exit() — системный вызов. Системный вызов
_exit() прерывает программу немедленно, и
exitCode сохраняется в качестве кода возврата процесса. Когда используется
exit(), то перед тем, как запустить системный вызов
_exit(exitCode), вызываются функции, зарегистрированные в
atexit(). Помимо всего прочего, это позволяет стандартной библиотеке ввода-вывода ANSI/ISO сбросить все свои буферы.
Регистрация функций, которые должны быть запущены при вызове
exit(), выполняется с помощью функции
atexit():
int atexit(void (*function) (void));
Единственный параметр, переданный
atexit() — это указатель на функцию. Когда вызывается
exit(), все функции, зарегистрированные через
atexit(), вызываются в порядке, обратном тому, в котором они регистрировались. Следует отметить, что если используется
_exit() либо процесс прерывается сигналом (подробно о сигналах читайте в главе 12), то функции, зарегистрированные
atexit(), не вызываются.
10.4.6. Уничтожение других процессов
Разрушение другого процесса почти столь же просто, как создание нового — нужно просто уничтожить его:
int kill(pid_t pid, int signum);
pid должен быть идентификатором процесса, который требуется уничтожить, а
signum описывает, как это нужно сделать. Доступны два варианта выполнения операции
[25] прерывания дочернего процесса. Вы можете применить
SIGTERM, чтобы прервать его "вежливо". Это означает, что процесс при этом может сообщить ядру о том, что кто-то пытается его уничтожить; в результате появляется возможность завершить его корректно (сохранив файлы, например). Процесс может в этом случае игнорировать запрос на прерывание такого типа и продолжать выполняться. Применение значения
SIGKILL в качестве параметра
signum вызывает немедленное прерывание процесса без каких-либо вопросов. Если
signum равно
0, то
kill() проверяет, имеет ли тот процесс, что вызвал
kill(), соответствующие полномочия, возвращает ноль, если это так, либо ненулевое значение, если полномочий недостаточно. Это обеспечивает процессу возможность проверки корректности
pid.
Параметр
pid в среде Linux может принимать перечисленные ниже значения.
pid > 0 |
Сигнал отправляется процессу с идентификатором pid. Если такого процесса нет, возвращается ESRCH. |
pid < -1 |
Сигнал посылается всем процессам, принадлежащим группе с pgid, равным -pid. Например, kill(-5316, SIGKILL) немедленно прерывает все процессы из группы 5316. Такая возможность используется оболочками управления заданиями, как описано в главе 15. |
pid = 0 |
Сигнал отправляется всем процессам группы, к которой относится текущий процесс. |
pid = -1 |
Сигнал посылается всем процессам системы за исключением инициализирующего процесса (init). Это применяется для полного завершения системы. |
Процессы могут нормально уничтожать вызовом
kill() только те процессы, которые разделяют тот же эффективный идентификатор пользователя, что и у них самих. Существуют два исключения из этого правила. Во-первых, процессы с эффективным uid, равным 0, могут уничтожать любые процессы в системе. Во-вторых, любой процесс может посылать сигнал
SIGCONT любому процессу в том же сеансе
[26].
10.4.7. Дамп ядра
Хотя мы уже упоминали, что передача
SIGTERM и
SIGKILL функции
kill() прерывает процесс, вы также можете использовать несколько других значений (все они описаны в главе 12). Некоторые из них, такие как
SIGABRT, заставляют программу перед уничтожением сбрасывать дамп ядра (dump core).
Дамп ядра программы содержит полную хронологию состояния программы перед ее уничтожением
[27]. Большинство отладчиков, включая
gdb, могут анализировать файл дампа и рассказывать, что программа делала непосредственно перед тем, как была уничтожена, а также поможет исследовать образ памяти процесса. Дамп ядра выгружается в файл по имени core, расположенный в текущем каталоге процесса.
Когда процесс нарушает какие-то системные требования (например, пытается обратиться к памяти, доступ к которой запрещен), ядро прерывает процесс, вызывая встроенную версию
kill() с параметром, который заставляет выгрузить дамп ядра. Ядро может уничтожать процессы по разным причинам, включая арифметические ошибки, такие как деление на ноль, либо по причине выполнения программой некорректных инструкций, либо при попытке доступа к запрещенной области памяти. Последняя причина вызывает
ошибку сегментации, что выражается в сообщении
segmentation fault (core dumped) (ошибка сегментации (дамп ядра сброшен)). Если вы обладаете хоть каким-нибудь опытом программирования в Linux, то наверняка неоднократно получали это сообщение.
Если для процесса установлен лимит на размер файла дампа, равный 0 (рассматривался ранее в этой главе), то никакой дамп ядра не выгружается.
10.5. Простые дочерние процессы
Хотя функции
fork(),
exec() и
wait() позволяют программам в полной мере использовать модель процессов Linux, многим приложениям не нужен такой контроль дочерних процессов. Существуют две библиотечных функции, которые упрощают создание дочерних процессов:
system() и
popen().
10.5.1. Запуск и ожидание с помощью system()
Программам часто требуется запускать другие программы и ожидать их завершения, прежде чем продолжать свою работу. Функция
system() позволяет это делать достаточно просто.
int system (const char* cmd);
system() порождает дочерний процесс, который выполняет
exec() для
/bin/sh, который, в свою очередь, запускает
cmd. Исходный процесс ожидает завершения дочерней оболочки и возвращает тот же код, что
wait()[28]. Если вам не нужно оставлять в памяти оболочку (что случается редко),
cmd должна включать предшествующее слово
"exec", которое заставляет оболочку вызывать
exec() вместо запуска
cmd как подпроцесса.
Поскольку
cmd запускается из оболочки
/bin/sh, то здесь применимы все обычные правила расширения команд. Ниже показан пример вызова
system(), который отображает исходные тексты С из текущего каталога.
#include <stdlib.h>
#include <sys/wait.h>
int main() {
int result;
result = system("exec ls *.c");
if (!WIFEXITED(result))
printf("(аварийный выход)\n");
exit(0);
}
Команда
system() должна применяться с большой осторожностью в программах, которые запускаются со специальными полномочиями. Поскольку системная оболочка предоставляет множество мощных средств и сильно зависит от переменных окружения,
system() является уязвимым местом в плане безопасности, которым могут воспользоваться злоумышленники для проникновения в систему. Однако до тех пор, пока приложение не является демоном или программой
setuid/setgid, вызов
system() совершенно безопасен.
10.5.2. Чтение и запись из процесса
Хотя
system() отображает результат работы команды на устройство стандартного вывода и позволяет дочерним программам читать стандартный ввод, это не всегда идеально. Часто процесс желает читать вывод другого процесса либо отправлять текст на стандартный ввод.
popen() облегчает процессам решение этой задачи
[29].
FILE * popen(const char *cmd, const char *mode);
cmd выполняется через оболочку, как и в
system(). Параметр
mode должен быть
"r", если родительский процесс желает читать командный вывод, и
"w" — для записи в стандартный ввод дочернего процесса. Следует отметить, что с помощью
popen() делать одновременно чтение и запись нельзя.
Два процесса, которые читают и пишут друг в друга, достаточно сложны
[30] и выходят за рамки возможностей
popen()[31].
popen() возвращает
FILE* (как это определено в стандартной библиотеке ввода-вывода ANSI/ISO), который может быть прочитан и записан подобно любому другому потоку
stdio[32], либо
NULL, если операция не удается. Когда завершается родительский процесс, он может воспользоваться
pclose() для закрытия потока и прерывания дочернего процесса, если он все еще выполняется. Подобно
system(),
pclose() возвращает состояние дочернего процесса из
wait4().
int pclose(FILE *stream);
Ниже приведен пример простой программы-калькулятора, которая использует программу
bc для выполнения всей реальной работы. Важно сбрасывать поток, полученный от
popen(), после записи в него, чтобы предотвратить буферизацию
stdio от задержки вывода (подробности о буферизации стандартных функций библиотеки
stdio можно найти в [15]).
1: /*calc.c*/
2:
3: /* Это очень простой калькулятор, который использует внешнюю команду bc
4: для выполнения всей работы. Открывает канал к bc, читает команду,
5: передает ее bc и завершается. */
6: #include <stdio.h>
7: #include <sys/wait.h>
8: #include <unistd.h>
9:
10: int main(void) {
11: char buf[1024];
12: FILE *bc;
13: int result;
14:
15: /* открыть канал на bc и выйти в случае неудачи */
16: bc = popen("bc", "w");
17: if (!bc) {
18: perror("popen");
19: return 1;
20: }
21:
22: /* пригласить ввести выражение, и прочитать его */
23: printf("expr:"); fflush(stdout);
24: fgets(buf, sizeof(buf), stdin);
25:
26: /* послать выражение bc для вычисления */
27: fprintf(bc, "%s\n", buf);
28: fflush(bc);
29:
30: /* закрыть канал на bc и ожидать выхода из нее */
31: result = pclose(bc);
32:
33: if (!WIFEXITED(result))
34: printf("(аварийный выход)\n");
35:
36: return 0;
37: }
Подобно
system(),
popen() запускает команды через системную оболочку и должна использоваться с большой осторожностью, если вызывается из программы со специальными полномочиями.
10.6. Сеансы и группы процессов
В Linux, как и в других системах Unix, пользователи обычно взаимодействуют с группами взаимосвязанных процессов. Хотя изначально они входят через единственный терминал и используют единственный процесс (а именно —
оболочку, предоставляющую интерфейс командной строки), пользователи затем запускают множество процессов в результате перечисленных ниже действий.
• Запуск неинтерактивных заданий в фоновом режиме.
• Переключение между интерактивными заданиями с помощью
управления заданиями (job control), которое более подробно обсуждается в главе 15.
• Запуск множества процессов, взаимодействующих через программные каналы.
• Запуск оконной системы, вроде X Window System, которая позволяет открывать несколько терминальных окон.
Чтобы управлять всеми этими процессами, ядру необходимо группировать процессы более сложным образом, чем простое отношение "родительский-дочерний", которое мы описали. Этот способ группировки называется
сеансами и
группами процессов. На рис. 10.1 показано отношение между сеансами, группами процессов и процессами.
 Рис. 10.1
Рис. 10.1. Сеансы, группы процессов и процессы
10.6.1. Сеансы
Когда пользователь выходит из системы, ядро должно прервать все процессы, которые пользователь запустил (иначе может остаться множество процессов, которые будут ожидать ввода, а тот никогда не последует). Чтобы упростить эту задачу, процессы организуются в наборы
сеансов. Идентификатор сеанса — это то же, что pid процесса, который создает сеанс с помощью системного вызова
setsid(). Этот процесс называют
лидером сеанса (session leader) для данной группы процессов. Все потомки процесса являются членами сеанса, если только явно не будут удалены из него. Вызов функции
setsid() не принимает аргументов, а возвращает идентификатор нового сеанса.
#include <unistd.h>
pid_t setsid(void);
10.6.2. Управление терминалом
Каждый сеанс привязывается к терминалу, от которого процессы и сеансы получают ввод и куда отправляют свой вывод. Терминал может быть локальной консолью машины, терминальным подключением через последовательный порт или псевдотерминалом, который отображается на окно X либо на сетевое подключение (см. главу 16). Терминал, к которому относится сеанс, называется
управляющим терминалом (или
управляющим tty) данного сеанса. Терминал может быть управляющим одновременно только для одного сеанса.
Хотя управляющий терминал сеанса может быть изменен, обычно это делается только процессами, которые управляют начальным входом пользователя в систему. Информацию о том, как сменить управляющий терминал сеанса, можно найти в главе 16.
10.6.3. Группы процессов
Одной из главных целей Unix было создание набора простых инструментов, которые могут быть использованы вместе сложными способами (с помощью механизмов, подобных программным каналам). Большинство пользователей Linux делали нечто вроде следующего практического примера этой философии:
ls | grep "^[аА].*\.gz" | more
Другое популярное средство, появившееся в Unix достаточно давно — управление заданиями (job control). Управление заданиями дает возможность пользователям прерывать текущее задание (известное как
задание переднего плана (foreground task)) в то время, пока они уходят и делают на терминале что-то другое. Когда приостановленное задание представляет собой последовательность процессов, работающих вместе, система должна отслеживать, какие именно процессы должны быть приостановлены, когда пользователь желает приостановить задание переднего плана. Группы процессов позволяют системе видеть, какие процессы работают вместе, а потому должны управляться совместно средствами управления заданиями.
Процессы добавляются в группы с помощью
setpgid().
int setpgid(pid_t pid, pid_t pgid);
pid — это процесс, который должен быть помещен в новую группу (
0 обозначает текущий процесс),
pgid — это идентификатор группы процессов, к которой должен принадлежать процесс
pid, или
0, если процесс должен быть включен в новую группу процессов, чей
pgid тот же, что и
pid процесса. Подобно сеансам, лидер группы процессов — это процесс, чей
pid совпадает в
pgid группы.
Правила применения
setpgid() несколько сложны.
1. Процесс может устанавливать группу для себя или одного из своих потомков. Он не может изменять группу для любого другого процесса в системе, даже если процесс, вызвавший
setpgid(), имеет административные полномочия.
2. Лидер сеанса не может изменить свою группу.
3. Процесс не может быть перемещен в группу, чей лидер представляет другой сеанс, чем он сам. Другими словами, все процессы в группе должны относиться к одному и тому же сеансу.
Вызов
setpgid() помещает вызывающий процесс в свою собственную группу и собственный сеанс. Это необходимо для того, чтобы гарантировать, что два сеанса не содержат процессы, принадлежащие к одной и той же группе.
Полный пример групп процессов будет приведен при обсуждении системы управления заданиями в главе 15.
Когда соединение с терминалом теряется, ядро посылает сигнал (
SIGHUP; подробнее о сигналах рассказывается в главе 12) лидеру сеанса, содержащему группу процессов переднего плана данного терминала. Обычно это командная оболочка. Это позволит оболочке безусловно прерывать пользовательские процессы, извещая их о том, что пользователь выходит из системы (обычно посредством
SIGHUP), либо выполнить некоторые другие действия (или бездействие). Хотя это все может показаться усложненным, это дает возможность лидеру группы сеанса принимать решения о том, как управлять закрывающимися терминалами, вместо того, чтобы возлагать эту обязанность на ядро. Это также дает возможность администраторам гибко управлять политиками пользовательских учетных записей.
Определение группы процесса может быть выполнено просто, с помощью функций
getpgid() и
getpgrp().
pid_t getpgid(pid_t pid) |
Возвращает pgid процесса pid. Если pid равен 0, возвращается pgid текущего процесса. Для вызова не требуется никаких специальных полномочий. Любой процесс может определять группу, к которой принадлежит любой другой процесс. |
pid_t getpgrp(void) |
Возвращает pgid текущего процесса pid (эквивалентно getprgid(0)) |
10.6.4. Висячие группы процессов
Механизм прерывания процессов (либо возобновления их работы после приостановки) при исчезновении их сеанса довольно сложен. Представьте себе сеанс со многими группами процессов в нем (см. рис. 10.1). Сеанс запущен на терминале, и обычная системная оболочка является его лидером.
Когда лидер сеанса (оболочка) завершается, ее группы процессов оказываются в сложной ситуации. Если они активно работают, то лишаются возможности использовать стандартные потоки
stdin и
stdout, поскольку терминал закрыт. Если они приостановлены, то вероятно, никогда не будут запущены снова, поскольку пользователь терминала не имеет возможности перезапустить их, к тому же то, что они не могут быть запущены, означает также, что они не могут быть и прерваны.
В этой ситуации каждая такая группа процессов получает название
висячей (orphaned). Стандарт POSIX определяет ее как группу процессов, чей родитель является также членом этой группы либо не является членом сеанса этой группы. Другими словами, группа процессов не является висячей до тех пор, пока у нее есть родительский процесс, принадлежащий тому же сеансу, но другой группе.
Хотя оба определения выглядят сложными, концепция достаточно проста. Если группа процессов приостановлена, и не существует процесса, который бы принудил ее возобновиться, то эта группа становится висячей
[33].
Когда завершает работу командная оболочка, все ее дочерние процессы становятся дочерними по отношению к процессу init, оставаясь при этом в своих исходных сеансах. Предполагая, что все программы в сеансе являются потомками оболочки, все группы процессов этого сеанса становятся висячими
[34]. Когда группа процессов превращается в висячую, каждый процесс этой группы получает сигнал
SIGHUP, что обычно прерывает программу.
Программы, которые не прерываются по сигналу
SIGHUP, получают сигнал
SIGCONT, который продолжает выполнение приостановленных процессов. Такая последовательность прерывает большинство процессов и обеспечивает оставшимся возможность работать (то есть гарантирует, что они не будет в приостановленном состоянии)
[35].
Как только процесс становится висячим, он принудительно отключается от своего управляющего терминала (позволяя новому пользователю при необходимости применять этот терминал). Если продолжающие работать программы пытаются получить доступ к терминалу, эти попытки вызывают ошибки, устанавливающие
errno в значение
EIO. Процессы остаются в том же сеансе, и идентификатор сеанса не используется для новых идентификаторов процессов до тех пор, пока не завершатся все процессы данного сеанса.
10.7. Введение в ladsh
Чтобы помочь проиллюстрировать идеи, обсуждаемые в нашей книге, на протяжении последующих разделов книги мы разработаем подмножество командной оболочки Unix. В конечном итоге наша оболочка будет поддерживать следующее.
• Простые встроенные команды.
• Запуск внешних команд.
• Перенаправление ввода-вывода (
>,
| и так далее).
• Управление заданиями.
Полный исходный текст окончательной версии этой оболочки,
ladsh4.с, представлен в приложении Б. По мере добавления в
ladsh новых средств, изменения исходного текста описываются в тексте книги. Чтобы уменьшить количество изменений, которые мы вносим между версиями, некоторые ранние версии несколько более сложны, чем было бы нужно. Эти небольшие усложнения, однако, далее в книге упрощают разработку оболочки, поэтому будьте терпеливы. Просто пока поверьте, что эти фрагменты кода необходимы; все они будут объяснены позднее.
10.7.1. Запуск внешних программ с помощью ladsh
Вот первая (и самая простая) версия
ladsh, называемая
ladsh1.
1: /*ladsh1.c*/
2:
3: #include <ctype.h>
4: #include <errno.h>
5: #include <fcntl.h>
6: #include <signal.h>
7: #include <stdio.h>
8: #include <stdlib.h>
9: #include <string.h>
10: #include <sys/ioctl.h>
11: #include <sys/wait.h>
12: #include <unistd.h>
13:
14: #define MAX_COMMAND_LEN 250 /* максимальная длина отдельной
15: командной строки */
16: #define JOB_STATUS_FORMAT "[%d]%-22s%.40s\n"
17:
18: struct jobSet {
19: struct job *head; /* заголовок списка запущенных заданий */
20: struct job *fg; /* текущее задание переднего плана */
21: };
22:
23: struct childProgram {
24: pid_t Pid; /* 0 на выходе */
25: char **argv; /* имя программы с аргументами */
26: };
27:
28: struct job {
29: int job Id; /* номер задания */
30: int numProgs; /* общее кол-во программ в задании */
31: int runningProgs; /* кол-во работающих программ */
32: char *text; /* имя задания */
33: char *cmdBuf; /* буфер различных argv */
34: pid_t pgrp; /* идентификатор группы процессов задания */
35: struct childProgram *progs; /* массив программ в задании */
36: struct job *next; /* для слежения за фоновыми программами */
37: };
38:
39: void freeJob(struct job *cmd) {
40: int i;
41:
42: for (i=0; i<cmd->numProgs; i++) {
43: free (cmd->progs[i].argv);
44: }
45: free(cmd->progs);
46: if (cmd->text) free(cmd->text);
47: free(cmd->cmdBuf);
48: }
49:
50: int getCommand(FILE *source, char *command) {
51: if (source == stdin) {
52: printf("#");
53: fflush(stdout);
54: }
55:
56: if (!fgets(command, MAX_COMMAND_LEN, source)) {
57: if (source==stdin) printf("\n");
58: return 1;
59: }
60:
61: /* удалить завершающий перевод строки */
62: command[strlen(command) - 1] = '\0';
63:
64: return 0;
65: }
66:
67: /* Возвратить cmd->numProgs как 0, если нет никаких команд (то есть пустая
68: строка). Если найдена правильная команда, commandPtr устанавливается в
69: указатель на начало следующей команды (если исходная команда имеет более
70: одного задания, ассоциированного с ней) или NULL, если
71: больше нет команд.*/
72: int parseCommand(char **commandPtr, struct job *job, int *isBg) {
73: char *command;
74: char *returnCommand = NULL;
75: char *src, *buf;
76: int argc = 0;
77: int done = 0;
78: int argvAlloced;
79: char quote = '\0';
80: int count;
81: struct childProgram *prog;
82:
83: /* Пропустить ведущие пробелы */
84: while(**commandPtr && isspace(**commandPtr)) (*commandPtr)++;
85:
86: /* здесь обрабатываются пустые строки и ведущие символы '#' */
87: if (!**commandPtr || (**commandPtr=='#')) {
88: job->numProgs = 0;
89: *commandPtr = NULL;
90: return 0;
91: }
92:
93: *isBg = 0;
94: job->numProgs = 1;
95: job->progs = malloc(sizeof(*job->progs));
96:
97: /* Мы устанавливаем элементы argv в указатели внутри строки.
98: Память освобождается freeJob().
99:
100: Получение чистой памяти позволяет далее иметь дело с
101: NULL-завершающимися вещами и делает все остальное немного
102: яснее (к тому же, это добавляет эффективности) */
103: job->cmdBuf = command = calloc(1, strlen(*commandPtr) + 1);
104: job->text = NULL;
105:
106: prog = job->progs;
107:
108: argvAlloced = 5;
109: prog->argv = malloc(sizeof(*prog->argv) * argvAlloced);
110: prog->argv[0] = job->cmdBuf;
111:
112: buf = command;
113: src = *commandPtr;
114: while (*src && !done) {
115: if (quote==*src) {
116: quote='\0';
117: } else if (quote) {
118: if (*src == '\\') {
119: src++;
120: if (!*src) {
121: fprintf(stderr,
122: "ожидается символ после\\\n");
123: freeJob(job);
124: return 1;
125: }
126:
127: /* в оболочке, "\'" должно породить \' */
128: if (*src != quote) *buf++='\\';
129: }
130: *buf++ = *src;
131: } else if (isspace(*src)) {
132: if (*prog->argv[argc]) {
133: buf++, argc++;
134: /* +1 здесь оставляет место для NULL,
135: которым завершается argv */
136: if ((argc+1) == argvAlloced) {
137: argvAlloced += 5;
138: prog->argv = realloc(prog->argv,
139: sizeof(*prog->argv)*argvAlloced);
140: }
141: prog->argv[argc]=buf;
142: }
143: } else switch(*src) {
144: case '"':
145: case '\'':
146: quote = *src;
147: break;
148:
149: case '#' : /* комментарий */
150: done=1;
151: break;
152:
153: case '&': /* фоновый режим */
154: *isBg = 1;
155: case ';': /* множественные команды */
156: done=1;
157: return Command = *commandPtr + (src - *commandPtr) + 1;
158: break;
159:
160: case '\\' :
161: src++;
162: if (!*src) {
163: freeJob(job);
164: fprintf(stderr, "ожидается символ после \\\n");
165: return 1;
166: }
167: /* двигаться дальше */
168: default:
169: *buf++=*src;
170: }
171:
172: src++;
173: }
174:
175: if (*prog->argv[argc]) {
176: argc++;
177: }
178: if (!argc) {
179: freeJob(job);
180: return 0;
181: }
182: prog->argv[argc]=NULL;
183:
184: if (!returnCommand) {
185: job->text = malloc(strlen(*commandPtr) + 1);
186: strcpy(job->text,*commandPtr);
187: } else {
188: /* Это оставляет хвостовые пробелы, что несколько излишне */
189:
190: count = returnCommand - *commandPtr;
191: job->text = malloc(count + 1);
192: strncpy(job->text,*commandPtr,count);
193: job->text[count] = '\0';
194: }
195:
196: *commandPtr = returnCommand;
197:
198: return 0;
199: }
200:
201: int runCommand(struct jobnewJob, struct jobSet *jobList,
202: intinBg) {
203: struct job *job;
204:
205: /* обходной путь "вручную" - мы не используем fork(),
206: поэтому не можем легко реализовать фоновый режим */
207: if (!strcmp(newJob.progs[0].argv[0], "exit")) {
208: /* это должно вернуть реальный код возврата */
209: exit(0);
210: } else if(!strcmp(newJob.progs[0].argv[0], "jobs")) {
211: for (job = jobList->head; job; job = job->next)
212: printf(JOB_STATUS_FORMAT, job->jobId, "Работаю",
213: job->text);
214: return 0;
215: }
216:
217: /* у нас пока только одна программа на дочернее задание,
218: потому это просто */
219: if (!(newJob.progs[0].pid = fork())) {
220: execvp(newJob.progs[0].argv[0],newJob.progs[0].argv);
221: fprintf(stderr, "exec() для %s потерпела неудачу: %s\n",
222: newJob.progs[0].argv[0],
223: strerror(errno));
224: exit(1);
225: }
226:
227: /* поместить дочернюю программу в отдельную группу процессов */
228: setpgid(newJob.progs[0].pid,newJob.progs[0].pid);
229:
230: newJob.pgrp = newJob.progs[0].pid;
231:
232: /* найти идентификатор для задания */
233: newJob.jobld = 1;
234: for (job = jobList->head; job; job = job->next)
235: if (job->jobId >= newJob.jobId)
236: newJob.jobId = job->jobId+1;
237:
238: /* задание для списка заданий */
239: if (!jobList->head) {
240: job = jobList->head = malloc(sizeof(*job));
241: } else {
242: for (job = jobList->head; job->next; job = job->next);
243: job->next = malloc(sizeof(*job));
244: job = job->next;
245: }
246:
247: *job = newJob;
248: job->next = NULL;
249: job->runningProgs = job->numProgs;
250:
251: if (inBg) {
252: /* мы не ждем завершения фоновых заданий - добавить
253: в список фоновых заданий и оставить в покое */
254:
255: printf("[%d]%d\n", job->jobId,
256: newJob.progs[newJob.numProgs-1].pid);
257: } else {
258: jobList->fg=job;
259:
260: /* переместить новую группу процессов на передний план */
261:
262: if (tcsetpgrp(0,newJob.pgrp))
263: perror("tcsetpgrp");
264: }
265:
266: return 0;
267: }
268:
269: void removeJob(struct jobSet *jobList, struct job *job) {
270: struct job *prevJob;
271:
272: freeJob(job);
273: if (job == jobList->head) {
274: jobList->head=job->next;
275: } else {
276: prevJob = jobList->head;
277: while (prevJob->next != job) prevJob = prevJob->next;
278: prevJob->next=job->next;
279: }
280:
281: free(job);
282: }
283:
284: /* Проверить, завершился ли какой-то из фоновых процессов -
285: если да, выяснить, почему и определить, завершилось ли задание */
286: void checkJobs(struct jobSet *jobList) {
287: struct job *job;
288: pid_t childpid;
289: int status;
290: int progNum;
291:
292: while ((childpid = waitpid(-1, &status, WNOHANG))>0) {
293: for (job = jobList->head;job;job = job->next) {
294: progNum = 0;
295: while (progNum<job->numProgs &&
296: job->progs[progNum].pid != childpid)
297: progNum++;
298: if (progNum<job->numProgs) break;
299: }
300:
301: job->runningProgs--;
302: job->progs[progNum].pid = 0;
303:
304: if (!job->runningProgs) {
305: printf(JOB_STATUS_FORMAT,job->jobId,"Готово",
306: job->text);
307: removeJob(jobList, job);
308: }
309: }
310:
311: if (childpid == -1 && errno!= ECHILD)
312: perror("waitpid");
313: }
314:
315: int main(int argc, const char **argv) {
316: char command [MAX_COMMAND_LEN + 1];
317: char *nextCommand = NULL;
318: struct jobSetjobList = {NULL, NULL};
319: struct jobnewJob;
320: FILE *input = stdin;
321: int i;
322: int status;
323: int inBg;
324:
325: if (argc>2) {
326: fprintf(stderr,"Непредвиденные аргументы; использование: ladsh1 "
327: "<команды>\n");
328: exit(1);
329: } else if (argc == 2) {
330: input = fopen(argv[1], "r");
331: if (!input) {
332: perror("fopen");
333: exit(1);
334: }
335: }
336:
337: /* не обращать внимания на этот сигнал; он только вводит
338: в заблуждение и не имеет особого значения для оболочки */
339: signal(SIGTTOU, SIG_IGN);
340:
341: while(1) {
342: if (!jobList.fg) {
343: /* нет заданий переднего плана */
344:
345: /* проверить, завершились ли какие-то фоновые процессы */
346: checkJobs(&jobList);
347:
348: if (!nextCommand) {
349: if (getCommand(input, command)) break;
350: nextCommand=command;
351: }
352:
353: if (!parseCommand(&nextCommand, &newJob, &inBg) &&
354: newJob.numProgs) {
355: runCommand(newJob,&jobList,inBg);
356: }
357: } else {
358: /* задание выполняется на переднем плане; ждать завершения */
359: i = 0;
360: while (!jobList.fg->progs[i].pid) i++;
361:
362: waitpid(jobList.fg->progs[i].pid,&status,0);
363:
364: jobList.fg->runningProgs--;
365: jobList.fg->progs[i].pid=0;
366:
367: if (!jobList.fg->runningProgs) {
368: /* дочернее завершилось */
369:
370: removeJob(&jobList, jobList.fg);
371: jobList.fg = NULL;
372:
373: /* переместить оболочку на передний план */
374: if (tcsetpgrp(0, getpid()))
375: perror("tcsetpgrp");
376: }
377: }
378: }
379:
380: return 0;
381: }
Эта версия не делает ничего, кроме запуска внешней программы с аргументами, поддержки комментариев стиля
# (все, что следует за символом
#, игнорируется), и позволяет программам выполняться в фоновом режиме. Она работает как интерпретатор простых сценариев оболочки, написанных в нотации
#!, но ничего сверх этого не делает. Она разработана в качестве имитации обычного интерпретатора оболочки, используемого в системах Linux, несмотря на то, что в значительной степени упрощена.
Прежде всего, взглянем на структуры данных, которые здесь используются. На рис. 10.2 показаны структуры данных, используемые в
ladsh1.с для отслеживания запускаемых дочерних процессов, на примере применения программы
grep в фоновом режиме и
links — в режиме переднего плана,
struct jobSet описывает набор функционирующих заданий. Он содержит связный список заданий и указатель на текущее задание, выполняемое на переднем плане. Если такового нет, то указатель равен
NULL,
ladsh1.с использует
struct jobSet для того, чтобы отслеживать задания, выполняемые в данный момент в фоновом режиме.
 Рис. 10.2
Рис. 10.2. Структуры данных, описывающие задания для
ladsh1.с
struct childProgram описывает отдельную выполняемую программу. Это не совсем то же самое, что задание — в конце концов, каждое задание может состоять из нескольких программ, связанных по программным каналам. Для каждой дочерней программы
ladsh отслеживает
pid, имя программы и аргументы командной строки. Первый элемент
argv,
argv[0], содержит имя запущенной программы, которое передается также потомку в виде первого аргумента.
Множество программ объединяется в одно задание с помощью
struct job. Каждое задание имеет уникальный идентификатор в оболочке, соответствующее количество программ, составляющих задание (хранимых в
progs, указателе на массив
struct childProgram), а также указатель на другое (следующее) задание, что позволяет объединять их вместе в связный список (который описывает
struct jobSet). Задание также отслеживает, сколько отдельных программ составляет его, и сколько их них все еще выполняются (поскольку не все компоненты задания могут завершаться одновременно). Остальные два члена —
text и
cmdBuf — служат в качестве буферов для хранения различных строк, которые используются структурами
struct childProgram, содержащимися в задании.
Большая часть
struct jobSet состоит из динамически распределенной памяти, которая должна быть освобождена по завершении задания. Первая функция в
ladsh1.с,
freeJob(), освобождает память, использованную заданием.
Следующая функция,
getCommand(), получает команду, введенную пользователем, и возвращает строку. Если команды читаются из файла, то никакого приглашения не выводится (вот почему код сравнивает входной файловый поток со
stdin).
parseCommand() разбивает строку команды в структуру
struct job для использования в
ladsh. Первый аргумент — это указатель на указатель на команду. Если в строке множество команд, он переставляется на начало следующей команды. Он устанавливается в
NULL, когда завершается разбор последней команды в строке. Это позволяет
parseCommand() разбирать только одну команду при каждом вызове и дает возможность вызывающей функции просто разбирать строку за несколько вызовов. Следует отметить, что несколько программ, объединенных каналами, не рассматриваются как отдельные команды — независимыми друг от друга считаются только команды, разделенные символами
; или
&. Поскольку
parseCommand() — это просто пример разбора строк, мы не будем углубляться в детали ее работы.
Функция
runCommand() отвечает за запуск отдельного задания. Она принимает структуру
struct job, описывающую запускаемое задание, список заданий, выполняющихся в данный момент, а также флаг, указывающий, должно ли задание выполняться в фоновом режиме или же на переднем плане.
Пока
ladsh не поддерживает каналов, поэтому каждое задание может состоять только из одной программы (хотя большая часть инфраструктуры, поддерживающей каналы, уже присутствует в
ladsh1.с). Если пользователь запускает
exit, происходит немедленный выход из программы. Это пример
встроенной команды, которую выполняет сама оболочка для обеспечения правильного поведения. Другая встроенная команда —
jobs — также здесь реализована.
Если же команда не является встроенной, необходимо выполнить дочернюю команду. Поскольку каждое задание состоит только из одной программы (до тех пор, пока не будут реализованы каналы), это сделать достаточно просто.
219: if (!(newJob.progs[0].pid = fork())) {
220: execvp(newJob.progs[0].argv[0], newJob.progs[0].argv);
221: fprintf(stderr, "exec() для %s потерпела неудачу: %s\n",
222: newJob.progs[0].argv[0],
223: strerror(errno));
224: exit(1);
225: }
Во-первых, с помощью
fork() порождается дочерний процесс. Родитель сохраняет идентификатор pid дочернего процесса в
newJob.progs[0].pid, тогда как дочерний процесс сохраняет там
0 (помните, что родитель и потомок имеют разные образы памяти, хотя изначально они и содержат одинаковую информацию). В результате управление в дочернем процессе входит в тело оператора
if, в то время как родитель пропускает его. Дочерний немедленно запускает новую программу с помощью вызова
execvp(). Если ему этот вызов не удается, печатается сообщение об ошибке и работа завершается. Это все необходимо, чтобы породить простой дочерний процесс.
После порождения дочернего процесса родитель помещает его в его собственную группу и записывает задание в список запущенных заданий. Если процесс должен выполняться на переднем плане (не в фоне), родитель вносит дочерний процесс в группу процессов переднего плана управляющего терминала, на котором работает командная оболочка.
Следующая функция,
checkJobs(), ищет фоновые задания, которые были завершены, и соответствующим образом чистит список работающих заданий. Для каждого процесса, который был завершен (помните, что
waitpid() возвращает только информацию о завершенных процессах, если только не было указано
WUNTRACED), оболочка делает следующие вещи.
1. Ищет задание, частью которого является процесс.
2. Помечает программу как завершенную (устанавливая сохраненный pid равным 0) и уменьшает количество работающих программ в задании на единицу.
Если задание, содержавшее завершенный процесс, не имеет других работающих процессов, что всегда верно для данной версии
ladsh, оболочка печатает сообщение пользователю о том, что процесс завершен, и удаляет задание из списка фоновых процессов.
Процедура
main() из
ladsh1.с контролирует поток управления оболочки. Если при ее запуске
ей передан аргумент, он трактуется как имя файла, из которого нужно читать последовательность команд. В противном случае в качестве источника команд используется
stdin. Затем программа игнорирует сигнал
SIGTTOU. Это элемент "магии" управления заданиями, который обеспечивает, что все происходит гладко. Смысл этого будет пояснен в главе 15. Пока что это только скелет.
Остаток функции
main() составляет главный цикл программы. Условие выхода из цикла не предусмотрено. Программа завершается вызовом
exit() внутри функции
runCommand().
Переменная
nextCommand указывает на исходное (не разобранное) строковое представление следующей команды, которая должна быть выполнена, либо
NULL, если команда должна быть прочитана из входного файла, коим обычно является
stdin. Когда никакое задание не выполняется на переднем плане,
ladsh вызывает
checkJobs() для проверки выполняющихся фоновых заданий, читает следующую команду из входного файла, если
nextCommand равно
NULL, затем разбирает и выполняет следующую команду.
Когда выполняется задание переднего плана,
ladsh1.с ожидает завершения одного из процессов задания переднего плана. Когда все процессы задания переднего плана завершены, задание исключается из списка запущенных заданий и
ladsh1.с читает следующую команду, как описано выше.
10.8. Создание клонов
Хотя
fork() является традиционным способом создания новых процессов в Unix, Linux также предлагает системный вызов
call(), позволяющий процессам дублироваться с указанием ресурсов, которые родительский процесс должен разделять со своими потомками.
int clone(int flags);
Это ненамного отличается от
fork(). Единственная разница в наличии параметра
flags. Он должен быть установлен равным сигналу, который посылается родительскому процессу, когда потомок завершает работу (обычно это
SIGCHLD), объединенному логическим "или" с любым сочетанием перечисленных ниже флагов, определенных в
<sched.h>.
CLONE_VM |
Два процесса разделяют пространство виртуальной памяти (включая стек). |
CLONE_FS |
Разделяется информация файловой системы (такая как текущий каталог). |
CLONE_FILES |
Разделяются открытые файлы. |
CLONE_SIGHAND |
Обработчики сигналов разделяются двумя процессами. |
Когда ресурсы разделяется двумя процессами, оба они видят эти ресурсы идентично. Если указан
CLONE_SIGHAND, то когда один процесс заменяет обработчик определенного сигнала, оба начинают использовать новый обработчик (подробности об обработчиках сигналов представлены в главе 12). Когда используется
CLONE_FILES, разделяются не только наборы открытых файлов, но также текущие позиции в каждом файле. Значения возврата для
clone() те же самые, что и у
fork().
Если для доставки родительскому процессу специфицирован сигнал, отличный от
SIGCHLD, то семейство функций
wait() по умолчанию не будет возвращать информацию об этих процессах. Если вы хотите получать информацию об этих процессах, как и в случае процессов, использующих нормальный механизм
SIGCHLD, то флаг
__WCLONE должен быть объединен с помощью логического "или" с параметром
flags вызова
wait(). Хотя такое поведение может показаться странным, оно обеспечивает большую гибкость. Если бы функция
wait() возвращала информацию о клонированных процессах, было бы сложнее построить стандартные библиотеки потоков вокруг
clone(), потому что
wait() должна возвращать информацию о других потоках, а также о дочерних процессах.
Хотя и не рекомендуется, чтобы приложения непосредственно использовали
clone(), доступно множество библиотек пространства пользователя, которые применяют
clone() и предоставляют полностью POSIX-совместимую реализацию потоков. Библиотека
glibc включает
libthread — наиболее популярную реализацию потоков. Теме программирования потоков POSIX посвящено несколько хороших книг, среди которых [4] и [23].
Глава 11
Простое управление файлами
Файлы — это наиболее распространенная абстракция ресурсов, используемая в мире Unix. Такие ресурсы, как память, дисковое пространство, устройства и каналы межпроцессного взаимодействия (IPC), могут быть представлены в виде файлов. Поддерживая унифицированную абстракцию для этих ресурсов, Unix уменьшает количество программных интерфейсов, которые обязан знать программист. Ниже перечислены ресурсы, доступные через файловые операции.
•
Обычные файлы. Это то, о чем большинство пользователей компьютеров думают как о файлах. Они служат репозиториями данных, которые могут расти до необходимых размеров, и обеспечивают произвольный доступ. Файлы Unix являются байт-ориентированными — любое другое логическое представление является результатом программных преобразований; ядро ничего не знает о них.
•
Каналы (pipes). Простейший механизм IPC в Unix. Обычно один процесс пишет информацию в канал в то время как другой читает из него. Каналы — это то, что командные оболочки используют для перенаправления ввода-вывода (например,
ls -LR | grep notes или
ls | more), и многие программы применяют каналы для того, чтобы передавать свой ввод программам, запущенным в виде их подпроцессов. Существуют два типа каналов: именованные и неименованные.
Неименованные каналы создаются по мере необходимости и исчезают, как только читатель и писатель на концах канала закрывают его. Неименованные каналы называются так, потому что они не существуют в файловой системе и потому не имеют файловых имен
[36].
Именованные каналы обладают именами файлов, и имя файла используется для того, чтобы позволить двум независимым процессам общаться через канал (подобно тому, как работают сокеты доменов Unix (см. главу 17)). Каналы также известны как FIFO (first-in-first-out), потому что данные упорядочены в манере "первым вошел — первым вышел".
•
Каталоги. Специальные файлы, которые содержат списки файлов, хранящихся внутри них. Старые реализации Unix позволяли программам читать и писать их в той же манере, что и обычные файлы. Чтобы обеспечить большую степень абстракции, добавлен специальный набор системных вызовов для обеспечения манипуляций каталогами, хотя каталоги по-прежнему открываются и закрываются подобно обычным файлам. Эти функции рассматриваются в главе 14.
•
Файлы устройств. Большинство физических устройств представлены в виде файлов. Есть два типа файлов устройств: блочные устройства и символьные устройства. Файлы блочных устройств представляют аппаратные устройства
[37], которые не могут быть прочитаны побайтно; они должны читаться блоками определенного размера. В Linux блочные устройства принимают специальное управление от ядра
[38]и могут содержать файловые системы
[39]. Дисковые приводы, включая CD-ROM и RAM-диски, являются наиболее часто используемыми блочными устройствами.
Символьные устройства могут быть прочитаны по одному символу за раз, и ядро не представляет для них никаких средств кэширования или упорядочивания. Модемы, терминалы, принтеры, звуковые карты и мыши — все это символьные устройства. Традиционно к каждому из них привязана некая сущность в каталоге
/dev, что позволяет пользовательским процессам получать доступ к ресурсам устройств как к файлам.
•
Символические ссылки. Специальный тип файла, который содержит путь к другому файлу. Когда открывается символическая ссылка, система распознает ее как ссылку, читает ее значение и открывает файл, на который она ссылается, вместо самой ссылки. Когда используется значение, сохраняемое в символической ссылке, говорят, что система
следует по ссылке. Если не указано другое, предполагается, что системные вызовы следуют по ссылкам, которые переданы им.
•
Сокеты. Подобно каналам, сокеты представляют собой каналы IPC. Они более гибки, чем каналы, и могут создавать IPC-каналы между процессами, запущенными на разных машинах. Сокеты обсуждаются в главе 17.
Во многих операционных системах отношение между файлами и файловыми именами построены по принципу соответствия "один к одному". Каждый файл имеет имя в файловой системе, и каждое имя отображается на один файл. Unix разделяет эти две концепции, обеспечивая более высокую гибкость.
Единственной уникальной отличительной чертой файла является его inode (от
information node — информационный узел). Информационный узел файла содержит всю информацию о файле, включая права доступа, ассоциированные с ним, его текущий размер, количество имен, которые он имеет (оно может быть равно нулю, одному, двадцати или больше). Существуют два типа информационных узлов, in-core inode (информационный узел в ядре) — единственный тип, о котором нам нужно заботиться; каждый открытый файл в системе имеет его. Ядро отслеживает такие узлы в памяти, и они одинаковы для файловых систем всех типов. Другой тип узлов — on-disk inode (информационный узел на диске). Каждый файл в файловой системе имеет такой узел, и его точная структура зависит от типа файловой системы, в которой хранится файл.
Когда процесс открывает файл в файловой системе, on-disk inode загружается в память и превращается в in-core inode. Когда последний модифицируется, он трансформируется обратно в on-disk inode и сохраняется в файловой системе
[40].
in-core inode и on-disk inode не содержат абсолютно одинаковую информацию. Так, например, только in-core inode отслеживает, сколько процессов в системе в данный момент используют файл, ассоциированный с ним.
Когда in-core inode и on-disk inode синхронизируются ядром, большинство системных вызовов завершаются обновлением этих узлов. Когда такое происходит, мы просто будем говорить об обновлении узла; это подразумевает, что изменением затронуты как in-core inode, так и on-disk inode. Некоторые файлы (такие как неименованные каналы), не имеют on-disk inode. В этом случае обновляется только in-core inode.
Имя файла существует только в каталоге, который связывает имя с on-disk inode. Вы можете воспринимать об именах файлов, как об указателях на дисковые узлы для файлов, ассоциированных с ними. Дисковый узел содержит в счетчике ссылок количество имен файлов, которые на него ссылаются. Когда файл удаляется, счетчик ссылок уменьшается на единицу, и если достигает 0, и ни один процесс не держит его открытым, то занятое файлом пространство освобождается. Если же другие процессы держат файл открытым, дисковое пространство освобождается тогда, когда последний из них закрывает файл.
Все это делает доступными следующие возможности.
• Можно иметь множество процессов, имеющих доступ к файлу, который не существует в файловой системе (такому, например, как канал).
• Можно создать файл на диске, удалить его вход в каталоге и продолжать выполнять чтение и запись файла.
• Можно изменить
/tmp/foo и немедленно увидеть изменения в
/tmp/bar, если оба имени файла ссылаются на один узел.
Система Unix всегда работала описанным образом, хотя эти операции и могут привести в замешательство новых пользователей и программистов. До тех пор, пока вы помните, что имя файла — это всего лишь указатель на дисковый узел, а сам узел — реальный ресурс, с вами все будет в порядке.
11.1. Режим файла
Каждый файл в системе имеет как тип (вроде неименованного канала или символьного устройства), так и набор прав доступа, определяющих, какие процессы могут иметь доступ к файлу. Тип файла и права доступа комбинируются в 16-битное значение (тип
short в С), называемое
режимом файла (file mode).
Младшие 12 бит режима файла представляют права, регламентирующие доступ к файлу, или модификаторы доступа. Они служат для множества функций. Наиболее важной функцией является возможность изменять идентификатор эффективного пользователя и идентификаторы групп файла при его выполнении.
Режим файла обычно записывается в виде шести восьмеричных разрядов. Представленные в восьмеричном виде, три младших разряда содержат модификаторы доступа файла, а два старших разряда указывают на его тип. Например, файл с режимом 0041777 имеет тип 04, модификатор прав 1 и биты доступа 0777
[41]. Аналогично, файл с режимом 0100755 имеет тип 010, не имеет установленного модификатора доступа, а правами доступа к нему являются 0755.
11.1.1. Права доступа к файлу
Каждый из этих трех разрядов доступа представляет права для разных классов пользователей. Первый разряд — это права владельца файла, второй — права пользователей, входящих в группу, к которой относится файл, а последний разряд представляет права доступа для всех остальных пользователей. Каждый восьмеричный разряд образован из трех бит, представляющих права на чтение, на запись и на выполнение — от более значащего к менее значащему биту. Термин
мировой доступ (world permission) обычно используется для обозначения прав, представленных всем трем классам пользователей.
Попробуем немного конкретизировать последний абзац с помощью нескольких примеров. Команда Linux
chmod дает возможность пользователю специфицировать режим доступа в восьмеричном виде и затем применить его к одному или более файлам. Если имеется файл
somefile, который мы хотим сделать доступным для записи только его владельцу, а всем пользователям (включая владельца) разрешить его чтение, мы должны использовать режим 0644 (помните, это восьмеричные цифры). Ведущая цифра 6 — это в двоичном виде 110, а это означает, что тип пользователя, к которому она относится (в данном случае — владелец), имеет право как читать, так и писать в файл; 4 в двоичном виде выглядит как 010, что дает остальным пользователям (членам группы и прочим) права только для чтения.
$ chmod 0644 somefile
$ ls -l somefile
-rw-r--r-- 1 ewt devel 31 Feb 15 15:12 somefile
Если мы хотим позволить любому члену группы
devel писать в файл, то должны использовать режим 0664.
$ chmod 0664 somefile
$ ls -l somefile
-rw-rw-r-- 1 ewt devel 31 Feb 15 15:12 somefile
Если
somefile —
сценарий оболочки (программы, которые используют
#! в начале для указания командного интерпретатора), который мы хотим запускать на выполнение, необходимо сообщить системе, что файл является исполняемым, включив бит выполнения — в данном случае мы позволяем владельцу читать, писать и запускать файл, а членам группы
devel — читать и запускать этот файл. Всем другим пользователям запрещено манипулировать файлом любым образом.
$ chmod 0750 somefile
$ ls -l somefile
-rwxr-x--- 1 ewt devel 31 Feb 15 15:12 somefile
Каталоги имеют тот же набор бит доступа, что и нормальные файлы, но со слегка отличающейся семантикой. Права чтения разрешают процессам доступ к самому каталогу, что дает возможность пользователям получать список содержимого каталога. Права на запись позволяют процессу создавать новые файлы в каталоге и удалять существующие. Бит выполнения, однако, не транслируется так однозначно (что вообще должно означать выполнение каталога?). Это позволяет процессу осуществлять
поиск в каталоге, а это означает, что он может иметь доступ к файлу в каталоге, если он знает имя этого файла.
Большинство системных каталогов на машинах Linux имеют права доступа 0755 и принадлежат пользователю root. Это дает возможность пользователям системы просматривать файлы в каталоге и получать доступ к ним по имени, но разрешает запись в каталоги только пользователю root. Анонимные ftp-сайты, которые позволяют любому пользователю отправлять файлы, но не дают возможность им загружать их до тех пор, пока администратор не просмотрит их содержимое, обычно устанавливают права на входящие каталоги в значение 0722. Это позволяет всем пользователям создавать новые файлы в каталоге, не предоставляя им возможность ни видеть содержимое каталога, ни получать доступа к файлам.
Дополнительную информацию о правах доступа к файлам можно найти в любой книге по Linux или Unix.
11.1.2. Модификаторы прав доступа к файлам
Модификаторы прав доступа файлов — это также битовые маски, значения которых представляют биты setuid, setgid и sticky-бит ("липкий" бит). Если бит setuid установлен для исполняемого файла, то эффективный идентификатор пользователя процесса устанавливается равным идентификатору владельца файла, когда программы выполняется (в главе 10 можно найти информацию о том, почему это удобно). Бит setgid ведет себя аналогичным образом, но устанавливает эффективный идентификатор группы в значение группы файла. Бит setuid не имеет значения для неисполняемых файлов, но если бит setgid устанавливается для неисполняемого файла, любая блокировка, выполняемая над файлом, носит обязательный, а не рекомендательный характер (см. главу 13). В Linux биты setuid и setgid игнорируются для сценариев оболочки, поскольку устанавливать setuid для сценариев было бы опасно.
Ни setuid, ни setgid не имеют очевидного смысла для каталогов. И setuid действительно не имеет семантики установки для каталогов. Если же для каталога установлен бит setgid, то все новые файлы, созданные в этом каталоге, будут принадлежать к той же группе, которая владеет самим каталогом. Это облегчает применение каталогов для организации совместной работы пользователей.
Sticky-бит — последний значащий бит в разряде модификатора доступа к файлу, имеет интересную историю, связанную с его наименованием. Старые реализации Unix должны были загружать в память всю программу целиком, прежде чем начать выполнять ее. Это означало, что крупные программы отнимали значительное время на запуск, что было довольно-таки неприятно. Если же программа имела установленный sticky-бит, то операционная система пыталась сохранить ее "привязанной" в памяти настолько долго, насколько возможно, даже когда эта программа не запущена, чтобы уменьшить время запуска. Хотя это было немного некрасиво, но работало достаточно хорошо с часто используемыми программами, такими как компилятор С. Современные реализации Unix, включая Linux, используют загрузку по требованию — кусочек за кусочком, что сделало sticky-бит излишним, поэтому Linux игнорирует его для обычных файлов.
Sticky-бит по-прежнему используется для каталогов. Обычно любой пользователь с правами записи в каталог может удалить любой файл в этом каталоге. Однако если sticky-бит каталога установлен, файлы могут быть удалены только пользователем-владельцем либо пользователем root. Такое поведение удобно, если каталог служит репозиторием для файлов, созданных многими пользователями, например,
/tmp.
Последний раздел режима файла указывает тип файла. Он содержится в старших восьмеричных разрядах и не является битовой маской. Вместо этого значение этих разрядов равно специфическому типу файлов (04 означает каталог, 06 — блочное устройство). Тип файла устанавливается при его создании. Он никогда не может быть изменен, кроме как посредством удаления файла.
Включаемый файл
<sys/stat.h> представляет символические константы для всех этих битов доступа, что делает код более читабельным. Пользователи Unix и Linux обычно чувствуют себя увереннее с восьмеричными представлениями режимов файла, поэтому обычно в программах используются восьмеричные представления непосредственно. В табл. 11.1 перечислены символические имена прав и модификаторов доступа к файлам.
Таблица 11.1. Константы прав доступа к файлам
| Имя |
Значение |
Описание |
S_ISUID |
0004000 |
Программа является setuid-программой. |
S_ISGID |
0002000 |
Программа является setgid-программой. |
S_ISVTX |
0001000 |
Sticky-бит. |
S_IRWXU |
00700 |
Владелец файла имеет права на чтение, запись и выполнение. |
S_IRUSR |
00400 |
Владелец файла имеет права на чтение. |
S_IWUSR |
00200 |
Владелец файла имеет права на запись. |
S_IXUSR |
00100 |
Владелец файла имеет права на выполнение. |
S_IRWXG |
00070 |
Группа файла имеет права на чтение, запись и выполнение. |
S_IRGRP |
00040 |
Группа файла имеет права на чтение. |
S_IWGRP |
00020 |
Группа файла имеет права на запись. |
S_IXGRP |
00010 |
Группа файла имеет права на выполнение. |
S_IRWXO |
00007 |
Прочие пользователи имеют права на чтение, запись и выполнение. |
S_IROTH |
00004 |
Прочие пользователи имеют права на чтение. |
S_IWOTH |
00002 |
Прочие пользователи имеют права на запись. |
S_IXOTH |
00001 |
Прочие пользователи имеют права на выполнение. |
11.1.3. Типы файлов
Старшие четыре бита режима файла указывают тип файла. В табл. 11.2 перечислены константы, имеющие отношение к типам файлов. Объединение с помощью битовой операции "И" любых этих констант с режимом файла порождает ненулевое значение, если бит установлен.
Таблица 11.2. Константы типов файлов
| Имя |
Значение (восьмеричное) |
Описание |
S_IFMT |
00170000 |
Это значение, побитно объединенное с режимом с помощью операции "И", дает тип файла (который эквивалентен одному из остальных значений S_IF). |
S_IFSOCK |
0140000 |
Файл является сокетом. |
S_IFLNK |
0120000 |
Файл является символической ссылкой. |
S_IFREG |
0100000 |
Файл является обычным файлом. |
S_IFBLK |
0060000 |
Файл представляет блочное устройство. |
S_IFDIR |
0040000 |
Файл является каталогом. |
S_IFCHR |
0020000 |
Файл представляет символьное устройство. |
S_IFIFO |
0010000 |
Файл представляет коммуникационный канал "первый вошел — первый вышел". |
Описанные ниже макросы принимают в качестве аргумента режим файла и возвращают
true или
false.
S_ISLINK(m) |
Истинно, если файл является символической ссылкой. |
S_ISREC(m) |
Истинно, если файл является обычным файлом. |
S_ISDIR(m) |
Истинно, если файл является каталогом. |
S_ISCHR(m) |
Истинно, если файл представляет символьное устройство. |
S_ISBLK(m) |
Истинно, если файл представляет блоковым устройство. |
S_ISFIFO(m) |
Истинно, если файл является каналом "первый вошел — первый вышел" |
S_ISSOCK(m) |
Истинно, если файл является сокетом. |
11.1.4. Маска umask процесса
Права доступа, назначаемые вновь созданным файлам, зависят как от настроек системы, так и от предпочтений конкретного пользователя. Чтобы помочь индивидуальным программам, которые нуждаются в предположениях об использовании файла, система дает возможность пользователям отключить отдельные привилегии для вновь создаваемых файлов (и каталогов, которые являются специальными файлами). Каждый процесс имеет маску
umask, определяющую отключенные биты привилегий для создания файлов. Это позволяет процессу специфицировать достаточно либеральные права (обычно это касается общих прав на чтение и запись) и обеспечивать права, которые пользователь предпочитает. Если определенный файл особо важен, процесс создания может включать назначение более ограниченных прав, чем обычно, потому что umask никогда не влияет на менее строгие ограничения прав, а только на более строгие.
Текущая установка umask для процесса выполняется системным вызовом
umask().
#include <sys/stat.h>
int umask(int newmask);
Возвращается старое значение и устанавливается новое значение umask процесса. Для файла могут быть указаны только права на чтение, запись и исполнение — вы не можете использовать umask для запрещения установки setuid, setgid или sticky-бита. Команда
umask представлена в большинстве командных процессоров и позволяет пользователю устанавливать umask для самой командной оболочки и всех его последующих дочерних процессов.
В качестве примера, команда
touch создает новые файлы с правами 0666 (общие права на чтение и запись). Так как пользователю подобное редко подходит, он может заставить команду
touch отключать общие и групповые права записи для файла с помощью команды
umask 022, как показано ниже.
$ umask 022
$ touch foo
$ ls -l foo
-rw-r--r-- 1 ewt ewt 0 Feb 24 21:24 foo
Если он предпочитает давать права на запись группе, то может вместо этого назначит
umask 002.
$ umask 002
$ touch foo
$ ls -l foo
-rw-rw-r-- 1 ewt ewt 0 Feb 24 21:24 foo
Если же он хочет, чтобы его файлы были доступны только ему, это обеспечит
umask 077.
$ umask 077
$ touch foo
$ ls -l foo
-rw------- 1 ewt ewt 0 Feb 24 21:24 foo
umask процесса влияет на системные вызовы
open(),
creat(),
mknod() и
mkdir().
11.2. Основные файловые операции
Поскольку значительная часть системных вызовов Linux манипулирует файлами, начнем с демонстрации наиболее широко используемых функций. Более специализированные функции обсудим далее в настоящей главе. Функции, применяемые для чтения каталогов, представлены в главе 14, чтобы сделать настоящую главу более краткой.
11.2.1. Файловые дескрипторы
Когда процесс получает доступ к файлу (что обычно называют
открытием файла), то ядро возвращает ему
файловый дескриптор, который затем используется процессом для всех операций с файлом. Файловые дескрипторы — это маленькие положительные целые числа, которые служат индексами массива открытых файлов, создаваемого ядром для каждого процесса.
Первые три файловых дескриптора для процессов (0, 1 и 2) имеют стандартное назначение. Первый, 0, известен как стандартный ввод (
stdin) и является местом, откуда программы должны получать свой интерактивный ввод. Файловый дескриптор 1 называется стандартным выводом (
stdout), и большая часть вывода программ должна быть направлена в него. Сообщения об ошибках должны направляться в стандартный поток ошибок (
stderr), который имеет файловый дескриптор 2. Стандартная библиотека С следует этим правилам, поэтому
gets() и
printf() используют stdin и stdout соответственно, и это соглашение дает возможность командным оболочкам правильно перенаправлять ввод и вывод процессов.
Заголовочный файл
<unistd.h> представляет макросы
STDIN_FILENO,
STDOUT_FILENO и
STDERR_FILENO, которые вычисляются как файловые дескрипторы stdin, stdout и stderr соответственно. Использование этих символических имен делает код более читабельным.
Многие из файловых операций, которые манипулируют файловыми узлами inode, доступны в двух формах. Первая форма принимает в качестве аргумента имя файла. Ядро использует этот аргумент для поиска inode файла и выполняет соответствующую операцию над ним (обычно это включает следование символическим ссылкам). Вторая форма принимает файловый дескриптор в качестве аргумента и выполняет операцию над inode, на который он ссылается. Эти два набора системных вызовов используют похожие имена, но системные вызовы, работающие с файловыми дескрипторами, имеют префикс
f. Например, системный вызов
chmod() изменяет права доступа для файла, ссылка на который осуществляется по имени;
fchmod() устанавливает права доступа к файлу, ссылаясь на него по указанному файловому дескриптору.
Чтобы меньше тратить слов, мы представим обе версии системных вызовов, если они существуют, а обсуждать будет только первую из их (та, которая использует имена файлов).
11.2.2. Закрытие файлов
Одной из операций, которые одинаковы для файлов всех типов, является закрытие файла. Ниже показано, как закрыть файл.
#include <unistd.h>
int close(int fd);
Очевидно, что это базовая операция. Однако есть один важный момент, касающийся закрытия файлов, о котором следует помнить — она может завершиться сбоем. Некоторые системы (в первую очередь, следует вспомнить сетевые файловые системы вроде NFS) не пытаются поместить последнюю порцию записываемых данных в файл до тех пор, пока он не будет закрыт. Если такая операция вызовет сбой (например, по причине недоступности удаленного хоста), то
close() вернет ошибку. Если ваше приложение пишет данные, но не синхронизирует записи (см. обсуждение
O_SYNC в следующем разделе), то вы всегда должны проверять результат закрытия файла. Если
close() дает сбой, то это значит, что обновленный файл поврежден самым непредсказуемым образом! К счастью подобное случается достаточно редко.
11.2.3. Открытие файлов в файловой системе
Хотя Linux предусматривает множество типов файлов, обычные файлы используются наиболее часто. Программы, конфигурационные файлы, файлы данных — все они подпадают под это определение, и многие приложения не могут (явно) использовать файлы любых других типов. Есть два способа открытия файла, который имеет ассоциированное с ним имя.
#include <fcntl.h>
#include <unistd.h>
int open(char *pathname, int flags, mode_t mode);
int creat(char *pathname, mode_t mode);
Функция
open() возвращает файловый дескриптор, указывающий на
pathname. Если возвращенное значение меньше нуля, значит, произошла ошибка (как всегда,
errno содержит код ошибки). Аргумент
flags описывает тип доступа, который нужен вызывающему процессу, а также управляет различными атрибутами открытия и манипулирования файлом. Режим доступа всегда должен быть указан, и он может быть одним из следующих:
O_RDONLY,
O_RDWR либо
O_WRONLY, что запрашивает доступ, соответственно, только по чтению, по чтению и записи либо только по записи. С этим режимом может быть объединены логическим "И" следующие значения для управления прочей семантикой файлов.
O_CREAT |
Если файл еще не существует, создать его как обычный файл. |
O_EXCL |
Этот флаг должен использоваться только с O_CREAT. Если он указан, то open() дает сбой в случае существования файла. Этот флаг позволяет реализовать простую блокировку, но не надежен при использовании в сетевых файловых системах типа NFS (подробно о блокировке файлов рассказывается в главе 13). |
O_NOCTTY |
Открываемый файл не становится управляющим терминалом процесса (см. главу 10). Этот флаг имеет значение только тогда, когда процесс, не имеющий управляющего терминала, открывает устройство tty. Если же он указан в любом другом случае, этот флаг игнорируется. |
O_TRUNC |
Если файл уже существует, его содержимое отбрасывается, и его размер устанавливается равным 0. |
O_APPEND |
Все операции записи выполняются в конец файла, хотя произвольный доступ по чтению также разрешен. |
O_NONBLOCK |
Файл открывается в неблокирующем режиме. Операции с нормальными файлами всегда блокируются, потому что они работают с локальными жесткими дисками, имеющими предсказуемое время отклика, но операции на некоторых типах файлов требуют непредсказуемого времени для завершения. Например, чтение из канала, в котором нет данных, блокирует процесс чтения до тех пор, пока данные в нем не появятся. Если же специфицирован флаг O_NONBLOCK, вызов read() вместо блокирования вернет ноль байт. Файлы, на операции с которыми может понадобиться непредсказуемый объем времени, называются медленными файлами. (Примечание. O_NDELAY — оригинальное имя O_NONBLOCK, теперь устаревшее.) |
O_SYNC |
Обычно ядро перехватывает операции записи и сбрасывает их на физическое устройство тогда, когда это удобно. Хотя такая реализация значительно повышает производительность, появляется также возможность потери данных, чем в том случае, когда они немедленно пишутся на диск. Если при открытии файла указан флаг O_SYNC, то все изменения в файле сохраняются на диске перед тем, как ядро возвращает управления процессу, выполняющему запись. Это очень важно для некоторых приложений, таких как системы управления базами данных, в которых принудительная запись используется для предотвращения повреждения данных в случае сбоя системы. |
Параметр
mode указывает права доступа для файла, если он создается и если он модифицируется текущей установкой
umask процесса. Если не указано
O_CREAT, то
mode игнорируется.
Функция
creat() в точности эквивалентна следующему вызову:
open(pathname, O_CREAT | O_WRONLY | O_TRUNC, mode)
Мы не используем
creat() в этой книге, потому что находим функцию
open() более простой для чтения и понимания.
11.2.4. Чтение, запись и перемещение
Хотя есть несколько способов читать и писать файлы, мы обсудим здесь только простейшие из них
[42]. Чтение и запись почти идентичны, поэтому рассмотрим их одновременно.
#include <unistd.h>
size_t read(int fd, void * buf, size_t length);
size_t read(int fd, const void * buf, size_t length);
Обе функции принимают файловый дескриптор
fd, указатель на буфер
buf и длину буфера
length,
read() читает из файлового дескриптора и помещает полученные данные в буфер;
write() пишет
length байт из буфера в файл. Обе функции возвращают количество переданных байт, или
-1 в случае ошибки (это означает, что ничего не было прочитано или записано).
Теперь, когда мы описали эти системные вызовы, рассмотрим простой пример, создающий файл
hw в текущем каталоге и записывающий в него строку "Добро пожаловать!".
1: /* hwwrite.с */
2:
3: #include <errno.h>
4: #include <fcntl.h>
5: #include <stdio.h>
6: #include <stdlib.h>
7: #include <unistd.h>
8:
9: int main(void) {
10: int fd;
11:
12: /* открыть файл, создавая его, если он не существовал, и удаляя
13: его содержимое в противном случае */
14: if ((fd = open("hw", O_TRUNC | O_CREAT | O_WRONLY, 0644)) < 0) {
15: perror("open");
16: exit(1);
17: }
18:
19: /* магическое число 18 - это кол-во символов, которые
20: будут записаны */
21: if (write(fd, "Добро пожаловать!\n", 18) != 18) {
22: perror("write");
23: exit(1);
24: }
25:
26: close(fd);
27:
28: return 0;
29: }
Ниже показано, что получится, если запустить
hwwrite.
$ cat hw
cat: hw: No such file or directory
cat: hw: Файл или каталог не существует
$ ./hwwrite
$ cat hw
Добро пожаловать!
$
Для изменения этой программы, чтобы она читала файл, нужно просто изменить
open(), как показано ниже, и заменить
write() статической строки на
read() в буфер.
open("hw", O_RDONLY);
Файлы Unix можно разделить на две категории: просматриваемые (seekable) и непросматриваемые (nonseekable)
[43]. Непросматриваемые файлы представляют собой каналы, работающие в режиме "первый вошел — первый вышел" (FIFO), которые не поддерживают произвольное чтение или запись, их данные не могут быть перечитаны или перезаписаны. Просматриваемые файлы позволяют читать и писать в произвольное место файла. Каналы и сокеты являются не просматриваемыми файлами; блоковые устройства и обычные файлы являются просматриваемыми.
Поскольку FIFO — это непросматриваемые файлы, то, очевидно, что
read() читает их с начала, a
write() пишет в конец. С другой стороны, просматриваемые файлы не имеют очевидной точки для этих операций. Вместо этого здесь вводится понятие "текущего" положения, которое перемещается вперед после операции. Когда просматриваемый файл изначально открывается, текущее положение устанавливается в его начало, со смещением 0. Если затем из него читается 10 байт, то текущее положение перемещается в точку со смещением 10 от начала, а запись 5 байт переписывает данные, начиная с одиннадцатого байта в файле (то есть, со смещения 10, где расположена текущая позиция после чтения). После такой записи текущая позиция находится в позиции, смещенной на 15 относительно начала файла — сразу после перезаписанных данных.
Если текущая позиция совпадает с концом файла и процесс пытается читать их этого файла, то
read() возвращает 0 вместо ошибки. Если же данные записываются в конец файла, то он растет с тем, чтобы вместить дополнительные данные, и его текущая позиция устанавливается в конец файла. Каждый файловый дескриптор отслеживает независимую текущую позицию
[44] (она не хранится в файловом inode), поэтому если файл открыт множество раз множеством процессов, или несколько раз одним и тем же процессом, то чтения и записи, выполняемые через один дескриптор, никак не влияют на позиции чтения и записи, выполненные через другой дескриптор. Конечно, множественные операции записи могут повредить файл другими способами, поэтому блокировка определенного рода в такой ситуации может понадобиться.
Файлы, открытые с флагом
O_APPEND ведут себя несколько иначе. Для таких файлов текущая позиция перемещается в конец файла перед тем, как ядро осуществит в него запись. После записи текущая позиция перемещается в конец записанных данных, как обычно. Для файлов, работающих в режиме только для добавления, это гарантирует, что текущая позиция файла всегда будет находиться в его конце немедленно после вызова
write().
Приложения, которые хотят читать и писать данные с произвольного места файла, должны установить текущую позицию перед выполнением операции чтения или записи данных, используя
lseek().
#include <unistd.h>
int lseek(int fd, off_t offset, int whence);
Текущая позиция для файла
fd перемещается на
offset байт относительно
whence, где whence принимает одно из следующих значений:
SEEK_SET[45] Начало файла.
SEEK_CUR Текущая позиция в файле.
SEEK_END Конец файла.
Для
SEEK_CUR и
SEEK_END значение
offset может быть отрицательным. В этом случае текущая позиция перемещается в сторону начала файла (от
whence), а не в сторону конца. Например, приведенный ниже код перемещает текущую позицию на 5 байт назад от конца файла.
lseek(fd, -5, SEEK_END);
Системный вызов
lseek() возвращает новую текущую позицию в файле относительно его начала, либо -1 в случае ошибки. То есть
lseek(fd, 0, SEEK_END) — это просто способ определения размера файла, но следует убедиться, что вы сбросили текущую позицию, прежде чем читать из
fd.
Хотя текущая позиция не разделяется другими процессами, которые одновременно имеют доступ к файлу
[46], это не значит, что множество процессов могут безопасно осуществлять совместную запись в файл. Пусть имеется следующая последовательность.
Процесс A Процесс B
lseek(fd, 0, SEEK_END);
lseek(fd, 0,SEEK_END);
write (fd, buf, 10);
write(fd, buf, 5);
В этом случае процесс А перепишет первые 5 байт данных, которые запишет процесс В, а это наверняка не то, чего вы хотели. Если множеству процессов нужно совместно писать данные в конец файла, должен быть использован флаг
O_APPEND, который делает эту операцию атомарной.
В большинстве систем POSIX процессам разрешается перемещать текущую позицию за конец файла. При этом файл увеличивается до соответствующего размера и его текущая позиция устанавливается в новый конец файла. Единственной ловушкой может быть то, что большинство систем при этом не выделяют никакого дискового пространства для той части файла, которая не была записана — они просто изменяют логический размер файла.
Части файлов, которые "создаются" подобным образом, называют "
дырками" (holes). Чтение из такой "дырки" в файле возвращает буфер, полный двоичных нулей, а запись в них может завершиться ошибкой по причине отсутствия свободного пространства на диске. Все это значит, что вызов
lseek() не должен применяться для резервирования дискового пространства для позднейшего использования, поскольку такое пространство может быть и не выделено. Если ваше приложение нуждается в выделении некоторого дискового пространства для последующего использования, вы должны применять
write(). Файлы с "дырками" часто используют для хранения редко расположенных в них данных, таких как файлы, представляющие хеш-таблицы.
Для простой демонстрации "дырок" в файлах, основанной на командной оболочке, рассмотрим следующий пример (
/dev/zero — это символьное устройство, которое возвращает столько двоичных нулей, сколько процесс пытается прочитать из него).
$ dd if=/dev/zero of=foo bs=1k count=10
10+0 records in
10+0 records out
$ ls -l foo
-rw-rw-r-- 1 ewt ewt 10240 Feb 6 21:50 foo
$ du foo
10 foo
$ dd if=/dev/zero of=bar bs=1k count=1 seek=9
1+0 records in
1+0 records out
$ ls -l bar
-rw-rw-r-- 1 ewt ewt 10240 Feb 6 21:50 foo
$ du bar
1 bar
$
Хотя оба файла — и
foo, и
bar — имеют длину в 10 Кбайт, файл
bar занимает только 1 Кбайт дискового пространства, потому что остальные 9 Кбайт были пропущены
seek(), когда файл был создан или записан.
11.2.5. Частичное чтение и запись
Хотя обе функции — и
read(), и
write() — принимают параметр, указывающий, сколько байт нужно прочитать или записать, ни одна из них не гарантирует, что обработает указанное количество байт, даже если не случается никаких ошибок. Простейший пример этого — попытки чтения из обычного файла, который уже позиционирован в конце. Система не может прочитать ни одного байта, но это в то же время не является ошибкой. Вместо этого
read() возвращает 0 байт. Точно так же, если текущая позиция находилась в 10 байт от конца файла, и была выполнена попытка прочитать из файла более 10 байт, то прочитано будет ровно 10 байт и вызов
read() вернет число 10. Опять-таки это не рассматривается как ошибочная ситуация.
Поведение
read() также зависит от того, был ли файл открыт с флагом
O_NONBLOCK. Для файлов многих типов
O_NONBLOCK не влияет ни на что. Файлы, для которых система может гарантировать завершенность операции в пределах разумного периода времени, всегда блокирует чтение и запись; такие файлы часто называют
быстрыми файлами. Это множество файлов включает локальные блочные устройства и обычные файлы. Для других типов файлов, таких как каналы, и символьных устройств вроде терминалов процесс может ожидать другого процесса (или человека), чтобы тот либо выполнил чтение, либо освободил ресурсы системы при обработке запроса на
write(). В обоих случаях система не имеет способа знать — будет ли вообще возможно дождаться завершения системного вызова. Когда такие файлы открываются с флагом
O_NONBLOCK, то для каждой операции с файлом система просто делает максимум того, что удается сделать немедленно, а затем возвращает управление вызывающему процессу.
Неблокирующий ввод-вывод — это важная тема, и больше примеров вы найдете в главе 13. После стандартизации системного вызова
poll(), однако, необходимость в нем (особенно при чтении) минимизирована. Если вам нужно интенсивно использовать неблокирующий ввод-вывод, попробуйте пересмотреть свою программу в терминах
poll(), чтобы увидеть, нельзя ли ее сделать более эффективной.
Чтобы показать конкретный пример чтения и записи файлов, приведем простую реализацию
cat. Она копирует стандартный поток ввода (stdin) на стандартный вывод (stdout) до тех пор, пока есть что копировать.
1: /* cat.с */
2:
3: #include <stdio.h>
4: #include <unistd.h>
5:
6: /* Пока есть данные на стандартном входе (fd0), копировать их в
7: стандартный выход (fd1). Выйти, когда не будет доступных данных. */
8:
9: int main(void) {
10: char buf[1024];
11: int len;
12:
13: /* len будет >= 0, пока доступны данные
14: и read() успешен */
15: while ((len = read(STDIN_FILENO, buf, sizeof(buf))) > 0) {
16: if (write(1, buf, len) != len) {
17: perror("write");
18: return 1;
19: }
20: }
21:
22: /* len будет <= 0; если len = 0, больше нет
23: доступных данных. Иначе - ошибка. */
24: if (len < 0) {
25: perror("read");
26: return 1;
27: }
28:
29: return 0;
30: }
11.2.6. Сокращение файлов
Хотя обычные файлы автоматически растут при записи данных в их конец, у системы нет способа автоматически усекать файлы, когда данные в конце не нужны. К тому же, как система может узнать, что данные стали излишними? Это находится в компетенции процесса — извещать систему о том, когда файл можно сократить до определенной точки.
#include <unistd.h>
int truncate(const char *pathname, size_t length);
int ftruncate(int fd, size_t length);
Размер файла устанавливается равным
length, и все данные, находящиеся за новым концом файла, теряются.
Если
length больше текущего размера файла, то файл увеличивается до заданного размера (по возможности используя "дырки"), хотя такое поведение и не гарантируется POSIX, поэтому на него нельзя полагаться при написании переносимых программ.
11.2.7. Синхронизация файлов
Когда программа пишет данные в файл, обычно они сохраняются в кэше ядра до тех пор, пока оно не выполнит запись на физический носитель (такой как жесткий диск), но ядро возвращает управление программе сразу после того, как данные скопируются в кэш. Это обеспечивает значительный рост производительности, так как позволяет ядру определять порядок записи на диск и объединять несколько записей в одну блочную операцию. Однако в случае системного сбоя у такой технологии есть два существенных недостатка, которые могут оказаться важными. Например, приложение, которое предполагает, что данные сохранены в базе данных прежде, чем был сохранен индекс для этих данных, может не справиться со сбоем, явившимся результатом того, что индекс был просто обновлен.
Есть несколько механизмов, которые может использовать приложение, чтобы дождаться записи данных на физический носитель. Флаг
O_SYNC, описанный ранее в этой главе, при каждой операции записи в файл вызывает блокирование вызывающего процесса до тех пор, пока носитель не будет действительно обновлен. Хотя это, конечно, работает, все же такой подход не является достаточно аккуратным. Обычно приложения не нуждаются в том, чтобы все операции были синхронизированы, гораздо чаще они нуждаются в том, чтобы гарантировать, что некий набор операций завершился перед тем, как может быть начат другой набор операций. Системные вызовы
fsync() и
fdatasync() обеспечивают такую семантику.
#include <unistd.h>
int fsync(int fd);
int fdatasync(int fd);
Оба системных вызова приостанавливают приложение до тех пор, пока в файл
fd не будут записаны все данные,
fsync() также ожидает обновления информации в inode файла, подобной времени доступа (информация inode для файлов перечислена в табл. 11.3). Однако ни один из этих вызовов не гарантирует записи на неразрушимое устройство хранения. Современные дисковые приводы имеют большие собственные кэши, поэтому сбой питания может привести к тому, что некоторые данные, сохраненные в кэше, будут потеряны.
11.2.8. Прочие операции
Файловая модель Linux достаточно хорошо поддерживает стандартизацию большинства файловых операций через обобщенные функции наподобие
read() и
write() (например, запись в программный канал выполняется так же, как запись в файл на диске). Однако некоторые устройства поддерживают операции, которые плохо моделируются такой абстракцией. Например, терминальные устройства, представленные как устройства символьные, нуждаются в представлении метода изменения скорости терминала, и приводы CD-ROM, представленные как блочные устройства, нуждаются в том, чтобы знать, кода они должны воспроизводить аудиодорожки, чтобы помочь увеличить производительность работы программистов.
Все эти разнообразные операции доступны через единственный системный вызов —
ioctl() (сокращение для "I/O control" — управление вводом-выводом), прототип которого показан ниже.
#include <sys/ioctl.h>
int ioctl(int fd, int request, ...);
Хотя часто он применяется следующим образом:
int ioctl (int fd, int request, void *arg);
Всякий раз когда используется
ioctl(), его первый аргумент — это файл, с которым выполняются манипуляции, а второй аргумент указывает операцию, которая должна быть выполнена. Последний аргумент обычно представляет собой указатель на нечто, но на что именно, а так же точная семантика возвращаемого кода зависит от типа файла
fd и типа запрошенной операции. Для некоторых операций
arg — длинное целое вместо указателя; в этих случаях обычно применяется приведение типов. В нашей книге есть множество примеров применения
ioctl(), и вам нет нужды заботиться об
ioctl() до тех пор, пока вы не доберетесь до них.
11.3. Запрос и изменение информации inode
11.3.1. Поиск информации inode
В начале этой главы информационный узел файла (inode) был представлен как структура данных, которая отслеживает информацию о файле, независимо от представления ее для процесса. Например, размер файла является константой в любой момент времени — он не изменяется для разных процессов, которые имеют доступ к этому файлу (сравните это с текущей позицией в файле, которая уникальна для каждого вызова
open(), а не свойство самого файла). Linux предлагает три способа чтения информации inode.
#include <sys/stat.h>
int stat(const char *pathname, struct stat *statbuf);
int lstat (const char *pathname, struct stat *statbuf);
int fstat(int fd, struct stat *statbuf);
Первая версия,
stat() возвращает информацию
inode для файла, на который осуществляется ссылка через
pathname, следуя всем символическим ссылкам, которые она представляет. Если вы не хотите следовать символическим ссылкам (например, чтобы проверить, не является ли само имя такой ссылкой), то используйте вместо этого
lstat(). Последняя версия,
fstat(), возвращает
inode, на который ссылается текущий открытый файловый дескриптор. Все три системных вызова заполняют структуру
struct stat, на которую указывает параметр
statbuf, информацией о файловом inode. В табл. 11.3 описана информация, доступная в
struct stat.
Таблица 11.3. Члены структуры struct stat
| Тип |
Поле |
Описание |
dev_t |
st_dev |
Номер устройства, на котором находится файл. |
ino_t |
st_ino |
Номер файлового on-disk inode. Каждый файл имеет номер on-disk inode, уникальный в пределах устройства, на котором он расположен. То есть пара (st_dev, st_ino) представляет собой уникальный идентификатор файла. |
mode_t |
st mode |
Режим файла. Сюда включена информация о правах доступа и типе файла. |
nlink_t |
st_nlink |
Количество путевых имен, ссылающихся на данный inode. Сюда не включаются символические ссылки, потому что они ссылаются на другие имена, а не на inode. |
uid_t |
st_uid |
Идентификатор пользователя, владеющего файлом. |
gid_t |
st_gid |
Идентификатор группы, владеющей файлом. |
dev_t |
st_rdev |
Если файл — символьное или блочное устройство, это задает старший (major) и младший (minor) номера файла. Чтобы получить информацию о членах и макросах, которые манипулируют этим значением, обратитесь к обсуждению mknod() далее в этой главе. |
off_t |
st size |
Размер файла в байтах. Это определено только для обычных файлов. |
unsigned long |
st_blksize |
Размер блока в файловой системе, хранящей файл. |
unsigned long |
st_blocks |
Количество блоков, выделенных файлу. Обычно st_blksize * st_blocks — это немного больше, чем st_size, потому что некоторое пространство в конечном блоке не используется. Однако для файлов с "дырками" st_blksize * st_blocks может быть заметно меньше, чем st_size. |
time_t |
st_atime |
Время последнего доступа к файлу. Обновляется при каждом открытии файла или модификации его inode. |
time_t |
st_mtime |
Время последней модификации файла. Обновляется при изменении данных файла. |
time_t |
st_ctime |
Последнее время изменения файла или его inode, включая владельца, группу, счетчик связей и так далее. |
11.3.2. Простой пример stat()
Рассмотрим простую программу, которая отображает информацию из
lstat() для каждого имени файла, переданного в аргументе. Она иллюстрирует, как использовать значения, возвращенные семейством функций
stat().
1: /* statsamp.с */
2:
3: /* Для каждого имени файла, переданного в командной строке, отображаем
4: всю информацию, которую возвращает lstat() для файла. */
5:
6: #include <errno.h>
7: #include <stdio.h>
8: #include <string.h>
9: #include <sys/stat.h>
10: #include <sys/sysmacros.h>
11: #include <sys/types.h>
12: #include <time.h>
13: #include <unistd.h>
14:
15: #define TIME_STRING_BUF 50
16:
17: /* Пользователь передает buf (минимальной длины TIME_STRING_BUF) вместо
18: использования статического для функции буфера, чтобы избежать применения
19: локальных статических переменных и динамической памяти. Никаких ошибок
20: происходить не должно, поэтому никакой проверки ошибок не делаем. */
21: char *time String (time_t t, char *buf) {
22: struct tm *local;
23:
24: local = localtime(&t);
25: strftime(buf, TIME_STRING_BUF, "%c", local);
26:
27: return buf;
28: }
29:
30: /* Отобразить всю информацию, полученную от lstat() по имени
31: файла как единственному параметру. */
32: int statFile(const char *file) {
33: struct stat statbuf;
34: char timeBuf[TIME_STRING_BUF];
35:
36: if (lstat(file, &statbuf)) {
37: fprintf(stderr, "не удалось lstat %s: %s\n", file,
38: strerror(errno));
39: return 1;
40: }
41:
42: printf("Имя файла : %s\n", file);
43: printf("На устройстве: старший %d/младший %d Inode номер: %ld\n" ,
44: major(statbuf.st_dev), minor(statbuf.st_dev),
45: statbuf.st_ino);
46: printf ("Размер : %-101d Тип: %07o"
47: "Права доступа : %05o\n", statbuf.st_size,
48: statbuf.st_mode & S_IFMT, statbuf.st_mode &~(S_IFMT));
49: printf("Владелец : %d Группа : %d"
50: " Количество ссылок : %d\n",
51: statbuf.st_uid, statbuf.st_gid, statbuf.st_nlink);
52: printf("Время создания : %s\n",
53: timeString(statbuf.st_ctime, timeBuf));
54: printf("Время модификации : %s\n",
55: timeString(statbuf.st_mtime, timeBuf));
56: printf("Время доступа : %s\n",
57: timeString (statbuf.st_atime, timeBuf));
58:
59: return 0;
60: }
61:
62: int main(int argc, const char **argv) {
63: int i;
64: int rc = 0 ;
65:
66: /* Вызвать statFile() для каждого имени файла,
67: переданного в командной строке. */
68: for (i = 1; i < argc; i++) {
69: /* Если statFile() сбоит, rc будет содержать не ноль.*/
70: rc |= statFile(argv[i]);
71:
72: /* это печатает пробел между позициями,
73: но не за последней */
74: if ((argc - i) > 1) printf ("\n");
75: }
76:
77: return rc;
78: }
11.3.3. Простое определение прав доступа
Хотя режим файла представляет всю информацию, которая может понадобиться программе, для определения того, имеет ли она доступ к файлу, тестирование набора прав — дело хитрое и чреватое ошибкам. Поскольку ядро ухе включает в себя код для проверки прав доступа, предусмотрен простой системный вызов, который позволяет программам определять, могут ли они получить доступ к файлу определенным образом.
#include <unistd.h>
int access(const char *pathname, int mode);
mode — это маска, которая содержит одно или более перечисленных ниже значений.
F_OK |
Файл существует. Это требует прав на выполнение по всем каталогам, составляющим путь, поэтому может закончиться сбоем, даже если файл существует. |
R_OK |
Процесс может читать файл. |
W_OK |
Процесс может писать файл. |
X_OK |
Процесс может исполнять файл (или искать в каталоге). |
access() возвращает 0, если указанный режим доступа разрешен, в противном случае возвращает ошибку
EACCESS.
11.3.4. Изменение прав доступа к файлу
Права доступа и модификаторы прав доступа к файлу изменяются с помощью системного вызова
chmod().
#include <sys/stat.h>
int chmod(const char *pathname, mode_t mode);
int fchmod(int fd, mode_t mode);
Хотя
chmod() позволяет указать путь, помните, что права доступа к файлу определяет inode, а не имя файла. Если у файла есть множество жестких ссылок, то изменение прав доступа по одному из имен файла изменяет права доступа к нему везде, где он встречается в файловой системе. Параметр
mode может быть любой комбинацией прав доступа и модификаторов прав доступа, объединенных по логическому "И". Хотя это достаточно нормально — специфицировать по несколько этих значений за раз, общей практикой для программ является указание новых прав доступа непосредственно в восьмеричном виде. Только пользователь root и владелец файла могут изменять права доступа к файлу — все остальные, кто попытается это сделать, получат ошибку
EPERM.
11.3.5. Смена владельца и группы файла
Точно так же, как права доступа, информация о группе и владельце файла хранится в inode, поэтому все жесткие ссылки на файл имеют одинакового владельца и группу. Похожий системный вызов используется для смены владельца и группы файла.
#include <unistd.h>
int chown(const char *pathname, uid_t owner, gid_t group);
int fchown(int fd, uid_t owner, gid_t group);
Параметры
owner и
group указывают нового владельца и группу для файла. Если любой из них равен
-1, соответствующее значение не изменяется. Только пользователь root имеет право сменить владельца файла. Когда владелец файла меняется или файл записывается, то бит setuid для этого файла всегда очищается из соображений безопасности. Как root, так и владелец файла могут менять группу, которая владеет файлом, но при условии, что владелец сам является членом этой группы. Если у файла установлен бит выполнения для группы, то бит setgid очищается из тех же соображений безопасности. Если же бит выполнения для группы не установлен, то у файла включена принудительная блокировка и режим предохраняется.
11.3.6. Изменение временных меток файла
Владелец файла может изменять mtime и atime файла на любое желаемое значение. Это делает такие метки бесполезными для целей аудита, но позволяет инструментам архивирования вроде
tar и
cpio сбрасывать временные метки файлов в то значение, когда они были архивированы. Метка ctime изменяется, когда обновляются mtime и atime, поэтому
tar и
cpio не могут восстановить их.
Существуют два способа изменения этих меток:
utime() и
utimes().
utime() появилась в System V, после чего была адаптирована POSIX, в то время как
utimes() пришла из BSD. Обе функции эквивалентны; они отличаются только способом, каким указываются новые временные метки.
#include <utime.h>
int utime(const char *pathname, struct utimbuf *buf);
#include <sys/time.h>
int utimes(const char *pathname, struct timeval *tvp);
Версия POSIX,
utime(), принимает
struct utimbuf, которая определена в
<utime.h>, как показано ниже.
struct utimbuf {
time_t асtime;
time_t modtime;
};
utimes() из BSD вместо этого передает новое значение
atime и
mtime через
struct timeval, которая определена в
<sys/time.h>.
struct timeval {
long tv_sec;
long tv_usec;
};
Элемент
tv_sec содержит новое значение
atime;
tv_usec содержит новое значение
mtime для
utimes().
Если каждой из функций вторым параметром передать
NULL, то обе временные метки должны быть установлены в текущее время. Новые значения
atime и
mtime устанавливаются в секундах, прошедших с начала эры (так же, как значение, возвращаемое
time()), как определено в главе 18.
11.3.7. Расширенные атрибуты Ext3
Главная файловая система, используемая в Linux — это Third Extended File System (третья расширенная файловая система)
[47], обычно упоминаемая как ext3. Хотя она поддерживает все традиционные функциональные средства файловых систем Unix, такие как значение отдельных бит в режиме файла, она также позволяет хранить некоторые дополнительные атрибуты для каждого файла. В табл. 11.4 описаны поддерживаемые в настоящее время дополнительные атрибуты. Эти флаги могут быть установлены и просмотрены с помощью программ
chattr и
lsattr.
Таблица 11.4. Расширенные атрибуты файла
| Атрибут |
Определение |
EXT3_APPEND_FL |
Если файл открыт для записи, должен быть указан флаг O_APPEND. |
EXT3_IMMUTABLE_FL |
Файл не может быть модифицирован или удален ни одним пользователем, включая root. |
EXT3_NODUMP |
Файл должен быть проигнорирован командой dump. |
EXT3_SYNC_FL |
Файл должен обновляться синхронно, как если бы при открытии был указан флаг O_SYNC |
Поскольку расширенные атрибуты ext3 выходят за пределы стандартного интерфейса файловых систем, они не могут модифицироваться с помощью
chmod(), как все остальные атрибуты. Вместо этого используется
ioctl(). Вспомним, как определен вызов
ioctl().
#include <sys/ioctl.h>
#include <linux/ext3_fs.h>
int ioctl(int fd, int request, void *arg);
Файл, атрибуты которого меняются, должен быть открыт, как для
fchmod(). Запрос (параметр request) на получение текущего состояния флагов —
EXT3_IOC_GETFLAGS, а для установки их —
EXT3_IOC_SETFLAGS. В обоих случаях
arg должен быть указателем на
int. Если используется
EXT3_IOC_GETFLAGS, то
long устанавливается в текущее значение программных флагов. Если применяется
EXT3_IOC_SETFLAGS, то новое значение файловых флагов берется из
int, на который указывает
arg.
Это дополнение и неизменяемые флаги могут быть изменены только пользователем root, поскольку это связано с операциями, которые может выполнять только root.
Другие флаги могут быть модифицированы либо пользователем root, либо владельцем файла.
Приведем пример небольшой программы, которая отображает флаги для любого файла, переданного в командной строке. Она работает только с файлами из файловой системы ext3
[48]. Вызов
ioctl() завершится неудачей, если применить его к файлам из любой другой файловой системы.
1: /* checkflags.c */
2:
3: /* Для каждого имени файла, переданного в командной строке, отобразить
4: информацию об атрибутах этого файла в файловой системе ext3. */
5:
6: #include <errno.h>
7: #include <fcntl.h>
8: #include <linux/ext3_fs.h>
9: #include <stdio.h>
10: #include <string.h>
11: #include <sys/ioctl.h>
12: #include <unistd.h>
13:
14: int main(int argc, const char **argv) {
15: const char **filename = argv + 1;
16: int fd;
17: int flags;
18:
19: /* Пройти по каждому имени файла, переданному в командной строке. Последний
20: указатель в argv[] равен NULL, поэтому такие циклы while() корректны. */
21: while(*filename) {
22: /* В отличие от нормальных атрибутов, атрибута ext3 можно опрашивать только
23: если есть файловый дескриптор (имя файла не годится).
24: Для выполнения запроса атрибутов ext3 нам не нужен доступ на запись,
25: поэтому O_RDONLY подойдет. */
26: fd = open(*filename, O_RDONLY);
27: if (fd<0) {
28: fprintf(stderr, "не открывается %s: %s\n", *filename,
29: strerror(errno));
30: return 1;
31: }
32:
33: /* Этот вызов получает атрибуты, и помещает их в flags */
34: if (ioctl(fd, EXT3_IOC_GETFLAGS, &flags)) {
35: fprintf(stderr, "ioctl завершился ошибкой на %s: %s\n", *filename,
36: strerror(errno));
37: return 1;
38: }
39:
40: printf("%s: ", *filename++);
41:
42: /* Проверить каждый атрибут, и отобразить сообщение для каждого,
43: который включен. */
44: if (flags & EXT3_APPEND_FL) printf("Append");
45: if (flags & EXT3_IMMUTABLE_FL) printf("Immutable");
46: if (flags & EXT3_SYNC_FL) printf("Sync");
47: if (flags & EXT3_NODUMP_FL) printf("Nodump");
48:
49: printf("\n");
50: close(fd);
51: }
52:
53: return 0;
54: }
Ниже приведена похожая программа, которая устанавливает расширенные атрибуты ext3 для указанного списка файлов. Первый параметр должен быть списком флагов, которые нужно установить. Каждый флаг представляется в списке в виде одной буквы: А — только для добавления (append only), I — неизменяемый (immutable), S — синхронизированный (sync), N — недампированный (nodump). Эта программа не модифицирует существующие флаги файла; она только устанавливает флаги, переданные в командной строке.
1: /* setflags.c */
2:
3: /* Первый параметр этой программы — строка, состоящая из
4: 0 (допускается пустая) или более букв из набора I, A, S,
5: N. Эта строка указывает, какие из атрибутов ext3 должны
6: быть включены для файлов, указанных в остальных
7: параметрах командной строки — остальные атрибуты выключаются
8: буквы обозначают соответственно: immutable, append-only, sync и nodump.
9:
10: Например, команда "setflags IN file1, file2" включает
11: флаги immutable и nodump для файлов file1 и file2, но отключает
12: флаги sync и append-only для этих файлов. */
13:
14: #include <errno.h>
15: #include <fcntl.h>
16: #include <linux/ext3_fs.h>
17: #include <stdio.h>
18: #include <string.h>
19: #include <sys/ioctl.h>
20: #include <unistd.h>
21:
22: int main(int argc, const char **argv) {
23: const char **filename = argv + 1;
24: int fd;
25: int flags = 0;
26:
27: /* Убедиться, что указаны устанавливаемые флаги, вместе
28: с именами файлов. Позволить установить "0", как признак
29: того, что все флаги должны быть сброшены. */
30: if (argc<3){
31: fprintf(stderr, "Использование setflags: [0][I][A][S][N]"
32: "<filenames>\n");
33: return 1;
34: }
35:
36: /* каждая буква представляет флаг; установить
37: флаг, которые указаны */
38: if (strchr(argv[1], 'I') ) flags |= EXT3_IMMUTABLE_FL;
39: if (strchr(argv[1], 'A') ) flags |= EXT3_APPEND_FL;
40: if (strchr(argv[1], 'S') ) flags |= EXT3_SYNC_FL;
41: if (strchr(argv[1], 'N') ) flags |= EXT3_NODUMP_FL;
42:
43: /* пройти по всем именам в argv[] */
44: while (*(++filename)) {
45: /* В отличие от нормальных атрибутов, атрибута ext3 можно опрашивать,
46: только если есть файловый дескриптор (имя файла не годится).
47: Для выполнения запроса атрибутов ext3 нам не нужен доступ на запись,
48: поэтому O_RDONLY подойдет. */
49: fd = open(*filename, O_RDONLY);
50: if (fd < 0) {
51: fprintf(stderr, "невозможно открыть %s:%s\n", *filename,
52: strerror(errno));
53: return 1;
54: }
55:
56: /* Установить атрибуты в соответствии с переданными
57: флагами. */
58: if (ioctl(fd, EXT3_IOC_SETFLAGS, &flags)) {
59: fprintf(stderr, "Сбой ioctl в %s:%s\n", *filename,
60: strerror(errno));
61: return 1;
62: }
63: close(fd);
64: }
65:
66: return 0;
67: }
11.4. Манипулирование содержимым каталогов
Вспомните, что компоненты каталогов (имена файлов) — это ни что иное, как указатели на дисковые информационные узлы (on-disk inodes); почти вся важная информация, касающаяся файла, хранится в его inode. Вызов
open() позволяет процессу создавать компоненты каталогов, которые являются обычными файлами, но для создания файлов других типов и для манипулирования компонентами каталогов могут понадобиться другие функции. Функции, которые позволяют создавать, удалять и выполнять поиск каталогов, описаны в главе 14; файлы сокетов — в главе 17. В настоящем разделе раскрываются символические ссылки, файлы устройств и FIFO.
11.4.1. Создание входных точек устройств и именованных каналов
Процессы создают файлы устройств и именованных каналов в файловой системе с помощью вызова
mknod().
#include <fcntl.h>
#include <unistd.h>
int mknod(const char *pathname, mode_t mode, dev_t dev);
pathname — это имя файла, который нужно создать,
mode — это и режим доступа (который модифицируется текущим
umask), и тип нового файла (
S_IFIFO,
S_IFBLK,
S_IFCHR). Последний параметр,
dev, содержит старший (major) и младший (minor) номера создаваемого устройства. Тип устройства (символьное или блочное) и старший номер устройства сообщают ядру, какой драйвер устройств отвечает за операции с этим файлом устройства. Младший номер используется внутри драйвером устройства, чтобы различать отдельные устройства среди многих, которыми он управляет. Только пользователю root разрешено создавать файлы устройств; именованные же каналы могут создавать все пользователи.
Заголовочный файл
<sys/sysmacros.h> представляет три макроса для манипулирования значениями типа
dev_t. Макрос
makedev() принимает старшие номера в первом аргументе, младшие — во втором и возвращает значение
dev_t, ожидаемое
mknod(). Макросы
major() и
minor() принимают значение типа
dev_t в качестве единственного аргумента и возвращают, соответственно, старший и младший номер устройства.
Программа
mknod, доступная в Linux, предоставляет пользовательский интерфейс к системному вызову
mknod() (подробности см. в
man 1 mknod). Ниже приведена упрощенная реализация
mknod для иллюстрации системного вызова
mknod(). Следует отметить, что программа создает файл с режимом доступа 0666 (предоставляя право на чтение и запись всем пользователям) и зависит от системной установки umask процесса для получения прав доступа.
1: /* mknod.с */
2:
3: /* Создать устройство или именованный канал, указанный в командной строке.
4: См. подробности о параметрах командной строки
5: на man-странице mknod(1). */
6:
7: #include <errno.h>
8: #include <stdio.h>
9: #include <stdlib.h>
10: #include <string.h>
11: #include <sys/stat.h>
12: #include <sys/sysmacros.h>
13: #include <unistd.h>
14:
15: void usage(void) {
16: fprintf (stderr, "использование: mknod <путь> [b | с | u | p]"
17: "<старший> <младший>\n");
18: exit(1);
19: }
20:
21: int main(int argc, const char **argv) {
22: int major = 0, minor = 0;
23: const char *path;
24: int mode = 0666;
25: char *end;
26: int args;
27:
28: /* Всегда необходимы, как минимум, тип создаваемого inode
29: и путь к нему. */
30: if (argc < 3) usage();
31:
32: path = argv[1];
33:
34: /* второй аргумент указывает тип создаваемого узла */
35: if (!strcmp(argv[2], "b")) {
36: mode | = S_IFBLK;
37: args = 5;
38: } else if (!strcmp(argv[2] , "с") || !strcmp(argv[2], "u")) {
39: mode |= S_IFCHR;
40: args = 5;
41: } else if(!strcmp(argv[2], "p")) {
42: mode |= S_IFIFO;
43: args = 3;
44: } else {
45: fprintf(stderr, "неизвестный тип узла %s\n", argv[2]);
46: return 1;
47: }
48:
49: /* args сообщает, сколько аргументов ожидается, поскольку нам нужно
50: больше информации при создания устройств, чем именованных каналов*/
51: if (argc != args) usage();
52:
53: if (args == 5) {
54: /* получить старший и младший номера файла устройств,
55: который нужно создать */
56: major = strtol(argv[3], &end, 0);
57: if (*end) {
58: fprintf(stderr,"неверный старший номер %s\n", argv[3]);
59: return 1;
60: }
61:
62: minor = strtol(argv[4], &end, 0);
63: if (*end) {
64: fprintf(stderr, "неверный младший номер %s\n", argv[4]);
65: return 1;
66: }
67: }
68:
69: /* если создается именованный канал, то финальный параметр
70: игнорируется */
71: if (mknod(path, mode, makedev(major, minor))) {
72: fprintf(stderr, "вызов mknod не удался : %s\n", strerror(errno));
73: return 1;
74: }
75:
76: return 0;
77: }
11.4.2. Создание жестких ссылок
Когда множество имен файлов в файловой системе ссылаются на единственный inode, такие файлы называют
жесткими ссылками (hard links) на него. Все эти имена должны располагаться на одном физическом носителе (обычно это значит, что они должны быть на одном устройстве). Когда файл имеет множество жестких ссылок, все они равны — нет способа узнать, с каким именем первоначально был создан файл. Одно из преимуществ такой модели заключается в том, что удаление одной жесткой ссылки не удаляет файл с устройства — он остается до тех пор, пока все ссылки на него не будут удалены. Системный вызов
link() связывает новое имя файла с существующим inode.
#include <unistd.h>
int link(const char *origpath, const char *newpath);
Параметр
origpath ссылается на существующее путевое имя, a
newpath представляет собой путь для новой жесткой ссылки. Любой пользователь может создавать ссылку на файл, к которому у него есть доступ по чтению, до тех пор, пока он имеет право записи в каталоге, в котором ссылка создается, и право выполнения в каталоге, в котором находится
origpath. Только пользователь root имеет право создавать жесткие ссылки на каталоги, но поступать так — обычно плохая идея, поскольку большинство файловых систем и некоторые утилиты не работают с ними достаточно хорошо — они полностью их отвергают.
11.4.3. Использование символических ссылок
Символические ссылки — это более гибкий тип ссылок, чем жесткие, но они не дают равноправного доступа к файлу, как это делают жесткие. В то время как жесткие ссылки разделяют один и тот же inode, символические ссылки просто указывают на другие имена файлов. Если файл, на который указывает символическая ссылка, удаляется, то она указывает на несуществующий файл, что приводит к появлению висячих ссылок. Использование символических ссылок между подкаталогами — обычная практика, и они могут также пересекать границы физических систем, чего не могут жесткие ссылки.
Почти все системные вызовы, которые обращаются к файлам по путевым именам, автоматически следуют по символическим ссылкам для поиска правильного inode. Ниже перечислены вызовы, которые не следуют по символическим ссылкам.
•
chown()
•
lstat()
•
readlink()
•
rename()
•
unlink()
Символически ссылки создаются почти так же, как жесткие, но при этом используется системный вызов
symlink().
#include <unistd.h>
int symlink(const char *origpath, const char *newpath);
Если вызов успешен, создается файл
newpath как символическая ссылка, указывающая на
oldpath (часто говорят, что
newpath содержит в качестве своего значения
oldpath).
Поиск значения символической ссылки немного сложнее.
#include <unistd.h>
int readlink(const char *pathname, char *buf, size_t bufsiz);
Буфер, на который указывает
buf, наполняется содержимым символической ссылки
pathname до тех пор, пока хватает длины
buf, указанной в
bufsize в байтах. Обычно константы
PATH_MAX применяется в качестве размера буфера, поскольку она должна быть достаточно большой, чтобы уместить содержимое любой символической ссылки
[49]. Одна странность функции
readlink() связана с тем, что она не завершает строку, которую записывает в
buf, символом
'\0', поэтому
buf не содержит корректную строку С, даже если
readlink() выполняется успешно. Вместо этого она возвращает количество байт, записанных в
buf в случае успеха и
-1 — при неудаче. Из-за этой особенности код, использующий
readlink(), часто выглядит так, как показано ниже.
char buf[PATH_MAX + 1];
int bytes;
if ( (bytes = readlink (pathname, buf, sizeof (buf) - 1)) < 0) {
perror("ошибка в readlink");
} else {
buf[bytes]= '\0';
}
11.4.4. Удаление файлов
Удаление файла — это удаление указателя на его inode и удаление содержимого файла, если не остается ни одой жесткой ссылки на него. Если любой процесс держит файл открытым, то inode этого файла предохраняется до тех пор, пока финальный процесс не закроет его, после чего и inode, и содержимое файла уничтожаются. Поскольку нет способа принудительно удалить файл немедленно, эта операция называется
разъединением (unlinking) файла, поскольку она удаляет связь между именем файла и inode.
#include <unistd.h>
int unlink(char *pathname);
11.4.5. Переименование файлов
Имя файла может быть изменено на любое другое до тех пор, пока оба имени относятся к одному и тому же физическому носителю (это то же ограничение, что и касается создания жестких ссылок). Если новое имя уже ссылается на файл, то такое имя разъединяется перед тем, как произойдет переименование. Атомарность системного вызова
rename() гарантируется. Другие процессы в системе всегда видят существование файла под тем или иным именем, но не под обеими сразу. Поскольку открытые файлы не связаны с именами (а только с inode), то переименование файла, который открыт в других процессах, никак не влияет на их работу. Ниже показано, как выглядит системный вызов для переименования файлов.
#include <unistd.h>
int rename(const char *oldpath, const char *newpath);
После вызова файл, на который ссылалось имя
oldpath, получает ссылку
newpath вместо
oldpath.
11.5. Манипуляции файловыми дескрипторами
Почти все связанные с файлами системные вызовы, о которых мы говорили, за исключением
lseek(), манипулируют inode файлов, что позволяет разделять их результаты между процессами, в которых этот файл открыт. Есть несколько системных вызовов, которые вместо этого имеют дело с самим файловыми дескрипторами. Системный вызов
fcntl() может
использоваться для множества манипуляций с файловыми дескрипторами.
fcntl() выглядит следующим образом.
#include <unistd.h>
int fcntl (int fd, int command, long arg);
Для многих команд
arg не используется. Ниже мы обсудим большую часть применений
fcntl(). Этот вызов используется для блокировки файлов, аренды файлов, неблокирующего ввода-вывода, который рассматривается в главе 13, а также уведомления об изменениях каталогов, представленного в главе 14.
11.5.1. Изменение режима доступа к открытому файлу
Режим добавления (указываемый флагом
O_APPEND при открытии файла) и неблокирующий режим (флаг
O_NONBLOCK), могут быть включены и отключены уже после того, как файл был открыт, с помощью команды
F_SETFL в
fcntl(). Параметр
arg при этом должен содержать флаги, которые нужно установить — если какой-то из флагов не указан для
fd, он отключается.
F_GETFL можно использовать для запроса текущих установленных флагов файла. Это возвращает все флаги, включая режим чтения/записи для открытого файла.
F_SETFL позволяет только устанавливать упомянутые выше флаги — любые другие флаги, представленные в аргументе
arg, игнорируются.
fcntl(fd, F_SETFL, fcntl(fd, F_GETFL, 0) | O_RDONLY);
Такой вызов абсолютно правильный, но он не делает ничего. Включение режима добавления для открытого файлового дескриптора выглядит так, как показано ниже.
fcntl(fd, F_SETFL, fcntl(fd, F_GETFL, 0) | O_APPEND);
Следует отметить, что это предохраняет установку
O_NONBLOCK. Отключение режима добавления выглядит похоже.
fcntl(fd, F_SETFL, fcntl(fd, F_GETFL, 0) & ~O_APPEND);
11.5.2. Модификация флага "закрыть при выполнении"
Во время системного вызова
exec() дескрипторы файлов обычно остаются открытыми для использования в новых программах. В некоторых случаях может потребоваться, чтобы файлы закрывались, когда вызывается
exec(). Вместо закрытия их вручную вы можете попросить систему закрыть соответствующий файловый дескриптор при вызове
exec() с помощью команд
F_GETFD и
F_SETFD в
fcntl(). Если флаг "закрыть при выполнении" (close-on-exec) установлен, когда применяется
F_GETFD, возвращается ненулевое значение, в противном случае возвращается ноль. Флаг "закрыть при выполнении" устанавливается командой
F_SETFD; он отключается, если
arg равно 0, в противном случае он включается.
Ниже показано, как можно заставить
fd закрываться, когда процесс вызывает
exec().
fcntl(fd, F_SETFD, 1);
11.5.3. Дублирование файловых дескрипторов
Иногда процессам требуется создать новый файловый дескриптор, который ссылается на ранее открытый файл. Командные оболочки используют эту функциональность для перенаправления стандартного ввода, вывода и потока ошибок по запросу пользователя. Если процессу не важно, какой файловый дескриптор будет использован для новой ссылки, он должен использовать
dup().
#include <unistd.h>
int dup(int oldfd);
dup() возвращает файловый дескриптор, который ссылается на тот же inode, что и
oldfd, или
-1 в случае ошибки,
oldfd остается корректным дескриптором, по-прежнему ссылающимся на исходный файл. Новый файловый дескриптор — это всегда наименьший доступный файловый дескриптор. Если процессу нужно получить новый файловый дескриптор с определенным значением (например,
0, чтобы перенаправить стандартный ввод), то он должен использовать
dup2().
#include <unistd.h>
int dup2(int oldfd, int newfd);
Если
newfd ссылается на уже открытый дескриптор, то он закрывается. Если вызов завершен успешно, он возвращает новый файловый дескриптор и
newfd ссылается на тот же файл, что
oldfd. Системный вызов
fcntl() представляет почти ту же функциональность командой
F_DUPFD. Первый аргумент —
fd — это уже открытый файловый дескриптор. Новый файловый дескриптор — это первый доступный дескриптор, равный или больший, чем значение последнего аргумента
fcntl(). (В этом состоит отличие от работы
dup2().) Вы можете реализовать
dup2() через
fcntl() следующим образом.
int dup2(int oldfd, int newfd) {
close(newfd); /* ensure new fd is available */
return fcntl(oldfd, F_DUPFD, newfd);
}
Создание двух файловых дескрипторов, ссылающихся на один и тот же файл — это не то же самое, что открытие файла дважды. Почти все атрибуты дублированных дескрипторов разделяются: они разделяют текущую позицию, режим доступа и блокировки. (Все это записывается в
файловой структуре[50], которая создается при каждом открытии файла. Файловый дескриптор ссылается на файловую структуру, и дескриптор, возвращенный
dup(), ссылается на одну и ту же структуру.) Единственный атрибут, который может независимо управляться в этих двух дескрипторах — это состояние "закрыть при выполнении". После того, как процесс вызывает
fork(), то файлы, открытые в родительском процессе, наследуются дочерним, и эти пары файловых дескрипторов (один в родительском процессе, другой — в дочернем) ведут себя так, будто файловые дескрипторы были дублированы с текущей позицией и другими разделенными атрибутами
[51].
11.6. Создание неименованных каналов
Неименованные каналы подобны именованным, но они в файловой системе не существуют. Они не имеют путевых имен, ассоциированных с ними, и все они и их следы исчезают после того, как последний файловый дескриптор, ссылающийся на них, закрывается. Они почти исключительно используются для межпроцессных коммуникаций между дочерними и родительскими процессами либо между родственными процессами.
Оболочки применяют неименованные каналы для выполнения команд вроде
ls | head. Процесс
ls пишет в тот канал, из которого
head читает свой ввод, выдавая ожидаемый пользователем результат.
Создание неименованного канала выполняется по двум файловым дескрипторам, один из которых доступен только для чтения, а второй — только для записи.
#include <unistd.h>
int pipe(int fds[2]);
Единственный параметр-массив включает два файловых дескриптора —
fd[0] для чтения и
fd[1] для записи.
11.7. Добавление перенаправления для ladsh
Теперь, когда мы рассмотрели основные манипуляции с файлами, мы можем научить
ladsh перенаправлению ввода и вывода через файлы и каналы.
ladsh2.с, который мы представим здесь, работает с каналами (описанными символом
| в командах
ladsh, как это делается в большинстве командных оболочек) и перенаправление ввода и вывода в файловые дескрипторы. Мы покажем только модифицированные части кода здесь — полный исходный текст
ladsh2.с доступен по упомянутым в начале книги адресам. Изменения в
parseCommand() — это простое упражнение по разбору строк, поэтому мы не будем надоедать дискуссией об этом.
11.7.1. Структуры данных
Хотя код в
ladsh1.с поддерживает концепцию задания как множества процессов (предположительно, объединенных вместе каналами), он не предоставляет способа указания того, какие файлы использовать для ввода и вывода. Чтобы позволить это, добавляются новые структуры данных и модифицируются существующие.
24: REDIRECT_APPEND};
25:
26: struct redirectionSpecifier {
27: enum redirectionTypetype; /* тип перенаправления */
28: int fd; /*перенаправляемый файловый дескриптор*/
29: char * filename; /* файл для перенаправления fd */
30: };
31:
32: struct childProgram {
33: pid_t pid; /* 0 если завершен */
34: char **argv; /* имя программы и аргументы */
35: int numRedirections; /* элементы в массиве перенаправлений */
36: struct redirectionSpecifier *redirections; /* перенаправления ввода-вывода*/
37: } ;
Структура
struct redirectionSpecifier сообщает
ladsh2.с о том, как установить отдельный файловый дескриптор. Она содержит
enum redirectionTypetype, который указывает, является ли это перенаправление перенаправлением ввода, перенаправлением вывода, который должен быть добавлен к существующему файлу, либо перенаправлением вывода, которое заменяет существующий файл. Она также включает перенаправляемый файловый дескриптор и имя файла. Каждая дочерняя программа (
struct childProgram) теперь специфицирует нужное ей количество перенаправлений.
Эти новые структуры данных не связаны с установкой каналов между процессами. Поскольку задание определено как множество дочерних процессов с каналами, связывающими их, нет необходимости в более подробной информации, описывающей каналы. На рис. 11.1 показано, как эти новые структуры должны выглядеть для команды
tail < input-file | sort > output-file.
 Рис. 11.1
Рис. 11.1. Структуры данных, описывающие задание для
ladsh2.с
11.7.2. Изменения в коде
Как только в
parseCommand() будут правильно отражены структуры данных, то запуск команд в правильном порядке становится довольно простым при достаточном внимании к деталям. Прежде всего, мы добавляем цикл в
parseCommand() для запуска дочерних процессов, поскольку теперь их может быть множество. Прежде чем войти в цикл, мы устанавливаем
nextin и
nextout, которые являются файловыми дескрипторами, используемыми в качестве стандартных потоков ввод и вывода для следующего запускаемого процесса. Для начала мы используем те же stdin и stdout, что и оболочка.
Теперь посмотрим, что происходит внутри цикла. Основная идея описана ниже.
1. Если это финальный процесс в задании, убедиться, что
nextout указывает на stdout. В противном случае нужно подключить вывод этого задания к входному концу неименованного канала.
2. Породить новый процесс. Внутри дочернего перенаправить stdin и stdout, как указано с помощью
nextin,
nextout и всех специфицированных ранее перенаправлений.
3. Вернувшись обратно в родительский процесс, закрыть
nextin и
nextout, используемые только что запущенным дочерним процессом (если только они не являются потоками ввода и вывода самой оболочки).
4. Теперь настроить следующий процесс в задании для приема его ввода из вывода процесса, который мы только что создали (через
nextin).
Вот как эти идеи перевести на С.
365: nextin=0, nextout=1;
366: for (i=0; i<newJob.numProgs; i++) {
367: if ((i+1) < newJob.numProgs) {
368: pipe(pipefds);
369: nextout = pipefds[1];
370: } else {
371: nextout = 1;
372: }
373:
374: if (!(newJob.progs[i].pid = fork())) {
375: if (nextin != 0) {
376: dup2(nextin, 0);
377: close(nextin);
378: }
379:
380: if (nextout != 1) {
381: dup2(nextout, 1);
382: close(nextout);
383: }
384:
385: /* явное перенаправление перекрывает каналы */
386: setupRedirections(newJob.progs+i);
387:
388: execvp(newJob.progs[i].argv[0], newJob.progs[i].argv);
389: fprintf(stderr, "exec() of %s failed: %s\n",
390: newJob.progs[i].argv[0],
391: strerror(errno));
392: exit(1);
393: }
394:
395: /* поместить наш дочерний процесс в группу процессов,
396: чей лидер - первый процесс канала */
397: setpgid(newJob.progs[i].pid, newJob.progs[0].pid);
398:
399: if (nextin != 0) close(nextin);
400: if (nextout != 1) close (nextout);
401:
402: /* Если больше нет процессов, то nextin - мусор,
403: но это не имеет значения */
404: nextin = pipefds[0];
Единственный код, добавленный в
ladsh2.с для обеспечения перенаправлений — это функция
setupRedirections(), код которой останется неизменным во всех последующих версиях
ladsh. Ее задача состоит в обработке спецификаторов
struct redirectionSpecifier для дочерних заданий и соответствующей модификации дочерних файловых дескрипторов. Мы рекомендуем просмотреть код этой функции в приложении Б.
Глава 12
Обработка сигналов
Сигналы — это простейшая форма межпроцессного взаимодействия в мире POSIX. Они позволят одному процессу быть прерванным асинхронным образом по инициативе другого процесса (или ядра) для того, чтобы обработать какое-то событие. Обработав сигнал, прерванный процесс может продолжить выполнение с точки прерывания. Сигналы используются для решения таких задач, как завершение процессов и сообщения демонам о необходимости перечитать конфигурационный файл.
Сигналы всегда были неотъемлемой частью Unix. Ядро использует их для извещения процессов о разнообразных событиях, включая перечисленные ниже.
• Уничтожение одного из дочерних процессов.
• Установка предупреждений устаревшим процессам.
• Изменение размеров окна терминала.
Эти сообщения имеют важное свойство: все они асинхронные. Процесс не имеет никакого контроля над тем, когда завершится один из его дочерних процессов — это может случиться в любой точке выполнения родительского процесса. Каждое из этих событий посылает сигнал процессу. При получении сигнала процесс может сделать одну из трех вещей.
• Проигнорировать сигнал.
• Позволить ядру запустить специальную часть процесса, прежде чем продолжить выполнение основной его части (это называется перехватом сигнала).
• Позволить ядру выполнить действие по умолчанию, которое зависит от конкретного полученного сигнала.
Концептуально это довольно просто. Однако история развития средств работы с сигналами видна, когда вы сравните различные интерфейсы сигналов, которые поддерживаются различными реализациями Unix. BSD, System V и System 3 поддерживают различные и несовместимые программные интерфейсы сигналов. POSIX определил стандарт, теперь поддерживаемый почти всеми версиями Unix (включая Linux), который был тогда расширен для обработки новой семантики сигнала (вроде формирования очереди сигналов) как части определения сигнала в режиме реального времени POSIX (POSIX Real Time Signal). В этой главе обсуждается исходное выполнение сигналов Unix перед объяснением основ программного интерфейса POSIX и их расширений Real Time Signal, поскольку появление многих возможностей POSIX API было мотивировано недостатками в более ранних реализациях системы сигналов.
12.1. Концепция сигналов
12.1.1. Жизненный цикл сигнала
Сигналы имеют четко определенный жизненный цикл: они создаются, сохраняются до тех пор, пока ядро не выполнит определенное действие на основе сигнала, а затем вызывают совершение этого действия. Создание сигнала называют по-разному:
поднятие (raising),
генерация или
посылка сигнала. Обычно процесс
посылает сигнал другому процессу, в то время как ядро
генерирует сигналы для отправки процессу. Когда процесс посылает сигнал самому себе, говорят, что он
поднимает его. Однако эти термины используются не особо согласованно.
Между временем, когда сигнал отправлен и тем, когда он вызывает какое-то действие, его называют
ожидающим (pending). Это значит, что ядро знает, что сигнал должен быть обработан, но пока не имеет возможности сделать это. Как только сигнал поступает в процесс назначения, он называется
доставленным. Если доставленный сигнал вызывает выполнение специального фрагмента кода (имеется в виду
обработчик сигнала), то такой сигнал считается
перехваченным. Есть разные способы, которыми процесс может предотвратить асинхронную доставку сигнала, но все же обработать его (например, с помощью системного вызова
sigwait()). Когда такое случается, сигнал называют
принятым.
Чтобы облегчить понимание, мы будем использовать эту терминологию на протяжении всей книги
[52].
12.1.2. Простые сигналы
Изначально обработка сигналов была проста. Системный вызов
signal() использовался для того, чтобы сообщить ядру, как доставить процессу определенный сигнал.
#include <signal.h>
void * signal(int signum, void *handler);
Здесь
signum — это сигнал, который нужно обработать, a
handler определяет действия, которое должно быть выполнено при доставке сигнала. Обычно
handler — это указатель на функцию-обработчик сигнала, которая не принимает параметров и не возвращает значения. Когда сигнал доставлен процессу, ядро как можно скорее запускает функцию-обработчик. Когда функция возвращает управление, ядро возобновляет выполнение процесса с того места, где он был прерван. Системные инженеры распознают в этом механизме обработки сигналов аналог доставки аппаратных прерываний. Прерывания и сигналы очень похожи и у них возникают сходные проблемы.
Доступно множество номеров сигналов. В табл. 12.1 перечислены все сигналы, поддерживаемые в настоящее время Linux, за исключением сигналов реального времени. Они имеют символические имена, начинающиеся с
SIG, и мы будем использовать
SIGЧТО-ТО, говоря о каком-то из них.
Параметр handler может иметь два специальных значения —
SIG_IGN и
SIG_DFL (оба определены в
<signal.h>). Если указано
SIG_IGN, сигнал игнорируется,
SIG_DFL сообщает ядру, что нужно выполнить действие по умолчанию, как правило, уничтожив процесс либо проигнорировав сигнал. Два сигнала —
SIGKILL и
SIGSTOP — не могут быть перехвачены. Ядро всегда выполняет действие по умолчанию для этих сигналов, соответственно, уничтожая процесс и приостанавливая его.
Функция
signal() возвращает предыдущий обработчик сигнала (который мог быть
SIG_IGN или
SIG_DFL). Обработчики сигналов резервируются при создании новых процессов вызовом
fork(), и все сигналы, которые установлены в
SIG_IGN, игнорируются и после вызова
exec()[53]. Все не игнорируемые сигналы после
exec() устанавливаются в
SIG_DFL.
Все это выглядит достаточно простым, пока вы не спросите себя: что произойдет, если сигнал
SIGЧТО-ТО будет отправлен процессу, который уже исполняет обработчик сигнала для
SIGЧТО-ТО.
Очевидно, что должно сделать ядро — так это прервать процесс и запустить обработчик сигнала сначала. Это порождает две проблемы. Первая — обработчик сигнала должен работать правильно, если он вызван тогда, когда уже сам работает. Хотя само по себе это и не сложно, но обработчики сигналов, которые манипулируют общепрограммными ресурсами, такими как глобальные структуры данных или файлы, должны быть написаны очень аккуратно. Функции, которые ведут себя правильно, когда вызваны подобным образом, называются
реентерабельными функциями[54].
Простая техника блокировки, которая достаточна для координации доступа к данным между конкурирующими процессами, не обеспечивает реентерабельности. Например, техника блокировки файлов, представленная в главе 13, не может использоваться для того, чтобы позволить обработчику сигналов, манипулирующему файлами данных, быть реентерабельным. Когда обработчик сигналов вызывается первый раз, он может просто изумительно заблокировать файл данных и начать запись в него. Если же этот обработчик будет прерван другим сигналом, в то время пока он удерживает блокировку, второй вызов обработчика не сможет блокировать файл, поскольку его блокировал первый вызов. К сожалению, вызов, который удерживает блокировку, приостанавливается до тех пор, пока второй вызов, который будет ожидать разблокировки, завершит работу.
Сложность написания реентерабельных обработчиков сигналов — это главная причина того, почему ядро не доставляет сигнал процессу, который уже его обрабатывает. Такая модель также затрудняет процессам возможность обрабатывать большое количество сигналов, поступающих ему слишком быстро. Как только сигнал осуществляет новый вызов обработчика, стек процесса растет безо всякого предела, пренебрегая правильным поведением самой программы.
Первое решение этой проблемы было неудачным. Прежде чем вызывается обработчик сигнала, для программы значение этого обработчика устанавливалось в
SIG_DFL, и ожидалось, что правильное его значение будет восстановлено немедленно, как только возможно. Хотя это упрощало написание обработчиков сигналов, но также делало невозможным для программиста обрабатывать сигналы надежным образом. Если два экземпляра одного и того же сигнала поступали быстро друг за другом, то ядро обрабатывало второй из них способом, принятым по умолчанию. Это означало, что сигнал, пришедший вторым, игнорировался (и пропадал навсегда), или же процесс прерывался. Эта реализация известна под названием
ненадежных сигналов, потому что не позволяла написать обработчики, ведущие себя надежным, правильным образом.
К сожалению, именно такая модель сигналов используется в ANSI/ISO-стандарте С
[55]. Хотя программные интерфейсы надежных сигналов, в которых исправлен этот недостаток, уже широко распространены, стандартизация ненадежных сигналов в ANSI/ISO, видимо, останется навсегда.
12.1.3. Надежные сигналы
Реализация BSD для решения проблемы множества сигналов полагается на простое ожидание завершения работы каждого обработчика сигналов в процессе перед доставкой следующего. Это гарантирует то, что каждый сигнал будет рано или поздно обработан, а также исключает риск переполнения стека. Вспомним, что когда ядро удерживает сигнал для отложенной доставки, сигнал называется
ожидающим (pending).
Однако если процессу отправлен сигнал
SIGЧТО-ТО, в то время, как
SIGЧТО-ТО уже находится в состоянии ожидания, то в этом случае процессу доставляется только первый из них. У процесса нет никакой возможности узнать, сколько раз один и тот же сигнал был отправлен ему, поскольку множество одинаковых сигналов подряд воспринимаются как один. Обычно это не представляет собой проблему. Поскольку сигнал не несет в себе никакой информации помимо собственно номера сигнала, двойная посылка сигнала за очень короткий отрезок времени может быть воспринята как одиночная, потому если программа примет сигнал только однажды, это не имеет особого значения. Это отличается от варианта с обработкой второго сигнала по умолчанию (что делается при ненадежной схеме обработки сигналов)
[56].
Идея об автоматической
блокировке сигналов была расширена для того, чтобы позволить процессам блокировать сигналы явным образом. Это облегчает защиту критичных участков кода, в то же время гарантируя обработку всех отправленных сигналов. Такая защита позволяет обработчикам сигналов манипулировать структурами данных, которые поддерживаются другими участками кода, за счет простой синхронизации.
Хотя BSD представляет адаптированную версию модели сигналов POSIX, комитет по стандартизации POSIX упростил ее для системных вызовов, с тем чтобы модифицировать диспозицию групп сигналов, предлагая новые системные вызовы для оперирования наборами сигналов. Наборы сигналов представлены типом данных
sigset_t, и для манипулирования ими предусмотрен набор макросов
[57].
12.1.4. Сигналы и системные вызовы
Часто сигналы доставляются процессу, который находится состоянии ожидания наступления некоторого внешнего события. Например, текстовый редактор часто ожидает завершения
read(), чтобы возвратить ввод терминала. Когда системный администратор посылает процессу сигнал
SIGTERM (нормальный сигнал, посылаемый командой
kill, позволяющий процессу завершиться чисто), то процесс может обработать его, как описано ниже.
1. Не пытаться перехватить сигнал и быть прерванным ядром (обработка
SIGTERM по умолчанию). Это оставляет пользовательский терминал в нестандартной конфигурации, затрудняя ему продолжение работы.
2. Перехватить сигнал, очистить терминал с помощью обработчика этого сигнала, затем выйти. Хотя это кажется привлекательным, в сложных программах трудно написать такой обработчик, который знал бы достаточно о том, что делает программа в момент прерывания, чтобы правильно выполнить очистку.
3. Перехватить сигнал, установить флаг, обозначающий, что сигнал получен, и каким-то образом обеспечить выход из блокирующего системного вызова (в данном случае
read()) с индикацией ошибки — в знак того, что произошло что-то необычное. Нормальный порядок выполнения затем должен проверить флаг и обработать его соответствующим образом.
Поскольку последний вариант выглядит намного чище и легче остальных, оригинальная реализация сигналов заставляет
медленные системные вызовы возвратить
EINTR, когда они прерываются сигналом, в то время как
быстрые системные вызовы завершаются перед тем, как сигнал будет доставлен.
Медленные системные вызовы требуют неопределенного времени для своего завершения. Системные вызовы, которые для завершения своей работы ожидают непредсказуемых ресурсов, таких как другие процессы, сетевые данные либо действия со стороны человека, рассматриваются как медленные. Семейство системных вызовов
wait(), например, не возвращают управление до тех пор, пока дочерние процессы не завершатся. Поскольку невозможно узнать, насколько долго продлится это ожидание, считается, что
wait() — медленный системный вызов. Системные вызовы доступа к файлам рассматриваются как медленные, если они обращаются к медленным файлам, и быстрые — если к быстрым файлам
[58].
Обязанностью процесса является обработка
EINTR и перезапуск системных вызовов в случае необходимости. Хотя это обеспечивает всю функциональность, которая требуется людям, намного сложнее написать код, который обрабатывает сигналы. Всякий раз когда
read() вызывается на медленном файловом дескрипторе, код должен проверять его возврат на равенство
EINTR, и перезапускать вызов, либо он не будет делать то, что ожидается.
Чтобы "упростить" ситуацию, 4.2BSD автоматически перезапускает такие системные вызовы (особенно
read() и
write()). Поэтому для большинства операций программы более не должны беспокоиться об
EINTR, поскольку выполнение системных вызовов продолжится после того, как процесс обработает сигнал. В последних версиях Unix изменен перечень системных вызовов, которые автоматически перезапускаются, a 4.3BSD позволяет вам выбрать, какие системные вызовы перезапускать. Стандарт обработки сигналов POSIX не указывает, какое поведение должно применяться, но все популярные системы согласны в том, как обрабатывать этот случай. По умолчанию системные вызовы не перезапускаются, но для каждого сигнала процесс может установить флаг, который указывает, что система должна перезапускать системные вызовы, прерванные этим сигналом.
12.2. Программный интерфейс сигналов Linux и POSIX
12.2.1. Посылка сигналов
Посылка сигналов от одного процесса другому обычно осуществляется с помощью системного вызова
kill(). Этот системный вызов подробно обсуждался в главе 10. Вариантом
kill() является
tkill(), который не предназначен для прямого использования в программах.
int tkill(pid_t pid, int signum);
Существуют два отличия между
kill() и
tkill()[59]. Первое:
pid должен быть положительным числом;
tkill() не может использоваться для отправки сигналов группам процессов, как это может
kill(). Другое отличие позволяет обработчикам сигналов определять, применялся ли вызов
kill() или
tkill() для генерации сигнала: подробности см. далее в главе.
Функция
raise(), которая представляет собой способ генерации сигналов, указанный ANSI/ISO, использует системный вызов
tkill() для генерации сигналов в системах Linux.
int raise(int signum);
Функция
raise() посылает текущему процессу сигнал, указанный в
signum[60].
12.2.2. Использование sigset_t
Большинство функций сигналов POSIX принимают набор сигналов в качестве одного из своих параметров (или части одного из параметров). Тип данных
sigset_t служит для представления набора сигналов и определен в
<signal.h>. POSIX определяет пять функций для манипулирования наборами сигналов.
#include <signal.h>
int sigemptyset(sigset_t *set);
int sigfillset(sigset_t *set);
int sigaddset(sigset_t *set, int signum);
int sigdelset(sigset_t *set, int signum);
int sigismember(const sigset_t *set, int signum);
int sigemptyset(sigset_t *set); |
Делает пустым набор сигналов, на который указывает set (никаких сигналов в set представлено не будет). |
int sigfillset(sigset_t *set); |
Включает все доступные сигналы в set. |
int sigaddset(sigset_t *set, int signum); |
Добавляет сигнал signum в набор set. |
int sigdelset(sigset_t *set, int signum); |
Удаляет сигнал signum из набора set. |
int sigismember(const sigset_t *set, int signum); |
Возвращает не 0, если сигнал signum содержится в set. В противном случае возвращает 0. |
Единственной причиной возврата ошибки любой из этих функций может быть то, что параметр
signum будет содержать неправильный номер сигнала. В этом случае возвращается
EINVAL. Излишне говорить, что подобное никогда не должно случаться.
12.2.3. Перехват сигналов
Вместо использования функции
signal() (чья семантика в процессе эволюции стала неправильной) POSIX-программы регистрируют обработчики сигналов с помощью
sigaction().
#include <signal.h>
int sigaction(int signum, struct sigaction *act, struct sigaction *oact);
Этот системный вызов устанавливает обработчик сигнала
signum, как определено с помощью
act. Если
oact не равен
NULL, он принимает расположение обработчика перед вызовом
sigaction(). Если
act равен
NULL, текущая установка обработчика остается неизменной, позволяя программе получить текущее расположение, не изменяя его.
sigaction() возвращает 0 в случае успеха и ненулевое значение в случае ошибки. Ошибки случаются только если один или несколько параметров, переданных
sigaction(), не верны.
Обработка сигнала ядром полностью описывается структурой
struct sigaction.
#include <signal.h>
struct sigaction {
__sighandler_t sa_handler;
sigset_t sa_mask;
int sa_flags;
};
sa_handler — это указатель на функцию со следующим прототипом:
void handler(int signum);
Здесь
signum устанавливается равным номеру сигнала, который является причиной вызова функции,
sa_handler может указывать на функцию этого типа либо быть равным
SIG_IGN или
SIG_DFL.
Программа также специфицирует набор сигналов, которые должны блокироваться во время функционирования обработчика сигнала. Если обработчик предназначен для обработки нескольких различных сигналов (что легко сделать благодаря параметру
signum), это средство существенно для предотвращения возникновения условия состязаний.
sa_mask — это набор сигналов, включающий все сигналы, которые должны блокироваться при вызове обработчика. Однако доставленный сигнал блокируется независимо от того, что содержит
sa_mask — если вы не хотите, чтобы он блокировался, укажите это флагом
sa_flags — членом структуры
struct sigaction.
Член
sa_flags позволяет процессу модифицировать различные поведения сигнала. Он содержит один или более флагов, объединенных битовой операцией "ИЛИ"
[61].
SA_NOCLDSTOP |
Обычно SIGCHLD генерируется, когда один из потомков процесса прерван или приостановлен (то есть всякий раз, когда wait4() должен вернуть информацию о состоянии процесса). Если флаг SA_NOCLDSTOP указан для сигнала SIGCHLD, то сигнал генерируется лишь в случае прерывания дочернего процесса; приостановка дочернего процесса не приводит к генерации каких-либо сигналов. SA_NOCLDSTOP не оказывает влияния ни на какой другой сигнал. |
SA_NODEFER |
Когда вызывается обработчик сигнала, сигнал автоматически не блокируется. Применение этого флага приводит к ненадежным сигналам, и он должен использоваться только для эмуляции ненадежных сигналов в приложениях, зависящих от такого поведения. Это идентично флагу SA_NOMASK в System V. |
SA_RESETHAND |
Когда присылается сигнал, обработчик сбрасывается в SIG_DFL. Этот флаг позволяет эмулировать функцию ANSI/ISO signal() в библиотеке пользовательского пространства. Идентично флагу SA_ONESHOT в System V. |
SA_RESTART |
Когда сигнал посылается процессу во время выполнения медленного системного вызова, системный вызов перезапускается после возврата управления из обработчика. Если флаг не указан, то системный вызов в этом случае возвращает ошибку и устанавливает errno равным EINTR. |
12.2.4. Манипулирование маской сигналов процесса
Манипулировать структурами данных, которые используются в других частях программы — обычное дело для обработчика сигналов. К сожалению, асинхронная природа сигналов делает это опасным, если только не обращаться с этим с осторожностью. Манипулирование всеми, за исключением простейших структур данных, приводит программу к состоянию состязаний.
Пример немного прояснит эту проблему. Ниже показан простой обработчик
SIGHUP, изменяющий значение строки, на которую указывает глобальная переменная
someString.
void handleHup(int signum) {
free(someString);
someString = strdup("другая строка");
}
В реальных программах новое значение
someString вероятно, будет читаться из внешнего источника (такого как FIFO), но некоторые концепции актуальны и так. Теперь предположим, что основная часть программы копирует строку (этот код аналогичен реализации
strcpy(), хотя и не очень оптимизирован), когда поступает сигнал
SIGHUP.
src = someString;
while(*src)
*dest++ = *src++;
Когда главная часть программы возобновит выполнение,
src будет указывать на память, которая была освобождена обработчиком сигналов. Излишне говорить, что это очень плохая идея
[62].
Чтобы решать проблемы такого типа, программный интерфейс сигналов POSIX позволяет процессу блокировать доставку процессу произвольного набора сигналов. При этом сигналы не отбрасываются, просто их доставка задерживается до тех пор, пока процесс не обозначит свою готовность обработать эти сигналы, разблокировав их. Чтобы правильно выполнить показанное выше копирование строки, программа должна блокировать
SIGHUP перед выполнением копирования и разблокировать его после. Обсудив интерфейс манипулирования масками сигналов, далее мы представим соответствующую версию кода.
Набор сигналов, которые процесс блокирует, часто называют
маской сигнала этого процесса. Маска сигналов процесса задается типом
sigset_t и содержит сигналы, заблокированные в данный момент. Функция
sigprocmask() позволяет процессу управлять его текущей маской сигналов.
#include <signal.h>
int sigprocmask(int what, sigset_t *set, sigset_t *oldest);
Первый параметр,
what, описывает, как должна выполняться манипуляция. Если
set равно
NULL, то
what игнорируется.
SIG_BLOCK |
Сигналы в set добавляются к текущей маске сигналов. |
SIG_UNBLOCK |
Сигналы в set исключаются из текущей маски сигналов. |
SIG_SETMASK |
Блокируются сигналы из набора set, остальные разблокируются. |
Во всех трех случаях параметр
oldset типа
sigset_t указывает на исходную маску сигналов, если только он не равен
NULL — в этом случае
oldset игнорируется. Следующий вызов ищет текущую маску сигналов для запущенных процессов.
sigprocmask(SIG_BLOCK, NULL, ¤tSet);
Системный вызов
sigprocmask позволяет исправить код, представленный выше, который мог вызвать состояние состязаний. Все, что потребуется сделать — это блокировать
SIGHUP перед копированием строки и разблокировать после копирования. Следующее усовершенствование делает код более безопасным.
sigset_t hup;
sigemptyset(&hup);
sigaddset(&hup, SIGHUP);
sigprocmask(SIG_BLOCK, &hyp, NULL);
src = someString;
while(*src)
*dest++ = *src++;
sigprocmask(SIG_UNBLOCK, &hup, NULL);
Сложность обеспечения безопасности обработчика сигналов от состояния состязаний должно заставить вас писать обработчики, насколько возможно, простыми.
12.2.5. Нахождение набора ожидающих сигналов
Очень легко найти сигналы, находящиеся в состоянии ожидания (сигналы, которые должны быть доставлены, но в данный момент заблокированы).
#include <signal.h>
int sigpending(sigset_t *set);
Эта функция записывает по адресу, указанному
set, набор сигналов, которые в данный момент находятся в состоянии ожидания.
12.2.6. Ожидание сигналов
Когда программа построена преимущественно вокруг сигналов, часто необходимо, чтобы она ожидала появления какого-то сигнала, прежде чем продолжать работу. Системный вызов
pause() предоставляет простую возможность для этого.
#include <unistd.h>
int pause(void);
Функция
pause() не возвращает управления до тех пор, пока сигнал не будет доставлен процессу. Если зарегистрирован обработчик для этого сигнала, то он запускается до того, как
pause() вернет управление,
pause() всегда возвращает
-1 и устанавливает
errno равным
EINTR.
Системный вызов
sigsuspend() предлагает альтернативный метод ожидания вызова сигнала.
#include <signal.h>
int sigsuspend(const sigset_t *mask);
Как и
pause(),
sigsuspend() временно приостанавливает процесс до тех пор, пока не будет получен сигнал (и обработан связанным с ним обработчиком, если таковой предусмотрен), возвращая
-1 и устанавливая
errno в
EINTR.
В отличие от
pause(),
sigsuspend() временно устанавливает маску сигналов процесса в значение, находящееся по адресу, указанному в
mask, на период ожидания появления сигнала. Как только сигнал поступает, маска сигналов восстанавливается в то значение, которое она имела до вызова
sigsuspend(). Это позволяет процессу ожидать появления определенного сигнала за счет блокирования всех остальных сигналов
[63].
12.3. Доступные сигналы
Linux предоставляет в распоряжение процессов сравнительно немного сигналов, и все они собраны в табл. 12.1.
Таблица 12.1. Сигналы
| Сигнал |
Описание |
Действие по умолчанию |
SIGABRT |
Доставляется вызовом abort(). |
Прервать, сбросить дамп |
SIGALRM |
Истек срок действия alarm(). |
Прервать |
SIGBUS |
Ошибка, зависящая от оборудования. |
Прервать, сбросить дамп |
SIGCHLD |
Дочерний процесс прерван. |
Игнорировать |
SIGCONT |
Выполнение процесса продолжается после приостановки. |
Игнорировать |
SIGFPE |
Арифметическая ошибка. |
Прервать, сбросить дамп |
SIGHUP |
Закрыт процесс, управляющий терминалом. |
Прервать |
SIGILL |
Обнаружена недопустимая инструкция. |
Прервать |
SIGINT |
Пользователь послал символ прерывания (^C). |
Прервать |
SIGIO |
Принят асинхронный ввод-вывод. |
Прервать |
SIGKILL |
Не перехватываемое прерывание процесса. |
Прервать |
SIGPIPE |
Процесс пишет в канал при отсутствии читателя. |
Прервать |
SIGPROF |
Закончился сегмент профилирования. |
Прервать |
SIGPWR |
Обнаружен сбой питания. |
Прервать |
SIGQUIT |
Пользователь послал символ выхода (^\). |
Прервать, сбросить дамп |
align = "left" valign = "top" >SIGSEGV
Нарушение памяти. |
Прервать, сбросить дамп |
SIGSTOP |
Приостановка процесса без его прерывания. |
Процесс приостановить |
SIGSYS |
Неверный системный вызов. |
Прервать, сбросить дамп |
SIGTERM |
Перехватываемый запрос на прерывание процесса. |
Прервать |
SIGTRAP |
Получена инструкция точки прерывания. |
Прервать, сбросить дамп |
SIGTSTP |
Пользователь послал символ приостановки (^Z). |
Процесс приостановить |
SIGTTIN |
Фоновый процесс читает с управляющего терминала. |
Процесс приостановить |
SIGTTOU |
Фоновый процесс пишет на управляющий терминал. |
Процесс приостановить |
SIGURG |
Условие срочного ввода-вывода. |
Игнорировать |
SIGUSR1 |
Определяемый процессом сигнал. |
Прервать |
SIGUSR2 |
Определяемый процессом сигнал. |
Прервать |
SIGVTALRM |
Таймер, установленный с помощью setitimer(), устарел. |
Прервать |
SIGWINCH |
Размер управляющего терминала изменился. |
Игнорировать |
SIGXCPU |
Достигнуто ограничение ресурсов центрального процессора. |
Прервать, сбросить дамп |
SIGXFSZ |
Достигнуто ограничение размера файла. |
Прервать, сбросить дамп |
Предусмотрены четыре действия по умолчанию, которые ядро может предпринять при поступлении сигнала: игнорировать его, приостановить процесс (он остается жив и может быть перезапущен позднее), прервать процесс либо прервать процесс и сбросить дамп памяти ядра
[64]. Ниже приведено более подробное описание каждого из перечисленных в табл. 12.1 сигналов.
SIGABRT |
Функция abort() посылает сигнал процессу, который ее вызвал, прерывая процесс со сбросом файла дампа ядра. Под Linux библиотека С вызывает abort(), когда происходит сбой утверждения (assertion). Примечание. Утверждения описаны в книгах по С начального уровня, например, [15]. |
SIGALRM |
Вызывается, когда предупреждение, установленное alarm(), устаревает. Предупреждения (alarms) — это основа функции sleep(), описанной в главе 18. |
SIGBUS |
Когда процесс нарушает ограничения, накладываемые оборудованием, но не связанные с защитой памяти, посылается этот сигнал. Обычно это случается на традиционных платформах Unix, когда выполняется попытка "невыровненного" доступа, но ядро Linux исправляет такие попытки и продолжает выполнять процесс. Выравнивание памяти обсуждается в главе 7. |
SIGCHLD |
Этот сигнал посылается процессу, когда один из его дочерних процессов устаревает или остановлен. Это позволяет процессу избежать появления "зомби" за счет вызова одной из функций wait() из обработчика сигнала. Если родитель всегда ожидает завершения дочерних процессов, прежде чем продолжить работу, этот сигнал может быть проигнорирован. Это отличается от сигнала SIGCHLD, представленного в ранних версиях System V. SIGCHLD устарел и более не должен применяться. |
SIGCONT |
Этот сигнал перезапускает приостановленный процесс. Также он может быть вызван процессом, позволяющим выполнить действие после перезапуска. Большинство редакторов перехватывают этот сигнал и обновляют терминал после перезапуска. В главе 15 дана более подробная информация об останове и перезапуске процесса. |
SIGFPE |
Этот сигнал посылается, когда процесс вызывает арифметическое исключение. Все исключения плавающей точки, такие как переполнение и потеря значимости, вызывают этот сигнал, как это происходит при делении на 0. |
SIGHUP |
Когда терминал отсоединяется, лидер сеанса, ассоциированного с терминалом, получает этот сигнал, если только на терминале не выставлен флаг CLOCAL. Если лидер сеанса завершается, SIGHUP отправляется лидеру каждой группы процессов в данном сеансе. Большинство процессов прерываются при получении SIGHUP, поскольку это значит, что пользователя уже нет в системе. Многие процессы-демоны интерпретируют SIGHUP как запрос на закрытие и повторное открытие журнальных файлов, а также на перечитывание конфигурационных файлов. |
SIGILL |
Процесс пытается запустить некорректную аппаратную команду. |
SIGINT |
Этот сигнал посылается всем процессам в группе процессов переднего плана, когда пользователь нажимает клавиатурную комбинацию прерывания (обычно ^C). |
SIGIO |
Произошло асинхронное событие ввода-вывода. Асинхронный ввод-вывод редко используется и в этой книге не описан. По вопросам асинхронного ввода-вывода обращайтесь к соответствующим источникам, например, [35]. |
SIGKILL |
Этот сигнал генерируется только вызовом kill() и разрешает пользователю безусловно прервать процесс. |
SIGPIPE |
Процесс выполнил запись в канал, который не имеет читателя. |
SIGPROF |
Завершилось действие таймера профилирования. Это сигнал обычно используется профилировщиками, которые проверяют другие характеристики процесса времени выполнения. Профилировщики обычно используются для оптимизации времени выполнения программ, помогая программистам находить узкие места. Простейшим профилировщиком является утилита gprof, входящая в состав всех дистрибутивов Linux. |
SIGPWR |
Система обнаружила надвигающуюся потерю питания. Обычно этот сигнал отправляется процессу init демоном, отслеживающим источники питания машины, позволяя корректно завершить работу до отключения питания. |
SIGQUIT |
Этот сигнал посылается всем процессам в группе процессов переднего плана, когда пользователь нажимает клавиатурную комбинацию завершения (обычно ^/). |
SIGSEGV |
Этот сигнал посылается, когда процесс пытается прочитать неотображаемую память, выполнить страницу памяти, которая не была отображена с привилегиями на выполнение, или же выполнить запись в память, к которой не имеет прав доступа на запись. |
SIGSTOP |
Этот сигнал генерируется только вызовом kill(), и дает возможность пользователю безусловно остановить процесс. Более подробно о приостановке процессов можно почитать в главе 15. |
SIGSYS |
Когда программа пытается выполнить несуществующий системный вызов, ядро прерывает программу с помощью этого сигнала. Это никогда не должно происходить в программах, которые осуществляют системные вызовы посредством системой библиотеки С. |
SIGTERM |
Этот сигнал генерируется только вызовом kill() и дает возможность пользователю элегантно прервать процесс. Процесс должен прекратиться насколько возможно быстро, немедленно после получения сигнала. |
SIGTRAP |
Когда программа проходит через точку прерывания, этот сигнал посылается процессу. Обычно он перехватывается процессом отладчика, который установил точку прерывания. |
SIGTSTP |
Этот сигнал посылается всем процессам в группе процессов переднего плана, когда пользователь нажимает клавиатурную комбинацию прерывания (обычно ^Z). |
SIGTTIN |
Этот сигнал посылается фоновому процессу, который пытается осуществить чтение из контролируемого им терминала. Об управлении заданиями подробнее читайте в главе 15. |
SIGTTOU |
Этот сигнал посылается фоновому процессу, который пытается осуществить запись на контролируемый им терминал. Об управлении заданиями подробнее читайте в главе 15. |
SIGURG |
Этот сигнал посылается, когда по сокету принимается экстренное сообщение. Экстренные данные — тема, касающаяся сетевых технологий, которая выходит за рамки освещаемых в настоящей книге. В [33] это рассматривается более подробно. |
SIGUSR1 |
Для этого сигнала нет предопределенного назначения; процессы могут использовать его для собственных нужд. |
SIGUSR2 |
Для этого сигнала нет предопределенного назначения; процессы могут использовать его для собственных нужд. |
SIGVTALRM |
Отправляется, когда истекает период действия таймера, установленного вызовом settimer(). Информацию о применении таймеров можно найти в главе 18. |
SIGWINCH |
Когда окно терминала изменяет размер, например, когда пользователь растягивает окно xterm, все процессы в группе процессов переднего плана получают этот сигнал. В главе 16 представлена информация об определении текущего размера управляющего терминала. |
SIGXCPU |
Процесс превысил свой мягкий лимит использования ресурсов процессора. Этот сигнал посылается раз в секунду до тех пор, пока данный процесс не превысит жесткий лимит использования ресурсов процессора. Как только это произойдет, процесс прерывается сигналом SIGKILL. Информацию о лимитах ресурса процессора можно найти в главе 10. |
SIGXFSZ |
Когда программа превышает лимит максимального размера файла, ей посылается этот сигнал, что обычно уничтожает процесс. Если сигнал перехвачен, то системный вызов, который послужил причиной превышения лимита на размер файла, возвращает ошибку EFBIG. Информацию о лимитах ресурса процессора можно найти в главе 10. |
12.3.1. Описание сигналов
Иногда приложения нуждаются в описании сигнала для отображения пользователю или помещения в журнал. Существуют три способа сделать это (см. главу 9). К сожалению, ни один из них не стандартизован.
Самый старый метод предусматривает применение
sys_siglist — массива строк, описывающих каждый сигнал, проиндексированного номерами самих сигналов. Он включает описания всех сигналов за исключением сигналов реального времени. Применение
sys_siglist более переносимо, чем прочие методы, описанные ниже. В системах BSD предусмотрена функция
psignal(), которая является сокращенным способом отображения сообщений. Вот как выглядит версия
psignal().
#include <signal.h>
#include <stdio.h>
void psignal(int signum, const char *msg) {
printf("%s: %s\n", msg, sys_siglist[signum]);
}
Следует отметить, что эта функция использует тот же список сигналов, что и
sys_siglist, поэтому сигналы реального времени также исключаются.
Библиотека GNU С, используемая Linux, предлагает еще один метод —
strsignal(). Эта функция не входит ни в какой стандарт, поэтому для доступа к файлу прототипа нужно определить
_GNU_SOURCE.
#define _GNU_SOURCE
#include <signal.h>
char *strsignal(int signum);
Подобно
sys_siglist,
strsignal() также представляет описание сигнала по номеру
signum. Он использует
sys_siglist для большинства сигналов и конструирует описания для сигналов реального времени. Например,
SIGRTMIN + 5 будет описан как "Real-time signal 5". Пример использования
strsignal() можно найти в строках 639–648 и 717 файла
ladsh4.с, приведенного в приложении Б.
12.4. Написание обработчиков сигналов
Хотя обработчик сигнала выглядит подобно обычной функции С, он не вызывается так, как она. Вместо того чтобы быть частью нормальной последовательности вызовов программы, обработчик вызывается ядром. Ключевое различие между этими двумя вещами заключается в том, что обработчик может быть вызван почти в любое время, даже во время выполнения отдельного оператора С! Есть только несколько ограничений того, когда система может вызвать обработчик сигнала, на который вы полагаетесь.
1. Семантика некоторых сигналов ограничивает, когда они могут быть посланы. Так, например,
SIGCHLD обычно посылается программам, у которых нет дочерних процессов
[65]. Большинство сигналов, подобных
SIGHUP, посылаются в непредсказуемые моменты.
2. Если процесс находится в процессе обработки некоторого сигнала, то обработчик сигнала не вызывается повторно для обработки того же сигнала, если только не была задана опция
SA_NODEFER. Процесс также может блокировать дополнительные сигналы, если сигнал, который обрабатывается, указан в члене
sa_mask структуры
struct sigaction.
3. Процесс может блокировать сигналы, когда выполняется часть кода, используя
sigprocmask(). Ранее в этой главе был дан пример использования этого средства для обеспечения атомарного обновления структур данных.
Поскольку обработчики сигналов могут быть запущены почти в любое время, важно писать их так, чтобы они не делали никаких негарантированных предположений относительно остальной части программы, и чтобы они сами не изменяли ничего таким образом, что это могло бы запутать остальную программу, когда она возобновит выполнение.
Одним из наиболее важных моментов, за которым нужно следить, является модификация глобальных данных. Если только не делать этого аккуратно, возможно получение ситуации состязаний. Простейший способ обеспечить безопасность обновления глобальных данных — просто избегать его. Второй, и лучший, способ — это блокировка всех обработчиков сигналов, которые модифицируют определенные структуры данных, всякий раз, когда остальная часть кода модифицирует их, с тем, чтобы обеспечить одновременное манипулирование этими данными только одним сегментом кода одновременно.
Хотя обработчик сигнала может читать структуры данных, когда его прерывает другой читатель этих данных, все прочие комбинации являются небезопасными. Более безопасно обработчику сигнала модифицировать структуры данных, которые читает остальная часть программы, чем наоборот — обработчику сигналов читать структуры данных, которые остальная часть программы выполняет запись. Некоторые специализированные структуры данных спроектированы так, чтобы позволить параллельный доступ, но их описание выходит за круг тем, рассматриваемых в настоящей книге.
Если вам требуется доступ к глобальным данным из обработчика сигналов (что и делает большинство обработчиков), оставляйте структуры данных простыми. Хотя достаточно просто безопасно модифицировать отдельный элемент данных, такой как int, более сложные структуры обычно требуют блокировки сигналов. Любые глобальные переменные, которые могут быть модифицированы обработчиками сигналов, должны быть объявлены с ключевым словом
volatile. Это сообщает компилятору, что переменная может быть изменена вне нормального потока программы, и он не должен пытаться оптимизировать доступ к этой переменной.
Другая вещь, с которой нужно соблюдать осторожность в обработчиках сигналов — это вызов других функций, потому что они тоже могут изменять глобальные данные! Библиотека С
stdio пытается облегчить это и не допускает вызовов своих функций из обработчиков сигналов. В табл. 12.2 перечислены функции, которые гарантированно являются безопасными для вызова из обработчиков сигналов
[66]; вызовов всех прочих функций следует избегать.
Таблица 12.2. Реентерабельные функции
abort() |
accept() |
access() |
aio_error() |
aio_return() |
aio_suspend() |
alarm() |
bind() |
cfgetispeed() |
cfgetospeed() |
cfsetispeed() |
cfsetospeed() |
chdir() |
chmod() |
chown() |
close() |
connect() |
creat() |
dup() |
dup2() |
execle() |
execve() |
_exit() |
fchmod() |
fchown() |
fcntl() |
fdatasync() |
fork() |
fpathconf() |
fstat() |
fsync() |
getegid() |
geteuid() |
getgid() |
getgroups() |
getpeername() |
getpgrp() |
getpid() |
getppid() |
getuid() |
kill() |
link() |
listen() |
lseek() |
lstat() |
mkdir() |
mkfifo() |
open() |
pathconf() |
pause() |
pipe() |
poll() |
posix_trace_event() |
pselect() |
raise() |
read() |
readlink() |
recv() |
recvfrom() |
recvmsg() |
rename() |
rmdir() |
select() |
sem_post() |
send() |
sendmsg() |
sendto() |
setgid() |
setpgid() |
setsid() |
setsockopt() |
setuid() |
shutdown() |
sigaction() |
sigaddset() |
sigdelset() |
sigemptyset() |
sigfillset() |
sigismember() |
signal() |
sigpause() |
sigpending() |
sigprocmask() |
sigqueue() |
sigset() |
sigsuspend() |
sleep() |
socket() |
socketpair() |
stat() |
symlink() |
sysconf() |
tcdrain() |
tcflow() |
tcflush() |
tcgetattr() |
tcgetpgrp() |
tcsendbreak() |
tcsetattr() |
tcsetpgrp() |
time() |
timer_getoverrun() |
timer_gettime() |
timer_settime() |
times() |
umask() |
uname() |
unlink() |
utime() |
wait() |
wait3() |
wait4() |
waitpid() |
write() |
12.5. Повторное открытие журнальных файлов
Большинство системных демонов ведут журнальные файлы, записывая в них все, что они делают. Поскольку многие системы Unix месяцами работают без остановки, эти журнальные файлы могут стать достаточно большими. Простое периодическое удаление (или переименование) журнальных файлов — не самое хорошее решение, потому что демоны будут продолжать записывать в эти файлы, несмотря на их недоступность, а необходимость останавливать и запускать каждый демон для очистки журнальных файлов приводит к недоступности системы (хоть и на незначительное время). Общий способ для демонов справиться с упомянутой ситуацией — перехватывать
SIGHUP и повторно открывать журнальные файлы. Это позволяет организовать
ротацию журналов (периодическое открытие новых журнальных файлов при сохранении старых), используя простой сценарий вроде приведенного ниже.
dd /var/log
mv messages messages.old
killall -HUP syslogd
Logrotate (ftp://ftp.redhat.com/pub/redhat/code/logrotate/) — одна из программ, которая использует преимущество такого метода для выполнения безопасной ротации журналов.
Включение этой возможности у большинства демонов достаточно просто. Одним их наиболее легких подходов является использование глобальной переменной, которая индицирует необходимость повторного открытия журналов.
Затем обработчик сигнала
SIGHUP в своем вызове устанавливает эту переменную, и главная часть программы проверяет эту переменную насколько можно часто. Ниже приведен пример соответствующей программы.
1: /*sighup.c*/
2:
3: #include <errno.h>
4: #include <signal.h>
5: #include <stdio.h>
6: #include <string.h>
7: #include <unistd.h>
8:
9: volatile int reopenLog = 0; /* volatile - поскольку модифицируется
10: обработчиком сигнала */
11:
12: /* записать строку в журнал */
13: void logstring(int logfd, char *str) {
14: write(logfd, str, strlen(str));
15: }
16:
17: /* когда приходит SIGHUP, сделать запись об этом и продолжить */
18: void hupHandler(int signum) {
19: reopenLog = 1;
20: }
21:
22: int main() {
23: int done = 0;
24: struct sigaction sa;
25: int rc;
26: int logfd;
27:
28: logfd = STDOUT_FILENO;
29:
30: /* Установить обработчик сигнала SIGHUP. Использовать memset() для
31: инициализации структуры sigaction чтобы обеспечить очистку
32: всего. */
33: memset(&sa, 0, sizeof(sa));
34: sa.sa_handler = hupHandler;
35:
36: if (sigaction(SIGHUP, &sa, NULL)) perror("sigaction");
37:
38: /* Записывать сообщение в журнал каждые две секунды, и
39: повторно открывать журнальный файл по требованию SIGHUP */
40: while (!done) {
41: /*sleep() возвращает не ноль, если не спит достаточно долго*/
42: rc = sleep(2);
43: if (rc) {
44: if (reopenLog) {
45: logstring(logfd,
46: "* повторное открытие журналов по запросу SIGHUP\n");
47: reopenLog = 0;
48: } else {
49: logstring(logfd,
50: "* sleep прервано неизвестным сигналом "
51: "--dying\n");
52: done=1;
53: }
54: } else {
55: logstring(logfd, "Периодическое сообщение\n");
56: }
57: }
58:
59: return 0;
60: }
Чтобы протестировать эту программу, запустите ее в одном окне
xterm и отправьте сигнал
SIGHUP из другого. Для каждого сигнала
SIGHUP, который принимает программа, она печатает сообщение, когда выполняет нормальную ротацию своих журналов. Помните, что если сигнал поступает в тот момент, когда работает другой экземпляр обработчика, доставляется только один экземпляр сигнала, поэтому не отправляйте их слишком часто.
12.6. Сигналы реального времени
Учитывая некоторые ограничения модели сигналов POSIX, например, недостающую возможность присоединения к сигналам никаких данных и вероятность того, что множество сигналов сольются в одной доставке, было разработано расширение POSIX Real Time Signals (сигналы реального времени POSIX)
[67]. Системы, которые поддерживают сигналы реального времени, включая Linux, также поддерживают описанный ранее традиционный механизм сигналов POSIX. Для обеспечения наивысшего уровня переносимости между системами, мы советуем использовать стандартные интерфейсы POSIX, если только не возникает необходимости в некоторых дополнительных средствах, предоставляемых расширением реального времени.
12.6.1. Очередность и порядок сигналов
Два из ограничений стандартной модели сигналов POSIX заключаются в том, что когда сигнал перебивает сигнал, это не приводит к множественной доставке этих сигналов, и отсутствуют гарантии упорядоченной доставки множества разнородных сигналов (если вы пошлете
SIGTERM, а следом
SIGKILL, то нет способа узнать, какой из них придет первым). Расширение POSIX Real Time Signals добавляет новый набор сигналов, которые не подпадают под упомянутые ограничения.
Существует множество доступных сигналов реального времени, и они не используются ядром ни для каких предопределенных целей. Все сигналы между
SIGRTMIN и
SIGRTMAX являются сигналами реального времени, хотя точные номера их в POSIX не специфицированы (на момент написания этой книги Linux предоставляет 32 таких сигнала, но в будущем их количество может увеличиться).
Сигналы реального времени всегда ставятся в очередь; каждый такой сигнал, посланный приложению, доставляется ему (если только приложение не прервано перед тем, как такой сигнал будет доставлен). Упорядочение сигналов реального времени также хорошо определено. Сигналы с меньшими номерами всегда доставляются перед сигналами с большими номерами, и когда множество сигналов с одинаковым номером поставлены в очередь, то они доставляются в порядке постановки. Порядок доставки сигналов, не относящихся к расширению реального времени, не определен, как и порядок доставки смеси сигналов реального времени и не относящихся к ним.
Ниже показан пример кода, иллюстрирующий постановку сигналов в очередь и их упорядочивание.
1: /* queued.с */
2:
3: /* получить определение strsignal() из string.h */
4: #define _GNU_SOURCE1
5:
6: #include <sys/signal.h>
7: #include <stdlib.h>
8: #include <stdio.h>
9: #include <string.h>
10: #include <unistd.h>
11:
12: /* Глобальные переменные для построения списка сигналов */
13: int nextSig = 0;
14: int sigOrder[10];
15:
16: /* Перехватить сигнал и записать, что он был обработан */
17: void handler(int signo) {
18: sigOrder[nextSig++] = signo;
19: }
20:
21: int main() {
22: sigset_t mask;
23: sigset_t oldMask;
24: struct sigaction act;
25: int i;
26:
27: /* Обрабатываемые в программе сигналы */
28: sigemptyset(&mask);
29: sigaddset(&mask, SIGRTMIN);
30: sigaddset(&mask, SIGRTMIN+1);
31: sigaddset(&mask, SIGUSR1);
32:
33: /* Отправить сигнал handler() и сохранять их блокированными,
34: чтобы handler() был сконфигурирован во избежание
35: состязаний при манипулировании глобальными переменными */
36: act.sa_handler = handler;
37: act.sa_mask = mask;
38: act.sa_flags = 0;
39:
40: sigaction(SIGRTMIN, &act, NULL);
41: sigaction(SIGRTMIN+1, &act, NULL);
42: sigaction(SIGUSR1, &act, NULL);
43:
44: /* Блокировать сигналы, с которыми мы работаем, чтобы
45: была видна очередность и порядок */
46: sigprocmask(SIG_BLOCK, &mask, &oldMask);
47:
48: /* Генерировать сигналы */
49: raise(SIGRTMIN+1);
50: raise(SIGRTMIN);
51: raise(SIGRTMIN);
52: raise(SIGRTMIN+1);
53: raise(SIGRTMIN);
54: raise(SIGUSR1);
55: raise(SIGUSR1);
56:
57: /* Разрешить доставку этих сигналов. Все они будут доставлены
58: прямо перед возвратом этого вызова (для Linux; это
59: НЕПЕРЕНОСИМОЕ поведение). */
60: sigprocmask(SIG_SETMASK, &oldMask, NULL);
61:
62: /* Отобразить упорядоченный список перехваченных сигналов */
63: printf("Принятые сигналы:\n");
64: for (i = 0; i < nextSig; i++)
65: if (sigOrder[i] < SIGRTMIN)
66: printf("\t%s\n", strsignal(sigOrder[i]));
67: else
68: printf("\tSIGRTMIN + %d\n", sigOrder[i] - SIGRTMIN);
69:
70: return 0;
71: }
Эта программа посылает себе некоторое количество сигналов и выводит на дисплей порядок их получения. Когда сигналы отправляются, она блокирует их, чтобы предотвратить немедленную доставку. Также она блокирует сигналы всякий раз, когда вызывается обработчик, устанавливая значение члена
sa_mask структуры
struct sigaction при настройке обработчика для каждого сигнала. Это предотвращает возможное состояние состязаний при обращении к глобальным переменным
nextSig и
sigOrder изнутри обработчика.
Запуск этой программы выдаст показанные ниже результаты.
Принятые сигналы:
User defined signal1
SIGRTMIN + 0
SIGRTMIN + 0
SIGRTMIN + 0
SIGRTMIN + 1
SIGRTMIN + 1
Это показывает, что все сигналы реального времени были доставлены, в то же время, был доставлен только один экземпляр сигнала
SIGUSR1. Вы также видите изменение порядка сигналов реального времени — все сигналы
SIGRTMIN были доставлены перед
SIGRTMIN + 1.
12.7. Дополнительные сведения о сигналах
Сигналы, которые мы обсуждали до сих пор, не несли в себе никаких данных; появление сигнала — это единственная информация, которую получает приложение. В некоторых случаях было бы неплохо знать, что послужило причиной отправки сигнала (как, например, неправильная адресация памяти, генерирующая
SIGSEGV), или же иметь возможность включить данные в сигналы, генерируемые приложением. Расширение реального времени Real Time Signals позволяет решить обе эти задачи.
12.7.1. Получение контекста сигнала
Информация о том, как и почему был сгенерирован сигнал, называется
контекстом[68] сигнала. Приложения, которые должны видеть этот контекст, используют обработчики сигналов, отличающиеся от нормальных. Они включают два дополнительных параметра — указатель на
siginfo_t, предоставляющий контекст сигнала, и указатель на
void*, который может быть использован некоторыми низкоуровневыми системными библиотеками
[69]. Вот как выглядит полный прототип такого обработчика.
void handler(int signum, siginfo_t *siginfo, void *context);
Приложение должно указать ядру на необходимость передачи полной информации о контексте, устанавливая флаг
SA_SIGINFO члена
sa_mask структуры
struct sigaction, применяемой для регистрации обработчика сигнала. Член
sa_handler также не используется, потому что он является указателем на функцию с другим прототипом. Вместо этого новый член,
sa_sigaction, указывает на обработчик сигнала с правильным прототипом. Чтобы снизить потребление памяти,
sa_handler и
sa_sigaction разрешено использовать один и тот же участок памяти, поэтому только один из двух должен применяться в одно и то же время. Чтобы сделать это прозрачным, библиотека С определяет
struct sigaction следующим образом.
#include <signal.h>
struct sigaction {
union {
__sighandler_t sa_handler;
__sigaction_t sa_sigaction;
} __sigaction_handler;
sigset_t sa_mask;
unsigned long sa_flags;
};
#define sa_handler __sigaction_handler.sa_handler
#define sa_sigaction __sigaction_handler.sa_sigaction
Использование представленной комбинации объединений и макросов позволяет этим двум членам разделять одну и ту же память без необходимости усложнения с точки зрения приложений.
Структура
siginfo_t содержит информацию о том, где и почему был сгенерирован сигнал. Всем сигналам доступны два члена:
sa_signo и
si_code. Какие другие члены доступны — зависит от конкретного сигнала, и эти члены разделяют память подобно тому, как это делают члены
sa_handler и
sa_sigaction структуры
struct sigaction. Член
sa_signo содержит номер доставленного сигнала и всегда равен значению первого параметра, переданного обработчику сигнала, в то время как
si_code указывает, почему сигнал был сгенерирован, и изменяется в зависимости от номера сигнала. Для большинства сигналов он может принимать перечисленные ниже значения.
[70]
SI_USER
Приложение пространства пользователя вызвало
kill() для отправки сигнала. Примечание. Функция
sigsend(), включенная в Linux для совместимости с некоторыми системами Unix, также выдает
SI_USER.
SI_QUEUE
Приложение пространства пользователя вызвало
sigqueue() для от правки сигнала, что обсуждается в самом конце этой главы.
SI_TKILL
Приложение пространства пользователя вызвало
tkill(). В то время как ядро Linux использует
SI_TKILL, его значение не специфицировано в текущей версии библиотеки С.
Если вам нужно проверить
SI_TKILL, используйте следующий сегмент кода для определения этого значения:
#ifndef SI_TKILL
#define SI_TKILL -6
#endif
SI_TKILL не специфицирован ни в каком стандарте (хотя допускается ими), поэтому его следует применять осторожно в переносимых программах.
SI_KERNEL
Сигнал сгенерирован ядром.
Когда
SIGILL,
SIGFPE,
SIGSEGV,
SIGBUS и
SIGCHLD посылаются ядром, то si_
code вместо
si_kernel принимает значения, перечисленные в табл. 12.3
[71].
Таблица 12.3. Значения si_code для специальных сигналов
| Сигнал |
si_code |
Описание |
SIGILL |
ILL_ILLOPC |
Неправильный код операции (opcode). |
|
ILL_ILLOPC |
Неправильный операнд. |
|
ILL_ILLOPC |
Неправильный режим адресации. |
|
ILL_ILLOPC |
Неправильная ловушка (trap). |
|
ILL_ILLOPC |
Привилегированный код операции. |
|
ILL_ILLOPC |
Привилегированный регистр. |
|
ILL_ILLOPC |
Внутренняя ошибка стека. |
|
ILL_ILLOPC |
Ошибка сопроцессора. |
SIGFPE |
FPE_INTDIV |
Деление целого на ноль. |
|
FPE_INTOVF |
Переполнение целого. |
|
FPE_FLTDIV |
Деление числа с плавающей точкой на ноль. |
|
FPE_FLTOVF |
Переполнение числа с плавающей точкой. |
|
FPE_FLTUND |
Потеря значимости числа с плавающей точкой. |
|
FPE_FLTRES |
Неточный результат числа с плавающей точкой. |
|
FPE_FLTINV |
Неверная операция с плавающей точкой. |
|
FPE_FLTSUB |
Число с плавающей точкой вне диапазона. |
SIGSEGV |
SEGV_MAPPER |
Адрес не отображается на объект. |
|
SEGV_ACCERR |
Неверные права доступа для адреса. |
SIGBUS |
BUS_ADRALN |
Неверное выравнивание адреса. |
|
BUS_ADRERR |
Несуществующий физический адрес. |
|
BUS_OBJERR |
Специфичный для объекта сбой оборудования. |
SIGCHLD |
CLD_EXITED |
Дочерний процесс завершен. |
|
CLD_KILLED |
Дочерний процесс уничтожен. |
|
CLD_DUMPED |
Дочерний процесс уничтожен с выводом дампа памяти в файл. |
|
CLD_TRAPPED |
Дочерний процесс достиг точки останова. |
|
CLD_STOPPED |
Дочерний процесс приостановлен. |
Чтобы помочь прояснить разные значения, которые может принимать
si_code, рассмотрим пример, в котором
SIGCHLD генерируется четырьмя разными способами:
kill(),
sigqueue(),
raise() (использует системный вызов
tkill()) и созданием дочернего процесса, который немедленно прерывается.
1: /* sicode.с */
2:
3: #include <sys/signal.h>
4: #include <stdlib.h>
5: #include <stdio.h>
6: #include <unistd.h>
7:
8: #ifndef SI_TKILL
9: #define SI_TKILL -6
10: #endif
11:
12: void handler(int signo, siginfo_t *info, void *f ) {
13: static int count = 0;
14:
15: printf("перехвачен сигнал, отправленный ");
16: switch(info->si_code) {
17: case SI_USER:
18: printf("kill()\n");break;
19: case SI_QUEUE:
20: printf("sigqueue()\n"); break;
21: case SI_TKILL:
22: printf("tkill() или raise()\n"); break;
23: case CLD_EXITED:
24: printf ("ядро сообщает, что дочерний процесс завершен\n"); exit(0);
25: }
26:
27: if (++count == 4) exit(1);
28: }
29:
30: int main() {
31: struct sigaction act;
32: union sigval val;
33: pid_t pid = getpid();
34:
35: val.sival_int = 1234;
36:
37: act.sa_sigaction = handler;
38: sigemptyset(&act.sa_mask);
39: act.sa_flags = SA_SIGINFO;
40: sigaction(SIGCHLD, &act, NULL);
41:
42: kill(pid, SIGCHLD);
43: sigqueue(pid, SIGCHLD, val);
44: raise(SIGCHLD);
45:
46: /* Чтобы получить SIGCHLD от ядра, мы создаем дочерний процесс
47: и немедленно завершаем его. Обработчик сигнала выйдет после
48: получения сигнала от ядра, поэтому мы просто засыпаем
49: на время и позволяем программе прерваться подобным образом. */
50:
51: if (!fork()) exit(0);
52: sleep(60);
53:
54: return 0;
55: }
Если
si_code равно
SI_USER,
SI_QUEUE или
SI_TKILL, то доступны два дополнительных члена
siginfo_t:
si_pid и
si_uid, которые представляют идентификатор процесса, пославшего сигнал и действительный идентификатор пользователя этого процесса.
Когда ядром посылается
SIGCHLD, доступны члены
si_pid,
si_status,
si_utime и
si_stime. Первый из них,
si_pid, задает идентификатор процесса, состояние которого изменилось
[72]. Информация о новом состоянии доступна как в
si_code (как показано в табл. 12.3) и в
si_status, что идентично целому значению состояния, возвращаемому семейством функций
wait().
Последние два члена,
si_utime и
si_stime, определяют период времени, которое потрачено дочерним приложением на работу в пользовательском режиме и в режиме ядра, соответственно (это подобно тому, что возвращают вызовы
wait3() и
wait4() в структуре
struct rusage). Это время измеряется в тиках часов, заданных целым числом. Количество тиков в секунду задает макрос
_SC_CLK_TCK, определенный в
<sysconf.h>.
SIGSEGV,
SIGBUS,
SIGILL и
SIGFPE — все они представляют
si_addr, специфицирующий адрес, который вызвал сбой, описанный
si code.
Ниже приведен простой пример проверки контекста сигнала. Он устанавливает обработчик сигнала для
SIGSEGV, который печатает контекст сигнала и прерывает процесс. Нарушение сегментации генерируется попыткой обращения к
NULL.
1: /* catch-segv.c */
2:
3: #include <sys/signal.h>
4: #include <stdlib.h>
5: #include <stdio.h>
6:
7: void handler(int signo, siginfo_t *info, void *f) {
8: printf("перехват");
9: if (info->si_signo == SIGSEGV)
10: printf("segv accessing %p", info->si_addr);
11: if (info->si_code == SEGV_MAPERR)
12: printf("SEGV_MAPERR");
13: printf("\n");
14:
15: exit(1);
16: }
17:
18: int main() {
19: struct sigactin act;
20:
21: act.sa_sigaction = handler;
22: sigemptyset(&act.sa_mask);
23: act.sa_flags = SA_SIGINFO;
24: sigaction(SIGSEGV, &act, NULL);
25:
26: *((int *)NULL) = 1 ;
27:
28: return 0;
29: }
12.7.2. Отправка данных с сигналом
Механизм
siginfo_t также позволяет сигналам, которые посылают программы, присоединять к себе один элемент данных (этот элемент может быть указателем, что позволяет неявно передавать любой необходимый объем данных). Чтобы отправить данные, используется
union sigval.
#include <signal.h>
union sigval {
int sival_int;
void *sival_ptr;
};
Любой из членов объединения —
sival_int или
sival_ptr — может быть установлен в требуемое значение, которое включается в
siginfo_t, доставляемое вместе с сигналом. Чтобы сгенерировать сигнал с
union sigval, должна использоваться функция
sigqueue().
#include <signal.h>
void *sigqueue(pid_t pid, int signum, const union sigval value);
В отличие от
kill(),
pid должен быть корректным идентификатором процесса (отрицательные значения не допускаются),
signum указывает номер посылаемого сигнала. Подобно
kill(),
sigqueue() допускает нулевое значение
signum нулю, чтобы проверить, позволяет ли вызывающий процесс посылать целевому сигналы, в действительности не выполняя такой посылки. Последний параметр,
value, представляет собой элемент данных, передаваемый вместе с сигналом.
Чтобы принять
union sigval, процесс, перехватывающий сигнал, должен использовать
SA_SIGINFO при регистрации обработчика сигналов с помощью
sigaction(). Когда член
si_code структуры
siginfo_t равен
SI_QUEUE, то
siginfo_t представляет член
si_value, который содержит значение
value, переданное
sigqueue.
Ниже приведен пример отправки элемента данных с сигналом. Он устанавливает в очередь три сигнала
SIGRTMIN с разными элементами данных. Он демонстрирует, что сигналы доставляются в том же порядке, что были отправлены, как мы и ожидаем при работе с сигналами реального времени
[73]. Более сложный пример, использующий сигналы для отслеживания изменений в каталогах, можно найти в главе 14.
1: /* sigval.с */
2:
3: #include <sys/signal.h>
4: #include <stdlib.h>
5: #include <stdio.h>
6: #include <string.h>
7: #include <unistd.h>
8:
9: /* Захватить сигнал и зарегистрировать факт его обработки */
10: void handler(int signo, siginfo_t *si, void *context) {
11: printf("%d\n", si->si_value.sival_int);
12: }
13:
14: int main() {
15: sigset_t mask;
16: sigset_t oldMask;
17: struct sigaction act;
18: int me = getpid();
19: union sigval val;
20:
21: /* Отправить сигналы handler() и сохранять все сигналы заблокированными,
22: чтобы handler() был сконфигурирован для перехвата с исключением
23: состязаний при манипулировании глобальными переменными */
24: act.sa_sigaction = handler;
25: act.sa_mask = mask;
26: act.sa_flags = SA_SIGINFO;
27:
28: sigaction(SIGRTMIN, &act, NULL);
29:
30: /* Блокировать SIGRTMIN, чтобы можно было увидеть очередь и упорядочение*/
31: sigemptyset(&mask);
32: sigaddset(&mask, SIGRTMIN);
33:
34: sigprocmask(SIG_BLOCK, &mask, &oldMask);
35:
36: /* Сгенерировать сигналы */
37: val.sival_int = 1;
38: sigqueue(me, SIGRTMIN, val);
39: val.sival_int++;
40: sigqueue(me, SIGRTMIN, val);
41: val.sival_int++;
42: sigqueue(me, SIGRTMIN, val);
43:
44: /* Разрешить доставку сигналов */
45: sigprocmask(SIG_SETMASK, &oldMask, NULL);
46:
47: return 0;
48: }
Глава 13
Расширенная обработка файлов
В Linux файлы применяются при решении большого количества задач, среди которых, например, хранение долговременных данных, организация сетей с помощью сокетов и доступ к устройствам посредством файлов устройств. Разнообразие приложений, работающих с файлами, привело к созданию множества специальных способов управления файлами. В главе 11 рассматривались наиболее распространенные действия с файлами; в настоящей же главе исследуются специализированные файловые операции. В частности, мы рассмотрим следующие вопросы: использование одновременно нескольких файлов, отображение файлов на системную память, блокировка файлов, чтение и запись вразброс.
13.1. Мультиплексирование входных и выходных данных
Многим клиент-серверным приложениям необходимо считывать входные данные или записывать выходные данные с помощью одновременно нескольких файловых дескрипторов. Например, современные Web-браузеры открывают одновременно несколько сетевых подключений, чтобы уменьшить время загрузки Web-страницы. Это позволяет им загружать множество изображений, имеющихся на большинстве Web-страниц, быстрее, чем с помощью последовательных подключений. Кроме канала межпроцессных взаимодействий (IPC), используемого графическими браузерами для связи с X-сервером, на котором они отображаются, браузеры работают с множеством файловых дескрипторов.
Браузеру легче всего обработать эти файлы, считывая и обрабатывая данные из них (системный вызов
read() в сетевом подключении, так же, как и в канале, возвращает доступные в настоящий момент данные и блокирует их только в случае неготовности). Этот подход эффективен, пока все подключения доставляют данные достаточно регулярно.
Если одно из сетевых подключений является медленным, начинают возникать проблемы. Когда браузер снова считывает из этого файла, он перестает работать, в то время как
read() блокируется в ожидании поступления данных. Не стоит и упоминать, что подобное поведение не является удобоваримым для пользователя браузера.
Для иллюстрации этих проблем рассмотрим короткую программу, считывающую из двух файлов,
p1 и
p2. Для ее испытания откройте три сеанса работы с X-терминалом (или воспользуйтесь тремя виртуальными консолями). Создайте каналы под именами
p1 и
p2 (с помощью команды
mknod), затем запустите
cat > p1 и
cat > p2 в двух терминалах, одновременно запустив
mpx-blocks в третьем. После этого набирайте любой текст в каждом окно
cat и смотрите, как он появляется. Помните, что две команды
cat не будут записывать данные в каналы до конца строки.
1: /* mpx-blocks.с */
2:
3: #include <fcntl.h>
4: #include <stdio.h>
5: #include <unistd.h>
6:
7: int main(void) {
8: int fds[2];
9: char buf[4096];
10: int i;
11: int fd;
12:
13: if ((fds[0] = open("p1", O_RDONLY) ) < 0) {
14: perror("open p1");
15: return 1;
16: }
17:
18: if ( (fds[1] = open("p2", O_RDONLY)) < 0) {
19: perror("open p2");
20: return 1;
21: }
22:
23: fd = 0;
24: while (1) {
25: /* если данные доступны, прочитать и отобразить их */
26: i = read (fds[fd], buf, sizeof (buf) - 1);
27: if (i < 0) {
28: perror("read");
29: return 1;
30: } else if (!i) {
31: printf("канал закрыт\n");
32: return 0;
33: }
34:
35: buf[i] = '\0';
36: printf ("чтение: %s", buf);
37:
38: /* читать из другого файлового дескриптора */
39: fd = (fd + 1) % 2;
40: }
41: }
Хотя программа
mpx-blocks может считывать одновременно из обоих каналов, это не является особо эффективным. Она считывает из каждого канала по очереди. После запуска программа читает из первого файла, пока в нем доступны данные, второй файл игнорируется вплоть до возврата из
read() для первого файла. Как только произошел возврат, первый файл игнорируется вплоть до чтения данных из второго файла. Этот метод не поддерживает гладкое мультиплексирование данных. На рис. 13.1 показана программа
mpx-blocks во время выполнения.
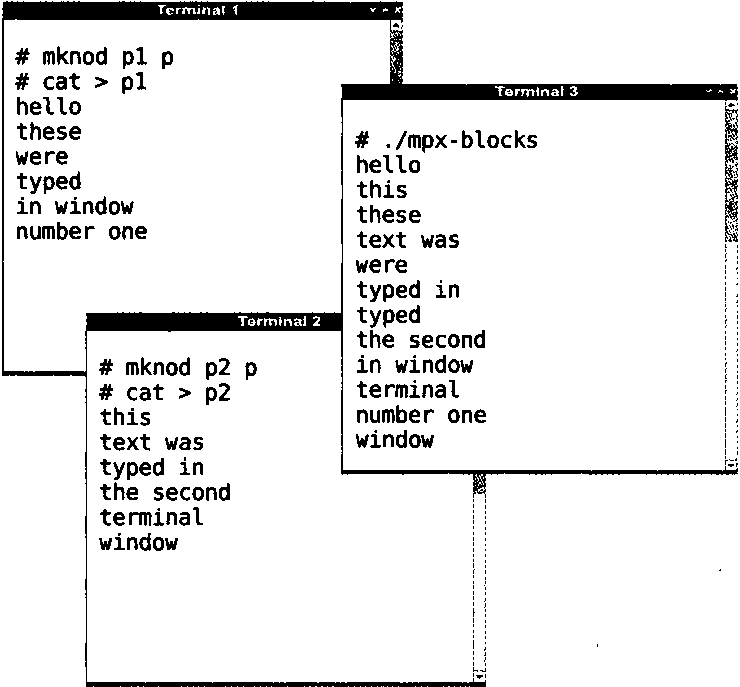 Рис. 13.1
Рис. 13.1. Примеры запуска мультиплексной передачи
13.1.1. Неблокируемый ввод-вывод
Как упоминалось в главе 11, неблокируемый файл можно определить с помощью системного вызова
fcntl. Если медленный файл неблокируемый,
read() сразу же возвращается. Если данные недоступны, она просто возвращает 0. Неблокируемый ввод- вывод предоставляет простое решение мультиплексирования, предотвращая блокирование файловых операций.
Показанная ниже модифицированная версия
mpx-blocks пользуется преимуществом неблокируемого ввода-вывода для более гладкого переключения между
p1 и
p2.
1: /* mpx-nonblock.c */
2:
3: #include <errno.h>
4: #include <fcntl.h>
5: #include <stdio.h>
6: #include <unistd.h>
7:
8: int main(void) {
9: int fds[2];
10: char buf[4096];
11: int i;
12: int fd;
13:
14: /* открыть оба канала в неблокирующем режиме */
15: if ((fds[0] = open("p1", O_RDONLY | O_NONBLOCK)) < 0) {
16: perror("open p1");
17: return 1;
18: }
19:
20: if ((fds[1] = open("p2", O_RDONLY | O_NONBLOCK)) < 0) {
21: perror("open p2");
22: return 1;
23: }
24:
25: fd = 0;
26: while (1) {
27: /* если данные доступны, прочитать и отобразить их */
28: i = read(fds[fd], buf, sizeof (buf) - 1);
29: if ((i < 0) && (errno ! = EAGAIN)) {
30: perror("read");
31: return 1;
32: } else if (i > 0) {
33: buf[i] = '\0';
34: printf("чтение: %s", buf);
35: }
36:
37: /* читать из другого файлового дескриптора */
38: fd = (fd + 1) % 2;
39: }
40: }
Важное различие между
mpx-nonblock и
mpx-blocks состоит в том, что программа
mpx-nonblock не закрывается, когда один из каналов, из которого она считывает, закрыт. Неблокируемый
read() из канала без записывающих устройств возвращает 0 байт, из канала с таковыми, но без доступных данных
read() возвращает
EAGAIN.
Простое переключение неблокируемого ввода-вывода между дескрипторами файлов достается высокой ценой. Программа всегда опрашивает два файловых дескриптора для ввода — она никогда не блокируется. Постоянная работа программы приносит системе массу проблем, поскольку операционная система не может перевести процесс в режим ожидания (попробуйте запустить 10 копий
mpx-nonblock в своей системе и посмотрите, как это скажется на ее производительности).
13.1.2. Мультиплексирование с помощью poll()
Для эффективного мультиплексирования Linux предоставляет системный вызов
poll(), позволяющий процессу блокировать одновременно несколько файловых дескрипторов. Постоянно проверяя каждый файловый дескриптор, процесс создает отдельный системный вызов, определяющий, из каких файловых дескрипторов процесс будет читать, а на какие — записывать. Когда один или несколько таких файлов имеют данные, доступные для чтения, или могут принимать данные, записываемые в них,
poll() завершается, и приложение может считывать и записывать данные в дескрипторах, не беспокоясь о блокировке. После обработки этих файлов процесс создает еще один вызов
poll(), блокируемый до готовности файла. Ниже показано определение
poll().
#include <sys/poll.h>
int poll(struct pollfd * fds, int numfds, int timeout);
Последние два параметра очень просты;
numfds задает количество элементов в массиве, на который указывает первый параметр, a
timeout определяет, насколько долго
poll() должна ожидать события. Если в качестве тайм-аута задается 0,
poll() никогда не входит в состояние тайм-аута.
Первый параметр,
fds, описывает, какие файловые дескрипторы следует контролировать, и для каких типов ввода-вывода. Это указатель на массив структур
struct pollfd.
struct pollfd {
int fd; /* файловый дескриптор */
short events; /* ожидаемые события ввода-вывода */
short revents; /* происшедшие события ввода-вывода */
};
Первый элемент,
fd, является контролируемым файловым дескриптором, а элемент events описывает, какие типы событий подлежат мониторингу. Последний представляет собой один или несколько перечисленных флагов, объединенных с помощью логического "ИЛИ".
POLLIN |
Нормальные данные доступны для считывания из файлового дескриптора. |
POLLPRI |
Приоритетные (внешние) данные доступны для считывания. |
POLLOUT |
Файловый дескриптор может принимать записываемые на него данные. |
Элемент
revents структуры
struct pollfd заполняется системным вызовом
poll() и отражает состояние файлового дескриптора
fd. Это похоже на элемент
events, но вместо определения интересующих приложение событий ввода-вывода он определяет доступные такие типы. Например, если приложение контролирует канал как для чтения, так и для записи (
events установлено в
POLLIN | POLLOUT), после успешного вызова
poll() в
revents устанавливается бит
POLLIN, если канал готов для чтения, и бит
POLLOUT, если в канале имеется пространство для записи дополнительных данных. Если верно и то, и другое, устанавливаются оба бита.
Существует несколько битов, которые ядро может установить в
revents, но которые невозможно установить в
events.
POLLERR |
В дескрипторе файла имеется ожидающая ошибка; выполнение системного вызова на файловом дескрипторе приведет к установке errno в подходящий код. |
POLLHUP |
Файл был отключен; в него больше невозможно ничего записывать (хотя могут остаться данные для считывания). Это происходит в случае отключения терминала либо закрытия удаленного конца канала или сокета. |
POLLNVAL |
Файловый дескриптор недоступен (он не относится к открытому файлу). |
Возвращаемое значение
poll() равно нулю в случае тайм-аута вызова, -1 в случае ошибки (например,
fds — неверный указатель; ошибки в самих файлах вызывают установку
POLLERR), или же положительное число, описывающее количество файлов с ненулевыми элементами revents.
В отличие от неэффективного метода мультиплексирования входных и выходных данных из каналов, используемого ранее,
poll() довольно легко решает ту же проблему. Применяя
poll() к файловым дескрипторам одновременно для обоих каналов, мы знаем, что когда
poll() возвращается, один из каналов готов для чтения либо закрыт. Мы проверяем элемент
revents для обоих файловых дескрипторов, чтобы узнать, какие действия предпринять, и по завершении возвращаемся в вызов
poll(). Теперь большая часть времени тратится на блокирование вызова
poll(), а не на постоянную проверку файловых дескрипторов, использующих неблокируемый ввод-вывод, что значительно уменьшает нагрузку на систему. Ниже показан код
mpx-poll.
1: /* mpx-poll.с */
2:
3: #include <fcntl.h>
4: #include <stdio.h>
5: #include <sys/poll.h>
6: #include <unistd.h>
7:
8: int main(void) {
9: struct pollfdfds[2];
10: char buf [4096];
11: int i, rc;
12:
13: /* открыть оба канала */
14: if ( (fds[0].fd = open("p1", O_RDONLY | O_NONBLOCK)) < 0) {
15: perror("open p1");
16: return 1;
17: }
18:
19: if ((fds[1].fd = open("p2", O_RDONLY | O_NONBLOCK)) < 0) {
20: perror("open p2");
21: return 1;
22: }
23:
24: /* начать чтение из обоих файловых дескрипторов */
25: fds[0].events = POLLIN;
26: fds[1].events = POLLIN;
27:
28: /* пока наблюдаем за одним из fds[0] или fds[1] */
29: while (fds[0].events || fds[1].events ) {
30: if (poll(fds, 2, 0) < 0) {
31: perror("poll");
32: return 1;
33: }
34:
35: /* проверить, какой из файловых дескрипторов
36: готов для чтения из него */
37: for (i = 0; i < 2; i++) {
38: if (fds[i].revents) {
39: /* fds[i] готов для чтения, двигаться дальше... */
40: rc = read(fds[i].fd, buf, sizeof(buf) - 1);
41: if (rc < 0) {
42: perror("read");
43: return 1;
44: } else if (!rc) {
45: /* этот канал закрыт, не пытаться
46: читать из него снова */
47: fds[i].events = 0;
48: } else {
49: buf[rc] = '\0';
50: printf("чтение : %s", buf);
51: }
52: }
53: }
54: }
55:
56: return 0;
57: }
13.1.3. Мультиплексирование с помощью select()
Системный вызов
poll() был изначально представлен как часть Unix-дерева System V. Усилиями разработчиков BSD та же основная проблема была решена похожим способом — предоставлением системного вызова
select().
#include <sys/select.h>
int select(int numfds, fd_set * readfds, fd_set * writefds,
fd_set * exceptfds, struct timeval * timeout);
Три промежуточных параметра —
readfds,
writefds и
exceptfds — определяют, за какими файловыми дескрипторами необходимо следить. Каждый параметр — это указатель на
fd_set, структуру данных, позволяющую процессу определить произвольное количество файловых дескрипторов
[74]. Ею манипулируют с помощью перечисленных ниже макросов.
FD_ZERO(fd_set * fds); |
Очищает fds — в наборе не содержатся файловые дескрипторы. Этот макрос используется для инициализации структур fd_set. |
FD_SET(intfd, fd_set * fds); |
Добавляет fd к fd_set. |
FD_CLR(intfd, fd_set * fds); |
Удаляет fd из fd_set. |
FD_ISSET(int fd, fd_set * fds); |
Возвращает true, если fd содержится в установленном fds. |
Первый набор файловых дескрипторов
select(),
readfds, содержит перечень файловых дескрипторов, вызывающих возврат вызова
select(), когда они готовы для чтения
[75] или (для каналов и сокетов) когда процесс на другом конце файла закрыл его. Когда любой файловый дескриптор в
writefds готов к записи,
select() возвращается,
exceptfds содержит файловые дескрипторы для слежения за исключительными условиями. В Linux (так же, как и в Unix) это происходит только при поступлении внешних данных в сетевое подключение. В качестве любого из них можно указать
NULL, если тот или иной тип события вас не интересует.
Окончательный параметр,
timeout, определяет, насколько долго (в миллисекундах) вызову
select() необходимо ожидать какого-либо события. Это указывает на
struct timeval, которая выглядит следующим образом.
#include <sys/time.h>
struct timeval {
int tv_sec; /* секунды */
int tv_usec; /* микросекунды */
};
Первый элемент —
tv_sec — это количество оставшихся секунд, a
tv_usec — это количество оставшихся микросекунд. Если значением
timeout является
NULL,
select() блокируется до следующего события. Если он указывает на
struct timeval, содержащую 0 в обоих элементах, вызов
select() не блокируется. Он обновляет наборы файловых дескрипторов, чтобы определить, какой файловый дескриптор в настоящее время готов для чтения или записи, а затем немедленно возвращается.
Первый параметр,
numfds, вызывает наибольшие трудности. Он задает количество файловых дескрипторов (начиная с файлового дескриптора 0), которое может быть определено с помощью
fd_sets. Еще один (и, возможно, более легкий) способ поведения
numfds намного лучше максимального файлового дескриптора
select()[76].
Поскольку Linux обычно позволяет каждому процессу иметь до 1024 файловых дескрипторов,
numfds избавляет ядро от необходимости просмотра всех 1024 файловых дескрипторов, которые может содержать каждая структура
fd_set, что улучшает показатели производительности.
После возврата три структуры
fd_set содержат файловые дескрипторы с задержкой входных данных, на которые можно произвести запись или которые находятся в исключительном состоянии. Вызов
select() в Linux возвращает общее количество элементов, установленных в трех структурах
fd_set,
0 в случае тайм-аута вызова либо
-1 в случае ошибки. Однако многие системы Unix считают определенные файловые дескрипторы в возвращаемом значении только один раз, даже если они находятся как в
readfds, так и в
writefds, поэтому в целях переносимости лучше совершать проверку только тогда, когда возвращаемое значение больше
0. Если возвращаемое значение равно
-1, не думайте, что структуры
fd_set остаются незатронутыми. Linux обновляет их только в случае, если
select() возвращает значение больше 0, однако некоторые системы Unix демонстрируют иное поведение.
Еще одним параметром, связанным с переносимостью, является
timeout. Ядра Linux
[77] обновляют его, чтобы отобразить количество времени, оставшегося до тайм-аута вызова
select(), но большинство других систем Unix его не обновляют
[78]. Однако другие системы не обновляют тайм-аут с целью соответствия более привычной реализации.
Для переносимости устраните зависимость от поведения и явно настройте структуру
timeout перед вызовом
select().
Теперь рассмотрим несколько примеров применения
select(). Для начала используем
select() без связи с файлами, создав вторичный вызов
sleep().
#include <sys/select.h>
#include <sys/stdlib.h>
int usecsleep(int usees) {
struct timeval tv;
tv.tv_sec = 0;
tv.tv_usec = useсs;
return select(0, NULL, NULL, NULL, &tv);
}
Этот код разрешает переносимые паузы длительностью менее секунды (это обеспечивает также библиотечная функция BSD
usleep(), но
select() намного более переносима). Например,
usecsleep(500000) вызывает паузу минимум на полсекунды.
Вызов
select() также используется для решения примера мультиплексирования каналов, с которым мы работали. Решение очень похоже на решение при использовании
poll().
1: /* mpx-select.c */
2:
3: #include <fcntl.h>
4: #include <stdio.h>
5: #include <sys/select.h>
6: #include <unistd.h>
7:
8: int main(void) {
9: int fds[2];
10: char buf[4096];
11: int i, rc, maxfd;
12: fd_set watchset; /* fds для чтения */
13: fd_set inset; /* обновляется select() */
14:
15: /* открыть оба канала */
16: if ((fds[0] = open("p1", O_RDONLY | O_NONBLOCK)) < 0) {
17: perror("open p1");
18: return 1;
19: }
20:
21: if ((fds[1] = open("p2", O_RDONLY | O_NONBLOCK)) < 0) {
22: perror("open p2");
23: return 1;
24: }
25:
26: /* начать чтение из обоих файловых дескрипторов */
27: FD_ZERO(&watchset);
28: FD_SET(fds[0], &watchset);
29: FD_SET(fds[1], &watchset);
30:
31: /* найти максимальный файловый дескриптор */
32: maxfd = fds[0] > fds[1] ? fds[0] : fds[1];
33:
34: /* пока наблюдаем за одним из fds[0] или fds[1] */
35: while (FD_ISSET(fds[0], &watchset) ||
36: FD_ISSET(fds[1], &watchset)) {
37: /* здесь копируем watchset, потому что select() обновляет его */
38: inset = watchset;
39: if (select(maxfd + 1, &inset, NULL, NULL, NULL) < 0) {
40: perror("select");
41: return 1;
42: }
43:
44: /* проверить, какой из файловых дескрипторов
45: готов для чтения из него */
46: for (i = 0; i < 2; i++) {
47: if (FD_ISSET(fds[i], &inset )) {
48: /* fds[i] готов для чтения, двигаться дальше... */
49: rc = read(fds[i], buf, sizeof (buf) - 1);
50: if (rc < 0) {
51: perror("read");
52: return 1;
53: } else if (!rc) {
54: /* этот канал закрыт, не пытаться
55: читать из него снова */
56: close(fds[i]);
57: FD_CLR(fds[i], &watchset);
58: } else {
59: buf[rc] = '\0';
60: printf("чтение: %s", buf);
61: }
62: }
63: }
64: }
65:
66: return 0;
67: }
13.1.4. Сравнение poll() и select()
Обладая одинаковой функциональностью,
poll() и
select() также имеют существенные отличия. Наиболее очевидным отличием является тайм-аут, поддерживающий миллисекундную точность для
poll() и микросекундную точность для
select(). В действительности же это отличие почти незначительно, поскольку ни один системный вызов не будет подготовлен с точностью до микросекунды.
Более важное отличие связано с производительностью. Интерфейс
poll() обладает несколькими свойствами, делающими его намного эффективнее, чем
select().
1. При использовании
select() ядру необходимо проверить все файловые дескрипторы между
0 и
numfds - 1, чтобы убедиться, заинтересовано ли приложение в событиях ввода-вывода для этого файлового дескриптора. Для приложений с большим количеством открытых файлов это может привести к существенным затратам, поскольку ядро проверяет, какие именно файловые дескрипторы являются объектом интереса.
2. Набор файловых дескрипторов передается ядру как битовая карта для
select() и как список для
poll(). Сложные битовые операции, необходимые для проверки и установки структур данных
fd_set, менее эффективны, чем простые проверки, требуемые для
struct pollfd.
3. Поскольку ядро переписывает структуры данных, передаваемые
select(), приложение вынуждено сбрасывать эти структуры каждый раз перед вызовом
select(). С
poll() результаты ядра ограничены элементом
revents, что устраняет потребность в восстановлении структур данных после каждого вызова.
4. Использование структуры, основанной на множествах (например,
fd_set) не масштабируется по мере увеличения количества доступных процессу файловых дескрипторов. Поскольку ее размер статичен, а не динамичен (обратите внимание на отсутствие соответствующего макроса, например,
FD_FREE), она не может расширяться или сжиматься в соответствии с потребностями приложения (или возможностями ядра). В Linux максимальный файловый дескриптор, который можно установить в
fd_set, равен 1023. Если понадобится больший файловый дескриптор,
select() работать не будет.
Единственным преимуществом
select() перед
poll() является лучшая переносимость в старые системы. Поскольку небольшое количество таких реализаций все еще используется, следует применять
select(), прежде всего, для понимания и эксплуатации существующих кодовых баз.
Следующая короткая программа, подсчитывающая количество системных вызовов в секунду, демонстрирует, насколько
poll() эффективнее
select().
1: /* select-vs-poll.с */
2:
3: #include <fcntl.h>
4: #include <stdio.h>
5: #include <sys/poll.h>
6: #include <sys/select.h>
7: #include <sys/signal.h>
8: #include <unistd.h>
9:
10: int gotAlarm;
11:
12: void catch(int sig) {
13: gotAlarm = 1;
14: }
15:
16: #define HIGH_FD 1000
17:
18: int main(int argc, const char ** argv) {
19: int devZero;
20: int count;
21: fd_set select Fds;
22: struct pollfd pollFds;
23:
24: devZero = open("/dev/zero", O_RDONLY);
25: dup2(devZero, HIGH_FD);
26:
27: /* с помощью signal выяснить, когда время истекло */
28: signal(SIGALRM, catch);
29:
30: gotAlarm =0;
31: count = 0;
32: alarm(1);
33: while (!gotAlarm) {
34: FD_ZERO(&selectFds);
35: FD_SET(HIGH_FD, &selectFds);
36:
37: select(HIGH_FD + 1, &selectFds, NULL, NULL, NULL);
38: count++;
39: }
40:
41: printf("Вызовов select() в секунду: %d\n", count);
42:
43: pollFds.fd = HIGH_FD;
44: pollFds.events = POLLIN;
45: count = 0;
46: gotAlarm = 0;
47: alarm(1);
48: while (!gotAlarm) {
49: poll(&pollFds, 0, 0);
50: count++;
51: }
52:
53: printf("Вызовов poll() в секунду: %d\n", count);
54:
55: return 0;
56: }
Здесь используется устройство
/dev/zero, предоставляющее бесконечное количество нулей, что обеспечивает немедленный возврат системных вызовов. Значение
HIGH_FD можно изменить, чтобы посмотреть, как деградирует
select() по мере роста значений файловых дескрипторов.
В определенной системе при не очень высоком значении
HIGH_FD, равном 2, программа показала, что ядро за секунду может обрабатывать в четыре раза больше вызовов
poll(), чем вызовов
select(). При увеличении
HIGH_FD до 1000 эффективность
poll() становится в 40 раз выше, чем у
select().
13.1.5. Мультиплексирование с помощью epoll
В версии 2.6 ядра Linux был предложен третий метод для мультиплексированного ввода-вывода по имени
epoll. Будучи более сложным, чем
poll() или
select(),
epoll ликвидирует узкие места, связанные с производительностью, которые характерны для обоих методов.
Оба системных вызова
poll() и
select() передают на проверку полный список файловых дескрипторов при каждом вызове. Каждый из этих дескрипторов должен быть обработан системным вызовом, даже если только один из них готов к чтению или записи. Когда проверяются десятки, сотни или тысячи файловых дескрипторов, эти системные вызовы превращаются в узкие места; ядро тратит много времени на выяснение того, какие именно файловые дескрипторы приложению необходимо проверить.
При использовании
epoll приложения обеспечивают ядро списком файловых дескрипторов для проверки с помощью одного системного вызова, а затем для проверки этих дескрипторов с помощью другого системного вызова. После создания списка ядро постоянно проверяет эти дескрипторы для событий, интересующих приложение
[79], а затем сообщает о событии. Как только приложение запрашивает у ядра файловые дескрипторы, готовые для дальнейшей обработки, ядро предоставляет список без необходимости проверки каждого файлового дескриптора.
Преимущества в плане производительности
epoll требуют более сложного, чем у
poll() или
select(), интерфейса системных вызовов. В то время как
poll() использует массив
struct pollfd для предоставления набора файловых дескрипторов, a
select() с той же целью — три разных структуры
fd_set,
epoll перемещает эти наборы файловых дескрипторов в ядро, а не хранит их в адресном пространстве программы. На каждый из этих наборов ссылаются с помощью дескриптора
epoll, являющегося файловым дескриптором, который можно применять только для системных вызовов
epoll. Новые дескрипторы epoll распределяются системным вызовом
epoll_create().
#include <sys/epoll.h>
int epoll_create (int numDescriptors);
Единственный параметр
numDescriptors — это наилучшее предположение программы о том, на какое количество файловых дескрипторов будет ссылаться заново созданный дескриптор
epoll. Это не жесткий предел, это просто подсказка ядру для более точной инициализации его внутренних структур.
epoll_create() возвращает дескриптор
epoll, а когда программа заканчивает работу с дескриптором, его следует передать
close(), чтобы позволить ядру освободить память, используемую этим дескриптором.
Хотя дескриптор
epoll является файловым дескриптором, его следует применять только с двумя системными вызовами.
#include <sys/epoll.h>
int epoll_ctl(int epfd, int op, int fd, struct epoll_event * event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents,
int timeout);
Большинство этих параметров используют структуру
struct epoll_event, которая определяется, как показано ниже.
#include <sys/epoll.h>
struct epoll_event {
int events;
union {
void * ptr;
int fd;
unsigned int u32;
unsigned long long u64;
} data;
};
Эта структура обслуживает три цели: определяет, какие типы событий следует проверять, определяет типы произошедших событий и ассоциирует отдельный элемент данных с файловым дескриптором. Поле
events предназначено для первых двух функций и является одной или несколькими перечисленными далее значениями, объединенными с помощью логического "ИЛИ"
[80].
EPOLLIN |
Определяет, что операция read() не блокируется; данные или уже готовы, или их уже не осталось для считывания. |
EPOLLOUT |
Связанный файл готов для записи. |
EPOLLPRI |
Файл имеет внешние данные, готовые для чтения. |
Второй элемент
struct epoll_event, data, представляет собой объединение, содержащее целое число (для хранения файлового дескриптора), указатель, а также 32- и 64-битные целые числа
[81]. Этот элемент данных хранится в
epoll и возвращается в программу всякий раз, когда происходит событие подходящего типа. Элемент
data — это единственный способ, с помощью которого программе нужно выяснить, какой файловый дескриптор необходимо обслужить; интерфейс
epoll не передает файловый дескриптор программе, в отличие от
poll() и
select() (если
data не содержит файловый дескриптор). Этот метод обеспечивает дополнительную гибкость приложениям, которые отслеживают файлы как нечто, более сложное, чем простые файловые дескрипторы.
Системный вызов
epoll_ctl() добавляет файловые дескрипторы к набору, на который ссылается дескриптор
epfdepoll, и удаляет их из него.
Второй параметр,
op, описывает, каким образом следует модифицировать набор файловых дескрипторов, и является одним из перечисленных ниже.
EPOLL_CTL_ADD |
Файловый дескриптор fd добавляется к набору файловых дескрипторов набором событий events. Если файловый дескриптор уже присутствует, он возвращает EEXIST. (Несколько потоков могут добавлять тот же файловый дескриптор к набору epoll более одного раза, но это действие ничего не меняет.) |
EPOLL_CTL_DEL |
Файловый дескриптор fd удаляется из контролируемого набора файловых дескрипторов. Параметр events должен указывать на struct epoll_event, но содержимое этой структуры игнорируется. (Это еще раз доказывает, что events должен быть допустимым указателем; он не может быть NULL.) |
EPOLL_CTL_MOD |
Системный вызов struct epoll_event для fd обновляется на основе информации, на которую указывает events. Это позволяет контролировать набор событий и обновлять элемент данных, ассоциируемый с файловым дескриптором, не создавая условий состязания. |
Последним системным вызовом
epoll является
epoll_wait(), который блокирует до тех пор, пока один или несколько контролируемых файловых дескрипторов не будут иметь данные для чтения или же не будут готовы к записи. Первым аргументом является дескриптор
epoll, а последний — тайм-аутом в секундах. Если файловые дескрипторы не готовы к обработке до истечения тайм-аута,
epoll_wait() возвращает
0.
Два промежуточных параметра определяют буфер для ядра, в который можно копировать структуры
struct epoll_event. Параметр
events указывает на буфер,
maxevents определяет, какое количество структур
struct epoll_event помещается в буфер, а возвращаемое значение сообщает программе количество структур, помещенных в этот буфер (пока вызов не попадет в состояние тайм-аута либо не произойдет ошибка).
Каждый системный вызов
struct epoll_event сообщает программе полное состояние контролируемого файлового дескриптора. Элемент
events может иметь установленные флаги
EPOLLIN,
EPOLLOUT или
EPOLLPRI, а также два новых флага, которые описаны ниже.
EPOLLERR |
С файлом связано ожидающее состояние ошибки; это случается, если ошибка происходит в сокете, когда приложение не считывает из него или не записывает в него. |
EPOLLHUP |
Файловый дескриптор завис; в главе 10 дана информация о том, когда это обычно происходит. |
На первый взгляд это все может показаться сложным, но на самом деле это очень похоже на работу
poll(). Вызов
epoll_create() — это то же, что и распределение массива
struct pollfd, a
epoll_ctl() — это то же, что и инициализация элементов этого массива. Главный цикл, обрабатывающий файловые дескрипторы, использует
epoll_wait() вместо системного вызова
poll(), а
close() аналогичен освобождению памяти, занимаемой массивом
struct pollfd. Эти параллели помогают переписывать с применением
epoll программы мультиплексирования, которые изначально были реализованы с помощью
poll() или
select().
Интерфейс
epoll предлагает еще одну возможность, которую невозможно сравнить с
poll() или
select(). Поскольку дескриптор
epoll в действительности является файловым дескриптором (вот почему его можно передавать
close()), имеется возможность контролировать дескриптор
epoll как часть еще одного дескриптора
epoll либо через
poll() или
select(). Дескриптор
epoll будет готов к чтению из любого места, а вызов
epoll_wait() вернет события.
В окончательном решении проблемы мультиплексирования каналов, предложенном в данном разделе, используется
epoll. Оно очень похоже на другие примеры, вот только определенная часть кода инициализации перемещена в
новую функцию
addEvent() для предотвращения нежелательного удлинения программы.
1: /* mpx-epoll.c */
2:
3: #include <fcntl.h>
4: #include <stdio.h>
5: #include <stdlib.h>
6: #include <sys/epoll.h>
7: #include <unistd.h>
8:
9: #include <sys/poll.h>
10:
11: void addEvent(int epfd, char * filename) {
12: int fd;
13: struct epoll_event event;
14:
15: if ((fd = open (filename, O_RDONLY | O_NONBLOCK)) < 0) {
16: perror("open");
17: exit(1);
18: }
19:
20: event.events = EPOLLIN;
21: event.data.fd = fd;
22:
23: if (epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &event)) {
24: perror("epoll_ctl(ADD)");
25: exit(1);
26: }
27: }
28:
29: int main(void) {
30: char buf[4096];
31: int i, rc;
32: int epfd;
33: struct epoll_event events[2];
34: int num;
35: int numFds;
36:
37: epfd = epoll_create(2);
38: if (epfd < 0) {
39: perror("epoll_create");
40: return 1;
41: }
42:
43: /* открыть оба канала и добавить их в набор epoll */
44: addEvent(epfd, "p1");
45: addEvent(epfd, "p2");
46:
47: /* продолжать, пока есть один или более файловых дескрипторов
48: для слежения */
49: numFds = 2;
50: while (numFds) {
51: if ((num = epoll_wait(epfd, events,
52: sizeof(events) / sizeof(* events),
53: -1)) <= 0) {
54: perror("epoll_wait");
55: return 1;
56: }
57:
58: for (i = 0; i < num; i++) {
59: /* events[i].data.fd готов для чтения */
60:
61: rc = read(events[i].data.fd, buf, sizeof(buf) - 1);
62: if (rc < 0) {
63: perror("read");
64: return 1;
65: } else if (!rc) {
66: /* этот канал закрыт, не пытаться
67: читать из него снова */
68: if (epoll_ctl(epfd, EPOLL_CTL_DEL,
69: events[i].data.fd, &events[i])) {
70: perror("epoll_ctl (DEL)");
71: return 1;
72: }
73:
74: close(events[i].data.fd);
75:
76: numFds--;
77: } else {
78: buf[rc] = '\0';
79: printf("чтение: %s", buf);
80:
81: }
82: }
83:
84: close(epfd);
85:
86: return 0;
87: }
13.1.6 Сравнение poll() и epoll
Методы
poll() и
epoll существенно отличаются;
poll() хорошо стандартизован, но плохо масштабируется, в то время как
epoll существует только в Linux, но очень хорошо масштабируется. Приложения, наблюдающие за небольшим количеством файловых дескрипторов и переносимости величин, должны использовать
poll(), но любому приложению, которому необходимо контролировать большое количество дескрипторов, лучше применять
epoll, даже если ему нужно поддерживать
poll() для других платформ.
Отличия в производительности двух методов поразительны. Чтобы продемонстрировать, насколько лучше масштабируется
epoll, в коде
poll-vs-epoll.с измеряется количество системных вызовов
poll() и
epoll_wait(), которые можно создать за одну секунду для наборов файловых дескрипторов разных размеров (количество файловых дескрипторов для помещения в набор задается в командной строке). Каждый файловый дескриптор ссылается на считывающую часть канала, и они создаются с помощью
dup2().
В табл. 13.1 суммируются результаты запуска
poll-vs-epoll.с для установленных размеров диапазоном от одного до 100 000 файловых дескрипторов
[82]. В то время как количество системных вызовов в секунду резко падает для
poll(), оно остается почти постоянным для
epoll[83]. Как поясняет эта таблица,
epoll добавляет в систему намного меньше нагрузки, чем
poll(), и в результате гораздо лучше масштабируется.
Таблица 13.1. Результаты сравнения poll() и epoll()
| Файловые дескрипторы |
poll() |
epoll() |
1 |
310063 |
714848 |
10 |
140842 |
726108 |
100 |
25866 |
726659 |
1000 |
3343 |
729072 |
5000 |
612 |
718424 |
10000 |
300 |
730483 |
25000 |
108 |
717097 |
50000 |
38 |
729746 |
100000 |
18 |
712301 |
1: /* poll-vs-epoll.с */
2:
3: #include <errno.h>
4: #include <fcntl.h>
5: #include <stdio.h>
6: #include <sys/epoll.h>
7: #include <sys/poll.h>
8: #include <sys/signal.h>
9: #include <unistd.h>
10: #include <sys/resource.h>
11: #include <string.h>
12: #include <stdlib.h>
13:
14: #include <sys/select.h>
15:
16: int gotAlarm;
17:
18: void catch(int sig) {
19: gotAlarm = 1;
20: }
21:
22: #define OFFSET 10
23:
24: int main(int argc, const char ** argv) {
25: int pipeFds[2];
26: int count;
27: int numFds;
28: struct pollfd * pollFds;
29: struct epoll_event event;
30: int epfd;
31: int i;
32: struct rlimit lim;
33: char * end;
34:
35: if (!argv[1]) {
36: fprintf(stderr, "ожидалось число\n");
37: return 1;
38: }
39:
40: numFds = strtol(argv[1], &end, 0);
41: if (*end) {
42: fprintf(stderr, "ожидалось число\n");
43: return 1;
44: }
45:
46: printf("Запуск теста для %d файловых дескрипторов.\n", numFds);
47:
48: lim.rlim_cur = numFds + OFFSET;
49: lim.rlim_max = numFds + OFFSET;
50: if (setrlimit(RLIMIT_NOFILE, &lim)) {
51: perror("setrlimit");
52: exit(1);
53: }
54:
55: pipe(pipeFds);
56:
57: pollFds = malloc(sizeof (*pollFds) * numFds);
58:
59: epfd = epoll_create(numFds);
60: event.events = EPOLLIN;
61:
62: for (i = OFFSET; i < OFFSET + numFds; i++) {
63: if (dup2(pipeFds[0], i) != i) {
64: printf("сбой в %d: %s\n", i, strerror(errno));
65: exit(1);
66: }
67:
68: pollFds[i - OFFSET].fd = i;
69: pollFds[i - OFFSET].events = POLLIN;
70:
71: event.data.fd = i;
72: epoll_ctl(epfd, EPOLL_CTL_ADD, i, &event);
73: }
74:
75: /* с помощью signal выяснить, когда время истекло */
76: signal(SIGALRM, catch);
77:
78: count = 0;
79: gotAlarm = 0;
80: alarm(1);
81: while (!gotAlarm) {
82: poll(pollFds, numFds, 0);
83: count++;
84: }
85:
86: printf("Вызовов poll() в секунду: %d\n", count);
87:
88: alarm(1);
89:
90: count = 0;
91: gotAlarm = 0;
92: alarm(1);
93: while (!gotAlarm) {
94: epoll_wait(epfd, &event, 1, 0);
95: count++;
96: }
97:
98: printf("Вызовов epoll() в секунду: %d\n", count);
99:
100: return 0;
101: }
13.2. Отображение в памяти
Операционная система Linux позволяет процессу отображать файлы в их адресное пространство. Такое отображение создает взаимно однозначное соответствие между данными в файле и в отображаемой области памяти. Отображение в памяти обладает рядом преимуществ.
Высокоскоростной доступ к файлам. Нормальные механизмы ввода-вывода, такие как
read() и
write(), вынуждают ядро копировать данные через буфер ядра, а не непосредственно между файлом, содержащим устройство, и процессом пространства пользователя. Карты памяти устраняют этот промежуточный буфер, сохраняя копию памяти
[84].
Исполняемые файлы можно отображать на память программы, позволяя программе динамически загружать новые исполняемые области. Именно так реализуется динамическая загрузка, описанная в главе 27.
Новую память можно распределить отображением части
/dev/zero, специального устройства, состоящего из нулей
[85], или же через анонимное отображение. Средство Electric Fence, описанное в главе 7, использует этот механизм для распределения памяти.
Новую память, распределенную посредством карт памяти, можно сделать исполняемой, наполняя ее машинными командами, которые затем запускаются. Это свойство используется оперативными (just-in-time) компиляторами.
Файлы могут рассматриваться как память и читаться с использованием указателей, а не системных вызовов. Это существенно упрощает программы, избавляя от необходимости применения вызовов
read(),
write() и
seek().
Отображение в памяти позволяет процессам совместно использовать области памяти, участвующие в создании и уничтожении процесса. Содержимое памяти хранится в отображаемом файле, делая его независимым от процессов.
13.2.1. Выравнивание по страницам
Системная память делится на порции под названием
страницы. Размер страницы изменяется в зависимости от архитектуры, и на некоторых процессорах размер страницы может изменяться ядром. Функция
getpagesize() возвращает размер (в байтах) каждой страницы системы.
#include <unistd.h>
size_t getpagesize(void);
Для каждой страницы системы ядро сообщает оборудованию, каким образом каждый процесс может получить доступ к странице (например, записать, выполнить или не выполнять никаких действий). Когда процесс пытается получить доступ к странице способом, нарушающим ограничения ядра, это вызывает ошибку сегментации (
SIGSEGV), которая обычно приводит к завершению процесса.
Адрес памяти должен быть
выровнен по страницам, если это адрес начала страницы. Иначе говоря, адрес должен быть целым, кратным размеру страницы архитектуры. В системе со страницами в 4 Кбайт адреса 0, 4 096, 16 384 и 32 768 являются выровненными по страницам (конечно, это далеко не весь список), потому что первая, вторая, пятая и девятая страницы системы начинаются с указанных адресов.
13.2.2. Установка отображения в памяти
Новые карты памяти создаются с помощью системного вызова
mmap().
#include <sys/mman.h>
caddr_tmmap(caddr_t address, size_t length , int protection, int flags,
int fd, off_t offset);
Параметр
address указывает, где именно в памяти необходимо отображать данные. Обычно
address — это
NULL, который означает, что для процесса не имеет значения местонахождение новой карты, и позволяет ядру выбрать любой адрес. Если адрес указан, он должен быть выровнен по страницам и в данный момент не использоваться. Если запрашиваемая карта будет конфликтовать с другой картой или не будет выровнена по страницам,
mmap() может дать сбой.
Второй параметр,
length, сообщает ядру, какую часть файлов следует отображать в памяти. Можно успешно отобразить больше памяти, чем количество данных в наличии у файла, но попытка доступа к нему может привести к
SIGSEGV[86].
Процесс проверяет, какие типы доступа разрешены новой области памяти. Это должно быть одно или несколько значений из табл. 13.2, объединенных с помощью битового "ИЛИ", либо
PROT_NONE, если доступ к отображаемой области запрещен. Файл может отображаться только для типов доступа, которые также были запрошены при изначальном открытии файла. Например, файл, открытый как
O_RDONLY, не может быть отображен для записи с помощью
PROT_WRITE.
Таблица 13.2. Флаги защиты mmap()
| Флаг |
Описание |
PROT_READ |
Из отображаемой области можно читать. |
PROT_WRITE |
В отображаемую область можно записывать. |
PROT_EXEC |
Отображаемую область можно выполнять. |
Принудительное применение определенной защиты ограничено аппаратной платформой, на которой работает программа. Во многих архитектурах не разрешено выполнение кода в области памяти, если из нее запрещено чтение. При таком оборудовании отображение области с помощью
PROT_EXEC эквивалентно ее отображению с помощью
PROT_EXEC | PROT_READ.
По этой причине на флаги защиты памяти, передаваемые в
mmap(), следует полагаться лишь как на обеспечивающие минимальную защиту.
В
flags определяются другие атрибуты отображаемой области. В табл. 13.3 описаны все флаги. Многие флаги, поддерживаемые Linux, нестандартны, но могут быть полезны при особых условиях. В табл. 13.3 приведены различия между стандартными флагами
mmap() и дополнительными флагами Linux. Во всех вызовах
mmap() должен быть специфицирован
MAP_PRIVATE или
MAP_SHARED; остальные флаги устанавливать необязательно.
Таблица 13.3. Флаги mmap()
| Флаг |
POSIX? |
Описание |
MAP_ANONYMOUS |
Да |
Игнорировать fd, создать анонимную карту. |
MAP_FIXED |
Да |
Сбой в случае недопустимого адреса (address). |
MAP_PRIVATE |
Да |
Запись приватна для процесса. |
MAP_SHARED |
Да |
Запись копируется в файл. |
MAP_DENYWRIТЕ |
Нет |
Не разрешать нормальную запись в файл. |
MAP_GROWSDOWN |
Нет |
Расширить область памяти сверху вниз. |
MAP_LOCKED |
Нет |
Блокировать страницы в памяти. |
MAP_ANONYMOUS |
Вместо отображения файла возвращается анонимное отображение. Оно ведет себя подобно обычному отображению, но без участия физического файла. Хотя эту область памяти нельзя ни использовать совместно с другими процессами, ни автоматически сохранять в файле, анонимное отображение позволяет процессам распределять новую память для индивидуального использования. Такое отображение часто применяется реализациями malloc(), а также еще несколькими специализированными приложениями. Параметр fd игнорируется при использовании этого флага. |
MAP_FIXED |
Если карту нельзя поместить по запрашиваемому адресу, mmap() завершается неудачей. Если этот флаг не определен, ядро попытается разместить карту по указанному адресу, но если это не удастся, то отобразит ее на альтернативный адрес. Если адрес, переданный в address, уже использовался mmap(), элемент, отображаемый в этой области, будет замещен новой картой памяти. Это означает, что лучше передавать только те адреса, которые были возвращены предыдущими вызовами в mmap(); если применяются произвольные адреса, может быть перезаписана область памяти, используемая системными библиотеками. |
MAP_PRIVATE |
Модификации области памяти должны быть индивидуальными для процесса. Их не следует совместно использовать с другими процессами, которые отображают этот же файл (процессами, отличающимися от связанных процессов, которые ответвляются после создания карты памяти), а также отражать в самом файле. Должен использоваться флаг MAP_SHARED или MAP_PRIVATE. Если область памяти незаписываемая, тип используемого флага не имеет значения. |
MAP_SHARED |
Изменения в области памяти копируются обратно в файл, который был отображен и использован совместно с другими процессами, отображающими этот же файл. (Для записи изменений в область памяти следует установить PROT_WRITE; иначе область памяти будет постоянной). Должен использоваться флаг MAP_SHARED или MAP_PRIVATE. |
MAP_DENYWRITE |
Обычно системные вызовы для нормального доступа к файлам (например, write()) могут модифицировать отображенный файл. Однако если область запускается, это будет не самым лучшим решением. Указание MAP_DENYWRITE приводит к тому, что операции записи файлов, отличные от тех, что совершаются через карту памяти, будут возвращать etxtbsy. |
MAP_GROWSDOWN |
Попытка немедленного доступа к памяти, расположенной непосредственно перед отображаемой областью, обычно вызывает SIGSEGV. Этот флаг заставляет ядро расширять область для младших адресов памяти по страницам, если процесс пытается получить доступ к памяти на младшей смежной странице, и продолжает процесс обычным образом. Это разрешает ядру автоматически расширять стеки процессов на платформах, на которых стеки расширяются сверху вниз (наиболее распространенный случай). Это специфичный для платформы флаг, применяемый обычно только для системного кода. Единственным ограничением для MAP_GROWSDOWN является ограничение размеров стека, рассматриваемое в главе 10. Если ограничение не установлено, ядро расширит отображенный сегмент, несмотря на то, выгодно ли это. Однако оно не будет расширять сегмент поверх остальных отображаемых областей. |
MAP_GROWSUP |
Этот флаг работает так же, как и MAP_GROWSDOWN, но предназначен для тех редких платформ, на которых стеки расширяются снизу вверх, что означает расширение области со старших, а не младших адресов. (В ядре версии 2.6.7 только архитектура parisc имеет стеки, расширяющиеся снизу вверх.) Как и MAP_GROWSDOWN, этот флаг зарезервирован для системного кода с установленным ограничением на размер стека. |
MAP_LOCKED |
Область блокируется в памяти. Это означает, что она никогда не будет подлежать страничному обмену. Это важно для систем реального времени (mlock(), рассматриваемый далее в этой главе, предоставляет еще один метод блокирования памяти). Обычно это может установить только привилегированный пользователь; обычным пользователям не разрешено блокировать страницы в памяти. Некоторые системы Linux допускают ограниченное распределение заблокированной памяти непривилегированными пользователями, и эта возможность, вероятно, вскоре будет добавлена к стандартному ядру Linux. |
За флагами следует файловый дескриптор,
fd, для файла, который предстоит отобразить в памяти. Если применялся флаг
MAP_ANONYMOUS, его значение игнорируется. Последний параметр определяет, где именно в файле должно начаться отображение. Он должен быть целым числом, кратным размеру страницы. Большинство приложений начинают отображение с начала файла, указывая в качестве
offset ноль.
Системный вызов
mmap() возвращает адрес, который должен храниться в указателе. Если произошла ошибка, он возвращает адрес, эквивалентный
-1. Для проверки этого необходимо привести тип константы
-1 к
caddr_t, а не к
int. Это гарантирует, что результат будет верным независимо от размеров указателей и целых чисел.
Ниже приведена программа, действующая подобно команде
cat и ожидающая отдельного имени в качестве аргумента командной строки. Она открывает этот файл, отображает его в памяти и записывает целый файл на стандартное устройство вывода одним вызовом
write(). Полезно сравнить этот пример с простой реализацией
cat из главы 11. Код примера также иллюстрирует, что карты памяти остаются на месте после закрытия отображаемого файла.
1: /* map-cat.с */
2:
3: #include <errno.h>
4: #include <fcntl.h>
5: #include <sys/mman.h>
6: #include <sys/stat.h>
7: #include <sys/types.h>
8: #include <stdio.h>
9: #include <unistd.h>
10:
11: int main(int argc, const char ** argv) {
12: int fd;
13: struct stat sb;
14: void * region;
15:
16: if ( fd = open(argv[1], O_RDONLY)) < 0) {
17: perror("open");
18: return 1;
19: }
20:
21: /* Вызвать fstat для файла, чтобы узнать, сколько необходимо памяти для его отображения */
22: if (fstat(fd, &sb)) {
23: perror("fstat");
24: return 1;
25: }
26:
27: /* можно было бы также отобразить как MAP_PRIVATE, поскольку
28: запись в эту память не планируется */
29: region = mmap(NULL, sb.st_size, PROT_READ, MAP_SHARED, fd, 0);
30: if (region == ((caddr_t) -1)) {
31: perror("mmap");
32: return 1;
33: }
34:
35: close(fd);
36:
37: if (write(1, region, sb.st_size) != sb.st_size) {
38: perror("write");
39: return 1;
40: }
41:
42: return 0;
43: }
13.2.3. Отмена отображения областей
После окончания отображения в памяти процесс может отменить отображение памяти с помощью
munmap(). Это приводит к тому, что последующие доступы к этому адресу будут генерировать
SIGSEGV (если только память не будет перераспределена) и сохраняет некоторые системные ресурсы. Отображение всех областей памяти отменяется, когда процесс заканчивает или начинает новую программу с помощью системного вызова
exec().
#include <sys/mman.h>
int munmap(caddr_t addr, int length);
Параметр
addr — это адрес начала области памяти для отмены отображения, а
length определяет, отображение какой части области памяти должно быть отменено. Обычно отображение каждой области отменяется отдельным вызовом
munmap(). Linux может фрагментировать карты, если отменено отображение только части области, но такой код будет непереносимым.
13.2.4. Синхронизация областей памяти на диск
Если для записи в файл используется карта памяти, модифицированные страницы памяти и файл будут в течение некоторого времени отличаться. Если процессу необходимо немедленно записать страницы на диск, для этого служит
msync().
#include <sys/mman.h>
int msync(caddr_t addr, size_t length, int flags);
Первые два параметра,
addr и
length, устанавливают область для синхронизации с диском. Параметр
flags устанавливает, каким образом должны синхронизироваться память и диск. Он состоит из одного или нескольких перечисленных ниже флагов, объединенных с помощью битового "ИЛИ".
MS_ASYNC |
Модифицированные версии области памяти запланированы на "скорую" синхронизацию. Использовать можно только либо MS_ASYNC, либо MS_SYNC. |
MS_SYNC |
Модифицированные страницы в области памяти записываются на диск до возврата системного вызова msync(). Использовать можно только либо MS_ASYNC, либо MS_SYNC. |
MS_INVALIDATE |
Эта опция позволяет ядру выяснять, записываются ли изменения на диск. Хотя эта опция не дает гарантию того, что они не будут записаны, она сообщает ядру, что необходимость сохранения изменений отсутствует. Этот флаг применяется только при особых условиях. |
0 |
Передача 0 в msync() работает в ядрах Linux, хотя она не очень хорошо документирована. Она похожа на MS_ASYNC, но означает, что страницы должны записываться на диск при любом удобном случае. Обычно это значит, что они будут сбрасываться на диск при каждом следующем запуске потока ядра bdflush (обычно он запускается каждые 30 секунд), в то время как MS_ASYNC записывает страницы более интенсивно. |
13.2.5. Блокировка областей памяти
В Linux и многих других современных операционных системах для областей памяти можно организовать страничный обмен с диском (или отклонять, если их невозможно заменить каким-либо другим способом), когда возникает дефицит памяти. На приложения, чувствительные к ограничениям внешней синхронизации, может неблагоприятно повлиять задержка, к которой приводит подкачка страниц обратно в ОЗУ, когда это необходимо процессу. Для улучшения надежности таких приложений Linux позволяет процессу
блокировать области памяти в ОЗУ, чтобы сделать эти синхронизации более предсказуемыми. В целях безопасности блокировка памяти разрешена только процессам с полномочиями привилегированного пользователя
[87]. Если блокировать области памяти сможет любой процесс, то какой-то неисправный процесс может заблокировать все ОЗУ системы и привести ее к краху. Общее количество памяти, блокируемой процессом, не может превышать предел использования
RLIMIT_MEMLOCK (см. главу 10).
Для блокирования и разблокирования областей памяти применяются перечисленные ниже вызовы.
#include <sys/mman.h>
int mlock(caddr_t addr, size_t length);
int mlockall(int flags);
int munlock(caddr_t addr, size_t length);
int munlockall(void);
Первый вызов,
mlock(), блокирует
length байт, начиная с адреса
addr. За один раз должна блокироваться полная страница памяти, поэтому
mlock() фактически блокирует все страницы между страницей, содержащей первый адрес, и страницей, содержащей последний адрес, включительно. После завершения
mlock() все страницы, на которые распространился вызов, окажутся в ОЗУ.
Если процессу необходимо заблокировать все свое адресное пространство, применяется
mlосkall(). Аргумент
flags принимает значение одного или обоих описанных ниже флагов, объединенных с помощью битового "ИЛИ".
MCL_CURRENT |
Все страницы, в данный момент находящиеся в адресном пространстве процесса, блокируются в ОЗУ. После завершения вызова mlockall() они все будут в ОЗУ. |
MCL_FUTURE |
Все страницы, добавленные к адресному пространству процесса, будут заблокированы в ОЗУ. |
Разблокирование памяти — это почти то же, что ее блокирование. Если процесс больше не нуждается в блокировании памяти,
munlockall() разблокирует все его страницы.
munlock() принимает те же аргументы, что и
mlock(), и разблокирует страницы, относящиеся к указанной области.
Многократное блокирование страницы эквивалентно однократному. В каждом случае отдельный вызов
munlock() разблокирует страницы, подпадающие под его влияние.
13.3. Блокирование файлов
Хотя доступ к одному и тому же файлу со стороны нескольких процессов — вполне обычное явление, делать это следует осторожно. Многие файлы содержат сложные структуры данных, и обновление этих структур создает те же условия состязаний, что и в обработчиках сигналов и областях совместно используемой памяти.
Существует два типа блокирования файлов. Наиболее распространенное —
рекомендательное блокирование, которое ядром принудительно не осуществляется. Это просто соглашение, которому должны следовать все процессы, имеющие доступ к файлу. Второй тип,
обязательное блокирование, принудительно выполняется ядром. Когда процесс блокирует файл для записи, другие процессы, пытающиеся прочитать или записать в файл, приостанавливаются до снятия блокировки. Хотя этот метод может показаться более очевидным, обязательное блокирование вынуждает ядро совершать проверку наличия блокировок при каждом вызове
read() и
write(), существенно снижая производительность этих системных вызовов.
Операционная система Linux предоставляет два метода блокирования файлов: блокировочные файлы и блокирование записей.
13.3.1. Блокировочные файлы
Блокировочные файлы являются наиболее простым методом блокирования. Каждый нуждающийся в блокировании файл данных ассоциируется с блокировочным файлом. Когда блокировочный файл существует, файл данных считается заблокированным, и другие процессы не имеют к нему доступа. Когда блокировочный файл не существует, процесс создает его и затем получает доступ к файлу данных. До тех пор, пока процедура создания блокировочного файла атомарна (только один процесс за раз может "владеть" блокировочным файлом), этот метод гарантирует доступ к файлу со стороны только одного процесса в каждый момент времени.
Идея довольно проста. Когда процесс намеревается получить доступ к файлу, он блокирует файл следующим образом.
fd = open("somefile.lck", O_RDONLY, 0644);
if (fd >= 0) {
close(fd);
printf("файл уже заблокирован");
return 1;
} else {
/* блокировочный файл не существует, мы можем заблокировать его
и получить доступ */
fd = open("somefile.lck", O_CREAT | O_WRONLY, 0644");
if (fd < 0) {
perror("ошибка при создании блокировочного файла");
return 1;
}
/* можем записать pid в файл */
close(fd);
}
Когда процесс заканчивает обработку файла, он вызывает
unlink("somefile.lck") для снятия блокировки.
Несмотря на то что показанный выше фрагмент кода выглядит корректным, он позволяет при некоторых обстоятельствах нескольким процессам блокировать один файл, а именно этого и следует избегать в блокировании. Если процесс проверяет существование блокировочного файла, убеждается в том, что блокировочный файл не существует, и прерывается ядром, чтобы позволить выполняться прочим процессам, то какой-то другой процесс сможет заблокировать файл до того, как исходный процесс создаст блокировочный файл. Флаг
O_EXCL для
open() может сделать создание блокировочного файла атомарным и, следовательно, защищенным от условия состязаний. После установки
O_EXCL вызов
open() завершается неудачей, если файл уже существует. Это упрощает создание блокировочных файлов, которое происходит так, как показано ниже.
fd = open("somefile.lck", O_WRONLY | O_CREAT | O_EXCL, 0644);
if (fd < 0 && errno == EEXIST) {
printf("файл уже заблокирован");
return 1;
} else if (fd < 0) {
perror("непредвиденная ошибка при проверке блокировки");
return 1;
}
/* можем записать pid в файл */
close(fd);
Блокировочные файлы используются для блокирования широкого ряда стандартных файлов Linux, включая последовательные порты и файл
/etc/passwd. Хотя они хорошо работают со многими приложениями, им присущи и несколько серьезных недостатков.
• Только один процесс за один раз может иметь блокировку, предотвращая одновременное чтение файла несколькими процессами. Если файл обновляется атомарно
[88], то процессы, читающие файл, могут проигнорировать вопросы блокирования, но атомарные обновления сложно поддерживать для сложных файловых структур.
• Флаг
O_EXCL надежен только в локальных файловых системах. Ни одна из сетевых файловых систем, поддерживаемых Linux, не сохраняет семантику
O_EXCL между несколькими машинами, блокирующими общий файл
[89].
• Блокирование является только рекомендательным; процессы могут обновить файл, несмотря на существование блокировки.
• Если процесс, удерживающий блокировку, аварийно завершается, блокировочный файл остается. Если идентификатор блокирующего процесса сохранен в блокировочном файле, другие процессы могут проверить существование блокирующего процесса и снять блокировку, если тот завершился. Это, однако, сложная процедура, которая не поможет, если идентификатор процесса повторно используется другим процессом при проверке.
13.3.2. Блокировка записей
С целью преодоления проблем, присущих блокировочным файлам, в System V и BSD 4.3 была добавлена
блокировка записей, реализуемая с помощью системных вызовов
lockf() и
flock() соответственно. Стандарт POSIX определил третий механизм для блокировки записей, который использует системный вызов
fcntl(). Хотя Linux поддерживает все три интерфейса, мы обсудим только интерфейс POSIX, поскольку сейчас его поддерживают почти все платформы Unix. Кроме того, функция
lockf() реализована как интерфейс для
fcntl(), поэтому оставшаяся часть данного обсуждения касается обоих методов.
Существуют два значительных отличия между блокировками записей и блокировочными файлами. Во-первых, блокировки записей применяются к произвольной части файла. Например, процесс А может заблокировать байты с 50-го по 200-й файла, в то время как другой процесс блокирует байты с 2500-го по 3000-й без конфликта двух блокировок. Мелкомодульное блокирование полезно, когда нескольким процессам необходимо обновить один файл. Еще одно преимущество блокирования записей заключается в том, что блокировки удерживаются в ядре, а не в файловой системе. По окончании процесса все блокировки, которые он содержит, освобождаются.
Как и блокировочные файлы, блокировки POSIX также являются рекомендательными. Linux, как и System V, предоставляет обязательный вариант блокирования записей, который можно использовать, но нарушая при этом переносимость. Блокирование файлов может работать или не работать в сетевой файловой системе (NFS). В последних версиях Linux блокирование файлов работает в NFS, если на всех машинах, участвующих в блокировке, выполняется демон блокировки NFS
lockd.
При блокировке записей используются два типа блокировок:
блокировка чтения и
блокировка записи. Блокировки чтения также известны как
разделяемые блокировки, поскольку несколько процессов могут одновременно удерживать блокировки чтения на одной и той же области. Для нескольких процессов чтение структуры данных, которая не обновляется, безопасно всегда. Когда процессу необходимо записать файл, ему понадобится блокировка записи (или
эксклюзивная блокировка). Только один процесс может удерживать блокировку на определенной записи, и пока блокировка записи существует, блокировки чтения не допускаются. Это гарантирует, что процесс не повлияет на модули чтения, пока будет осуществлять запись в область.
Множество блокировок одного процесса никогда не конфликтуют друг с другом
[90].
Если процесс имеет блокировку чтения на байтах 200—250 и пытается установить блокировку записи на байты 200–225, ему это удастся. Исходная блокировка смещается и становится блокировкой чтения на байтах 226–250, а новая блокировка записи устанавливается на байты 200–225
[91]. Это позволяет предотвратить взаимоблокировку одного процесса (хотя ситуация взаимоблокировки нескольких процессов по-прежнему возможна).
Блокирование записей POSIX осуществляется с помощью системного вызова
fcntl(). В главе 11 было показано, что
fcntl() выглядит следующим образом.
#include <fcntl.h>
int fcntl (int fd, int command, long arg);
Для всех операций блокировки третий параметр (
arg) указывает на структуру
struct flock, представленную ниже.
#include <fcntl.h>
struct flock {
short l_type;
short l_whence;
off_t l_start;
off_t l_len;
pid_t l_pid;
};
Первый элемент,
l_type, определяет тип установленной блокировки.
F_RDLCK |
Устанавливается блокировка чтения (разделяемая). |
F_WRLCK |
Устанавливается блокировка записи (эксклюзивная). |
F_UNLCK |
Снимается существующая блокировка. |
Следующие два элемента,
l_whence и
l_start, определяют начало области тем же способом, что и файловые смещения, передаваемые в
lseek().
l_whence сообщает о способе интерпретации
l_start и принимает одно из значений
SEEK_SET,
SEEK_CUR или
SEEK_END; более подробно эти значения рассматривались в главе 11. Следующий элемент,
l_len, сообщает размер блокировки в байтах. Если
l_len равно 0, считается, что блокировка распространяется до конца файла. Последний элемент,
l_pid, используется только тогда, когда запрашиваются блокировки. Он устанавливается в идентификатор процесса, владеющего запрашиваемой блокировкой.
Существуют три команды
fcntl(), относящиеся к блокировке файла. Они передаются
fcntl() во втором аргументе,
fcntl() возвращает
-1 в случае ошибки и
0 — в противном случае. Ниже перечислены допустимые значения параметра
command.
F_SETLK |
Устанавливает блокировку, описанную в arg. Если блокировку невозможно выдать из-за конфликта с блокировками других процессов, возвращается EAGAIN. Если l_type устанавливается в F_UNLCK, существующая блокировка снимается. |
F_SETLKW |
Подобно F_SETLK, но блокирует только при условии предоставления блокировки. Если сигнал поступает во время блокирования процесса, вызов fcntl() возвращает EAGAIN. |
F_GETLK |
Проверяет возможность выдачи описанной в arg блокировки. Если блокировка предоставляется, содержимое struct flock не меняется, кроме l_type, который устанавливается в F_UNLCK. Если блокировка не выдается, l_pid устанавливается в идентификатор процесса, содержащего конфликтующую блокировку. Значение 0 возвращается независимо от того, будет ли предоставлена блокировка. |
Хотя
F_GETLK позволяет процессу проверить, будет ли выдана блокировка, следующий код все еще не сможет получить блокировку.
fcntl(fd, F_GETLK, &lockinfo);
if (lockinfо.l_type != F_UNLCK) {
fprintf(stderr, "конфликт блокировок\n");
return 1;
}
lockinfо.l_type = F_RDLCK;
fcntl(fd, F_SETLK, &lockinfo);
Другой процесс мог заблокировать область между двумя вызовами
fcntl(), приводя к тому, что второму вызову
fcntl() не удается установить блокировку.
В качестве простого примера блокировки записей ниже приведена программа, которая открывает файл, устанавливает на нем блокировку чтения, освобождает блокировку чтения, устанавливает блокировку записи и закрывается. В промежутках между каждым из этих шагов программа ожидает, пока пользователь нажмет клавишу <Enter>. Если получить блокировку не удается, программа отображает идентификатор процесса, содержащего конфликтующую блокировку, и запрашивает у пользователя о необходимости повторить попытку. Запуск этой программы на двух терминалах облегчит экспериментирование с правилами блокировок POSIX.
1: /* lock.с */
2:
3: #include <errno.h>
4: #include <fcntl.h>
5: #include <stdio.h>
6: #include <unistd.h>
7:
8: /* выводит сообщение и ожидает нажатия
9: пользователем клавиши <Enter> */
10: void waitforuser(char * message) {
11: char buf[10];
12:
13: printf("%s", message);
14: fflush(stdout);
15:
16: fgets(buf, 9, stdin);
17: }
18:
19: /* Получает блокировку заданного типа на файловом дескрипторе fd.
20: Типом блокировки может быть F_UNLCK, F_RDLCK или F_WRLCK */
21: void getlock(int fd, int type) {
22: struct flock lockinfo;
23: char message[80];
24:
25: /* будет блокироваться весь файл */
26: lockinfo.l_whence = SEEK_SET;
27: lockinfo.l_start = 0;
28: lockinfo.l_len = 0;
29:
30: /* продолжать попытки, пока того желает пользователь */
31: while (1) {
32: lockinfo.l_type = type;
33: /* если блокировка получена, немедленно возвратиться */
34: if (!fcntl(fd, F_SETLK, &lockinfo)) return;
35:
36: /* найти, кто удерживает конфликтующую блокировку */
37: fcntl(fd, F_GETLK, &lockinfo);
38:
39: /* есть шанс, что блокировка освобождена между F_SETLK
40: и F_GETLK; проверить, существует ли еще конфликт
41: перед тем, как сообщать об этом */
42: if (lockinfo.l_type != F_UNLCK) {
43: sprintf (message, "конфликт с процессом %d... нажмите "
44: "<enter> для повторения:",lockinfo.l_pid);
45: waitforuser(message);
46: }
47: }
48: }
49:
50: int main(void) {
51: int fd;
52:
53: /* подготовить файл для блокировки */
54: fd = open("testlockfile", O_RDWR | O_CREAT, 0666);
55: if (fd < 0) {
56: perror("open");
57: return 1;
58: }
59:
60: printf("получение блокировки чтения\n");
61: getlock(fd, F_RDLCK);
62: printf("блокировка чтения получена\n");
63:
64: waitforuser("\nдля продолжения нажмите <enter>:");
65:
66: printf("освобождение блокировки\n");
67: getlock(fd, F_UNLCK);
68:
69: printf("получение блокировки записи\n");
70: getlock(fd, F_WRLCK);
71: printf("блокировка записи получена\n");
72:
73: waitforuser("\nдля завершения нажмите <enter>:");
74:
75: /* при закрытии файла блокировки освобождаются */
76:
77: return 0;
78: }
С блокировками следует обращаться иначе, чем с другими файловыми атрибутами. Блокировки ассоциируются с парой
(pid, inode), в отличие от многих атрибутов открытых файлов, которые связаны с файловым дескриптором или файловой структурой. Следовательно, если процесс выполняет перечисленные ниже действия, то файл уже не блокируется процессом.
1. Открытие одного файла дважды, что дает два разных файловым дескриптора.
2. Поучение блокировки чтения на одной области в обоих файловых дескрипторах.
3. Закрытие одного из файловых дескрипторов.
Выдана лишь одна блокировка чтения, потому что была задействована только одна пара
(pid, inode) (вторая попытка блокировки удалась, поскольку блокировки одного и того же процесса никогда не конфликтуют), и после закрытия одного из файловых дескрипторов у процесса больше нет блокировок на файле.
После
fork() родительский процесс сохраняет свои файловые блокировки, но дочерний процесс — нет. Если бы дочерние процессы наследовали блокировки, два процесса пришли бы, в конечном счете, к блокировке записи на одной области файла.
Однако файловые блокировки наследуются в
exec(). Поскольку в POSIX не определено, что происходит с блокировками после
exec(), все варианты Unix сохраняют их
[92].
13.3.3. Обязательные блокировки
И Linux, и System V поддерживают как обычные, так и обязательные блокировки. Обязательные блокировки устанавливаются и реализуются с помощью того же механизма
fcntl(), который используется для рекомендательной блокировки записей. Блокировки считаются обязательными, если бит setgid заблокированного файла установлен, но его бит группового выполнения — нет. В противном случае применяется рекомендательное блокирование.
При активизации обязательного блокирования системные вызовы
read() и
write() блокируются, если они конфликтуют с уже установленными блокировками. Если процесс пытается осуществить запись в часть файла, на которой имеется блокировка чтения или записи от другого процесса, первый процесс блокируется до тех пор, пока существующая блокировка не будет снята. Подобным же образом вызовы
read() блокируются на областях, включенных в обязательные блокировки записи.
Обязательное блокирование записи приводит к большей потере производительности, чем рекомендательное блокирование, поскольку каждый вызов
read() и
write() должен быть проверен на предмет конфликтов с блокировками. Оно также не настолько переносимо, как рекомендательное блокирование POSIX, поэтому в большинстве приложений обязательное блокирование применять не следует.
13.3.4. Аренда файла
И рекомендательное, и обязательное блокирование предназначены для предотвращения доступа процесса к файлу или его части, которая используется другим процессом. Когда блокировка установлена, процесс, которому необходим доступ к файлу, должен подождать завершения процесса, владеющего блокировкой. Эта структура подходит для большинства применений, но иногда программа использует файл до тех пор, пока он не понадобится другой программе, и желает получить при необходимости эксклюзивный доступ к файлу. Для этого Linux предлагает механизм
аренды файлов (в других системах это называется
периодическими блокировками (oplocks))
[93].
Взятие файла в аренду позволяет процессу получать уведомления (через сигнал) о доступе к файлу со стороны другого процесса. Существуют два типа аренды: аренда чтения и аренда записи. Аренда чтения вызывает передачу сигнала при открытии файла для записи, открытии с указанием
O_TRUNC или вызове
truncate(). Аренда записи также посылает сигнал при открытии файла для чтения
[94]22. Аренды файлов работают только для модификаций, внесенных в файл той же системой, которая владеет арендой. Если файл локальный (не файл, доступ к которому возможен через сеть), любой подходящий доступ к файлу инициирует сигнал. Если доступ к файлу возможен через сеть, передачу сигнала вызывают только процессы на одной машине с процессо-арендатором; доступ с любой другой машины удается в случае отсутствия аренды.
Системный вызов
fcntl() используется для создания, реализации и запроса аренды файлов. Аренды можно размещать только на обычных файлах (для каналов и каталогов это невозможно), кроме того, аренды записи предоставляются только владельцу файла. Первый аргумент
fcntl() — это интересующий для слежения файловый дескриптор, а второй аргумент,
command, определяет, какую операцию следует выполнить.
F_SETLEASE
Аренда создается или освобождается в зависимости от значения последнего параметра, передаваемого в
fcntl();
F_RDLCK создает аренду чтения,
F_WRLCK — аренду записи, a
F_UNLCK освобождает любую аренду, которая может существовать. Если запрашивается новая аренда, она заменяет любую существующую аренду. В случае ошибки возвращается отрицательное число; ноль или положительное число свидетельствуют об успехе операции
[95].
F_GETLEASE
Возвращается тип аренды, существующей в настоящий момент для файла (
F_RDLCK,
F_WRLCK или
F_UNLCK).
Когда в арендованном файле происходит одно из контролируемых событий, ядро передает сигнал удерживающему аренду процессу. По умолчанию передается
SIGIO, но процесс может выбрать, какой сигнал передавать этому файлу, с помощью вызова
fcntl(), в котором второй параметр установлен в
F_SETSIG, а последний — в сигнал, который должен использоваться вместо
SIGIO.
Использование
F_SETSIG дает один значительный эффект. По умолчанию
siginfo_t не передается обработчику при доставке
SIGIO. Если используется
F_SETSIG, даже когда сигналом, передаваемым в ядро, является
SIGIO, a
SA_SIGINFO был установлен при регистрации обработчика сигнала, файловый дескриптор, аренда которого инициировала событие, передается в обработчик сигналов одновременно с элементом
siginfo_t по имени
si_fd. Это позволяет применять отдельный сигнал к аренде множества файлов, в то время как
si_fd сообщает сигналу, какому файлу необходимо уделить внимание
[96].
Единственные два системных вызова, которые могут инициировать передачу сигнала для арендуемого файла — это
open() и
truncate(). Когда они вызываются процессом для арендуемого файла, они блокируются
[97], и процессу-владельцу передается сигнал,
open() или
truncate() завершаются после удаления аренды с файла (или его закрытия процессом-владельцем, что вызывает удаление аренды). Если процесс, удерживающий аренду, не отменяет снятие в течение времени, указанного в файле
/proc/sys/fs/lease-break-time, ядро прерывает аренду и позволяет завершиться запускающему системному вызову.
Ниже приведен пример применения владений файлами для уведомления о намерении другого процесса получить доступ к файлу. Список файлов берется командной строки, и на каждый файл помещается аренда записи. Когда другой процесс намеревается получить доступ к файлу (даже для чтения, поскольку использовалась блокировка записи), программа освобождает блокировку файла, позволяя другому процессу продолжать работу. Она также выводит сообщение о том, какой именно файл был освобожден.
1: /* leases.с */
2:
3: #define GNU_SOURCE
4:
5: #include <fcntl.h>
6: #include <signal.h>
7: #include <stdio.h>
8: #include <string.h>
9: #include <unistd.h>
10:
11: const char ** fileNames;
12: int numFiles;
13:
14: void handler (int sig, siginfo_t * siginfo, void * context) {
15: /* Когда аренда истекает, вывести сообщение и закрыть файл.
16: Предполагается, что первый открываемый файл получит файловый
17: дескриптор 3, следующий - 4 и так далее. */
18:
19: write(1, "освобождение", 10);
20: write(1, fileNames[siginfo->si_fd - 3],
21: strlen(fileNames[siginfo->si_fd - 3]));
22: write(1, "\n", 1);
23: fcntl(siginfo->si_fd, F_SETLEASE, F_UNLCK);
24: close(siginfo->si_fd);
25: numFiles--;
26: }
27:
28: int main(int argc, const char ** argv) {
29: int fd;
30: const char ** file;
31: struct sigaction act;
32:
33: if (argc < 2) {
34: fprintf(stderr, "использование: %s <filename>+\n", argv[0]);
35: return 1;
36: }
37:
38: /* Зарегистрировать обработчик сигналов. Указав SA_SIGINFO, предоставить
39: обработчику возможность узнать, какой файловый дескриптор имеет
40: истекшую аренду. */
41: act.sa_sigaction = handler;
42: act.sa_flags = SA_SIGINFO;
43: sigemptyset(&act.sa_mask);
44: sigaction(SIGRTMIN, &act, NULL);
45:
46: /* Сохранить список имен файлов в глобальной переменной, чтобы
47: обработчик сигналов мог иметь доступ к нему. */
48: fileNames = argv + 1;
49: numFiles = argc - 1;
50:
51: /* Открыть файлы, установить используемые сигнал
52: и создать аренду */
53: for (file = fileNames; *file; file++) {
54: if ((fd = open(* file, O_RDONLY)) < 0) {
55: perror("open");
56: return 1;
57: }
58:
59: /* Для правильного заполнения необходимо использовать F_SETSIG
60: для структуры siginfo */
61: if (fcntl(fd, F_SETSIG, SIGRTMIN) < 0) {
62: perror("F_SETSIG");
63: return 1;
64: }
65:
66: if (fcntl(fd, F_SETLEASE, F_WRLCK) < 0) {
67: perror("F_SETLEASE");
68: return 1;
69: }
70: }
71:
72: /* Пока файлы остаются открытыми, ожидать поступления сигналов. */
73: while (numFiles)
74: pause();
75:
76: return 0;
77: }
13.4. Альтернативы read() и write()
Несмотря на то что системные вызовы
read() и
write() как нельзя лучше подходят приложениям для извлечения и хранения данных в файле, все же они не всегда являются самыми быстрыми методами. Они допускают управление отдельными порциями данных; для записи же нескольких порций данных требуется несколько системных вызовов. Подобным образом, если приложению необходим доступ к данным в разных частях файла, оно должно вызывать
lseek() между каждым
read() или
write(), удваивая количество необходимых системных вызовов. Для улучшения эффективности существуют другие системные вызовы.
13.4.1. Разбросанное/сборное чтение и запись
Приложениям часто требуется читать и записывать данные различных типов в последовательные области файла. Несмотря на то что это можно делать сравнительно легко с помощью множества вызовов
read() и
write(), такое решение не является особо эффективным. Вместо этого приложения могут перемещать все данные в последовательную область памяти, делая возможным один системный вызов. Однако эти действия приводят к множеству ненужных операций с памятью.
Linux предлагает системные вызовы
readv() и
writev(), реализующие разбросанное/сборное чтение и запись
[98]. В отличие от стандартных элементов своего уровня, получающих по одному указателю и размеру буфера, эти системные вызовы получают массивы записей, каждая запись которых описывает буфер. Буферы читаются или записываются в том порядке, в каком они приведены в массиве. Каждый буфер описывается с помощью структуры
struct iovec.
#include <sys/uio.h>
struct iovec {
void * iov_base; /* адрес буфера */
size_t iov_len; /* длина буфера */
};
Первый элемент,
iov_base, указывает на буферное пространство. Элемент
iov_len — это количество символов в буфере. Эти элементы представляют собой то же, что и второй и третий параметры, передаваемые
read() и
write().
Ниже показаны прототипы
readv() и
writev().
#include <sys/uio.h>
int readv(int fd, const struct iovec * vector, size_t count);
int writev(int fd, const struct iovec * vector, size_t count);
Первый аргумент является файловым дескриптором, с которого можно считывать или на который можно записывать. Второй аргумент,
vector, указывает на массив элементов
count struct iovec. Обе функции возвращают общее количество прочитанных или записанных байтов.
Ниже приведена простая программа-пример, использующая
writev() для отображения простого сообщения на стандартном устройстве вывода.
1: /* gather.с */
2:
3: #include <sys/uio.h>
4:
5: int main(void) {
6: struct iovec buffers[3];
7:
8: buffers[0].iov_base = "hello";
9: buffers[0].iov_len = 5;
10:
11: buffers[1].iov_base = " ";
12: buffers[1].iov_len = 1;
13:
14: buffers[2].iov_base = "world\n";
15: buffers[2].iov_len = 6;
16:
17: writev(1, buffers, 3);
18:
19: return 0;
20: }
13.4.2. Игнорирование указателя файла
Программы, использующие бинарные файлы, часто выглядят, как показано ниже.
lseek(fd, SEEK_SET, offset1);
read(fd, buffer, bufferSize);
offset2 = someOperation(buffer);
lseek(fd, SEEK_SET, offset2);
read(fd, buffer2, bufferSize2);
offset3 = someOperation(buffer2);
lseek(fd, SEEK_SET, offset3);
read(fd, buffer3, bufferSize3);
Необходимость поиска нового расположения с помощью
lseek() перед каждым read() удваивает количество системных вызовов, поскольку указатель файла никогда не располагается правильно после read() из-за непоследовательной природы хранения данных в файле. Существуют альтернативы
read() и
write(), принимающие смещение файла в качестве параметра, и ни одна из альтернатив не использует указатель файла, чтобы выяснить, к какой части файла можно получить доступ, или какую его часть можно обновить. Обе функции работают только применительно к просматриваемым файлам, поскольку непросматриваемые файлы можно читать или записывать только в текущем расположении.
#define XOPEN_SOURCE 500
#include <unistd.h>
size_tpread(int fd, void * buf, size_t count, off_t offset);
size_t pwrite(int fd, void * buf, size_t count, off_t offset);
#endif
Это выглядит подобно прототипам
read() и
write() с четвертым параметром,
offset. offset определяет, с какой точки файла следует читать, а в какую — записывать. Как и их "тезки", эти функции возвращают количество переданных байтов. Ниже приведена версия
pread(), реализованная с помощью
read() и
lseek(), что облегчает понимание ее функции
[99].
int pread (int fd, void * data, int size, int offset) {
int oldOffset;
int rc;
int oldErrno;
/* переместить указатель файла в новое расположение */
oldOffset = lseek(fd, SEEK_SET, offset);
if (oldOffset < 0) return -1;
rc = read(fd, data, size);
/* восстановить указатель файла, предварительно сохранив errno */
oldErrno = errno;
lseek(fd, SEEK_SET, oldOffset);
errno = oldErrno;
return rc;
}
Глава 14
Операции с каталогами
Как и во многих других операционных системах, для организации файлов в Linux используются каталоги. Каталоги (представляющие собой особые типы файлов, которые содержат списки имен файлов) состоят из файлов, а также других каталогов, образуя иерархию файлов. Все системы Linux содержат корневой каталог, известный как
/, через который (прямо или непрямо) можно получить доступ ко всем файлам системы.
14.1. Текущий рабочий каталог
14.1.1. Поиск текущего рабочего каталога
Функция
getcwd() позволяет процессу найти имя своего текущего каталога относительно корневого каталога системы.
#include <unistd.h>
char * getcwd(char * buf, size_t size);
Первый параметр,
buf, указывает на буфер, хранящий путь к текущему каталогу. Если длина текущего пути превышает
size - 1 байт (-1 позволяет пути завершаться символом
'\0'), функция возвращает ошибку
ЕRANGE. Если вызов удается, возвращается
buf; в случае ошибки возвращается
NULL. Несмотря на то что в большинстве современных оболочек поддерживается переменная окружения
PWD, хранящая путь в текущий каталог, ее значение необязательно равняется значению, возвращаемому
getcwd().
PWD часто содержит элементы путей, являющиеся символическими ссылками на другие каталоги, но
getcwd() всегда возвращает путь, свободный от символических ссылок.
Если текущий путь неизвестен (например, во время запуска программы), буфер, содержащий текущий каталог, должен быть динамически распределен, поскольку размер текущего пути может быть произвольным. Код, должным образом читающий текущий путь, выглядит так, как показано ниже.
char * buf;
int len = 50;
buf = malloc(len);
while (!getcwd(buf, len) && errno == ERANGE) {
len += 50;
buf = realloc(buf, len);
}
Как и многие другие Unix-подобные системы, Linux предоставляет полезное расширение POSIX-спецификации
getcwd(). Если
buf является
NULL, функция распределяет буфер, размер которого достаточен для содержания текущего пути, с помощью нормального механизма
malloc(). Несмотря на то что вызывающий код должен позаботиться о надлежащем освобождении памяти, используемой результатом, это расширение обеспечивает лучшую очистку, нежели цикл, как показано в предыдущем примере.
Функция BSD по имени
getwd() является наиболее распространенной альтернативой
getcwd(), но ее определенные дефекты привели к разработке
getcwd().
#include <unistd.h>
char * getwd(char * buf);
Как и
getcwd(),
getwd() заполняет
buf текущим путем, хотя функция не имеет представления о размере
buf.
getwd() никогда не записывает в буфер больше, чем
PATH_MAX (определенная в
<limits.h>), что позволяет программам избегать переполнения буферов, но не предоставляет программе механизма поиска правильного пути, если он превышает
PATH_MAX байт
[100]. Эта функция поддерживается Linux только для унаследованных приложений и не может использоваться новыми приложениями. Вместо этого применяйте правильную и более переносимую функцию
getcwd().
Если для пользователей необходимо отображать текущий путь каталога, хорошим решением будет проверка переменной окружения
PWD. Если она установлена, она содержит путь, который применяется пользователем и который может содержать символические ссылки на некоторые элементы пути. Этот путь обычно и должен отображаться приложением по желанию пользователя. Для облегчения задачи библиотека С в Linux предоставляет функцию
get_current_dir_name(), реализуемую следующим образом.
char * get_current_dir_name() {
char * env = getenv("PWD");
if (env)
return strdup(env);
else
return getcwd(NULL, 0);
}
14.1.2. Специальные файлы . и ..
Каждый каталог, включая корневой, содержит также два специальных файла под именами
. и
.., полезные при определенных условиях. Первый,
. — то же самое, что и текущий каталог. Это означает, что имена
somefile и
./somefile эквивалентны.
Еще одно специальное имя файла,
.., является родительским каталогом текущего каталога. В случае корневого каталога
.. относится к самому корневому каталогу (поскольку у корневого каталога нет родительского каталога).
И
., и
.. можно применять везде, где можно использовать имя каталога. Нормально то, что отношение символических ссылок к путям вроде
../include/mylib и именам файлов наподобие
/./foo/.././bar/./fubar/../../usr/bin/less является законным (хотя эти названия довольно запутаны)
[101].
14.1.3. Смена текущего каталога
Предусмотрено два системных вызова, меняющих текущий каталог процесса:
chdir() и
fchdir().
#include <unistd.h>
int chdir(const char * pathname);
int fchdir(int fd);
Первый системный вызов получает имя каталога в качестве единственного аргумента; второй принимает файловый дескриптор, являющийся открытым каталогом. В каждом случае специфицированный каталог делается текущим рабочим каталогом. Эти функции могут не работать, если в аргументе определен файл, который не является каталогом, или если у процесса нет соответствующих полномочий.
14.2. Смена корневого каталога
Хотя в системе имеется один корневой каталог, значение
/ может меняться для каждого процесса в системе. Это обычно делается для предотвращения доступа к файловой системе со стороны сомнительных процессов (например, демоны ftp, обрабатывающие запросы ненадежных пользователей). Например, если в качестве корневого каталога процесса определен
/home/ftp, запуск
chdir("/") сделает текущий каталог процесса
/home/ftp, a
getcwd() вернет
/ для поддержания последовательности данного процесса. С целью обеспечения безопасности, если процесс пытается выполнить
chdir("/.."), он остается в своем каталоге
/ (каталог
/home/ftp в масштабах всей системы), так же как и нормальные процессы, выполняющие
chdir("/..") остаются в корневом каталоге в масштабах всей системы. Процесс может легко изменять свой текущий корневой каталог с помощью системного вызова
chroot(). Но путь нового корневого каталога процесса интерпретируется с помощью текущего установленного корневого каталога, поэтому
chroot("/") не модифицирует текущий корневой каталог процесса.
#include <unistd.h>
int chroot(const char * path);
Здесь
path определяет новый корневой каталог для процесса. Этот системный вызов, однако, не изменяет текущий каталог процесса. У процесса все еще есть доступ к файлам в текущем каталоге, а также в родственном ему каталоге (
../../directory/file). Большинство процессов, выполняющих
chroot(), немедленно меняют свои текущие каталоги, чтобы находиться внутри новой корневой иерархии, с помощью
chdir("/") или чего-либо подобного. Отмена этого действия может вызвать проблемы с безопасностью в некоторых приложениях.
14.3. Создание и удаление каталогов
14.3.1. Создание новых каталогов
Создание новых каталогов выполняется очень просто.
#include <fcntl.h>
#include <unistd.h>
int mkdir(const char * dirname, mode_t mode);
Путь, определенный в
dirname, создается как новый каталог с полномочием
mode (что модифицируется
umask процесса). Если
dirname определяет существующий файл, или некоторые элементы dirname не являются каталогом или символической ссылкой на него, системный вызов не удается.
14.3.2. Удаление каталогов
Удаление каталога — это практически то же, что и удаление файла; меняется разве что имя системного вызова.
#include <unistd.h>
int rmdir(char * pathname);
Для успешного выполнения
rmdir() каталог должен быть пустым (он не должен содержать ничего, кроме вездесущих
. и
..); в противном случае возвращается
ENOTEMPTY.
14.4. Чтение содержимого каталога
Обычно программам требуется получать список файлов, содержащихся в каталоге. Linux предоставляет ряд функций, позволяющих обрабатывать каталог как абстрактный объект, что дает возможность избежать зависимости программ от точного формата каталогов, реализуемого файловой системой. Открытие и закрытие каталогов осуществляется очень просто.
#include <dirent.h>
DIR * opendir(const char * pathname);
int closedir(DIR * dir);
Системный вызов
opendir() возвращает указатель на тип данных
DIR, который является абстрактным (как и структура
stdio по имени
FILE) и которым не следует манипулировать вне библиотеки С. Поскольку каталоги можно открывать только для чтения, нет необходимости определять, в каком режиме открывается каталог,
opendir() срабатывает только в случае существования каталога — этот вызов нельзя использовать для создания новых каталогов (для этого служит
mkdir()). Закрытие каталога может не сработать только в случае некорректного значения аргумента
dir.
После открытия каталога его элементы читаются последовательно до конца каталога.
Системный вызов
readdir() возвращает имя следующего файла в каталоге. Каталоги не упорядочены каким-либо образом, поэтому не стоит предполагать, что оглавление каталога отсортировано. Если необходим упорядоченный список файлов, сортировку придется выполнять самостоятельно. Функция
readdir() определяется, как показано ниже.
#include <dirent.h>
struct dirent * readdir (DIR * dir);
Вызывающему коду возвращается указатель на структуру
struct dirent. Несмотря на то что
struct dirent содержит несколько элементов, единственным переносимым элементом является
d_name, содержащий имя файла элемента каталога. Остальные элементы
struct dirent зависят от системы. Однако интересным является элемент
d_ino, содержащий inode-номер файла.
Самой сложной частью этого процесса является определение ошибки. К сожалению,
readdir() возвращает
NULL, и когда происходит ошибка, и когда в каталоге больше нет элементов. Чтобы различать эти две ситуации, необходимо проверять
errno. Эта задача усложняется тем, что
readdir() не меняет
errno, пока не произойдет ошибка. Это означает, что для корректной проверки ошибок
errno необходимо установить перед вызовом
readdir() в заранее известное значение (обычно 0). Ниже показана простая программа, записывающая имена файлов текущего каталога в stdout.
1: /* dircontents.с */
2:
3: #include <errno.h>
4: #include <dirent.h>
5: #include <stdio.h>
6:
7: int main(void) {
8: DIR * dir;
9: struct dirent * ent;
10:
11: /* "." - текущий каталог */
12: if (!(dir = opendir("."))) {
13: perror("opendir");
14: return 1;
15: }
16:
17: /* установить errno в 0, чтобы можно было выяснить, когда readdir() даст сбой*/
18: errno = 0;
19: while ((ent = readdir(dir))) {
20: puts (ent->d_name);
21: /* сбросить errno, поскольку puts() может модифицировать ее */
22: errno = 0;
23: }
24:
25: if (errno) {
26: perror("readdir");
27: return 1;
28: }
29:
30: closedir(dir);
31:
32: return 0;
33: }
14.4.1. Прохождение по каталогу
Если требуется перечитать содержимое каталога, уже открытого
opendir(), с помощью
rewinddir() структура
DIR сбрасывается, чтобы следующий вызов
readdir() мог вернуть первый файл в каталоге.
#include <dirent.h>
int rewinddir(DIR * dir);
14.5. Универсализация файловых имен
Большинство пользователей Linux принимают как должное то, что запуск
ls *.с не сообщает сведения о файле в текущем каталоге, именем которого является
*.с. Вместо этого они ожидают увидеть список всех файлов в текущем каталоге, имена которых заканчиваются на
.с. Это расширение имени файла от
*.с до
ladsh.с dircontents.с (например) обычно обрабатывается оболочкой, которая универсализирует все параметры для программ, выполняющихся под ее управлением. Программы, помогающие пользователям манипулировать файлами, тоже часто нуждаются в универсализации файловых имен. Существуют два распространенных способа универсализации имен файлов внутри программ.
14.5.1. Использование подпроцесса
Самый старый метод универсализации предусматривает запуск оболочки в качестве дочернего процесса и указание ей универсализировать файловые имена. Стандартная функция
popen() (см. главу 10) упрощает этот метод — просто запустите команду
ls *.с с помощью
popen() и прочитайте результат. Этот подход может показаться несколько упрощенным, но все же он обеспечивает переносимое решение проблемы универсализации (вот почему приложения вроде Perl используют его).
Ниже приведена программа, которая универсализирует все аргументы и отображает все совпадения.
1: /* popenglob.c */
2:
3: #include <stdio.h>
4: #include <string.h>
5: #include <sys/wait.h>
6: #include <unistd.h>
7:
8: int main(int argc, const char ** argv)
9: char buf[1024];
10: FILE * ls;
11: int result;
12: int i;
13:
14: strcpy(buf, "ls");
15:
16: for (i = 1; i < argc; i++) {
17: strcat(buf, argv[i]);
18: strcat(buf, " ");
19: }
20:
21: ls = popen(buf, "r");
22: if (!ls) {
23: perror("popen");
24: return 1;
25: }
26:
27: while (fgets(buf, sizeof(buf), ls))
28: printf("%s", buf);
29:
30: result = pclose(ls);
31:
32: if (!WIFEXITED(result)) return 1;
33:
34: return 0;
35: }
14.5.2. Внутренняя универсализация
Если необходимо универсализировать несколько файловых имен, запуск нескольких подоболочек с помощью
popen() будет неэффективным. Функция
glob() позволяет универсализировать имена файлов без запуска каких-либо подпроцессов, однако за счет увеличения сложности и снижения переносимости. Несмотря на то что вызов
glob() описан в стандарте POSIX.2, многие варианты Unix до сих пор его не поддерживают.
#include <glob.h>
int glob(const char * pattern, int flags,
int (*errfunc)(const char * epath, int eerrno), glob_t* pglob);
Первый параметр,
pattern, определяет шаблон, которому должны соответствовать имена файлов. В нем допускается применение операций универсализации
*,
? и
[], а также необязательно
{,
} и
~ которые трактуются так же, как в стандартных оболочках. Последний параметр указывает на структуру, которая заполняется результатами универсализации. Эта структура определена следующим образом.
#include <glob.h>
typedef struct {
int gl_pathc; /* количество путей в gl_pathv */
char **gl_pathv; /* список gl_pathc, соответствующих именам путей */
int gl_offs; /* пространство, зарезервированное в gl_pathv для GLOB_DOOFFS*/
} glob_t;
flags — это одно или несколько перечисленных ниже значений, объединенных с помощью битового "ИЛИ".
GLOB_ERR |
Возвращается в случае ошибки (если функция не может прочесть оглавление каталога, например, из-за проблем с доступом). |
GLOB_MARK |
Если шаблон соответствует имени каталога, при возврате к этому имени будет добавлен символ /. |
GLOB_NOSORT |
Обычно возвращаемые имена путей сортируются в алфавитном порядке. Если этот флаг установлен, они не сортируются. |
GLOB_DOOFFS |
При установке первые строки pglob->gl_offs в возвращаемом списке имен путей оставляются пустыми. Это позволяет использовать glob() во время выстраивания ряда аргументов, которые будут переданы прямо в execv(). |
GLOB_NOCHECK |
Если ни одно из файловых имен не соответствует шаблону, в качестве единственного совпадения возвращается сам шаблон (обычно не возвращается ни одного совпадения). В обоих случаях шаблон возвращается, если он не содержит операций универсализации. |
GLOB_APPEND |
pglob предположительно является действительным результатом предыдущего вызова glob(), и любые результаты этого вызова добавляются к результатам предыдущего вызова. Это облегчает универсализацию множества шаблонов. |
GLOB_NOESCAPE |
Обычно если операции универсализации предшествует символ \, она воспринимается как обычный символ. Например, шаблон а\* обычно соответствует только файлу по имени а*. Если устанавливается GLOB_NOESCAPE, символ \ теряет свое особое значение, aa\* соответствует любому имени файла, начинающемуся с символов а\. В таком случае имена а\. и a\bcd будут соответствовать, но arachnid — нет, поскольку оно не содержит \. |
GLOB_PERIOD |
Большинство оболочек не позволяют применять операции универсализации для файловых имен, начинающихся с . (запустите ls * в своем домашнем каталоге и сравните полученное с результатом ls - а .). Функция glob() обычно ведет себя подобным образом, но GLOB_PERIOD позволяет операциям универсализации работать с ведущим символом. Значение GLOB_PERIOD в POSIX не определено. |
GLOB_BRACE |
Многие оболочки (следуя примеру csh) разворачивают последовательности с фигурными скобками как альтернативы; например, шаблон {a, b} разворачивается до a b, а шаблон a {, b, c} — до a ab ас. GLOB_BRACE делает возможным такое поведение. Значение GLOB_BRACE в POSIX не определено. |
GLOB_NOMAGIС |
Действует подобно GLOB_NOCHECK за исключением того, что он добавляет шаблон к списку результатов только в том случае, если она не содержит специальных знаков. Значение GLOB_NOMAGIC в POSIX не определено. |
GLOB_TILDE |
Включает расширение с тильдой, в котором ~ или подстрока ~/ разворачиваются до пути к домашнему каталогу текущего пользователя, а ~user — до пути к домашнему каталогу пользователя user. Значение GLOB_TILDE в POSIX не определено. |
GLOB_ONLYDIR |
Совпадает только с каталогами, а не с другими типами файлов. Значение GLOB_ONLYDIR в POSIX не определено. |
Часто
glob() наталкивается на каталоги, к которым у процесса нет доступа, что вызывает ошибки. Хотя ошибку можно каким-то образом обработать, однако если
glob() возвращает ошибку (
GLOB_ERR), операцию универсализации нельзя перезапустить там, где предыдущая операция универсализации столкнулась с ошибкой. Поскольку сложно одновременно устранять ошибки, происходящие во время выполнения
glob(), и завершать универсализацию,
glob() позволяет передать ошибку в специально предусмотренную для этого функцию, которая определяется в третьем параметре
glob().
Прототип этой функции показан ниже.
int globerr(const char * pathname, int globerrno);
Функции передается путевое имя, вызвавшее ошибку, и значение
errno, возвращенное одним из системных вызовов
opendir(),
readdir() или
stat(). Если функция ошибки возвращает величину больше нуля,
glob() возвращается с ошибкой. В противном случае операция универсализации продолжается.
Результаты универсализации хранятся в структуре
glob_t, на которую ссылается
pglob. Она включает описанные ниже элементы, позволяющие абоненту найти согласованные имена файлов.
gl_pathc |
Количество путевых имен, соответствующих шаблону. |
gl_pathv |
Массив путевых имен, соответствующих шаблону. |
После использования возвращенного результата
glob_t занимаемую им память следует освободить, передав его в
globfree().
void globfree(glob_t * pglob);
Системный вызов
glob() возвращает
GLOB_NOSPACE в случае нехватки памяти,
GLOB_ABEND, если ошибка чтения привела к неудачному выполнению функции,
GLOB_NOMATCH, если соответствия не были найдены, или
0, если функция выполнилась удачно и нашла соответствия.
Для иллюстрации работы
glob() ниже приведена программа
globit, которая принимает множество шаблонов в качестве аргументов, универсализирует их и отображает результат. В случае ошибки отображается сообщение, описывающее ошибку, а операция универсализации продолжается.
1: /* globit.с */
2:
3: #include <errno.h>
4: #include <glob.h>
5: #include <stdio.h>
6: #include <string.h>
7: #include <unistd.h>
8:
9: /* Это функция ошибки, которая передается в glob(). Она просто отображает
10: сообщение об ошибке и возвращает состояние успеха, что позволяет glob()
11: продолжить работу. */
12: int errfn(const char * pathname, int theerr) {
13: fprintf(stderr, "ошибка при доступе к %s: %s\n", pathname,
14: strerror(theerr));
15:
16: /* Операция универсализации должна продолжаться, поэтому вернуть 0 */
17: return 0;
18: }
19:
20: int main(int argc, const char ** argv) {
21: glob_t result;
22: int i, rc, flags;
23:
24: if (argc < 2) {
25: printf("необходимо передать хотя бы один аргумент\n") ;
26: return 1;
27: }
28:
29: /* установить flags в 0; позже он будет изменен на GLOB_APPEND */
30: flags = 0;
31:
32: /* совершить проход по всем аргументам командной строки */
33: for (i = 1; i < argc; i++) {
34: rc = glob(argv[i], flags, errfn, &result);
35:
36: /* благодаря errfn, GLOB_ABEND не происходит */
37: if (rc == GLOB_NOSPACE) {
38: fprintf(stderr, "не хватает памяти для выполнения универсализации\n");
39: return 1;
40: }
41:
42: flags |= GLOB_APPEND;
43: }
44:
45: if (!result.gl_pathc) {
46: fprintf(stderr, "соответствий нет\n");
47: rc = 1;
48: } else {
49: for (i = 0; i < result.gl_pathc; i++)
50: puts(result.gl_pathv[i]);
51: rc = 0;
52: }
53:
54: /* структура glob_t занимает память из пула malloc(),
55: которая должна быть освобождена */
56: globfree(&result);
57:
58: return rc;
59: }
14.6. Добавление к ladsh возможностей работы с каталогами и универсализацией
Продолжим эволюцию
ladsh, добавив к
ladsh3.с четыре новых возможности.
1. Встроенная команда
cd для смены каталогов.
2. Встроенная команда
pwd для отображения текущего каталога.
3. Универсализация файловых имен.
4. Отображение ряда новых сообщений, позволяющее воспользоваться преимуществами
strsignal(). Эти изменения обсуждались в главе 12.
14.6.1. Добавление встроенных команд cd и pwd
Добавление встроенных команд является прямым применением вызовов
chdir() и
getcwd(). Код соответствует
runProgram() как раз там, где обрабатываются другие встроенные команды. Ниже показан раздел обработки встроенных команд в
ladsh3.с.
422: if (!strcmp(newJob.progs[0].argv[0], "exit")) {
423: /* здесь должен возвращаться реальный код завершения */
424: exit(0);
425: } else if (!strcmp(newJob.progs[0].argv[0], "pwd")) {
426: len = 50;
427: buf = malloc(len);
428: while (!getcwd(buf, len) && errno == ERANGE) {
429: len += 50;
430: buf = realloc(buf, len);
431: }
432: printf("%s\n", buf);
433: free(buf);
434: return 0;
435: } else if (!strcmp(newJob.progs[0].argv[0], "cd")) {
436: if (!new Job.progs[0].argv[1] == 1)
437: newdir = getenv("HOME");
438: else
439: newdir = newJob.progs[0].argv[1];
440: if (chdir(newdir))
441: printf("сбой при смене текущего каталога: %s\n",
442: strerror(errno));
443: return 0;
444: } else if (!strcmp(newJob.progs[0].argv[0], "jobs")) {
445: for (job = jobList->head; job; job = job->next)
446: printf(JOB_STATUS_FORMAT, job->jobId, "Выполняется",
447: job -> text);
448: return 0;
449: }
14.6.2. Добавление универсализации файловых имен
Универсализацию файловых имен, при которой оболочка разворачивает символы
*,
[] и
? в соответствующие файловые имена, в определенной мере сложно реализовать из-за разнообразных методов применения кавычек. Первая модификация заключается в построении каждого аргумента в виде строки, подходящей для передачи в
glob(). Если символ универсализации помещен в кавычки, принятые в оболочке (например, двойные кавычки), тогда символу универсализации предшествует
\ с целью предотвращения его разворачивания в
glob(). Этот процесс реализуется легко, хотя с первого
взгляда может показаться сложным.
Две части синтаксического разбора команд в
parseCommand() необходимо слегка изменить. Последовательности
" и
' обрабатываются ближе к началу цикла, что обеспечивает разделение командной строки на аргументы. Если во время синтаксического разбора мы находимся в середине строки в кавычках и сталкиваемся с символом универсализации, мы заключаем его в кавычки с предваряющим символом
\, что выглядит следующим образом.
189: } else if (quote) {
190: if (*src == '\\') {
191: src++;
192: if (!*src) {
193: fprintf(stderr,
194: "после \\ ожидался символ\n");
195: freeJob(job);
196: return 1;
197: }
198:
199: /* в оболочке "\'" должен дать \' */
200: if (* src ! = quote) *buf++ = '\\';
201: } else if (*src = '*' | | *src == '?' || *src == '[' ||
202: *src == ']')
203: *buf++ = '\\';
204: *buf++ = *src;
205: } else if (isspace(*src)) {
В код были добавлены только средний
else if и оператор присваивания в его теле. Похожий код потребуется предусмотреть для обработки символов
\, встречающихся вне строк в кавычках. Это реализовано в конце главного цикла
parseCommand(). Ниже приведен измененный код.
329: case '\\':
330: src++;
331: if (!*src) {
332: freeJob(job);
333: fprintf(stderr, "после \\ ожидался символ\n");
334: return 1;
335: }
336: if (* src == '*' || *srс == '[' | | *src == ']'
337: || *srс == '?')
338: *buf++ = '\\';
339: /* сквозная обработка */
340: default:
341: *buf++ = *src;
Для заключения знаков универсализации в кавычки здесь был добавлен тот же самый код.
Эти две кодовые последовательности обеспечивают передачу каждого аргумента в
glob() без поиска неожиданных совпадений.
Теперь добавим функцию
globLastArgument(), которая универсализирует самый последний аргумент для дочерней программы и замещает его любым найденным совпадением.
Для облегчения управления памяти к
struct childProgram добавляется элемент
globResult типа
glob_t, используемый для хранения результатов всех операций универсализации. Кроме того, добавляется целочисленный элемент
freeGlob, не равный нулю, если
freeJob() должна освободить
globResult. Ниже показано полное описание
struct childProgram в
ladsh3.c.
35: struct childProgram {
36: pid; /* 0, если завершена */
37: char ** argv; /* имя и аргументы программы */
38: int numRedirections; /* элементы в массиве перенаправлений */
39: struct redirection Specifier * redirections; /* перенаправления ввода-вывода */
40: glob_t globResult; /* результат универсализации параметров */
41: int freeGlob; /* нужно ли освобождать globResult? */
42: };
Во время первого запуска для командной строки функция
globLastArgument() (когда
argc для текущей дочерней оболочки равно 1) инициализирует
globResult. Для остальных аргументов она пользуется преимуществом
GLOB_APPEND для добавления новых совпадений к существующим. Это избавляет от необходимости распределения собственной памяти для целей универсализации, поскольку одиночный
glob_t при необходимости автоматически расширяется.
Если
globLastArgument() не находит совпадений, символы
\ с кавычками удаляются из аргумента. В противном случае все новые совпадения копируются в список аргументов, создаваемый для дочерней программы.
Ниже приведена полная реализация
globLastArgument(). Все сложные ее части относятся к управлению памятью; фактическая универсализация похожа на реализованную в программе
globit.с, которая представлена ранее в главе.
87: void globLastArgument(struct childProgram * prog, int * argcPtr,
88: int * argcAllocedPtr) {
89: int argc = *argcPtr;
90: int argcAlloced = *argcAllocedPtr;
91: int rc;
92: int flags;
93: int i;
94: char * src, * dst;
95:
96: if (argc >1) {/* cmd->globResult уже инициализирован */
97: flags = GLOB_APPEND;
98: i = prog->globResult.gl_pathc;
99: } else {
100: prog->freeGlob = 1;
101: flags = 0;
102: i = 0;
103: }
104:
105: rc = glob(prog->argv[argc - 1], flags, NULL, &prog->globResult);
106: if (rc == GLOB_NOSPACE) {
107: fprintf (stderr, "не хватает памяти для выполнения универсализации\n");
108: return;
109: } else if (rc == GLOB_NOMATCH ||
110: (!rc && (prog->globResult.gl_path - i) == 1 &&
111: !strcmp(prog->argv[argc - 1],
112: prog->globResult.gl_pathv[i]))) {
113: /* необходимо удалить кавычки в \, если они все еще присутствуют */
114: src = dst = prog->argv[argc - 1];
115: while (*src) {
116: if (*src ! = '\\') *dst++ = *src;
117: src++;
118: }
119: *dst = '\0';
120: } else if (!rc) {
121: argcAlloced += (prog->globResult.gl_pathc - i);
122: prog->argv = realloc(prog->argv,
123: argcAlloced * sizeof(*prog->argv));
124: memcpy(prog->argv + (argc - 1),
125: prog->globResult.gl_pathv + i,
126: sizeof(*(prog->argv)) *
127: (prog->globResult.gl_pathc - i));
128: argc += (prog->globResult.gl_pathc - i - 1);
129: }
130:
131: *argcAllocedPtr = argcAlloced;
132: *argcPtr = argc;
133: }
Последними изменениями касаются вызовов
globLastArgument(), которые должны совершаться после синтаксического разбора нового аргумента. Вызовы добавляются в двух местах: когда за пределами строки в кавычках найдены пробелы и когда вся командная строка разобрана. Оба вызова выглядят следующим образом:
globLastArgument(prog, &argc, &argvAlloced);
Полный код
ladsh3.с доступен на Web-сайте издательства, а также на сайте, посвященном книге.
14.7. Обход деревьев файловых систем
Существуют две функции, которые облегчают приложениям просмотр всех файлов каталога, включая файлы в подкаталогах. Рекурсивный просмотр всех элементов древовидной структуры (например, файловой системы) часто называется
обходом (walk) дерева и он реализуется функциями
ftw() и
nftw().
nftw() представляет собой усовершенствованную версию
ftw.
14.7.1. Использование ftw()
#include <ftw.h>
int ftw(const char *dir, ftwFunctionPointer callback, int depth);
Функция
ftw() начинает с каталога
dir и вызывает указанную в
callback функцию для каждого файла в этом каталоге и его подкаталогах. Функция вызывается для всех типов файлов, включая символические ссылки и каталоги. Реализация
ftw() открывает каждый найденный каталог (с помощью файлового дескриптора) и для увеличения производительности не закрывает их, пока не закончит чтение всех элементов каталога. Это означает, что он использует количество файловых дескрипторов, равное количеству уровней подкаталогов. Чтобы предотвратить недостаток файловых дескрипторов в приложении, параметр
depth ограничивает количество файловых дескрипторов
ftw(), остающихся одновременно открытыми. Если этот предел достигается, производительность снижается, поскольку каталоги необходимо часто открывать и закрывать.
Функция, на которую указывает
callback, определяется следующим образом:
int ftwCallbackFunction(const char * file, const struct stat * sb, int flag);
Эта функция вызывается один раз для каждого файла в дереве каталогов, а первый параметр,
file, представляет собой имя файла, начинающееся с
dir, которое передается
ftw(). Например, если бы аргумент
dir принимал значение
., одним из файловых имен было бы .
/bashrc. Если бы вместо этого использовалось
/etc, имя файла выглядело бы как
/etc/hosts.
Следующий аргумент обратного вызова,
sb, указывает на структуру
struct stat как на результат применения
stat() к файлу
[102]. Аргумент
flag предоставляет информацию о файле и принимает одно из следующих значений.
FTW_F |
Файл не является символической ссылкой или каталогом. |
FTW_D |
Файл является каталогом либо символической ссылкой, указывающей на каталог. |
FTW_DNR |
Файл является каталогом, полномочий на чтение которого у приложения нет (то есть его обход невозможен). |
FTW_SL |
Файл является символической ссылкой. |
FTW_NS |
Файл является объектом, к которому не удалось применить stat(). Примером может служить файл в каталоге, права на чтение которого приложение имеет (приложение может получить список файлов этого каталога), но не имеет права на выполнение (что предотвращает успешный вызов stat() применительно к файлам этого каталога). |
Когда файл является символической ссылкой,
ftw() пытается последовать за этой ссылкой и вернуть информацию о файле, на который она указывает (
ftw() проходит один и тот же каталог несколько раз, если на него имеется несколько символических ссылок). Однако для поврежденной ссылки не определено, вернется
FTW_SL или
FTW_NS. Это хорошая причина, чтобы использовать
nftw().
Если функция обратного вызова возвращает ноль, обход каталога продолжается. Если возвращается ненулевое значение, обход дерева файлов завершается и эта величина возвращается функцией
ftw(). При удачном завершении обхода
ftw() возвращает ноль, а в случае ошибки возвращается -1.
14.7.2. Обход дерева файлов с помощью nft()
Новая версия
ftw() —
nftw() — решает неоднозначность символических ссылок, присущих
ftw(), и содержит несколько дополнительных свойств. С целью правильного определения
nftw() заголовочными файлами значение
_XOPEN_SOURCE в приложении должно быть определено 500 или больше. Ниже показан прототип
nftw().
#define _XOPEN_SOURCE 600
#include <ftw.h>
int nftw(const char * dir, ftwFunctionPointer callback, int depth, int flags);
int nftwCallbackFunction(const char *file, const struct stat * sb,
int flag, struct FTW * ftwInfo);
Сравнивая
nftw() с
ftw(), легко заметить новый параметр —
flags. Это может быть один или несколько следующих флагов, объединенных с помощью логического "ИЛИ".
FTW_CHDIR |
Функция nftw() обычно не меняет текущий каталог программы. Если определен флаг FTW_CHDIR функция nftw() меняет текущий каталог на любой другой каталог, читаемый в данный момент. Иначе говоря, при активизации обратного вызова имя файла, передаваемое ему, всегда относится к текущему каталогу. |
FTW_DEPTH |
По умолчанию nftw() выводит имя каталога перед списком имен файлов в этом каталоге. Этот флаг вызывает изменение порядка на обратный, то есть содержимое каталога выводится перед его именем. (Примечание. Этот флаг заставляет nftw() выполнять поиск в глубину. Подобного флага для поиска в ширину не существует.) |
FTW_MOUNT |
Это флаг запрещает nftw() переходить границу файловой системы во время обхода. Более подробно файловые системы описаны в [32]. |
FTW_PHYS |
Вместо следования символическим ссылкам nftw() сообщает о ссылках, но не следует по ним. Побочный эффект заключается в том, что обратный вызов получает результат вызова lstat(), а не stat(). |
Аргумент обратного вызова
flag может принимать два новых значения для
nftw() вдобавок к значениям, уже упомянутым для
ftw().
FTW_DP |
Этот элемент является каталогом, об оглавлении которого уже сообщили (это может произойти только в случае установки FTW_DEPTH). |
FTW_SLN |
Этот элемент является символической ссылкой, указывающей на несуществующий файл (поврежденная ссылка). Это происходит только в том случае, если FTW_PHYS не был установлен; если же он был установлен, передается FTW_SL. |
Эти дополнительные значения
flag надлежащим образом определяют
nftw() для символических ссылок. При использовании
FTW_PHYS все символические ссылки возвращают
FTW_SL. Без
nftw() поврежденные ссылки выдают
FTW_NS, а другие символические ссылки дают тот же результат, что и цель ссылки.
Обратный вызов для
nftw() принимает еще один аргумент,
ftwInfо. Это указатель на
struct FTW, которая определяется следующим образом.
#define _XOPEN_SOURCE 600
#include <ftw.h>
struct FTW {
int base;
int level;
};
Элемент
base — это смещение имени файла в полном пути, передаваемое обратному вызову. Например, если переданный полный путь выглядит как
/usr/bin/ls,
base будет равно 9, a
file + ftwInfo->base даст имя файла
ls.
level — это количество каталогов под текущим каталогом. Если
ls был найден в
nftw(), начинающемся с
/usr, уровень будет равен 1. Если поиск начался с
/usr/bin, уровень будет равен 0.
14.7.3. Реализация find
Команда
find выполняет в одном или нескольких деревьях каталогов поиск файлов, соответствующих определенным характеристикам. Ниже приведена простая реализация
find, реализованная на основе
nftw(). Она использует
fnmatch() (см. главу 23) для реализации переключателя
-name и иллюстрирует многие флаги, воспринимаемые
nftw().
1: /* find.с */
2:
3: #define _XOPEN_SOURCE 600
4:
5: #include <fnmatch.h>
6: #include <ftw.h>
7: #include <limits.h>
8: #include <stdio.h>
9: #include <stdlib.h>
10: #include <string.h>
11:
12: const char * name = NULL;
13: int minDepth = 0, maxDepth = INT_MAX;
14:
15: int find (const char * file, const struct stat * sb, int flags,
16: struct FTW * f) {
17: if (f->level < minDepth) return 0;
18: if (f->level > maxDepth) return 0;
19: if (name && fnmatch(name, file + f->base, FNM_PERIOD)) return 0;
20:
21: if (flags == FTW_DNR) {
22: fprintf(stderr, "find: %s: недопустимые полномочия\n", file);
23: } else {
24: printf("%s\n", file);
25: }
26:
27: return 0;
28: }
29:
30: int main(int argc, const char ** argv) {
31: int flags = FTW_PHYS;
32: int i;
33: int problem = 0;
34: int tmp;
35: int rc;
36: char * chptr;
37:
38: /* поиск первого параметры командной строки (который должен
39: находиться после списка путей */
40: i = 1;
41: while (i < argc && *argv[i] != '-') i++;
42:
43: /* обработать опции командной строки */
44: while (i < argc && !problem) {
45: if (!strcmp(argv[i], "-name")) {
46: i++;
47: if (i == argc)
48: problem = 1;
49: else
50: name = argv[i++];
51: } else if (!strcmp(argv[i], "-depth")) {
52: i++;
53: flags |= FTW_DEPTH;
54: } else if (!strcmp (argv[i], "-mount") ||
55: !strcmp(argv[i], "-xdev")) {
56: i++;
57: flags |= FTW_MOUNT;
58: } else if (!strcmp (argv[i], "-mindepth") ||
59: !strcmp (argv[i], "-maxdepth")) {
60: i++;
61: if (i == argc)
62: problem = 1;
63: else {
64: tmp = strtoul(argv[i++], &chptr, 10);
65: if (*chptr)
66: problem = 1;
67: else if (!strcmp(argv[i - 2], "-mindepth"))
68: minDepth = tmp;
69: else
70: maxDepth = tmp;
71: }
72: }
73: }
74:
75: if (problem) {
76: fprintf(stderr, "использование: find <пути> [-name <строка>]"
77: "[-mindepth <целое>] [-maxdepth <целое>]\n");
78: fprintf(stderr, " [-xdev] [-depth]\n");
79: return 1;
80: }
81:
82: if (argc == 1 || *argv[1] == '-') {
83: argv[1] = ".";
84: argc = 2;
85: }
86:
87: rc = 0;
88: i = 1;
89: flags = 0;
90: while (i < argc && *argv[i] != '-')
91: rc |= nftw (argv [i++], find, 100, flags);
92:
93: return rc;
94: }
14.8. Уведомление о смене каталога
Иногда приложения желают получать уведомления об изменении оглавления каталога. Например, диспетчеры файлов могут выводить оглавление каталога в окне и обновлять это окно каждый раз при изменении каталога другими программами. В то время как приложение регулярно перепроверяет каталог, Linux может послать программе сигнал о модификации каталога, позволяя своевременные обновления без накладных расходов и задержек на страничный обмен.
Системный вызов
fcntl() используется для регистрации уведомлений об обновлениях каталога. В главе 11 уже говорилось о том, что этот системный вызов принимает три аргумента. Первый аргумент — это интересующий файловый дескриптор, второй — это команда, которую необходимо выполнить
fcntl(), а последний — это целое число, специфическое для этой команды. Для уведомлений каталогов первый аргумент является файловым дескриптором, относящимся к интересующему каталогу. Это единственный случай, при котором каталог следует открывать с помощью нормального системного вызова
open() вместо
opendir(). Командой регистрации уведомлений является
F_NOTIFY, а последний аргумент определяет, какие типы событий вызывают отправку сигнала. Это должен быть один или несколько перечисленных ниже флагов, объединенных по логическому "ИЛИ".
DN_ACCESS |
Файл в каталоге, который читается. |
DN_ATTRIB |
Права владения или доступа к файлу в каталоге были изменены. |
DN_CREATE |
В каталоге создан новый файл (включая новые жесткие ссылки на уже существующие файлы). |
DN_DELETE |
Файл удален из каталога. |
DN_MODIFY |
Файл в каталоге был модифицирован (тип модификации — усечение). |
DN_RENAME |
Файл в каталоге был переименован. |
Для отмены уведомления о событии вызовите
fcntl() с командой
F_NOTIFY и последним аргументом, равным нулю.
Обычно уведомление каталога автоматически отменяется после передачи одного сигнала. Для эффективного уведомления каталога окончательный аргумент для
fcntl() должен быть объединен операцией "ИЛИ" с
DN_MULTISHOT, что вызывает отправку сигналов для всех подходящих событий до отмены уведомления.
По умолчанию для уведомления каталога передается
SIGIO. Если приложение желает использовать для этого другой сигнал (например, для разных каталогов могут понадобиться разные сигналы), можно применить команду
F_SETSIG в
fcntl(), а в качестве последнего аргумента определить нужный сигнал. Если используется
F_SETSIG (даже если установлен сигнал
SIGIO), ядро также помещает файловый дескриптор на каталог в элементе
si_fd аргумента обработчика сигналов
siginfo_t[103], позволяя приложению узнать, какие из контролируемых каталогов обновились
[104].
Если контролируется несколько каталогов и для всех каталогов выбран один сигнал, крайне необходимо использовать сигнал реального времени, чтобы убедиться, что ни одно из событий не затерялось.
Ниже приведена программа, использующая уведомление о смене каталога для вывода сообщений об удалении либо добавлении файлов в любые контролируемые ею каталоги (их количество указывается в командной строке). Она отказывается принять
SIGRTMIN при смене каталога и использует
si_fd, чтобы обнаружить, какой именно каталог был изменен. С целью предотвращения условий состязаний программа использует сигналы с очередизацией и блокирование сигналов. Сигнал может быть доставлен только один раз — при вызове
sigsuspend() в строке 203. Это обеспечивает повторное сканирование каталога в случае внесения изменений в каталог во время его сканирования; иначе эти изменения останутся незамеченными. Использование сигналов с очередизацией разрешает любые изменения каталога во время работы программы; эти сигналы доставляется при каждом новом вызове
sigsuspend(), гарантируя, что ничего не пропущено.
1: /* dirchange.с */
2:
3: #define _GNU_SOURCE
4: #include <dirent.h>
5: #include <errno.h>
6: #include <fcntl.h>
7: #include <signal.h>
8: #include <stdio.h>
9: #include <stdlib.h>
10: #include <string.h>
11: #include <unistd.h>
12:
13: /* Для сохранения имен файлов из каталога используется связный
14: список. Поле exists служит для хранения служебной информации
15: при проверке изменений. */
16: struct fileInfo {
17: char * name;
18: struct fileInfo * next;
19: int exists;
20: };
21:
22: /* Это глобальный массив. Он отображает файловые дескрипторы на пути
23: каталогов, сохраняет список файлов в каталоге и предоставляет
24: обработчику сигналов место для отображения того факта, что каталог
25: должен сканироваться повторно. Последний элемент имеет path,
26: равный NULL, обозначающий конец массива. */
27:
28: struct directoryInfo {
29: char * path;
30: int fd;
31: int changed;
32: struct fileInfo * contents;
33: } * directoryList;
34:
35: /* Это никогда не возвращает пустой список; любой каталог содержит,
36: по крайней мере, "." и ".." */
37: int buildDirectoryList(char * path, struct fileInfo ** listPtr) {
38: DIR * dir;
39: struct dirent * ent;
40: struct fileInfo * list = NULL;
41:
42: if (!(dir = opendir(path))) {
43: perror("opendir");
44: return 1;
45: }
46:
47: while ((ent = readdir(dir))) {
48: if (!list) {
49: list = malloc(sizeof(*list));
50: list->next = NULL;
51: *listPtr = list;
52: } else {
53: list->next = malloc(sizeof(*list));
54: list = list->next;
55: }
56:
57: list->name = strdup(ent->d_name);
58: }
59:
60: if (errno) {
61: perror("readdir");
62: closedir(dir);
63: return 1;
64: }
65:
66: closedir(dir);
67:
68: return 0;
69: }
70:
71: /* Сканирует путь каталога в поисках изменений предыдущего
72: содержимого, как указано *listPtr. Связанный список
73: обновляется новым содержимым, и выводятся сообщения,
74: описывающие произошедшие изменения. */
75: int updateDirectoryList(char * path, struct fileInfo ** listPtr) {
76: DIR * dir;
77: struct dirent * ent;
78: struct fileInfo * list = *listPtr;
79: struct fileInfo * file, * prev;
80:
81: if (!(dir = opendir(path))) {
82: perror("opendir");
83: return 1;
84: }
85:
86: for (file = list; file; file = file->next)
87: file->exists = 0;
88:
89: while ((ent = readdir(dir))) {
90: file = list;
91: while (file && strcmp(file->name, ent->d_name))
92: file = file->next;
93:
94: if (!file) {
95: /* новый файл, добавить его имя в список */
96: printf("%s создан в %s\n", ent->d_name, path);
97: file = malloc(sizeof(*file));
98: file->name = strdup(ent->d_name);
99: file->next = list;
100: file->exists = 1;
101: list = file;
102: } else {
103: file->exists = 1;
104: }
105: }
106:
107: closedir(dir);
108:
109: file = list;
110: prev = NULL;
111: while (file) {
112: if (!file->exists) {
113: printf("%s удален из %s\n", file->name, path);
114: free(file->name);
115:
116: if (!prev) {
117: /* удалить головной узел */
118: list = file->next;
119: free(file);
120: file = list;
121: } else {
122: prev->next = file->next;
123: free(file);
124: file = prev->next;
125: }
126: } else {
127: prev = file;
128: file = file->next;
129: }
130: }
131:
132: *listPtr = list;
133:
134: return 0;
135: }
136:
137: void handler(int sig, siginfo_t * siginfo, void * context) {
138: int i;
139:
140: for (i = 0; directoryList[i].path; i++) {
141: if (directoryList[i].fd == siginfo->si_fd) {
142: directoryList[i].changed = 1;
143: return;
144: }
145: }
146: }
147:
148: int main(int argc, char ** argv) {
149: struct sigaction act;
150: sigset_t mask, sigio;
151: int i;
152:
153: /* Блокировать SIGRTMIN. Мы не хотим получать его нигде,
154: кроме как внутри системного вызова sigsuspend(). */
155: sigemptyset(&sigio);
156: sigaddset(&sigio, SIGRTMIN);
157: sigprocmask(SIG_BLOCK, &sigio, &mask);
158:
159: act.sa_sigaction = handler;
160: act.sa_flags = SA_SIGINFO;
161: sigemptyset(&act.sa_mask);
162: sigaction(SIGRTMIN, &act, NULL);
163:
164: if (!argv[1]) {
165: /* ни одного аргумента не передано, привести argc/argv
166: к виду ".", как будто передается единственный аргумент */
167: argv[1] = ".";
168: argc++;
169: }
170:
171: /* каждый аргумент представляет собой отслеживаемый каталог */
172: directoryList = malloc(sizeof(*directoryList) * argc);
173: directoryList[argc - 1].path = NULL;
174:
175: for (i = 0; i < (argc - 1); i++) {
176: directoryList[i].path = argv[i + 1];
177: if ((directoryList[i].fd =
178: open(directoryList[i].path, O_RDONLY)) < 0) {
179: fprintf(stderr, "ошибка при открытии %s: %s\n",
180: directoryList[i].path, strerror(errno));
181: return 1;
182: }
183:
184: /* Отслеживание каталога перед первым сканированием;
185: это гарантирует, что мы захватим файлы, созданные кем-то
186: во время сканирования каталога. Если кто-то изменит его,
187: будет сгенерирован сигнал (и заблокирован, пока
188: мы не будем готовы принять его) */
189: if (fcntl(directoryList[i].fd, F_NOTIFY, DN_DELETE |
190: DN_CREATE | DN_RENAME | DN_MULTISHOT) ) {
191: perror("fcntl F_NOTIFY");
192: return 1;
193: }
194:
195: fcntl(directoryList[i].fd, F_SETSIG, SIGRTMIN);
196:
197: if (build DirectoryList(directoryList[i].path,
198: &directoryList[i].contents))
199: return 1;
200: }
201:
202: while (1) {
203: sigsuspend(&mask);
204:
205: for (i = 0; directoryList[i].path; i++)
206: if (directoryList[i].changed)
207: if (updateDirectoryList(directoryList[i].path,
208: &directoryList[i].contents))
209: return 1;
210: }
211:
212: return 0;
213: }
Глава 15
Управление заданиями
Управление заданиями — возможность, стандартизованная в POSIX.1 и предоставляемая многими другими стандартами — позволяет одному терминалу выполнять несколько заданий. Задание (job) — это один процесс или группа процессов, обычно соединенных каналами. Для перемещения заданий между передним планом и фоном и предотвращения доступа к терминалу фоновых заданий предусмотрены специальные механизмы.
15.1. Основы управления заданиями
Из главы 10 уже известно, что каждый активный терминал запускает группу процессов, которая называется сеансом. Каждый сеанс состоит из групп процессов, а каждая группа, в свою очередь, содержит один или несколько индивидуальных процессов.
Одна из групп процессов в сеансе является группой переднего плана. Остальные группы являются фоновыми. Фоновую группу можно заменить любой группой процессов, принадлежащей к сеансу, позволяя пользователю переключаться между группами процессов переднего плана. Процессы, являющиеся элементами группы процессов переднего плана, часто называют процессами переднего плана; остальные процессы называются фоновыми.
15.1.1. Перезапуск процессов
Каждый процесс может пребывать в трех состояниях: выполнение, останов и "зомби". Выполняющиеся процессы завершаются системным вызовом
exit() или отправкой сигнала фатального завершения. Процессы перемещаются между состояниями работы и остановки исключительно посредством сигналов, сгенерированных другим процессом, ядром либо ими самими
[105].
Когда процесс получает
SIGCONT, ядро перемещает его из состояния останова в состояние выполнения; если процесс уже работает, сигнал не влияет на его состояние. Процесс может захватить сигнал; ядро в это время будет перемещать процесс в рабочее состояние перед передачей сигнала.
15.1.2. Остановка процессов
Четыре сигнала перемещают работающий процесс в состояние останова.
SIGSTOP никогда не генерируется ядром. Он предназначен для остановки произвольных процессов. Его невозможно захватить или проигнорировать; он всегда останавливает целевой процесс. Остальные три сигнала, останавливающие процессы —
SIGTSTP,
SIGTTIN и
SIGTTOU — могут генерироваться терминалом, на котором работает процесс, или другим процессом. Хотя эти сигналы ведут себя похожим образом, они генерируются при разных обстоятельствах.
SIGTSTP
Этот сигнал передается каждому процессу группы процессов переднего плана, когда пользователь нажимает клавиатурную комбинацию приостановки терминала
[106].
SIGTTIN
Когда фоновый процесс пытается считывать из терминала, ему передается
SIGTTIN.
SIGTTOU
Этот сигнал обычно генерируется фоновым процессом, пытающимся выполнить запись в свой терминал. Сигнал генерируется только в случае установки атрибута терминала
TOSTOP, как рассматривается в главе 16.
Данный сигнал генерируется также фоновым процессом, вызывающим
tcflush(),
tcflow(),
tcsetattr(),
tcsetpgrp(),
tcdrain() или
tcsendbreak().
Действием по умолчанию каждого из этих трех сигналов является останов процесса. Все эти процессы можно поймать или игнорировать. В обоих случаях процесс не останавливается.
15.1.3. Обработка сигналов управления заданиями
Хотя многие приложения можно останавливать и перезапускать без побочных эффектов, другим процессам требуется обрабатывать состояния останова и запуска. Например, большинству редакторов необходимо модифицировать параметры терминала в рабочем состоянии. Когда пользователи приостанавливают процесс, они ожидают, что их терминал восстановит свое состояние по умолчанию.
Когда процессу нужно выполнять действия перед приостановкой, должен быть предусмотрен обработчик сигнала для
SIGTSTP. Это позволяет ядру уведомлять процесс о необходимости приостановки.
При получении
SIGTSTP процесс должен немедленно выполнить все необходимые ему действия, чтобы разрешить приостановку (например, восстановление исходного состояния терминала) и приостановиться самому. Самый простой способ приостановки процесса — передача самому себе сигнала
SIGSTOP. Однако большинство оболочек отображают сообщения с типом сигнала, вызвавшего остановку процесса, и если процесс передаст себе sigstop, он будет отличаться от большинства приостановленных процессов. Во избежание этого неудобства многие приложения сбрасывают свой обработчик
SIGTSTP в
SIG_DFL и передают себе
SIGTSTP.
Процессам, которые требуют специальный код для правильных приостановок, обычно необходимо выполнять специальные действия при перезапуске. Это легко делается предоставлением обработчика сигнала для
SIGCONT, который выполняет такие действия. Если процесс приостанавливается с помощью
SIGTSTP, такие специальные действия, возможно, включают установку обработчика сигнала для
SIGTSTP.
Ниже приведен код простого обработчика сигналов
SIGCONT и
SIGTSTP. Когда пользователь приостанавливает или перезапускает процесс, последний отображает сообщение перед остановкой или продолжением.
1: /* monitor.с */
2:
3: #include <signal.h>
4: #include <stdio.h>
5: #include <string.h>
6: #include <unistd.h>
7:
8: void catchSignal(int sigNum, int useDefault);
9:
10: void handler(int signum) {
11: if (signum == SIGTSTP) {
12: write(STDOUT_FILENO, "получен SIGTSTP\n", 12);
13: catchSignal(SIGTSTP, 1);
14: kill(getpid(), SIGTSTP);
15: } else {
16: write(STDOUT_FILENO, "получен SIGCONT\n", 12);
17: catchSignal(SIGTSTP, 0);
18: }
19: }
20:
21: void catchSignal(int sigNum, int useDefault) {
22: struct sigaction sa;
23:
24: memset(&sa, 0, sizeof(sa));
25:
26: if (useDefault)
27: sa.sa_handler = SIG_DFL;
28: else
29: sa.sa_handler = handler;
30:
31: if (sigaction(sigNum, &sa, NULL)) perror("sigaction");
32: }
33:
34: int main() {
35: catchSignal(SIGTSTP, 0);
36: catchSignal(SIGCONT, 0);
37:
38: while(1);
39:
40: return 0;
41: }
15.2. Управление заданиями в ladsh
Добавление управления заданиями к
ladsh — это последнее добавление к простой оболочке, окончательный исходный код которой можно найти в приложении Б. Для начала потребуется добавить по элементу в структуры
struct childProgram,
struct job и
struct jobSet. Поскольку
ladsh некоторое время не рассматривался, вернитесь в главу 10, где были впервые представлены эти структуры данных. Ниже показано окончательное определение
struct childProgram.
35: struct childProgram {
36: pid_t pid; /* 0 на выходе */
37: char ** argv; /* имя программы с аргументами * /
38: int numRedirections; /* элементы в массиве переадресации */
39: struct redirectionSpecifier * redirections; /* переадресации ввода-вывода */
40: glob_t globResult; /* результат универсализации параметров */
41: int freeGlob; /* должен ли освобождаться globResult? */
42: int isStopped; /* выполняется ли программа в данный момент?*/
43: };
Мы уже различаем работающие и завершенные дочерние программы с помощью элемента
pid структуры
struct childProgram, равного нулю в случае завершения дочерней программы, а в противном случае содержащего действительный идентификатор процесса. Новый элемент,
isStopped, не равен нулю, если процесс был остановлен, в ином же случае он равен нулю. Обратите внимание, что его значение неважно, если
pid равен нулю.
Аналогичные изменения потребуется внести и в
struct job. Ранее эта структура отслеживала определенное количество программ в задании и количество выполняющихся процессов. Ее новый элемент,
stoppedProgs, записывает количество процессов задания, остановленных в данный момент. Он может быть вычислен на основе элементов
isStopped дочерних программ, содержащихся в задании, но лучше отслеживать его отдельно. После этого изменения получаем окончательную форму структуры
struct job.
45: struct job {
46: int jobld; /* номер задания */
47: int numProgs; /* количество программ в задании */
48: int runningProgs; /* количество выполняющихся программ */
49: char * text; /* имя задания */
50: char * cmdBuf; /* буфер различных argv */
51: pid_t pgrp; /* идентификатор группы процессов задания */
52: struct childProgram* progs; /* массив программ в задании */
53: struct job * next; /* для слежения за фоновыми программами */
54: int stopped Progs; /* количество активных, однако остановленных программ */
55: };
Как и предыдущие версии
ladsh, код
ladsh4.с игнорирует
SIGTTOU. Это делается, чтобы позволить использовать
tcsetpgrp() даже тогда, когда оболочка не является процессом переднего плана. Однако поскольку оболочка уже будет поддерживать правильное управление заданиями, дочерним процессам не следует игнорировать сигнал. Как только новый процесс разветвляется с помощью
runCommand(), он устанавливает обработчик для
SIGTTOU в
SIG_DFL. Это позволяет драйверу терминала приостановить фоновые процессы, пытающиеся выполнить запись в терминал или провести с ним еще какие-то действия. Ниже приведен код, который начинается с создания дочернего процесса, где сбрасывается
SIGTTOU и выполняется дополнительная работа по синхронизации.
514: pipe(controlfds);
515:
516: if (!(newJob.progs[i].pid = fork())) {
517: signal(SIGTTOU, SIG_DFL);
518:
519: close(controlfds[1]);
520: /* это чтение вернет 0, когда закроется записывающая сторона*/
521: read(controlfds[0], &len, 1);
522: close(controlfds[0]);
Канал
controlfds используется для приостановки дочернего процесса до того, как оболочка переместит этот процесс в подходящую группу процессов. Закрытием записывающей стороны канала и чтением из считывающей стороны дочерний процесс останавливается до тех пор, пока родительский процесс закроет записывающую сторону, что происходит после вызова
setpgid() в строке 546. Этот тип механизма необходим для гарантии того, что дочерний процесс перемещается в группу процессов до происшествия
exec(). Если подождать до
exec(), то не будет уверенности, что процесс попадет в правильную группу процессов, пока он не начнет доступ к терминалу (который может быть запрещен).
Завершенные дочерние процессы проверяются
ladsh два раза. Первый раз это происходит во время ожидания процессов в группе процессов переднего плана. После завершения либо остановки процесса переднего плана
ladsh проверяет изменения в состояниях своих фоновых процессов с помощью функции
checkJobs(). Обе этих кодовых цепочки необходимо модифицировать с целью обработки остановленных и завершенных дочерних процессов.
Добавление флага
WUNTRACED к вызову
waitpid(), ожидающему на процессах переднего плана, позволяет заметить также остановленные процессы. Когда процесс скорее останавливается, чем завершается, устанавливается флаг дочернего процесса
isStopped и увеличивается номер задания
stoppedProgs. Если все программы задания были остановлены,
ladsh снова перемещается на передний план и ожидает команды пользователя. Вот как выглядит часть главного цикла
ladsh, ожидающая на процессе переднего плана.
708: /* задание выполняется на переднем плане; ожидать его */
709: i = 0;
710: while (!jobList.fg->progs[i].pid ||
711: jobList.fg->progs[i].isStopped) i++;
712:
713: waitpid(jobList.fg->progs[i].pid, &status, WUNTRACED);
714:
715: if (WIFSIGNALED(status) &&
716: (WTERMSIG(status) != SIGINT)) {
717: printf("%s\n", strsignal(status));
718: }
719:
720: if (WIFEXITED(status) || WIFSIGNALED(status)) {
721: /* дочерний процесс завершен */
722: jobList.fg->runningProgs--;
723: jobList.fg->progs[i].pid = 0;
724:
725: if (!jobList.fg->runningProgs) {
726: /* дочерний процесс завершен */
727:
728: removeJob(&jobList, jobList.fg);
729: jobList. fg = NULL;
730:
731: /* переместить оболочку на передний план */
732: if (tcsetpgrp (0, getpid()))
733: perror("tcsetpgrp");
734: }
735: } else {
736: /* дочерний процесс остановлен */
737: jobList.fg->stoppedProgs++;
738: jobList.fg->progs[i].isStopped = 1;
739:
740: if (jobList.fg->stoppedProgs ==
741: jobList.fg->runningProgs) {
742: printf ("\n" JOB_STATUS_FORMAT,
743: jobList.fg->jobId,
744: "Остановлен", jobList.fg->text);
745: jobList.fg = NULL;
746: }
747: }
748:
749: if (!jobList.fg) {
750: /* переместить оболочку на передний план */
751: if (tcsetpgrp (0, getpid()))
752: perror("tcsetpgrp");
753: }
754: }
Подобным образом фоновые задания могут прерываться с помощью сигналов. Мы снова добавляем
WUNTRACED к
waitpid(), что проверяет состояния фоновых процессов. После остановки фонового процесса обновляются флаг
isStopped и счетчик
stoppedProgs, а в случае остановки всего задания выводится сообщение.
Последняя возможность, требуемая для
ladsh — перемещение задания между состоянием выполнения на переднем плане, состоянием выполнения в фоне и остановом. Это делается с помощью двух встроенных команд:
fg и
bg. Они являются ограниченными версиями нормальных команд оболочки, носящих те же имена. Оба принимают один параметр, являющийся номером задания, которому предшествует знак
% (для совместимости со стандартными оболочками). Команда
fg перемещает определенное задание на передний план, a
bg запускает его в фоне.
Обе операции выполняются передачей
SIGCONT каждому процессу в активизируемой группе процессов. Поскольку этот сигнал может передаваться каждому процессу с помощью отдельных вызовов
kill(), несколько проще передать его всей группе процессов, используя отдельный вызов
kill(). Ниже приведена реализация встроенных команд
fg и
bg.
461: } else if (! strcmp(newJob.progs[0].argv[0], "fg") ||
462: !strcmp(newJob.progs[0].argv[0], "bg")) {
463: if (!newJob.progs[0].argv[1] || newJob.progs[0].argv[2]) {
464: fprintf(stderr,
465: "%s: ожидался в точности один аргумент\n",
466: newJob.progs[0].argv[0]);
467: return 1;
468: }
469:
470: if (sscanf(newJob.progs[0].argv[l], "%%%d", &jobNum) != 1)
471: fprintf(stderr, "%s: ошибочный аргумент '%s'\n",
472: newJob.progs[0].argv[0],
473: newJob.progs[0].argv[1]);
474: return 1;
475: }
476:
477: for (job = jobList->head; job; job = job->next)
478: if (job->jobId == jobNum) break;
479:
480: if (!job) {
481: fprintf(stderr, "%s: неизвестное задание %d\n",
482: newJob.progs[0].argv[0], jobNum);
483: return 1;
484: }
485:
486: if (* new Job.progs[0].argv [0] == 'f') {
487: /* Перевести это задание на передний план */
488:
489: if (tcsetpgrp(0, job->pgrp))
490: perror("tcsetpgrp");
491: jobList->fg = job;
492: }
493:
494: /* Перезапустить процессы в задании */
495: for (i = 0; i < job->numProgs; i++)
496: job->progs[i].isStopped = 0;
497:
498: kill (-job->pgrp, SIGCONT);
499:
500: job->stoppedProgs = 0;
501:
502: return 0;
503: }
Управление заданиями — последняя возможность примера
ladsh, необходимая для нормального функционирования. В нем до сих пор не хватает многих свойств, присущих регулярным оболочкам, например, переменные оболочки и окружения, однако он иллюстрирует все низкоуровневые задания, выполняемые оболочками. Полный исходный код окончательной версии
ladsh доступен в приложении Б.
Глава 16
Терминалы и псевдотерминалы
Устройства, предназначенные для интерактивного использования
[107], обладают сходным интерфейсом, который был выведен десятилетия назад для последовательных терминалов TeleType и получил название
tty. Интерфейс tty используется для доступа к последовательным терминалам, консолям, терминалам xterm, сетевым регистрационным именам и тому подобному.
Интерфейс tty прост концептуально, но сложен в реализации. Будучи гибким и мощным, он может записывать приложения, не знающие, сколько входных и выходных данных они получают, а также работать в сети, на локальном экране либо через модем. Приложения можно даже запускать без их ведома под управлением другой программы.
К сожалению, разработчикам Unix пришлось предпринять несколько попыток совершенствования интерфейса. Они оставили пользователям три разных интерфейса для соединения с устройствами tty. Интерфейсы
sgtty (BSD) и
termio (System V) теперь вытеснены интерфейсом
termios (POSIX), который представляет собой супермножество команд интерфейса termio. Так как все существующие системы поддерживают интерфейс termios, и поскольку это самый мощный интерфейс, мы документируем только termios, а не ранние интерфейсы. (Ради поддержки унаследованного исходного кода Linux поддерживает termio, а также termios. Ранее он также ограниченно поддерживал интерфейс sgtty, но эта поддержка впоследствии была изъята, поскольку этот интерфейс никогда не был идеален, и в нем уже не было существенной потребности.)
Интерфейс termios должен поддерживать не только интерактивное использование программ, но и другие виды трафика. Последовательный канал, по которому осуществляется вход в сеть через модем, можно также использовать для дозвона через модем и связи с последовательным принтером либо другим специализированным элементом оборудования.
Устройство tty имеет два конца. Если рассуждать упрощенно, один конец присоединяется к программе, а второй — к аппаратному устройству. Это верно для последовательного порта; в данном случае драйвер последовательного устройства присоединяет последовательный порт (и, таким образом, терминал или модем) к оболочке, редактору или другой программе. Это также верно для консоли; драйвер консоли соединяет клавиатуру и экран с такими же типами программ. Но в некоторых случаях на каждом конце находится по программе; при этом один из концов занимает место оборудования.
Например, при сетевом подключении один конец устройства tty соединяется с программой, предоставляющей сетевое подключение, а второй — с оболочкой, редактором или другой потенциально интерактивной программой. Если программы находятся на каждом конце, вы должны ясно понимать, на каком конце эмулируется оборудование; при сетевом подключении к сети подключается аппаратная сторона.
Устройства tty с программным обеспечением на обоих концах называются
псевдотерминалами (pseudo-tty, или же просто
pty). В первой части главы они рассматриваться не будут, поскольку программный конец pty обрабатывается так же, как и любое другое устройство tty. Позже мы поговорим о программировании аппаратного конца pty.
16.1. Операции tty
Устройства tty предоставляют огромное количество опций обработки данных; они относятся к наиболее сложным устройствам ядра. Настраивать можно опции обработки входных и выходных данных, а также потока данных. Также можно контролировать ограниченное манипулирование данными на уровне драйвера устройства.
Интерфейсы tty работают в двух основных режимах: неформатируемый режим и режим обработки.
Неформатируемый режим передает данные в приложение без изменений.
Режим обработки, известный также как
канонический режим, поддерживает ограниченный построчный редактор внутри драйвера устройства и пересылает отредактированные входные данные в приложение по одной строке за раз. Этот режим изначально произрастает из универсальных систем, в которых специализированные устройства обработки входных данных предоставляли режим обработки без прерывания ЦП.
Режим обработки обрабатывает определенные управляющие символы; например, по умолчанию ^U
уничтожает (стирает) текущую строку, ^W стирает текущее слово, забой (^Н) или Delete — предыдущий символ, a ^R стирает и затем повторно набирает текущую строку. Каждое из этих управляющих действий может быть повторно назначено другом символу. Например, на многих терминалах символу DEL (код 127) назначается действие забоя.
16.1.1. Служебные функции терминалов
Иногда невозможно узнать, соответствует ли файловый дескриптор tty. Чаще всего это связано со стандартным дескриптором выходного файла. Программы, выводящие текст на стандартные устройства, часто форматируются иначе при записи в канал, чем при отображении информации для пользователей. Например, в случае применения команды
ls для получения списка файлов, она отобразит несколько колонок при простом запуске (удобнее читать человеку), но когда вы перенаправите ее вывод в другую программу, она отобразит по одному файлу в строке (удобнее читать программе). Запустите
ls и
ls | cat и почувствуйте разницу.
Определить, соответствует ли файловый дескриптор tty, можно с помощью функции
isatty(), принимающей файловый дескриптор в качестве своего аргумента и возвращающей 1, если дескриптор соответствует tty, и 0 в противном случае.
#include <unistd.h>
int isatty(int fd);
Функция
ttyname() предоставляет каноническое имя для терминала, ассоциированное с файловым дескриптором. В качестве аргумента она принимает любой файловый дескриптор, возвращая указатель в поток символов.
#include <unistd.h>
char *ttyname(int fd);
Поскольку поток символов расположен в статическом пространстве, потребуется сделать копию возвращенной строки перед повторным вызовом
ttyname(); эта функция не реентерабельна.
ttyname() возвращает
NULL при любой ошибке, включая случай передачи файлового дескриптора, не ассоциированного с tty.
16.1.2. Управляющие терминалы
Каждый сеанс (см. главу 10) привязан к терминалу, с которого процессы сеанса получают свои входные данные и в который пересылают свои выходные данные. Этот терминал может быть локальной консолью машины, терминалом, подключенным через последовательный канал, либо псевдотерминалом, устанавливающим соответствия во внешнем окне или по всей сети (подробнее о псевдотерминалах читайте в конце этой главы). Терминал, к которому относится сеанс, называется
управляющим терминалом (или
управляющим tty) сеанса. Терминал может быть управляющим терминалом только в одном сеансе за раз.
Нормальные процессы не могут менять свои управляющие терминалы; это может делать только лидер сеанса. В Linux изменение управляющего терминала лидера сеанса не распространяется на другие процессы того же сеанса. Лидеры сеансов почти всегда устанавливают управляющий терминал при запуске до создания каких-либо дочерних процессов, чтобы гарантировать, что все процессы сеанса совместно используют один управляющий терминал.
Существуют два интерфейса для смены управляющего tty лидера сеанса. Первый реализуется с помощью нормальных системных вызовов
open() и
close().
1. Закройте все файловые дескрипторы, относящиеся к текущему управляющему терминалу.
2. Откройте новый терминал без установки флага
O_NOCTTY.
Второй метод включает вызовы
ioctl() на отдельных файловых дескрипторах, ссылающихся на старые и новые терминалы.
1. Установите флаг
TIOCNOTTY на файловый дескриптор, привязанный к исходному управляющему tty (обычно
ioctl(0, TIOCNOTTY, NULL) нормально работает). Это разрывает соединение между сеансом и tty.
2. Установите флаг
TIOCSCTTY на файловый дескриптор, привязанный к новому управляющему tty. Это устанавливает новый управляющий tty.
Терминал, используемый сеансом, отслеживает то, какая группа процессов считается
группой процессов переднего плана. Процессам в этой группе разрешается читать и записывать в терминал, в то время как процессам в другой группе это не разрешено (более подробно о том, что происходит, когда фоновые процессы пытаются читать и производить запись в управляющий терминал, рассказывается в главе 15).
Функция
tcsetpgrp() позволяет процессу, работающему на терминале, сменить группу процессов переднего плана для этого терминала
[108].
int tcsetpgrp(int ttyfd, pid_t pgrp);
Первый параметр определяет tty, управляющая группа процессов которого изменяется, a
pgrp является группой процессов, которую необходимо переместить на передний план. Процессы могут менять группу процессов переднего плана только для своего управляющего терминала. Если процесс, совершающий изменение, не принадлежит к группе процессов переднего плана на этом терминале, генерируется сигнал
SIGTTOU, если только он не игнорируется или заблокирован
[109].
16.1.3. Принадлежность терминала
Существуют две системные базы данных, используемые для отслеживания зарегистрированных пользователей;
utmp применяется для пользователей, зарегистрированных в данный момент, a
wtmp является записью всех предыдущих регистраций со времени создания файла. Команда
who использует базу данных utmp для отображения списка зарегистрированных пользователей, а команда
last — базу данных wtmp для отображения списка пользователей, зарегистрированных в системе после регенерации базы данных wtmp. В системах Linux база данных utmp хранится в файле
/var/run/utmp, а база данных wtmp — в файле
/var/log/wtmp.
Программы, использующие tty для сеансов регистрации пользователей (независимо от того, ассоциируются ли они с графической регистрацией), должны обновлять эти две системные базы данных, пока пользователь явно не сделает иной запрос; например, некоторые пользователи не хотят, чтобы каждый сеанс оболочки, запускаемый ими в эмуляторе терминала в системе X Window, перечислялся как процесс входа. Добавляйте только интерактивные сеансы, поскольку utmp и wtmp не предназначены для регистрации автоматизированных программ. Любые tty, не являющиеся контролирующими терминалами, обычно в базы данных utmp и wtmp не добавляются.
16.1.4. Запись с помощью utempter
Приложения со встроенными средствами безопасности, использующие pty, имеют недостаточно полномочий для модификации файлов баз данных. Эти приложения должны предоставлять опцию для использования простой вспомогательной программы, доступной в большинстве систем Linux и в некоторых других системах, но не стандартизованной — утилиты
utempter. Утилита
utempter является setgid (или, при необходимости, setuid) с достаточными полномочиями для модификации баз данных utmp и wtmp. Доступ к ней можно получить через простую библиотеку. Утилита
utempter проверяет, владеет ли процесс tty, который пытается войти в базу данных utmp до разрешения операции,
utempter предназначена только для pty; другие tty обычно открываются демонами с достаточными полномочиями для модификации файлов системных баз данных.
#include <utempter.h>
void addToUtmp(const char *pty, const char *hostname, int ptyfd);
void removeLineFromUtmp(const char *pty, int ptyfd);
void removeFromUtmp(void);
Функция
addToUtmp() принимает три аргумента. Первый,
pty, является полным путем к добавляемому pty. Второй,
hostname, может быть
NULL или сетевым именем системы, из которой сетевое подключение использует этот порожденный pty (что запускает
ut_host, рассматриваемый в следующем разделе главы). Третий,
ptyfd, должен быть открытым файловым дескриптором, ссылающимся на устройство, названное в аргументе
pty.
Функция
removeLineFromUtmp() принимает два аргумента; они определяются в точности как аргументы с таким же именем, передаваемые функции
addToUtmp().
Некоторые существующие приложения записываются с помощью структуры, усложняющей хранение имени и файлового дескриптора для очистки элемента utmp. Из-за этого библиотека
utempter поддерживает кэш самого позднего имени устройства и файлового дескриптора, передаваемого
addToUtmp(), и удобную функцию
removeFromUtmp(), не принимающую никаких аргументов и действующую как
removeLineFromUtmp() на кэшированную информацию. Это подходит только для приложений, добавляющих лишь один элемент
utmp; более сложные приложения, использующие более одного pty, должны вместо этого применять
removeLineFromUtmp().
16.1.5. Запись вручную
Область обработки utmp и wtmp является одной из тех противоречивых областей, где механизмы различаются между системами и меняются на протяжении лет; даже определение информации, доступной в utmp и wtmp, до сих пор различается между системами. Изначально utmp и wtmp были просто массивами структур, записанных на диск; через некоторое время были созданы программные интерфейсы приложений (API) для надежной обработки записей.
По крайней мере, два таких интерфейса были официально стандартизованы; исходный интерфейс utmp (описанный в XSI, XPG2 и SVID2) и расширенный интерфейс
utmpx (описанный в XPG4.2 и в поздних версиях POSIX). В Linux доступны оба интерфейса (utmp и utmpx). Интерфейс utmp, широко варьирующийся между машинами, имеет набор определений, которые делают возможной запись переносимого кода. Этот код пользуется преимуществом расширений, предоставляемых glibc. Более строго стандартизованный интерфейс utmpx в данный момент не предоставляет эти определения, но все еще поддерживает расширения.
Интерфейс Linux utmp был изначально задуман как супермножество других существующих интерфейсов utmp, a utmpx был стандартизован как супермножество других существующих интерфейсов utmp; к счастью, оба набора во многом одинаковы. В Linux различие между структурами данных utmp и utmpx заключается лишь в букве x.
Если вы не хотите применять расширения, мы рекомендуем использовать интерфейс utmpx, поскольку он наиболее переносим, пока вы не используете расширения, и строго стандартизован.
Однако если вы хотите применять расширения, мы рекомендуем использовать интерфейс utmp, поскольку glibc предоставляет определения, позволяющие записать переносимый код, пользующийся преимуществами расширений.
Существует также смешанный подход — включите оба заголовочных файла и используйте определения, предоставляемые glibc для интерфейса utmp, чтобы решить, применять ли расширения в интерфейсе utmpx. Этого мы не рекомендуем, поскольку нет гарантии, что заголовочные файлы
utmp.h и
utmpx.h не будут конфликтовать с системами, не относящимися к Linux. Если ожидается максимальная переносимость и функциональность, в одной из этих областей придется записать некоторые коды дважды — первую версию с использованием utmpx для легкого переноса в новые системы, а вторую с применением
#ifdef — для максимальной функциональности в каждой новой системе, в которую вы перемещаетесь.
Здесь документируются лишь наиболее распространенные расширения; документация glibc покрывает все поддерживаемые расширения. Функции utmp работают в терминах
struct utmp; мы игнорируем некоторые расширения. Структура и функции utmpx работают точно так же, как структура и функции utmp, поэтому мы не документируем их отдельно. Обратите внимание, что такая же структура используется и для utmp, и для wtmp, поскольку обе базы данных очень похожи.
struct utmp {
short int ut_type; /* тип входа */
pid_t ut_pid; /* идентификатор процесса входа */
char ut_line[UT_LINESIZE]; /* 32 символа */
char ut_id[4]; /* идентификатор inittab */
char ut_user[UT_NAMESIZE]; /* 32 символа */
char ut_host[UT_HOSTSIZE]; /* 256 символов */
struct timeval ut_tv;
struct exit_status ut_exit; /* состояние бездействующего процесса */
long ut_session;
int32_t ut_addr_v6[4];
};
Многие одинаковые элементы являются частью
struct utmpx под тем же именем. Элементы, от которых не требуется быть элементами
struct utmpx, комментируются как "не стандартизованные POSIX" (ни один из них не стандартизован как часть
struct utmp, поскольку сама
struct utmp не стандартизована).
Элементы массива символов необязательно являются строками, завершающимися
NULL. Используйте
sizeof() либо другие ограничения размеров благоразумно.
ut_type |
Одно из следующих значений: EMPTY, INIT_PROCESS, LOGIN_PROCESS, USER_PROCESS, DEAD_PROCESS, BOOT_TIME, NEW_TIME, OLD_TIME, RUN_LVL или ACCOUNTING, каждое из которых описано ниже. |
ut_tv |
Время, ассоциированное с событием. Это единственный элемент, кроме ut_type, определяемый POSIX как всегда подходящий для непустых элементов. В некоторых системах вместо этого есть элемент ut_time, измеряемый только в секундах. |
ut_pid |
Идентификатор ассоциированного процесса для всех типов, заканчивающихся на _PROCESS. |
ut_id |
Идентификатор inittab ассоциированного процесса, для всех типов, заканчивающихся на _PROCESS. Это первое поле в незакомментированных строках файла /etc/inittab, где поля разделены символами :. Сетевые регистрации, не ассоциированные с inittab, могут использовать это по-другому; например, могут включать части информации об устройстве.4 |
ut_line |
Строка (базовое имя устройства или номер локального дисплея для X), ассоциированная с процессом. Спецификация POSIX о состоянии ut_line не ясна; она не считает ut_line значащей для LOGIN_PROCESS, но с другой стороны предполагает, что она значащая для LOGIN_PROCESS, и это подтверждается на практике. POSIX утверждает, что ut_line значащая для USER_PROCESS. На практике она также часто значащая для DEAD_PROCESS, в зависимости от происхождения бездействующего процесса. |
ut_user |
Обычно это имя зарегистрированного пользователя; это также может быть имя зарегистрированного процесса (обычно LOGIN) в зависимости от значения ut_type. |
ut_host |
Имя удаленного хоста, вошедшего в систему или иным образом ассоциированного с этим процессом. Элемент ut_host относится только к USER_PROCESS. Этот элемент не стандартизован POSIX. |
ut_exit |
ut_exit.e_exit дает код завершения, что предоставляется макросом WEXITSTATUS(), a ut_exit.e_termination дает сигнал, вызвавший завершение процесса (если он был завершен сигналом), что предоставляется макросом WTERMSIG(). Этот элемент не стандартизован POSIX. |
ut_session |
Идентификатор сеанса в системе X Window. Этот элемент не стандартизован POSIX. |
ut_addr_v6 |
IP-адрес удаленного хоста в случае активизации USER_PROCESS подключением с удаленного хоста. Используйте функцию inet_ntop() для генерирования печатного содержания. Если первая группа не равна нулю, тогда это адрес IPV4 (inet_ntop() принимает аргумент AF_INET); в противном случае это адрес IPV6 (inet_ntop() принимает аргумент AF_INET6). Этот элемент не стандартизован POSIX. |
Элемент
ut_type устанавливает, каким образом определяются остальные элементы. Некоторые величины
ut_type зарезервированы для записи системной информации; они полезны только для специализированных системных программ и документируются не полностью.
EMPTY |
В данной записи utmp нет достоверных данных (такие записи позже можно повторно использовать), поэтому игнорируйте ее содержимое. Другие элементы структуры являются незначащими. |
INIT_PROCESS |
Приведенный процесс был порожден непосредственно инициализацией. Это значение могут устанавливать системные программы (обычно только сам процесс инициализации); приложения должны прочитывать и распознавать это значение, но не должны ее устанавливать. Значащими являются элементы ut_pid, ut_id и ut_tv. |
LOGIN_PROCESS |
Экземпляры регистрационной программы, ожидающие регистрации пользователя. Элементы ut_id, ut_pid и ut_tv полезны; элемент ut_user полезен номинально (в Linux он сообщает LOGIN, но это имя процесса регистрации определяется реализацией в соответствии с POSIX). |
USER_PROCESS |
Этот элемент определяет лидера сеанса для зарегистрированного пользователя. Это может быть регистрационная программа после регистрации пользователя, управляющая программа монитора либо сеанса для входа в X Window System, программа эмуляции терминала, сконфигурированная для пометки сеансов регистрации, или любая интерактивная регистрация пользователя. Значащими являются элементы ut_id, ut_user, ut_line, ut_pid и ut_tv. |
DEAD_PROCESS |
Приведенный процесс был лидером сеанса для зарегистрированного пользователя, но завершился. Значащими являются элементы ut_id, ut_pid и ut_tv в соответствии POSIX. Элемент ut_exit (не установленный POSIX) значащий только в данном контексте. |
BOOT_TIME |
Время начальной загрузки системы. В utmp это самая поздняя загрузка; в wtmp это элемент для каждой загрузки системы со времени очистки wtmp. Значащим является только ut_tv. |
OLD_TIME и NEW_TIME |
Используются только для записи "скачков" времени. Записываются парами. Не рекомендуется зависеть от записи этих элементов в систему, даже если время на часах по какой-либо причине изменилось. |
RUN_LVL и ACCOUNTING |
Внутренние системные величины; в приложениях использовать не следует. |
Ниже приведены интерфейсы, определяемые XPG2, SVID 2 и FSSTND 1.2.
#include <utmp.h>
int utmpname(char * file);
struct utmp *getutent(void);
struct utmp *getutid(const struct utmp * id);
struct utmp *getutline(const struct utmp * line);
struct utmp *pututline(const struct utmp * ut);
void setutent(void);
void endutent(void);
void updwtmp(const char * file, const struct utmp * ut);
void logwtmp(const char * line, const char * name, const char * host);
Каждая запись в базе данных utmp или wtmp называется
строкой. Все функции, возвращающие указатель на
struct utmp, возвращают его на статические данные в случае успеха и
NULL — в случае ошибки. Обратите внимание, что статические данные переписаны каждым новым вызовом на каждую функцию, возвращающую
struct utmp. Также стандарт POSIX (для utmpx) требует очистки статических данных приложением перед началом какого-либо поиска.
Версии utmpx этих функций принимают
struct utmpx вместо
struct utmp, требуют включения
utmpx.h и называются
getutxent,
getutxid,
getutxline,
pututxline,
setutxent и
endutxent, но в другом случае они идентичны версиям utmp этих функций в Linux. Функции
utmpxname(), определенной POSIX, не существует, хотя некоторые платформы могут определять ее в любом случае (например, glibc).
Функция
utmpname() используется для определения просматриваемой базы данных. Базой данных по умолчанию является utmp, но вместо этого функцию можно применять для указания на wtmp. Два предопределенных имени — это
_PATH_UTMP для файла utmp и
_PATH_WTMP для файла wtmp; для целей тестирования можно выбрать указатель на локальную копию. Функция
utmpname() возвращает ноль в случае успеха и ненулевое значение в случае ошибки. Но успех может означать просто то, что имя файла удалось скопировать в библиотеку; это не означает, что база данных действительно существует в пути, предоставленном для нее.
Функция
getutent() просто возвращает следующую строку из базы данных. Если база данных еще не открыта, она возвращает содержимое первой строки. Если строки больше не доступны, она возвращает
NULL.
Функция
getutid() принимает
struct utmp и рассматривает лишь один или два элемента. Если
ut_type является
BOOT_TIME,
OLD_TIME или
NEW_TIME, она возвращает следующую строку этого типа. Если
ut_type является
INIT_PROCESS,
LOGIN_PROCESS,
USER_PROCESS или
DEAD_PROCESS, тогда
getutid() возвращает следующую строку, которая соответствует любому из типов, также имеющему значение
ut_id, которое соответствует значению
ut_id в
struct utmp, передаваемой
getutid(). Перед повторным вызовом потребуется удалить из
struct utmp данные, возвращаемые
getutid(); POSIX разрешает возвращать ту же строку, что и предыдущий вызов. Если соответствующих строк нет, возвращается
NULL.
Функция
getutline() возвращает следующую строку с
ut_id, установленным в
LOGIN_PROCESS или
USER_PROCESS. Эти процессы тоже имеют значение
ut_line, соответствующее значению
ut_line в
struct utmp, которая передается в
getutline(). Как и в случае
getutid(), необходимо удалить данные, возвращаемые
getutline(), из
struct utmp перед его повторным вызовом; в противном случае POSIX разрешает возвращать ту же строку, что и предыдущий вызов. Если соответствующих строк нет, возвращается
NULL.
Функция
pututline() модифицирует (или по необходимости добавляет) запись базы данных, соответствующую элементу
ut_line аргумента
struct utmp. Она делает это только в том случае, если у процесса есть полномочия на модификацию базы данных. Если модификация базы данных прошла успешно, она возвращает
struct utmp, который соответствует данным, записанным в базу. В ином случае возвращается
NULL. Функция
pututline() не применима к базе данных wtmp. Для модификации базы данных wtmp используйте
updwtmp() или
logwtmp().
Функция
setutent() перемещает внутренний указатель базы данных в начало.
Функция
endutent() закрывает базу данных. Это закрывает файловый дескриптор и освобождает ассоциированные данные. Вызывайте
endutent() как перед использованием
utmpname() для доступа к другому файлу utmp, так и после завершения доступа к данным utmp.
Наиболее надежным способом модификации базы данных wtmp являются две функции, определенные BSD и доступные как часть glibc.
Функция
updwtmp() принимает файловое имя базы данных wtmp (обычно
_PATH_WTMP) и заполненную структуру
struct utmp, пытаясь добавить элемент к файлу wtmp. Эта функция не сообщает об ошибках.
Функция
logwtmp() является удобной функцией, заполняющей
struct utmp и вызывающей
updwtmp() для нее. Аргумент
line копируется в
ut_line,
name — в
ut_user,
host — в
ut_host,
ut_tv заполняется текущим показанием времени, a
ut_pid — текущим идентификатором процесса. Как и
updwtmp(), эта функция не сообщает об ошибках.
В программе utmp демонстрируются некоторые методы чтения баз данных utmp и wtmp.
1: /* utmp.с */
2:
3: #include <stdio.h>
4: #include <unistd.h>
5: #include <string.h>
6: #include <time.h>
7: #include <sys/time.h>
8: #include <sys/types.h>
9: #include <sys/socket.h>
10: #include <netinet/in.h>
11: #include <arpa/inet.h>
12: #include <utmp.h>
13: #include <popt.h>
14:
15: void print_utmp_entry(struct utmp * u) {
16: struct tm *tp;
17: char * type;
18: char addrtext[INET6_ADDRSTRLEN];
19:
20: switch (u->ut_type) {
21: case EMPTY: type = "EMPTY"; break;
22: case RUN_LVL: type = "RUN_LVL"; break;
23: case BOOT_TIME: type = "BOOT_TIME"; break;
24: case NEW_TIME: type = "NEW_TIME"; break;
25: case OLD_TIME: type = "OLD_TIME"; break;
26: case INIT_PROCESS: type = "INIT_PROCESS"; break;
27: case LOGIN_PROCESS: type = "LOGIN_PROCESS"; break;
28: case USER_PROCESS: type = "USER_PROCESS"; break;
29: case DEAD_PROCESS: type = "DEAD_PROCESS"; break;
30: case ACCOUNTING: type = "ACCOUNTING "; break;
31: }
32: printf("%-13s:", type);
33: switch (u->ut_type) {
34: case LOGIN_PROCESS:
35: case USER_PROCESS:
36: case DEAD_PROCESS:
37: printf(" line: %s", u->ut_line);
38: /* fall through */
39: case INIT_PROCESS:
40: printf("\n pid: %6d id: %4.4s", u->ut_pid, u->ut_id);
41: }
42: printf ("\n");
43: tp = gmtime(&u->ut_tv.tv_sec);
44: printf("time: %24.24s.%lu\n", asctime(tp), u->ut_tv.tv_usec);
45: switch (u->ut_type) {
46: case USER_PROCESS:
47: case LOGIN_PROCESS:
48: case RUN_LVL:
49: case BOOT_TIME:
50: printf("пользователь: %s\n", u->ut_user);
51: }
52: if (u->ut_type == USER_PROCESS) {
53: if (u->ut_session)
54: printf(" сеанс: %lu\n", u->ut_session);
55: if (u->ut_host)
56: printf (" хост: %s\n", u->ut_host);
57: if (u->ut_addr_v6[0]) {
58: if (!(u->ut_addr_v6[1] |
59: u->ut_addr_v6[2] |
60: u->ut_addr_v6[3])) {
61: /* заполнение только первой группы означает адрес IPV4 */
62: inet_ntop(AF_INET, u->ut_addr_v6,
63: addrtext, sizeof(addrtext));
64: printf(" IPV4: %s\n", addrtext);
65: } else {
66: inet_ntop(AF_INET_6, u->ut_addr_v6,
67: addrtext, sizeof(addrtext));
68: printf (" IPV6: %s\n", addrtext);
69: }
70: }
71: }
72: if (u->ut_type == DEAD_PROCESS) {
73: printf(" завершение : %u: %u\n",
74: u->ut_exit.e_termination,
75: u->ut_exit.e_exit);
76: }
77: printf("\n");
78: }
79:
80: struct utmp * get_next_line (char * id, char * line) {
81: struct utmp request;
82:
83: if (!id && !line)
84: return getutent();
85:
86: memset(&request, 0, sizeof(request));
87:
88: if (line) {
89: strncpy(&request.ut_line[0], line, UT_LINESIZE);
90: return getutline(&request);
91: }
92:
93: request.ut_type = INIT_PROCESS;
94: strncpy(&request.ut_id[0], id, 4);
95: return getutid(&request);
96: }
97:
98: void print_file(char * name, char * id, char * line) {
99: struct utmp * u;
100:
101: if (utmpname(name)) {
102: fprintf (stderr, "сбой при открытии базы данных utmp %s\n", name);
103: return;
104: }
105: setutent();
106: printf("%s:\n====================\n", name);
107: while ((u = get_next_line(id, line))) {
108: print_utmp_entry(u);
109: /* POSIX требует очистки статических данных перед
110: * повторным вызовом getutline или getutid
111: */
112: memset(u, 0, sizeof(struct utmp));
113: }
114: endutent();
115: }
116:
117: int main(int argc, const char **argv) {
118: char * id = NULL, *line = NULL;
119: int show_utmp = 1, show_wtmp = 0;
120: int c;
121: poptContext optCon;
122: struct poptOption optionsTable[] = {
123: {"utmp", 'u', POPT_ARG_NONE|POPT_ARGFLAG_XOR,
124: &show_utmp, 0,
125: "переключить просмотр содержимого файла utmp", NULL},
126: { "wtmp", 'w', POPT_ARG_NONE | POPT_ARGFLAG_XOR,
127: &show_wtmp, 0,
128: "переключить просмотр содержимого файла wtmp", NULL},
129: {"id", 'i', POPT_ARG_STRING, &id, 0,
130: "показать записи процесса для заданного идентификатора inittab",
131: "<inittab id>" },
132: {"line", 'l', POPT_ARG_STRING, &line, 0,
133: "показать записи процесса для заданной строки устройства",
134: "<line>" },
135: POPT_AUTOHELP
136: POPT_TABLEEND
137: };
138:
139: optCon = poptGetContext("utmp", argc, argv, optionsTable, 0);
140: if ((c = poptGetNextOpt(optCon)) < -1) {
141: fprintf(stderr, "%s:%s\n",
142: poptBadOption(optCon, POPT_BADOPTION_NOALIAS),
143: poptStrerror(c));
144: return 1;
145: }
146: poptFreeContext(optCon);
147:
148: if (id && line)
149: fprintf(stderr, "Невозможно выбирать сразу по идентификатору и строке,"
150: "выбор по строке\n");
151:
152: if (show_utmp)
153: print_file(_PATH_UTMP, id, line);
154: if (show_utmp && show_wtmp)
155: printf("\n\n\n");
156: if (show_wtmp)
157: print_file(_PATH_WTMP, id, line);
158:
159: return 0;
160: }
16.2. Обзор termios
Все манипуляции tty осуществляются с помощью одной структуры,
struct termios, а также нескольких функций, определенных в заголовочном файле
<termios.h>. Из этих функций широко применяются только шесть. Когда не нужно устанавливать скорость передачи данных по линии, используются только две наиболее важных функции —
tcgetattr() и
tcsetattr().
#include <termios.h>
struct termios {
tcflag_t c_iflag; /* флаги режима ввода */
tcflag_t c_oflag; /* флаги режима вывода */
tcflag_t c_cflag; /* флаги управляющего режима */
tcflag_t c_lflag; /* флаги локального режима */
cc_t c_line; /* дисциплина линии связи */
cc_t c_cc[NCCS]; /* управляющие символы */
};
int tcgetattr(int fd, struct termios * tp);
int tcsetattr(int fd, int oact, struct termios * tp);
Почти в каждом случае программы должны использовать
tcgetattr() для получения текущих установок устройства, модифицировать эти установки, а затем применять
tcsetattr() для активизации модифицированных установок. Многие программы также сохраняют копии оригинальных установок и восстанавливают их перед завершением. В общем случае, следует модифицировать только интересующие вас установки; изменение других установок может усложнить работу пользователей с необычными системными конфигурациями (или сбоями в вашем коде).
Вызов
tcsetattr() может не принять на обработку выбранные вами установки; разрешено игнорировать произвольные установки. Если оборудование просто не поддерживает установку,
tcsetattr() игнорирует ее, а не возвращает ошибку. Если вам небезразлично воздействие, оказываемое установкой, следует использовать
tcgetattr() после
tcsetattr() и проверить, оказало ли воздействие внесенное вами изменение.
Для получения установок устройства tty необходимо открыть устройство и передать файловый дескриптор
tcgetattr(). Это вызывает проблемы с некоторыми устройствами tty; некоторые обычно можно открыть лишь один раз с целью предотвращения конфликта устройств. К счастью, передача флага
O_NONBLOCK в
open() вызывает его немедленное открытие и предотвращает блокирование любых операций. Однако все равно можно предпочесть блокирование
read(); в таком случае используйте
fcntl() для отключения режима
O_NONBLOCK перед тем, как появится возможность читать или записывать в него.
fcntl(fd, F_SETFL, fcntl(fd, F_GETFL, 0) & ~O_NONBLOCK);
Четыре флага
termios контролируют четыре отдельных части управления вводом и выводом. Флаг входных данных,
с_iflag, определяет, каким образом интерпретируются и обрабатываются принятые символы. Флаг выходных данных,
c_oflag, определяет, каким образом интерпретируются и обрабатываются символы, записываемые вашим процессом в tty. Управляющий флаг,
c_cflag, определяет характеристики последовательного протокола устройства и полезен лишь для физических устройств. Локальный флаг,
c_lflag, определяет, каким образом символы собираются и обрабатываются перед отправкой на обработку выходных данных. На рис. 16.1 показана упрощенная схема того, какое место занимает каждый флаг в общей схеме обработки символов.
 Рис. 16.1
Рис. 16.1. Упрощенная схема обработки tty
Сначала мы продемонстрируем способы применения
termios, а затем представим короткую справку о нем.
16.3. Примеры использования termios
16.3.1. Пароли
Самой распространенной причиной модификации установок
termios является чтение пароля без эхо-контроля символов. Для этого следует отключить локальное эхо во время чтения пароля. Ваш код должен выглядеть следующим образом:
struct termios ts, ots;
Первая структура хранит оригинальные установки для восстановления, а вторая является копией для модификации.
tcgetattr(STDIN_FILENO, &ts);
Обычно пароли читаются со стандартного устройства ввода.
ots = ts;
Сохраните копию оригинальных установок
termios, чтобы позже восстановить их.
ts.c_lflag &= ~ECHO;
ts.c_lflag |= ECHONL;
tcsetattr(STDIN_FILENO, TCSAFLUSH, fits);
Отключите эхо-контроль символов (кроме символов новой строки) после завершения обработки всех выходных данных. (Первая
l в
c_lflag означает локальную (local) обработку.)
read_password();
Теперь вы читаете пароль. Это может быть простой вызов
fgets() или
read(), либо же более сложная обработка, в зависимости от режима tty (неформатируемый режим или режим обработки) и от требований программы.
tcsetattr(STDIN_FILENO, TCSANOW, &ots);
Это немедленно восстанавливает исходные установки
termios. (Остальные опции объясняются позже, в справочном разделе далее в главе.)
Полный код программы-примера,
readpass, показан ниже.
1: /* readpass.с */
2:
3: #include <stdio.h>
4: #include <stdlib.h>
5: #include <termios.h>
6: #include <unistd.h>
7:
8: int main (void) {
9: struct termios ts, ots;
10: char passbuf[1024];
11:
12: /* получить и сохранить текущие настройки termios */
13: tcgetattr(STDIN_FILENO, &ts);
14: ots = ts;
15:
16: /* изменить и установить новые настройки termios */
17: ts.c_lflag & = ~ECHO;
18: ts.c_lflag |= ECHONL;
19: tcsetattr(STDIN_FILENO, TCSAFLUSH, &ts);
20:
21: /*хоть это и параноидально, но проверить, возымели ли эффект новые настройки*/
22: tcgetattr(STDIN_FILENO, &ts);
23: if (ts.c_lflag & ECHO) {
24: fprintf(stderr, "Сбой при отключении эхо-контроля\n");
25: tcsetattr(STDIN_FILENO, TCSANOW, &ots);
26: exit(1);
27: }
28:
29: /* получить и вывести пароль */
30: printf("введите пароль:");
31: fflush(stdout);
32: fgets(passbuf, 1024, stdin);
33: printf("прочитан пароль: %s", passbuf);
34: /* в passbuf был завершающий символ \n */
35:
36: /* восстановить старые настройки termios */
37: tcsetattr(STDIN_FILENO, TCSANOW, &ots);
38:
39: exit(0);
40: }
16.3.2. Последовательные коммуникации
В качестве примера программирования обоих концов tty рассмотрим программу, подключающую текущий терминал к последовательному порту. На одном tty программа под названием
robin сообщается с вами во время набора. На другом tty она взаимодействует с последовательным портом. С целью мультиплексирования вводных и выходных данных на локальном tty и последовательном порте программа использует системный вызов
poll(), описанный в главе 13.
Ниже приведен полный код программы
robin.с, за которым даны объяснения.
1: /* robin.с */
2:
3: #include <sys/poll.h>
4: #include <errno.h>
5: #include <fcntl.h>
6: #include <popt.h>
7: #include <stdio.h>
8: #include <stdlib.h>
9: #include <signal.h>
10: #include <string.h> /* для strerror() */
11: #include <termios.h>
12: #include <unistd.h>
13:
14: void die(int exitcode, const char *error, const char *addl) {
15: if (error) fprintf(stderr, "%s: %s\n", error, addl);
16: exit(exitcode);
17: }
18:
19: speed_t symbolic_speed(int speednum) {
20: if (speednum >= 460800) return B460800;
21: if (speednum >= 230400) return B230400;
22: if (speednum >= 115200) return B115200;
23: if (speednum >= 57600) return B57600;
24: if (speednum >= 38400) return B38400;
25: if (speednum >= 19200) return B19200;
26: if (speednum >= 9600) return B9600;
27: if (speednum >= 4800) return B4800;
28: if (speednum >= 2400) return B2400;
29: if (speednum >= 1800) return B1800;
30: if (speednum >= 1200) return B1200;
31: if (speednum >= 600) return B600;
32: if (speednum >= 300) return B300;
33: if (speednum >= 200) return B200;
34: if (speednum >= 150) return B150;
35: if (speednum >= 134) return B134;
36: if (speednum >= 110) return B110;
37: if (speednum >= 75) return B75;
38: return B50;
39: }
40:
41: /* Это нужно дляобласти видимости в пределах файла, так что
42: * их можно будет использовать в обработчиках сигналов */
43: /* старые настройки порта termios для восстановления */
44: static struct termios pots;
45: /* старые настройки stdout/stdin termios для восстановления */
46: static struct termios sots;
47: /* файловый дескриптор порта */
48: int pf;
49:
50: /* восстановить первоначальные настройки терминала при выходе */
51: void cleanup_termios(int signal) {
52: tcsetattr(pf, TCSANOW, &pots);
53: tcsetattr(STDIN_FILENO, TCSANOW, &sots);
54: exit(0);
55: }
56:
57: /* обработать одиночный управляющий символ */
58: void send_escape(int fd, char c) {
59: switch (c) {
60: case 'q':
61: /* восстановить настройки termios и выйти */
62: cleanup_termios(0);
63: break;
64: case 'b':
65: /* послать символ разрыва*/
66: tcsendbreak(fd, 0);
67: break;
68: default:
69: /* пропустить символ */
70: /* "C-\ C-\" sends "C-\" */
71: write(fd, &c, 1);
72: break;
73: }
74: return;
75: }
76:
77: /* обработать управляющие символы, записывая их в вывод */
78: void cook_buf(int fd, char * buf, int num) {
79: int current = 0;
80: static int in_escape = 0;
81:
82: if (in_escape) {
83: /* cook_buf последний раз вызывался с незавершенной
84: управляющей последовательностью */
85: send_escape(fd, buf[0]);
86: num--;
87: buf++;
88: in_escape = 0;
89: }
90: while (current < num) {
91: # define CTRLCHAR(c) ((c)-0x40)
92: while ((current < num) && (buf[current] != CTRLCHAR('W')))
93: current++;
94: if (current) write (fd, buf, current);
95: if (current < num) {
96: /* найден управляющий символ */
97: current++;
98: if (current >= num) {
99: /*интерпретировать первый символ следующей последовательности*/
100: in_escape = 1;
101: return;
102: }
103: send_escape(fd, buf[current]);
104: }
105: num -= current;
106: buf += current;
107: current = 0;
108: }
109: return;
110: }
111:
112: int main(int argc, const char * argv[]) {
113: char с; /* используется для разбора аргументов */
114: struct termios pts; /* настройки termios для порта */
115: struct termios sts; /* настройки termios для stdout/stdin */
116: const char *portname;
117: int speed = 0; /* используется при разборе аргументов для скорости */
118: struct sigaction sact; /* используется для инициализации обработчика сигналов */
119: struct pollfd ufds[2]; /* взаимодействие с poll() */
120: int raw = 0; /* неформатированный режим? */
121: int flow = 0; /* тип управления потоком, если применяется*/
122: int crnl = 0; /* посылать ли символ возврата каретки с символом новой строки? */
123: int i = 0; /* используется в цикле мультиплексирования*/
124: int done = 0; 125: # define BUFSIZE 1024
126: char buf[BUFSIZE];
127: poptContext optCon; /* контекст опций командной строки */
128: struct poptOption optionsTable[] = {
129: { "bps", 'b', POPT_ARG_INT, &speed, 0,
130: "скорость передачи сигналов, бит/с",
131: "<BPS>" },
132: { "crnl", 'с', POPT_ARG_VAL, &crnl, 'с',
133: "посылать символ возврата каретки с символом новой строки", NULL },
134: { "hwflow", 'h', POPT_ARG_VAL, &flow, 'h',
135: "использовать аппаратное управление потоком", NULL },
136: { "swflow", 's', POPT_ARG_VAL, &flow, 's',
137: "использовать программное управление потоком", NULL },
138: { "noflow", 'n', POPT_ARG_VAL, &flow, 'n',
139: "отключить управление потоком", NULL },
140: { "raw", 'r', POPT_ARG_VAL, &raw, 1,
141: "включить неформатированный режим", NULL },
142: POPT_AUTOHELP
143: { NULL, '\0', 0, NULL, '\0', NULL, NULL }
144: };
145:
146: #ifdef DSLEEP
147: /* ожидать 10 минут, что позволить подключить отладчик */
148: sleep(600);
149: #endif
150:
151: optCon = poptGetContext("robin", argc, argv, optionsTable, 0);
152: poptSetOtherOptionHelp(optCon, "<port>");
153:
154: if (argc < 2) {
155: poptPrintUsage(optCon, stderr, 0);
156: die(1, "He достаточно аргументов", "");
157: }
158:
159: if ((с = poptGetNextOpt(optCon)) < -1) {
160: /* ошибка во время обработки опций */
161: fprintf(stderr, "%s: %s\n",
162: poptBadOption(optCon, POPT_BADOPTION_NOALIAS),
163: poptStrerror(c));
164: return 1;
165: }
166: portname = poptGetArg(optCon);
167: if (!portname) {
168: poptPrintUsage(optCon, stderr, 0);
169: die(1, "He указано имя порта", "");
170: }
171:
172: pf = open(portname, O_RDWR);
173: if (pf < 0) {
174: poptPrintUsage(optCon, stderr, 0);
175: die(1, strerror(errno), portname);
176: }
177: poptFreeContext(optCon);
178:
179: /* изменить конфигурацию порта */
180: tcgetattr(pf, &pts);
181: pots = pts;
182: /* некоторые настройки устанавливаются произвольно */
183: pts.c_lflag &= ~ICANON;
184: pts.c_lflag &= ~(ECHO | ECHOCTL | ECHONL);
185: pts.c_cflag |= HUPCL;
186: pts.c_cc[VMIN] = 1;
187: pts.c_cc[VTIME] = 0;
188:
189: /* Стандартная обработка CR/LF: это неинтеллектуальный терминал.
190: * Не транслируется:
191: * нет NL -> отображение CR/NL в выводе,
192: * нет CR -> отображение NL во вводе.
193: */
194: pts.c_oflag &= ~ONLCR;
195: pts.c_iflag &= ~ICRNL;
196:
197: /* Теперь перейти на сторону локального терминала */
198: tcgetattr(STDIN_FILENO, &sts);
199: sots = sts;
200: /* и снова несколько произвольных настроек */
201: sts.c_iflag &= ~(BRKINT | ICRNL);
202: sts.c_iflag |= IGNBRK;
203: sts.c_lflag &= ~ISIG;
204: sts.c_cc[VMIN] = 1;
205: sts.c_cc[VTIME] = 0;
206: sts.c_lflag &= ~ICANON;
207: /* нет локального эхо: разрешить эхо-контроль на другом конце */
208: sts.c_lflag &= ~(ECHO | ECHOCTL | ECHONL);
209:
210: /* обработка опций сейчас будет модифицировать pts и sts */
211: switch (flow) {
212: case 'h' :
213: /* аппаратное управление потоком */
214: pts.c_cflag |= CRTSCTS;
215: pts.c_iflag &= ~(IXON | IXOFF | IXANY);
216: break;
217: case 's':
218: /* программное управление потоком */
219: pts.c_cflag &= ~CRTSCTS;
220: pts.c_iflag |= IXON | IXOFF | IXANY;
221: break;
222: case 'n':
223: /* отключение управления потоком */
224: pts.c_cflag &= ~CRTSCTS;
225: pts.c_iflag &= ~(IXON | IXOFF | IXANY);
226: break;
227: }
228: if (crnl) {
229: /* послать CR с NL */
230: pts.c_oflag |= ONLCR;
231: }
232:
233: /* скорость не изменяется, пока не будет указано -b */
234: if (speed) {
235: cfsetospeed(&pts, symbolic_speed(speed));
236: cfsetispeed(&pts, symbolic_speed(speed));
237: }
238:
239: /* установить обработчик сигналов для восстановления
240: * старого обработчика termios */
241: sact.sa_handler = cleanup_termios;
242: sigaction(SIGHUP, &sact, NULL);
243: sigaction(SIGINT, &sact, NULL);
244: sigaction(SIGPIPE, &sact, NULL);
245: sigaction(SIGTERM, &sact, NULL);
246:
247: /* установить измененные настройки termios */
248: tcsetattr(pf, TCSANOW, &pts);
249: tcsetattr(STDIN_FILENO, TCSANOW, &sts);
250:
251: ufds[0].fd = STDIN_FILENO;
252: ufds[0].events = POLLIN;
253: ufds[1].fd = pf;
254: ufds[1].events = POLLIN;
255:
256: do {
257: int r;
258:
259: r = poll(ufds, 2, -1);
260: if ((r < 0) && (errno != EINTR))
261: die(1, "неожиданный сбой poll", "");
262:
263: /* сначала проверить возможность завершения */
264: if ((ufds[0].revents | ufds[1].revents) &
265: (POLLERR | POLLHUP | POLLNVAL)) {
266: done = 1;
267: break;
268: }
269:
270: if (ufds[1].revents & POLLIN) {
271: /* pf содержит символы */
272: i = read (pf, buf, BUFSIZE);
273: if (i >= 1) {
274: write(STDOUT_FILENO, buf, i);
275: } else {
276: done = 1;
277: }
278: }
279: if (ufds[0].revents & POLLIN) {
280: /* стандартный ввод содержит символы */
281: i = read(STDIN_FILENO, buf, BUFSIZE);
282: if (i >= 1) {
283: if (raw) {
284: write(pf, buf, i);
285: } else {
286: cook_buf(pf, buf, i);
287: }
288: } else {
289: done = 1;
290: }
291: }
292: } while (!done);
293:
294: /* восстановить первоначальные настройки терминала и завершиться*/
295: tcsetattr(pf, TCSANOW, &pots);
296: tcsetattr(STDIN_FILENO, TCSANOW, &sots);
297: exit(0);
298: }
Код
robin.с начинается с включения нескольких заголовочных файлов (почитайте man-страницы для каждого системного вызова и библиотечной функции, чтобы узнать, какие файлы включать), а затем в нем определяются несколько полезных функций.
Функция
symbolic_speed() в строке 19 преобразует целочисленную скорость в символическую, которую поддерживает
termios. К сожалению, termios не предназначен для работы с произвольными скоростями, так что каждая скорость, которую вы хотите использовать, должна быть частью интерфейса пользователь — ядро
[110].
Обратите внимание, что предусмотрены и довольно высокие скорости. Не все последовательные порты поддерживают скорости 230 400 или 460 800 бит/с; в стандарте POSIX определены скорости лишь до 38 400 бит/с. Чтобы сделать эту программу переносимой, каждую строку над строкой, в которой устанавливается скорость 38 400 бит/с, потребуется расширить до трех строк, как показано ниже:
#ifdef В460800
if (speednum >= 460800) return B46000;
#end if
Это позволит пользователям устанавливать скорости выше тех, которые последовательные порты способны поддерживать, а исходный код теперь будет компилироваться в любой системе с POSIX
termios. (Как упоминалось ранее в этой главе, любой последовательный порт может отказаться принять на обработку любую установку
termios, которую он не способен поддержать, включая также установки скорости. Поэтому установка
B460800 не означает, что можно установить скорость порта равной 460 800 бит/с.)
В строках 44—55 определяются глобальные переменные для передачи некоторых переменных обработчику сигналов и сам обработчик сигналов. Обработчик сигналов предназначен для восстановления настроек termios на обоих интерфейсах tty при доставке сигнала, поэтому ему необходимо получить доступ к структурам, содержащим старые настройки
termios. Ему также необходимо знать файловый дескриптор или последовательный порт (файловый дескриптор для стандартных входных данных не меняется, поэтому компилируется в бинарный). Этот код идентичен коду в случае нормального пути завершения, который рассматривается позже. Обработчик сигналов затем прикрепляется к сигналам, которые завершат процесс, если они были проигнорированы.
Функции
send_escape() и
cook_buf() будут рассматриваться позже. Они используются как часть обработки входных данных в цикле ввода-вывода в конце функции
main().
Условно скомпилированный
sleep(600) в начале функции
main() предназначен для отладки. С целью отладки программ, модифицирующих настройки
termios для стандартных входных или выходных данных, лучше всего присоединить процесс в другой окне или терминальном сеансе. Однако это означает, что нельзя установить точку прерывания на основную функцию и проходить по одной инструкции за раз. Необходимо запустить программу, найти идентификатор ее процесса и присоединиться к ней из отладчика. Более подробно этот процесс описан далее в настоящей главе.
Поэтому если необходимо отладить код, запускаемый до того, как программа дождется входных данных, нужно перевести программу в режим ожидания, чтобы оставить время для присоединения. После прикрепления режим ожидания прерывается, поэтому длительный режим ожидания безопасен. Чтобы активизировать это свойство, скомпилируйте
robin.с с опцией
-DDSLEEP.
Игнорируя отладку, мы в первую очередь анализируем опции, используя библиотеку
popt, описанную в главе 26, а затем открываем последовательный порт, с которым будем взаимодействовать.
Затем мы вызываем функцию
tcgetattr(), чтобы получить существующую конфигурацию
termios последовательного порта, а затем сохраняем копию в
pots, чтобы восстановить ее по окончании.
Начиная со строки 183, мы модифицируем установки последовательного порта:
183: pts.c_lflag &= ~ICANON;
Эта строка отключает приведение к каноническому виду в драйвере последовательного порта — то есть переводит его в неформатируемый режим. В этом режиме нет специальных символов — ни символов новой строки, ни управляющих символов:
184: pts.c_lflag &= ~(ECHO | ECHOCTL | ECHONL);
Это отключает локальный эхо-контроль в последовательном порте:
185: pts.c_cflag |= HUPCL;
Если подключен модем,
HUPCL сообщает ему об отбое при закрытии устройства конечной программой:
186: pts.с_сс[VMIN] = 1;
187: pts.с_сс[VTIME] = 0;
Когда tty находится в неформатируемом режиме, эти две установки определяют поведение системного вызова
read(). Эта особая установка сообщает, что при вызове
read() мы хотим, чтобы он подождал с возвратом, пока не считаются один или несколько байтов. Мы никогда не вызовем
read(), пока не будем знать, что остался хотя бы один байт для чтения, потому это функциональный эквивалент неблокирующего
read(). Определение
VMIN и
VTIME сложное, как показано далее в настоящей главе.
Настройки
termios по умолчанию включают преобразование некоторых символов в конце строки. Это подходит для модемных линий и терминальных сеансов, но при соединении двух tty повтор преобразования нежелателен. Нежелательно отображать символы новой строки на пару "возврат каретки/перевод строки" при выводе, а также принимаемый возврат каретки — на перевод строки при вводе, поскольку мы уже получаем пары "возврат каретки/перевод строки" с удаленной системы.
194: pts.c_oflag &= ~ONLCR;
195: pts.c_iflag &= ~ICRNL;
Без этих двух строк использование программы
robin для соединения с другим компьютером Linux или Unix приведет к тому, что удаленная система увидит, что вы нажимаете клавишу <Enter> дважды всякий раз, когда вы нажимаете ее один раз. И всякий раз, когда она будет пытаться отобразить новую строку на вашем экране, вы будете видеть две строки. Поэтому каждый раз при нажатии <Enter> (предполагая, что у вас получится зарегистрироваться в этих установках терминала) вы увидите отраженные подсказки. Если же вы запустите
vi, то увидите символы
~, расположенные через строку, а не в каждой строке.
Таким образом, мы внесли в настройки
termios все изменения, которые необходимо сделать перед обработкой аргументов командной строки. Теперь приступим к модификации настроек tty, предоставляющего стандартные входные и выходные данные. Поскольку это один tty, необходимо обработать лишь один файловый дескриптор из пары. Мы отдали предпочтение стандартному вводу, выбрав соглашение, установленное программой
stty. И снова все начинается с получения и сохранения атрибутов.
Затем потребуется модифицировать несколько флагов:
201: sts.c_iflag &= ~(BRKINT | ICRNL);
202: sts.c_iflag |= IGNBRK;
203: sts.c_lflag &= ~ISIG;
Отключение
BRKINT играет роль только в том случае, если robin вызывается из регистрационного сеанса, присоединенного к другому последовательному порту, на котором можно получить разрыв. Его отключение означает, что драйвер tty не посылает
SIGINT в
robin, когда в стандартном устройстве ввода
robin возникает разрыв, поскольку
robin не может сделать ничего полезного при получении разрыва. Отключение
ICRNL предотвращает сообщение в
robin о любых символах возврата каретки (
'\r') как о символах новой строки (
'\n'). Как и при отключении
BRKINT это действует лишь тогда, когда сеанс регистрации присоединяется к другому последовательному порту. Также это действует тогда, когда символы возврата каретки не игнорируются (то есть если не установлен флаг
IGNCR).
Функция
IGNBRK заставляет драйвер tty игнорировать разрывы. Включение
IGNBRK будет здесь излишним. При установке
IGNBRK игнорируется
BRKINT. Но не беда, если вы установите обе функции.
Это флаги обработки входных данных. Также модифицируется локальный флаг обработки: отключается
ISIG. Это предотвращает драйвер tty от передачи
SIGINT,
SIGQUIT и
SIGTSTP при получении соответствующего символа (
INTR,
QUIT или
SUSP). Мы делаем это потому, что хотим переслать эти символы на удаленную систему (или на другое устройство, подключенное к последовательному порту) для последующей обработки там.
Затем следует обработка опций. В некоторых случаях модификаций настроек
termios по умолчанию может оказаться недостаточно, или же, наоборот, слишком много. В таких случаях мы предлагаем некоторые опции командной строки для модификации опций
termios.
По умолчанию мы оставляем последовательный порт в том состоянии управления потоком, в котором мы его находим. Однако в строке 212 есть опции аппаратного управления потоком (использующего управляющие провода CTS и RTS), программного управления потоком (резервирование ^S и ^Q для STOP и START соответственно) и полного отключения управления потоком.
212: case 'h':
213: /* аппаратное управление потоком */
214: pts.c_cflag |= CRTSCTS;
215: pts.c_iflag &= ~(IXON | IXOFF | IXANY);
216: break;
217: case 's' :
218: /* программное управление потоком */
219: pts.c_cflag &= ~CRTSCTS;
220: pts.c_iflag |= IXON | IXOFF | IXANY;
221: break;
222: case 'n':
223: /* отключение управления потоком */
224: pts.q._cflag &= ~CRTSCTS;
225: pts.c_iflag &= ~(IXON | IXOFF | IXANY);
226: break;
Обратите внимание, что программное управление потоком включает три флага.
IXON |
Прекратить пересылать выходные данные при получении символа STOP (обычно ^S) и начать заново при получении символа START (обычно ^Q). |
IXOFF |
Передать символ STOP, когда во входящем буфере накопится слишком много данных. В случае прочтения достаточного количества данных отправите символ START. |
IXANY |
Позволить любому принятому символу, не только START, перезапустить вывод. (Этот флаг обычно реализован в системах Unix, но не определен в POSIX.) |
Когда другая программа использует
robin как вспомогательную, может помешать обработка спецсимволов (
robin обычно интерпретирует последовательность
^\), поэтому во избежание такой обработки устанавливается неформатируемый режим. В строке 120 мы предоставляем переменную, определяющую, включен ли неформатируемый режим; по умолчанию этот режим не включается. В строке 140 мы сообщаем popt о том, как информировать, когда в командной строке была указана опция
-r или
-raw, включающая неформатируемый режим.
Некоторые системы требуют передачи им символа возврата каретки для представления новой строки. Слово "системы" здесь следует понимать буквально; например, это применимо ко многим интеллектуальным периферийным устройствам, например, источникам бесперебойного питания (UPS) с последовательными портами, поскольку они предназначены для функционирования в DOS, где пара "возврат каретки/перевод строки" всегда используется для обозначения новой строки. В строке 228 определяется это DOS-ориентированное поведение.
228: if (crnl) {
229: /* послать CR с NL */
230: pts.c_oflag |= ONLCR;
231: }
Последняя часть обработки опций управляет скоростью передачи в битах в секунду
[111]. Вместо включения огромного вложенного оператора выбора мы вызываем уже описанную ранее функцию
symbolic_speed(), чтобы получить
speed_t, понимаемый
termios, как показано в строке 233.
233: /* скорость не изменяется, пока не будет указано -b */
234: if (speed) {
235: cfsetospeed(&pts, symbolic_speed(speed));
236: cfsetispeed(&pts, symbolic_speed(speed));
237: }
Перед тем, как зафиксировать изменения наших копий структур
termios, в строке 241 регистрируются обработчики для важных сигналов, которые могут в противном случае вызвать уничтожение процесса и оставить tty в неформатируемом состоянии. Более подробно обработчики сигналов рассматриваются в главе 12.
241: sact.sa_handler = cleanup_termios;
242: sigaction(SIGHUP, &sact, NULL);
243: sigaction(SIGINT, &sact, NULL);
244: sigaction(SIGPIPE, &sact, NULL);
245: sigaction(SIGTERM, &sact, NULL);
Как только обработчик сигналов окажется на месте для восстановления старых настроек
termios в случае уничтожения
robin, мы можем благополучно обновить установки
termios.
248: tcsetattr(pf, TCSANOW, &pts);
249: tcsetattr(STDIN_FILENO, TCSANOW, &sts);
На этом этапе программа
robin готова читать и записывать символы. У
robin есть два файловых дескриптора для чтения: данные с последовательного порта и данные с клавиатуры. Для мультиплексирования ввода-вывода между четырьмя файловыми дескрипторами используется
poll() (см. главу 13).
Цикл
poll() делает упрощенческое предположение о том, что он всегда может записать столько, сколько в состоянии прочитать. Это почти всегда верно и не вызывает проблем на практике, поскольку блокирование на короткие периоды незаметно при нормальных условиях. Цикл никогда не считывает из файлового дескриптора, пока
poll() не сообщит, что файловый дескриптор ожидает считывания данных, чтобы мы знали, что блокировки во время чтения нет.
Для данных, поступающих с клавиатуры, может понадобиться обработка управляющих последовательностей перед записью, если пользователь не выбрал неформатируемый режим при запуске
robin. Вместо включения этого кода в цикл мы вызываем функцию
cook_buf() (строка 78), которая при необходимости обращается к
send_escape() (строка 58). Обе эти функции просты. Единственный трюк состоит в том, что
cook_buf() может быть вызвана один раз с управляющим символом, а затем второй раз с интерпретируемым символом, а также в оптимизации количества вызовов функции
write().
Функция
cook_buf() вызывает функцию
send_escape() один раз для каждого символа, которому предшествует неотменяемый управляющий символ
^\. Символ
q восстанавливает исходные установки
termios и завершается вызовом обработчика сигнала (с фальшивым номером сигнала 0), что восстанавливает настройки
termios перед выходом. Символ
b генерирует состояние разрыва, которое является длинной строкой, состоящей из нулей. Любой другой символ, включая второй управляющий символ
^\, передается в последовательный порт без изменений.
Если какой-то из входных файловых дескрипторов вернет признак конца файла,
robin выходит из цикла
poll() и передает управление обработке завершения, что соответствует обработчику сигнала: восстановление старых настроек
termios на обоих входных файловых дескрипторов и завершение. В неформатируемом режиме существует только два способа завершения
robin: закрыть один из файловых дескрипторов или передать ей сигнал.
16.4. Отладка termios
Отладка кода tty далеко не всегда проста. Варианты пересекаются и влияют друг на друга разными способами, часто незапланированными. Но с помощью лишь отладчика невозможно увидеть то, что происходит, поскольку обработка, которой вы пытаетесь управлять, происходит в ядре.
Эффективным способом отладки кода, передающего информацию через последовательный порт, является использование программы-сценария. Во время разработки
robin мы соединили два компьютера последовательным кабелем и убедились, что соединение работает, запустив известную программу
kermit. В то время как программа
kermit уже работала на локальном компьютере, мы запустили программу-сценарий на удаленном компьютере, которая начала регистрировать все символы в файле. Затем мы вышли из
kermit и запустили сценарий на локальном компьютере, поместив полученный файл в текущий каталог на местном компьютере. Затем мы попытались запустить
robin по сценарию и сравнили два файла в начале и после каждого запуска, чтобы проследить разницу в символах. Таким образом мы разобрались с эффектами выбранных опций обработки.
Еще один метод отладки использует преимущества программы stty. Если во время проверки программы вы распознаете ошибку в настройках
termios, можете воспользоваться программой stty для немедленного внесения изменений вместо повторной компиляции своей программы. Если вы работаете на
/dev/ttyS0 и хотите установить флаг
ECHOCTL, просто во время работы своей программы запустите следующую команду:
stty echoctl < /dev/ttyS0
Подобным же образом можно отображать текущее состояние используемого в данный момент порта:
stty -а < /dev/ttyS0
Как объяснялось ранее, трудно использовать один tty для запуска отладчика и программы искажения tty, которая отлаживается. Вместо этого следует присоединиться к процессу. Это не сложно. В одном сеансе X-терминала (делайте это под управлением X Window, чтобы одновременно видеть оба tty) запустите программу, которую собираетесь отладить. В случае надобности поместите ее в долгий режим ожидания в точке, где вы собираетесь присоединиться к процессу:
$ ./robin -b 38400 /dev/ttyS1
Теперь с помощью другого сеанса X-терминала найдите идентификатор процесса программы, которую вы пытаетесь отладить, одним из двух способов:
$ ps | grep robin
30483 ? S 0:00 ./robin - b 38400 /dev/ttyS1
30485 ? S 0:00 grep robin
$ pidof robin
30483
Более удобным является
pidof, но он может быть недоступен в системе. Запомните найденный номер (в данном случае 30483) и начните обычный сеанс отладки.
$ gdb robin 30483
GDB is free software...
...
Attaching to program '... /robin', process 30483
Reading symbols from...
0x40075d88 in sigsuspend()
Далее можно устанавливать точки прерывания и слежения, пошагово выполнять программу и так далее.
16.5. Справочник по termios
Интерфейс
termios состоит из структуры, набора функций, оперирующих с нею, и множества флагов, которые можно лично устанавливать.
#include <termios.h>
struct termios {
tcflag_t c_iflag; /* флаги режима ввода */
tcflag_t c_oflag; /* флаги режима вывода */
tcflag_t c_cflag; /* флаги управляющего режима */ tcflag_t c_lflag; /* флаги локального режима */
cc_t c_line; /* дисциплина линии связи */
cc_t c_cc[NCCS]; /* управляющие символы */
};
Элемент
c_line используется лишь в системных специфических приложениях
[112], выходящих за рамки материала данной книги. Однако остальные пять элементов имеют отношение почти ко всем ситуациям, требующим манипулирования настройками терминала.
16.5.1. Функции
Интерфейс
termios определяет несколько функций. Все они объявлены в
<termios.h>. Четыре из них являются обслуживающими функциями для переносимого манипулирования структурой
struct termios; остальные представляют собой системные вызовы. Функции, начинающиеся с
cf, являются обслуживающими, а функции, начинающиеся с
tc — системными вызовами
управления терминалом. Все системные вызовы управления терминалом генерируют
SIGTTOU, если процесс в данный момент работает в фоне и пытается манипулировать своим управляющим терминалом (см. главу 15).
Кроме того, что уже было отмечено, эти функции возвращают
0 в случае успеха и
-1 при ошибке. Вызовы функций, которые можно использовать для управления терминалом, описаны ниже.
int tcgetattr(int fd, struct termios * t);
Восстанавливает текущие настройки файлового дескриптора
fd и помещает их в структуру, на которую указывает t.
int tcsetattr(int fd, int options, struct termios * t);
Устанавливает текущие настройки терминала для файлового дескриптора
fd в настройки, приведенные в
t. Всегда используйте
tcgetattr() для заполнения
t, затем модифицируйте его. Никогда не заполняйте
t вручную: некоторые системы требуют установки или снятия флагов, кроме флагов, определенных POSIX, поэтому заполнение вручную является непереносимым.
Аргумент
options определяет, когда изменения вступают в силу.
TCSANOW |
Изменение немедленно вступает в силу. |
TCSADRAIN |
Изменение вступает в силу после того, как передаются все входные данные, уже записанные в fd; перед вступлением в силу оно очищает очередь. Необходимо использовать это при смене выходных параметров. |
TCSAFLUSH |
Изменение вступает в силу после того, как выходная очередь была очищена; входная же очередь отбрасывается перед вступлением изменений в силу. |
Если система не может обработать некоторые настройки, например, скорость передачи данных, ей разрешается
игнорировать их без выдачи сообщения об ошибке. Единственный способ, с помощью которого можно узнать, были ли приняты настройки — вызвать
tcgetattr() и сравнить содержимое возвращаемой им структуры с содержимым структуры, переданной
tcsetattr().
Поэтому более переносимые приложения используют код вроде показанного ниже.
#include <termios.h>
struct termios save;
struct termios set;
struct termios new;
int fd;
...
tcgetattr(fd, &save);
set = save;
cfsetospeed(&set, B2400);
cfsetispeed(&set, B2400);
tcsetattr(fd, &set);
tcgetattr(fd, &new);
if ((cfgetospeed(&set) != B2400) ||
(cfgetispeed(&set) != B2400)) {
/* объяснение */
}
Обратите внимание, что если не имеет значения, "зависнет" ли настройка
termios, лучше проигнорировать это условие, как делается в
robin.
speed_t cfgetospeed(struct termios * t);
speed_t cfgetispeed(struct termios * t);
Извлекает скорость, соответственно, вывода или ввода из
t. Эти функции возвращают символическую скорость, такую же, которая дается
cfsetospeed() и
cfsetispeed().
int cfsetospeed(struct termios * t, speed_t speed);
int cfsetispeed(struct termios * t, speed_t speed);
Устанавливает, соответственно, вывода или ввода в
t на
speed. Обратите внимание, что эта функция не меняет скорость соединения на любом файловом дескрипторе; она просто устанавливает скорость в структуре
termios. Скорость, как и другие характеристики, применяется к файловому дескриптору с помощью
tcsetattr().
Эти функции принимают символическую скорость — то есть число, соответствующее определению одного из следующих макросов, имена которых определяют скорость в битах в секунду:
B0 (0 бит в секунду, определяет отключенное состояние)
B50,
B75,
B110,
B134[113],
B150,
B200,
B300,
B600,
B1200,
B1800,
B2400,
B4800,
B9600,
B19200,
B38400,
B57600,
B115200,
B230400,
B460800,
B500000,
B576000,
B921600,
B1000000,
B1152000,
B1500000,
B2000000,
B2500000,
B3000000,
B3500000 или
B4000000.
B57600 и выше в POSIX не описаны; переносимые исходные коды использует их только в том случае, если они защищены операторами
#ifdef.
По мере того, как будут разрабатываться драйверы Linux для оборудования, поддерживающего другие скорости передачи данных, в заголовочный файл будут добавляться новые символические скорости.
В настоящий момент скорость ввода игнорируется. Интерфейс termios устанавливает отдельные скорости ввода и вывода для асинхронного оборудования, допускающего раздельные скорости, но такое оборудование встречается довольно редко. Просто вызовите
cfsetospeed() и
cfsetispeed() попарно, чтобы ваш код продолжил работать в системах, поддерживающих раздельные скорости.
Не все tty поддерживают все скорости — последовательные порты на стандартных ПК не поддерживают более 115 200 бит/с. Как уже упоминалось выше, если для вас имеет значение, вступит ли в силу определенная настройка, необходимо использовать
tcgetattr() для проверки после того, как вы попытаетесь установить ее с помощью
tcsetattr(). Также обратите внимание, что установленная вами скорость является необязательной. Некоторые tty, например, локальные консоли, благополучно принимают и игнорируют любую установленную вами скорость.
int tcsendbreak(int fd, int duration)
Посылает поток нулей в
fd, чтобы узнать определенную длительность (
duration), которая также известна как
разрыв. Если
duration равняется 0, разрыв длится не менее 250 и не более 500 миллисекунд. К сожалению, POSIX не определяет элемент, длительность которого измеряется, поэтому единственной переносимой величиной для
duration является
0. В Linux длительность увеличивает разрыв;
0 или
1 задают длительность между четвертью секунды и полсекунды;
2 — между полсекунды и секундой и так далее.
int tcdrain(int fd)
Ожидает, пока не передадутся все входные данные, ожидающие в данный момент на файловом дескрипторе
fd.
int tcflush(int fd, int queue_selector)
Отбрасывает некоторые данные в файловом дескрипторе
fd в зависимости от величины
queue_selector.
TCIFLUSH |
Сбрасывает на диск все полученные, но еще не прочитанные интерфейсом данные. |
TCOFLUSH |
Сбрасывает на диск все данные, записанные в интерфейс, но еще не отправленные. |
TCIOFLUSH |
Сбрасывает на диск все ожидающие входные и выходные данные. |
int tcflow(int fd, int action)
Приостановить или возобновить вывод или ввод в файловом дескрипторе
fd. Более точные действия определяются
action.
TCOOFF |
Приостановить вывод. |
TCOON |
Восстановить вывод. |
TCIOFF |
Передать символ STOP, запрашивающий прекращение передачи символов вторым концом соединения. |
TCION |
Передать символ START, запрашивающий восстановление передачи символов вторым концом соединения. |
Обратите внимание, что
TCIOFF и
TCION необязательны, и даже если второй конец соединения принимает их на обработку, перед этим может возникнуть задержка.
16.5.2. Размеры окна
Существуют два запроса
ioctl(), которые, к сожалению, не были закодированы как часть интерфейса
termios, хотя и должны были. Размер tty, измеряемый строками и столбцами, должен управляться
tcgetwinsize() и
tcsetwinsize(), но, поскольку они не существуют, вместо этого следует использовать
ioctl(). Для запроса текущего размера и установки нового размера применяйте структуру
struct winsize.
#include <termios.h>
struct winsize {
unsigned short ws_row; /* количество строк */
unsigned short ws_col; /* количество столбцов */
unsigned short ws_xpixel; /* не используется */
unsigned short ws_ypixel; /* не используется */
};
Для запроса текущего размера используйте следующий вызов:
struct winsize ws;
ioctl(fd, TIOCGWINSZ, &ws);
Для установки нового размера заполните
struct winsize и предусмотрите такой вызов:
ioctl(fd, TIOCSWINSZ, &ws);
В конце этой главы представлен пример условий, при которых возникает потребность в установке нового размера окна.
При изменении размеров окна лидеру группы процессов переднего плана на данном tty передается сигнал
SIGWINCH. Ваш код может перехватить этот сигнал; используйте
TIOCGWINSZ для запроса нового размера и внесите в свою программу все необходимые изменения.
16.5.3. Флаги
Четыре флаговых переменных —
c_iflag,
с_oflag,
c_cflag и
c_lflag — хранят флаги, управляющие определенными характеристиками. Заголовочный файл
<termios.h> предоставляет символические константы битовых масок, которые, в свою очередь, предоставляют эти флаги. Устанавливайте их с помощью
|= и переустанавливайте с помощью
&= и как показано ниже.
t.c_iflag |= BRKINT;
t.c_iflag &= ~IGNBRK;
Некоторые из этих символических определений в действительности являются битовыми масками, охватывающими несколько взаимозависимых констант. Они используются с целью извлечения частей структуры для сравнения:
if ((t.c_cflag & CSIZE) == CS7) character_size = 7;
Набор флагов меняется от системы к системе. Наиболее важные флаги определены POSIX, но Linux, как и System V, включает несколько полезных флагов, не описанных в POSIX. Эта документация неполная; Linux поддерживает флаги, которые вряд ли понадобятся. Будут рассмотрены только те флаги, которые будут нужны наверняка.
Чтобы предоставить возможность создавать переносимое программное обеспечение, мы пометили каждый флаг, не определенный стандартом POSIX. Для таких флагов потребуется писать такой код:
#ifdef IUCLC
t.c_iflag |= IUCLC;
#endif
Также упоминаются области, представляющие особые проблемы переносимости, поэтому мы рассмотрим некоторые подробности функционирования других систем.
16.5.4. Флаги режима ввода
Флаги режима ввода влияют на обработку входных данных, хотя иногда они влияют и на выходные данные. Флаги, устанавливаемые в
с_iflag, описаны ниже.
BRKINT и IGNBRK |
При установке IGNBRK состояние разрыва игнорируется (см. описанную ранее tcsendbreak()). Если IGNBRK не установлен, а BRKINT установлен, состояние разрыва заставляет tty сбросить все очередизованные входные и выходные данные и послать сигнал SIGINT процессам в группе процессов переднего плана для tty. Если IGNBRK и BRKINT не установлены, состояние разрыва читается как нулевой символ ('\0'), кроме случая установки PARMRK, в котором обнаруживается ошибка кадрирования и вместо этого в приложение передаются три байта '\377' '\0' '\0'. |
PARMRK и IGNPAR |
При установке IGNPAR полученные байты, содержащие ошибки четности или кадрирования, игнорируются (кроме того, что было ранее определено для состояния разрыва). Если IGNPAR не установлен, а PARMRK установлен, полученный байт с ошибкой четности или кадрирования передается приложению как трехбайтовая последовательность '\377' '\0' '\n', где n — это байт в виде, в котором он был получен. В этом случае, если ISTRIP не установлен, допустимый символ '\377' передается приложению как последовательность двух символов '\377' '\377'; при установке ISTRIP старший разряд символа '\377' разделяется и передается как '\177'. Если не установлены ни PARMRK, ни IGNPAR, полученный байт с ошибкой четности или кадрирования (отличной от состояния разрыва) передается приложению как отдельный символ '\0'. |
INPCK |
При установке INPCK включается проверка четности. Если она не включается, PARMRK и IGNPAR не влияют на полученные ошибки четности. |
ISTRIP |
При установке ISTRIP старший разряд отсекается из всех полученных байтов, ограничивая их семью битами. |
INLCR |
При установке INLCR полученные символы новой строки ('\n') преобразуются в символы возврата каретки ('\r'). |
IGNCR |
При установке IGNCR полученные символы возврата каретки ('\r') игнорируются (не передаются приложению). |
ICRNL |
Если установлен ICRNL, а IGNCR не установлен, полученные символы возврата каретки ('\r') сообщаются приложению как символы новой строки ('\n'). |
IUCLC |
При установке IUCLC и IEXTEN полученные символы верхнего регистра передаются приложению как символы нижнего регистра. Этот флаг в POSIX не определен. |
IXOFF |
При установке IXOFF tty может передать символы Control-S и Control-Q терминалу, чтобы заставить его, соответственно, остановиться и восстановить вывод (то есть передачу данных на компьютер) с целью переполнения входных буферов tty. Это имеет отношение только к последовательным терминалам, поскольку сетевые и локальные терминалы имеют более прямые формы управления потоком. Даже последовательные терминалы часто поддерживают аппаратное управление потоком, контролируемое управляющим флагом (c_cflag) и делающее неуместным программное управление потоком (Control-S и Control-Q). |
IXON |
При установке IXON принятый символ Control-S прекращает передачу входных данных вэтот tty, а принятый символ Control-Q перезапускает передачу выходных данных в этот tty. Это соответствует любой форме терминального ввода-вывода, поскольку некоторые пользователи вводят буквенные символы Control-S и Control-Q для приостановки и восстановления вывода. |
IXANY |
При установке IXANY любой принятый символ (не просто Control-Q) перезапускает передачу выходных данных. Этот флаг в POSIX не определен. |
IMAXBEL |
При установке IMAXBEL предупреждающий символ ('\а') передается тогда, когда символ принимается, а входной буфер уже полон. Этот флаг в POSIX не определен. |
16.5.5. Флаги режима вывода
Флаги режима вывода модифицируют обработку выходных данных
только в случае установки OPOST. Ни один из этих флагов не переносим, поскольку POSIX определяет только
OPOST и называет его "реализация определена". Однако вы обнаружите, что настоящие приложения обработки терминалов часто нуждаются в обработке выходных данных, а флаги режима вывода, доступные в Linux, доступны также в большинстве систем Unix, включая SVR4.
Код терминала отслеживает
текущий столбец, что позволяет подавить лишние символы возврата каретки (
'\r') и преобразовать, где возможно, табуляцию в пробелы. Столбцы отсчитываются, начиная с нуля. Текущий столбец устанавливается в ноль всякий раз, когда передается или предполагается символ возврата каретки (
'\r'), как может быть вызвано символом новой строки (
'\n') при установке
ONLRET или
ONLCR, или когда текущий столбец установлен в единицу и передается символ забоя (
'\b').
Флаги, работающие на
с_oflag, перечислены ниже.
OPOST |
Это единственный флаг режима вывода, определенный в POSIX, который сообщает, что он включает обработку выходных данных, "определяемую реализацией". Если OPOST не установлен, к другим флагам режима вывода не обращаются и обработка выходных данных не выполняется. |
OLCUC |
При установке OLCUC символы нижнего регистра передаются терминалу как символы верхнего регистра. Этот флаг в POSIX не определен. |
ONLCR |
При установке ONLCR перед передачей символа новой строки ('\n') передается символ возврата каретки ('\r'). Текущий столбец устанавливается в ноль. Этот флаг в POSIX не определен. |
ONOCR |
При установке ONOCR символы возврата каретки ('\r') ни обрабатываются, ни передаются, если текущий столбец равен нулю. Этот флаг в POSIX не определен. |
OCRNL |
При установке OCRNL символы возврата каретки ('\r') преобразуются в символы новой строки ('\n'). При установке ONLRET текущий столбец устанавливается в ноль. Этот флаг в POSIX не определен. |
ONLRET |
При установке ONLRET во время передачи символа новой строки ('\n') или возврата каретки ('\r') текущий столбец устанавливается в ноль. Этот флаг в POSIX не определен. |
OXTABS |
При установке OXTABS символы табуляции преобразуются в пробелы. Позиции табуляции установлены после каждого восьмого символа, а количество передаваемых пробелов определяется текущим столбцом. Этот флаг в POSIX не определен. |
Кроме того, существуют флаги задержки, которые устанавливать не нужно; они предназначены для компенсации старого, плохо спроектированного и на данный момент, к счастью, редко встречающегося оборудования. За управление флагами задержки ответственны библиотеки
termcap и
terminfo. Это означает, что в их модификации нет необходимости. В [37] они упомянуты как устаревшие. Ядро Linux не реализует их в данный момент, и, поскольку это свойство не пользуется спросом, они вряд ли будут реализованы в будущем.
16.5.6. Управляющие флаги
Флаги режима управления влияют на такие параметры протокола, как четность и управление потоком
[114]. Флаги, устанавливаемые в
с_cflag, описаны ниже.
CLOCAL |
При установке CLOCAL линии управления модемом игнорируются. Если он не установлен, open() блокируется до тех пор, пока модем не объявит состояние ответа абонента, утвердив линию обнаружения несущей. |
CREAD |
Символы могут приниматься только в случае установки CREAD. Его сбрасывать не обязательно. (Примечание. Попробуйте запустить stty -cread.) |
CSIZE |
CSIZE — это маска для кодов, устанавливающих размер передаваемого символа в битах. Размер символа следует установить в перечисленные ниже значения. CS5 для пяти бит на символ; CS6 для шести бит на символ; CS7 для семи бит на символ; CS8 для восьми бит на символ. |
CSTOPB |
При установке CSTOPB на конце каждого кадра символа генерируется по два стоповых бита. Если CSTOPB не установлен, генерируется лишь по одному стоповому биту. Устаревшее оборудование, требующее двух стоповых битов, встречается редко. |
HUPCL |
Если установлен, то при закрытии последнего открытого файлового дескриптора на устройстве уровень на линиях последовательного порта DTR и RTS (если они существуют) будет снижен, чтобы заставить модем разорвать соединение. То есть, например, если пользователь, вошедший в систему через модем, затем выходит из нее, модем разрывает соединение. Если программа передачи данных открывает устройство для исходящих вызовов, а процесс затем закрывает устройство (или завершается), модем разорвет соединение. |
PARENB и PARODD |
При установке PARENB генерируется бит четности. Если PARODD не установлен, генерируется проверка на четность. Если PARODD установлен, генерируется проверка нечетность. Если PARENB не установлен, PARODD игнорируется. |
CRTSCTS |
Использовать аппаратное управление потоком (линии RTS и CTS). При высоких скоростях (19 200 бит/с и более) программное управление потоком с помощью символов XON и XOFF становится неэффективным. Вместо этого следует использовать аппаратное управление потоком. Этот флаг не определен в POSIX и не доступен под этим именем в большинстве других систем Unix. Это особенно непереносимая область управления терминалом, несмотря на распространенную потребность в аппаратном управлении потоком в современных системах. Система SVR4 особенно характерна тем, что она не предоставляет возможности установки управления потоком с помощью termios, а только через другой интерфейс под названием termiox. |
16.5.7. Управляющие символы
Управляющие символы — это символы со специальными значениями, которые могут отличаться в зависимости от того, находится ли терминал в каноническом или неформатируемом режиме ввода, и в зависимости от установок различных управляющих флагов. Каждое смещение (кроме
VMIN и
VTIME) в массиве
с_сс обозначает действие и содержит код символа, предназначенный для этого действия. Например, установите символ прерывания на Control-C с помощью следующего кода:
ts.с_сс[VINTR] = CTRLCHAR('С');
Макрос
CTRLCHAR() определен как
#define CTRLCHAR(ch) ((ch)&0x1F)
Некоторые системы имеют макрос
CTRL(), определенный в
<termios.h>, но не поддерживаемый во всех системах, поэтому определение нашей собственной версии будет более надежным. Мы используем запись ^C для обозначения Control-C.
Расположения символов, не определенные POSIX, активны только в случае установки локального управляющего флага
IEXTEN(c_lflag).
Управляющие символы, которые вы видите как индексы массива
с_сс, перечислены ниже.
VINTR |
Смещение VINTR обычно устанавливается в ^C. Оно обычно сбрасывает на диск очереди ввода-вывода и передает SIGINT элементам группы процесса переднего плана, ассоциированным с tty. Процессы, неявно обрабатывающие SIGINT, немедленно завершаются. |
VQUIT |
Смещение VQUIT обычно устанавливается в ^\. Оно обычно сбрасывает на диск очереди ввода-вывода и передает SIGQUIT элементам группы процесса переднего плана, ассоциированным с tty. Процессы, неявно обрабатывающие SIGQUIT, завершаются, при возможности сброса дампа ядра (см. главу 10). |
VERASE |
Смещение VERASE обычно устанавливается в ^H или ^?. В каноническом режиме оно обычно стирает предыдущий символ в строке. В неформатируемом режиме это несущественно. |
VKILL |
Смещение VKILL обычно установлено в ^U. В каноническом режиме оно обычно стирает всю строку. В неформатируемом режиме это несущественно. |
VEOF |
Смещение VEOF обычно установлено в ^D. В каноническом режиме оно заставляет read() на файловом дескрипторе возвращать 0, сигнализируя о состоянии конца файла. На некоторых системах оно может делить пространство с символом VMIN, активным лишь в неформатируемом режиме. (Это не проблема, если вы сохраните struct termios с каноническими установками режима для восстановления действий в неформатируемом режиме, что все равно присуще практике программирования с применением termios.) |
VSTOP |
Смещение VSTOP обычно установлено в ^S. Оно заставляет tty приостановить передачу выходных данных до получения символа VSTART, или, в случае установки IXANY, до получения любого символа. |
VSTART |
Смещение VSTART обычно установлено в ^Q. Оно запускает приостановленный вывод tty. |
VSUSP |
Смещение VSUSP обычно установлено в ^Z. Оно вызывает передачу SIGTSTP текущей группе процессов переднего плана; более подробно об этом рассказывается в главе 15. |
VEOL и VEOL2 |
В каноническом режиме эти символы, а также символ новой строки ('\n'), сигнализируют о состоянии конца строки. Это вызывает передачу скомпонованного буфера и запуск нового буфера. На некоторых системах VEOL может делить пространство с символом VTIME, активным лишь в неформатируемом режиме, так же, как VEOF может делить пространство с VMIN. Символ VEOL2 в POSIX не определен. |
VREPRINT |
Смещение VREPRINT обычно установлено в ^R. В каноническом режиме в случае установки флага ECHO оно вызывает локальное отражение символа VREPRINT, новой строки (и возврата каретки, если это допустимо), а также перепечатку всего текущего буфера. Этот символ в POSIX не определен. |
VWERASE |
Смещение WERASE обычно установлено в ^W. В каноническом режиме оно стирает все пробелы в конце буфера, затем все остальные символы, что дает эффект стирания предыдущего слова в строке. Этот символ в POSIX не определен. |
VLNEXT |
Смещение VLNEXT обычно установлено в ^V. Само оно не вводится в буфер, но вызывает литеральное помещение в буфер следующего символа, даже если это один из управляющих символов. Для того чтобы ввести один литеральный символ VLNEXT, введите его дважды. Этот символ в POSIX не определен. |
Для отключения любой позиции управляющего символа установите его значение в
_POSIX_VDISABLE. Это работает только в случае определения
_POSIX_VDISABLE как значения, не равного -1.
_POSIX_VDISABLE работает в Linux, но переносимая программа, к сожалению, не сможет зависеть от отключения расположений управляющих символов во всех системах.
16.5.8. Локальные флаги
Флаги локального режима влияют на локальную обработку, что в какой-то мере относится к способу сбора символов перед их выводом. Когда устройство находится в каноническом режиме (режиме с обработкой), символы отражаются локально без передачи в удаленную систему до тех пор, пока не встретится символ новой строки. На этом этапе передается вся строка, а удаленный конец обрабатывает ее без повторного отражения. В неформатируемом режиме каждый символ передается в удаленную систему в таком виде, в каком он принимается. Иногда символ отображается только удаленной системой, иногда только локальной, а иногда, например, при чтении пароля, он и вовсе не отображается.
Некоторые флаги могут вести себя иначе, в зависимости от того, в каком режиме находится терминал: каноническом или неформатируемом. Флаги, ведущие себя иначе в каноническом и неформатируемом режимах, отмечены.
Флаги, работающие на
c_cflag, перечислены ниже.
ICANON |
При установке ICANON включается канонический режим. Если ICANON не установлен, включается неформатируемый режим. |
ECHO |
При установке ECHO включается локальное эхо. Если ECHO не установлен, все остальные флаги, названия которых начинаются с ECHO, эффективно отключаются и функционируют так, как будто они все, кроме ECHONL, не установлены. |
ECHOCTL |
При установке ECHOCTL управляющие символы выводятся как ^C, где С — это символ, формирующийся добавлением восьмеричного 0100 к управляющему символу, по модулю восьмеричного 0200. Поэтому Control-C отображается как ^C, a Control-? (восьмеричный 0177) отображается как ^? (? — это восьмеричный 77). Этот флаг в POSIX не определен. |
ECHOE |
В каноническом режиме при установке ECHOE в случае получения символа ERASE предыдущий символ на дисплее по возможности стирается. |
ECHOK и ECHOKE |
В каноническом режиме при получении символа KILL вся текущая строка стирается из буфера. Если не установлены ни ECHOK, ни ECHOKE, ни ECHOE, выводится представление символа KILL с помощью ECHOCTL (^U по умолчанию) для обозначения стертой строки. Если установлены ECHOE и ECHOK, но ECHOKE не установлен, выводится представление символа KILL с помощью ECHOCTL, сопровождаемое новой строкой, которая затем обрабатывается OPOST в случае установки OPOST. Если установлены ECHOE, ECHOK и ECHOKE, строка стирается. См. описание ECHOPRT для другой вариации на эту тему. Флаг ECHOKE в POSIX не определен. В системах без флага ECHOKE установка флага ECHOK может быть эквивалентна установке и ECHOK, и ECHOKE в Linux. |
ECHONL |
В каноническом режиме при установке ECHONL символы новой строки ('\n') отражаются даже в том случае, если ECHO не установлен. |
ECHOPRT |
В каноническом режиме при установке ECHOPRT символы выводятся при стирании, когда принимаются символы ERASE или WERASE (или KILL, если установлены ECHOK и ECHOKE). Когда принимается первый в последовательности символ стирания, выводится \, а при выводе последнего символа стирания (достигается конец строки или вводится нестертый символ), выводится /. Каждый вводимый вами нормальный символ просто отображается. Поэтому ввод asdf, сопровождаемый двумя символами ERASE, а также df и символом KILL, будет выглядеть следующим образом: asdf\fd/df\fdsa/. Этот флаг полезен для отладки и использования документирующих терминалов вроде первоначального телетайпа, где символы печатаются на бумаге; в другом случае он не пригодится. Этот флаг в POSIX не определен. |
ISIG |
Если установлен ISIG, управляющие символы INTR, QUIT и SUSP вызывают отправку соответствующего сигнала (SIGINT, SIGQUIT или SIGTSTP соответственно; см. главу 12) всем процессам в текущей группе процессов переднего плана на данном tty. |
NOFLSH |
Обычно при получении символов INTR и QUIT очереди ввода и вывода сбрасываются. При установке NOFLSH очереди не сбрасываются. |
TOSTOP |
Если установлен TOSTOP, то в том случае, когда процесс, не находящийся в текущей группе процессов переднего плана, пытается выполнить запись в свой управляющий терминал, передается SIGTTOU всей группе процессов, членом которой является данный процесс. По умолчанию этот сигнал останавливает процесс, как при нажатии комбинации клавиш, соответствующей символу SUSP. |
IEXTEN |
Этот флаг описан в POSIX как определяемый реализацией. Он включает обработку символов ввода, определяемую реализацией. Хотя переносимые программы не устанавливают этот бит, IUCLC и определенные возможности стирания символов в Linux зависимы от его установки. К счастью, он чаще всего разрешен по умолчанию в системах Linux, поскольку ядро изначально разрешает его при установке tty, поэтому обычно не нужно устанавливать его по какой-либо причине. |
16.5.9. Управление read()
Два элемента в массиве
с_сс не являются управляющими символами и имеют отношение только к неформатируемому режиму:
VTIME и
VMIN. В этом режиме они определяют, когда возвращается
read(). В каноническом режиме
read() возвращается только в том случае, если строки были собраны или был достигнут конец файла, за исключением случая установки опции
O_NONBLOCK.
В неформатируемом режиме считывание по одному байту за раз неэффективно. Также неэффективно опрашивать порт чтением в неблокируемом режиме. Существуют два намного более эффективных дополнительных метода чтения.
Первый заключается в использовании
poll(), как описано в главе 13 и демонстрируется в коде
robin.с. Если
poll() сообщает, что файловый дескриптор готов к чтению, то известно, что вы можете немедленно прочитать некоторое количество байтов. Однако сочетание
poll() со вторым методом сделает ваш код более эффективным, предоставляя возможность считывать больше байтов за один раз.
"Управляющие символы"
VTIME и
VMIN состоят в сложных взаимоотношениях.
VTIME определяет промежуток времени для ожидания в десятых долях секунды (он не может быть больше
cc_t, обычно это 8-битный
unsigned char), который также может равняться нулю.
VMIN определяет минимальное количество байт для ожидания (не для считывания — третий аргумент
read() определяет максимальное количество байтов для считывания), которое тоже может равняться нулю.
• Если
VTIME равен нулю,
VMIN определяет количество байт для ожидания. Вызов
read() не возвращается, пока не будут считано
VMIN байт или пока не будет получен сигнал.
• Если
VMIN равен нулю,
VTIME определяет количество десятых частей секунд для ожидания
read() перед возвращением, даже если данные недоступны. В таком случае
read(), возвращающий нуль, необязательно сигнализирует о состоянии конца файла, как он обычно делает.
• Если ни
VTIME, ни
VMIN не равняются нулю,
VTIME определяет количество десятых долей секунды для ожидания
read() после того, как будет доступен хотя бы один байт. Если данные доступны при вызове
read(), таймер немедленно запускается. Если данные недоступны при вызове
read(), таймер запускается при принятии первого байта. Вызов
read() возвращается или тогда, когда были приняты хотя бы байты
VMIN, или по истечении таймера, независимо от того, что произойдет раньше. Он всегда возвращает хотя бы один байт, поскольку таймер не запускается, пока не будет доступен хотя бы один байт.
• Если и
VTIME, и
VMIN равны нулю,
read() всегда немедленно возвращается, даже если данные недоступны. И снова ноль необязательно указывает на состояние конца файла.
16.6. Псевдотерминалы
Псевдотерминалы, или pty — это механизм, позволяющий программе на уровне пользователя заменять место (логически говоря) драйвера tty для элемента оборудования. pty имеет два отдельных конца: конец, эмулирующий оборудование, называется в
едущим устройством pty, а конец, обеспечивающий программы обычным интерфейсом tty, называется
подчиненным компонентом pty. Подчиненный компонент выглядит как обычный tty; ведущее устройство выглядит как стандартное устройство символьного ввода-вывода и не является tty.
Драйвер последовательного порта обычно реализуется как часть кода ядра, управляемая прерываниями. Однако так бывает не всегда. Например, существует хотя бы один терминальный сервер, основанный на SCSI, который использует обобщенный интерфейс SCSI для организации программы на уровне пользователя, сообщающейся с терминальным сервером и предоставляющей доступ к последовательным портам через pty.
Сеансы работы с сетевыми терминалами происходят подобным образом; программы
rlogind и
telnetd подключают сетевой сокет к ведущему устройству pty и запускают оболочку в подчиненном компоненте pty, чтобы заставить сетевые подключения действовать как tty, позволяя запускать интерактивные программы в сетевом подключении, не имеющем ничего общего с tty. Экранная программа мультиплексирует несколько соединений pty на один tty, который может или не может быть pty, соединенным с пользователем. Ожидаемая программа позволяет программам, настаивающим на запуске в интерактивном режиме в tty, быть запущенными в подчиненном компоненте pty под управлением другой программы, соединенной с ведущим устройством pty.
16.6.1. Открытие псевдотерминалов
Существует широкое разнообразие способов открытия псевдотерминалов. Обычно это делается (по крайней мере, в Linux) способом, более или менее соответствующим стандартам, основанным на SysV, а также устаревшим способом, основанным на практике BSD. Наиболее распространенным методом среди системных программистов в Linux является набор расширений BSD, реализованных также как часть glibc. Менее распространенный метод документируется как часть стандарта 1998 года — Unix98, и документируется иначе в версии 2000 года стандарт Unix98.
Исторически существует два различных метода открытия псевдотерминалов в Unix и подобных системах. Linux изначально придерживался модели BSD, хотя она более сложная в использовании, поскольку модель SysV явно написана в рамках STREAMS, а в Linux STREAMS не реализована. Однако модель BSD требует, чтобы каждое приложение искало неиспользуемое ведущее устройство pty, зная о многих специфических именах устройств. Между 64 и 256 устройства pty обычно доступны, а с целью поиска первого открытого устройства программы проводят поиск в устройствах, начиная с наименьшего числа. Они выполняют поиск в специфической манере, которая демонстрируется в программе
ptypair, включенной в данный раздел.
С моделью BSD связано несколько проблем.
• Каждое приложение должно знать весь набор доступных имен. При расширении набора возможных псевдотерминалов каждое приложение, использующее псевдотерминал, должно быть модифицировано с явным знанием всех возможных имен устройств, что вызывает неудобства и подвержено ошибкам.
• Время, уходящее на поиск, становится ощутимым при поиске среди тысяч узлов устройств в каталоге
/dev. Системное время тратится, и доступ к системе замедляется, что очень плохо масштабируется в больших системах.
• Обработка полномочий может оказаться проблематичной. Например, если программа выполняет аварийное завершение, она может оставить файлы устройств псевдотерминалов с несоответствующими полномочиями.
Поскольку модель SysV явно написана в рамках STREAMS и требует использования вызовов ioctl() для запуска подчиненных компонентов, она не является вариантом выбора Linux. Однако интерфейс Unix98 не определяет
функции, присущие STREAMS, поэтому в 1998 году в Linux была добавлена поддержка псевдотерминалов стиля Unix98.
Ядро Linux может быть скомпилировано без поддержки интерфейса Unix98, и можно встретить более старые системы без псевдотерминалов стиля Unix98, поэтому мы представим код, который пытается открыть псевдотерминалы стиля Unix98, но также может вернуться к интерфейсу BSD. (Мы не документируем части модели SysV, присущие STREAMS; в [35] подробно описан интерфейс STREAMS. Вам вряд ли понадобится код, специфичный для STREAMS; спецификация Unix98 не требует его.)
16.6.2. Простые способы открытия псевдотерминалов
В библиотеке
libutil glibc предлагает две функции —
openpty() и
forkpty(), — выполняющие почти всю работу по поддержке псевдотерминалов.
#include <pty.h>
int openpty(int * masterfd, int * slavefd, char * name,
struct termios * term, struct winsize * winp);
int forkpty(int * masterfd, char * name,
struct termios * term, struct winsize * winp);
Функция
openpty() открывает ведущие и подчиненные псевдотерминалы, необязательно используя структуры
struct termios и
struct winsize, передаваемые как опции настройки псевдотерминала, возвращая
0 в случае успеха и
-1 в случае ошибки. Файловые дескрипторы ведущего устройства и подчиненного компонента возвращаются аргументам
masterfd и
slavefd соответственно. Аргументы
term и
winp могут быть
NULL, в случае чего они игнорируются, и настройка не выполняется.
Функция
forkpty() работает так же, как и
openpty(), но вместо возврата файлового дескриптора подчиненного компонента она разветвляет псевдотерминал как управляющий терминал stdin, stdout и stderr для дочернего процесса, а затем, подобно
fork(), возвращает идентификатор дочернего процесса родительскому и 0 дочернему либо -1 при возникновении ошибки.
Даже с этими удобными интерфейсами связана значительная проблема: аргумент name был изначально предназначен для возврата имени устройства псевдотерминала вызывающему коду, но его использование небезопасно, поскольку
openpty() и
forkpty() не знают размера буфера. Всегда передавайте
NULL в аргументе
name. Используйте функцию
ttyname(), описанную в начале этой главы, чтобы получить путевое имя файла устройства псевдотерминала.
Предпочтительный способ работы с
struct termios заключается в использовании цикла чтение-модификация-запись, но данному случаю это не соответствует по двум причинам. Можно передать
NULL и принять значения по умолчанию, что достаточно в большинстве случаев; а когда вы хотите предоставить настройки
termios, вы часто заимствуете настройки у другого tty, или знаете точно, какими они должны быть (например, в случае концентратора последовательного порта SCSI, описанного ранее в этой главе).
tcgetattr(STDIN_FILENO, &term);
ioctl(STDIN_FILENO, TIOCGWINSZ, &ws);
pid = forkpty(&masterfd, NULL, &term, &ws);
16.6.3. Сложные способы открытия псевдотерминалов
Интерфейс Unix98 для распределения пары псевдотерминала представляет собой следующий набор функций.
#define _XOPEN_SOURCE 600
#include <stdlib.h>
#include <fcntl.h>
int posix_openpt(int oflag);
int grantpt(int fildes);
int unlockpt(int fildes);
char * ptsname(int fildes);
Функция
posix_openpt() — это то же, что и открытие устройства
/dev/ptmx, но теоретически она более переносима (поскольку везде принимается). Рекомендуется в этот раз использовать
open("/dev/ptmx", oflag) для максимальной практической переносимости. Если вы хотите установить один или два флага
open() или
posix_openpt(), используйте
O_RDWR, как обычно; если вы вместо этого не открываете управляющий tty для процесса, используйте
O_RDWR | O_NOCTTY.
open() или
posix_openpt() вернет открытый файловый дескриптор управляющему устройству псевдотерминала. Затем вызовите
grantpt() с файловым дескриптором управляющего устройства псевдотерминала, возвращенным из
posix_openpt(), для изменения режима и владельца подчиненного компонента псевдотерминала, а потом —
unlockpt(), чтобы сделать подчиненный компонент псевдотерминала доступным для открытия. Интерфейс Unix98 для открытия подчиненного устройства псевдотерминала должен просто открыть имя, возвращенное
ptsname(). Все эти функции возвращают
-1 в случае ошибки, кроме
ptsname(), возвращающей в такой ситуации
NULL.
Функции в
ptypair.c распределяют согласованную пару устройств pty. Пример функции
get_master_pty() в строке 22
ptypair.с открывает управляющее устройство pty и возвращает файловый дескриптор родительскому процессу, а также предоставляет имя соответствующему подчиненному компоненту pty. Он сначала испытывает интерфейс Unix98 на распределение управляющего устройства pty, а если это не работает (например, если ядро скомпилировано без поддержки pty Unix98, возможно, для встроенных систем), возвращается к старому интерфейсу стиля BSD. Соответствующая функция
get_slave_pty() в строке 87 может быть использована после
fork() для открытия соответствующего подчиненного компонента pty.
1: /* ptypair.c */
2:
3: #define _XOPEN_SOURCE 600
4: #include <errno.h>
5: #include <fcntl.h>
6: #include <grp.h>
7: #include <stdlib.h>
8: #include <string.h>
9: #include <sys/types.h>
10: #include <sys/stat.h>
11: #include <unistd.h>
12:
13:
14: /* get_master_pty() принимает дважды косвенный символьный указатель на
15: * место помещения имени подчиненного компонента pty и возвращает целочисленный
16: * файловый дескриптор. Если возвращается значение < 0, значит, возникла ошибка.
17: * В противном случае возвращается файловый дескриптор ведущего устройства pty
18: * и заполняет *name именем соответствующего подчиненного компонента pty. После
19: * открытия подчиненного компонента pty, вы отвечаете за освобождение *name.
20: */
21:
22: int get_master_pty(char **name) {
23: int i, j;
24: /* значение по умолчанию, соответствующее ошибке */
25: int master = -1;
26: char *slavename;
27:
28: master = open("/dev/ptmx", O_RDWR);
29: /* Это эквивалентно, хотя и более широко реализовано,
30: * но теоретически менее переносимо, следующему:
31: * master = posix_openpt(O_RDWR);
32: */
33:
34: if (master >= 0 && grantpt(master) >= 0 &&
35: unlockpt(master) >= 0) {
36: slavename = ptsname(master);
37: if (!slavename) {
38: close(master);
39: master = -1;
40: /* сквозной проход для нейтрализации ошибки */
41: } else {
42: *name = strdup(slavename);
43: return master;
44: }
45: }
46:
47: /* Остаток этой функции — нейтрализация ошибки для старых систем */
48:
49: /* создать фиктивное имя для заполнения */
50: *name = strdup("/dev/ptyXX");
51:
52: /* искать неиспользуемый pty */
53: for (i=0; i<16 && master <= 0; i++) {
54: for (j = 0; j<16 && master <= 0; j++) {
55: (*name)[8] = "pqrstuvwxyzPQRST"[i];
56: (*name)[9] = "0123456789abcdef"[j];
57: /* открыть ведущее устройство pty */
58: if ((master = open(*name, O_RDWR)) < 0) {
59: if (errno == ENOENT) {
60: /* устройства pty исчерпаны */
61: free(*name);
62: return(master);
63: }
64: }
65: }
66: }
67:
68: if ((master < 0) && (i == 16) && (j == 16)) {
69: /* необходимо для каждого неудачного pty */
70: free(*name);
71: return(master);
72: }
73:
74: /* Подставляя букву, изменить имя ведущего устройства pty
75: * в имени подчиненного компонента pty.
76: */
77: (*name)[5] = 't';
78:
79: return(master);
80: }
81:
82: /* get_slave_pty() возвращает целочисленный файловый дескриптор.
83: * Если возвращается значение < 0, значит, возникла ошибка.
84: * В противном случае возвращается файловый дескриптор подчиненного
85: * компонента. */
86:
87: int get_slave_pty(char * name) {
88: struct group *gptr;
89: gid_t gid;
90: int slave = -1;
91:
92: if (strcmp(name, "/dev/pts/")) {
93: /* Интерфейс Unix98 не использовался, необходима
94: * специальная обработка полномочий или прав владения.
95: *
96: * Выполнить chown/chmod для соответствующего pty, если возможно.
97: * Это будет работать, только если имеет полномочия root.
98: * В качестве альтернативы можно написать и запустить небольшую
99: * setuid-программу, которая сделает все это.
100: *
101: * В противном случае все проигнорировать и пользоваться
102: * только интерфейсом Unix98.
103: */
104: if ((gptr = getgrnam("tty")) != 0) {
105: gid = gptr->gr_gid;
106: } else {
107: /* если группа tty не существует, не изменять группу
108: * на подчиненном компоненте pty, а только владельца
109: */
110: gid = -1;
111: }
112:
113: /* Обратите внимание, что здесь не осуществляется проверка на ошибки.
114: * Однако если выполняемые действия являются критически важными,
115: * проверка ошибок должна быть. */
116: chown(name, getuid(), gid);
117:
118: /* Этот код делает подчиненный компонент доступным для чтения/записи
119: * только конкретному пользователю. Если код предназначен для
120: * интерактивной оболочки, которая должна получать сообщения
121: * "write" и "wall", добавьте ниже "ИЛИ" с S_IWGRP во второй аргумент.
122: * В таком случае потребуется перенести эту строку за пределы
123: * оператора if(), чтобы код мог выполняться для интерфейсов как
124: * BSD-стиля, так и Unix98-стиля.
125: */
126: chmod(name, S_IRUSR|S_IWUSR);
127: }
128:
129: /* открыть соответствующий подчиненный компонент pty */
130: slave = open(name, O_RDWR);
131:
132: return(slave);
133: }
Функция
get_slave_pty() не делает ничего нового. Все функции описываются в других местах этой книги, поэтому здесь они не объясняются.
16.6.4. Примеры псевдотерминалов
Возможно, одной из самых простых программ, которая может быть написана для использования pty, является программа, открывающая пару pty и запускающая оболочку на подчиненном компоненте pty, соединяя его с управляющим устройством pty. Написав эту программу, вы можете расширять ее любым подходящим способом,
forkptytest.с является примером использования функции
forkpty(), a
ptytest.с — это пример, который использует функции, определенные в
ptypair.с, и является несколько более сложным.
1: /* forkptytest.с */
2:
3: #include <errno.h>
4: #include <signal.h>
5: #include <stdio.h>
6: #include <stdlib.h>
7: #include <sys/ioctl.h>
8: #include <sys/poll.h>
9: #include <termios.h>
10: #include <unistd.h>
11: #include <pty.h>
12:
13:
14: volatile int propagate_sigwinch = 0;
15:
16: /* sigwinch_handler
17: * распространяет изменения размеров окна из входного файлового
18: * дескриптора на ведущую сторону pty.
19: */
20: void sigwinch_handler(int signal) {
21: propagate_sigwinch = 1;
22: }
23:
24:
25: /* forkptytest пытается открыть пару pty с запуском оболочки
26: * на подчиненной стороне pty.
27: */
28: int main(void) {
29: int master;
30: int pid;
31: struct pollfd ufds[2];
32: int i;
33: #define BUFSIZE 1024
34: char buf[1024];
35: struct termios ot, t;
36: struct winsize ws;
37: int done = 0;
38: struct sigaction act;
39:
40: if (ioctl(STDIN_FILENO, TIOCGWINSZ, &ws) < 0) {
41: perror("ptypair: не удается получить размеры окна");
42: exit(1);
43: }
44:
45: if ((pid = forkpty(&master, NULL, NULL, &ws)) < 0) {
46: perror("ptypair");
47: exit(1);
48: }
49:
50: if (pid == 0) {
51: /* запустить оболочку */
52: execl("/bin/sh", "/bin/sh", 0);
53:
54: /* сюда управление никогда не попадет */
55: exit(1);
56: }
57:
58: /* родительский процесс */
59: /* установить обработчик SIGWINCH */
60: act.sa_handler = sigwinch_handler;
61: sigemptyset(&(act.sa_mask));
62: act.sa_flags = 0;
63: if (sigaction(SIGWINCH, &act, NULL) < 0) {
64: perror("ptypair: невозможно обработать SIGWINCH");
65: exit(1);
66: }
67:
68: /* Обратите внимание, что настройки termios устанавливаются только
69: * для стандартного ввода; ведущая сторона pty НЕ является tty.
70: */
71: tcgetattr(STDIN_FILENO, &ot);
72: t = ot;
73: t.c_lflag &= ~(ICANON | ISIG | ECHO | ECHOCTL | ECHOE |
74: ECHOK | ECHOKE | ECHONL | ECHOPRT);
75: t.c_iflag |= IGNBRK;
76: t.c_cc[VMIN] = 1;
77: t.c_cc[VTIME] = 0;
78: tcsetattr(STDIN_FILENO, TCSANOW, &t);
79:
80: /* Этот код взят без изменений из robin.с
81: * Если дочерний процесс завершается, читающая ведущая сторона
82: * дoлжнa вернуть -1 и завершиться.
83: */
84: ufds[0].fd = STDIN_FILENO;
85: ufds[0].events = POLLIN;
86: ufds[1].fd = master;
87: ufds[1].events = POLLIN;
88:
89: do {
90: int r;
91:
92: r = poll(ufds, 2, -1);
93: if ((rs < 0) && (errno != EINTR)) {
94: done = 1;
95: break;
96: }
97:
98: /* сначала проверить возможность завершения */
99: if ((ufds[0].revents | ufds[1].revents) &
100: (POLLERR | POLLHUP | POLLNVAL)) {
101: done = 1;
102: break;
103: }
104:
105: if (propagate_sigwinch) {
106: /* обработчик сигналов запросил распространение SIGWINCH */
107: if (ioctl(STDIN_FILENO, TIOCGWINSZ, &ws) < 0) {
108: perror("ptypair: не удается получить размеры окна");
109: }
110: if (ioctl(master, TIOCSWINSZ, &ws) < 0) {
111: perror("не удается восстановить размеры окна");
112: }
113:
114: /* не делать этого снова до поступления следующего SIGWINCH */
115: propagate_sigwinch = 0;
116:
117: /* опрос мог быть прерван SIGWINCH,
118: * потому повторить попытку.
119: */
120: continue;
121: }
122:
123: if (ufds[1].revents & POLLIN) {
124: i = read (master, buf, BUFSIZE);
125: if (i >= 1) {
126: write(STDOUT_FILENO, buf, i);
127: } else {
128: done = 1;
129: }
130: }
131:
132: if (ufds[0].revents & POLLIN) {
133: i = read (STDIN_FILENO, buf, BUFSIZE);
134: if (i >= 1) {
135: write(master, buf, i);
136: } else {
137: done = 1;
138: }
139: }
140:
141: } while (!done);
142:
143: tcsetattr(STDIN_FILENO, TCSANOW, &ot);
144: exit(0);
145: }
Программа
forkptytest.с делает очень немногое из того, чего вы раньше не видели. Обработка сигналов рассматривается в главе 12, а цикл
poll() почти полностью переписан из кода
robin.с, представленного ранее в этой главе (за исключением обработки управляющих символов), равно как и код, модифицирующий настройки
termios.
Остается лишь объяснить распространение изменений размеров окна.
В строке 105 после завершения
poll() мы проверяем, является ли причиной завершения
poll() сигнал
SIGWINCH, доставляемый функции
sigwinch_handler в строке 20. Если это так, необходимо получить новый размер текущего окна из стандартного ввода и распространить его в pty подчиненного компонента. Установкой размера окна
SIGWINCH передается
автоматически процессу, работающему на pty; мы не должны явно передавать
SIGWINCH этому процессу.
Теперь для сравнения посмотрите, насколько усложняется этот код в случае использования функций, определенных в
ptypair.с.
1: /* ptytest.с */
2:
3: #include <errno.h>
4: #include <fcntl.h>
5: #include <signal.h>
6: #include <stdio.h>
7: #include <stdlib.h>
8: #include <string.h>
9: #include <sys/ioctl.h>
10: #include <sys/poll.h>
11: #include <sys/stat.h>
12: #include <termios.h>
13: #include <unistd.h>
14: #include "ptypair.h"
15:
16:
17: volatile int propagate_sigwinch = 0;
18:
19: /* sigwinch_handler
20: * распространяет изменения размеров окна из входного файлового
21: * дескриптора на ведущую сторону pty.
22: */
23: void sigwinch_handler(int signal) {
24: propagate_sigwinch = 1;
25: }
26:
27:
28: /* ptytest пытается открыть пару pty с запуском оболочки
29: * на подчиненной стороне pty.
30: */
31: int main(void) {
32: int master;
33: int pid;
34: char * name;
35: struct pollfd ufds[2];
36: int i;
37: #define BUFSIZE 1024
38: char buf[1024];
39: struct termios ot, t;
40: struct winsize ws;
41: int done = 0;
42: struct sigaction act;
43:
44: if ((master = get_master_pty(&name)) < 0) {
45: perror("ptypair: не удается открыть ведущее устройство pty");
46: exit(1);
47: }
48:
49: /* установить обработчик SIGWINCH */
50: act.sa_handler = sigwinch_handler;
51: sigemptyset(&(act.sa_mask));
52: act.sa_flags = 0;
53: if (sigaction (SIGWINCH, &act, NULL) < 0) {
54: perror("ptypair: невозможно обработать SIGWINCH");
55: exit(1);
56: }
57:
58: if (ioctl(STDIN_FILENO, TIOCGWINSZ, &ws) < 0) {
59: perror("ptypair: не удается получить размеры окна");
60: exit(1);
61: }
62:
63: if ((pid = fork()) < 0) {
64: perror("ptypair");
65: exit(1);
66: }
67:
68: if (pid == 0) {
69: int slave; /* файловый дескриптор для подчиненного компонента pty*/
70:
71: /* Мы находимся в дочернем процессе */
72: close(master);
73:
74: if ((slave = get_slave_pty(name)) < 0) {
75: perror("ptypair: не удается открыть подчиненный компонент pty");
76: exit(1);
77: }
78: free(name);
79:
80: /* Мы должны сделать этот процесс лидером группы сеансов,
81: * поскольку он выполняется на новом PTY, а функции вроде
82: * управления заданиями просто не будут корректно работать,
83: * если нет лидера группы сеансов и лидера группы процессов
84: * (который автоматически является лидером группы сеансов).
85: * Это также разъединяет со старым управляющим tty.
86: */
87: if (setsid() < 0) {
88: perror("невозможно установить лидер сеанса");
89: }
90:
91: /* Соединиться с новым управляющим tty. */
92: if (ioctl(slave, TIOCSCTTY, NULL)) {
93: perror("невозможно установить новый управляющий tty");
94: }
95:
96: /* сделать подчиненный pty стандартным устройством ввода, вывода и ошибок */
97: dup2(slave, STDIN_FILENO);
98: dup2(slave, STDOUT_FILENO);
99: dup2(slave, STDERR_FILENO);
100:
101: /* в этой точке подчиненный pty должен быть стандартным устройством ввода */
102: if (slave > 2) {
103: close(slave);
104: }
105:
106: /* Попытаться восстановить размеры окна; сбой не является критичным */
107: if (ioctl(STDOUT_FILENO, TIOCSWINSZ, &ws) < 0) {
108: perror("не удается восстановить размеры окна");
109: }
110:
111: /* запустить оболочку */
112: execl("/bin/sh", "/bin/sh", 0);
113:
114: /* сюда управление никогда не попадет */
115: exit(1);
116: }
117:
118: /* родительский процесс */
119: free(name);
120:
121: /* Обратите внимание, что настройки termios устанавливаются только
122: * для стандартного ввода; ведущая сторона pty НЕ является tty.
123: */
124: tcgetattr(STDIN_FILENO, &ot);
125: t = ot;
126: t.c_lflag &= ~(ICANON | ISIG | ECHO | ECHOCTL | ECHOE |
127: ECHOK | ECHOKE | ECHONL | ECHOPRT);
128: t.c_iflag |= IGNBRK;
129: t.c_cc[VMIN] = 1;
130: t.c_cc[VTIME] = 0;
131: tcsetattr(STDIN_FILENO, TCSANOW, &t);
132:
133: /* Этот код взят без изменений из robin.с
134: * Если дочерний процесс завершается, читающая ведущая сторона
135: * должна вернуть -1 и завершиться.
136: */
137: ufds[0].fd = STDIN_FILENO;
138: ufds[0].events = POLLIN;
139: ufds[1].fd = master;
140: ufds[1].events = POLLIN;
141:
142: do {
143: int r;
144:
145: r = poll(ufds, 2, -1);
146: if ((r < 0) && (errno != EINTR)) {
147: done = 1;
148: break;
149: }
150:
151: /* сначала проверить возможность завершения */
152: if ((ufds[0].revents | ufds[1].revents) &
153: (POLLERR | POLLHUP | POLLNVAL)) {
154: done = 1;
155: break;
156: }
157:
158: if (propagate_sigwinch) {
159: /* обработчик сигнала запросил распространение SIGWINCH */
160: if (ioctl(STDIN_FILENO, TIOCGWINSZ, &ws) < 0) {
161: perror("ptypair: не удается получить размеры окна");
162: }
163: if (ioctl(master, TIOCSWINSZ, &ws) < 0) {
164: perror("не удается восстановить размеры окна");
165: }
166:
167: /* не делать этого снова до поступления следующего SIGWINCH */
168: propagate_sigwinch = 0;
169:
170: /* опрос мог быть прерван SIGWINCH,
171: * потому повторить попытку. */
172: continue;
173: }
174:
175: if (ufds[1].revents & POLLIN) {
176: i = read (master, buf, BUFSIZE);
177: if (i >= 1) {
178: write(STDOUT_FILENO, buf, i);
179: } else {
180: done = 1;
181: }
182: }
183:
184: if (ufds[0].revents & POLLIN) {
185: i = read (STDIN_FILENO, buf, BUFSIZE);
186: if (i >= 1) {
187: write(master, buf, i);
188: } else {
189: done = 1;
190: }
191: }
192: } while (!done);
193:
194: tcsetattr(STDIN_FILENO, TCSANOW, &ot);
195: exit(0);
196: }
Вся добавленная сложность
ptytest.с по сравнению с
forkptytest.с связана с обработкой старого интерфейса. Все это было описано в данной главе, кроме запуска дочернего процесса, который рассматривался в главе 10.
Глава 17
Работа в сети с помощью сокетов
По мере того, как компьютерный мир все шире объединяется в единую сеть, важность сетевых приложений все больше и больше возрастает. Система Linux предлагает программный интерфейс сокетов Беркли (Беркли), который уже стал стандартным сетевым API. Мы рассмотрим основы использования сокетов Беркли и через сетевой протокол TCP/IP, и через простое
межпроцессное взаимодействие (interprocess communication — IPC) с помощью сокетов домена Unix.
Мы не планировали превратить данную главу в полное руководство по программированию для сетей. Это отдельная сложная тема, и для тех программистов, которые планируют серьезную работу с сокетами, мы рекомендуем специализированные книги по программированию для сетей, например, [33]. Этой главы, однако, будет достаточно для того, чтобы вы смогли создавать несложные сетевые приложения.
17.1. Поддержка протоколов
API-интерфейс сокетов Беркли был сконструирован в виде шлюза для нескольких протоколов. Хотя это и приводит к дополнительным сложностям в интерфейсе, это все- таки гораздо легче, чем создавать (или изучать) новый интерфейс для каждого нового протокола, который встречается в работе. В Linux используется интерфейс сокетов для многих протоколов, включая TCP/IP (версии 4 и 6), AppleTalk и IPX.
Мы обсудим применение сокетов для двух протоколов, доступных через реализацию сокетов Linux. Наиболее важным протоколом, поддерживаемым системой Linux, является TCP/IP
[115] (Transmission Control Protocol/Internet Protocol — протокол управления передачей/протокол Internet), поскольку именно он управляет всем Internet. Мы также обратим внимание на сокеты домена Unix — механизм IPC, ограниченный одним компьютером. Хотя они и не работают через сеть, сокеты домена Unix широко применяются для приложений, работающих на одном компьютере.
Протоколы, как правило, используются группами, или семействами протоколов. Общераспространенное семейство протоколов TCP/IP среди прочих включает в себя протоколы TCP и UDP (User Datagram Protocol — протокол передачи дейтаграмм пользователя). Для того чтобы хорошо ориентироваться в различных протоколах, потребуется овладеть некоторой терминологией.
17.1.1. Идеальная работа в сети
Большинство пользователей ожидают от сетевых протоколов обеспечения эквивалента каналов Unix между компьютерами. Если байт (или последовательность байтов) поступает в один конец соединения, он обязательно выйдет из другого конца. Причем должен быть гарантирован не просто выход байта из другого конца, а выход непосредственно после того байта, который был отправлен перед ним, и перед байтом, посланным следующим. Конечно, все байты должны быть доставлены в первозданном виде без каких-либо изменений. Никакой другой процесс не может прерывать передачу дополнительными байтами; соединение ограничивается только двумя исходными сторонами.
Хорошей визуализацией этой идеи является телефон. При разговоре предполагается, что собеседник слышит те же самые слова и в том же порядке, что вы произносите.
17.1.2. Реальная работа в сети
Хотя все это кажется достаточно базовым, основные компьютерные сети работают далеко не так. Сеты склонны быть хаотическими и случайными. Представьте себе школьников на перемене, которым не только нельзя разговаривать, но и нужно находиться на расстоянии не менее пяти метров друг от друга. При этом они должны найти способ пообщаться — хотя бы с помощью бумажных самолетиков!
Предположим, что всякий раз, когда школьники хотят кому-нибудь передать информацию, они просто записывают ее на листах бумаги, вкладывают в самолетики, подписывают снаружи имя получателя и бросают их тому, кто расположен ближе к конечному адресату. Посредник смотрит на самолетик, видит назначенную цель и передает письмо следующему лицу. В конечном счете, адресат, которому предназначено сообщение, получит (точнее,
может быть, получит) самолетик, развернет его и прочтет письмо.
Хотите верьте, хотите нет, но такая схема практически точно отображает процесс функционирования компьютерных сетей
[116]. Посредники здесь носят название
маршрутизаторов, а самолетики называются
пакетами, но в остальном все происходит именно так. Как и в жизни, некоторые из отправленных самолетиков (или пакетов) теряются. Если сообщение слишком длинное для одного пакета, его нужно распределить по нескольким пакетам (для каждого из которых есть шанс потеряться). Все школьники-посредники могут прочесть пакеты, если им захочется
[117], и даже просто выбросить их вместо того, чтобы попытаться доставить их по адресу. При этом кто угодно может прервать ваш диалог, направив в него новые пакеты.
17.1.3. Как заставить реальность играть по точным правилам?
Встречаясь лицом к лицу с реальностью (миллионами бумажных самолетиков), разработчики протоколов прилагают все усилия для того, чтобы представлять сети по аналогии с телефонными линиями, а не со школьниками. Для описания сетевых протоколов установились разнообразные термины.
•
Протоколы на основе логических соединений имеют две конечные точки подобно телефонным разговорам. Соединение должно быть установлено до начала передачи информации (ведь вы отвечаете на звонок словом "Алло!", а не начинаете сразу же разговаривать). Остальные пользователи не могут (и даже не должны иметь возможности) вторгаться в соединение. Протоколы, не имеющие таких характеристик, называются
протоколами без установления соединения.
• Говорят, что протоколы обеспечивают
упорядочение, если они гарантируют доставку данных в том же порядке, в котором они были отправлены.
• Протоколы предоставляют
защиту от ошибок в том случае, если они автоматически отбрасывают поврежденные сообщения и подготавливаются к повторной передаче данных.
•
Потоковые протоколы распознают только байтовые границы. Последовательности байтов могут разделяться и доставляться адресату по мере появления данных.
•
Пакетные протоколы обрабатывают пакеты данных, сохраняя границы пакета и доставляя полные пакеты получателям. Пакетные протоколы, как правило, требуют определенного максимального размера пакета.
Хотя каждый из перечисленных атрибутов не зависит от остальных, в приложениях употребляются только два основных типа протоколов.
Дейтаграммные протоколы являются механизмами пакетной передачи, не предоставляя при этом ни упорядочения, ни защиты от ошибок. Широко используется дейтаграммный протокол UDP, являющийся представителем семейства протоколов TCP/IP.
Потоковые протоколы (такие как TCP из TCP/IP) — это протоколы потоковой передачи, которые обеспечивают и упорядочение, и защиту от ошибок.
Несмотря на то что дейтаграммные протоколы вроде UDP, несомненно, полезны
[118], мы остановимся на применении потоковых протоколов, поскольку их легче использовать для большинства приложений. Подробное описание разработки протоколов и различий между их отдельными видами можно найти во многих книгах, например, [33] и [34].
17.1.4. Адреса
Поскольку каждый протокол поддерживает собственное определение сетевого адреса, интерфейс сокетов должен абстрагировать адреса. В качестве базовой формы адреса используется структура
struct sockaddr; его содержимое устанавливается по-разному для каждого семейства адресов. Передавая
struct sockaddr в системный вызов, процесс также указывает размер передаваемого адреса. Тип
socklen_t определяется как число, достаточно большое для хранения размера любого сокета, который используется системой.
Все типы
struct sockaddr соответствуют приведенному ниже определению.
#include <sys/socket.h>
struct sockaddr {
unsigned short sa_family;
char sa_data[MAXSOCKADDRDATA];
}
Первые два байта (размер
short) указывают
семейство адресов, к которому относится данный адрес. Перечень стандартных адресных семейств, используемых приложениями Linux, приведен в табл. 17.1.
Таблица 17.1. Семейства протоколов и адресов
| Адрес |
Протокол |
Описание протокола |
AF_UNIX |
PF_UNIX |
Домен Unix. |
AF_INET |
PF_INET |
TCP/IP (версия 4). |
AF_INET6 |
PF_INET6 |
TCP/IP (версия 6). |
AF_AX25 |
PF_AX25 |
AX.25, используется радиолюбителями. |
AF_IPX |
PF_IPX |
Novell IPX. |
AF_APPLETALK |
PF_APPLETALK |
AppleTalk DDS. |
AF_NETROM |
PF_NETROM |
NetROM, используется радиолюбителями. |
17.2. Служебные функции
Во всех примерах этого раздела используются две функции:
copyData() и
die(). Функция
copyData() считывает данные из одного файлового дескриптора и записывает их в какой-то другой дескриптор (до тех пор, пока имеются данные для чтения). Функция
die() вызывает
perror() и завершает программу. Мы ввели обе указанные функции в файл
sockutil.с для того, чтобы сделать обучающие программы немного проще. Для справки ниже показана реализация двух данных функций.
1: /* sockutil.с */
2:
3: #include <stdio.h>
4: #include <stdlib.h>
5: #include <unistd.h>
6:
7: #include "sockutil.h"
8:
9: /* выдает сообщение об ошибке через функцию perror() и прекращает работу программы */
10: void die(char * message) {
11: perror(message);
12: exit(1);
13: }
14:
15: /* Копирует данные из дескриптора файла 'from' в дескриптор файла
16: 'to' до полного завершения копирования. Выходит из программы, если
17: происходит ошибка. Предполагается, что для обоих файлов установлено
18: блокирующее чтение и запись. */
19: void copyData(int from, int to) {
20: char buf[1024];
21: int amount;
22:
23; while ((amount = read(from, buf, sizeof(buf))) > 0) {
24: if (write(to, buf, amount) != amount) {
25: die("write");
26: return;
27: }
28: }
29: if (amount < 0)
30: die("read");
31: }
17.3. Основные действия с сокетами
Подобно большинству остальных ресурсов Linux сокеты реализуются через файловую абстракцию. Они создаются при помощи системного вызова
socket(), который возвращает файловый дескриптор. После соответствующей инициализации сокета данный дескриптор может использоваться для запросов
read() и
write(), как и любой другой файловый дескриптор. Когда процесс завершает работу с сокетом, его необходимо закрыть через функцию
close() для того, чтобы освободить все ресурсы, ассоциированные с ним.
В настоящем разделе представлены основные системные вызовы для создания и инициализации сокетов для любого протокола. Для того чтобы не зависеть от протоколов, информация в некоторой степени абстрагирована, по этой же причине мы не приводим примеры. Следующие два раздела посвящены применению сокетов в двух различных протоколах (домен Unix и TCP/IP). Здесь вы найдете подробные примеры использования большинства системных вызовов, описанных ниже.
17.3.1. Создание сокета
Новые сокеты создаются системным вызовом
socket(), который возвращает файловый дескриптор для
неинициализированного сокета. При создании сокет привязывается к определенному протоколу, однако соединение для сокета не устанавливается. На данном этапе еще невозможно считывать информацию из сокета и записывать в него.
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
Подобно
open(), функция
socket() возвращает значение меньше 0, если имела место ошибка, и файловый дескриптор, больший или равный нулю, если все прошло благополучно. Три параметра устанавливают протокол, который нужно использовать.
Первый параметр указывает семейство протоколов и, как правило, принимает одно из значений, перечисленных в табл. 17.1.
Следующий параметр
type может иметь одно из значений:
SOCK_STREAM,
SOCK_DGRAM или
SOCK_RAW.
[119] Здесь
SOCK_STREAM указывает потоковый протокол из данного семейства, a
SOCK_DGRAM специфицирует дейтаграммный протокол из того же семейства. Параметр
SOCK_RAW предоставляет возможность передавать пакеты прямо в драйвер сетевого устройства, что позволяет пользовательским приложениям поддерживать сетевые протоколы, которые не воспринимаются ядром.
Последний параметр устанавливает протокол для использования с учетом всех ограничений, введенных первыми двумя параметрами. Как правило, значение этого параметра равно 0, что позволяет ядру использовать стандартный протокол установленного типа из указанного семейства. В табл. 17.2 перечислены некоторые допустимые протоколы для семейства
PF_INET. Стандартными протоколами здесь считаются
IPPROTO_TCP (потоковый) и
IPPROTO_UDP (дейтаграммный).
Таблица 17.2. Протоколы IP
| Протокол |
Описание |
IPPROTO_ICMP |
Internet Control Message Protocol (протокол управляющих сообщений в сети Internet) для IPv4. |
IPPROTO_ICMPV6 |
Internet Control Message Protocol (протокол управляющих сообщений в сети Internet) для IPv6. |
IPPROTO_IPIP |
Тоннели IPIP |
IPPROTO_IPV6 |
Заголовки IPv6. |
IPPROTO_RAW |
Пакеты Raw IP. |
IPPROTO_TCP |
Transmission Control Protocol (TCP) (протокол управления передачей). |
IPPROTO_UDP |
User Datagram Protocol (UDP) (протокол передачи дейтаграмм пользователя). |
17.3.2. Установка соединений
После создания потокового сокета его необходимо присоединить к чему-то часто используемому. Установка соединений сокетов является в большой степени несимметричной задачей, поскольку каждая сторона проводит соединение по-разному. Одна сторона получает сокет, который готов к соединению, и затем ожидает кого-либо для того, чтобы присоединиться к нему. Эту функцию, как правило, выполняют серверные приложения, которые однажды активизируются и постоянно продолжают работать, ожидая подключения со стороны других процессов.
Клиентские процессы, в свою очередь, создают сокет, сообщают системе адрес, к которому они хотят подключиться, и после этого пытаются установить соединение. Как только сервер (ожидающий клиента) принимает попытку соединения, устанавливается соединение между двумя сокетами. После этого сокет может использоваться для двусторонней связи.
17.3.3. Связывание адреса с сокетом
И серверный, и клиентский процессы должны сообщить системе, какой адрес использовать для сокета. Прикрепление адреса к локальной стороне сокета называется
связыванием сокета и выполняется через системный вызов
bind().
#include <sys/socket.h>
int bind(int sock, struct sockaddr * my_addr, socklen_t addrlen);
Первый параметр — это связываемый сокет, остальные параметры задают адрес для локальной конечной точки.
17.3.4. Ожидание соединений
После создания сокета сервер привязывает к нему адрес с помощью функции
bind(). Далее процесс сообщает системе путем вызова функции
listen(), что он готов разрешить другим процессам соединение с данным сокетом (по указанному адресу). Если сокет привязан к адресу, ядро получает возможность обрабатывать попытки соединения с данным адресом, поступающие от процессов. Однако соединение не устанавливается немедленно. Слушающий процесс сначала должен согласиться с попыткой соединения через системный вызов
accept(). До тех пор, пока новая попытка соединения с определенным адресом не принята, она называется
ожидающим соединением.
Как правило, функция
accept() блокируется до тех пор, пока к ней не пытается присоединиться некоторый клиентский процесс. Если сокет был помечен как неблокируемый через
fcntl(), то функция
accept() возвращает значение
EAGAIN в том случае, если нет ни одного доступного клиентского процесса
[120]. Системные вызовы
select(),
poll() и
epoll могут использоваться для указания, ждать ли соединению обработки (эти вызовы помечают сокет как готовый для считывания)
[121].
Ниже показаны прототипы
listen() и
accept().
#include <sys/socket.h>
int listen(int sock, int backlog);
int accept(int sock, struct sockaddr * addr, socklen_t * addrlen);
В обеих функциях предполагается, что первый параметр — это файловый дескриптор. Второй параметр
backlog функции
listen() задает максимальное количество соединений, которые могут одновременно ожидать обработки на данном сокете. Сетевые соединения не устанавливаются до тех пор, пока сервер не примет соединение через
accept(); все входящие соединения считаются приостановленными. Поддерживая небольшое количество ожидающих соединений в очереди, ядро тем самым освобождает серверные процессы от необходимости быть в постоянной готовности принимать соединения. Исторически принято ограничивать в приложениях количество невыполненных заданий пятью, хотя иногда необходимо большее количество. Функция
listen() возвращает ноль в случае успеха и какое-то другое число в случае неудачи.
Вызов
accept() превращает отложенное соединение в установленное. Установленное соединение получает новый файловый дескриптор, который возвращает функция
accept(). Новый дескриптор наследует все атрибуты того сокета, к которому обращалась функция
listen(). Необычное свойство
accept() состоит в том, что она возвращает сетевые ошибки, ожидающие обработки, как ошибки принятия от
accept()[122]. При возврате ошибки серверы не должны прерывать работу, если параметр
errno принимает одно из следующих значений:
ECONNABORTED,
ENETDOWN,
EPROTO,
ENOPROTOOPT,
EHOSTDOWN,
ENONET,
EHOSTUNREACH,
EOPNOTSUPP или
ENETUNREACH. Все эти ошибки необходимо игнорировать, просто вызвав функцию
accept() на сервере еще раз.
Параметры
addr и
addrlen указывают данные, в которых ядро размещает адрес удаленного (клиентского) конца соединения. В исходном состоянии
addrlen представляет собой целое число, содержащее размер буфера, на который ссылается
addr. Функция
accept() аналогично open() возвращает файловый дескриптор или некоторое отрицательное значение, если возникла ошибка.
17.3.5. Подключение к серверу
Как и серверы, клиенты могут сразу после создания сокета связывать с ним локальный адрес. Обычно клиент пропускает этот шаг, предоставляя ядру присвоить сокету любой подходящий локальный адрес.
После этапа связывания (который, впрочем, может быть пропущен) клиент соединяется с сервером через системный вызов
connect().
#include <sys/socket.h>
int connect(int sock, struct sockaddr * servaddr, socklen_t addrlen);
Процесс переходит к подключению, придерживаясь адреса, с которым должен соединиться сокет.
На рис. 17.1 показаны системные вызовы, которые обычно используются для установки соединений сокетов, и порядок, в котором они выполняются.
 Рис 17.1
Рис 17.1. Установка соединений сокетов
17.3.6. Поиск адресов соединения
После того как соединение установлено, приложение может найти адреса как удаленного, так и локального концов сокета с помощью функций
getpeername() и
getsockname().
#include <sys/socket.h>
int getpeername(int s, struct sockaddr * addr, socklen_t * addrlen);
int getsockname(int s, struct sockaddr * addr, socklen_t * addrlen);
Обе функции передают адреса соединений сокета s в те структуры, на которые указывают их параметры
addr. Адрес удаленной стороны возвращается функцией
getpeername(), тогда как
getsockname() сообщает адрес локальной части соединения. Для обеих функций в качестве первоначального целочисленного значения, на которое указывает параметр
addrlen, должен быть установлен размер пространства, которое выделяется параметром
addr. Это целое число заменяется количеством байт в возвращаемом адресе.
17.4. Сокеты домена Unix
Сокеты домена Unix — это простейшее семейство протоколов, доступное через API- интерфейс сокетов. Они фактически не являются сетевыми протоколами, поскольку могут соединяться с сокетами только на одном и том же компьютере. Несмотря на то что это значительно ограничивает их полезность, они все же используются многими приложениями благодаря гибкому механизму IPC, который они поддерживают. Их адреса — это путевые имена, которые создаются в файловой системе, когда сокет привязывается к путевому имени. Файлы сокетов, представляющие адреса доменов Unix, могут быть запущены функцией
stat(), но не могут быть открыты с помощью
open(); вместо этого нужно использовать API сокетов.
Домен Unix предусматривает как дейтаграммные, так и потоковые интерфейсы. Дейтаграммный интерфейс используется редко, и здесь обсуждаться не будет. Мы рассмотрим потоковый интерфейс, работа которого подобна именованным каналам. При этом сокеты домена Unix, однако, не идентичны именованным каналам.
Если несколько процессов одновременно открывают именованный канал, то любой из них может прочесть сообщение, передаваемое через канал другим процессом. Каждый канал похож на доску объявлений. Если процесс располагает сообщение на доске, то любой другой процесс (с достаточными полномочиями) может прочитать это сообщение с доски.
Сокеты домена Unix работают на основе соединений; в результате каждого соединения с сокетом возникает новый канал связи. Сервер, который может обрабатывать множество соединений одновременно, сохраняет для каждого из них свой файловый дескриптор. Благодаря этому свойству сокеты домена Unix лучше подходят для выполнения многих задач IPC, чем именованные каналы. Это главная причина, по которой они применяются большинством стандартных служб Linux, включал X Window System и системный регистратор.
17.4.1. Адреса домена Unix
Адреса для сокетов домена Unix являются путевыми именами в файловой системе. Если файл еще не существует, то он создается как файл сокетного типа в тот момент, когда сокет привязывается к путевому имени через функцию
bind(). Если уже существует файл (или даже сокет) с указанным путевым именем, то функция
bind() завершается и возвращает значение
EADDRINUSE,
bind() устанавливает права доступа для созданного файла сокета равными 0666, как измененные текущей маской umask.
Для того чтобы присоединиться к существующему сокету, процесс должен иметь права на чтение и запись в файл сокета
[123].
Адреса сокетов домена Unix передаются через структуру
struct sockaddr_un.
#include <sys/socket.h>
#include <sys/un.h>
struct sockaddr_un {
unsigned short sun_family; /* AF_UNIX */
char sun_path[UNIX_PATH_MAX]; /* путевое имя */
};
В ядре Linux 2.6.7 значение переменной
UNIX_PATH_MAX равно
108, но в последующих версиях ядра Linux оно может измениться.
Первый член
sun_family должен содержать
AF_UNIX для того, чтобы показать, что структура содержит адрес домена Unix. Параметр
sun_path хранит путевое имя, которое нужно использовать для соединения. Если системным вызовам, относящимся к сокету, передается размер адреса, то передаваемая длина равна количеству символов в путевом имени плюс размер элемента
sun_family. Параметр
sun_path не обязательно должен заканчиваться
'\0', хотя обычно делают именно так.
17.4.2. Ожидание соединения
Как объяснялось выше, ожидание установки соединения на сокете домена Unix придерживается следующей процедуры: создание сокета, привязка адреса к сокету, перевод системы в режим ожидания соединений и принятие соединения.
Ниже показан пример простого сервера, который многократно принимает соединения с сокетом домена Unix (файл
sample-socket в текущем каталоге) и считывает все данные из сокета, посылая их на стандартный вывод.
1: /* userver.c */
2:
3: /* Ожидает соединения на сокете ./sample-socket домена Unix.
4: После установки соединения копирует данные
5: из сокета в stdout до тех пор, пока вторая сторона не
6: закрывает соединение. Далее ожидает следующее соединение
7: с сокетом. */
8:
9: #include <stdio.h>
10: #include <sys/socket.h>
11: #include <sys/un.h>
12: #include <unistd.h>
13:
14: #include "sockutil.h" /* некоторые служебные функции */
15:
16: int main (void) {
17: struct sockaddr_un address;
18: int sock, conn;
19: size_t addrLength;
20:
21: if ((sock = socket(PF_UNIX, SOCK_STREAM, 0)) < 0)
22: die("socket");
23:
24: /* Удалить все сокеты (или файлы), существовавшие ранее */
25: unlink("./sample-socket");
26:
27: address.sun_family = AF_UNIX; /* сокет домена Unix */
28: strcpy(address.sun_path, "./sample-socket");
29:
30: /* Общая длина адреса, включая элемент
31: sun_family */
32: addrLength = sizeof(address.sun_family) +
33: strlen(address.sun_path);
34:
35: if (bind(sock, (struct sockaddr *) &address, addrLength))
36: die("bind");
37:
38: if (listen(sock, 5))
39: die("listen");
40:
41: while ((conn = accept(sock, (struct sockaddr *) &address,
42: &addrLength)) >=0) {
43: printf("---- получение данных\n");
44: copyData(conn, 1);
45: printf("---- готово\n");
46: close(conn);
47: }
48:
49: if (conn < 0)
50: die("accept");
51:
52: close(sock);
53: return 0;
54: }
Несмотря на небольшой размер приведенной программы, она хорошо иллюстрирует, как написать простой серверный процесс. Этот сервер является
итеративным, поскольку он обрабатывает только одного клиента за раз. Можно создавать также
параллельные серверы, управляющие несколькими клиентами одновременно
[124].
Обратите внимание на то, что функция
unlink() вызывается до связывания сокета. Поскольку функция
bind() прекращает работу, если файл сокета уже существует, то этот шаг позволяет запускать программу более одного раза без необходимости удаления файла сокета вручную.
Серверный код приводит тип указателя
struct sockaddr_un, передаваемого и в
bind(), и в
accept(), к
(struct sockaddr *). При прототипировании различных системных вызовов, относящихся к сокетам, предполагается, что они принимают указатель на
struct sockaddr. Приведение типа предотвращает появление уведомлений от компилятора о несоответствии типов указателей.
17.4.3. Соединение с сервером
Процесс соединения с сервером через сокет домена Unix состоит из создания сокета и присоединения к требуемому адресу через функцию
connect(). Как только сокет присоединен, он может обрабатываться как любой другой файловый дескриптор.
Следующая программа подключается с тем же самым сокетом, который использовался в примере сервера, и копирует его стандартные входные данные на сервер.
1: /* uclient.c */
2:
3: /* Подключиться к сокету ./sample-socket домена Unix, скопировать stdin
4: в сокет, после этого выйти из программы. */
5:
6: #include <sys/socket.h>
7: #include <sys/un.h>
8: #include <unistd.h>
9:
10: #include "sockutil.h" /* некоторые служебные функции */
11:
12: int main(void) {
13: struct sockaddr_un address;
14: int sock;
15: size_t addrLength;
16:
17: if ((sock = socket(PF_UNIX, SOCK_STREAM, 0)) < 0)
18: die("socket");
19:
20: address.sun_family = AF_UNIX; /* сокет домена Unix */
21: strcpy(address.sun_path, "./sample-socket");
22:
23: /* Общая длина адреса, включая элемент
24: sun_family */
25: addrLength = sizeof(address.sun_family) +
26: strlen(address.sun_path);
27:
28: if (connect(sock, (struct sockaddr *) &address, addrLength))
29: die("connect");
30:
31: copyData(0, sock);
32:
33: close(sock);
34:
35: return 0;
36: }
Клиент не особенно отличается от сервера. Единственные изменения состоят в том, что последовательность функций
bind(),
listen(),
accept() заменяется одним вызовом
connect(), при этом копируется немного другой набор данных.
17.4.4. Запуск примеров домена Unix
Две предыдущие программы-примера (серверная и клиентская) сконструированы для совместной работы. Запустите сервер с одного терминала, после этого активизируйте клиента из другого терминала (но в том же самом каталоге). При вводе строк в клиентской программе они автоматически передаются через сокет на сервер. После того, как вы завершите работу клиента, сервер будет ожидать следующего соединения. Вы можете передавать файлы через сокет путем переадресации входных данных в клиентскую программу.
17.4.5. Неименованные сокеты домена Unix
Благодаря тому, что сокеты домена Unix обладают некоторыми преимуществами перед каналами (например, они являются полнодуплексными), они часто используются в качестве механизма IPC. Для того чтобы облегчить этот процесс, вводится системный вызов
socketpair().
#include <sys/socket.h>
int socketpair(int domain, int type, int protocol, int sockfds[2]);
Первые три параметра совпадают с теми, которые передаются в
socket(). Последний параметр
sockfds() заполняется функцией
socketpair() двумя файловыми дескрипторами (по одному для каждой стороны сокета).
Пример применения
socketpair() показан далее в главе.
17.4.6. Передача файловых дескрипторов
Сокеты домена Unix обладают уникальным свойством: через них могут передаваться файловые дескрипторы. Ни один из прочих механизмов IPC не поддерживает подобную возможность. Она позволяет процессу открыть файл и передать файловый дескриптор в другой (возможно, несвязанный) процесс. Все проверки доступа выполняются при открытии файла, поэтому получающий процесс приобретает те же самые права доступа к файлу, что и исходный процесс.
Файловые дескрипторы передаются как часть более сложного сообщения, которое отправляется с помощью системного вызова
sendmsg() и принимается через
recvmsg().
#include <sys/socket.h>
int sendmsg(int fd, const struct msghdr * msg, unsigned int flags);
int recvmsg(int fd, struct msghdr * msg, unsigned int flags);
Параметр
fd является файловым дескриптором, через который передается сообщение; второй параметр служит указателем на структуру, описывающую сообщение. Параметр
flags обычно не используется и для большинства приложений должен быть равен нулю. В специализированных книгах по программированию для сетей обсуждаются доступные флаги [33].
Сообщение описывается показанной ниже структурой.
#include <sys/socket.h>
#include <sys/un.h>
struct msghdr {
void * msg_name; /* дополнительный адрес */
unsigned int msg_namelen; /* размер msg_name */
struct iovec * msg_iov; /* массив для чтения вразброс/сборной записи*/
unsigned int msg_iovlen; /* количество элементов в msg_iov */
void * msg_control; /* вспомогательные данные */
unsigned int msg_controllen;/* длина буфера вспомогательных данных */
int msg_flags; /* флаги на получаемом сообщении */
};
Первые два члена
msg_name и
msg_namelen не используются в потоковых протоколах. Приложения, посылающие сообщения через потоковые сокеты, должны устанавливать для
msg_name значение
NULL, для
msg_namelen — ноль.
msg_iov и
msg_iovlen описывают набор буферов, которые отправляют или принимают. Чтение вразброс и сборная запись, а также
struct iovec, обсуждаются в конце главы 13. Последний член структуры
msg_flags в настоящее время не используется и должен равняться нулю.
Два элемента, которые мы пропустили,
msg_control и
msg_controllen предоставляют возможность передачи файлового дескриптора. Член
msg_control указывает на массив заголовков управляющих сообщений;
msg_controllen устанавливает количество байт, которые содержит массив. Каждое управляющее сообщение состоит из структуры
struct cmsghdr, которая сопровождается дополнительными данными.
#include <sys/socket.h>
struct cmsghdr {
unsigned int cmsg_len; /* длина управляющего сообщения */
int cmsg_level; /* SOL_SOCKET */
int cmsg_type; /* SCM_RIGHTS */
int cmsg_data[0]; /* здесь должен быть файловый дескриптор */
};
Размер управляющего сообщения, включая заголовок, хранится в переменной
cmsg_len. В текущий момент определен только один тип управляющих сообщений —
SCM_RIGHTS, который передает файловые дескрипторы
[125]. Для данного типа сообщений параметры
cmsg_level и
cmsg_type должны быть равны соответственно
SOL_SOCKET и
SCM_RIGHTS. Последний член
cmsg_data является массивом нулевого размера. Это расширение gcc, которое позволяет приложению копировать данные в конец структуры (в следующей программе показан пример).
Получение файлового дескриптора происходит аналогично. Необходимо выделить достаточное пространство буфера для управляющего сообщения, и каждая приходящая структура
struct cmsghdr будет сопровождаться новым файловым дескриптором.
Для иллюстрации использования таких вложенных структур мы написали пример программы, которая по нашей прихоти названа просто
cat. Она принимает имя файла в качестве единственного аргумента, открывает указанный файл в дочернем процессе и передает результирующий файловый дескриптор в родительский процесс через сокет домена Unix. Родительский процесс затем копирует файл на стандартный вывод. Имя файла
посылается вместе с файловым дескриптором с демонстрационной целью.
1: /* passfd.с */
2:
3: /* Программа ведет себя подобно обычной команде /bin/cat, которая обрабатывает
4: только один аргумент (имя файла). Мы создаем сокеты домена Unix при помощи
5: socketpair(), затем разветвляем через fork(). Дочерний процесс открывает файл,
6: имя которого передается в командной строке, пересылает файловый дескриптор и
7: имя файла обратно в порождающий процесс, после этого завершается. Родительский
8: процесс ожидает файловый дескриптор от дочернего процесса, а потом копирует
9: данные из файлового дескриптора в stdout до тех пор, пока данные не
10: заканчиваются. Затем родительский процесс завершается. */
11:
12: #include <alloca.h>
13: #include <fcntl.h>
14: #include <stdio.h>
15: #include <string.h>
16: #include <sys/socket.h>
17: #include <sys/uio.h>
18: #include <sys/un.h>
19: #include <sys/wait.h>
20: #include <unistd.h>
21:
22: #include "sockutil.h" /* простые служебные функции */
23:
24: /* Дочерний процесс. Он пересылает файловый дескриптор. */
25: int childProcess(char * filename, int sock) {
26: int fd;
27: struct iovec vector; /* некоторые данные для передачи fd в w/ */
28: struct msghdr msg; /* полное сообщение */
29: struct cmsghdr * cmsg; /* управляющее сообщение, которое */
30: /* включает в себя fd */
31:
32: /* Открыть файл, дескриптор которого будет передан. */
33: if ((fd = open(filename, O_RDONLY)) < 0) {
34: perror("open");
35: return 1;
36: }
37:
38: /* Передать имя файла через сокет, включая завершающий
39: символ '\0' */
40: vector.iov_base = filename;
41: vector.iov_len = strlen(filename) + 1;
42:
43: /* Соединить первую часть сообщения. Включить
44: имя файла iovec */
45: msg.msg_name = NULL;
46: msg.msg_namelen = 0;
47: msg.msg_iov = &vector;
48: msg.msg_iovlen = 1;
49:
50: /* Теперь управляющее сообщение. Мы должны выделить участок памяти
51: для файлового дескриптора. */
52: cmsg = alloca(sizeof(struct cmsghdr) + sizeof(fd));
53: cmsg->cmsg_len = sizeof(struct cmsghdr) + sizeof(fd);
54: cmsg->cmsg_level = SOL_SOCKET;
55: cmsg->cmsg_type = SCM_RIGHTS;
56:
57: /* Копировать файловый дескриптор в конец
58: управляющего сообщения */
59: memcpy(CMSG_DATA(cmsg), &fd, sizeof(fd));
60:
61: msg.msg_control = cmsg;
62: msg.msg_controllen = cmsg->cmsg_len;
63:
64: if (sendmsg(sock, &msg, 0) != vector.iov_len)
65: die("sendmsg");
66:
67: return 0;
68: }
69:
70: /* Родительский процесс. Он получает файловый дескриптор. */
71: int parentProcess(int sock) {
72: char buf[80]; /* пространство для передачи имени файла */
73: struct iovec vector; /* имя файла от дочернего процесса */
74: struct msghdr msg; /* полное сообщение */
75: struct cmsghdr * cmsg; /* управляющее сообщение с fd */
76: int fd;
77:
78: /* установка iovec для имени файла */
79: vector.iov_base = buf;
80: vector.iov_len = 80;
81:
82: /* сообщение, которое мы хотим получить */
83:
84: msg.msg_name = NULL;
85: msg.msg_namelen = 0;
86: msg.msg_iov = &vector;
87: msg.msg_iovlen = 1;
88:
89: /* динамическое распределение (чтобы мы могли выделить участок
90: памяти для файлового дескриптора) */
91: cmsg = alloca(sizeof(struct cmsghdr) + sizeof(fd));
92: cmsg->cmsg_len = sizeof(struct cmsghdr) + sizeof(fd);
93: msg.msg_control = cmsg;
94: msg.msg_controllen = cmsg->cmsg_len;
95:
96: if (!recvmsg(sock, &msg, 0))
97: return 1;
98:
99: printf("получен файловый дескриптор для '%s'\n",
100: (char *) vector.iov_base);
101:
102: /* присвоение файлового дескриптора из управляющей структуры */
103: memcpy(&fd, CMSG_DATA(cmsg), sizeof(fd));
104:
105: copyData(fd, 1);
106:
107: return 0;
108: }
109:
110: int main(int argc, char ** argv) {
111: int socks[2];
112: int status;
113:
114: if (argc != 2) {
115: fprintf(stderr, "поддерживается только один аргумент\n");
116: return 1;
117: }
118:
119: /* Создание сокетов. Один служит для родительского процесса,
120: второй — для дочернего (мы можем поменять их местами,
121: если нужно). */
122: if (socketpair(PF_UNIX, SOCK_STREAM, 0, socks))
123: die("socketpair");
124:
125: if (!fork()) {
126: /* дочерний процесс */
127: close(socks[0]);
128: return childProcess(argv[1], socks[1]);
129: }
130:
131: /* родительский процесс */
132: close(socks[1]);
133: parentProcess(socks[0]);
134:
135: /* закрытие дочернего процесса */
136: wait(&status);
137:
138: if (WEXITSTATUS(status))
139: fprintf(stderr, "childfailed\n");
140:
141: return 0;
142: }
17.5. Сетевая обработка с помощью TCP/IP
Самое важное применение сокетов заключается в том, что они позволяют приложениям, работающим на основе различных механизмов, общаться друг с другом. Семейство протоколов TCP/IP [34] используется в Internet самым большим в мире числом компьютеров, объединенных в сеть. Система Linux предлагает полную устойчивую реализацию TCP/IP, которая позволяет действовать и как сервер, и как клиент TCP/IP.
Наиболее распространенной версией TCP/IP является версия 4 (IPv4). В данный момент для большинства операционных систем и продуктов сетевой инфраструктуры уже доступна версия 6 протокола TCP/IP (IPv6), однако IPv4 доминирует до сих пор. В данном разделе мы сосредоточимся на создании приложений для IPv4, но обратим внимание на отличия для приложений IPv6, а также для тех программ, которые должны поддерживать обе версии.
17.5.1. Упорядочение байтов
Сети TCP/IP, как правило, являются неоднородными; они включают в себя широкий ряд механизмов и архитектур. Одно из основных отличий между архитектурами связано со способом хранения чисел.
Машинные числа составляются из последовательности байтов. Например, целые числа в С обычно представляются 4 байтами (32 битами). Существует довольно много способов хранения этих четырех байтов в памяти компьютера. Архитектуры с
обратным порядком байтов сохраняют старший (наиболее значимый) байт в наименьшем аппаратном адресе, остальные следуют в порядке от более значимого к менее значимому. Механизмы с
прямым порядком байтов хранят многобайтовые значения в абсолютно противоположном порядке: наименее значимый байт отправляется в наименьший адрес памяти. В других механизмах байты сохраняются в различных порядках.
Так как многобайтовые значения являются частью протокола TCP/IP, то разработчики протоколов позаботились о едином стандарте способа передачи многобайтовых значений через сеть
[126]. TCP/IP требует использования обратного порядка байтов для передачи протокольной информации и рекомендует также применять его к данным приложений (хотя попытки зафиксировать формат потока данных приложений не предпринимались)
[127]. Упорядочение, которое применяется для многобайтовых значений, передаваемых через сеть, известно как
сетевой порядок байтов.
Для преобразования порядка байтов хоста в сетевой порядок байтов используются четыре функции.
#include <netinet/in.h>
unsigned int htonl(unsigned int hostlong);
unsigned short htons(unsigned short hostshort);
unsigned int ntohl(unsigned int netlong);
unsigned short ntohs(unsigned short netshort);
Несмотря на то что прототип каждой из этих функций принимает значение без знака, все они отлично работают и для значений со знаком.
Первые две функции
htonl() и
htons() преобразуют длинные и короткие числа соответственно из порядка байтов хоста в сетевой порядок байтов. Последние две
ntohl() и
ntohs() выполняют обратные преобразования длинных и коротких чисел (из сетевого порядка в порядок хоста).
Хотя мы использовали термин
длинный в описаниях, на самом деле, это неправильно. Обе функции
htonl() и
ntohl() принимают 32-битные значения, а не те, которые относятся к типу
long. В прототипах обеих функций предполагалось, что они обрабатывают значения
int, поскольку все платформы Linux в настоящее время используют 32-битные целые числа.
17.5.2. Адресация IPv4
Соединения IPv4 представляют собой кортеж из 4-х элементов (
локальный хост,
локальный порт,
удаленный хост,
удаленный порт). До установки соединения необходимо определить каждую его часть. Элементы
локальный хост и удаленный хост являются IPv4-адресами. IPv4-адреса — это 32-битные (4-байтовые) числа, уникальные для всей установленной сети. Как правило, они записываются в виде
aaa.bbb.ccc.ddd, где каждый элемент адреса является десятичным представлением одного из байтов адреса машины. Первое слева число в адресе соответствует самому значимому байту в адресе. Такой формат для IPv4-адресов известен как
десятичное представление с разделителями-точками.
В связи с тем, что большинство компьютеров вынуждено поддерживать работу нескольких параллельных TCP/IP приложений, IP-номер не обеспечивает уникальную идентификацию для соединения на одной машине.
Номера портов — это 16-битные числа, которые позволяют однозначно распознавать одну из сторон соединения на данном хосте. Объединение IPv4-адреса и номера порта обеспечивает идентификацию стороны соединения где-либо в пределах одной сети TCP/IP (например, Internet является единой TCP/IP сетью). Две конечные точки соединения образуют полное TCP-соединение, таким образом, две пары, состоящие из IP-номера и номера порта, однозначно определяют TCP/IP соединение в сети.
Распределение номеров портов для различных протоколов производится на основе раздела стандартов Internet, известного как
официальные номера портов, который утверждается Агентством по выделению имен и уникальных параметров протоколов Internet (
Internet Assigned Numbers Authority, LANA)
[128]. Общие протоколы Internet, такие как ftp, telnet и http, имеют свои номера портов. Большинство серверов предусматривают данные службы на присвоенных номерах, что позволяет их легко найти. Некоторые сервера запускаются на альтернативных номерах портов, как правило, для поддержки нескольких служб на одной машине
[129]. Поскольку официальные номера портов не изменяются, система Linux просто находит соответствие между именами протоколов (обычно называемых
службами) и номерами портов с помощью файла
/etc/services.
Все номера портов попадают в диапазон от 0 до 65 535; в системе Linux они разделяются на два класса.
Зарезервированные порты с номерами от 0 до 1 024 могут использоваться только процессами, работающими как root. Это позволяет клиентским программам иметь гарантию того, что программа, запущенная на сервере, не является троянским конем, активизированным каким-то пользователем
[130].
IPv4-адреса хранятся в структуре
struct sockaddr_in, которая определяется следующим образом.
#include <sys/socket.h>
#include <netinet/in.h>
struct sockaddr_in {
short int sin_family; /* AF_INET */
unsigned short int sin_port; /* номер порта */
struct in_addr sin_addr; /* IP-адрес */
}
Первым членом должен быть
AF_INET, указывающий, что это IP-адрес. Следующий член — это номер порта в сетевом порядке байтов. Последний элемент — это IP-номер машины для данного TCP адреса. IP-номер, хранящийся в
sin_addr, должен трактоваться как непрозрачный тип и не иметь возможности прямого доступа.
Если хотя бы одна из переменных
sin_port или
sin_addr заполнена байтами
\0 (обычно функцией
memset()), то это указывает на условие "пренебречь". Серверные процессы, как правило, не беспокоятся о том, какой IP-адрес используется для локального соединения. Другими словами, они согласны принимать соединения с любым адресом, имеющимся на данной машине. Если в приложении требуется принимать соединения только на одном интерфейсе, то при этом нужно обязательно указать адрес. Такой адрес иногда называется
неустановленным, поскольку он не представляет собой полное определение адреса соединения (для него требуется еще IP-адрес)
[131].
17.5.3. Адресация IPv6
В IPv6 используется тот же самый кортеж (
локальный хост,
локальный порт,
удаленный хост,
удаленный порт), что и в IPv4, и одни и те же номера портов (16-битные значения).
IPv6-адреса локального и удаленного хостов являются 128-битными (16-байтовыми) числами вместо 32-битных чисел, которые использовались в IPv4. Применение таких больших адресов обеспечивает протоколы достаточным количеством адресов для будущего развития (можно без проблем предоставить уникальный адрес каждому атому в Млечном Пути). На первый взгляд, это может показаться избыточной тратой ресурсов. Однако сетевые архитектуры имеют склонность небрежно относиться к адресам и растрачивать огромное их число впустую, поэтому разработчики версии IPv6 предпочли перейти к 128-битным адресам сейчас, чем переживать о возможной необходимости изменять адреса в будущем.
Аналогом десятичного представления с разделителями-точками, которое используется в IPv4, для версии IPv6 является представление с разделителями-двоеточиями. Как подсказывает название, двоеточия отделяют каждую пару байтов в адресе (вместо точки, которая отделяет каждый отдельный байт). Из-за большой длины IPv6-адреса записываются в шестнадцатеричной (а не в десятичной) форме, что помогает уменьшить их длину. Ниже показано несколько примеров того, как выглядит IPv6-адрес в представлении с разделителями-двоеточиями
[132].
1080:0:0:0:8:800:200С:417А
FF01:0:0:0:0:0:0:43
0:0:0:0:0:0:0:1
В связи с тем, что такие адреса являются слишком громоздкими и часто содержат приличное количество нулей, допускается сокращение. Все нули можно просто выбросить из записи адреса, а группы более чем из двух последовательных двоеточий заменить только одной парой двоеточий. Применение этих правил к записанным выше адресам дает следующий результат.
1080::8:800:200C:417A
FF01::43
::1
Если рассмотреть самый крайний случай, то адрес
0:0:0:0:0:0:0:0 превращается просто в выражение
::[133].
Последний метод записи IPv6-адресов заключается в том, что последние 32 бита представляются с разделительными точками, а первые 96 битов — с разделительными двоеточиями. При этом адрес обратной связи IPv6
::1 будет записан либо как
::0.0.0.1, либо как
0:0:0:0:0:0:0.0.0.1.
IPv6 определяет любой адрес с 96 начальными нулями (за исключением адреса обратной связи и неустановленного адреса) как совместимый IPv4-адрес, который позволяет сетевым маршрутизаторам передавать через сети IPv6 пакеты, предназначенные для IPv4-хостов. Сокращение двоеточий позволяет легко записать IPv4-адрес как IPv6-адрес путем добавления
:: перед стандартным десятичным адресом с точками. Такой тип адресов называется IPv4-совместимым IPv6-адресом. Такая адресация применяется только маршрутизаторами; обычные программы не могут воспользоваться ее преимуществами.
Программы, работающие на машинах IPv6 и требующие обращения к машинам IPv4, могут использовать отображенные IPv4-адреса. Они дополняют IPv4-адрес 80-ю нулевыми старшими разрядами и 16-битным значением
0xffff, которое записывается как
::ffff:, а за ним следует десятичный IPv4-адрес с точками. Подобная адресация позволяет большинству программ в системе, поддерживающей только версию IPv6, явно общаться с узлами IPv4.
IPv6-адреса хранятся в переменных типа
struct sockaddr_in6.
#include <sys/socket.h>
#include <netinet/in.h>
struct sockaddr_in6 {
short int sin6_family; /* AF_INET6 */
unsigned short int sin6_port; /* номер порта */
unsigned int sin6_flowinfo; /* информация о потоке обмена IPv6 */
struct in6_addr sin6_addr; /* IP-адрес */
unsigned int sin6_scope_id; /* набор граничных интерфейсов */
}
Данная структура подобна
struct sockaddr_in; здесь первый член сохраняет семейство адресов (в этом примере
AF_INET6), а следующий — 16-битный номер порта в сетевом порядке байтов.
Четвертый член содержит двоичное представление IPv6-адреса, выполняя те же самые функции, что и последний член структуры
struct sockaddr_in. Оставшиеся два элемента
sin6_flowinfo и
sin6_scope_id используются в более сложных задачах и для большинства приложений должны быть равны нулю.
Стандарты ограничивают
struct sockaddr_in в точности тремя членами, тогда как
struct sockaddr_in6 позволительно иметь дополнительные элементы. По этой причине программы, которые вручную заполняют
struct sockaddr_in6, должны обнулить все данные структуры с помощью функции
memset().
17.5.4. Манипулирование IP-адресами
В приложениях нередко требуется преобразовывать IP-адреса из удобочитаемых для человека представлений (либо десятичное с разделителями-точками, либо с разделителями-двоеточиями) в двоичное представление
struct in_addr и наоборот. Функция
inet_ntop() принимает двоичный IP-адрес и возвращает указатель на строку, содержащую десятичную форму с точками или двоеточиями.
#include <arpa/inet.h>
const char * inet_ntop(int family, const void * address, char * dest,
int size);
Здесь
family — это адресное семейство того адреса, который передается во втором параметре; поддерживаются только
AF_INET и
AF_INET6. Следующий параметр указывает на
struct in_addr или
struct in6_addr6 в зависимости от первого параметра. Значение
dest представляет массив символов, состоящий из
size элементов, в котором хранится адрес, удобочитаемый для человека. Если форматирование адреса прошло успешно, то функция
inet_ntop() возвращает
dest, в противном случае возвращается
NULL. Существуют только две причины, по которым
inet_ntop() может не выполнить свою работу: если буфер назначения недостаточно велик для хранения форматированного адреса (переменной errno присваивается значение
ENOSPC) или если параметр
family задан неверно (errno содержит
EAFNOSUPPORT).
INET_ADDRSTRLEN является константой, определяющей наибольший размер
dest, необходимый для хранения любого IPv4-адреса. Соответственно,
INET6_ADDRSTRLEN определяет максимальный размер массива для IPv6-адреса.
Программа-пример
netlookup.с демонстрирует использование
inet_ntop(); полная программа представлена далее в этой главе.
120: if (addr->ai_family == PF_INET) {
121: struct sockaddr_in * inetaddr = (void*)addr->ai_addr;
122: char nameBuf[INET_ADDRSTRLEN];
123:
124: if (serviceName)
125: printf("\tport %d", ntohs(inetaddr->sin_port));
126:
127: if (hostName)
128: printf("\thost %s",
129: inet_ntop(AF_INET, &inetaddr->sin_addr,
130: nameBuf, sizeof(nameBuf)));
131: } else if (addr->ai_family == PF_INET6) {
132: struct sockaddr_in6 *inetaddr =
133: (void *) addr->ai_addr;
134: char nameBuf[INET6_ADDRSTRLEN];
135:
136: if (serviceName)
137: printf("\tport %d", ntohs(inetaddr->sin6_port));
138:
139: if (hostName)
140: printf("\thost %s",
141: inet_ntop(AF_INET6, &inetaddr->sin6_addr,
142: nameBuf, sizeof(nameBuf)));
143: }
Обратное преобразование строки, содержащей адрес с точками или двоеточиями, в двоичный IP-адрес выполняет функция
inet_pton().
#include <arpa/inet.h>
int inet_pton(int family, const char * address, void * dest);
Параметр
family определяет тип преобразуемого адреса (либо
AF_INET, либо
AF_INET6), a
address указывает на строку, в которой содержится символьное представление адреса. Если используется
AF_INET, то десятичная строка с точками преобразуется в двоичный адрес, хранящийся в переменной, на которую указывает параметр
dest структуры
struct in_addr. Для
AF_INET6 строка с двоеточиями преобразуется и сохраняется в переменной, на которую указывает
dest структуры
struct in6_addr. В отличие от большинства библиотечных функций,
inet_pton() возвращает
1, если преобразование прошло успешно,
0, если
dest не содержит соответствующий адрес, и
-1, если параметр
family не совпадает с
AF_INET или
AF_INET6.
Программа-пример
reverselookup, код которой представлен далее в главе, использует функцию
inet_pton() для преобразования IPv4- и IPv6-адресов, передаваемых пользователем, в структуры
struct sockaddr. Ниже приводится раздел кода, выполняющий преобразования IP-адреса, на который указывает
hostAddress. В конце данного кода
struct sockaddr * addr указывает на структуру, содержащую преобразованный адрес.
79: if (!hostAddress) {
80: addr4.sin_family = AF_INET;
81: addr4.sin_port = portNum;
82: } else if (! strchr(hostAddress, ':')) {
83: /* Если в hostAddress появляется двоеточие, то принимаем версию IPv6.
84: В противном случае это IPv4-адрес */
85:
86: if (inet_pton(AF_INET, hostAddress,
87: &addr4.sin_addr) <= 0) {
88: fprintf(stderr, "ошибка преобразования IPv4-адреса %s\n",
89: hostAddress);
90: return 1;
91: }
92:
93: addr4.sin_family = AF_INET;
94: addr4.sin_port = portNum;
95: } else {
96:
97: memset(&addr6, 0, sizeof(addr6));
98:
99: if (inet_pton(AF_INET6, hostAddress,
100: &addr6.sin6_addr) <= 0) {
101: fprintf(stderr, "ошибка преобразования IPv6-адреса %s\n",
102: hostAddress);
103: return 1;
104: }
105:
106: addr6.sin6_family = AF_INET6;
107: addr6.sin6_port = portNum;
108: addr = (struct sockaddr *) &addr6;
109: addrLen = sizeof(addr6);
110: }
17.5.5. Преобразование имен в адреса
Длинные последовательности чисел являются отлично подходящим методом идентификации для компьютеров, позволяющим им однозначно узнавать друг друга. Однако большинство людей охватывает ужас при мысли о том, что придется иметь дело с большим количеством цифр. Для того чтобы разрешить людям применять текстовые названия для компьютеров вместо числовых, в состав протоколов TCP/IP входит распределенная база данных для взаимных преобразований имен хостов и IP-адресов. Эта база данных называется
DNS (Domain Name System — служба имен доменов), она подробно рассматривается в [34] и [1].
Служба DNS предлагает много функций, но сейчас нас интересует одна — возможность преобразования IP-адресов в имена хостов и наоборот. Несмотря на то что это преобразование должно выполняться как однозначное соответствие, на самом деле оно представляет собой отношение типа "многие ко многим". Другими словами, каждый IP-адрес может соответствовать нулю или более именам хостов, а каждое имя хоста соответствует нулю или более IP-адресам.
Использование неоднозначного соответствия между именами хостов и IP-адресами может показаться странным. Однако многие Internet-сайты применяют одну и ту же машину для ftp-сайта и Web-сайта. При этом адреса
www.some.org и
ftp.some.org должны ссылаться на одну и ту же машину, а для одной машины не нужны два IP-адреса. Таким образом, два имени хостов сводятся к одному IP-адресу. Каждый IP-адрес имеет одно первичное, или
каноническое имя хоста, которое используется, если IP-адрес требуется преобразовать в единственное имя хоста во время
обратного поиска имен.
Наиболее распространенной причиной, по которой одному имени хоста ставится в соответствие несколько IP-адресов, является балансировка нагрузки. Серверы имен (программы, предлагающие преобразование имен хостов в IP-адреса) часто конфигурируются так, что возвращают в разное время разные адреса для одного и того же имени. Это позволяет нескольким физическим машинам поддерживать единую службу.
Появление IPv6 повлекло за собой еще одну причину, по которой одно имя хоста должно иметь несколько адресов. Многие машины сейчас имеют одновременно и IPv4-, и IPv6-адреса.
Библиотечная функция
getaddrinfo()[134] предлагает программам простой доступ к преобразованиям имен хостов DNS.
#include <sys/types.h>
#include <socket.h>
#include <netdb.h>
int getaddrinfo(const char * hostname, const char * servicename,
const struct addrinfo * hints, struct addrinfo ** res);
Концепция этой функции достаточно простая, однако весьма мощная, в связи с этим ее описание может показаться несколько запутанным. Идея заключается в том, что функция принимает имя хоста, имя службы (или оба из них) и превращает их в список IP-адресов. Затем с использованием
hints список фильтруется и те адреса, которые не нужны приложению, отбрасываются. Окончательный список возвращается в виде связного списка в переменной
res.
Искомое имя хоста содержится в первом параметре и может равняться
NULL, если производится поиск только службы. Параметр
hostname может быть именем (например,
www.ladweb.net) или IP-адресом (с точками или двоеточиями в качестве разделителей), который функция
getaddrinfo() преобразует в двоичный адрес.
Второй параметр
servicename указывает имя той службы, для которой нужно извлечь официальный порт. Если он равен
NULL, то поиск службы не выполняется.
Структура
struct addrinfo используется как для
hints (при фильтрации полного списка адресов), так и для передачи окончательного списка в приложение.
#include <netdb.h>
struct addrinfo {
int ai_flags;
int ai_family;
int ai_socktype;
int ai_protocol;
socklen_t ai_addrlen;
struct sockaddr_t * ai_addr;
char * ai_canonname;
struct addrinfo * next;
}
Если
struct addrinfo используется для параметра
hints, то участвуют только первые четыре члена, остальные должны равняться нулю или
NULL. Если задано значение
ai_family, то
getaddrinfo() возвращает адреса только для указанного семейства протоколов (например,
PF_INET). Аналогично, если устанавливается
ai_socktype, то возвращаются только адреса данного типа сокета.
Член
ai_protocol позволяет ограничивать результаты определенным протоколом. Этот параметр нельзя применять, если не установлен параметр
ai_family, а также, если числовое значение протокола (такое как
IPPROTO_TCP) не является уникальным среди всех протоколов; он хорошо подходит только для
PF_INET и
PF_INET6.
Последний член, используемый для
hints — это
aflags, который принимает одно или несколько (объединенных логическим "ИЛИ") из перечисленных ниже значений.
AI_ADDRCONFIG
По умолчанию функция
getaddrinfo() возвращает все адреса, соответствующие запросу. Данный флаг указывает на возврат адресов только тех протоколов, чьи адреса сконфигурированы в локальной системе. Другими словами, она возвращает только IPv4-адреса в системах с IPv4-интерфейсами и только IPv6-адреса в системах с интерфейсами IPv6.
AI_CANONNAME
При возврате поле
ai_canonname содержит каноническое имя хоста для адреса, указанного в
struct addrinfo. Поиск этого адреса сопровождается дополнительными поисками в службе DNS и, как правило, не является необходимым.
AI_NUMERICHOST
Параметр
hostname должен представлять собой адрес в форме с разделительными запятыми или двоеточиями. Никакие преобразования имени хоста не выполняются. Это предохраняет
getaddrinfo() от каких-либо поисков имени хоста, которые могут оказаться весьма длительным процессом.
AI_PASSIVE
Если hostname равен
NULL и присутствует этот флаг, то возвращается неустановленный адрес, который позволяет ожидать соединений на всех интерфейсах. Если данный флаг не указан (а значение
hostname равно
NULL), возвращается адрес обратной связи
[135].
Последний параметр
res в
getaddrinfo() должен быть адресом указателя на
struct addrinfo. Для успешного завершения переменная, на которую указывает
res, устанавливается на первую запись в односвязном списке адресов, который соответствует запросу. Член
ai_next структуры
struct addrinfo указывает на следующий член связного списка, и для последнего узла в списке параметр
ai_next равен
NULL.
Когда приложение завершает работу с возвращенным связным списком, функция
freeaddrinfo() освобождает память, занимаемую списком.
#include <sys/types.h>
#include <socket.h>
#include <netdb.h>
void freeaddrinfo(struct addrinfo * res);
Единственным параметром для
freeaddrinfo является указатель на первый узел в списке.
Каждый узел в возвращаемом списке имеет тип
struct addrinfo и специфицирует один адрес, соответствующий запросу. Каждый адрес содержит не только IPv4- или IPv6-адрес, он также определяет тип соединения (например, дейтаграмма) и протокол (такой как UDP). Если для одного IP-адреса в запросе подходит несколько типов соединений, то данный адрес включается в несколько узлов.
Каждый узел содержит описанную ниже информацию.
•
ai_family — семейство протоколов (
PF_INET или
PF_INET6), к которому принадлежит адрес.
•
ai_socktype — тип соединения для адреса (как правило, принимает одно из значений
SOCK_STREAM,
SOCK_DGRAM или
SOCK_RAW).
•
ai_protocol — протокол для адреса (обычно
IPPROTO_TCP или
IPPROTO_UDP).
• Если в параметре
hints был указан флаг
AI_CANONNAME, то
ai_canonname содержит каноническое имя для адреса.
•
ai_addr указывает на
struct sockaddr для соответствующего протокола. Например, если
ai_family принимает значение
PF_INET, то
ai_addr указывает на
struct sockaddr_in. Член
ai_addrlen определяет длину структуры, на которую указывает
ai_addr.
• Если предусмотрен параметр
servicename, то в качестве номера порта в каждом адресе устанавливается официальный порт данной службы. В противном случае номер порта для каждого адреса равен нулю.
• Если не был передан параметр
hostname, то номера портов устанавливаются для каждого адреса, однако в качестве IP-адреса определяется или адрес обратной связи, или неустановленный адрес (как указывалось ранее в описании флага
AI_PASSIVE).
Все это может показаться достаточно запутанным. На самом деле, существует только два различных способа стандартного применения функции
getaddrinfo(). Большинство клиентских программ стремятся превратить имя хоста, передаваемое пользователем, и имя службы, известное программе, в полностью определенный адрес, с которым пользователь может установить соединение. Достичь этой цели нетрудно. Ниже приводится программа, которая принимает имя хоста как первый аргумент и имя службы как второй, после чего выполняет все необходимые преобразования.
1: /* clientlookup.c */
2:
3: #include <netdb.h>
4: #include <stdio.h>
5: #include <string.h>
6:
7: int main(int argc, const char ** argv) {
8: struct addrinfo hints, * addr;
9: const char * host = argv[1], * service = argv[2];
10: int rc;
11:
12: if (argc != 3) {
13: fprintf(stderr, "требуется в точности два аргумента\n");
14: return 1;
15: }
16:
17: memset(&hints, 0, sizeof(hints));
18:
19: hints.ai_socktype = SOCK_STREAM;
20: hints.ai_flags = AI_ADDRCONFIG;
21: if ((rc = getaddrinfo(host, service, &hints, &addr)))
22: fprintf(stderr, "сбой поиска\n");
23: else
24: freeaddrinfo(addr);
25:
26: return 0;
27: }
Давайте обратим внимание на строки 17–24 этой программы. После очистки структуры hints приложение запрашивает адреса
SOCK_STREAM, которые используют протокол, сконфигурированный на локальной системе (путем установки флага
AI_ADDRCONFIG). Затем активизируется функция
getaddrinfo() с именем хоста, именем службы, подсказками и в случае невозможности найти соответствие отображается сообщение об ошибке. Если все проходит нормально, то первый элемент в связном списке, на который указывает
addr, представляет собой соответствующий адрес, который программа может использовать для установки соединения с указанной службой и хостом. Программа не решает, через какой протокол (IPv4 или IPv6) соединение будет лучшим.
Серверные приложения немного проще. В них, как правило, требуется согласиться на соединение с определенным портом, при этом на всех адресах. Если установлены флаги
AI_PASSIVE, функция
getaddrinfo() возвращает адрес, вынуждающий ядро разрешать все соединения (со всеми адресами, которые оно знает) при условии, что в качестве первого параметра передается
NULL. Как и в клиентском примере, используется
AI_ADDRCONFIG, дабы убедиться, что возвращаемый адрес соответствует протоколу, который поддерживает данная машина.
1: /* serverlookup.с */
2:
3: #include <netdb.h>
4: #include <stdio.h>
5: #include <string.h>
6:
7: int main(int argc, const char ** argv) {
8: struct addrinfo hints, * addr;
9: const char * service = argv[1];
10: int rc;
11:
12: if (argc != 3) {
13: fprintf(stderr, "требуется в точности один аргумент\n");
14: return 1;
15: }
16:
17: memset(&hints, 0, sizeof(hints));
18:
19: hints.ai_socktype = SOCK_STREAM;
20: hints.ai_flags = AI_ADDRCONFIG | AI_PASSIVE;
21: if ((rc = getaddrinfo(NULL, service, &hints, &addr)))
22: fprintf(stderr, "сбой поиска\n");
23: else
24: freeaddrinfo(addr);
25:
26: return 0;
27: }
После успешного завершения работы
getaddrinfo() первый узел в связном списке может использоваться сервером для установки сокета.
Следующий пример демонстрирует куда более полезную программу. Она предоставляет интерфейс командной строки для большинства возможностей
getaddrinfo(). Она дает возможность пользователю указывать имя хоста или имя службы (или оба имени), тип сокета (потоковый или дейтаграммный), семейство адресов, протокол (TCP или UDP). Пользователь может также запрашивать программу отображать каноническое имя или только те адреса для протоколов, для которых сконфигурирована машина (через флаг
AI_ADDRCONFIG). Ниже показано, как можно применить программу для извлечения адреса для telnet-соединения с локальной машиной (данная машина сконфигурирована и под IPv4, и под IPv6).
$ ./netlookup --hdst localhost --service telnet
IPv6 stream tcp port 23 host ::1
IPv6 dgram udp port 23 host ::l
IPv4 stream tcp port 23 host 127.0.0.1
IPv4 dgram udp port 23 host 127.0.0.1
Поскольку для telnet не определен ни один протокол через дейтаграммное соединение (хотя официальный порт для подобной службы зарезервирован), мы рекомендуем ограничить поиск потоковыми протоколами.
[ewt@patton code]$ ./netlookup --host localhost -service telnet --stream
IPv6 stream tcp port 23 host ::1
IPv4 stream tcp port 23 host 127.0.0.1
После возврата локальной машины в исходное состояние для IPv6, та же самая команда выглядит следующим образом.
[ewt@patton code]$ ./netlookup --host localhost --service telnet —stream
IPv4 stream tcp port 23 host 127.0.0.1
Вот так выглядит поиск соответствия для хоста Internet, который имеет и IPv4, и IPv6 конфигурации.
$ ./netlookup --host www.6bone.net —stream
IPv6 stream tcp host 3ffe:b00:c18:1::10
IPv4 stream tcp host 206.123.31.124
Для того чтобы увидеть полный перечень опций командной строки, которые предлагает
netlookup.с, запустите данную программу без параметров.
1: /* netlookup.с */
2:
3: #include <netdb.h>
4: #include <arpa/inet.h>
5: #include <netinet/in.h>
6: #include <stdio.h>
7: #include <string.h>
8: #include <stdlib.h>
9:
10: /* Вызывается, если во время обработки командной строки происходит ошибка;
11: отображает короткое сообщение для пользователя и завершается. */
12: void usage(void) {
13: fprintf(stderr, "использование: netlookup [--stream] [--dgram] "
14: "[--ipv4] [--ipv6] [--name] [--udp]\n");
15: fprintf (stderr, " [--tcp] [--cfg] "
16: "[--service <служба>] [--host <имя_хоста>]\n");
17: exit(1);
18: }
19:
20: int main(int argc, const char ** argv) {
21: struct addrinfo * addr, * result;
22: const char ** ptr;
23: int rc;
24: struct addrinfo hints;
25: const char * serviceName = NULL;
26: const char * hostName = NULL;
27:
28: /* очищает структуру подсказок */
29: memset(&hints, 0, sizeof(hints));
30:
31: /* анализирует аргументы командной строки, игнорируя argv[0]
32:
33: Структура hints, параметры serviceName и hostName будут
34: заполнены на основе переданных аргументов. */
35: ptr = argv + 1;
36: while (*ptr && *ptr[0] == '-') {
37: if (!strcmp(*ptr, "--ipv4"))
38: hints.ai_family = PF_INET;
39: else if (!strcmp(*ptr, "--ipv6"))
40: hints.ai_family = PF_INET6;
41: else if (!strcmp(*ptr, "--stream"))
42: hints.ai_socktype = SOCK_STREAM;
43: else if (!strcmp(*ptr, "--dgram"))
44: hints.ai_socktype = SOCK_DGRAM;
45: else if (!strcmp(*ptr, "--name"))
46: hints.ai_flags |= AI_CANONNAME;
47: else if (!strcmp(*ptr, "--cfg"))
48: hints.ai_flags |= AI_ADDRCONFIG;
49: else if (!strcmp(*ptr, "--tcp")) {
50: hints.ai_protocol = IPPROTO_TCP;
51: } else if (!strcmp(*ptr, "--udp")) {
52: hints.ai_protocol = IPPROTO_UDP;
53: } else if (!strcmp(*ptr, "--host")) {
54: ptr++;
55: if (!*ptr) usage();
56: hostName = *ptr;
57: } else if (!strcmp(*ptr, "--service")) {
58: ptr++;
59: if (!*ptr) usage();
60: serviceName = *ptr;
61: } else
62: usage();
63:
64: ptr++;
65: }
66:
67: /* необходимы имена hostName, serviceName или оба */
68: if (!hostName && !serviceName)
69: usage();
70:
71: if ((rc = getaddrinfo(hostName, serviceName, &hints,
72: &cresult))) {
73: fprintf(stderr, "сбой поиска службы: %s\n",
74: gai_strerror(rc));
75: return 1;
76: }
77:
78: /* проходит по связному списку, отображая все результаты */
79: addr = result;
80: while (addr) {
81: switch (addr->ai_family) {
82: case PF_INETs: printf("IPv4");
83: break;
84: case PF_INET6: printf("IPv6");
85: break;
86: default: printf("(%d) addr->ai_family);
87: break;
88: }
89:
90: switch (addr->ai_socktype) {
91: case SOCK_STREAM: printf("\tstream");
92: break;
93: case SOCK_DGRAM: printf("\tdgram");
94: break;
95: case SOCK_RAW: printf("\traw");
96: break;
97: default: printf("\t(%d)
98: addr->ai_socktype);
99: break;
100: }
101:
102: if (addr->ai_family == PF_INET ||
103: addr->ai_family == PF_INET6)
104: switch (addr->ai_protocol) {
105: case IPPROTO_TCP: printf("\ttcp");
106: break;
107: case IPPROTO_UDP: printf("\tudp");
108: break;
109: case IPPROTO_RAW: printf("\traw");
110: break;
111: default: printf("\t(%d)
112: addr->ai_protocol);
113: break;
114: }
115: else
116: printf("\t");
117:
118: /* отобразить информацию и для IPv4-, и для IPv6-адресов */
119:
120: if (addr->ai_family == PF_INET) {
121: struct sockaddr_in * inetaddr = (void*)addr->ai_addr;
122: char nameBuf[INET_ADDRSTRLEN];
123:
124: if (serviceName)
125: printf("\tпорт%d", ntohs(inetaddr->sin_port));
126:
127: if (hostName)
128: printf("\tхост%s",
129: inet_ntop(AF_INET, &inetaddr->sin_addr,
130: nameBuf, sizeof(nameBuf)));
131: } else if (addr->ai_family == PF_INET6) {
132: struct sockaddr_in6 * inetaddr =
133: (void*)addr->ai_addr;
134: char nameBuf[INET6_ADDRSTRLEN];
135:
136: if (serviceName)
137: printf("\tпорт%d", ntohs(inetaddr->sin6_port));
138:
139: if (hostName)
140: printf("\tхост%s",
141: inet_ntop(AF_INET6, &inetaddr->sin6_addr,
142: nameBuf, sizeof(nameBuf)));
143: }
144:
145: if (addr->ai_canonname)
146: printf("\tname%s", addr->ai_canonname);
147:
148: printf("\n");
149:
150: addr = addr->ai_next;
151: }
152:
153: /* очистить результаты getaddrinfo() */
154: freeaddrinfo(result);
155:
156: return 0;
157: }
В отличие от большинства библиотечных функций,
getaddrinfo() возвращает целое число, которое равно нулю в случае успеха, и описывает ошибку в случае неудачи. Такие функции, как правило, не используют
errno. В табл. 17.3 описаны различные коды ошибок, которые могут возвращать подобные функции.
Таблица 17.3. Ошибки поиска соответствия адреса и имени
| Ошибка |
Описание |
EAI_AGAIN |
Имя не может быть найдено. Повторный поиск может оказаться успешным. |
EAI_BADFLAGS |
В функцию переданы недействительные флаги. |
EAI_FAIL |
В процессе поиска соответствия возникла постоянная ошибка. |
EAI_FAMILY |
Семейство адресов не распознано. |
EAI_MEMORY |
Запрос на выделение памяти не выполнен. |
EAI_NONAME |
Имя или адрес невозможно преобразовать. |
EAI_OVERFLOW |
Переданный буфер слишком мал. |
EAI_SERVICE |
valign = "top" >Для данного типа сокета служба не существует. |
EAI_SOCKTYPE |
Был передан недействительный тип сокета. |
EAI_SYSTEM |
Произошла системная ошибка; сама ошибка содержится в переменной errno. |
Коды ошибок можно преобразовать в строки, описывающие проблему, с помощью функции
gai_strerror().
#include <netdb.h>
const char * gai_strerror(int error);
Здесь параметр
error должен быть ненулевым значением, возвращенным функцией
getaddrinfo(). Если произошла ошибка
EAI_SYSTEM, то для получения более точного описания программа должна использовать
strerror(errno).
17.5.6. Преобразование адресов в имена
К счастью, переводить IP-адреса и номера портов в имена хостов и служб гораздо проще, чем наоборот.
#include <sys/socket.h>
#include <netdb.h>
int getnameinfo(struct sockaddr * addr, socklen_t addrlen,
char * hostname, size_t hostlen,
char * servicename, size_tservicelen, intflags);
Здесь параметр
addr указывает либо на
struct sockaddr_in, либо на
struct sockaddr_in6, член
addrlen содержит размер структуры, на которую указывает
addr. IP-адрес и номер порта, определенные
addr, преобразуются в имя хоста, сохраняющееся в ячейке, на которую указывает
hostname, и в имя службы, сохраняющееся в
servicename.
Один из параметров может равняться
NULL, при этом функция
getnameinfo() не ищет соответствие имени для данного параметра.
Параметры
hostlen и
servicelen определяют, сколько байт доступно в буферах, на которые указывают
hostname и
servicename соответственно. Если ни одно имя не умещается в доступном пространстве, буфера переполняются и возвращается ошибка (
EAI_OVERFLOW).
Последний аргумент
flags изменяет способ, которым функция
getnameinfo() производит поиск имен. Параметр должен быть равен нулю или принимать одно или несколько (объединенных логическим "ИЛИ") из описанных ниже значений.
NI_DGRAM |
Отыскивается имя службы UDP для указанного порта (вместо имени службы TCP). Примечание. Эти два имени почти всегда идентичны, однако существует несколько портов, определенных только для UDP-портов (протокол прерывания SNMP — один из них), и несколько случаев, когда один и тот же номер порта используется для различных TCP и UDP служб (например, порт 512 применяется и для TCP-службы exec, и для UDP-службы biff). |
NI_NAMEREQD |
Если преобразование IP-адреса в имя хоста завершается неудачей и установлен данный флаг, то функция getnameinfo() возвращает ошибку. В противном случае она возвращает IP-адрес в формате с разделительными точками или двоеточиями. |
NI_NOFQDN |
Имена хостов обычно возвращаются как полностью уточненные имена доменов. Это означает, что возвращается полное имя хоста, а не локальное сокращение. Если, к примеру, установлен данный флаг, вашим хостом является digit.iana.org, и вы ищете IP-адрес, соответствующий www.iana.org, тогда будет возвращено имя хоста www. Поиск имен хостов для остальных машин при этом не затрагивается (в предыдущем примере поиск адреса для www.ietf.org предоставит полное имя хоста www.ietf.org. |
NI_NUMERICHOST |
Вместо выполнения поиска имен хостов функция getnameinfo() преобразует IP-адрес в IP-адрес по аналогии с inet_ntop(). |
NI_NUMERICSERV |
Номер порта размещается в servicename в виде форматированной числовой строки (а не преобразуется в имя службы). |
Возвращаемые коды для
getnameinfo() — те же самые, что и для
gethostinfо(); в случае успеха возвращается нуль, в случае неудачи — код ошибки. Полный перечень возможных ошибок приведен в табл. 17.3. Для преобразования этих ошибок в описательные строки служит функция
gai_strerror().
Ниже приведен пример, показывающий использование
getnameinfo() для выполнения обратного поиска имени для адресов IPv4 и IPv6.
$ ./reverselookup --host ::1
hostname: localhost
$ ./reverselookup --host 127.0.0.1
hostname: localhost
$ ./reverselookup --host 3ffe:b00:c18:1::10
hostname: www.6bone.net
$ ./reverselookup --host 206.123.31.124 --service 80
hostname: www.6bone.net service name: http
1: /* reverselookup.с */
2:
3: #include <netdb.h>
4: #include <arpa/inet.h>
5: #include <netinet/in.h>
6: #include <stdio.h>
7: #include <string.h>
8: #include <stdlib.h>
9:
10: /* Вызывается, если во время обработки командной строки происходит ошибка;
11: отображает короткое сообщение для пользователя и завершается. */
12: void usage(void) {
13: fprintf(stderr, "использование: reverselookup [--numerichost] "
14: "[--numericserv] [--namereqd] [--udp]\n");
15: fprintf(stderr, " [--nofqdn] "
16: "[--service<служба>] [--host<имя_хоста>]\n");
17: exit(1);
18: }
19:
20: int main(int argc, const char ** argv) {
21: int flags;
22: const char * hostAddress = NULL;
23: const char * serviceAddress = NULL;
24: struct sockaddr_in addr4;
25: struct sockaddr_in6 addr6;
26: struct sockaddr *addr = (struct sockaddr *) &addr4;
27: int addrLen = sizeof(addr4);
28: int rc;
29: int portNum = 0;
30: const char ** ptr;
31: char hostName[1024];
32: char serviceName[256];
33:
34: /* очистить флаги */
35: flags = 0;
36:
37: /* разобрать аргументы командной строки, игнорируя argv[0] */
38: ptr = argv + 1;
39: while (*ptr && *ptr[0] == '-') {
40: if (!strcmp(*ptr, "—numerichost")) {
41: flags |= NI_NUMERICHOST;
42: } else if (!strcmp (*ptr, "--numericserv")) {
43: flags |= NI_NUMERICSERV;
44: } else if (!strcmp (*ptr, "--namereqd")) {
45: flags |= NI_NAMEREQD;
46: } else if (!strcmp(*ptr, "--nofqdn")) {
47: flags |= NI_NOFQDN;
48: } else if (!strcmp (*ptr, "--udp")) {
49: flags |= NI_DGRAM;
50: } else if (!strcmp(*ptr, "--host")) {
51: ptr++;
52: if (!*ptr) usage();
53: hostAddress = *ptr;
54: } else if (!strcmp(*ptr, "--service")) {
55: ptr++;
56: if (!*ptr) usage();
57: serviceAddress = *ptr;
58: } else
59: usage();
60:
61: ptr++;
62: }
63:
64: /* необходимы адреса hostAddress, serviceAddress или оба */
65: if (!hostAddress && !serviceAddress)
66: usage();
67:
68: if (serviceAddress) {
69: char * end;
70:
71: portNum = htons(strtol(serviceAddress, &end, 0));
72: if (*end) {
73: fprintf(stderr, "сбой при преобразовании %s в число\n",
74: serviceAddress);
75: return 1;
76: }
77: }
78:
79: if (!hostAddress) {
80: addr4.sin_family = AF_INET;
81: addr4.sin_port = portNum;
82: } else if (!strchr(hostAddress, ':')) {
83: /* Если hostAddress содержит двоеточие, то предполагаем версию IPv6.
84: В противном случае это IPv4 */
85:
86: if (inet_pton(AF_INET, hostAddress,
87: &addr4.sin_addr) <= 0) {
88: fprintf(stderr, "ошибка преобразования IPv4-адреса %s\n",
89: hostAddress);
90: return 1;
91: }
92:
93: addr4.sin_family = AF_INET;
94: addr4.sin_port = portNum;
95: } else {
96:
97: memset(&addr6, 0, sizeof(addr6));
98:
99: if (inet_pton(AF_INET6, hostAddress,
100: &addr6.sin6_addr) <= 0) {
101: fprintf(stderr, "ошибка преобразования IPv6-адреса %s\n",
102: hostAddress);
103: return 1;
104: }
105:
106: addr6.sin6_family = AF_INET6;
107: addr6.sin6_port = portNum;
108: addr = (struct sockaddr *) &addr6;
109: addrLen = sizeof(addr6);
110: }
111:
112: if (!serviceAddress) {
113: rc = getnameinfo(addr, addrLen, hostName, sizeof(hostName),
114: NULL, 0, flags);
115: } else if (!hostAddress) {
116: rc = getnameinfo(addr, addrLen, NULL, 0,
117: serviceName, sizeof(serviceName), flags);
118: } else {
119: rc = getnameinfo(addr, addrLen, hostName, sizeof(hostName),
120: serviceName, sizeof(serviceName), flags);
121: }
122:
123: if (rc) {
124: fprintf(stderr, "сбой обратного поиска: %s\n",
125: gai_strerror(rc));
126: return 1;
127: }
128:
129: if (hostAddress)
130: printf("имя хоста: %s\n", hostName);
131: if (serviceAddress)
132: printf("имя службы: %s\n", serviceName);
133:
134: return 0;
135: }
17.5.7. Ожидание TCP-соединений
Ожидание соединений TCP происходит почти идентично ожиданию соединений домена Unix. Единственные различия заключаются в семействах протоколов и адресов. Ниже показан вариант примера сервера домена Unix, который работает через сокеты TCP.
1: /* tserver.с */
2:
3: /* Ожидает соединение на порте 4321. Как только соединение установлено,
4: из сокета в stdout копируются данные до тех пор, пока вторая
5: сторона не закроет соединение. Затем ожидает следующее соединение
6: с сокетом. */
7:
8: #include <arpa/inet.h>
9: #include <netdb.h>
10: #include <netinet/in.h>
11: #include <stdio.h>
12: #include <string.h>
13: #include <sys/socket.h>
14: #include <unistd.h>
15:
16: #include "sockutil.h" /* некоторые служебные функции */
17:
18: int main(void) {
19: int sock, conn, i, rc;
20: struct sockaddr address;
21: size_t addrLength = sizeof(address);
22: struct addrinfo hints, * addr;
23:
24: memset(&hints, 0, sizeof(hints));
25:
26: hints.ai_socktype = SOCK_STREAM;
27: hints.ai_flags = AI_PASSIVE | AI_ADDRCONFIG;
28: if ((rc = getaddrinfo(NULL, "4321", &hints, &addr))) {
29: fprintf(stderr, "сбой поиска имени хоста: %s\n",
30: gai_strerror(rc));
31: return 1;
32: }
33:
34: if ((sock = socket(addr->ai_family, addr->ai_socktype,
35: addr->ai_protocol)) < 0)
36: die("socket");
37:
38: /* Позволяет ядру повторно использовать адрес сокета. Это разрешает
39: нам запускать программу два раза подряд, не ожидая пока истечет
40: время для кортежа (ip-адрес, порт). */
41: i = 1;
42: setsockopt(sock, SOL_SOCKET, SO_REUSEADDR, &i, sizeof(i));
43:
44: if (bind(sock, addr->ai_addr, addr->ai_addrlen))
45: die("bind");
46:
47: freeaddrinfo(addr);
48:
49: if (listen(sock, 5))
50: die("listen");
51:
52: while ((conn = accept(sock, (struct sockaddr *) &address,
53: &addrLength)) >=0) {
54: printf("----получение данных\n");
55: copyData(conn, 1);
56: printf("----готово\n");
57: close(conn);
58: }
59:
60: if (conn < 0)
61: die("accept");
62:
63: close(sock);
64: return 0;
65: }
Обратите внимание на то, что IP-адрес, привязанный к сокету, указывает номер порта 4321, но не IP-адрес. Это предоставляет ядру возможность при необходимости воспользоваться локальным IP-адресом.
Код в строках 41–42 требует дополнительного объяснения.
41: i = 1;
42: setsockopt(sock, SOL_SOCKET, SO_REUSEADDR, &i, sizeof(i));
Linux-реализация TCP, как и в остальных системах Unix, вводит ограничения на то, насколько скоро можно повторно использовать кортеж (
локальный хост,
локальный порт)
[136]. Этот код устанавливает опцию на сокет, которая обходит это ограничение и позволяет дважды запускать сервер за короткий период времени. По сходной причине сервер-пример сокета домена Unix удаляет любой существующий файл сокета, прежде чем вызывать
bind().
Функция
setsockopt() позволяет устанавливать множество специальных опций для сокета и протокола:
#include <sys/socket.h>
int setsockopt(int sock, int level, int option,
const void * valptr, int vallength);
Первый аргумент — это сокет, для которого определяется опция. Второй аргумент,
level, указывает тип устанавливаемой опции. В нашем сервере используется
SOL_SOCKET, что указывает на установку опции обобщенного сокета. Параметр
option определяет опцию, которая подлежит изменению. Указатель на новое значение опции передается через
valptr, а размер значения, на которое указывает valptr, передается как
vallength. Для нашего сервера применяется указатель на ненулевое целое число, которое вводит в действие опцию
SO_REUSEADDR.
17.5.8. Клиентские приложения TCP
Клиенты TCP подобны клиентам домена Unix. Как правило, сразу же после создания сокета, клиент подключается к серверу с помощью функции
connect(). Единственное различие состоит в способе передачи адреса в
connect(). Вместо того, чтобы использовать имя файла, большинство клиентов TCP отыскивают имя хоста через функцию
getaddrinfo(), которая предоставляет информацию для
connect().
Ниже приводится несложный TCP-клиент, который взаимодействует с сервером, представленным в предыдущем разделе. Он принимает один аргумент: имя хоста, на котором работает сервер, или его IP-номер (в десятичном представлении с разделительными точками). Во всем остальном программа ведет себя также как клиент сокета домена Unix, показанный ранее в этой главе.
1: /* tclient.с */
2:
3: /* Подключиться к серверу, чье имя хоста или IP-адрес переданы в качестве
4: аргумента, на порте 4321. После соединения скопировать все содержимое
5: stdin в сокет, затем завершить работу. */
6:
7: #include <arpa/inet.h>
8: #include <netdb.h>
9: #include <netinet/in.h>
10: #include <stdio.h>
11: #include <stdlib.h>
12: #include <string.h>
13: #include <sys/socket.h>
14: #include <unistd.h>
15:
16: #include "sockutil.h" /* некоторые служебные функции */
17:
18: int main(int argc, const char ** argv) {
19: struct addrinfo hints, *addr;
20: struct sockaddr_in * addrinfo;
21: int rc;
22: int sock;
23:
24: if (argc !=2) {
25: fprintf(stderr, "поддерживается только одиночный аргумент\n");
26: return 1;
27: }
28:
29: memset(&hints, 0, sizeof(hints));
30:
31: hints.ai_socktype = SOCK_STREAM;
32: hints.ai_flags = AI_ADDRCONFIG;
33: if ((rc = getaddrinfo(argv[1], NULL, &hints, &addr))) {
34: fprintf(stderr, "сбой поиска имени хоста: %s\n",
35: gai_strerror(rc));
36: return 1;
37: }
38:
39: /* это позволяет получить доступ к sin_family и sin_port
40: (которые расположены там же, где и sin6_family и sin6_port) */
41: addrinfo = (struct sockaddr_in *) addr->ai_addr;
42:
43: if ((sock = socket(addrInfo->sin_family, addr->ai_socktype,
44: addr->ai_protocol)) < 0)
45: die("socket");
46:
47: addrInfo->sin_port = htons(4321);
48:
49: if (connect(sock, (struct sockaddr *) addrinfo,
50: addr->ai_addrlen))
51: die("connect");
52:
53: freeaddrinfo(addr);
54:
55: copyData(0, sock);
56:
57: close(sock);
58:
59: return 0;
60: }
17.6. Использование дейтаграмм UDP
Наряду с тем, что большинство приложений пользуются преимуществами потокового протокола TCP, некоторые предпочитают применять UDP. Давайте рассмотрим несколько причин, по которым дейтаграммная модель без установления соединений, предоставляемая UDP, может оказаться весьма полезной.
• Протоколы без соединений обрабатывают перезапуски машин более плавно, поскольку нет необходимости в переустановке соединений. Это очень заманчивое свойство для сетевых файловых систем (таких как NFS, действующей на основе UDP), поскольку оно позволяет перезапускать файловый сервер без уведомления клиента.
• Простейшие протоколы могут работать гораздо быстрее через дейтаграммный протокол. Служба имен доменов DNS использует UDP только по этой причине (несмотря на то что наряду с этим дополнительно поддерживается TCP). При установке соединения TCP клиентская машина отправляет сообщение на сервер, получает от сервера подтверждение, указывающее на активность соединения, затем сообщает серверу о том, что установлена клиентская сторона соединения
[137]23. После этого клиент может отправить свой запрос имени хоста на взаимодействующий сервер. Все это в итоге составляет процесс из пяти сообщений, не считая проверки ошибок и ожидания фактического отправления запроса и ответа на него. Используя UDP, запросы имени хоста пересылаются как первый пакет на сервер, который отвечает одним или более UDP-пакетами, тем самым уменьшая общий счетчик пакетов до пяти. Если клиент не получает ответ, то он просто перепосылает запрос.
• При первичной установке компьютеров часто требуется установить для них IP-адрес, а затем загрузить первую часть операционной системы через сеть
[138]. Применение UDP для подобных операций создает набор протоколов, который внедряется в такие машины гораздо проще, чем, если бы требовалась полная TCP-реализация.
17.6.1. Создание UDP-сокета
Как и любой другой сокет, UDP-сокет создается с помощью функции
socket(), однако второй аргумент должен быть
SOCK_DGRAM, а последний — либо
IPPROTO_UDP, либо просто ноль (так как UDP является стандартным IP-дейтаграммным протоколом).
После создания сокета ему необходимо присвоить номер локального порта. Это происходит тогда, когда программа удовлетворяет одному из следующих трех условий.
• Номер порта задается явно через вызов функции bind(). Этот шаг является обязательным для тех серверов, для которых необходимо получение дейтаграмм на номер официального порта. Системный вызов в точности совпадает с системным вызовом для TCP-серверов.
• Дейтаграмма посылается через сокет. Ядро присваивает данному сокету номер порта UDP при первой передаче данных через него. В большинстве клиентских программ применяется именно этот прием, поскольку номер используемого порта для них не имеет значения.
• Для сокета устанавливается удаленный адрес через функцию
connect() (которая является дополнительной для UDP-сокетов).
Также существует два различных способа присвоения номера удаленного порта. Вспомните о том, что TCP-сокеты имеют удаленный адрес, который присваивается через
connect(). Этот адрес может использоваться и для UDP-сокетов
[139]. При этом функция
connect() для TCP вызывает обмен пакетами для инициализации соединения (что делает
connect() медленным системным вызовом), в то время как вызов
connect() для UDP-сокетов просто присваивает удаленный IP-адрес и номер порта для исходящих дейтаграмм (и является быстрым системным вызовом). Еще одно различие состоит в том, что приложения могут подключаться к TCP-сокету только один раз; UDP-сокеты могут повторно использовать свои адреса назначения
[140].
Преимущество использования подключенных UDP-сокетов состоит в том, что только та машина и порт, которые указаны как удаленный адрес для сокета, могут передавать дейтаграммы в данный сокет. Произвольный IP-адрес и порт может посылать дейтаграммы в неподключенный UDP-сокет, который требуется в некоторых случаях (именно через него новые клиенты впервые связываются с серверами), однако при этом программы должны отслеживать место отправки дейтаграмм.
17.6.2. Отправка и получение дейтаграмм
Для отправки и получения UDP-пакетов обычно используются четыре системных вызова
[141]:
send(),
sendto(),
recv(),
recvfrom()[142].
#include <sys/types.h>
#include <sys/sockets.h>
int send(int s, const void * data, size_t len, int flags);
int sendto(int s, const void * data, size_t len, int flags,
const struct sockaddr * to, socklen_t toLen);
int recv(int s, void * data, size_t maxlen, int flags);
int recvfrom(int s, void * data, size_t maxlen, int flags,
struct sockaddr * from, socklen_t * fromLen);
Здесь во всех случаях параметр
flags всегда равен нулю. В других ситуациях он может принимать множество значений, они подробно рассматриваются в [33].
Первый из названных вызовов
send() может применяться только для тех сокетов, для которых IP-адрес назначения и порт устанавливались через вызов
connect(). Он посылает первые
len байтов, на которые указывает
data, на другой конец сокета
s. Данные передаются как единая дейтаграмма. Если параметр
len задает слишком большое количество данных для передачи в одной дейтаграмме, то в переменной
errno возвращается значение
EMSGSIZE.
Следующий системный вызов
sendto() работает аналогично
send(), но позволяет указывать IP-адрес и номер порта назначения для неподключенных сокетов. Последние два параметра являются указателями на адрес сокета и длину адреса сокета. Применение этой функции не устанавливает адрес назначения для сокета; он остается неподключенным. Последующие вызовы
sendto() могут передавать дейтаграммы в другие пункты назначения. Если аргумент to равен
NULL, то функция
sendto() ведет себя точно также как и
send().
Системные вызовы
recv() и
recvfrom() подобны
send() и
sendto(), но они получают дейтаграммы, а не отправляют их. Оба вызова записывают одну дейтаграмму в
data (не более чем
*maxlen байт) и отбрасывают некоторую часть дейтаграммы, которая не помещается в буфер. Удаленный адрес, отправивший дейтаграмму, сохраняется в параметре
from функции
recvmsg(), если только его длина не превышает
fromLen байт.
17.6.3. Простой tftp-сервер
Данный простой tftp-сервер иллюстрирует отправку и получение UDP-дейтаграмм как для подключенных, так и для неподключенных сокетов. Протокол tftp представляет собой несложный протокол передачи файлов, построенный на основе UDP
[143]. Он часто используется встроенными компьютерными программами для пересылки первоначального загрузочного образа при сетевой загрузке. Сервер, который мы предлагаем рассмотреть, обладает рядом ограничений, поэтому он непригоден для какой-либо практической работы.
• С сервером одновременно может взаимодействовать только один клиент (этот недостаток легко устранить).
• Сервер может только отправлять файлы, но не может получать.
• Отсутствуют условия для ввода ограничений на передачу файлов анонимному удаленному пользователю.
• Выполняется очень поверхностная проверка ошибок, что, скорее всего, приведет к проблемам во время эксплуатации.
Клиент tftp начинает tftp-сеанс передачей "пакета запроса на чтение", содержащего имя файла, который нужно получить, и режим. Существует два исходных режима:
netascii (выполняет некоторые простые преобразования файла) и
octet (передает файл точно в таком же состоянии, в каком он находится на диске). Рассматриваемый сервер поддерживает только режим
octet, поскольку он проще.
При получении запроса для чтения tftp-сервер посылает файл (512 байт за один раз). Каждая дейтаграмма содержит номер блока (нумерация начинается с единицы). Когда клиент получает блок данных, содержащий менее 512 байтов, он знает, что файл получен должным образом. После каждой дейтаграммы клиент посылает ответную дейтаграмму с номером блока, подтверждающую, что данный блок успешно получен. Как только сервер видит подтверждение, он отправляет следующий блок данных.
Основной формат дейтаграммы определен в строках 17-46. Некоторые константы указывают тип посылаемой дейтаграммы, а также код ошибки, отправляемой в том случае, если запрашиваемый файл не существует (все остальные ошибки обрабатываются непосредственно сервером). Структура
struct tftpPacket описывает внешний вид дейтаграммы и код операции, следующей за данными, которая зависит от типа дейтаграммы. Затем логическое объединение, вложенное в структуру, определяет остальные форматы дейтаграмм для ошибок, данных и пакетов подтверждения.
Первая часть
main() (строки 156—169) создает UDP-сокет и устанавливает номер локального порта с помощью вызова
bind(). Последний является либо официальной tftp-службой, либо портом, указанным в качестве единственного аргумента командной строки программы. В отличие от нашего примера TCP-сервера здесь нет необходимости вызывать ни
listen(), ни
accept(), поскольку UDP работает без установки соединений.
После создания сокета сервер ожидает получение дейтаграммы путем вызова
recvfrom(). Функция
handleRequest(), которая активизируется в строке 181, преобразует запрашиваемый файл и возвращает его. После этого вызова сервер еще раз активизирует
recvfrom() и ожидает запрос от следующего клиента.
Комментарий, расположенный перед вызовом
handleRequest(), сообщает, что данный сервер можно легко переключить с итеративного сервера на параллельный, позволив каждому вызову
handleRequest() работать как самостоятельному процессу.
В то время как главная часть программы использует неподключенный UDP-сокет (позволяющий любому клиенту соединение с ним),
handleSocket() применяет для преобразования файла подключенный UDP-сокет
[144]. После анализа имени файла, который нужно передать, и проверки правильности режима преобразования в строке 93 создается сокет с тем же самым семейством, типом и протоколом, с которыми контактировал сервер. Затем используется
connect() для установки удаленного конца сокета на том адресе, от которого поступил запрос на файл, и начинается передача файла. После отправки каждого блока сервер ожидает пакет подтверждения, прежде чем продолжить передачу. Когда приходит последний пакет подтверждения, сервер закрывает сокет и возвращается к главному циклу.
Данный сервер, как правило, запускается с единственным аргументом — номером порта. Для проверки можно применить стандартную клиентскую программу
tftp, где первый аргумент является именем хоста для соединения (неплохим выбором будет
localhost), а второй — номером порта, на котором работает сервер. После запуска клиента нужно активизировать команду
bin, при этом файлы будут запрашиваться в режиме
octet, а не в стандартном режиме
netascii. Как только это сделано, команда
get позволит передать любой файл от сервера клиенту.
1: /* tftpserver.c */
2:
3: /* Это частичная реализация tftp. Она не поддерживает даже тайм-ауты
4: или повторную передачу пакетов, и она не очень хорошо
5: обрабатывает непредвиденные события.*/
6:
7: #include <netdb.h>
8: #include <stdio.h>
9: #include <stdlib.h>
10: #include <string.h>
11: #include <sys/socket.h>
12: #include <unistd.h>
13: #include <fcntl.h>
14:
15: #include "sockutil.h" /* некоторые служебные функции */
16:
17: #define RRQ 1 /* запрос на чтение */
18: #define DATA 3 /* блок данных */
19: #define ACK 4 /* подтверждение */
20: #define ERROR 5 /* возникла ошибка */
21:
22: /* коды ошибок tftp */
23: #define FILE_NOT_FOUND 1
24:
25: struct tftpPacket {
26: short opcode;
27:
28: union {
29: char bytes[514]; /* самый большой блок, который мы
30: можем обработать, содержит 2 байта
31: для номера блока и 512 для данных */
32: struct {
33: short code;
34: char message[200];
35: } error;
36:
37: struct {
38: short block;
39: char bytes[512];
40: } data;
41:
42: struct {
43: short block;
44: } ack;
45: } u;
46: };
47:
48: void sendError(int s, int errorCode) {
49: struct tftpPacket err;
50: int size;
51:
52: err.opcode = htons(ERROR);
53:
54: err.u.error.code = htons(errorCode); /* файл не найден */
55: switch (errorCode) {
56: case FILE_NOT_FOUND:
57: strcpy(err.u.error.message, "файл не найден");
58: break;
59: }
60:
61: /* 2 байта кода операции, 2 байта кода ошибки, сообщение и '\0' */
62: size = 2 + 2 + strlen(err.u.error.message) + 1;
63: if (send(s, &err, size, 0) != size)
64: die("erarorsend");
65: }
66:
67: void handleRequest(struct addrinfo tftpAddr,
68: struct sockaddr remote, int remoteLen,
69: struct tftpPacket request) {
70: char * fileName;
71: char * mode;
72: int fd;
73: int s;
74: int size;
75: int sizeRead;
76: struct tftpPacket data, response;
77: int blockNum = 0;
78:
79: request.opcode = ntohs(request.opcode);
80: if (request.opcode != RRQ) die("неверный код операции");
81:
82: fileName = request.u.bytes;
83: mode = fileName + strlen(fileName) + 1;
84:
85: /* здесь поддерживается только режим bin */
86: if (strcmp(mode, "octet")) {
87: fprintf(stderr, "неверный режим %s\n", mode);
88: exit(1);
89: }
90:
91: /* требуется передача при помощи сокета того же семейства и типа,
92: с которым мы начинали */
93: if ((s = socket(tftpAddr.ai_family, tftpAddr.ai_socktype,
94: tftpAddr.ai_protocol)) < 0)
95: die("send socket");
96:
97: /* установить удаленный конец сокета на адрес, который
98: инициирует данное соединение */
99: if (connect(s, &remote, remoteLen))
100: die("connect");
101:
102: if ((fd = open(fileName, O_RDONLY)) < 0) {
103: sendError(s, FILE_NOT_FOUND);
104: close(s);
105: return;
106: }
107:
108: data.opcode = htons(DATA);
109: while ((size = read(fd, data.u.data.bytes, 512)) > 0) {
110: data.u.data.block = htons(++blockNum);
111:
112: /* размер составляют 2 байта (код операции), 2 байта (номер блока) и данные*/
113: size += 4;
114: if (send(s, &data, size, 0) != size)
115: die("data send");
116:
117: sizeRead = recv(s, &response, sizeof(response), 0);
118: if (sizeRead < 0) die("recv ack");
119:
120: response.opcode = ntohs(response.opcode);
121: if (response.opcode != ACK) {
122: fprintf(stderr, "непредвиденный код операции в отклике\n");
123: exit(1);
124: }
125:
126: response.u.ack.block = ntohs(response.u.ack.block);
127: if (response.u.ack.block != blockNum) {
128: fprintf(stderr, "получено подтверждение неверного блока\n");
129: exit(1);
130: }
131:
132: /* если блок, который мы только что отправили, содержит
133: меньше 512 байт, то задача выполнена */
134: if (size < 516) break;
135: }
136:
137: close(s);
138: }
139:
140: int main(int argc, char ** argv) {
141: struct addrinfo hints, * addr;
142: char * portAddress = "tftp";
143: int s;
144: int rc;
145: int bytes, fromLen;
146: struct sockaddr from;
147: struct tftpPacket packet;
148:
149: if (argc > 2) {
150: fprintf(stderr, "использование: tftpserver [порт]\n");
151: exit(1);
152: }
153:
154: if (argv[1]) portAddress = argv[1];
155:
156: memset(&hints, 0, sizeof (hints));
157:
158: hints.ai_socktype = SOCK_DGRAM;
159: hints.ai_flags = AI_ADDRCONFIG | AI_PASSIVE;
160: if ((rc = getaddrinfo(NULL, portAddress, &hints, &addr)))
161: fprintf(stderr, "сбой поиска порта %s\n",
162: portAddress);
163:
164: if ((s = socket(addr->ai_family, addr->ai_socktype,
165: addr->ai_protocol)) < 0)
166: die("socket");
167:
168: if (bind(s, addr->ai_addr, addr->ai_addrlen))
169: die("bind");
170:
171: /* Основной цикл состоит из ожидания tftp-запроса, его обработки
172: и затем ожидания следующего запроса. */
173: while (1) {
174: bytes = recvfrom(s, &packet, sizeof(packet), 0, &from,
175: &fromLen);
176: if (bytes < 0) die("recvfrom");
177:
178: /* Если выполнить разветвление перед вызовом handleRequest() и
179: завершить дочерний процесс после возврата функции, то данный
180: сервер будет работать точно как параллельный tftp-сервер */
181: handleRequest(*addr, from, fromLen, packet);
182: }
183: }
17.7. Ошибки сокетов
Некоторые значения
errno встречаются только при работе с сокетами. Ниже приведен список специфических ошибок сокетов вместе с краткими их описаниями.
EADDRINUSE |
Запрашиваемый адрес уже используется и не может быть переприсвоен. |
EADDRNOTAVAIL |
Запрашивается несуществующий адрес. |
EAFNOSUPPORT |
Указано неподдерживаемое семейство адресов. |
ECONNABORTED |
Соединение прервано программным обеспечением. |
ECONNREFUSED |
Удаленная машина отклонила попытку соединения. |
ECONNRESET |
Соединение переустановлено удаленным концом. Это, как правило, указывает на то, что удаленная машина была перезагружена. |
EDESTADDRREQ |
Выполнена попытка передачи данных через сокет без предоставления адреса назначения. Это может происходить только в дейтаграммных сокетах. |
EHOSTDOWN |
Удаленный хост не находится в сети. |
EHOSTUNREACH |
Удаленный хост недоступен. |
EISCONN |
Для сокета уже установлено соединение. |
EMSGSIZE |
Данные, передаваемые через сокет, слишком велики для отправления в одном элементарном сообщении. |
ENETDOWN |
Сетевое соединение прекратилось. |
ENETRESET |
Сеть была сброшена, что вызвало потерю соединения. |
ENETUNREACH |
Указанная сеть недоступна. |
ENOBUFS |
Для обработки запроса доступного пространства буфера недостаточно. |
ENOPROTOOPT |
Выполнена попытка установить неправильную опцию. |
ENOTCONN |
До выполнения операции необходимо установить соединение. |
ENOTSOCK |
Специфическая сокетная операция была направлена на файловый дескриптор, который ссылается не на сокет. |
EPFNOSUPPORT |
Указано неподдерживаемое семейство протоколов. |
EPROTONOSUPPORT |
Запрос был сделан для неподдерживаемого протокола. |
EPROTOTYPE |
Для сокета был указан несоответствующий тип протокола. |
ESOCKTNOSUPPORT |
Выполнена попытка создания неподдерживаемого типа сокета. |
ETIMEDOUT |
Время соединения истекло. |
17.8. Унаследованные сетевые функции
В данный момент действует множество библиотечных функций, относящихся к работе сетей TCP/IP, которые нельзя применять в новых приложениях. Однако они широко используются в существующих IPv4-программах. В связи с этим они рассматриваются ниже для того, чтобы помочь вам понять и обновить старые коды.
17.8.1. Манипулирование IPv4-адресами
Функции
inet_ntop() и
inet_pton() являются относительно новыми и были введены для того, чтобы один набор функций мог обрабатывать и IPv4-, и IPv6-адреса. До их появления в программах использовались функции
inet_addr(),
inet_aton() и
inet_ntoa(), которые предназначены только для IPv4.
Вспомните, что
struct sockaddr_in определяется следующим образом
struct sockaddr__in {
short int sin_family; /* AF_INET */
unsigned short int sin_port; /* номер порта */
struct in_addr sin_addr; /* IP-адрес */
}
Член
sin_addr представляет собой структуру
struct in_addr; унаследованные функции используют его в качестве параметра
[145]. Подразумевается, что данная структура является непрозрачной; программы приложений могут обрабатывать
struct in_addr исключительно через библиотечные функции. Старой функцией для преобразования IPv4-адреса в десятичную форму с разделительными точками служит
inet_ntoa().
#include <netinet/in.h>
#include <arpa/inet.h>
char * inet_ntoa(struct in_addr address);
Передаваемый адрес преобразуется в строку в десятичном формате с разделительными точками, возвращается указатель на данную строку. Строка сохраняется в статическом буфере библиотеки С и уничтожается при следующем вызове
inet_ntoa()[146].
Существуют две функции, которые предлагают обратное преобразование десятичной строки в двоичный IP-адрес. Более старая из них функция
inet_addr() имеет две проблемы, обе вызванные тем, что она возвращает результат типа
long. Она не возвращает
struct in_addr, как предполагается остальными стандартными функциями, поэтому программисты были вынуждены выполнять неуклюжие приведения. К тому же, если переменная типа
long имела 32 бита, то программы не могли различить возврат числа -1 (что указывает на ошибку, например, неправильный адрес) и двоичного представления адреса 255.255.255.255.
#include <netinet/in.h>
#include <arpa/inet.h>
unsigned long int inet_addr(const char * ddaddress);
Функция принимает передаваемую строку, которая должна содержать десятичный IP-адрес с разделительными точками, и преобразует ее в двоичный IP-адрес.
Для исправления недостатков
inet_addr() была введена функция
inet_aton().
#include <netinet/in.h>
#include <arpa/inet.h>
int inet_aton(const char * ddaddress, struct in_addr * address);
Данная функция ожидает строку, содержащую десятичный IP-адрес, и размещает двоичное представление этого адреса в структуре
struct in_addr, на которую указывает параметр
address. В отличие от большинства библиотечных функций
inet_aton() возвращает нуль в случае ошибки и ненулевое значение, если преобразование прошло успешно.
17.8.2. Преобразование имен хостов
Функции
getaddrinfo(),
getnameinfo(), позволяющие легко создавать программы, которые поддерживают и IPv4, и IPv6, были введены именно с этой целью. Исходные функции имен хостов было сложно расширить на IPv6, их интерфейсы требовали, чтобы приложения учитывали множество особенностей версии в структурах, сохраняющих IP-адрес. Новые интерфейсы абстрактны, поэтому поддерживают IPv4 и IPv6 одинаково.
Вместо того чтобы возвращать связный список, как это делает
getaddrinfo(), старые функции имен хостов используют
struct hostent, которая может содержать все имена хостов и адреса для одного хоста.
#include <netdb.h>
struct hostent {
char* h_name; /* каноническое имя хоста */
char** h_aliases; /* псевдонимы (завершающиеся NULL) */
int h_addrtype; /* тип адреса хоста */
int h_length; /* длина адреса */
char** h_addr_list; /* список адресов (завершающийся NULL) */
};
Здесь
h_name — каноническое имя хоста. Массив
h_aliases содержит все псевдонимы данного хоста. Последняя запись в
h_aliases — это указатель NULL, сигнализирующий о конце массива.
Параметр
h_addrtype сообщает тип адреса хоста. В данной главе будет применяться только
AF_INET. Приложения, которые создавались для поддержки IPv6, получат и другие типы адресов
[147]. Следующий член
h_length указывает длину двоичных адресов для данного хоста. Для адресов
AF_INET эта длина равна
sizeof(struct in_addr). Последний элемент
h_addr_list представляет собой массив указателей на адреса данного хоста, последний из которых равен
NULL для обозначения конца списка. Если
h_addrtype равен
AF_INET, то каждый указатель в этом списке указывает на структуру
struct in_addr.
Две библиотечные функции выполняют преобразования между IP-номерами и именами хостов. Первая из них
gethostbyname() возвращает
struct hostent для имени хоста. Вторая —
gethostbyaddr() — возвращает информацию о машине с данным IP-адресом.
#include <netdb.h>
struct hostent * gethostbyname(const char * name);
struct hostent * gethostbyaddr(const char * addr, int len, int type);
Обе функции возвращают указатель на
struct hostent. Структура может быть перезаписана при последующем вызове одной из функций, поэтому все значения, которые могут понадобиться позже, программа должна сохранять.
Функция
gethostbyname() принимает один параметр — строку, содержащую имя хоста. Функция
gethostbyaddr() принимает три параметра, которые вместе определяют адрес. Первый из них
addr указывает на
struct in_addr. Следующий
len устанавливает длину информации, на которую
указывает параметр
addr. Последний
type излагает тип адреса, который нужно преобразовать в имя хоста (
AF_INET для IPv4-адресов).
Если во время поиска имени хоста происходят ошибки, то код ошибки передается в
h_errno. Вызов функции
herror() распечатывает описание ошибки (данная функция почти идентична стандартной функции
perror()).
Единственный код ошибки, на котором тестируется большинство программ, это
NETDB_INTERNAL, который указывает на неудачный системный вызов. При возвращении этой ошибки параметр errno содержит описание той проблемы, которая привела к отказу.
17.8.3. Пример поиска информации хоста с использованием унаследованных функций
Ниже приводится пример программы, использующей
inet_aton(),
inet_ntoa(),
gethostbyname(),
gethostbyaddr(). Она принимает единственный аргумент, который может быть либо именем хоста, либо IP-адресом в десятичном представлении с точками. Она отыскивает хост и распечатывает все имена хоста и IP-адреса, ассоциированные с ним.
Любой аргумент, который является действительным десятичным адресом, считается IP-номером, а не именем хоста.
1: /* lookup.с */
2:
3: /* Получает либо имя хоста, либо IP-адрес в командной строке, выводит
4: каноническое имя хоста для данного хоста и все IP-номера и имена
5: хостов, ассоциированные с ним. */
6:
7: #include <netdb.h> /* для gethostby* */
8: #include <sys/socket.h>
9: #include <netinet/in.h> /* для адресных структур */
10: #include <arpa/inet.h> /* для inet_ntoa() */
11: #include <stdio.h>
12:
13: int main(int argc, const char ** argv) {
14: struct hostent * answer;
15: struct in_addr address, ** addrptr;
16: char ** next;
17:
18: if (argc != 2) {
19: fprintf(stderr, "поддерживается только одиночный аргумент\n");
20: return 1;
21: }
22:
23: /* Если аргумент выглядит как IP, то принимаем его как таковой
24: и выполняет обратный поиск имени */
25: if (inet_aton(argv[1], &address))
26: answer = gethostbyaddr((char *)&address, sizeof(address),
27: AF_INET);
28: else
29: answer = gethostbyname(argv[1])
30:
31: /* поиск имени хоста не удался */
32: if (!answer) {
33: herror("ошибка поиска хоста");
34: return 1;
35: }
36:
37: printf("Каноническое имя хоста: %s\n", answer->h_name);
38:
39: /* если есть псевдонимы, все они выводятся на печать */
40: if (answer->h_aliases[0]) {
41: printf("Псевдонимы:");
42: for(next = answer->h_aliases; *next; next++)
43: printf(" %s", *next);
44: printf("\n");
45: }
46:
47: /* отобразить все IP-адреса для данной машины */
48: printf("Адреса:");
49: for (addrptr = (structin_addr **) answer->h_addr_list;
50: *addrptr; addrptr++)
51: printf (" %s", inet_ntoa(**addrptr));
52: printf("\n");
53:
54: return 0;
55: }
Ниже показан пример вывода этой программы.
$ ./lookup ftp.netscape.com
Каноническое имя хоста: ftp25.netscape.com
Псевдонимы: ftp.netscape.com anonftp10.netscape.com
Адреса: 207.200.74.21
17.8.4. Поиск номеров портов
Новые функции
getaddrinfo() и
getnameinfo() предлагают простое выполнение преобразований имен служб в номера портов с одновременным определением имени хоста. В старых реализациях поиск имен служб проводился абсолютно независимо от поиска имен хостов. Доступ к именам служб можно получить через функцию
getservbyname().
#include <netdb.h>
struct servent * getservbyname(const char * name,
const char * protocol);
Первый параметр
name представляет собой имя службы, о которой в приложении требуется информация. Параметр
protocol указывает протокол для использования. База данных служб содержит информацию о других протоколах (особенно UDP); конкретное определение протокола позволяет функции игнорировать информацию по другим протоколам. Параметр
protocol обычно является строкой
"tcp", хотя могут использоваться и другие имена протоколов, например,
"udp".
Функция
getservbyname() возвращает указатель на структуру, которая содержит информацию о запрашиваемой службе. Информация может перезаписываться при последующем вызове
getservbyname(), поэтому важные данные нужно сохранять в приложении. Функция
getservbyname() возвращает следующую информацию:
#include <netdb.h>
struct servent {
char * s_name; /* имя службы */
char ** s_aliases; /* псевдонимы службы */
int s_port; /* номер порта */
char * s_proto; /* протокол для использования */
}
Каждая служба может иметь несколько имен, ассоциированных с ней, но только один номер порта. Переменная
s_name регистрирует каноническое имя службы,
s_port содержит официальный номер порта данной службы (представленный в сетевом порядке байтов),
s_proto представляет протокол для использования (например,
"tcp"). Член
s_aliases является массивом указателей псевдонимов службы (указатель
NULL обозначает конец списка).
Если функция не выполняет свою работу, то она возвращает
NULL и устанавливает
h_errno. Ниже приведен пример программы, которая извлекает TCP-службу, указанную в командной строке, и выводит на экран каноническое имя, номер порта и все псевдонимы данной службы.
1: /* services.с */
2:
3: #include <netdb.h>
4: #include <netinet/in.h>
5: #include <stdio.h>
6:
7: /* Отображает номер порта TCP и все псевдонимы службы,
8: указанной в командной строке */
9:
10: /* services.с отыскивает номер порта для службы */
11: int main(int argc, const char ** argv) {
12: struct servent * service;
13: char ** ptr;
14:
15: if (argc != 2) {
16: fprintf(stderr, "поддерживается только одиночный аргумент\n");
17: return 1;
18: }
19:
20: /* поиск службы в /etc/services, в случае неудачи
21: передается ошибка */
22: service = getservbyname(argv[1] , "tcp");
23: if (!service) {
24: herror("getservbyname failed");
25: return 1;
26: }
27:
28: printf("служба: %s\n", service->s_name);
29: printf("tcp-порт: %d\n", ntohs(service->s_port));
31: /* отобразить все псевдонимы, которые имеет данная служба */
32: if (*service->s_aliases) {
33: printf("псевдонимы:");
34: for (ptr = service->s_aliases; *ptr; ptr++)
35: printf(" %s", *ptr);
36: printf("\n");
37: }
38:
39: return 0;
40: }
Ниже показан пример запуска программы. Обратите внимание на то, что она извлекает службы либо по каноническому имени, либо по псевдониму.
$ ./services http
служба: http
tcp-порт: 80
$ ./services source
служба: chargen
tcp-порт: 19
псевдонимы: ttytst source
Глава 18
Время
18.1. Вывод времени и даты
18.1.1. Представление времени
В системах Unix и Linux время отслеживается в секундах до или после
начала эпохи, которое определяется как полночь 1 января 1970 года по UTC
[148]. Положительные значения времени относятся к периоду после начала эпохи; отрицательные — до начала эпохи. Для того чтобы обеспечить работу процессов в режиме текущего времени, в Linux, как и во всех остальных версиях Unix, предусмотрен системный вызов
time().
#include <time.h>
time_t time (time_t *t);
Функция
time() возвращает количество секунд, прошедших с момента начала эпохи. Если значение
t не является нулевым, то данная функция передает в эту переменную количество секунд, прошедших с начала эпохи.
Для решения некоторых проблем требуется более высокая разрешающая способность. В Linux предусмотрен еще один системный вызов —
gettimeofday(), который предоставляет более подробную информацию.
#include <sys/time.h>
#include <unistd.h>
int gettimeofday(struct timeval *tv, struct timezone *tz);
struct timeval {
int tv_sec; /* секунды */
int tv_usec; /* микросекунды */
};
struct timezone {
int tz_minuteswest; /* минуты на запад от Гринвича */
int tz_dsttime; /* тип корректировки dst */
};
На большинстве платформ, включая i386, система Linux поддерживает возможность очень точного измерения времени. Стандартные персональные компьютеры содержат встроенные часы, которые обеспечивают информацию о текущем времени с точностью до микросекунд. Оборудование Alpha и SPARC также предлагает высокоточный таймер. На некоторых других платформах система Linux может отслеживать время только в пределах разрешающей способности системного таймера, который в общем случае устанавливается на значение 100 Гц. В связи с этим член
tv_usec структуры
timeval в подобных системах может иметь меньшую точность.
В
sys/time.h определены пять макросов для обработки структур
timeval.
timerclear(struct timeval *)
Данный макрос очищает структуру
timeval.
timerisset(struct timeval *)
Данный макрос проверяет структуру
timeval на заполнение (другими словами, отличен ли хотя бы один элемент от нуля).
timercmp(struct timeval *t0, struct timeval *t1, operator)
Данный макрос позволяет сравнивать две структуры
timeval в одном временном интервале. Он вычисляется в логический эквивалент
t0 операция t1, если
t0 и
t1 относятся к арифметическим типам. Обратите внимание на то, что макрос
timercmp() не работает для операций
<= и
>=. Вместо этого нужно применять формы
!timercmp(t1, t2, >) и
!timercmp(t1, t2, <).
timeradd(struct timeval *t0, struct timeval *t1, struct timeval *result)
Добавляет
t0 к
t1 и размещает сумму в переменной
result.
timersub(struct timeval *t0, struct timeval *t1, struct timeval *result)
Вычитает
t1 из
t0 и передает разность в переменную
result.
Третье представление времени
struct tm дает время в исчислении, более привычном для человека.
struct tm {
int tm_sec;
int tm_min;
int tm_hour;
int tm_mday;
int tm_mon;
int tm_year;
int tm_wday;
int tm_yday;
int tm_isdst;
long int tm_gmtoff;
const char *tm_zone;
};
Первые девять элементов являются стандартными, последние два — нестандартные, однако очень полезные (они существуют в системах Linux).
tm_sec |
Количество прошедших секунд в минуте. Принимает значения от 0 до 61 (две дополнительные секунды выделяются для учета лишних секунд, относящихся к високосному году). |
tm_min |
Количество прошедших минут в часе. Принимает значения от 0 до 59. |
tm_hour |
Количество прошедших часов в сутках. Принимает значения от 0 до 23. |
tm_mday |
Номер дня месяца. Принимает значения от 1 до 31. Это единственный элемент, который не может равняться нулю. |
tm_mon |
Количество прошедших месяцев в году. Принимает значения от 0 до 11. |
tm_year |
Количество прошедших лет (считая с 1900 года). |
tm_wday |
Количество прошедших дней в неделе (считая от воскресенья). Принимает значения от 0 до 6. |
tm_yday |
Количество прошедших дней в году. Принимает значения от 0 до 365. |
tm_isdst |
Определяет, поддерживается ли летнее время в текущем часовом поясе, tm_isdst принимает положительное значение, если время переведено на летнее, 0 — если не переведено, 1 — если система не может это определить. |
tm_gmtoff |
Параметр не является переносимым, поскольку он используется не во всех системах. Если он существует, то он может также называться __tm_gmtoff. Данная переменная указывает число секунд к востоку от UTC или отрицательное число секунд к западу от UTC для часовых поясов к востоку от линии перемены дат. |
tm_zone |
Параметр не является переносимым, поскольку он используется не во всех системах. Если он существует, то он может также называться __tm_zone. Он содержит название текущего часового пояса (некоторые часовые пояса могут иметь несколько имен). |
В завершение, стандарт POSIX.1b обработки данных в режиме реального времени поддерживает даже большую разрешающую способность, чем доступные в стандарте
struct timeval микросекунды. В структуре
struct timespec используются наносекунды, а также выделено больше пространства для размещения чисел.
struct timespec {
long int tv_sec; /* секунды */
long int tv_nsec; /* наносекунды */
};
18.1.2. Преобразование, форматирование и разбор значений времени
Для взаимно-обратных преобразований времени, выраженного в показателях
time_t, и времени, выраженного в показателях
struct tm, используются четыре функции. Три из них являются стандартными и доступны во всех системах Linux и Unix. Четвертая, не менее полезная, может применяться не всегда, поскольку она работает только в современных системах Linux. Пятая функция (стандартная) вычисляет разность в секундах между значениями времени
time_t. (Обратите внимание на то, что даже аргументы
time_t передаются как указатели, а не как только аргументы
struct tm.)
struct tm * gmtime(const time_t *t)
Сокращенная форма времени по Гринвичу; функция
gmtime() преобразует значение
time_t в
struct tm, которое выражает данное время в UTC.
struct tm * localtime(const time_t *t)
localtime() ведет себя подобно
gmtime() за исключением того, что создается объект
struct tm, выраженный в показателях местного времени. Местное время определяется для всей системы путем установки файлов часовых поясов. Его можно переопределить с помощью переменной окружения
TZ для пользователей, работающих в часовом поясе, отличном от того, в котором находится компьютер.
time_t mktime(struct tm *tp);
mktime() преобразует
struct tm в
time_t, предполагая, что
struct tm выражается в показателях местного времени.
time_t timegm(struct tm *tp);
timegm() ведет себя подобно
mktime() за исключением предположения о том, что
struct tm выражается в показателях UTC. Данная функция не является стандартной.
double difftime(time_t time1, time_t time0);
difftime() возвращает число с плавающей запятой, представляющее разность во времени в секундах между двумя значениями
time_t. Хотя
time_t гарантированно принадлежит к арифметическому типу, единица измерения не определяется в ANSI/ISO С;
difftime() возвращает разность в секундах в зависимости от единиц измерения
time_t.
Еще четыре функции применяются для преобразований времени из чисел, которые обрабатывает компьютер, в текстовые представления, удобные для человека. Последняя функция не входит в число стандартных вопреки своей очевидной всеобщей полезности.
char *asctime(struct tm *tp);
char *ctime(time_t *t);
asctime() и
ctime() служат для преобразования временных значений в стандартную строку даты Unix, которая выглядит примерно так:
Tue Jun 17 23:17:29 1997
В обоих случаях длина сроки равна 26 символам и включает в себя завершающие символы новой строки и
'\0'.
Не во всех локалях длина строки обязательно равна 26 символам, как в стандартной локали С.
ctime() выражает указанную дату в местном времени;
asctime() — в том часовом поясе, который указан в
struct tm. Если последний объект был создан с помощью
gmtime(), то в показателях UTC, если при помощи
localtime(), то по местному времени.
size_t strftime (char *s, size_t max, char *fmt, struct tm *tp);
strftime() работает также как
sprintf() для времени. Она форматирует
struct tm в соответствии с форматом
fmt и размещает результат в не более чем
max байтах (включая завершающий символ
'\0') строки
s.
Подобно
sprintf(), функция
strftime() использует символ
% для ввода управляющих последовательностей, в которые подставляются данные. Все подстановочные строки выражаются в показателях текущей локали. Однако сами управляющие последовательности являются совершенно разными. В некоторых случаях строчные буквы применяются для аббревиатур, а заглавные буквы — для полных имен. В отличие от
sprintf(), здесь отсутствует опция употребления чисел в середине управляющей последовательности для ограничения длины подстановочной строки; выражение
%.6А недопустимо. По аналогии с функцией
sprintf(),
strftime() возвращает количество символов, выведенных в буфер
s. Равенство данной величины значению
max означает, что объем буфера недостаточен для текущей локали; необходимо выделить больший буфер и попытаться снова.
strftime() использует те же самые подстановки, что и программа работы с датами. Ниже приводятся определения для подстановок в стандартной локали, они служат для того, чтобы помочь вам идентифицировать тип информации. В остальных локалях они могут отличаться.
%а |
Трехбуквенная аббревиатура для названия дня недели. |
%А |
Полное название дня недели. |
%b |
Трехбуквенная аббревиатура для названия месяца. |
%В |
Полное название месяца. |
%с |
Предпочтительное локальное выражение даты и времени (такое как возвращают функции ctime() и asctime()). |
%d |
День месяца в числовом виде (отсчет ведется от нуля). |
%Н |
Час дня по 24-часовому времени (отсчет ведется от нуля). |
%I |
Час дня по 12-часовому времени (отсчет ведется от нуля). |
%j |
День года (отсчет ведется от единицы). |
%m |
Месяц года (отсчет ведется от единицы). |
%М |
Минута в часе (отсчет ведется от нуля). |
%p |
Соответствующая строка для локального эквивалента выражений AM или PM. |
%S |
Секунда в минуте (отсчет ведется от нуля). |
%U |
Неделя года в числовом виде (первая неделя начинается с первого воскресенья года). |
%W |
Неделя года в числовом виде (первая неделя начинается с первого понедельника года). |
%w |
День недели в числовом виде (отсчет ведется с нуля). |
%x |
Предпочтительное локальное выражение только для даты, без времени. |
%X |
Предпочтительное локальное выражение только для времени, без даты. |
%y |
Двухзначное представление года (без столетия). Не рекомендуется использовать такой формат — это потенциальный источник "проблемы 2000-го года". |
%Y |
Полное четырехзначное числовое представление года. |
%Z |
Название стандартной аббревиатуры часовой зоны. |
%% |
Буквенный символ %. |
char *strptime(char *s, char *fmt, struct tm *tp);
Как и
scanf(), функция
strptime() преобразует строку в разобранный формат. Она пытается быть либеральной при интерпретации введенной строки
s в соответствии с форматирующей строкой
fmt. Она принимает те же самые управляющие последовательности, что и
strftime(), при этом для каждого типа ввода она допускает как аббревиатуры, так и полные имена. Она не различает символы верхнего и нижнего и регистра, а также не распознает
%U и
%W.
Функция
strptime() предусматривает несколько дополнительных управляющих последовательностей; также она интерпретирует несколько последовательностей иначе (не так, как
strftime()). В последующем списке перечислены только те управляющие последовательности, которые отличаются значительно (другими словами, выходят за рамки тех изменений, на которые мы уже указывали). Числа могут предваряться нулями, но это не обязательно.
%h |
Эквивалент %b и %B. |
%с |
Считывает дату и время так, как печатает функция strftime() с форматирующей строкой %x %X. |
%С |
Считывает дату и время так, как печатает функция strftime() с форматирующей строкой %с. |
%e |
Эквивалент %d. |
%D |
Считывает дату так, как печатает функция strftime() с форматирующей строкой %m/%d/%y. |
%k |
Эквивалент %Н. |
%l |
Эквивалент %I. |
%r |
Считывает время так, как печатает функция strftime() с форматирующей строкой %I:%М:%S %p. |
%R |
Считывает время так, как печатает функция strftime() с форматирующей строкой %Н:%М. |
%T |
Считывает время так, как печатает функция strftime() с форматирующей строкой %Н:%М:%S. |
%y |
Считывает год в пределах двадцатого столетия. Допустимы значения только от 0 до 99, поскольку к ним добавляется число 1900. |
%Y |
Считывает полный год. Применяйте, по возможности, этот формат вместо %у для того, чтобы избежать "проблемы 2000-го года". |
Функция
strptime() возвращает указатель на символ в
s — символ, находящийся за последним прочитанным во время разбора.
Функция
strptime(), к сожалению, не определена ни в ANSI/ISO, ни в POSIX, что ограничивает ее переносимость.
18.1.3. Ограничения, связанные со временем
В 32-разрядных системах Linux, как и в большинстве систем Unix, переменная
time_t является целым числом со знаком длиной 32 бита. Это означает, что в 10:14:07 вечера 18 января (четверг) 2038 года она переполнится. Поэтому время 10:14:08 вечера 18 января (четверг) 2038 года будет представлено как 3:45:52 вечера 13 декабря (пятница) 1901 года. Как видите, система Linux не проявляет "проблему 2000-го года" (поскольку используются собственные библиотеки времени), однако с ней связана "проблема 2038-го года".
На 64-разрядных платформах переменная
time_t является соответственно 64-битовым числом со знаком. Это действительно эффективное решение, поскольку 64-битовое время со знаком можно назвать астрономическим.
Для того чтобы определить начальное время, текущее время, конечное время для используемой системы можно создать и запустить данную программу
daytime.с.
1: /* daytime.с */
2:
3: #include <stdio.h>
4: #include <sys/time.h>
5: #include <unistd.h>
6:
7: int main () {
8: struct timeval tv;
9: struct timezone tz;
10: time_t now;
11: /* beginning_of_time — это наименьшее значении, измеряемое time_t*/
12: time_t beginning_of_time = 1L<<(sizeof(time_t)*8 - 1);
13: /* end_of_time - это наибольшее значение, измеряемое time_t */
14: time_t end_of_time = ~beginning_of_time;
15:
16: printf("time_t имеет %d бит в длину\n\n", sizeof(time_t) *8);
17:
18: gettimeofday(&tv, &tz);
19: now = tv.tv_sec;
20: printf("Текущее время дня, представленное в виде структуры timeval:\n"
21: "tv.tv_sec = 0x%08x, tv.tv_usec = 0x%08х\n"
22: "tz.tz_minuteswest = 0x%08х, tz.tz_dsttime = 0x%08x\n\n",
23: tv.tv_sec, tv.tv_usec, tz.tz_minuteswest, tz.tz_dsttime);
24:
25: printf("Демонстрация ctime()%s:\n",
26: sizeof(time_t)*8 <= 32 ? "" :
27: " (может зависнуть после печати первой строки; нажмите "
28: "Control-C)") ;
29: printf("текущее время: %s", ctime(&now));
30: printf("начало времени: %s", ctime(&beginning_of_time));
31: printf("конец времени: %s", ctime(&end_of_time));
32:
33: exit(0);
34: }
К сожалению, функция
ctime() является итеративной по своей природе. Это означает, что она (при любых практических целях) никогда не прерывает свою работу в 64-разрядных системах даже для астрономических дат (вроде 64-битового времени начала и завершения). Если вы устали ждать, когда же программа завершит свою работу, нажмите Control-C для ее завершения.
18.2. Использование таймеров
Таймер — это простое средство для указаний определенной точки в будущем, в которой должно произойти некоторое событие. Вместо того чтобы циклически запрашивать текущее время и проводить лишние растраты циклов центрального процессора, программа может отправить в ядро запрос на получение уведомления о том, что прошло определенное количество времени.
Существуют два способа применения таймеров: синхронный и асинхронный. Синхронное использование таймера возможно в единственном режиме — режиме ожидания (дожидаться истечения времени таймера). Асинхронная работа таймера, как и любого другого асинхронного устройства, сопровождается сигналами. Сюрпризом может оказаться то, что синхронный таймер может также вызывать сигналы.
18.2.1. Режим ожидания
Процесс, сопровождающийся запросом на невыполнение в течение определенного количества времени, называется
отложенным (или "спящим"). Для режима ожидания доступны четыре функции; каждая из них измеряет время в различных единицах. Они также ведут себя и взаимодействуют с остальными частями системы по-разному.
unsigned int sleep(unsigned int seconds);
Функция
sleep() вынуждает текущий процесс засыпать на время (в секундах), указанное параметром
seconds, или до тех пор, пока процесс не получит сигнал, который он не может проигнорировать. На большинстве платформ функция
sleep() реализуется в терминах сигнала
SIGALRM, поэтому она не очень хорошо совмещается с системным вызовом
alarm(), созданием обработчика
SIGALRM, игнорированием сигнала
SIGALRM, или применением интервальных таймеров (рассматриваются далее), которые разделяют один и тот же таймер и сигнал.
Если работа
sleep() завершается раньше истечения полного выделенного времени, она возвращает количество оставшихся секунд. Если режим ожидания длился ровно столько, сколько запрашивалось, она возвращает ноль.
void usleep(unsigned long usec);
Функция
usleep() вынуждает текущий процесс засыпать на время (в микросекундах), указанное параметром
usec. Никакие сигналы не используются. На большинстве платформ
usleep() реализуется с помощью
select().
int select(0, NULL, NULL, NULL, struct timeval tv);
Функция
select(), описанная в главе 13, предлагает мобильный способ откладывания процессов на точное количество времени. Просто введите в объект
struct timeval минимальное время, которое нужно ожидать, и можете быть уверены — ни одно событие не произойдет.
int nanosleep(struct timespec *req, struct timespec *rem);
Функция
nanosleep() вынуждает текущий процесс засыпать на время, указанное параметром
req (описание объекта
timespec можно найти в начале этой главы), пока процесс не получит сигнал. Если работа
nanosleep() прекращается раньше из-за полученного сигнала, то она возвращает
-1 и устанавливает для
errno значение
EINTR, а также, если
rem не является
NULL, то передает в переменную
rem количество времени, оставшегося в периоде ожидания.
Функция
nanosleep() наименее переносима из всех рассмотренных, поскольку она была определена как часть спецификации POSIX.1b реального времени (ранее она называлась POSIX.4), которая выполняется не во всех версиях Unix. Однако все новые реализации Unix поддерживают ее, так как функции POSIX.1b в настоящее время являются стандартной частью Single Unix Specification (Единая спецификация Unix).
Не все платформы, предусматривающие функцию
nanosleep(), обеспечивают высокую точность, однако Linux, как и остальные операционные системы реального времени, стремится принимать короткие запросы на обработку с предельной точностью. Более подробную информацию о программировании в режиме реального времени можно найти в [12].
18.2.2. Интервальные таймеры
Интервальные таймеры, будучи активизированными, непрерывно передают сигналы в процесс на систематической основе. Точное значение термина
систематический зависит от используемого интервального таймера. С каждым процессом ассоциированы три таймера.
ITIMER_REAL |
Отслеживает время в терминах настенных часов — в реальном времени (в зависимости от выполнения процесса) — и генерирует сигнал SIGALRM. Несовместим с системным вызовом alarm(), который используется функцией sleep(). Не применяйте ни alarm(), ни sleep(), если имеется реальный интервальный таймер. |
ITIMER_VIRTUAL |
Подсчитывает время только при исполнении процесса — не учитывая системные вызовы, которые производит процесс — и генерирует сигнал SIGVTALRM. |
ITIMER_PROF |
Подсчитывает время только при выполнении процесса — включая время, за которое ядро посылает исполнительные системные вызовы от имени процесса, и не включая время, потраченное на прерывание процесса по инициативе самого процесса — и генерирует сигнал SIGPROF. Учет времени, затраченного на обработку прерываний, оказывается настолько трудоемким, что даже может изменить настройки таймера. |
Комбинация таймеров
ITIMER_VIRTUAL и
ITIMER_PROF часто используется в профилирующих кодах.
Каждый из этих таймеров генерирует ассоциированный сигнал об истечении таймера в пределах одного хода системных часов (как правило, 1-10 миллисекунд). Если процесс работает в данное время, то сигнал генерируется сразу же; в противном случае сигнал генерируется немного позже (в зависимости от загрузки системы). Поскольку таймер
ITIMER_VIRTUAL следит за временем только во время работы процесса, то сигнал всегда доставляется незамедлительно.
Используйте структуру
struct itimerval для передачи запроса и установки интервальных таймеров.
struct itimerval {
struct timeval it_interval;
struct timeval it_value;
};
Член
it_value показывает количество времени, оставшееся до отправления следующего сигнала. Член
it_interval определяет время между сигналами; каждый раз при истечении таймера это значение присваивается переменной
it_value.
Для взаимодействия с интервальными таймерами предусмотрены два системных вызова. Оба принимают аргумент
which, указывающий обрабатываемый таймер.
int getitimer(int which, struct itimerval *val);
Переменной
val присваивается текущее состояние таймера
which.
int setitimer(int which, struct itimerval *new, struct itimerval *old);
Устанавливает таймер
which на значение new и заменяет
old предыдущей установкой, если она не равна
NULL.
Если параметр таймера
it_value приравнять к нулю, он немедленно заблокируется. Ввод нулевого значения для
it_interval отключает таймер после следующего запуска.
В следующем примере родительский процесс активизирует дочерний процесс, запускает односекундный таймер
ITIMER_REAL, засыпает на 10 секунд, а затем уничтожает дочерний процесс.
1: /* itimer.c */
2:
3: #include <stdio.h>
4: #include <stdlib.h>
5: #include <sys/wait.h>
6: #include <unistd.h>
7: #include <string.h>
8: #include <signal.h>
9: #include <sys/time.h>
10:
11:
12: void catch_signal(int ignored) {
13: static int iteration=0;
14:
15: printf("получен сигнал интервального таймера, итерация %d\n",
16: iteration++);
17: }
18:
19: pid_t start_timer(int interval) {
20: pid_t child;
21: struct itimerval it;
22: struct sigaction sa;
23:
24: if (!(child = fork())) {
25: memset(&sa, 0, sizeof(sa));
26: sa.sa_handler = catch_signal;
27: sigemptyset(&sa.sa_mask);
28: sa.sa_flags = SA_RESTART;
29:
30: sigaction(SIGALRM, &sa, NULL);
31:
32: memset(&it, 0, sizeof(it));
33: it.it_interval.tv_sec = interval;
34: it.it_value.tv_sec = interval;
35: setitimer(ITIMER_REAL, &it, NULL);
36:
37: while (1) pause();
38: }
39:
40: return child;
41: }
42:
43: void stop_timer(pid_t child) {
44: kill(child, SIGTERM);
45: }
46:
47: int main (int argc, const char **argv) {
48: pid_t timer = 0;
49:
50: printf("Демонстрация интервальных таймеров для 10 секунд, "
51: "ожидайте...\n");
52: timer = start_timer(1);
53: sleep(10);
54: stop_timer(timer);
55: printf("Готово.\n");
56:
57: return 0;
58: }
Глава 19
Случайные числа
Слово
случайный имеет разный смысл для разных программистов в различное время. Для большинства приложений оказываются достаточно эффективными псевдослучайные числа, предусмотренные библиотекой С. Благодаря тому, что псевдослучайные числа позволяют воспроизводить первоначальные условия, если это необходимо (например, с целью отладки), они оказываются предпочтительнее действительно случайных чисел.
Однако некоторые приложения (включая криптографические) для достижения наилучших результатов требуют использования действительно случайных чисел. Ядро Linux для предоставления криптографически устойчивых случайных чисел производит выборку событий из непредсказуемого внешнего мира.
Все компьютеры поддаются прогнозированию. В большинстве задач, которые мы поручаем компьютеру, предсказуемость является наиболее важным обстоятельством. Даже если в вашей программе появляются ошибки, необходимо, чтобы их возникновение было предсказуемым, иначе вы не сможете найти их и ликвидировать.
19.1. Псевдослучайные числа
В некоторых ситуациях все же требуется обеспечить невозможность прогнозирования. Библиотека С содержит функции для генерирования ожидаемых последовательностей псевдослучайных чисел. Эти функции легки в применении и являются одинаковыми на всех платформах Unix. Рассмотрим пример типичного использования данных функций.
#include <stdlib.h>
#include <time.h>...
srand(time(NULL) +getpid());
for (...;...;...) {
do_something(rand());
}
Общепринято в качестве
начального значения для генератора псевдослучайных чисел задавать текущую дату в формате, возвращаемом функцией
time(). Последняя возвращает количество секунд, прошедших с 1 января 1970 года, поэтому начальное значение изменяется каждую секунду. Таким образом, оно может считаться уникальным в течение достаточно длинного интервала времени (приблизительно 49 710 дней на 32-разрядном компьютере). Если необходимо предотвратить возможность одинаковой активизации программы для двух пользователей, которые запускают ее в одну и ту же секунду, добавьте в начальном значении ко времени идентификатор текущего процесса.
Числа, возвращаемые функцией
rand(), удовлетворяют математическим свойствам случайного распределения, но не обладают высокой энтропией (уровнем неупорядоченности). Для достаточно больших выборок они хорошо распределены в пределах всевозможных 32-битовых чисел, однако для одного и того же начального значения можно получить различные наборы чисел. Это означает, что такие псевдослучайные числа пригодны почти для всех приложений, требующих случайного распределения чисел. К таким приложениям относятся игры, методы Монте-Карло (здесь важно сохранить начальное значение, чтобы любой желающий мог проверить ваши результаты), а также протоколы, которые обрабатывают коллизии путем ввода случайной задержки.
Обратите внимание на то, что при отладке вам потребуется сохранить начальное значение, с которым была вызвана функция
srand(). Если во время работы программы происходит ошибка, зависящая от данных, переданных функцией
rand(), то вы можете использовать это значение для вывода того же самого потока случайных чисел и воспроизведения ошибки.
19.2. Криптография и случайные числа
Мы не являемся экспертами в области криптографии. Написание программного обеспечения шифрования — это чрезвычайно искусное дело, и тот, кто берется за него без соответствующих исследований, не сможет создавать устойчивые и надежные криптографические приложения. Эта глава преследует две и только две цели.
• Убедить тех программистов, которые не являются специалистами в шифровании, оставить работу в этой области экспертам.
• Продемонстрировать криптографическим знатокам очень удобный инструмент, доступный для применения.
Если вы недостаточно хорошо знакомы с криптографией, однако вынуждены ее применять, мы рекомендуем [30] в качестве превосходного вводного руководства по этой теме.
В общем случае условия прогнозируемости в криптографии не отличаются от требований остального программного обеспечения. Если вы задаете программе ключ для расшифровки данных, то естественно ожидаете точно такую же кодировку этих же данных при каждой последующей дешифровке. Есть одно исключение: выбор действительно случайного ключа. И любой сложнейший алгоритм кодирования не устоит перед атакующим, если последний догадается, какой ключ был использован при генерировании данных. Например, все зашифрованные сообщения содержат некоторую временную метку, указывающую примерное время их создания. Если вы взяли текущее время в качестве начального значения для общего генератора псевдослучайных чисел, то хакер не потратит много времени на декодирование данных. Потребуется всего лишь ввести время создания сообщения в различные генераторы псевдослучайных чисел и испытать ключи, основанные на полученных числах.
Не лучшим способом решения проблемы является обращение к человеку для создания ключа. Чаще всего люди выбирают ключи, которые трудно назвать случайными. Подбор ключа, как правило, имеет отношение к естественному языку, словарный запас которого в терминах теории информации достаточно предсказуем. Говорят, что естественный язык обладает низкой энтропией; действительно случайный ключ имеет
высокую энтропию.
Если бы каждый компьютер имел встроенный источник радиации, то непрогнозируемый временной интервал между испусканием частиц распадающимися атомами мог бы использоваться для вывода действительно случайных чисел. Никакая общеизвестная информация не поможет предсказать числа, созданные радиоактивной эмиссией.
Поскольку компьютеры не оснащены подобными устройствами, в системе Linux предлагается выход из ситуации. Тед Тсо (Ted Ts'o) написал код, который измеряет временные диаграммы внешних событий (щелчок мыши, нажатие кнопки клавиатуры и так далее), извлекает из них информацию и сохраняет ее в
пуле энтропии. Некоторые компоненты человеческого (и другого внешнего) взаимодействия с компьютером являются в высшей степени случайными. Код, заполняющий пул энтропии, старается некоторым образом охарактеризовать величину добавленной энтропии, что позволяет программисту оценить степень неупорядоченности при генерировании случайной информации. В последнее время во многих компьютерах предусматриваются аппаратные источники криптографически случайных данных. В Linux такие случайные данные подаются в системном пуле энтропии, поэтому все программы Linux могут применять один и тот же интерфейс в зависимости от оборудования, которое они используют.
Если программисту требуются случайные числа, основанные на непредсказуемых событиях, он может воспользоваться пулом энтропии с помощью одного из двух
похожих устройств:
/dev/random и
/dev/urandom. Устройство
/dev/random возвращает только то количество байт случайных данных, которое находится в пуле по текущей оценке самого устройства. Устройство
/dev/urandom не предоставляет никаких гарантий касательно уровня неупорядоченности возвращаемой информации; оно генерирует на основе пула столько случайных данных, сколько вам нужно. Какое бы устройство не использовалось, оно уменьшает счетчик энтропии на количество прочитанных байтов.
Оба устройства не просто возвращают данные в том виде, в каком они содержатся в пуле энтропии. Они также перемешивают данные с помощью алгоритма однонаправленного хеширования, который в своих выходных данных не воспроизводит состояние пула.
• Не используйте ни
/dev/random, ни
/dev/urandom для тех данных, которые потребуется продублировать. Они также являются крайне неподходящими источниками данных для методов Монте-Карло. Даже последовательность 1, 2, …,
n–1,
n для них более приемлема; ее, по крайней мере, можно воспроизвести.
• Если вам требуется определенное количество энтропии, но в виде необработанных данных, вы можете извлечь небольшое множество при помощи одного из случайных методов (в зависимости от того, какое качество вы хотите гарантировать), а после этого расширить его одной из функций хеширования, такой как MD5 или SHA.
Исходный код драйвера случайных чисел,
drivers/char/random.с, включает в себя важную информацию о технических деталях. Если вы планируете создание криптографической программы на основе данных, предоставляемых одним из описанных интерфейсов, настоятельно рекомендуем сначала изучить всю документацию.
Глава 20
Программирование виртуальных консолей
Интерфейс программирования виртуальных консолей Linux основан на интерфейсе, который предоставляют некоторые версии UNIX. Это не полная реализация (хотя ее достаточно для совместимости исходного кода почти со всеми программами), но в ней также предусмотрено несколько важных дополнений.
Система Linux может переключать несколько сеансов работы с терминалом на одном экране и одной клавиатуре. Специальные клавиатурные последовательности позволяют пользователю определять, какой сеанс отображается в данный момент. Каждый из этих сеансов входа в систему имеет собственные установки клавиатуры (подобные тем, которые работают при нажатии или отключении клавиши <Caps Lock>), установки терминала (размеры, графический режим экрана, шрифты и так далее), компоненты устройств (такие как
/dev/tty1,
/dev/vcs1 и
/dev/vcsa1).
Клавиатурные и терминальные установки вместе называются
виртуальными консолями (virtual console — VC). Это название объясняется их схожестью с виртуальной памятью, в которой система использует дисковое пространство для предоставления большего объема доступной памяти, чем физически установлено в компьютере.
Если вы не собираетесь управлять или обрабатывать VC, то можете пропустить эту главу. Работу с VC могут выполнять вместо вас несколько программных библиотек. При этом вам, возможно, захочется узнать, что они делают "за кулисами", чтобы вы могли работать с ними, а не против них.
Например,
svgalib (библиотека для использования графики на нескольких типах графических контроллеров) содержит функции, которые производят большинство основных операций над виртуальными консолями. При этом требуется, чтобы вы избегали передачи случайных битов в графический контроллер в то время, когда он находится в текстовом режиме. Это может привести к искажению экрана. Из-за того, что документация по
svgalib в настоящее время отсутствует, еще более важным для вас становится понимание того, что происходит внутри
[149].
Виртуальные консоли предлагают пользователям множество опций, однако многие пренебрегают ними и просто используют X Window System. Те пользователи, которые предпочитают применять VC, имеют перечисленные ниже возможности.
• Выбор отдельного шрифта для каждой VC.
• Выбор индивидуального размера терминала в каждой VC.
• Выбор соответствий ключа (подробнее об этом далее) для
всех VC.
• Выбор различных клавиатурных кодировок для
всех VC.
• Переключение виртуальных консолей при помощи особых нажатий клавиш, установленных пользователем.
Проект документации Linux (Linux Documentation Project — LDP) предлагает документацию, объясняющую, как использовать существующие программы, извлекая все преимущества описанных возможностей. Перед вами стоит другая цель — вы хотите программировать для VC, а не просто их использовать. В утилитах
[150] хорошо инкапсулированы установки шрифтов и клавиатуры, поэтому вы можете просто вызывать их из своих программ. Однако встречаются ситуации, в которых такие внешние программы бесполезны.
20.1. Начало работы
Ниже приведен список тех действий, которые вы можете производить над VC. Некоторые из них относятся только к отдельной виртуальной консоли (как правило, к той, которая активна в данный момент); некоторые используются для всех работающих VC.
• Найти текущую VC.
• Инициировать переключение VC.
• Отклонить или принять переключение VC.
• Полностью запретить переключение VC.
• Найти неиспользуемую VC.
• Динамически назначить или освободить память VC в ядре.
• Генерировать простые звуки.
Во всех случаях необходима одна и та же подготовительная работа. Вы будете применять команды
ioctl() на
/dev/tty — поэтому нужно начать с включения заголовочных файлов, которые определяют аргументы
ioctl().
#include <signal.h>
#include <sys/ioctl.h>
#include <sys/vt.h>
#include <sys/kd.h>
#include <sys/param.h>
После этого нужно открыть
/dev/tty.
if ((fd = open("/dev/tty", O_RDWR)) < 0) {
perror("myapp: не удается открыть /dev/tty");
exit(1);
}
Если вы обнаруживаете, что не можете открыть
/dev/tty, то, возможно, у вас проблемы с полномочиями: устройство
/dev/tty должно быть доступно для чтения и записи всем без исключения.
Обратите внимание на то, что в качестве дополнения к
ioctl.h существуют два главных заголовочных файла, в которых определены вызовы
ioctl(), обрабатывающие VC. В файле
vt.h определяются вызовы, начинающиеся с букв
VT, и реализуется управление виртуальным терминалом (экраном), как частью виртуальных консолей. В файле
kd.h определены вызовы, которые начинаются с
KD и обрабатывают клавиатуру и шрифты. Почти все содержимое
kd.h можно проигнорировать, поскольку эти функциональные возможности прекрасно инкапсулируются в утилитах. Однако оно окажется весьма полезным при выдаче звуковых сигналов консолью на управляемых частотах.
Данные основные заголовочные файлы также определяют структуры, которые используются с
ioctl().
Структура
vt_mode применяется для поиска и изменения текущей VC:
struct vt_mode {
char mode;
char waitv;
short relsig;
short acqsig;
short frsig;
};
• Переменная
mode принимает одно из двух значений:
VT_AUTO (вынуждает ядро автоматически переключать консоли во время нажатия клавиш или при получении запроса от программы на переключение VC) или
VT_PROCESS (предписывает ядру запрашивать подтверждение прежде чем переключать консоли).
• Переменная
waitv не используется, однако для совместимости с SVR4 ей нужно присвоить значение
1.
• Переменная
relsig именует сигнал, который должно сгенерировать ядро для передачи в процесс запроса на освобождение VC.
• Переменная
acqsig именует сигнал, который должно сгенерировать ядро для извещения процесса о том, что он получает VC.
• Переменная
frsig не используется, однако для совместимости с SVR4 ей нужно присвоить значение
0.
struct vt_stat {
unsigned short v_active;
unsigned short v_signal;
unsigned short v_state;
};
• Переменная
v_active хранит количество VC, активных в данный момент.
• Переменная
v_signal не реализована.
• Переменная
v_state хранит битовую маску, сообщающую, какие из
первых 16 VC открыты в данный момент (в системе Linux поддерживается до 63 VC). В системе Linux редко появляется смысл консультироваться с данной маской, поскольку она недостаточно велика, чтобы содержать полную информацию. В большинстве случаев вам понадобится знать только номера ряда открытых консолей, которые вы можете извлечь с помощью функции
VT_OPENQRY (рассматривается далее в этой главе).
20.2. Выдача звукового сигнала
Заставить консоль генерировать звуковой сигнал в течение определенного периода времени на указанной частоте совсем не сложное дело. Для этого существуют два способа. Первый состоит во включении или отключении постоянной тональной посылки. Команда
KIOCSOUND отключает звук, если ее аргумент равен нулю. В противном случае она устанавливает частоту звука (причем довольно необычным способом, как показано в следующем коде).
void turn_tone_on(int fd, int hertz) {
ioctl(fd, KIOCSOUND, 1193180/hertz)
}
void turn_tone_off(int fd) {
ioctl(fd, KIOCSOUND, 0)
}
Вторым вариантом для выдачи консолью звукового сигнала является применение команды управления вводом-выводом
KDMKTONE. Она включает тональную посылку на время, указанное в тиках системных часов (jiffy). К сожалению, время одного тика в различных архитектурах разное. Макрос
HZ, определенный
sys/param.h, позволяет получить количество тиков в секунду. Функция
tone(), показанная ниже, демонстрирует, как извлекать количество тиков в сотых долях секунды и значение макроса
HZ[151].
#include <sys/param.h>
void tone(int fd, int hertz, int hundredths) {
unsigned int ticks = hundredths * HZ / 100;
/* ticks & 0xffff не будет работать, если ticks — 0xf0000;
* вместо этого нужно округлить до наибольшего допустимого значения */
if (ticks > 0xffff) ticks = 0xffff;
/* еще одна ошибка округления */
if (hundredths && ticks == 0) ticks = 1;
ioctl(fd, KDMKTONE, (ticks << 16 | (1193180/hertz)));
}
20.3. Определение, является ли терминал виртуальной консолью
Для того чтобы определить, является ли текущий терминал виртуальной консолью, можно открыть
/dev/tty и применить
VT_GETMODE для запроса режима:
struct vt_mode vtmode;
fd = open("/dev/tty", O_RDWR);
retval = ioctl (fd, VT_GETMODE, &vtmode);
if (retval < 0) {
/* Данный терминал не является VC; выполните соответствующие действия */
}
20.4. Поиск текущей виртуальной консоли
Для извлечения номера текущей VC применяется команда управления вводом-выводом
VT_GETSTATE, которая принимает указатель на структуру
struct vt_stat и возвращает номер текущей консоли в ее элементе
v_active.
unsigned short get_current_vc(int fd) {
struct vt_stat vs;
ioctl(fd, VT_GETSTATE, &vs);
return(vs.v_active);
}
Для локализации соответствующего элемента устройства для текущей VC служит следующая функция:
sprintf(ttyname, "/dev/tty%d", get_current_vc(fd));
20.5. Управление переключением виртуальных консолей
Для того чтобы найти неиспользуемую VC (другими словами, консоль, на которую в данный момент не ссылается ни один открытый файловый дескриптор в процессах) и активизировать ее, используется команда управления вводом-выводом
VT_OPENQRY.
retcode = ioctl(fd, VT_OPENQRY, &vtnum);
if ((retcode < 0) || (vtnum == -1)) {
perror("myapp: нет доступных виртуальных терминалов");
/* выполнить соответствующее действие */
}
Если в настоящее время используется менее 63 VC, и все из них заняты, то ядро автоматически выделяет память для новой VC
[152].
Для запуска переключения на другую VC (например, на ту свободную консоль, которую вы только что обнаружили) используется команда управления вводом-выводом
VT_ACTIVATE. Если нужно подождать до тех пор, пока консоль не станет активной, применяется команда
VT_WAITACTIVE. Смена консоли может занять некоторое время, возможно, несколько секунд. Это объясняется тем, что активизируемая консоль может находиться в графическом режиме, при этом содержимое экрана нужно реконструировать из памяти, выбрать из буфера обмена или восстановить каким-то другим способом, отнимающим немало времени
[153].
ioctl(fd, VT_ACТIVATE, vtnum);
ioctl(fd, VT_WAITACTIVE, vtnum);
Для осуществления контроля над переключениями VC или для получения уведомлений о подобных переключениях необходимо предусмотреть надежные обработчики сигналов с
sigaction, как обсуждалось в главе 12. Здесь мы применяем
SIGUSR1 и
SIGUSR2; если нужно, вы можете использовать любые другие два сигнала, которые не предназначены для других целей (например,
SIGPROF и
SIGURG). Просто убедитесь, что выбранные вами сигналы удовлетворяют перечисленным ниже критериям.
• Они не требуются остальным системным функциям, особенно это касается тех сигналов, которые не могут быть перехвачены или проигнорированы.
• Они нигде не используются в вашем приложении для других целей.
• Они не представляют один и тот же сигнальный номер с двумя различными именами, как
SIGPOLL и
SIGIO (определения смотрите в
/usr/include/asm/signal.h, либо ограничьте себя использованием сигналов из табл. 12.1).
void relsig(int signo) {
/* выполнить соответствующее действие для освобождения VC */
}
void acqsig(int signo) {
/* выполнить соответствующее действие для запроса VC */
}
void setup_signals(void) { struct sigaction sact;
/* He маскировать никаких сигналов в то время,
* когда активизированы данные обработчики. */
sigemptyset(&sact.sa_mask);
/* Здесь может понадобиться добавление вызовов sigaddset(),
* если существуют сигналы, которые нужно маскировать
* при переключении VC. */
sact.flags = 0;
sact.sa_handler = relsig;
sigaction(SIGUSR1, &sact, NULL);
sact.sa_handler = acqsig;
sigaction(SIGUSR2, &sact, NULL);
}
После этого потребуется изменить стандартный режим VC (
mode) с
VT_AUTO на
VT_PROGRESS, пока консоль уведомляется об обработчиках сигналов путем установки
relsig и
acqsig.
void control_vc_switching(int fd) {
struct vt_mode vtmode;
vtmode.mode = VT_PROCESS;
vtmode.waitv = 1;
vtmode.relsig = SIGUSR1;
vtmode.acqsig = SIGUSR2;
vtmode.frsig = 0;
ioctl(fd, VT_SETMODE, &vtmode);
}
Обработчики сигналов, которые вызываются тогда, когда консоль находится в режиме
VT_PROCESS, не должны соглашаться на переключение. Говоря более точно, обработчик
relsig может отклонить разрешение на переключение VC. Обработчик
acqsig, как правило, управляет процессом передачи консоли, но существует вероятность того, что он инициирует переключение на другую консоль. Будьте внимательны при кодировании обработчиков сигналов, чтобы избежать вызова любых нереентерабельных библиотечных функций. POSIX.1 устанавливает, что функции, перечисленные в табл. 12.2, являются реентерабельными. Значит, вы должны считать все остальные функции нереентерабельными, особенно, если хотите написать переносимую программу. Обратите внимание, в частности, на то, что
malloc() и
printf() являются нереентерабельными.
Ниже приведены примеры функций
relsig() и
acqsig(), выполняющих полезную работу. Особо следует отметить, что для функции
relsig() вызов
VT_RELDISP является обязательным, тогда как для
acqsig() вызов
VT_RELDISP рекомендуется только ради переносимости.
void relsig (int signo) {
if (change_vc_ok()) {
/* Разрешено переключение VC */
save_state();
ioctl(fd, VT_RELDISP, 1);
} else {
/* Запрещено переключение VC */
ioctl(fd, VT_RELDISP, 0);
}
}
void acqsig (int signo) {
restore_state();
ioctl(fd, VT_RELDISP, VT_ACKACQ);
}
Теперь вы в состоянии реализовать код функций
change_vc_ok(),
save_state() и
restore_state().
Динамическое выделение памяти под виртуальные консоли происходит при их открытии, однако, они
не удаляются автоматически, когда закрываются. Для того чтобы освободить память ядра, в которой сохранялось состояние VC, нужно вызвать
ioctl().
ioctl(fd, VT_DISALLOCATE, vtnum);
Вы можете заблокировать и повторно открыть переключение VC с помощью нескольких простых команд управления вводом-выводом:
void disallow_vc_switch(int fd) {
ioctl(fd, VT_LOCKSWITCH, 0);
}
void allow_vc_switch(int fd) {
ioctl(fd, VT_UNLOCKSWITCH, 0);
}
20.6. Пример команды open
Ниже показан пример кода, выполняющий следующие задачи: поиск неиспользуемой VC, запуск на ней оболочки, ожидание завершения оболочки, переключение обратно, а также освобождение памяти, выделенной под VC, по завершении программы. Программа
open, входящая в состав дистрибутива Linux, выполняет те же самые действия, но при этом она содержит больше опций и лучший контроль ошибок, таким образом, является более надежной. Хотя приведенная ниже версия тоже будет работать, ее трудно назвать удобной, надежной или безопасной.
1: /* minopen.c */
2:
3: #include <stdio.h>
4: #include <unistd.h>
5: #include <stdlib.h>
6: #include <signal.h>
7: #include <fcntl.h>
8: #include <sys/ioctl.h>
9: #include <sys/vt.h>
10: #include <sys/stat.h>
11: #include <sys/types.h>
12: #include <sys/wait.h>
13:
14: int main (int argc, const char ** argv) {
15: int vtnum;
16: int vtfd;
17: struct vt_stat vtstat;
18: char device[32];
19: int child;
20:
21: vtfd = open("/dev/tty", O_RDWR, 0);
22: if (vtfd < 0) {
23: perror("minopen: не удается открыть /dev/tty");
24: exit(1);
25: }
26: if (ioctl(vtfd, VT_GETSTATE, &vtstat) < 0) {
27: perror("minopen: tty не является виртуальной консолью");
28: exit(1);
29: }
30: if (ioctl(vtfd, VT_OPENQRY, &vtnum) < 0) {
31: perror("minopen: нет свободных виртуальных консолей");
32: exit(1);
33: }
34: sprintf(device, "/dev/tty%d", vtnum);
35: if (access(device, (W_OK|R_OK)) < 0) {
36: perror("minopen: недостаточные полномочия на tty");
37: exit(1);
38: }
39: child = fork();
40: if (child == 0) {
41: ioctl(vtfd, VT_ACTIVATE, vtnum);
42: ioctl(vtfd, VT_WAITACTIVE, vtnum);
43: setsid();
44: close(0); close(1); close(2);
45: close(vtfd);
46: vtfd = open(device, O_RDWR, 0); dup(vtfd); dup(vtfd);
47: execlp("/bin/bash", "bash", NULL);
48: }
49: wait(&child);
50: ioctl(vtfd, VT_ACTIVATE, vtstat.v_active);
51: ioctl(vtfd, VT_WAITACTIVE, vtstat.v_active);
52: ioctl(vtfd, VT_DISALLOCATE, vtnum);
53: exit(0);
54: }
Глава 21
Консоль Linux
Консоль Linux, как правило, имитирует последовательный терминал. Выводя специальные последовательности символов в компонент консоли, можно управлять всеми аспектами воспроизведения на экране. Для вывода информации на экран обычно применяются S-Lang, curses или ряд других библиотек рисования на экране; они используют упомянутые управляющие последовательности. Консоль можно также читать и модифицировать через альтернативный полноэкранный интерфейс, который особенно полезен для некоторых специализированных программ.
Программисты для DOS, впервые сталкиваясь с программированием для Linux, обнаруживают пугающий их факт. Оказывается, вывод символов на экран — это не просто инициализация указателя на адрес экрана в памяти и последующая запись прямо через него. Некоторые даже жалуются в полный голос на эту "отсталую" систему, которая вынуждает их делать вид, что они выводят информацию в последовательный терминал, вписывая между символами
управляющие последовательности. Последние выводятся на экран для управления перемещением курсора, цветом, очисткой экрана и так далее.
Существует несколько веских причин для того, чтобы рассматривать консоль как фиктивный последовательный терминал. И не последняя из них заключается в том, что когда программа
уже активизирована на последовательном терминале, она все еще работает. Еще более важным является то, что программа корректно работает в сетях (в наше время Internet), а также в окне терминального эмулятора под X или каким-либо другим графическим интерфейсом пользователя. Более того, удаленно работающие программы (либо через сеть, либо через последовательное соединение) соответствующим образом выводят информацию на вашу консоль.
Кроме того, вы заметите, что управляющие коды являются рациональными низкоуровневыми интерфейсами для экрана. Они также служат хорошей основой для построения примитивов более высокого уровня вроде модуля curses, описанного в [36]. И это не просто случайность; последовательные терминалы являются весьма уважаемой технологией, которая годами превосходно отвечает фактическим потребностям программистов. Консоль Linux основана на наиболее популярном семействе последовательных терминалов, наследников DEC VT100.
Большинство управляющих последовательностей используют символ перехода (escape) ANSI, который не имеет печатного представления. Мы будем следовать библиотекам
termcap и
terminfo, в которых для обозначения символа перехода ANSI применяется
^[. Имейте в виду при чтении, что они иногда ссылаются на тот же самый символ, как на
\Е. Всюду в данной книге, как и в
termcap и
terminfo, выражение
^C указывает на символ Control-C.
21.1. Базы данных возможностей
Действия, контролируемые заданными управляющими последовательностями, часто называются
возможностями (capabilities). Некоторые управляющие последовательности совместно используются большим числом терминалов. Многие из таких последовательностей определены в стандарте ANSI X3.64-1979. Почти все терминалы с возможностями поддержки цвета используют одни и те же последовательности для выбора цветов изображения. При этом многие терминалы поддерживают совершенно различные управляющие последовательности. Например, на терминале Wyse 30 нажатие <F1> передает последовательность
^A@\r, тогда как на консоли Linux — последовательность
^[[[А. Аналогично, для того, чтобы переместить курсор вверх на Wyse 30, нужно послать символ
^K, а на консоли Linux — последовательность
^[[А. Для создания программы, которая может работать на любом терминале, вам крайне необходим метод абстрагирования подобных различий, который позволит программировать возможности, а не необработанные последовательности символов.
Наиболее известная библиотека программирования, которая предоставляет такую абстракцию, называется
curses[154] (предписания); она описана в [36]. В нее входит два важных концептуальных уровня. Первый уровень предлагает функции, которые (говоря в общем) посылают одну управляющую последовательность для выполнения одного действия, такого как перемещение курсора вверх или вниз, прокрутка экрана и так далее. Второй уровень реализует концепцию "окон": независимые области окна, которые могут обрабатываться отдельно, при этом
curses обеспечивает кратчайшие последовательности символов для достижения требуемого эффекта.
Библиотека
curses определяет, какие последовательности передавать в терминал, консультируясь с базой данных, которая для каждого терминала ставит в соответствие названия возможностей строкам, которые должны пересылаться.
Linux, как все современные системы Unix, предлагает две базы данных, которые описывают терминалы в смысле их возможностей и соответствующих им управляющих последовательностей. Более старая база данных называется
termcap (сокращение от
terminal capabilities — терминальные возможности) и хранится в одном большом двумерном ASCII-файле по имени
/etc/termcap. Этот файл постепенно стал очень громоздким; его размер вырос приблизительно до половины мегабайта. Более новая база данных называется
terminfo (сокращение от terminal information — терминальная информация) и хранится во множестве бинарных файлов (по одному на терминал), как правило, в подкаталогах каталога
/usr/lib/terminfo.
Внутри каждой базы данных информация о возможностях для каждого терминала индексируется одним (или более) уникальным именем. Обе базы данных используют одно и то же имя для одного и того же сериала. Например, консоль Linux называется
linux и в
termcap, и в
terminfo. Вы сообщаете программам, какой терминальный вход использовать, путем установки переменной окружения
TERM. При создании программ, использующих
termcap и
terminfo, вам редко придется обращаться к переменной
TERM; обычно это берут на себя низкоуровневые библиотеки для получения доступа к базам данных
termcap или
terminfo.
Если же вы хотите произвести специфическую для Linux оптимизацию, особенно если требуется применение нестандартных возможностей Linux, которые не описаны в базах данных, вы можете извлечь содержимое переменной окружения
TERM с помощью показанного ниже кода.
if (!strcmp("linux", getenv("TERM"))) {
/* должна быть консоль Linux */
} else {
/* обрабатывать как обычный последовательный терминал */
}
Также если вы создаете программы на языках программирования, которые не предоставляют упрощенный доступ к
curses или другим библиотекам, вы обязательно оцените удобство применения этой документации.
Разумеется, то, что ваш терминал имеет тип
linux, не является гарантией того, что программа работает на локальном терминале. Это означает только то, что у вас есть доступ к управляющим последовательностям, описанным в данной главе, при этом вы не знаете, можете ли вы использовать устройства
vcs (о них позже в этой главе) или
ioctl(). Стандарт POSIX определяет функцию
ttyname(), которую вы можете применить для извлечения имени файла устройства для управляющего терминала. В системе Linux виртуальные консоли называются
/dev/ttyn, где
n принимает значения от 1 до 63 (
/dev/tty0 — всегда текущая консоль).
Полное описание систем
termcap и
terminfo можно найти в [37]. В настоящий момент базы данных
termcap и
terminfo поддерживает Эрик Раймонд (Eric Raymond), и они доступны по адресу http://www.ccil.org/~esr/terminfo/.
Исходный код
ncurses (новая библиотека
curses — реализация
curses, используемая в Linux) включает в себя введение в программирование с применением
curses (файл
misc/ncurses-intro.html).
21.2. Глифы, символы и отображения
Когда вы выводите символ на любой терминал, могут произойти несколько шагов преобразования. Значение, выводимое на терминал, представляет собой номер символа, или его код. Однако такого кода символа недостаточно для определения того, что нужно изобразить на экране. Форма зависит от используемого шрифта. Символьный код 97 может быть распечатан как
а (в шрифте, предназначенном для визуализации латиницы) или как
∂ (в шрифте для визуализации греческого алфавита или математических знаков). Изображаемая на экране форма называется
глифом (glyph). Преобразование символьных кодов в глифы называется отображением.
21.3. Возможности консоли Linux
Консоль Linux, как и большинство терминалов, является
модальной: ее взаимодействие с данными зависит от того, в каком режиме она находится. По умолчанию она выводит на экран передаваемые символы, пока не получает управляющий символ или символ перехода.
Управляющий символ просто вызывает некоторое регулирующее действие, а следующий символ уже читается обычным образом. Изменений в режиме обработки не происходит.
Символ перехода сигнализирует о начале управляющей последовательности и изменяет режим обработки на режим управления.
Например, рассмотрим следующую строку С:
"this is a line\na \033[1mbold\033[0m word\n"
Консоль обрабатывает эту строку в описанной ниже последовательности.
1. Начиная с текущей позиции курсора, консоль печатает слова
this is a line.
2. Обнаруживается символ новой строки (
\n), поэтому (так как Linux и Unix обычно работают в режиме, когда новая строка сигнализирует также о возврате каретки) консоль перемещает курсор в начало следующей строки. При этом если курсор уже был на самой нижней строке, весь экран прокручивается вверх на одну строку.
3. В начале данной линии отображается строка
а.
4. Консоль сталкивается с символом перехода
\033 и переводится в управляющий режим.
5. Считывается символ
[, консоль переходит в режим
ввода командной последовательности (Command Sequence Introduction — CSI).
6. В режиме CSI считывается последовательность десятичных чисел, закодированных в ASCII и разделенных знаками
;, которые называются параметрами. Это продолжается до тех пор, пока не встретится первая буква. Буква определяет действие, которое нужно предпринять, с учетом данных в параметрах. В данном случае имеется один параметр
1, а буква
m означает, что параметр используется для определения
изображения символа. Например, параметр
1 устанавливает атрибут полужирного шрифта.
7. Распечатывается строка
bold в полужирном представлении.
8. Далее идет другая последовательность изображения символов, которая восстанавливает все стандартные атрибуты, поэтому строка
word выводится в обычном изображении.
9. В завершение встречается и обрабатывается еще один символ новой строки.
Таким образом, считая, что курсор находился в начале строки, выходные данные полностью будут выглядеть примерно так:
this is a line
a bold word
21.3.1. Управляющие символы
Консоль считывает управляющие символы незамедлительно, действует в соответствии с ними и затем продолжает считывать символы в нормальном режиме.
В файлах и документации
termcap и
terminfo управляющие символы изображаются символом
^c. Мы будем часто в данной книге использовать это условное обозначение, поскольку оно более универсально и удобно для вас, чем восьмеричные управляющие последовательности С. Для отыскания числового значения управляющего символа в некоторых системах предусмотрен макрос
CTRL() в
<termios.h>, но он не является стандартным для всех систем.
В качестве замены мы предлагаем нашу собственную версию
CTRLCHAR().
#define CTRLCHAR(ch) ((ch)&0x1F)
Она используется так:
if (с == CTRLCHAR('С')) {
/* был нажат символ Control-C */
}
Управляющие символы, воспринимаемые консолью Linux, описаны в табл. 21.1. Символ
^? фактически представляет собой
'?'+0100, а не
'?'-0100, поэтому это не настоящий управляющий знак вопроса, но в любом случае стандартное обозначение для него
^?. Его значение есть 0177 (восьмеричное), 127 (десятичное), 7F (шестнадцатеричное). Вы не сможете использовать макрос
CTRL, описанный только что, для проверки. Вместо этого придется применять числовое значение 127.
Таблица 21.1. Символы управления консолью
| Управляющий символ |
Имя ASCII |
Описание |
^G |
BEL |
Выдает тональный сигнал. |
^Н |
BS |
Курсор перемещается к предыдущему символу, не перезаписывая его (если только курсор не находится в первой колонке). |
^I |
НТ |
Горизонтальная табуляция; курсор перемещается к следующей точке табуляции. |
^J |
LF |
Новая строка; курсор перемещается на следующую строку; если курсор уже находился в самой нижней точке области прокручивания, то она продвигается вверх. |
^K |
VT |
Вертикальная табуляция; интерпретируется так же, как новая строка. |
^L |
FF |
Подача страницы; интерпретируется так же, как новая строка. |
^М |
CR |
Возврат каретки; курсор перемещается в начало текущей строки. |
^N |
SO |
Сдвиг; используется альтернативный (G1) символ, установленный для отображения глифов; изображаются глифы для управляющих символов. |
^O |
SI |
Сдвиг; используется стандартный (G0) символ, установленный для отображения глифов; не изображаются глифы для управляющих символов. |
^X |
CAN |
Отменяется любая действующая управляющая последовательность. |
^Z |
SUB |
Отменяется любая действующая управляющая последовательность. |
^[ |
ESC |
ESCape; начало управляющей последовательности. |
^? |
DEL |
Игнорируется. |
ALT-^[ |
- |
Вводится последовательность команд, которая будет описана далее. |
Обратите внимание на то, что результат некоторых из данных кодов зависит от настроек tty. Хотя сама консоль описана здесь абсолютно точно, настройки tty могут изменять передаваемые символы. Например, передача
^J (LF) обычно вынуждает уровень tty также передавать
^M (CR), а символ
^? (DEL) может быть настроен на передачу
^Н (BS).
Символ
ALT-^[ вообще не является символом ASCII. Это восьмибитовый символ ESC, тогда как ASCII определяет только семибитовые символы. Вы можете применять этот символ в качестве комбинации быстрого вызова для ввода последовательности CSI. Однако мы рекомендуем избегать этого, так как при этом понадобится чистый восьмибитовый канал связи, который может помешать удаленной работе вашей программы на другой подключенной системе Linux, возможно, из-за последовательного канала, передающего только семь битов из каждого байта.
Для получения более подробной информации о символах ASCII обратитесь к man-странице ascii(7). Кроме того, на man-странице iso_8859_1(7) рассматривается набор восьмибитовых знаков ISO Latin 1 (точнее говоря, ISO 8859 Latin Alphabet number 1); этот более новый стандарт стал фактической заменой ASCII и сейчас официально называется ISO 646-IRV.
21.3.2. Управляющие последовательности
Существуют несколько отдельных типов управляющих последовательностей. Самый простой тип представляет собой символ перехода (
^[), за которым следует один командный символ. (Несмотря на то что символ перехода отображается в строках С как
\033, в файлах и документации по
termcap и
terminfo принято обозначение
^[.) Пять из таких односимвольных команд предваряют более сложные управляющие последовательности, которые называются
командными последовательностями. Остальные побуждают консоль предпринимать простые действия и немедленно покидать режим перехода. Простейшие управляющие последовательности описаны в табл. 21.2.
Таблица 21.2. Последовательности управления консолью
| Управляющие последовательности |
Описание |
^[М |
Курсор перемещается вверх на одну строку в текущей колонке; если необходимо, то экран прокручивается вниз (обратный перевод строки). |
^[D |
Курсор перемещается вниз на одну строку в текущей колонке; если необходимо, то экран прокручивается вверх (перевод строки) |
^[E |
Возврат каретки и перевод строки. |
^[Н |
Точка табуляции устанавливается в текущей колонке. |
^[7 |
Сохраняются позиция и атрибуты курсора. |
^[8 |
Восстанавливаются позиция и атрибуты курсора. |
^[> |
Переводит малую клавиатуру в числовой режим (стандартный). |
^[= |
Переводит малую клавиатуру в режим приложения (она ведет себя как функциональные клавиши DEC VT102). |
^[с |
Сбрасывает все терминальные установки, которые могут быть получены через управляющие символы и последовательности. |
^[Z |
Запрашивается идентификатор терминала. Ответом будет ^[[?6с; это говорит о том, что консоль точно эмулирует DEC VT102 (она включает в себя расширенный набор возможностей DEC VT102). |
Сохранение и восстановление позиции курсора (
^[7 и
^[8) не осуществляется в стеке. Если вы делаете два сохранения в одной строке, то вторая сохраняемая позиция перезаписывает первую. Наоборот, один раз сохранив позицию курсора, вы можете восстанавливать ее столько раз, сколько нужно. Всякий раз курсор будет возвращаться в одно и то же расположение. При восстановлении положения курсора также восстанавливаются атрибуты изображения курсора, текущий набор символов, описания набора символов (все это будет описываться далее в данной главе).
Позиция курсора задается в показателях
адреса знакоместа, парой чисел
x,y, которая обозначает одну позицию на экране. Нумерация адресов знакомест на большинстве терминалов, включая консоль Linux, не начинается с нуля, как это принято в обычной компьютерной практике. Верхний левый символ на экране является
началом отсчета и получает адрес как знакоместо 1,1.
Обратите внимание на то, что управляющие символы могут включаться внутри управляющей последовательности. Например,
^[^G8 сначала выдает тональный сигнал, а затем восстанавливает позицию и атрибуты курсора. Последовательность
^[^X8 просто печатает число 8.
21.3.3. Тестирование последовательностей
Для проверки большинства последовательностей вам нужно просто войти в виртуальную консоль и запустить
cat. Введите последовательности, которые вы хотите протестировать, и увидите результаты. Для
^[ нажмите клавишу <Esc>.
Терминалы отвечают на команды вроде идентификации терминала
^[Z или команды
CSIn, рассматриваемые позже, управляющим последовательностями, которые на терминалах не отображаются. В тех случаях, когда вы хотите увидеть подобное взаимодействие, просто запустите
cat > /tmp/somefile
Затем введите команды, после которых укажите возврат каретки и
^D. Используйте
less,
vi, Emacs или какую-то другую программу, которая может обрабатывать произвольные символы для того, чтобы прочитать
/tmp/somefile, где непосредственно после напечатанных вами последовательностей вы найдете ответы на них.
21.3.4. Составные управляющие последовательности
Пять двухсимвольных управляющих последовательностей (которые показаны в табл. 21.3) фактически являются префиксами более длинных и сложных последовательностей. Рассмотрим каждую из них по очереди.
Таблица 21.3. Составные последовательность управления консолью
| Управляющие последовательности |
Описание |
^[[ |
Начинается последовательность CSI (ALT-^[ является синонимом). |
^[] |
Начинается последовательность управления палитрой. |
^[% |
Начинается последовательность UTF (UTF-8 wide-character Unicode). |
^[( |
Выбирается шрифт, соответствующий набору символов G0. |
^[) |
Выбирается шрифт, соответствующий набору символов G1. |
^[#8 |
Внутренняя тестовая последовательность DEC; заполняет экран символами Е. |
Последовательности CSI имеют три или четыре части.
1.
^[[ запускает последовательность CSI, переводя терминал в режим CSI.
2. Только для последовательностей
h и
l вы можете добавлять символ
?, что позволит устанавливать или очищать собственные режимы DEC (см. табл. 21.9).
3. Предусматривается не более чем 16 параметров. Параметры — это десятичные числа, разделенные символами
;. Например,
1;23;45 представляет собой список из трех параметров: 1, 23 и 45. (Если после прочтения 16 параметров обнаруживается разделитель
;, то последовательность CSI немедленно прерывает работу и терминал переходит в нормальный режим, распечатывая оставшуюся часть последовательности).
4.
Командный символ прерывает последовательность и определяет способ интерпретации параметров, которые терминал только что обнаружил.
На параметры обычно ссылаются как на некоторые переменные от
par1 до
par16. Если вы не установили параметр явно, то его значение автоматически приравнивается к нулю или единице, в зависимости от смысла операции. Командные символы CSI перечислены в табл. 21.4.
Таблица 21.4. Последовательности CSI
| Символ |
Описание |
h |
Устанавливает режим; см. табл. 21.8. |
l |
Очищает режим; см. табл. 21.8. |
n |
par1=5 Отчет о состоянии: терминал отвечает ^[[0n, что означает "OK" par1=6 Отчет о положении курсора: терминал отвечает ^[[x;yR, где у указывается относительно начала отсчета, а не области (если выбран режим начала отсчета, смотрите табл. 21.9) |
G или ` |
Устанавливает горизонтальное положение курсора в колонке par1. |
A |
Передвигает вертикальную позицию курсора вверх на par1 строк. |
В или e |
Передвигает вертикальную позицию курсора вниз на par1 строк. |
С или a |
Передвигает горизонтальную позицию курсора вправо на par1 колонок. |
D |
Передвигает горизонтальную позицию курсора влево на par1 колонок. |
E |
Передвигает курсор в начало линии и ниже на par1 строк (1 по умолчанию). |
F |
Передвигает курсор в начало линии и выше на par1 строк (1 по умолчанию). |
d |
Устанавливает вертикальное положение курсора в строке par1. |
H или f |
Устанавливает вертикальное положение курсора в строке par1 и горизонтальное положение курсора в колонке par2 (по умолчанию оба параметра равны нулю, перемещая курсор в начало отсчета). |
J |
par1=0 Очищает экран от курсора до конца дисплея par1=1 Очищает экран от начала отсчета до курсора par1=2 Очищает экран полностью |
K |
par1=0 Очищает экран от курсора до конца строки par1=1 Очищает экран от начала строки до курсора par1=2 Очищает строку полностью |
L |
Вставляет par1 строк ниже текущей строки. |
М |
Удаляет par1 строк, начиная с текущей строки. |
P |
Удаляет par1 символов, начиная с текущей позиции, передвигая остальную часть строки влево. |
с |
Отвечает ^[[?6c (синоним ^[Z). |
g |
par1=0 Удаляет точку табуляции в текущем столбце (по умолчанию) par1=3 Удаляет все точки табуляции |
m |
Последовательность изображения символов; смотрите табл. 21.7. |
q |
Включает клавиатурный LED par1 и отключает остальные (0 выключает все). |
r |
Устанавливает область прокручивания (применяется только в режиме начала отсчета DEC; см. табл. 21.9): par1 Первая строка области, должна находиться в пределах от 1 (по умолчанию) до par2–1 par2 Последняя строка области, должна находиться в пределах от par1+1 и нижней строкой (по умолчанию) |
s |
Сохраняет позицию и атрибуты курсора (синоним ^[7). |
u |
Восстанавливает позицию и атрибуты курсора (синоним ^[8). |
X |
Стирает par1 символов (до конца текущей строки). |
@ |
Стирает par1 символов (до конца текущей строки). |
] |
Последовательности setterm; смотрите табл. 21.10. |
Несколько последовательностей принимают аргументы, описывающие цвета. Во всех таких последовательностях используется одно и то же соответствие между числами и цветами, приведенное в табл. 21.5. Последовательности, которые указывают цвета фона, допускают номера цветов только от 0 до 7. Те последовательности, которые задают цвет переднего плана, принимают числа от 8 до 15 (они описывают насыщенные или яркие цвета).
Таблица 21.5. Коды цветов
| Число |
Цвет |
Число |
Яркий цвет |
| 0 |
Черный |
8 |
Темно-серый |
| 1 |
Красный |
9 |
Светло-красный |
| 2 |
Зеленый |
10 |
Светло-зеленый |
| 3 |
Коричневый |
11 |
Желтый |
| 4 |
Голубой |
12 |
Светло-голубой |
| 5 |
Пурпурный |
13 |
Ярко-красный |
| 6 |
Синий |
14 |
Светло-синий |
| 7 |
Серый |
15 |
Белый |
Указанные цвета фактически представляют собой смещения — названия цветов в таблице описывают стандартные цвета, которые хранятся по данным смещениям. Однако вы можете изменять эти цвета при помощи последовательности установки палитры. Например, последовательность
^[]P определяет отдельный компонент палитры; последовательность
^[]R восстанавливает стандартную системную палитру. Компоненты палитры определяются семью шестнадцатеричными цифрами, введенными после
^[]P, как описано в табл. 21.6. Таким образом, для каждого элемента палитры вы можете предоставить 24-битовое определение цвета с восемью битами для каждого цвета.
Таблица 21.6. Компоненты цветовой палитры
| Число |
Что определяет |
| 1 |
Элемент палитры, который нужно переопределить. |
| 2*16+3 |
Значение красного компонента элемента палитры. |
| 4*16+5 |
Значение зеленого компонента элемента палитры. |
| 6*16+7 |
Значение синего компонента элемента палитры. |
Последовательности изображения символов, указанные командами
CSIm, могут принимать в произвольном порядке до 16 параметров, перечисленных в табл. 21.7. Параметры применяются к терминалу в том порядке, в котором они передаются. Таким образом, если
0 (установка стандартного изображения) сопровождается
1 (для установки полужирного шрифта), то результатом будет полужирный символ (а не мерцающее негативное видеоизображение) или подчеркнутый символ в зависимости от предыдущих установок изображения.
Таблица 21.7. Параметры изображения символов
| par |
Описание |
| 0 |
Стандартное изображение: средняя интенсивность, без подчеркивания, без негативного изображения, без мерцания, с обычной цветовой схемой (белое на черном, если не установлен другой способ при помощи последовательности сохранения setterm ^[[]8). |
| 1 |
Интенсивность — насыщенная. |
| 2 |
Интенсивность — матовая. |
| 4 |
Включается подчеркивание. |
| 5 |
Включается мерцание. |
| 7 |
Включается негативное видеоизображение. |
| 10 |
Выбирается исходный шрифт (ISO latin 1), при этом не отображаются управляющие символы, сбрасывает бит 8 в выводе. |
| 11 |
Выбирается альтернативный шрифт (IBM Codepage 437), при этом управляющие символы отображаются как графические данные, сбрасывает бит 8 в выводе. |
| 12 |
Выбирается альтернативный шрифт (IBM Codepage 437), при этом управляющие символы отображаются как графические данные, оставляет бит 8 в выводе. |
| 21 22 |
Интенсивность — стандартная. |
| 24 |
Отключается подчеркивание. |
| 25 |
Отключается мерцание. |
| 27 |
Отключается негативное видеоизображение. |
| 30-37 |
Устанавливается цвет переднего плана par||30; см. табл. 21.5. |
| 38 |
Включается подчеркивание и используется стандартный цвет текста. |
| 39 |
Отключается подчеркивание и используется стандартный цвет текста. |
| 40-47 |
Устанавливается цвет фона par||40; см. табл. 21.5. |
| 49 |
Используется стандартный цвет фона. |
Некоторое отношение к последовательностям изображения символов имеют последовательности режимов. Существует два типа режимов: режимы ANSI и внутренние режимы DEC. Последовательность
СSIh устанавливает режимы ANSI, описанные в табл. 21.8; последовательность
CSIl сбрасывает их. В последовательность может входить более одного параметра. Последовательность
CSI?h определяет внутренние режимы DEC, перечисленные в табл. 21.9; последовательность
CSI?l сбрасывает их. Также может приниматься более одного параметра.
Таблица 21.8. Режимы ANSI
| par |
Описание |
| 3 |
Отображаются управляющие символы. |
| 4 |
Режим вставки. |
| 20 |
Режим CRLF (при получении символа новой строки выполняется возврат каретки). |
Таблица 21.9. Внутренние режимы DEC
| par |
Описание |
| 1 |
Клавиши управления курсором работают как клавиши приложения; в режиме приложения к ним добавляется префикс ^[O вместо обычного ^[[. |
| 3 |
На данный момент не реализован; в будущем предназначен для переключения между режимами 80 и 132 колонки. |
| 5 |
Весь экран переводится в режим негативного изображения. |
| 6 |
Устанавливается режим начала отсчета DEC, при котором принимаются области прокрутки; перемещается в начало отсчета (текущей области прокрутки, если она задана). |
| 7 |
Устанавливается режим автоматического перехода на новую строку (по умолчанию), при котором продолжается ввод текста с новой строки, когда курсор достигает конца текущей строки. Если данный режим выключен, то лишние символы печатаются поверх самого правого символа текущей строки. |
| 8 |
Клавиатура переводится в режим повторения символов (включен по умолчанию). |
| 9 |
Режим отчета мыши 1 (поддержка может предоставляться внешней программой). |
| 25 |
Курсор становится видимым (включен по умолчанию). |
| 1000 |
Режим отчета мыши 2 (поддержка может предоставляться внешней программой). |
Последовательности setterm представляют собой набор последовательностей CSI с управляющим символом
]. Они перечислены в табл. 21.10.
Таблица 21.10. Консольные последовательности setterm
| par |
Описание |
| 1 |
Устанавливает цвет для представления атрибута подчеркивания параметра par2. |
| 2 |
Устанавливает цвет для представления атрибута тусклости параметра par2. |
| 8 |
Текущие атрибуты setterm сохраняются как значения по умолчанию, тем самым они становятся стандартными атрибутами изображения символов. |
| 9 |
Устанавливает интервал гашения экрана на par2 минуты, но не более чем на 60 минут. Если параметр par2 равен нулю, то гашение экрана блокируется. |
| 10 |
Частота звонковой сигнализации консоли приравнивается к par2 Гц или к стандартному шагу, если параметр par2 не определен. |
| 11 |
Длительность звукового сигнала консоли приравнивается к par2 миллисекундам, если параметр par2 указан, но не более чем 2000. Если par2 не задан, то восстанавливается стандартная длительность. |
| 12 |
Если для консоли par2 выделена память, то консоль par2 становится активной (см. главу 20). |
| 13 |
Восстанавливает экран после гашения. |
| 14 |
Интервал выключения питания VESA приравнивается к par2 минутам, но не более чем 60 минут. Если параметр par2 равен нулю, то отключение питания VESA блокируется. |
Сообщение консоли того, что она должна отображать — далеко не все; вы также обязаны распознавать последовательности нажатия клавиш и знать, к каким клавишам они привязаны. Некоторые из этих последовательностей определены в базе данных
terminfo, некоторые — нет. Кроме этого, клавиатура является модальной для увеличения разнообразия возможностей. В
режиме приложения клавиши курсора порождают другие коды. Как показано в табл. 21.9, к ним добавляется префикс
^[О вместо
^[[. Это необходимо для поддержки унаследованных приложений, в которых предполагается, что они обращаются к терминалам DEC.
Последовательности нажатия клавиш описаны в табл. 21.11. Обратите внимание на то, что в нумерации функциональных клавиш имеются пропуски. Это спланировано для того, чтобы пользователи клавиатур, у которых нет клавиш <F11> и <F12>, не были ущемлены.
Таблица 21.11. Кодирование функциональных клавиш
| Последовательности нажатия клавиш |
Клавиша (клавиши) |
^[[[А |
<F1> |
^[[[В |
<F2> |
^[[[С |
<F3> |
^[[[D |
<F4> |
^[[[Е |
<F5> |
^[[17~ |
<F6> |
^[[18~ |
<F7> |
^[[19~ |
<F8> |
^[[20~ |
<F9> |
^[[21~ |
<F10> |
^[[23~ |
<F11>, <Shift+F1>, <Shift+F11> |
^[[24~ |
<F12>, <Shift+F2>, <Shift+F11> |
^[[25~ |
<Shift+F3> |
^[[26~ |
<Shift+F4> |
^[[28~ |
<Shift+F5> |
^[[29~ |
<Shift+F6> |
^[[31~ |
<Shift+F7> |
^[[32~ |
<Shift+F8> |
^[[33~ |
<Shift+F9> |
^[[34~ |
<Shift+F10> |
^[[А |
<Стрелка вверх> |
^[[D |
<Стрелка влево> |
^[[В |
<Стрелка вниз> |
^[[С |
<Стрелка вправо> |
^[[1~ |
<Home> |
^[[2~ |
<Insert> |
^[[3~ |
<Delete> |
^[[4~ |
<End> |
^[[5~ |
<Page Up> |
^[[6~ |
<Page Down> |
21.4. Прямой вывод на экран
В некоторых случаях наличие одной только способности выводить символы на экран не является достаточным. Частично это связано с невозможностью определить текущее состояние экрана. В системе Unix принята стандартная практика — состояние экрана игнорируется. Если нужно, вы можете задать настройки экрана, при появлении необходимости внести в них изменения, после чего полностью перерисовывать экран всякий раз, когда этого требует пользователь (как правило, нажатием комбинации
^L). Можно планировать и другие применения.
В частности, для работы программ и функций, предназначенных для фиксирования и восстановления экрана, требуется доступ к текущему содержимому экрана. Система Linux предоставляет такой доступ через два интерфейса. Один из них предлагает только текстовое содержимое экрана, второй содержит атрибуты (цвет и так далее).
Простейший текстовый механизм носит название
vcs, что, вероятно, означает
virtual console screen (экран виртуальной консоли)
[155]. Чтение устройства
/dev/vcs0 дает содержимое текущей виртуальной консоли, как оно выглядит на момент чтения. Если экран в настоящий момент прокручен (по умолчанию для прокрутки экрана назначаются клавиатурные последовательности <Control+PageUp> и <Control+PageDown>), устройство
/dev/vcs0 содержит прокрученное содержимое, видимое на экране. Остальные устройства
vcs,
/dev/vcsn, представляют текущее состояние виртуальной консоли
n и обычно доступны через
/dev/ttyn.
При чтении файла
/dev/vcs* не дается никаких указаний относительно новых строк или размера консоли, кроме метки EOF в конце экрана. Если вы прочитали 2000 байт и затем получили EOF, вы не сможете определить размеры экрана: может быть, он содержит 80 столбцов и 25 строк, а, может быть, 40 столбцов и 50 строк. Для отметки конца строк не выводятся символы новой строки, к тому же каждая пустая символьная ячейка (независимо от того, записывалась ли в нее когда-либо информация) обозначается символом пробела. Существует несколько популярных конфигураций экрана, и нет никакой гарантии, что каждая из них имеет однозначное количество строк и столбцов. Механизм vcs предлагает легкий способ для находчивых системных администраторов или разработчиков увидеть содержимое любой виртуальной консоли. Однако он не особенно полезен с точки зрения программистов, по крайней мере, без посторонней помощи.
Один из удобных способов — это использование
vcs из X. По умолчанию XFree86 запускает X-сервер на первой свободной виртуальной консоли, но не на той консоли, из которой была активизирована программа. Если вы запускаете XFree86 из виртуальной консоли 1, то вам не нужно возвращаться в консоль 1 для того, чтобы увидеть регистрационные сообщения, которые XFree86 выводит на экран. Просто перенесите наверх окно терминала того же самого размера, что и консоль (обычно 80 столбцов на 25 строк), войдите в систему как привилегированный пользователь (для того чтобы получить доступ к механизму
vcs) и запустите
cat /dev/vcs1. Содержимое первой виртуальной консоли заполнит ваше терминальное окно.
Для того чтобы создавать надежные программы, вам, тем не менее, нужны некоторые базовые сведения о состоянии экрана, который не предоставляет механизм
vcs.
• Цвета.
• Другие атрибуты (например, мерцание).
• Текущая позиция курсора.
• Конфигурация экрана (количество строк и столбцов).
Механизм
vcsа (что означает virtual console screen with attributes —
экран виртуальной консоли с атрибутами) предоставляет всю необходимую информацию. Первые четыре байта
/dev/vcsan (для того же самого значения
n, что и в
vcs) содержат заголовок, показывающий текущую позицию курсора и конфигурацию экрана. Первый байт указывает количество строк, второй — количество колонок, третий — текущий столбец курсора, четвертый — текущую строку курсора. Остальная часть файла содержит переменные байты, которые отображают текст, и байты атрибутов текста данной консоли.
Таким образом, если вам требуется знать только размеры консоли и ее текстовое содержимое, то вы можете прочитать первые два байта из соответствующего механизма
vcsa, а после этого работать только с механизмом
vcs. Если вы хотите задать текущую позицию курсора, то нужно заполнить третий и четвертый байты механизма
vcsa. Обратите внимание на то, что первые два байта предназначены только для чтения (то есть первые два символа являются просто заполнителями). Мы предпочитаем применять пробелы или другие подобные символы для того, чтобы подчеркнуть это. В качестве примера показано перемещение курсора на четвертой виртуальной консоли в восьмую строку и двенадцатый столбец (отсчитывая от нуля):
echo -n -е '..\023\007' > /dev/vcsa4
Параметр
-n предотвращает добавление символа новой строки в конце,
-е выполняет интерпретацию кодов смены алфавита, поэтому выражение
\nnn трактуется как восьмеричный символ
nnn.
Атрибуты и символьное содержимое отображаются как переменные байты, первый из которых содержит символ, а второй — атрибуты для применения к этому символу. Байт атрибута, как правило, определяется по аналогии с байтом атрибута, используемым на оборудовании VGA. Остальные виды технических средств, включая карты TGA, применяемые во многих машинах Linux/Alpha, и консольный драйвер SPARC, эмулируют обработку атрибутов VGA. На видеоаппаратуре без поддержки цвета, но с поддержкой подчеркивания, атрибуты могут считываться несколько по-другому. Однако способ разработки позволяет делать вид, что все оборудование ведет себя как VGA.
В каждом атрибутном байте отдельные биты интерпретируются так, как описано в табл. 21.12. Это VGA представление; некоторые цветовые устройства заменяют мерцание ярким задним фоном. Монохромное изображение использует нулевой бит цвета переднего плана для указания подчеркивания.
Таблица 21.12. Атрибуты
| Бит (биты) |
Результат |
| 7 |
Мерцание |
| 6-4 |
Фон |
| 3 |
Полужирный шрифт |
| 2-0 |
Передний план |
Глава 22
Написание защищенных программ
Подавляющее большинство компьютеров, на которых работает система Linux, подключены к Internet, и многие из них используются большим количеством людей. Для того чтобы сохранить компьютер и его программное обеспечение в безопасности, предотвратить анонимные угрозы, поступающие через сетевое соединение, а также от локальных пользователей, которые пытаются проникнуть на несанкционированные уровни доступа, требуется тщательное программирование как основной операционной системы, так и множества приложений.
В данной главе предлагается краткий обзор тех важных моментов, которые необходимо учитывать при создании защищенных программ на языке С. Мы выясним, какие типы программ нуждаются в особом уровне надежности и защищенности, а также как минимизировать риски. Мы обратим внимание на самые общие ошибки в вопросе обеспечения безопасности. Все это может послужить введением в написание безопасных программ. Если вам необходима более глубокая информация, обратитесь к книге Давида Вилера (David A. Wheeler)
Secure Programming for Linux and UNIX HOW TO. В нее входит также замечательная биография автора, а найти эту книгу можно по адресу http://www.dwheeler.com/secure-programs.
22.1. Когда безопасность имеет значение?
Компьютерные программы — это очень сложные вещи. Даже самая простая программа "Hello World" является на удивление запутанной. Игнорируя все, что происходит в ядре, библиотека С должна отыскать соответствующие совместно используемые библиотеки, загрузить их в систему, инициализировать стандартные методы ввода-вывода. На компьютере, с помощью которого готовилась данная глава, полная программа состояла из 25 системных вызовов. Только один из них оказался вызовом функции
write(), который использовался непосредственно для вывода слов "Hello World".
С увеличением функциональности программ очень быстро возрастает их сложность. Большинство реально работающих программ принимают входные данные из нескольких источников (например, из командной строки, файлов конфигурации, терминала) и обрабатывают полученные данные сложными способами. Любая ошибка в процессе может вызвать непредсказуемое поведение, однако опытный программист чаще всего обрабатывает такие сюрпризы без появления нежелательных последствий. Если в эту "адскую смесь" добавить еще несколько сложных библиотек, то любому программисту (не говоря о команде программистов) будет очень трудно полностью представить себе реакцию программы на определенный набор входных данных.
Большинство программ очень внимательно тестируются, для гарантии того, что они дают соответствующие результаты для корректных наборов входных данных. При этом работа большинства программ с неожиданными входными данными проверяется недостаточно
[156]. Несмотря на то что при проектировании ядра тщательно учитывается необходимость предотвращения риска для системы из-за неисправностей в пользовательских программах, все же ошибки в некоторых типах программ могут отразиться на целостности системы.
Существуют три типа программ, при создании которых программисты должны постоянно помнить о безопасности.
• Программы, обрабатывающие данные, которые могут поступать из ненадежных источников, очень уязвимы. Такие данные могут содержать скрытые атаки, использующие программные ошибки и вызывающие непредсказуемое поведение программ. Нередко целью таких атак является получение полного доступа к компьютеру для анонимных пользователей. Любая программа, имеющая доступ к данным через сеть (как клиентская, так и серверная) становится потенциальным мишенью для атак. Но даже безобидные программы вроде текстовых процессоров, могут быть поражены через поврежденные файлы данных
[157].
• Программы, которые во время запуска могут переключаться между пользовательскими или групповыми контекстами (через биты setuid и setgid в исполняемом файле), несут потенциальную опасность передачи прав и информации привилегированного пользователя другому (непривилегированному) пользователю.
• Любая программа, работающая как системный демон, может вызвать проблему безопасности. Подобные программы работают в системе как привилегированные пользователи (довольно часто они выступают в качестве root), поэтому любое взаимодействие с обычными пользователями подвергает систему опасности.
22.1.1. Когда выходит из строя система безопасности?
Дефекты в системе безопасности программ являются причиной четырех обширных категорий атак: удаленная эксплуатация, локальная эксплуатация, удаленные атаки отказа в обслуживании и локальные атаки отказа в обслуживании. Удаленные эксплуатации позволяют пользователям, имеющим доступ к сетевым службам компьютера, запустить на этом компьютере произвольный код. Для того чтобы удаленная атака могла иметь место, в программе, обращающейся к сети, должна быть некоторая неисправность. Обычно такие ошибки встречаются в сетевых серверах, что позволяет удаленному взломщику ввести сервер в заблуждение и получить доступ в систему. С недавних пор начали эксплуатироваться и ошибки в сетевых клиентах. Например, если Web-браузер имеет изъян в способе анализа HTML-данных, то Web-страница, загружаемая этим браузером, может побудить браузер активизировать произвольную последовательность кодов.
Локальная эксплуатация дает пользователям возможность выполнять такие действия, на которые у них обычно нет полномочий (на них часто ссылаются как на разрешение
превышения локальных полномочий), например, нелегально проникать в систему под видом другого пользователя. Такой тип эксплуатации, как правило, направлен на локальных демонов (таких как серверы
cron или
sendmail) и setuid-программы (вроде
mount или
passwd).
Атаки отказа в обслуживании не позволяют взломщику получить контроль над системой, однако они могут помешать законному использованию данной системы. Это наиболее хитрые помехи, многие из них очень трудно ликвидировать. Например, многие программы, использующие файлы блокировок, подвергаются опасности таких атак. Хакер может просто вручную создать файл блокировки и ни одна программа никогда не удалит его. Одна из простейших атак отказа в обслуживании для пользователей заключается в заполнении их домашних каталогов ненужными файлами, тем самым исключая возможность создания новых файлов другими пользователями в той же файловой системе
[158]. В общем случае для локальных атак рассматриваемого типа существует гораздо больше удобных случаев, чем для удаленных атак. Мы не будем здесь изучать атаки отказа в обслуживании подробно, поскольку они часто являются следствием всей программной архитектуры, а не одного дефекта.
22.2. Минимизация возможности появления атак
Одной из наилучших стратегий по обеспечению безопасности программ перед попытками несанкционированного использования прав доступа является создание отдельных частей программы, которые чрезвычайно легко атаковать. Подобную стратегию иногда трудно воплотить в сетевых программах и системных демонах, однако в тех программах, которые должны запускаться с особыми правами доступа (через биты setuid и setgid либо при активизации привилегированным пользователем), как правило, можно применить несколько алгоритмов для уменьшения их областей уязвимости.
22.2.1. Передача полномочий
Многие программы, которые требуют определенных прав доступа, используют эти права только во время запуска. Например, некоторые сетевые демоны могут активизироваться только привилегированным пользователем для того, чтобы они имели возможность подключиться к резервному порту с помощью функции
listen(), но после этого никакие особые полномочия не понадобятся. Большинство Web-серверов используют этот прием для усиления защиты от атак путем переключения на другого пользователя (обычно пользователь называется
nobody или
apache) сразу после открытия TCP/IP-порта 80. В это время сервер все еще остается объектом для удаленного использования, но, по крайней мере, такая эксплуатация больше не сможет предоставить взломщику доступ к процессу, активизированному как root. Сетевые клиенты, нуждающиеся в резервных портах (таких как
rsh), могут применять подобную методику. Они запускаются как setuid на root, что позволяет им открывать подходящий порт. Как только порт открыт, необходимость в привилегиях root отпадает, и особые возможности можно отключить.
Для восстановления полномочий процесса необходимо использовать один или более из следующих методов:
setuid(),
setgid(),
setgroups(). Этот прием эффективен только в том случае, если используется настоящая действующая файловая система и для всех сохраненных идентификаторах uid (или gid) установлены соответствующие значения. Если программа является setuid (или setgid), то процесс, вероятно, пожелает присвоить данным идентификаторам uid их сохраненное значение uid. Системные демоны, передающие управление другому пользователю после запуска от имени root, должны изменять пользовательские и групповые идентификаторы, а также очищать свой дополнительный групповой список. Более подробное описание того, как процесс может изменять свои сертификаты, можно найти в главе 10.
22.2.2. Получение вспомогательной программы
Если программа нуждается в особых полномочиях не только во время первоначального запуска, то неплохое решение проблемы могут предложить вспомогательные программы. Вместо активизации с повышенными правами доступа всего приложения целиком, главная программа работает как стандартный пользователь, запустивший ее, а также активизирует еще одну очень маленькую программу, которая обладает достаточными сертификатами для выполнения требуемой задачи. При проектировании приложения таким способом значительно снижается сложность того кода, который может подвергнуться атаке. Подобное упрощение позволяет легче обнаружить и исправить любые ошибки. Если в главном приложений есть некоторые проблемные места, позволяющие пользователю выполнять произвольные действия, то эти действия можно будет производить только со стандартными пользовательскими сертификатами. Тем самым любые атаки затрагивают только конкретного стандартного пользователя, но не привилегированного.
Применение маленьких вспомогательных программ приобрело широкую популярность в сообществе Linux. Библиотека
utempter (обсуждаемая в главе 16) использует вспомогательную setgid-программу для обновления базы данных
utmp. Эта программа очень внимательно проверяет правильность аргументов командной строки, а также контролирует, имеет ли вызывающее приложение разрешение на обновление базы данных
utmp. Тем программам, которые предусматривают данную службу через вспомогательное приложение
utempter, вообще не требуется никаких особых полномочий. До создания этой библиотеки каждая программа, использующая псевдотерминалы, была обязана быть setgid для той группы, которой принадлежит база данных utmp.
Еще одним примером вспомогательной программы может послужить программа
unix_chkpwd, которая используется РАМ (Pluggable Authentication Modules — подключаемые модули аутентификации, подробнее рассматривается в главе 28). Пароли в большинстве систем Linux хранятся в файле, доступном для чтения только пользователю root. Это предотвращает словарные атаки на зашифрованные пароли пользователей
[159]. Некоторые программы проверяют, действительно ли возле компьютера находится тот пользователь, который вошел в систему (программа
xscreensaver может применяться для блокировки экрана до возвращения пользователя), но они обычно работают не как программы root. Вместо того чтобы делать такие программы setuid на root, дабы они могли проверить правильность пользовательского пароля, стандартная аутентификация РАМ Unix вызывает
unix_chkpwd для подтверждения пароля. Таким образом, необходимость быть setuid на root существует только для программы
unix_chkpwd. Это означает, что потребность создавать
xscreensaver как привилегированную программу отпадает, а также что все слабые места в системе безопасности библиотек X11 не допускают локальной эксплуатации.
Применение вспомогательных программ подобным способом является очень хорошим методом устранения в приложениях возможных проблем безопасности. Создание таких вспомогательных программ, как правило, является достаточно прямолинейным процессом, а их правильность определить относительно просто. Однако в конструкции таких программ есть пара моментов, в которых нужно проявить осторожность.
Довольно часто между главным приложением и вспомогательной программой передаются конфиденциальные данные. Например, для программы
unix_chkpwd необходимо передавать незакодированный пароль пользователя для подтверждения его правильности. При передаче такой информации нужно принять некоторые меры предосторожности. Очень заманчиво использовать аргумент командной строки, однако это позволит любому пользователю, который в нужное время запустит
ps, увидеть незакодированные пользовательские пароли. Если вместо этого для подачи данных применяется канал (обычно указанный в качестве стандартного ввода для вспомогательной программы), то во время передачи ни одна другая программа не сможет увидеть данные.
Вспомогательные программы также должны тщательно проверять тот факт, что вызывающая их программа имеет разрешение на выполнение запрашиваемого действия. Вспомогательная программа
unx_chkpwd не позволяет программе проверять пароли ни одного пользователя, кроме того, который ее запустил. Здесь применяется свой собственный uid для подтверждения того, что активизирующая программа может проверять пароль пользователя. Вспомогательная программа
utempter выполняет аналогичные проверки для того, чтобы убедиться, что программы не могут удалять терминалы из базы данных
utmp, если только они не предназначены делать это.
22.2.3. Ограничение доступа к файловой системе
Еще одним способом устранения ошибок в кодах, предоставляющих возможность для атак, является ограничение набора файлов, к которым программа имеет доступ, с помощью системного вызова
chroot(). Как обсуждалось в главе 14, метод
chroot(), сопровождающийся вызовом
chdir(), изменяет корневой каталог процесса, ограничивая совокупность файлов, доступных процессу. Это не предотвращает возможность эксплуатации, но иногда может нарушать работу приложения. Если сетевой сервер, работающий как не root, эксплуатируется удаленно, то данному удаленному пользователю значительно труднее применить этот сервер в качестве базы локальной эксплуатации, поскольку он не сможет получить доступ ни к каким setuid-файлам (этим могут воспользоваться наиболее простые локальные
эксплуатации программ).
Анонимные ftp-серверы являются наиболее распространенными программами, использующими преимущества механизма
chroot(). В последнее время он становится более популярным и в других программах, многие системные администраторы применяют команду
chroot для того, чтобы перевести работу системных демонов в ограниченное окружение и предусмотреть проникновение "незваных гостей".
22.3. Общие бреши системы безопасности
После рассмотрения некоторых способов, позволяющих уменьшить потенциальное воздействие незащищенного кода, давайте перейдем к изучению самых общих программных ошибок, которые приводят к появлению проблем в системе безопасности. Несмотря на то что вся оставшаяся часть данной главы освещает некоторые вопросы, на которые нужно обратить внимание, это отнюдь не полный перечень. Любой автор программ, которые должны быть безопасными, обязан изучить не только данную главу.
22.3.1. Переполнение буфера
Пожалуй, наиболее распространенной программной ошибкой, которая становится причиной локальных и удаленных эксплуатаций, является переполнение буфера. Ниже приведен пример программы с возможностью переполнения буфера.
1: /* bufferoverflow.с */
2:
3: #include <limits.h>
4: #include <stdio.h>
5: #include <string.h>
6:
7: int main(int argc, char ** argv) {
8: char path[_POSIX_PATH_MAX];
9:
10: printf("копирование строки длиной %d\n", strlen(argv[1]));
11:
12: strcpy(path, argv[1]);
13:
14: return 0;
15: }
16:
На первый взгляд код кажется довольно безопасным; хотя в итоге эта программа фактически даже ничего не делает. Она копирует строку, передаваемую пользователем, в фиксированное пространство стека, даже не проверяя, есть ли в стеке для этого свободное место. Попробуйте запустить эту программу с одним длинным аргументом командной строки (скажем, 300 символов). Это вызовет ошибку сегментации, когда
strcpy() попытается записать информацию, превышающую пространство, выделенное для массива
path.
Чтобы лучше понять, как происходит распределение памяти для программного стека, взгляните на рис. 22.1. В большинстве систем стек процессора растет вниз; то есть, чем раньше какой-либо объект размещается в стеке, тем больший адрес логической памяти он получает. К тому же первый элемент стека является защищенной областью памяти; любая попытка получить к нему доступ приводит к ошибке сегментации.
 Рис. 22.1
Рис. 22.1. Карта памяти стека приложения
Следующий участок стека содержит локальные переменные, используемые кодом, который запускает остальную часть программы. Здесь мы вызываем функцию
_main(), несмотря на то что это может принести дополнительные сложности, поскольку касается таких моментов, как динамическая загрузка. Когда запускающий код вызывает для программы метод
main(), он сохраняет адрес, который метод
main() возвращает при завершении работы со стеком. Когда активизируется
main(), может понадобиться сохранение некоторых регистров микропроцессора в стеке с возможностью повторного использования этих регистров. Затем метод выделяет пространство для своих локальных переменных.
Возвращаясь к нашему примеру переполнения буфера, следует отметить, что для переменной
path выделяется память на верхушке стека. Байт
path[0] находится на самом верху, затем следующий байт —
path[1] и так далее. Если наша программа-пример записывает в
path более _
POSIX_PATH_MAX байтов, то начинается перезапись остальных элементов стека. Если этот процесс продолжается, то происходит попытка записи за пределами верхушки стека, что вызывает ошибку сегментации.
Существенная проблема возникает, если программа записывает возвращаемый адрес вне пределов стека, но не порождает ошибку сегментации. Это позволяет изменять адрес, возвращаемый из работающей функции, на любой случайный адрес в памяти. Когда функция возвращает управление, программа переходит к данному случайному адресу и продолжает выполнение с этой точки.
Реализации, использующие переполнение буфера, как правило, включают некоторый код в массив, записываемый в стек, и возвращаемый адрес устанавливается на этот код. Этот прием позволяет взломщику запускать любой произвольно выбранный код с теми правами доступа, которыми обладает атакуемая программа. Если эта программа является сетевым демоном, работающим как root, то любой удаленный пользователь получает доступ root к локальной системе!
Обработка строк — не единственное место, в котором встречается переполнение буфера (хотя, пожалуй, наиболее распространенное). Еще одним уязвимым моментом является чтение файлов. Файловые форматы нередко сохраняют размер элемента данных, за которым следуют сами данные. Если размер сохранения используется для выделения буфера, а конец поля данных определяется каким-то другим способом, может произойти ошибка переполнения буфера. Этот тип ошибки сделал возможным для Web-сайтов обращение к файлам, которые искажены так, чтобы предоставить удаленное пользование.
Чтение данных через сетевое соединение предоставляет еще одну возможность для переполнения буфера. Многие сетевые протоколы указывают максимальный размер для полей данных. Например, протокол ВООТР
[160] фиксирует для всех пакетов размер 300 байтов. Это, однако, не мешает другой машине передать через сеть 350-байтовый пакет ВООТР. Если в сети работают программы с дефектами, то они попытаются скопировать этот нестандартный 350-байтовый пакет в пространство, выделенное для корректного 300-байтового пакета ВООТР, тем самым вызовут переполнение буфера.
Локализация и трансляция служат еще двумя побудителями переполнения буфера. Если программа написана для английского языка, то без сомнения для хранения названия месяца, загружаемого из таблицы, будет достаточно десятисимвольной строки. Когда эта программа переводится на испанский, "September" превращается в "Septiembre" и может произойти переполнение буфера. Всякий раз, когда программа поддерживает различные языки и локали, большинство первоначально статических строк становятся динамическими, и внутренние строковые буферы должны это учитывать.
Теперь уже очевидно, что переполнение буфера представляет собой критическую проблему в системе безопасности. Ее очень легко упустить из виду во время программирования (в конце концов, кто должен волноваться о файловых именах, длина которых превышает
_POSIX_PATH_MAX?), и этим чрезвычайно легко воспользоваться.
Существует несколько приемов для устранения из кода возможности переполнения буфера. Хорошо продуманные программы используют множество способов для внимательного выделения буферов соответствующих размеров.
Лучшим способом распределения памяти для объектов является метод
malloc(), который устраняет проблемы, возникающие из-за перезаписывания возвращаемого адреса, поскольку
malloc() не выделяет память из стека. Аккуратное применение функции
strlen() для вычисления необходимого размера и динамическое выделение буфера в программной куче обеспечивает хорошую защиту от переполнения. К сожалению, при этом также расходуется память, поскольку каждый вызов метод
malloc() требует вызова метода
free(). В главе 7 обсуждалось несколько способов отслеживания ненужных расходов памяти, однако даже с описанными инструментами трудно точно знать, когда можно освободить память, занимаемую объектом. Особенно в том случае, если динамическое распределение памяти для объекта подстроено под уже существующий код. Функция
alloca() предлагает альтернативу
malloc().
#include <alloca.h>
void * alloca(size_t size);
Подобно
malloc(),
alloca() выделяет область памяти длиной
size байтов и возвращает указатель на начало этой области. Вместо использования памяти из программной кучи этот метод распределяет память из вершины стека, из того же места, где хранятся локальные переменные. Первое преимущество данной функции перед локальными переменными состоит в том, что необходимое количество байтов точно вычисляется в программе, а не определяется приблизительно. Превосходство над
malloc() заключается в том, что при завершении работы функции память освобождается автоматически. Все это позволяет охарактеризовать
alloca() как легкий способ распределения памяти, которая требуется только временно. До тех пор, пока размер буфера вычисляется должным образом (не забудьте учесть
'\0' в конце каждой строки С!), можно не бояться переполнения буфера
[161].
Есть еще также несколько других функций, которые помогают избежать переполнения буфера. Библиотечные методы
strncpy() и
strncat() легко предотвращают перегрузки буфера при копировании строк.
#include <string.h>
char * strncpy (char * dest, const char * src, size_t max);
char * strncat (char * dest, const char * src, size_t max);
Обе функции ведут себя как их родственники, называемые аналогично,
strcpy() и
strcat(), но они возвращают за один раз только max байт, копируемые в строку назначения. Если достигнут предел, то результирующая строка не завершается
'\0', поэтому обычные строковые функции не смогут с ней работать. По этой причине необходимо явно завершить строку после вызова одной из подобных функций.
strncpy(dest, src, sizeof(dest));
dest[sizeof(dest) - 1] = '\0';
Частой ошибкой при использовании
strncat() является передача общего размера
dest в качестве параметра
max. Это приводит к потенциальному переполнению буфера, так как
strncat() добавляет до
max байт в
dest; она не прекращает копировать байты, когда общая длина
dest достигает
max байтов.
Несмотря на то что эти функции могут сделать выполнение программы некорректным при передаче длинных строк (из-за усечения этих строк), данный прием хорошо предотвращает перегрузки в буферах статических размеров. Во многих случаях это приемлемый компромисс (во всяком случае, при этом не произойдет ничего хуже того, что может случиться из-за переполнения буфера).
Функция
strncpy() решает проблему копирования строки в статический буфер без переполнения его. А функции
strdup() автоматически выделяют буфер, достаточный для хранения строки, до начала копирования в него исходной строки.
#include <string.h>
char * strdup(const char * src);
char * strdupa(const char * src);
char * strndup(const char * src, int max);
char * strndupa(const char * src, int max);
Первая из приведенных функций,
strdup(), копирует строку
src в буфер, выделенный методом
malloc(), и возвращает буфер вызывающему оператору. Вторая функция,
strdupa(), выделяет буфер с помощью
alloca(). При этом обе функции выделяют буфер, в точности достаточный для хранения строки и замыкающего символа
'\0'.
Остальные две функции,
strndup() и
strndupa(), копируют не более чем max байтов из
str в буфер вместе с замыкающим
'\0' (и выделяют не более чем
max+1 байтов). При этом выделение буфера происходит при помощи метода
malloc() (для
strndup()) или
alloca() (для
strndupa()).
Функция
sprintf() также входит в число тех, которые часто вызывают переполнение буфера. Так же как
strcat() и
strcpy(), функция
sprintf() имеет разновидность, позволяющую облегчить защиту от перегрузок.
#include <stdio.h>
int snprintf(char * str, size_t max, char * format, ...);
Попытки определить размер буфера, необходимый для
sprintf(), могут оказаться слишком сложными. Он зависит от таких элементов, как значения всех форматируемых чисел (для которых могут быть нужны или не нужны знаки чисел), используемые аргументы форматирования и длины всех строк, которые были затронуты форматированием. Для того чтобы избежать переполнения буфера, функция
snprintf() помещает в
str не более чем max символов, включая замыкающий
'\0'. В отличие от
strcat() и
strncat(), функция
snprintf() корректно завершает строку, при необходимости пренебрегая символом из форматируемой строки. Она возвращает количество символов, которые будет занимать конечная строка при наличии доступного пространства. Также сообщается, нужно ли усекать строку до
max символов (не считая последний
'\0')
[162]. Если возвращаемое значение меньше чем
max, значит, функция успешно завершила свою работу. Если же равно или больше, значит, предел
max превышен.
Функция
vsprintf() несет те же проблемы, a
vsnprintf() предлагает способ их преодоления.
22.3.2. Разбор имен файлов
Абсолютно обычным действием для привилегированных приложений является предоставление доступа к файлам ненадежным пользователям и разрешение этим пользователям передавать имена файлов, к которым необходим доступ. Хорошим примером служит Web-сервер. URL-адрес HTTP содержит имя файла, полученное сервером как запрос на передачу удаленному (ненадежному) пользователю. На Web-сервере необходимо убедиться, что возвращаемый файл — это именно тот, который был сконфигурирован на отправку, а также внимательно проверить правильность имен файлов.
Представьте Web-сервер, обслуживающий файлы из
home/httpd/html, выполняющий это посредством простого добавления имени файла из URL, который требуется предоставить, концу
/home/httpd/html. Такой процесс дает правильный файл, однако это также позволяет удаленным пользователям увидеть любой файл системы, к которой Web-сервер имеет доступ, просто запросив, к примеру, файл
../../.. /etc/passwd. Подобные каталоги
.. необходимо явно проверять и отклонять. Системный вызов
chroot() предоставляет хороший способ, позволяющий сделать обработку имен файлов в программах более простой.
Если имена файлов передаются в другие программы, то необходима еще более тщательная проверка. Например, если в имени файла используется начальный символ
-, то весьма вероятно, что другая программа интерпретирует его как опцию командной строки.
22.3.3. Переменные окружения
В программах, работающих с возможностями setuid или setgid, нужно проявлять особую осторожность с установками окружения. Эти переменные определяются пользователем, активизировавшим программу, тем самым открывается путь для атак. Самая явная атака может пройти через переменную окружения
PATH, изменяющую те каталоги, в которых функции
execlp() и
execvp() отыскивают программы. Если привилегированная программа запускает другие программы, то она должна убедиться, что это именно те программы, которые нужны! Пользователь, который имеет возможность подменить программный путь поиска, легко может подвергнуть программу опасности.
Существуют и другие переменные окружения, которые могут оказаться опасными. Например, переменная
LD_PRELOAD позволяет пользователю указать некоторую библиотеку для загрузки до стандартной библиотеки С. Это может быть полезным, но одновременно и очень опасным в привилегированных приложениях (по этой же причине переменная окружения игнорируется, если реальное и эффективное универсальные имена совпадают).
Если программа локализована, то переменная
NLSPATH также становится проблемной. Она позволяет пользователю переключать используемый программой языковой каталог, который определяет способ перевода строк. Это означает, что в переводных программах пользователь имеет возможность указать значение для любой переводимой строки. Строку можно сделать сколько угодно длинной, вынуждая программу быть крайне осторожной при выделении буфера. Еще более опасным является то, что при переводе форматирующих строк для таких функций, как
printf(), можно изменить формат. Например, строка
Hello World, today is %s может превратиться в
Hello World, today is %c%d%s. Трудно предсказать, какое воздействие могут оказать подобные изменения на функционирование программы!
Все это сводится к тому, что наилучшим решением для переменных окружения setuid- или setgid-программ является исключение этих переменных. Функция
clearenv()[163] стирает все значения из окружения, оставляя его пустым. После этого программа может заполнить любые необходимые ей переменные окружения известными значениями.
22.3.4. Запуск командной оболочки
Запуск системной командной оболочки из любой программы, в которой важен вопрос безопасности, является плохой идеей. При этом защита от тех проблем, которые мы уже обсуждали, становится еще более трудной.
Каждую строку, передаваемую в оболочку, необходимо очень тщательно проверять на достоверность. К примеру, символ
'\n' или
;, вставленный в строку, может привести к тому, что оболочка примет две команды вместо одной. Если строка содержит символы
` или последовательность
$(), оболочка запускает другую программу для построения аргумента командной строки. Может также иметь место обычное расширение оболочки, при этом переменные окружения и универсализация файловых имен становятся доступными для взломщиков. Переменная
IFS позволяет указать символы (отличные от пробела и табуляции) для разделения полей при анализе командных строк при помощи символов, тем самым, открывая новые бреши для атак. Другие специальные символы, такие как
<,
> и
|, предоставляют еще больший простор для построения командных строк, которые ведут себя не так, как подразумевает программа.
Очень трудно выполнить полную проверку всех этих возможностей. Наилучшим способом предотвращения всех возможных атак против командной оболочки служит в первую очередь уклонение от ее запуска. Функции вроде
pipe(),
fork(),
exec() и
glob() позволяют достаточно легко выполнять большинство тех задач, для которых обычно используется оболочка. При этом проблемы расширения командной строки оболочки не возникают.
22.3.5. Создание временных файлов
Довольно часто в программах применяются временные файлы. Система Linux даже предусматривает для этой цели особые каталоги (
/tmp и
/var/tmp). К сожалению, использование временных файлов в безопасном режиме — дело очень ненадежное. Лучшим решением будет создание временных файлов в каталоге, который доступен только через эффективный uid программы. Неплохим выбором, например, может стать домашний каталог данного пользователя. При таком подходе употребление временных файлов становится простым и безопасным. Однако большинство программистов не любят этот способ, так как он загромождает каталоги, причем вполне возможно, что эти файлы никогда не будут удалены, если программа неожиданно выйдет из строя.
Давайте представим программу, активизированную пользователем root, которая создает основной сценарий во временном файле и затем запускает его. Для разрешения одновременного запуска нескольких экземпляров программы, возможно, сценарий включает программный идентификатор как часть имени файла и создает файл со следующим кодом:
char fn[200];
int fd;
sprintf(fn, "/tmp/myprogram.%d", getpid());
fd = open(fn, O_CREAT | O_RDWR | O_TRUNC, 0600);
Программа создает уникальное имя файла и усекает любой существующий файл с таким именем перед записью в него. Хотя на первый взгляд этот способ может показаться рациональным, фактически им легко воспользоваться для атак. Если файл, который программа пытается создать, уже существует как символическая ссылка, то открытый запрос следует по такой ссылке и открывает произвольный указываемый файл. Первым примером эксплуатации в такой ситуации является создание символических ссылок в
/tmp с использованием многих (или всех) возможных программных идентификаторов, указывающих на файл типа
/etc/passwd. При запуске данной программы это приводит к перезаписыванию системного файла паролей, результатом чего становится атака отказа в обслуживании.
Еще более опасной является атака, при которой символические ссылки указывают на собственный файл взломщика (или когда в
/tmp создаются нормальные файлы со всеми возможными именами). При открытии файла целевой файл искажается, но во временной промежуток между открытием файла и выполнением программы атакующий (который все еще владеет файлом) может записать в него все, что угодно (добавление строки типа
chmod u+s /bin/sh определенно будет полезным в основном сценарии, работающим как root!). Может показаться трудным точно угадать время, однако, режимы состязаний такого типа часто эксплуатируются, подвергая риску безопасность программы. Если программа была setuid, а не запущенная как root, то эксплуатация фактически становится еще легче, так как пользователь может передать
SIGSTOP в программу сразу после открытия файла, а затем после эксплуатации этого режима состязаний послать
SIGCONT.
Добавление
O_EXCL в вызов
open() мешает
open() открывать файл, который является символической ссылкой, а также уже существующий файл. В данном случае также есть возможность простой атаки отказа в обслуживании, поскольку код выйдет из строя, если первое испробованное имя файла уже существует. Это легко исправить, разместив
open() в цикле, испытывающем различные имена файлов до тех пор, пока одно из них не подойдет.
Самым лучшим способом создания временных файлов является применение библиотечной функции
mkstemp() интерфейса POSIX, которая гарантирует, что файл создается соответствующим образом
[164].
int mkstemp(char * template);
Параметр
template — это имя файла, в котором последние шесть символов должны выглядеть как
"XXXXXX". Последняя часть заменяется номером, который позволяет имени файла стать уникальным в данной файловой системе. Такой подход предоставляет функции
mkstemp() возможность испытывать различные имена файлов до тех пор, пока одно из них не подойдет. Параметр
template обновляется тем именем файла, которое использовалось (позволяя программе удалить файл), также возвращается файловый дескриптор, ссылающийся на временный файл. Если функция прерывает свою работу, возвращается значение
-1.
В более старых версиях библиотеки С системы Linux создавался файл с режимом 0666 (общедоступное чтение/запись) и в зависимости от umask программы приобретались соответствующие права на файл. В более новых версиях читать и записывать в файл разрешено только текущему пользователю, но поскольку POSIX не определяет такое поведение, неплохо явно установить umask процесса (077 — хороший выбор!) до вызова
mkstemp().
Система Linux и некоторые другие операционные системы предлагают функцию
mkdtemp() для создания временных каталогов.
char * mkdtemp(char * template);
Параметр
template работает так же, как и для
mkstemp(), за исключением того, что функция возвращает указатель на
template при успешном завершении работы и
NULL в случае неудачи.
Многие операционные системы, поддерживающие
mkdtemp(), также предоставляют программу
mktemp, которая позволяет основным сценариям создавать временные файлы и каталоги в безопасном режиме.
С временными файлами связана еще одна проблема, которая не рассматривалась до сих пор. Они содержат режимы состязаний, добавляемые временными каталогами, которые постоянно хранятся в сетевых (особенно NFS) файловых системах, а также программами, которые регулярно удаляют старые файлы из этих каталогов. При повторном открытии временных файлов после их создания следует проявлять крайнюю осторожность. Более подробное описание этих и других проблем, связанных с временными файлами, можно найти в книге Давида Вилера
Secure Programming for Linux and UNIX HOW TO (http://www.dwheeler.com/secure-programs/). Если вам необходимо реализовать один из таких моментов, возможно, лучше будет создавать временные файлы в домашнем каталоге текущего пользователя.
22.3.6. Режимы состязаний и обработчики сигналов
Всякий раз когда взломщик может заставить программу вести себя неправильно, появляется потенциальная возможность для злоумышленной эксплуатации. Ошибки, кажущиеся безобидными, вроде двукратного освобождения одной и той же порции памяти успешно использовались злоумышленниками в прошлом, что еще раз указывает на необходимость быть очень внимательным при создании привилегированных программ.
Режимы состязаний и обработчики сигналов, которые легко могут стать причиной возникновения режима состязаний, являются щедрым источником программных ошибок. Самые общие ошибки при написании обработчиков сигналов описаны ниже.
• Выполнение динамического распределения памяти. Функции распределения памяти не являются реентерабельными и не должны применяться в обработчиках сигналов.
• Применение каких-либо функций, кроме перечисленных в табл. 12.2, всегда приводит к ошибке. Программы, вызывающие такие функции, как
printf(), из обработчика сигналов, содержат режимы состязаний, поскольку
printf() имеет внутренние буферы и не является реентерабельной.
• Неправильное блокирование остальных сигналов. Большинство обработчиков сигналов не являются реентерабельными, однако, довольно часто в обработчиках, управляющих несколькими сигналами, не блокируются автоматически остальные сигналы. Применение
sigaction() помогает исправить ситуацию (если программист старательный).
• Неблокирование сигналов в тех областях кода, модифицирующих переменные, к которым обработчик сигналов также имеет доступ. (Такие зоны часто называются критическими областями.)
В то время как режимы состязаний, порожденные сигналами, могут показаться не опасными, сетевые коды, setuid- и setgid-программы могут использовать сигналы, посылаемые ненадежными пользователями. Передача экстренных данных в программу может стать причиной отправки
SIGURG, в то время как setuid- и setgid-программы могут принимать сигналы от пользователя, который запускает их, при этом фактические универсальные имена данных процессов не изменяются. Даже если эти программы изменяют свои действительные имена для предупреждения передачи сигналов, при закрытии пользователем терминала все программы, использующие этот терминал, посылают
SIGHUP.
22.3.7. Закрытие файловых дескрипторов
В системах Linux и Unix файловые дескрипторы, как правило, наследуются через системные вызовы
exec() (и всегда наследуются через
fork() и
vfork()). В большинстве случаев такое поведение нежелательно, поскольку только разделяться должны только stdin, stdout и stderr. Программы, запускаемые привилегированным процессом, не должны иметь доступа к файлам через унаследованный файловый дескриптор. Поэтому очень важно, чтобы программы внимательно закрывали все файловые дескрипторы, к которым не должна получить доступ новая программа. Это может стать проблемой, если ваша программа вызывает библиотечные функции, которые открывают файлы и не закрывают их. Одним из методов закрытия файловых дескрипторов является закрытие всех файловых дескрипторов вслепую из дескриптора номер 3 (тот, который следует сразу за stderr) произвольным большим значением (скажем, 100 или 1024)
[165]. В большинстве программ это обеспечивает закрытие всех надлежащих файловых дескрипторов
[166].
Наиболее удобным способом является установка флага закрытия после выполнения для каждого файла, который программа оставляет открытым на длительный период времени (включая сокеты и файловые устройства), что предотвращает получение доступа к данным файлам новыми запускаемыми программами. Описание флага закрытия после выполнения можно найти в главе 11.
22.4. Запуск в качестве демона
При разработке программ, создаваемых для работы в качестве системных демонов, нужно очень внимательно проводить их становление как демонов для правильного определения всех деталей. Ниже приведен перечень тех обстоятельств, на которые необходимо обратить внимание.
1. Большинство действий по инициализации должны быть произведены до того, как программа становится фактическим демоном. Это гарантирует, что пользователь при запуске не будет получать сообщения об ошибках, и будет возвращаться значащий код завершения. Этот вид деятельности включает в себя анализ конфигурационных файлов и открытие сокетов.
2. Текущий каталог должен быть изменен на какой-либо подходящий. Это может быть корневой каталог, но никогда не может быть тот каталог, из которого была запущена программа. Если демон этого не сделает, то, возможно, он будет работать соответствующим образом, но это не позволяет удалить тот каталог, из которого он был активизирован, поскольку он остается текущим каталогом программы. Если это возможно, то неплохо применить
chroot() на какой-то каталог. Причины обсуждались ранее в этой главе.
3. Все ненужные файловые дескрипторы должны быть закрыты. Это может показаться очевидным, однако вы легко можете упустить закрытие тех дескрипторов, которые были унаследованы, а не открыты самой программой. Об этом речь шла в предыдущем разделе.
4. Затем программа должна вызвать
fork(), а родительский процесс должен вызвать
exit(), позволяя программе, запустившей демон (чаще всего командному процессору), продолжить работу.
5. Дочерний процесс, продолжающий работу, должен закрыть stdin, stdout и stderr, поскольку он не будет больше использовать терминал. Вместо повторного применения файловых дескрипторов 0, 1 и 2 лучше открывать эти файлы как
/dev/null. Это гарантирует, что ни одна библиотечная функция, передающая отчеты о состоянии ошибок в stdout или stderr, не запишет эти ошибки в другие файлы, открытые демоном. При этом демон сможет запускать внешние программы, не беспокоясь об их выходных данных.
6. Для полного разъединения с терминалом, из которого был запущен демон, он должен вызвать
setsid(), чтобы разместить его в собственной группе процесса. Это предотвращает получение сигналов при закрытии терминала, а также сигналов управления заданиями.
Библиотека С предлагает функцию
daemon(), которая обрабатывает некоторые из перечисленных задач.
int daemon(int nochdir, in tnoclose);
Данная функция сразу осуществляет ветвление, и если оно прошло успешно, родительский процесс вызывает
_exit() с кодом завершения 0. Затем дочерний процесс переходит в корневой каталог, если
nochdir не является нулем, и перенаправляет stdin, stdout и stderr в
/dev/null, если
noclose не равен нулю. Перед возвратом в дочерний процесс она также вызывает
setsid(). При этом унаследованные файловые дескрипторы все равно могут оставаться открытыми, поэтому в программах, использующих
daemon(), необходимо следить за ними. Если возможно, в программе также нужно использовать
chroot().
Часть IV
Библиотеки для разработки
Глава 23
Сопоставление строк
Осуществлять сравнение строк можно не только с помощью функции
strcmp() или даже
strncmp(). Linux предлагает несколько общих функций сопоставления строк, использование которых позволяет упростить решение задач программирования. Мы рассмотрим сначала самые простые примеры, а затем перейдем к более сложным.
23.1. Универсализация произвольных строк
В главе 14 мы говорили о том, как с помощью функции
glob() производится универсализация имен файлов, однако пользователи, знакомые с возможностями универсализации, нередко пытаются применить их и к другим разновидностям строк. Функция
fnmatch() позволяет применять правила универсализации в отношении произвольных строк:
#include <fnmatch.h>
int fnmatch(const char * pattern, const char * string, int flags);
Предложенный шаблон является стандартным выражением универсализации с четырьмя специальными символами, за которые отвечает аргумент
flags.
* |
Соответствует любой строке, включая пустую. |
? |
Соответствует любому одиночному символу. |
[ |
Начинает список символов для сопоставления или, если следующим символом является ^, то список символов для несовпадения. Весь список может совпадать, или не совпадать с одним символом. Список заканчивается знаком ]. |
\ |
Следующий символ будет интерпретироваться как литерал, а не как специальный символ. |
На результаты универсализации влияет аргумент
flags, и здесь он будет полезен, прежде всего, для универсализации имен файлов. Если вы не будете осуществлять универсализацию имен файлов, то вам, скорее всего, нужно будет присвоить аргументу
flags значение
0.
FNM_NOESCAPE |
Обработка символа \ как обычного, а не специального символа. |
FNM_PATHNAME |
Символы / в строке string не сопоставляются с последовательностью *, ?, или даже [/] в шаблоне pattern; сопоставление производится только с литералом, а не специальным символом /. |
FNM_NOESCAPE |
Первый символ . в шаблоне pattern соответствует символу . в строке string только в том случае, если он является первым символом в строке string или если задано значение FNM_PATHNAME, а символ . в string непосредственно следует за символом \. |
Функция
fnmatch() возвращает нулевое значение, если шаблон соответствует строке,
FNM_NOMATCH, если шаблон не соответствует строке, или другое неопределенное значение в случае возникновения ошибки.
Пример использования функции
fnmatch() вы можете посмотреть в программе, приведенной в разделе 14.7.3 главы 14, в которой эта функция используется как часть простой реализации команды
find.
23.2. Регулярные выражения
Регулярные выражения, используемые в программах
sed,
awk,
grep,
vi, а также во множестве других программ Unix, со временем приобрели большое значение в среде программирования Unix. Регулярные выражения можно применять и при написании программ на языке С. В этом разделе будет рассказано об их использовании и будет предложен пример простой программы синтаксического анализа файла, построенной на этих функциях.
23.2.1. Регулярные выражения в Linux
Существуют две разновидности регулярных выражений:
базовые регулярные выражения (basic regular expression — BRE) и
расширенные регулярные выражения (extended regular expression — ERE). Они соответствуют (в первом приближении) командам grep и egrep. Описание каждой разновидности регулярных выражений можно найти на man-странице grep, в стандарте POSIX.2 (IEEE, 1993), в [32], а также в других источниках, поэтому здесь мы не станем описывать их синтаксис, а рассмотрим только интерфейс функции, с помощью которой вы сможете применять регулярные выражения в своих программах.
23.2.2. Сопоставление с регулярными выражениями
Стандарт POSIX определяет четыре функции обработки регулярных выражений.
#include <regex.h>
int regcomp(regex_t *preg, const char * regex, int cflags);
int regexec(const regex_t *preg, const char * string, size_t nmatch,
regmatch_t pmatch[], int eflags);
void regfree(regex_t *preg);
size_t regerror(int errcode, const regex_t *preg, char * errbuf,
size_t errbuf_size);
Прежде чем сравнивать строку с регулярным выражением, нужно выполнить ее
компиляцию с помощью функции
regcomp(). Аргумент
regex_t *preg указывает на область хранения регулярного выражения. Чтобы каждое регулярное выражение было доступно одновременно, для него потребуется отдельный аргумент
regex_t. Структура
regex_t включает только один важный член,
re_nsub, который определяет количество подвыражений в регулярном выражении, заключенных в скобки. Рассмотрим оставшуюся часть непрозрачной структуры.
Аргумент
сflags определяет варианты интерпретации регулярного выражения
regex. Он может иметь нулевое значение или быть любой комбинацией перечисленных ниже значений, объединенных битовым "ИЛИ".
REG_EXTENDED |
Вместо синтаксической структуры BRE будет использоваться структура ERE. |
REG_ICASE |
Не будет учитываться регистр. |
REG_NOSUB |
Не будут выделяться подстроки. Функция regexec() будет игнорировать аргументы nmatch и pmatch. |
REG_NEWLINE |
Если значение REG_NEWLINE не будет задано, то символ новой строки будет обрабатываться точно так же, как и любой другой символ. Символы ^ и $ соответствуют только началу и концу всей строки, а не соседним символам новой строки. Если значение REG_NEWLINE будет задано, то результат будет таким же, как и в случае использования grep, sed и других стандартных системных инструментальных средств; символ ^ осуществляет привязку к началу строки и символу, следующему после символа новой строки (фактически он соответствует строке нулевой длины, следующей за символом новой строки); $ осуществляет привязку к концу строки и символу, следующему после символа новой строки (фактически, он соответствует строке нулевой длины, предшествующей символу новой строки); символ . не соответствует символу новой строки. |
Ниже представлен пример типичного вызова функции.
if ((rerr = regcomp(&p, "(^(.*[^\\])#.*$)|(^[^#]+$)",
REG_EXTENDED|REG_NEWLINE))) {
if (rerr == REG_NOMATCH) {
/* строка просто не совпадает с регулярным выражением */
} else {
/* какая-то другая ошибка, например, неправильно сформированное регулярное выражение */
}
}
Данное расширенное регулярное выражение находит строки в файле, которые не включены в комментарии, или которые, по крайней мере, частично, заключены в комментарии посредством символов
# без префикса
\. Эту разновидность регулярного выражения удобно использовать в качестве простого анализатора синтаксиса для конфигурационного файла какого-нибудь приложения.
Даже если вы компилируете выражение, которое, по вашему мнению, является нормальным, вам все равно необходимо проверить его на наличие ошибок. Функция
regcomp() возвращает нулевое значение при успешном выполнении компиляции и ненулевой код ошибки — в противном случае. Большинство ошибок может быть связано с разного рода ошибками в регулярных выражениях, но не исключено, что ошибка может быть связана с переполнением памяти. Далее в этой главе дается описание функции
regerror().
#include <regex.h>
int regexec(const regex_t *preg, const chat *string, size_t nmatch,
regmatch_t pmatch[], int eflags);
Функция
regexec() сравнивает строку с предварительно компилированным регулярным выражением. Аргумент
eflags может иметь нулевое значение или быть любой комбинацией перечисленных ниже значений, объединенных битовым "ИЛИ".
REG_NOTBOL |
Первый символ строки не будет соответствовать символу ^. Любой символ, следующий за символом новой строки, будет соответствовать при том условии, что в вызове функции regcomp() будет задано значение REG_NEWLINE. |
REG_NOTEOL |
Последний символ строки не будет соответствовать символу $. Любой символ, предшествующий символу новой строки, будет соответствовать символу $ при том условии, что в вызове функции regcomp() будет задано значение REG_NEWLINE. |
Массив структур
regmatch_t используется для представления местоположения подвыражений в регулярном выражении.
#include <regex.h>
typedef struct {
regoff_t rm_so; /* индекс байта в строке в начале сопоставления*/
regoff_t rm_eo; /* индекс байта в строке в конце сопоставления*/
} regmatch_t;
Первый элемент
regmatch_t описывает всю совпавшую строку; обратите внимание, что вся эта строка содержит любой символ начала строки, включая хвостовой символ новой строки, независимо от того, задано ли значение
REG_NEWLINE.
Следующие элементы массива хранят подвыражения, заключенные в скобки, в том порядке, в котором они присутствуют в регулярном выражении, в порядке расположения открывающих скобок. (В коде на языке С элемент
i эквивалентен выражению замены
\i в программах
sed или
awk.) В несовпадающих подвыражениях член
regmatch_t.rm_so имеет значение
-1.
В следующем коде производится сопоставление строки с регулярным выражением, содержащим подвыражения. После сопоставления на экран выводятся все совпавшие подвыражения.
1: /* match.с */
2:
3: #include <alloca.h>
4: #include <sys/types.h>
5: #include <regex.h>
6: #include <stdlib.h>
7: #include <string.h>
8: #include <stdio.h>
9:
10: void do_regerror(int errcode, const regex_t *preg) {
11: char *errbuf;
12: size_t errbuf_size;
13:
14: errbuf_size = regerror(errcode, preg, NULL, 0);
15: errbuf = alloca(errbuf_size);
16: if (!errbuf) {
17: perror("alloca");
18: return;
19: }
20:
21: regerror(errcode, preg, errbuf, errbuf_size);
22: fprintf(stderr, "%s\n", errbuf);
23: }
24:
25: int main() {
26:
27: regex_t p;
28: regmatch_t *pmatch;
29: int rerr;
30: char *regex = "(^(.*[^\\])#.*$)|(^[^#]+$)";
31: char string[BUFSIZ+1];
32: int i;
33:
34: if ((rerr = regcomp(&p, regex, REG_EXTENDED | REG_NEWLINE))) {
35: do_regerror(rerr, &p);
36: }
37:
38: pmatch = alloca(sizeof(regmatch_t) * (p.re_nsub+1));
39: if (!pmatch) {
40: perror("alloca");
41: }
42:
43: printf("Введите строку: ");
44: fgets(string, sizeof(string), stdin);
45:
46: if ((rerr = regexec(&p, string, p.re_nsub+1, pmatch, 0))) {
47: if (rerr == REG_NOMATCH) {
48: /* эту ситуацию может обработать regerror,
49: * но зачастую она обрабатывается особым образом
50: */
51: printf("Строка не совпадает с %s\n", regex);
52: } else {
53: do_regerror(rerr, &p);
54: }
55: } else {
56: /* сопоставление закончено */
57: printf("Строка совпадает с регулярным выражением %s\n", regex);
58: for (i = 0; i <= p.re_nsub; i++) {
59: /* вывод на экран совпавшей части (частей) строки */
60: if (pmatch[i].rm_so != -1) {
61: char *submatch;
62: size_t matchlen = pmatch[i].rm_eo - pmatch[i].rm_so;
63: submatch = malloc(matchlen+1);
64: strncpy(submatch, string+pmatch[i].rm_so,
65: matchlen);
66: submatch[matchlen] = '\0';
67: printf("совпавшее подвыражение %d: %s\n", i,
68: submatch);
69: free(submatch);
70: } else {
71: printf ("нет совпадения с подвыражением %d\n", i);
72: }
73: }
74: }
75: exit(0);
76: }
В примере регулярного выражения из программы
match.с имеется три подвыражения. Первое из них представляет собой всю строку, содержащую текст, за которым следует символ комментария, вторым является текст в строке, предшествующей символу комментария, а третье представляет всю строку без символа комментария. Для строки, в начале которой содержится комментарий, элементу
rm_so во втором и третьем элементе из массива
pmatch[] присвоено значение
-1. Для строки, в начале которой содержится комментарий, значение
-1 присваивается первому и второму элементу; для строки, не содержащей символы комментария, второму и третьему элементу присваивается значение
-1.
Каждый раз после завершения работы с компилированным регулярным выражением его необходимо освободить, чтобы избежать утечек памяти. Для освобождения памяти необходимо использовать функцию
regfree(), но не
free():
#include <regex.h>
void regfree(regex_t *preg);
В стандарте POSIX четко не сказано, следует ли использовать функцию
regfree() каждый раз при вызове функции
regcomp(), или же только после того, как вы в последний раз вызывали функцию
regcomp() в одной структуре
regex_t. Таким образом, чтобы избежать утечек памяти, в промежутках между использованием структур
regex_t необходимо вызывать функцию
regfree().
Всякий раз когда функция
regcomp() или
regex() возвращает ненулевой результат, функция
regerror() может предоставить подробное сообщение, в котором будет указано, в чем состоит ошибка. Она записывает по возможности все сообщение об ошибке в буфер и возвращает размер всего сообщения. Поскольку вы заранее не знаете, какой размер будет иметь сообщение, то сначала вам необходимо узнать его размер, а затем распределить и использовать буфер, как показано в следующем далее примере кода. Поскольку этот вариант обработки ошибок быстро становится устаревшим, и вам придется включать его как минимум дважды (один раз после функции
regcomp() и один раз после функции
regex()), мы советуем вам написать код собственной оболочки функции
regerror(), как показано в строке 10 из листинга
math.с.
23.2.3. Простая утилита grep
grep является популярной утилитой, определенной в стандарте POSIX, которая предлагает возможности поиска регулярного выражения в текстовых файлах. Ниже показана простая (не соответствующая стандарту POSIX) версия утилиты
grep, реализованная с помощью функций стандартного регулярного выражения.
1: /* grep.с */
2:
3: #include <alloca.h>
4: #include <ctype.h>
5: #include <popt.h>
6: #include <regex.h>
7: #include <stdio.h>
8: #include <string.h>
9: #include <unistd.h>
10:
11: #define MODE_REGEXP 1
12: #define MODE_EXTENDED 2
13: #define MODE_FIXED 3
14:
15: void do_regerror(int errcode, const regex_t *preg) {
16: char *errbuf;
17: size_t errbuf_size;
18:
19: errbuf_size = regerror(errcode, preg, NULL, 0);
20: errbuf = alloca(errbuf_size);
21: if (!errbuf) {
22: perror("alloca");
23: return;
24: }
25:
26: regerror(errcode, preg, errbuf, errbuf_size);
27: fprintf(stderr, "%s\n", errbuf);
28: }
29:
30: int scanFile(FILE * f, int mode, const void * pattern,
31: int ignoreCase, const char * fileName,
32: int * maxCountPtr) {
33: long lineLength;
34: char * line;
35: int match;
36: int rc;
37: char * chptr;
38: char * prefix = "";
39:
40: if (fileName) {
41: prefix = alloca(strlen(fileName) + 4);
42: sprintf(prefix, "%s: ", fileName);
43: }
44:
45: lineLength = sysconf(_SC_LINE_MAX);
46: line = alloca(lineLength);
47:
48: while (fgets(line, lineLength, f) && (*maxCountPtr)) {
49: /* если у нас не будет завершающего символа '\n'
50: то мы не сможем получить всю строку целиком */
51: if (line [strlen (line) -1] != '\n') {
52: fprintf(stderr, " %s line слишком длинная\n", prefix);
53: return 1;
54: }
55:
56: if (mode == MODE_FIXED) {
57: if (ignoreCase) {
58: for (chptr = line; *chptr; chptr++) {
59: if (isalpha(*chptr)) *chptr = tolower(*chptr);
60: }
61: }
62: match = (strstr(line, pattern) != NULL);
63: } else {
64: match = 0;
65: rc = regexec (pattern, line, 0, NULL, 0);
66: if (!rc)
67: match = 1;
68: else if (rc != REG_NOMATCH)
69: do_regerror(match, pattern);
70: }
71:
72: if (match) {
73: printf("%s%s", prefix, line);
74: if (*maxCountPtr > 0)
75: (*maxCountPtr)--;
76: }
77: }
78:
79: return 0;
80: }
81:
82: int main(int argc, const char ** argv) {
83: const char * pattern = NULL;
84: regex_t regPattern;
85: const void * finalPattern;
86: int mode = MODE_REGEXP;
87: int ignoreCase = 0;
88: int maxCount = -1;
89: int rc;
90: int regFlags;
91: const char ** files;
92: poptContext optCon;
93: FILE * f;
94: char * chptr;
95: struct poptOption optionsTable[] = {
96: { "extended-regexp", 'E', POPT_ARG_VAL,
97: &mode, MODE_EXTENDED,
98: "шаблоном для соответствия является расширенное регулярное "
99: "выражение"},
100: { "fixed-strings", 'F', POPT_ARG_VAL,
101: &mode, MODE_FIXED,
102: "шаблоном для соответствия является базовая строка (не "
103: "регулярное выражение)", NULL },
104: { "basic-regexp", 'G', POPT_ARG_VAL,
105: &mode, MODE_REGEXP,
106: "шаблоном для соответствия является базовое регулярное выражение" },
107: { "ignore-case", 'i', POPT_ARG_NONE, &ignoreCase, 0,
108: "выполнять поиск, чувствительный к регистру", NULL },
109: { "max-count", 'm', POPT_ARG_INT, &maxCount, 0,
110: "завершить после получения N. совпадений", "N" },
111: { "regexp", 'e', POPT_ARG_STRING, &pattern, 0,
112: "регулярное выражение для поиска", "pattern" },
113: POPT_AUTOHELP
114: { NULL, '\0', POPT_ARG_NONE, NULL, 0, NULL, NULL }
115: };
116:
117: optCon = poptGetContext("grep", argc, argv, optionsTable, 0);
118: poptSetOtherOptionHelp(optCon, "<шаблон> <список файлов>");
119:
120: if ((rc = poptGetNextOpt(optCon)) < -1) {
121: /* во время обработки параметра возникла ошибка */
122: fprintf(stderr, "%s: %s\n",
123: poptBadOption(optCon, POPT_BADOPTION_NOALIAS),
124: poptStrerror(rc));
125: return 1;
126: }
127:
128: files = poptGetArgs(optCon);
129: /* если мы не получили шаблон, то он должен быть первым
130: из оставшихся */
131: if (!files && !pattern) {
132: poptPrintUsage(optCon, stdout, 0);
133: return 1;
134: }
135:
136: if (!pattern) {
137: pattern = files[0];
138: files++;
139: }
140:
141: regFlags = REG_NEWLINE | REG_NOSUB;
142: if (ignoreCase) {
143: regFlags |= REG_ICASE;
144: /* преобразование шаблона в нижний регистр; этого можно не делать,
145: если мы игнорируем регистр в регулярном выражении, однако позволяет
146: функции strstr() правильно обработать -i */
147: chptr = alloca(strlen(pattern) + 1);
148: strcpy(chptr, pattern);
149: pattern = chptr;
150:
151: while (*chptr) {
152: if (isalpha(*chptr)) *chptr = tolower(*chptr);
153: chptr++;
154: }
155: }
156:
157:
158: switch (mode) {
159: case MODE_EXTENDED:
160: regFlags |= REG_EXTENDED;
161: case MODE_REGEXP:
162: if ((rc = regcomp(®Pattern, pattern, regFlags))) {
163: do_regerror(rc, ®Pattern);
164: return 1;
165: }
166: finalPattern = ®Pattern;
167: break;
168:
169: case MODE_FIXED:
170: finalPattern = pattern;
171: break;
172: }
173:
174: if (!*files) {
175: rc = scanFile(stdin, mode, finalPattern, ignoreCase, NULL,
176: &maxCount);
177: } else if (!files[1]) {
178: /* эта часть обрабатывается отдельно, поскольку имя файла
179: выводить не нужно */
180: if (!(f = fopen(*files, "r"))) {
181: perror(*files);
182: rc = 1;
183: } else {
184: rc = scanFile(f, mode, finalPattern, ignoreCase, NULL,
185: &maxCount);
186: fclose(f);
187: }
188: } else {
189: rc = 0;
190:
191: while (*files) {
192: if (!(f = fopen(*files, "r"))) {
193: perror(*files);
194: rc = 1;
195: } else {
196: rc |= scanFile(f, mode, finalPattern, ignoreCase,
197: *files, &maxCount);
198: fclose(f);
199: }
200: files++;
201: if (!maxCount) break;
202: }
203: }
204:
205: return rc;
206: }
Глава 24
Управление терминалами с помощью библиотеки S-Lang
С помощью библиотеки S-Lang, написанной Джоном Дэвисом (John Е. Davis), можно осуществлять доступ к терминалам на среднем уровне. Все действия, связанные с управлением терминалами на низком уровне, осуществляются посредством набора подпрограмм, предлагающих прямой доступ к видеотерминалам и автоматически управляющих прокруткой и цветами. Несмотря на незначительную прямую поддержку окон и отсутствие в S-Lang каких-либо элементов управления, для таких задач эта библиотека предлагает удобную основу
[167].
Библиотеку S-Lang можно использовать и для работы в DOS, что делает ее привлекательной для создания приложений, которые будут выполняться на платформах Unix и DOS.
Возможности управления терминалами с помощью библиотеки S-Lang можно разделить на две категории. Во-первых, библиотека предлагает набор функций для управляемого считывания нажатий клавиш из терминала. Во-вторых, она содержит набор подпрограмм для полноэкранного вывода на терминал. Многие возможности терминалов будут недоступными для программистов, однако функциональными возможностями каждого терминала можно будет воспользоваться
[168]. В этой главе вы узнаете о том, каким образом можно использовать библиотеку S-Lang применительно ко всем этим функциональным возможностям, а в конце главы вам будет предложен пример программы для закрепления материала.
24.1. Обработка ввода
Подсистема управления вводом на терминалах является одной из наименее доступных подсистем в мире Unix.
Широко распространенными подсистемами являются BSD sgtty, System termio, a также POSIX termios. За работу по управлению входными данными в библиотеке S-Lang отвечают несколько функций, предназначенных специально для того, чтобы сделать обработку данных, поступающих с клавиатуры, более простой и доступной.
Чтобы написать программу для посимвольного чтения из терминала и вывода каждого символа в отдельной строке потребуется несложный код.
1: /* slecho.c */
2:
3: #include <ctype.h>
4: #include <slang/slang.h>
5: #include <stdio.h>
6:
7: int main(void) {
8: char ch = '\0';
9:
10: /*
11: Начать обработку SLANG tty со следующими параметрами:
12: -1 символ прерывания по умолчанию (обычно Ctrl-C)
13: 0 управление потоком не производится; все символы (кроме
14: символа прерывания) будут переданы в программу 1 разрешение
15: обработки выходных данных OPOST управляющих последовательностей
16: */
17: SLang_init_tty(-1, 0, 1);
18:
19: while (ch != 'q') {
20: ch = SLang_getkey();
21: printf("чтение: %c 0x%x\n", isprint(ch) ? ch : ' ', ch);
22: }
23:
24: SLang_reset_tty();
25:
26: return 0;
27: }
Эта программа предполагает, что все заголовочные файлы S-Lang содержатся в каталоге
/usr/include/slang. Если в вашей системе они находятся в другом каталоге, то тогда следует изменить соответствующим образом код (это касается всех примеров в этой главе). Для компилирования и компоновки этой программы в команду компоновки потребуется добавить
-lslang, чтобы компоновщик мог найти функции S-Lang.
24.1.1. Инициализация обработки ввода в S-Lang
Прежде чем какая-либо функция обработки входных данных сможет работать, с помощью функции
Slang_init_tty() нужно перевести терминал в состояние, которое ожидается S-Lang:
int SLang_init_tty(int abort_char, int flow_ctrl, int opost);
Первый параметр функции
Slang_init_tty() определяет символ, который будет использован для прекращения работы. При передаче значения
-1 будет сохранен текущий символ прерывания tty (обычно, <Ctrl+C>); в противном случае символу прерывания будет назначено переданное значение. Каждый раз при вводе на терминале символа прекращения работы ядро посылает сигнал
SIGINT тому процессу, который обычно завершает работу приложения. В главе 12 мы рассказывали о том, как производится обработка сигналов, подобных
SIGINT.
Следующий параметр отвечает за включение и отключение управления потоком. Управляя потоком на уровне терминала, пользователь может приостанавливать процесс вывода данных на терминал, не допуская прокрутки, а затем возобновлять его. Обычно для приостановления процесса вывода данных на экран используется <Ctrl+S> и <Ctrl+Q> — для возобновления этого процесса. Хотя эта особенность удобна для некоторых утилит, ориентированных на работу со строками, программы, работающие с библиотекой S-Lang, обычно ориентированы на работу с экраном, поэтому она может оказаться излишней. S-Lang позволяет приложениям отключать эту функциональность, в результате чего программа сможет назначить нажатия клавиш Stop (Стоп) и Start (Пуск) для других команд. Чтобы включить управление потоками, функции
SLang_init_tty() необходимо передать ненулевое значение в качестве второго параметра.
Последний параметр разрешает заключительную обработку вывода на терминале. Любой механизм ядра, связанный с заключительной обработкой, будет включен, если последний параметр будет иметь ненулевое значение. Информацию об обработке выходных данных можно найти в главе 16.
24.1.2. Восстановление состояния терминала
После того как состояние терминала было изменено с помощью функции
SLang_init_tty(), программа, прежде чем завершить свою работу, должна явным образом восстановить первоначальное состояние терминала. Если этого не сделать, то вряд ли можно будет работать с терминалом после завершения программы. Функция
SLang_init_tty() не принимает и не возвращает никаких аргументов.
Если вы пишете программу, работу которой нужно будет приостановить (обычно посредством нажатия <Ctrl+Z>), то эту функцию также необходимо вызывать после получения сигнала
SIGTSTP. Более подробно об обработке сигнала
SIGTSTP можно прочитать в главе 15.
Не исключено, что в процессе разработки программ с помощью библиотеки S-Lang в них будут неоднократно происходить сбои, после которых терминал будет находиться в нестандартном состоянии. С этой проблемой можно справиться, если выполнить команду
stty sane.
24.1.3. Чтение символов с терминала
После правильной инициализации терминала чтение одиночных нажатий клавиш не составит труда. Функция
SLang_getkey() возвращает одиночный символ из терминала. Однако это не означает, что функция возвращает одиночное нажатие клавиши, ведь в системе Unix после многих нажатий клавиш может быть возвращено несколько символов. Например, на терминале VT100 (а также на многих других терминалах, включая консоль Linux) при нажатии клавиши <F1> на экран посылается четыре символа —
ESC [ [ А (попробуйте запустить
slecho, нажать клавишу <F1> и посмотрите, что получится). Чтобы установить соответствие между подобными многосимвольными последовательностями и нажатиями клавиш, можно использовать базу данных
terminfo [37].
Функция
SLang_get_key(), прежде чем вернуть результат, в течение неопределенного периода времени ожидает нажатие символа, который необходимо представить. В случае возникновения ошибки вместо действительного символа эта функция возвращает значение
0xFFFF[169].
24.1.4. Проверка ожидающего ввода
Во многих случаях вам нужно будет проверять доступные символы, не прибегая при этом к блокировке. Это удобно делать тогда, когда программе необходимо перейти к фоновой обработке, а пользователю в этот момент посылается запрос на ввод данных (особенно в видеоиграх). Функция
SLang_input_pending() определена следующим образом:
int SLang_input_pending(int timeout);
Функция
SLang_input_pending() возвращает
true, если символы стали доступными в течение n десятых долей секунды. Она возвращает результат, как только символы становятся доступными, и
false, если ни один из символов не окажется доступным в течение определенного периода времени. Если задать нулевой период времени, то функция
SLang_input_pending() сообщит о доступных в данный момент символах.
Это поведение легко пронаблюдать. Для этого в программе
slecho.с достаточно изменить проверку в цикле
while:
while (ch != 'q' && SLang_input_pending(20))
Теперь программа будет ожидать ввода дополнительных данных не более двух секунд. По истечении двух секунд, если никакие данные не будут введены, работа программы будет завершена.
24.2. Обработка вывода
Функции библиотеки S-Lang, предназначенные для вывода данных на терминал, бывают двух разновидностей: функции управления терминалом (семейство
SLtt) и функции высокого уровня для управления экраном (семейство
SLsmg).
Функции, принадлежащие семейству
SLtt, работают напрямую с терминалом; к ним принадлежат функции, осуществляющие отображение данных в строгом соответствии с возможностями, определенными в терминальной базе данных. Это семейство также включает набор подпрограмм для определения пар цветов переднего плана и фона, а также включения и выключения курсора. Разработчики приложений обычно используют только некоторые из этих функций, а остальные вызываются внутри самой библиотеки S-Lang.
Семейство
SLsmg предлагает высокий уровень абстракции терминала. Хотя эти функции используют функции семейства
SLtt для управления терминалом, они предлагают разработчикам приложений интерфейс с более широкими возможностями.
Эти функции отвечают за вывод строк, рисование линий и отправку запросов к экрану. Чтобы не допустить снижения производительности, эти подпрограммы осуществляют запись во внутренний буфер, а не напрямую на терминал. Когда приложение посылает библиотеке S-Lang запрос на обновление физического терминала, она сравнивает новое содержимое с исходным и соответствующим образом оптимизирует последовательность выходных данных.
24.2.1. Инициализация управления экраном
Прежде чем использовать функции библиотеки S-Lang для вывода данных на терминал, программа должна послать S-Lang запрос на поиск текущего терминала (как это определено в переменной окружения
TERM) в терминальной базе данных. Это осуществляется следующим образом:
void SLtt_get_terminfo(void);
Одной из главных задач функции
SLtt_get_terminfo() является установка физического размера экрана в соответствии с размером, указанным в базе данных терминала. Информация о количестве строк и колонок в терминале хранится, соответственно, в
SLtt_Screen_Rows и
SLtt_Screen_Cols. Хотя данные в терминальной базе данных обычно корректны, в настоящее время широкую популярность приобрели терминалы с изменяемыми размерами (например,
xterms). После того как размер такого терминала будет изменен по отношению к размеру, принятому по умолчанию, терминальная база данных не будет содержать корректной информации о размерах терминала. Для компенсации этой неточности библиотека S-Lang позволяет программам восстанавливать исходные значения
SLtt_Screen_Rows и
SLtt_Screen_Cols после вызова функции
SLtt_get_terminfo(). В системе Unix текущие размеры терминала всегда можно узнать с помощью команды
TIOCGWINSZ управления вводом-выводом, которая подробно описана в главе 16.
Инициализировать уровень управления экраном в S-Lang можно очень просто:
void SLsmg_init_smg(void);
SLsmg_init_smg()
24.2.2. Обновление экрана
Прежде чем результаты выполнения последовательности подпрограмм
SLsmg смогут быть отражены на физическом терминале, необходимо вызвать функцию
SLsmg_refresh(). Эта функция не принимает аргументы и не возвращает значения, а обновляет физический терминал по результатам рисования чего-либо на экране, которое было выполнено со времени ее последнего вызова.
24.2.3. Перемещение курсора
Как и в большинстве программ, курсор терминала используется библиотекой S-Lang для обозначения позиции, принятой по умолчанию, для ввода текста и для подсказки пользователю. Программы S-Lang могут перемещать курсор с помощью показанной ниже функции.
extern void SLsmg_gotorc(int row, int column);
Имейте в виду, что верхний левый угол экрана определяется координатами (
0, 0), а нижний правый угол — (
SLtt_Screen_Rows - 1, SLtt_Screen_Cols - 1).
24.2.4. Завершение управления экраном
Когда программа, использующая
SLsmg, завершает свою работу, она должна послать библиотеке S-Lang соответствующее сообщение об этом, после чего библиотека освободит буферы и восстановит состояние терминала. Прежде чем сделать это, будет правильным переместить курсор вниз экрана и обновить дисплей, чтобы пользователь смог увидеть все выводимые данные.
24.2.5. Скелет программы управления экраном
Ниже приведен пример программы, которая сначала инициализирует возможности библиотеки S-Lang для управления экраном, а затем закрывает их. Хотя эта программа выполняет лишь некоторые действия, она иллюстрирует основы использования функциональных возможностей
SLsmg библиотеки S-Lang.
1: /* slinit.с */
2:
3: #include <slang/slang.h>
4: #include <stdio.h>
5: #include <sys/ioctl.h>
6: #include <termios.h>
7:
8: int main(void) {
9: struct winsize ws;
10:
11: /* получение размеров терминала, подключенного к stdout */
12: if (ioctl(1, TIOCGWINSZ, &ws)) {
13: perror("сбой при получении размеров окна");
14: return 1;
15: }
16:
17: SLtt_get_terminfo();
18:
19: SLtt_Screen_Rows = ws.ws_row;
20: SLtt_Screen_Cols = ws.ws_col;
21:
22: SLsmg_init_smg();
23:
24: /* здесь находится ядро программы */
25:
26: SLsmg_gotorc(SLtt_Screen_Rows - 1, 0);
27: SLsmg_refresh();
28: SLsmg_reset_smg();
29: SLang_reset_tty();
30:
31: return 0;
32: }
24.2.6. Переключение наборов символов
Большинство современных терминалов (включая VT100, который достаточно точно эмулирует консоль Linux) поддерживают как минимум два набора символов. Основным набором обычно является ISO-8859-1 или ему подобный; другой набор используется главным образом для линейных символов. Библиотека S-Lang позволяет выбирать набор тех символов, которые будут применяться для вычерчивания символов.
void SLsmg_set_char_set(int useAlternate)
Если функцию
SLsmg_set_char_set() вызвать с ненулевым аргументом, на экране будут выводиться новые символы, отображаемые с применением альтернативного набора символов. Если функцию
SLsmg_set_char_set() вызвать с нулевым аргументом, то это отображение использоваться не будет, вследствие чего на экране будут появляться обычные символы.
S-Lang определяет набор символических имен для наиболее часто используемых линейных символов, входящих в альтернативный набор. В табл. 24.1 перечислены доступные линейные символы и имена S-Lang для каждого из них.
Таблица 24.1. Линейные символы
| Глиф |
Символическая константа |
─ |
SLSMG_HLINE_CHAR |
│ |
SLSMG_VLINE_CHAR |
┌ |
SLSMG_ULCORN_CHAR |
┐ |
SLSMG_URCORN_CHAR |
└ |
SLSMG_LLCORN_CHAR |
┘ |
SLSMG_LRCORN_CHAR |
┤ |
SLSMG_RTEE_CHAR |
├ |
SLSMG_LTEE_CHAR |
┬ |
SLSMG_UTEE_CHAR |
┴ |
SLSMG_DTEE_CHAR |
┼ |
SLSMG_PLUS_CHAR |
24.2.7. Запись на экран
Записать строки на экран под управлением S-Lang можно несколькими различными способами, суть которых одинакова. Далее приводится полный список функций, предназначенных для этой цели.
void SLsmg_write_char(char ch);
void SLsmg_write_string(char * str);
void SLsmg_write_nchars(char * chars, int length);
void SLsmg_write_nstring(char * str, int length);
void SLsmg_printf(char * format, ...);
void SLsmg_vprintf(char * format, va_list args);
void SLsmg_write_wrapped_string(char * str, int row, int column, int height,
int width, int fill);
Каждая из этих функций, за исключением
SLsmg_write_wrapped_string(), записывает требуемую строку в буфер экрана
[170] в текущую позицию курсора, используя текущий цвет и набор символов. Однако все они по-разному определяют, какую строку необходимо записать. После того как информация будет записана, курсор переместится в конец выделенной для этого области, как и на обычном терминале. Любая строка, выходящая за пределы правого края экрана, усекается, а не переносится на другую строку. Хотя этот способ отличается от обычного вывода на терминал, он подходит для большинства полноэкранных приложений, в которых текст, переводимый на новую строку, искажает содержимое экрана.
SLsmg_write_char() |
Среди всех функций вывода данных на экран это самая простая функция. Она записывает передаваемый символ в текущую позицию курсора и перемещает курсор. |
SLsmg_write_string() |
Выводит на экран передаваемую ей строку. |
SLsmg_write_nchars() |
Выводит на экран символы length, на которые указывает chars. Символ конца строки NULL игнорируется — если он будет найден, выводится комбинация '\0' и подпрограмма продолжает работу после окончания строки. |
SLsmg_write_nstring() |
Выводит на экран не более length символов из str. Если str содержит менее length символов, оставшееся пространство заполняется пробелами. |
SLsmg_printf() |
Как можно судить из имени функции, она работает подобно стандартной функции printf(), форматируя первый аргумент, а остальные аргументы используются в качестве параметров для форматирования. После этого на экран выводится сформатированная строка. |
SLsmg_vprintf() |
Подобно функции vfprintf() из библиотеки С. Эта функция ожидает получение аргумента va_arg, который она использует для форматирования первого параметра. Затем на экран выводится сформатированная строка. |
SLsmg_write_wrapped_string() |
Хотя S-Lang отсекает строки, а не переносит их на следующие строки, она предлагает простую функцию для записи строк, перенесенных в произвольную прямоугольную область экрана. Функция SLsmg_write_wrapped_string() записывает строку str в прямоугольную область, которая начинается в row и column и имеет размеры height и width. Несмотря на то что эта подпрограмма осуществляет перенос границ слов, последовательность \n указывает на необходимость перехода на следующую строку. Если последний параметр fill имеет ненулевое значение, то каждая строка будет заполнена по всей ширине прямоугольной области, а при необходимости будут добавляться пробелы. |
24.2.8. Рисование линий и прямоугольников
Хотя функция
SLsmg_set_char_set() предлагает весь спектр функциональных возможностей, необходимых для рисования простой линейной графики на терминале, в библиотеке S-Lang для этого предусмотрено несколько простых функций.
void SLsmg_draw_hline(int row);
void SLsmg_draw_vline(int column);
void SLsmg_draw_box(int row, int column, int height, int width);
Функция
SLsmg_draw_hline() рисует одну горизонтальную линию в строке
row, а функция
SLsmg_draw_vline() — одну вертикальную линию в колонке
col.
Функция
SLsmg_draw_box() рисует прямоугольник, начиная с
row и
col, который простирается на
height строк и
width колонок. Функция
SLsmg_draw_box() подобна комбинации функций
SLsmg_draw_hline() и
SLsmg_draw_vline(), однако вдобавок она получает информацию о вершинах.
Далее представлен пример программы, которая рисует экран, отображающий обычный и альтернативный наборы символов. В программе также демонстрируется простое использование функции
SLsmg_draw_box().
1: /* slcharset.с */
2:
3: #include <slang/slang.h>
4: #include <stdio.h>
5: #include <sys/ioctl.h>
6: #include <termios.h>
7:
8: /* отображает таблицу, содержащую 256 символов из одного набора символов,
9: начиная со столбца col. Поверх таблицы отображается метка 'label',
10: а альтернативный набор символов будет отображаться в том случае,
11: если isAlternate будет иметь ненулевое значение */
12: static void drawCharSet(int col, int isAlternate, char * label) {
13: int i, j;
14: int n = 0;
15:
16: /* нарисовать прямоугольник */
17: SLsmg_draw_box(0, col, 20, 38);
18:
19: /* центрировать надпись */
20: SLsmg_gotorc(0, col + 2);
21: SLsmg_write_string(label);
22:
23:
24: /* нарисовать горизонтальную линию */
25: SLsmg_gotorc(2, col + 4);
26: SLsmg_write_string("0123456789ABCDEF");
27:
28: /* задать используемый набор символов */
29: SLsmg_set_char_set(isAlternate);
30:
31: /* итерация по 4 самым старшим битам */
32: for (i = 0; i < 16; i++) {
33: SLsmg_gotorc(3 + i, 2 + col);
34: SLsmg_write_char(i < 10 ? i + '0' : (i - 10) + 'A');
35:
36: /* итерация по 4 самым младшим битам */
37: for (j = 0; j < 16; j++) {
38: SLsmg_gotorc(3 + i, col + 4 + (j * 2));
39: SLsmg_write_char(n++);
40: }
41: }
42:
43: SLsmg_set_char_set(0);
44: }
45:
46: int main (void) {
47: struct winsize ws;
48:
49: /* получить размеры терминала, подключенного к stdout */
50: if (ioctl(1, TIOCGWINSZ, &ws)) {
51: perror("сбой при получении размеров окна");
52: return 1;
53: }
54:
55: SLtt_get_terminfо();
56:
57: SLtt_Screen_Rows = ws.ws_row;
58: SLtt_Screen_Cols = ws.ws_col;
59:
60: SLsmg_init_smg();
61: SLang_init_tty(-1, 0, 1);
62:
63: drawCharSet(0, 0, "Normal Character Set");
64: drawCharSet(40, 1, "Alternate Character Set");
65:
66: SLsmg_refresh();
67: SLang_getkey();
68:
69: SLsmg_gotorc(SLtt_Screen_Rows - 1, 0);
70: SLsmg_refresh();
71: SLsmg_reset_smg();
72: SLang_reset_tty();
73:
74: return 0;
75: }
24.2.9. Использование цвета
Библиотека S-Lang упрощает процесс добавления цветов в приложения. Она позволяет использовать палитру, состоящую из 256 элементов
[171], каждый из которых определяет цвет переднего плана и фона. В большинстве приложений используется элемент палитры для одного визуализируемого объекта, например, рамки окна или пункта списка. Настроить цвета палитры можно с помощью функции
SLtt_set_color().
void SLtt_set_color(int entry, char * name, char * fg, char * bg);
Первый параметр определяет модифицируемый элемент палитры. Параметр
name в настоящий момент игнорируется и должен быть равен
NULL. Два последних элемента задают новые цвета переднего плана и фона для данного элемента палитры. В табл. 24.2 приведен список цветов, которые поддерживает библиотека S-Lang;
fg и
bg должны представлять строки, содержащие имя используемого цвета. Все цвета в левой колонке таблицы могут использоваться как для переднего плана, так и для фона. Цвета в правой колонке таблицы могут служить только в качестве цветов переднего плана. Попытка использования этих цветов для фона может привести к непредсказуемым результатам
[172].
Таблица 24.2. Цвета в S-Lang
| Передний план и фон |
Передний план |
black |
gray |
red |
brightred |
green |
brightgreen |
brown |
yellow |
blue |
brightblue |
magenta |
brightmagenta |
cyan |
brightcyan |
lightgray |
white |
Запись на экран осуществляется с применением текущего элемента палитры, который можно задать с помощью функции
Slsmg_set_color().
void SLsmg_set_color(int entry);
Эта функция задает текущий элемент палитры по определенному элементу. Цвета, определяемые этим элементом, будут использоваться при последующих записях на экран.
Хотя приложение может вызывать функции для работы с цветом на терминале любого типа, возможность отображения того или иного цвета будет определяться некоторыми факторами. Глобальная переменная
SLtt_Use_Ansi_Colors контролирует отображение цветов. Если эта переменная будет иметь нулевое значение, цвета не используются, а если любое другое значение — то используются.
Функция
SLtt_get_terminfo() пытается предположить, будет ли цвет доступен на текущем терминале. К сожалению, многие базы данных termcap и terminfo в этом отношении несовершенны. Если будет задана переменная среды
COLORTERM, то S-Lang установит переменную
SLtt_Use_Ansi_Colors независимо от того, что отражено в базе данных терминала.
Большинство приложений, обеспечивающих поддержку цветов, также предлагают опцию командной строки, позволяя избирательно разрешать поддержку цветов. Указание этой опции приводит к явной установке переменной
SLtt_Use_Ansi_Colors в приложении.
Глава 25
Библиотека хешированных баз данных
Приложениям часто необходимо хранить некоторую разновидность бинарных данных в файлах. Хранение таких данных, когда во главу угла ставится задача эффективного их извлечения, отличается сложностью и слабой устойчивостью к ошибкам. Существует несколько библиотек, которые предлагают простые API-интерфейсы для хранения информации в файлах. В системах семейства Unix одной из первых использовалась библиотека
dbm (впоследствии она была повторно реализована как
ndbm), что привело затем к появлению библиотек Berkley db и
gdbm проекта GNU. Все эти библиотеки обеспечивали простой доступ к файлам, организованным в виде хеш-таблиц, с двоичным ключом, который обеспечивал доступ к области бинарных данных
[173].
Несмотря на то что
gdbm и Berkley db широко доступны в системах Linux, лицензии, сопровождаемые их, снижают удобство их коммерческого использования
[174]. Библиотека
gdbm во многом похожа на другие библиотеки, но подпадает под действие лицензии LGPL, что делает ее более привлекательной для большинства разработчиков. Базовый API-интерфейс каждой из этих библиотек похож на остальные, поэтому переносить код между библиотеками несложно.
Полный исходный код и документацию по библиотеке
gdbm можно найти на Web-сайте по адресу http://qdbm.sourceforge.net. В этой главе будут описаны все функции, которые большинство приложений должны использовать для
qdbm (каждая из них имеет близкие аналоги в Berkley db,
adbm и
ndbm). Доступны также и другие функции API, описание которых можно найти на Web-сайте
qdbm.
25.1. Обзор
qdbm предлагает несколько различных API-интерфейсов. Самый основной из них, Depot, является низкоуровневым API, который мы и рассмотрим в этой главе. Интерфейс
Curia позволяет разбивать базу данных на несколько файлов (для повышения масштабируемости или с целью работы в файловой системе с ограничениями), а функции
Villa предлагают две модели: модель B-деревьев и модель транзакций. API-интерфейс
Odeon позволяет работать с инвертированными индексами
[175]. Два последних API,
Relic и
Hovel, предлагают реализацию таких интерфейсов, как
ndbm и
qdbm.
Функции
Depot обеспечивают выполнение основных операций по схеме "ключ-значение", при этом ключ используется для извлечения значения. Ключ и значение представляют собой произвольные бинарные потоки, размер которых передается отдельно от данных; библиотеке ничего не нужно знать об их структуре. Однако у интерфейса
Depot имеется пара функциональных средств, благодаря которым применение строк в качестве ключей и элементов данных становится более удобным. Во-первых, всякий раз при передаче размера ключа или элемента данных в библиотеку вместо них может быть передано значение
-1, на основании которого
Depot будет использовать функцию
strlen() для вычисления используемого размера. Во-вторых, большинство функций чтения ключей и элементов данных автоматически добавляют к возвращаемому значению байт
0. Этот дополнительный символ не включается в возвращаемый размер, поэтому его можно проигнорировать, если значение не является строкой. Если же это строка, то возвращаемое значение может быть обработано как строка, и приложению не нужно будет завершать ее с помощью
NULL.
Depot использует глобальную целочисленную переменную
dpecode для хранения кодов ошибок. Когда функции
Depot возвращают сбой,
dpecode сообщает о том, что произошло (это почти то же самое, что и в случае с переменной
errno, которая относится к системным вызовам и библиотеке С). За текстовые сообщения об ошибках отвечает функция
dperrmsg().
#include <depot.h>
const char * dperrmsg(int ecode);
Подобно
strerror(), функция
dperrmsg() принимает код ошибки (обычно из
dpecode) и возвращает строку, в которой приводится описание возникшей ошибки.
Функции в API-интерфейсе
Depot используют указатель на структуру
DEPOT. Это непрозрачная структура (программы, использующие
Depot, не могут самостоятельно проверять значения в структуре), однако в ней содержится вся информация, используемая библиотекой для обслуживания файла, хранящегося на диске.
25.2. Основные операции
25.2.1. Открытие файла qdbm
Библиотечная функция
dpopen() используется для открытия файлов базы данных.
#include <depot.h>
DB * dpopen(const char * filename, int omode, int bnum);
Первый аргумент представляет имя файла, который будет использоваться
для базы данных
[176]. Аргумент
omode определяет способ доступа к файлу, и должен иметь одно из двух значений:
DP_OREADER и
DP_OWRITER, в зависимости от того, какой вид доступа к базе данных необходим программе — для чтения или для записи. По умолчанию база данных блокируется, чтобы разрешить нескольким программам доступ для чтения или одной программе доступ для записи. Если приложению не нужна блокировка, производимая
qdbm, то
DP_ONOLCK может быть объединен с
omode битовым "ИЛИ".
Когда приложения создают новые базы данных, они должны также использовать битовое "ИЛИ" с
DP_CREAT для отправки
qdbm запроса на создание нового файла, если он еще не был создан. Флаг
DP_OTRUNC сигнализирует о том, что первоначальное содержимое
filename будет удалено и заменено пустой базой данных.
Последний параметр функции
dpopen(),
bnum, сообщает
qdbm о том, сколько сегментов памяти нужно задействовать в хеш-массиве. Чем меньшим будет значение этого параметра, тем меньший размер будет иметь база данных; чем больше будет его значение, тем быстрее она будет работать благодаря сокращению количества конфликтных ситуаций в хеш-памяти. В документации к
qdbm рекомендуется, чтобы это значение составляло от половины до величины, в четыре раза большей от того количества элементов, которые, предположительно, будет иметь база данных
[177]. Если вы не уверены, какое следует использовать значение, можно присвоить нулевое значение, которое является значением по умолчанию
[178].
Функция
dpopen() возвращает указатель на структуру
DEPOT, который передается остальным функциям
Depot. В случае возникновения ошибки функция
dpopen() возвращает
NULL и устанавливает
dpecode.
25.2.2. Закрытие базы данных
Чтобы закрыть файлы базы данных, используйте функцию
dpclose().
int dpclose(DEPOT * depot);
Функция
dpclose() возвращает нулевое значение после успешного закрытия файлов и ненулевое — при сбое, который может произойти из-за невозможности очистки данных из буферов базы данных. Ниже показан пример программы, которая открывает файл базы данных в текущем каталоге и сразу же закрывает его.
1: /* qdbmsimple.c */
2:
3: #include <depot.h>
4: #include <errno.h>
5: #include <fcntl.h>
6: #include <stdio.h>
7:
8: int main(void) {
9: DEPOT * dp;
10:
11: dp = dpopen("test.db", DP_OWRITER | DP_OCREAT, 0);
12: if (!dp) {
13: printf("ошибка: %s\n", dperrmsg(dpecode));
14: return 1;
15: }
16:
17: dpclose(dp);
18:
19: return 0;
20: }
25.2.3. Получение файлового дескриптора
Помимо возможности использования автоматической блокировки, которую предлагает
qdbm, в некоторых программах потребуется изменять их собственную схему блокировки. Для этой цели
qdbm обеспечивает доступ к файловому дескриптору, который ссылается на базу данных.
int dpfdesc(DEPOT * depot);
Эта функция возвращает файловый дескриптор базы данных
depqt[179].
25.2.4. Синхронизация базы данных
qdbm кэширует данные в оперативной памяти для ускорения доступа к базе данных, а ядро Linux кэширует записи на диске, чтобы свести к минимуму задержку между вызовами функции
write(). Чтобы база данных, хранящаяся на диске, оставалась согласованной с буферизированными структурами, приложение может осуществлять ее синхронизацию. В процессе синхронизации базы данных qdbm очищает все ее внутренние буферы и вызывает функцию
fsync() для файлового дескриптора.
int dpsync(DEPOT * depot);
25.3. Чтение записей
Прочитать записи в базе данных можно двумя способами: посредством поиска записи по ее ключу и путем чтения последовательных пар "ключ-значение".
25.3.1. Чтение определенной записи
Функции
dpget() и
dpgetwb() производят поиск записей в базе данных по ключу.
int dpget(DEPOT * depot, const char * key, int keySize, int start,
int max, int * dataSize);
key является элементом (ключом), с помощью которого производится поиск по базе данных, a
keySize определяет длину ключа (или значение
-1, при котором
Depot использует функцию
strlen(key) для определения длины ключа). С помощью следующих двух параметров,
start и
max, можно производить частичное чтение записей; параметр
start задает смещение в данных, с которого начнется операция чтения, а
max — максимальное количество байтов для чтения. Например, если область данных представляла бы собой массив из четырехбайтовых целочисленных значений
int, то в результате присвоения параметру
start значения
12 и параметру
max значения
8 производилось бы чтение четвертого и пятого элементов массива. Если для чтения доступно менее
start байтов, функция
dpget() вернет
NULL. Чтобы прочитать все байты из данных, параметру
max следует присвоить значение
-1.
Если последний параметр,
dataSize, не будет равен
NULL, то целое число, на которое он указывает, будет соответствовать количеству прочитанных байтов.
В случае сбоя эта функция возвращает
NULL, а в случае успешного завершения она возвращает указатель на прочитанные данные. В случае сбоя
dpcode сообщает о том, что стало причиной сбоя. В частности, если элемент не существует или имеет менее
start байтов данных,
dpcode будет присвоено
DP_ENOITEM.
Когда функция
dpget() возвращает данные, к ним добавляется байт
0, позволяя работать с ними как со строкой. Размещение указателя производится с помощью функции
malloc(), и приложение отвечает за освобождение памяти после завершения своей работы. Если приложениям необходимо поместить данные в буфер, вместо того чтобы
Depot размещала его с помощью функции
malloc(), то они должны использовать функцию
dpgetwb().
int dpgetwb(DEPOT * depot, const char * key, int keySize, int start,
int max, const char * data);
Функции
dpgetwb() и
dpget() отличаются друг от друга только двумя параметрами:
max (который интерпретируется по-разному) и
data (который заменяет параметр
dataSize из функции
dpgetwb()). Параметр
data должен указывать на буфер из
max байтов, в который функция
dpgetwb() будет помещать данные, прочитанные из базы данных. В функции
dpgetwb() параметр
max не должен иметь значение
-1, и буфер не будет иметь байт
0, автоматически добавляемый в него этой функцией. Функция
dpgetwb() возвращает количество байтов, хранящихся в
data, и
-1, если запись не была найдена, если данных оказалось меньше
start байтов или если возникла ошибка.
25.3.2. Последовательное чтение записей
С помощью функций
dpiterinit() и
dpiternext() приложения могут производить итерации по всем ключам в базе данных. Ключи не возвращаются в каком-то определенном порядке
[180], а базу данных не нужно модифицировать во время итераций, производимых приложением.
int dpiterinit(DEPOT * depot);
char * dpiternext(DEPOT * depot, int * keySize);
В результате вызова функции
dpiterinit() qdbm вернет первый ключ в базе данных во время следующего вызова функции
dpiternext().
Функция
dpiternext() возвращает указатель либо на первый ключ в базе данных (если только что была вызвана функция
dpiterinit()), либо ключ в базе данных, который следует за ключом, возвращенным в последний раз. Если же в базе данных больше не окажется ключей, будет возвращено
NULL. Если
keySize не равен
NULL, то целочисленное значение, на которое указывает этот параметр, будет задано в качестве размера возвращаемого ключа.
Функция
dpiternext() буфера возвращает указатель на размещение, выполненное функцией
malloc(); после того как приложение завершит работу с ключом, указатель необходимо освободить функцией
free(). Буфер также завершается
NULL, поэтому при необходимости его можно трактовать как строку.
25.4. Модификация базы данных
Предусмотрены две операции, которые модифицируют базу данных
qdbm: добавление записей и удаление записей. Обновление записей производится с помощью той же функции, что и добавления записей.
25.4.1. Добавление записей
Новые и обновленные записи заносятся в базу данных с использованием функции
dpput().
int dpput(DEPOT * dfepot, const char * key, int keySize, const char * data,
int dataSize, int dmode);
key представляет собой значение индекса, который впоследствии может использоваться для получения информации, на которую указывает
data. Параметры
keySize и
dataSize могут иметь значение
-1, при котором функция
dpput() будет использовать функцию
strlen() для получения размера данного поля. Проверка параметра
dmode производится только в том случае, если параметр
key в базе данных уже связан с элементом данных. Параметр
dmode может иметь одно из перечисленных ниже значений.
DP_DCAT |
Новые данные добавляются в конец данных, которые уже находятся в базе данных. |
DP_DKEEP |
База данных не модифицируется; функция dpput() возвращает сбой, а параметру dpecode присваивается значение DP_EKEEP. |
DP_DOVER |
Вместо существующего значения записывается новое. |
Функция
dpput() возвращает нулевое значение в случае возникновения ошибки (или если ключ уже существует, и было определено значение
DP_DKEEP), и ненулевое значение, если данные для ключа были успешно обновлены.
25.4.2. Удаление записей
Удаление записей из базы данных осуществляется путем вызова функции
dpout() и передачи ей ключа, данные которого необходимо удалить.
int dpout(DEPOT * depot, const char * key, int keySize);
Заданный ключ и связанные с ним данные удаляются из базы, после чего возвращается ненулевое значение. Если для заданного ключа данные не существовали, возвращается нулевое значение. Как и для всех остальных функций, принимающих ключ, если параметр
keySize равен
-1, то функция
dpout() использует
strlen() для определения длины ключа.
25.5. Пример
Для закрепления материала этой главы ниже приводится пример приложения, в котором задействовано большинство функциональных возможностей
qdbm. Подразумевается, что в результате выполнения этого приложения будет создана простая база данных телефонных номеров, хотя ее можно использовать и для хранения любых простых пар "имя-значение". Приложение хранит базу данных в домашнем каталоге пользователя как
.phonedb.
Флаг
-а добавляет запись в базу данных. Если будет указан флаг
-f, то любой существующий элемент будет заменен новыми данными. Следующий параметр представляет собой значение ключа, которое необходимо использовать, а последний параметр — собственно данные (номер телефона).
Флаг
-q запрашивает в базе данных определенный ключ, который должен быть представлен другим указанным параметром. Записи удаляются из базы данных с помощью флага
-d, который принимает значение ключа для удаления в другом параметре.
Если задать флаг
-l, то будут перечислены все пары "ключ-значение", имеющиеся в базе данных.
Вот как выглядят пример использования
phones.
$ ./phones -a Erik 374-5876
$ ./phones -a Michael 642-4235
$ ./phones -a Larry 527-7976
$ ./phones -a Barbara 227-2272
$ ./phones -q Larry
Larry 527-7976
$ ./phones -l
Larry 527-7976
Erik 374-5876
Michael 642-4235
Barbara 227-2272
$ ./phones -d Michael
$ ./phones -l
Larry 527-7976
Erik 374-5876
Barbara 227-2272
Эта программа выполняет определенные полезные действия, состоит менее чем из 200 строк исходного кода, и с успехом может применяться для работы с большим количеством пар "ключ-значение", четко раскрывая назначение библиотеки
qdbm.
1: /* phones.с */
2:
3: /* Программа реализует очень простую базу данных телефонных номеров.
4: Всю необходимую информацию по ее использованию можно найти в тексте. */
5:
6: #include <alloca.h>
7: #include <depot.h>
8: #include <errno.h>
9: #include <fcntl.h>
10: #include <stdio.h>
11: #include <stdlib.h>
12: #include <string.h>
13: #include <unistd.h>
14:
15: void usage(void) {
16: fprintf(stderr, "использование: phones -a [-f] <имя> <телефон>\n");
17: fprintf(stderr, " -d <имя>\n");
18: fprintf(stderr, " -q <имя>\n");
19: fprintf(stderr, " -l\n");
20: exit(1);
21: }
22:
23: /* Открыть базу данных $НОМЕ/.phonedb. Если writeable имеет ненулевое
24: значение, база данных открывается для обновления. Если writeable
25: равен 0, база данных открывается только для чтения. */
26: DEPOT * openDatabase(int writeable) {
27: DEPOT * dp;
28: char * filename;
29: int flags;
30:
31: /* Установить режим открытия */
32: if (writeable) {
33: flags = DP_OWRITER | DP_OCREAT;
34: } else {
35: flags = DP_OREADER;
36: }
37:
38: filename = alloca(strlen(getenv("HOME")) + 20);
39: strcpy(filename, getenv("HOME"));
40: strcat(filename, "/.phonedb");
41:
42: dp = dpopen(filename, flags, 0);
43: if (!dp) {
44: fprintf(stderr, "сбой при открытии %s: %s\n", filename,
45: dperrmsg(dpecode));
46: return NULL;
47: }
48:
49: return dp;
50: }
51:
52: /* добавить новую запись в базу данных; произвести
53: прямой разбор аргументов командной строки */
54: int addRecord(int argc, char ** argv) {
55: DEPOT * dp;
56: char * name, * phone;
57: int rc = 0;
58: int overwrite = 0;
59: int flag;
60:
61: /* проверить параметры; -f означает перезапись
62: существующего элемента, а имя и номер телефона
63: должны оставаться неизмененными */
64: if (!argc) usage();
65: if (!strcmp(argv[0], " -f")) {
66: overwrite = 1;
67: argc--, argv++;
68: }
69:
70: if (argc! = 2) usage();
71:
72: name = argv[0];
73: phone = argv[1];
74:
75: /* открыть базу данных для записи */
76: if (!(dp = openDatabase(1))) return 1;
77:
78: /* если не перезаписывается существующий элемент,
79: проверить, не используется ли уже это имя */
80: if (!overwrite) {
81: flag = DP_DKEEP;
82: } else {
83: flag = DP_DOVER;
84: }
85:
86: if (!dpput(dp, name, -1, phone, -1, flag)) {
87: if (dpecode == DP_EKEEP) {
88: fprintf(stderr, "%s уже существует\n", name);
89: } else {
90: fprintf(stderr, "сбой записи: %s\n", dperrmsg(dpecode));
91: }
92:
93: rc = 1;
94: }
95:
96: dpclose(dp);
97:
98: return rc;
99: }
100:
101: /* найти имя и вывести номер телефона, с которым оно связано;
102: напрямую разобрать командную строку */
103: int queryRecord(int argc, char ** argv) {
104: DEPOT * dp;
105: int rc;
106: char * phone;
107:
108: /* ожидается только один аргумент, имя для поиска */
109: if (argc != 1) usage();
110:
111: /* открыть базу данных для чтения */
112: if (!(dp = openDatabase(0))) return 1;
113:
114: phone = dpget(dp, argv[0], -1, 0, -1, NULL);
115: if (!phone) {
116: if (dpecode == DP_ENOITEM)
117: fprintf(stderr, "%s не существует\n", argv[0]);
118: else
119: fprintf(stderr, "ошибка чтения базы данных: %s\n"
120: dperrmsg(dpecode));
121:
122: rc = 1;
123: } else {
124: printf("%s %s\n", argv[0], (char *) phone);
125: rc = 0;
126: }
127:
128: dpclose(dp);
129:
130: return rc;
131: }
132:
133: /* удалить определенную запись; имя передается в качестве
134: аргумента командной строки */
135: int delRecord(int argc, char ** argv) {
136: DEPOT * dp;
137: int rc;
138:
139: /* ожидается только один аргумент */
140: if (argc != 1) usage();
141:
142: /* открыть базу данных для обновления */
143: if (!(dp = openDatabase(1))) return 1;
144:
145: if (!(rc = dpout(dp, argv[0], -1))) {
146: if (dpecode == DP_ENOITEM)
147: fprintf(stderr, "%s не существует\n", argv[0]);
148: else
149: fprintf(stderr, "ошибка удаления элемента: %s\n",
150: dperrmsg(dpecode));
151:
152: rc = 1;
153: }
154:
155: dpclose(dp);
156:
157: return rc;
158: }
159:
160: /* вывести список всех записей, имеющихся в базе данных */
161: int listRecords(void) {
162: DEPOT * dp;
163: char * key, * value;
164:
165: /* открыть базу данных только для чтения */
166: if (!(dp = openDatabase(0))) return 1;
167:
168: dpiterinit(dp);
169:
170: /* итерация по всем записям */
171: while ((key = dpiternext(dp, NULL))) {
172: value = dpget(dp, key, -1, 0, -1, NULL);
173: printf("%s %s\n", key, value);
174: }
175:
176: dpclose(dp);
177:
178: return 0;
179: }
180:
181: int main(int argc, char ** argv) {
182: if (argc == 1) usage();
183:
184: /* найти флаг режима и вызвать соответствующую функцию
185: с остальными аргументами */
186: if (!strcmp(argv[1], "-а"))
187: return addRecord(argc - 2, argv + 2);
188: else if (!strcmp(argv[1], "-q"))
189: return queryRecord(argc - 2, argv + 2);
190: else if (!strcmp(argv[1], "-d"))
191: return delRecord(argc - 2, argv + 2);
192: else if (!strcmp(argv[1], "-l")) {
193: if (argc != 2) usage();
194: return listRecords();
195: }
196:
197: usage(); /* не обнаружено никаких параметров */
198: return 0; /* возврат */
199: }
Глава 26
Синтаксический анализ параметров командной строки
Многие Linux-программы позволяют задавать параметры командной строки. Эти параметры выполняют самые разнообразные функции, однако имеют практически одинаковую синтаксическую структуру.
Короткие параметры состоят из символа
-, за которым следует один алфавитно-цифровой символ.
Длинные параметры, обычные для утилит GNU, состоят из пары символов
--, за которыми следует строка, состоящая из букв, цифр и дефисов. После любого из этих параметров может стоять аргумент. Пробел отделяет короткий параметр от его аргументов, а пробел или знак равенства отделяют длинный параметр от аргумента.
Проверить синтаксис параметров командной строки можно многими способами. Наиболее популярным методом является проверка синтаксиса массива
argv, выполняемая вручную. Помочь в проверке синтаксиса параметров могут библиотечные функции
getopt() и
getoptlong(). Функция
getopt() присутствует во многих реализациях Unix, однако она поддерживает только короткие параметры. Функция
getoptlong() доступна в Linux и позволяет автоматически анализировать синтаксис коротких и длинных параметров
[181].
Библиотека
popt предназначена специально для синтаксического анализа параметров. По сравнению с функциями
getopt() она обладает некоторыми преимуществами.
• В ней не используются глобальные переменные, что позволяет применять ее при многократных проходах, необходимых для синтаксического анализа
argv.
• Она может анализировать синтаксис произвольного массива, состоящего из элементов в стиле
argv. Поэтому библиотеку
popt можно применять для синтаксического анализа текстовых строк, представленных в стиле командной строки, из любого источника.
• Библиотека может анализировать синтаксис аргументов многих типов, не требуя для этого дополнительного кода в приложении.
• Она предлагает стандартный метод использования псевдонимов параметров. Программы, использующие библиотеку
popt, могут позволить пользователям добавлять новые параметры командной строки, которые будут определяться как комбинации уже существующих параметров. Благодаря этому пользователь может определять новое сложное поведение или изменять поведение существующих параметров, принятое по умолчанию.
• Благодаря особому механизму библиотеки могут анализировать синтаксис одних параметров в тот момент, когда главное приложение анализирует синтаксис других параметров.
• Она может автоматически генерировать сообщение об использовании, в котором будут перечислены параметры, воспринимаемые программой, а также более подробное справочное сообщение.
• Библиотека может генерировать обычные сообщения об ошибках.
Подобно функции
getoptlong(), библиотека
popt поддерживает короткие и длинные параметры.
Библиотека
popt является в высшей степени доступной и может работать на любой POSIX-платформе. Самую последнюю версию библиотеки можно найти по адресу ftp://ftp.rpm.org/pub/rpm. Библиотека
popt обладает целым рядом функциональных возможностей, не упоминаемых в этой главе; их описание можно найти на man-странице для popt.
Библиотека
popt может распространяться либо под лицензией General Public License GNU, либо под лицензией Library General Public License GNU.
26.1. Таблица параметров
26.1.1. Определение параметров
Приложения передают библиотеке
popt информацию о своих параметрах командной строки через массив структур
struct poptOption.
#include <popt.h>
struct poptOption {
const char * longName; /* может иметь значение NULL */
char shortName; /* может иметь значение '\0' */
int argInfo;
void * arg; /* зависит от argInfo */
int val; /*0 означает не возвращаться, а просто обновить флаг*/
char * descrip; /* необязательное описание параметра */
char * argDescrip; /* необязательное описание аргумента */
};
Каждый элемент таблицы определяет один параметр, который может быть передан программе. Длинные и короткие параметры рассматриваются как один параметр, который может встречаться в двух различных формах. Первые два элемента,
longName и
shortName, определяют имена параметров; первый соответствует длинному имени, а второй — одиночный символ.
Элемент
argInfo сообщает библиотеке
popt о том, какой тип аргумента ожидается после параметра. Если не ожидается никакого параметра, будет использоваться значение
РОPT_ARG_NONE. Остальные допустимые значения перечислены в табл. 26.1
[182].
Таблица 26.1. Типы аргументов popt
| Значение |
Описание |
Тип arg |
POPT_ARG_NONE |
He ожидается ни одного аргумента. |
int |
POPT_ARG_STRING |
Не должна выполняться проверка соответствия типов. |
char * |
POPT_ARG_INT |
Ожидается целочисленный аргумент. |
int |
POPT_ARG_LONG |
Ожидается длинный целочисленный тип. |
long |
POPT_ARG_FLOAT |
Ожидается тип с плавающей точкой. |
float |
POPT_ARG_DOUBLE |
Ожидается тип с плавающей точкой двойной точности. |
double |
POPT_ARG_VAL |
Не ожидается ни одного аргумента (см. текст). |
int |
Следующий элемент,
arg, позволяет библиотеке
popt обновлять переменные в программе автоматически в случае использования параметра. Если
arg имеет значение
NULL, то он будет проигнорирован, и
popt не будет выполнять никаких действий. В противном случае он будет указывать на переменную, тип которой задан в правой колонке табл. 26.1.
Если параметр не принимает аргументов (
argInfo имеет значение
POPT_ARG_NONE), то переменная, на которую указывает
arg, получает единичное значение при использовании параметра. Если параметр принимает аргумент, то значение переменной, на которую указывает
arg, обновляется до значения аргумента. Аргументы
POPT_ARG_STRING могут принимать любую строку, а аргументы
POPT_ARG_INT,
POPT_ARG_LONG,
POPT_ARG_FLOAT и
POPT_ARG_DOUBLE преобразуются в соответствующий тип, при этом, если преобразование не удастся выполнить, будет сгенерирована ошибка.
Если используется значение
POPT_ARG_VAL, то никаких аргументов не ожидается. Вместо этого
popt скопирует целочисленное значение
val в адрес, на который указывает
arg. Это будет полезно в том случае, когда в программе имеется набор взаимно исключающих аргументов, и выбор падает на последний указанный аргумент. Определяя различные значения
val для каждого параметра, когда член
arg каждого параметра будет указывать на одно и то же целочисленное значение, и, определяя для каждого из них значение
POPT_ARG_VAL, можно легко узнать, какой из этих параметров был определен последним. Если будет задано более одного параметра, то сгенерировать ошибку не удастся.
Член
val устанавливает значение, возвращаемое функцией проверки синтаксиса
popt при обнаружении параметра, если только не используется значение
POPT_ARG_VAL. Если значение будет равно нулю, функция проверки синтаксиса продолжит проверку следующего аргумента командной строки, и не будет возвращать результат.
Два последних члена являются необязательными, и должны иметь значение
NULL, если они не нужны. Первый из них,
descrip, представляет строку, описывающую параметр. Он используется библиотекой
popt во время генерации справочного сообщения, в котором описываются все доступные параметры. Член
descrip предлагает эталонный аргумент для параметра, который также используется для отображения справочной информации. Генерация справочных сообщений рассматривается далее в этой главе.
В последней структуре таблицы все значения указателей должны быть равны
NULL, а все арифметические значения должны быть нулевыми, отмечая конец таблицы.
Давайте посмотрим, как можно было бы определить таблицу параметров для обычного приложения. Ниже показана таблица параметров для простой версии утилиты
grep[183].
const char * pattern = NULL;
int mode = MODE_REGEXP;
int ignoreCase = 0;
int maxCount = -1;
struct poptOption optionsTable[] = {
{ "extended-regexp", 'E', POPT_ARG_VAL, &mode, MODE_EXTENDED,
"шаблоном для соответствия является расширенное регулярное выражение",
NULL },
{ "fixed-strings", 'F', POPT_ARG_VAL, &mode, MODE_FIXED,
"шаблоном для соответствия является базовая строка (не "
"регулярное выражение)", NULL } ,
{ "basic-regexp", 'G', POPT_ARG_VAL, &mode, MODE_REGEXP,
"шаблоном для соответствия является базовое регулярное выражение" },
{ "ignore-case", 'i', POPT_ARG_NONE, &ignoreCase, 0,
"выполнять поиск, чувствительный к регистру", NULL },
{ "max-count", 'm', POPT_ARG_INT, &maxCount, 0,
"завершить после получения N совпадений", "N" },
{ "regexp", 'e', POPT_ARG_STRING, &pattern, 0,
"регулярное выражение для поиска", "pattern" },
{ NULL, '\0', POPT_ARG_NONE, NULL, 0, NULL, NULL }
};
Параметр
retry не принимает аргумента, поэтому
popt присваивает переменной
retry единицу, если определен
--retry. Параметры
bytes и
lines принимают целочисленные аргументы, которые хранятся в переменных с идентичными именами. Последний параметр,
follow, может быть либо литеральным
name, либо
descriptor. Переменная
followType задается таким образом, чтобы она указывала на каждое значение, которое будет введено в командной строке, и требует проверки на корректность. Если первоначально она будет указывать на
"descriptor", то будет предоставлено полезное значение по умолчанию.
26.1.2. Вложенные таблицы параметров
Некоторые библиотеки предлагают реализацию набора общих параметров командной строки. Например, одно из первых инструментальных средств X Window обрабатывало параметры
-geometry и
-display для приложений, предоставляя большинству программ X Window стандартный набор параметров командной строки для управления обычным поведением. К сожалению, сделать это далеко не просто. Если массивы
argc и
argv передать функции инициализации в библиотеке, то библиотека сможет обрабатывать соответствующие параметры, однако приложение должно знать, какие параметры необходимо проигнорировать во время синтаксического анализа
argv.
Чтобы не допустить возникновения этой проблемы, функция
XtAppInitialize() принимала массивы
argc и
argv в качестве параметров и возвращала новые значения для каждого из них с параметрами, обработанными удаленной библиотекой. Несмотря на то что такой подход мог работать, с ростом количества библиотек он стал излишне громоздким.
Чтобы выйти из этой ситуации,
popt позволяет формировать вложенные таблицы параметров. Благодаря этому подходу библиотеки определяют те параметры, которые им нужны для обработки (для этого может потребоваться еще одна вложенная таблица), а главная программа может предоставить эти параметры путем вложения таблиц с параметрами библиотек внутри самих себя.
Таблица параметров, которая будет представлена в форме вложенной таблицы, определяется подобно любой другой таблице. Чтобы включить ее в другую таблицу, необходимо создать новый параметр с пустыми параметрами
longName и
shortName. В поле
argInfo должна быть назначена переменная
POPT_ARG_INCLUDE_TABLE, а член
arg должен указывать на таблицу, представляемую в форме вложенной таблицы. Ниже показан пример таблицы параметров, включающей другую таблицу.
struct poptOption nestedArgs[] = {
{ "option1", 'a', POPT_ARG_NONE, NULL, 'a' },
{ "option2", 'b', POPT_ARG_NONE, NULL, 'b' },
{ NULL, '\0', POPT_ARG_NONE, NULL, 0 }
};
struct poptOption mainArgs[] = {
{ "anoption", 'о', POPT_ARG_NONE, NULL, 'o' },
{ NULL, '\0', POPT_ARG_INCLUDE_TABLE, nestedArgs, 0 },
{ NULL, '\0', POPT_ARG_NONE, NULL, 0 }
};
В этом примере приложение заканчивается тремя параметрами,
--option1,
--option2 и
--anoption. Более сложный пример с вложенными таблицами параметров рассматривается далее в главе.
26.2. Использование таблиц параметров
26.2.1. Создание содержимого
popt может чередовать синтаксический анализ нескольких совокупностей командных строк. Для этого она сохраняет всю информацию о состоянии для определенной совокупности аргументов командных строк в структуре данных
poptContext непрозрачного типа, которую нельзя модифицировать вне библиотеки
popt.
Новое содержимое
popt формируется с помощью функции
poptGetContext().
#include <popt.h>
poptContext poptGetContext(char * name, int argc, const char ** argv,
struct poptOption * options, int flags);
Первый параметр,
name, используется для работы с псевдонимами и в справочных сообщениях, и должен представлять имя того приложения, параметры которого будут проходить проверку синтаксиса. Следующие два параметра определяют те аргументы командной строки, которые будут проходить проверку синтаксиса. Как правило, они передаются функции
poptGetContext(), точно так, как если бы они передавались функции
main() программы
[184]. Параметр
options указывает на таблицу параметров командной строки, которая была определена в предыдущем разделе. Последний параметр,
flags, определяет способ синтаксического анализа параметров и включает перечисленные ниже флаги (которые могут быть объединены битовым "ИЛИ").
POPT_CONTEXT_KEEP_FIRST |
Как правило, popt игнорирует значение в argv[0], которое обычно представляет имя выполняемой программы, а не аргумент командной строки. Если определить этот флаг, то popt будет обрабатывать argv[0] как параметр. |
POPT_CONTEXT_POSIXMEHADER |
Стандарт POSIX гласит, что все параметры должны стоять перед дополнительными параметрами командной строки. Например, в соответствии с POSIX, rm -f file1 file2 приведет к удалению файлов file1 и file2, тогда как rm file1 file2 -f приведет к обычному удалению трех файлов: file1, file2 и -f. В большинстве Linux-программы это частное условие игнорируется, поэтому popt не придерживается этого правила по умолчанию. Этот флаг сообщает библиотеке popt о необходимости анализировать синтаксис параметров в соответствии с этим условием. |
Помимо всего прочего,
poptContext следит за тем, какие параметры прошли проверку синтаксиса, а какие нет. Если программе необходимо перезапустить обработку параметров в наборе аргументов, она может восстановить исходное состояние
poptContext, передавая функции
poptResetContext() содержимое в качестве единственного аргумента.
После завершения обработки аргумента процесс должен освободить структуру
poptContext, поскольку в ней содержатся динамически размещаемые компоненты. Функция
poptFreeContext() принимает
poptContext в качестве своего единственного аргумента и освобождает ресурсы, занятые в содержимом.
Ниже представлены прототипы функций
poptResetContext() и
poptFreeContext().
#include <popt.h>
void poptFreeContext(poptContext con);
void poptResetContext(poptContext con);
26.2.2. Синтаксический анализ командной строки
После того как приложение создаст
poptContext, оно может приступить к синтаксическому анализу аргументов. Функция
poptGetNextContext() выполняет синтаксический анализ аргумента.
#include <popt.h>
int poptGetNextOpt(poptContext con);
Принимая содержимое в качестве своего единственного аргумента, эта функция анализирует синтаксис следующего обнаруженного аргумента командной строки. После того как следующий аргумент будет обнаружен в таблице параметров, функция заполняет объект, на который указывает указатель
arg элемента таблицы параметров, если только он не равен
NULL. Если элемент
val для параметра имеет ненулевое значение, функция возвращает это значение. В противном случае функция
poptGetNextOpt() переходит к следующему аргументу.
Функция
poptGetNextOpt() возвращает значение
-1, если был проанализирован синтаксис последнего аргумента, и другие отрицательные значения в случае возникновения ошибки. Поэтому лучше всего присваивать элементам
val в таблице параметров значения больше нуля.
Если все параметры командной строки обрабатываются через указатели
arg, то синтаксический анализ командной строки сокращается до следующей строки кода:
rc = poptGetNextOpt(poptcon);
Тем не менее, для многих приложений требуется более сложный синтаксический анализ командной строки, нежели этот, и применяется показанная ниже структура.
while ((rc = poptGetNextOpt(poptcon)) > 0) {
switch (rc) {
/* здесь обрабатываются специфические аргументы */
}
}
Во время обработки возвращенных параметров приложению необходимо знать значение каждого аргумента, который был определен после параметра. Это можно сделать двумя способами. Один из них заключается в том, чтобы
popt присваивала переменной значение параметра из элементов arg таблицы параметров. Другой способ предусматривает применение функции
poptGetOptArg().
#include <popt.h>
char * poptGetOptArg(poptContext con);
Эта функция возвращает аргумент, заданный для последнего параметра, возвращенного функцией
poptGetNextOpt(), или возвращает значение
NULL, если ни один из аргументов не был определен.
26.2.3. Остаточные аргументы
Многие приложения принимают произвольное количество аргументов командной строки, например, список имен файлов. Когда
popt встречает аргумент, перед которым отсутствует дефис
-, она считает его таким аргументом и добавляет его в список остаточных аргументов. Доступ к этим аргументам в приложениях можно реализовать с помощью описанных далее трех функций.
char * poptGetArg(poptContext con);
Эта функция возвращает следующий остаточный аргумент и помечает его как обработанный.
char * poptPeekArg(poptContext con);
Эта функция возвращает следующий аргумент, не помечая его как обработанный. Таким образом, приложение может продолжить рассмотрение списка аргументов, не модифицируя список.
char ** poptGetArgs(poptContext con);
Эта функция возвращает все остаточные аргументы в виде
argv. Последний элемент в возвращаемом массиве указывает на
NULL, подтверждая конец аргументов.
26.2.4. Автоматические справочные сообщения
Одним из преимуществ использования библиотеки
popt является ее способность автоматически генерировать справочные сообщения и сообщения об использовании. В справочных сообщениях указывается каждый параметр командной строки и приводится его подробное описание, а в сообщениях об использовании приводится краткий перечень доступных параметров без какого-либо сопроводительного текста. Для создания каждого типа сообщения в библиотеке
popt предусмотрена отдельная функция.
#include <popt.h>
void poptPrintHelp(poptContext con, FILE * f, int flags);
void poptPrintUsage(poptContext con, FILE * f, int flags);
Обе эти функции ведут себя практически одинаково, записывая соответствующий тип сообщения в файл
f. Аргумент
flags на данный момент не используется ни одной из этих функций, и должен быть равен нулю для совместимости с будущими версиями библиотеки
popt.
Поскольку за справочное сообщение отвечает параметр
--help, а за сообщение об использовании — параметр
--usage, библиотека
popt предлагает простой способ добавления этих двух параметров в программу. Чтобы добавить эти параметры в таблицу параметров, можно использовать макрос
POPT_AUTOHELP[185], который выводит соответствующие сообщения в
STDOUT и закрывается после возвращения кода
0[186]. В следующем примере показана таблица параметров в файле
grep.с; мы должны добавить одну строку в таблицу параметров для grep, чтобы активизировать автоматическое генерирование справочных сообщений.
95: struct poptOption optionsTable[] = {
96: { "extended-regexp", 'E', POPT_ARG_VAL,
97: &mode, MODE_EXTENDED,
98: "шаблоном для соответствия является расширенное регулярное "
99: "выражение" },
100: { "fixed-strings", 'F', POPT_ARG_VAL,
101: &mode, MODE_FIXED,
102: "шаблоном для соответствия является базовая строка, (не "
103: "регулярное выражение)", NULL },
104: { "basic-regexp", 'G', POPT_ARG_VAL,
105: &mode, MODE_REGEXP,
106: "шаблоном для соответствия является базовое регулярное выражение" },
107: { "ignore-case", 'i', POPT_ARG_NONE, &ignoreCase, 0,
108: "выполнять поиск, чувствительный к регистру", NULL },
109: { "max-count", 'm', POPT_ARG_INT, &maxCount, 0,
110: "завершить после получения N совпадений", "N" },
111: { "regexp", 'е', POPT_ARG_STRING, &pattern, 0,
112: "регулярное выражение для поиска", "pattern" },
113: POPT_AUTOHELP
114: { NULL, ' \0', POPT_ARG_NONE, NULL, 0, NULL, NULL }
115: };
Ниже показан пример того, как выглядит справочное сообщение, сгенерированное данной таблицей параметров.
Usage: grep [OPTION...]
Использование: grep [ПАРАМЕТРЫ...]
-Е, --extended-regexp шаблоном для соответствия является
расширенное регулярное выражение
-F, --fixed-strings шаблоном для соответствия является
базовая строка (не регулярное выражение)
-G, --basic-regexp шаблоном для соответствия является базовое
регулярное выражение
-i, --ignore-case выполнять поиск, чувствительный к регистру
-m, --max-count=N завершить после получения N совпадений
-е, --regexp=pattern регулярное выражение для поиска
Help options:
-?, --help Show this help message
--usage Display brief usage message
Параметры справки:
-?, --help Показать это сообщение
--usage Отобразить краткое сообщение об использовании
Хотя эта информация и имеет привлекательный вид, она требует некоторых уточнений. В первой строке не сказано, что команда ожидает имена файлов в командной строке. Показанный здесь текст
[OPTION...] принят в
popt по умолчанию, и с помощью функции
poptSetOtherOptionHelp() может быть изменен для получения более детального описания.
#include <popt.h>
poptSetOtherOptionHelp(poptContext con, const char * text);
Первым параметром является содержимое, а второй параметр определяет текст, который должен появиться после имени программы. Если добавить следующий вызов
poptSetOtherOptionHelp(optCon, "<шаблон> <список файлов>");
то первая строка в справочном сообщении будет изменена на
Usage: grep <шаблон> <список файлов>
Использование: grep <шаблон> <список файлов>
что является более точным.
Последнее, что требуется уточнить в отношении справочных сообщений, это способ обработки вложенных таблиц. Давайте снова обратимся к справочному сообщению для нашей программы
grep; для параметров справки выделяется отдельный раздел справочного сообщения. Если элемент
POPT_ARG_INCLUDE_TABLE таблицы параметров содержит член
descrip, то строка будет использоваться в качестве описания для всех параметров во вложенной таблице, и эти параметры будут отображаться в своем собственном разделе справочного сообщения (подобно параметрам справки для
tail). Если
descrip будет иметь значение
NULL, то параметры для вложенной таблицы будут отображаться вместе с параметрами из главной таблицы, а не в своем собственном разделе.
Иногда программы предлагают параметры, которые, возможно, не должны использоваться; они могут быть включены для поддержки унаследованных приложений или приложений, разработанных только для тестирования. Автоматическая генерация справочных сообщений для такого параметра можно подавить с помощью битового "ИЛИ"
POPT_ARGFLAG_DOC_HIDDEN и члена
arg структуры
struct poptOption, описывающей данный параметр.
26.3. Использование обратных вызовов
Мы показали два способа обработки параметров с помощью библиотеки
popt: с помощью возврата параметра функцией
poptGetNextOpt() и путем автоматического изменения переменных во время представления параметров. К сожалению, ни один из этих способов не подходит для вложенных таблиц. Очевидно, что возвращение параметров, определяемых во вложенной таблице для обработки в приложении, не будет работать, поскольку вложенные таблицы предназначены для того, чтобы приложению не нужно было знать, какие параметры предлагает библиотека. Присвоение переменным значений тоже не подходит, поскольку в этом случае не ясно, каким переменным нужно присваивать значения. Использование глобальных переменных часто тоже является неподходящим, а библиотека не имеет доступных для использования локальных переменных, поскольку синтаксический анализ выполняется из главного приложения, а не из библиотеки. Чтобы обеспечить гибкую обработку параметров во вложенных таблицах, библиотека
popt предлагает использовать обратные вызовы (callback).
Каждая таблица может определять свою собственную функцию обратного вызова, которая подменяет обычную обработку параметров, определенных в этой таблице. Вместо нее функция обратного вызова вызывается для каждого обнаруживаемого параметра. Параметры, определяемые в других таблицах параметров (включая таблицы, вложенные в таблицу, определяющую обратный вызов), обрабатываются с использованием обычных правил, если только в других таблицах не будут определены свои собственные обратные вызовы.
Обратные вызовы можно определять только в первом элементе таблицы параметров. Если этот элемент определяет обратный вызов, член
argInfo будет иметь значение
POPT_ARG_CALLBACK, a
arg будет указывать на функцию обратного вызова. Член
descrip может представлять любое значение указателя, и передается в обратный вызов каждый раз во время его инициирования, открывая доступ к любым произвольным данным. Все остальные члены структуры
struct poptOption должны иметь нулевое значение или
NULL.
Во время обработки параметров обратный вызов можно инициировать в трех точках: до начала обработки, при нахождении параметра в таблице для данного обратного вызова и после завершения обработки. Это дает библиотекам возможность инициализировать любые необходимые им структуры (включая данные, определяемые членом
descrip), и выполнять любые служебные действия, которые могут понадобиться после завершения обработки (например, очищать динамическую память, выделенную для члена
descrip). Они всегда вызываются при нахождении параметра, однако в таблице параметров необходимо указать, что их нужно вызывать в двух других местах. Чтобы сделать это, значения
POPT_CBFLAG_PRE или
POPT_CBFLAG_POST (или оба) должны объединяться битовым "ИЛИ" со значением
POPT_ARG_CALLBACK, присвоенным члену
arg структуры, которая определяет обратный вызов.
Далее показан прототип, который следует использовать для определения функции обратного вызова:
void callback(poptContext con, enum poptCallbackReason reason,
const struct poptOption * opt, const char * arg,
const void * data);
Первый параметр представляет содержимое, синтаксический анализ которого будет выполнен во время инициирования обратного вызова. Следующим параметров является
POPT_CALLBACK_REASON_PRE, если обработка параметра еще не началась,
POPT_CALLBACK_REASON_POST, если обработка параметров завершена, или
POPT_CALLBACK_REASON_OPTION, если в таблице для данного обратного вызова был обнаружен параметр. Если этот параметр является последним, то аргумент opt будет указывать на элемент таблицы параметров для обнаруженного параметра, а аргумент
arg будет указывать на строку, определяющую аргумент для данного параметра. Если ожидается аргумент, не представленный в виде строки, обратный вызов будет отвечать за проверку типа и преобразование аргумента. Последний параметр для обратного вызова,
data, представляет собой значение поля
descrip в элементе таблицы параметров, который задает обратный вызов.
Ниже показан пример библиотеки, которая использует вложенную таблицу
popt и обратные вызовы для синтаксического анализа некоторых параметров командной строки. Структура данных инициализируется до начала синтаксического анализа командной строки, а затем отображаются последние значения.
1: /* popt-lib.с */
2:
3: #include <popt.h>
4: #include <stdlib.h>
5:
6: struct params {
7: int height, width;
8: char*fg,*bg;
9: };
10:
11: static void callback(poptContext con,
12: enum poptCallbackReason reason,
13: const struct poptOption * opt,
14: const char * arg,
15: const void * data);
16:
17: /* Здесь сохраняются переменные, которые прошли синтаксический анализ. Обычно
18: глобальные переменные использовать не рекомендуется, зато работать с ними проще.*/
19: struct params ourParam;
20:
21: struct poptOption libTable[] = {
22: { NULL, '\0',
23: POPT_ARG_CALLBACK | POPT_CBFLAG_PRE | POPT_CBFLAG_POST,
24: callback, '\0', (void *) &ourParam, NULL },
25: { "height", 'h', POPT_ARG_STRING, NULL, '\0', NULL, NULL },
26: { "width", 'w', POPT_ARG_STRING, NULL, '\0', NULL, NULL },
27: { "fg", 'f', POPT_ARG_STRING, NULL, '\0', NULL, NULL },
28: { "bg", 'b', POPT_ARG_STRING, NULL, '\0', NULL, NULL },
29: { NULL, '\0', POPT_ARG_NONE, NULL, '\0', NULL, NULL }
30: };
31:
32: static void callback(poptContext con,
33: enum poptCallbackReason reason,
34: const struct poptOption * opt,
35: const char * arg,
36: const void * data) {
37: struct params * p = (void *) data;
38: char * chptr = NULL;
39:
40: if (reason == POPT_CALLBACK_REASON_PRE) {
41: p->height = 640;
42: p->width = 480;
43: p->fg = "white";
44: p->bg = "black";
45: } else if (reason == POPT_CALLBACK_REASON_POST) {
46: printf("используется высота %d ширина %d передний план %s фон %s\n",
47: p->height, p->width, p->fg, p->bg);
48:
49: } else {
50: switch (opt->shortName) {
51: case 'h': p->height = strtol(arg, &chptr, 10); break;
52: case 'w': p->width = strtol(arg, &chptr, 10); break;
53: case 'f' : p->fg = (char *) arg; break;
54: case 'b': p->bg = (char *) arg; break;
55: }
56:
57: if (chptr && *chptr) {
58: fprintf(stderr, "для %s ожидался числовой аргумент\n",
59: opt->longName);
60: exit(1);
61: }
62: }
63: }
64:
Программа, для которой необходимо обеспечить эти аргументы командной строки, должна включать одну дополнительную строку в своей таблице
popt. Обычно этой строкой является макрос, задаваемый в заголовочном файле (подобно тому, как реализуется
POPT_AUTOHELP), но в целях упрощения в данном примере мы просто явным образом покажем эту строку.
1: /* popt-nest.c */
2:
3: #include <popt.h>
4:
5: /* Обычно это объявление осуществляется в заголовочном файле */
6: extern struct poptOption libTable[];
7:
8: int main(int argc, const char * argv[]) {
9: poptContext optCon;
10: int rc;
11: struct poptOption options[] = {
12: { "app1", '\0', POPT_ARG_NONE, NULL, '\0' },
13: { NULL, '\0', POPT_ARG_INCLUDE_TABLE, libTable,
14: '\0', "Nested:", }
15: POPT_AUTOHELP
16: { NULL, '\0', POPT_ARG_NONE, NULL, '\0' }
17: };
18:
19: optCon = poptGetContext("popt-nest", argc, argv, options, 0);
20:
21: if ((rc = poptGetNextOpt (optCon)) < -1) {
22: fprintf(stderr, "%s: %s\n",
23: poptBadOption(optCon, POPT_BADOPTION_NOALIAS),
24: poptStrerror(rc));
25: return 1;
26: }
27:
28: return 0;
29: }
26.4. Обработка ошибок
Каждая из функций
popt, которая может возвращать ошибки, возвращает целочисленные значения. В случае возникновения ошибки возвращается отрицательный код. В табл. 26.2 перечислены коды возможных ошибок. После таблицы дается подробное обсуждение каждой ошибки.
Таблица 26.2. Коды ошибок popt
| Код ошибки |
Описание |
POPT_ERROR_NOARG |
Отсутствует аргумент для данного параметра. |
POPT_ERROR_BADOPT |
Невозможно проанализировать синтаксис аргумента параметра. |
POPT_ERROR_OPTSTOODEEP |
Слишком глубокое вложение замещений имени параметра. |
POPT_ERROR_BADQUOTE |
Несоответствие кавычек. |
POPT_ERROR_BADNUMBER |
Невозможно преобразовать параметр в число. |
POPT_ERROR_OVERFLOW |
Данное число слишком большое или слишком маленькое. |
POPT_ERROR_NOARG |
Параметр, для которого требуется аргумент, был определен в командной строке, однако аргумент не был предоставлен. Эта ошибка может быть возвращена только функцией poptGetNextOpt(). |
POPT_ERROR_BADOPT |
Параметр был определен в массиве argv, однако его нет в таблице параметров. Эта ошибка может быть возвращена только функцией poptGetNextOpt(). |
POPT_ERROR_OPTSTOODEEP |
Совокупность замещений имени параметра имеет большую глубину вложений. На данный момент popt отслеживает параметры только до 10 уровня, чтобы избежать возникновения бесконечной рекурсии. Эту ошибку возвращает только функция poptGetNextOpt(). |
POPT_ERROR_BADQUOTE |
В строке, прошедшей синтаксический анализ, было обнаружено несоответствие кавычек (например, была обнаружена только одна одинарная кавычка). Эту ошибку могут возвращать функции poptParseArgvString(), poptReadConfigFile() и poptReadDefaultConfig(). |
POPT_ERROR_BADNUMBER |
Преобразование строки в число (int или long) не было выполнено вследствие того, что строка содержит нецифровые символы. Эта ошибка возникает в том случае, когда функция poptGetNextOpt() обрабатывает аргумент типа РOРТ_ARG_INT или POPT_ARG_LONG. |
POPT_ERROR_OVERFLOW |
Преобразование из строки в число не было выполнено вследствие того, что число было слишком большим или слишком маленьким. Подобно ошибке POPT_ERROR_BADNUMBER, эта ошибка может возникнуть только в том случае, если функция poptGetNextOpt() обрабатывает аргумент типа РОРТ_ARG_INT или POPT_ARG_LONG. |
POPT_ERROR_ERRNO |
Системный вызов был возвращен вместе с ошибкой, а errno до сих пор содержит ошибку из системного вызова. Эту ошибку могут возвращать функции poptReadConfigFile() и poptReadDefaultConfig(). |
Приложения могут генерировать качественные сообщения об ошибках с помощью следующих двух функций.
const char * poptStrerror(const int error);
Эта функция принимает код ошибки
popt и возвращает строку с описанием ошибки, как и стандартная функция
strerror().
char * poptBadOption(poptContext con, int flags);
Если во время выполнения функции
poptGetNextOpt() возникла ошибка, эта функция возвращает параметр, вызвавший ошибку. Если аргументу
flags присвоено значение
POPT_BADOPTION_NOALIAS, возвращается самый внешний параметр. В противном случае аргумент
flags должен иметь нулевое значение, а возвращаемый параметр может быть определен посредством псевдонима.
Для большинства приложений эти две функции существенно упрощают обработку ошибок
popt. Если ошибка возникает во время выполнения большинства функций, то выводится сообщение об ошибке, а функция
poptStrerror() возвращает строку с описанием ошибки. Если ошибка возникла во время синтаксического анализа аргумента, то код, подобный представленному ниже, отобразит информативное сообщение об ошибке.
fprintf(stderr, "%s: %s\n",
poptBadOption(optCon, POPT_BADOPTION_NOALIAS),
poptStrerror(rc));
26.5. Псевдонимы параметров
Одним из основных преимуществ использования библиотеки
popt по сравнению с функцией
getopt() является возможность использования псевдонимов параметров. Благодаря ним пользователь может определить параметры, которые
popt будет расширять их на другие параметры по мере их определения. Если стандартная программа
grep использовала
popt, то пользователи могли добавлять параметр
--text, который расширялся до
-i -n -Е -2, облегчая поиск информации в текстовых файлах.
26.5.1. Определение псевдонимов
Псевдонимы обычно определяются в двух местах: в
/etc/popt и в файле
.popt, хранящемся в домашнем каталоге пользователя (его можно найти через переменную окружения
HOME). Оба файла имеют одинаковую форму в виде произвольного количества строк, форматированных следующим образом:
appname alias newoption expansion
appname представляет имя приложения, которое должно быть таким же именем, как и имя в параметре
name, переданное функции
poptGetContext(). Благодаря этому в каждом файле можно определять псевдонимы для нескольких программ. Ключевое слово
alias указывает на то, что определяется псевдоним; на данный момент конфигурационные файлы
popt поддерживают только псевдонимы, однако в будущем появятся новые возможности. Следующим параметром является параметр, для которого необходимо задать псевдоним; это может быть как короткий, так и длинный параметр. Остальная часть строки определяет расширение псевдонима. Синтаксический анализ строки выполняется по аналогии с командой оболочки, в которой в качестве кавычек можно использовать символы
\,
" и
'. Если последним символом строки будет обратная косая черта, то следующая строка в файле трактуется как логическое продолжение строки, содержащей этот символ, как и в оболочке.
Следующий элемент добавляет параметр
--text в команду
grep, как было предложено в начале этого раздела.
grep alias --text -i -n -E -2
26.5.2. Разрешение псевдонимов
Приложение должно разрешать разворачивание псевдонимов для
popContext перед первым вызовом функции
poptGetNextOpt(). Псевдонимы для содержимого определяются с помощью трех функций.
int poptReadDefaultConfig(poptContext con, int flags);
Эта функция считывает псевдонимы из
/etc/popt и файла
.popt в домашнем каталоге пользователя. На данный момент
flags должен иметь нулевое значение, поскольку он зарезервирован только для будущего использования.
int poptReadConfigFile(poptContext con, char * fn);
Файл, определяемый посредством
fn, открывается и анализируется как конфигурационный файл
popt. Это позволяет программам использовать конфигурационные файлы конкретных программ.
int poptAddAlias(poptContext con, struct poptAlias alias, int flags);
В некоторых случаях в программах необходимо определять псевдонимы, не читая их из конфигурационного файла. Эта функция добавляет новый псевдоним в содержимое. Аргумент
flags должен иметь нулевое значение, и в настоящий момент он зарезервирован только для будущего использования. Новый псевдоним определяется как
struct poptAlias следующим образом:
struct poptAlias {
char * longName; /* может быть NULL */
char shortName; /* может быть '\0' */
int argc;
char ** argv; /*должна быть возможность освобождения с помощью free()*/
};
Первые два элемента,
longName и
shortName, определяют параметр, для которого вводится псевдоним. Два последних аргумента,
argc и
argv, определяют разворачивание, которое будет использовано при обнаружении псевдонима параметра.
26.6. Синтаксический анализ строк аргументов
Хотя библиотека
popt обычно используется для синтаксического анализа аргументов, уже разделенных на массив вида
argv, в некоторых программах необходимо анализировать синтаксис строк, формат которых идентичен командным строкам. Для этой цели
popt предлагает функцию, которая анализирует синтаксис строки в виде массива строки, руководствуясь правилами, подобными обычному синтаксическому анализу в оболочке.
#include <popt.h>
int poptParseArgvString(char * s, int * argcPtr, char *** argvPtr);
Строка
s разбирается в массив
argv. Целочисленное значение, на которое указывает второй параметр,
argcPtr, содержит количество проанализированных элементов, а указатель, на который ссылается последний параметр, указывает на вновь созданный массив. Размещение массива осуществляется динамически; после того как приложение завершит работу с массивом, необходимо вызвать функцию
free().
Массив
argvPtr, созданный функцией
poptParseArgvString(), подходит для прямой передачи функции
poptGetContext()[187].
26.7. Обработка дополнительных аргументов
Некоторые приложения реализуют эквивалент псевдонимов параметров, однако для этого им необходима специальная логика. Функция
poptStuffArgs() позволяет приложению вставлять новые аргументы в текущую структуру
poptContext.
#include <popt.h>
int poptStuffArgs(poptContext con, char ** argv);
Передаваемый массив
argv должен иметь указатель
NULL в качестве своего последнего элемента. Когда функция
poptGetNextContext() будет вызвана в следующий раз, то анализироваться будут сначала "заполненные" аргументы. Библиотека popt возвращает обычные аргументы после того, как закончатся все "заполненные".
26.8. Пример приложения
Библиотека
popt используется для обработки параметров во многих примерах из других глав книги. Простая реализация
grep представлена в главе 23, a
robin — в главе 16. Обе реализации предлагают хорошие примеры использования библиотеки
popt в большинстве приложений.
RPM, популярная программа для управления пакетами Linux, интенсивно использует функциональные возможности библиотеки
popt. Многие из ее аргументов командной строки реализованы через псевдонимы
popt, что делает RPM превосходным примером применения преимуществ
popt[188]. Более подробную информацию о RPM доступна по адресу http://www.rpm.org.
Программа Logrotate помогает в управлении системными файлами-журналами. Подобно RPM, она являет собой простой пример использования библиотеки
popt и входит в состав большинства дистрибутивов Linux.
Глава 27
Динамическая загрузка во время выполнения
Загрузка разделяемых (совместно используемых) объектов во время выполнения может оказаться полезным способом для структурирования собственных приложений. Если правильно организовать этот процесс, то тогда можно будет сделать ваше приложение расширяемым, а кроме этого, вы сможете разбивать свой код на логически отдельные модули, что является хорошим стилем написания программ.
Многие Unix-приложения, в частности крупные приложения, в основном реализуются в виде отдельных блоков кода, часто называемых
подключаемыми модулями или просто
модулями. В некоторых случаях они реализуются в виде полностью независимых программ, которые связываются с основным кодом приложения через каналы или с помощью какой-то другой разновидности межпроцессного взаимодействия (interprocess communication — IPC). В остальных случаях они реализуются в виде разделяемых объектов.
Разделяемые объекты обычно создаются подобно стандартным разделяемым библиотекам (см. главу 8), однако используются они совершенно иначе. Компоновщику никогда не сообщается о разделяемых объектах, и во время компоновки приложения они даже не нужны. Их не нужно устанавливать в системе таким же способом, как и разделяемые библиотеки.
Подобно обычным разделяемым библиотекам, разделяемые объекты должны компоноваться явным образом с каждой библиотекой, которая их вызывает. Это позволит гарантировать, что динамический загрузчик корректно разрешит работу всех внешних ссылок при загрузке разделяемого объекта. Если этого не сделать, то внешние ссылки будут разрешены только в контексте того приложения, которое в данном случае будет загружать разделяемый объект. Теоретически разделяемые объекты могут быть стандартными объектными файлами. Однако так поступать не рекомендуется, поскольку внешние зависимости разделяемой библиотеки не будут разрешены должным образом, как и разделяемой библиотеки, явным образом не скомпонованной относительно всех библиотек, от которых она зависит.
Символьные имена, используемые в разделяемых объектах, не обязательно должны быть уникальными среди различных разделяемых объектов, загружаемых в одну и ту же программу; обычно они таковыми и не являются. Различные разделяемые объекты, написанные для одного и того же интерфейса, обычно используют точки входа с одинаковыми именами. Для обычных разделяемых библиотек такая практика будет истинным бедствием, а для разделяемых объектов, динамически загружаемых во время выполнения, именно так и поступают.
Пожалуй, чаще всего разделяемые объекты, загружаемые во время выполнения, применяются при создании интерфейса для некоторого общего средства, которое может иметь множество различных реализаций. Рассмотрим, к примеру, процедуру сохранения графического файла. Приложение может иметь один внутренний формат для управления его графикой, однако существует много других форматов файлов, в которых приложению понадобится сохранить графические данные, и еще больше форматов создано для разнообразных частных ситуаций [21]. Обобщенный интерфейс для сохранения графического файла, который экспортируется разделяемыми объектами, загружаемыми во время выполнения, позволяет программистам добавлять новые форматы графических файлов в приложение без повторной его компиляции. Если интерфейс хорошо документирован, то даже независимые разработчики, не имеющие исходного кода приложения, смогут включать новые форматы графических файлов.
Точно так же используется и код
каркаса (framework), который предлагает только интерфейс, а не реализацию. Например, каркас РАМ (Pluggable Authentication Modules — подключаемые модули аутентификации) предлагает обобщенный интерфейс для методов аутентификации с запросом и подтверждением, например, с участием имен пользователей и паролей. Сам процесс аутентификации осуществляется посредством модулей, а решение о выборе модуля аутентификации для отдельно взятого приложения принимается во время выполнения (а не во время компиляции) за счет обращения к конфигурационным файлам. Этот интерфейс имеет хорошее описание и является стабильным, а новые модули можно внедрять и использовать в любой момент без повторной компиляции каркаса или приложения. Каркас загружается в виде разделяемой библиотеки, а код в этой разделяемой библиотеке загружает и выгружает модули, обеспечивающие методы аутентификации.
27.1. Интерфейс dl
Процесс динамической загрузки заключается в открытии библиотеки, поиске любого количества символов, обработке любых возникающих ошибок и закрытии библиотеки. Все функции динамической загрузки объявляются в одном заголовочном файле,
<dlfcn.h>, и определяются в
libdl (чтобы воспользоваться функциями динамической загрузки скомпонуйте приложение с
-ldl).
Функция
dlerror() возвращает строку, описывающую самую последнюю ошибку, которая возникла в одной из трех других функций динамической загрузки:
const char * dlerror(void);
Каждый раз при возврате значения она очищает состояние ошибки. Если не будет создано другое состояние ошибки, она продолжит выполнение, чтобы вернуть
NULL вместо строки. Объяснение этого необычного поведения можно найти в описании функции
dlsym().
Функция
dlopen() открывает библиотеку. Этот процесс включает поиск библиотечного файла, открытие файла и выполнение некоторой предварительной обработки. Переменные окружения и параметры, переданные функции
dlopen(), определяют детали этого процесса.
void * dlopen(const char * filename, int flag);
Если
filename является абсолютным путем (то есть начинается с символа
/), то функции
dlopen() не нужно производить поиск библиотеки. Это обычный способ применения функции
dlopen() в коде приложения. Если
filename является простым именем файла, то функция
dlopen() произведет поиск библиотеки
filename в перечисленных ниже местах.
• Набор каталогов, разделенных двоеточием, который определен в переменной окружения
LD_ELF_LIBRARY_PATH, или, если ее не существует, в переменной
LD_LIBRARY_PATH.
• Библиотеки, определенные в файле
/etc/ld.so.cache. Этот файл генерируется программой
ldcoding, регистрирующей каждую библиотеку, которую она находит в каталоге, указанном в
/etc/ld.so.conf, во время ее выполнения.
•
/usr/lib
•
/lib
Если filename равен
NULL, то функция
dlopen() открывает экземпляр текущего исполняемого файла. Это полезно только в редких случаях. В случае сбоя функция
dlopen() возвращает
NULL.
Поиск файлов является простой частью работы функции
dlopen(); разрешение символов является более сложной задачей. Существует два фундаментально разных типа разрешения символов: немедленный (immediate) и отложенный (lazy). При немедленном разрешении функция
dlopen() разрешает все неразрешенные символы до возвращения результата; под отложенным разрешением подразумевается, что разрешение символов будет происходить по требованию.
Если большинство символов будет разрешено в самом конце, то гораздо эффективнее будет выполнить немедленное разрешение. Однако для библиотек со многими неразрешенными символами время, потраченное на разрешение символов, может оказаться продолжительным; если это существенно сказывается на вашем пользовательском интерфейсе, можно отдать предпочтение отложенному разрешению. Разница в общей эффективности будет незначительной.
Во время разработки и отладки вы практически во всех случаях будете использовать немедленное разрешение. Если ваши разделяемые объекты имеют неразрешенные символы, вам нужно будет знать об этом немедленно, а не тогда, когда в программе произойдет сбой во время выполнения кода, который на первый взгляд не будет иметь к этому отношения. Отложенное разрешение станет причиной сложно воспроизводимых ошибок, если вы не проверите свои разделяемые объекты сначала с немедленным разрешением.
Это особенно относится к тем случаям, когда вам необходимо, чтобы разделяемые объекты, зависящие от других разделяемых объектов, могли передавать некоторые свои символы. Если разделяемый объект А зависит от символа
b в разделяемом объекте В, а В загружается после А, то отложенное разрешение
b сможет быть выполнено только после загрузки объекта В, а до его загрузки — нет. Если написать код с немедленным разрешением, то вы сможете перехватить эту ошибку еще до того, как она сможет стать причиной возникновения проблем.
Здесь подразумевается, что загружать модули нужно всегда в обратном порядке по отношению к их зависимостям: если объект А зависит от объекта В в некоторых его символах, вы должны загрузить объект В до загрузки объекта А, и должны выгрузить объект А до выгрузки объекта B. К счастью, многие приложения с динамически загружаемыми разделяемыми объектами не имеют подобных взаимозависимостей.
По умолчанию символы в разделяемом объекте не экспортируются и потому не используются для разрешения символов в остальных разделяемых объектах. Они будут доступны только для их поиска и использования, о чем будет сказано в следующем разделе. Однако вы можете экспортировать все символы из одного разделяемого объекта во все остальные разделяемые объекты; эти символы будут доступны всем разделяемым объектам, которые будут загружены позже.
Управление всеми этими действиями осуществляется через аргумент
flags. Он должен иметь значение
RTLD_LAZY для отложенного разрешения и
RTLD_NOW для немедленного разрешения. Любое из этих значений может быть объединено битовым "ИЛИ" с
RTLD_GLOBAL, чтобы разрешить экспортирование символов в остальные модули.
Если разделяемый объект экспортирует программу
_init, то она будет выполняться до того, как функция
dlopen() вернет результат.
Функция
dlopen() возвращает
дескриптор (handle) того разделяемого объекта, который она открыла. Это непрозрачный объектный дескриптор, который следует использовать только как аргумент для последующих вызовов функций
dlsym() и
dlclose(). Если разделяемый объект открывается несколько раз, функция
dlopen() каждый раз будет возвращать один и тот же дескриптор, и с каждым новым вызовом счетчик ссылок будет увеличиваться на единицу.
Функция
dlsym() производит поиск символа в библиотеке:
void * dlsym(void * handle, char * symbol);
handle должен представлять собой дескриптор, возвращенный функцией
dlopen(), a
symbol должен содержать строку с завершающим
NULL, которая именует искомый символ. Функция
dlsym() возвращает адрес определенного вами символа или
NULL в случае возникновения неустранимой ошибки. Если вы будете знать, что
NULL не является правильным адресом символа (например, при поиске адреса функции), можно выполнить проверку на наличие ошибок, посмотрев, возвращает ли она
NULL. Однако в общем случае некоторые символы могут иметь нулевые значения и быть равными
NULL. Тогда вам нужно будет узнать, не возвращает ли функция
dlerror() ошибку. Поскольку функция
dlerror() возвращает ошибку только один раз, возвращая после этого
NULL, вы должны организовать свой код следующим образом.
/* удалить любое состояние ошибки, которое еще не было прочитано */
dlerror();
p = dlsym(handle, "this_symbol");
if ((error = dlerror()) != NULL) {
/* обработка ошибки */
}
Так как функция
dlsym() возвращает
void *, вам необходимо использовать приведение типов, чтобы компилятор С не выдавал сообщений об ошибках. Если вы сохраняете указатель, возвращенный функцией
dlsym(), сохраните его в переменной того типа, который вы хотите использовать, и выполните приведение типа во время вызова функции
dlsym(). Не сохраняйте результат в переменной
void *; вам придется выполнять приведение типов каждый раз во время ее использования.
Функция
dlclose() закрывает библиотеку.
void * dlclose(void * handle);
Функция
dlclose() проверяет счетчик обращений, который увеличивался на единицу при каждом повторном вызове функции
dlopen(), и если он равен нулю, она закрывает библиотеку. Этот счетчик обращений позволяет библиотекам применять функции
dlopen() и
dlclose() для произвольных объектов, не беспокоясь о том, что код, в котором производится вызов, уже открыл какие-либо из этих объектов.
27.1.1. Пример
В главе 8 был представлен пример использования обычной разделяемой библиотеки. Библиотеку
libhello.so, которую нам удалось создать, можно загружать во время выполнения. Программа
loadhello загружает
libhello.so динамически и вызывает функцию
print_hello, которая находится в библиотеке.
Ниже показан код
loadhello.с.
1: /* loadhello.с */
2:
3: #include <dlfcn.h>
4: #include <stdio.h>
5: #include <stdlib.h >
6:
7: typedef void (*hello_function) (void);
8:
9: int main(void) {
10: void * library;
11: hello_function hello;
12: const char * error;
13:
14: library = dlopen("libhello.so", RTLD_LAZY);
15: if (library == NULL) {
16: fprintf (stderr, "He удается открыть libhello.so: %s\n",
17: dlerror());
18: exit(1);
19: }
20:
21: /* Хотя в данном случае мы знаем, что символ print_hello никогда
22: * не должен быть равен NULL, при поиске произвольных символов
23: * все происходит иначе. Поэтому вместо проверки результата функции dlsym()
24: * мы показываем пример проверки кода, возвращаемого функцией dlerror().
25: */
26: dlerror();
27: hello = dlsym(library, "print_hello");
28: error = dlerror();
29: if (error) {
30: fprintf(stderr, "He удается найти print_hello: %s\n", error);
31: exit(1);
32: }
33:
34: (*hello)();
35: dlclose(library);
36: return 0;
37: }
Глава 28
Идентификация и аутентификация пользователей
В модели безопасности Linux для идентификации пользователей и групп используются числа, однако люди отдают предпочтение именам. Имена, наряду с другой важной информацией, сохраняются в двух системных базах данных.
28.1. Преобразование идентификатора в имя
В результате выполнения команды
ls -l для вывода списка содержимого текущего каталога в третьей и четвертой колонках указываются идентификаторы (ID) пользователя и группы, к которой принадлежит каждый файл. Этот список выглядит примерно следующим образом.
drwxrwxr-x 5 christid christid 1024 Aug 15 02:30 christid
drwxr-xr-x 73 johnsonm root 4096 Jan 18 12:48 johnsonm
drwxr-xr-x 25 kim root 2048 Jan 12 21:13 kim
drwxrwsr-x 2 tytso tytso 1024 Jan 30 1996 tytso
Однако нигде в ядре не хранится строка
christid. Программа
ls осуществляет преобразование номеров, предоставленных ядром, в имена. Она получает номера из системного вызова
stat() и производит поиск имен в двух системных базах данных. Обычно эти базы данных хранятся в файлах
/etc/passwd и
/etc/group, хотя в некоторых системах информация может располагаться где-нибудь в сети или в каком-то другом нестандартном месте. Программистам не нужно беспокоиться о том, где хранится эта информация; библиотека С предлагает обобщённые функции, которые считывают конфигурационные файлы для определения места хранения этой информации, производят выборку информации и возвращают ее незаметно для вас.
Чтобы продемонстрировать, что программа
ls получает из ядра, выполним команду
ls -ln.
drwxrwxr-x 5 500 500 1024 Aug 15 02:30 christid
drwxr-xr-x 73 100 0 4096 Jan 18 12:48 johnsonm
drwxr-xr-x 25 101 0 2048 Jan 12 21:13 kim
drwxrwsr-x 2 1008 1008 1024 Jan 30 1996 tytso
Структура, представляющая элементы в
/etc/passwd (или эквивалентной базы данных системы), определена в
<pwd.h>.
struct passwd {
char * pw_name; /* Имя пользователя */
char * pw_passwd; /* Пароль */
__uid_t pw_uid; /* Идентификатор пользователя */
__gid_t pw_gid; /* Идентификатор группы */
char * pw_gecos; /* Настоящее имя */
char * pw_dir; /* Домашний каталог */
char * pw_shell; /* Программа shell */
};
•
pw_name представляет
уникальное имя пользователя.
•
pw_passwd может представлять зашифрованный пароль или нечто подобное, связанное с процедурой аутентификации. Зависит от системы.
•
pw_uid представляет номер (обычно уникальный), который используется в ядре для идентификации пользователя.
•
pw_gid представляет главную группу, которую ядро связывает с пользователем.
•
pw_gecos представляет член, зависящий от системы, который хранит информацию о пользователе. Обычно сюда включается настоящее имя пользователя; во многих системах здесь приводится список членов, разделенных запятыми, который включает номера домашних и рабочих телефонов.
•
pw_dir представляет домашний каталог, связанный с пользователем. Обычные сеансы регистрации начинают работать с этим каталогом в качестве текущего каталога.
•
pw_shell представляет имя командной оболочки, которая запускается в случае успешной регистрации пользователя. Сюда обычно относятся
/bin/bash,
/bin/tcsh,
bin/zsh и так далее. Однако элементы, используемые для других целей, могут иметь другие оболочки,
/bin/false применяется для элементов
passwd, которые не используются для регистрации пользователей. Специализированные оболочки часто служат для целей, рассмотрение которых выходит за рамки настоящей книги.
Структура, которая представляет элементы в
/etc/group (или в эквивалентных базах данных), определена в
<grp.h>.
struct group {
char * gr_name; /* Имя группы */
char * gr_passwd; /* Пароль */
__gid_t gr_gid; /* Идентификатор группы */
char ** gr_mem; /* Список членов */
};
•
gr_name представляет уникальное имя группы.
•
gr_passwd представляет пароль (обычно неиспользуемый). К нему применимы те же требования, что и к
pw_passwd, только в еще большей степени.
•
gr_gid представляет номер (обычно неуникальный), который ядро использует для идентификации группы.
•
gr_mem представляет список членов группы, разделенных запятыми. Это список имен пользователей, которые присваиваются этой группе на вторичной основе (см. главу 10).
Существуют две общих причины, по которым производится доступ к системным идентификационным базам данных: если ядро получает номер, а вам необходимо имя, или если какой-то пользователь или какая-то программа предоставляют вам имя, а вы должны сообщить ядру номер. Предусмотрены две функции поиска числовых идентификаторов,
getpwuid() и
getgrgid(), которые принимают целочисленный идентификатор и возвращают указатель на структуру, содержащую информацию из соответствующей системной базы данных. Точно так же имеются две функции, которые производят поиск имен,
getpwnam() и
getgrnam(), и они возвращают те же две структуры.
|
База данных пользователей |
База данных групп |
| Номер |
getpwuid() |
getgrgid() |
| Имя |
getpwnam() |
getgrnam() |
Каждая из этих функций возвращает указатели на структуры. Структуры являются статическими и перезаписываются при последующем вызове функции, поэтому если вам по какой-либо причине нужно отслуживать структуру, потребуется сделать ее копию.
Четыре вышеупомянутых функции являются, по сути, сокращениями, предлагающими наиболее часто используемые функции для доступа к системным базам данных. Функции низкого уровня,
getpwent() и
getgrent(), производят итерации по строкам в базе данных вместо поиска конкретной записи. Каждый раз при вызове одной из этих функций она будет считывать другой элемент из соответствующей системной базы данных, и возвращать его. После того как вы завершите чтение элементов, вызовите функцию
endpwent() или
endgrent(), чтобы закрыть файл.
В качестве примера далее приводится функция
getpwuid(), записанная в отношении функции
getpwent().
struct passwd * getpwuid(uid_t uid) {
struct passwd * pw;
while (pw = getpwent()) {
if (!pw)
/* обнаружена ошибка; * сквозной проход для обработки ошибки */
break;
if (pw->pw_uid == uid) {
endpwent();
return(pw);
}
}
endpwent();
return NULL;
}
28.1.1. Пример: команда id
Команда
id использует многие из этих функций и предлагает несколько хороших примеров работы с ними. Она также использует некоторые функциональные возможности ядра, описанные в главе 10.
1: /* id.с */
2:
3: #include <grp.h>
4: #include <pwd.h>
5: #include <sys/types.h>
6: #include <stdlib.h>
7: #include <stdio.h>
8: #include <string.h>
9: #include <unistd.h>
10:
11: void usage (int die, char *error) {
12: fprintf(stderr, "Использование: id [<имя_пользователя>]\n") ;
13: if (error) fprintf(stderr, "%s\n", error);
14: if (die) exit(die);
15: }
16:
17: void die(char *error) {
18: if (error) fprintf(stderr, "%s\n", error);
19: exit(3);
20: }
21:
22: int main(int argc, const char *argv[]) {
23: struct passwd *pw;
24: struct group *gp;
25: int current_user = 0;
26: uid_t id;
27: int i;
28:
29: if (argc > 2)
30: usage(1, NULL);
31:
32: if (argc == 1) {
33: id = getuid();
34: current_user = 1;
35: if (!(pw = getpwuid(id)))
36: usage(1, "Имя пользователя не существует");
37: } else {
38: if (!(pw = getpwnam(argv[1])))
39: usage(1, "Имя пользователя не существует");
40: id = pw->pw_uid;
41: }
42:
43: printf("uid=%d(%s)", id, pw->pw_name);
44: if ((gp = getgrgid(pw->pw_gid)))
45: printf(" gid=%d(%s)", pw->pw_gid, gp->gr_name);
46:
47: if (current_user) {
48: gid_t *gid_list;
49: int gid_size;
50:
51: if (getuid() != geteuid()) {
52: id = geteuid();
53: if (!(pw = getpwuid(id)))
54: usage(1, "Имя пользователя не существует");
55: printf(" euid=%d(%s)", id, pw->pw_name);
56: }
57:
58: if (getgid() != getegid()) {
59: id = getegid();
60: if (!(gp = getgrgid(id)))
61: usage(1, "Группа не существует");
62: printf(" egid=%d(%s)", id, gp->gr_name);
63: }
64:
65: /* использование интерфейса getgroups для получения текущих групп */
66: gid_size = getgroups(0, NULL);
67: if (gid_size) {
68: gid_list = malloc(gid_size * sizeof(gid_t));
69: getgroups(gid_size, gid_list);
70:
71: for (i = 0; i < gid_size; i++) {
72: if (!(gp = getgrgid(gid_list[i])))
73: die("Группа не существует");
74: printf("%s%d(%s)", (i == 0) ? " groups=" : ",",
75: gp->gr_gid, gp->gr_name);
76: }
77:
78: free(gid_list);
79: }
80: } else {
81: /* получение списка групп из базы данных групп */
82: i = 0;
83: while ((gp = getgrent())) {
84: char *c = * (gp->gr_mem);
85:
86: while (c && *c) {
87: if (!strncmp(c, pw->pw_name, 16)) {
88: printf("%s%d(%s)",
89: (i++ == 0) ? " groups=" : ",",
90: gp->gr_gid, gp->gr_name);
91: с = NULL;
92: } else {
93: c++;
94: }
95: }
96: }
97: endgrent();
98: }
99:
100: printf("\n");
101: exit(0);
102: }
Код обработки аргументов, который начинается в строке 29, обращается к нескольким важным функциям. При вызове без аргументов командной строки
id производит поиск информации, основанной на том, какую программу запустил пользователь, и сообщает об этом. Описание функции
getuid() можно найти в главе 10; она возвращает идентификатор пользователя процесса, который вызвал его. Затем функция
getpwuid() производит поиск элемента в файле паролей для данного идентификатора пользователя. Если программе
id в качестве аргумента командной строки будет задано имя пользователя, то вместо этого она будет искать элемент, основанный на заданном имени, независимо от идентификатора пользователя, запустившего его.
Вначале программа
id выводит имя и числовой идентификатор пользователя. Файл паролей содержит имя главной группы пользователя. Если эта группа существует в файле групп,
id выводит его номер и имя.
В главе 10 описаны все различные формы идентификаторов, используемых в ядре. Программа
id должна применять функции
geteuid() и
getegid() для проверки
uid и
gid и выводить их, если они отличаются от эффективных
uid и
gid. И снова, структуры паролей и групп просматриваются по числовому идентификатору.
В завершение программа
id должна вывести все дополнительные группы. Здесь кроется маленькая хитрость, поскольку определить список дополнительных групп можно двумя способами. Если пользователь запускает программу
id без аргументов, то
id будет использовать функцию
getgroups(), чтобы определить, к какой группе принадлежит пользователь. В противном случае она получает список групп не из базы данных групп.
Применение функции
getgroups() предпочтительнее, так как она выводит список групп, к которым принадлежит текущий процесс, а не список групп, к которым мог принадлежать пользователь, если он в данный момент прошел регистрацию. Другими словами, если пользователь уже зарегистрировался, и ему была назначен набор дополнительных групп, а после этого база данных групп была изменена, то функция
getgroups() получает набор групп, относящихся к данному процессу регистрации пользователя; в процессе проверки базы данных групп будет получен набор групп, которые будут назначены во время
следующего сеанса регистрации пользователя.
Как говорилось в главе 10, функция
getgroups() может использоваться необычным (но удобным) образом: ее можно вызвать один раз с нулевым размером и проигнорировать указатель (который, как в данном случае, может быть равен
NULL), и она вернет то количество элементов данных, которые ей нужно вернуть. Таким образом, после этого программа
id выделит список точного размера и вызовет функцию
getgroups() еще раз, но теперь уже с точным размером, и список сможет хранить всю необходимую информацию.
Далее программа
id производит итерации по всему списку, получая все необходимые ей элементы из базы данных групп. Обратите внимание, что этот процесс отличается от использования базы данных групп для получения списка групп, к которым принадлежит пользователь. В данном случае
id использует базу данных групп только для установления соответствия между членами группы и именами группы. Более эффективный интерфейс мог бы использовать функцию
getgrent() для производства итераций по базе данных групп и поиска элементов в списке, а не наоборот. По окончания работы не забывайте вызывать функцию
endgrent(). Если этого не сделать, то индекс файла останется открытым, что впоследствии может привести к сбою в коде, если этот код предполагает (что он и должен делать), что функция
getgrent() начнет работу с первого элемента.
Следует отметить, что элементы в списке, возвращаемом функцией
getgroups(), не всегда могут быть отсортированы в том порядке, в каком они появляются в базе данных групп, хотя часто бывает именно так.
Если пользователь ввел имя пользователя в качестве аргумента командной строки, то программа
id выполнит итерацию по файлу групп, производя поиск групп, в которых будет определено введенное имя пользователя. Не забывайте, что после всех действий необходимо вызывать функцию очистки
endgrent()!
28.2. Подключаемые модули аутентификации (РАМ)
Интерфейс библиотеки С удобен для поиска информации о пользователе, однако он не позволяет администратору системы в достаточной мере управлять процессом выполнения аутентификации.
РАМ (Pluggable Authentication Modules — подключаемые модули аутентификации) является спецификацией и библиотекой, предназначенной для конфигурирования процесса аутентификации в системе. Библиотека предлагает стандартный и относительно простой интерфейс для аутентификации пользователей и изменения информации об аутентификации (например, пароля пользователя). Реализация РАМ в Linux (http://www.kernel.org/pub/linux/libs/pam) содержит полную документацию по программированию интерфейса РАМ, включая документацию по написанию новых модулей РАМ (
The Module Writer's Manual), а также по написанию приложений, которые могут использовать РАМ (
The Application Developer's Manual). Здесь мы только покажем пример простого использования РАМ в приложении, с помощью которого необходимо выполнять проверку паролей.
РАМ является стандартным интерфейсом, определяемым DCE, X/Open и The Open Group. Он включается как часть в некоторые версий Unix и входит в состав практически всех версий Linux. Этот интерфейс является переносимым, поэтому мы рекомендуем осуществлять аутентификацию пользователей именно с помощью РАМ. Если вам понадобится перенести код, написанный в соответствии со стандартом РАМ, в операционную систему, не поддерживающую РАМ, то сделать это можно будет очень просто. Однако поскольку РАМ является несколько жестким стандартом, то он может оказаться более сложным для переноса приложений, не поддерживающих РАМ, в систему, в которой РАМ используется.
Помимо служб, связанных с аутентификацией (определяющих, действительно ли пользователь является тем, за кого себя выдает, изменяющих информацию об аутентификации, например, паролей), РАМ также может справиться с управлением учетных записей (определяя, может ли пользователь зарегистрироваться в данный момент и на этом терминале) и управлением сертификатами (обычно, признаки аутентификации, которые используются для X и Kerberos — но определенно не uid- и gid-идентификаторы).
Реализация РАМ в Linux предлагает как стандартную библиотеку
libpam, так и набор нестандартных вспомогательных функций в библиотеке
libpam_misc. Главным заголовочным файлом для написания приложений, которые смогут работать с РАМ, является
<security/pam_appl.h>.
Мы займемся рассмотрением программ яра, используемых для создания приложения, зависящего от РАМ в смысле его аутентификации пользователей, а затем предложим простое приложение
pamexample, которое будет использовать библиотеки
libpam и
libpam_misc.
28.2.1. Диалоги РАМ
РАМ проводит различие между политикой и механизмом; модули РАМ, которые реализуют политику, не взаимодействуют с пользователем напрямую, а приложение не определяет политику. Политику определяет администратор системы в файле выработки политики, и реализуется она с помощью модулей, вызываемых файлом определения политики. На основании структуры диалога,
struct pam_conv, модули определяют способ, посредством которого приложениям будет посылаться запрос на получение информации от пользователя.
#include <security/pam_appl.h>
struct pam_conv {
int (*conv) (int num_msg, const struct pam_message ** msg,
struct pam_response ** resp, void * appdata_ptr);
void * appdata_ptr;
};
Член
conv() является указателем на функцию диалога, которая принимает сообщения для передачи пользователю в структуру
struct pam_message и возвращает введенную пользователем информацию в структуру
struct pam_response. Библиотека
libpam_misc предлагает функцию диалога
misc_conv, которая отвечает за работу с текстовыми консольными приложениями. Чтобы использовать ее (мы рекомендуем вам делать это по мере возможности), вам нужно будет включить заголовочный файл
<security/pam_misc.h> и присвоить члену
conv значение
misc_conv. Этот простой механизм использован в программе
pamexample, представленной в конце этой главы.
Как вариант, вам будет необходимо реализовать свою собственную функцию диалога. Для этого вы должны разобраться еще с двумя структурами данных.
struct pam_message {
int msg_style;
const char * msg;
};
struct pam_response {
char * resp;
int resp_retcode; /*пока что не используется, ожидается нулевое значение*/
};
Функции диалога передается массив указателей на структуры
pam_message и массив указателей на структуры pam_response, каждый из которых имеет длину
num_msg. При получении отклика его необходимо передавать каждой структуре
pam_message в структуре
pam_response с одним и тем же индексом массива,
msg_style может принимать одно из перечисленных ниже значений.
PAM_PROMPT_ECHO_OFF |
Выводит текст, определенный в msg как информационный (например, в стандартном дескрипторе выходного файла), просит пользователя об отклике, не отображая введенные символы (например, пароль), и возвращает текст в новую сформированную строку символов, хранящуюся в соответствующей структуре resp pam_response. |
PAM_PROMPT_ECHO_ON |
Выводит текст, определенный в msg как информационный (например, в стандартном дескрипторе выходного файла), просит пользователя об отклике, отображая введенные символы (например, имя пользователя), и возвращает текст в новую сформированную строку символов, хранящуюся в соответствующей структуре resp pam_response. |
PAM_ERROR_MSG |
Выводит текст, определенный в msg как текст ошибки (например, стандартный дескриптор файла ошибок), присваивает соответствующей структуре resp pam_response значение NULL. |
PAM_TEXT_INFO |
Выводит текст, определенный в msg как информационный (например, стандартный дескриптор выходного файла), присваивает структуре resp pam_response значение NULL. |
Остальные значения могут быть определены как расширения стандарта; ваша функция диалога должна игнорировать их, если они не записываются для последующей их обработки, и должна просто передавать им
NULL-отклик. РАМ (вернее, модуль РАМ, производящий запрос) отвечает за освобождение каждой строки
resp, не содержащей
NULL, а также массивов структур
pam_message и
pam_response.
Член
appdate_ptr, который задается в структуре диалога, передается функции диалога. Это будет полезно в тех случаях, когда вы используете одну функцию диалога в нескольких контекстах, или если вы хотите передать контекстную информацию функции диалога. Эта информация может включать спецификацию дисплея X, внутреннюю структуру данных, в которой хранятся описатели файлов для соединения, или любые другие данные, которые могут быть полезны для вашего приложения. В любом случае, эта информация не интерпретируется библиотекой РАМ.
Функция диалога должна вернуть
PAM_CONVERR, если во время выполнения возникнет ошибка, в противном случае —
PAM_SUCCESS.
28.2.2. Действия РАМ
РАМ не хранит никакой статической информации в библиотеке между вызовами, а хранит всю постоянную информацию с использованием непрозрачной структуры данных, передаваемой всем вызовам. Этот непрозрачный объект,
pam_handle, управляется РАМ, однако хранится в вызывающем приложении. Он инициализируется с помощью функции
pam_start() и освобождается функцией
pam_end().
#include <security/pam_appl.h>
int pam_start (const char * service_name, const char * user,
const struct pam_conv * pam_conversation,
pam_handle_t ** pamh);
int pam_end(pam_handle_t * pamh, int pam_status);
Аргумент
service_name должен представлять уникальное имя для вашего приложения. Это уникальное имя позволяет администратору системы конфигурировать защиту применительно к вашему приложению; два приложения, использующие одно и то же имя
service name, разделяют одну и ту же конфигурацию. Аргумент
user представляет имя аутентифицированного пользователя. Аргумент
pam_conversation представляет структуру диалога, о которой мы уже говорили. Аргумент
pamh представляет непрозрачный объект, который следит за внутренним состоянием. Функция
pam_start() показана в строке 97 кода.
Функция
pam_end(), показанная в строке 137 кода
pamexample.с, очищает каждое; состояние, хранящееся в непрозрачном объекте
pamh, и информирует модули, на которые он ссылается, о конечном состоянии действий. Если приложение успешно использовало РАМ, оно должно присвоить
pam_status значение
PAM_SUCCESS; в противном случае оно должно предоставить самую последнюю ошибку, возвращенную РАМ.
Бывают ситуации, когда модули РАМ могут использовать дополнительную информацию при принятии решения об аутентификации пользователя; эту информацию предоставляет система, а не пользователь. Кроме того, в некоторых случаях модули РАМ должны посылать приложению предупреждение об изменениях. Механизмом передачи этой дополнительной информации является
элемент РАМ. Значение элемента задается с помощью функции
pam_set_item(), а его запрос осуществляется функцией
pam_get_item().
#include <security/pam_appl.h>
extern int pam_set_item(pam_handle_t * pamh, int item_type,
const void * item);
extern int pam_get_item(const pam_handle_t * pamh, int item_type,
const void ** item);
Аргумент
item_type определяет идентичность и семантику элемента РАМ
item. Мы рассмотрим только наиболее часто используемые значения
item_type.
PAM_TTY |
item представляет указатель на строку, содержащую имя устройства TTY, с которым связан запрос аутентификации. Это может быть tty59 для первого последовательного порта в стандартной системе или pts/0 для первого псевдотерминала, или tty1 для первой виртуальной консоли. |
PAM_USER |
Функция pam_start() автоматически присваивает это значение аргументу user, переданному функции pam_start(). Важно отметить, что это имя может изменяться! Если вашему приложению нужно имя пользователя, то оно должно проверять значение посредством функции pam_get_item() после попадания в стек РАМ и перед производством изменения имени в другом коде. |
PAM_RUSER |
Для сетевых протоколов (например, rsh и ssh) этот элемент должен применяться для передачи имени пользователя удаленной системы любым модулям РАМ, которые используют его. Благодаря этому администратор системы сможет определить, разрешена ли аутентификация типа rhost. |
PAM_RHOST |
Подобно PAM_RUSER, PAM_RHOST необходимо задавать для сетевых протоколов, в которых имя удаленного хоста может использоваться как компонент аутентификации, или при управлении учетной записью. |
Все остальные функции принимают по два аргумента: непрозрачный объект
pamh и целое число, которое может быть либо нулевым, либо флагом
РАМ_SILENT. Флаг
PAM_SILENT требует, чтобы каркас и модули РАМ не генерировали информационных сообщений, однако при этом будет производиться запрос на ввод пароля. В обычных приложениях флаг РАМ_
SILENT не задается.
Функция
pam_authenticate(), показанная в строке 100 кода
pamexample.с, выполняет все, что было сконфигурировано администратором системы в данном приложении (что определяется аргументом
service_name функции
pam_start()) для аутентификации пользователя. Сюда может быть включено следующее: запрос на ввод одного или нескольких паролей; проверка, что пользователь с текущим именем пользователя (что определяется по элементу РАМ
РАМ_USER, а не по текущему uid; модули РАМ не рассматривают uid, поскольку приложения, вызывающие РАМ, обычно явным образом не выполняются после аутентификации пользователя) является текущим пользователем консоли; проверка, что текущий пользователь (снова по имени пользователя) недавно прошел аутентификацию для эквивалентного уровня обслуживания; проверка элементов РАМ PAM_RUSER и PAM_RHOST в отношении локальных таблиц эквивалентных удаленных пользователей и хостов (например, то, что выполняет демон
rsh), или что-либо подобное. (Обратите внимание, что в большинстве систем задействована система "теневых паролей", при котором с целью защиты пароля только процессы с полномочиями root могут проверять пароли произвольных пользователей; процесс, который не выполняется как root, может проверять только собственный пароль uid. Это единственное исключение из правила, когда модули РАМ принимают во внимание uid.)
Функция
pam_acct_mgmt(), показанная в строке 107, предполагает, что функция
pam_authenticate() уже была вызвана и продолжает свою работу, а затем проверяет (также по имени), разрешено ли пользователю осуществлять запрошенный доступ. Она может рассматривать элементы РАМ
PAM_USER,
PAM_TTY,
PAM_RUSER и
PAM_RHOST, определяя разрешение на доступ. Например, какому-то одному пользователю могут быть разрешены некоторые tty только в течение определенных часов, или каждому пользователю в некотором классе может быть разрешено только некоторое количество параллельных регистраций, или некоторым совокупностям удаленных пользователей и хостов могут быть даны разрешения только на несколько часов.
Функция
pam_setcred(), показанная в строке 118, предполагает, что аутентификация была пройдена, и затем устанавливает сертификаты для пользователя. Хотя uid, gid и дополнительные группы технически являются сертификатами, они не находятся под управлением функции
pam_setcred(), поскольку во многих приложениях это не будет соответствовать модели безопасности. Наоборот, она устанавливает дополнительные сертификаты. Вероятным кандидатом для использования в качестве сертификата является мандат Kerberos — файл, содержащий зашифрованные данные, которые предоставляют пользователю разрешение на доступ к некоторым ресурсам.
Функция
pam_open_session(), показанная в строке 113, открывает новый сеанс. Если в процессе есть ветвления, то функцию
pam_open_session() необходимо вызывать после ветвления, поскольку при этом могут происходить такие действия, как установка
rlimits (см. стр. 120–121). Если ваш процесс запускается как root, а затем изменяется на uid аутентифицированного пользователя, функцию
pam_open_session() нужно вызывать перед сбросом привилегий root, поскольку модули сеанса могут попытаться выполнить системные операции (например, монтирование домашних каталогов), которые зарезервированы только для root.
Функция
pam_close_session(), показанная в строке 128, закрывает существующий сеанс. Ее можно вызывать из другого процесса, а не только из того, который вызвал функцию
pam_open_session(), при том условии, что РАМ будут доступны одни и те же данные — те же аргументы, заданные для РАМ, и те же элементы РАМ, которые используются для открытия сеанса. Обратите внимание, что поскольку элемент
PAM_USER может быть изменен во время аутентификации и управления учетной записью, вы должны убедиться, что производится учет любых изменений, производимых с
PAM_USER, если вы вызываете ее из отдельного процесса, установившего сеанс. Для работы функции
pam_close_session() могут потребоваться привилегии root.
1: /* pamexample.с */
2:
3: /* Программа pamexample демонстрирует вариант простой обработки РАМ.
4: * Вам нужно будет либо использовать параметр командной строки —service
5: * для выбора имени уже установленной службы (может работать "system-auth",
6: * проверьте наличие /etc/pam.d/system-auth в своей системе), либо
7: * установки системного файла */etc/pam.d/pamexample со следующими
8: * четырьмя строками (игнорируя ведущие символы "*") :
9: * #%РАМ-1.0
10: * auth required /lib/security/pam_unix.so
11: * account required /lib/security/pam_unix.so
12: * session required /lib/security/pam_limits.so
13: *
14: * Обратите внимание, что если вы запустите эту программу не как root, то
15: * можете столкнуться с ограничениями системы; при управлении учетными
16: * записями может произойти сбой, вам может быть не разрешено проверять
17: * другие пароли пользователей, в управлении сеансом может произойти
18: * сбой - все будет зависеть от того, как сконфигурирована служба.
19: */
20:
21: #include <security/pam_appl.h>
22: #include <security/pam_misc.h>
23: #include <popt.h>
24: #include <pwd.h>
25: #include <sys/types.h>
26: #include <stdio.h>
27: #include <stdlib.h>
28: #include <unistd.h>
29:
30: /* Эта структура может быть автоматической, но она не должна выходить
31: * за пределы между функциями pam_start() и pam_end(), поэтому в простых
32: * программах легче всего сделать ее статической.
33: */
34: static struct pam_conv my_conv = {
35: misc_conv, /* использование функции диалога TTY из libpam_misc */
36: NULL /* у нас нет специальных данных для передачи в misc_conf */
37: };
38:
39: void check_success(pam_handle_t * pamh, int return_code) {
40: if (return_code != PAM_SUCCESS) {
41: fprintf (stderr, '"%s\n", pam_strerror(pamh, return_code));
42: exit(1);
43: }
44: }
45:
46: int main(int argc, const char ** argv) {
47: pam_handle_t * pamh;
48: struct passwd * pw;
49: char * username=NULL, * service=NULL;
50: int account = 1, session = 0;
51: int c;
52: poptContext optCon;
53: struct poptOption optionsTable[] = {
54: { "username", 'u', POPT_ARG_STRING, &username, 0,
55: "Имя пользователя для аутентификации", "<имя_пользователя>" },
56: { "service", 'S', РОPT_ARG_STRING, &service, 0,
57: "Имя службы для инициализации как (pamsample)",
58: "<служба>" },
59: { "account", 'a', POPT_ARG_NONE|POPT_ARGFLAG_XOR,
60: &account, 0,
61: "включение/выключение управления учетными записями (включено)", "" },
62: { "session", 's', POPT_ARG_NONE|POPT_ARGFLAG_XOR,
63: &session, 0,
64: "включение/выключение запуска сеанса (выключено)", "" },
65: POPT_AUTOHELP
66: POPT_TABLEEND
67: };
68:
69: optCon = poptGetContext("pamexample", argc, argv,
70: optionsTable, 0);
71: if ((c = poptGetNextOpt(optCon)) < -1) {
72: fprintf(stderr, "%s: %s\n",
73: poptBadOption(optCon, POPT_BADOPTION_NOALIAS),
74: poptStrerror(c));
75: return 1;
76: }
77: poptFreeContext(optCon);
78:
79: if (!service) {
80: /* Обратите внимание, что обычное приложение не должно предоставлять
81: * этот параметр пользователю; он присутствует здесь, чтобы можно было
82: * проверить это приложение, не производя изменений в системе,
83: * требующих доступа root.
84: */
85: service = "pamexample";
86: }
87:
88: if (!username) {
89: /* по умолчанию для текущего пользователя */
90: if (!(pw = getpwuid (getuid())) ) {
91: fprintf(stderr, "Имя пользователя не существует");
92: exit(1);
93: }
94: username = strdup(pw->pw_name);
95: }
96:
97: с = pam_start(service, username, &my_conv, &pamh);
98: check_success(pamh, c);
99:
100: с = pam_authenticate(pamh, 0);
101: check_success(pamh, c);
102:
103: if (account) {
104: /* если аутентификация не была закончена, управление
105: * учетной записью не определено
106: */
107: с = pam_acct_mgmt(pamh, 0);
108: check_success(pamh, с);
109: }
110:
111: if (session) {
112: /* В случае необходимости мы могли бы организовывать здесь ветвление */
113: с = pam_open_session(pamh, 0);
114: check_success(pamh, с);
115:
116: /* Обратите внимание, что здесь не устанавливается uid, gid
117: или дополнительные группы */
118: с = pam_setcred(pamh, 0);
119:
120: /* В случае необходимости мы могли бы закрыть здесь полномочия */
121:
122: /* Вызов оболочки, которая была "аутентифицирована" */
123: printf("Запуск оболочки...\n");
124: system("exec bash -");
125:
126: /* Здесь мы могли бы использовать wait4(), если бы организовывали
127: ветвление вместо вызова system() */
128: с = pam_close_session(pamh, 0);
129: check_success(pamh, с);
130: }
131:
132: /* Реальные приложения могли бы сообщать о сбое вместо
133: * выхода, что мы и делали в check_success на каждой стадии,
134: * поэтому в таких случаях с может иметь значения, отличные
135: * от PAM_SUCCESS.
136: */
137: с = pam_end(pamh, с);
138: check_success(pamh, с);
139:
140: return 0;
141: }
Приложения
Приложение A
Заголовочные файлы
В этом приложении показаны все локальные заголовочные файлы для исходного кода, рассмотренного в книге.
1: /* libhello.h */
2:
3: #ifndef LIBHELLO_H_
4: #define LIBHELLO_H_
5:
6: void print_hello(void);
7:
8: #endif /* LIBHELLO_H_ */
1: /* ptypair.h */
2:
3: #ifndef _PTYPAIR_H
4: #define _PTYPAIR_H
5: int get_master_pty(char **name);
6: int get_slave_pty(char *name);
7: #endif /* _PTYPAIR_H */
1: /* sockutil.h */
2:
3: void die(char * message);
4: void copyData(int from, int to);
5: #ifndef CMSG_DATA
6: #define CMSG_DATA (cmsg) ((cmsg)->cmsg_data)
7: #endif
Приложение Б
Исходный код ladsh
1: /* ladsh4.c */
2:
3: #define _GNU_SOURCE
4:
5: #include <ctype.h>
6: #include <errno.h>
7: #include <fcntl.h>
8: #include <glob.h>
9: #include <signal.h>
10: #include <stdio.h>
11: #include <stdlib.h>
12: #include <string.h>
13: #include <sys/ioctl.h>
14: #include <sys/wait.h>
15: #include <unistd.h>
16:
17: #define MAX_COMMAND_LEN 250 /* максимальная длина одной
18: командной строки */
19: #define JOB_STATUS_FORMAT "[%d] %-22s %.40s\n"
20:
21: struct jobSet {
22: struct job * head; /* заголовок списка выполняющихся заданий */
23: struct job * fg; /* текущее высокоприоритетное задание */
24: };
25:
26: enum redirectionType { REDIRECT_INPUT, REDIRECT_OVERWRITE,
27: REDIRECT_APPEND };
28:
29: struct redirectionSpecifier {
30: enum redirectionType type; /* тип переадресации */
31: int fd; /* переадресация fd */
32: char * filename; /* файл, в который будет переадресовано fd */
33: };
34:
35: struct childProgram {
36: pid_t pid; /* 0 в случае выхода */
37: char ** argv; /* имя программы и аргументы */
38: int numRedirections; /* элементы в массиве переадресации */
39: struct redirectionSpecifier* redirections; /* переадресации ввода-вывода */
40: glob_t globResult; /* результат универсализации параметра */
41: int freeGlob; /* нужно ли освобождать globResult? */
42: int isStopped; /* выполняется ли в данный момент программа?*/
43: };
44:
45: struct job {
46: int jobId; /* номер задания */
47: int numProgs; /* количество программ в задании */
48: int runningProgs; /* количество выполняющихся программ */
49: char * text; /* имя задания */
50: char * cmdBuf; /* буфер, на который ссылаются различные массивы argv */
51: pid_t pgrp; /* идентификатор группы процесса для задания */
52: struct childProgram* progs; /* массив программ в задании */
53: struct job* next; /* для отслеживания фоновых команд */
54: int stoppedProgs; /* количество активных, но приостановленных программ */
55: };
56:
57: void freeJob (struct job * cmd) {
58: int i;
59:
60: for (i = 0; i <cmd->numProgs; i++) {
61: free(cmd->progs[i].argv);
62: if (cmd->progs[i].redirections)
63: free(cmd->progs[i].redirections);
64: if (cmd->progs[i].freeGlob)
65: globfree(&cmd->progs[i].globResult);
66: }
67: free(cmd->progs);
68: if (cmd->text) free(cmd->text);
69: free(cmd->cmdBuf);
70: }
71:
72: int getCommand(FILE * source, char * command) {
73: if (source == stdin) {
74: printf("# ");
75: fflush(stdout);
76: }
77:
78: if (!fgets(command, MAX_COMMAND_LEN, source)) {
79: if (source == stdin) printf("\n");
80: return 1;
81: }
82:
83: /* удаление хвостового символа новой строки */
84: command[strlen(command) - 1] = '\0';
85:
86: return 0;
87: }
88:
89: void globLastArgument(struct childProgram * prog, int * argcPtr,
90: int * argcAllocedPtr) {
91: int argc = *argcPtr;
92: int argcAlloced = *argcAllocedPtr;
93: int rc;
94: int flags;
95: int i;
96: char * src, * dst;
98: if (argc>1) { /* cmd->globResult уже инициализирован */
99: flags = GLOB_APPEND;
100: i = prog->globResult.gl_pathc;
101: } else {
102: prog->freeGlob = 1;
103: flags = 0;
104: i = 0;
105: }
106:
107: rc = glob(prog->argv[argc - 1], flags, NULL, &prog->globResult);
108: if (rc == GLOB_NOSPACE) {
109: fprintf(stderr, "недостаточно пространства для универсализации\n");
110: return;
111: } else if (rc == GLOB_NOMATCH ||
112: (!rc && (prog->globResult.gl_pathc - i) == 1 &&
113: !strcmp(prog->argv[argc - 1],
114: prog->globResult.gl_pathv[i]))) {
115: /* нам нужно удалить все, что до сих пор было заключено между \ */
116: src = dst = prog->argv[argc - 1];
117: while (*src) {
118: if (*src != '\\') *dst++ = *src;
119: src++;
120: }
121: *dst = '\0';
122: } else if (!rc) {
123: argcAlloced += (prog->globResult.gl_pathc - i);
124: prog->argv = realloc(prog->argv,
125: argcAlloced * sizeof(*prog->argv));
126: memcpy(prog->argv + (argc - 1),
127: prog->globResult.gl_pathv + i,
128: sizeof(*(prog->argv)) *
129: (prog->globResult.gl_pathc - i));
130: argc += (prog->globResult.gl_pathc - i - 1);
131: }
132:
133: *argcAllocedPtr = argcAlloced;
134: *argcPtr = argc;
135: }
136:
137: /* Возвращаем cmd->numProgs как 0, если не представлено ни одной команды
138: (например, пустая строка). Если будет обнаружена допустимая команда,
139: commandPtr будет ссылаться на начало следующей команды (если исходная
140: команда была связана с несколькими заданиями) или будет равно NULL,
141: если больше не представлено ни одной команды. */
142: int parseCommand(char ** commandPtr, struct job * job, int * isBg) {
143: char * command;
144: char * returnCommand = NULL;
145: char * src, * buf, * chptr;
146: int argc = 0;
147: int done = 0;
148: int argvAlloced;
149: int i;
150: char quote = '\0';
151: int count;
152: struct childProgram * prog;
153:
154: /* пропускаем первое свободное место (например, пробел) */
155: while (**commandPtr && isspace(**commandPtr)) (*commandPtr)++;
156:
157: /* обрабатываем пустые строки и первые символы '#' */
158: if (!**commandPtr || (**commandPtr=='#')) {
159: job->numProgs = 0;
160: *commandPtr = NULL;
161: return 0;
162: }
163:
164: *isBg = 0;
165: job->numProgs = 1;
166: job->progs = malloc(sizeof(*job->progs));
167:
168: /* Мы задаем элементы массива argv для ссылки внутри строки.
169: Освобождение памяти осуществляется с помощью функции freeJob().
170:
171: Получив незанятую память, нам не нужно будет использовать завершающие
172: значения NULL, поэтому оставшаяся часть будет выглядеть аккуратнее
173: (хотя, честно говоря, менее эффективно). */
174: job->cmdBuf = command = calloc(1, strlen(*commandPtr) + 1);
175: job->text = NULL;
176:
177: prog = job->progs;
178: prog->numRedirections = 0;
179: prog->redirections = NULL;
180: prog->freeGlob = 0;
181: prog->isStopped = 0;
182:
183: argvAlloced = 5;
184: prog->argv = malloc(sizeof(*prog->argv) * argvAlloced);
185: prog->argv[0] = job->cmdBuf;
186:
187: buf = command;
188: src = *commandPtr;
189: while (*src && !done) {
190: if (quote == *src) {
191: quote = '\0';
192: } else if (quote) {
193: if (*src ==0 '\\') {
194: src++;
195: if (!*src) {
196: fprintf(stderr,
197: "после \\ ожидался символ\n");
198: freeJob(job);
199: return 1;
200: }
201:
202: /* в оболочке сочетание "\'" должно дать */
203: if (*src != quote) *buf++ = '\\';
204: } else if (*src == '*' | | *src == ' ?' | | *src == '[' ||
205: *src == ']')
206: *buf++ = '\\';
207: *buf++ = *src;
208: } else if (isspace(*src)) {
209: if (*prog->argv[argc]) {
210: buf++, argc++;
211: /* +1 здесь оставляет место для NULL, которое
212: завершает массив argv */
213: if ((argc + 1) == argvAlloced) {
214: argvAlloced += 5;
215: prog->argv = realloc(prog->argv,
216: sizeof(*prog->argv) * argvAlloced);
217: }
218: prog->argv[argc] = buf;
219:
220: globLastArgument(prog, &argc, &argvAlloced);
221: }
222: } else switch (*src) {
223: case '"':
224: case '\'':
225: quote = *src;
226: break;
227:
228: case '#': /* комментарий */
229: done = 1;
230: break;
231:
232: case '>': /* переадресации */
233: case '<':
234: i = prog->numRedirections++;
235: prog->redirections = realloc(prog->redirections,
236: sizeof(*prog->redirections) * (i+1));
237:
238: prog->redirections[i].fd= -1;
239: if (buf != prog->argv[argc]) {
240: /* перед этим символом может быть указан номер
241: переадресовываемого файла */
242: prog->redirections[i].fd =
243: strtol(prog->argv[argc], &chptr, 10);
244:
245: if (*chptr && *prog->argv[argc]) {
246: buf++, argc++;
247: globLastArgument(prog, &argc, &argvAlloced);
248: }
249: }
250:
251: if (prog->redirections[i].fd == -1) {
252: if (*src == '>')
253: prog->redirections[i].fd = 1;
254: else
255: prog->redirections[i].fd = 0;
256: }
257:
258: if (*src++ == '>') {
259: if (*src == '>') {
260: prog->redirections[i].type = REDIRECT_APPEND;
261: src++;
262: } else {
263: prog->redirections[i].type = REDIRECT_OVERWRIТЕ;
264: }
265: } else {
266: prog->redirections[i].type = REDIRECT_INPUT;
267: }
268:
269: /* Это не соответствует стандарту sh POSIX. Ну и ладно. */
270: chptr = src;
271: while (isspace(*chptr)) chptr++;
272:
273: if (!*chptr) {
274: fprintf(stderr, "после %c ожидалось имя файла\n",
275: *src);
276: freeJob(job);
277: return 1;
278: }
279:
280: prog->redirections[i].filename = buf;
281: while (*chptr && !isspace(*chptr))
282: *buf++ = *chptr++;
283:
284: src = chptr - 1; /* src++ будет сделано позже */
285: prog->argv[argc] = ++buf;
286: break;
287:
288: case '|': /* канал */
289: /* завершение этой команды */
290: if (*prog->argv[argc]) argc++;
291: if (large) {
292: fprintf(stderr, "пустая команда в канале\n");
293: freeJob(job);
294: return 1;
295: }
296: prog->argv[argc] = NULL;
297:
298: /* и начало следующей */
299: job->numProgs++;
300: job->progs = realloc(job->progs,
301: sizeof (*job->progs) *
302: job->numProgs);
303: prog = job->progs + (job->numProgs - 1);
304: prog->numRedirections = 0;
305: prog->redirections = NULL;
306: prog->freeGlob = 0;
307: argc = 0;
308:
309: argvAlloced = 5;
310: prog->argv = malloc(sizeof(*prog->argv) *
311: argvAlloced);
312: prog->argv[0] = ++buf;
313:
314: src++;
315: while (*src && isspace(*src)) src++;
316:
317: if (!*src) {
318: fprintf(stderr, "пустая команда в канале\n");
319: return 1;
320: }
321: src--; /* инкремент ++ мы сделаем в конце цикла */
322:
323: break;
324:
325: case '&': /* фон */
326: *isBg = 1;
327: case ';': /* разнообразные команды */
328: done = 1;
329: returnCommand = *commandPtr + (src - * commandPtr) + 1;
330: break;
331:
332: case '\\':
333: src++;
334: if (!*src) {
335: freeJob(job);
336: fprintf(stderr, "после \\ ожидался символ\n");
337: return 1;
338: }
339: if (*src == '*' | | *src == '[' || *src == '] '
340: || *src == '?')
341: *buf++ = '\\';
342: /* неудача */
343: default:
344: *buf++ = *src;
345: }
346:
347: src++;
348: }
349:
350: if (*prog->argv[argc]) {
351: argc++;
352: globLastArgument(prog, &argc, &argvAlloced);
353: }
354: if (!argc) {
355: freeJob(job);
356: return 0;
357: }
358: prog->argv[argc] = NULL;
359:
360: if (!returnCommand) {
361: job->text = malloc(strlen(*commandPtr) + 1);
362: strcpy(job->text, *commandPtr);
363: } else {
364: /*Оставляем любые хвостовые пробелы, хотя и получится это несколько небрежно*/
365:
366: count = returnCommand - *commandPtr;
367: job->text = malloc(count + 1);
368: strncpy(job->text, *commandPtr, count);
369: job->text[count] = '\0';
370: }
371:
372: *commandPtr = returnCommand;
373:
374: return 0;
375: }
376:
377: int setupRedirections(struct childProgram * prog) {
378: int i;
379: int openfd;
380: int mode;
381: struct redirectionSpecifier * redir = prog->redirections;
382:
383: for (i = 0; i < prog->numRedirections; i++, redir++) {
384: switch (redir->type) {
385: case REDIRECT_INPUT:
386: mode = O_RDONLY;
387: break;
388: case REDIRECT_OVERWRITE:
389: mode = O_RDWR | O_CREAT | O_TRUNC;
390: break;
391: case REDIRECT_APPEND:
392: mode = O_RDWR | O_CREAT | O_APPEND;
393: break;
394: }
395:
396: openfd = open(redir->filename, mode, 0666);
397: if (openfd < 0) {
398: /* мы могли потерять это в случае переадресации stderr,
399: хотя bash и ash тоже потеряют его (а вот
400: zsh - нет!) */
401: fprintf(stderr, "ошибка при открытии %s: %s\n",
402: redir->filename, strerror(errno));
403: return 1;
404: }
405:
406: if (openfd != redir->fd) {
407: dup2(openfd, redir->fd);
408: close(openfd);
409: }
410: }
411:
412: return 0;
413: }
414:
415: int runCommand(struct job newJob, struct jobSet * jobList,
416: int inBg) {
417: struct job * job;
418: char * newdir, * buf;
419: int i, len;
420: int nextin, nextout;
421: int pipefds[2]; /* pipefd[0] предназначен для чтения */
422: char * statusString;
423: int jobNum;
424: int controlfds[2] ;/*канал для возможности приостановки работы дочернего процесса*/
425:
426: /* здесь производится обработка встраиваемых модулей — мы не используем fork(),
427: поэтому, чтобы поместить процесс в фон, придется потрудиться */
428: if (!strcmp(newJob.progs[0].argv[0], "exit")) {
429: /* здесь возвращается реальный код выхода */
430: exit(0);
431: } else if (!strcmp(newJob.progs[0].argv[0], "pwd")) {
432: len = 50;
433: buf = malloc(len);
434: while (!getcwd(buf, len) && errno == ERANGE) {
435: len += 50;
436: buf = realloc(buf, len);
437: }
438: printf("%s\n", buf);
439: free(buf);
440: return 0;
441: } else if (!strcmp(newJob.progs[0].argv[0], "cd")) {
442: if (!newJob.progs[0].argv[1] == 1)
443: newdir == getenv("HOME");
444: else
445: newdir = newJob.progs[0].argv[1];
446: if (chdir(newdir))
447: printf("сбой при смене текущего каталога: %s\n",
448: strerror(errno));
449: return 0;
450: } else if (!strcmp(newJob.progs[0].argv[0], "jobs")) {
451: for (job = jobList->head; job; job = job->next) {
452: if (job->runningProgs == job->stoppedProgs)
453: statusString = "Остановлено";
454: else
455: statusString = "Выполняется";
456:
457: printf(JOB_STATUS_FORMAT, job->jobId, statusString,
458: job->text);
459: }
460: return 0;
461: } else if (!strcmp(newJob.progs[0].argv[0], "fg") ||
462: !strcmp(newJob.progs[0].argv[0], "bg")) {
463: if (!newJob.progs[0].argv[1] || newJob.progs[0].argv[2]) {
464: fprintf(stderr,
465: "%s: ожидался в точности один аргумент\n",
466: newJob.progs[0].argv[0]);
467: return 1;
468: }
469:
470: if (sscanf(newJob.progs[0].argv[1], "%%%d", &jobNum) != 1) {
471: fprintf(stderr, "%s: неверный аргумент '%s'\n",
472: newJob.progs[0].argv[0],
473: newJob.progs[0].argv[1]);
474: return 1;
475: }
476:
477: for (job = jobList->head; job; job = job->next)
478: if (job->jobId == jobNum) break;
479:
480: if (!job) {
481: fprintf(stderr, "%s: неизвестное задание %d\n",
482: newJob.progs[0].argv[0], jobNum);
483: return 1;
484: }
485:
486: if (*new Job. progs[0].argv[0] == 'f') {
487: /* Переводим задание на передний план */
488:
489: if (tcsetpgrp(0, job->pgrp))
490: perror("tcsetpgrp");
491: jobList->fg = job;
492: }
493:
494: /* Повторяем запуск процессов в задании */
495: for (i = 0; i<job->numProgs; i++)
496: job->progs[i].isStopped = 0;
497:
498: kill(-job->pgrp, SIGCONT);
499:
500: job->stoppedProgs = 0;
501:
502: return 0;
503: }
504:
505: nextin = 0, nextout = 1;
506: for (i = 0; i < newJob.numProgs; i++) {
507: if ((i + 1) < newJob.numProgs) {
508: pipe(pipefds);
509: nextout = pipefds[1];
510: } else {
511: nextout = 1;
512: }
513:
514: pipe(controlfds);
515:
516: if (!(newJob.progs[i].pid = fork())) {
517: signal(SIGTTOU, SIG_DFL);
518:
519: close(controlfds[1]);
520: /* при чтении будет возвращен 0, когда записывающая сторона закрыта */
521: read(controlfds[0], &len, 1);
522: close(controlfds[0]);
523:
524: if (nextin != 0) {
525: dup2(nextin, 0);
526: close(nextin);
527: }
528:
529: if (nextout != 1) {
530: dup2(nextout, 1);
531: close(nextout);
532: }
533:
534: /* явные переадресации подменяют каналы */
535: setupRedirections(newJob.progs + i);
536:
537: execvp(newJob.progs[i].argv[0], newJob.progs[i].argv);
538: fprintf(stderr, "сбой exec() для %s: %s\n",
539: newJob.progs[i].argv[0],
540: strerror(errno));
541: exit(1);
542: }
543:
544: /* помещаем дочерний процесс в группу процессов, лидером в которой
545: является первый процесс в этом канале */
546: setpgid(newJob.progs[i].pid, newJob.progs[0].pid);
547:
548: /* закрываем канал управления, чтобы продолжить работу дочернего процесса */
549: close(controlfds[0]);
550: close(controlfds[1]);
551:
552: if (nextin !=0) close(nextin);
553: if (nextout !=1) close(nextout);
554:
555: /* Если другого процесса нет, то nextin является "мусором",
556: хотя это и не является помехой */
557: nextin = pipefds[0];
558: }
559:
560: newJob.pgrp = newJob.progs[0].pid;
561:
562: /* поиск идентификатора используемого задания */
563: newJob.jobld = 1;
564: for (job = jobList->head; job; job = job->next)
565: if (job->jobId> = newJob.jobId)
566: newJob.jobId = job->jobId + 1;
567:
568: /* добавляем задание в список выполняющихся заданий */
569: if (!jobList->head) {
570: job = jobList->head = malloc(sizeof(*job));
571: } else {
572: for (job = jobList->head; job->next; job = job->next);
573: job->next = malloc(sizeof(*job));
574: job = job->next;
575: }
576:
577: *job = newJob;
578: job->next = NULL;
579: job->runningProgs = job->numProgs;
580: job->stoppedProgs = 0;
581:
582: if (inBg) {
583: /* мы не ожидаем возврата фоновых заданий - добавляем их
584: в список фоновых заданий и оставляем их */
585:
586: printf("[%d] %d\n", job->jobId,
587: newJob.progs[newJob.numProgs - 1].pid);
588: } else {
589: jobList->fg = job;
590:
591: /* перемещаем новую группу процессов на передний план */
592:
593: if (tcsetpgrp(0, newJob.pgrp))
594: perror("tcsetpgrp");
595: }
596:
597: return 0;
598: }
599:
600: void removeJob(struct jobSet * jobList, struct job * job) {
601: struct job * prevJob;
602:
603: freeJob(job);
604: if (job == jobList->head) {
605: jobList->head = job->next;
606: } else {
607: prevJob = jobList->head;
608: while (prevJob->next != job) prevJob = prevJob->next;
609: prevJob->next = job->next;
610: }
611:
612: free(job);
613: }
614:
615: /* Проверяем, завершился ли какой-либо фоновый процесс - если да, то
616: устанавливаем причину и проверяем, окончилось ли выполнение задания */
617: void checkJobs(struct jobSet * jobList) {
618: struct job * job;
619: pid_t childpid;
620: int status;
621: int progNum;
622: char * msg;
623:
624: while ((childpid = waitpid(-1, &status,
625: WNOHANG | WUNTRACED)) > 0) {
626: for (job = jobList->head; job; job = job->next) {
627: progNum = 0;
628: while(progNum < job->numProgs &&
629: job->progs[progNum].pid != childpid)
630: progNum++;
631: if (progNum < job->numProgs) break;
632: }
633:
634: if (WIFEXITED(status) || WIFSIGNALED(status)) {
635: /* дочерний процесс завершил работу */
636: job->runningProgs--;
637: job->progs[progNum].pid = 0;
638:
639: if (!WIFSIGNALED(status))
640: msg = "Завершено";
641: else
642: msg = strsignal(WTERMSIG(status));
643:
644: if (!job->runningProgs) {
645: printf(JOB_STATUS_FORMAT, job->jobId,
646: msg, job->text);
647: removeJob(jobList, job);
648: }
649: } else {
650: /* выполнение дочернего процесса остановлено */
651: job->stoppedProgs++;
652: job->progs[progNum].isStopped = 1;
653:
654: if (job->stoppedProgs == job->numProgs) {
655: printf(JOB_STATUS_FORMAT, job->jobId, "Остановлено",
656: job->text);
657: }
658: }
659: }
660:
661: if (childpid == -1 && errno != ECHILD)
662: perror("waitpid");
663: }
664:
665: int main(int argc, const char ** argv) {
666: char command[MAX_COMMAND_LEN + 1];
667: char * nextCommand = NULL;
668: struct jobSet jobList = { NULL, NULL };
669: struct job newJob;
670: FILE * input = stdin;
671: int i;
672: int status;
673: int inBg;
674:
675: if (argc > 2) {
676: fprintf(stderr, "неожиданный аргумент; использование: ladsh1 "
677: "<команды>\n");
678: exit(1);
679: } else if (argc == 2) {
680: input = fopen(argv[1], "r");
681: if (!input) {
682: perror("fopen");
683: exit(1);
684: }
685: }
686:
687: /* не обращаем внимания на этот сигнал; это просто помеха,
688: не имеющая никакого значения для оболочки */
689: signal(SIGTTOU, SIG_IGN);
690:
691: while (1) {
692: if (!jobList.fg) {
693: /* на переднем плане нет ни одного задания */
694:
695: /* проверяем, не завершилось выполнение какого-либо фонового задания */
696: checkJobs(&jobList);
697:
698: if (!nextCommand) {
699: if (getCommand(input, command)) break;
700: nextCommand = command;
701: }
702:
703: if (!parseCommand(&nextCommand, &newJob, &inBg) &&
704: newJob.numProgs) {
705: runCommand(newJob, &jobList, inBg);
706: }
707: } else {
708: /* задание выполняется на переднем плане; ожидаем, пока оно завершится */
709: i = 0;
710: while (!jobList:fg->progs[i].pid ||
711: jobList.fg->progs[i].isStopped) i++;
712:
713: waitpid(jobList.fg->progs[i].pid, &status, WUNTRACED);
714:
715: if (WIFSIGNALED(status) &&
716: (WTERMSIG(status) != SIGINT)) {
717: printf("%s\n", strsignal(status));
718: }
719:
720: if (WIFEXITED(status) || WIFSIGNALED(status)) {
721: /* дочерний процесс завершил работу */
722: jobList.fg->runningProgs--;
723: jobList.fg->progs[i].pid = 0;
724:
725: if (!jobList.fg->runningProgs) {
726: /* дочерний процесс завершил работу */
727:
728: removeJob(&jobList, jobList.fg);
729: jobList.fg = NULL;
730:
731: /* переводим оболочку на передний план */
732: if (tcsetpgrp(0, getpid()))
733: perror("tcsetpgrp");
734: }
735: } else {
736: /* выполнение дочернего процесса было остановлено */
737: jobList.fg->stoppedProgs++;
738: jobList.fg->progs[i].isStopped = 1;
739:
740: if (jobList.fg->stoppedProgs ==
741: jobList.fg->runningProgs) {
742: printf("\n" JOB_STATUS_FORMAT,
743: jobList.fg->jobId,
744: "Остановлено", jobList.fg->text);
745: jobList.fg = NULL;
746: }
747: }
748:
749: if (!jobList.fg) {
750: /* переводим оболочку на передний план */
751: if (tcsetpgrp(0, getpid()))
752: perror("tcsetpgrp");
753: }
754: }
755: }
756:
757: return 0;
758: }
Глоссарий
advisory locking — рекомендательное блокирование. Блокирование, которое не применяется принудительно: все процессы, манипулирующие заблокированными файлами, должны явно проверять наличие блокировки.
anonymous mapping — анонимное отображение. Отображение памяти, которое на связано с inode в файловой системе и ограничено приватным использованием внутри процесса.
ar. Утилита архивирования, наиболее часто используемая для создания библиотек.
basic regular expression (BRE) — базовое регулярное выражение. Тип выражения для сопоставления строк, используемый утилитой
grep.
big-endian — обратный порядок байтов. Многобайтное значение, сохраненное с
наиболее значащим байтом в младших адресах памяти, за которым следуют остальные байты в порядке значимости.
blocked signals — блокированные сигналы. Сигналы, которые процесс не намерен принимать. Обычно сигналы блокируются на короткий период времени, пока процесс выполняет важную работу. Когда сигнал посылается процессу, блокирующему этот сигнал, последний остается отложенным до тех пор, пока он не будет разблокирован.
break — разрыв. Длинный поток нулевых бит в последовательном интерфейсе.
buffer overflow — переполнение буфера. Запись данных за концом области памяти, выделенной под эти данные, которая обычно приводит к сбою работы программы произвольным образом, а также к появлению уязвимостей безопасности.
buffer underrun — недогрузка буфера. Запись данных перед началом области памяти, выделенной под эти данные.
canonical hostname — каноническое имя хоста. Имя хоста, на которое отображается IP-адрес. В то время как множество имен хостов могут отображаться на единственный IP- адрес, этот адрес отображается обратно только на одно, каноническое, имя хоста.
capability — возможность. Действия, которые может совершить терминал в ответ на полученную управляющую последовательность.
catching a signal — перехват сигнала. Предоставление функции, которая запускается, когда определенный сигнал послан процессу.
Command Sequence Introduction (CSI) — ввод командной последовательности. Символ, который инициирует относительно сложную командную последовательность.
concurrent server — параллельный сервер. Сервер, который может обрабатывать множественные запросы (обычно поступающие из нескольких хостов) одновременно.
connection-oriented protocol — протокол с установкой соединения. Сетевой протокол, который обеспечивает взаимодействие между двумя конечными точками, устанавливая соединение, поддерживая по нему взаимодействие и затем закрывая соединение.
connectionless protocol — протокол без установки соединения. Сетевой протокол, который позволяет двум конечным точкам взаимодействовать без первоначального создания соединения между ними.
control character — управляющий символ. Символ в потоке данных, который предоставляет управляющую информацию обрабатывающей программе, но не изменяет режим обработки.
copy-on-write — копирование при записи. Пометка страницы как доступной только для чтения, которая во множестве процессов рассматривается как приватная и доступная для записи, и выдача записываемой ее версии, как только процесс пытается осуществить запись в нее.
dangling link — висячая ссылка. Символическая ссылка, указывающая на несуществующий файл.
deadlocks — взаимоблокировки. Ситуации, при которых, по крайней мере, два потребителя ресурса (такие как процессы) ожидают ресурса, удерживаемого другим потребителем в том же наборе, что приводит к останову продвижения всей работы.
device files — файлы устройств. Специальные файлы, представляющие физические или логические устройства в системе. Представление устройств как файлов позволяет программам получать доступ к ним с использованием обычных вызовов файловой системы.
directories — каталоги. Специальные файлы, которые содержат списки имен файлов и могут включать другие каталоги. Каталоги широко используются для организации большого числа файлов в виде иерархий.
dotted-decimal notation — десятичное представление с разделителями-точками. Стандартная форма записи IPv4-адресов в виде десятичных чисел для каждого байта адреса, разделенных точками.
effective uid — эффективный uid. Идентификатор пользователя для большинства проверок сертификатов. В среде Linux для проверок прав доступа к файлам применяется uid файловой системы, а для всех других проверок сертификатов — эффективный uid.
environment variables — переменные окружения. Пары "имя-значение", представленные в форме строк вида
ИМЯ=ЗНАЧЕНИЕ; набор таких строк определяет окружение программы.
epoch — эпоха. Точка, от которой начинается отчет времени. В Linux, как и во всех системах Unix, такой точкой является 1 января 1970 года по универсальному синхронизированному времени.
error control — контроль ошибок. Характеристика ряда сетевых протоколов, которая гарантирует безошибочную доставку данных.
escape character — символ перехода. Символ в потоке данных, переключающий режим обработки данных с
нормального на
управляющий, в котором ожидается прием последующих символов управляющей информации.
escape sequence — управляющая последовательность. Серия символов, которая трактуется читающей ее программой по-разному. С помощью управляющих последовательностей кодируется управляющая информация в потоке данных.
Executable and Linking Format (ELF) — формат исполняемых и компонуемых модулей. Обобщенный файловый формат для разнообразных типов бинарных файлов, включая объектные файлы, библиотеки, разделяемые библиотеки и исполняемые модули.
extended regular expression (ERE) — расширенное регулярное выражение. Тип выражения для сопоставления строк, используемый утилитой
egrep.
File descriptor — файловый дескриптор. Небольшое целое число, используемое процессом для ссылки на открытый файл.
File mode — режим файла. 16-битное значение, которое определяет тип файла и права доступа к нему.
File structure — файловая структура. Структура, которая выделяется при каждом открытии файла. Файловый дескриптор связывает процесс с файловой структурой, и на каждую файловую структуру может ссылаться множество дескрипторов в нескольких процессах.
glob — универсализация. Расширение символов
*,
? и
[] в соответствие с правилами сопоставления имен файлов.
glyph — глиф. Форма, применяемая для представления символа.
heap — куча. Динамическая область памяти, в которой библиотечный вызов
malloc() выделяет память во время выполнения программы.
init process — начальный процесс. Первый процесс в Linux-системе. Он является единственным процессом, который запускается ядром, и отвечает за запуск всех остальных процессов в системе. Для висячих процессов начальный процесс становится родительским и отвечает за то, чтобы этот процесс не превратился в "зомби".
iterative server — итеративный сервер. Сервер, обрабатывающий по одному процессу за раз.
jiffies — тики. Тики системных часов, или искусственная копия системных часов.
job control — управление заданиями. Средство, которое позволяет группировать связанные процессы для управления ими как одним терминалом.
kernel mode — режим ядра. Неограниченная привилегированная исполняющая среда, в которой выполняется ядро, защищенная от программ, выполняющихся в режиме пользователя.
ld. Компоновщик, который комбинирует объектные файлы в исполняемый модуль.
little-endian — прямой порядок байтов. Многобайтное значение, сохраненное с
наименее значащим байтом в младших адресах памяти, за которым следуют остальные байты в порядке значимости.
locked memory — заблокированная память. Область памяти, которая никогда не подвергается страничному обмену.
major fault — первостепенный сбой. Сбой, случившийся во время доступа процесса к памяти, которая в данный момент не доступна, и заставляющий ядро обратиться к диску.
mandatory locking — обязательное блокирование. Блокирование, которое выполняется принудительно; например, процессы, пытающиеся записать в область, на которой другой процесс установил блокировку записи, блокируются до тех пор, пока эта блокировка записи не будет снята.
memory leak — утечка памяти. Выделение памяти без ее освобождения, обычно включающее удаление всех ссылок на выделенную память.
minor fault — второстепенный сбой. Сбой, случившийся во время доступа процесса к памяти, которая в данный момент не доступна, но не заставляющий ядро обращаться к диску.
modal — модальный. Способ управления, когда ответ на ввод зависит от режима, в котором пребывает программа, что в общем случае означает приоритетность ввода.
network byte order — сетевой порядок байт. Порядок, байты многобайтного значения передаются по сети. Для протокола TCP/IP сетевым порядком байт является обратный (big-endian).
origin — начало отсчета. Первый символ в первой строке символьного дисплея.
orphan process — висячий процесс. Процесс, у которого уничтожен родительский процесс.
packet-based protocols — пакетные протоколы. Сетевые протоколы, передающие данные как группы байт; каждая группа доставляется как отдельный блок и никогда не сливается с другими группами и не разделяется.
pending connections — задержанные соединения. Соединения с сокетами, сделанные по адресам, которые прослушаны, но не приняты.
pending signals — задержанные сигналы. Сигналы, которые посланы процессу, но пока еще не доставлены.
pid — идентификатор процесса. Положительное целое число, уникальным образом идентифицирующее процесс.
pipes — каналы. Простой механизм межпроцессного взаимодействия, который позволяет процессам записывать данные в файловый дескриптор, который выглядит как данные для чтения через другой файловый дескриптор.
process group — группа процессов. Набор логически связанных процессов. Группы процессов перемещаются между передним планом и фоном терминала с помощью механизма управления заданиями, чаще всего командной оболочкой.
real uid — реальный uid. Идентификатор пользователя, который в действительности отвечает за выполнения процесса. Он может быть изменен только пользователем root и позволяет setgid-программам узнать, какой пользователь их запустил.
reentrant functions — реентерабельные функции. Функции, которые могут быть прерваны сигналом и вызваны заново из обработчика сигнала. В общем случае реентерабельность означает способность кодового сегмента выполняться одновременно во множестве потоков.
regular files — обычные файлы. Файлы, хранящие нормальные данные.
reliable signals — надежные сигналы. Реализации сигналов, определенные для непротиворечивой и корректной обработки сигналов.
reserved ports — зарезервированные порты. Номера портов TCP/IP от 0 до 1024, которые могут использоваться только процессами, выполняющимися как root.
resident set size — размер резидентного набора. Объем ОЗУ, в настоящий момент используемый процессом. В него не входят порции, выгруженные в результате страничного обмена.
reverse name lookup — обратный поиск имен. Процесс преобразования IP-адреса в связанное с ним каноническое имя хоста.
saved uid — сохраненный uid. Идентификатор пользователя, который делается равным эффективному uid, если они не имеют достаточных полномочий, предполагаемых этим uid.
sequencing — упорядочение. Характеристика некоторых сетевых протоколов, гарантирующая прибытие данных в порядке их отправки и без потерь.
session — сеанс. Набор групп процессов, выполняющихся на одном терминале.
shell — оболочка. Программа, главное назначение которой — запускать другие программы и осуществлять управление заданиями; в число популярных оболочек Linux входит Bourne again (
bash) и расширенная оболочка С (
tcsh).
shell script — сценарий оболочки. Программа, в которой первыми двумя символами являются
#!, специфицирующие командный интерпретатор, применяемый для выполнения программы.
sockets — сокеты. Файловая абстракция коммуникационных протоколов. Сокеты могут взаимодействовать через сеть или на отдельной машине. Unix Domain Sockets работают только на отдельной машине и имеют записи в файловой системе, используемые для доступа к ним.
streaming protocols — потоковые протоколы. Сетевые протоколы, которые передают данные как последовательности байт без каких-либо разграничений между ними.
symbolic links — символические ссылки. Файлы, которые ссылаются на другие файлы в рамках файловой системы. Это позволяет одному файлу выглядеть так, будто он существует во множестве каталогов, даже если эти каталоги относятся к разным устройствам (или даже в разных сетевых файловых системах).
system call — системный вызов. Механизм, используемый процессами режима пользователя для запроса служб режима ядра.
termcap. Первоначальная база данных возможностей терминалов.
terminfo. Новая, улучшенная база данных возможностей терминалов.
tty — терминал. Терминальный интерфейс, ориентированный на битовые потоки.
unreliable signals — ненадежные сигналы. Реализации сигналов, которые делают непротиворечивую обработку сигналов невозможной. Большинство реализаций ненадежных сигналов либо доставляют сигналы, не учитывая состояние выполнения процесса, либо сбрасываются обработчиками сигналов в стандартные значения при доставке сигнала.
user mode — режим пользователя. Ограниченная исполняющая среда, в которой запускаются программы.
vcs. Устройство в памяти, предназначенное для доступа и изменения содержимого виртуальной консоли.
vcsa. Устройство в памяти, предназначенное для доступа и изменения содержимого и атрибутов виртуальной консоли.
well-known port — официальный порт. Номер порта, который Internet центр Assigned Numbers Authority принял в качестве основного для конкретной службы. Например, HTTP, основной протокол для Web, имеет официальный номер порта 80, и большинство Web-серверов прослушивают этот порт. Официальные порты обычно, но не всегда, являются зарезервированными.
zombie — "зомби". Процесс, который был завершен, но его родительский процесс не учел его состояние завершения, в результате чего такой процесс не отображается в таблице процессов системы.
Литература
1. Albitz, Paul; and Liu, Cricket.
DNS and BIND (second edition). O'Reilly, 1996. ISBN 1-54592-236-0.
2. Bach, Maurice J.
The Design of the UNIX Operating System. Prentice Hall, 1986. ISBN 0-13-201799-7.
3. Beck, Michael; Bohme, Harold; Dziadzka, Mirko; Kunitz, Ulrich; Magnus, Robert; and Verworner, Dirk.
LINUX Kernel Internals. Addison-Wesley, 1996. ISBN 0-201-87741-4.
4. Butenhof, David R.
Programming with POSIX Threads. Addison-Wesley, 1997. ISBN 0-201-63392-2.
5. Cameron, Debra; Rosenblatt, Bill; and Raymond, Eric.
Learning GNU Emacs. O'Reilly, 1996. ISBN 1-56592-152-6.
6. Computer Systems Research Group, UC Berkeley.
4.4BSD Programmer's Reference Manual. O'Reilly, 1994. ISBN 1-56592-078-3.
7. Computer Systems Research Group, UC Berkeley.
4.4BSD Programmer's Supplementary Documents. O'Reilly, 1994. ISBN 1-56592-079-1.
8. Computer Systems Research Group, UC Berkeley.
4.4BSD User's Reference Manual. O'Reilly, 1994. ISBN 1-56592-075-9.
9. Computer Systems Research Group, UC Berkeley.
4.4BSD User's Supplementary Documents. O'Reilly, 1994. ISBN 1-56592-076-7.
10. Computer Systems Research Group, UC Berkeley.
4.4BSD System Manager's Manual. O'Reilly, 1994. ISBN 1-56592-080-5.
11. Cormen, Thomas H.; Leiserson, Charles E.; and Rivest, Ronald L.
Introduction to Algorithms. McGraw-Hill, 1992. ISBN 0-07-013143-0.
12. Gallmeister, Bill O. POSIX.4:
Programming for the Real World. O'Reilly, 1995. ISBN 1-56592-074-0.
13. Garfinkel, Simson; and Spafford, Gene.
Practical UNIX & Internet Security. O'Reilly, 1996. ISBN 1-56592-148-8.
14. IEEE. Portable Operating System Interface (POSIX) Part 2. IEEE, 1993. ISBN 1-55937-255-9.
15. Kernighan, Brian W.; and Ritchie, Dennis M.
The С Programming Language (second edition). Prentice Hall, 1988. ISBN 0-13-110362-8.
16. Koenig, Andrew.
CTraps and Pitfalls. Addison-Wesley, 1989. ISBN 0-201-17928-8.
17. Lamb, Linda.
Learning the vi Editor. O'Reilly, 1990. ISBN 0-937175-67-6.
18. Lehey, Greg.
Porting UNIX Software. O'Reilly, 1995. ISBN 1-56592-126-7.
19. Loukides, Mike; and Oram, Andy.
Programming with GNU Software. O'Reilly, 1997. ISBN 1-56592-112-7.
20. McKusick, Marshall Kirk; Bostic, Keith; Karels, Michael J.; and Quarterman, John S.
The Design and Implementation of the 4.4BSD Operating System. Addison-Wesley, 1996. ISBN 0-201-54979-4.
21. Murray, James D.; and van Ryper, William.
Encyclopedia of Graphics File Formats (second edition). O'Reilly, 1996. ISBN 1-56592-161-5.
22. Newham, Cameron; and Rosenblatt, Bill.
Learning the bash Shell. O'Reilly, 1995. ISBN 1-56592-147-X.
23. Nichols, Bradford; Buttlar, Dick; and Proulx Farrell, Jacqueline.
Pthreads Programming. O'Reilly, 1996. ISBN 1-56592-115-1.
24. Nohr, Mary Lou.
Understanding ELF Object Files and Debugging Tools. Prentice Hall, 1994. ISBN 0-13-091109-7.
25. The Open Group.
The Single UNIX(R) Specification — Authorized Guide to Version 3. The Open Group, 2002. ISBN 1-931624-13-5.
26. Oram, Andrew; and Talbott, Steve.
Managing Projects with make. O'Reilly, 1993. ISBN 0-93715-90-0.
27. Oualline, Steven.
Practical С Programming. O'Reilly, 1993. ISBN 1-56592-03-5.
28. Rubini, Alessandro.
Linux Device Drivers. O'Reilly, 1998. ISBN 1-56592-292-1.
29. Salus; Peter H. A Quarter Century of UNIX. Addison-Wesley, 1994. ISBN 0-201-54777-5.
30. Schneier, Bruce. Applied Cryptography. John Wiley and Sons, 1996. ISBN 0-471-11709-9.
31. Siever, Ellen; Weber, Aaron; and Figgens, Stephen P.
Linux in a Nutshell. O'Reilly, 2003. ISBN 0-59600-482-6.
32. Sobell, Mark G.
A Practical Guide to Red Hat Linux 8. Addison-Wesley, 2002. ISBN 0-201-70313-0.
33. Stevens, W. Richard; Fenner, Bill; and Rudoff, Andrew M.
UNIX Network Programming, Volume 1. Addison-Wesley, 2004. ISBN 0-13-141155-1.
34. Stevens, W. Richard.
TCP/IP Illustrated, Volume 1: The Protocols. Addison-Wesley, 1994. ISBN 0-201-63346-9.
35. Stevens, W. Richard.
Advanced Programming in the UNIX Environment. Addison-Wesley, 1992. ISBN 0-201-56317-7.
36. Strang, John.
Programming with curses. O'Reilly, 1991. ISBN 0-937175-02-1.
37. Strang, John; Mui, Linda; and O'Reilly, Tim.
termcap & terminfo. O'Reilly, 1991. ISBN 0-937175-22-6.
38. Summit, Steve.
С Programming FAQs; Frequently Asked Questions. Addison-Wesley, 1996. ISBN 0-201-84519-9.
39. Tranter, Jeff.
Linux Multimedia Guide. O'Reilly, 1996. ISBN 1-56592-219-0.
40. Vahalia, Uresh.
UNIX Internals: The New Frontiers. Prentice Hall, 1997. ISBN 0-13-101902-2.
41. Vaughan, Gary; Elliston, Ben; Tromey, Tom; and Taylor, Ian Lance.
GNU Autoconf Automake, and Libtool. New Riders, 2000. ISBN 1-57870-190-2.
42. Welsh, Matt and Kaufman, Lars.
Running Linux (second edition). O'Reilly, 1996. ISBN 1-565-92151-8.
Примечания
1
Andrew Tanenbaum, Computer Networks, Prentice Hall, 1981, стр. 168.
(обратно)
2
По этой причине некоторые люди называют GPL "вирусом". —
Примеч. авт.
(обратно)
3
Это справедливо для тех, кто привык к раскладке qwerty. Те, кто обучался на клавиатуре Дворака, используют множество макросов vi, которые делают его удобным в наборе.
(обратно)
4
Несмотря на то что такое поведение выглядит неудобным, это важное средство, а не ошибка. Неразворачиваемые переменные критически важны при написании обобщенных суффиксных правил, которые создают подразумеваемые зависимости.
(обратно)
5
Большинство версий make, включая версию GNU, распространяемую с Linux, определят бесконечный цикл и завершатся с выдачей соответствующего сообщения об ошибке.
(обратно)
6
Большинство, но не все, поставщики услуг доступа в Internet назначают динамические IP-адреса, а не статические.
(обратно)
7
Несмотря на имя, которое может ввести в заблуждение, этот системный вызов устанавливает имя узла, а не имя Internet-хоста машины.
(обратно)
8
Сетевые информационные службы (Network Information Services — NIS) предоставляют для машин в сети механизм совместного использования информации, такой как пользовательские имена и пароли. Ранее они назывались "желтыми страницами" (Yellow Pages — YP). Имя домена NIS — часть этого механизма, который реализуется за пределами ядра системы с тем исключением, что доменное имя хранится в структуре
utsname.
(обратно)
9
К сожалению, ни одно из средств, описанных в этой главе, не может отследить ошибки в памяти, связанные с глобальными переменными; для этого нужна помощь компилятора. В первом издании этой книги рассматривался инструмент под названием Checker, который представлял собой модифицированную версию компилятора
gcc, однако он больше не поддерживается. К официальному компилятору
gcc добавлена новая технология под названием mudflap, которая описана в текущем руководстве по
gcc.
(обратно)
10
Для большей переносимости многие из средств
mpr анализа журнала используют
gdb для связывания адреса с соответствующим местом в исходном коде. Чтобы это работало, программа должна содержать отладочную информацию.
(обратно)
11
Большинство традиционных систем Unix передают ошибку шины (
SIGBUS) процессу, который пытается использовать невыровненные данные. Ядро Linux обрабатывает доступ к невыровненным данным так, чтобы процесс мог нормально продолжать работу, хотя за это приходится платить существенным снижением производительности.
(обратно)
12
Во всяком случае это справедливо для систем Linux/Intel и Linux/SPARC. Размер страницы зависит от базовой аппаратной архитектуры и в некоторых системах может составлять 16 Кбайт и больше.
(обратно)
13
Разница между
-fPIC и
-fpic заключается в способе генерации независимого от расположения кода. В некоторых архитектурах с помощью
-fpic можно собрать только относительно небольшие совместно используемые библиотеки, тогда как в других эти флаги дают один и тот же эффект. Если только нет веских причин на обратное, лучше использовать
-fPIC вместо
-fpic, тогда все будет работать должным образом во всех архитектурах.
(обратно)
14
В случае удаления
/etc/ld.so.cache система может замедлиться. Для восстановления
/etc/ld.so.cache запустите
ldconfig.
(обратно)
15
Для многопоточных приложений библиотека хранит код ошибки там, где функция
errno(), которой известно, какой поток является текущим, может получить ее. Разные потоки могут содержать разные текущие коды возврата ошибок.
(обратно)
16
uid и gid обычно представляют собой положительные целые, но отрицательные целые тоже имеют определенное назначение. Применение -1 для идентификатора проблематично, однако многие системные вызовы, работающие с uid и gid, используют
-1 в качестве признака, что модифицировать значение не нужно (см. пример этого в
setregid() далее в главе).
(обратно)
17
Процессы Linux также имеют четвертый uid и gid, используемые для файлового доступа. Они обсуждаются в следующем разделе этой главы.
(обратно)
18
Большинство систем передают окружение в виде параметра
main(), но такой метод не включен в стандарт POSIX. Переменная
environ — это метод, утвержденный POSIX.
(обратно)
19
Детальную информацию о том, как родительские и дочерние открытые файлы соотносятся друг с другом, можно найти в главе 11.
(обратно)
20
Группы процессов рассматриваются далее в этой главе
(обратно)
21
В главе 15 описаны причины, по которым это может произойти.
(обратно)
22
Это тот же формат, который использует команда
env для печати текущих значений переменных окружения, и аргумент
envp имеет тот же тип, что и глобальная переменная
environ.
(обратно)
23
Технически это указатель на завершающийся
NULL массив указателей на массивы символов, каждый из которых завершается символом
'\0'. Более подробно об это рассказано в [15].
(обратно)
24
Появление
vfork() было мотивировано старыми системами, которым необходимо было копировать всю память, используемую исходным процессом, как часть
fork().Современные операционные системы используют
копирование при записи, которое копирует области памяти только по необходимости, как это описано во многих источниках, посвященных операционным системам, в частности [40] и [2]. Это свойство делает
fork() почти таким же быстрым, как
vfork(), и намного более простым в использовании.
(обратно)
25
Это — существенное упрощение. В действительности
kill() посылает сигнал, а сигналы сами по себе достаточно сложная тема. См. полное описание того, что такое сигналы и как их применять, в главе 12.
(обратно)
26
Это нужно для того, чтобы управляющая заданиями оболочка могла перезапускать процессы, у которых изменился эффективный идентификатор пользователя. Более подробно об управлении заданиями рассказывается в главе 15.
(обратно)
27
Одна из популярных ранее форм компьютерной памяти выглядела как набор маленьких железных колечек, расположенных на матрице, к каждому из которых подводились два проводка, служащих для установки и считывания магнитной полярности кольца. Эти кольца назывались ядрами (cores), а все вместе — ядерной памятью. Поэтому дамп ядра — это копия состояния системной памяти в определенный момент времени.
(обратно)
28
В процессе работы
system() блокирует
SIGCHILD, что заставляет передавать этот сигнал программе непосредственно перед тем, как
system() вернет управление (но после того, как
system() вызовет
wait() для порожденного процесса), поэтому программы, которые используют обработчики сигналов, должны это учитывать и обрабатывать такие ложные сигналы осторожно. Функция
system() также игнорирует
SIGINT и
SIGQUIT, а это означает, что быстрые циклические повторные вызовы
system() может оказаться невозможно прервать ничем, кроме
SIGSTOP и
SIGKILL.
(обратно)
29
Хотя функция
popen() это делает просто, с ней связаны некоторые побочные эффекты, которые не сразу становятся очевидны. Она создает дочерний процесс, который может быть прерван перед тем, как будет вызвана
pclose(), что заставит функцию
wait() вернуть состояние процесса. Когда этот процесс завершится, он также сгенерирует
SIGCHLD, что может привести в замешательство упрощенно написанный обработчик сигналов.
(обратно)
30
Этот тип обработки часто приводит к взаимоблокировкам, при которых процесс А ожидает, пока процесс В выполнит какую-то работу, в то время как процесс В ожидает процесса А, в результате чего ничего не происходит.
(обратно)
31
Если вам понадобится делать это, запустите дочерний процесс с помощью
fork() и
exec(), а потом воспользуйтесь
poll() для чтения и записи в дочерний процесс. Для этого предназначена программа под названием
expect.
(обратно)
32
Информацию о чтении и записи в поток
stdio можно найти в [15].
(обратно)
33
В главе 15 все это проясняется, поэтому, возможно, будет полезно сначала прочитать ее.
(обратно)
34
Но, может быть, не сразу. Может существовать группа процессов, содержащая процессы, чьи родители относятся к другой группе в том же сеансе. Поскольку отношения "родительский-дочерний" между процессами образуют дерево, иногда может оказаться, что существует группа процессов, которая содержит только те процессы, чьим родителем является оболочка, и когда такая группа процессов завершается, другая становится висячей.
(обратно)
35
Обсуждение станет более понятным после того, как вы прочитаете главы, посвященные сигналам (глава 12) и управлению заданиями (глава 15).
(обратно)
36
В среде Linux файловая система
/proc включает информацию о каждом файле, открытом в системе в данный момент. Хотя это значит, что неименованные каналы могут быть найдены в файловой системе, все же они не имеют постоянных имен, потому что исчезают при завершении процесса, использующего их.
(обратно)
37
Не все блочные устройства представляют реальное оборудование. Более правильное описание блочных устройств — это нечто, на чем может располагаться файловая система; блочное устройство обратной связи (loopback block device) отображает на обычный файл логическое блочное устройство, что позволяет файлам содержать в себе целые файловые системы.
(обратно)
38
Точнее говоря, они кэшируются и доступ к ним упорядочен.
(обратно)
39
Это отличается от ряда систем, которые способны монтировать файловые системы как на символьных устройствах, так и на блочных.
(обратно)
40
В Linux всегда используется термин
inode для обоих типов информационных узлов, в то время, как другие варианты Unix резервируют термин inode только для дисковых узлов, а узлы в памяти называют
vnode. Хотя такая терминология менее запутана, мы будем использовать термин inode для обоих типов узлов, чтобы сохранять соответствие стандартам Linux.
(обратно)
41
Это режим, обычно используемый для каталога
/tmp.
(обратно)
42
readv(),
writev() и
mmap() обсуждаются в главе 13;
sendmsg() и
recvmsg() упоминаются в главе 17.
(обратно)
43
Хотя такое разделение почти ясно, сокеты TCP поддерживают "внеполосные" данные, что несколько усложняет ситуацию. Такие данные выходят за пределы тем, рассматриваемых в этой книге. Их полное описание можно найти в [33].
(обратно)
44
Почти независимую; см. описание исключений из этого правила в дискуссии о
dup() в конце этой главы.
(обратно)
45
Поскольку в большинстве систем
SEEK_SET определена как 0, часто можно увидеть использование
lseek(fd, offset, 0) вместо
lseek(fd, offset, SEEK_SET). Это делает код непереносимым (или плохо читабельным), чем
SEEK_SET, но подобное часто встречается в старом коде.
(обратно)
46
Все же не всегда. Если процессы разделяют файловые дескрипторы (имеются в виду дескрипторы, полученные от одного вызова
open()),эти процессы разделяют одни и те же файловые структуры и одно и тоже текущее положение. Наиболее часто такое случается после вызова
fork(),как обсуждается в конце этой главы. Другая ситуация, когда такое может случиться — это если файловый дескриптор передается другому процессу через доменный сокет Unix, описанный в главе 17.
(обратно)
47
Она так называется потому, что это протоколируемая версия Second Extended File System (второй расширенной файловой системы), которая была наследницей Linux Extended File System, которая, в свою очередь, была спроектирована как более сложная файловая система, чем файловая система Minix — единственная, которую изначально поддерживалась в Linux.
(обратно)
48
В действительности это хорошо работает и на файловой системе ext2. Эти две файловые
системы очень похожи (можно даже смонтировать систему ext3 на ext2), и представленные программы работают на обеих. Фактически, если в исходных тексте заменить 3 на 2, программы будут функционировать точно так же.
(обратно)
49
Хотя не гарантировано, что
PATH_MAX будет достаточно велик, но для большинства практических целей она подходит. Если вы имеете дело с патологическими случаями, то должны вызывать
readlink() последовательно, увеличивая буфер, до тех пор, пока
readlink() не вернет значение меньше чем
bufsiz.
(обратно)
50
В зависимости от операционной системы, файловые структуры также известны как позиции в таблице файлов или объекты открытых файлов.
(обратно)
51
Файловый дескриптор в каждом процессе ссылается на одну и ту же файловую структуру.
(обратно)
52
Эта терминология распространена в большей части литературы по стандартам, включая единую спецификацию Unix (Single Unix Specification).
(обратно)
53
Это механизм, используемый для утилиты
nohup.
(обратно)
54
Необходимость в реентерабельных функциях не ограничивается обработчиками сигналов. Многопоточные приложения должны с большой осторожностью относиться к обеспечению реентерабельности и блокировкам.
(обратно)
55
Вообще-то, не совсем так. Модель обработки сигналов ANSI/ISO С специфицирована немного иначе, чем мы ее представили. Однако она допускает сброс обработчика в значение
SIG_DFL перед доставкой сигнала, что делает функции
signal() в ASNI/ISO С ненадежными.
(обратно)
56
Спецификация POSIX Real Time Signal позволяет некоторые сигналам ставить в очередь, и для сигналов, работающих с ограниченными объемами данных, существенно изменяет эту модель. Сигналы реального времени обсуждаются ближе к концу этой главы.
(обратно)
57
Это аналогично типу
fd_set, который используется системным вызовом
select(), описанным в главе 13.
(обратно)
58
Разница между быстрыми и медленными файлами та же, что и между быстрыми и медленными системными вызовами, и она обсуждается в главе 11.
(обратно)
59
Имеются и другие отличия между этими вызовами; они касаются многопоточных программ, которые в настоящей книге не рассматриваются.
(обратно)
60
В действительности она отправляет сигнал текущему потоку текущего процесса.
(обратно)
61
Эти флаги определены в Single Unix Specification. Многие из них имеют имена, отличающиеся от описанных в тексте.
(обратно)
62
Хотя ссылка на память, которая может быть заполнена, может работать в некоторых системах, это не является переносимым. Некоторые реализации
malloc() возвращают память операционной системе, что при обращении к возвращенной памяти вызывает ошибку сегментации; другие — перезаписывают части заполненной памяти служебной информацией.
(обратно)
63
Применение
sigprocmask() и
pause() для получения требуемого поведения может вызвать состояние состязаний, если сигнал, появление которого ожидается, поступит между этими двумя системными вызовами.
(обратно)
64
Более подробно о дампах памяти рассказывается в главе 10.
(обратно)
65
Хотя пользователи могут посылать
SIGCHLD любым процессам, которыми они владеют, программы не обладают возможностью должным образом реагировать на непредвиденные сигналы.
(обратно)
66
В табл. 12.2 перечислены функции, которые могут отсутствовать в некоторых, а может, даже во всех системах Linux. Мы включаем все функции, которые POSIX специфицирует в качестве безопасных для вызова из обработчиков сигналов.
(обратно)
67
Термин
реальное время употребляется здесь неправильно, поскольку это расширение не делает попыток обеспечить гарантии времени задержки при доставке сигнала. Однако средства, которые оно добавляет, удобны для построения реализаций систем реального времени.
(обратно)
68
До появления стандарта POSIX приложение могло обращаться к
struct sigcontext за информацией того же рода, что теперь представляет
siginfo_t, и термин "контекст" остался от этой старой реализации.
(обратно)
69
Этот третий параметр на самом деле указывает на структуру
struct ucontext, которая позволяет процессам выполнять полное переключение контекстов в пользовательском пространстве. Данные вопросы выходят за пределы тем, рассматриваемых в настоящей книге, но это хорошо документировано в Single Unix Specification.
(обратно)
70
Существует гораздо больше значений
si_code, нежели мы обсуждаем здесь, и эти значения имеют отношение к асинхронному вводу-выводу, очередям сообщений и таймерам реального времени, что выходит за границы тем, обсуждаемых в книге.
(обратно)
71
Он также принимает специальное значение
SIGTRAP, которое используется отладчиками, и
SIGPOLL, применяемое механизмом ненадежного асинхронного ввода-вывода. Ни один из них не описан в настоящей книге, поэтому подробности об этих сигналах не включены в табл. 12.3.
(обратно)
72
Вспомните, что
SIGCHLD посылается не только при завершении дочернего процесса, но и при его приостановке или возобновлении работы.
(обратно)
73
Дополнительные примеры обработки сигналов вы можете найти в программах для аренды файлов (глава 13), управления терминалом (глава 16) и работы с интервальными таймерами (глава 18).
(обратно)
74
Это похоже на тип
sigset_t, используемый для шаблонов сигналов.
(обратно)
75
Когда сетевой сокет прослушивается (
listen()) и готов к приему (
accept()), считается, что он готов к считыванию для целей
select(); информацию о сокетах можно найти в главе 17.
(обратно)
76
Если сравнить это с параметром
numfds для
poll(), то можно понять, почему возникают затруднения.
(обратно)
77
Кроме некоторых экспериментальных ядер серии 2.1.
(обратно)
78
Когда Линус Торвальдс впервые реализовал
select(), неспособность ядра BSD обновлять
timeout была отмечена как ошибка на man-странице для
select(). Вместо написания ошибочного кода Линус решил "исправить" эту ошибку. К сожалению, комитеты по стандартам одобрили поведение BSD.
(обратно)
79
Фактически ядро устанавливает обратный вызов для каждого файла, а затем, когда происходит событие, активизирует обратный вызов. Этот механизм устраняет проблемы масштабируемости при очень большом количестве файловых дескрипторов, поскольку опрос не используется в каждой точке.
(обратно)
80
EPOLLET — это еще одно значение, которое может иметь
events, переключающее
epoll с запуска уровнем на запуск фронтом сигнала. Эта тема выходит за рамки настоящей книги, и
epoll, запускаемую фронтом, следует применять только в особых случаях.
(обратно)
81
Структура, показанная в тексте, предоставляет правильные размеры элементов на большинстве платформ, но они неправильны для машин, в которых
int имеет 64 бита.
(обратно)
82
Эту программу необходимо запускать от имени root для наборов, содержащих более 1000 дескрипторов.
(обратно)
83
Настоящее тестирование не гарантирует статистическую точность. Был проведен лишь один тестовый прогон, поэтому результаты поначалу будут неустойчивыми, что, однако, исчезнет после большого количества повторов.
(обратно)
84
Сохранение копии памяти может показаться не столь важным, но благодаря эффективному механизму кэширования Linux, эти задержки копий являются самой медленной частью записи в файлы данных, в которых нет набора
O_SYNC.
(обратно)
85
Хотя большинство устройств символьного ввода-вывода не могут быть отображены,
/dev/zero отображается именно для этого типа приложений.
(обратно)
86
Ошибка сегментации возникнет при попытке доступа к нераспределенной странице.
(обратно)
87
В будущем это может измениться, поскольку в ядре реализуются мелкомодульные системные полномочия.
(обратно)
88
Файл
/etc/passwd обновляется только процессами, создающими новую копию файла с модификациями и затем заменяющими оригинал с помощью системного вызова
rename(). Поскольку такая последовательность является атомарной, процессы могут считывать из
etc/passwd в любое время.
(обратно)
89
Файловая система Andrew Filesystem (AFS), доступная в Linux, но не включенная в стандартное ядро, поддерживает
O_EXCL во всей сети.
(обратно)
90
Эта ситуация более сложна для потоков. Многие ядра и библиотеки Linux рассматривают потоки как разные процессы, что увеличивает потенциал возникновения конфликтов файловых блокировок между потоками (а это не совместимо со стандартной моделью потоков POSIX). Linux предлагает более традиционную модель потоков, при которой файловые блокировки разделяются между всеми потоками одного процесса, но в многопоточных программах лучше применять потоковые механизмы блокировки POSIX, а не полагаться на поведение файловых блокировок.
(обратно)
91
Эта манипуляция блокировками происходит атомарно — не имеет значения, какая часть области разблокирована.
(обратно)
92
Эффект, производимый вызовами
fork() и
exec() на файловые блокировки, является наиболее существенным отличием между файловой блокировкой POSIX (а, следовательно, и блокировкой
lockf()) и файловой блокировкой
flock() в BSD.
(обратно)
93
Одним из самых частых пользователей аренды файлов является файловый сервер Samba, позволяющий клиентам кэшировать свои записи для увеличения производительности.
(обратно)
94
Если тот факт, что аренда записи уведомляет процесс об открытии файла для чтения, может показаться несколько странным, посмотрите на него с точки зрения процесса, получающего аренду. Ему необходимо знать, делает ли другой процесс читать файл, только в случае, когда основной процесс сам что-либо записывает в этот файл.
(обратно)
95
Ядра предшествующих версий при успешной операции возвращает ноль либо единицу, тогда как более новые ядра всегда возвращают в данном случае ноль. В другом случае проверка на положительное или отрицательное значение работает нормально.
(обратно)
96
Если один сигнал используется для аренды множества файлов, убедитесь, что сигнал является сигналом реального времени, так что множество событий аренды ставятся в очередь. Если используется обычный сигнал, он может потеряться либо события аренды могут возникать через очень короткие промежутки времени.
(обратно)
97
До тех пор пока
O_NONBLOCK не будет определен как флаг
open(); в этом случае возвращается
EWOULDBLOCK.
(обратно)
98
Они так именуются, поскольку чтение разбрасывает данные по всей памяти, а запись собирает данные из разных областей памяти. Они также известны как векторное чтение и запись. Этим объясняется наличие "v" в конце
readv() и
writev().
(обратно)
99
Эта эмулированная версия в большинстве случаев ведет себя корректно, но действует не так, как фактический системный вызов, если сигналы принимаются во время его выполнения.
(обратно)
100
Это верно;
PATH_MAX не является фактическим пределом. POSIX считает его
неопределенным, что обычно является эквивалентом "не используйте его".
(обратно)
101
Имя этого пути эквивалентно более простому
/usr/bin/less.
(обратно)
102
Функции
ftw() необходимо выполнять
stat() для каждого файла для выяснения, является ли он каталогом, и передача этой информации обратному вызову во многих случаях избавляет последний от необходимости повторного выполнения
stat() для файлов.
(обратно)
103
Это то же, что и метод, используемый для владения файлами (глава 13).
(обратно)
104
Обработчик сигналов все еще следует регистрировать с помощью флага
SA_SIGINFO, чтобы файловый дескриптор надлежащим образом получил доступ к сигналу.
(обратно)
105
Остановленные процессы, однако, не могут генерировать сигналы, поэтому они также не могут перезапускаться.
(обратно)
106
Обычно клавиатурной комбинацией приостановки является <Ctrl+Z>. Программа stty позволяет пользователям менять эту комбинацию. Подробнее это рассматривается в главе 16.
(обратно)
107
То есть устройства, используемые как для ввода, так и для вывода.
(обратно)
108
Реализации Unix старого типа предоставляли эту функцию с помощью
TIOCSPGRP ioctl(), до сих пор поддерживаемого Linux. Для сравнения,
tcsetpgrp() можно реализовать как
ioctl(ttyfd, TIOCSPGRP, &pgrp).
(обратно)
109
Более подробно о сигналах и их взаимодействии с управлением заданиями рассказывается в главе 12.
(обратно)
110
На man-странице
setserial описан способ обхода этого ограничения, специфический для Linux.
(обратно)
111
Обратите внимание: "бит в секунду" ("бит/с"), а не "бод". Бит в секунду определяет интенсивность передачи информации. Бод является техническим термином, описывающим смены фаз в течение секунды. Бод не соответствует
termios, но слово бод, к сожалению, попало в названия некоторых флагов
termios, не рассматриваемых в этой книге.
(обратно)
112
Например, приложения настройки сетевых протоколов, передающие информацию с помощью устройств tty.
(обратно)
113
B134 в действительности равняется 134,5 бит/с, скорость, используемая устаревшим терминалом IBM.
(обратно)
114
Linux также использует
c_cflag для хранения скорости, но не стоит на это полагаться. Вместо этого применяйте
cfsetospeed() и
cfstispeed().
(обратно)
115
Ядра 2.6.x, рассматриваемые в настоящей книге, поддерживают как версию 4, так и версию 6 (на последнюю обычно ссылаются как на IPv6 из набора TCP/IP).
(обратно)
116
Кстати, именно так работают сети на основе
коммутации пакетов. Альтернативная конструкция, сети с
коммутацией каналов, более похожа на телефонные соединения. Однако они не часто используются при организации компьютерных сетей.
(обратно)
117
Вот почему криптография приобрела такую значимость с тех пор как появилась всемирная сеть Internet.
(обратно)
118
Многие высокоуровневые протоколы, такие как BOOTP и NFS, построены на основе UDP.
(обратно)
119
Допустимы еще несколько значений данного параметра, однако они редко применяются в коде приложений.
(обратно)
120
Системный вызов
connect() может также быть неблокируемым, что позволит пользователям гораздо быстрее открывать несколько TCP соединений (он позволяет продолжать работу программы, в то время как выполняется процесс синхронизации TCP). Подробности по этой теме можно найти в [33].
(обратно)
121
Различные формы
select() помечают сокет как открытый для чтения, тогда как
accept() не может блокировать его, даже если сокет не помечен как неблокируемый. Для обеспечения максимальной переносимости функцию
select() необходимо применять только для принятия соглашений с неблокируемыми сокетами, хотя в системе Linux это фактически не нужно. Причины этого подробно рассматриваются в [33].
(обратно)
122
Варианты BSD не поддерживают такую модель поведения, в таких системах ошибки проходят без отчетов.
(обратно)
123
И для
bind(), и для
connect() процесс должен иметь права на выполнение для каталогов, через которые проходит поиск путевого имени (почти как при открытии стандартных файлов).
(обратно)
124
Исходя из условий реального мира, большинство серверных программ должны быть параллельными. Однако многие из них фактически созданы как итерационные сервера. Например, Web-серверы, в основном, обрабатывают только одно соединение за раз через данный процесс. Для того чтобы разрешить соединение нескольким клиентам, сервер организован в виде множества отдельных процессов. Это делает создание Web-сервера более простым. Если ошибка прерывает работу одного из таких процессов, она затрагивает только одно клиентское соединение.
(обратно)
125
Это иногда называется передачей прав доступа.
(обратно)
126
Несмотря на то что это может показаться очевидным, некоторые протоколы позволяют отправителю использовать любой порядок байтов и в зависимости от получателя преобразовывать информацию в соответствующем порядке. Это приводит к увеличению производительности, если взаимодействуют подобные механизмы, за счет повышения сложности алгоритма.
(обратно)
127
Все процессоры Intel и совместимые с Intel хранят данные с прямым порядком байтов, поэтому здесь получение права преобразования очень важно для корректной работы программ.
(обратно)
128
Информация о IANA доступна по адресу http://www.iana.org.
(обратно)
129
Либо, все чаще и чаще, чтобы скрыть их от широкополосных поставщиков Internet-услуг, которые не хотят разрешить своим рядовым клиентам запускать серверы на домашних машинах.
(обратно)
130
Однако она может оказаться троянским конем, запущенным привилегированным пользователем.
(обратно)
131
Значения для неустановленных IPv4-адресов содержатся в константе
INADDR_ANY, которая является 32-битным числом.
(обратно)
132
Эти примеры взяты из документа RFC 1884, в котором определена структура адресации IPv6.
(обратно)
133
Это так называемый неустановленный адрес для IPv6.
(обратно)
134
Если у вас большой опыт в программировании сокетов (или вы сравниваете данную книгу с ее первым изданием), то вы обязательно заметите, что функции, применявшиеся для преобразования имен, значительно изменились. Эти изменения позволяют создавать программы абсолютно независимо от того протокола, который они используют. Теперь гораздо легче разрабатывать программы, работающие как на IPv4-, так и на IPv6-машинах. Они также должны распространяться на остальные протоколы, хотя функция
getaddrinfo() в данный момент работает только для IPv4 и IPv6.
(обратно)
135
Адрес обратной связи — это специальный адрес, который позволяет программам взаимодействовать через TCP/IP с приложениями только на одной и той же машине.
(обратно)
136
Для TCP-портов данная комбинация не может использоваться в течение двух минут.
(обратно)
137
Это называется трехсторонним квитированием TCP, которое на самом деле проходит несколько сложнее, чем описано выше.
(обратно)
138
Этот процесс называется сетевой загрузкой.
(обратно)
139
UDP-сокеты, которые имеют постоянные пункты назначения, присвоенные через функцию
connect(), иногда называются присоединенными UDP-сокетами.
(обратно)
140
Есть также возможность превратить подключенный сокет в неподключенный с помощью функции
connect(), однако эта процедура не стандартизирована. Если вам все же необходимо ее применить, обратитесь к [33].
(обратно)
141
Данные функции могут применяться для передачи данных через любой сокет, и иногда возникают причины для использования их в TCP-соединениях.
(обратно)
142
Возможно также применение системных вызовов
sendmsg() и
recvmsg(), однако необходимость в этом встречается редко.
(обратно)
143
Полное описание tftp можно найти в [33] и [34].
(обратно)
144
Спецификация tftp-протокола требует, чтобы серверы посылали данные клиенту на номер порта, отличающийся от порта, на котором сервер ожидает новые соединения. При этом нетрудно создать параллельный сервер, поскольку каждый сокет сервера предназначен только для одного клиента.
(обратно)
145
Применение этой структуры делает невозможным расширение данных функций на IPv6 без изменения их интерфейса.
(обратно)
146
Функции, использующие статическую память для сохранения результатов, усложняют построение многопоточных приложений, поскольку в код приложения требуется добавлять блокировки для защиты этих статических буферов.
(обратно)
147
Наверное, не существует IPv6-программ, использующих
struct hostaddr, однако они могут это делать. Функции, которые мы обсуждаем здесь, по умолчанию возвращают только информацию IPv4. Мы не будем рассматривать применение этих функций с IPv6.
(обратно)
148
UTC — Universal Coordinated Time (универсальное синхронизированное время), на которое иногда ошибочно ссылаются как на UCT, приблизительно эквивалентное среднему времени по Гринвичу (GMT) и зулу. Описание всех часовых поясов выходит за рамки материала, рассматриваемого в настоящей книге.
(обратно)
149
Мы не рекомендуем применять библиотеку
svgalib для графического программирования. Во многих книгах описывается программирование для X Window System, и система X предоставляет более разумный, безопасный и мобильный метод программирования графики. С другой стороны, если вы действительно собираетесь программировать для сервера X Window, то не сможете обойтись без кодирования VC. Таким образом, в любом случае данная глава окажется полезной.
(обратно)
150
Прочтите man-страницы для утилит
loadkeys,
dumpkeys,
keytables,
setfont и
mapscrn.
(обратно)
151
Данный интерфейс имеет недостаток. Для него необходимо устанавливать некоторые постоянные доли секунды и осуществлять преобразование. Макрос
HZ больше не является константой даже на отдельной платформе. Однако, по крайней мере, для архитектуры Intel i86 Линус Торвальдс установил, что все определенные интерфейсы в отношении
HZ должны представлять синтетический интерфейс в 100 Гц. Возможно, что в будущем периодические системные часы исчезнут, в таком случае тики станут полностью искусственным понятием.
(обратно)
152
В большинстве остальных систем с виртуальными консолями или терминалами динамическое распределение для них не производится.
(обратно)
153
Отдельные системы (но не Linux) инициируют автоматическое переключение, если вызывается консоль, которая не исполняется в текущий момент.
(обратно)
154
Библиотека
curses определена в X/Open. Реализация, которая входит в состав Linux, представляет собой совместимую в данный момент с X/Open XSI Curses версию базового уровня.
(обратно)
155
Эта тема логически относится к главе 20, поскольку она имеет отношение к виртуальным консолям. Однако практический смысл вынуждает поместить этот раздел в данную главу — поскольку, как упоминалось во введении, настоящую книгу можно читать и выборочно.
(обратно)
156
Популярным способом проверки в ранних ядрах Linux было создание последовательности абсолютно случайных байтов и запуск их на выполнение как программы. Кроме того, что таким методом невозможно сделать что-либо полезное, он довольно часто вызывает полную блокировку ядра. Поскольку попытки выполнения совершенно случайных последовательностей кодов не входят в "должностные инструкции" ядра, пользовательские программы не должны вызывать остановку корректной работы ядра. Таким образом, этот прием помогает находить большое число дефектов, которые необходимо устранить.
(обратно)
157
Атака на программное обеспечение приложений сейчас является основным способом распространения вирусов.
(обратно)
158
Системные квоты предотвращают возможность успешности такой атаки.
(обратно)
159
Словарная атака — это довольно прямолинейный метод обнаружения паролей, когда автоматическая программа прогоняет огромный список обычных паролей (таких как слова в словаре) до тех пор, пока один из них не подойдет.
(обратно)
160
ВООТР — это предшественник DHCP, позволяющий компьютерам автоматически узнавать свои IP-адреса при запуске сетевых интерфейсов.
(обратно)
161
Функция
alloca() не является стандартным средством языка С, однако компилятор gcc предоставляет
alloca() в большинстве поддерживаемых операционных систем. В более старых версиях gcc (до версии 3.3)
alloca() не всегда должным образом взаимодействовала с массивами динамических размеров (другое расширение GNU), поэтому примите во внимание, что использовать нужно только одну из версий.
(обратно)
162
В некоторых устаревших версиях библиотеки С вместо этого возвращается -1 (если строка не помещается). Старая версия библиотеки С уже не поддерживается и не используется в защищенных программах, однако на man-странице по функции
snprintf() демонстрируется код, обрабатывающий оба варианта.
(обратно)
163
К сожалению, функция
clearenv() не очень хорошо стандартизирована. Она входит в последние версии POSIX, однако она была выброшена из стандарта Single Unix Standard и не доступна во всех системах типа Unix. Если вам необходимо поддерживать операционную систему, не включающую эту переменную, установите
environ=NULL;.
(обратно)
164
Существует еще несколько библиотечных функций, имеющих дело с временными файлами, такие как
tmpnam(),
tempnam(),
mktemp() и
tmpfile(). К сожалению, их применение приносит небольшую пользу, поскольку они могут привести к возникновению состязаний в программах, которые невнимательно реализованы.
(обратно)
165
Система Linux позволяет программам открывать очень большое количество файлов. Процессы, работающие как root, могут одновременно открывать сотни файлов, однако большинство дистрибутивов устанавливают предел ресурсов на количество файлов, который может открывать пользовательский процесс. Этот предел также ограничивает максимальный файловый дескриптор, который можно использовать, с помощью метода
dup2(), тем самым, предоставляя удобный верхний предел для закрывающего файлового дескриптора.
(обратно)
166
Еще одним способом закрытия всех файлов, открытых программой, является прохождение через каталог файловой системы процесса
/proc, в котором перечислены все открытые файлы, и закрытие каждого из них. Каталог
/proc/PID/fd (где
PID —это pid текущего процесса) содержит символическую ссылку для каждого файлового дескриптора, открытого процессом. Имя каждой символической ссылки представляет собой файловый дескриптор, которому она соответствует. Считывая содержимое каталога, программа легко может закрыть все файловые дескрипторы, которые больше не нужны.
(обратно)
167
Один из авторов этой книги разработал набор инструментальных средств
newt для управления окнами на высоком уровне на основе S-Lang; этот набор входит в состав большинства распространяемых дистрибутивов Linux.
(обратно)
168
Как это описано в базе данных
terminfo.
(обратно)
169
Ошибка возникает, если получение сигнала происходит в тот момент, когда S-Lang ожидает нажатие клавиши.
(обратно)
170
Помните, что обновление физического терминала производится только с помощью функции
SLsmg_refresh().
(обратно)
171
Со временем эта цифра может возрасти, однако маловероятно, что это когда-нибудь будет необходимо.
(обратно)
172
В частности, в некоторых системах это может привести к мерцанию текста.
(обратно)
173
Библиотека Berkley db была существенно расширена, и сейчас включает реализацию B-деревьев и весь спектр работы с транзакциями.
(обратно)
174
В настоящее время Berkley db разрабатывается некоммерческой организацией, которая продает альтернативные лицензии для своей библиотеки, поэтому на них вполне можно ориентироваться при разработке определенного рода приложений.
(обратно)
175
Инвертированные индексы представляют собой структуры данных, предназначенные для полнотекстового поиска.
(обратно)
176
В отличие от некоторых библиотек баз данных, использующих множество файлов с расширениями
.pag и
.dir, библиотека
Depot использует один файл.
(обратно)
177
Хорошее описание хеш-таблиц можно найти в [11].
(обратно)
178
Это значение можно изменить только путем оптимизации базы данных с помощью функции
dpoptimize(), описание которой можно найти на Web-сайте
qdbm.
(обратно)
179
Несмотря на то что
qdbm обеспечивает доступ к файловому дескриптору, использовать его следует осторожно. Дело в том, что все операции по чтению и записи в файл должны производиться через библиотеку
qdbm; операции, не связанные с изменением данных в файле, например, блокировка или установка флага для закрытия после выполнения, допускаются.
(обратно)
180
Вернее, они возвращаются в том порядке, в котором производятся ссылки на элементы из хеш-области. Хотя это и есть порядок, он является совершенно бесполезным.
(обратно)
181
Библиотека
glibc также предлагает библиотеку
argp, с помощью которой можно осуществлять альтернативный вариант проверки синтаксиса параметров.
(обратно)
182
Те, кто знаком с функцией
getopt(), заметят, что
argInfo является единственным обязательным членом структуры
struct poptOption, который отличается от члена в таблице аргументов
getoptlong(). Благодаря этому сходству существенно упрощается переход от
getoptlong() к
popt.
(обратно)
183
Полный исходный код для данного примера можно найти в главе 23.
(обратно)
184
Распространенной ошибкой является определение массива
argv как
char **, а не как
const char **, что является правильным вариантом. Благодаря прототипу функции
poptGetContext() компилятор генерирует предупреждающее сообщение, если массив
argv будет определен неправильно.
(обратно)
185
Он также добавляет параметр
-?, который соответствует
--help.
(обратно)
186
Макрос
POPT_AUTOHELP расширяется для включения вложенной таблицы параметров, определяющей новые параметры и обратный вызов, при котором реализуются эти параметры.
(обратно)
187
Часто в подобных случаях удобно использовать
POPT_CONTEXT_KEEP_FIRST.
(обратно)
188
Первоначально библиотека
popt была реализована для RPM, и многие параметры запросов RPM реализованы в виде простых макросов
popt.
(обратно)
Оглавление
Введение
Часть I
Начало работы
Глава 1
История создания Linux
1.1. Краткая история свободного программного обеспечения Unix
1.2. Разработка Linux
1.3. Важные факты в создании систем Unix
1.4. Происхождение Linux
Глава 2
Лицензии и авторские права
2.1. Авторское право
2.2. Лицензирование
2.3. Лицензии на свободное ПО
2.3.1. Общедоступная лицензия GNU
2.3.2. Общедоступная лицензия библиотеки GNU
2.3.3. Лицензии стиля MIT/X/BSD
2.3.4. Лицензии старого стиля BSD
2.3.5. Лицензия Artistic License
2.3.6. Несовместимости лицензий
Глава 3
Онлайновая системная документация
3.1. Оперативные страницы руководства
3.2. Информационные страницы
3.3. Прочая документация
Часть II
Инструментальные средства и среда разработки
Глава 4
Инструментальные средства разработки
4.1. Редакторы
4.1.1. Emacs
4.1.2. vi
4.2. make
4.2.1 Сложные командные строки
4.2.2. Переменные
4.2.3. Суффиксные правила
4.3. Отладчик GNU
4.4. Действия при трассировке программы
Глава 5
Опции и расширения gcc
5.1. Опции gcc
5.2. Заголовочные файлы
5.2.1. long long
5.2.2. Встроенные функции
5.2.3. Альтернативные расширенные ключевые слова
5.2.4. Атрибуты
Глава 6
Библиотека GNU C
6.1. Выбор возможностей glibc
6.2. Интерфейсы POSIX
6.2.1. Обязательные типы POSIX
6.2.2. Раскрытие возможностей времени выполнения
6.2.3. Поиск и настройка базовой системной информации
6.3. Совместимость
Глава 7
Средства отладки использования памяти
7.1. Код, содержащий ошибки
7.2. Средства проверки памяти, входящие в состав glibc
7.2.1. Поиск повреждений кучи
7.2.2. Использование mtrace() для отслеживания распределений памяти
7.3. Поиск утечек памяти с помощью mpr
7.4. Обнаружение ошибок памяти с помощью Valgrind
7.5. Electric Fence
7.5.1. Использование Electric Fence
7.5.2. Выравнивание памяти
7.5.3. Другие средства
7.5.4. Ограничения
7.5.5. Потребление ресурсов
Глава 8
Создание и использование библиотек
8.1. Статические библиотеки
8.2. Совместно используемые библиотеки
8.3. Разработка совместно используемых библиотек
8.3.1. Управление совместимостью
8.3.2. Несовместимые библиотеки
8.3.3. Разработка совместимых библиотек
8.4. Сборка совместно используемых библиотек
8.5. Инсталляция совместно используемых библиотек
8.5.1. Пример
8.6. Работа с совместно используемыми библиотеками
8.6.1. Использование деинсталлированных библиотек
8.6.2. Предварительная загрузка библиотек
Глава 9
Системное окружение Linux
9.1. Окружение процесса
9.2. Системные вызовы
9.2.1. Ограничения системных вызовов
9.2.2. Коды возврата системных вызов
9.2.3. Использование системных вызовов
9.2.4. Общие коды возврата ошибок
9.3. Поиск заголовочных и библиотечных файлов
Часть III
Системное программирование
Глава 10
Модель процессов
10.1. Определение процесса
10.1.1. Усложнение концепции — потоки
10.1.2. Подход Linux
10.2 Атрибуты процессов
10.2.1. Идентификатор процесса и происхождение
10.2.2. Сертификаты
10.2.3. Идентификатор uid файловой системы
10.2.4. Резюме по идентификаторам пользователей и групп
10.3. Информация опроцессе
10.3.1. Аргументы программы
10.3.2 Использование ресурсов
10.3.3. Применение ограничений использования ресурсов
10.4. Примитивы процессов
10.4.1. Создание дочерних процессов
10.4.2. Наблюдение за уничтожением дочерних процессов
10.4.3. Запуск новых программ
10.4.4. Ускоренное создание процессов с помощью vfork()
10.4.5. Уничтожение процессом самого себя
10.4.6. Уничтожение других процессов
10.4.7. Дамп ядра
10.5. Простые дочерние процессы
10.5.1. Запуск и ожидание с помощью system()
10.5.2. Чтение и запись из процесса
10.6. Сеансы и группы процессов
10.6.1. Сеансы
10.6.2. Управление терминалом
10.6.3. Группы процессов
10.6.4. Висячие группы процессов
10.7. Введение в ladsh
10.7.1. Запуск внешних программ с помощью ladsh
10.8. Создание клонов
Глава 11
Простое управление файлами
11.1. Режим файла
11.1.1. Права доступа к файлу
11.1.2. Модификаторы прав доступа к файлам
11.1.3. Типы файлов
11.1.4. Маска umask процесса
11.2. Основные файловые операции
11.2.1. Файловые дескрипторы
11.2.2. Закрытие файлов
11.2.3. Открытие файлов в файловой системе
11.2.4. Чтение, запись и перемещение
11.2.5. Частичное чтение и запись
11.2.6. Сокращение файлов
11.2.7. Синхронизация файлов
11.2.8. Прочие операции
11.3. Запрос и изменение информации inode
11.3.1. Поиск информации inode
11.3.2. Простой пример stat()
11.3.3. Простое определение прав доступа
11.3.4. Изменение прав доступа к файлу
11.3.5. Смена владельца и группы файла
11.3.6. Изменение временных меток файла
11.3.7. Расширенные атрибуты Ext3
11.4. Манипулирование содержимым каталогов
11.4.1. Создание входных точек устройств и именованных каналов
11.4.2. Создание жестких ссылок
11.4.3. Использование символических ссылок
11.4.4. Удаление файлов
11.4.5. Переименование файлов
11.5. Манипуляции файловыми дескрипторами
11.5.1. Изменение режима доступа к открытому файлу
11.5.2. Модификация флага "закрыть при выполнении"
11.5.3. Дублирование файловых дескрипторов
11.6. Создание неименованных каналов
11.7. Добавление перенаправления для ladsh
11.7.1. Структуры данных
11.7.2. Изменения в коде
Глава 12
Обработка сигналов
12.1. Концепция сигналов
12.1.1. Жизненный цикл сигнала
12.1.2. Простые сигналы
12.1.3. Надежные сигналы
12.1.4. Сигналы и системные вызовы
12.2. Программный интерфейс сигналов Linux и POSIX
12.2.1. Посылка сигналов
12.2.2. Использование sigset_t
12.2.3. Перехват сигналов
12.2.4. Манипулирование маской сигналов процесса
12.2.5. Нахождение набора ожидающих сигналов
12.2.6. Ожидание сигналов
12.3. Доступные сигналы
12.3.1. Описание сигналов
12.4. Написание обработчиков сигналов
12.5. Повторное открытие журнальных файлов
12.6. Сигналы реального времени
12.6.1. Очередность и порядок сигналов
12.7. Дополнительные сведения о сигналах
12.7.1. Получение контекста сигнала
12.7.2. Отправка данных с сигналом
Глава 13
Расширенная обработка файлов
13.1. Мультиплексирование входных и выходных данных
13.1.1. Неблокируемый ввод-вывод
13.1.2. Мультиплексирование с помощью poll()
13.1.3. Мультиплексирование с помощью select()
13.1.4. Сравнение poll() и select()
13.1.5. Мультиплексирование с помощью epoll
13.1.6 Сравнение poll() и epoll
13.2. Отображение в памяти
13.2.1. Выравнивание по страницам
13.2.2. Установка отображения в памяти
13.2.3. Отмена отображения областей
13.2.4. Синхронизация областей памяти на диск
13.2.5. Блокировка областей памяти
13.3. Блокирование файлов
13.3.1. Блокировочные файлы
13.3.2. Блокировка записей
13.3.3. Обязательные блокировки
13.3.4. Аренда файла
13.4. Альтернативы read() и write()
13.4.1. Разбросанное/сборное чтение и запись
13.4.2. Игнорирование указателя файла
Глава 14
Операции с каталогами
14.1. Текущий рабочий каталог
14.1.1. Поиск текущего рабочего каталога
14.1.2. Специальные файлы . и ..
14.1.3. Смена текущего каталога
14.2. Смена корневого каталога
14.3. Создание и удаление каталогов
14.3.1. Создание новых каталогов
14.3.2. Удаление каталогов
14.4. Чтение содержимого каталога
14.4.1. Прохождение по каталогу
14.5. Универсализация файловых имен
14.5.1. Использование подпроцесса
14.5.2. Внутренняя универсализация
14.6. Добавление к ladsh возможностей работы с каталогами и универсализацией
14.6.1. Добавление встроенных команд cd и pwd
14.6.2. Добавление универсализации файловых имен
14.7. Обход деревьев файловых систем
14.7.1. Использование ftw()
14.7.2. Обход дерева файлов с помощью nft()
14.7.3. Реализация find
14.8. Уведомление о смене каталога
Глава 15
Управление заданиями
15.1. Основы управления заданиями
15.1.1. Перезапуск процессов
15.1.2. Остановка процессов
15.1.3. Обработка сигналов управления заданиями
15.2. Управление заданиями в ladsh
Глава 16
Терминалы и псевдотерминалы
16.1. Операции tty
16.1.1. Служебные функции терминалов
16.1.2. Управляющие терминалы
16.1.3. Принадлежность терминала
16.1.4. Запись с помощью utempter
16.1.5. Запись вручную
16.2. Обзор termios
16.3. Примеры использования termios
16.3.1. Пароли
16.3.2. Последовательные коммуникации
16.4. Отладка termios
16.5. Справочник по termios
16.5.1. Функции
16.5.2. Размеры окна
16.5.3. Флаги
16.5.4. Флаги режима ввода
16.5.5. Флаги режима вывода
16.5.6. Управляющие флаги
16.5.7. Управляющие символы
16.5.8. Локальные флаги
16.5.9. Управление read()
16.6. Псевдотерминалы
16.6.1. Открытие псевдотерминалов
16.6.2. Простые способы открытия псевдотерминалов
16.6.3. Сложные способы открытия псевдотерминалов
16.6.4. Примеры псевдотерминалов
Глава 17
Работа в сети с помощью сокетов
17.1. Поддержка протоколов
17.1.1. Идеальная работа в сети
17.1.2. Реальная работа в сети
17.1.3. Как заставить реальность играть по точным правилам?
17.1.4. Адреса
17.2. Служебные функции
17.3. Основные действия с сокетами
17.3.1. Создание сокета
17.3.2. Установка соединений
17.3.3. Связывание адреса с сокетом
17.3.4. Ожидание соединений
17.3.5. Подключение к серверу
17.3.6. Поиск адресов соединения
17.4. Сокеты домена Unix
17.4.1. Адреса домена Unix
17.4.2. Ожидание соединения
17.4.3. Соединение с сервером
17.4.4. Запуск примеров домена Unix
17.4.5. Неименованные сокеты домена Unix
17.4.6. Передача файловых дескрипторов
17.5. Сетевая обработка с помощью TCP/IP
17.5.1. Упорядочение байтов
17.5.2. Адресация IPv4
17.5.3. Адресация IPv6
17.5.4. Манипулирование IP-адресами
17.5.5. Преобразование имен в адреса
17.5.6. Преобразование адресов в имена
17.5.7. Ожидание TCP-соединений
17.5.8. Клиентские приложения TCP
17.6. Использование дейтаграмм UDP
17.6.1. Создание UDP-сокета
17.6.2. Отправка и получение дейтаграмм
17.6.3. Простой tftp-сервер
17.7. Ошибки сокетов
17.8. Унаследованные сетевые функции
17.8.1. Манипулирование IPv4-адресами
17.8.2. Преобразование имен хостов
17.8.3. Пример поиска информации хоста с использованием унаследованных функций
17.8.4. Поиск номеров портов
Глава 18
Время
18.1. Вывод времени и даты
18.1.1. Представление времени
18.1.2. Преобразование, форматирование и разбор значений времени
18.1.3. Ограничения, связанные со временем
18.2. Использование таймеров
18.2.1. Режим ожидания
18.2.2. Интервальные таймеры
Глава 19
Случайные числа
19.1. Псевдослучайные числа
19.2. Криптография и случайные числа
Глава 20
Программирование виртуальных консолей
20.1. Начало работы
20.2. Выдача звукового сигнала
20.3. Определение, является ли терминал виртуальной консолью
20.4. Поиск текущей виртуальной консоли
20.5. Управление переключением виртуальных консолей
20.6. Пример команды open
Глава 21
Консоль Linux
21.1. Базы данных возможностей
21.2. Глифы, символы и отображения
21.3. Возможности консоли Linux
21.3.1. Управляющие символы
21.3.2. Управляющие последовательности
21.3.3. Тестирование последовательностей
21.3.4. Составные управляющие последовательности
21.4. Прямой вывод на экран
Глава 22
Написание защищенных программ
22.1. Когда безопасность имеет значение?
22.1.1. Когда выходит из строя система безопасности?
22.2. Минимизация возможности появления атак
22.2.1. Передача полномочий
22.2.2. Получение вспомогательной программы
22.2.3. Ограничение доступа к файловой системе
22.3. Общие бреши системы безопасности
22.3.1. Переполнение буфера
22.3.2. Разбор имен файлов
22.3.3. Переменные окружения
22.3.4. Запуск командной оболочки
22.3.5. Создание временных файлов
22.3.6. Режимы состязаний и обработчики сигналов
22.3.7. Закрытие файловых дескрипторов
22.4. Запуск в качестве демона
Часть IV
Библиотеки для разработки
Глава 23
Сопоставление строк
23.1. Универсализация произвольных строк
23.2. Регулярные выражения
23.2.1. Регулярные выражения в Linux
23.2.2. Сопоставление с регулярными выражениями
23.2.3. Простая утилита grep
Глава 24
Управление терминалами с помощью библиотеки S-Lang
24.1. Обработка ввода
24.1.1. Инициализация обработки ввода в S-Lang
24.1.2. Восстановление состояния терминала
24.1.3. Чтение символов с терминала
24.1.4. Проверка ожидающего ввода
24.2. Обработка вывода
24.2.1. Инициализация управления экраном
24.2.2. Обновление экрана
24.2.3. Перемещение курсора
24.2.4. Завершение управления экраном
24.2.5. Скелет программы управления экраном
24.2.6. Переключение наборов символов
24.2.7. Запись на экран
24.2.8. Рисование линий и прямоугольников
24.2.9. Использование цвета
Глава 25
Библиотека хешированных баз данных
25.1. Обзор
25.2. Основные операции
25.2.1. Открытие файла qdbm
25.2.2. Закрытие базы данных
25.2.3. Получение файлового дескриптора
25.2.4. Синхронизация базы данных
25.3. Чтение записей
25.3.1. Чтение определенной записи
25.3.2. Последовательное чтение записей
25.4. Модификация базы данных
25.4.1. Добавление записей
25.4.2. Удаление записей
25.5. Пример
Глава 26
Синтаксический анализ параметров командной строки
26.1. Таблица параметров
26.1.1. Определение параметров
26.1.2. Вложенные таблицы параметров
26.2. Использование таблиц параметров
26.2.1. Создание содержимого
26.2.2. Синтаксический анализ командной строки
26.2.3. Остаточные аргументы
26.2.4. Автоматические справочные сообщения
26.3. Использование обратных вызовов
26.4. Обработка ошибок
26.5. Псевдонимы параметров
26.5.1. Определение псевдонимов
26.5.2. Разрешение псевдонимов
26.6. Синтаксический анализ строк аргументов
26.7. Обработка дополнительных аргументов
26.8. Пример приложения
Глава 27
Динамическая загрузка во время выполнения
27.1. Интерфейс dl
27.1.1. Пример
Глава 28
Идентификация и аутентификация пользователей
28.1. Преобразование идентификатора в имя
28.1.1. Пример: команда id
28.2. Подключаемые модули аутентификации (РАМ)
28.2.1. Диалоги РАМ
28.2.2. Действия РАМ
Приложения
Приложение A
Заголовочные файлы
Приложение Б
Исходный код ladsh
Глоссарий
Литература
*** Примечания ***
Последние комментарии
12 часов 26 минут назад
21 часов 18 минут назад
21 часов 21 минут назад
3 дней 3 часов назад
3 дней 8 часов назад
3 дней 9 часов назад